MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011
1
IMPLEMENTASI DETEKSI PENJIPLAKAN DENGAN ALGORITMA
WINNOWING PADA DOKUMEN TERKELOMPOK
I Wayan Surya Priantara 1, Diana Purwitasari2, Umi Laili Yuhana3 Teknik Informatika, Fakultas Teknologi Informasi, ITS
email : [email protected], [email protected], [email protected]
Abstract— Penjiplakan merupakan masalah yang
semakin berkembang terutama dalam bidang pendidikan. Banyak karya tulis yang sebagian isinya dibuat dengan menjiplak dari karya orang lain. Saat ini sudah terdapat sistem yang dapat mendeteksi penjiplakan antar dokumen. Pada sistem tersebut mampu melakukan pengecekan penjiplakan secara one-to-many atau many-to-many. Namun, pada sistem tersebut membandingkan satu persatu dokumen sehingga terdapat kemungkinan dokumen yang dibandingkan tidak memiliki kesamaan topik. Sehingga diperlukan fungsi yang dapat mengelompokan dokumen dan mendeteksi penjiplakan pada tiap kelompok.
Pada tugas akhir ini dibuat aplikasi yang mampu mengelompokan dokumen secara partisi dan mendeteksi penjiplakan pada tiap kelompok. Dalam melakukan pengelompokan dokumen dipergunakan algoritma K-means++. Algoritma K-means++ memerlukan masukan jumlah kelompok yang seharusnya terbentuk. Pada aplikasi ini dapat memperoleh rekomendasi jumlah kelompok yang sebaiknya terbentuk dengan algoritma Hartigan Index. Dalam melakukan pendeteksian penjiplakan dengan algoritma Winnowing. Algoritma ini berfungsi untuk melakukan proses document fingerprinting, yang mengubah teks menjadi sekumpulan nilai-nilai hash.
Kata kunci : Deteksi Plagiat, Winnowing, K-means++. Hartigan Index.
I. PENDAHULUAN
Pesatnya pekembangan internet menyebabkan semakin banyaknya informasi yang tersedia. Hal ini memudahkan seseorang dalam melakukan penjiplakan suatu karya. Penjiplakan menurut Kamus Besar Bahasa Indonesia (KBBI) berarti menggambar atau menulis garis-garis gambaran atau tulisan yang telah tersedia (dengan menempelkan kertas kosong pada gambar atau tulisan yang akan ditiru), mencontoh atau meniru tulisan atau pekerjaan orang lain, mencuri karangan orang lain dan mengakui sebagai karangan sendiri, mengutip karangan orang lain tanpa seizin penulisnya[1].
Dalam bidang pendidikan kegiatan ini sering dilakukan oleh para pelajar dalam pembuatan tugas seperti tugas sekolah/kuliah dan pembuatan laporan. Di sisi pengajar,
kegiatan penjiplakan ini sangat menyusahkan dalam hal evaluasi dan penilaian, walau sudah ada sanksi yang tegas jika ada seorang pelajar melakukan penjiplakan. Kegiatan penjiplakan susah dideteksi bila dokumen tugas yang diperiksa berjumlah sangat banyak dan seorang pengajar mengajar lebih dari satu mata pelajaran. Oleh karena itu, diperlukan suatu aplikasi yang digunakan untuk mendeteksi penjiplakan pada suatu dokumen.
Kegiatan deteksi penjiplakan ini dilakukan untuk mengetahui tingkat presentase penjiplakan sebuah dokumen pada dokumen lain. Sehingga, dapat diketahui apakah seseorang telah melakukan penjiplakan pada suatu dokumen. Selain itu dapat memudahkan pekerjaan seorang pengajar dalam hal mengevaluasi tugas-tugas yang berbentuk dokumen.
II. RISET TERKAIT
Saat ini sudah terdapat sistem yang mampu mendeteksi penjiplakan pada beberapa dokumen, untuk membantu pengajar menyelesaikan pekerjaannya. Pada sistem ini mampu melakukan pengecekan yang bersifat one to many hingga many to many, sehingga dapat digunakan mendeteksi penjiplakan pada dokumen-dokumen yang berjumlah banyak[2].
Namun, pada sistem tersebut memiliki waktu komputasi yang cukup lama ketika melakukan pengecekan penjiplakan pada dokumen yang berjumlah banyak. Hal ini di karenakan sistem tersebut membandingkan satu persatu dari dokumen yang ada. Ada kemungkinan bahwa sebuah dokumen dibandingkan dengan dokumen lain yang memiliki perbedaan topik, hal ini merupakan kegiatan yang sia-sia karena tingkat presentase penjiplakan antara kedua dokumen tersebut sangat kecil bahkan 0%. Hal ini pula dapat menyebabkan waktu proses akan menjadi lama.
Oleh karena itu, diperlukan sebuah sistem yang dapat mengelompokan secara otomatis dokumen-dokumen yang akan dilakukan deteksi penjiplakan. Dokumen-dokumen dikelompokan berdasarkan topik-topik bahasan yang sama atau kalimat-kalimat umum yang menjadi ciri. Diharapkan pengelompokan secara otomatis dokumen-dokumen ini menyebabkan waktu proses dalam pengecekan penjiplakan menjadi lebih singkat.
Saat ini sudah banyak penelitian dalam bidang deteksi penjiplakan. salah satunya adalah sebuah alat yang diberi
MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011
2 nama siff. Siff digunakan untuk menemukan semua file yang mirip pada file sistem yang besar. Pada aplikasi ini terdapat dua mode yaitu all-against-all dan one-against-all[3].
III. DETEKSI KALIMAT SAMA SEBAGAI INDIKASI PENJIPLAKAN
Penjiplakan mempunyai beberapa tipe seperti[4] : 1. Word for word plagiarism
Menyalin setiap kata secara lansung tanpa diubah sedikitpun.
2. Plagirism of authorship
Mengakui hasil karya orang lain sebagai hasil karya sendiri dengan cara mencatumkan nama sendiri menggantikan nama pengarang sebenarnya.
3. Plagiarism of ideas
Mengakui hasil pemikiran atau ide orang lain sebagai pemikirin diri sendiri
4. Plagiarism of sources
Jika seorang penulis menggunakan kutipan dari penulis tanpa mencantumkan narasumbernya.
Untuk melakukan pendeteksian penjiplakan terdapat kebutuhan mendasar yang harus dipenuhi oleh suatu algoritma penjiplakan seperti[5]:
1. Whitespace Insensitivity, yang berarti dalam melakukan pencocokan terhadap file teks seharusnya tidak terpengaruh oleh spasi, jenis huruf (kapital atau normal), tanda baca dan sebagainya.
2. Noise Surpression, yang berarti menghindari penemuan kecocokan dengan panjang kata yang terlalu kecil atau kurang relevan, misal: ‘the’. Panjang kata yang ditengarai merupakan penjiplakan harus cukup untuk membuktikan bahwa kata-kata tersebut telah dijiplak dan bukan merupakan kata yang umum digunakan. 3. Position Independence, yang berarti penemuan
kecocokan / kesamaan tidak harus bergantung pada posisi kata-kata. Walau tidak dalam berada posisi yang sama pencocokan juga harus dilakukan.
Dalam melakukan pendeteksi penjiplakan terdapat tiga metode yaitu[6] :
1. Perbandingan Teks Lengkap
Metode ini diterapkan dengan membandingkan semua isi dokumen. Pendekatan ini membutuhkan waktu yang lama tetapi cukup efektif.
2. Dokumen Fingerprint
Dokumen fingerprint merupakan metode yang digunakan untuk mendeteksi keakuratan kesamaan antar dokumen. Prinsip kerja dari metode dokumen fingerprint ini dengan menggunakan teknik hashing. Teknik hashing
adalah sebuah fungsi yang menkonversi setiap string menjadi bilangan.
3. Kesamaan Kata Kunci
Prinsip dari metode kesamaan kata kunci adalah mencari kata kunci dari dokumen dan kemudian dibandingkan dengan kata kunci pada dokumen lain.
Sebuah karya tulis dikatakan telah menjiplak karya tulis lain apabila memiliki tingkat kesamaan yang melebihi batas toleransi tertentu yang telah ditentukan.
Pada aplikasi ini melakukan pendeteksian penjiplakan dengan tipe word for word plagiarism pada sebuah karya tulisan. Dalam melakukan pendeteksian dilakukan dengan metode dokumen fingerprint. Algoritma yang digunakan adalah algoritma Winnowing, dimana algoritma ini dapat memenuhi kebutuhan dasar dalam penjiplakan.
IV. ALGORITMA WINNOWING UNTUK DETEKSI KALIMAT SAMA
Algoritma Winnowing merupakan algoritma yang digunakan dalam deteksi penjiplakan. input dari algoritma ini adalah dokumen teks yang diproses sehingga menghasilkan output berupa kumpulan nilai-nilai hash, nilai hash merupakan nilai numerik yang terbentuk dari perhitungan ASCII tiap karakter . Kumpulan-kumpulan nilai hash tersebut selanjutnya disebut fingerprint. Fingerprint inilah yang digunakan dalam deteksi penjiplakan[5].
Langkah awal dalam penerapan algoritma Winnowing adalah membuang karakter-karakter dari isi dokumen yang tidak relevan misal tanda baca spasi dan simbol lain. Sebagai contoh
Langkah kedua isi dokumen yang telah dilakukan pembersihan selanjutnya dilakkukan pembentukan rangkaian gram, dimana n =5.
the classic problem in machine learning
theclassicprobleminmachinelearning
theclassicprobleminmachinelearning
thecl hecla eclas class lassi assic ssicp sicpr icpro cprob probl roble oblem blemi lemin eminm minma inmac nmach machi achin chine hinel inele nelea elear learn earni arnin rning
MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011
3 Langkah ketiga dari rangkaian gram yang telah terbentuk dibentuk nilai hash dengan nilai ASCII tiap karakter. Pembentukan nilai hash menggunakan persamaan rolling hash. Persamaan rolling hash ditunujukan pada Persamaan (1) :
(1)
Keterangan :
c : nilai ASCII karakter b : basis (bilangan prima) k : banyak karakter
Keuntungan dari menggunakan rolling hash adalah untuk mendapatkan nilai hash selanjutnya dapat
dengan cara:
(2)
Langkah keempat nilai-nilai hash yang telah terbentuk dibentuk window-window. Dari window-window yang telah terbentuk dilakukan pemilihan nilai hash terkecil pada tiap window untuk dijadikan fingerprint tiap dokumen. [13518 12463 12232 12268] [12463 12232 12268 12852] [12232 12268 12852 12411] [12268 12852 12411 13774] [12852 12411 13774 13491] [12411 13774 13491 12639] [13774 13491 12639 12500] [13491 12639 12500 13551] [12639 12500 13551 13538] [12500 13551 13538 13021] [13551 13538 13021 12195] [13538 13021 12195 12881] [13021 12195 12881 12508] [12195 12881 12508 13078] [12881 12508 13078 12846] [12508 13078 12846 13127] [13078 12846 13127 12756] [12846 13127 12756 11891] [13127 12756 11891 12203] [12756 11891 12203 12660] [11891 12203 12660 12809] [12203 12660 12809 13009] [12660 12809 13009 12411] [12809 13009 12411 12800] [13009 12411 12800 12261] [12411 12800 12261 12350] [12800 12261 12350 13582]
Maka fingerprint yang dihasilkan : 12232 12268 12411 12500 12195 12508 12756 11891 12203 12411 12261
Nilai-nilai fingerprint inilah yang digunakan untuk menemukan tingkat presentase kesamaan sebuah dokumen dengan dokumen lain. Untuk mendapatkan tingkat presentase kesamaan sebuah dokumen dengan dokumen lain dapat menggunakan Persamaan Jaccard Coefficient yang ditunjukan pada Persamaan (3)
Similaritas(di,dj) = (3)
V. ALGORITMA K-MEANS++ UNTUK PENGKLASTERAN
Algoritma K-means++ merupakan algoritma pengelompokan secara partisi yang merupakan pengembangan dari algoritma K-means. K-Means merupakan salah satu metode pengklasteran dengan pendekatan partisi yang mempartisi data yang ada ke dalam bentuk satu atau lebih kelompok. Metode ini mempartisi data ke dalam kelompok sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu kelompok dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok yang lain.
Dari dasar algoritma K-means dilakukan penyesuaian untuk data yang berupa dokumen-dokumen adalah sebagai berikut :
1. Menentukan nilai k sebagai jumlah kelompok yang ingin dibentuk.
2. Menentukan centroid (titik pusat klaster) awal secara acak sebanyak k. Centroid merupakan kumpulan dari nilai-nilai hash. Pada awalnya nilai-nilai centroid sama dengan nilai-nilai fingerprint dari dokumen yang dipilih.
3. Menghitung tingkat kesamaan setiap dokumen ke masing-masing centroid menggunakan Persamaan (3)
4. Mengelompokkan setiap dokumen berdasarkan tingkat kesamaan terbesar antara dokumen dengan centroid-nya.
5. Menentukan nilai – nilai hash sebagai centroid baru dengan Persamaan (4):
centroidᵧ(C) = f(Cᵧ, h) | h ∈ ⊎ W(di), (hf(h,C))/n ≥ γ (4)
dimana hf(h,C) merupakan banyaknya sebuah hash dalam gabungan seluruh dokumen pada satu klaster (C), dan f(Cᵧ, h) merupakan nilai-nilai yang terbentuk dari nilai hash yang berjumlah minimal (((hf(h,C))/n ))⁄γ. Nilai γ merupakan masukan dari pengguna.
6. Kembali ke langkah 3 jika nilai – nilai hash pada centroid baru dengan centroid lama tidak sama. Namun, algoritma K-means ini memiliki kelemahan yaitu memiliki kemungkinan waktu proses yang cukup besar. thecl hecla eclas class
lassi assic ssicp sicpr icpro cprob probl roble oblem blemi lemin eminm minma inmac nmach machi achin chine hinel inele nelea elear learn earni arnin rning 13518 12463 12232 12268 12852 12411 13774 13491 12639 12500 13551 13538 13021 12195 12881 12508 13078 12846 13127 12756 11891 12203 12660 12809 13009 12411 12800 12261 12350 13582
MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011
4 Hal ini disebabkan pada pemilihan awal centroid yang bersifat acak yang setiap data mempunyai kemungkinan terpilih sama besar. Oleh karena itu digunakan algoritma K-means++ untuk menutup kekurangan tersebut[8]. Dasar algoritma K-means++ adalah :
1. Menentukan satu centroid awal pada seluruh data dokumen secara acak dengan distribusi uniform. 2. Untuk setiap data dokumen d, hitung D(d),
ketidakmiripan (dissimilar) antara data dokumen dan centroid terdekat yang telah dipilih. Untuk mencari nilai ketidakmiripan dapat dengan menggunakan Persamaan (5)
Dissimilar(di, dc) = 1 -
(4)
Nilai ketidakmiripan didapatkan dari 1 dikurangi dengan tingkat kemiripan. Nilai kemiripan didapatkan dari Persamaan (3).
3. Tambahkan satu centroid lagi dari semua data yang belum terpilih sebagai centroid, menggunakan weighted probability distribution dimana data dokumen yang dipilih dengan probabilitas D(d2).
4. Ulangi langkah 2 dan 3 hingga sejumlah k centroid telah dipilih
5. Lakukan pengelompokan algoritma K-means. VI. PENENTUAN JUMLAH KELOMPOK YANG
OPTIMAL
Dalam pengelompokan diperlukan jumlah kelompok yang akan dibentuk. Jumlah kelompok yang akan dibentuk berasal dari masukan pengguna. Masukan dari pengguna mempunyai kemungkinan tidak sesuai dengan jumlah kelompok yang sebaiknya terbentuk dari data-data dokumen yang ada. Untuk itu diperlukan algoritma dalam menentukan jumlah kelompok yang sebaiknya terbentuk dari data-data yang ada seperti Rule of Thumb dan Hartigan Index.
V.1 RULE OF THUMB
Rule of Thumb merupakan algoritma penentuan jumlah kelompok yang sebaiknya terbentuk dalam pengklasteran berdasarkan banyaknya data yang tersedia[9]. Persamaan Rule of Thumb adalah :
5) dimana k merupakan jumlah kelompok yang harus terbentuk dan n adalah banyaknya data yang akan dilakukan pengklasteran.
V.2 HARTIGAN INDEX
Hartigan index merupakan salah satu metode statistik untuk menguji perubahan relatif dari nilai perubahan suatu kelompok. Metode ini dapat digunakan untuk mengetahui jumlah kelompok yang sesuai dari perbandingan tingkat error suatu kelompok dengan kelompok satu setelahnya. Untuk mencari nilai Hartigan Index dari suatu kelompok yang terbentuk dengan Persamaan (7) : H(k) = (n – k – 1) 6) Keterangan k : jumlah kelompok n : banyaknya data err(k) = 7) dimana
d = ketidakmiripan antara data dengan centroid terdekat Jumlah kelompok yang seharusnya terbentuk adalah k dari nilai h(k) yang paling maksimal[10].
VII. IMPLEMENTASI DETEKSI PENJIPLAKAN Perangkat lunak yang dibangun adalah sistem pengelompokan dokumen-dokumen serta pendeteksian penjiplakan pada tiap kelompok. Dalam implementasinya perangkat lunak ini menggunakan algoritma K-means++ untuk melakukan pengelompokan secara partisi dan algoritma Winnowing untuk membantu mencari kesamaan antara file satu dengan yang lain.
Aplikasi Pembacaan Dokumen Algoritma Winnowing Pembentukan Fingerprint Pengelompokan PenentuanJumlah Kelompok Penentuan Jumlah Kelompok Pengelompokan dengan K-means++ Penentuan Kelompok pada Dokumen Baru Pengecekan Tingkat Kesamaan Dokumen, Fingerprint, Centroid, Hasil Similar String teks Fingerprint
k
Gambar 1 Arsitektur Aplikasi
Pada gambar diatas dapat diketahui bahwa aplikasi ini terdiri dari :
Pembacaan Dokumen
Bertugas mengekstrak konten / isi dari file yang ingin diperiksa menjadi sebuah string.
Pembentukan Fingerprint
Bertugas memproses string yang merupakan hasil ekstraksi dari pembacaan dokumen menjadi fingerprint dari file yang berupa nilai-nilai hash. Penentuan Kelompok
MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011
5 Bertugas menentukan kelompok mana berdasarkan isi dari dokumen.
Penentuan Jumlah Kelompok
Bertugas menentukan jumlah kelompok yang seharusnya terbentuk. Dalam menentukan jumlah dokumen dapat secara manual atau rekomendasi dari aplikasi. Jumlah kelompok yang didapatkan dari rekomendasi menggunakan algoritma Rule of Thumb dan Hartigan Index.
Pengelompokan Dokumen
Bertugas melakukan pengelompokan sejumlah dokumen. Jumlah kelompok yang terbentuk bisa dari masukan pengguna (manual) atau nilai dari Rule of Thumb dan Hartigan Index.
Pengecekan Tingkat Kesamaan
Bertugas melakukan pengecekan tingkat kesamaan dengan membandingkan nilai fingerprint antardokumen dan menampikan hasil tingkat kemiripan ke pengguna.
Pada antarmuka terdapat beberapa fungsi-fungsi yang dapat dilakukan sehingga pengguna dapat dengan mudah menggunakannya. Gambar antarmuka ditunjukan pada Gambar 2.
Gambar 2 Antarmuka Aplikasi
Pada bagian daftar dokumen menampilkan semua nama-nama dokumen yang sudah ada pada database. Selain itu menampilkan tanggal upload dari tiap dokumen dan tingkat otentik isi dari tiap dokumen. Tampilan antarmuka daftar dokumen dapat dilihat pada Gambar 3.
Gambar 3 Antarmuka Daftar Dokumen
Tingkat otentik sebuah dokumen merupakan tingkat orisinil atau keaslian dari isi sebuah dokumen. Tingkat otentik sebuah dokumen didapatkan dengan mencari jumlah nilai hash yang tidak dimiliki oleh dokumen lain.
Tingkat otentik ini bertujuan untuk mengetahui tingkat keaslian atau original dari sebuah dokumen.
Pada bagian daftar plagiat menampilkan daftar-daftar tingkat kemiripan antar dua dokumen. Tampilan antarmuka daftar plagiat dapat dilihat pada Gambar 4.
Gambar 4 Antarmuka Daftar Plagiat
Pada daftar plagiat dapat menampilkan laporan isi dokumen yang memiliki kesamaan kalimat dengan dokumen lain. Agar mudah dalam melihat kalimat yang sama, maka kalimat sama tersebut diberi tanda. Tampilan laporan kesamaan kalimat pada sebuah dokumen dapat dilihat pada Gambar 5.
Gambar 5 Antarmuka Laporan Kalimat Sama
VIII. UJI COBA DAN EVALUASI
Pada uji coba ini dibedakan menjadi tiga bagian yaitu penentuan jumlah kelompok terbaik, penentuan kelompok untuk dokumen baru dan perbandingan waktu deteksi plagiat. Data uji coba untuk tugas akhir ini adalah dokumen-dokumen tugas mata kuliah sosio etika pada semester gasal 2009/2010. Pada mata kuliah ini terdapat tiga buah tugas. Data tugas yang digunakan dapat dilihat pada Tabel 1.
Tabel 1 Dataset yang Digunakan Dalam Evaluasi
No Nama
Tugas Topik Jumlah
1 Tugas 1 Komunikasi 15
2 Tugas 2 Bioinformatika 15 Surface Recontruction 15 3 Tugas 3 Hyperspectral 15
Total 60
VIII.1. UJI COBA PENENTUAN JUMLAH KELOMPOK Dalam uji coba penentuan jumlah kelompok ini dilakukan dalam dua kegiatan yaitu menggunakan Latent Semantic Analysis (LSA) dan Hartigan Index.
Latent Semantic Analysis (LSA) adalah sebuah teknik matematika/statistik untuk menggali dan menyimpulkan hubungan kontekstual dari kata-kata dalam sebuah wacana. LSA menggunakan metode Singular Value
MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011
6 Decomposition (SVD) untuk memproses kata-kata yang ada dalam dokumen[11]. Pada pengujian ini memanfaatkan fungsi SVD yang sudah terdapat pada Matlab. Fungsi dari SVD memerlukan masukan berupa matriks yang merepresentasikan hubungan jumlah frekuensi antara kata dan dokumen sehingga menghasilkan tiga buah matriks yaitu matriks S, matriks V dan matriks D.
Pada uji coba menggunakan Hartigan Index untuk mengetahui jumlah kelompok yang sebaiknya terbentuk dari data-data dokumen yang tersedia. Pada pengujian ini dilakukan dengan mengatur nilai alpha dan mengamati jumlah kelompok yang terbentuk dari data dokumen yang ada. Nilai alpha merupakan nilai batas sebuah kalimat atau topik bahasan pada satu kelompok. Hal ini bertujuan untuk mencari nilai alpha terbaik dalam pengelompokan.
VIII.2. UJI COBA PENENTUAN KELOMPOK UNTUK DOKUMEN BARU
Pada pengujian penentuan kelompok untuk dokumen baru melakukan pengamatan pada dokumen baru yang masuk kedalam sistem saat kelompok-kelompok sudah terbentuk. Pada dokumen baru dilakukan pengecekan penentuan kelompok yang sesuai dengan isi dari dokumen baru. Pada penggujian ini dilakukan pengamatan kesesuaian dokumen baru terhadap hasil kelompoknya.
VIII.3. UJI COBA WAKTU DETEKSI PENJIPLAKAN Dalam pengujian ini terdapat dua skenario percobaan yaitu dokumen dideteksi penjiplakan pada kumpulan dokumen dan dokumen dideteksi penjiplakan pada kumpulan dokumen yang sudah dikelompokan dengan nilai alpha 0,5. Tujuan dari dilakukan dua skenario ini untuk melihat perbedaan waktu yang diperlukan sebuah dokumen dalam mendeteksi penjiplakan.
VIII.4. EVALUASI HASIL UJI COBA
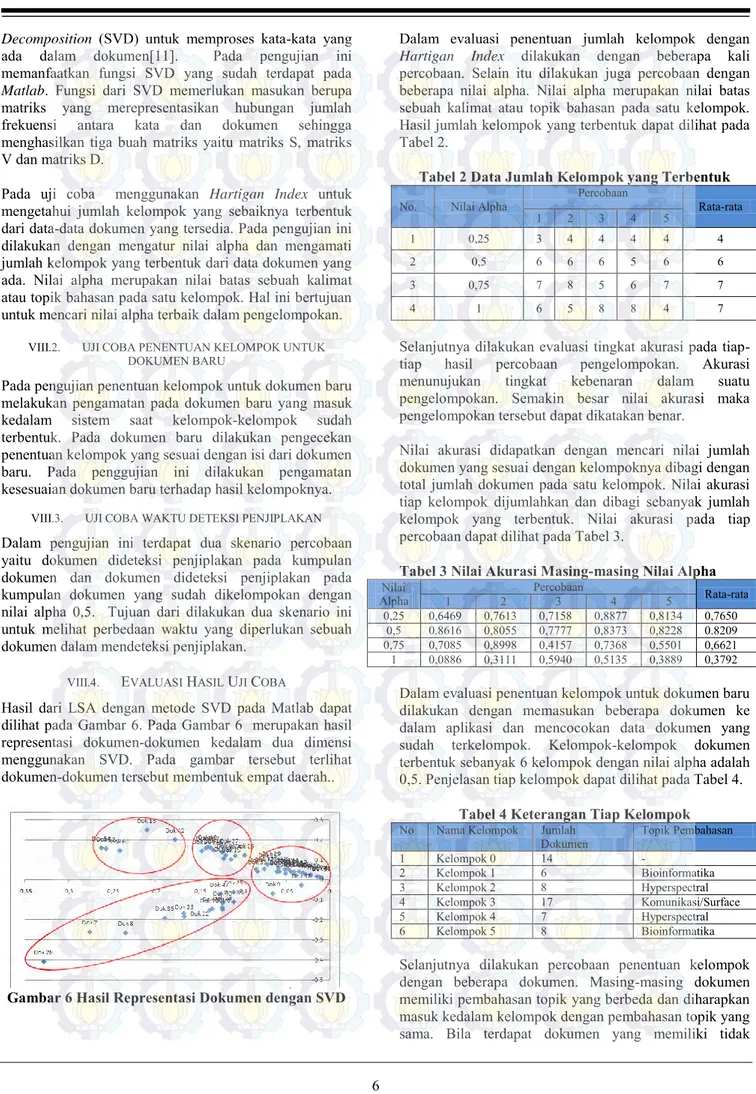
Hasil dari LSA dengan metode SVD pada Matlab dapat dilihat pada Gambar 6. Pada Gambar 6 merupakan hasil representasi dokumen-dokumen kedalam dua dimensi menggunakan SVD. Pada gambar tersebut terlihat dokumen-dokumen tersebut membentuk empat daerah..
Gambar 6 Hasil Representasi Dokumen dengan SVD
Dalam evaluasi penentuan jumlah kelompok dengan Hartigan Index dilakukan dengan beberapa kali percobaan. Selain itu dilakukan juga percobaan dengan beberapa nilai alpha. Nilai alpha merupakan nilai batas sebuah kalimat atau topik bahasan pada satu kelompok. Hasil jumlah kelompok yang terbentuk dapat dilihat pada Tabel 2.
Tabel 2 Data Jumlah Kelompok yang Terbentuk
No. Nilai Alpha Percobaan Rata-rata 1 2 3 4 5
1 0,25 3 4 4 4 4 4
2 0,5 6 6 6 5 6 6
3 0,75 7 8 5 6 7 7
4 1 6 5 8 8 4 7
Selanjutnya dilakukan evaluasi tingkat akurasi pada tiap-tiap hasil percobaan pengelompokan. Akurasi menunujukan tingkat kebenaran dalam suatu pengelompokan. Semakin besar nilai akurasi maka pengelompokan tersebut dapat dikatakan benar.
Nilai akurasi didapatkan dengan mencari nilai jumlah dokumen yang sesuai dengan kelompoknya dibagi dengan total jumlah dokumen pada satu kelompok. Nilai akurasi tiap kelompok dijumlahkan dan dibagi sebanyak jumlah kelompok yang terbentuk. Nilai akurasi pada tiap percobaan dapat dilihat pada Tabel 3.
Tabel 3 Nilai Akurasi Masing-masing Nilai Alpha
Nilai
Alpha 1 2 Percobaan 3 4 5 Rata-rata 0,25 0,6469 0,7613 0,7158 0,8877 0,8134 0,7650
0,5 0.8616 0,8055 0,7777 0,8373 0,8228 0.8209 0,75 0,7085 0,8998 0,4157 0,7368 0,5501 0,6621 1 0,0886 0,3111 0,5940 0,5135 0,3889 0,3792
Dalam evaluasi penentuan kelompok untuk dokumen baru dilakukan dengan memasukan beberapa dokumen ke dalam aplikasi dan mencocokan data dokumen yang sudah terkelompok. Kelompok-kelompok dokumen terbentuk sebanyak 6 kelompok dengan nilai alpha adalah 0,5. Penjelasan tiap kelompok dapat dilihat pada Tabel 4.
Tabel 4 Keterangan Tiap Kelompok
No Nama Kelompok Jumlah
Dokumen Topik Pembahasan
1 Kelompok 0 14 - 2 Kelompok 1 6 Bioinformatika 3 Kelompok 2 8 Hyperspectral 4 Kelompok 3 17 Komunikasi/Surface 5 Kelompok 4 7 Hyperspectral 6 Kelompok 5 8 Bioinformatika Selanjutnya dilakukan percobaan penentuan kelompok dengan beberapa dokumen. Masing-masing dokumen memiliki pembahasan topik yang berbeda dan diharapkan masuk kedalam kelompok dengan pembahasan topik yang sama. Bila terdapat dokumen yang memiliki tidak
MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011
7 kesamaan topik dengan topik yang telah ada pada aplikasi maka dokumen tersebut akan dikelompokan pada kelompok 0. Hasil dari percobaan dapat dilihat pada Tabel 5.
Tabel 5 Hasil Uji Coba Penentuan Kelompok untuk Dokumen Baru
Nama Dokumen Topik Hasil
Pengelompokan Ket Tugas 2 Sostek - 5107100125 Kelas B.doc Bioinformatika Kelompok 1 Bioinformatika Benar Tugas 2 Sostek-5107100032 kelas B.doc Surface Kelompok 3 Surface Benar Tugas 2 Sostek-5107100167 Kelas B.doc Surface Kelompok 3 Surface Benar Tugas 2 SosTek_5107100070_ Kelas B.doc Bioinformatika Kelompok 3 Surface Salah Tugas 3 Soset - 5101700098 - Kelas B.doc Hyperspectral Kelompok 2 Hyperspectral Benar Tugas 3 sosioetika-5107100116 Kelas B.doc Hyperspectral Kelompok 4 Hyperspectral Benar Tugas 3 Sostek - 5106100024 - Kelas B.doc Hyperspectral Kelompok 2 Hyperspectral Benar Dalam evaluasi waktu deteksi penjiplakan dilakukan pencatatan waktu yang diperlukan sebuah dokumen melakukan pendeteksian penjiplakan dengan kumpulan dokumen dan dengan kumpulan dokumen yang sudah dikelompokan sesuai dengan topik masing-masing. Hasil dari percobaan dapat dilihat pada Tabel 6
Tabel 6 Hasil Uji Coba Waktu Deteksi Penjiplakan
Nama Dokumen Jumlah Kelompok 1 6 Quick Sort2.docx 64 detik 4 detik Tugas 1 Soset - 5107100098 - Kelas B.doc 98 detik 4 detik Tugas 1 sostek - 5107100100 kelas B.doc 88 detik 5 detik Tugas 1 Sostek - 5106100093 Kelas B.doc 84 detik 5 detik Tugas 1 Sostek - 5106100104 kelas (B).doc 107 detik 9 detik Tugas 1 Sostek - 5106100117 Kelas B.docx 74 detik 9 detik
IX. KESIMPULAN
Dalam penentuan jumlah kelompok dengan LSA dari 60 dokumen yang dilakukan representasi kedalam dua dimensi bahwa sebaiknya dibentuk dengan menggunakan LSA sebanyak empat kelompok sedangkan dengan Hartigan Index bahwa jumlah kelompok yang sebaiknya terbentuk dari data yang ada adalah 6 dengan nilai alpha yang terbaik adalah 0,50. Hal ini dikarenakan dari jumlah kelompok yang terbentuk stabil dan nilai akurasi yang dimiliki cukup tinggi. Selain itu pembahasan topik pada tiap kelompok tidak terlalu tinggi atau pun rendah sehingga jumlah pembagian anggota tiap kelompok hampir merata.
Dalam pemilihan nilai alpha dapat disimpulkan bahwa semakin kecil nilai alpha maka jumlah kelompok yang
terbentuk semakin sedikit. Hal ini dikarenakan pembahasan topik pada sebuah kelompok bersifat umum atau luas sehingga diperlukan sedikit kelompok untuk menampung topik-topik yang ada. Begitu pula semakin besar nilai alpha maka jumlah kelompok yang terbentuk semakin banyak hal ini dikarenakan pembahasan topik pada sebuah topik semakin spesifik atau khusus sehingga diperlukan banyak kelompok untuk menampunt topik-topik yang ada.
Dari hasil percobaan penentuan kelompok untuk dokumen baru bahwa proses ini memiliki tingkat kebenaran yang cukup tinggi, sehingga dalam melakukan penentuan kelompok untuk dokumen baru sesuai dengan topik pembahasan.
Dari pencatatan waktu deteksi penjiplakan dapat disimpulkan bahwa waktu yang diperlukan lebih sedikit dalam pendeteksian penjiplakan pada kumpulan dokumen yang telah dikelompokan daripada kumpulan dokumen yang tidak dikelompokan. Hal ini karena jumlah dokumen yang dibandingkan lebih sedikit dan dokumen yang dibandingkan memiliki kesamaan topik.
REFERENSI
[1] ____,____, Kamus Besar Bahasa Indonesia, <URL:http://www.pusatbahasa.diknas.go.id/kbbi>, diakses tanggal 12 April 2011.
[2] Yuwono, Putu., Yuhana, Umi Laili., dan Purwitasari, Diana. 2010. Aplikasi deteksi penjiplakan pada file teks dengan algoritma winnowing. Surabaya.
[3] Manber, Ubi. 1994. Finding similar files in a large file system. In proceedings of the USENIX Winter 1994 Technical Conference.
[4] Iyer, Parvati dan Singh, Abhipsita. 2005. Document similarity analysis for a plagiatrism detection system. In Proceedings of the 2nd Indian International Cenfrence on Artificial Intelegence (IICAI-05. pp 2534-2544.
[5] Schleimer, S., Wilkerson, D., dan Aiken, A. 2003. Winnowing: Local algorithms for document fingerprinting. In Proceedings of the ACM SIGMOD international conference on management of data. pp 76–85.
[6] Stein, S. Meyer zu Eissen. 2006. Near similarity search and plagiarism analysis. In Proceedings of the 29th Annual Conference of the German Classification Society (GfKI), Magdeburg, ISDN 1431-8841. pp. 430-437.
[7] Parapar., Javier dan Barreiro, Alvaro. 2009. Evaluation of text clustering algorithms with n-gram-based document fingerprints. In Proceedings of the 31st European Conference on Information Retrieval Research ECIR 2009, Toulouse, France, April 2009, Lecture Notes in Computer Science vol. 5478, pp. 645-653..
MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011
8 [8] Arthur, D., dan S, Vassilvitskii. 2007. K-means++:
The advantages of careful seeding. In Proceeding of the 18th Annual ACM-SIAM Symposium of Discrete Analysis, Jan. 7-9, ACM Press, New Orleans, Louisiana. pp. 1027-1035
[9] Mardia, Kantia et al. 1979. Multivariate Analysis. Academic Press.
[10] Li, Xiang., Ramachandran, Rahul., Movva, Sunil., Graves, Sara., Plale, Beth., dan Vijayakumar, Nithya. 2008. Storm Clustering for Data-driven Weather Forecasting. 24th Conference on IIPS, AMS, To Appear 2008.
[11] Landauer, T. K., Foltz, P. W., & Laham, D. 1998. Introduction to Latent Semantic Analysis. Discourse
MAKALAH SEMINAR TUGAS AKHIR PERIODE JULI 2011