KAJIAN EMPIRIS PERBANDINGAN METODE SAMPLING DALAM
MENDUGA POPULASI MINIMARKET DI INDONESIA
ABADI WIBOWO
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK
CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul “Kajian Empiris Perbandingan Metode Sampling dalam Menduga Populasi Minimarket di Indonesia ” adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini. Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Oktober 2015
Abadi Wibowo G152130334
* Pelimpahanhak cipta atas karya tulis dari penelitian kerjasama dengan pihak luar IPB harus didasarkan pada perjanjian kerjasama yang terkait
RINGKASAN
ABADI WIBOWO. Kajian Empiris Perbandingan Metode Sampling dalam Menduga Populasi Minimarket di Indonesia. Dibimbing oleh INDAHWATI, I MADE SUMERTAJAYA, dan ERNI TRI ASTUTI. Minimarket merupakan salah satu dari tiga jenis toko modern. Minimarket dapat memberikan kontribusi positif terhadap sektor perdagangan. Namun, keberadaannya juga dapat membuat makin semrawutnya tata kota di suatu wilayah. Selama ini informasi populasi minimarket, hanya berasal dari data yang dikumpulkan 3 kali dalam 10 tahun. Survei secara berkala (3 atau 6 bulan sekali) dapat menjadi solusi untuk menduga populasi seperti berapa jumlahnya dan sejauh mana dampak nya terhadap sektor-sektor ekonomi yang berkaitan.
Survei memerlukan sejumlah tahapan. Salah satunya adalah melakukan sampling. Dengan melakukan sampling, parameter populasi yang tidak diketahui dapat diperkirakan berdasarkan nilai-nilai dari unit pengamatan dalam sampel. Tujuan dari penelitian ini adalah untuk mendapatkan metode sampling yang terbaik untuk memperkirakan populasi minimarket di Indonesia.
Sumber data untuk simulasi adalah dari PODES 2011, menggunakan data dari desa-desa yang memiliki minimarket. Metode analisis memiliki beberapa langkah. Langkah pertama adalah eksplorasi data minimarket dan langkah kedua adalah estimasi parameter menggunakan 100 kali simulasi di beberapa ukuran sampel yang berbeda. Langkah selanjutnya adalah membandingkan hasil estimasi parameter berdasarkan nilai bias, standard error, dan MSE. Penelitian ini membandingkan estimasi parameter dalam satu metode sampling, dan antara satu metode sampling dengan yang lain. Untuk metode satu tahap sampling, stratified random sampling (menggunakan status pemerintah daerah sebagai strata) pada ukuran sampel 1000 hasil estimasi parameter memiliki akurasi tertinggi. Nilai MSE adalah 3,9 juta. Dan untuk metode sampling dua tahap, stratified two stage cluster sampling pada ukuran sampel 1000 di 15 provinsi (menggunakan status pemerintah daerah sebagai strata) memiliki akurasi tertinggi dengan MSE sebesar 4,3 juta.
SUMMARY
ABADI WIBOWO. Empirical Comparison Study of Sampling Methods in Predicting Population Minimarket in Indonesia. Supervised by INDAHWATI, I MADE SUMERTAJAYA and ERNI TRI ASTUTI.
Minimarket is one of three types of modern stores. Minimarket can make a positive contribution to the trade sector. However, its existence can also create more chaotic urban planning in the region. All this information minimarket population, only comes from data collected 3 times in 10 years. Surveys regularly (3 or 6 months) may be a solution for estimating populations such as how much and how far its impact on the economic sectors concerned.
Surveys require a number of stages. One of them is doing the sampling. By doing sampling, unknown population parameters can be estimated based on the values of the unit of observation in the sample. The objective of this study is to obtain the best sampling method to estimate the population of minimarket in Indonesia.
Data source for the simulation is from PODES 2011, using the data of villages which have minimarket. The method of analysis has several steps. The first step is exploring minimarket data and the second step is estimating the parameters using 100 times simulation at some different sample size. The next step is comparing the result of parameter estimation based on the value of bias, standard error, and MSE. The study is comparing the parameter estimation in one sampling method, and between one sampling method with another.
For one-stage sampling method, the stratified random sampling (using local government status as strata) at sample size of 1000 results in parameter estimation with the highest accuracy. Its MSE value is 3,9 million. And for two-stage sampling method, the stratified two stage cluster sampling at sample size of 1000 in 15 provinces (using local government status as strata) has the highest accuracy with MSE is 4,3 million.
Keywords: sampling, comparison, simple, stratified, cluster, minimarket, random
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpamencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah, dan pengutipan tersebut tidak merugikan kepentingan IPB
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini dalam bentuk apapun tanpa izin IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika Terapan
KAJIAN EMPIRIS PERBANDINGAN METODE SAMPLING
DALAM MENDUGA POPULASI MINIMARKET DI
INDONESIA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Tesis : Kajian Empiris Perbandingan Metode Sampling dalam Menduga Populasi Minimarket di Indonesia
Nama : Abadi Wibowo NIM : G152130334
Disetujui oleh Komisi Pembimbing
Dr Ir Indahwati, M.Si Ketua
Dr Ir I Made Sumertajaya, M.Si Anggota
Dr Erni Tri Astuti, M.Math Anggota
Diketahui oleh
Ketua Program Studi Statistika Terapan
Dr Ir Indahwati, MSi
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis ucapkan kehadirat Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan tesis yang berjudul “Kajian Empiris Perbandingan Metode Sampling dalam Menduga Populasi Minimarket di Indonesia”. Keberhasilan penulisan tesis ini tidak lepas dari bantuan, bimbingan, dan petunjuk dari berbagai pihak.
Terima kasih penulis ucapkan kepada Ibu Dr. Ir.Indahwati, M.Si sebagai ketua komisi pembimbing, Bapak Dr. Ir. I Made Sumertajaya, M. Si dan Ibu Dr. Erni Tri Astuti, M.Math sebagai anggota komisi pembimbing yang telah memberikan bimbingan, arahan serta saran kepada penulis. Penulis juga mengucapkan terima kasih kepada Pimpinan Badan Pusat Statistik (BPS) atas kesempatan yang diberikan kepada penulis untuk menempuh jenjang Magister Statistika Terapan. Ungkapan terima kasih terkhusus penulis sampaikan kepada orang tua, istri dan anak-anak tercinta serta seluruh keluarga besar atas do’a, dukungan dan pengertiannya. Terimakasih pula kepada seluruh staf Program Studi Statistika Terapan, teman-teman Statistika (S2 dan S3) dan Statistika Terapan (S2) khususnya kelas BPS atas bantuan dan kebersamaannya. Terima kasih tak lupa penulis sampaikan kepada semua pihak yang tidak dapat penulis sebutkan satu per satu yang telah membantu dalam penyusunan tesis ini.
Penulis menyadari bahwa tesis ini masih banyak kekurangan. Semoga penelitian selanjutnya dapat lebih baik dari penelitian ini. Semoga penelitian ini bermanfaat bagi yang membutuhkan.
Bogor, Oktober 2015
DAFTAR ISI
DAFTAR ISI vi
DAFTAR TABEL vii
DAFTAR GAMBAR vii
1 PENDAHULUAN 1
Latar Belakang 1 Tujuan Penelitian 3 2 TINJAUAN PUSTAKA 4
Karakteristik Penduga Parameter Populasi 4 Konsep Dasar 5 Simple Random Sampling 6 Stratified Random Sampling 6 Two Stage Cluster Sampling 7 Stratified Two Stage Cluster Sampling 8 3 METODE PENELITIAN 10
Data 10 Metode Analisis 10 Evaluasi Pemilihan Metode Sampling 13
4 HASIL DAN PEMBAHASAN 15
Eksplorasi Data 15 Simple Random Sampling 17 Stratified Random Sampling 17 Prinsip Pelapisan 17 Pengalokasian Sampel ke Lapisan 18 Lapisan Berdasarkan Jumlah Penduduk 18 Lapisan Berdasarkan Status Desa 19 Lapisan Berdasarkan Status Pemerintah Daerah 19 Two Stage Cluster Sampling 20 Stratified Two Stage Cluster Sampling 21 Lapisan Berdasarkan Status Pemerintah Daerah 21 Lapisan Berdasarkan Status Desa 22 Perbandingan Antar Metode Sampling 23 Kriteria Validitas 23
Kriteria Reliabilitas 25
Kriteria Akurasi 27
5 SIMPULAN DAN SARAN 30
DAFTAR PUSTAKA 31
LAMPIRAN 32
DAFTAR TABEL
4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 4.10 4.11 4.12Ringkasan data populasi minimarket di Indonesia tahun 2011 15 Ringkasan data populasi minimarket dan penduduk menurut
propinsi di Indonesia tahun 2011 16
Persentase minimarket menurut pulau di Indonesia tahun 2011 16 Hasil simulasi pada metode simple random sampling 17 Rata-rata dan ragam jumlah penduduk per desa pada setiap lapisan
Hasil simulasi pada metode stratified random sampling
berdasarkan jumlah penduduk 19
Hasil simulasi pada metode stratified random sampling
berdasarkan status desa 19
Hasil simulasi pada metode stratified random sampling
berdasarkan status pemerintah daerah 20
Hasil simulasi pada metode two stage cluster sampling 20 Hasil simulasi pada metode stratified two stage cluster
sampling berdasarkan status pemerintah daerah 19
Hasil simulasi pada metode stratified two stage cluster
sampling berdasarkan status desa 20
Rata-rata dan ragam penduduk per desa pada stratified two
stage cluster sampling berdasarkan status pemerintah daerah 27
15 16 16 17 18 19 19 20 20 21 22
DAFTAR GAMBAR
3.1 3.2 3.3 3.4 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8Diagram alir simulasi pendugaan total populasi dan ragam pada
simple random sampling
Diagram alir simulasi pendugaan total populasi dan ragam pada
stratified random sampling
Diagram alir simulasi pendugaan total populasi dan ragam pada two
stages cluster sampling
Diagram alir simulasi pendugaan total populasi dan ragam pada
stratified two stages cluster sampling
Persentase minimarket menurut status desa di Indonesia tahun 2011 Rasio bias terhadap galat baku penduga (<0,1) pada sampling satu tahap
Persentase bias terkecil terhadap total populasi pada sampling satu tahap
Persentase bias terkecil terhadap total populasi pada sampling dua tahap
Sebaran relative standar error terkecil pada sampling satu tahap Sebaran relative standar error terkecil pada sampling dua tahap
Sebaran MSE terkecil pada sampling satu tahap Sebaran MSE terkecil pada sampling dua tahap
11 12 12 13 15 24 24 25 26 26 28 29
1
1 PENDAHULUAN
Latar Belakang
Minimarket merupakan salah satu dari tiga jenis toko modern dengan daya jangkau penyebaran hingga ke pelosok-pelosok desa. Dua jenis toko modern yang lain adalah supermarket dan hipermarket. Keberadaan minimarket lebih mendekati konsumen akhir, seperti di pinggiran kota atau di tengah-tengah pemukiman penduduk. Semakin banyak penduduk di suatu wilayah, keberadaan minimarket semakin mudah untuk dijumpai.
Beberapa sisi positif keberadaan minimarket dari segi konsumen akhir adalah semakin mudah mendapatkan barang konsumsi khususnya produk fast moving consumer goods (FMCG), belanja nyaman dengan ruang AC, dan sering ada promo-promo khusus yang menguntungkan konsumen. Sisi positif lainnya dari segi pendapatan regional, minimarket memiliki nilai tambah yang dapat memberikan kontribusi kepada sektor perdagangan khususnya sub sektor perdagangan besar dan eceran. Minimarket menjadi sarana pemasaran yang efektif bagi pelaku industri khususnya makanan dan minuman. Namun, di sisi lain, keberadaan minimarket dapat memberikan dampak negatif. Secara khusus bagi warung-warung kecil atau perdagangan eceran sejenis, minimarket berpotensi mengurangi omset pada usaha-usaha tersebut. Persaingan perang harga atau keinginan konsumen untuk belanja lebih nyaman dapat menjadi faktor semakin berkembangnya minimarket. Dampak negatif lain dari keberadaan minimarket adalah semakin semrawutnya tata kota di suatu wilayah. Kini semakin mudah menjumpai minimarket yang sangat berdekatan. Bahkan dalam radius 100 meter persegi, bisa terdapat 4 sampai 5 minimarket di suatu wilayah. Data BPS menunjukkan bahwa sentra penetrasi minimarket di Indonesia berada di Pulau Jawa dan Sumatera. Tahun 2011, jumlahnya mencapai lebih dari 75 persen dari total populasi minimarket. Jumlah ini sejalan dengan distribusi penduduk Indonesia di Pulau Jawa dan Sumatera yang juga mencapai lebih dari 75 persen.
Peraturan Menteri Perdagangan RI Nomor 70 tahun 2013 mensyaratkan pelaku usaha minimarket untuk melengkapi dokumen analisa kondisi sosial ekonomi masyarakat setempat. Beberapa dokumen tersebut adalah struktur penduduk menurut mata pencaharian dan pendidikan, tingkat pendapatan ekonomi rumah tangga, tingkat kepadatan dan pertumbuhan penduduk di masing-masing daerah, penyerapan tenaga kerja, serta dampak positif dan negatif terhadap pasar tradisional atau toko eceran tradisional yang telah ada sebelumnya. Salah satu tujuan diterbitkannya peraturan menteri tersebut adalah optimalisasi penataan minimarket di setiap wilayah. Implementasinya, banyak diserap oleh pemerintah daerah melalui peraturan daerah (perda).
Salah satu contoh perda berasal dari perda Pemerintah Kabupaten Bogor No.11 Tahun 2012 tentang penataan pasar tradisonal, pusat perbelanjaan dan toko modern. Isinya adalah minimarket harus berjarak minimal 500 meter dari pasar tradisional dan 100 meter dari usaha kecil sejenis dan waktu operasional dimulai pukul 08.00-23.00. Waktu operasional tersebut tidak berlaku untuk minimarket di Stasiun Pengisian Bahan Bakar Umum (SPBU), di dalam area wisata, dan/atau rest area. Dengan kalimat lain, peraturan tersebut mengatur penataan minimarket
2
dari sisi lokasi dan waktu operasional. Dari sisi lokasi adalah bagaimana agar usaha kecil dan sejenis dapat tetap tumbuh. Sedangkan dari sisi waktu operasional adalah bagaimana standar waktu operasionalnya. Di lokasi-lokasi tertentu waktu operasionalnya terbatas namun lokasi yang lain bisa 24 jam sehari. Secara eksplisit, baik peraturan menteri maupun peraturan daerah dapat menjadi salah satu cara dalam mengendalikan populasi minimarket khususnya di wilayah-wilayah dengan jumlah minimarket yang sangat tinggi.
Idealnya, penataan minimarket sejalan dengan peraturan daerah di masing-masing kabupaten/kota. Jika perda kabupaten/kota lain, sejalan dengan perda Kabupaten Bogor tentang persyaratan minimarket maka keberadaan minimarket seharusnya tidak memberikan dampak negatif kepada warung-warung tradisional dan usaha kecil sejenis.
Populasi minimarket dapat terpantau secara berkala sehingga keberadaannya sesuai dengan kebijakan tata ruang di setiap wilayah. Selama ini informasi populasi minimarket secara nasional hanya bersumber dari pendataan Potensi Desa yang dilaksanakan 3 kali dalam 10 tahun. Survei secara periodik berskala nasional menjadi cara untuk menduga populasi minimarket. Survei tersebut bisa dilakukan setiap 3 atau 6 bulan. Informasi yang diperoleh melalui survei dapat lebih detail sehingga dapat diketahui potensi minimarket di Indonesia dalam jangka panjang dan menengah. Informasi lainnya juga dapat diketahui sejauh mana penyebaran minimarket, berapa tenaga kerja yang terserap, dan bagaimana kontribusinya terhadap perekonomian lokal bahkan nasional.
Survei memiliki beberapa tahapan. Salah satu tahapannya agar menghasilkan informasi yang akurat adalah melakukan sampling. Metode sampling yang tepat dapat menyajikan hasil pendugaan yang akurat. Sedikitnya jumlah responden yang diwawancarai akan meningkatkan ketelitian petugas pengumpul data sehingga non-sampling error bisa dikurangi. Scheaffer et al (2012) menyatakan sampel yang ditarik secara benar akan memberikan landasan kuat untuk mewakili karakteristik populasi. Oleh karena itu, penelitian tentang perbandingan metode sampling dapat menjadi landasan dalam memperkirakan hasil pendugaan tentang karakterisik populasi. Beberapa penelitian tentang perbandingan metode sampling untuk menduga populasi sudah dilakukan. Pada tahun 2006, Widaningsih melakukan penelitian perbandingan metode sampling untuk menduga populasi sapi potong di Kabupaten Karangasem. Kemudian Nurhayati tahun 2008 melakukan studi perbandingan metode sampling antara simple random sampling dengan stratified random sampling menggunakan data bangkitan. Selanjutnya, pada tahun 2011, Kusmayadi melakukan penelitian perbandingan metode sampling untuk menduga hasil pemilukada di Kabupaten Jembrana. Penelitian ini mencoba melakukan simulasi beberapa metode sampling untuk menduga populasi minimarket berskala nasional. Cara pendugaan dilakukan secara langsung. Hasil penelitian dapat mengungkap metode sampling mana yang paling tepat digunakan untuk menduga populasi minimarket di Indonesia.
3
Tujuan Penelitian
Penelitian ini bertujuan untuk mendapatkan metode sampling yang paling tepat dalam menduga populasi minimarket di Indonesia dengan membandingkan beberapa metode sampling seperti simple random sampling dan stratified random sampling sebagai sampling satu tahap, two stage cluster sampling, dan stratified two stage cluster sampling sebagai sampling dua tahap.
4
2 TINJAUAN PUSTAKA
Karakteristik Penduga Parameter Populasi
Menurut Levy dan Lemeshow (1999), penduga parameter populasi mempunyai beberapa karakteristik, yaitu:
Bias, B (𝜏̂) dari penduga populasi (𝜏̂) terhadap parameter populasi didefinisikan sebagai perbedaan antara nilai harapan E(𝜏̂) dari distribusi sampling dan nilai sebenarnya dari parameter yang tidak diketahui (τ). Dengan kata lain, B (𝜏̂) = E(𝜏̂) – τ. Penduga populasi (𝜏̂) dikatakan tidak bias jika B (𝜏̂) = 0 yang berarti nilai harapan E(𝜏̂) = τ.
Mean Square Error, dari pendugaan populasi (𝜏̂), dilambangkan dengan MSE (𝜏̂) didefinisikan sebagai rata-rata dari perbedaan kuadrat atas semua sampel yang mungkin antara nilai pendugaan dan nilai sebenarnya τ dari parameter yang tidak diketahui dikalikan peluang 𝜋𝑖. MSE dari pendugaan
berbeda dengan ragam dari pendugaan. MSE adalah rata-rata simpangan kuadrat terhadap parameter sebenarnya, MSE (𝜏̂) = ∑𝑐𝑖=1(𝜏̂𝑖 -τ)2 𝜋𝑖. Ragam
penduga adalah rata-rata simpangan kuadrat terhadap rata-rata distribusi sampling. Jika pendugaan tidak bias atau dengan kata lain jika pendugaan rata-rata dari distribusi sampling sama dengan ragam dari pendugaan, MSE dari pendugaan berhubungan dengan bias dan ragam penduga adalah sebagai berikut: MSE (𝜏̂) = Var (𝜏̂) + B2(𝜏̂).
Dengan persamaan awal sebagai berikut (Cochran 1991): MSE (𝜏̂) = E (𝜏̂ − 𝜏)2
= E[(𝜏̂ − E(𝜏̂)) + (E(𝜏̂) − 𝜏)]2
= E(𝜏̂ − E(𝜏̂))2+ 2(E(𝜏̂) − 𝜏)E(𝜏̂ − E(𝜏̂)) + (E(𝜏̂) − 𝜏)2
= Var (𝜏̂) + B2(𝜏̂), di mana B = Bias = E(𝜏̂) − 𝜏
Hasil perhitungan silangnya hilang karena E(𝜏̂ − E(𝜏̂)) = 0
Reliabilitas. Karakteristik terandal dari suatu penduga populasi berhubungan dengan bagaimana kemampuan suatu penduga menghasilkan suatu nilai dugaan. Jika diasumsikan tidak ada kesalahan pengukuran dalam suatu survei, maka reliabilitas dari suatu penduga dapat dinyatakan dalam konteks ragam penarikan contoh, atau setara dengan galat baku. Makin kecil galat baku suatu penduga, maka makin besar reliabilitasnya.
Validitas. Karakteristik valid dari suatu penduga populasi berhubungan dengan bagaimana nilai tengah suatu penduga menghasilkan suatu dugaan berbeda dengan nilai parameter sebenarnya. Jika diasumsikan tidak ada kesalahan pengukuran, validitas dapat dievaluasi dengan mengamati nilai bias dari penduganya. Makin kecil bias, validitas makin besar.
Akurasi dari suatu penduga adalah sejauh mana rata-rata suatu nilai dugaan menyimpang dari nilai parameter yang diukur. Akurasi suatu penduga pada umumnya dievaluasi oleh nilai MSEnya, atau setara dengan nilai akar pangkat dari MSE (disimbolkan dengan RMSE atau Root Mean Square Error). Makin kecil nilai MSE suatu penduga, makin besar nilai akurasinya. Akurasi dari suatu penduga mencakup kedua karakteristik sebelumnya yaitu reliabilitas dan validitas.
5
Konsep Dasar
Menurut Supangat (2007), populasi memiliki definisi yaitu sekumpulan objek yang akan dijadikan sebagai bahan penelitian dengan ciri mempunyai karakteristik yang sama. Ada 2 jenis populasi, antara lain populasi terhingga dan populasi tak terhingga. Populasi terhingga adalah populasi yang jumlahnya tertentu, sedangkan populasi tak terhingga adalah populasi yang jumlahnya tak terhingga banyaknya. Sampel adalah bagian dari populasi sebagai bahan penelitian dengan harapan bagian tersebut mewakili populasinya.
Supangat (2007) juga menjelaskan bahwa sampling adalah cara untuk melakukan pengambilan sampel dari populasi yang diketahui, baik dari cara penentuan jumlah sampel maupun dari model pengambilan sampel dimaksud, dengan harapan agar sampel yang diambil dapat mewakili populasinya.
Dalam melakukan penelitian, para peneliti umumnya lebih banyak menggunakan data sampel dibandingkan harus melakukan sensus, hal ini disebabkan karena:
Faktor biaya penelitian yang dapat lebih ditekan
Faktor waktu penelitian yang lebih singkat
Faktor akurasi data dapat lebih meyakinkan
Supangat (2007) menjelaskan bahwa ada beberapa tahapan yang dapat dilakukan dalam rangka pengambilan data sampel, antara lain:
Tahap pemilihan populasi
Pemilihan populasi adalah tahap awal penelitian yang mencakup semua unsur yang akan diteliti, seperti: elemen populasi, unit sampling, dan lainnya. Elemen populasi adalah semua objek penelitian yang mempunyai karakteristik sama, sedangkan unit sampling adalah unit yang digunakan dalam proses pengambilan sampel.
Penentuan kerangka sampling
Tahapan ini adalah tahapan yang sangat menentukan agar sampel yang diambil, mewakili terhadap populasinya. Kerangka sampling dapat berupa nama-nama anggota populasi, nama wilayah yang akan dijadikan objek penelitian, daftar kepangkatan seseorang pada instansi tertentu, atau data base lainnya.
Menetapkan desain sampel
Desain sampel harus disesuaikan dengan tujuan penelitian, dengan demikian peneliti akan dapat menentukan metode pendekatan yang digunakan dalam penentuan unit sampling secara baik.
Menetapkan ukuran sampel
Penetapan ukuran sampel tergantung dari karakteristik elemen populasinya (homogeny atau tidak). Jika karakteristik elemen populasi homogen, ukuran sampel yang diambil relatif kecil. Jika karakteristik elemen populasi heterogen, ukuran sampel yang diambil relatif besar. Pada prinsipnya, penentuan ukuran sampel tergantung dari seberapa tinggi tingkat kepercayaan, seberapa besar tingkat akurasi yang dikehendaki, dan sumber daya yang dimiliki seperti biaya, waktu, dan personil.
6
Metode penetapan sampel
Penetapan data sampel sedapat mungkin dilakukan dengan cara acak agar dapat mengukur parameter dengan baik (tidak ada kesan dipilih yang baik saja atau yang mudah dijangkau saja)
Simple Random Sampling
Simple random sampling atau penarikan contoh acak sederhana adalah penarikan sampel secara acak di mana pemilihan elemen-elemen populasinya dilakukan sedemikian rupa sehingga setiap elemen memiliki kesempatan yang sama untuk dipilih. Penduga parameter populasi untuk total dan ragamnya adalah sebagai berikut: 𝜏̂ = 𝜇̂. Ν = y̅. Ν = 1 𝑛 ∑ 𝑦𝑖 𝑛 𝑖=1 . Ν 𝑣̂ (𝜏̂) = (Ν2s2 𝑛 ) ( Ν−𝑛 Ν ) keterangan:
𝜇̂ = penduga rata-rata populasi (rata-rata sampel) 𝜏̂ = penduga total populasi
𝑣̂ (𝜏̂) = penduga ragam total populasi N = jumlah elemen dalam populasi n = jumlah elemen terpilih
yi = nilai karakteristik Y dari elemen
s2 = ragam penduga
Stratified Random Sampling
Stratified Random Sampling atau penarikan contoh acak dengan prinsip pelapisan adalah cara pengambilan sampel, di mana populasi dibagi menjadi subpopulasi yang tidak boleh tumpang tindih, masing-masing N1 , N2 , N3 ,….. NL
unit. Bila seluruh subpopulasi dijumlahkan, maka diperoleh:
N1 + N2 + N3 +….. + NL = N
Subpopulasi disebut lapisan (strata). Jika lapisan sudah ditentukan, sebuah sampel diambil dari masing-masing lapisan, pengambilannya dilakukan secara bebas untuk lapisan yang berbeda. Ukuran sampel di dalam lapisannya dinotasikan n1 , n2 , n3 ……nL.
Menurut Asra dan Prasetyo (2015), prinsip pelapisan memiliki beberapa keuntungan, antara lain:
1. Disain survei akan lebih baik karena sampel akan terjamin mewakili populasi akibat diambilnya sampel dari setiap lapisan dalam populasi 2. Pendugaan lebih efisien, artinya galat baku yang lebih kecil dibanding
disain tanpa prinsip pelapisan
3. Dapat dilakukan pendugaan setiap lapisan, sehingga dapat dipelajari kondisi setiap lapisan, dan dapat pula dibandingkan kondisi antar lapisan
(2)
(3) (1)
7 Pendugaan parameter populasi untuk total dan ragamnya adalah sebagai berikut:
𝜏̂ = 𝑦̅1. Ν1+ y̅2. Ν2+ ⋯ + y̅L. ΝL= ∑Lh=1y̅h. Νh
𝑣̂ (𝜏̂) = ∑ (Νℎ2𝑠ℎ2 𝑛ℎ ) ( Νℎ−𝑛ℎ Νℎ ) 𝐿 ℎ=1 keterangan:
𝜇̂ = penduga rata-rata populasi (rata-rata sampel) 𝜏̂ = penduga total populasi
𝑣̂ (𝜏̂) = penduga ragam total populasi Nh = jumlah elemen pada lapisan ke h
nh = jumlah elemen terpilih pada lapisan ke h
sh2 = ragam sampel pada lapisan ke h
Beberapa cara dalam mengalokasikan sampel sebesar n ke lapisan (Asra & Prasetyo 2015), antara lain:
1. Alokasi Sembarang (Random/Subjective Allocation) Pengalokasian terserah pada selera peneliti
2. Alokasi Sama (Equal Allocation)
Besarnya sampel pada setiap lapisan sama besar, tanpa memperhatikan situasi lapisan.
3. Alokasi Proporsional (Proportional Allocation)
Besarnya sampel pada setiap lapisan tergantung banyaknya unit dalam lapisan tersebut. Digunakan bila rata-rata strata yang satu dengan yang lain berbeda sekali. Prosedur ini menghasilkan penduga yang tertimbang secara otomatis (self weighted estimator).
4. Alokasi Neyman (Neyman Allocation)
Besarnya sampel di setiap lapisan tidak hanya tergantung pada besarnya lapisan, tapi juga pada tingkat homogenitas atau heterogenitas dari ciri unit-unit pada lapisan tersebut. Semakin heterogen lapisan, maka banyak sampel yang harus diambil. Alokasi ini untuk memperkecil galat baku dari pendugaan.
5. Alokasi Optimum (Optimum Allocation)
Mongoptimumkan total biaya yang tersedia dengan memperhatikan keragaman di dalam setiap subpopulasi serta biaya per unit di setiap subpopulasi.
Two Stage Cluster Sampling
Metode two stage cluster sampling atau penarikan contoh secara klaster dua tahap adalah pengambilan sampel dilakukan secara dua tahap, yaitu tahap pertama, memilih beberapa gerombol dari gerombol-gerombol dalam populasi secara acak, dan tahap kedua, memiilih secara acak pula beberapa unit sampel dari tiap gerombol terpilih.
Cluster sampling lebih murah dari pada simple random sampling dan stratified random sampling apabila biaya untuk memperoleh kerangka sampel sangat mahal. Kerangka sampel adalah daftar seluruh elemen populasi. Supranto
(4) (5)
8
(2007) menjelaskan bahwa biaya untuk melakukan observasi akan meningkat sejalan dengan jauh jarak antar elemen (objek) yang satu dengan lainnya. Cluster sampling dapat menjadi desain sampling yang efektif dan biayanya murah jika daftar elemen tidak tersedia, biaya sangat mahal dalam membuat daftar elemen apalagi jika jarak antar elemen berjauhan secara geografis. Contoh cluster adalah provinsi, kabupaten/kota, kecamatan, desa, blok sensus, rumah tangga, blok toko, rayon sekolah, segmen pasar, dan lain-lain.
Menurut Asra dan Prasetyo (2015), pengambilan sampel dengan cluster memiliki beberapa keuntungan, antara lain:
1. Cenderung menghasilkan unit pengamatan yang berdekatan sehingga pengumpulan data lebih mudah, cepat, dan secara operasional lebih baik/nyaman; biaya lebih hemat.
2. Ketika kerangka sampel tidak tersedia.
Pendugaan parameter populasi untuk total dan ragamnya adalah sebagai berikut: 𝜏̂ = Ν 𝑛∑ Μℎ. y̅ℎ 𝑛 ℎ=1 𝑣 ̂(𝜏̂)= (Ν 2𝑠 𝑏 2 𝑛 ) ( Ν−𝑛 Ν )+( Μℎ−𝑚ℎ Μℎ ) ( 𝑠ℎ2 𝑚ℎ) keterangan:
N = jumlah gerombol dalam populasi
n = jumlah gerombol yang terpilih dalam sampel acak Mh = jumlah elemen dalam gerombol h
mh = jumlah elemen terpilih dalam acak sederhana gerombol h
𝑦̅ℎ = rata-rata pendugaan dari gerombol h
sb2 = ragam antara gerombol terpilih
sh2 = ragam elemen terpilih dalam gerombol terpilih
Stratified Two Stage Cluster Sampling
Metode stratified two stage cluster sampling atau penarikan contoh dua tahap dengan prinsip pelapisan adalah pengembangan dari metode two stage cluster sampling. Tahap pertama, terlebih dahulu mengelompokkan unit-unit penarikan sampel berdasarkan karakteristik yang memiliki kemiripan. Tahap kedua memilih sampel kelompok secara acak dari populasi kelompok kemudian memilih sampel elemen dari kelompok yang terpilih sebagai sampel. Variabel yang digunakan sebagai dasar pembentukan strata dapat berupa variabel kategorik.
Pendugaan parameter populasi untuk total dan ragamnya adalah sebagai berikut: 𝜏̂ = ∑ Νℎ 𝑛ℎ 𝐿 ℎ=1 ∑ 𝑀ℎ𝑖 𝑚ℎ𝑖 ∑𝑚ℎ𝑖𝑦ℎ𝑖𝑗 𝑗=1 𝑛ℎ 𝑖=1 𝑣(𝜏̂) = ∑𝐿ℎ=1Νℎ2Μ̅h2(1 − nh Νh) 𝑠𝑏ℎ2 𝑛ℎ+ Νℎ 𝑛ℎ∑ Μℎ𝑖 2 [(1 −𝑚ℎ𝑖 Μℎ𝑖)] 𝑠𝑤ℎ𝑖2 𝑚ℎ𝑖 𝑛 𝑖=1 (7) (9) (6) (8)
9 keterangan: Nh Mhi yhij nh mhi 𝑀ℎ ̅̅̅̅ s2 bh s2 whi = = = = = = = =
jumlah unit sampling tahap pertama pada seluruh lapisan jumlah unit tahap kedua pada unit sampling tahap pertama ke i dalam lapisan ke-h
nilai karakteristik Y dari unit sampling tahap kedua ke-j dalam unit sampling tahap pertama ke-i pada lapisan ke-h
jumlah sampel yang diambil dari unit sampling tahap pertama di setiap lapisan ke-h
jumlah sampel yang diambil dari unit sampling tahap kedua ke-i lapisan ke-h
rata-rata jumlah ssu (secondary sampling units) sampel dalam setiap lapisan
ragam antara gerombol terpilih
10
3 METODE PENELITIAN
DataData yang digunakan dalam penelitian ini adalah data hasil Pendataan Potensi Desa (PODES) 2011. Data tersebut digunakan sebagai bahan simulasi. Unit pengamatan adalah minimarket yang ada di setiap desa. Dalam penelitian ini, unit pengamatan sama dengan unit sampling. Struktur data yang dipakai meliputi kode propinsi, kode kabupaten/kota, kode kecamatan, kode desa, jumlah minimarket, dan jumlah penduduk. Definisi minimarket adalah toko modern dengan luas lantai kurang dari 400 meter persegi. Toko modern adalah toko dengan sistem pelayanan mandiri dan menjual berbagai jenis barang secara eceran dengan label harga.
Metode Analisis
Tahap pertama melihat kondisi data populasi minimarket dan penduduk sebagai dasar untuk melakukan eksplorasi. Tahap kedua membuat simulasi pendugaan total populasi dan ragamnya dengan menggunakan metode simple random sampling, stratified random sampling, two stage cluster sampling, dan stratified two stage cluster sampling. Tahap berikutnya membandingkan hasil-hasil pendugaan parameter populasi berbagai metode sampling tersebut terhadap total populasi minimarket PODES 2011.
Simulasi dilakukan sebanyak 100 kali dengan mengambil ukuran sampel n1=300, n2=400, n3=500, n4=800, n5=900, dan n6=1000 . Simulasi dilakukan untuk
melihat tingkat keakuratan pada berbagai ukuran sampel. Di samping itu, terkait dengan sampling dua tahap juga dibandingkan penggunaan gerombol-gerombol. Untuk melakukan simulasi digunakan program (makro) dengan Minitab 17 Statistical Software.
Simple Random Sampling
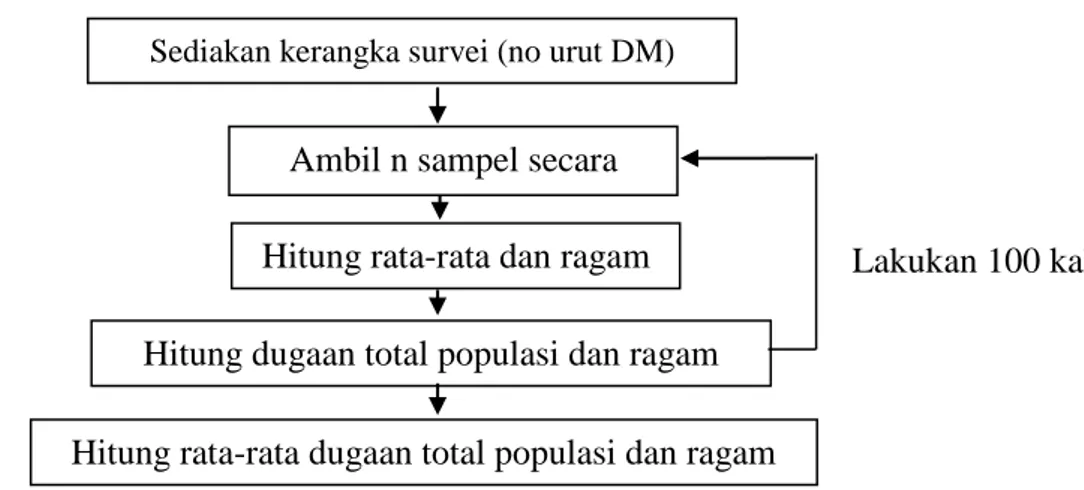
Sebagai kerangka survei adalah daftar (nomor urut) desa minimarket (DM) di seluruh Indonesia. Mekanisme menduga populasi adalah sampel diambil secara acak dari semua nomor urut DM sebanyak 8591 di seluruh Indonesia. Sampel diambil sebanyak 300, 400, 500, 800, 900, dan 1000 digunakan untuk menduga total populasi minimarket seluruh Indonesia dan ragam penduganya, pendugaan ini dilakukan 100 kali hingga diperoleh rata-rata penduga total populasi dan ragamnya (Gambar 3.1).
11
Gambar 3.1 Diagram alir simulasi pendugaan total populasi dan ragam pada simple random sampling
Stratified Random Sampling
Stratified random sampling adalah penarikan sampel dengan membagi populasi menjadi beberapa lapisan yang tidak saling tumpang tindih dan dilakukan pengambilan secara acak dari setiap lapisan tersebut, sehingga lapisan yang terbentuk merupakan sub populasi. Sampel diambil secara acak dari masing-masing lapisan secara proporsional.
Tahapannya adalah membagi populasi menjadi 3 jenis lapisan. Jenis lapisan pertama adalah populasi provinsi menurut jumlah penduduk. Pada jenis lapisan ini, lapisan pertama adalah provinsi dengan jumlah penduduk di bawah 1,5 juta. Lapisan kedua adalah provinsi dengan jumlah jumlah penduduk 1,5 juta sampai 3 juta. Lapisan ketiga adalah provinsi dengan jumlah penduduk di atas 3 juta sampai 7 juta. Lapisan keempat adalah provinsi dengan jumlah penduduk di atas 7 juta.
Jenis lapisan kedua adalah populasi provinsi menurut status desa. Pada jenis lapisan ini, lapisan pertama adalah populasi provinsi menurut desa perkotaan dan lapisan kedua adalah populasi provinsi menurut desa perdesaan.
Jenis lapisan ketiga adalah populasi menurut status pemerintah daerah (kotamadya-kabupaten). Pada jenis lapisan ini, populasi dibagi menjadi 6 lapisan. Lapisan pertama adalah kotamadya di Pulau Sumatera. Lapisan kedua adalah kotamadya di Pulau Jawa dan Bali. Lapisan ketiga adalah kotamadya di luar Pulau Sumatera, Jawa, dan Bali. Lapisan keempat adalah kabupaten di Pulau Sumatera. Lapisan kelima adalah kabupaten di Pulau Jawa dan Bali. Lapisan keenam adalah kabupaten di luar Pulau Sumatera, Jawa, dan Bali. Total sampel sebesar 300, 400, 500 800, 900, dan 1000. Jadi sebagai kerangka sampel adalah DM di setiap lapisan. Untuk lebih jelas metode simulasinya dapat dilihat Gambar 3.2 berikut.
Sediakan kerangka survei (no urut DM)
Ambil n sampel secara acak
Hitung rata-rata dan ragam Hitung dugaan total populasi dan ragam Hitung rata-rata dugaan total populasi dan ragam
12
Gambar 3.2 Diagram alir simulasi pendugaan total populasi dan ragam pada stratified random sampling
Two Stage Cluster Sampling
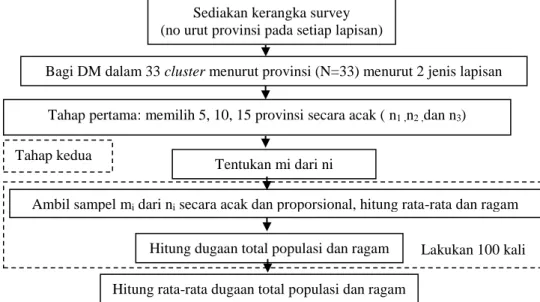
Provinsi dijadikan sebagai cluster. Tahap pertama: memilih 5, 10, 15 provinsi secara acak. Tahap kedua memilih DM dari 5, 10, 15 provinsi terpilih secara acak dan proporsional. Total sampel sebesar 300, 400, 500, 800, 900 dan 1000. Jadi sebagai kerangka survei tahap pertama adalah daftar seluruh provinsi. Sedangkan tahap kedua, dari provinsi yang terpilih pada tahap pertama, masing-masing sebagai kerangka survei. Untuk lebih jelas metode simulasinya dapat dilihat Gambar 3.3 berikut.
Gambar 3.3 Diagram alir simulasi pendugaan total populasi dan ragam pada two stages cluster sampling
Stratified Two Stage Cluster Sampling
Tahapannya adalah membagi populasi menjadi 2 jenis lapisan. Jenis lapisan pertama adalah populasi provinsi menurut status desa. Pada jenis lapisan ini,
Sediakan kerangka survey (no urut DM pada setiap lapisan) Tahap pertama: Bagi populasi minimarket dalam nh lapisan
Tentukan ni
Hitung dugaan total populasi dan ragam Lakukan 100 kali
Hitung rata-rata dugaan total populasi dan ragam Ambil sampel nh secara acak, hitung rata-rata dan ragam
Bagi DM dalam 33 cluster menurut provinsi (N=33) Tahap pertama: memilih 5, 10, 15 provinsi secara acak ( n1 ,n2 ,dan n3)
Ambil sampel mi dari ni secara acak dan
proporsional, hitung rata-rata dan ragam Hitung dugaan total populasi dan ragam Hitung rata-rata dugaan total populasi dan ragam
Lakukan 100 kali Sediakan kerangka survey (no urut provinsi pada setiap lapisan)
Ulangi untuk n berbeda
13 lapisan pertama adalah populasi provinsi menurut desa perkotaan dan lapisan kedua adalah populasi provinsi menurut desa perdesaan.
Gambar 3.4 Diagram alir simulasi pendugaan total populasi dan ragam pada stratified two stages cluster sampling
Jenis lapisan kedua adalah populasi menurut status pemerintah daerah. Pada jenis lapisan ini, lapisan pertama adalah populasi provinsi menurut kotamadya dan lapisan kedua adalah populasi provinsi menurut kabupaten.
Total sampel sebesar 300, 400, 500, 800, 900 dan 1000. Jadi sebagai kerangka sampel adalah DM di setiap lapisan. Untuk lebih jelas metode simulasinya dapat dilihat pada Gambar 3.4.
Evaluasi Pemilihan Metode Sampling
Kriteria pemilihan sampling terbaik menurut Levy dan Lemeshow (1999) didasarkan pada kriteria reliabilitas (berdasarkan nilai galat baku), validitas (berdasarkan nilai simpangan/bias), dan akurasi (berdasarkan nilai MSE). Makin kecil nilai MSE suatu penduga, makin besar nilai akurasinya. Akurasi dari suatu penduga sudah mencakup kedua karakteristik lainnya yaitu reliabilitas dan validitas. Rumusannya adalah sebagai berikut:
Bias, B(𝜏̂) dari penduga populasi (𝜏̂) terhadap parameter populasi (τ) adalah selisih antara nilai harapan E (𝜏̂) dengan nilai sebenarnya (τ), Β(𝜏̂) = |Ε(𝜏̂) − 𝜏|, sedangkan E(𝜏̂) diduga oleh 𝜏̂̅ =∑100𝑖=1𝜏̂𝑖
100
Ragam penduga adalah rata-rata simpangan kuadrat terhadap rata-rata distribusi penarikan sampel, 𝑣(𝜏̂) = ∑ (𝜏̂𝑖−𝜏̂̅)
100 𝑖=1
2
100
Galat baku penduga adalah akar dari ragam penduga, √𝑣(𝜏̂). Galat baku digunakan untuk melihat perkiraan kesalahan yang timbul akibat penggunaan metode sampling.
Sediakan kerangka survey (no urut provinsi pada setiap lapisan)
Bagi DM dalam 33 cluster menurut provinsi (N=33) menurut 2 jenis lapisan
Tentukan mi dari ni
Tahap pertama: memilih 5, 10, 15 provinsi secara acak ( n1 ,n2 ,dan n3)
Ambil sampel mi dari ni secara acak dan proporsional, hitung rata-rata dan ragam
Hitung dugaan total populasi dan ragam Hitung rata-rata dugaan total populasi dan ragam
Lakukan 100 kali Tahap kedua
14
Relatif Standard Error (RSE) adalah perbandingan antara galat baku penduga terhadap rata-rata penduga dikali 100%, 𝑅𝑆𝐸 = √𝑣(𝜏̂)
Ε(𝜏̂) ×
100%. RSE menunjukkan persentase kesalahan dari galat baku.
MSE adalah penjumlahan rata-rata simpangan kuadrat terhadap parameter sebenarnya, dan ragam penduga. Hubungan MSE dan ragam penduga adalah sebagai berikut, MSE (τ ̂) = Var (τ ̂) + B2(τ ̂).
15
4 HASIL DAN PEMBAHASAN
Eksplorasi DataLangkah awal dari analisis data yakni melakukan eksplorasi data. Eksplorasi dapat dilakukan secara deskriptif dalam sajian tabel dan grafik. Penyajian pada Gambar 4.1 menjelaskan deskripsi data jumlah minimarket menurut status desa di Indonesia tahun 2011. Persentase minimarket lebih banyak berada di desa perkotaan (59%) dibanding desa perdesaan (41%).
Gambar 4.1 Persentase Minimarket Menurut Status Desa di Indonesia Tahun 2011 Penyajian pada Tabel 4.1 menunjukkan deskripsi populasi minimarket di Indonesia Tahun 2011. Populasi minimarket dihitung berdasarkan desa dengan keberadaan minimarket minimal 1 gerai. Berdasarkan penghitungan tersebut dapat dijelaskan bahwa jumlah minimarket ada sebanyak 35148 gerai dengan rata-rata minimarket di setiap desa sebesar 4,09 gerai dan ragamnya 74,3 gerai. Total jumlah desa dengan keberadaan minimarket minimal 1 gerai ada sebanyak 8591 desa.
Tabel 4.1 Ringkasan data populasi minimarket di Indonesia tahun 2011
Data Populasi Nilai
Jumlah Minimarket (τ) 35148
Rata-Rata (μ) 4,09
Ragam (σ2) 74,3
Jumlah Desa (N) 8591
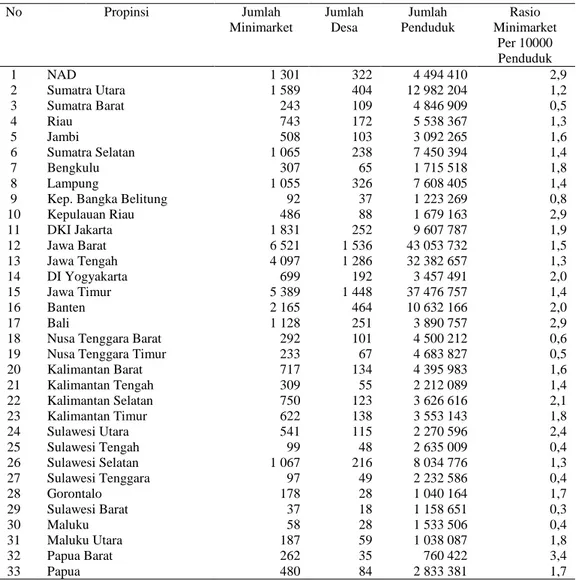
Populasi minimarket tertinggi di Propinsi Jawa Barat sebesar 6521 gerai, sedangkan populasi minimarket terendah di Propinsi Sulawesi Barat sebesar 37 gerai. Rincian deskripsi populasi minimarket berdasarkan propinsi di Indonesia tahun 2011 dapat dilihat dari Tabel 4.2.
Rata-rata rasio minimarket per 10 ribu penduduk di Indonesia adalah 1,5. Angka tersebut menjelaskan bahwa pada setiap 10 ribu penduduk tersedia minimarket sebanyak 1,5 gerai. Menurut pulau, rasio minimarket per 10000 penduduk di Pulau Jawa-Bali sebesar 1,9 dan Pulau Sumatra sebesar 1,6 serta Pulau Selainnya sebesar 1,4. Rasio minimarket per 10 ribu penduduk di Pulau Jawa-Bali adalah yang tertinggi dan angka ini sejalan dengan pusat populasi penduduk Indonesia yang berada di Pulau Jawa dan Bali.
Perkotaan 59% Perdesaan
16
Tabel 4.2 Ringkasan data populasi minimarket dan penduduk menurut propinsi di Indonesia tahun 2011
No Propinsi Jumlah Minimarket Jumlah Desa Jumlah Penduduk Rasio Minimarket Per 10000 Penduduk 1 NAD 1 301 322 4 494 410 2,9 2 Sumatra Utara 1 589 404 12 982 204 1,2 3 Sumatra Barat 243 109 4 846 909 0,5 4 Riau 743 172 5 538 367 1,3 5 Jambi 508 103 3 092 265 1,6 6 Sumatra Selatan 1 065 238 7 450 394 1,4 7 Bengkulu 307 65 1 715 518 1,8 8 Lampung 1 055 326 7 608 405 1,4
9 Kep. Bangka Belitung 92 37 1 223 269 0,8
10 Kepulauan Riau 486 88 1 679 163 2,9 11 DKI Jakarta 1 831 252 9 607 787 1,9 12 Jawa Barat 6 521 1 536 43 053 732 1,5 13 Jawa Tengah 4 097 1 286 32 382 657 1,3 14 DI Yogyakarta 699 192 3 457 491 2,0 15 Jawa Timur 5 389 1 448 37 476 757 1,4 16 Banten 2 165 464 10 632 166 2,0 17 Bali 1 128 251 3 890 757 2,9
18 Nusa Tenggara Barat 292 101 4 500 212 0,6
19 Nusa Tenggara Timur 233 67 4 683 827 0,5
20 Kalimantan Barat 717 134 4 395 983 1,6 21 Kalimantan Tengah 309 55 2 212 089 1,4 22 Kalimantan Selatan 750 123 3 626 616 2,1 23 Kalimantan Timur 622 138 3 553 143 1,8 24 Sulawesi Utara 541 115 2 270 596 2,4 25 Sulawesi Tengah 99 48 2 635 009 0,4 26 Sulawesi Selatan 1 067 216 8 034 776 1,3 27 Sulawesi Tenggara 97 49 2 232 586 0,4 28 Gorontalo 178 28 1 040 164 1,7 29 Sulawesi Barat 37 18 1 158 651 0,3 30 Maluku 58 28 1 533 506 0,4 31 Maluku Utara 187 59 1 038 087 1,8 32 Papua Barat 262 35 760 422 3,4 33 Papua 480 84 2 833 381 1,7
Tabel 4.3 menjelaskan bahwa hampir 80 persen minimarket berada di Pulau Jawa dan Sumatra. Dengan kalimat lain, sebagian besar minimarket tersebar di pulau-pulau Indonesia bagian barat. Pulau Jawa menjadi wilayah dengan sebaran minimarket tertinggi di Indonesia. Sisanya sekitar 20 persen berada di pulau-pulau Indonesia bagian timur.
Tabel 4.3 Persentase minimarket menurut pulau di Indonesia tahun 2011 No Pulau Persentase Persentase Kumulatif
1 Sumatra 21,02 21,02
2 Jawa 58,91 79,93
3 Bali, NTB dan NTT 4,70 84,63
4 Kalimantan 6,82 91,45
5 Sulawesi 5,74 97,19
17 Setelah melakukan eksplorasi dengan analisis sajian tabel dan gambar, disajikan analisa lebih lanjut hasil simulasi pendugaan total populasi dan ragam pada setiap metode sampling.
Simple Random Sampling
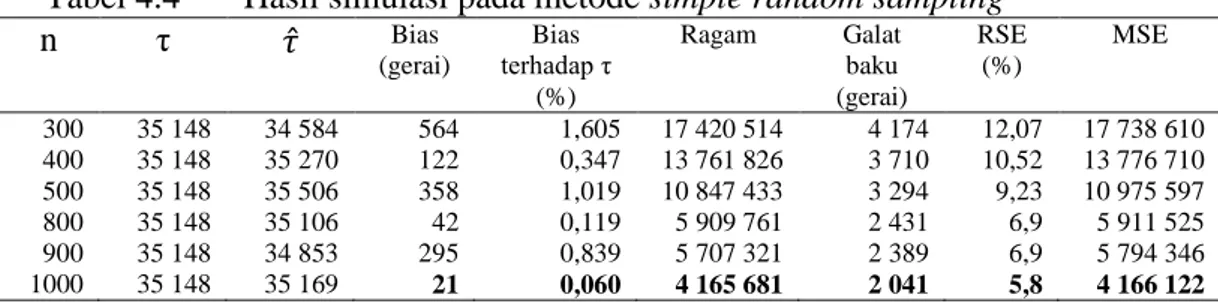
Hasil simulasi metode simple random sampling dapat dilihat pada Tabel 4.4. Simulasi mendapatkan hasil nilai dugaan total populasi minimarket dan ragam dari sampel sebanyak 300, 400, 500, 800, 900, dan 1000. Analisa dilakukan untuk mendapatkan nilai simpangan/bias, galat baku, dan MSE (Mean Square Error) sebagai dasar kriteria dalam pemilihan metode sampling. Di samping itu, penghitungan nilai RSE (Relative Standard Error) dengan merasiokan antara galat baku terhadap dugaan total minimarket (𝜏̂).
Tabel 4.4 Hasil simulasi pada metode simple random sampling
n τ 𝜏̂ Bias (gerai) Bias terhadap τ (%) Ragam Galat baku (gerai) RSE (%) MSE 300 35 148 34 584 564 1,605 17 420 514 4 174 12,07 17 738 610 400 35 148 35 270 122 0,347 13 761 826 3 710 10,52 13 776 710 500 800 900 1000 35 148 35 148 35 148 35 148 35 506 35 106 34 853 35 169 358 42 295 21 1,019 0,119 0,839 0,060 10 847 433 5 909 761 5 707 321 4 165 681 3 294 2 431 2 389 2 041 9,23 6,9 6,9 5,8 10 975 597 5 911 525 5 794 346 4 166 122
Metode simple random sampling pada 100 kali simulasi menghasilkan bias yang relative kecil, bias terkecil pada ukuran sampel 1000 (Tabel 4.4). Bias berkisar antara 21 sampai 564. Semakin besar ukuran sampel, menunjukkan ragam semakin kecil. Hal ini mengakibatkan MSE juga semakin kecil sejalan dengan makin kecilnya ragam dengan ukuran sampel diperbesar. Selain itu, RSE juga makin kecil sejalan dengan peningkatan ukuran sampel. Metode simple random sampling pada ukuran sampel 1000 memiliki MSE paling kecil sehingga dapat dikatakan memiliki tingkat akurasi tertinggi.
Stratified Random Sampling
Prinsip Pelapisan
Menurut Asra dan Prasetyo (2015), prinsip utama dalam prosedur ini adalah pengelompokan unit-unit yang heterogen ke dalam beberapa lapisan sehingga unit-unit dalam satu lapisan mempunyai ciri yang kurang lebih homogen dan antar lapisan mempunyai ciri yang seheterogen mungkin. Peubah yang dipakai dalam pembuatan lapisan hendaknya berkorelasi kuat dengan ciri yang akan diamati. Dalam kajian ini, peubah yang dijadikan sebagai dasar pelapisan adalah jumlah penduduk. Menurut provinsi, jumlah penduduk berkorelasi terhadap jumlah minimarket. Angkanya mencapai 0,98 dan signifikan pada tingkat keyakinan 95 persen. Tabel 4.6 menunjukkan rata-rata dan ragam jumlah penduduk per desa pada pada setiap lapisan.
18
Tabel 4.5 Rata-rata dan ragam jumlah penduduk per desa pada setiap lapisan
Lapisan Rata-rata Ragam
5 Provinsi (penduduk <1,5 juta) 4 469 18 993 733 8 Provinsi (penduduk 1,5 juta-3 juta) 6 820 56 633 117 11 Provinsi (penduduk >3 juta-7 juta) 7 471 64 341 802 9 Provinsi (penduduk >7 juta) 10 603 125 723 604
Desa Perkotaan 11 950 134 022 859
Desa Perdesaan 4 327 13 944 207
Kota di Sumatra 10 493 69 585 789
Kota di Jawa-Bali 20 029 281 908 343
Kota Selain Sumatra-Jawa-Bali 11 068 88 002 565
Kabupaten di Sumatra 4 785 27 666 428
Kabupaten di Jawa-Bali 8 082 47 438 454
Kabupaten Selain Sumatra-Jawa-Bali 4 833 23 589 355
33 Provinsi (Tanpa Lapisan) 9 619 109 636 162
Pada jenis lapisan pertama, penduduk di 5 provinsi memiliki rata-rata dan ragam terkecil, sedangkan penduduk di 9 provinsi memiliki rata-rata dan ragam terbesar. Pada jenis lapisan kedua, penduduk di desa perkotaan memiliki rata-rata hampir tiga kali lipat dibandingkan penduduk di desa perdesaan. Dari sisi ragamnya, penduduk di desa perkotaan memiliki ragam hampir sepuluh kali lipat dibandingkan desa perdesaan. Pada jenis lapisan ketiga, penduduk kota di Pulau Jawa dan Bali memiliki rata-rata-rata dan ragam terbesar, sedangkan penduduk kabupaten di Pulau Sumatra memiliki rata-rata terkecil dan penduduk kabupaten selain di Pulau Sumatra, Jawa, dan Bali memiliki ragam terkecil. Informasi rata-rata dan ragam yang berbeda antar pelapisan menjadi dasar dalam pembuatan pelapisan.
Pengalokasian Sampel ke Lapisan
Cara mengalokasikan sampel dalam penelitian ini menggunakan metode alokasi proporsional (proportional allocation). Alasan penggunaan cara alokasi proporsional karena rata-rata antara lapisan yang satu dengan yang lainnya berbeda sekali. Deskripsi rata-rata antar lapisan dapat dilihat dalam Tabel 4.6. Besarnya sampel pada setiap lapisan tergantung pada banyaknya unit dalam lapisan tersebut. Semakin besar unit maka semakin besar sampel yang diambil. Keuntungan dari alokasi proporsional adalah kepraktisan pengolahan hasil survey. Hal ini disebabkan karena prosedur ini akan menghasilkan penduga yang tertimbang secara otomatis (self-weighted estimator).
Lapisan Berdasarkan Jumlah Penduduk
Metode stratified random sampling berdasarkan jumlah penduduk sebagai lapisan menghasilkan bias yang bervariasi. Kisaran bias antara 24 sampai 458. Bias terkecil pada ukuran sampel 400. Jika melihat bias, tidak terlihat bahwa semakin besar ukuran sampel, bias semakin kecil.
Ragam terkecil ada pada ukuran sampel 1000. Sejalan dengan itu mengakibatkan MSE dan RSE pada ukuran sampel tersebut paling kecil. Angka MSE sebesar 4,05 juta dan RSE sebesar 5,7 persen. Kisaran RSE antara 5,7
19 persen sampai 12 persen, sedangkan kisaran MSE antara 4,05 juta sampai 17,4 juta. Metode stratified random sampling berdasarkan jumlah penduduk sebagai lapisan dengan ukuran sampel 1000 memiliki tingkat akurasi tertinggi. Tingkat akurasinya mencapai 4 kali lipat lebih dibandingkan jika hanya mengambil sampel sebanyak 300. Hasil simulasi juga dapat menjelaskan bahwa peningkatan sampel sebesar 3 kali lipat (n=900), mampu meningkatkan tingkat akurasi mencapai hampir 3 kali lipat atau dari 17,4 juta menjadi 6,06 juta. Hasil simulasi selengkapnya dapat dilihat dari Tabel 4.6.
Tabel 4.6 Hasil simulasi pada metode stratified random sampling berdasarkan jumlah penduduk n τ 𝜏̂ Bias (gerai) Bias terhadap τ (%) Ragam Galat baku (gerai) RSE (%) MSE 300 35 148 34 815 333 0,947 17 364 012 4 167 12,0 17 474 838 400 35 148 35 124 24 0,069 9 449 476 3 074 8,8 9 450 066 500 800 900 1000 35 148 35 148 35 148 35 148 35 212 34 935 35 606 34 912 64 213 458 236 1,181 0,606 1,303 0,671 11 605 030 5 089 536 5 851 561 3 996 001 3 406 2 256 2 419 1 999 9,7 6,5 6,8 5,7 11 609 089 5 134 905 6 061 325 4 051 697 Lapisan Berdasarkan Status Desa (Perkotaan-Perdesaan)
Hasil simulasi metode stratified random sampling berdasarkan status desa (perkotaan dan perdesaan) sebagai lapisan dapat ditunjukkan pada Tabel 4.7. Hasil simulasi menghasilkan bias antara 20 sampai 607. Kisaran ini lebih lebar dibandingkan dengan menggunakan jumlah penduduk sebagai lapisan.
Pada ukuran sampel 1000 menghasilkan ragam terkecil. Pada ukuran tersebut juga mengakibatkan MSE dan RSE paling kecil. MSE berkisar antara 5,2 juta sampai 17,6 juta. Kisaran MSE lapisan ini lebih lebar jika dibandingkan dengan menggunakan jumlah penduduk sebagai lapisan. Metode stratified random sampling berdasarkan status desa sebagai lapisan dengan ukuran sampel 1000 memiliki tingkat akurasi tertinggi. Semakin tinggi ukuran sampel, tingkat akurasi semakin besar. Pada sampel sebesar 900, tingkat akurasi 3 kali lipat lebih jika dibandingkan hanya mengambil sampel sebesar 300.
Tabel 4.7 Hasil simulasi pada metode stratified random sampling berdasarkan status desa n τ 𝜏̂ Bias (gerai) Bias terhadap τ (%) Ragam Galat baku (gerai) RSE (%) MSE 300 35 148 34 864 284 0,808 17 581 249 4 193 12,0 17 661 905 400 35 148 35 493 345 0,982 9 909 904 3 148 8,9 10 028 929 500 800 900 1000 35 148 35 148 35 148 35 148 35 099 34 541 35 455 35 168 49 607 307 20 0,139 1,727 0,873 0,057 11 155 600 6 446 521 5 513 104 5 299 204 3 340 2 539 2 348 2 302 9,5 7,4 6,6 6,5 11 158 001 6 814 970 5 607 353 5 299 604 Lapisan Berdasarkan Status Pemerintah Daerah (Kotamadya-Kabupaten)
Berdasarkan status pemerintah daerah sebagai lapisan, menghasilkan bias antara 20 sampai 1076 (lihat Tabel 4.8). Persentase bias terhadap total populasi
20
terkecil ada pada sampel 400 sebesar 0,82 persen. Pada ukuran sampel 900 dan 1000, masing-masing persentase bias terhadap total populasi sebesar 0,87 persen dan 0,89 persen.
Dari hasil simulasi ini, ragam terkecil ada pada ukuran sampel 1000. Jika dibandingkan dengan 2 jenis lapisan sebelumnya, pada lapisan ini memiliki MSE terkecil. Hal ini menunjukkan bahwa metode stratified random sampling berdasarkan status pemerintah daerah sebagai lapisan dengan ukuran sampel 1000 memiliki tingkat akurasi tertinggi.
Hasil simulasi juga dapat menjelaskan bahwa semakin besar ukuran sampel, tingkat akurasi semakin tinggi seperti ditunjukkan pada Tabel 4.8. Pada sampel 300 memiliki MSE sebesar 17,3 juta dan pada sampel 1000, MSE turun hingga 3,9 juta. Hal ini juga berarti bahwa dengan meningkatkan sampel sebesar 700, dapat meningkatkan tingkat akurasi sebesar 4 kali lipat lebih.
Tabel 4.8 Hasil simulasi pada metode stratified random sampling berdasarkan status pemerintah daerah
n τ 𝜏̂ Bias (gerai) Bias terhadap τ (%) Ragam Galat baku (gerai) RSE (%) MSE 300 35 148 36 224 1 076 3,061 16 184 529 4 023 11,1 17 342 305 400 35 148 35 437 289 0,822 14 745 600 3 840 10,8 14 829 121 500 800 900 1000 35 148 35 148 35 148 35 148 34 650 34 642 34 842 34 837 498 506 307 311 1,417 1,440 0,871 0,885 8 874 441 7 091 569 5 536 609 3 806 401 2 979 2 663 2 353 1 951 8,6 7,7 6,8 5,6 9 122 445 7 347 605 5 630 245 3 903 122
Two Stage Cluster Sampling
Pada metode two stage cluster sampling memiliki bias antara 74 sampai 1716. Persentase bias terhadap total populasi terkecil ada pada sampel 900 sebesar 0,21 persen pada 15 gerombol. Rincian selengkapnya dapat dilihat pada Tabel 4.9.
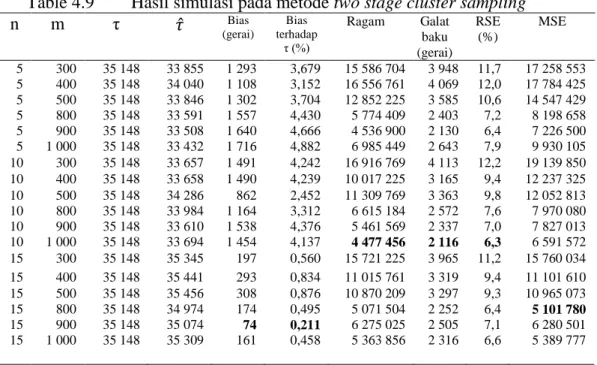
Table 4.9 Hasil simulasi pada metode two stage cluster sampling
n m τ 𝜏̂ Bias (gerai) Bias terhadap τ (%) Ragam Galat baku (gerai) RSE (%) MSE 5 300 35 148 33 855 1 293 3,679 15 586 704 3 948 11,7 17 258 553 5 400 35 148 34 040 1 108 3,152 16 556 761 4 069 12,0 17 784 425 5 5 5 5 500 800 900 1 000 35 148 35 148 35 148 35 148 33 846 33 591 33 508 33 432 1 302 1 557 1 640 1 716 3,704 4,430 4,666 4,882 12 852 225 5 774 409 4 536 900 6 985 449 3 585 2 403 2 130 2 643 10,6 7,2 6,4 7,9 14 547 429 8 198 658 7 226 500 9 930 105 10 300 35 148 33 657 1 491 4,242 16 916 769 4 113 12,2 19 139 850 10 400 35 148 33 658 1 490 4,239 10 017 225 3 165 9,4 12 237 325 10 10 10 10 500 800 900 1 000 35 148 35 148 35 148 35 148 34 286 33 984 33 610 33 694 862 1 164 1 538 1 454 2,452 3,312 4,376 4,137 11 309 769 6 615 184 5 461 569 4 477 456 3 363 2 572 2 337 2 116 9,8 7,6 7,0 6,3 12 052 813 7 970 080 7 827 013 6 591 572 15 300 35 148 35 345 197 0,560 15 721 225 3 965 11,2 15 760 034 15 400 35 148 35 441 293 0,834 11 015 761 3 319 9,4 11 101 610 15 15 15 15 500 800 900 1 000 35 148 35 148 35 148 35 148 35 456 34 974 35 074 35 309 308 174 74 161 0,876 0,495 0,211 0,458 10 870 209 5 071 504 6 275 025 5 363 856 3 297 2 252 2 505 2 316 9,3 6,4 7,1 6,6 10 965 073 5 101 780 6 280 501 5 389 777
21 Ragam terkecil ada pada ukuran sampel 1000 pada 10 gerombol. RSE terletak antara 6,3 persen sampai 12,2 persen. RSE terkecil ada pada ukuran sampel 1000 pada 10 gerombol. MSE terletak antara 5,1 juta sampai 19,1 juta. MSE terkecil ada pada ukuran sampel 800 pada 15 gerombol. Dengan demikian, berdasarkan tingkat keakuratan, maka pengambilan 15 gerombol pada ukuran sampel 800 memiliki tingkat akurasi terbaik.
Secara umum, pada penggunaan gerombol yang sama, peningkatan ukuran sampel mampu meningkatkan tingkat akurasi. Demikian juga, pada ukuran sampel yang sama pada gerombol yang berbeda, secara umum menunjukan semakin besar gerombol, tingkat akurasi semakin baik.
Metode Stratified Two Stage Cluster Sampling
Lapisan Berdasarkan Status Pemerintah Daerah (Kotamadya-Kabupaten)
Hasil simulasi metode stratified two stage cluster sampling dapat dilihat pada Tabel 4.10. Kisaran bias terletak antara 18 sampai 1912. Persentase bias terhadap total populasi terkecil adalah sampel 800 sebesar 0,051 persen pada 15 gerombol.
Tabel 4.10 Hasil simulasi pada metode stratified two stage cluster sampling berdasarkan status pemerintah daerah
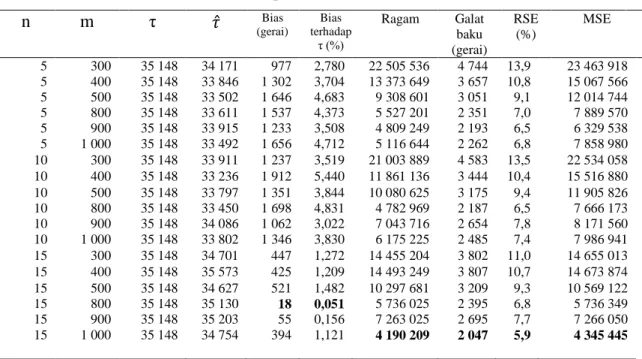
n m τ 𝜏̂ Bias (gerai) Bias terhadap τ (%) Ragam Galat baku (gerai) RSE (%) MSE 5 300 35 148 34 171 977 2,780 22 505 536 4 744 13,9 23 463 918 5 400 35 148 33 846 1 302 3,704 13 373 649 3 657 10,8 15 067 566 5 5 5 5 500 800 900 1 000 35 148 35 148 35 148 35 148 33 502 33 611 33 915 33 492 1 646 1 537 1 233 1 656 4,683 4,373 3,508 4,712 9 308 601 5 527 201 4 809 249 5 116 644 3 051 2 351 2 193 2 262 9,1 7,0 6,5 6,8 12 014 744 7 889 570 6 329 538 7 858 980 10 300 35 148 33 911 1 237 3,519 21 003 889 4 583 13,5 22 534 058 10 400 35 148 33 236 1 912 5,440 11 861 136 3 444 10,4 15 516 880 10 10 10 10 500 800 900 1 000 35 148 35 148 35 148 35 148 33 797 33 450 34 086 33 802 1 351 1 698 1 062 1 346 3,844 4,831 3,022 3,830 10 080 625 4 782 969 7 043 716 6 175 225 3 175 2 187 2 654 2 485 9,4 6,5 7,8 7,4 11 905 826 7 666 173 8 171 560 7 986 941 15 300 35 148 34 701 447 1,272 14 455 204 3 802 11,0 14 655 013 15 400 35 148 35 573 425 1,209 14 493 249 3 807 10,7 14 673 874 15 15 15 15 500 800 900 1 000 35 148 35 148 35 148 35 148 34 627 35 130 35 203 34 754 521 18 55 394 1,482 0,051 0,156 1,121 10 297 681 5 736 025 7 263 025 4 190 209 3 209 2 395 2 695 2 047 9,3 6,8 7,7 5,9 10 569 122 5 736 349 7 266 050 4 345 445
Dari hasil simulasi ini, ragam terkecil adalah sampel 1000 pada 15 gerombol. RSE terletak antara 5,9 persen sampai 13,9 persen. RSE terkecil adalah sampel 1000 pada 15 gerombol. MSE terletak antara 4,3 juta sampai 23,4 juta. MSE terkecil adalah sampel 1000 pada 15 gerombol. Artinya, berdasarkan tingkat keakuratan, maka pengambilan 15 gerombol pada sampel 1000 memiliki tingkat akurasi terbaik.
22
Jika dibandingkan dengan hasil simulasi metode two stage cluster sampling, metode ini menghasilkan kisaran MSE yang lebih lebar. Namun, angka MSE terkecil pada metode ini, lebih kecil jika dibandingkan dengan metode two stage cluster sampling.
Pada gerombol yang sama, dapat dilihat semakin besar ukuran sampel, MSE semakin kecil. Di samping itu, pada ukuran sampel yang sama, dapat juga dilihat semakin besar jumlah gerombol, MSE juga semakin kecil. Dengan demikian, dapat dikatakan, peningkatan jumlah gerombol dan jumlah sampel, dapat memperkecil MSE.
Lapisan Berdasarkan Status Desa (Perkotaan-Perdesaan)
Tabel 4.11 menjelaskan bahwa hasil simulasi metode stratified two stage cluster sampling memiliki bias antara 78 sampai 2287. Persentase bias terhadap total populasi terkecil adalah sampel 500 sebesar 0,222 persen pada 15 gerombol. Dalam hasil simulasi ini, ragam terkecil adalah sampel 1000 pada 5 gerombol. RSE terletak antara 4,4 persen sampai 13,4 persen. RSE terkecil adalah sampel 1000 pada 5 gerombol. MSE terletak antara 6,1 juta sampai 22,4 juta. MSE terkecil adalah sampel 1000 pada 15 gerombol. Jadi, berdasarkan tingkat keakuratan, maka pengambilan 15 gerombol pada sampel 1000 memiliki tingkat akurasi terbaik.
Tabel 4.11 Hasil simulasi pada metode stratified two stage cluster sampling berdasarkan status desa
n m τ 𝜏̂ Bias (gerai) Bias terhadap τ (%) Ragam Galat baku (gerai) RSE (%) MSE 5 300 35 148 33 765 1 383 3,935 20 484 676 4 526 13,4 22 397 365 5 400 35 148 33 563 1 585 4,510 11 464 996 3 386 10,1 13 977 221 5 5 5 5 500 800 900 1 000 35 148 35 148 35 148 35 148 33 868 32 179 32 439 32 240 1 280 2 969 2 709 2 908 3,642 8,447 7,707 8,274 12 390 400 4 575 321 3 794 704 2 005 056 3 520 2 139 1 948 1 416 10,4 6,6 6,0 4,4 14 028 800 13 390 282 11 133 385 10 461 520 10 300 35 148 32 861 2 287 6,507 15 745 024 3 968 12,1 20 975 393 10 400 35 148 34 392 756 2,151 10 220 809 3 197 9,3 10 792 345 10 10 10 10 500 800 900 1 000 35 148 35 148 35 148 35 148 34 088 31 319 31 581 31 822 1 060 3 829 3 567 3 326 3,016 10,894 10,149 9,463 10 556 001 3 869 089 3 686 400 2 954 961 3 249 1 967 1 920 1 719 9,5 6,3 6,1 5,4 11 679 601 18 530 330 16 409 889 14 017 237 15 300 35 148 34 818 330 0,939 12 567 025 3 545 10,2 12 675 925 15 400 35 148 34 800 348 0,990 12 054 784 3 472 10,0 12 175 888 15 15 15 15 500 800 900 1 000 35 148 35 148 35 148 35 148 35 070 33 657 33 335 33 918 78 1 491 1 813 1 230 0,222 4,242 5,158 3,499 10 004 569 4 884 100 3 625 216 4 583 881 3 163 2 210 1 904 2 141 9,0 6,6 5,7 6,3 10 010 653 7 107 181 6 912 185 6 096 781
Jika dibandingkan dengan metode yang sama dengan lapisan berdasarkan status pemerintah daerah, metode ini menghasilkan kisaran MSE lebih pendek. Hasil simulasi dapat menjelaskan pergerakan nilai MSE pada gerombol yang sama di ukuran sampel yang berbeda atau pada ukuran sampel yang sama di gerombol yang berbeda. Secara umum peningkatan ukuran sampel baik pada gerombol yang sama atau berbeda, dapat menurunkan nilai MSE. Dengan
23 demikian, hasil simulasi dapat menjelaskan bahwa peningkatan ukuran sampel dapat meningkatkan tingkat akurasi.
Jika melihat pada nilai RSE, kisaran nilai RSE pada 15 gerombol paling pendek dibandingkan pada 10 dan 5 gerombol. Kisaran RSE pada 15 gerombol sebesar 3 persen, sedangkan kisaran RSE pada 10 dan 5 gerombol masing-masing sebesar 9,7 persen dan 6,7 persen.
Perbandingan Antar Metode Sampling
Kriteria Validitas
Hasil simulasi dapat menjelaskan tingkat validitas antar metode sampling. Tingkat validitas ditunjukkan oleh nilai bias. Semakin kecil bias, tingkat validitas semakin baik.
Sampling satu tahap memiliki kisaran bias antara 20 gerai sampai 1076 gerai. Bias terkecil pada metode simple random sampling adalah 21 pada sampel 1000. Bias terkecil pada metode stratified random sampling dengan lapisan berdasarkan jumlah penduduk adalah 24 pada sampel 400. Bias terkecil pada metode stratified random sampling dengan lapisan berdasarkan status desa adalah 20 pada sampel 1000. Bias terkecil pada metode stratified random sampling dengan lapisan berdasarkan status pemerintah daerah adalah 289 pada sampel 400. Dari semua nilai bias terkecil tersebut, metode stratified random sampling dengan lapisan berdasarkan status desa memiliki bias terkecil.
Sampling dua tahap memiliki kisaran bias antara 18 gerai sampai 2969 gerai. Kisaran ini lebih lebar dibandingkan dengan kisaran bias pada sampling satu tahap. Bias terkecil pada metode two stage cluster sampling adalah 74 pada sampel 900 di 15 provinsi. Bias terkecil pada metode stratified two stage cluster sampling dengan lapisan berdasarkan status pemerintah daerah adalah 18 pada sampel 800 di 15 provinsi. Bias terkecil pada metode stratified two stage cluster sampling dengan lapisan berdasarkan status desa adalah 78 pada sampel 500 di 15 provinsi. Pada metode sampling dua tahap, metode stratified two stage cluster sampling pada sampel 800 di 15 provinsi dengan lapisan berdasarkan status pemerintah daerah memiliki bias terkecil.
Metode stratified two stage cluster sampling dapat menjadi pilihan terbaik jika tidak seluruh provinsi tidak terkena sampel. Dapat dikatakan, cukup mengambil sampel di 15 provinsi, maka tingkat validitas terbaik bisa didapatkan.
Menurut Cochran (1991), pengaruh dari bias terhadap ketelitian suatu pendugaan dapat diabaikan jika biasnya kurang dari sepersepuluh galat baku pendugaannya. Pada semua ukuran sampel, metode two stage cluster sampling pada 15 gerombol memiliki rasio bias terhadap galat baku penduga di bawah 0,1. Angka ini menunjukkan bahwa bias tidak merugikan metode tersebut. Dua istilah yang digunakan dalam membahas tingkat ketelitian, yaitu presisi dan akurasi. Presisi adalah selisih pendugaan dengan nilai harapannya. Akurasi adalah selisih pendugaan dengan nilai sebenarnya/parameter. Gambar 4.2 menjelaskan sebaran rasio bias terhadap galat baku penduga pada metode sampling dua tahap di mana
24
bias dapat diabaikan atau secara statistik bias tersebut tidak berarti (Supranto 2007).
Gambar 4.2 Rasio bias terhadap galat baku penduga (<0,1) sampling dua tahap Secara detail, pada sampling satu tahap, perbandingan sebaran bias terkecil terhadap total populasi dapat dilihat pada Gambar 4.3. Rata-rata persentase bias terhadap total populasi adalah 0,91 persen. Persentase bias terhadap populasi terkecil adalah metode stratified random sampling dengan lapisan menurut status desa pada ukuran sampel 1000. Angkanya sebesar 0,057 persen.
Gambar 4.3 Persentase bias terkecil terhadap total populasi sampling satu tahap Pada sampling dua tahap, perbandingan sebaran bias terkecil terhadap total populasi dapat dilihat pada Gambar 4.4. Rata-rata persentase bias terhadap total populasi adalah 3,67 persen. Angka ini mencapai empat kali lipat dibandingkan rata-rata persentase bias pada sampling satu tahap. Persentase bias terhadap