BAB 2
LANDASAN TEORI
2.1 Peringkas Teks Otomatis
Peringkasan teks adalah proses untuk mengambil dan mengekstrak informasi penting dari sebuah teks sehingga menghasilkan teks yang lebih singkat dan mengandung poin-poin penting dari sumber. Sebuah sistem peringkas diberi masukan berupa teks, kemudian melakukan peringkasan, dan menghasilkan keluaran berupa teks yang lebih singkat dari teks aslinya. Pada peringkasan teks terdapat dua pendekatan yaitu, ekstraksi (shallower approaches) dan abstraksi (deeper approaches) (Mustaqhfiri, Abidin, & Kusumawati, 2011). Pendekatan ekstraksi adalah peringkasan yang memilih suatu paragraf atau kalimat penting dalam menginterpretasikan dokumen ke dalam sebuah bentuk sederhana. Sedangkan pendekatan abstraksi menghasilkan ringkasan yang bukan dari kumpulan kalimat penting tetapi menangkap hasil dari konsep utama pada teks dan merepresentasikannya menjadi sebuah kalimat baru (Pradnyana & Mogi, 2014). Berdasarkan jumlah sumbernya, peringkas teks otomatis dapat dibagi menjadi dua yaitu single document dan multi document (Mulyana et al., 2012). Single document merupakan sumber dokumen yang akan diekstraksi berupa dokumen tunggal sedangkan multi-document adalah dokumen yang akan diekstraksi terdiri dari beberapa dokumen.
2.2 Text Preprocessing
Text preprocessing adalah tahapan untuk mempersiapkan teks menjadi data
olah pada tahap berikutnya. Beberapa proses dari text preprocessing pada penelitian ini yaitu pemecahan kalimat, proses case folding, proses filtering, proses stemming, dan proses tokenizing kata. Berikut adalah penjelasan proses pada tahap text
preprocessing.
a. Pemecahan kalimat
Pemecahan kalimat merupakan langkah awal dari proses text preprocessing. Pada tahap ini, teks berita yang terdiri dari kumpulan paragraf akan dipecah menjadi kalimat agar dapat dihitung similarity antar kalimat pada tahapan proses nanti. Pemisahan kalimat tersebut dilakukan dengan bantuan tanda baca, seperti tanda titik (.), tanda seru (!), dan tanda tanya (?) (Pinandhita, 2013).
b. Case folding
Teks berita yang telah dipisah menjadi kalimat kemudian akan melalui proses
case folding. Case folding adalah tahapan proses mengubah semua teks menjadi
karakter dengan huruf kecil, serta menghilangkan karakter selain a-z. c. Filtering
Filtering adalah proses penghilangan stopword. Stopword adalah kata-kata
yang sering muncul (umum) dalam dokumen namun artinya tidak deskriptif dan tidak memiliki katerkaitan dengan tema tertentu. Beberapa contoh stopword dalam Bahasa Indonesia contohnya “di”, “oleh”, “pada”, dan sebagainya.
d. Stemming
Stemming merupakan proses mencari akar (root) kata tiap token kata yaitu
e. Tokenizing kata
Tokenizing kata adalah proses pemisahan string input berdasarkan setiap kata
yang menyusunnya. Kalimat pada teks akan dipisahkan menjadi kata-kata tunggal dengan memindai kalimat dengan pemisah (delimiter) white space seperti spasi, tab, dan newline.
2.3 Word Embedding
Pada tahun 2003, Bengio dkk. (Bengio et al., 2003) memperkenalkan istilah
word embedding. Word embedding adalah sebuah fungsi parameter yang
memetakan setiap kata ke dalam vektor berdimensi tinggi. Keunggulan word
embedding tidak membutuhkan anotasi, dapat langsung diturunkan dari korpus tak
teranotasi. Word embedding dapat dibuat langsung dari dataset yang dimiliki atau menggunakan pre-trained word embedding yang telah tersedia. Pre-trained word
embedding ini adalah word embedding yang telah dilatih menggunakan dataset
yang besar pada domain permasalahan tertentu yang dapat digunakan untuk menyelesaikan permasalahan lain yang serupa. Penggunaan word embedding ini harus disesuaikan dengan domain dari kasus yang dimiliki. Misalkan permasalahan pada domain biomedik tidak akan cocok menggunakan pretrained word embedding dari korpus berita atau Wikipedia.
2.4 One-hot Encoding
One-hot encoding merupakan salah satu cara merepresentasikan sebuah
kata atau kalimat di dalam sebuah dokumen teks. Pembentukan One-hot encoding yaitu dengan cara memberikan sebuah integer unik pada setiap kata dan kemudian mengubah integer ke-i menjadi sebuah binary vector (bernilai 0 atau 1) dengan
jumlah dimensi sebesar K (jumlah kata pada kamus kata). Semua vektor yang terbentuk akan bernilai 0, kecuali kata dengan indeks i, yaitu 1 (Chollet, 2017).
Gambar 2.1 Representasi Kata Dengan One-Hot Encoding
2.5 TF-IDF
TF-IDF adalah metode untuk memberikan bobot hubungan suatu kata (term) terhadap sebuah dokumen. Metode ini bekerja dengan menghitung frekuensi kemunculan kata dalam dokumen (Term Frequency) dan dibandingkan dengan
inverse frekuensi dokumen yang mengandung kata tersebut (Inverse Document Frequency). Frekuensi kemunculan kata di dalam dokumen menunjukkan seberapa
penting kata tersebut dalam dokumen. Selain itu, semakin besar nilai frekuensi kemunculan kata tersebut pada sebuah dokumen juga menunjukkan seberapa umum kata tersebut. Sehingga, hubungan antara sebuah kata dan sebuah dokumen akan tinggi jika frekuensi kata tersebut tinggi di dalam suatu dokumen dan kemunculan kata tersebut rendah dalam kumpulan dokumen (Term Frequency – Inverse
Document Frequency). Berikut merupakan penjabaran rumus untuk TF (Term Frequency):
𝑊𝑡𝑓𝑡,𝑑 = 1 + log10𝑡𝑓𝑡,𝑑 ...(2.1) Keterangan:
𝑊𝑡𝑓𝑡,𝑑 = log-term frequency weighting pada term ke t, dokumen ke d. 𝑡𝑓𝑡,𝑑 = nilai dari term frequency weighting pada term ke t, dokumen ke d.
Sedangkan untuk rumus IDF (Inverse Document Frequency) dapat dijabarkan sebagai berikut:
𝑖𝑑𝑓𝑡= log10(
𝑁 𝑑𝑓𝑡
) ...(2.2)
Keterangan:
𝑖𝑑𝑓𝑡 = nilai inverse document frequency pada term ke t.
N = jumlah keseluruhan kalimat pada dokumen yang ada pada teks. 𝑑𝑓𝑡 = nilai dari document frequency pada term ke t.
Berikut merupakan rumus TF-IDF (Term Frequency - Inverse Document
Frequency) dapat dijabarkan sebagai berikut:
𝑊𝑡,𝑑 = 𝑊𝑡𝑓𝑡,𝑑 𝑥 𝑖𝑑𝑓𝑡 ...(2.3)
Keterangan:
𝑊𝑡,𝑑 = nilai TF-IDF pada term ke t, dokumen ke d.
𝑊𝑡𝑓𝑡,𝑑 = log-term frequency weighting pada term ke t, dokumen ke d.
Berbeda dengan perhitungan menggunakan library sklearn.feature_extraction pada Python, bobot TF-IDF dihitung berdasarkan rumus
berikut:
𝑊𝑡,𝑑 = 𝑡𝑓𝑡,𝑑 𝑥 [ln (𝑁
𝑑𝑓𝑡) + 1]
...(2.4)
Hal ini disebabkan perhitungan log pada library TF-IDF sklearn menggunakan logaritma natural, yaitu dapat ditulis dengan eloga atau dengan kata lain logaritma dengan basis e dengan nilai e = 2.718281828459…. Selain itu, dalam TfidfVectorizer terdapat beberapa parameter untuk diatur, seperti smooth_idf dan
norm. Default parameter norm dan smooth_idf adalah True, jika parameter norm
diubah menjadi False maka perhitungan bobot adalah sebagai berikut:
𝑊𝑡,𝑑= 𝑡𝑓𝑡,𝑑 𝑥 log ( 𝑁 + 1 𝑑𝑓𝑡+ 1 ) + 1 𝑡𝑓𝑡,𝑑 𝑥 [ln (𝑁 + 1 𝑑𝑓𝑡+ 1) + 1] ...(2.5) Keterangan:
𝑊𝑡,𝑑 = nilai TF-IDF pada term ke t, dokumen ke d.
𝑡𝑓𝑡,𝑑 = nilai dari term frequency weighting pada term ke t, dokumen ke d. 2.6 FastText
FastText adalah library open-source yang dibuat oleh Facebook AI Research (FAIR) dan merupakan pengembangan lebih lanjut dari Word2Vec. FastText dapat digunakan untuk melakukan text representation dan text
classification (Fasttext.cc, 2021). Selain itu, FastText juga menyediakan model pre-trained untuk 157 bahasa yang telah dilatih berdasarkan common crawl dan
untuk semua kata, termasuk kata yang tidak berada pada word dictionary model. Hal ini dikarenakan FastText mempertimbangkan suku kata (subwords) dalam mencari vektor dari kata yang tidak berada pada word dictionary dan merepresentasikannya sebagai kumpulan karakter n-gram. Oleh karena itu, FastText dapat mempelajari prefix dan suffix dalam sebuah kata. Model FastText dapat menggunakan Continuous Bag-of-Word (CBOW) ataupun Skip-Gram untuk merepresentasikan kata, namun secara default FastText menggunakan Skip-Gram. Hal ini dikarenakan model Skip-Gram bekerja lebih baik dibandingkan Continuous
Bag-of-Word (CBOW) dalam subword information (Fasttext.cc, 2021).
Dalam representasi kata menggunakan model Skip-Gram, model akan dilatih menggunakan data training terlebih dahulu. Kata yang diambil dalam model
training adalah kata yang memiliki frekuensi kemunculan terbanyak (menggunakan
parameter minCount) dalam teks. Sebagai contoh, dimisalkan kalimat “I like natural language processing” sebagai data training. Training example pada kalimat tersebut dengan jumlah window_size bernilai 1 dan jumlah n-gram bernilai 3 adalah sebagai berikut
Tabel 2.1 Contoh Training Data Menggunakan FastText
Training example Context Words Target Words 1 (<i>, <na, nat, atu, tur, ura, ral, al>) Like 2 (<li, lik, ike, ke>, <la, lan, ang, ngu,
gua, uag, age, ge>
Natural
3 dan sebagainya
Tujuan dari proses training ini adalah untuk melatih model memprediksi kata di sekitar target words (context words) jika diberikan target words. Dalam proses training ini, model akan belajar memahami konteks dari kata tersebut agar dapat menebak context words. Berbeda dengan proses training, pada proses testing
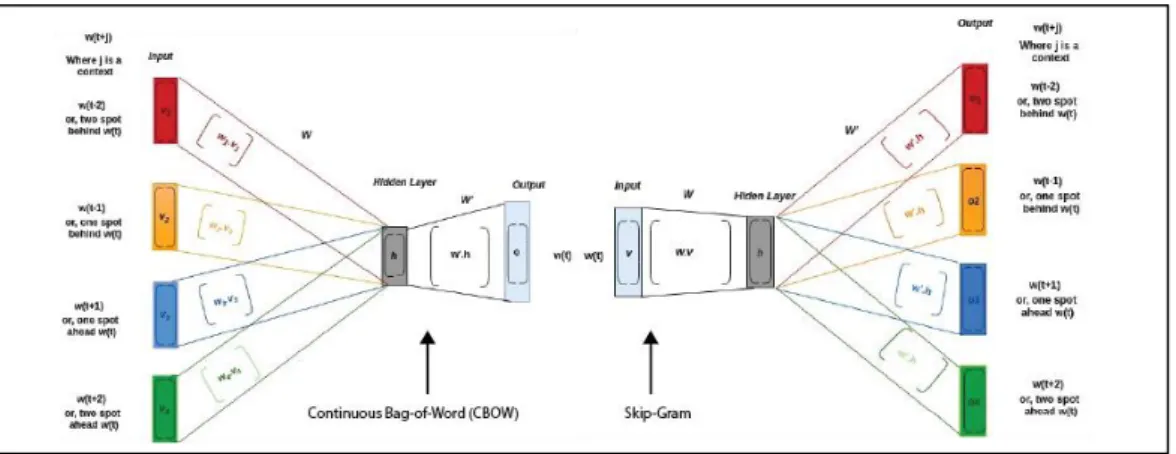
model akan diberikan sebuah kata untuk dicari nilai representasinya. Dalam mencari nilai representasi suatu kata, akan dilakukan proses prediksi menggunakan model yang sudah dibentuk dan dilatih. Hasil dari representasi kata berupa nilai prediksi pada hidden layer sehingga dimensinya sebesar jumlah hidden neurons pada hidden layer. Hal ini dikarenakan pada fungsi model untuk merepresentasi kata, tidak perlu sampai memprediksi context words sebagai output model. Gambar 2.2 menunjukkan perbedaan arsitektur Continuous Bag-of-Word (CBOW) dan Skip-Gram.
Gambar 2.2 Perbedaan Arsitektur FastText CBOW dan Skip-Gram
Dalam mencari kata yang tidak berada dalam word dictionary model (dengan catatan kata tersebut merupakan variasi dari data latih), FastText bekerja dengan memecah kata tersebut menjadi n-gram data input. Kemudian mencari irisan subwords serupa pada word dictionary dengan asumsi jika sebagian besar irisan subwords sama, vektor yang dihasilkan juga serupa. Sebagai contoh, kata “memakan” dan “makan” akan menghasilkan vektor yang serupa.
2.7 Algoritme TextRank
Algoritme TextRank merupakan algoritme yang bekerja dengan memberikan peringkat pada graf (Mihalcea & Tarau, 2004). Implementasi
algoritme berbasis graf pada pemrosesan teks dapat dijabarkan menjadi 4 tahapan yaitu:
a. Mengidentifikasi text unit yang paling sesuai untuk dijadikan simpul pada graf. b. Mengidentifikasi relasi yang berhubungan dengan text unit dan menggunakan relasi ini untuk menarik tepi antara simpul dalam grafik. Pemberian tepi dapat berbobot atau tidak, berarah atau tidak berarah.
c. Mengintegrasi graph based ranking algorithm sehingga tercapainya konvergensi.
d. Menyortir simpul berdasarkan skor akhir dengan menggunakan nilai pada setiap simpul untuk ranking decision.
Berdasarkan penelitian sebelumnya, algoritme TextRank efektif untuk diaplikasikan pada peringkas teks otomatis. Menurut Anwar (2015), TextRank memiliki beberapa keunggulan di antaranya:
a. Unsupervised, atau dengan kata lain TextRank dapat bekerja tanpa membutuhkan proses pelabelan untuk memproses data sesungguhnya.
b. Language independent, yang berarti TextRank tidak bergantung pada bahasa tertentu atau pemahaman tentang suatu bahasa seperti grammar. Hal ini karena TextRank bekerja hanya menggunakan kata-kata dalam teks.
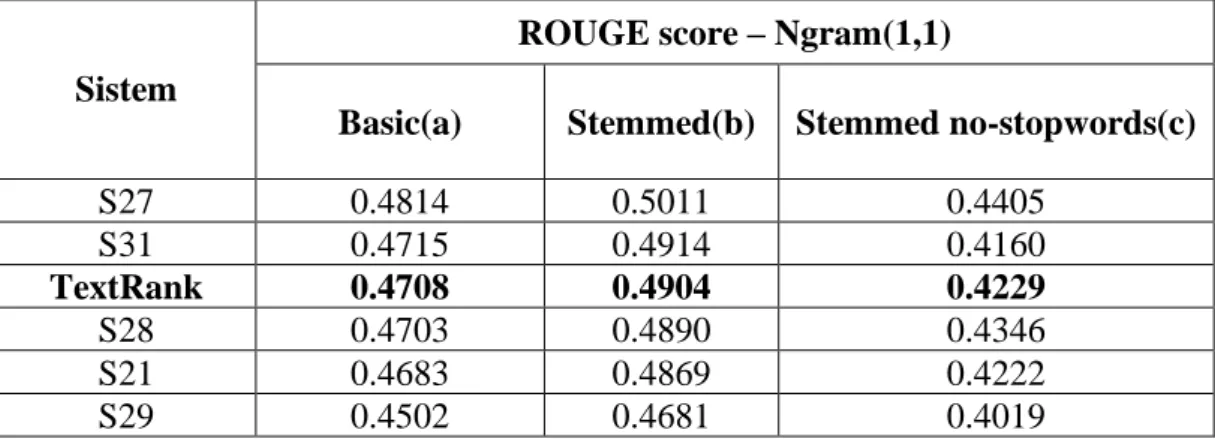
Hasil evaluasi peringkas teks menggunakan algoritme TextRank menduduki posisi 5 besar dari hasil penilaian menggunakan DUC (Document Understanding
Tabel 2.2 Hasil Evaluasi Algoritme TextRank Dengan Evaluasi ROUGE
Sistem
ROUGE score – Ngram(1,1)
Basic(a) Stemmed(b) Stemmed no-stopwords(c)
S27 0.4814 0.5011 0.4405 S31 0.4715 0.4914 0.4160 TextRank 0.4708 0.4904 0.4229 S28 0.4703 0.4890 0.4346 S21 0.4683 0.4869 0.4222 S29 0.4502 0.4681 0.4019
Sedangkan untuk hasil evaluasi Algoritme TextRank dengan menggunakan evaluasi co-selection berupa nilai precision, recall, dan f-measure pada penelitian Kanitha et al. (2018), diperoleh nilai evaluasi sebagai berikut
Tabel 2.3 Hasil Evaluasi Algoritme TextRank Dengan Evaluasi Co-Selection
Artikel Precision Recall F-measure
1 0.40 0.50 0.44 2 0.40 0.80 0.53 3 0.47 0.58 0.52 4 0.60 0.60 0.60 5 0.56 0.33 0.42 6 0.63 0.54 0.58 Rata-Rata 0.51 0.558 0.515
Terdapat dua jenis pengelolahan bahasa dalam TextRank, yaitu TextRank
for keyword extraction (ekstraksi kata kunci) dan TextRank for sentence extraction
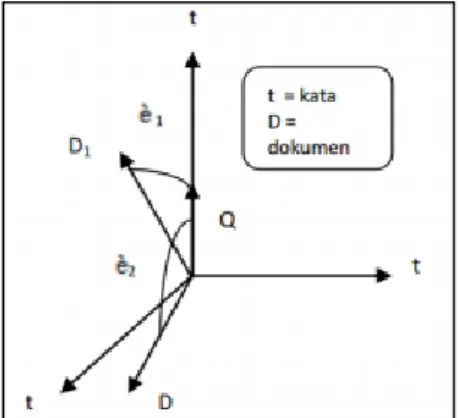
(ekstraksi kalimat). Pada TextRank for sentence extraction akan dibangun sebuah graf yang berisi hubungan antar kalimat dalam dokumen. Vertex di dalam graf ini direpresentasikan sebagai unit satuan yang akan diberikan peringkat. Vertex ini mempunyai similiarity yang dihubungkan oleh edges. Jenis similiarty yang digunakan adalah yang sering digunakan pada Natural Language Processing (NLP) yaitu cosine similarity (McKeown, Kathleen, dan Nenkova, Ani, 2012). Nilai relevansi pada cosine similarity di dapat dengan mengukur kesamaan antara 2
vektor. Nilai relevansi memiliki rentang antara 0 dan 1, di mana nilai 1 menunjukkan tingkat relevansi yang tinggi. Berikut merupakan penjabaran rumus dari cosine similarity (Grossman, 1998):
Gambar 2.3 Cosine Similarity
𝐶𝑂𝑆(𝑋, 𝑌) = ∑𝑖𝑋𝑖. 𝑌𝑖 √∑𝑖(𝑋𝑖)2. √∑𝑖(𝑌𝑖)2
...(2.6)
Keterangan:
𝑖 = term dalam kalimat 𝑋 = kalimat 1
Y = kalimat 2
𝑋𝑖 = bobot term dalam kalimat 1 𝑌𝑖 = bobot term dalam kalimat 2
TextRank sendiri merupakan rumus yang berasal dari metode PageRank.
Rumus pada metode PageRank ini telah diubah/dimodifikasi untuk kebutuhan meringkas suatu dokumen. Rumus dari PageRank adalah sebagai berikut (Mihalcea, R., & Tarau, P., 2004):
𝑆(𝑉𝑖) = (1 − 𝑑) + 𝑑 ∗ ∑ 𝑊𝑗𝑖 ∑𝑣𝑘 ∈ 𝑜𝑢𝑡(𝑉𝑗)𝑊𝑗𝑘 𝑆(𝑉𝑗) 𝑗 ∈ ln(𝑉𝑖) ...(2.7) Keterangan:
S = Skor dari setiap sentence 𝑉𝑖 = Vertex Input (dari kalimat asal) 𝑉𝑗 = Vertex Output (ke kalimat tujuan) 𝑊𝑗𝑖 = bobot dari input ke output
𝑊𝑗𝑘 = bobot dari row tersebut
d = damping factor yang nilainya antara 0 dan 1, biasanya 0.85.
Faktor d dapat diatur antara 0 dan 1 untuk menentukan probabilitas suatu
vertex pindah ke random vertex lainnya. Pada umumnya faktor d bernilai 0,85.
Iterasi akan dilakukan dengan menghitung selisih dari value sebelumnya terhadap
value sekarang sampai lebih kecil dari threshold yaitu 0,0001 dan jika belum lebih
kecil dari 0,0001 maka iterasi akan dilanjutkan (Brin dan Page, 1998). Setelah dijalankan terus menerus, akan menghasilkan skor untuk menentukan tingkat kepentingan suatu vertex di graph tersebut.
2.8 Metrik Evaluasi
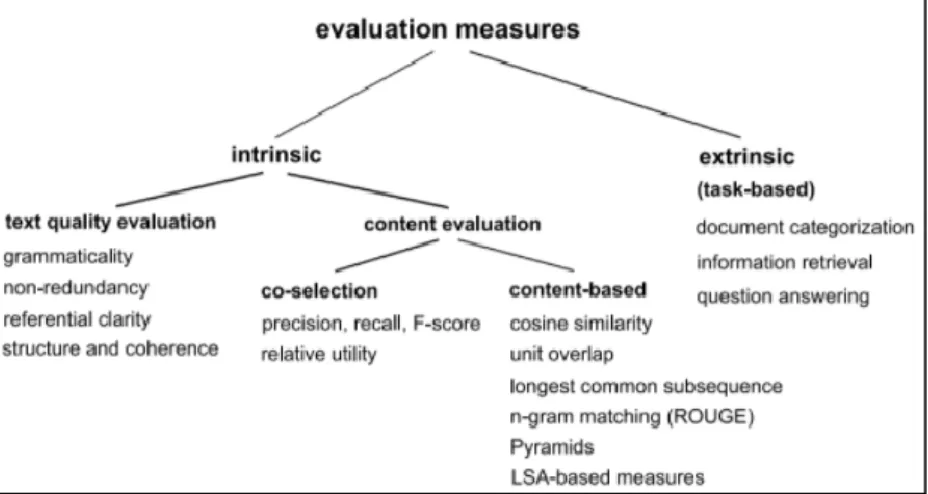
Berdasarkan pemaparan Josef (2009), proses evaluasi hasil text
summarization dapat diklasifikasikan seperti Gambar 2.4.
Evaluasi pada peringkas teks sering kali dilakukan dengan membandingkan hasil sistem dan pakar. Pendekatan evaluasi dapat dilakukan secara intriksik dan ekstrinsik (task-based method). Pendekatan secara intrinsik bekerja dengan membandingkan hasil sistem dan hasil ringkasan ideal pakar. Untuk peringkasan teks secara ekstraktif evaluasi konten dari ringkasan dapat dilakukan dengan menggunakan metode co-selection dan untuk peringkasan teks secara abstraktif dapat dilakukan dengan menggunakan metode content-based. Metode co-selection bekerja dengan mencari tahu berapa banyak kalimat ideal yang terkanding dalam ringkasan. Sedangkan metode content-based bekerja dengan membandingkan kata-kata ideal pakar pada kalimat ringkasan sistem. Di sisi lain, pendekata-katan ekstraktif bekerja dengan mengukur kinerja menggunakan ringkasan untuk tujuan tertentu.
Peneitian ini menghasilkan ringkasan secara ekstraktif, oleh sebab itu akan digunakan pendekatan intrinsik co-selection untuk mengevaluasi hasil ringkasan. Evaluasi dilakukan dengan menggunakan tiga parameter yaitu precision, recall, dan F-measure. Proses uji coba dan evaluasi terhadap sistem dapat dilakukan dengan membandingkan hasil ringkasan otomatis dari sistem dengan ringkasan manual. Perbandingan ringkasan manual dengan hasil ringkasan pada sistem dapat dilakukan dengan rumus berikut.
𝑃 =|𝑅
𝑀∩ 𝑅𝐻|
|𝑅𝑀|
...(2.8)
Precision merupakan jumlah kalimat yang muncul pada ringkasan manual
dan ringkasan sistem dibagi dengan jumlah kalimat yang muncul pada ringkasan sistem (Josef Steinberger, 2009). Di mana untuk sebuah dokumen 𝐷 yang terdiri dari sejumlah 𝑛 kalimat (𝑠1, … , 𝑠𝑛), dan 𝑠𝑖 ∈ 𝐷. Hasil precision (𝑃) dihitung
berdasarkan nilai ringkasan dari mesin, 𝑅𝑀, di mana 𝑅𝑀 ⊆ 𝐷 dan hasil ringkasan dari manusia, 𝑅𝐻, di mana 𝑅𝐻 ⊆ 𝐷.
𝑅 =|𝑅
𝑀∩ 𝑅𝐻|
|𝑅𝐻|
...(2.9)
Recall merupakan jumlah kalimat yang muncul pada ringkasan manual dan
ringkasan sistem dibagi dengan jumlah kalimat yang muncul pada ringkasan manual (Josef Steinberger, 2009). Di mana untuk sebuah dokumen 𝐷 yang terdiri dari sejumlah 𝑛 kalimat (𝑠1, … , 𝑠𝑛), dan 𝑠𝑖 ∈ 𝐷. Hasil recall (𝑅) dihitung
berdasarkan nilai ringkasan dari manusia, 𝑅𝐻, di mana 𝑅𝐻 ⊆ 𝐷 dan hasil ringkasan
dari mesin, 𝑅𝑀, di mana 𝑅𝑀 ⊆ 𝐷.
𝐹1 = 2 ∗ 𝑅 ∗ 𝑃 (𝑅 + 𝑃)
...(2.10)
F-measure (F1) merupakan hubungan antara recall dan precision yang
mempresentasikan akurasi sistem. Dengan kata lain, F-measure merupakan nilai yang diperoleh dari gabungan perhitungan precision dan recall (Josef Steinberger, 2009).