56 A. Jenis Penelitian
Penelitian yang dilakukan digolongkan ke dalam jenis penelitian kausal, yang fokus penelitiannya bertujuan untuk menguji hipotesis tentang pengaruh satu atau beberapa variabel independen terhadap variabel dependen. Selanjutnya, dalam penelitian ini dilakukan pendekatan analisis kuantitatif yang terdiri atas perumusan masalah, menyusun model, proses mendapatkan data, mencari solusi, menganalisis hasil dan mengimplementasikan hasil.
B. Definisi dan Operasionalisasi Variabel
Variabel dalam penelitian ini dijelaskan sebagai berikut: 1. Variabel total penerimaan
Variabel ini didefinisikan sebagai total pendapatan operasional perbankan terhadap total asset. Pendapatan operasional sendiri terdiri dari dua jenis yaitu pendapatan bunga/operasional dan pendapatan operasional lainnya. Variabel ini digunakan sebagai variabel dependen yang merupakan proksi dari output bank.
2. Variabel Return on Asset
Variabel ini merupakan rasio laba bersih terhadap total asset. Variabel ini digunakan sebagai variabel dependen menggantikan variabel total penerimaan ketika akan digunakan untuk menguji keseimbangan model (salah satu asumsi P-R Model).
3. Beban Tenaga Kerja
Variabel ini didefinisikan sebagai total beban gaji dan tunjangan terhadap total asset. Variabel ini digunakan sebagai variabel independen yang merupakan proksi dari input bank yaitu tenaga kerja.
4. Beban Bunga
Variabel ini didefinisikan sebagai beban bunga terhadap deposito dan kewajiban lainnya. Variabel ini digunakan sebagai variabel independen yang merupakan proksi dari input bank yaitu deposito/modal finansial.
5. Beban non bunga
Variabel ini didefinisikan sebagai beban operasional lain dikurangi beban gaji dan tunjangan terhadap total asset. Variabel ini digunakan sebagai variabel independen yang merupakan proksi dari input bank yaitu modal fisik.
6. Struktur Modal
Variabel ini adalah rasio total hutang terhadap total asset. Variabel ini digunakan sebagai variabel independen dan digunakan untuk melihat dampak penggunaan hutang terhadap pendapatan.
7. Penyaluran kredit
Variabel ini adalah rasio penyaluran kredit terhadap total asset. Variabel ini digunakan sebagai variabel independen dan sebagai proksi dari tingkat intermediasi perbankan.
C. Pengukuran Variabel
1. Variabel Total Penerimaan (Trev)
Pendapatan oprs + pendapatan oprs lain Total Penerimaan (Trev) =
Total Asset 2. Return on Asset (ROA)
Laba Bersih Return on Asset (ROA) =
Total asset 3. Beban Tenaga Kerja
Total beban gaji dan tunjangan Beban tenaga kerja (PL) = Total Asset
4. Beban Bunga
Beban Bunga Beban Bunga (PF) =
Deposito dan kewajiban lainnya
5. Beban Non Bunga (PK)
Beban oprs lain- (beban gaji dan tunjangan) Beban Non Bunga (PK) = Total Asset
6. Struktur Modal (DA)
Total kewajiban (hutang)
Struktur Modal (DA) = Total Asset
7. Penyaluran Kredit (LO)
Total Kredit Yang disalurkan Penyaluran Kredit (LO) =
Total Asset
Populasi dalam penelitian ini adalah semua bank yang beroperasi di Indonesia. Namun karena keterbatasan peneliti, maka yang diteliti hanya sampel. Adapun pengambilan sampel menggunakan teknik purposive sampling metode
judgment, dengan kriteria:
1) Bank pemerintah dan bank swasta nasional devisa tahun 2003 sampai dengan tahun 2012.
2) Bank yang dipilih menyediakan laporan keuangan pada periode observasi. Adapun data akan dianalisis dalam bentuk tahunan.
E. Teknik Pengumpulan Data
Teknik pengumpulan data menggunakan data arsip berupa data sekunder. Data sekunder merupakan data yang sudah disediakan oleh organisasi (unit bisnis) sehingga peneliti tinggal menggunakan (Herliansyah, 2013). Pengumpulan data dilakukan dengan melihat dan melakukan pencatatan data terhadap data pada statistik perbankan, laporan moneter Bank Indonesia yang dirilis setiap tahunnya serta menggunakan studi kepustakaan, yaitu literatur dan jurnal ilmiah yang berkaitan dengan masalahan penelitian.
F. Metode Analisis
Dalam penelitian ini akan dilakukan pengujian hipotesis berdasarkan data yang telah tersedia dengan pemodelan data panel. Data panel merupakan gabungan dari data cross section dan time series, (Nachrowi, 2006). Model data panel dapat dituliskan menjadi sebagai berikut:
Yit = α + β Xit + eit ; i = 1,2,...,N; t= 1,2,...,t Dimana:
N = banyaknya observasi t = banyaknya waktu N x t = banyaknya data panel
Untuk menjawab tujuan penelitian, dilakukan regresi dengan pemodelan data panel berdasarkan bentuk persamaan pendapatan yang telah dimodifikasi (reduced form revenue equation) atas model Panzar dan Rosse sebagai berikut.
LnTRevit = α0 + α1 LnPLit + α2LnPFit + α3LnPKit + α4LnTAit + α5LnDAit + eit (1)
dimana, subskrip i menyatakan bank i, dan t menyatakan tahun dan Ln merupakan log natural.
TRevit = rasio pendapatan bunga + pendapatan operasional lainnya
terhadap total asset (sebagai proksi output bank)
PLit = rasio beban gaji + tunjangan terhadap total asset (sebagai
proksi input tenaga kerja)
PFit = rasio beban bunga terhadap deposito dan kewajiban lainnya
(sebagai proksi input deposito/modal finansial)
PKit = rasio beban operasional lain - (beban gaji + tunjangan)
terhadap total asset (sebagai proksi dari input modal fisik) LAit = rasio total kredit terhadap total asset
DAit = rasio total kewajiban terhadap total asset
Persamaan regresi (1) di atas akan diestimasi dalam beberapa periode, yaitu periode total observasi (2003-2012), periode sebelum krisis (2003-2007), periode krisis (2008-2009) dan periode setelah krisis (2010-2012). Untuk
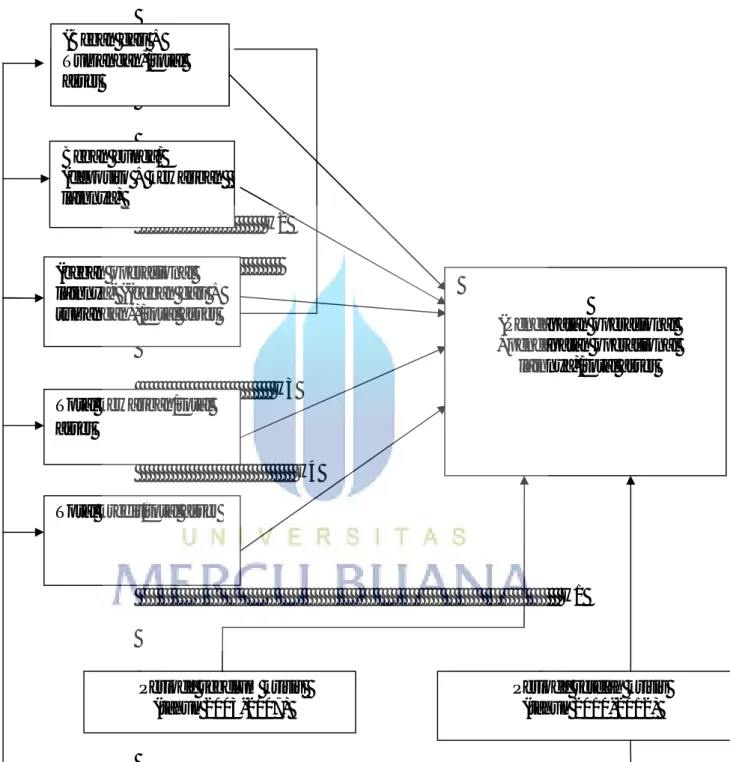
menjawab hipotesa pertama akan dilakukan uji beda dengan menggunakan uji Chow Test pada periode observasi, sebelum dan setelah krisis. Berdasarkan persamaan di atas, maka desain penelitian dapat digambarkan seperti pada gambar 4.1.
Gambar 4.1. Desain Penelitian H2 H3 H4 H1
Sumber: penggambaran peneliti berdasarkan hipotesis dan persamaan regresi. (Beban gaji + Tunjangan)/total asset Beban bunga/ (deposito + kewajiban lainnya) (beban operasional lainnya- ((beban gaji + tunjangan))/total asset
Total kewajiban/total asset
Total kredit/total asset
(Pendapatan operasional +pendapatan operasional
lainnya)/total asset
Periode sebelum krisis (tahun 2003-2007)
Periode setelah krisis (tahun 2010-2012)
1. Alat Analisis
1.1. Uji pilihan model panel terbaik (pooled least squared, fixed effect atau
random effect)
1.1.1 Model Pooled Least Squared
Untuk penelitian ini, dilakukan pengolahan data dengan menggunakan metode panel. Selain harus memenuhi asumsi klasik seperti non-autokorelasi,
homoscedasticity dan non-multicolinearity terdapat beberapa asumsi tambahan
untuk model regresi data panel, asumsi tersebut: • Tidak adanya hubungan antar individu i • αi dan eit bersifat independen
Jika asumsi tersebut dipenuhi maka dihasilkan persamaan OLS yang bisa diestimasi dengan metode pooled estimation. Namun hal tersebut mengandung kesukaran. Beberapa kelemahannya:
• Asumsi sulit dipenuhi
• Asumsi yang sangat sempit tentang asumsi klasik (homoscedastiity dan otokorelasi)
Untuk mengatasi permasalahan tersebut, ada dua buah teknik yang biasanya digunakan untuk membuat model dari data panel, yaitu Metode Efek Tetap (The Fixed Effect) dan Metode Efek Random (The Random Effect).
1.1.2 Metode Efek Tetap
Untuk mengestimasi pooling data dengan menggunakan model ini, diperlukan variabel boneka (dummy variable) untuk menghitung pengaruh dari variabel-variabel yang dihilangkan yang spesifik terhadap unit-unit individu tetapi
tetap konstan antar waktu. Penggunaan model ini menangkap perbedaan antar unit individu sedangkan perubahan antar waktu dianggap konstan. Dengan kata lain, yang dianalisis adalah perbedaan antar unit individu/cross section yang dicerminkan dalam variabel boneka dan tidak ada efek yang ditimbulkan dalam variabel antar waktu.
Bila asumsi seluruh gangguan tidak dapat dinyatakan mengikuti semua asumsi random noise seperti dalam persamaan regresi linear klasik, maka menggunakan OLS dan GLS tidak akan menghasilkan sifat yang BLUE. Gangguan dalam model akan menjadi satu dengan konstanta intercept. Gangguan diasumsikan memiliki pengaruh yng tetap oleh karenanya dianggap sebagai bagian dari konstanta intersept model persamaan.
1.1.3 Model Efek Random
Berbeda dengan fixed effect, model efek random dapat melihat terjadinya perbedaan nilai parameter-parameter antar individu maupun antar waktu dimasukkan ke dalam error. Sehingga kita dapat menghemat pemakaian derajat kebebasan dan tidak mengurangi jumlahnya seperti yang dilakukan pada metode efek tetap. Hal ini berimplikasi parameter yang merupakan hasil estimasi akan menjadi semakin efisien.
Bentuk efek random dapat dijelaskan pada persamaan berikut: Yit = α + βXit + εit
Eit = ui + vt +Wit
Dimana : ui N (0, δu2 ) = komponen cross section error
wit N (0, δw2 ) = komponen error kombinasi
Untuk pemilihan model panel data yang paling tepat, maka perlu dilakukan serangkaian pengujian secara ekonometrika. Secara umum urutan dari pengujian tersebut adalah melakukan pengujian Chow, kemudian melakukan uji Hausman.
1) Chow Test
Chow test merupakan uji untuk memilih apakah model yang digunakan pooled
least square atau model efek tetap. Pengujian ini disebut Chow Test karena
kemiripannya dengan Chow Test yang digunakan untuk menguji stabilitas dari parameter (stability test). Dalam pengujian ini dilakukan hipotesa sebagai berikut: H0 = model pooled least square (restricted)
H1 = model tetap (unrestricted)
Chow test menggunakan distribusi F dengan rumus sebagai berikut: (RRSS – URSS)
(N-1) FN-1,NT-N-K =
URSS / (NT-N-K)
Dimana:
RSSS = Restricted Residual Sum Square URSS = Unrestricted Residual Sum Square N = Jumlah data cross section
T = jumlah data time series K = jumlah variabel penjelas
Statistik F menggunakan distribusi F dengan N-1 dan N-K derajat kebebasan. Jika F hitung lebih besar dari F tabel atau F signifikan maka pendekatan yang dipakai adalah unrestricted atau pendekatan model efek tetap atau LSDV.
2) Hausman Test
Dalam memilih pendekatan mana yang sesuai dengan model persamaan dan data antara fixed effect dan random effect dapat digunakan dengan menggunakan spesifikasi yang dikembangkan oleh Hausman. Hausman Test ini menggunakan nilai Chi Square sehingga keputusan pemilihan metode data panel ini dapat ditentukan secara statistik. Dengan asumsi bahwa error secara individual tidak saling berkorelasi begitu juga error kombinasinya, rumus uji hausman adalah: H = (βRE – βFE)1 (Ʃ FE – Ʃ RE) -1 (βRE – βFE)
Dimana:
βRE = random effectestimator
βFE = fixed effect estimator
Ʃ FE = matriks kovarians fixed effect Ʃ RE = matriks kovarian random effect
Selain itu, uji Hausman ini dilakukan dengan hipotesis sebagai berikut: Ho = Model efek random
H1 = Model efek tetap
Statistik Hausman menggunakan nilai Chi Square Statistics. Jika hasil uji Huasman test signifikan maka metode yang digunakan dalam pengolahan data panel adalah model efek tetap.
1.2. Uji Keseimbangan P-R Model
Uji ini dilakukan dengan mengganti variabel dependen total pendapatan terhadap total asset pada persamaan (1) di atas dengan variabel return on asset (ROA). Model dikatakan seimbang jika estimasi yang dilakukan menghasilkan nilai probabilitas F-statistik kurang dari 0,05.
1.3. Uji Perbedaan kinerja perbankan di Indonesia pada periode sebelum dan setelah krisis (uji Chow Test)
Uji ini digunakan untuk melihat apakah ada perbedaan kinerja perbankan di Indonesia pada periode sebelum dan setelah krisis dengan menggunakan uji Chow Test. Adapun langkah-langkah melakukan uji Chow test adalah: (Ghozali, 2011:181-184).
1) Lakukan regresi dengan observasi total (periode 2003-2012) dan dapatkan nilai restricted residual sum of squares atau RSSr dengan df = (n1 + n2 – k) dimana
k adalah jumlah parameter yang diestimasi dalam penelitian ini sebanyak 6; 2) Lakukan regresi dengan observasi periode sebelum krisis (2003-2007) dan
dapatkan nilai RSS1 dengan df = (n1 - k);
3) Lakukan regresi dengan observasi periode sesudah krisis (2010-2012) dan dapatkan nilai RSS2 dengan df = (n2 – k);
4) Jumlahkan nilai RSS1 dan RSS2 untuk mendapatkan unrestricted residual sum of squares (RSSur) dengan df = (n1 + n2 - 2k);
5) Hitung nilai F test dengan rumus: (RSSr – RSSur )/k
F =
6) Nilai rasio F mengikuti distribusi F dengan k dan (n1 +n2 – 2k) sebagai df untuk penyebut maupun pembilang;
7) Jika nilai F hitung > F tabel, maka model regresi sebelum krisis dan model regresi setelah krisis memang berbeda.
1.4. Uji Statistik
Setelah ditetapkan pendekatan apa dalam data panel yang akan digunakan, maka langkah berikutnya adalah melakukan pengujian secara statistik. Ketepatan fungsi regresi dalam menaksir nilai aktual dapat diukur dari goodeness
of fit-nya. Nilai goodeness of fit ini dapat diukur dari nilai statistiknya t,f dan
koefisien determinasinya.
1.4.1 Uji statistik t (uji signifikansi parsial)
Uji t-test ini ingin melihat secara individual apakah suatu variabel independen berpengaruh signifikan terhadap variabel dependen atau tidak. Pengambilan keputusan hipotesis juga dapat dilihat dengan melihat probabilitasnya (p-value). Jika nilai p-value lebih kecil dari nilai alpha (α) maka kita dapat menolak hipotesa Ho, dengan tingkat keyakinan 1 – alpha (α).
1.4.2 Uji statistik F (uji goodness of fit model)
Berbeda dengan t-test yang melihat secara individual, uji F-test ini digunakan untuk melihat secara bersama-sama pengaruh variabel independen terhadap variabel dependen, apakah variabel independen dalam suatu model persamaan bersama-sama mempengarui variabel dependen. Pengambilan kesimpulan hipotesis apakah Ho ditolak atau tidak ditolak dengan membandingkan nilai F-statistik dengan nilai kritisnya. Jika F statistik lebih besar
dari nilai kritis maka Ho ditolak yang artinya variabel independen dalam model persamaan tersebut bersama-sama berpengaruh signifikan terhadap variabel dependennya. Perhitungan F-statistik adalah:
R2/(k-1) F =
(1-R2)/ (n-k)
Dimana: K = jumlah variabel independen dan dependen n = Jumlah observasi
1.4.3 Koefisien Determinasi (R2)
Koefisien determinasi ini digunakan untuk mengukur seberapa besar variasi dari variabel dependennya dapat dijelaskan oleh variasi nilai dari variabel-variabel bebasnya. Dengan kata lain Nilai R2 statistik mengukur tingkat keberhasilan model regresi yang kita gunakan dalam memprediksi nilai variabel dependen atau mengetahui kecocokan (goodness of fit) dari model regresi. Nilai R2 ini terletak antara nol sampai satu. Semakin dekat satu maka model dapat kita katakan semakin baik. Akan tetapi, dalam pengolahan data panel model yang terbaik tidak selalu memperhatikan nilai R2 .
Kelemahan dari pengukuran R2 adalah nilainya akan meningkat jika ditambah variabel bebasnya. Oleh karena itu, diperlukan adjusted R2 yang akan memberikan penalti terhadap penambahan variabel bebas yang tidak mampu menambah daya prediksi suatu model. Sehingga adjusted R2 merupakan R2 yang telah dikoreksi dengan varians error. Nilai adjusted R2 tidak akan pernah melebihi nilai R2 dan dapat turun jika menambahkan variabel bebas yang tidak
perlu. Bahkan untuk model yang memiliki kecocokan (goodness of fit) yang rendah, adjusted R2 dapat memiliki nilai yang negatif.
1.5. Uji Asumsi klasik
Selain melakukan uji statistik di atas, pada saat analisis regresi sering muncul beberapa masalah yang termasuk dalam pengujian asumsi klasik, yaitu ada tidaknya masalah autokorelasi, heteroskedastisitas dan multikolinearitas. 1.5.1 Autokorelasi
Autokorelasi merupakan terdapatnya hubungan antar error terms. Adanya autokorelasi ini menyebabkan parameter yang akan diestimasi menjadi tidak efisien. Salah satu uji formal yang paling populer untuk mendeteksi adanya autokorelasi adalah Durbin Watson (D-W statistic)
Durbin Watson (D-W statistic) terletak pada interval 4. Jika nilai D-W statistics semakin mendekati nilai 2 maka model tersebut tidak memiliki masalah autocorrelation. Sebaliknya jika DW menjauhi 2 mengindikasikan adanya autokorelasi positif atau autokorelasi negatif. Walaupun demikian, uji D-W statistik seringkali menimbulkan ambiguitas atau keragu-raguan karena terdapat daerah yang tidak dapat diputuskan apakah niali tersebut termasuk autokorelasi positif dan negatif atau tidak. Untuk lebih jelasnya pengambilan keputusan adanya autokorelasi atau tidak, dapat menggunakan tabel DW yang terdiri atas dua nilai yaitu batas bawah (dL) dan batas atas (dU). Nilai-nilai ini dapat digunakan sebagai pembanding uji DW, dengan aturan sebgai berikut:
0<D-W<dL = autokorelasi positif dL<D-W<dU = tidak ada kesimpulan
dU<D-W<4-dU = tidak ada autokorelasi 4-dU<D-W<4-dL = tidak ada kesimpulan 4-dL<D-W<4 = autokorelasi negatif 1.5.2. Heteroskedastisitas
Heteroskedastisitas merupakan variasi dari error term tidak konstan atau E (ui2) = δi2. Hal tersebut mengakibatkan parameter yang kita duga menjadi
tidak efisien akibat besaran varians selalu berubah-ubah. Untuk mendeteksi adanya heteroskedastisitas dapat dilihat dengan cara membandingkan sum of
squared residual weighted (SSRW) dan sum of squared residual unweighted
(SSRUW). Jika SSRW < SSRW maka dapat disimpulkan tidak terjadi heteroskedastisitas. Selain itu, adanya heteroskedastisitas dapat dilakukan dengan uji White Heteroscedasticity Test. Uji White Heteroscedasticity Test yang mengikuti distribusi χ2 ini memiliki 2 pilihan antara lain:
1) No cross term = apabila 5 X jumlah variabel bebas > jumlah observasi 2) Cross term = apabila 5 X jumlah variabel bebas < jumlah observasi
Pengujian hipotesis White Heterocedasticity Test adalah Ho = Homocedasticity
H1 = Heterocedasticity
Jika nilai Obs * R-squared > nilai kritis maka Ho ditolak yang berarti terdapat heterocedasticity atau P-value < α maka Ho ditolak yang berarti terdapat
hererocedasticity.
1) Menggunakan Weighted Least Squared atau Generalized Least Squared (GLS) yakni regresi yang menggunakan pembobotan pada variabel yang signifikan dan membobot observasi secara terbalik dengan varians-nya. Biasanya penggunaan metode ini ketika δi2 diketahui.
2) Menggunakan white is heterocedasticity consistent variance and standard error atau robust standar error. Penggunaan metode ini ketika δi2 tidak
diketahui.
1.5.3. Multikolinearitas
Multikolinearitas merupakan pelanggaran asumsi dasar berupa terdapatnya hubungan antara variabel bebas sehingga nilai parameter yang BLUE tidak dapat terpenuhi. Adanya multikolinearitas dapat dideteksi dengan:
• Nilai R-squared (R2) tinggi dan nilai F-stat yang signifikan, namun sebagian besar nilai dari t-stat tidak signifikan.
• Tingkat korelasi yang cukup tinggi antar 2 variabel bebas yakni r > 0,8. Jika hal tersebut terpenuhi maka diindikasikan terjadi masalah multikolinearitas dalam persamaan tersebut. multikolinearitas ini terbagi menjadi 2 yakni multikolinearitas sempurna apabila r =1 dan multikolinearitas tidak sempurna apabila r <1.
• Besarnya condition number yang berkaitan dengan variabel bebas bernilai lebih dari 20 atau 30. Nilai condition number dapat diperoleh dengan prosedur pemisahan matriks variabel-variabel bebas.
• Menggunakan data panel (jika model yang digunakan adalah model time
series)
• Menghilangkan variabel bebas yang tidak signifikan atau memiliki korelasi tinggi
• Mentransformasi variabel, misalnya merubah menjadi bentuk first defference • Menambah data atau memilih sampel baru
• Tidak melakukan apa-apa
Namun demikian, dalam data panel, masalah multikolinearity biasanya tidak terlalu menggangu efisiensi sebuah model. Menurut Gujarati (2003),
• Walaupun terdapat multikolinearitas, estimator dari OLS tetap tidak bias. Namun properti tersebut terdapat dalam multisample atau repeated sampling. • Adanya multikolinearitas tidak merusak properti minimum variance.
Implikasinya estimator dari OLS akan tetap efisien.
• Multikolinearitas merupakan fenomena yang terjadi dalam sampel. Walaupun secara teori tidak berhubungan dengan populasi, namun bisa saja dalam sampel variabel yang didapatkan mengandung multikolinearitas.