HALAMAN JUDUL
LAPORAN PROYEK AKHIR
ANALISIS SENTIMEN BERDASARKAN
KOMENTAR PUBLIK TERHADAP TOKO
ONLINE DI SOSIAL MEDIA FACEBOOK
(STUDI KASUS : ZALORA DAN
BERRYBENKA)
Syahmia Gusriani NIM. 1257301057
Pembimbing
Kartina Diah Kusuma Wardhani, S.T., M.T. Muhammad Ihsan Zul, S.Pd., M.Eng.
PROGRAM STUDI SISTEM INFORMASI POLITEKNIK CALTEX RIAU
ABSTRAK
Maraknya penggunaan jejaring sosial seperti Facebook mendorong munculnya data tekstual yang tidak terbatas, sehingga muncul kebutuhan penyajian informasi tanpa mengurangi nilai dari informasi tersebut. Salah satu pemanfaatan data ini adalah untuk mengetahui opini atau sentimen publik terhadap pelayanan dan produk suatu toko online. Metodologi yang digunakan untuk melakukan analisis sentimen dimulai dari data collecting, preprocessing, feature selection, klasifikasi dan pengukuran akurasi. Metode klasifikasi naïve bayes, k-NN dan decision tree digunakan untuk membandingkan hasil prediksi klasifikasi yang terbaik. Hasil analisis pengujian menunjukkan naïve bayes memiliki kestabilan akurasi setelah diuji dengan nilai minimum support 0.036 pada Frequent Itemset. Naïve bayes memiliki rata-rata akurasi 90.1%.
ABSTRACT
The widespread use of social networks such as Facebook encourage the emergence of textual data that is infinite, so it appears the need of presenting information without reducing the value of the information. One of the utilization of this data is to find out the opinion or public sentiment to services and products an online store. The methodology used to perform sentiment analysis starts from the collecting data, preprocessing, feature selection, classification and measurement accuracy. Naïve bayes bayes classification method, k-NN and decision tree are used to compare the results of the classification best predictions. The results of the analysis shows naïve bayes test has an accuracy stability tested by minimum support value 0.036 in frequent itemset. Naïve bayes has an average accuracy of 90.1%.
KATA PENGANTAR
Segala puji syukur kehadirat Allah SWT yang telah melimpahkan rahmat dan barokah-Nya sehingga penulis dapat menyelesaikan proyek akhir yang berjudul “ANALISIS SENTIMEN BERDASARKAN KOMENTAR PUBLIK TERHADAP TOKO ONLINE PADA SOSIAL MEDIA FACEBOOK (STUDY KASUS : ZALORA DAN BERRYBENKA)”. Proyek akhir ini disusun sebagai salah satu syarat untuk menyelesaikan jenjang pendidikan Diploma IV pada Program Studi Sistem Informasi Politeknik Caltex Riau.
Pada kesempatan ini, penulis ingin mengucapkan terima kasih kepada pihak yang telah banyak memberikan bantuan dan dukungan yang tiada terhingga baik secara langsung maupun tidak langsung. Ucapan terima kasih tersebut penulis tujukan kepada: 1. Allah SWT atas rahmat dan karunia-Nya, sehingga penulis bisa
menyelesaikan tugas akhir ini tepat waktu.
2. Kedua orang tua penulis atas dukungan dan kasih sayang tak terhingga, sehingga penulis bisa menyelesaikan tugas akhir tepat waktu.
3. Ibu Kartina Diah Kusuma Wardhani, S.T., M.T. selaku pembimbing utama, dan Bapak Muhammad Ihsan Zul, S.Pd., M.Eng. selaku dosen pembimbing, yang telah memberikan ilmu dan bimbingan dengan penuh kesabaran kepada penulis dalam menyelesaikan proyek akhir.
4. Dr. Hendriko, S.T., M.Eng. selaku Direktur Politeknik Caltex Riau yang telah memberikan dukungan moral dalam menyelesaikan proyek akhir ini.
5. Bapak Bapak Wawan Yunanto, S.Kom., M.T.selaku Ketua Program Studi Sistem Informasi yang telah memberikan izin untuk menyelesaikan proyek akhir.
Penulis sangat menyadari sepenuhnya bahwa laporan proyek akhir ini masih jauh dari sempurna, oleh karena itu segala jenis kritik, saran dan masukan yang membangun sangat penulis harapkan agar dapat memberikan wawasan bagi pembaca dan yang paling utama penulis sendiri.
Pekanbaru, 15 Agustus 2016
DAFTAR ISI
HALAMAN JUDUL i
ABSTRAK ii
ABSTRACT iii
KATA PENGANTAR iv
DAFTAR ISI vi
DAFTAR GAMBAR viii
DAFTAR TABEL xii
BAB I PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Batasan Masalah 2
1.4 Tujuan Penelitian 2
1.5 Manfaat Penelitian 2
BAB II TINJAUAN PUSTAKA 4
2.1 Tinjauan Pustaka 4
2.1.1 Penelitian Terdahulu 4
2.2 Landasan Teori 6
2.2.1 Text Mining 6
2.2.2 Frequent Itemset 11
2.2.3 Sentimen, Opini dan Analisis Sentimen 13 2.2.4 Naïve Bayes Classifier 15
2.2.5 K-Nearest Neighbor 16
2.2.6 Decision Tree 17
2.2.7 Pengujian / Pengukuran Akurasi 18 2.2.8 Ms. Excel dan Power Query 21
BAB III PERANCANGAN 22
3.1.1 Sumber Data 23
3.1.2 Preprocessing 25
3.1.3 Metode Klasifikasi 32
3.1.4 Pengujian 42
BAB IV PENGUJIAN DAN ANALISIS 45
4.1 Implementasi 45
4.1.1 Data Latih 45
4.1.2 Punctuation and Number Filter 48 4.1.3 Case Folding and Filtering/Stopword Removal
49
4.1.4 Stemming 50
4.1.5 Convert Negation 51
4.1.6 Frequent Itemset 52
4.1.7 Klasifikasi k-NN dan Pengujian 56 4.1.8 Klasifikasi Naïve Bayes dan Pengujian 59 4.1.9 Klasifikasi Decision Tree dan Pengujian 61
4.2 Analisis 63
4.2.1 Analisis Sentimen Zalora dan Visualisasi Kata Sentimen 63
BAB V KESIMPULAN DAN SARAN 89
5.1 Kesimpulan 89
5.2 Saran 89
DAFTAR PUSTAKA 91
Lampiran A. Daftar Kecenderungan Sentimen Berdasarkan
SentimenWordNet A
DAFTAR GAMBAR
Gambar 1 Proses Text Mining (Even, Yair and Zohar, 2002) 7 Gambar 2 Ilustrasi Tahap Functuation & Number Filtering 8 Gambar 3 Ilustrasi Tahapan CaseFolding 8
Gambar 4 Stemming 10
Gambar 5 Prosedur 5-fold cross validation (Bramer, 2007) 19 Gambar 6 Alur Perancangan Analisis Sentimen 22 Gambar 7 Contoh Hasil Crawling Menggunakan Power Query 23 Gambar 8 Contoh Penggunaan Power Query Editor 23 Gambar 9 Hasil Percobaan Decision Tree 41 Gambar 10 Percobaan DecisionTree Menggunakan KNIME 41 Gambar 11 Data Komentar Sebelum Preprocessing 48 Gambar 12 Punctuation and Number Filter 48 Gambar 13 Hasil Punctuation and Number Filter 49 Gambar 14 Hasil Case Folding and Stopword Removal 49 Gambar 15 Case Folding and Stopword Removal 49 Gambar 16 Stemming Java Snippet 50 Gambar 17 Tampilan Code Pada Editor Java Snippet 50 Gambar 18 Hasil Stemming dengan Java Snippet 51 Gambar 19 Rangkaian Proses Convert Negation 51 Gambar 20 Hasil Convert Negation 52 Gambar 21 Proses Frequent Itemset 52
Gambar 23 Hasil GroupBy 54 Gambar 24 Tampilan hasil Document Vector 55 Gambar 25 Hasil Category to class 55
Gambar 26 Proses setelah FIM (1) 56
Gambar 27 Proses setelah FIM (2) 56
Gambar 28 Klasifikasi k-NN, k-Fold Cross Validation dan
Confusion Matrix 56
Gambar 44 Akurasi ConfusionMatrix Zalora Layanan 69 Gambar 45 Visualisasi Kata Sentimen Positif Zalora Layanan (FIM) 69 Gambar 46 Visualisasi Kata Sentimen Negatif Zalora Layanan (FIM) 70 Gambar 47 Visualisasi Kata Sentimen Negatif Zalora Layanan
(SentiWord) 70
Gambar 48 Visualisasi Kata Sentimen Positif Zalora Layanan
(SentiWord) 71
Gambar 49 Hasil ConfusionMatrix Zalora Layanan dan Produk 73 Gambar 50 Visualisasi Kata Sentimen Negatif Zalora Layanan dan
Produk (FIM) 74
Gambar 51 Visualisasi Kata Sentimen Positif Zalora Layanan dan
Produk (FIM) 74
Gambar 52 Visualisasi Kata Sentimen Negatif Zalora Layanan dan
Produk (SentiWord) 75
Gambar 53 Visualisasi Kata Sentimen Positif Zalora Layanan dan
Produk (SentiWord) 75
Gambar 54 Hasil ConfusionMatrix Berrybenka Produk 77 Gambar 55 Visualisasi Kata Sentimen Positif Berrybenka Produk
(FIM) 78
Gambar 56 Visualisasi Kata Sentimen Negatif Berrybenka Produk
(SentiWord) 79
Gambar 57 Visualisasi Kata Sentimen Positif Berrybenka Produk
(SentiWord) 79
Gambar 58 Visualisasi Kata Sentimen Negatif Berrybenka Produk
(FIM) 79
Gambar 60 Visualisasi Kata Sentimen Positif Berrybenka Layanan
(FIM) 82
Gambar 61 Visualisasi Kata Sentimen Negatif Berrybenka Layanan
(FIM) 83
Gambar 62 Visualisasi Kata Sentimen Negatif Berrybenka Layanan
(Sentiword) 83
Gambar 63 Hasil ConfusionMatrix Berrybenka Layanan dan Produk 85 Gambar 64 Visualisasi Kata Sentimen Positif Berrybenka Layanan
dan Produk (FIM) 86
Gambar 65 Visualisasi Kata Sentimen Negatif Berrybenka Layanan
dan Produk (SentiWord) 87
Gambar 66 Visualisasi Kata Sentimen Positif Berrybenka Layanan
dan Produk (FIM) 87
Gambar 67 Visualisasi Kata Sentimen Positif Berrybenka Layanan
dan Produk (SentiWord) 88
Gambar 68. Library yang dibutuhkan Java Snippet E Gambar 69Gambar 3.4 Percobaan Decision Tree Menggunakan
KNIME// Mulai proses stemming F
Table 1 Perbandingan Penelitian Terdahulu 5
Table 2 StopwordList 9
Table 3 Contoh Itemset/Basket 12
Table 4 Contoh Tabel ConfusionMatrix Prediksi Dua Kelas 20 Table 5 Contoh Komentar Data Training 24 Table 6 Data Komentar Toko Online 26 Table 7 Penerapan CaseFolding dan Tokenizing 27 Table 8 Contoh Penerapan Filtering 28 Table 9 Contoh Penerapan Stemming 29 Table 10 Contoh Penerapan Convert Negation 30
Table 11 Hasil Jumlah Kata 31
Table 12 Data Atribut 32
Table 13 Data Hasil Preprocessing 32
Table 14 Data Atribut 33
Table 15 Data Training Berdasarkan Atribut Data 34 Table 16 Hasil Training Model Probabilitas Dari Data Training 35
Table 17 Nilai Vmap 36
Table 18 Data Training Berdasarkan Atribut Data 37
Table 19 Hasil Perhitungan k-NN 38
Table 20 Hasil Klasifikasi Jarak Euclid 38 Table 21 Memilih Jarak Euclid Terdekat 38 Table 22 Perhitungan decision tree algrotima C4.5 39 Table 23 Tabel Skenario Uji Stabilitas dengan 5-fold cross
Table 24 Contoh hasil data aktual dan prediksi 43
Table 25 Tabel Confusion Matrix 44
BAB I
PENDAHULUAN 1.1 Latar BelakangBelanja online merupakan proses membeli barang dan jasa dari pedagang yang dijual di internet. Konsumen dapat mengunjungi toko online dari rumah secara nyaman sambil duduk di depan komputer (Ling & Jusoh, 2012). Berdasarkan survey pembelian online secara global termasuk Indonesia, sebanyak 71% konsumen melakukan peninjauan terhadap toko online sebelum membeli produk. Sebanyak 43% setuju bahwa media sosial menjadi alat bantu untuk memenuhi kebutuhan pengetahuan berupa review produk dan ulasan forum, guna membantu membuat keputusan pembelian (Nielsen, 2014). Review produk maupun ulasan forum disampaikan melalui komentar di sosial media yang berisi keluhan, pujian atau pandangan terhadap produk atau jasa dari suatu toko online. Komentar tersebut mendeskripsikan tanggapan yang berbeda-beda dari setiap konsumen.
Komentar-komentar berupa teks tersebut dapat dikumpulkan dan diolah dengan analisis sentimen. Analisis sentimen mempelajari opini yang mengungkapkan atau mengekspresikan pandangan positif atau negatif (Liu, 2012). Opini yang dibutuhkan untuk melakukan analisis berasal dari komentar halaman fanpage toko online di Facebook. Facebook dipilih karena penggunanya saling berinteraksi secara massif, dimana total pengguna Facebook sebanyak 1,44 miliar dengan pengguna harian sebanyak 936 juta (CNBC, 22 April 2015).
memberikan pengetahuan baru berupa kecenderungan positif atau negatif dan sebagai alat bantu untuk mengetahui sentimen konsumen terhadap toko online yang dituju.
1.2 Rumusan Masalah
Perumusan masalah dalam pembuatan proyek akhir ini adalah “Bagaimana mengimplementasikan analisis sentimen untuk menentukan kecenderungan padangan publik terhadap toko online dengan membandingkan metode klasifikasi naïve bayes, k-NN dan decision tree?”
1.3 Batasan Masalah
Batasan masalah dalam pembuatan proyek akhir ini adalah: 1. Data teks komentar pelayanan dan kategori fashion diambil
dari halaman toko online Zalora dan BerryBenka pada Facebook dalam Bahasa Indonesia.
2. Data komentar merupakan komentar setahun terakhir, yaitu 2014 s/d 2015.
3. Crawling teks komentar menggunakan power query pada Ms Excel.
4. Pemilihan data training berdasarkan keyword dan keberadaan kata sentimen.
5. Pemrosesan text processing dan klasifikasi menggunakan tools miner.
1.4 Tujuan Penelitian
Adapun tujuan dari pembuatan proyek akhir ini adalah melakukan klasifikasi sentimen dengan membandingkan hasil perhitungan metode naïve bayes, k-NN dan decision tree berdasarkan komentar-komentar publik terhadap produk dan layanan suatu toko online dan mendapatkan metode klasifikasi terbaik.
1.5 Manfaat Penelitian
1. Sebagai referensi konsumen sebelum membeli produk / menggunakan layanan pada toko online.
2. Media alternatif bagi konsumen untuk memilih produk-produk yang berkualitas.
3. Referensi indikator kualitas produk dan layanan berdasarkan tanggapan konsumen bagi pemilik toko online.
4. Sebagai referensi penelitian dan menambah pengetahuan terkait analisis sentimen terhadap toko online di sosial media.
BAB II
TINJAUAN PUSTAKA 2.1 Tinjauan Pustaka
1.5.1 Penelitian Terdahulu
Analisis sentimen dilakukan oleh Ismail Sunni (2012), dengan meneliti data twitter terkait opini terhadap tokoh publik. Topik pembicaraan mengenai tokoh politik menjadi domain penelitian. Metode yang digunakan adalah F3 (F3 is Factor Finder) untuk menangani model bahasa. Sedangkan naïve bayes classifier digunakan untuk melakukan analisis sentimen dengan menggunakan frequency based selection untuk mengurangi kesalahaan eja dari banyaknya word. Hasil analisis menyebutkan bahwa casefolding justru menurunkan hasil akurasi karena program menyamakan kata yang muncul sebagai kabar berita dan opini hasil dari pengguna Twitter.
Penelitian lain mengenai analisis sentimen dilakukan oleh Nur dan Santika (2011). Objek yang diteliti adalah dokumen-dokumen berbahasa Indonesia terkait merk telepon seluler. Penelitian ini bertujuan untuk mengetahui akurasi perbandingan dua klasifikasi yang digunakan dalam analisis. Penelitian analisis sentimen menggunakan pendekatan machine learning yang dikenal dengan Support Vector Machine (SVM) dan dikhususkan pada dokumen teks berbahasa Indonesia.
Pada tahun 2014, Ahmad Fathan juga melakukan penelitian analisis sentimen. Objek penelitiannya adalah tweet yang membicarakan tokoh publik dengan tujuan mengetahui suatu topik terkait tokoh publik atau kejadian yang menyebabkan sentimen publik turun. Nama tokoh publik yang dianalisis adalah tokoh publik dengan hasil survei tertinggi berdasarkan survei lembaga-lembaga kompeten di Indonesia. Naïve bayes classifier digunakan untuk memperoleh hasil klasifikasi dari sentimen terkait tokoh publik.
Table 1 Perbandingan Penelitian Terdahulu
Penelitian Merk telepon seluler; apple, blackberry,
2.2 Landasan Teori
1.5.2 Text Mining
Text mining adalah lintas disiplin ilmu yang mengacu pada pencarian informasi, data mining, machine learning, statistik, dan komputasi linguistik (Han dkk, 2012). Text mining juga dikenal dengan text data mining atau pencarian pengetahuan di basis data tekstual adalah proses yang semi otomatis melakukan ekstraksi dari pola data (Turban dkk, 2011).
Tipe pekerjaan text mining meliputi kategorisasi, text clustering, ekstraksi konsep/entitas, analisis sentimen, document summarization, dan entity-relation modeling (yaitu, hubungan pembelajaran antara entitas) (Han dkk, 2012). Sumber data yang digunakan pada text mining adalah kumpulan teks yang memiliki format yang tidak terstruktur atau minimal semi terstruktur. Tujuan dari text mining adalah untuk mendapatkan informasi yang berguna dari sekumpulan dokumen.
Gambar 1 Proses Text Mining (Even, Yair and Zohar, 2002) 1.5.2.1
Text
Sama halnya dengan permasalahan pada data mining, pada text mining data yang akan diolah jumlahnya sangat banyak, dimensi yang tinggi, data dan struktur yang terus berubah dan data noise. Perbedaan di antara keduanya adalah pada data yang digunakan. Pada data mining, data yang digunakan adalah structured data, sedangkan pada text mining, data yang digunakan text mining pada umumnya adalah unstructured data, atau minimal semistructured. Hal ini menyebabkan adanya tantangan tambahan pada text mining yaitu struktur text yang complex dan tidak lengkap, arti yang tidak jelas dan tidak standar, dan bahasa informal.
Gambar 2 Ilustrasi Tahap Functuation & Number Filtering
Gambar 3 Ilustrasi Tahapan CaseFolding dari halaman website Sentiwordnet. Bobot sentimen dapat dilihat pada Lampiran A.
1.5.2.2 Text Preprocessing
Preprocessing dilakukan untuk menghindari data yang kurang sempurna, gangguan pada data, dan data-data yang tidak konsisten (Hemalatha, dkk, 2012). Tahap preprocessing diperlukan untuk membersihkan data dari noise, menyeragamkan bentuk kata dan mengurangi volume kata. Agar pada tahap masuk ke dalam metode klasifikasi lebih optimal dalam perhitungannya. Tahap preprocessing pada penelitian ini diantaranya:
1. Punctuation and Number Filter
Punctuation dan number filter merupakan tahap menghapus tanda baca dan angka yang terdapat pada teks komentar. Tahap ini sangat diperlukan untuk mengurangi noise.
a. Case folding
Case
folding yaitu penyeragaman bentuk huruf menjadi lower case atau upper case serta penghapusan angka dan tanda baca. Dalam hal ini yang digunakan hanya huruf latin antara “a” sampai dengan “z” (Putranti, 2014).
@Lucu....keren!! Unik2 banget ini konsepnya.. suka
banget!
Lucu keren unik banget ini konsepnya suka banget
Lucu keren unik banget ini konsepnya suka banget
1.5.2.3 Text Transformation (Feature Generation)
Transformasi teks atau pembentukan atribut mengacu pada proses untuk mendapatkan representasi dokumen yang diharapkan. Pendekatan representasi dokumen yang lazim adalah bag of words (Yuliana, 2014). 1.5.2.4 Featured Selection
Tahap feature selection merupakan tahap lanjut dari pengurangan dimensi pada proses transformasi teks. Pada tahap feature selection terbagi atas :
a. Filtering
Filtering adalah proses untuk memilih kata-kata penting dari hasil tokenization. Filtering dilakukan dengan menggunakan algoritma stopword removal. Stopword removal digunakan untuk membuang kata-kata yang sering muncul dan bersifat umum, kurang menunjukan relevansinya dengan teks (Sentiaji, 2014). Membuang kata-kata yang sering muncul namun tidak memiliki pengaruh apapun terhadap ekstraksi sentimen. Misalnya “di”, “oleh”, “pada”, “sebuah”, “karena” dan lain sebagainya. Kata-kata yang akan dibuang didefenisikan dalam stopword list.
Table 2 StopwordList
b. Stemming
Stemming adalah tahap membuat kata yang berimbuhan kembali ke bentuk asalnya (Sentiaji, 2014). Atau dengan kata lain, stemming merupakan proses mencari akar kata dan menghilangkan imbuhan pada kata (Hidayatullah, 2014). Stemming bertujuan mengurangi variasi kata yang memiliki kata dasar sama.
Atau Di Oleh Karena
Saya Gue Min Dalam
Sih Aja Bagi Iya
Dengan Ke Lu Gaul
Gambar 4 Stemming
c. Convert Negation
Convert negation adalah proses mengganti negasi yang terdapat dalam komentar. Negasi adalah sesuatu yang dikenal dalam semua bahasa dan biasanya negasi digunakan untuk mengubah polaritas dari suatu pernyataan (Blanco dan Moldovan, 2011). Kata-kata yang bersifat negasi adalah keseluruhan teks. Tindakan yang lazim dilakukan pada tahap ini adalah operasi text mining, dan biasanya menggunakan teknik-teknik data mining (Yuliana, 2014). Untuk menentukan pola ini, proses text mining dikombinasikan dengan proses-proses data mining.
1.5.2.6 Interpretation / Evaluation
merupakan tahap akhir dari proses text mining dan akan melakukan ekstraksi informasi dari database berdasarkan seberapa sering suatu event terjadi, yaitu suatu peristiwa atau suatu set peristiwa (Moens dkk, 2013 ). Frequent itemset merupakan tahapan awal yang digunakan pada teknik Association Rules atau sering disebut market basket analysis, yang digunakan untuk menemukan relasi diantara himpunan item-item (event). Market basket analysis adalah analisis dari kebiasaan membeli customer dengan mencari asosiasi dan korelasi antara item-item berbeda yang diletakkan customer dalam keranjang belanjaannya.
Model data market basket sering digunakan untuk mendeskripsikan bentuk umum dari banyak hubungan diantara dua objek. Dengan kata lain, ada items dan juga ada baskets atau disebut juga “transaksi”. Setiap basket berisi satu set item (an itemset). Itemset yaitu himpunan dari item-item yang muncul bersama-sama. Setiap satu itemset yang muncul di banyak basket disebut “frequent”. Frequent itemset didefinisikan sebagai itemset dimana support-nya lebih besar atau sama dengan minsupport yang merupakan ambang yang diberikan oleh user.
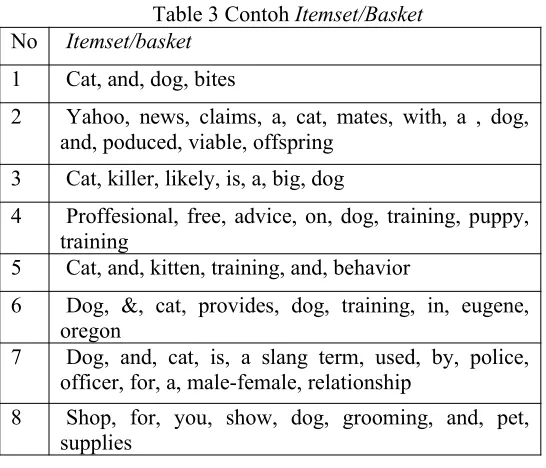
Table 3 Contoh Itemset/Basket
1.
Tabel 3 merupakan contoh baskets yang berisi item-item yang berupa kata-kata. Diantara sets tunggal, secara jelas kata “cat” dan “dog” banyak muncul (frequent). “dog” muncul hampir pada semua basket kecuali (5), sehingga nilai supportnya adalah 7. Sementara itu, “cat” muncul kecuali No Itemset/basket
1 Cat, and, dog, bites
2 Yahoo, news, claims, a, cat, mates, with, a , dog, and, poduced, viable, offspring
3 Cat, killer, likely, is, a, big, dog
4 Proffesional, free, advice, on, dog, training, puppy, training
5 Cat, and, kitten, training, and, behavior
6 Dog, &, cat, provides, dog, training, in, eugene, oregon
7 Dog, and, cat, is, a slang term, used, by, police, officer, for, a, male-female, relationship
pada (4) dan (8), sehingga nilai supportnya adalah 6. Kata “and” juga muncul cukup sering pada (1), (2), (5), (7), dan (8), sehingga supportnya adalah 5. Kata “a” dan “training” muncul pada 3 sets, sementara “for” dan “is” masing-masing muncul dua kali. Selebihnya, tidak ada kata lain yang muncul lebih dari dua kali. Jika ditentukan ambang supportnya adalah s = 3. Itu berarti ada lima itemset tunggal yang sering muncul yaitu, dog,cat, and,a, dan training.
1.5.4 Sentimen, Opini dan Analisis Sentimen
1.5.4.1 Sentimen
Menurut Kamus Besar Bahasa Indonesia (KBBI), sentimen berarti pendapat atau pandangan yang didasarkan pada perasaan yang berlebih-lebihan terhadap sesuatu. Sedangkan menurut Merriam-Webster’s Online Dictionary, sentimen menunjukkan pendapat tetap(terus menerus) yang merefleksikan / mencerminkan perasaan seseorang.
1.5.4.2 Opini
Opini dan konsep terkait seperti sentimen, evaluasi, tingkah laku, dan emosi merupakan subjek studi dari analisis sentimen dan opinion mining (Bing Liu, 2012). Opini atau pendapat merupakan pusat hampir semua aktivitas manusia dan menjadi pengaruh utama dari perilaku. Persepsi terhadap realitas untuk mengevaluasi objek disekitar.
Defenisi Opini menurut Hajmohammadi dkk dalam jurnal Opinion Mining and Sentiment Analysis: A Survey pada tahun 2012, yaitu:
2. Keyakinan atau pandangan dari sejumlah besar atau mayoritas orang-orang tentang hal tertentu.
Secara umum, opini mengacu pada apa yang orang pikirkan tentang sesuatu. Dengan kata lain, opini adalah keyakinan subjektif, dan merupakan hasil emosi atau interpretasi fakta.
1.5.4.3 Analisis Sentimen
Analisis sentimen disebut juga opinion mining, adalah bidang ilmu yang menganalisa pendapat, sentimen, evaluasi, penilaian, sikap dan emosi publik terhadap entitas seperti produk, jasa, organisasi, individu, masalah, peristiwa, topik, dan atribut mereka (Bing Liu, 2012). Analisis sentimen berfokus pada opini-opini yang mengekspresikan atau mengungkapkan sentimen positif atau negatif.
Secara umum analisis sentimen yang telah diteliti memiliki tiga tingkat (level), yaitu:
1. Level dokumen: mengklasifikasikan apakah seluruh dokumen opini mengungkapkan sentimen positif atau negatif. Analisis mengasumsikan bahwa setiap dokumen mengungkapkan opini yang objektif tentang suatu entitas tunggal (misalnya, produk tunggal).
2. Level kalimat: menentukan apakah setiap kalimat menyatakan opini positif, negatif, atau netral.
panggilan dan daya tahan baterai iPhone adalah target pendapat.
Analisis sentimen merupakan salah satu cabang penelitian text mining (Purwanto dan Santoso, 2015). Analisis sentimen hadir untuk menangani kondisi ledakan informasi teks yang tidak terstruktur. Seperti yang diprediksi Putten (2002) pada penelitiannya, kondisi ledakan informasi semakin menyulitkan proses data mining karena bentuk data tidak terstuktur dan jumlahnya sangat banyak.
1.5.5 Naïve Bayes Classifier
Naïve bayes classifier membuat asumsi yang sangat kuat (naif) akan independensi dari masing-masing kelas kejadian yang diberikan label (Han dkk, 2012). Naive bayes classifer digunakan untuk klasifikasi sentimen dari data komentaryang telah diperoleh. Naive bayes juga digunakan oleh Hidayatullah (2014) untuk menentukan sentimen terhadap toko publik yang disampaikan melalui
tweet berbahasa Indonesia.
Naïve bayes merupakan metode pembelajaran mesin yang memiliki model dalam membentuk probalilitas dan peluang. Maka dari itu, naïve bayes akan menghitung probabilitas kemunculan fitur yang mempresentasikan komentar berdasarkan kelas positif maupun negatif. Persamaan naïve bayes yang digunakan untuk menentukan kelas dari komentas ditunjukkan dalam persamaan berikut.
V
MAP=
argmax
vjϵ
v
P
(v
j)∏
i=1 nP
(a
i|
v
j) ……...[1]Keterangan :
ai = atribut atau fitur ke-i
V = himpunan kelas target
VMAP = kelas sentimen suatu komentar
Menghitung probabilitas P(vj) ditentukan pada saat
pelatihan, yang nilainya didekati dengan:
P
(v
j)=
¿
doc
j∨
|contoh
¿
|¿
…………...[2]Dimana |docj| adalah banyaknya dokumen yang
memiliki kategori j dalam pelatihan dan |contoh| adalah banyaknya dokumen dalam contoh yang digunakan untuk pelatihan. Untuk nilai P(ai | vj), yaitu menentukan
probabilitas kata ai dalam kategori j ditentukan dengan
persamaan berikut :
P
(a
i|
v
j¿
=
n
i+
1
n
+
¿
vocabulary
∨
¿ ¿
…………...[3] Berdasarkan persamaan, ni adalah frekuensimunculnya kata ai dalam dokumen berkategori vj, sedangkan
nilai n adalah banyaknya seluruh kata dalam berkategori vj,
dan |vocabulary| adalah banyaknya kata dalam contoh pelatihan.
Berdasarakan persamaan diatas, dapat dilihat bahwa setiap atribut atau fitur diasumsikan tidak memiliki keterhubungan satu sama lainnya. Naïvebayes menggunakan asumsi dalam sebuah dokumen kemunculan kata tidak mempengaruhi kemunculan kata yang lain. Meskipun asumsi ini bertentangan dengan aturan bahasa, namun tidak mengurangi keakuratan metode naïve bayes (Nur, 2011).
1.5.6 K-Nearest Neighbor
2012). K-Nearest Neighbor merupakan salah satu metode machine learning yang melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut (Putri, 2014). Adapun rumus k-NN yang digunakan :
d
(
x
i, x
j)=
√
∑
r=1n
(
a
r(x
i)−
a
r(x
j))
2 ……...[4]Keterangan:
d
(
x
i, x
j)
= Jarak Euclidean (Euclidean Distance)(
x
¿¿
i
)
¿
= record ke-i(
x
¿¿
j
)
¿
= record ke-j(
a
¿¿
r
)
¿
= data ke-ri , j
= 1, 2, 3, … , nBerikut merupakan langkah-langkah dalam menghitung metode Algoritma k-NN :
1. Menentukan Parameter K (Jumlah tetangga paling dekat).
2. Menghitung kuadrat jarak euclid (queri instance) masing-masing objek terhadap data sampel yang diberikan.
3. Kemudian mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak euclid terkecil. 4. Mengumpulkan kategori Y (Klasifikasi Nearest
Neighbor).
1.5.7 Decision Tree
Decision tree merupakan metode yang menyimpulkan pernyataan-pernyataan dari sebuah label data testing pada data training, untuk menemukan masalah-masalah yang mengarah dalam membuat sebuah keputusan (Han & Kamber, 2006). Decision tree adalah model prediksi berupa miniatur struktur pohon dimana terdapat node internal (bukan daun) yang mendeskripsikan atribu-atribut, setiap cabang menggambarkan hasil dari atribut yang diuji, dan setiap daun menggambarkan kelas. Adapun rumus yang digunakan pada algoritma decision tree sebagai berikut.
Entropy
(S
)=
∑
i=1c
p
ilog
2p
i ………...[5]Keterangan :
C = jumlah nilai yang ada pada attribut target (jumlah kelas klasifikasi).
Pi = jumlah proporsi sampel (peluang) untuk kelas i
Entropy merupakan suatu parameter untuk mengukur tingkat keberagaman (heterogenitas) dari kumpulan data. Semakin heterogen, nilai entropy semakin besar. Menghitung nilai Gain ialah untuk mengetahui ukuran efektifitas suatu atribut dalam mengklasifikasikan data.
Gain
(S , A
)=
Entropy
(S
)−
∑
V = nilai yang mungkin untuk atribut A
|S| = jumlah seluruh sampel data.
Entropy(Sv ) = Entropy untuk sampel yang memiliki nilai v
1.5.8 Pengujian / Pengukuran Akurasi 1.5.8.1 K-Fold Cross Validation
Cross validation digunakan sebagai metode evaluasi hasil klasifikasi (Alvino, 2013). Pengujian dilakukan untuk memprediksi error rate. Training data dibagi menjadi K buah subset secara acak dengan ukuran yang sama, satu diantara subset acak tersebut digunakan sebagai testing data. Setelah itu dilakukan iterasi sebanyak K kali dan dilakukan perhitungan error rate tiap subset. Kemudian hitung error rate pada setiap subset. Berdasarkan hasil error rate tiap subset, dihitung rata-ratanya untuk mendapatkan nilai error rate keseluruhan.
Pada proses evaluasi k-fold cross validation, perlu dibentuk k subset dari data sets yang ada. Misalnya, 5-fold cross validation berarti 4 subsets digunakan sebagai data training dan 2 subset digunakan sebagai data testing, dilakukan 5 kali iterasi. Hasil pengukuran adalah nilai rata-rata dari 5 kali pengujian, seperti ilustrasi pada Gambar 5 berikut.
1.5.8.2 Confusion Matrix
Salah satu metode evaluasi yang digunakan untuk klasifikasi naïve bayes adalah confusion matrix. Confusion matrix adalah salah satu tools penting dalam metode visualisasi yang digunakan pada mesin pembelajaran yang biasanya memuat dua kategori atau lebih (Manning dkk, 2009; Horn, 2010). Sebanyak setengah atau dua pertiga dari data keseluruhan digunakan untuk keperluan proses training sedangkan sisanya digunakan untuk keperluan testing (Kantardzic, 2003).
Untuk memperoleh informasi hasil pencarian akurasi, dilakukan perhitungan recall dan precision. Precision dapat dianggap sebagai ukuran ketepatan atau ketelitian, sedangkan recall adalah kesempurnaan (Yuliana, 2014).
Confusion matrix merupakan tabel yang digunakan untuk mengevaluasi kinerja dari suatu model klasifikasi. Tabel terdiri atas banyaknya baris data uji yang diprediksi bernar atau tidak benar dari model klasifikasi. Berikut contoh perhitungan akurasi tabel confusion matrix:
Table 4 Contoh Tabel ConfusionMatrix Prediksi Dua Kelas Prediksi
Positi f
Negati f
Aktual Positif TP FN
Negatif FP TN
yang salah dari contoh positif, FP adalah jumlah prediksi yang salah prediksi dari contoh negatif dan TN adalah jumlah prediksi yang benar dari contoh positif.
Rumus Accuracy (AC) adalah jumlah prediksi yang benar. Ini ditentukan dengan persamaan :
AC
=
TP
TP
+
TN
+
FP
+
TN
+
FN
…….………[7]
Recall atau truepositifrate (TP) adalah proporsi dari kasus positif yang telah diidentifikasi dengan benar, rumus mencari Recall:
True Positive
/
Recall
=
TP
TP
+
TN
………[8]True negative rate (TN) adalah proporsi dari kasus negatif yang telah diidentifikasi dengan benar, rumus TN:
True Negative
=
TN
TN
+
FN
………[9]1.5.9 Ms. Excel dan Power Query
Microsoft Excel adalah sebuah program aplikasi lembar kerja dikembangkan yang dibuat oleh Microsoft Corporation pada sistem operasi Microsoft Windows dan Mac OS. Kemampuan aplikasi ini di fokuskan untuk pengolahan data, baik data angka, karakter (string), maupun waktu (jam dan tanggal).
Power query merupakan fitur analisis data yang tersedia untuk Excel yang memungkinkan pengguna menemukan, menggabungkan dan memperbaiki data. Power query memungkinkan mentransformasikan data web dan menambahkan query ke model data ke worksheet yang ada.
Gambar 6 Alur Perancangan Analisis Sentimen
BAB III
PERANCANGAN 2.1 Perancangan Alur Analisis Sentimen
Perancangan alur analisis sentimen merupakan gambaran umum terkait alur penelitian yang akan dilakukan pada tugas akhir ini. Alur kerja dari analisis sentimen dapat dilihat pada Gambar 3.1 berikut:
Alur pertama dari analisis sentimen ialah mendapatkan data komentar dengan melakukan crawling data dan pemilihan training data. Langkah kedua, dilakukan preprocessing utama data komentar yang terdiri dari dua tahap, yaitu functuation and number filtering dan case folding. Langkah ketiga, yakni featured selection dengan tiga tahapan, filtering, stemming dan convet negation. Selanjutnya menentukan atribut sebelum masuk ke proses klasifikasi dengan metode frequent itemset. Setelah didapat atribut-atribut yang sering muncul, barulah dilakukan proses klasifikasi dengan metode klasifikasi naïve bayes, k-NN dan decision tree. Hasil dari klasifikasi selanjutnya diukur keakuratannya dengan kombinasi metode K-fold cross validation dan confusion matrix.
Collecting Data k-NN, Naïve Bayes &
Gambar 8 Contoh Hasil Crawling Menggunakan Power Query Gambar 7 Contoh Penggunaan Power Query Editor 2.1.1 Sumber Data
Berdasarkan data komentar hasil crawling, data training dikumpulkan dengan menyaring keywords yang berhubungan dengan pelayanan/produk fashion dikombinasikan dengan kata-kata sentimen dan atau emoticon. Berikut ketentuan yang digunakan dalam memilih data training diantara ribuan data komentar yang hasil crawling :
1. Menentukan target/entitas.
a. Pelayanan, yaitu terkait pelayanan pengiriman dan respon komplain pelanggan. Keyword terkait pelayanan diantaranya; kirim, order, pesan, paket, klarifikasi, komplain, balas, respon, jawab, retur, barang, konfirmasi, jawab dan retur.
b. Produk fashion, yaitu terkait kualitas produk yang dikirim apakah bentuk, ukuran, jenis, motif ataupun warnanya sesuai dengan yang dipesan. Keyword yang digunakan ialah baju, shirt, kaos, kasu, dress, ukuran, warna, size, sepatu, jam, watch, celana, sandal, sendal, heels, wedges, tas, koko, kemeja.
2. Menentukan keyword sentimen positif/negatif dan atau emoticon yang mengiringi suatu kalimat komentar.
a. Pelayanan-sentimen-positif ; sampai, sampe, cepat, cepet, sudah, datang, mudah, thx, dan terima kasih.
b. Pelayanan-sentimen-negatif ; lama, kecewa, lambat, telat, susah, sulit, parah, bohong, salah, batal dan maaf.
c. Produk-sentimen-positif ; bagus, percaya, keren, cantik, cakep, puas, oke dan sesuai.
d. Produk-sentimen-negatif ; kecewa, jelek, rusak, parah, komplain, salah, ganti, tukar, retur, refund, rongsok dan bohong.
3. Melakukan filtering kata target/entitas dan sentimen ada dalam satu kalimat komentar. jika salah satu tidak ada, maka tidak layak menjadi data training.
Table 5 Contoh Komentar Data Training
1 orderan saya sdh dikirim blm min ? no order 205595279 mau saya cek status di web tp kok tdk ditemukan. thx. 2 zalora, saya ingin melakukan pembatalan pemesanan yg
saya lakukan. tapi mengapa CS via telepon hanya bisa mengecek status order saja. apakah tidak bisa berbicara langsung?
3 halo, mau tanya proses retur order 202167159 yg sudah berminggu2 ga ada kabar :( kalau ga bisa retur kan bisa kirim balik aja yg kemarin saya kirim :(
4 thanks ZALORA barangnya udah sampe cepat banget :) 5 Terima kasih ZALORA paketnya sudah sampai,
6 Udah sampai nih zalora pesanan saya, terima kasih ya 7 pelayanan na cepat bgt. selalu konfirmasi. Cuma kemarin
sempat nyebelin krn pake jasa pengiriman yg memiliki jam terbang yg masih pendek. Tapi berkat kegigihan cs zalora, semua teratasi. Tq
8 Mav saya telp cs kok gak bsa untuk pembatalan no order 203387759 soalnya mau ganti barang sma ganti alamatnya . Mohon konfirmasinya terimakasih
9 maaf, sy sdh bayar untuk pembelanjaan dgn no order 209342847 tpi sy dpat sms lgi jika belum membayar, sy bayar atas nama Rohani Sibuea, trus uang sy kemana? 10 Puas banget belanja di Zalora ...^^ barangnya oke Dan
sesuai dengan gw bangeeeeet.:))
2.1.2 Preprocessing
akan mempengaruhi keoptimalan hasil klasifikasi nantinya. Tahapan preprocessing terdiri dari tiga tahap. Setiap tahapan akan dijabarkan pada subab ini. Berdasarkan data komentar pada Tabel 5, berikut contoh dilakukannya proses preprocessing.
2.1.2.1 Tahap Punctuation dan Number Filter
Table 6 Data Komentar Toko Online
No Komentar
1 orderan saya sudah dikirim order saya status tidak ditemukan terimakasih
2 zalora saya ingin melakukan pembatalan pemesanan saya lakukan tapi mengapa telepon hanya bisa mengecek status order saja apakah tidak bisa berbicara langsung
3 halo mau tanya proses retur order sudah berminggu tidak ada kabar sedih kalau tidak bisa retur bisa kirim balik kemarin saya kirim sedih
4 Terimakasih ZALORA barangnya udah sampe cepat banget senyum
5 Terimakasih ZALORA paketnya sudah sampai 6 Sudah sampai zalora pesanan saya terimakasih 7 pelayanan cepat selalu konfirmasi Cuma kemarin
sempat nyebelin pake jasa pengiriman yg memiliki jam terbang yg masih pendek Tapi berkat kegigihan zalora semua teratasi terimakasih
8 Maaf saya telp tidak bisa untuk pembatalan no order soalnya ganti barang sama ganti alamatnya Mohon konfirmasinya terimakasih
9 maaf bayar untuk pembelanjaan order dapat jika belum membayar bayar atas nama Rohani Sibuea trus uang kemana
2.1.2.2 Tahap Case Folding
Pada tahapan ini data komentar akan diubah menjadi huruf kecil semua dan karakter selain huruf akan dihilangkan.
Table 7 Penerapan CaseFolding dan Tokenizing
N o
Komentar
1 orderan saya sudah dikirim order saya status tidak ditemukan terima kasih
2 zalora saya ingin melakukan pembatalan pemesanan saya lakukan tapi mengapa telepon hanya bisa mengecek status order saja apakah tidak bisa berbicara langsung
3 halo mau tanya proses retur order sudah berminggu tidak ada kabar sedih kalau tidak bisa retur bisa kirim balik kemarin saya kirim sedih
4 terima kasih zalora barangnya udah sampe cepat banget senyum
5 terima kasih zalora paketnya sudah sampai 6 sudah sampai zalora pesanan saya terimakasih
7 pelayanan cepat selalu konfirmasi cuma kemarin sempat nyebelin pake jasa pengiriman yg memiliki jam terbang masih pendek tapi berkat kegigihan zalora semua teratasi terimakasih
8 maaf saya telp tidak bisa untuk pembatalan order soalnya ganti barang sama ganti alamatnya mohon konfirmasinya terimakasih
belum membayar bayar atas nama rohani sibuea trus uang kemana
10 puas banget belanja di zalora barangnya bagus sesuai dengan bangeeeeet senyum
2.1.2.3 Tahap Filtering
Tahap filtering akan menghapus kata-kata yang sering muncul dan bersifat umum yang terdapat pada komentar. Contoh penerapan filtering berdasarkan stopwordlist pada Tabel 8.
Table 8 Contoh Penerapan Filtering
No Komentar
1 orderan sudah dikirim order status tidak ditemukan terimakasih
2 zalora ingin melakukan pembatalan pemesanan lakukan mengapa telepon bisa mengecek status order tidak bisa berbicara langsung
3 proses retur order sudah berminggu tidak ada kabar sedih kalau tidak bisa retur bisa kirim balik kemarin kirim sedih
4 terimakasih zalora barangnya udah sampe cepat senyum
5 terimakasih zalora paketnya sudah sampai 6 sudah sampai zalora pesanan terimakasih
7 pelayanan cepat selalu konfirmasi kemarin sempat nyebelin pake jasa pengiriman memiliki terbang masih pendek berkat kegigihan zalora semua teratasi terimakasih
8 maaf telp tidak bisa pembatalan order soalnya ganti barang ganti alamatnya mohon konfirmasinya terimakasih
9 maaf bayar pembelanjaan order dapat belum membayar bayar rohani sibuea uang kemana
bangeeeeet senyum
2.1.2.4 Tahap Stemming
Pada tahap ini kata-kata komentar akan dikembalikan ke bentuk dasarnya dengan menghilangkan imbuhan pada setiap kata.
Table 9 Contoh Penerapan Stemming
No Komentar
1 order sudah kirim order status tidak temu terimakasih 2 zalora ingin lakukan batal pesan lakukan mengapa
telepon bisa cek status order tidak bisa bicara langsung 3 proses retur order sudah minggu tidak ada kabar sedih
kalau tidak bisa retur bisa kirim balik kemarin kirim sedih
4 terimakasih zalora barang udah sampe cepat senyum 5 terimakasih zalora paket sudah sampai
6 sudah sampai zalora pesan terimakasih
7 layan cepat selalu konfirmasi kemarin sempat nyebelin pake jasa kirim milik terbang masih pendek berkat gigih zalora semua atasi terimakasih
8 maaf telp tidak bisa batal order soal ganti barang ganti alamat mohon konfirmasi terimakasih
9 maaf bayar belanja order dapat belum bayar bayar rohani sibuea uang kemana
2.1.2.5 Convert Negation
Kata-kata yang bersifat negasi yang akan di lakukan konversi diantaranya, “kurang”, “tidak”, “enggak”, “ga”, “nggak”, “tak”, dan “gak”. Contoh penerapan convert negation seperti pada tabel berikut.
Table 10 Contoh Penerapan Convert Negation
No Komentar
1 order sudahkirim order status tidaktemu terimakasih 2 zalora ingin lakukan batal pesan lakukan mengapa
telepon bisa cek status order tidakbisa bicara langsung 3 proses retur order sudah minggu tidakada kabar sedih kalau tidakbisa retur bisa kirim balik kemarin kirim sedih
4 terimakasih zalora barang udah sampe cepat senyum 5 terimakasih zalora paket sudahsampai
6 sudahsampai zalora pesan terimakasih
7 layan cepat selalu konfirmasi kemarin sempat nyebelin pake jasa kirim milik terbang masih pendek berkat gigih zalora semua atasi terimakasih
8 maaf telp tidakbisa batal order soal ganti barang ganti alamat mohon konfirmasi terimakasih
9 maaf bayar belanja order dapat belum bayar bayar rohani sibuea uang kemana
10 puas belanja zalora barang bagus sesuai bangeeeeet senyum
2.1.2.6 Penentuan Atribut
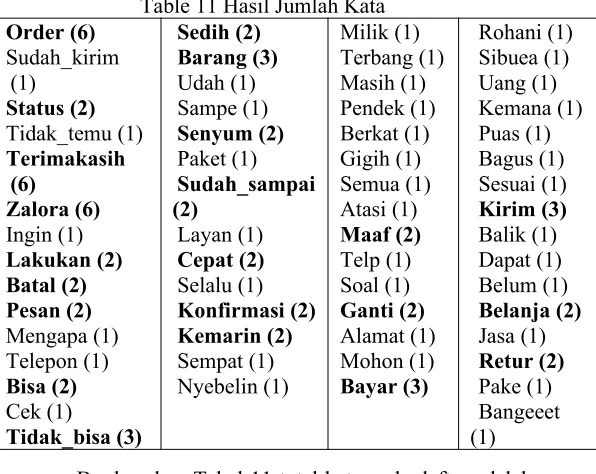
penentuan atribut. Tahap ini akan menyaring setiap kata yang muncul berdasarkan jumlah kemunculan kata. Skenario penentuan atribut ditentukan setelah menguji minimal kemunculan tertentu (k) dan dilihat pengaruhnya terhadap tingkat akurasi klasifikasi. K minimal kemunculan tertentu yang memiliki pengaruh hasil akurasi klasifikasi paling baik akan ditetapkan menjadi minimal kemunculan penentuan atribut. Pada percobaan ini, kata yang akan diambil hanya dengan kemunculan minimal 2 kali pada dokumen komentar.
Table 11 Hasil Jumlah Kata Order (6) Berdasarkan Tabel 11 total kata pada daftar adalah 60. Kata yang muncul <2 akan dihapus. Atribut yang dihasilkan ialah :
Table 12 Data Atribut
Status A2 Bisa A8 Konfirmasi A14 Belanja A20 Terimakasi
h A3 Tidak_bisa A9 Kemarin A15 Retur A21
Zalora A4 Sedih A10 Maaf A16 Senyum A22
Lakukan A5 Barang A11 Ganti A17
Batal A6 Sudah_sampai A12 Bayar A18
2.1.3 Metode Klasifikasi
Metode klasifikasi diterapkan menggunakan tools miner KNIME. Terdapat tiga metode klasifikasi yang akan digunakan pada penelitian ini. Diantaranya naïve bayes, k-NN dan decision tree. 2.1.3.1 Metode Naïve Bayes
Metode naïve bayes merupakan metode yang digunakan untuk mengkasifikasikan data komentar untuk memperoleh sentimen analisis. Untuk melakukan klasifikasi sentimen akan menggunakan data hasil preprocessing pada Tabel 3.9. terdapat sepuluh data training dan satu data testing.
Table 13 Data Hasil Preprocessing
I kabar sedih kalau tidak_bisa retur bisa kirim balik kemarin kirim sedih
Negatif
4 terimakasih zalora barang udah sampe cepat senyum
Positif
6 sudah_sampai zalora pesan terimakasih Positif 7 layan cepat selalu konfirmasi kemarin sempat
nyebelin pake jasa kirim milik terbang masih pendek berkat gigih zalora semua atasi
9 maaf bayar belanja order dapat belum bayar bayar rohani sibuea uang kemana
Negatif
11 maaf udah transfer kenapa bilang order batal order bayar mandiri konfirmasi zalora layan
?
Untuk melakukan perhitungan naïve bayes diperlukan data tabel atribut untuk melihat hasil training model probabilitas.
Table 14 Data Atribut
Order A1 Pesan A7 Cepat A13 Kirim A19
Status A2 Bisa A8 Konfirmasi A14 Belanja A20
Terimakasih A3 Tidak_bisa A9 Kemarin A15 Retur A21
Zalora A4 Sedih A10 Maaf A16 Senyum A22
Lakukan A5 Barang A11 Ganti A17
Batal A6 Sudah_sampai A12 Bayar A18
Tabel 15 menampilkan data training dengan menunjukkan kemunculan setiap atribut pada data training dan data testing. Angka 1 mewakilkan atribut muncul, sedangkan angka 0 mewakilkan atribut tidak muncul pada data.
Table 15 Data Training Berdasarkan Atribut Data
Perhitungan menggunakan metode naïve bayes dapat dilakukan dengan langkah-langka berikut.
a. Menghitung probabilitas pada setiap komentar terhadap sekumpulan komentar.
P(Positif) = 5/10 P(Negatif) = 5/10
b. Tahap pembelajaran klasifikasi naïve bayes untuk data training dengan menghitung nilai P ¿ ¿
Table 16 Hasil Training Model Probabilitas Dari Data Training
36 Kemunculan kata
P
¿ ¿
Positif Negatif
Order 1/103 7/ 124
Status 1/103 3/ 124
Terimakasih 5/103 3/ 124
Zalora 6/103 2/ 124
Lakukan 1/103 3/ 124
Batal 1/103 3/ 124
Pesan 2/103 2/ 124
Bisa 1/103 3/ 124
Tidak_bisa 1/103 4/ 124
Sedih 1/103 3/ 124
Barang 2/103 2/ 124
Sudah_sampai 3/103 1/ 124
Cepat 3/103 1/ 124
Konfirmasi 2/103 2/ 124
Kemaren 2/103 2/ 124
Maaf 2/103 3/ 124
Ganti 1/103 3/ 124
Bayar 1/103 4/ 124
Kirim 1/103 3/ 124
Belanja 2/103 2/ 124
c. Tahap berikutnya ialah menghitung nilai Vmap kata pada data testing yang terdapat pada data training.
Table 17 Nilai Vmap Kata yang
terdapat pada data training
Sentimen
Positif Negatif
P(Vj) 5/10 5/10
Maaf 2/103 3/ 124
Order 1/103 7/ 124
Batal 1/103 2/ 124
Order 1/103 7/ 124
Bayar 1/103 4/ 124
Konfirmasi 2/103 2/ 124
Zalora 6/103 2/ 124
Vmap 9.76 x 10-14 5.22x 10-12
Berdasarkan hasil Vmap pada Tabel 17 dapat dilihat bahwa nilai Vmap paling besar adalah pada sentimen negatif. Sehingga pada kasus ini diperoleh hasil klasifikasi sentimen data testing adalah negatif.
2.1.3.2 Metode k-NN
testing. Angka 1 mewakilkan atribut muncul, sedangkan angka 0 mewakilkan atribut tidak muncul pada data.
Table 18 Data Training Berdasarkan Atribut Data
ID A
Adapun langkah-langkah dalam menghitung sentimen menggunakan metode k-NN adalah sebagai berikut:
b. Menghitung kuadrat jarak euclid pada masing-masing atribut terhadap data sampel yang diberikan.berikut adalah perhitungan untuk data training pertama terhadap data testing.
D
1
=
√
(1
−
1
)2+
(1
−
0
)2+
(1
−
0
)2+
(0
−
1
)2+
(0
)2+
(0
−
1
)2+
¿
(0
)2+
…
+
(0
−
1
)2+
(0
)2+
(0
−
1
)2+
(0
)2+(
0
−
1
)
2Lakukan hal yang sama untuk tiap data training kedua hingga kesepuluh terhadap data testing. Hasil perhitungan tiap data training dapat dilihat pada Tabel 19.
Table 19 Hasil Perhitungan k-NN c.
Tahap selanjutnya ialah mengurutkan hasil perhitungan k-NN yang memiliki nilai jarak euclid terkecil hingga terbesar.
Table 20 Hasil Klasifikasi Jarak Euclid d.
Setelah diurutkan, kategori sentimen dikumpulkan berdasarkan tetangga terdekat dengan nilai k adalah 5.
Table 21 Memilih Jarak Euclid Terdekat e.
Berdasarkan hasil perhitungan jarak euclid terdekat, dapat diperdiksi bahwa data testing memiliki jarak terdekat dengan atribut sentimen negatif. Diketahui D9, D8, D1, D10 adalah data
D1 D2 D3 D4 D5 D6 D7 D8 D9 D10
2,64 2,82 3,46 2,82 2,64 2,82 2,64 2,23 2 2,64
D 9
D8 D1 D5 D7 D10 D2 D4 D6 D3
2 2,23 2,64 2,64 2,64 2,64 2,82 2,82 2,82 3,4 6
D 9
D8 D1 D5 D7 D10 D2 D4 D6 D3
training dengan label sentimen negatif. Sedangkan D5 memiliki label sentimen positif.
2.1.3.3 Metode Decision Tree
Dalam perhitungan decision tree, dilakukan pehitungan entropy. Dari data training diketahui jumlah data adalah 10, sentimen positif 5 record dan negatif 5 record.
a. Perhitungan Entropy
Entropy= (-5/10 . log 2 (5/10) + -5/10 . log 2 (5/10)) = 0.602
b. Menghitung nilai Gain setiap atribut data seperti pada Tabel 22. Nilai gain tertinggi yang dijadikan root atau akar pohon. Berdasarkan Tabel 3.15 diketahui nilai gain tertinggi adalah pada D9. Sehingga D9 menjadi root, yaitu sentimen negatif.
Table 22 Perhitungan decision tree algrotima C4.5
A3 6 4 2 0.92
A6 2 0 2 0
A9 3 0 3 0
A11 2 1 1 0.5
A14 2 1 1 0.5
A16 3 1 2 0.92
A17 2 0 2 0
D9 0.529
A1 6 0 6 0
A16 3 1 2 0.92
A18 3 0 3 0
A20 2 1 1 0.5
D10 0.473
A4 6 5 4 0.64
A11 2 1 1 0.5
A20 2 1 1 0.5
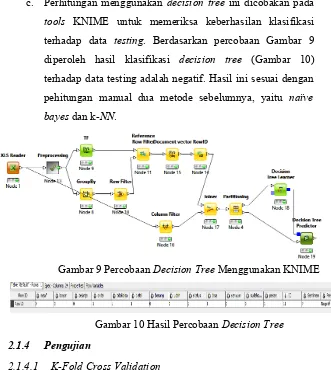
Gambar 10 Hasil Percobaan Decision Tree
Gambar 9 Percobaan DecisionTree Menggunakan KNIME c. Perhitungan menggunakan decisiontree ini dicobakan pada
tools KNIME untuk memeriksa keberhasilan klasifikasi terhadap data testing. Berdasarkan percobaan Gambar 9 diperoleh hasil klasifikasi decision tree (Gambar 10) terhadap data testing adalah negatif. Hasil ini sesuai dengan pehitungan manual dua metode sebelumnya, yaitu naïve bayes dan k-NN.
2.1.4 Pengujian
2.1.4.1 K-Fold Cross Validation
fold. Berikut merupakan skenario uji akurasi dengan metode 5-fold cross validation:
Table 23 Tabel Skenario Uji Stabilitas dengan 5-fold cross validation
Fold
Data
Subset
Fold 1
Training
S2, S3, S4, S5, S6, S7, S8, S9, S10
Testing
S1
Fold 2
Training
S1, S3, S4, S5, S6, S7, S8, S9, S10
Testing
S2
Fold 3
Training
S1, S2, S4, S5, S6, S7, S8, S9, S10
Testing
S3
Fold 4
Training
S1, S2, S3, S5, S6, S7, S8, S9, S10
Testing
S4
Fold 5
Training
S1, S2, S3, S4, S6, S7, S8, S9, S10
Testing
S5
Tahap pengujian dengan menggunakan metode 5-fold cross validation membagi dataset yang awalnya berjumlah 50 data akan dibagi menjadi 5 subset masing-masing subset berjumlah 10 data. Pada fold pertama terdapat kombinasi 9 subset yang berbeda digabung dan digunakan sebagai data training, sedangkan 1 subset digunakan sebagai data testing, selanjutnya proses training dan testing dilakukan sampai fold kelima. Selanjutnya untuk menghitung tingkat akurasinya menggunakan confusion matrix.
2.1.4.2 Confusion Matrix
jumlah berapa kali pengujian nilai k frequent itemset hingga
diperoleh hasil errorrate paling rendah dari confusion matrix. Table 24 Contoh hasil data aktual dan prediksi
No Label aktual
D
ib
an
di
ng
ka
n
Label prediksi
1 Negatif Negatif
2 Negatif Negatif
3 Negatif Negatif
4 Positif Positif
5 Positif Positif
6 Positif Positif
7 Positif Negatif
8 Negatif Positif
9 Negatif Negatif
10 Positif Positif
Table 25 Tabel Confusion Matrix
Akurasi=
5
6
+
+
5
6
∗
100 %
=
83,3 %
Hasil Prediksi Positif Negatif
Positif 5 1
Precision:
True Positive =
5
5
+
1
∗
100 %
=
83,3 %
True Negative =
1
5
+
5
∗
100 %
=
83,3 %
BAB IV
PENGUJIAN DAN ANALISIS 3.1 Implementasi
Penelitian dilakukan dengan menggunakan beberapa aplikasi open source. Crawling data komentar dilakukan dengan Ms.Excel, pemrosesan text mining dengan KNIME, web server Xampp untuk menyimpan data kata dasar database hingga visualisasi data dengan kombinasi tabel pivot dan tabel kembali menggunakan Ms.Excel. 3.1.1 Data Latih
Data latih diperoleh dari hasil crawling page toko online Zalora dan BerryBenka. Jumlah data BerryBenka yang diperoleh 8.900 baris dan Zalora 5.400 baris. Jumlah ini mengalami penyusutan saat dilakukan seleksi komentar yang mengandung sentimen. Penyusutan jumlah dikarenakan terdapat status admin, komentar iklan, komentar pertanyaan, dan komentar yang tidak ada hubungannya dengan pelayanan dan produk. Jenis komentar tersebut tidak menjadi data latih.
Table 26 Data keyword hasil FIM untuk Zalora produk
Baju Barang Beli Busana Celana Kacam
ata Kapok
Model Pakaian Ransel Sandal Sepatu Topi Tshirt
Belanja Biru Cardigan Casual Diskon Dress Fashion
Heels Kemeja Muslim Produk Sendal Size Sweater
Warna Wanita Wedges Flat Hijab Jaket Kaos
Mudah Kapok Kecewa Kekecilan Mantab Keren Bahan
Gamis Ukuran Sesuai
Table 27 Data keyword hasil FIM untuk Zalora layanan
Nunggu Order Pesan Tanggap Terimaka
sih
Bantua n
Batal
Belum Cancel Chat Datang Balas Kirim Proses
Inbox Info Komplain Konfirm
asi Layan Message Sampai
Ongkir Bayar Pemesanan Please Refund Resi Tolong
Tracking Transfer Tukar Sudah Website
Table 28 Data keyword hasil FIM untuk Berrybenka produk
Fashion Jeans Suka Bagus Baju Belanja Bigsize
Blazer Cantik Coklat Detail Diskon Dress Gamis
Gambar Hitam Jogger Jumpsuit Kalung Legging Lucu
Love Heart Mahal Pants Produk Sepatu Shirt
Style Ukuran Berlubang Beauty Gaya Size Stock
Table 29 Data keyword hasil FIM untuk Berrybenka layanan
Ongkir Overload Pesan Recomm Reply Cepat Tolong
Balas Barang Batal Belum Cancel Kirim Respon
Email Tidak Help Mau Terimakasih Please Order
Bayar Resi Susah Tanggap Transfer Konfirm
asi Telat
komentar menjadi kata yang sesuai dengan penulisan EYD. Proses ini sangat membantu preprocessing nantinya.
Table 30 Data latih Zalora produk dan layanan
I D
Komentar Sentime
n 1 selalu puas belanja disini,,,ukuran,,bahan,harga,, warnadll
pokoe top Positif
2 terimakasih zalora,pelayanannya memuaskan harga oke barang sesuai pesanan,dapet potongan lagi,recomended lahh
Positif
3 terimakasih zalora. cs na keren. omelanku ditanggapi terus. tiap hari aku ditelp sampai pesananku nyampek. tidak jadi nyesel belanja di zalora.
pelayanan na cepat bgt. selalu konfirmasi. Cuma kemarin sempat nyebelin krn pake jasa pengiriman yg memiliki jam terbang yg masih pendek. Tapi berkat kegigihan cs zalora, semua teratasi. terimakasih . hebat
Positif
4 Gak sia sia gua order , barang nya bagus seperti digambar
terimakasih min .. fast respon lagi kalo ada masalah . Positif
5 Min, barang nya bagus sama nyampe nya cepet. Jadi pelanggan setia nih kaya nya. senang
Positif
6 Kecewa banget belanja di zalora...proses pengirimannya atas order tgl 24 juni...tapi sampai hari ini tidak jelas tuh barangnya...masa solusinya refund...emang gitu ya cara zalora jual barang?? Bayar pake CC, trus nanti suruh refund???
Negatif
7 layan cepat selalu konfirmasi kemarin sempat nyebelin pake jasa kirim milik terbang masih pendek berkat gigih zalora semua atasi terimakasih
Positif
8 Hi Zalora team, sy kecewa no order 208548958 yg dijanjikan oleh Zalora pasti datang sebelum lebaran ternyata sampai sekarang belum tiba.. Padahal sy berada di wilayah jabodetabek dan menurut info barang dikirim oleh kurir zalora sedih
Negatif
9 Susah bggggggt si mau pesen... sy ud tlfn ke zalora ..ktny sruh msuk ke link Zalora dot co id flash promo-xl .... tp tetep q g bsa gunaen voucherny tolong donng kirimin link ny biar q bsa lngsung msuk
Negatif
Gambar 11 Data Komentar Sebelum Preprocessing
Gambar 12 Punctuation and Number Filter datang2 pesanan saya,,saya kecewa ini yang nelpon saya janjiin ke saya 02150321388 saya kecewa sudah 5 hari saya tunguin mn tidak ada barangnya
3.1.2 Punctuation and Number Filter
Gambar 13 Hasil Punctuation and Number Filter
Gambar 15 Hasil Case Folding and Stopword Removal Gambar 14 Case Folding and Stopword Removal
3.1.3 Case Folding and Filtering/Stopword Removal
Case folding dilakukan untuk menyamakan format huruf menjadi huruf kecil pada dokumen. Stopwordremoval menggunakan node stop word filter dengan melakukan attach file .txt yang sudah berisi list kata-kata tidak penting untuk dibandingkan dengan data komentar. Apabila terdapat kata pada komentar sama dengan kata yang ada dalam list stopword maka kata tersebut akan dihapus. Sehingga, dokumen hanya akan berisi kata-kata yang memungkinkan menjadi kata sentimen pada komentar.
3.1.4 Stemming
Gambar 16 Stemming Java Snippet
Gambar 17 Tampilan Code Pada Editor Java Snippet
Kode stemming Bahasa Indonesia terdiri dari beberapa 5 method utama yang berfungsi menghapus imbuhan di awal dan di akhir kata. Setiap kata pada data latih akan dicek apakah sebuah kata
dasar. Apabila terdapat kata yang terdeteksi memiliki imbuhan, maka akan masuk ke dalam proses stemming dengan memeriksa apa huruf yang mengawali atau pun yang mengakhiri kata tersebut. Sehingga diperoleh kata dasar dari kata yang distemming tersebut. Pada
Gambar 19 Rangkaian Proses Convert Negation 3.1.5 Convert Negation
Convert negation dilakukan dengan menghapus spasi diantara kata-kata yang mengandung memiliki makna kebalikan. Seperti kata tidak sesuai, tidak bagus, tidak sampai, tidak datang menjadi tidaksesuai, tidakbagus, dan seterusnya.
Gambar 21 Proses Frequent Itemset
dihitung sebagai satu kata bernilai negatif dan ‘bagus’ dihitung sebagai satu kata positif. Maka nilai sentimen pada komentar tersebut akan imbang. Sehingga, perhitungan klasifikasi dapat mengalami penurunan keakuratannya. Sampai pada prosess convert negation, preprocessing selesai dilakukan.
3.1.6 Frequent Itemset
FIM atau pemilihan atribut dilakukan dengan menggunakan node tf dan dikombinasikan dengan node GroupBy. Tf digunakan untuk mendapatkan nilai frequent term relative dari suatu kata sentimen.
Proses FIM sendiri terdiri dari serangkaian proses penting diantaranya :
1. BoW creator : membagi-bagi kata berdasarkan spasi sehingga diperoleh setiap kata pada tiap komentar. Proses ini disebut juga sebagai bag of words. Hasilnya adalah satu kata yang berdiri sendiri, bukan kalimat. 2. Term to String : node ini berfungsi mengkonversikan
Gambar 22 Hasil Term Frequent ‘term’. Pada kondisi ini, term tidak bisa diproses ketahap berikutnya sehingga harus dijadikan String.
3. Tf : Term frequent berfungsi menghitung nilai term relative / minimum support masing-masing kata hasil BoW. Semakin sering kata muncul pada dokumen, maka nilai term relative semakin besar. Nilai term relative adalah 0-1.
4.
GroupBy : node ini berperan untuk melihat kesamaan kata pada BoW. Jika ada kata yang berulang, maka kata tersebut dijadikan satu grup. Artinya pengulangan kata tidak akan terjadi dan setiap kata akan dihitung berapa kali kata tersebut muncul pada dokumen.
Gambar 23 Hasil GroupBy
Gambar 24 Tampilan hasil Document Vector 1. Hasil Tf dan GroupBy digabungkan pada node Reference
Row Filter untuk menyamakan Row ID kata yang telah dihitung dengan cara masing-masing. Sehingga kata yang sudah ditentukan minimal kemunculannya akan tersimpan bersamaan dengan nilai term relative-nya. Hal ini penting dilakukan agar data dokumen tidak tertukar.