PENERAPAN METODE ENHANCED CLASS OUTLIER DISTANCE BASED UNTUK IDENTIFIKASI OUTLIER PADA DATA HASIL UJIAN
NASIONAL, INDEKS INTEGRITAS DAN AKREDITASI SEKOLAH MENENGAH ATAS
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Angela Mediatrix Melly 135314074
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
IMPLEMENTATION OF ENHANCED CLASS OUTLIER DISTANCE BASED ALGORITHM FOR OUTLIER IDENTIFICATION ON THE
DATA OF NATIONAL EXAM RESULT, INTEGRITY INDEX AND ACCREDITATION OF SENIOR HIGH SCHOOL
THESIS
Present as Partial Fulfillment of the Requirement to Obtain the Sarjana Komputer Degree in Informatics Engineering Study Program
By :
Angela Mediatrix Melly 135314074
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
HALAMAN
PERSETUJUAN
SKRIPSI
PENERAPAN METOI}E ENEANCED CI^ASS OUTLIER DISTANCE
BASED UI{TT'K
IDEI{TIflKASI
OUTI,TER FAI}A I}ATA HASIL UJIAN NASTONAI, TNDEKS INTEGRTTAS DAI\I AKREIIITASI SEKOT,AHMENtrNGAE ATAS
Dosen Pembimbing,
P. H. PrimaRosa, S.Si., M.Sc. ranggar,...
i5...i.:lt
I .. ...2017llt
4*g
6{er-vqi
qt'Aneela
ffiarix
Mdlfr$=a"g.h ffiatrix
t"tit@
Ir;
rdsrlsTa
+
gjgE
gtr
ffiTnh
E
=
-p rc
/dn..'.''."
i4;'-,,,\\
F
F
b:E=5
+!i:-J z ,l ,
€- ,";. = E xl,--.v
1. . r ,,^l
Y)- r -1-Y
t,L
l- _a gj
-
11^
^^ g!^*i
-1
=-f,=LrGF
=-HALAMAN
PENGESAHAN
SKRIPSI
PENMRAPAN METODE ENHANCED CTASS OIJTLIER DISTANCE
BASED T}NTUK IDENTIFIKASI OUTI,TER PAI}A I}ATA HASIL UJIAN NASIONAL, INDEKS INTEGRITAS I}AN AKREDITASI SBKOLAH
MENENGAH ATAS
Ketua Sekretaris Anggota
Yogyakarta, ..t.4.
J.UN!
.39ff
Fakultas Sains dan Teknologiniversitas Sanata Dharma Dekan
&9",
S.Si, M.Math.Sc., Ph.Div
F _r- *7 rrvr ; r JJJTTI{FIIi _a-- -\-_E
:-r t = .*_ 1_
=. ,A!:
-t 7L AJ1A - q,-l \ tE
1 L ' IE tt .g \ !
r.-lft
ap"*n*r,&rio*pan rani
ti a$nsu:,\\
Dan fipyatirtarl n_i€ifienffi syarat-1.gE! f t ri+t.'l!r-,r r:!) ! rili\li i,tr:r t i t_ _
!# lr:,'' 'E- '..,1r-
.'-4
-;ffi
=
--
-
a e.--+.E
?
Susunan PJnitia Penguji*)
"\-
=
si
II@$ap
'
_-...f,*
-+(-"EE -r _4.
r\t'
s-S{fip4o3ro,
M.Ko4g€\
\3v
HALAMAN PERSEMBAHAN
“
Menjadi Garam dan Terang Dunia
”
Tugas akhir ini saya persembahkan kepada : Allah Bapa, Putra, Roh Kudus
Bunda Maria Orangtua Terkasih
dan Saudara – saudara Tersayang
PER}IYATAAN KEASLIAN
KARI
A
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak
memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan daftar pustak4 sebagaimana layaknya karya ilmiah.
yogryakarta, ... L(' ..J.gni ...
...zafi
Penulis,Angela Mediatrix Melly
vii
ABSTRAK
Pertumbuhan data yang semakin pesat menyebabkan penumpukan data yang sangat besar. Untuk itu diperlukan penambangan data untuk mengubah data yang sangat banyak dan tidak informatif menjadi data yang memberi suatu informasi. Outlier merupakan salah satu bidang penelitian di dalam penambangan data. Outliers adalah data yang menyimpang terlalu jauh dari data yang lainnya dalam suatu rangkaian data. Salah satu algoritma deteksi outlier adalah algoritma
Enhanced Class Outlier Distance Based (ECODB) yang merupakan peningkatan algoritma Class Outlier Distance Based (CODB). Algoritma ECODB mengurangi parameter dalam CODB dengan melakukan normalisasi. Algoritma ECODB dapat mengidentifikasi outlier pada data yang memiliki class label. Pada penelitian ini algoritma ECODB dipergunakan untuk mengidentifikasi outlier
viii
ABSTRACT
Rapid data growth leads to huge data stacks. Therefore, data mining is needed to change the large and uninformative data into more informative. Outlier detection is one field of research in data mining. Outliers are data that deviate too far from other data in a dataset. One of the outlier detection algorithms is the Enhanced Class Outlier distance based (ECODB) algorithm. ECODB algorithm is enhancement from Class Outlier Distance Based (CODB) algorithm. ECODB algorithm reduces CODB parameter using normalization technique. ECODB algorithm can identify outliers in data that have class label. In this study, the ECODB algorithm is used to identify outliers on national exam results, integrity index and accreditation of senior high schools in the Yogyakarta province year 2015. From the experimental results, it can be concluded that ECODB algorithm can identify outliers on national exam results, integrity index and accreditation of senior high school in the Yogyakarta province year 2015. The value of the nearest neighbor (K) and the expected number of outliers (N) effect the result of outlier identification. Varying the K value can affect the Probability Class Label (PCL) of each instance. Varying the N value can affect the Class Outlier Factor (COF) of each instance.
LEMBARAN PERI{YATAAN
PERSETUJUAN
PUBLIKASI
KARYA TLMIAH UNTUK KEPERLUAN KDPENTINGAN
AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Angela Mediatrix Melly
NIM
:13fi14474Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
PENERAPAN METODE ENHANCED CLASS OUTLIER DISTANCE
BASED UNTUK IDENTIFIKASI OUTLIER PADA DATA HASIL UJIAN NASIONAL, INDEKS INTEGRITAS I}AN AKREDITASI SEKOLAH
MENTf,NGAH ATAS
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan
kepada Perpustakaan Universitas Sanata Dharma
hak
untuk
menyimpan, mengalihkan dalam bentuk media lain, mengetotadi internet atau media
lain untuk kepentingan akademis tanpa perlu memintarjin
dari
saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.Demikian pemyataan ini saya buat dengan sebenarnya Dibuat di Yogyakarta
Pada tanggal ...\6 ..Jttti . ... z0t7
Yang menyatakan,
Angela Mediatrix Melly
x
KATA PENGANTAR
Puji dan syukur penulis haturkan kepada Tuhan Yang Maha Esa karena berkat rahmat dan karunianya, penulis dapat menyelesaikan tugas akhir ini yang
berjudul “PENERAPAN METODE ENHANCED CLASS OUTLIER DISTANCE BASED UNTUK IDENTIFIKASI OUTLIER PADA DATA HASIL UJIAN NASIONAL, INDEKS INTEGRITAS DAN AKREDITASI SEKOLAH MENENGAH ATAS”.
Dalam proses penyelesaian penyusunan tugas akhir ini penulis diberi banyak dukungan, doa dan motivasi dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada :
1. Tuhan Yesus Kristus dan Bunda Maria yang telah memberi kekuatan, bimbingan, keyakinan dan menyertai penulis.
2. Orang tua penulis, Bapak Herkulanus dan Ibu Fransisca Xaveria Sujarwati yang begitu menyayangi penulis dan selalu memberikan dukungan, doa, perhatian, nasihat dan motivasi.
3. Kakak dan adik yaitu Fidelia Diniarie, Silvia Dian Senja Sakti dan Septian Rendy Padangoan yang selalu menghibur dan mendukung.
4. Bapak Sudi Mungkasi, S.Si, M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan Teknologi.
5. Ibu Dr. Anastasia Rita Widiarti selaku Ketua Program Studi Teknik Informatika.
6. Ibu Paulina Heruningsih Prima Rosa, M.Sc. selaku Dosen Pembimbing Skripsi yang telah mencurahkan pikiran dan memberikan waktu serta membimbing penulis.
7. Bapak Albertus Agung Hadhiatma, S.T., M.T selaku Dosen Pembimbing Akademik.
9.
Sahabat-sahabat yaitu Windia Salura, Purbarini Sulysthian, Valenciahfaria G. Sitompul, I. Kristanto Ri]radi, Kasih ]Iandoyo dan Saftio Bagus
Wijalsono yang selalu mendtrkung, merrberikan kisah dan pengalarnan yang tidak akan penulis lupakan
10. Teman-teman Program Snrdi Teknik Informatika 2013 yarg bersama-sama dalam mengikuti kegiaun perkulialun selama 4 Ahun.
Penulis berharap penelitian ini dapat berguna dan membantu bagi pembaca
Penulis menyadari laporan penelitian
ini tidak
sepenuhnya sempurnq oleh karena ifir penulis mengharapkanldtik
dan saran agar penelitian ini menjadi lebih baik lagi.yogyakarta, ...Lb...J.,,ln . ... z0l7
Angela Mediatrix Melly
Penulis,
xii
Daftar Isi
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN... v
PERNYATAAN KEASLIAN KARYA ... vi
ABSTRAK ... vii
ABSTRACT ... viii
LEMBARAN PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN KEPENTINGAN AKADEMIS ... ix
KATA PENGANTAR ... x
Daftar Isi... xii
Daftar Tabel ... xv
Daftar Gambar ... xvii
Daftar Rumus ... xviii
Daftar Lampiran ... xix
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang... 1
1.2 Rumusan Masalah ... 3
1.3 Tujuan ... 3
1.4 Batasan Masalah ... 3
1.5 Manfaat Penelitian ... 4
1.6 Metodologi Penelitian ... 4
1.7 Sistematika Penulisan ... 5
BAB IILANDASAN TEORI ... 7
2.1 Penambangan Data ... 7
2.1.1 Pengertian Penambangan Data ... 7
2.1.2 Fungsi Penambangan Data ... 7
2.2 Outlier... 10
2.2.1 Pengertian Outlier ... 10
2.2.2 Metode Deteksi Outlier ... 11
2.3 Algoritma Enhanced Class Outlier Distance Based ... 13
2.4 Struktur Data ... 16
BAB IIIMETODE PENELITIAN... 18
xiii
3.2 Peralatan Penelitian ... 20
3.3 Tahap-tahap Penelitian ... 20
3.3.1 Studi Pustaka ... 20
3.3.2 Knowledge Discovery in Database (KDD) ... 20
3.3.3 Desain Alat Uji ... 22
3.3.4 Analisis dan Pembuatan Laporan ... 24
BAB IV PERANCANGAN PERANGKAT LUNAK ... 25
4.1 Perancangan Umum... 25
4.1.1 Input ... 25
4.1.2 Proses ... 25
4.1.3 Output ... 27
4.2 Diagram Use Case ... 27
4.2.1 Gambaran Umum Use Case ... 27
4.2.2 Narasi Use Case ... 27
4.3 Diagram Aktivitas ... 28
4.4 Perancangan Struktur Data ... 28
4.5 Diagram Kelas Analisis ... 29
4.6 Diagram Sekuen ... 30
4.7 Diagram Kelas Disain... 30
4.8 Algoritma per Method ... 30
4.9 Perancangan Antarmuka ... 30
4.9.1 Perancangan Halaman Home ... 30
4.9.2 Perancangan Halaman Preprocessing ... 31
4.9.3 Perancangan Halaman Hasil ... 33
4.9.4 Perancangan Halaman Tentang ... 34
4.9.5 Perancangan Halaman Bantuan... 35
BAB V IMPLEMENTASI DAN PENGUJIAN PERANGKAT LUNAK ... 37
5.1 Implementasi Rancangan Perangkat Lunak ... 37
5.1.1 Implementasi Kelas Model ... 37
5.1.2 Implementasi Kelas View ... 37
5.1.3 Implementasi Kelas Control ... 46
5.2 Pengujian Perangkat Lunak ... 47
5.2.1 Pengujian Perangkat Lunak (Black Box)... 47
xiv
5.2.1.2 Prosedur Pengujian Black Box dan Kasus Uji ... 48
5.2.1.3 Evaluasi Pengujian Black Box ... 48
5.2.2 Pengujian Perbandingan Hasil Pencarian Outlier Secara Manual dengan Hasil Pencarian Outlier Menggunakan Perangkat Lunak ... 49
5.2.2.1 Pencarian Outlier Secara Manual ... 49
5.2.2.2 Pencarian Outlier Menggunakan Perangkat Lunak ... 49
5.2.2.3 Evaluasi Pengujian Perbandingan Hasil Pencarian Outlier Secara Manual dengan Perangkat Lunak ... 50
BAB VI ANALISA HASIL DAN PEMBAHASAN ... 51
6.1 Dataset ... 51
6.2 Hasil Identifikasi Outlier ... 51
6.2.1 Hasil Identifikasi OutlierDataset Jurusan IPA ... 51
6.2.2 Hasil Identifikasi Outliet Dasaset Jurusan IPS ... 58
6.3 Analisa Hasil Identifikasi Outlier ... 64
6.3.1 Analisa Hasil Identifikasi Outlier Dataset Jurusan IPA ... 64
6.3.2 Analisa Hasil Identifikasi Outlier Dataset Jurusan IPS ... 70
6.4 Kelebihan Dan Kekurangan Perangkat Lunak ... 76
6.4.1 Kelebihan Perangkat Lunak ... 76
6.4.2 Kekurangan Perangkat Lunak ... 77
BAB VII PENUTUP ... 78
7.1 Kesimpulan ... 78
7.2 Saran ... 79
xv
Daftar Tabel
Tabel 3. 1 Tabel Atribut Data Hasil UN ... 18
Tabel 3. 2 Tabel Atribut Data Nilai Indeks Integritas ... 19
Tabel 3. 3 Tabel Atribut Data Nilai Akreditasi Sekolah ... 19
Tabel 3. 4 Tabel Atribut Terpilih ... 21
Tabel 4. 1 Objek Data Sekolah ... 28
Tabel 4. 2 Rincian Algoritma per Method Kelas controlECODB ... 96
Tabel 4. 3 Rincian Algoritma per Method Kelas controlExcel ... 100
Tabel 4. 4 Rincian Algoritma per Method Kelas DataModel ... 104
Tabel 4. 5 Rincian Algoritma per Method Kelas HasilECODBModel ... 107
Tabel 5. 1 Implementasi Kelas Model ... 37
Tabel 5. 2 Implementasi Kelas View ... 37
Tabel 5. 3 Spesifikasi Detail Kelas Home.java ... 38
Tabel 5. 4 Spesifikasi Detail Kelas Preprocessing.java ... 39
Tabel 5. 5 Spesifikasi Detail Kelas Hasil.java ... 42
Tabel 5. 6 Spesifikasi Detail Kelas Tentang.java ... 43
Tabel 5. 7 Spesifikasi Detail Kelas Bantuan.java ... 45
Tabel 5. 8 Implementasi Kelas Controller ... 46
Tabel 5. 9 Rencana Pengujian Black Box ... 47
Tabel 5. 10 Data Hasil UN, Indeks Integritas, Akreditasi SMA Jurusan SMA Kabupaten Kulonprogo ... 114
Tabel 5. 11 Distance atau Similarity Data Antar Sekolah ... 116
Tabel 5. 12 Hasil Probability of Class Label ... 117
Tabel 5. 13 Hasil Ranking Probability of Class Label ... 118
Tabel 5. 14 Hasil Penghitungan Deviation, KDist, normDev, dan normKDist .. 119
Tabel 5. 15 Hasil Penghitungan Class Outlier Factor ... 119
Tabel 5. 16 Hasil Rangking Class Outlier Factor ... 120
Tabel 6. 1 Hasil Identifikasi dengan N=5, K bervariasi ... 51
Tabel 6. 2 Hasil Identifikasi dengan K=10, N bervariasi ... 53
Tabel 6. 3 Hasil Identifikasi dengan N=5, K bervariasi ... 58
Tabel 6. 4 Hasil Identifikasi dengan K=10, N bervariasi ... 59
Tabel 6. 5 Tetangga Terdekat SMA ISLAM TERPADU ABU BAKAR... 65
Tabel 6. 6 Tetangga Terdekat SMA MUHAMMADIYAH 1 SLEMAN ... 66
Tabel 6. 7 Tetangga Terdekat SMA GAJAH MADA YOGYAKARTA ... 67
Tabel 6. 8 Tetangga Terdekat SMA MUHAMMADIYAH PIYUNGAN ... 68
xvi
Tabel 6. 10 Tetangga Terdekat SMA NEGERI 1 NGAGLIK ... 71
Tabel 6. 11 Tetangga Terdekat SMA ISLAM TERPADU ABU BAKAR... 72
Tabel 6. 12 Tetangga Terdekat SMA MUHAMMADIYAH MLATI ... 73
Tabel 6. 13 Tetangga Terdekat SMA ‘17’ YOGYAKARTA ... 74
xvii
Daftar Gambar
Gambar 4. 1 Diagram Flowchart ... 26
Gambar 4. 2 Diagram Use Case ... 27
Gambar 4. 3 Objek Jarak1 ... 29
Gambar 4. 4 Rancangan Antarmuka Halaman Home ... 31
Gambar 4. 5 Antarmuka Halaman Preprocessing ... 32
Gambar 4. 6 Antarmuka Halaman Hasil ... 33
Gambar 4. 7 Antarmuka Halaman Tentang ... 34
Gambar 4. 8 Antarmuka Halaman Bantuan ... 35
Gambar 5. 1 Implementasi Antarmuka Kelas Home ... 39
Gambar 5. 2 Implementasi Antarmuka Kelas Preprocessing... 41
Gambar 5. 3 Implementasi Antarmuka Kelas Hasil... 43
Gambar 5. 4 Implementasi Antarmuka kelas Tentang ... 44
Gambar 5. 5 Implementasi Antarmuka Kelas Bantuan ... 46
xviii
Daftar Rumus
Rumus 2.1 : PCL(T,K) ... 14
Rumus 2.2 : Deviation(T) ... 14
Rumus 2.3 : KDist(T) ... 14
Rumus 2.4 : norm(Deviation(T)) ... 14
Rumus 2.5 : norm(KDist(T))... 15
Rumus 2.6 : COF(T) ... 15
xix
Daftar Lampiran
LAMPIRAN 1 : Gambar Umum Use Case... 83
LAMPIRAN 2 : Narasi Use Case ... 84
LAMPIRAN 3 : Diagram Aktivitas ... 88
LAMPIRAN 4 : Diagram Kelas Analisis... 91
LAMPIRAN 5 : Diagram Sekuen ... 92
LAMPIRAN 6 : Diagram Kelas Disain ... 95
LAMPIRAN 7 : Algoritma Per Method... 96
LAMPIRAN 8 : Prosedur Pengujian dan Kasus Uji ... 111
LAMPIRAN 9 : Proses Penghitungan Manual ... 114
LAMPIRAN 10 : Tetangga Terdekat dan Kelas Label Hasil Running Dataset IPA ... 121
1
BAB I
PENDAHULUAN
1.1
Latar Belakang
Pertumbuhan data yang semakin pesat menyebabkan penumpukan data yang sangat besar. Penumpukan data yang terlalu besar seringkali hanya dianggap sebagai hal yang tidak berguna karena memenuhi ruang penyimpanan dan berisi informasi atau data yang sudah tidak gunakan. Untuk itu diperlukan penambangan data untuk mengubah data yang sangat banyak dan tidak informatif menjadi data yang memberi suatu informasi.
Di dalam penambangan data terdapat banyak metode atau teknik yang sering digunakan. Salah satunya adalah outlier yang merupakan salah satu bidang penelitian di dalam penambangan data. Outliers adalah data yang menyimpang terlalu jauh dari data yang lainnya dalam suatu rangkaian data. Adanya data outliers ini akan membuat analisis terhadap serangkaian data menjadi bias, atau tidak mencerminkan fenomena yang sebenarnya. Outlier sering dianggap sebagai noise dan sebagian besar algoritma di dalam penambangan data mencoba meminimalkan dan mengeliminasi
outlier(Fiona & Rosa, 2013). Namun outlier bisa merupakan representasi suatu data atau kejadian yang unik atau langka yang perlu dianalisa lebih lanjut(Fiona & Rosa, 2013).
Ada banyak teknik atau metode yang digunakan untuk mendeteksi
outlier. Kebanyakan dari metode-metode tersebut mengidentifikasi outlier
terlepas dari class label set data yang digunakan. Metode-metode tersebut hanya mengidentifikasi outlier secara keseluruhan dalam set data. Class Outlier Mining mengidentifikasi outliers dengan memperhitungkan class label yaitu mendeteksi outliers yang berbeda dari kelas label. Algoritma
Class Outlier Distance Based (CODB) merupakan metode Class Outlier Mining berdasarkan pendekatan jarak dan tetangga terdekat dengan menggunakan Class Outlier Factor (COF) yang mewakili derajat kelas
2
(2009) algoritma Enhanced Class Outlier Distance Based merupakan peningkatan algoritma Class Outlier Distance Based. Dalam algortima ECODB mengurangi parameter dalam CODB dengan melakukan normalisasi.
Pada penelitian yang dilakukan oleh Widowati (2015), algoritma ECODB dapat digunakan untuk mendeteksi outlier pada data debitur XYZ. Pada bidang pendidikan banyak data yang merupakan data yang memiliki
class label salah satunya adalah mengenai Ujian Nasional(UN). Data UN memiliki atribut yaitu nama sekolah, nilai UN, indeks integritas sekolah dan akreditasi sekolah. Nilai UN merupakan nilai yang dihasilkan dari Ujian Nasional yang diselenggarakan secara nasional pada tingkat akhir sekolah menengah pertama dan sekolah menengah atas. Atribut nilai UN merupakan atribut numerik. Indeks integritas sekolah merupakan nilai kejujuran dari sekolah tersebut. Atribut indeks integritas merupakan atribut numerik. Akreditasi sekolah merupakan penilaian yang dilakukan oleh pemerintah yang berwenang untuk menentukan kelayakan program dan/atau satuan pendidikan berdasarkan kriteria yang telah ditetapkan. Atribut akreditasi sekolah merupakan class label. Deteksi outlier pada data UN pernah diteliti oleh Octaviani (2015), yang mendeteksi outlier pada data UN SMA tahun ajaran 2011-2014 di Provinsi Daerah Istimewa Yogyakarta menggunakan algoritma Influenced Outlierness (INFLO). Pada penelitian tersebut data UN yang digunakan merupakan data yang tidak memiliki class label.
Dalam mendeteksi outlier, tidak setiap metode dapat digunakan untuk setiap kasus. Suatu metode digunakan untuk mendeteksi outlier suatu kasus dengan karakteristik data tertentu. Suatu metode harus tidak hanya mampu untuk menemukan outlier namun juga memberikan interpretasi dari
3
Yogyakarta tahun 2015 menggunakan metode ECODB. Data UN yang digunakan adalah data mulai tahun 2015 karena baru pada tahun tersebut indeks integritas digunakan.
Dengan melakukan penelitian ini diharapkan dapat memberikan informasi kejadian langka dari data UN. Data UN setiap sekolah menjadi representasi dari karakteristik sekolah tersebut. Dari penelitian ini pihak pemerintah dapat memperoleh informasi mengenai sekolah dengan data UN yang langka atau unik dari sekolah yang lainnya. Data UN yang unik bisa dihasilkan misalnya dari nilai UN yang tinggi namun memiliki indeks integritas yang rendah atau akreditasi yang rendah begitu pula sebaliknya. Hasil dari penelitian ini dapat dianalisa lebih lanjut oleh pihak sekolah atau pemerintah untuk pembinaan dan pengembangan sekolah.
1.2
Rumusan Masalah
1. Bagaimana menerapkan algoritma Enhanced Class Outlier Distance Based untuk mencari outlier pada data berlabel kelas dalam set data hasil UN, nilai indeks integritas dan akreditasi sekolah?
2. Sekolah mana sajakah yang diidentifikasi sebagai outlier?
1.3
Tujuan
1. Menganalisa kemampuan algoritma ECODB dapat mengidentifikasi
outlier pada data berlabel kelas dalam set data hasil UN, nilai indeks integritas dan akreditasi sekolah.
2. Menganalisa sekolah yang teridentifikasi sebagai outlier.
1.4
Batasan Masalah
Batasan masalah pada penelitian ini, yaitu :
1. Data yang digunakan adalah data nilai UN, nilai indeks integritas dan akreditasi tahun 2015.
4
1.5
Manfaat Penelitian
Manfaat dari penelitian ini, yaitu :
1. Menjelaskan mengenai cara mendeteksi outlier dengan menggunakan algoritma Enhanced Class Outlier Distance Based (ECODB).
2. Memberikan informasi mengenai outlier atau kejadian langka yang ada dalam data UN Sekolah Menengah Atas (SMA).
1.6
Metodologi Penelitian
Metodologi penelitian yang digunakan dalam menyelesaikan tugas akhir ini yaitu :
1. Studi Pustaka
Tahap studi pustaka merupakan proses mengumpulkan informasi mengenai teori-teori outlier dan algoritma yang dapat mengidentifikasi outlier dari berbagai sumber atau referensi. Kemudian mempelajari dan menganalisa informasi yang didapat sehingga menentukan algoritma Enhanced Class Outlier Distance Based untuk mengidentifikasi outlier pada data UN Sekolah Menengah Atas (SMA). 2. Knowledge Discovery in Database (KDD)
Metodologi Knowlegde Discovery in Database dikemukan oleh Han & Kamber (2011). Proses dalam Knowlegde Discovery in Database
adalah sebagai berikut :
a. Data Cleaning
Proses untuk menghilangkan kebisingan (noise) dan data yang tidak konsisten.
b. Data Integration
Proses menggabungkan beberapa sumber data.
c. Data Selection
Proses memilih data atau atribut yang relevan untuk penelitian ini.
d. Data Transformation
5
e. Data Mining
Proses menerapkan metode yang digunakan untuk menemukan pola pada data.
f. Pattern Evaluation
Proses mengidentifikasi pola-pola yang benar-benar menarik yang merupakan hasil dari penambangan data.
g. Knowledge Presentation
Proses menyajikan pengetahuan dari hasil penambangan data kepada pengguna.
3. Analisa Hasil
Analisa hasil merupakan proses menganalisa hasil identifikasi
outlier yang dilakukan oleh perangkat lunak.
1.7
Sistematika Penulisan
Sistematika pada penelitian ini yaitu : 1. BAB 1 Pendahuluan
Berisi latar belakang masalah, rumusan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian dan sistematika penulisan tugas akhir.
2. BAB II Landasan Teori
Berisi penjelasan teori-teori yang mendukung mengenai penambangan data, outlier dan algoritma Enhanced Class Outlier Distance Based. 3. BAB III Metodologi Penelitian
Berisi penjelasan mengenai langkah-langkah atau metodologi penelitian tugas akhir ini.
4. BAB IV Perancangan Perangkat Lunak
6
algoritma per method, perancangan struktur data dan perancangan antarmuka.
5. BAB V Implementasi Dan Pengujian Perangkat Lunak
Berisi penjelasan mengenai implementasi dan pengujian perangkat lunak. 6. BAB VI Analisa Hasil dan Pembahasan
Berisi penjelasan mengenai dataset, hasil Identifikasi outlier, analisa hasil identifikasi outlier dan kelebihan dan kekurangan perangkat lunak. 7. BAB VII Penutup
7
BAB II
LANDASAN TEORI
2.1
Penambangan Data
2.1.1 Pengertian Penambangan Data
Penambangan data adalah proses menemukan informasi yang berguna dalam repositori data yang besar secara otomatis. Teknik penambangan data digunakan untuk menemukan pola yang baru dan berguna yang mungkin tidak diketahui pada database yang besar. Penambangan data juga memiliki kemampuan untuk memprediksi hasil dari pengamatan masa depan. Penambangan data adalah bagian dari knowledge discovery in database yang mana merupakan proses mengubah data mentah menjadi informasi berguna. Tidak semua penemuan informasi dianggap penambangan data. Sebagai contoh, mencari data menggunakan sistem manajemen
database atau menemukan halaman web tertentu melalui query ke mesin pencarian pada internet merupakan tugas yang berhubungan dengan bidang pencarian informasi. Meskipun demikian, teknik penambangan data telah digunakan untuk meningkatkan sistem pencarian informasi (Tan et.al 2006).
2.1.2 Fungsi Penambangan Data
8
Deskripsi kelas atau konsep dapat berasal dari menggunakan karakterisasi data atau diskriminasi data atau baik karakterisasi data dan diskriminasi data. Karaterisasi data adalah dengan merangkum data dari kelas yang diteliti atau sering disebut kelas target. Diskriminasi data adalah dengan membandingkan kelas target dan kelas komparatif.
b. Penambangan Pola yang Sering Muncul, Asosiasi dan Korelasi Ada banyak jenis pola yang sering muncul dalam data yaitu
itemset yang sering muncul, subsequence atau pola berurutan yang sering muncul dan substruktur yang sering muncul. Sebuah
itemset yang sering muncul biasanya mengacu pada satu itemset
yang sering muncul bersamaan dalam transaksi seperti susu dan roti sering dibeli bersama-sama di toko-toko oleh banyak pelanggan. Sebuah subsequence yang sering muncul seperti pelanggan cenderung untuk membeli pertama laptop kemudian kamera digital dan kemudian kartu memori yang merupakan pola berurutan. Sebuah substruktur dapat merujuk ke berbagai bentuk struktural yang dapat dikombinasikan dengan itemsets atau
sequences. Jika substruktur sering terjadi disebut pola terstruktur. Penambangan pola sering mengarah pada penemuan asosiasi menarik dan korelasi dalam data.
c. Analisis Prediktif Klasifikasi dan Regresi
9
metode statistik yang paling sering digunakan untuk memprediksi numerik meskipun ada metode lainnya. Regresi juga mencakup identifikasi distribusi tren berdasarkan data yang tersedia. Klasifikasi dan regresi perlu didahului dengan analisis relevansi yaitu upaya untuk mengidentifikasi atribut yang relevan klasifikasi dan proses regresi. Atribut tersebut kemudian dipilih untuk proses klasifikasi dan regresi. Atribut yang tidak relevan dikeluarkan atau tidak digunakan.
d. Analisis Pengelompokan atau Klastering
Tidak seperti klasifikasi dan regresi yang menganalisa set data kelas berlabel, klastering menganalisa datatabpa label kelas. Dalam banyak kasus data dengan kelas berlabel mungkim tidak ada diawal. Klastering dapat digunakan untuk menghasilkan label kelas untuk sekelompok data. Objek yang bergerombol atau berkelompok berdasarkan pada prinsip memaksimalkan kesamaan intrakelas dan meminimalkan kesamaan antarkelas, sehingga objek dalam sebuah kelompok memiliki kesamaan yang tinggi dibandingkan satu sama lain tapi berbeda dengan objek dalam kelompok lainnya.
e. Analisis Outlier
Satu set data yang mungkin berisi objek yang tidak sesuai dengan perilaku umum atau model dari data atau yang disebut
outlier. Banyak metode dalam penambangan data membuang oulier karena dianggap sebagai kebisingan atau pengecualian. Namun, dalam beberapa aplikasi identifikasi peristiwa langka lebih menarik daripada peristiwa yang terjadi lebih teratur. Outlier dapat dideteksi menggunakan uji statistik yang mengasumsikan distribusi atau probabilitas model untuk data, atau menggunakan jarak antarobjek dimana objek yang jauh dari setiap kelompok lainnya adalah outlier. Metode density-based
10
teridentifikasi sebagai data yang normal dengan menggunakan metode statistik.
2.2
Outlier
2.2.1 Pengertian Outlier
Menurut Han dan Kamber (2012) outlier adalah objek data yang menyimpang jauh dalam suatu set data, seolah-olah objek tersebut dihasilkan dengan mekanisme yang berbeda. Deteksi outlier
adalah proses mencari objek data dengan perilaku atau karakteristik yang sangat berbeda dari harapan. Objek data tersebut disebut outlier
atau anomali.
Banyak algoritma dalam penambangan data mencoba meminimalisasikan atau bahkan mengeliminasi outlier. Namun
outlier bisa saja menghasilkan informasi penting yang tersembunyi karena noise satu orang bisa menjadi sinyal bagi orang lain. Deteksi
outlier penting dalam banyak aplikasi untuk mendeteksi penipuan seperti perawatan medis, keselamatan publik dan keamanan, deteksi kerusakan industri, pengolahan gambar, pengawasan jaringan sensor/video dan deteksi gangguan. Deteksi outlier dan analisis pengelompokan atau klastering merupakan dua tugas yang sangat terkait namun memiliki tujuan yang berbeda. Pengelompokan digunakan untuk menemukan pola mayoritas dalam kumpulan data dan mengatur data dalam kelompok yang sesuai, sedangkan deteksi
outlier digunakan untuk mendeteksi kasus-kasus yang menyimpang jauh dari pola mayoritas.
Menurut Tan et.al (2006) outlier dapat disebabkan oleh sebagai berikut :
1. Data Dari Kelas Yang Berbeda
11
yang berbeda dari pengguna kartu kredit yang menggunakan kartu kredit secara sah.
2. Variasi Alami
Sebagian besar suatu objek dekat dengan pusat objek (rata-rata objek) dan memiliki kemungkinan yang kecil suatu objek berbeda secara signifikan. Sebagai contoh orang yang sangat tinggi bukan anomali jika dari kelas objek yang terpisah, namun menjadi ekstrim jika dalam karakteristik tinggi badan rata-rata orang pada umumnya.
3. Pengukuran Data Dan Kesalahan Pengumpulan Data
Pengukuran data dan kesalahan pengumpulan data adalah sumber lain dari outlier. Sebagai contoh, pengukuran dan pengumpulan data dapat dicatat secara tidak benar karena
human error.
2.2.2 Metode Deteksi Outlier
Menurut Han & Kamber (2012) ada dua cara pengelompokan metode deteksi outlier. Pertama pengelompokan metode pendeteksian outlier berdasarkan ketersediaan label pada sampel data yang dianalisis yang dapat digunakan untuk membangun model deteksi outlier. Kedua pengelompokan metode menjadi kelompok-kelompok dengan mengasumsikan membandingkan obyek normal dengan outlier. Berikut ini adalah penjelasan dari kedua jenis pengelompokan tersebut :
1. Metode Supervised, Semi-Supervised, dan Unsupervised
Metode supervised untuk model data normal dan abnormal dengan memeriksa label sampel data yang mendasarinya. Deteksi outlier dapat dimodelkan dengan klasifikasi. Dalam beberapa aplikasi label hanya pada objek yang normal, objek lain yang tidak cocok dengan model objek normal dianggap sebagai
12
unsupervised. Mendeteksi outlier dengan menggunakan metode unsupervised mengasumsikan objek yang normal akan membentuk kelompok. Dengan kata lain metode unsupervised mengharapkan objek-objek yang normal akan mengikuti pola yang jauh lebih sering daripada outlier. Objek yang normal tidak harus selalu memiliki kesamaan yang tinggi dalam satu kelompok, namun dapat membentuk beberapa kelompok dimana setiap kelompok memiliki fitur yang berbeda. Outlier diharapkan berada jauh dari setiap kelompok objek yang normal. Dalam banyak aplikasi, jumlah objek yang memiliki label biasanya kecil. Ada beberapa kasus dimana hanya satu set kecil dari objek normal dan/atau outlier yang berlabel, sedangkan sebagian besar data tidak berlabel. Deteksi outlier menggunakan metode semisupervised dikembangkan untuk mengatasi kasus tersebut. Model objek yang normal dapat digunakan untuk mendeteksi benda-benda yang tidak sesuai dengan model objek normal diklasifikasikan sebagai outlier.
13
dalam mendeteksi outlier jika outlier dekat satu sama lain. Metode clustering-based mengasumsikan data yang normal termasuk dalam kelompok yang besar dan padat, sedangkan outlier termasuk dalam kelompok yang kecil dan jarang atau bahkan tidak termasuk dalam setiap kelompok.
2.3
Algoritma
Enhanced Class Outlier Distance Based
Class label adalah atribut yang dipilih dalam satu data set berdasarkan permintaan pengguna dan jenis aplikasi. Sebuah class label
dapat berisi diagnosa medis, keputusan persetujuan kredit atau pinjaman, golongan pelanggan, dll. Metode konvensional (Outlier Mining) mencari
outliers dalam kumpulan data terlepas dari class label, dianggap sebagai
outliers dalam seluruh dataset. Class Outlier Mining mencari outliers
dengan memperhitungkan class label. Outlier Mining tidak dapat mendeteksi outliers yang berbeda dari class label, sedangkan Class Outlier Mining dapat melakukannya (Hewahi & Saad, 2009).
Hewahi dan Saad mengusulkan definisi baru untuk class outlier
dan metode baru untuk Class Outlier Mining yang berdasarkan pendekatan jarak dan tetangga terdekat. Metode ini disebut algoritma Class Outlier Distance Based (CODB). Algoritma CODB didasarkan pada COF (Class Outlier Faktor) yaitu derajat outlier class dalam objek data. Algoritma
Enhanced Class Outlier Distance Based merupakan peningkatan algoritma dari algortima Class Outlier Distance Based. Algortima Enhanced Class Outlier Distance Based dikembangkan oleh Hewahi dan Saad (2009). Berdasarkan algoritma ECODB untuk instance T menghilangkan parameter
α dan β untuk menghilangkan trial dan eror, sehingga melakukan proses normalisasi pada Deviation(T) dan KDist(T). Langkah-langkah algoritma ECODB adalah sebagai berikut :
14
kelas label K tetangga terdekat. PCL (T, K) dapat dihitung dengan rumus berikut ini :
�, = ℎ � � � � � � � � � � �
… (2.1) Misalkan ada 7 tetangga terdekat dari instance T (termasuk dirinya) di dalam sebuah dataset dengan dua class label yaitu x dan y, dimana ada 5 dari tetangga terdekat memiliki class label x dan 2 memiliki class label y. Instance T memiliki class label y, oleh karena itu PCL dari
instance T yaitu 2/7.
2. Merangking daftar top N dari instance dengan nilai PCL (T, K) dari yang terkecil.
3. Untuk setiap instance pada daftar top N hitung Deviation(T) dan
Kdist(T). Deviation(T) adalah seberapa besar nilai instance T
menyimpang dari instances dengan kelas label yang sama. Deviation(T) dihitung dengan menjumlahkan jarak antara instance T dan setiap
instance yang memiliki kelas yang sama dengan instance T.
Deviation(T) dapat dihitung dengan rumus sebagai berikut :
�� � � = ∑�= �, � … (2.2) Keterangan :
n = jumlah instances yang memiliki kelas yang sama terhadap instance T
d(T,ti) = jarak antara instances yang memiliki kelas yang sama terhadap
instance T
KDist(T) adalah jumlah jarak antara instance T dan K tetangga terdekat.
KDist(T) dapat dihitung dengan menggunakan rumus sebagai berikut :
15 Keterangan :
K = jumlah tetangga terdekat
d(T,ti) = jarak antara tetangga terdekat terhadap instance T
Kemudian lakukan normalisasi pada Deviation dan KDist agar
Deviation dan KDist berada dalam range 0-1. Normalisasi Deviation
dan KDist dapat dihitung dengan rumus berikut ini :
( �� � � ) = �� � � − � / � − � …
(2.4)
( � � ) = � � − � � / � � − � � …(2.5)
Keterangan :
norm(Deviation(T)) = nilai Deviation(T) yang telah dinormalisasi
norm(KDist(T)) = nilai KDist(T) yang telah dinormalisasi
MaxDev = nilai deviation tertinggi dari top N class outliers MinDev = nilai deviation terendah dari top N class outliers MaxKDist = nilai KDist tertinggi dari top N class outliers MinKDist = nilai KDist terendah dari top N class outliers
4. Hitung nilai COF (Class Outlier Factor) untuk seluruh instances di dalam top N dengan rumus sebagai berikut :
� � = × �, − ( �� � � ) + ( � � )…
(2.6)
Keterangan :
COF(T) = nilai Class Outlier Faktor instance T
K = jumlah tetangga terdekat instance T
PCL(T,K) = nilai probabilitas label kelas dari instance T dengan kelas label K tetangga terdekat
norm(Deviation(T)) = nilai Deviation(T) yang telah di normalisasi
16
5. Kemudian mengurutkan daftar top N berdasarkan nilai COF dari yang terkecil.
2.4
Struktur Data
Struktur data adalah cara penyimpanan, penyusunan, pengaturan atau merepresentasikan data didalam komputer agar bisa dipakai secara efisien. Pada penelitian struktur data yang digunakan adalah sebagai berikut: 1. ArrayList
Arraylist merupakan struktur data berbentuk array namun memiliki jumlah indeks yang dinamis. Pada Arra yList saat mendeklarasi tidak perlu terlebih dahulu menentukan jumlah maksimum indeksnya.
ArrayList a = new ArrayList();
Pernyataan di atas merupakan contoh mendeklarasikan sebuah objek
ArrayList dengan nama a. Ilustrasi ArrayList sebagai berikut : a.add(5);
a.add(2); a.add(1);
[ ]
size : 3 a.add(4);
[ ]
size : 4
2. Matriks atau Array 2 dimensi
Array merupakan sejumlah data yang dirujuk berdasarkan indeksnya.
Array 2 dimensi digambarkan dengan matriks yang memiliki baris dan kolom. Array 2 dimensi merupakan struktur data statis oleh karena itu saat mendeklarasikan array 2 dimensi harus terlebih dahulu menentukan maksimum jumlah indeks baris dan kolomnya.
17
Pernyataan di atas merupakan contoh mendeklarasikan array 2 dimensi dengan nama a, bertipe Integer, jumlah baris 3 dan jumlah kolom 4. Ilustrasi dalam matriks sebagai berikut
[ ]
Kemudian untuk menyimpan dan mengambil data pada array 2 dimensi diilustrasikan sebagai berikut :
a [0][1] = 5; a [0][3] = 2; a [2][3] = 1;
[ ]
x = a [0][1]; Pernyataan di atas berarti x = 5.
18
BAB III
METODE PENELITIAN
3.1
Bahan Riset/Data
Pada penelitian ini mengunakan data hasil ujian nasional untuk jurusan Ilmu Pengetahuan Alam (IPA) dan Ilmu Pengetahuan Sosial (IPS), nilai indeks integritas dan nilai akreditasi Sekolah Menengah Atas (SMA) Daerah Istimewa Yogyakarta pada tahun 2015. Data yang digunakan merupakan file dengan ekstensi .xls yang diperoleh dari tiga sumber. Data hasil UN jurusan IPA dan IPS bersumber dari website resmi dari Badan Penelitian Pendidikan dan Pengembangan Kementrian Pendidikan dan Kebudayaan http://118.98.234.50/lhun/daftar.aspx. Data nilai akreditasi sekolah bersumber dari website resmi dari Badan Penelitian Pendidikan dan Pengembangan Kementrian Pendidikan dan Kebudayaan
http://bansm.or.id/sekolah/sudah_akreditasi/4. Data nilai indeks integritas bersumber dari Badan Penelitian Pendidikan dan Pengembangan
Kementrian Pendidikan dan Kebudayaan
http://puspendik.kemdikbud.go.id/hasil-un/. Untuk data hasil UN jurusan IPA sejumlah 169 record dan data jurusan IPS 198 record. Data nilai indeks integritas sejumlah 143 record untuk jurusan ipa dan 164 record
untuk jurusan ips. Data akreditasi sejumlah 195 record. Tabel 3. 1 Tabel Atribut Data Hasil UN
Nama Atribut Keterangan
Kode Sekolah Kode sekolah
Nama Sekolah Nama sekolah
Status Sekolah Status sekolah (Swasta/Negeri)
Jumlah Peserta Jumlah peserta ujian
Rank Urutan ranking
19
Bahasa Inggris Nilai Bahasa Inggris Matematika Nilai Matematika Fisika/Ekonomi Nilai Fisika/Ekonomi Kimia/Sosiologi Nilai Kimis/Sosiologi Biologi/Geografi Nilai Biologi/Geografi
Total Total nilai UN
Tabel 3. 2 Tabel Atribut Data Nilai Indeks Integritas
Nama Atribut Keterangan
Kode Sekolah Kode sekolah
NPSN Nomor Pokok Sekolah Nasional
Nama Sekolah Nama sekolah
Status Sekolah Status sekolah (Swasta/Negeri)
Jumlah Peserta Jumlah peserta ujian
Tahun 2016 Rerata UN Rata-rata nilai UN IIUN Nilai Indeks Integritas Tahun 2015 Rerata UN Rata-rata nilai UN
IIUN Indeks Integritas Ujian Nasional
Tabel 3. 3 Tabel Atribut Data Nilai Akreditasi Sekolah
Nama Atribut Keterangan
NPSN Nomor Pokok Sekolah Nasional
Nama Sekolah Nama sekolah
Status Sekolah Status sekolah (Swasta/Negeri)
Tipe Sekolah Tipe sekolah (Sekolah/MA)
Provinsi Nama provinsi dari sekolah
Kota/Kabupaten Nama kota/kabupaten dari sekolah
Nilai Nilai akreditasi
20
3.2
Peralatan Penelitian
Peralatan yang akan digunakan pada penelitian ini antara lain pc dengan spesifikasi RAM 6GB, prosesor Intel Core i3-3217U 1.8GHz, hardisk 500GB. Kemudian menggunakan Netbeans 7.3.1 sebagai aplikasi
Integrated Development Environment (IDE) yang berbasis java. Menggunakan mysql sebagai manajemen basis data sql.
3.3
Tahap-tahap Penelitian
3.3.1 Studi Pustaka
Tahap studi pustaka merupakan proses mengumpulkan informasi mengenai teori-teori outlier dan algoritma yang dapat mengidentifikasi outlier dari berbagai sumber atau referensi.
Kemudian mempelajari dan menganalisa informasi yang didapat sehingga menentukan algoritma Enhanced Class Outlier Distance Based untuk mengidentifikasi outlier pada data UN Sekolah Menengah Atas (SMA).
3.3.2 Knowledge Discovery in Database (KDD)
Metodologi Knowledge Discovery in Database dikemukan oleh Han & Kamber (2011). Proses dalam Knowledge Discovery in Database adalah sebagai berikut :
a. Data Cleaning
Proses untuk menghilangkan kebisingan (noise) dan data yang tidak konsisten. Data yang digunakan memiliki missing value
pada atribut IIUN sehingga pada tahap data cleaning
menghilangkan atau menghapus data yang tidak memiliki nilai IIUN.
b. Data Integration
21
integritas. Atribut dari data akreditasi dapat dilihat pada tabel 3.3. Atribut dari data hasil ujian nasional dapat dilihat pada tabel 3.1. Atribut dari data nilai indeks integritas dapat dilihat pada tabel 3.2. Pada tahap ini menggabungkan 3 file tersebut.
c. Data Selection
Proses memilih data atau atribut yang relevan untuk penelitian ini. Pada proses ini memilih atribut yang relevan untuk digunakan pada penelitian ini dan menghapus atribut yang tidak digunakan. Atribut yang digunakan pada penelitian ini yaitu :
Tabel 3. 4 Tabel Atribut Terpilih
Nama Atribut Keterangan Jenis
Atribut Bahasa Indonesia Nilai Bahasa Indonesia Numerik Bahasa Inggris Nilai Bahasa Inggris Numerik
Matematika Nilai Matematika Numerik
Fisika/Ekonomi Nilai Fisika/Ekonomi Numerik Kimia/Sosiologi Nilai Kimia/Sosiologi Numerik Biologi/Geografi Nilai Biologi/Geografi Numerik IIUN 2015 Indeks Integritas Ujian
Nasional
Numerik
Peringkat Peringkat Akreditasi Class Label
Tabel 3.5 Tabel Contoh Data Kode
Sekolah
Bahasa Indonesia
Bahasa
Inggris Matematika Fisika Kimia Biologi IIUN Akreditasi 02-021 78.69 67 55.86 74.1 51.1 67.05 74.14 A
22
04-023 86.7 68.67 67.15 71.26 73.52 70.78 92.82 A 03-016 74.68 49.68 41.38 37.45 45.81 58.45 75.62 A
d. Data Transformation
Proses dimana data diubah dan dikonsolidasikan ke dalam bentuk yang sesuai untuk ditambang. Pada penelitian ini set data yang digunakan memiliki skala data yang sama antar atribut yaitu antara 1-100. Class label tidak digunakan dalam perhitungan jarak sehingga tidak perlu diubah menjadi numerik. Pada penelitian ini tidak dilakukan tahap transformasi karena data yang digunakan memiliki atribut dengan skala yang sama dan tidak perlu diubah dalam bentuk numerik.
e. Data Mining
Proses menerapkan metode yang digunakan untuk menemukan pola pada data yaitu algoritma Enhance Class Outlier Distance Based.
f. Pattern Evaluation
Proses mengidentifikasi pola-pola yang benar-benar menarik yang merupakan hasil dari penambangan data. Pada tahap ini hasil dari identifikasi outlier akan dievaluasi dengan hipotesa yang telah dibentuk sebelumnya.
g. Knowledge Presentation
Proses menyajikan pengetahuan dari hasil penambangan data kepada pengguna. Pada tahap ini hasil dari identifikasi outlier
akan ditampilkan dengan bentuk yang mudah dimengerti oleh pengguna atau pihak yang berkepentingan. Pada tahap ini akan dilakukan pembuatan aplikasi komputer berbasis dekstop dengan bahasa pemrograman Java.
3.3.3 Desain Alat Uji
23
metode yang paling sering digunakan dalam tahap pengembangan perangkat lunak (Utami & Asnawati, 2015). Model waterfall
merupakan model klasik yang sederhana dengan aliran sistem yang linier. Output dari setiap tahap merupakan input bagi tahap berikutnya (Kristanto, 2004). Menurut Utami & Asnawati (2015) tahapan model waterfall meliputi :
a. Analisa Kebutuhan Perangkat Lunak
Analisa kebutuhan perangkat lunak merupakan tahap awal untuk menentukan gambaran perangkat lunak. Perangkat lunak yang baik dan sesuai dengan kebutuhan pengguna tergantung pada keberhasilan dalam melakukan analisa kebutuhan. Tahap ini merupakan proses untuk mendapatkan informasi, mode dan spesifikasi tentang perangkat lunak. Pada penelitian ini pengumpulan informasi didapatkan dengan cara mengunduh data hasil UN, indeks integritas dan akreditasi sekolah.
b. Desain Perangkat Lunak
Desain perangkat lunak merupakan langkah yang berfokus pada empat atribut yang berbeda dari sebuah program yaitu struktur data, arsitektur perangkat lunak, representasi interface dan prosedural rinci. Pada tahap merupakan proses mengubah kebutuhan perangkat lunak menjadi rancangan perangkat lunak. Tahap in menghasilkan sebuah arsitektur sistem yang dapat ditranformasikan ke dalam satu atau lebih program yang dapat dijalankan.
c. Pembuatan Kode (Coding)
Pada tahap ini merupakan proses menerjemahkan desain perangakat lunak ke dalam mesin yang dapat dibaca. Dalam tahap ini dilakukan pembuatan kode.
d. Pengujian (Testing)
24
pernyataan yang dibuat dalam coding) dan eksternal (melakukan tes untuk menemukan kesalahan dan memastikan bahwa input sesuai dengan apa yang dibutuhkan). Pada penelitian ini pengujian sistem menggunakan pendekatan black-box testing. Pendekatan inimerupakan pengujian terhadap fungsi operasional software.
3.3.4 Analisis dan Pembuatan Laporan
Analisis yang dilakukan pada penelitian ini adalah menganalisa sekolah yang teridentifikasi sebagai outlier
25
BAB IV
PERANCANGAN PERANGKAT LUNAK
4.1
Perancangan Umum
4.1.1 Input
Masukan pada sistem ini berupa file dengan ekstensi .xls. Pengguna dapat memilih file yang ingin digunakan dari direktori komputer. Pengguna memasukan nilai N dan nilai K yang akan digunakan dalam proses identifikasi outlier. Nilai N merupakan jumlah outlier yang diharapkan. Nilai K merupakan jumlah tetangga terdekat.
4.1.2 Proses
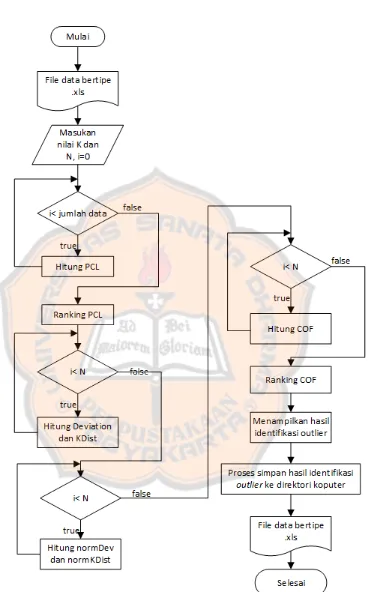
Proses sistem dalam mengidentifikasi outlier terdapat beberapa tahap. Tahap atau langkah-langkah tersebut yaitu :
1. Memilih data yang telah melalui proses preprocessing yang digunakan pada proses penambangan data
2. Menentukan nilai N dan K 3. Proses mengidentifikasi outlier
4. Menyimpan hasil identifikasi outlier
Proses umum pada sistem digambarkan dengan diagram
26
27 4.1.3 Output
Pada sistem ini keluaran yang dihasilkan adalah daftar sekolah yang teridentifikasi sebagai outlier.
4.2
Diagram
Use Case
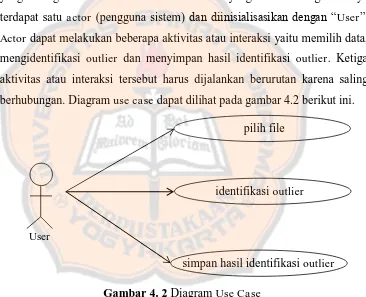
Pada sistem ini terdapat beberapa aktivitas atau interaksi yang dapat dilakukan oleh actor (pengguna sistem). Aktivitas atau interaksi tersebut berupa skenario yang mengidentifikasikan urutan pemakaian sistem yang sering disebut use case. Pada sistem yang akan dibangun hanya terdapat satu actor (pengguna sistem) dan diinisialisasikan dengan “User”.
Actor dapat melakukan beberapa aktivitas atau interaksi yaitu memilih data, mengidentifikasi outlier dan menyimpan hasil identifikasi outlier. Ketiga aktivitas atau interaksi tersebut harus dijalankan berurutan karena saling berhubungan. Diagram use case dapat dilihat pada gambar 4.2 berikut ini.
4.2.1 Gambaran Umum Use Case
Gambaran umum dari masing-masing usecase yang terdapat pada diagram use case terlampir pada lampiran 1.
4.2.2 Narasi Use Case
Narasi use case berisi serangkaian langkah-langkah aksi
actor terhadap sistem dan reaksi sistem terhadap aksi actor pada Gambar 4. 2 Diagram Use Case
User
pilih file
identifikasi outlier
28
setiap use case. Narasi use case terlampir pada lampiran 2.
4.3
Diagram Aktivitas
Terdapat tiga diagram aktivitas yang merupakan aktivitas dari masing-masing use case yaitu memilih data, mengidentifikasi outlier dan menyimpan hasil identifikasi outlier. Diagram aktivitas terlampir pada lampiran 3.
4.4
Perancangan Struktur Data
Sruktur data digunakan untuk mengelola penyimpan data agar data dapat dengan mudah diakses sewaktu-waktu jika sedang diperlukan. Pada penelitian ini konsep struktur data yang digunakan adalah :
1. ArrayList
Pada penelitian ini ArrayList digunakan untuk menampung data sekolah dan hasil identifikasi outlier. Data sekolah dan hasil identifikasi outlier
sebagai elemen pada ArrayList. Sebagai contoh dapat lihat pada ilustrasi berikut ini :
[ � � � � � � � � ]
Objek Data1, Data2, Data3 dan Data4 merupakan representasi dari data sekolah yang dijelaskan pada tabel 4.1 berikut ini :
Tabel 4. 1 Objek Data Sekolah
Objek Atribut
Kode Sek.
Nama Sek.
Nilai1 Nilai2 Nilai3 Nilai4 Nilai5 Nilai6 Nilai7 Akreditasi
Data1 001-001
SMA1 80 80 70 75 85 90 80 A
Data2 001-002
SMA 2
85 80 65 70 85 80 80 B
Data3 001-003
SMA 3
29
Akreditasi Data4
001-004
SMA 4
75 80 90 60 65 70 75 B
2. Matriks atau Array 2 Dimensi
Pada penelitian ini array 2 dimensi atau matriks digunakan untuk menampung jarak antar sekolah. Setiap elemen dari matriks berisi jarak sekolah dan sekolah tujuan. Setiap indeks baris merupakan jarak sekolah dari sekolah di indeks yang sama dari ArrayList data sekolah. Sebagai contoh dapat dilihat dari ilustrasi berikut ini :
ArrayList Data Sekolah sebagai berikut,
[ � � � � � � � � ]
Kemudian matriks jarak antar sekolah berikut ini,
[
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � �
]
Pada ilustrasi diatas matrik pada baris pertama merupakan jarak antar sekolah dari sekolah di kolom pertama dari ArrayList data sekolah, demikian pula pada baris selanjutnya. Jarak1, Jarak2, Jarak3 dan Jarak4 merupakan suatu objek dengan atribut jarakSekolah dan sekolahTujuan dapat dilihat pada gambar 4.3 berikut ini :
Jarak1
jarakSekolah sekolahTujuan Gambar 4. 3 Objek Jarak1
4.5
Diagram Kelas Analisis
30
4.6
Diagram Sekuen
Diagram sequance dari masing-masing use case terlampir pada lampiran 5.
4.7
Diagram Kelas Disain
Diagram kelas disain terlampir pada lampiran 6.
4.8
Algoritma per Method
Rincian algoritma per method terlampir pada lampiran 7.
4.9
Perancangan Antarmuka
Antarmuka digunakan sebagai penghubung antara pengguna dan sistem. Pada penelitian ini sistem yang akan dibangun memiliki 5 interface
atau antarmuka. Antar muka yang akan dibangun yaitu halaman home, halaman tentang, halaman bantuan, halaman preprocessing, dan halaman hasil.
4.9.1 Perancangan Halaman Home
31
Gambar 4. 4 Rancangan Antarmuka Halaman Home
Halaman home merupakan halaman pertama saat memasuki sistem. Pada halaman home terdapat tiga tombol yaitu “MASUK SISTEM”, “TENTANG”, dan “BANTUAN”. Tombol “MASUK SISTEM” digunakan untuk menuju halaman preprocessing untuk memulai proses identifikasi outlier. Tombol “TENTANG”
digunakan untuk menuju halaman tentang. Tombol “BANTUAN”
32
X
Sistem Identifikasi Outlier Menggunakan Algoritma ECODB
BERANDA
FILE
Angela Mediatrix Melly – 135314074 Fakultas Sains dan Teknologi
2017 Jumlah Tetangga
Jumlah Outlier
_
DATA
Jumlah Kolom Jumlah Data
IDENTIFIKASI
Perancangan antarmuka halaman preprocessing dapat dilihat pada gambar 4.5 berikut ini :
Halaman preprocessing merupakan halaman untuk menyiapkan data atau preprocessing data yang akan digunakan untuk mengidentifikasi outlier. Pada halaman preprocessing terdapat
dua tombol yaitu tombol “BERANDA” dan “IDENTIFIKASI”.
Tombol “BERANDA” digunakan untuk menuju halaman home.
Preprocessing data dimulai dengan memilih file berekstensi .xls.
Proses memilih data yaitu dengan menggunakan tombol “FILE”. Tombol “FILE” digunakan untuk membuka direktori file yang akan digunakan.
TITLE1 TITLE2 TITLE3 TITLE4 TITLE5
33
Tahap selanjutnya adalah menentukan jumlah tetangga terdekat dan jumlah outlier yang diinginkan. Setelah user
memasukan nilai jumlah tetangga terdekat dan jumlah outlier yang
diinginkan kemudian menggunakan tombol “IDENTIFIKASI” untuk
menuju halaman hasil. Kemudian terdapat tombol “KEMBALI” yang digunakan untuk menuju halaman home.
4.9.3 Perancangan Halaman Hasil
Perancangan antarmuka halaman hasil dapat dilihat pada gambar 4.6 berikut ini :
TITLE1 TITLE2 TITLE3 TITLE4 TITLE5
Gambar 4. 6 Antarmuka Halaman Hasil
X
Sistem Identifikasi Outlier Menggunakan Algoritma ECODB
BERANDA
Angela Mediatrix Melly – 135314074 Fakultas Sains dan Teknologi
2017 Jumlah Tetangga
Jumlah Outlier
_
HASIL IDENTIFIKASI OUTLIER
34
X
Sistem Identifikasi Outlier Menggunakan Algoritma ECODB
BERANDA
Angela Mediatrix Melly – 135314074 Fakultas Sains dan Teknologi
2017
_
TENTANG PENULIS
Halaman hasil merupakan halaman untuk menampilkan hasil identifikasi outlier. Pada halaman hasil terdapat tiga tombol yaitu tombol “BERANDA”, “KEMBALI” dan tombol “SIMPAN”.
Tombol “KEMBALI” digunakan untuk menuju halaman
preprocessing. Kemudian tombol “SIMPAN” digunakan untuk
menyimpan hasil identifikasi outlier dalam file berekstensi .xls pada direktori komputer. Tombol “BERANDA” digunakan untuk menuju halaman home.
4.9.4 Perancangan Halaman Tentang
Perancangan antarmuka halaman tentang dapat dilihat pada gambar 4.7 berikut ini :
35
X
Sistem Identifikasi Outlier Menggunakan Algoritma ECODB
BERANDA
Angela Mediatrix Melly – 135314074 Fakultas Sains dan Teknologi
2017
_
PANDUAN PENGGUNAAN SISTEM
Halaman tentang merupakan halaman yang berisi penjelasan mengenai identitas pembuat sistem atau perangkat lunak.
Pada halaman tentang terdapat tombol “BERANDA”. Tombol “BERANDA” digunakan untuk menuju halaman awal atau halaman
home.
4.9.5 Perancangan Halaman Bantuan
Perancangan antarmuka halaman tentang dapat dilihat pada gambar 4.8 berikut ini :
Halaman tentang merupakan halaman yang berisi penjelasan mengenai identitas pembuat sistem atau perangkat lunak.
Pada halaman tentang terdapat tombol “BERANDA”. Tombol
36
“BERANDA” digunakan untuk menuju halaman awal atau halaman
37
BAB V
IMPLEMENTASI DAN PENGUJIAN PERANGKAT LUNAK
5.1
Implementasi Rancangan Perangkat Lunak
Perangngkat lunak identifikasi outlier menggunakan algoritma ECODB terdapat 12 kelas yang terdiri dari tiga kelas model, lima kelas
view, dan empat kelas controller. 5.1.1 Implementasi Kelas Model
Implementasi kelas model dapat dilihat pada tabel berikut ini : Tabel 5. 1 Implementasi Kelas Model
No Nama Kelas Nama File Fisik Nama File Excetable
1 Data Data.java Data.class
2 HasilECODB HasilECODB.java HasilECODB.class
3 Jarak Jarak.java Jarak.class
5.1.2 Implementasi Kelas View
Implementasi kelas view dapat dilihat pada tabel berikut ini : Tabel 5. 2 Implementasi Kelas View
No Use Case Antarmuka Nama Kelas
Boundary 1 Memilih data Gambar 4.3 preprocessing.class 2 Identifikasi outlier Gambar 4.4 hasil.class
3 Simpan hasil Gambar 4.4 hasil.class
38
Tabel 5. 3 Spesifikasi Detail Kelas Home.java
Id_Objek Jenis Teks Keterangan
lblogo Label logo.png Gambar logo
Universitas Sanata Dharma.
lbjudul Label SISTEM
IDENTIFIKASI OUTLIER
Judul sistem atau perangkat lunak yang dibangun.
lbjudul1 Label MENGGUNAKAN ALGORITMA ECODB
Judul sistem atau perangkat lunak yang dibangun.
sistem Button MASUK SISTEM Jika di click maka akan menuju halaman
preprocessing.
lbnama Label Angela Mediatrix Melly-135314074
Identitas pembuat sistem atau perangkat lunak.
lbfakultas Label Fakultas Sains dan Teknologi
Identitas fakultas pembuat sistem atau perangkat lunak.
lbtahun Label 2017 Tahun pembuatan
sistem atau perangkat lunak.
tentang Button TENTANG Jika di click maka akan menuju halaman tentang.
39
Implementasi antarmuka dari kelas home (halaman home) dapat dilihat pada gambar 5.1 berikut ini.
Spesifikasi detail dari kelas preprocessing dapat dilihat pada tabel 5.4 berikut ini.
Tabel 5. 4 Spesifikasi Detail Kelas Preprocessing.java
Id_Objek Jenis Teks Keterangan
lbdata Label Data Mendeksripsikan
lokasi file yang akan digunakan.
path TextField Lokasi file
40
yang akan digunakan.
pilihfile Button FILE Jika di click maka akan membuka direktori file yang akan digunakan.
tabelData Table Berisi data yang
akan digunakan. lbljmltetangga Label Jumlah Tetangga
Terdekat
Mendeksripsikan jumlah tetangga terdekat.
tetangga TextField Isi jumlah tetangga
terdekat.
lbjmloutlier Label Jumlah Outlier Mendeskrispiskan jumlah outlier.
n TextField Isi jumlah outlier.
identifikasi Button IDENTIFIKASI Jika di click maka akan menuju halaman hasil. lbjmldata Label Jumlah Data Mendeskrispsikan
jumlah dari dari file
yang dipilih.
jmlData TextField Isi jumlah data dari
file yang dipilih.
jmlAtribut TextField Isi jumlah kolom
dari file yang dipilih.
lbjmlatribut Label Jumlah Atribut Mendeskripsikan jumlah kolom dari
41
beranda Button BERANDA Jika di click maka akan menuju halaman home.
lbnama Label Angela Mediatrix Melly-135314074
Identitas pembuat sistem atau perangkat lunak. lbfakultas Label Fakultas Sains
dan Teknologi
Identitas fakultas pembuat sistem atau perangkat lunak.
lbtahun Label 2017 Tahun pembuatan
sistem atau perangkat lunak.
Implementasi antarmuka dari kelas preprocessing (halaman
preprocessing) dapat dilihat pada gambar 5.2 berikut ini.
Spesifikasi detail dari kelas hasil dapat dilihat pada tabel 5.5 berikut ini.
42
Tabel 5. 5 Spesifikasi Detail Kelas Hasil.java
Id_Objek Jenis Teks Keterangan
tabelHasil Table Berisi hasil
identfikasi outlier. simpan Button SIMPAN Jika di click maka
akan menyimpan hasill identifikasi
outlier dalam file
berekstensi .xls pada direktori komputer. lbjmltetngga Label Jumlah Tetangga
Terdekat
Mendeskripsikan jumlah tetangga terdekat.
tetangga TextField Isi jumlah tetangga terdekat.
lbjmloutlier Label Jumlah Outlier Mendeskripsikan jumlah outlier.
topN TextField Isi jumlah outlier.
lbhasil Label HASIL
IDENTIFIKASI OUTLIER
Judul tabel pada halaman hasil.
kembali Button KEMBALI Jika di click maka akan menuju halaman
preprocessing. beranda Button BERANDA Jika di click maka
akan menuju halaman home.
lbnama Label Angela Mediatrix Melly-135314074
43
lbfakultas Label Fakultas Sains dan Teknologi
Identitas fakultas pembuat sistem atau perangkat lunak.
lbtahun Label 2017 Tahun pembuatan
sistem atau perangkat lunak.
Implementasi antarmuka dari kelas hasil (halaman hasil) dapat dilihat pada gambar 5.3 berikut ini.
Spesifikasi detail dari kelas tentang dapat dilihat pada tabel 5.6 berikut ini.
Tabel 5. 6 Spesifikasi Detail Kelas Tentang.java
Id_Objek Jenis Teks Keterangan
beranda Button BERANDA Jika di click maka akan menuju halaman home.
44
lbtetang Label TENTANG PENULIS
Judul dari halaman tentang.
informasi TextArea Berisi deskripsi
mengenai pembuat sistem atau perangkat lunak.
lbnama Label Angela Mediatrix Melly-135314074
Identitas pembuat sistem atau perangkat lunak.
lbfakultas Label Fakultas Sains dan Teknologi
Identitas fakultas pembuat sistem atau perangkat lunak.
lbtahun Label 2017 Tahun pembuatan
sistem atau perangkat lunak.
Implementasi antarmuka dari kelas tentang (halaman tentang) dapat dilihat pada gambar 5.4 berikut ini.
45
Spesifikasi detail dari kelas bantuan dapat dilihat pada tabel 5.7 berikut ini.
Tabel 5. 7 Spesifikasi Detail Kelas Bantuan.java
Id_Objek Jenis Teks Keterangan
beranda Button BERANDA Jika di click maka akan menuju halaman home.
lbbantuan Label PANDUAN PENGGUNAAN SISTEM
Judul dari halaman bantuan.
informasi TextArea Berisi deskripsi cara menggunakan sistem atau perangkat lunak. lbnama Label Angela Mediatrix
Melly-135314074
Identitas pembuat sistem atau perangkat lunak.
lbfakultas Label Fakultas Sains dan Teknologi
Identitas fakultas pembuat sistem atau perangkat lunak.
lbtahun Label 2017 Tahun pembuatan
sistem atau perangkat lunak.
46 5.1.3 Implementasi Kelas Control
Implementasi kelas controller dapat dilihat pada tabel 5.8 berikut ini. Tabel 5. 8 Implementasi Kelas Controller
No Use Case Nama File Fisik Nama File Excecutable
1 Memilih Data 1. ControlExcel. java
2. DataModel. java
1. ExcelControl. class
2. DataModel. class 2 Mengidentifikasi
Outlier
1. ControlECODB. java
2. HasilECODB Model.java
1. ControlECODB. class
2. HasilECODB Model.java 3 Menyimpan
hasil identifikasi
1. ControlExcel. java
1. ControlExcel. class
47
outlier
5.2
Pengujian Perangkat Lunak
5.2.1 Pengujian Perangkat Lunak (Black Box) 5.2.1.1Rencana Pengujian Black Box
Pada tabel 5.9 dibawah ini akan dijelaskan rencana pengujian dengan menggunakan metode black box.
Tabel 5. 9 Rencana Pengujian Black Box
No Use Case Butir Uji Kasus Uji
1. Memilih data Pengujian memasukan data dari file berekstensi .xls
UC1-01
Pengujian memasukan data dari file berekstensi .doc
UC1-02
Pengujian memasukan data dari file berekstensi .txt
UC1-03
2. Identifikasi
outlier
menggunakan algoritma ECODB
Pengujian
melakukan proses identifikasi outlier
UC2-01
3. Menyimpan hasil identifikasi
outlier
Pengujian
menyimpan hasil identifikasi outlier
ke dalam file
48
berekstensi .xls Pengujian
menyimpan hasil identifikasi outlier
ke dalam file
berekstensi .doc
UC3-02
Pengujian
menyimpan hasil identifikasi outlier
ke dalam file berekstensi .txt
UC3-03
5.2.1.2Prosedur Pengujian Black Box dan Kasus Uji
Setelah menyusun rencana pengujian pada tabel 5.9, maka dilakukan pengujian serta kasus uji yang terlampir pada lampiran 8.
5.2.1.3Evaluasi Pengujian Black Box
49
5.2.2 Pengujian Perbandingan Hasil Pencarian Outlier Secara Manual dengan Hasil Pencarian Outlier Menggunakan Perangkat Lunak 5.2.2.1Pencarian Outlier Secara Manual
Pengujian pencarian outlier secara manual menggunakan data hasil UN, indeks integritas dan akreditasi Sekolah Menengah Atas jurusan IPA di kabupaten Kulonprogo, Daerah Istimewa Yogyakarta tahun 2015.
Proses pencarian outlier secara manual dilakukan dengan menggunakan Microsoft Excel. Dalam proses identifikasi outlier menggunakan jumlah tetangga terdekat sebesar 6 dan topN sebesar 6. Proses dan hasil dari pencarian
outlier secara manual dapat dilihat pada lampiran 9. 5.2.2.2Pencarian Outlier Menggunakan Perangkat Lunak
Pengujian pencarian outlier menggunakan perangkat lunak menggunakan data yang sama dengan penghitungan manual yaitu data hasil UN, indeks integritas dan akreditasi Sekolah Menengah Atas jurusan IPA di kabupaten Kulonprogo, Daerah Istimewa Yogyakarta tahun 2015.