commit to user 17 BAB II TINJAUAN PUSTAKA 2. 1. Dasar Teori 2. 1. 1 Data mining
Data mining merupakan suatu proses penemuan pola dan pengetahuan atau informasi yang menarik dari data dengan jumlah yang besar. Data mining memiliki beberapa nama alternatif seperti knowledge mining from data, knowledge extraction, data/pattern analysis, data archaeology, data dredging, dan salah satu terminologi yang populer disebut dengan knowledge discovery from data (KDD). Data mining sebagai rangkaian suatu proses dapat dibagi menjadi beberapa tahap (Han, et al., 2012):
a. Data cleaning (pembersihan data). Bertujuan untuk membuang data yang tidak konsisten dan noise. Termasuk didalamnya penanganan terhadap missing value yang terdapat dalam data (bisa diisi dengan nilai yang paling sesuai atau diabaikan begitu saja) (Turban, et al., 2011).
b. Data integration (integrasi data). Proses dimana terjadi penggabungan data dari berbagai macam sumber.
c. Data selection (pemilihan data). Proses dimana hanya data yang relevan untuk dianalisis yang diambil dari database.
d. Data transformation (transformasi data). Data ditransformasi dan dikonsolidasikan menjadi suatu format yang sesuai untuk digali dengan menjalankan operasi penjumlahan atau agregasi.
e. Data mining (penggalian data). Suatu proses dengan menerapkan metode cerdas untuk ekstraksi pola data.
f. Pattern evaluation (evaluasi pola). Bertujuan untuk mengidentifikasi mana yang menjadi pola yang benar-benar menarik berdasarkan “penilaian ketertarikan”.
commit to user
g. Knowledge presentation (presentasi pengetahuan). Dimana proses visualisasi dan teknik representasi pengetahuan digunakan untuk menyajikan pengetahuan atau informasi yang telah digali kepada pengguna.
Berbagai macam metode yang digunakan dalam data mining pada saat ini cukuplah banyak. Berikut merupakan beberapa metode data mining yang paling banyak digunakan (Turban, et al., 2011):
a. Classification (klasifikasi). Klasifikasi kemungkinan merupakan salah satu metode data mining yang paling sering digunakan dalam menghadapi suatu masalah. Klasifikasi ini mempelajari pola-pola dari data yang telah lalu (kumpulan informasi, variabel, fitur) dengan tujuan untuk menempatkan instance baru (dengan label yang belum diketahui) ke grup atau kelasnya yang sesuai. Apabila hasil yang diprediksi merupakan label kelas, maka hal ini disebut dengan klasifikasi, tetapi apabila yang hasilnya merupakan suatu nilai angka, maka disebut dengan regresi.
b. Cluster Analysis for Data mining. Cluster analysis merupakan salah satu metode data mining yang penting untuk mengklasifikasi suatu barang, kejadian, atau konsep kedalam kelompok yang sama (cluster) atau memiliki karakteristik yang mirip. Berbeda dengan klasifikasi, clustering ini memiliki label kelas yang belum diketahui.
c. Association Rule Mining. Metode ini terkenal umumnya digunakan sebagai contoh untuk menjelaskan apa yang dimaksud dengan data mining dan apa yang dapat dilakukan untuk khalayak umum yang tidak begitu paham akan teknologi. Pada dasarnya associaton rule mining bertujuan untuk menemukan hubungan yang menarik (afinitas) antara variabel (item) dalam database besar. Dikarenakan kesuksesan penggunaannya dalam menangani masalah bisnis, sehingga biasa disebut dengan market-basket analysis.
2. 1. 2 Klasifikasi
Klasifikasi adalah suatu bentuk analisis data yang mengekstrak model yang menggambarkan kelas-kelas data. Suatu classifier, atau model klasifikasi (classification model), memprediksi label berkategori (classes) (Han, et al., 2012).
commit to user
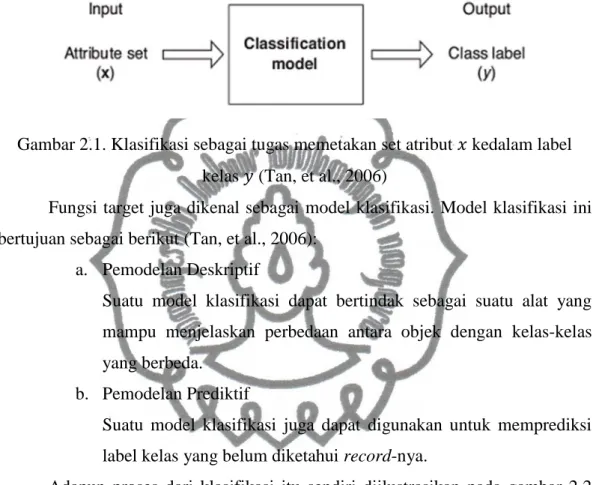
Sedangkan menurut Tan, et al. (2006) menjelaskan bahwa klasifikasi adalah tugas pembelajaran fungsi target 𝑓 yang memetakan setiap set atribut 𝑥 ke salah satu label kelas 𝑦 yang sudah dikenali. Gambar 2.1 merupakan ilustrasi penjelasan klasifikasi.
Gambar 2.1. Klasifikasi sebagai tugas memetakan set atribut 𝑥 kedalam label kelas 𝑦 (Tan, et al., 2006)
Fungsi target juga dikenal sebagai model klasifikasi. Model klasifikasi ini bertujuan sebagai berikut (Tan, et al., 2006):
a. Pemodelan Deskriptif
Suatu model klasifikasi dapat bertindak sebagai suatu alat yang mampu menjelaskan perbedaan antara objek dengan kelas-kelas yang berbeda.
b. Pemodelan Prediktif
Suatu model klasifikasi juga dapat digunakan untuk memprediksi label kelas yang belum diketahui record-nya.
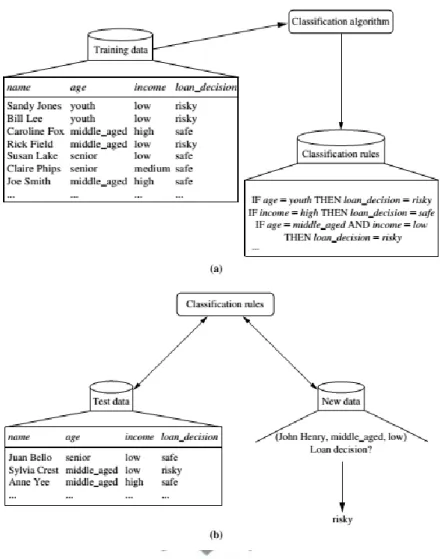
Adapun proses dari klasifikasi itu sendiri diilustrasikan pada gambar 2.2 dibawah ini:
commit to user
Gambar 2.2 Tahapan Proses Klasifikasi: (a) Pembelajaran: Data training dianalisis dengan menggunakan algoritma klasifikasi. (b) Klasifikasi: data tes
digunakan untuk memperkirakan akurasi dari aturan-aturan klasifikasi yang dipakai (Han, et al., 2012).
Berdasarkan ilustrasi diatas, proses klasifikasi data dibagi menjadi dua tahap (Han, et al., 2012), yaitu:
a. Tahap Pembelajaran
Disini tiap record data dari training set yang nilai atributnya saling berhubungan dianalisis dengan menggunakan suatu algoritma klasifikasi sehingga dapat menghasilkan suatu model pembelajaran atau classifier yang sesuai.
commit to user b. Tahap Klasifikasi
Pada tahap ini data tes digunakan untuk mengetahui ketepatan atau akurasi dari aturan-aturan klasifikasi yang berlaku pada model yang dihasilkan. Apabila tingkat akurasi yang diperoleh sesuai dengan nilai yang ditentukan, maka model tersebut dapat digunakan untuk mengklasifikasikan data record lain yang data kelasnya belum diketahui atau diujikan (dalam pembelajaran mesin, data tersebut juga dikenal sebagai data unkown atau prevously unseen data).
2. 1. 3 Naïve Bayes Classifier
Naïve Bayes Classifier merupakan salah satu teknik klasifikasi yang menggunakan metode probabilitas sederhana berdasarkan teorema bayes dengan asumsi ketidaktergantungan (independent) yang tinggi. Beberapa studi mengenai algoritma klasifikasi menunjukkan bahwa Naïve Bayes Classifier memiliki performa yang sebanding dengan decision tree dan neural network classifiers tertentu. Selain itu, metode ini juga menunjukkan akurasi dan kecepatan yang tinggi ketika digunakan dalam basis data yang berukuran besar (Han, et al., 2012). Teorema bayes yang digunakan sebagai dasar algoritma ini merupakan suatu teori yang dikemukakan oleh ilmuwan Inggris Thomas Bayes yang memprediksi probabilitas dimasa depan berdasarkan pengalaman dimasa sebelumnya. Teorema bayes diformulasikan sebagai berikut (Han, et al., 2012):
𝑃(𝐻|𝑋) = 𝑃(𝑋|𝐻)𝑃(𝐻) 𝑃(𝑋)
(2.1)
Dimana:
𝑋 : Data dengan class yang belum diketahui atau evidence. Digambarkan dengan ukuran yang dibuat dari sejumlah 𝑛 atribut
𝐻 : Hipotesis data tuple 𝑋 yang termasuk di dalam class tertentu 𝑃(𝐻|𝑋) : Probabilitas hipotesis 𝐻 berdasarkan kondisi 𝑋 (posetrior
probabiity)
𝑃(𝑋|𝐻) : Probabilitas 𝑋 berdasarkan kondisi pada hipotesis 𝐻 𝑃(𝐻) : Probabilitas hipotesis 𝐻 (prior probability)
commit to user
Untuk menjelaskan teorema Naïve Bayes, perlu diketahui bahwa proses dari klasifikasi membutuhkan sejumlah petunjuk untuk menentukan kelas yang sesuai dengan sampel yang dianalisis, sehingga teorema bayes diatas disesuaikan menjadi:
𝑃(𝐶𝑖|𝑋) =𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖) 𝑃(𝑋)
(2.2)
Disini 𝑋 memrepresentasikan vektor masukan yang berisikan fitur. Sedangkan 𝐶𝑖 merepresentasikan label kelas. Dengan asumsi bahwa nilai variabel dalam tiap kelas saling independen yang kuat (naïve) satu dengan yang lainnya maka: 𝑃(𝑋|𝐶𝑖) = ∏ 𝑃(𝑥𝑘|𝐶𝑖) 𝑛 𝑘=1 = 𝑃(𝑥1|𝐶𝑖) × 𝑃(𝑥2|𝐶𝑖) × … × 𝑃(𝑥𝑛|𝐶𝑖) (2.3)
Dikarenakan nilai 𝑃(𝑋) dalam setiap kelas bernilai konstan, maka model persamaan Naïve Bayes untuk klasifikasi dapat disederhanakan menjadi:
𝑃(𝐶𝑖|𝑋) = ∏ 𝑃(𝑥𝑘|𝐶𝑖)𝑃(𝐶𝑖)
𝑛
𝑘=1
(2.4)
Laplacian correction digunakan agar kemungkinan probabilitas yang dimaksudkan tidak ada yang bernilai 0. Rumus laplacian correction dalam kasus ini adalah sebagai berikut:
𝑃(𝑋 = 𝑥𝑘|𝐶𝑖) =
𝑁𝑖𝑘+ 𝑝 𝑁𝑖 + 𝑝. 𝑁𝑘
(2.5)
Dimana 𝑁𝑖𝑘 merupakan jumlah kejadian yang muncul di kolom 𝑘 dari baris 𝑖 pada data training, 𝑁𝑖 adalah jumlah kemunculan kejadian pada data training dari
kelas 𝐶𝑖, sedangkan 𝑁𝑘 adalah jumlah kejadian yang muncul pada kolom 𝑘 yang terdapat dalam data training, dan 𝑝 merupakan arbitrary probability, disini nilai 𝑝 = 1.
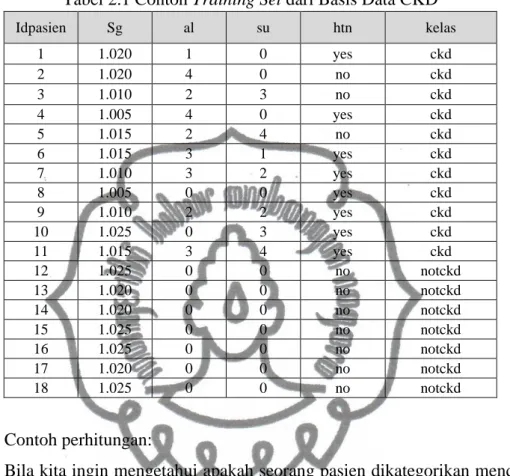
Tabel 2.1 menunjukkan contoh dataset ckd berdasarkan kondisi tertentu yang digunakan sebagai training set yang diambil secara acak. Dalam contoh ini atribut yang dipakai yaitu: sg (specific gravity) yang merupakan indikator kepekatan urine, al (albumin) merupakan kadar albumin dalam urine, su (sugar)
commit to user
merupakan kadar gula dalam urine, dan htn (hypertension) yang merupakan gejala hipertensi yang dimiliki pasien.
Tabel 2.1 Contoh Training Set dari Basis Data CKD
Contoh perhitungan:
Bila kita ingin mengetahui apakah seorang pasien dikategorikan menderita ckd atau tidak dengan kondisi sebagai berikut:
𝑿 = (𝑠𝑔 = 1.020, 𝑎𝑙 = 3, 𝑠𝑢 = 1, ℎ𝑡𝑛 = 𝑛𝑜)
Disini kita perlu menghitung nilai 𝑃(𝑿|𝐶𝑖)𝑃𝐶𝑖 untuk 𝑖 = 1, 2. Pertama yang dilakukan adalah menghitung nilai 𝑃(𝐶𝑖) masing-masing kelas dengan menerapkan
laplacian correction: 𝑃(𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) =11 + 1 18 + 2 = 12 20= 0,6 𝑃(𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) = 7 + 1 18 + 2 = 8 20= 0,4
Kemudian untuk menghitung 𝑃(𝑿|𝐶𝑖), untuk 𝑖 = 1, 2 kita perlu untuk menghitung masing-masing probabilitas dari tiap kondisi yang diberikan:
𝑃(𝑠𝑔 = 1.020|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) = 2 + 1 11 + 5= 3 16= 0,1875 Idpasien Sg al su htn kelas 1 1.020 1 0 yes ckd 2 1.020 4 0 no ckd 3 1.010 2 3 no ckd 4 1.005 4 0 yes ckd 5 1.015 2 4 no ckd 6 1.015 3 1 yes ckd 7 1.010 3 2 yes ckd 8 1.005 0 0 yes ckd 9 1.010 2 2 yes ckd 10 1.025 0 3 yes ckd 11 1.015 3 4 yes ckd 12 1.025 0 0 no notckd 13 1.020 0 0 no notckd 14 1.020 0 0 no notckd 15 1.025 0 0 no notckd 16 1.025 0 0 no notckd 17 1.020 0 0 no notckd 18 1.025 0 0 no notckd
commit to user 𝑃(𝑠𝑔 = 1.020|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) = 3 + 1 7 + 5= 4 12= 0,3333 𝑃(𝑎𝑙 = 3|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) = 3 + 1 11 + 5= 4 16= 0,25 𝑃(𝑎𝑙 = 3|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) = 0 + 1 7 + 5= 1 12= 0,0833 𝑃(𝑠𝑢 = 1|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) = 1 + 1 11 + 5= 2 16= 0,125 𝑃(𝑠𝑢 = 1|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) =0 + 1 7 + 5= 1 12= 0,0833 𝑃(ℎ𝑡𝑛 = 𝑛𝑜|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) = 3 + 1 11 + 2= 4 13= 0,3077 𝑃(ℎ𝑡𝑛 = 𝑛𝑜|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) = 7 + 1 7 + 2= 8 9= 0,8889 Berdasarkan probabilitas diatas, maka diperoleh:
𝑃(𝑿|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) = 𝑃(𝑠𝑔 = 1.020|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) × 𝑃(𝑎𝑙 = 3|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) × 𝑃(𝑠𝑢 = 1|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) × 𝑃(ℎ𝑡𝑛 = 𝑛𝑜|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) = 0,1875
×
0,25×
0,125×
0,3077 = 0,0018 𝑃(𝑿|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) = 𝑃(𝑠𝑔 = 1.020|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) × 𝑃(𝑎𝑙 = 3|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) × 𝑃(𝑠𝑢 = 1|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) × 𝑃(ℎ𝑡𝑛 = 𝑛𝑜|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) = 0,3333 × 0,0833 × 0,0833 × 0,8889 = 0,002Dengan demikian kelas penyakit 𝐶𝑖 didapatkan dengan menghitung nilai
𝑃(𝑿|𝐶𝑖)𝑃𝐶𝑖 sebagai berikut:
𝑃(𝑿|𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑)𝑃(𝑘𝑒𝑙𝑎𝑠 = 𝑐𝑘𝑑) = 0,6 × 0,0018 = 0,00108
𝑃(𝑿|𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑)𝑃(𝑘𝑒𝑙𝑎𝑠 = 𝑛𝑜𝑡𝑐𝑘𝑑) = 0,4 × 0,002 = 0,0008
Berdasarkan hasil diatas, maka Naïve Bayes classifier ini memprediksi pasien tersebut menderita ckd untuk kondisi 𝑿.
commit to user 2. 1. 4 AdaBoost
Algoritma AdaBoost pertama kali diperkenalkan pada tahun 1995 oleh Freund dan Schapire, telah banyak memecahkan berbagai masalah praktis dari algoritma boosting sebelumnya (Freund & Schapire, 1999). Boosting merupakan salah satu contoh metode ensemble (ensemble methods) yang menggabungkan suatu urutan model pembelajaran k (atau disebut juga sebagai classifier dasar), M1,
M2,...,Mk, dengan tujuan menciptakan model klasifikasi gabungan yang lebih baik,
M*. Metode ensemble ini mengembalikan hasil prediksi kelas berdasarkan penilaian
dari classifier dasarnya (Han, et al., 2012). Adapun algoritma AdaBoost memiliki pondasi teori yang solid, prediksi yang sangat akurat, tingkat kesederhanaan yang tinggi (cukup hanya dengan 10 baris kode), dan penggunaannya yang luas dan sukses (Wu, et al., 2007).
Penggambaran kerja dari algoritma AdaBoost adalah sebagai berikut: misalkan 𝒳 didenotasikan sebagai instance dan 𝒴 sebagai set label kelas. Diasumsikan 𝒴 = {−1, +1}. Kemudian diberikan algoritma pembelajaran dasar atau lemah (weak or base learning algorithm) dan sebuah training set {(𝒙1, 𝑦1), (𝒙2, 𝑦2), … , (𝒙𝑚, 𝑦𝑚)} dimana 𝒙𝑖 ∈ 𝒳 dan 𝑦𝑖 ∈ 𝒴. Kemudian algoritma AdaBoost bekerja sebagai berikut, pertama-tama tiap contoh training (training example) (𝑥𝑖, 𝑦𝑖)(𝑖 ∈ {1, … , 𝑚}) diberikan bobot yang sama. Denotasikan distribusi bobot pada putaran pembelajaran (learning round) ke-t sebagai 𝐷𝑡. Dari training set dan 𝐷𝑡 algoritma AdaBoost ini menghasilkan suatu weak atau base learner ℎ𝑡 ∶ 𝒳 → 𝒴 dengan memanggil algoritma pembelajaran dasarnya.
Kemudian contoh training tersebut digunakan untuk menguji ℎ𝑡, dan bobot-bobot dari contoh klasifikasi yang salah akan meningkat. Dengan demikian, suatu distribusi bobot yang telah diperbarui 𝐷𝑡+1 diperoleh. Dari training set dan 𝐷𝑡+1 AdaBoost menghasilkan weak learner lain dengan memanggil algoritma pembelajaran dasarnya lagi. Proses tersebut diulang untuk putaran T, dan model akhir diperoleh dengan suara terbanyak terbobot (weighted majority voting) dari kumpulan T weak learner, dimana bobot dari learner tersebut ditentukan selama proses pelatihan atau training (Wu, et al., 2007).
commit to user
Dalam pengembangannya, metode AdaBoost memiliki banyak varian turunan antara lain: AdaBoost.M1 (Freund & Schapire, 1996), AdaBoost.M1W (Eibl & Pfeiffer, 2002), Kullback-Leibler Boosting (KLBoosting) (Liu & Shum, 2003), dan Jensen-Shannon Boosting (JSBoost) (Huang, et al., 2005).
AdaBoost.M1 yang diajukan oleh Freund dan Schapire merupakan generalisasi langsung dari AdaBoost untuk dua kelompok dari masalah multikelas. Sedangkan AdaBoost.M1W merupakan pengembangan dari algoritma AdaBoost.M1 dengan meminimalisasi batas atas pengukuran kinerja yang disebut dengan guessing error (Eibl & Pfeiffer, 2002). Kemudian untuk algoritma KLBoosting dan JSBoost digunakan untuk pendeteksian pola atau objek gambar. Implementasi AdaBoost dalam WEKA sendiri menggunakan varian AdaBoost.M1. Berikut ini merupakan teknik pembobotan dari algoritma AdaBoost.M1:
Input:
Dataset 𝒟 = {(𝑥1, 𝑦1), … , (𝑥𝑚, 𝑦𝑚)}; dengan label 𝑦𝑖 ∈ 𝑌 = {1, … , 𝑘}
Algoritma pembelajaran dasar (base learning algorithm) ℒ; Jumlah iterasi atau perulangan 𝑇.
Proses:
#Inisialisasi nilai bobot 𝐷1(𝑖) = 1
𝑚 untuk 𝑖 = 1, … , 𝑚
Do for 𝑡 = 1, … , 𝑇:
# Latih weak learn ℎ𝑡 dari 𝒟 dengan menggunakan distribusi 𝐷𝑡
ℎ𝑡 = ℒ(𝒟, 𝐷𝑡); (2.6)
# Hitung error dari ℎ𝑡
𝜖𝑡= 𝑃𝑟𝑖~𝐷𝑖[ℎ𝑡(𝑥𝑖 ≠ 𝑦𝑖)]; (2.7) 𝜖𝑡= ∑ 𝐷𝑡(𝑖)
𝑖:ℎ𝑡(𝑥𝑖)≠𝑦𝑖
(2.8)
Jika 𝜖𝑡≥ ½, maka set 𝑇 = 𝑡 − 1, batalkan loop dan langsung menuju output
# Menentukan bobot dari ℎ𝑡
𝛼𝑡 = ln (1−𝜖𝑡
𝜖𝑡 );
(2.9)
commit to user 𝐷𝑡+1(𝑖) = 𝐷𝑡(𝑖) 𝑍𝑡 × { exp(−𝛼𝑡) if ℎ𝑡(𝑥𝑖) = 𝑦𝑖 exp(𝛼𝑡) if ℎ𝑡(𝑥𝑖) ≠ 𝑦𝑖 (2.10) # dimana 𝑍𝑡 sebuah faktor normalisasi yang mengaktifkan 𝐷𝑡+1 menjadi distribusi
Output: Tentukan classifier akhir 𝐻fin(𝑥)
𝐻fin(𝑥) = arg max
𝑦∈𝑌 ∑ 𝛼𝑡
𝑡:ℎ𝑡(𝑥)=𝑦
(2.11)
Berikut merupakan contoh perhitungan menggunakan algoritma AdaBoost.M1, dengan diberikan suatu data training (berisi 2 kelas yaitu {1,-1}) seperti pada tabel 2.2 dibawah ini:
Tabel 2.2 Contoh Data Training
Index 0 1 2 3 4 5 6 7 8 9
Nilai 𝑥 0 1 2 3 4 5 6 7 8 9
Nilai 𝑦 1 1 1 -1 -1 -1 1 1 1 -1
Berdasarkan data training diatas, weak learner menghasilkan hipotesis dengan form: 𝑥 ≤ 𝑣 dan 𝑥 ≥ 𝑣. Threshold (ambang batas) 𝑣 ditentukan untuk meminimalisasi kemungkinan kesalahan atas keseluruhan data. Pada data diatas diperoleh threshold 𝑥 ≤ 2, 𝑥 ≥ 5, dan 𝑥 ≤ 8.
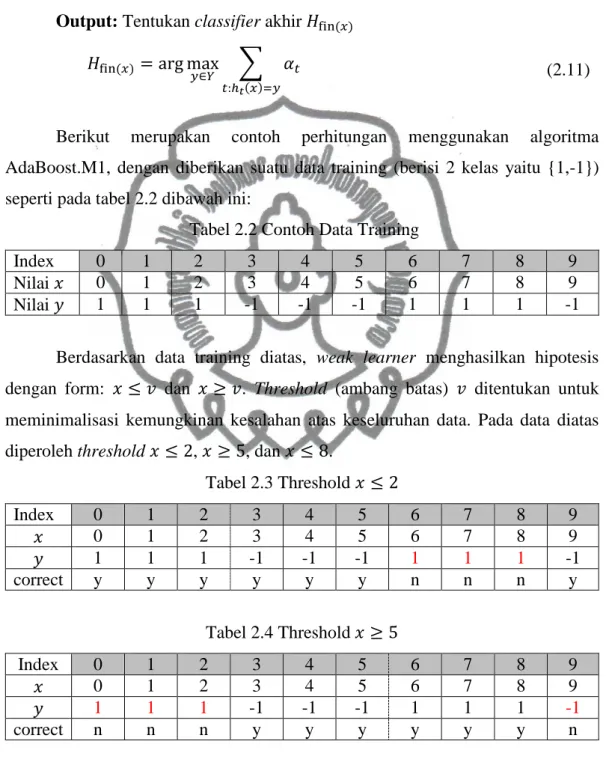
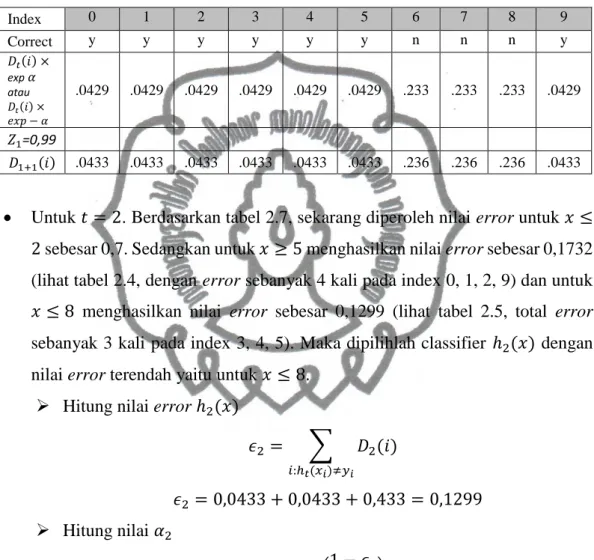
Tabel 2.3 Threshold 𝑥 ≤ 2 Index 0 1 2 3 4 5 6 7 8 9 𝑥 0 1 2 3 4 5 6 7 8 9 𝑦 1 1 1 -1 -1 -1 1 1 1 -1 correct y y y y y y n n n y Tabel 2.4 Threshold 𝑥 ≥ 5 Index 0 1 2 3 4 5 6 7 8 9 𝑥 0 1 2 3 4 5 6 7 8 9 𝑦 1 1 1 -1 -1 -1 1 1 1 -1 correct n n n y y y y y y n
commit to user Tabel 2.5 Threshold 𝑥 ≤ 8 Index 0 1 2 3 4 5 6 7 8 9 𝑥 0 1 2 3 4 5 6 7 8 9 𝑦 1 1 1 -1 -1 -1 1 1 1 -1 correct y y y n n n y y y y
Proses jalannya algoritma adalah sebagai berikut: Inisialisasi nilai bobot dari 𝐷1(𝑖) maka diperoleh:
Tabel 2.6 Inisialisasi Bobot Awal
Index 0 1 2 3 4 5 6 7 8 9
𝐷1(𝑖) 0,1 0,1 0,1 0,1 0,1 0,1 0,1 0,1 0,1 0,1 Untuk 𝑡 = 1, diperoleh classifier ℎ1(𝑥) dengan nilai error terendah berada
pada 𝑥 ≤ 2, dengan error di index 6, 7, dan 8. Untuk 𝑥 ≤ 2, nilai 𝑦 yang benar seharusnya bernilai 1, dan untuk 𝑥 > 2, nilai 𝑦 yang benar seharusnya bernilai -1.
Hitung nilai error ℎ1(𝑥)
𝜖1 = ∑ 𝐷1(𝑖) 𝑖:ℎ𝑡(𝑥𝑖)≠𝑦𝑖 𝜖1 = 0,1 + 0,1 + 0,1 = 0,3 Hitung nilai 𝛼1 𝛼1 = ln (1 − 𝜖1 𝜖1 ) 𝛼1 = ln (1 − 0,3 0,3 ) 𝛼1 = 0,8473 Update distribusi 𝐷𝑡+1(𝑖) = 𝐷1(𝑖) 𝑍1 × {exp(−𝛼1) if ℎ𝑡(𝑥𝑖) = 𝑦𝑖 exp(𝛼1) if ℎ𝑡(𝑥𝑖) ≠ 𝑦𝑖 = 0,1 0,99× { exp(−0,8473) = 0,4286 𝑗𝑖𝑘𝑎 𝑏𝑒𝑛𝑎𝑟 exp(0,8473) = 2,3333 𝑗𝑖𝑘𝑎 𝑠𝑎𝑙𝑎ℎ = 0,042860,99 = 0,04329 (benar); 0,233330,99 = 0,2357 (salah)
commit to user
𝑍𝑡 merupakan faktor normalisasi yang mengaktifkan 𝐷𝑡+1(𝑖) menjadi
distribusi, sehingga nilai 𝑍1 didapatkan dari penjumlahan seluruh nilai distribusi. Tabel 2.7 menunjukkan hasil masing-masing nilai terbobot yang dihasilkan.
Tabel 2.7 Hasil Probabilitas 𝑡 = 1 Pada 𝑥 ≤ 2
Index 0 1 2 3 4 5 6 7 8 9 Correct y y y y y y n n n y 𝐷𝑡(𝑖) × exp 𝛼 atau 𝐷𝑡(𝑖) × 𝑒𝑥𝑝 − 𝛼 .0429 .0429 .0429 .0429 .0429 .0429 .233 .233 .233 .0429 𝑍1=0,99 𝐷1+1(𝑖) .0433 .0433 .0433 .0433 .0433 .0433 .236 .236 .236 .0433
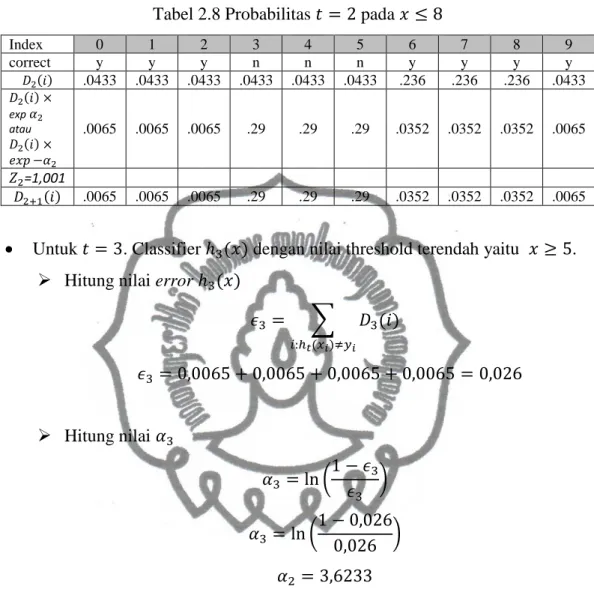
Untuk 𝑡 = 2. Berdasarkan tabel 2.7, sekarang diperoleh nilai error untuk 𝑥 ≤ 2 sebesar 0,7. Sedangkan untuk 𝑥 ≥ 5 menghasilkan nilai error sebesar 0,1732 (lihat tabel 2.4, dengan error sebanyak 4 kali pada index 0, 1, 2, 9) dan untuk 𝑥 ≤ 8 menghasilkan nilai error sebesar 0,1299 (lihat tabel 2.5, total error sebanyak 3 kali pada index 3, 4, 5). Maka dipilihlah classifier ℎ2(𝑥) dengan nilai error terendah yaitu untuk 𝑥 ≤ 8.
Hitung nilai error ℎ2(𝑥)
𝜖2 = ∑ 𝐷2(𝑖) 𝑖:ℎ𝑡(𝑥𝑖)≠𝑦𝑖 𝜖2 = 0,0433 + 0,0433 + 0,433 = 0,1299 Hitung nilai 𝛼2 𝛼2 = ln (1 − 𝜖2 𝜖2 ) 𝛼2 = ln (1 − 0,1299 0,1299 ) 𝛼2 = 1,9018
commit to user Update distribusi
Tabel 2.8 Probabilitas 𝑡 = 2 pada 𝑥 ≤ 8
Index 0 1 2 3 4 5 6 7 8 9 correct y y y n n n y y y y 𝐷2(𝑖) .0433 .0433 .0433 .0433 .0433 .0433 .236 .236 .236 .0433 𝐷2(𝑖) × exp 𝛼2 atau 𝐷2(𝑖) × 𝑒𝑥𝑝 −𝛼2 .0065 .0065 .0065 .29 .29 .29 .0352 .0352 .0352 .0065 𝑍2=1,001 𝐷2+1(𝑖) .0065 .0065 .0065 .29 .29 .29 .0352 .0352 .0352 .0065
Untuk 𝑡 = 3. Classifier ℎ3(𝑥) dengan nilai threshold terendah yaitu 𝑥 ≥ 5.
Hitung nilai error ℎ3(𝑥)
𝜖3 = ∑ 𝐷3(𝑖) 𝑖:ℎ𝑡(𝑥𝑖)≠𝑦𝑖 𝜖3 = 0,0065 + 0,0065 + 0,0065 + 0,0065 = 0,026 Hitung nilai 𝛼3 𝛼3 = ln (1 − 𝜖3 𝜖3 ) 𝛼3 = ln ( 1 − 0,026 0,026 ) 𝛼2 = 3,6233 Update distribusi
Tabel 2.9 Probabilitas 𝑡 = 3 pada 𝑥 ≥ 5
Index 0 1 2 3 4 5 6 7 8 9 correct n n n y y y y y y n 𝐷3(𝑖) .0065 .0065 .0065 .29 .29 .29 .0352 .0352 .0352 .0065 𝐷2(𝑖) × exp 𝛼2 atau 𝐷2(𝑖) × 𝑒𝑥𝑝 −𝛼2 .243 .243 .243 .008 .008 .008 .0009 .0009 .0009 .243 𝑍2=0,999 𝐷3+1(𝑖) .243 .243 .243 .008 .008 .008 .0009 .0009 .0009 .243
commit to user Output Classifier akhir 𝐻fin(𝑥)
𝐻fin(𝑥) = arg max
𝑦∈𝑌 ∑ 𝛼𝑡
𝑡:ℎ𝑡(𝑥)=𝑦
𝐻fin(𝑥) = arg max
𝑦∈𝑌 (𝛼1+ 𝛼2+ 𝛼3)
𝐻fin(𝑥) = arg max
𝑦∈𝑌 (0,8473 + 1,9018 + 3,6233)
𝐻fin(𝑥)= 6,3724
Hipotesis akhir atau final 𝐻fin adalah suara tertimbang (yaitu, threshold linear tertimbang) dari hipotesis lemah. Artinya, ketika diberikan suatu instance 𝑥, maka 𝐻fin(𝑥) menghasilkan output pada label (kelas) 𝑦 yang memaksimalkan jumlah bobot dari hipotesis lemah yang memprediksi label tersebut (Freund & Schapire, 1996).
2. 1. 5 Penyakit Ginjal Kronik (Chronic Kidney Disease, CKD)
Definisi dan klasifikasi dari CKD yang digulirkan oleh National Kidney Foundation Kidney Disease Outcome Quality Initiative pada tahun 2002 dan direvisi oleh Kidney Disease Improving Global Outcomes tahun 2004 menyebutkan bahwa CKD adalah kelainan struktur atau fungsi ginjal ≥3 bulan yang ditunjukkan dengan kerusakan ginjal, dengan atau tanpa penurunan GFR seperti yang diketahui melalui kelainan hispatologi, tanda-tanda kerusakan ginjal (kelainan komposisi urin dan darah maupun uji pencitraan ginjal), dan transpantasi ginjal. Laju filtrasi glomerulus (GFR) kurang dari 60 ml/menit/1,73 m2 ≥3 bulan dengan atau tanpa kerusakan ginjal (Levey, et al., 2007). Analisis terkini menunjukan bahwa peningkatan albuminaria juga memiliki pengaruh yang penting terhadap hasilnya (Jha, et al., 2013).
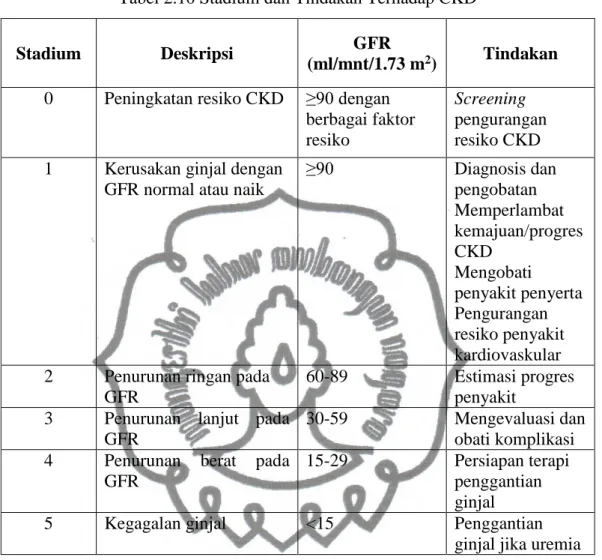
Tabel 2.10 merupakan stadium dan rencana tindakan terhadap CKD (Reilly & Perazella, 2005):
commit to user
Tabel 2.10 Stadium dan Tindakan Terhadap CKD
Stadium Deskripsi GFR
(ml/mnt/1.73 m2) Tindakan
0 Peningkatan resiko CKD ≥90 dengan berbagai faktor resiko
Screening pengurangan resiko CKD 1 Kerusakan ginjal dengan
GFR normal atau naik
≥90 Diagnosis dan pengobatan Memperlambat kemajuan/progres CKD Mengobati penyakit penyerta Pengurangan resiko penyakit kardiovaskular 2 Penurunan ringan pada
GFR
60-89 Estimasi progres
penyakit 3 Penurunan lanjut pada
GFR
30-59 Mengevaluasi dan
obati komplikasi 4 Penurunan berat pada
GFR
15-29 Persiapan terapi penggantian ginjal
5 Kegagalan ginjal <15 Penggantian
commit to user 2. 2. Penelitian Terkait
Penelitian ini mengacu pada penelitian atau studi sejenis yang telah dilakukan sebelumnya. Saputra melakukan penelitian dengan judul komparasi algoritma data mining untuk memprediksi penyakit tubercolusis yang merupakan studi kasus di Puskesmas Karawang Sukabumi pada tahun 2014. Pada penelitian ini, peneliti melakukan komparasi algoritma C4.5, Naïve Bayes, neural network, dan logistic regression yang diaplikasikan terhadap data pasien yang dinyatakan positif TB dan negatif TB. Dari hasil pengujian dengan mengukur kinerja dari keempat algoritma tersebut menggunakan metode pengujian Confusion matrix dan Kurva Receiver Operating Characteristic (ROC), diketahui bahwa algoritma Naïve Bayes memiliki nilai accuracy paling tinggi, yaitu 91,61% diikuti algoritma C4.5 sebesar 89,77%, metode neural network sebesar 84,07%, dan yang terendah adalah metode logistic regression dengan nilai accuracy 80,02%. Nilai Area Under Curve (AUC) untuk metode Naïve Bayes juga menunjukkan nilai tertinggi sebesar 0,995, disusul algoritma C4.5 dengan nilai AUC sebesar 0,982, metode logistic regression dengan nilai AUC 0,968 dan yang terendah adalah nilai AUC neural network sebesar 0,940.
Adapun penelitian mengenai penggunaan algoritma AdaBoost dilakukan oleh Korada, et al (2012). Penelitian ini menggunakan algoritma AdaBoost untuk meningkatkan akurasi dari weak learner berupa Naïve Bayes Classifier. Algoritma AdaBoost ini bekerja secara iteratif pada Naïve Bayesian classifier yang bobotnya sudah dinormalisasi dan menghasilkan klasifikasi dengan kelas yang berbeda sesuai dengan input yang diberikan. Maize Expert System merupakan sistem pakar yang digunakan untuk mendeteksi penyakit pada tanaman jagung, sistem pakar ini menggunakan algoritma Naïve Bayes yang ditingkatkan akurasinya dengan menggunakan logika AdaBoost. Dari hasil yang diperoleh, kinerja dari Naïve Bayes Classifier (sebagai weak learner) meningkat sebesar 33% dengan bantuan algoritma AdaBoost sehingga nilai error atau kesalahan dari misklasifikasi dapat berkurang.
Penelitian lain yang terkait dengan penggunaan metode Naïve Bayes dan algoritma AdaBoost yaitu penelitian yang dilakukan oleh Utami dan Wahono (2015). Metode
commit to user
yang tersebut digunakan untuk klasifikasi sentimen review restoran. Dalam penelitian ini, information gain digunakan sebagai seleksi fitur dan algoritma AdaBoost untuk mengurangi bias agar dapat meningkatkan akurasi algoritma Naïve Bayes. Dengan validasi 10-fold cross validation dan pengukuran akurasi dengan confusion matrix, hasil akurasi yang didapatkan dengan metode Naïve Bayes saja mencapai 70% dan AUC = 0,500. Sama halnya jika Naïve Bayes disertai dengan information gain, akurasi yang dicapaipun hanya 70% dan AUC=0,500 yang membuktikan bahwa information gain tidak mempengaruhi akurasi terhadap Naïve Bayes. Akan tetapi jika kedua metode tersebut digabungkan dengan AdaBoost, akurasi meningkat 29,5% menjadi 99,5% dan AUC = 0,995.
commit to user
35
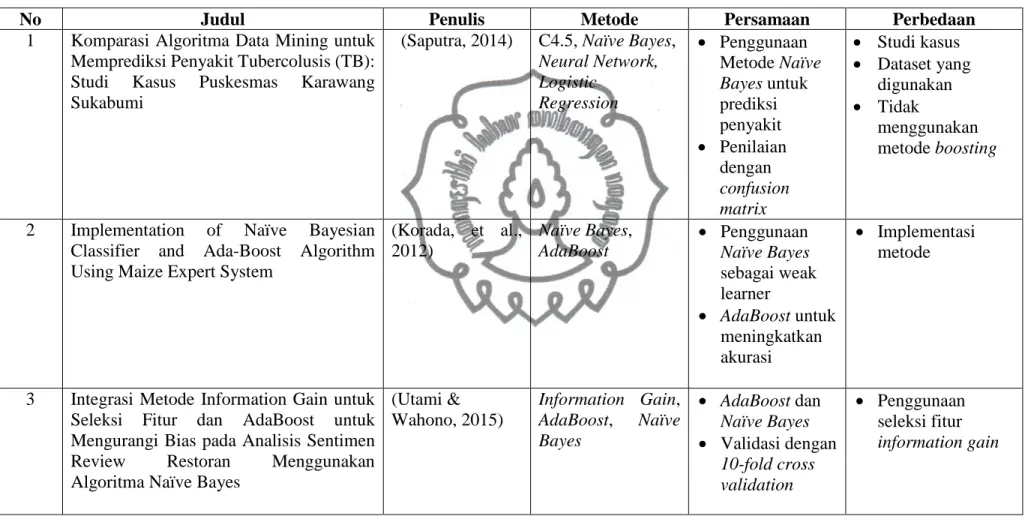
Tabel 2.11 Tabel Penelitian Terkait
No Judul Penulis Metode Persamaan Perbedaan
1 Komparasi Algoritma Data Mining untuk Memprediksi Penyakit Tubercolusis (TB): Studi Kasus Puskesmas Karawang Sukabumi
(Saputra, 2014) C4.5, Naïve Bayes, Neural Network, Logistic Regression Penggunaan Metode Naïve Bayes untuk prediksi penyakit Penilaian dengan confusion matrix Studi kasus Dataset yang digunakan Tidak menggunakan metode boosting
2 Implementation of Naïve Bayesian Classifier and Ada-Boost Algorithm Using Maize Expert System
(Korada, et al., 2012) Naïve Bayes, AdaBoost Penggunaan Naïve Bayes sebagai weak learner AdaBoost untuk meningkatkan akurasi Implementasi metode
3 Integrasi Metode Information Gain untuk Seleksi Fitur dan AdaBoost untuk Mengurangi Bias pada Analisis Sentimen Review Restoran Menggunakan Algoritma Naïve Bayes
(Utami & Wahono, 2015) Information Gain, AdaBoost, Naïve Bayes AdaBoost dan Naïve Bayes Validasi dengan 10-fold cross validation Penggunaan seleksi fitur information gain
commit to user
Penelitian yang akan dilakukan merupakan penelitian tentang analisis terhadap pengaruh algoritma AdaBoost dengan menggunakan metode Naïve Bayes sebagai classifier-nya. Data yang digunakan berasal dari UCI Machine Learning Repository berupa dataset mengenai stadium awal penyakit ginjal kronik (early stage of chronic kidney disease) yang terdiri dari 25 atribut (24 parameter input dan 1 parameter output berupa kelas) dan berisi 400 instance (250 CKD dan 150 notckd).
Algoritma AdaBoost digunakan untuk meningkatkan kinerja dari metode Naïve Bayes classifier. Dengan menggunakan metode validasi 10-fold cross validation, dataset CKD tersebut dibagi menjadi data training dan data testing. Penelitian ini dilakukan dengan dua cara yaitu pertama dataset tersebut dilakukan training dengan menggunakan metode Naïve Bayes, sedangkan yang kedua, dataset tersebut di-training menggunakan metode Naïve Bayes yang dioptimalisasi dengan algoritma AdaBoost. Hasil dari training dan testing dari masing-masing metode kemudian dibandingkan sehingga diperoleh suatu kesimpulan mengenai pengaruh algoritma AdaBoost terhadap peningkatan kinerja yang diterapkan pada metode Naïve Bayes classifier. Selain itu perbandingan performa juga dilakukan terhadap dataset yang masih memiliki missing value dan dataset yang sudah mengalami pengisian atau perubahan pada missing value-nya.