Abstrak: Kanker payudara sering menyebabkan kematian jika penanganannya terlambat. Sehingga perlu dilakukan pendeteksian dini terhadap kanker payudara. Salah satu metode yang digunakan untuk identifikasi kanker payudara dengan bantuan komputer adalah klasifikasi Support Vector Machine. Support Vector Machine melakukan klasifikasi terhadap citra mammogram. Kelemahan dari identifikasi kanker payudara dengan Support Vector Machine adalah jumlah citra mammogram yang digunakan untuk data pembelajaran jumlahnya terbatas. Sehingga untuk mengatasi keterbatasan data ini perlu menggunakan metode Adaptive Support Vector(Adaptive SVM) Machine. Adaptive SVM dibantu oleh hasil Sistem Temu Kembali Citra untuk melakukan pembelajaran ulang dan memperbaiki fungsi keputusan pada Support Vector Machine.
Ujicoba yang dilakukan menggunakan dua jenis data pembelajaran yaitu terpilih dan acak. 28 persen data ujicoba dengan pembelajaran terpilih perlu perbaikan dengan Adaptive SVM dan untuk 55 persen ujicoba data pembelajaran acak perlu dilakukan perbaikan dengan Adaptive SVM. Rata-rata Tingkat akurasi hasil ujicoba dengan menggunakan Adaptive SVM adalah 63 persen. Adaptive SVM mampu meningkatkan akurasi 0.84 persen sampai dengan 5 persen dibanding tingkat akurasi SVM.
Kata kunci—Support Vector Machine, Adaptive Support Vector Machine, Sistem Temu Kembali Citra, Kanker Payudara, Mammogram.
I. PENDAHULUAN
anker payudara adalah salah satu jenis kanker yang paling banyak menyerang kaum wanita. Menurut WHO 8-9% wanita akan mengalami kanker payudara. Pada tahun 2000 yang lalu WHO memperkirakan 1,2 juta wanita terdiaknosis kanker payudara dan lebih dari 700.000 meninggal dunia[1]. Di Indonesia, pada tahun 2005 kanker payudara menduduki peringkat kedua setelah kanker leher rahim diantara kanker yang menyerang wanita Indonesia. Kanker ini sering menyebabkan kematian jika penanganannya terlambat. Oleh karena itu, deteksi dini penyakit kanker payudara sangat diperlukan. Mammografi dengan sinar-X merupakan salah satu teknik pencitraan yang efektif untuk deteksi dini keberadaan kanker payudara. Resolusi spasialnya yang sangat tinggi cukup untuk mendeteksi sel kanker. Teknik ini sudah tersebar ke beberapa negara dan kemampuannya sudah tidak diragukan lagi. Mammogram adalah hasil dari proses mammografi. Mammogram inilah yang digunakan oleh dokter untuk
mendiagnosis kanker payudara. Jika citra mammogram yang didapat kurang bagus maka dokter sulit melakukan analisa. Selain itu jika didapatkan sebuah kasus yang jarang terjadi dokter perlu mendapatkan informasi tentang kejadian-kejadian yang serupa dimasa lampau secara manual.
Kondisi diatas menyebabkan dibutuhkan sebuah sistem yang mampu membantu dokter. Dengan sistem tersebut dokter bisa melakukan deteksi kanker payudara dan juga mendapat masukan dari sistem sebagai second opinion ketika melakukan diagnosis. Sistem yang dibuat menggunakan metode klasifikasi Support Vector Machine seperti yang telah dilakukan oleh Y. Ireaneus, dengan melakukan klasifikasi terhadap fitur dari citra mammogram dari proses segmentasi dan ekstraksi fitur[2]. Selain proses diagnosis, sistem juga diharapkan mampu memberikan masukan berupa contoh-contoh kasus yang pernah ada sebelumnya. Permasalahan ini dapat diselesaikan dengan sistem temu kembali citra, dengan memasukan citra ujicoba sistem mampu memberikan citra kembalian berupa citra yang mempunyai kemiripan dengan citra ujicoba seperti sebuah proyek sistem temu kembali citra berbasis medikal yang dikembangkan Pretti Aggarwal[3]. Sistem yang dibuat menggabungkan dua proses diatas yaitu menggunakan sistem temu kembali citra dan melakukan klasifikasi dengan menggunakan Support Vector Machine.
Deteksi kanker payudara dengan bantuan komputer dengan menggunakan metode Support Vector Machine melakukan pembelajaran untuk membuat sebuah fungsi keputusan. Pembelajaran dilakukan dari fitur-fitur citra mammogram yang telah dilakukan pengolahan citra dan ekstraksi fitur. Namun SVM mempunyai kekurangan yaitu data pembelajaran yang digunakan jumlahnya sangat terbatas. Permasalahan tersebut akan mempengaruhi akurasi dari sistem jika diterapkan dalam ujicoba. Untuk menyelesaikan permasalahan kekurangan data pembelajaran digunakan metode Adaptive Support Vector Machine (Adaptive SVM). Adaptive SVM melakukan pembelajaran ulang untuk membuat sebuah fungsi keputusan yang baru. Pembelajaran ulang dengan Adaptive SVM melibatkan hasil sistem temu kembali citra dengan memberikan penalti faktor yang lebih besar terhadap citra dari hasil temu kembali citra tersebut. Fungsi keputusan yang baru hasil pembelajaran ulang Adaptive SVM digunakan untuk melakukan klasifikasi citra yang akan didiagnosis. Penggunaan metode Adaptive SVM ini mampu menyelesaikan keterbatasan data dengan menggunakan citra hasil temu kembali citra dan
Implementasi Adaptive Support Vector Machine
untuk Membantu Identifikasi Kanker Payudara
Baktiar Karisma , Diana Purwitasari, Anny Yuniarti
Teknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember
Gedung Teknik Informatika, Kampus ITS Sukolilo-Surabaya 60111
email :
[email protected]
memperbaiki fungsi keputusan dari SVM biasa. Fungsi keputusan yang dihasilkan dari Adaptive SVM diharapkan akan memperbaiki tingkat akurasi dari sistem sehingga hasil diagnosis citra mammogram akan lebih akurat dibanding dengan menggunakan metode klasifikasi SVM biasa.
II. IDENTIFIKASI KANKER PAYUDARA DENGAN BANTUAN KOMPUTER
Sistem ini menawarkan bantuan kepada dokter dalam mendiagnosis kanker payudara, dan memberikan informasi tambahan kepada dokter. Karena dalam mengidentifikasi kanker payudara seorang dokter adakalanya membutuhkan beberapa citra mammogram sebagai masukan untuk memberikan diagnosisnya.Sistem ini dibuat dengan menggabungkan klasifikasi dan sistem temu kembali citra. Klasifikasi yang digunakan adalah SVM dan Adaptive SVM. Dalam sistem ini juga diperlukan peran aktif pengguna untuk melakukan diagnosis.
Penggunaan dari Adaptive SVM ini tidak terlepas dari kekurangan SVM. Walaupun SVM dikatakan sebuah klasifikasi yang bagus, namun dalam aplikasinya SVM mempunyai kekurangan terutama dalam masalah data pembelajaran. Data pembelajaran yang digunakan dalam identifikasi kanker payudara jumlahnya juga terbatas. Terbatasnya jumlah data pembelajaran tersebut akhirnya SVM tidak bisa menggambarkan permasalahan yang sebenarnya. Sehingga ketika pada waktu ujicoba jika diterapkan dengan data lain tingkat akurasinya tidak akan bagus. Berangkat dari permasalahan inilah maka perlu dibuatkan sebuah sistem yang mampu mengatasi keterbatasan data.
Penggunaan Adaptive SVM dengan menggunakan hasil dari sistem temu kembali citra ini dapat digunakan sebagai alternatif dari permasalahan data yang ada. Adaptive SVM menyesuaikan data pembelajaran berdasarkan data yang akan didiagnosa.
Sistem temu kembali citra penggunaannya selain memberikan informasi tentang mammogram yang mempunyai kemiripan dengan mammogram yang didiagnosis kepada dokter, juga digunakan untuk memberikan informasi kepada sistem tentang data mana saja yang dapat digunakan dan sesuai untuk data pembelajaran.
Secara keseluruhan sistem akan mengumpulkan data pembelajaran. Kemudian dilakukan sebuah pembelajaran klasifikasi. Setelah proses pembelajaran selesai sistem dapat digunakan untuk membantu dokter untuk mendiagnosis kanker payudara. Proses diagnosisnya dengan menginputkan sebuah citra mammogram kemudian dokter sebagai pengguna akan diberikan informasi berupa sejumlah citra mammogram yang mempunyai persamaan kasus dengan mammogram yang akan didiagnosis. Dengan hasil pencarian citra yang mirip tersebut diharapkan memberikan gambaran terhadap mammogram dari hasil yang akan didiagnosis. Proses selanjutnya pengguna akan memasukan jumlah mammogram hasil pencarian yang akan dilibatkan dalam pembelajaran Adaptive SVM. Dilangkah inilah proses perbaikan data pembelajaran terjadi yaitu dengan melibatkan citra-citra yang mirip dengan citra yang diujicobakan. Setelah proses pembelajaran selesai sistem akan memberikan bantuan diagnosis terhadap mammogram yang dimasukan. Diagnosis berupa keputusan apakah citra mammogram yang didiagnosis terkena kanker payudara atau
tidak. Selanjutnya untuk diagnosis akhir tetap akan diserahkan kepada dokter sebagai pengguna, karena sistem sifatnya adalah membantu dalam mendiagnosis.
III. PENGOLAHAN CITRA MAMMOGRAM UNTUK EKSTRAKSI FITUR
Kanker payudara dapat dideteksi dari citra mammogram. Citra mammogram diambil dari proses mammografi. Dari mammogram ini dapat dideteksi tumor dalam bentuk kecil. Dari citra mammogram dapat dikenali seseoarang terdeteksi kanker payudara jinak, ganas atau tidak terkena kanker payudara atau normal. Dalam sistem yang dibuat ini klasifikasi dengan Support Vector Machine dan Sistem Temu Kembali Citra memanfaatkan fitur dari mammogram untuk pengolahannya. Untuk mendapatkan fitur langkah yang dilalui adalah melakukan segmentasi citra dan ekstraksi citra.
A. Segmentasi citra
Segmentasi citra diperlukan dalam image prosessing dan pattern recognition. Segmentasi citra yaitu proses membagi citra menjadi beberapa bagian region. Salah satu jenis dari segmentasi adalah thresholding[4]. Metode Otsu Thresholding digunakan dalam segmentasi citra dalam sistem ini. Otsu thresholding bertujuan sama dengan thresholding yang lainnya yaitu memisahkan background dan foreground dengan mendapatkan nilai variance dari setiap tingkat keabuan[5]. Nilai threshold untuk memisahkan antara background dan foreground adalah tingkat keabuan yang mempunyai nilai variance terbesar. Otsu thresholding dalam sistem ini menerapkan kasus bi-level thresholding dari sebuah citra. Piksel di bagi menjadi dua kelas yaitu, C1 dengan tingkat keabuan [1, ..., t] dan C2 dengan tingkat keabuan [t+1, ..., L]. dimana t adalah threshold yang diperoleh dari perhitungan threshoding dengan mencari nilai maksimal variance dari tingkat keabuan.
Pencarian tingkat keabuan mana yang akan digunakan sebagai thresholding adalah dengan mencari nilai maximal variance sebagai berikut.
(1) Dalam mammogram terdapat background berupa warna hitam dan foreground berupa payudara. Sedangkan dalam tujuan segmentasi dalam sistem ini adalah mendapatkan daerah yang dicurigai sebagai kanker payudara. Sehingga dalam pencarian daerah yang perlu dicurigai harus dilakukan proses thresholding berulang sehingga mendapatkan daerah yang dicurigai.
B. Ekstraksi Fitur.
Ektraksi fitur dihitung dari citra mammogram yang telah tersegmentasi. Ekstraksi fitur ini digunakan untuk mencari fitur teksture seperti yang didefinisikan oleh Haralick[6]. Perhitungan dalam fitur teksture yang didefinisikan Haralick terdapat 2 langkah. Pertama adalah menghitung Gray Level Co-Occurrence Matrix(GLCM) dan yang kedua adalah menghitung 13 fitur teksture dengan menggunakan Matrix Co-Occurrence tersebut[7]. Proses menghitung GLCM ini adalah melakukan scaning untuk mencari jejak derajat keabuan setiap dua buah piksel yang dipisahkan dengan
2 2 2 2 1 1 2 ( ) ( ) t T B
jarak d dan sudut θ yang tetap. Biasanya yang digunakan 4 sudut yaitu (0o, 45o, 90o, dan 135o ).
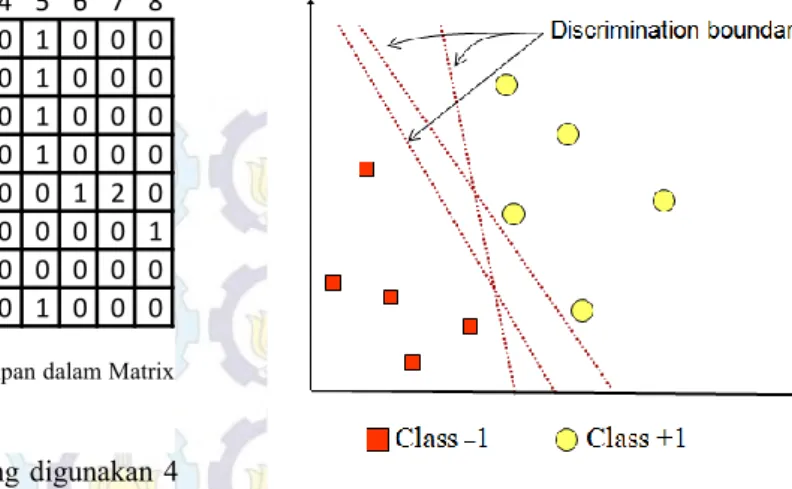
Jumlah ketetanggan dari tingkat keabuan tersebut disimpan dalam sebuah matrik yang disebut matrik Co-Occurence. Matrik ini mempunyai ukuran sesuai dengan tingkat keabuan dari citra. Citra mammogram ini menggunakan tingkat keabuan 1 sampai dengan 256. Maka dalam matrik Co-Occurrence yang dibuat adalah 256 × 256. Contoh dari perhitungan jumlah ketetanggan tingkat keabuan ditunjukan pada Gambar 1, dalam gambar tersebut menggunakan jarak ketetanggaan 1 dan derajat ketetanggaan 0o.
Matrix Co-Occurrence dari citra mammogram tersebut digunakan untuk menghitung fitur dari citra mammogram yang telah tersegmentasi. 13 Fitur yang diperoleh dari matrik co-occurrence dan digunakan dalam perangkat lunak ini adalah sebagai berikut[6]:
Angular Second Momment, Contrast, Correlation, Variance, Inverse Difference Momment, Sum Difference, Sum Variance, Sum Entropy, Entropy, Difference Variance, Difference Entropy, Information Measurement I, Information Measurement II
IV. KLASIFIKASI CITRA MAMMOGRAM DENGAN SUPPORT VECTOR MACHINE
Klasifikasi yang digunakan adalah SVM dan Adaptive SVM. Setiap klasifikasi membutuhkan proses pembelajaran dengan menggunakan fitur sebagai data. Proses pembelajaran akan menghasilkan sebuah fungsi keputusan untuk pengklasifikasian citra mammogram.
A. Support Vector Machine
Support vector Machine(SVM) adalah suatu pertama kali diperkenalkan oleh Vapnik pada tahun 1992 sebagai salah satu metode dalam pattern recognition. SVM berusaha untuk menemukan hyperplane pemisah terbaik antar kelas. Pada dasarnya SVM adalah sebuah linier klasifier, dan dalam perkembangannya SVM dapat digunakan sebagai non-linier klasifier dengan diperkenalkan konsep kernel[8]. Perkembangan SVM tersebut saat ini telah berhasil melakukan klasifikasi problem dunia nyata dan juga memberikan solusi yang baik dari problem tersebut.
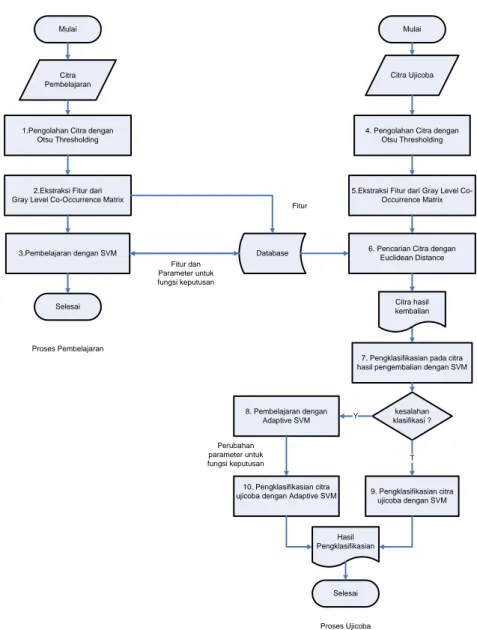
Konsep SVM adalah mencari hyperplane terbaik yang berfungsi memisahkan dua buah kelas. Gambar 2 memperlihatkan beberapa pola yang merupakan anggota dari dua kelas yaitu kelas -1 dan +1. Pola pada kelas -1 disimbolkan dengan bentuk segiempat dan pola +1 berupa lingkaran. Problem dalam klasifikasi ini dapat diartikan
bagaimana menemukan garis(Hyperplane) yang dapat memisahkan kedua kelas tersebut.
Berbagai alternatif garis pemisah antara dua kelas ditunjukkan pada Gambar 3. garis pemisah terbaik atau yg disebut hyperplane terbaik dapat ditemukan dengan cara mengukur margin hyperplane tersebut dan titik maksimalnya. Margin adalah jarak antara hyperplane dengan titik atau pola terdekat dari setiap kelas yang akan dipisahkan. Pola yang terdekat dengan margin disebut sebagai support vector. Support vector adalah pola yang paling informatif dalam kelas tersebut, dan yang nantinya sangat diperlukan dalam melakukan klasifikasi[9]. Hyperplane terbaik dimana hyperplane tersebut tepat ditengah-tengah kedua kelas. Dan pola yang dilingkari dengan warna hitam adalah yang disebut support vector. Sehingga dapat disimpulkan proses pembelajaran dalam SVM adalah bagaimana mencari hyperplane terbaik dalam memisahkan kedua kelas. Memisahkan dua kelas secara sempurna ini disebut dengan hard margin.
Penjelasan sebelumnya diasumsikan bahwa sebuah hyperplane dapat memisahkan kedua kelas secara sempurna. Namun yang terjadi pada umumnya dua buah kelas pada input space ditraining set tidak dapat dipisahkan secara sempurna. Membuat kelas terpisah secara sempurna menyebabkan optimasi tidak dapat dilakukan. Untuk mengatasi permasalah tersebut, SVM memperkenalkan teknik soft margin. Dalam sotfmargin diperkenalkan variable slack (slack variabel) . sehingga dalam soft margin SVM mendapatkan hyperplane yang terbaik dengan cara meminimalkan fungsi berikut,
(2) Dengan konstrain
(3) Parameter C dipilih untuk mengontrol tradeoff antara margin dan error klasifikasi ξ. Nilai C yang besar akan memberikan pinalti yang lebih besar terhadap error klasifikasi. Memberikan nilai C kecil akan melebarkan margin dan memperbolehkan banyak data atau pola misklasifikasi. Dengan nilai C yang besar maka akan semakin memperketat misklasifikasi data. Nilai C = ∞ hal ini berarti soft margin akan berubah menjadi hard margin.
l i i w w w C Min 1 2 2 1 i b x w yi( . )1i, 0 , i i
Gambar 2. Konsep SVM bagaimana mencari hyperplane(bidang pemisah) terbaik yang dapat memisahkan dua kelas secara sempurna. 1 2 3 4 5 6 7 8 1 1 5 6 8 1 1 2 0 0 1 0 0 0 2 3 4 7 1 2 0 0 1 0 1 0 0 0 4 5 7 1 2 3 0 0 0 0 1 0 0 0 8 5 1 2 5 4 0 0 0 0 1 0 0 0 5 1 0 0 0 0 1 2 0 6 0 0 0 0 0 0 0 1 7 2 0 0 0 0 0 0 0 8 0 0 0 0 1 0 0 0 Gambar 1. Mengukur jumlah ketetanggaan dan disimpan dalam Matrix Co-Occurrence
Proses meminimalisasi Persamaan 2 dalam pembelajaran SVM akan mendapatkan nilai Lagrange Multipliers untuk setiap data yang dilibatkan dalam pembelajaran. Nilai Lagrange Multipliers lebih dari nol yang akan digunakan dalam proses pengambilan keputusan. Data dengan nilai Lagrange Multipliers bukan 0 disebut dengan support vector.
Fungsi keputusan untuk melakukan klasifikasi dengan SVM dapat dituliskan sebagai berikut.
(4) Fungsi keputusan diatas akan memberikan nilai > 1 dan < -1 yang merupakan label dari kedua kelas yang diklasifikasikan.
Dalam domain dunia nyata(real world problem) problem yang dihadapi jarang bersifat linier separable (dapat dipisahkan secara linier) hal tersebut berarti problem yang dihadapi bersifat nonlinier. Untuk menyelesaikan persoalan tersebut maka data dipetakan kedalam fitur space yang lebih tinggi[8].
Pemetaan tersebut dilakukan dengan menjaga topologi data, dimana dua data yang berjarak dekat pada input space
akan berjarak dekat juga pada feature space, dan juga sebaliknya data yang berjarak jauh pada input space akan berjarak jauh pula pada feature space[9].
Proses pembelajaran pada SVM untuk menemukan titik-titik support vector untuk selanjutnya bergantung pada dot product dari data yang sudah ditransformasikan kedalam ruang baru yang berdimensi lebih tinggi.
(5) Karena transformasi Φ pada umumnya tidak diketahui dan sulit dipahami maka perhitungan dot product tersebut sesuai teori Mercer dapat digantikan dengan fungsi kernel[8]. Kernel yang sering dipakai dalam SVM adalah Kernel Polynomial, Kernel Fungsi Radial Basis, Kernel NN Dual Layer, Kernel Multi-Quadratic, Spline Thin Plate.
Sequential Minimal Optimization
SMO dapat memecahkan problem SVM QP tanpa membutuhkan matriks yang besar. Selain itu juga tidak melibatkan iterasi untuk setiap sub problem. SMO memilih untuk menyelesaikan optimasi terkecil untuk setiap stepnya. Untuk problem SVM QP standar, permasalahannya terletak
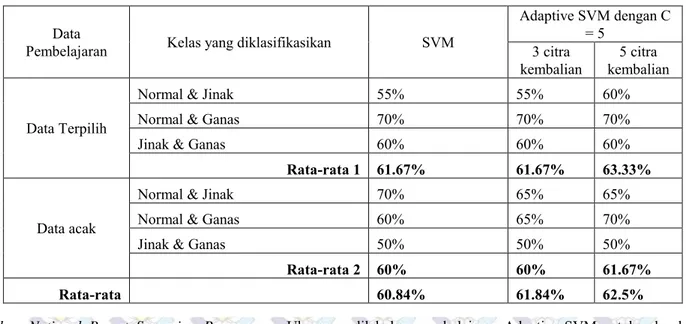
Mulai
4. Pengolahan Citra dengan Otsu Thresholding
5.Ekstraksi Fitur dari Gray Level Co-Occurrence Matrix
3.Pembelajaran dengan SVM 1.Pengolahan Citra dengan
Otsu Thresholding
2.Ekstraksi Fitur dari Gray Level Co-Occurrence Matrix
7. Pengklasifikasian pada citra hasil pengembalian dengan SVM
8. Pembelajaran dengan Adaptive SVM kesalahan klasifikasi ? 9. Pengklasifikasian citra ujicoba dengan SVM Hasil Pengklasifikasian Selesai Citra Pembelajaran Y T 10. Pengklasifikasian citra ujicoba dengan Adaptive SVM Selesai
Mulai
Citra Ujicoba
6. Pencarian Citra dengan Euclidean Distance Database Citra hasil kembalian Fitur Fitur dan Parameter untuk fungsi keputusan Perubahan parameter untuk fungsi keputusan Proses Pembelajaran Proses Ujicoba
Gambar 3. Sistem Perangkat Lunak yang dibuat, yang berada sebelah kiri proses pembelajaran disebelah kanan proses ujicoba b x w x f(()) .()
xi
xj .pada penyelesaian dua buah Lagrange Multipliers , karena Lagrange Multipliers tersebut harus mematuhi aturan persamaan linier. Pada SMO menggunakan 2 lagrange Multipliers untuk dilakukan proses optimasi, untuk menemukan nilai optimal dari Lagrange Multipliers tersebut dan mengubah SVM untuk mendapatkan nilai optimal yang baru[10].
Keuntungan dari SMO terletak pada bagaimana memecahkan dua buah Lagrange Multipliers secara analitical. SMO juga tidak membutuhkan matriks yang besar. Training SVM yang besar bisanya membutuhkan memori yang besar. Tetapi pada SMO menghindari perhitungan yang membutuhkan matriks yang besar[8].
Dalam rangka menyelesaikan problem dua Lagrange Multipliers , SMO terlebih dahulu menghitung konstrain pada Multipliers tersebut dan kemudian menyelesaikan konstrain maksimumnya. Setiap optimasi terjadi SMO melibatkan dua Lagrange Multipliers . Jika SMO hanya mengoptimasi satu, ini tidak dapat memenuhi konstrain persamaan linier disetiap stepnya.
SMO akan mengubah Lagrange Multipliers dalam setiap stepnya, dimana salah satu dari Lagrange Multipliers melanggar aturan KKT. Maka dari itu SMO akan mengubahnya dua Lagrange Multipliers sehingga tidak melanggar aturan KKT tersebut. Maka dari itu fungsi objectifnya akan berubah setiap step dan nilainya akan converage. Maka dari itu untuk mengontrol kecepatan konvergensinya SMO menggunakan heuristik untuk memilih dua Lagrange Multipliers yang akan dioptimasi.
Ada dua jenis untuk memilih heuristik. Heuristik pertama untuk Lagrange Multipliers yang pertama kemudian heuristik kedua untuk Lagrange Multipliers yang kedua. Untuk heuristik pertama yaitu menggunakan outer loop. Outer loop mengiterasi seluruh data training yang ada, dan menentukan data mana yang melanggar aturan KKT. Jika salah satu data melanggar aturan KKT, kemudian dilakukan optimasi. Jika ditemukan data training yang melanggar aturan KKT maka dilakukan pemilihan Lagrange Multipliers kedua dengan menggunakan heuristik kedua dan kedua Lagrange Multipliers tersebut dioptimasi. Kemudian SVM mengupdate nilainya, selanjutnya outer loop mencari lagi yang melanggar aturan KKT.
Untuk mempercepat training tidak harus dilakukan iterasi pada outer loop. Setelah satu kali training set di iterasi menggunakan outer loop, untuk selanjutnya hanya menggunakan nilai Lagrange Multipliers yang bukan 0 dan bukan C( data non-bound) untuk diiterasi. Seperti proses sebelumnya data tersebut dilakukkan pengecekan aturan KKT, jika melanggar maka dilakukan optimasi kembali. Outer loop digunakan kembali jika semua data non-bound memenuhi kondisi KKT. Langkah tersebut dilakukan berulang kali sampai perubahan nilai dalam batas tertentu. Heuristik diatas bertujuan penghematan waktu perhitungan oleh CPU pada data training yang melanggar aturan KKT.
Lagrange Multipliers pertama telah dipilih, SMO memilih Lagrange Multipliers yang kedua untuk memaksimalkan ukuran step selama optimasi. SMO menyimpan error cache E untuk setiap data non-bound pada training set. Kemudian memilih erorr yang maksimal untuk setiap stepnya. Dan jika nilai E1 positif maka pilih data dengan minimum error pada E2. Jika E1 negatif SMO memilih data yang bernilai maksimum pada E2.
Dalam keadaan tertentu, SMO tidak akan mendapatkan progres yang positif ketika menggunakan heuristik yang kedua tersebut. Untuk menyelesaikan masalah tersebut maka pada heuristik kedua terdiri dari: (A) jika heuristik diatas tidak mendapatkan progres positif, kemudian SMO melakukan iterasi pada data non-bound. (B) Jika non-bound tersebut tidak mendapatkan positif progres maka akan dilakukan iterasi untuk semua data, dimulai dengan random point. Pada keadaan ekstrim tidak ada positif progres maka akan dilanjutkan data selanjutnya pada outer loop.
Pada algoritma SMO terdiri dari tiga komponen. Yang pertama metode analisa untuk menyelesaikan dua lagrange Multipliers . Kedua heuristik untuk memilih Lagrange Multipliers yang mana yang akan di optimasi. Dan ketiga metode untuk menghitung bias.
B. Adaptive Support Vector Machine
Kesuksesan SVM dalam melakukan klasifikasi pada praktiknya ada beberapa kendala. Pertama problem yang dihadapi terlalu rumit dan sulit dipahami. Kedua terbatasnya data pembelajaran yang digunakan yang menyebabkan sulit untuk mendapatkan optimal classifiers. Sedikitnya data pembelajaran ini akan membuat fungsi keputusan yang kurang baik, fungsi keputusan tersebut tidak bisa merepresentasikan keadaan dalam dunia nyata. Hal tersebut yang membuat SVM sangat jauh dari kata sempurna untuk menjadi sebuah classifier dikarenakan hal tersebut[11].
Adaptive SVM menyesuaikan fungsi keputusan dengan melibatkan data yang mempunyai kemiripan terhadap citra mammogram yang akan didiagnosis. Sebelum SVM diterapkan pada citra mammogram untuk ujicoba, terlebih dahulu SVM melakukan klasifikasi terhadap citra yang mirip terhadap citra ujicoba. Jika hasilnya jelek maka akan jelek pula terhadap hasil klasifikasi pada citra ujicoba. Dan begitu pula sebaliknya.
Hal tersebut mengindikasikan bahwa proses pembelajaran tidak bagus untuk kasus yang serupa sehingga juga tidak bagus untuk citra ujicoba. Citra yang mirip dengan citra ujicoba didapatkan dari hasil pencarian citra melalui Sistem Temu Kembali Citra.
Hal diatas perlu dilakukan pengubahan fungsi keputusan dengan menambahkan hasil citra yang mirip dengan queri sebagai data training di Adaptive SVM. Perubahan problem minimasi adalah sebagai berikut.
(5) Dengan konstrain
(6) Dalam modifikasi cost function di atas, data pelatihan dalam N(x) lebih dekat (karena lebih mirip) untuk query x dari pada data pelatihan yang lain. Dituliskan bahwa Cs=tC dimana 1 < t < ∞ yang merupakan penalti faktor.
Ini akan mempunyai efek yang mengesankan pada penekanan yang lebih besar terhadap Cs pada sampel yang serupa dengan query x atas contoh lain (memberikan nilai lebih terhadap data sample yang mirip). Alasan adalah bahwa sampel serupa itu akan memiliki dampak yang lebih besar pada klasifikasi pada data ujicoba. Dengan demikian,
l x N x x Nx i i s w i i C C w w Min ) ( () 2 2 1 i
b
x
w
y
i(
.
)
1
i,
0
,
i
i
hukuman yang lebih besar diberikan dalam cost function diatas ketika data yang serupa salah klasifikasi. Adaptive SVM hanya menjadi SVM biasa di mana C adalah faktor yang sama digunakan untuk semua data pelatihan.
Adaptive SVM akan membutuhkan waktu komputasi yang cukup lama dibanding SVM. Waktu komputasi tersebut dapat dikurangi dengan cara proses pembelajaran Adaptive SVM tidak selalu dilakukan. Pembelajaran Adaptive SVM tergantung pada klasifikasi citra hasil pencarian oleh Sistem Temu Kembali Citra.
Jika SVM mampu mengklasifikasikan dengan sempurna citra yang mirip dengan citra ujicoba maka pembelajaran Adaptive SVM tidak akan dilakukan. Jika ternyata hasil klasifikasi terhadap citra hasil sistem temu kembali terdapat misklasifikasi maka akan dilakukan proses pembelajaran Adaptive SVM.
V. IMPLEMENTASI
Implementasi dari sistem yang dibuat terdiri dari proses pembelajaran dan Ujicoba . seperti ditunjukan dalam Gambar 5. Proses pembelajaran digambarkan disebelah kiri dan proses ujicoba disebelah kanan. Didalam proses ujicoba ada bagian sistem temu kembali citra yang dimanfaatkan untuk proses Adaptive SVM.
A. Proses pembelajaran
Proses pembelajaran dilakukan untuk melakukan pengumpulan data ujicoba. Citra mammogram yang digunakan untuk pembelajaran sebelumnya dilakukan pengolahan citra. Pengolahan citra ini digunakan untuk mensegmentasi citra mammogram. Metode yang digunakan adalah Otsu threshold. Dari citra yang telah tersegmentasi dilakukan ekstraksi fitur dengan menggunakan Gray Level Co-Occurrense Matrix dengan mengambil 13 fitur teksture. Jika seluruh data pembelajaran telah dapat didapatkan fiturnya kemudian dilakukan pembelajaran klasifikasi. Pembelajaran klasifikasi ini menggunakan Support Vector Machine(SVM). SVM akan membuat sebuah fungsi keputusan yang kemudian akan digunakan dalam proses ujicoba nantinya. Diagram proses ditunjukan pada Gambar 2. Proses pembelajaran terletak pada diagram gambar sebelah kiri.
B. Sistem Temu Kembali Citra
Proses pembelajaran Adaptive SVM melibatkan Sistem temu kembali citra untuk memutuskan apakah perlu dilakukan proses pembelajaran SVM atau tidak. Sistem temu
kembali citra melakukan pengukuran kedekatan antara citra yang diujicobakan dengan citra pembelajaran. Pengukuran jarak dengan cara melakukan pengukuran fitur antara dua citra. Metode yang digunakan untuk mengukur jarak adalah Euclidean Distance.
Hasil pengukuran diambil sepuluh jarak terdekat dan ditampilkan ke tampilan antarmuka. Selain untuk dilibatkan dalam proses pengambilan keputusan citra yang ditampilkan tersebut juga digunakan untuk memberikan informasi kepada pengguna tentang citra yang mempunyai kemiripan dengan citra yang akan diujicobakan. Contoh aplikasi Sistem Temu Kembali ditunjukan dalam Gambar 5.
C. Proses Ujicoba
Ujicoba langkah awalnya sama seperti proses pembelajaran yaitu pengolahan citra dan ekstraksi fitur. Metode yang digunakan sama dengan proses pembelajaran. Didalamnya juga terdapat sistem temu kembali citra. Proses ujicoba selanjutnya adalah menerapkan Adaptive SVM. proses pembelajaran Adaptive SVM dengan melibatkan hasil sistem temu kembali. Pembelajaran Adaptive SVM akan membutuhkan waktu komputasi ektra, namun hal tersebut dapat dikurangi, dengan melakukan klasifikasi citra hasil sistem temu kembali citra dengan menggunakan fungsi keputusan SVM. Jika hasil klasifikasi tersebut tidak ada misklasifikasi maka tidak perlu dilakukan dilakukan pembelajaran Adaptive SVM. Hal ini mengindikasikan bahwa data pembelajaran yang digunakan cocok untuk data yang akan diujicobakan dan citra yang diujicobakan cukup menggunakan dengan fungsi keputusan SVM. Jika ternyata terdapat misklasifikasi dari hasil sistem temu kembali maka data pembelajaran yang digunakan dalam SVM tidak cocok dengan data yang diujicobakan. Sehingga perlu dilakukan pembelajaran Adaptive SVM, dan citra ujicoba akan diklasifikasikan dengan Adaptive SVM.
Dengan memanfaatkan sistem temu kembali citra maka waktu komputasi dapat dikurangi karena proses Adaptive SVM tidak selalu dijalankan. Performa SVM untuk data ujicoba dikoreksi terlebih dahulu dengan citra yang mirip dengan citra ujicoba. Karena diduga Jika ternyata hasil dari klasifikasi citra hasil kembalian jelek maka akan jelek juga hasilnya pada citra yang diujicobakan dan begitu pula sebaliknya.
VI. UJICOBA DAN EVALUASI
Data pembelajaran dan testing yang digunakan dari database MIAS (Mammographic Citra Analysis Society). Citra pada data base ini telah dipilih secara teliti dari United Gambar 5. Aplikasi Sistem Temu Kembali Citra untuk mendapatkan citra mammogram didatabase yang sama dengan citra mammogram ujicoba
Kingdom National Breast Screening Programme. Ukuran piksel dengan tinggi 1024 dan lebar disesuaikan dengan lebar dari citra mammogram tanpa menggunakan background, yang telah dipotong secara manual.
Terdapat dua jenis data pembelajaran yaitu secara terpilih dan secara acak. Citra pembelajaran dan citra yang akan dikembalikan menggunakan data yang sama. Setiap jenis data pembelajaran berjumlah 90 citra mammogram yang terdiri 30 citra untuk untuk kelas normal, 30 citra untuk kelas jinak dan 30 citra untuk kelas ganas. Data testing yang digunakan sebanyak 30 citra yang terdiri 10 citra untuk kelas normal, 10 citra untuk kelas jinak dan 10 citra untuk kelas ganas.
Klasifikasi menggunakan SVM adalah termasuk binary klasifikasi. Sehingga dalam ujicoba akan selalu hanya melibatkan dua kelas. Didalam citra mammogram yang digunakan terdapat 3 kelas sehingga akan terdapat klasifier yaitu untuk Normal dengan Jinak, Normal dengan Ganas dan Jinak dengan Ganas.
Ujicoba yang dilakukan adalah melakukan klasifikasi citra ujicoba diantara dua kelas. Dua kelas tersebut yang telah dilakukan pembelajaran adalah Jinak, Normal-Ganas, Jinak-Normal. Semua uji coba dengan menggunakan penalti faktor (C) untuk pembelajaran Support Vector Machine adalah dengan nilai 3. Menggunakan hasil kembalian 3,5 sebagai proses diagnosa untuk menguji performa SVM maupun yang akan dilibatkan dalam Adaptive SVM. Sedangkan nilai penalti faktor(C) untuk Adaptive SVM adalah 5,10, dan 15. Berikutnya akan dijelaskan hasil ujicoba untuk setiap kelas pembelajaran. Sistem melakukan ujicoba terhadap hasil kembalian terlebih dahulu untuk mengkoreksi kinerja dari SVM. pada Tabel 2 menunjukan akurasi SVM terhadap pengklasifikasian data hasil dari sistem temu kembali citra. Ujicoba dengan menggunakan data yang telah dilakukan pemilihan menunjukan, pada pengklasifikasian normal dengan ganas seluruh hasil kembalian dapat diklasifikasikan dengan sempurna. Hal ini mengindikasikan citra yang akan didiagnosis tidak perlu dilakukan pembelajaran Adaptive SVM. Sedangkan pada klasifikasi terhadap kelas normal dengan jinak dengan melibatkan 3 citra hasil kembalian, semua hasil kembalian dari seluruh citra yang akan didignosis tidak ada misklasifikasi sehingga tidak perlu
dilakukan pembelajaran Adaptive SVM untuk seluruh citra yang akan didiagnosis. Ketika melibatkan 5 citra hasil kembalian pada pengklasifikasian terhadap normal dengan jinak 5 persen dari data yang akan diujicobakan, terdapat misklasifikasi pada hasil kembaliannya. Sehingga 5 persen data tersebut perlu dilakukan pembelajaran Adaptive SVM. Ujicoba selanjutnya terhadap kelas jinak dan ganas lebih dari separuh data yang akan didiagnosis perlu dilakukan pembelajaran Adaptive SVM. lebih tepatnya 80 persen dari seluruh data yang akan didiagnosis perlu dilakukan Adaptive SVM, ini dikarenakan pengklasifikasian hasil kembaliannya terdapat kesalahan klasifikasi. Ketika jumlah kembalian yang dilibatkan meningkat maka jumlah data yang didiagnosis pun yang harus dilakukan pembelajaran Adaptive SVM meningkat.
Ujicoba lainnya untuk data pembelajaran yang diacak. Tabel 2 menunjukan bahwa untuk pengklasifikasian normal dengan jinak terdapat 40 persen dari semua data yang akan diujicobakan perlu dilakukan pembelajaran Adaptive SVM dengan melibatkan 3 hasil kembalian. Sedangkan ketika melibatkan 5 hasil kembalian seluruh data ujicoba yang harus dilakukan pembelajaran Adaptive SVM meningkat sampai 70 persen. Namun pada pengklasifikasian normal dengan ganas dan jinak dengan ganas peningkatan hasil kembalian yang dilibatkan tidak mempengaruhi jumlah data ujicoba yang perlu dilakukan pembelajaran Adaptive SVM.
Ujicoba dengan menggunakan data terpilih pada pembelajaran menunjukan hanya sedikit jumlah data ujicoba yang perlu diklasifikasikan dengan Adaptive SVM. Sedangkan dengan data acak menunjukan bahwa lebih banyak data ujicoba yang perlu diklasifikasikan dengan Adaptive SVM daripada data terpilih. Semakin banyak citra kembalian yang dilibatkan, besar kemungkinan perlu dilakukan pembelajaran Adaptive SVM. Ketika Adaptive SVM diperlukan untuk melakukan pengambilan keputusan maka akan semakin banyak waktu yang dibutuhkan untuk diagnosa. Karena sistem perlu melakukan pembelajaran ulang dengan Adaptive SVM.
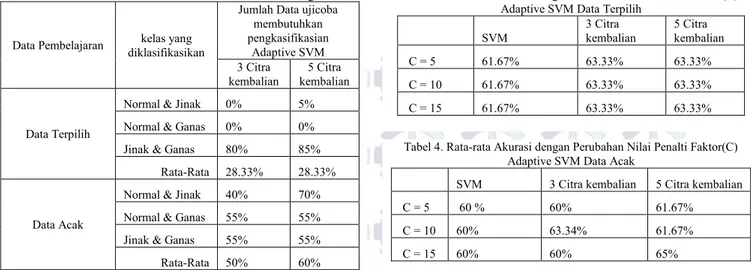
Ujicoba dilakukan untuk mengetahui berapa tingkat akurasi dari sitem yang dibuat. Ujicoba dilakukan terhadap SVM dan juga Adaptive SVM untuk melihat peningkatan akurasinya. Ujicoba pada Tabel 1 menggunakan nilai penalti faktor(C) 3 pada SVM dan nilai penalti faktor pada Tabel 1. Hasil Ujicoba dengan Nilai Penalti Faktor Adaptive SVM 5
Data
Pembelajaran Kelas yang diklasifikasikan SVM
Adaptive SVM dengan C = 5
3 citra
kembalian kembalian 5 citra Data Terpilih
Normal & Jinak 55% 55% 60%
Normal & Ganas 70% 70% 70%
Jinak & Ganas 60% 60% 60%
Rata-rata 1 61.67% 61.67% 63.33%
Data acak
Normal & Jinak 70% 65% 65%
Normal & Ganas 60% 65% 70%
Jinak & Ganas 50% 50% 50%
Rata-rata 2 60% 60% 61.67%
Adaptive SVM adalah 5. Secara keseluruhan ujicoba menunjukan tingkat akurasi Adaptive SVM meningkat ketika jumlah kembalian yang dilibatkan adalah 5. Ketika 3 hasil kembalian dilibatkan dalam diagnosis secara keseluruhan tingkat akurasi Adaptive SVM sama dengan SVM biasa.
Lebih jauh jika dibandingkan, untuk dua data pembelajaran yang digunakan, Tabel 1 menunjukan tingkat akurasi SVM untuk data terpilih lebih baik dari pada data acak. Data terpilih tingkat akurasinya adalah 61,67 persen sedangkan data acak 60,84 persen. Ketika Adaptive SVM diterapkan tingkat akurasi data terpilih lebih besar dibanding data acak. Pengunaan Adaptive SVM dengan melibatkan hasil kembalian tidak selalu meningkatkan akurasi hal ini dapat dilihat pada penggunaan data acak untuk pembelajarannya dan pengklasifikasian normal dengan jinak terdapat penurunan hasil pengklasifikasian dengan Adaptive SVM. Begitu juga peningkatan jumlah citra kembalian untuk dilibatkan dalam proses pengklasifikasian tidak selalu meningkatkan akurasi Adaptive SVM. namun yang lebih mempengaruhi adalah karakteristik citra yang dilibatkan dalam pembelajaran Adaptive SVM.
Pada Tabel 1 untuk ujicoba dengan data terpilih untuk klasifikasi normal dengan ganas tidak ada peningkatan dikarenakan tidak dilakukan proses pembelajaran Adaptive SVM. klasifikasi SVM oleh sistem diputuskan cukup baik untuk mengklasifikasikan data ujicoba dengan ditandai tidak ada misklasifikasi seperti ditunjukan di Tabel 2.
Ujicoba seperti ditunjukan pada Tabel 3 diujicobakan nilai penalti faktor (C) yang berbeda untuk Adaptive SVM. Tujuannya adalah untuk melihat pengaruh nilai penalti faktor terhadap peningkatan akurasi dari sistem klasifikasi. Masih dengan menggunakan dua jenis data ujicoba untuk pembelajaran yaitu terpilih dan acak. Data terpilih pada Adaptive SVM rata-rata dari keseluruhan ujicoba terjadi peningkatan tingkat akurasi, namun peningkatan hasil citra kembalian tidak mempengaruhi tingkat akurasi. hal ini dikarenakan hanya sedikit data ujicoba yang dikoreksi akurasi SVM-nya oleh Adaptive SVM. Percobaan untuk data terpilih ditunjukan pada Tabel 3.
Pada ujicoba dengan menggunakan data acak peningkatan penalti faktor(C) untuk Adaptive SVM menunjukan tidak selalu meningkatkan tingkat akurasinya. Begitu juga penambahan jumlah citra hasil kembalian yang dilibatkan tidak selalu meningkatkan tingkat akurasi. Dapat dilihat pada
Tabel 4 dengan menggunakan 3 citra hasil kembalian akurasinya sama dengan SVM biasa. Dengan meningkatkan penalti faktor sekalipun juga tidak akan selalu mempengaruhi hasil akurasi. Peningkatan nilai penalti faktor untuk Adaptive SVM dapat meningkatkan akurasi dari pengklasifikasian jika dikombinasikan dengan jumlah hasil kembalian yang dilibatkan dengan tepat.
Dari hasil seluruh ujicoba dengan menggunakan nilai penalti faktor 3 dan menggunaan 3 citra hasil kembalian sudah cukup untuk memaksimalkan akurasi dari klasifikasi dengan menggunakan data terpilih. Sedangakan pada data acak menggunakan nilai penalti faktor 15 dan menggunaan 5 hasil kembalian mempunyai tingkat akurasi tertinggi. selain itu karakteristik dari hasil kembalian yang dilibatkan dalam Adaptive SVM juga berpangaruh pada pada pembelajaran yang akan dilakukan oleh Adaptive SVM.
Dalam uji coba juga ditemukan untuk beberapa data yang hasil diagnosisnya berubah-ubah. Kejadian tersebut terjadi pada beberapa data ujicoba menggunakan data pembelajaran acak. Hal ini disebabkan karena dalam Hal ini disebabkan karena pada Sequential Minimal Optimization metode yang digunakan dalam pembelajaran Adaptive SVM terdapat random faktor. Random faktor tersebut terdapat pada heuristik dalam melakukan pemilihan posisi awal Lagrange Multipliers kedua yang akan dioptimasi. Selain itu terjadi overfitting ketika pembelajaran Adaptive SVM dijalankan, hal ini terjadi karena perubahan nilai Lagrange Multipliers yang dioptimasi belum memenuhi kondisi pemberhentian dikarenakan nilai perubahan Lagrange Multipliers masih terlalu besar.
VII. SIMPULAN DAN SARAN A. Simpulan
Ujicoba yang telah dapat disimpulkan bahwa tingkat keberhasilan pendeteksian kanker payudara rata-rata diatas 60 persen dengan menggunakan data terpilih maupun acak. Akurasi optimal pada data terpilih diperoleh dengan menggunakan nilai penalti faktor 5 dan 3 citra hasil kembalian. Sedangkan pada data acak akurasi tertingginya diperoleh dengan menggunakan nilai penalti faktor 15 dan hasil kembalian 5.
Peningkatan nilai penalti faktor tidak akan selalu meningkatkan tingkat akurasi. Penalti faktor dengan hasil yang bagus didapatkan dari ujicoba. Penggunaan hasil citra kembalian untuk meningkatkan akurasi dikarenakan dari Tabel 3. Rata-rata Akurasi dengan Perubahan Nilai Penalti Faktor(C)
Adaptive SVM Data Terpilih
SVM 3 Citra kembalian 5 Citra kembalian C = 5 61.67% 63.33% 63.33% C = 10 61.67% 63.33% 63.33% C = 15 61.67% 63.33% 63.33% Tabel 4. Rata-rata Akurasi dengan Perubahan Nilai Penalti Faktor(C)
Adaptive SVM Data Acak
SVM 3 Citra kembalian 5 Citra kembalian
C = 5 60 % 60% 61.67%
C = 10 60% 63.34% 61.67%
C = 15 60% 60% 65%
Tabel 2. Hasil Klasifikasi Citra dari Sistem Temu Kembali dengan SVM Data Pembelajaran diklasifikasikan kelas yang
Jumlah Data ujicoba membutuhkan pengkasifikasian
Adaptive SVM 3 Citra
kembalian kembalian 5 Citra
Data Terpilih
Normal & Jinak 0% 5% Normal & Ganas 0% 0% Jinak & Ganas 80% 85%
Rata-Rata 28.33% 28.33% Data Acak
Normal & Jinak 40% 70% Normal & Ganas 55% 55% Jinak & Ganas 55% 55% Rata-Rata 50% 60%
karakteristik data hasil kembalian itu sendiri bukan karena jumlah citra kembalian. Semakin banyak citra hasil kembalian yang dilibatkan dalam mengambil keputusan, maka semakin besar pula peluang citra hasil kembalian yang akan dideteksi misklasifikasi. hal tersebut menyebabkan perlu dilakukan proses pembelajaran Adaptive SVM sehingga memakan waktu komputasi proses pendeteksian.
Sistem ini juga mempunyai kelemahan yaitu, citra tertentu hasil deteksi kadang berubah-ubah. Penyebabnya adalah metode pembelajaran SVM yang digunakan yaitu Sequential Minimal Optimization (SMO). Didalam metode SMO terdapat random faktor pada saat memilih posisi awal Lagrange Multipliers kedua yang akan digunakan untuk optimasi dan inilah yang menyebabkan kadang hasilnya berubah-ubah.
B. Saran
Perlu dibuatkan antarmuka khusus yang bisa digunakan oleh seorang ahli untuk dapat memilih citra hasil kembalian mana saja yang akan dilibatkan dalam pembelajaran Adaptive SVM agar hasil pendeteksian lebih maksimal.
DAFTAR PUSTAKA
[1] Badan Koordinasi Dan Kerjasama Nasional, Kanker Payudara,
dilihat 14 Juli 2008, dari
www.hompedin.org/download/kankerpayudara.pdf
[2] Y. Ireaneus, Anna Rejani, Dr S.Thamarai Selvi. Early Detection Of Breast Cancer Using SVM Classifier Technique. Noorul Islam College of Engineering. India. 2009.
[3] Preeti Aggarwal, H.K. Sardana, Gagandeeo Jindal. Content Based Medical Image Retrieval : Theory, Gaps and Future Directions. ICGST. 2009
[4] Agus Z. A. Dan A. Asano. Image Segmentation by histrogram
thresholding using hierarchical cluster analysis. ELSEVIER, Pattern Recognition.2006.
[5] Otsu Thresholding. Diambil Mei 13, 2010, dari http://www.labbookpages.co.uk/software/imgProc/otsuThreshold.htm [6] R.M. Haralick, Textural fitur for image clasification, IEEE
transaction system vol 6 (1973).
[7] Eizan Miyamoto, Thomas. Fast Calculation Haralick Texture Features. Humman Computer Interaction, departement of Electrical and Computer Enginer
[8] Anto S. Nugroho, Arief B. W, Handoko Dwi. Support Vector Machine –teori dan penerapannya dalam bioinformatika-, Ilmu Komputer. 2003.
[9] M. Pontil and A. Verri. Properties of Support Vector Machines. MIT
AI Memo 1612, 1998.
[10] John C. Platt. Fast Training of Support Vector Machine using Sequential Minimal Optimization. Microsoft Research
[11] Liyang Wei, Yongyi Yang, Robert M. Nishikawa. Microcalcification classification assisted by content-based image retrieval for breast cancer diagnosis. ELSEVIER, Pattern Recognition. 2008