2.1 Citra
Citra atau gambar dapat didefinisikan sebagai sebuah fungsi dua dimensi, f(x,y), di mana x dan y adalah koordinat bidang datar, dan harga fungsi f di setiap pasangan koordinat (x,y) disebut intensitas atau level keabuan (grey level) dari gambar di titik itu. Jika x,y dan f semuanya berhingga (finite), dan nilainya diskrit, maka gambarnya disebut citra digital (gambar digital) (Hermawati, 2013).
2.1.1 Jenis Citra Digital
Menurut Sutoyo & Wijanarto (2009), ada 3 jenis citra digital yang sering digunakan, yaitu :
1. Citra Biner (Monokrom), citra ini mempunyai 2 warna saja, yaitu hitam dan putih dan membutuhkan 1 bit di memori untuk menyimpan kedua warna tersebut. Bit 0 mewakili warna hitam dan bit 1 mewakili warna putih. Contoh citra biner dapat dilihat pada gambar 2.1.
2. Citra Grayscale (Skala Keabuan), banyaknya warna pada citra ini tergantung pada jumlah bit yang disediakan di memori untuk menampung kebutuhan warna tersebut. Citra 2 bit mewakili 4 warna dan citra 3 bit mewakili 8 warna. Semakin besar jumlah bit warna yang disediakan di memori, semakin halus gradiasi warna yang terbentuk. Contoh citra grayscale dapat dilihat pada gambar 2.2.
Gambar 2.2 Contoh citra grayscale
3. Citra Warna (True Color), setiap piksel pada citra warna mewakili warna yang merupakan kombinasi dari tiga warna dasar (RGB = Red Greem Blue). Setiap warna dasar menggunakan penyimpanan 8 bit = 1 byte, yang berarti setiap warna mempunyai gradiasi sebanyak 255 warna. Berarti setiap piksel mempunyai kombinasi warna sebanyak 28 .28 .28 = 16 juta warna lebih. Format ini dinamakan true color karena mempunyai jumlah warna yang cukup besar sehingga bisa dikatakan hampir mencakup semua warna di alam. Contoh citra warna dapat dilihat pada gambar 2.3.
Gambar 2.3 Contoh citra warna 2.1.2 Format File Citra
Menurut Ahmad (2005), ada dua kategori besar untuk format file citra yaitu :
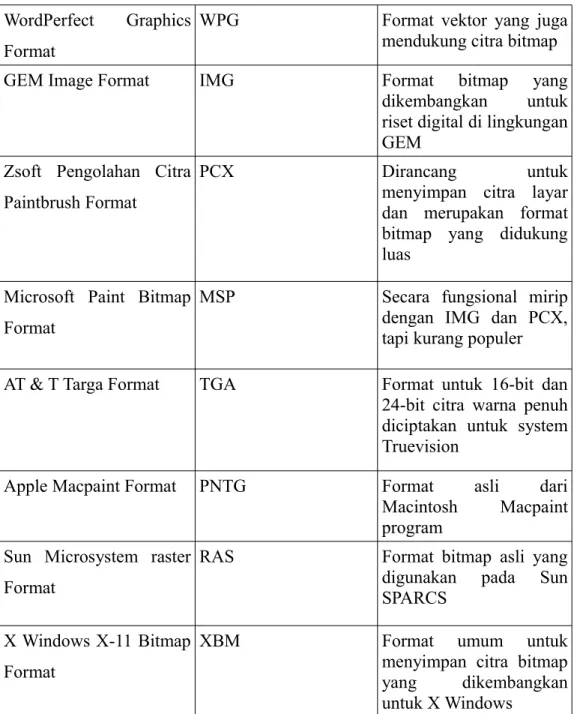
1. Format file bitmap, format ini menyimpan data kode citra secara digital dan lengkap. Format citra bitmap yang umum digunakan dalam pengolah citra dapat dilihat pada tabel 2.1.
Tabel 2.1 Format file grafik bitmap (Ahmad, 2015)
Nama Format Ekstensi Kegunaan
Microsoft Windows Bitmap Format
BMP Format umum untuk
menyimpan citra bitmap yang dikembangkan oleh Microsoft Compuserve Graphics Interchange Format
GIFF Format umum citra
yang dirancang untuk keperluan transmisi melalui modem
Aldus Tagged Image File Format
TIF Format kompleks dan
multiguna yang
dikembangkan oleh
Aldus bersama
Tabel 2.1 Format file grafik bitmap (Ahmad, 2015) (lanjutan) WordPerfect Graphics
Format
WPG Format vektor yang juga
mendukung citra bitmap
GEM Image Format IMG Format bitmap yang
dikembangkan untuk riset digital di lingkungan GEM
Zsoft Pengolahan Citra Paintbrush Format
PCX Dirancang untuk
menyimpan citra layar dan merupakan format bitmap yang didukung luas
Microsoft Paint Bitmap Format
MSP Secara fungsional mirip
dengan IMG dan PCX, tapi kurang populer AT & T Targa Format TGA Format untuk 16-bit dan
24-bit citra warna penuh diciptakan untuk system Truevision
Apple Macpaint Format PNTG Format asli dari
Macintosh Macpaint program
Sun Microsystem raster Format
RAS Format bitmap asli yang
digunakan pada Sun SPARCS
X Windows X-11 Bitmap Format
XBM Format umum untuk
menyimpan citra bitmap yang dikembangkan untuk X Windows
2. Format file vektor, format ini menyimpan elemen - elemen pembentuk citra secara individu.
2.2 Steganografi
Steganografi adalah ilmu menyembunyikan teks pada media lain yang telah ada sedemikian sehingga teks yang tersembunyi menyatu dengan media itu. Media tempat penyembunyian pesan tersembunyi dapat berupa media teks, gambar, audio, atau video. Steganografi yang kuat memiliki sifat media yang telah tertanam teks
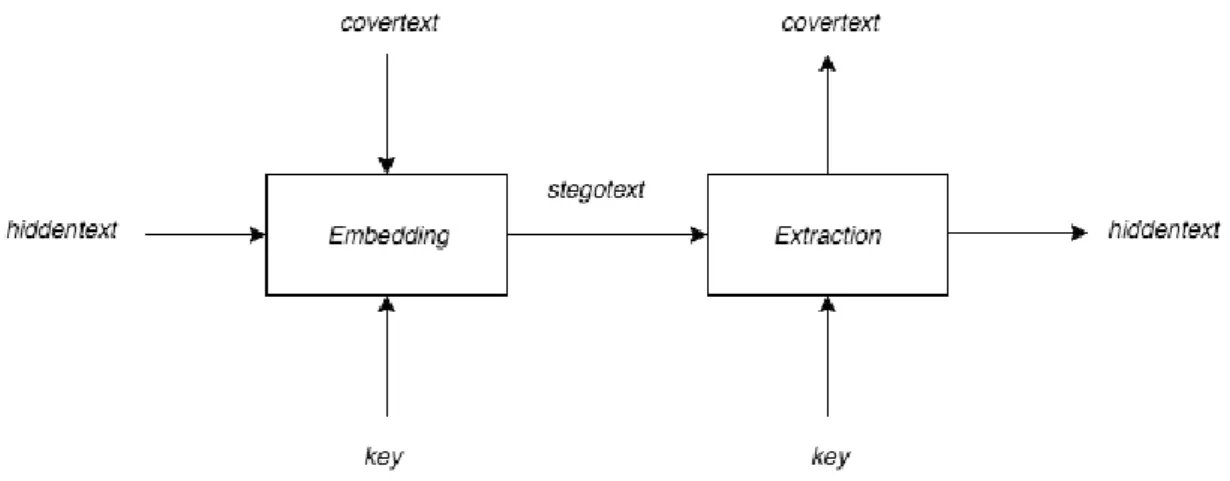
tersembunyi sulit dibedakan dengan media asli namun teks tersembunyi tetap dapat diekstrasi (Sadikin, 2012). Gambar 2.4 memperlihatkan diagram penyisipan dan ekstraksi pesan.
Gambar 2.4 Diagram penyisipan dan ekstraksi pesan (Munir, 2006)
2.2.1 Konsep Dan Terminologi
Menurut Munir (2006), terdapat beberapa istilah yang berkaitan dengan steganografi: 1. Hiddentext atau embedded message : pesan yang disembunyikan.
2. Covertext atau cover-object: pesan yang digunakan untuk menyembunyikan embedded message.
3. Stegotext atau stego-object: pesan yang sudah berisi embedded message. 2.2.2 Kriteria Penyembunyian Pesan
Menurut Munir (2006), kriteria yang harus diperhatikan dalam penyembunyian pesan adalah:
1. Imperceptibility. Keberadaan pesan rahasia tidak dapat dipersepsi oleh inderawi. Misalnya, jika covertext berupa citra, maka penyisipan pesan membuat citra stegotext sukar dibedakan oleh mata dengan citra covertext-nya. Jika covertext berupa audio (misalnya berkas mp3, wav, midi, dan sebagainya), maka indera telinga tidak dapat mendeteksi perubahan tersebut.
2. Fidelity. Mutu media penampung tidak berubah banyak akibat penyisipan. Perubahan tersebut tidak dapat dipersepsi oleh inderawi. Misalnya, jika covertext berupa citra, maka penyisipan pesan membuat citra stegotext sukar
dibedakan oleh mata dengan covertext-nya. Jika covertext berupa audio (misalnya berkas mp3, wav, midi, dan sebagainya), maka audio stegotext tidak rusak dan indera telinga tidak dapat mendeteksi perubahan tersebut.
3. Recovery. Pesan yang disembunyikan harus dapat diungkapkan kembali (reveal). Karena tujuan steganografi adalah data hiding, maka sewaktu-waktu pesan rahasia di dalam stegotext harus dapat diambil kembali untuk digunakan lebih lanjut.
2.2.3 Teknik steganografi
Menurut Ariyus (2009), terdapat tujuh teknik yang digunakan dalam steganografi: 1. Injection
Merupakan suatu teknik menanamkan pesan rahasia secara langsung ke suatu media. Salah satu masalah dari teknik ini adalah ukuran media yang diinjeksi menjadi lebih besar dari ukuran normalnya sehingga mudah dideteksi. Teknik itu sering juga disebut Embedding.
2. Substitusi
Data normal digantikan dengan data rahasia. Biasanya, hasil teknik itu tidak terlalu mengubah ukuran data asli, tetapi tergantung pada file media dan data yang akan disembunyikan. Teknik substitusi bisa menurunkan kualitas media yang ditumpanginya.
3. Transform Domain
Teknik ini sangat efektif. Pada dasarnya, transformasi domain menyembunyikan data pada “transform space”. Akan sangat lebih efektif bila teknik ini diterapkan pada file berekstensi Jpeg (gambar).
4. Spread Spectrum
Sebuah teknik pentransmisian menggunakan pseudo-noise code, yang independen terhadap data informasi sebagai modulator bentuk gelombang untuk menyebarkan energi sinyal dalam sebuah jalur komunikasi (bandwidth) yang lebih besar daripada sinyal jalur komunikasi informasi. Oleh penerima, sinyal dikumpulkan kembali menggunakan replika pseudo-noise code tersinkronisasi.
5. Statistical Method
Teknik ini disebut juga skema steganographic 1 bit. Skema tersebut menanamkan satu bit informasi pada media tumpangan dan mengubah statistik walaupun hanya 1 bit. Perubahan statistik ditunjukkan dengan indikasi 1 dan jika tidak ada perubahan, terlihat indikasi 0. Sistem ini bekerja berdasarkan kemampuan penerima dalam membedakan antara informasi yang dimodifikasi dan yang belum.
6. Distortion
Metode ini menciptakan perubahan atas benda yang ditumpangi oleh data rahasia.
7. Cover Generation
Metode ini lebih unik daripada metode lainnya karena cover object dipilih untuk menyembunyikan pesan. Contoh dari metode ini adalah Spam Mimic. 2.2.4 Metode LSB
LSB (Least Significant Bit) adalah suatu metode untuk menyimpan data ke cover image. Bit dengan bobot terkecil dari setiap piksel suatu gambar diubah menjadi bit dari pesan yang akan disembunyikan (Prashanti, 2013).
Misalkan barisan bit dari pesan yang akan dimasukkan adalah “111111110000000011111111000” dan akan dimasukkan pada beberapa piksel seperti pada gambar 2.5.
Gambar 2.5 Contoh gambar yang akan disisipi pesan menggunakan metode LSB
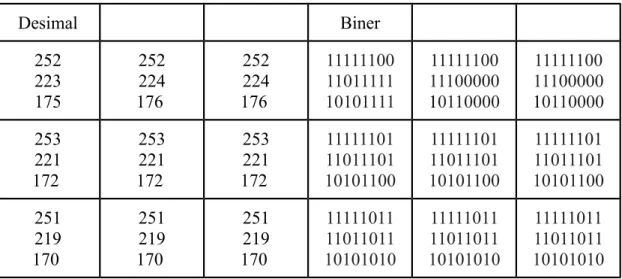
Jika nilai - nilai pada setiap piksel tersebut diubah ke biner, maka hasilnya akan seperti tabel 2.2.
Tabel 2.2 Nilai - nilai piksel sebelum disisipi pesan Desimal Biner 252 223 175 252 224 176 252 224 176 11111100 11011111 10101111 11111100 11100000 10110000 11111100 11100000 10110000 253 221 172 253 221 172 253 221 172 11111101 11011101 10101100 11111101 11011101 10101100 11111101 11011101 10101100 251 219 170 251 219 170 251 219 170 11111011 11011011 10101010 11111011 11011011 10101010 11111011 11011011 10101010
Selanjutnya barisan bit “111111110000000011111111000” dimasukkan pada bit terakhir dari setiap nilai -nilai pada piksel seperti yang ditunjukkan pada tabel 2.3.
Tabel 2.3 Nilai - nilai piksel setelah dimasukkan pesan dengan metode LSB
Desimal Biner 253 223 175 253 225 177 253 225 176 11111101 11011111 10101111 11111101 11100001 10110001 11111101 11100001 10110000 252 220 172 252 220 172 252 221 173 11111100 11011100 10101100 11111100 11011100 10101100 11111100 11011101 10101101 251 219 171 251 219 171 250 218 170 11111011 11011011 10101011 11111011 11011011 10101011 11111010 11011010 10101010
Pada tabel 2.2 dan tabel 2.3, dapat dilihat bahwa perubahan yang terjadi sangat kecil dan hal ini akan mengakibatkan pesan sulit terdeteksi secara kasat mata.
2.3 Kompresi Data
Proses kompresi merupakan proses mereduksi ukuran suatu data untuk menghasilkan representasi digital yang padat atau mampat (compact) namun tetap dapat mewakili
kuantitas informasi yang terkandung pada data tersebut. Pada citra, video, dan audio, kompresi mengarah pada minimisasi jumlah bit rate untuk representasi digital. Pada beberapa literatur, istilah kompresi sering disebut juga source coding, data compression, bandwidth compression, dan signal compression (Putra, 2010).
2.3.1 Kompresi Lossless Dan Lossy
Menurut Al-Hashemi & Kamall (2011), komprei data terbagi menjadi 2 bagian:
1. Lossless compression, data bisa dikompresi dan dikembalikan ke keadaan semula tanpa kehilangan informasi apapun.
2. Lossy compression, data yang didekompresi mungkin menjadi pendekatan yang dapat diterima dari data asli yang belum terkompresi.
2.3.2 Kriteria Kompresi Citra
Menurut Sutoyo & Wijanarto (2009), kriteria yang digunakan untuk mengukur pemampatan citra adalah :
1. Waktu kompresi dan waktu dekompresi, algorima pemampatan yang baik adalah algoritma yang membutuhkan waktu untuk kompresi dan dekompresi paling sedikit.
2. Kebutuhan memori, algoritma pemampatan yang baik akan menghasilkan memori yang dibutuhkan untuk menyimpan hasil kompresi yang berkurang secara berarti. Biasanya semakin besar persentase pemampatan, semakin kecil kebutuhan memori yang diperlukan sehingga kualitas citra makin berkurang. 3. Kualitas pemampatan (fidelity), metode kompresi yang baik adalah metode
kompresi yang mampu mengembalikan citra hasil kompresi menjadi citra semula tanpa kehilangan informasi apa pun.
4. Format keluaran, format citra hasil pemampatan yang baik adalah yang cocok dengan kebutuhan pengiriman dan penyimpanan data.
2.3.3 Redudansi Data
Menurut Sutoyo & Wijanarto (2009), ada 3 jenis redudansi data dalam masalah kompresi citra, yaitu :
1. Coding Redudancy adalah cara pengkodean citra sedemikian sehingga jumlah kode yang diberikan untuk menampilkan suatu grayscale melebihi dari apa yang dibutuhkan.
2. Interpixel Redudancy sering disebut juga sebagai spatial redudancy, geometric redudancy atau interframe redudancy, Maksud dari interpixel redudancy adalah data redudan dapat dinyatakan sebagai korelasi antarpiksel di mana intensitas suatu piksel dapat diperkirakan dari intensitas piksel-piksel tetangganya. Biasanya informasi yang dibawa oleh setiap piksel relatif kecil sehingga bisa dikatakan bahwa kontribusi setiap piksel pada citra secara keseluruhan adalah redudan.
3. Psychovisual Redudancy adalah suatu fenomena dengan intensitas keabuan yang bervariasi dilihat oleh mata sebagai intensitas konstan, yang bila dihilangkan tidak mengganggu persepsi kualitas citra. Dalam hal ini, mata tidak melihat nilai dari setiap piksel pada suatu cita secara kuantitatif.
2.3.4 Pengukuran Kinerja Kompresi Data
Pada suatu teknik yang digunakan dalam proses kompresi data terdapat beberapa faktor atau variabel yang biasa digunakan untuk mengukur kualitas dari suatu teknik kompresi data tersebut, yaitu :
1. Ratio of compression (Rc)
Ratio of compression (Rc) adalah perbandingan antara ukuran data sebelum dikompresi dengan ukuran data setelah dikompresi.
(Salomon & Motta, 2010)
Misalkan didapat sebuah nilai Ratio of Compression sebesar 2.75. Itu berarti besar data sebelum kompresi adalah 2.75 kali lipat dari besar data setelah dikompresi.
2. Compression ratio (Cr)
Compression ratio (Cr) adalah persentasi besar data yang telah dikompresi yang didapat dari hasil perbandingan antara ukuran data setelah dikompresi dengan ukuran data sebelum dikompresi.
Misalkan didapat sebuah nilai Compression Ratio sebesar 35%. Itu berarti setelah dikompresi ukuran data adalah 35% dari data sebelum dikompresi. 3. Redundancy (Rd)
Redundancy (Rd) adalah kelebihan yang terdapat di dalam data sebelum dikompresi. Jadi setelah data dikompresi dapat dihitung Redundancy data yaitu persentasi dari hasil selisih antara ukuran data sebelum dikompresi dengan data setelah dikompresi.
(Salomon & Motta, 2010)
Misalkan didapat sebuah nilai Redundancy sebesar 14%. Itu berarti besarnya kelebihan data sebelum dikompresi adalah 14%.
4. Space savings (Ss)
Space savings (Ss) adalah persentase selisih antara data yang belum dikompresi dengan besar data yang dikompresi
(Salomon & Motta, 2010) 5. Waktu Kompresi dan Dekompresi
Waktu kompresi dan dekompresi adalah waktu yang dibutuhkan oleh sebuah sistem untuk melakukan proses kompresi dan dekompresi dari mulai pembacaan data hingga proses encoding pada data tersebut. Semakin kecil waktu yang diperoleh maka semakin efisien metode yang digunakan dalam proses kompresi dan dekompresi itu.
2.3.5 Algoritma Huffman
Menurut Putra (2010), metode Huffman adalah metode pengkodean yang telah banyak diterapkan untuk aplikasi kompresi citra. Seperti metode Shannon-Fano, metode Huffman juga membentuk pohon atas dasar probabilitas setiap simbol, namun teknik pembentukan pohonnya berbeda. Berikut ini adalah langkah - langkah algoritma Huffman.
1. Data dianalisis dahulu dengan cara membuat frekuensi kemunculan setiap simbol ASCII, tabel frekuensi tersebut memiliki atribut berupa simbol ASCII dan frekuensi.
2. Dua data yang memiliki frekuensi kemunculan paling kecil dipilih sebagai simpul pertama pada pohon Huffman.
simpul pertama.
4. Kemudian dua simpul tersebut dihapus dari tabel digantikan oleh simpul induk tadi. Simpul ini kemudian dijadikan acuan untuk membentuk pohon.
5. Langkah 3-5 dilakukan berulang - ulang hingga isi tabel tinggal satu saja. Data inilah yang akan menjadi simpul bebas atau simpul akar.
6. Setiap simpul yang terletak pada cabang kiri (simpul dengan frekuensi lebih besar) diberi nilai 0 dan simpul yang terletak pada cabang kanan (simpul dengan frekuensi lebih kecil) diberi nilai 1.
7. Pembacaan dilakukan dari simpul akar ke arah simpul daun dengan memperhatikan nilai setiap cabang.
Berikut adalah contoh implementasi algoritma Huffman dengan menggunakan tabel 2.4.
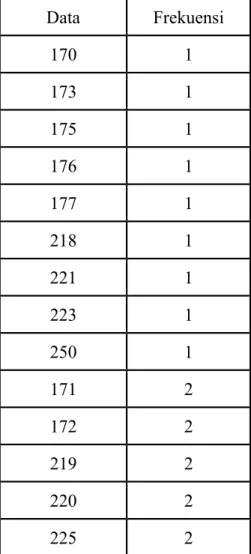
Tabel 2.4. Frekuensi dari data - data dari gambar 2.5
Data Frekuensi 170 1 173 1 175 1 176 1 177 1 218 1 221 1 223 1 250 1 171 2 172 2 219 2 220 2 225 2
251 2
252 3
253 3
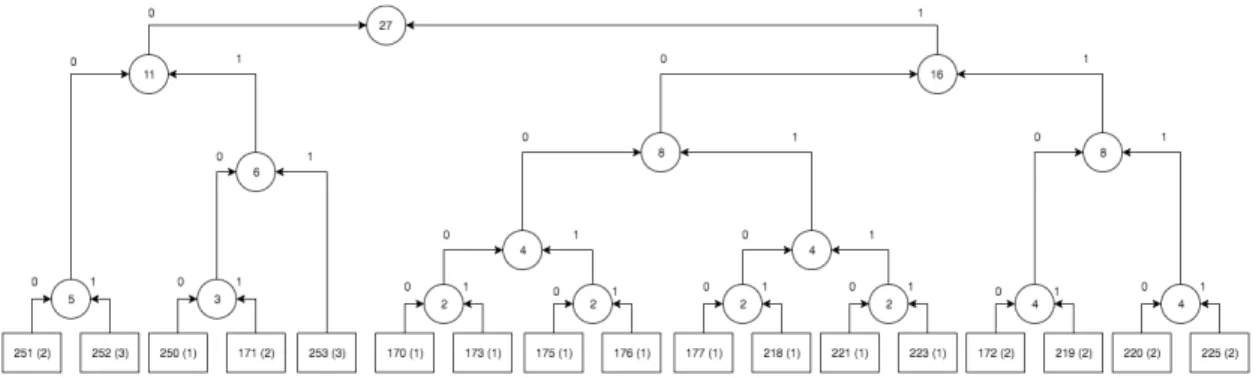
Dengan menggunakan langkah - langkah yang telah diuraikan di atas, maka bisa didapatkan pohon seperti pada gambar 2.6.
Gambar 2.6 Pohon Huffman dari tabel 2.4
Berdasarkan gambar 2.6, maka hasil proses pengkodean Huffman bisa dilihat pada tabel 2.5.
Tabel 2.5 Hasil Proses Pengkodean Huffman
Data Frekuensi Kode Jumlah bit kode Total bit
170 1 10000 5 5 173 1 10001 5 5 175 1 10010 5 5 176 1 10011 5 5 177 1 10100 5 5 218 1 10101 5 5 221 1 10110 5 5 223 1 10111 5 5 250 1 0100 4 4 171 2 0101 4 8
172 2 1100 4 8 219 2 1101 4 8 220 2 1110 4 8 225 2 1111 4 8 251 2 000 3 6 252 3 001 3 9 253 3 011 3 9 Total 27 108
Setelah mengamati hasil pengkodean Huffman di atas, maka dapat dilihat bahwa jumlah total bit adalah 108 bit. Sebelum dilakukan pengkodean, total bit dari data adalah 27 x 8 bit = 216 bit. Ratio of Compression (Rc) = 2. Compression Ratio (Cr) = 50%. Redundancy (Rd) = 50%. Space savings (Ss) = 50%.
2.4 Penelitian Kuantitatif
Menurut Abdullah (2015), penelitian kuantitatif adalah penelitian yang menguanakan data kuantitatif yaitu data yang berupa angka atau bilangan.
Contoh penelitian kuantitatif
(i) Penelitian untuk mengetahui laju pertumbuhan penduduk di Pedesaan Provinsi Kalimantan Selatan selama 10 tahun (2005 - 2015).
(ii) Penelitian untuk mengetahui laju pertumbuhan industri di kota Banjarmasin selama 5 tahun (2011 - 2015).
2.4.1 Pengukuran Indeks
Menurut Prasetyo, B & Jannah, L.M. (2005), indeks dan skala biasanya digunakan jika variabel - variabel yang ada termasuk dalam variabel ordinal. Dibandingkan dengan skala, indeks lebih sering digunakan karena lebih mudah digunakan. Indeks dibuat dari akumulasi nilai - nilai yang diberikan pada atribut - atribut individual, tanpa melihat ada tidaknya bobot. Jadi setiap pertanyaan dianggap memiliki nilai yang sama.
1. Skala Likert
Skala Likert berisi pernyataan yang sistematis untuk menunjukkan sikap seorang responden terhadap pernyataan itu. Indeks ini mengasumsikan bahwa masing - masing kategori jawaban ini memiliki intensitas yang sama. Keunggulan indeks ini adalah kategorinya memiliki urutan yang jelas mulai dari “sangat setuju”, “setuju”, “ragu-ragu”, “tidak setuju”, “sangat tidak setuju”.
2. Perbedaan Semantik
Indeks ini meminta responden untuk memilih antara dua pilihan yang bertentangan. Hal yang perlu ditentukan adalah dimensi - dimensi dari variabel yang diteliti, kemudian memilih dua istilah yang bertentangan yang mencerminkan dimensi - dimensi tersebut. Kata - kata yang digunakan adalah kata sifat karena lebih mudah dikomunikasikan. Indeks ini dipergunakan untuk banyak tujuan, misalnya di Penelitian Pemasaran digunakan untuk meneliti perasaan konsumen tentang suatu produk; di Penelitian Politik dapat digunakan untuk meneliti pendapat masyarakat tentang kandidat presiden, dan sebagainya. Responden hanya perlu memberikan tanda di atas garis untuk jawaban yang dipilihnya. Hasil jawaban responden dari setiap kategori ini yang kemudian digabungkan.
2.4.2 Kuesioner
Menurut Abdullah (2015), kuesioner (angket) adalah cara pengumpulan data dengan menyebarkan daftar pertanyaan kepada responden, dengan harapan mereka akan memberikan respon atas daftar pertanyaan tersebut. Daftar pertanyaan dapat bersifat terbuka, jika opsi jawaban tidak ditentukan sebelumnya, dan bersifat tertutup jika opsi jawaban telah disediakan sebelumnya