BAB I
PENDAHULUAN
1.1 Pengembangan Produk
Produk baru diartikan sebagai produk baru bagi perusahaan, modifikasi dari produk yang sudah ada, duplikat dari produk pesaing, produk yang diakuisisi dan produk asli innovatif. Produk baru diperkirakan bisa memberi sebuah proporsi yang tinggi bagi pertumbuhan perusahaan dan kadang-kadang memberikan kontribusi utama terhadap laba bisnis keseluruhan.
Dalam perencanaan produk, produk harus dipandang sebagai pemecahan masalah bagi konsumen, dimana jika seorang konsumen membeli sebuah produk mereka dapat memperoleh manfaat dari penggunaan produk tersebut. Dan yang terpenting disini adalah bagaimana konsumen percaya bahwa suatu produk dapat memenuhi kebutuhannya, bukan bagaimana penjual memandang produk tersebut. Jika kebutuhan konsumen sudah terpenuhi, diharapkan timbul kepuasan dalam diri mereka sehingga dimasa yang akan datang mereka akan melakukan pembelian berikutnya terhadap produk yang sama. Beberapa faktor penting yang perlu diperhatikan dalam perencanaan produk baru, yaitu :
1. Pengetahuan tentang kebutuhan dan keinginan konsumen lengkap. 2. Sumber daya yang mendukung terhadap pengembangan produk baru. 3. Perkiraan penyimpangan produk baru dalam memenuhi pasar sasaran
4. Perkiraan biaya yang dibutuhkan dalam pengembangan dan produksi produk baru.
5. Antisipasi terhadap reaksi para pesaing.
Terdapat empat tipe dasar dalam program pengembangan produk, yaitu : 1. Modifikasi produk lini.
2. Diluar produk lini/ produk substitusi. 3. Produk komplemen
4. Produk Innovasi
Produk baru berpeluang menawarkan nilai superior ke customer dan secara total produk baru dapat meningkatkan keberadaan produk.
1. Jenis-jenis produk baru :
Perkenalan barang atau jasa baru bisa diklasifikasikan menjadi : Benar-benar baru bagi pasar dan luasnya nilai yang disiptakan, menghasilkan jenis-jenis produk baru berikut ini :
a. Innovasi transformasional, produk yang secara radikal baru dan penciptaan nilai yang substansial.
b. Innovasi substansial, produk yang secara significan baru dan menciptakan nilai penting untuk customer.
c. Innovasi incremental, innovasi, produk baru yang menyediakan peningkatan performans atau nilai yang diterima lebih baik (atau biaya lebih rendah).
Sebuah perusahaan yang berinisiatip mengembangkan produk baru dapat melakukan innovasi dalam satu atau lebih dari ketiga kategori diatas. Kenyataannya, banyak produk baru merupakan perluasan dari jalur produk yang ada dari total produk baru yang dihasilkan.
2. Menemukan peluang nilai customer
pasar membantu untuk mengetahui segmen yang menawarkan peluang produk baru ke organisasi. Kepuasan konsumen mengindikasikan seberapa baik pengalaman menggunakan produk dibandingkan dengan nilai yang diharapkan oleh pembeli.
a. Nilai konsumen,
Tujuan analisis nilai customer adalah mengidentifikasi kebutuhan : Produk baru
Peningkatan produk yang ada. Peningkatan dalam proses produksi Peningkatan layanan pendukung
b. Kapabilitas yang cocok untuk peluang nilai,
Setiap peluang nilai harus dipertimbangkan pada saat organisasi mempunyai kapabilitas untuk membawa nilai customer yang superior. Organisasi secara normal akan mempunyai kapabilitas yang dibutuhkan perluasan lini produk dan tambahan peningkatan. Pengembangan produk untuk sebuah kategori produk baru membutuhkan penilaian pada kapabilitas organisasi mengenai kategori baru.
c. Innovasi transformasional
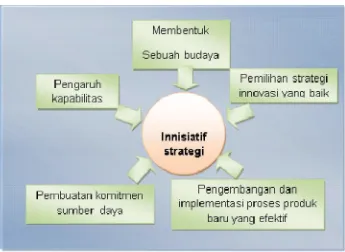
3. Karakteristik innovator yang berhasil
Gambar 1 : Karakteristik Innovator yang Berhasil
Tahap-Tahap Dalam Perencanaan Produk Baru
Perencanaan produk baru mencakup semua kegiatan perencanaan dari produsen dan penyalur untuk menyesuaikan produknya dengan permintaan pasar dan menentukan susunan produk lininya. Adanya perencanaan produk baru ini akan mendorong perusahaan meningkatkan perolehan labanya atau paling tidak membuat laba menjadi stabil.
Tahap-tahap dalam perencanaan produk baru terdiri dari :
juga apakah akan memodifikasi produk lama, membuat terobosan baru, atau meniru pesaing, ide baru bias dicari diberbagai sumber, misalnya dari konsumen, pesaing,ilmuan dll.
2. Penyaringan ide. Tujuan langkah ini adalah untuk menyaring ide ide yang buruk agar nantinya ide yang akan dikembangkan bisa realistis dan memungkinkan bisa diwujudkan secara nyata.
3. Pengembangan dan pengujian konsep. Dalam hal ini ide yang menarik akan dibuat konsep produk yang bias diuji, dari ide produk bias dibuat beberapa konsep, lalu ilmuan menguji apakah sudah sesuai dengan apa yang menjadi keinginan konsumen, apabila konsepnya sesuai dengan tujuan maka bisa dilakukan pabrikasi,,dan jika belum maka tim pengembang membuat konsep baru dengan memperbaiki konsep yang lama.
4. Strategi pemasaran. Tahapan ini merupakan tahap perancangan pemasaran yang strategis untuk memperkenalkan produknya ke pasaran
5. Analisa bisnis. Dalam hal ini perusahaan memperkirakan biaya dan laba,serta mengevaluasi manfaat suatu produk baru dengan analisis break event agar nantinya perusahaan mengetahui berapa produk yang akan dijual agar impas dengan harga dan struktur biaya tertentu.
6. Pengembangan produk. Jika konsep produk yang sudah matang dan sudah melalui analisis bisnis maka langkah yang selanjutnya adalah mengubah konsep produk tersebut kedalam bentuk fisik, hal ini akan menjawab pertanyaan apakah produk layak secara teknis dan komersil. Departemen peneliti dan pengembang harus mengembangkan satu atau lebih konsep produk agar nantinya mendapatkan suatu model Prototype yang mewakili semua konsep produk, setelah prototype jadi maka dilakukan uji fungsional dan uji konsumen.
penanganan, penggunaan,pembelian produk kembali dan seberapa besar pasarnya.
8. Komersialisasi. Uji pemasaran memberikan cukup informasi untuk bisa mengambil keputusan apakah produk akan dilincurkan atau tidak, adapun keputusan sebelum memasrkan ,diantaranya kapan produk akan diluncurkan, target pasar mana yang akan menjadi target, dimana awal produk akan dijual, biaya yang dibutuhkan untuk pemasaran produk.
2.1 Tools yang digunakan
Dalam pengembangan produk dibutuhkan alat bantu untuk membantu dalam pengambilan keputusan oleh manajemen. Dalam buku ajar ini tools yang digunakan adalah sebagai berikut :
a. Analisis Faktor.
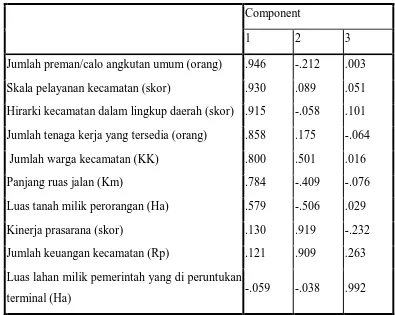
Analisis Faktor merupakan teknik analisis statistik yang bertujuan menerangkan struktur hubungan di antara variable-variabel yang diamati dengan jalan membangkitkan beberapa faktor yang jumlahnya lebih sedikit daripada banyaknya variable asal. Analisis ini dapat digunakan untuk menggambarkan hubungan-hubungan kovarian antara beberapa variabel yang mendasari tetapi tidak teramati, kuantitas random yang disebut faktor, (Johnson &Wichern, 2002).
b. Analisis Cluster
Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk
Berbeda dengan teknik multivariat lainnya, analisis ini tidak mengestimasi set variabel secara empiris sebaliknya menggunakan setvariabel yang ditentukan oleh peneliti itu sendiri. Analisis ini dapat digunakan untuk mempartisi suatu set objek menjadi dua kelompok atau lebih berdasarkan kesamaan karakteristik khusus yang dimilikinya.
c. Multidimensional Scaling (MDS)
Menurut Dilon (1984 ; 107) bahwa prosedur Multidimensional Scaling( MDS) memberikan informasi tentang hubungan yang ada antar obyek ketika dimensi dimensi evaluasi yang penting yang tidak diketahui. Dasar dari Multidimensional Scaling ini adalah asumsi yang menekankan persepsi subyek terhadap sejumlah obyek dikarenakan oleh sejumlah atribut atau dimensi. MDS dapat digunakan untuk memberikan gambaran visual dari pola kedekatan yang berupa kesamaan atau jarak diantara sekumpulan objek-objek. Penerapan MDS dapat dijumpai pada visualisasi ilmiah dan data mining dalam ilmu kognitif, informasi, pemasaran maupun ekologi.
d. Forecasting
Forecasting merupakan suatu cara atau pendekatan untuk memprediksi berapa besar peluang pasar yang tersedia di masa mendatang sehingga potensi pasar yang hendak dan sudah dimasuki itu tergambar secara proyektif ke depan. Secara garis besar terdapat dua macam metode forecasting yang biasa dilakukan, yaitu metode kualitatif yang terdiri atas teknik survey dan teknik pengumpulan opini. Sedangkan metode berikutnya adalah metode prakiraan kuantitatif, yang terdiri atas Analisis Runtut Waktu, Trend Seluler, Siklus Fluktuasi, Analisis Musiman dan Model Ekonometri.
e. Markov Chains
BAB II
TOOLS YANG DIGUNAKAN
Dalam pengembangan produk dibutuhkan alat bantu untuk membantu dalam pengambilan keputusan oleh manajemen. Dalam buku ajar ini tools yang digunakan adalah sebagai berikut :
2.1 Analisis Faktor
Analisis Faktor semakin banyak digunakan dalam penelitian, terutama dalam penelitian sosial, sebagai dampak positif perkembangan software aplikasi statistika seperti SPSS, SAS, Systat, Minitab dan sebagainya.
Konsep Dasar Analisis Faktor
Analisis Faktor merupakan teknik analisis statistik yang bertujuan menerangkan struktur hubungan di antara variable-variabel yang diamati dengan jalan membangkitkan beberapa faktor yang jumlahnya lebih sedikit daripada banyaknya variable asal.
Misalkan seorang peneliti pemasaran mempunyai seperangkat variabel nyata yang terdiri dari warna, kualitas, diskon, kemasan, pembayaran dapat dicicil, iklan, wiraniaga, barang dapat diperoleh dimana-mana, barang dapat diantar ke rumah. Ia dapat menggunakan analisis faktor untuk menemukan satu atau beberapa hipotetik (besar dan abstrak) yang mewakili variabel-variabel tersebut.
Tujuan Analisis Faktor
parsimoni) yang mempunyai penjelasan terbaik atau menghubungkan korelasi diantara variabel indikator. 2.) Mengidentifikasi, melalui faktor rotasi, solusi faktor yang paling masuk akal. 3.) Estimasi bentuk dan struktur loading, komunality dan varian unik dari indikator. 4.) Intrepretasi dari faktor umum. 5.) Jika perlu, dilakukan estimasi faktor skor. (Subash Sharma, 1996). Vektor random teramati X dengann p komponen, memiliki rata-rataμdan matrik kovarian ∑ . Model analisis faktor adalah sebagai berikut :
Atau dapat ditulis dalam notasi matrik sebagai berikut :
pxl komunalitas ke – i yang merupakan jumlah kuadrat dari loading variabel ke – i pada m common faktor (Johnson &Wichern, 2002), dengan rumus :
Penggunaan analisis factor menghasilkan pola hubungan seperti berikut :
Model analisis faktor menjelaskan bahwa vektor acak X tergantung secara linier pada beberapa variable acak yang tidak teramati F1, F2, F3, ….. Fm, yang disebut faktor-faktor bersama (common factor). Misal : Model analisis faktor-faktor tersebut adalah : X1 = c11F1+c12F2+……+C1mFm + e1
X2 = c21F1+c22F2+……+C2mFm + e2
Xp = cp1F1+cp2F2+……+CpmFm + ep
Dimana : F
j : (j=1,2,3,…..,m) merupakan faktor bersama ke j.
C
ij : (i=1,2,3,…..,p ; j=1,2,3,….,m) merupakan parameter yang merefleksikan
pentingnya faktor ke j dalam komposisi dari respon ke I dalam analisis faktor disebut sebagai bobot (loading) dari respon ke-I pada faktor bersama ke-j. e
i : (i=1,2,3,….,p) merupakan galat (error) dari respon ke-I dalam analisi faktor
disebut sebagai faktor spesifik ke-I yang bersifat acak.
Persamaan diatas dapat ditulis :
X = C F + e
dimana : X’ = (X
1,X2,X3, ……. Xp)
C =
e’ = (e
1, e2, e3, ……. ep)
Matrik C diatas dalam analisis faktor disebut matrik bobot faktor (matrix of factor loadings )
Struktur peragam untuk model analisis faktor dinyatakan dalam persamaan berikut : Var (Xi) = + + ….+ + ᴪ i atau
Var (Xi) =ℎ + ᴪ i
Dimana :
ℎ =
Dari rumus diatas terlihat bahwa ragam dari variabel Xi diterangkan oleh dua
komponen hi dan ᴪ i. komponen hi disebut sebagai komunalitas yang menunjukkan
proporsi ragam dari variabel respon Xi yang diterangkan oleh m faktor secara
bersama-sama, sedangkan komponen ᴪ I merupakan proporsi ragam dari variabel
respon Xi yang disebabkan oleh faktor spesifik (error). Dalam menduga parameter
dalam analisis faktor terdapat beberapa metode. Pada sebagian besar analisis terapan c11 c12 ….. c1m
c21 c21 ….. c2m
dan pada proses komputasi aplikasi komputer menggunakan metode komponen utama (principles component method).
2.2 Analisis Cluster
Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya. Analisis cluster mengklasifikasi objek sehingga setiap objek yang paling dekat kesamaannya dengan objek lain berada dalam cluster yang sama. Cluster-cluster yang terbentuk memiliki homogenitas internal yang tinggi dan heterogenitas eksternal yang tinggi. Berbeda dengan teknik multivariat lainnya, analisis ini tidak mengestimasi set variabel secara empiris sebaliknya menggunakan setvariabel yang ditentukan oleh peneliti itu sendiri.
Fokus dari analisis cluster adlah membandingkan objek berdasarkan set variabel, hal inilah yang menyebabkan para ahli mendefinisikan set variabel sebagai tahap kritis dalam analisis cluster. Set variabel cluster adalah suatu set variabel yang merpresentasikan karakteristik yang dipakai objek-objek. Bedanya dengan analisis faktor adalah bahwa analisis cluster terfokus pada pengelompokan objek sedangkan analisis faktor terfokus pada kelompok variabel.
Cara Kerja Analisis Cluster
Secara garis besar ada tiga hal yang harus terjawab dalam proses kerja analisis cluster, yaitu :
1. Bagaimana mengukur kesamaan ?
Ada tiga ukuran untuk mengukur kesamaaan antar objek, yaitu ukuran korelasi, ukuran jarak, dan ukuran asosiasi.
2. Bagaimana membentuk cluster ?
Prosedur yang diterapkan harus dapat mengelompokkan objek-objek yang memiliki kesamaan yang tinggi ke dalam sutau cluster yang sama.
3. Berapa banyak cluster/kelompok yang akan dibentuk ?
Pada prinsipnya jika jumlah cluster berkurang maka homogenitas alam cluster secra otomatis akan menurun.
Proses Analisis Cluster
Tahap Pertama : Tujuan Analisis Cluster
Tujuan utama analisis cluster adalah mempartisi suatu set objek menjadi dua kelompok atau lebih berdasarkan kesamaan karakteristik khusus yang dimilikinya. Dalam pembentukan kelompok/cluster dapat dicapai tiga tujuan, yaitu :
A. Deskripsi klasifikasi (taxonomy description)
Penerapan anallisis cluster secara tradisisonal bertujuan mengeksplorasi dan membentuk suatu klasisfikasi/taksonomi secara empiris. Karena kemampuan partisinya analisis cluster dapat diterapkan secara luas. Meskipun secara empiris merupakan teknik eksplorasi analisis cluster dapat pula digunakan untuk tujuan konfirmasi.
a. Penyederhanaan Data
b. Identifikasi Hubungan (Relationship Identification)
Hubunganantar objek diidentifikasi secara empiris. Struktur analisis cluster yang sederhana dapat menggambarkan adanya hubungan atau kesamaan dan perbedaan yang tidak dinyatakan sebelumnya.
Pemilihan pada Pengelompokan Variabel
Tujuan analisis cluster tidak dapat dipisahkan dengan pemilihan variabel yang digunakan untuk menggolongkan objek ke dalam clucter-cluster. Cluster yang terbentuk merefleksikan struktur yang melekat pada data seperti yang didefinisikan oleh variabel-variabel. Pemilihan variabel harus sesuai dengan teori dan konsep yang umum digunakan dan harus rasional. Rasionalitas ini didasarkan pada teori-teori eksplisit atau penelitian sebelumnya. Variabel-variabel yang dipilih hanyalah variabel yang dapat mencirikan objek yang akan dikelompokkan dan secara spesifik harus sesuai dengan tujuan analisis cluster.
Tahap Kedua : Desain Penelitian dalam Analisis Cluster
Tiga hal penting dalam tahap ini adalah pendeteksian outlier, mengukur kesamaan, dan standarisasi data.
A. Pendeteksian Outlier
Outlier adlah suatu objek yang sangat berbeda dengan objek lainnya. Outlier dapat digambarkan sebagai observasi yang secara nyata kebiasaan, tidak mewakili populasi umum, dan adanya undersampling dapat pula memunculkan outlier. Outlier menyebabkan menyebabkan struktur yang tidak benar dan cluster yang terbentuk menjadi tidak representatif.
B. Mengukur Kesamaan antar Objek
a. Ukuran Korelasi
Ukuran ini dapat diterapkan pada data dengan skala metrik, namun jarang digunakan karena titik bertnya pada nilai suatu pola tertentu, padahal tisik berat analisis cluster adalah besarnya objek. Kesamaan antar objek dapat dilihat dari koefisien korelasi antar pasangan objek yang diukur dengan beberapa variabel.
b. Ukuran Jarak
Merupakan ukuran yang paling sering digunakan. Diterapkan untuk data berskala metrik. Sebenarnya merupakan ukuran ketidakmiripan, dimana jarak yang besar menunjukkan sedikit kesamaan sebaliknya jarak yang pendek/kesil menunjukkan bahwa suatu objek makin mirip dengan objek lain. Bedanya dengan ukuran korelasi adalah bnahwa ukuran jarak fokusnya pada besarnya nilai. Cluster berdasarkan ukuran korelasi bisa saja tidak memiliki kesamaan nilai tapi memiliki kesamaan pola, sedangkan cluster dberdasrkan ukuran jarak lebih memiliki kesamaan nilai meskipun polanya berbeda.
Ada beberapa tipe ukuran jarak antara lain jarak Euklidian, jarak city-Box, dan jarak Mahalanobis. Ukuran yang paling sering digunakan adalah jarak Euklidian. Jarak Euklidian adalah besarnya jarak suatu garis lurus yang menghubungkan antar objek. Misalkan ada dua objek yaitu A dengan koordinat ( ) dan B dengan koordinat ( ) maka jarak antar kedua objek tersebut dapat diukur dengan rumus ....
c. Ukuran Asosiasi
C. Standarisasi Data
a. Standarisasi Variabel
Bentuk paling umum dalam standarisasi variabel adalah konversi setiap variabel terhadap skor atandar ( dikenal dengan Z score) dengan melakukan substraksi nilai tengan dan membaginyadengan standar deviasi tiap variabel.
b. Standarisasi Data
Berbeda dengan standarisasi variabel, standarisasi ndata dilakukan terhadap observasi/objek yang akan dikelompokkan.
Tahap Ketiga : Asumsi-asumsi dalam Analisis Cluster
Seperti hal teknik analisis lain,analisis cluster juga menetapkan adanya suatu asumsi. Ada dua asumsi dalam analisis cluster, yaitu :
A. Kecukupan Sampel untuk merepresentasikan/mewakili Populasi
Biasanya suatu penelitian dilakukan terhadap populasi diwakili oleh sekelompok sampel. Sampel yang digunakan dalam analisis ckuster harus dapat mewakili populasi yang ingin dijelaskan, karena analisis ini baik jika sampel representatif. Jumlah sampel yang diambil tergantung penelitinya, seorang peneliti harus yakin bahwa sampil yang diambil representatif terhadap populasi.
B. Pengaruh Multukolinieritas
Tahap Keempat : Proses Mendapatkan Cluster dan Menilai kelayakan secara
keseluruhan
Ada dua proses penting yaitu algoritma cluster dalam pembentukan cluster dan menentukan jumlah cluster yang akan dibentuk. Keduanya mempunyai implikasi substansial tidak hanya pada hasil yang diperoleh tetapi juga pada interpretasi yang akan dilakukan terhadap hasil tersebut.
Algoritma Cluster
Algoritma cluster harus dapat memaksimalkan perbedaan relatif cluster terhadap variasi dalam cluster. Dua metode paling umum dalam algoritma cluster adalahmetode hirarkhi dan metode non hirarkhi. Penentuan metode mana yag akan dipakai tergantung kepada peneliti dan konteks penelitian dengan tidak mengabaikan substansi, teori dan konsep yang berlaku. Keduanya memiliki kelebihan sendiri-sendiri. Keuntungan metode hirarkhi adalah cepat dalam proses pengolahan sehingga menghemat waktu, namun kelemahannya metode ini dapat menimbulkan kesalahan. Selain itu tidak baik diterapkan untuk menganalisis sampel dengan ukuran besar. Metode Non Hirarkhi memiliki keuntungan lebih daripada metode hirarkhi. Hasilnya memiliki sedikit kelemahan pada data outlier, ukuran jarak yang digunakan, dan termasuk variabel tak relevan atau variabel yang tidak tepat. Keuntungannya hanya dengan menggunakan titik bakal nonrandom, penggunaan metode non hirarkhi untuk titik bakal random secara nyata lebih buruk dari pada metode hirarkhi.
Alternatif lain adalah dengan mengkombinasikan kedua metode ini. Pertama gunakan metode hirarkhi kemudian dilanjutkan dengan metode non hirarkhi.
A. Metode Hirarkhi
yang paling tidak sama dipisah dan dibentuk cluster-cluster yang lebih kecil. Proses ini dilakukan hingga tiap observasi menjadi cluster sendiri-sendiri.
Hal penting dalam metode hirarkhi adalah bahwa hasil pada tahap sebelumnya selalu bersarang di dalam hasil pada tahap berikutnya, membentuk sebuah pohon.
Ada lima metode aglomerasi dalam pembentukan cluster, yatiu : a. Pautan Tunggal (Single Linkage)
Metode ini didasarkan pada jarak minimum. Dimulai dengan dua objek yang dipisahkan dengan jarak paling pendek maka keduanya akan ditempatkan pada cluster pertama, dan seterusnya. Metode ini dikenal pula dengan nama pendekatan tetangga terdekat.
b. Pautan Lengkap (Complete Linkage)
Disebut juga pendekatan tetangga terjauh. Dasarnya adalah jarak maksimum. Dalam metode ini seluruh objek dalam suatu cluster dikaitkan satu sama lain pada suatu jarak maksimuma atau dengan kesamaan minimum. c. Pautan Rata-rata (Average Linkage)
Dasarnya adalah jarak rata-rata antar observasi. pengelompokan dimulai dari tengan atau pasangan observasi dengan jarak paling mendekati jarak rata-rata.
d. Metode Ward (Ward’s Method)
Dalam metode ini jarak antara dua cluster adalah jumlah kuadrat antara dua cluster untuk seluruh variabel. Metode ini cenderung digunakan untuk mengkombinasi cluster-cluster dengan jumlah kecil.
e. Metode Centroid
B. Metode Non Hirarkhi
Masalah utama dalam metoda non hirarkhi adalah bagaimana memilih bakal cluster. Harus disadari pengaruh pemilihan bakal cluster terhadap hasil akhir analisis cluster. Bakal cluster pertama adalah observasi pertama dalam set data tanpa missing value. Bakal kedua adalah observasi lengkap berikutnya (tanpa missing data) yang dipisahkan dari bakal pertama oleh jarak minimum khusus.
Ada tiga prosedur dalam metode non hirarkhi, yaitu : a. Sequential threshold
Metode ini dimulai dengan memilih bakal cluster dan menyertakan seluruh objek dalam jarak tertentu. Jika seluruh objek dalam jarak tersebut disertakan, bakal cluster kedua terpilih, kemudian proses terus berlangsung seperti sebelumnya.
b. Parallel Threshold
Metode ini memilih beberapa bakal cluster secara simultan pada permulaannya dan menandai objek-objek dengan jarak permulaan ke bakal terdekat.
c. Optimalisasi
Metode ketiga ini mirip dengan kedua metode sebelumnya kecuali pada penandaan ulang terhadap objek-objek.
Tahap Kelima : Interpretasi terhadap Cluster
Tahap interpretasi meliputi pengujian tiap cluster dalam term untuk menamai dan menandai dengan suatu label yang secara akurat dapat menjelaskan kealamian cluster. Proes ini dimulai dengan suatu ukuran yang sering digunakan yaitu centroid cluster. Membuat profil dan interpretasi cluster tidak hanya tidak hanya untuk memoeroleh suatu gambaran saja melainkan pertama, menyediakan suatu rata-rata untuk menilai korespondensi pada cluster yang terbentuk, kedua, profil cluster memberikan araha bagi penilainan terhadap signifikansi praktis.
Tahap Keenam: Proses Validasi dan Pembuatan Profil (PROFILING) Cluster
A. Proses validasi solusi cluster
Proses validasi bertujuan menjamin bahwa solusi yang dihasilkan dari analisis cluster dapat mewakili populasi dan dapat digeneralisasi untuk objek lain. Pendekatan ini membandingkan solusi cluster dan menilai korespondensi hasil. Terkadang tidak dapat dipraktekkan karena adanya kendala waktu dan biaya atau ketidaktersediaan ibjek untuk analisis cluster ganda.
B. Pembuatan Profil ( PROFILING) Solusi Cluster
Tahap ini menggambarkan karakteristik tiap cluster untuk menjelaskan cluster-cluster tersebut dapat dapat berbeda pada dimensi yang relevan. Titik beratnya pada karakteristik yang secara signifikan berbeda antar clustre dan memprediksi anggota dalam suatu cluster khusus.
2.3 Multidimensional Scaling (MDS)
Menurut Dilon (1984 ; 107) bahwa prosedur Multidimensional Scaling (MDS) memberikan informasi tentang hubungan yang ada antar obyek ketika dimensi dimensi evaluasi yang penting yang tidak diketahui. Dasar dari Multidimensional Scaling ini adalah asumsi yang menekankan persepsi subyek terhadap sejumlah obyek dikarenakan oleh sejumlah atribut atau dimensi. Jadi dalam subyek, untuk membedakano byekt idak hanyab erdasarkan atas dimensi tertentu saja, namun meliputi perbedaan secara keseluruhan. Ada dua macam skala Multidimensional Scaling yaitu :
1. Metric MDS, skala ini memperlakukan data input berupa jarak antara pasangan objek sebagai jarak sebenarnya.
2. Nonmetric MDS, data input yang diberikan hanya berupa urutan peringkat atau pendapat kesamaan yang diberikan subyek terhadap persepsi ketidaksamaan diantara pasangan-pasangan
obyek dan tidak dianggap sebagai jarak sebenarnya, namun berupa informasi ordinal.
Tujuan dari multidimensional scaling (MDS) adalah untuk memberikan gambaran visual dari pola kedekatan yang berupa kesamaan atau jarak diantara sekumpulan objek-objek. Penerapan MDS dapat dijumpai pada visualisasi ilmiah dan data mining dalam ilmu kognitif, informasi, pemasaran maupun ekologi.
MDS sangat popular dalam penelitian bidang pemasaran untuk perbandingan brand, dan pada psikologi MDS digunakan untuk mempelajari dimensi ciri-ciri pribadi. Penggunaan lain adalah pada aplikasi yang menggunakan ranking, rating, pembedaan persepsi, atau dalam pengambilan suara (voting).
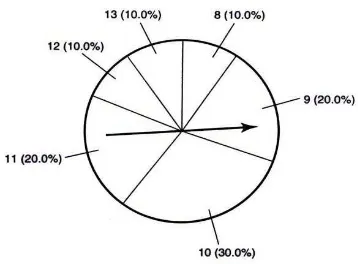
Dalam perencanaan kebutuhan data untuk menganalisa MDS memerlukan: Data kemiripan merk sebagai input Prosedur Multidimensional Scaling Data rating merk sebagai input Prosedur Property Fitting.
Langkah-langkah analisis multidimensional scaling adalah
1) Perumusan masalah, dalam perumusan masalah dibutuhkan suatu kejelasan tujuan untuk dapat menggunakan hasil MDS secara optimal,
2) Memperoleh data input, data input dari analisis MDS adalah nilai kesamaan dan ketidaksamaan antara setiap atau sebagian besar pasangan dari n objek, 3) Pemilihan prosedur MDS, prosedur MDS dapat berupa metrik dan nonmetrik, 4) Penentuan dimensi, pedoman yang disarankan untuk menentukan banyak
dimensi, yaitu penelitian sebelumnya, penginterpretasian peta dimensi, kriteria plot, dan kemudahan dalam penggunaan,
5) Penamaan dimensi dan penamaan konfigurasi,
6) Uji reliabilitas dan validitas, dua macam nilai yang dipakai untuk pengujian reliabilitas dan validitas, yaitu nilai stress dan R-square.
1. Metric Multidimensional Scaling
(similarity) atau ketidakmiripan (dissimilarity) data yang direpresentasikan secara tetap atau melalui pendekatan Euclidian distance.
Dalam classical scaling, dissimilarities (δij) diperlakukan sama dengan jarak (δij), yaitu dij = 0.Selain itu, sifat lain classical scaling yaitu non-degeneracy dan triangular unequality. Non-degeneracy berarti bahwa dii = 0, untuk setiap nilai i. Sedangkan triangular inequality menyatakan bahwa dij + dik ≥ djk, untuk setiap i, j, k. (n x n ) matriks jarak D = (dij) dikatakan Euclidean jika untuk titik x1, x2, …, xn Rp ; dij2 = (xi – xj )T (xi – xj)
2. Nonmetric Multidimensional Scaling
Dalam MDS nonmetrik mengasumsikan skala pengukuran nominal atau ordinal. Pada
kasus ini perhitungan kriteria adalah untuk menghubungkan nilai ketidaksamaan
suatu jarak ke nilai ketidaksamaan yang terdekat. Program MDS nonmetrik
menggunakan transformasi monoton (sama) ke data yang sebenarnya sehingga dapat
dilakukan operasi aritmatika terhadap nilai ketidaksamaannya, untuk menyesuaikan
jarak dengan nilai urutan ketidaksamaanya. Transformasi monoton akan memelihara
urutan nilai ketidaksamaannya sehingga jarak antara objek yang tidak sesuai dengan
urutan nilai ketidaksamaan dirubah sedemikian rupa sehingga akan tetap memenuhi
urutan nilai ketidaksamaan tersebut dan mendekati jarak awalnya. Hasil perubahan ini
disebut disparities. Disparities ini digunakan untuk mengukur tingkat ketidaktepatan
konfigurasi objek-objek dalam peta berdimensi tertentu dengan input data
ketidaksamaannya.
Pendekatan yang sering digunakan saat ini untuk mencapai hasil yang optimal dari
skala non metrik digunakan ‘Kruskal’s Least-Square Monotomic Transformation”
dimana disparities merupakan nilai rata-rata dari jarak-jarak yang tidak sesuai dengan
urutan ketidaksamaanya. Informasi ordinal kemudian dapat diolah dengan MDS
pada dimensi tertentu dan kemudian agar jarak antara objek sedekat mungkin dengan
input nilai ketidaksamaan atau kesamaannya. Koordinat awal dari setiap subjek dapat
diperoleh melalui cara yang sama seperti metoda MDS metrik dengan asumsi bahwa
meskipun data bukan jarak informasi yang sebenarnya tapi nilai urutan tersebut
dipandang sebagai variabel interval.
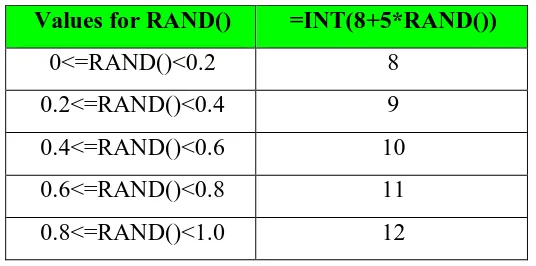
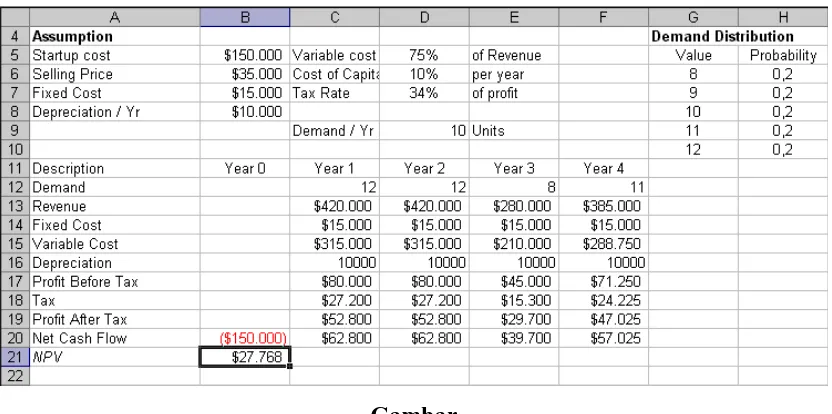
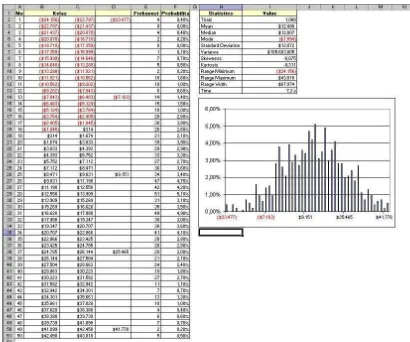
2.4 Forecasting
Forecasting permintaan dari pasar yang dimasuki oleh perusahaan adalah suatu pekerjaan yang perlu dilakukan oleh setiap manajer perusahaan dalam rangka memprediksi berapa besar peluang pasar yang tersedia di masa mendatang. Sehingga potensi pasar yang hendak dan sudah dimasuki itu tergambar secara proyektif ke depan.
Dengan melakukan forecasting permintaan pasar dengan cara yang tepat, akan dapat membantu manajer perusahaan dalam menggambarkan tersedianya potensi pasar. Jika hasil forecasting itu dapat meyakinkan para manajer perusdahaan maka akan dapat membantu menyiapkan perencanaan di bidang produksi, keuangan dan menyiapkan sarana dan prasarana pemasaran yang diperlukan dalam rangka memanfaatkan potensi pasar yang tersedia itu. Namun yang menjadi pertanyaan disini adalah bagaimana para manajer perusahaan melakukan forecasting terhadap permintaan pasar ini.
Forecasting Kualitatif
Forecasting dengan metode ini jika data kuantitatif yang berkaitan dengan faktor-faktor yang langsung mempengaruhi permintaan tidak cukup memadai. Apabila dari data yang tidak cukup memadai ini dipaksakan untuk dasar forecasting maka hasilnya diperkirakan atau dikhawatirkan terjadi bias, tidak proporsional, dan tidak memiliki relevansi yang cukup kuat. Oleh karena itu dipergunakan metode forecasting kualitatif.
Tetapi dengan metode ini dapat dipergunakan untuk mendukung metode forecasting kuantitatif. Hal ini dilakukan dalam rangka mengantisipasi jika metode kuantitatif yang biasa dilakukan berdasar data histories yang mungkin telah dilakukan itu perlu ada koreksi dari hasil metode kualitatif ini. Jadi dengan demikian metode kualitatif ini masih diperlukan dalam usaha mengoreksi hasil forecasting berdasar data historis. Karena metode kualitatif ini meliputu aspek-aspek tertentu yang paling terkini yang menyangkut perilaku permintaan dan konsumen. Justru di dalam metode kualitatif akan digali dan diselidiki fenomena terakhir yang menyangkut keinginan dan kebutuhan konsumen. Sehingga metode kualitatif merupakan kelengkapan dan penyempurnaan dari metode kuantitatif.
1. Teknik Survey
Teknik survey ini merupakan suatu alat memforecasting yang cukup penting khusunya untuk memprediksi kejadian-kejadian atau kecenderungzn-kecenderungan dalam jangka pendek mendatang ini.
a. Survey tentang budget keperluan rumah tangga masyarakat eksekutif bisnis dan pemerintahan yang sekiranya berkait dengan rencana perusahaan. Survey ini diharapkan dapat merekam keseluruhan anggaran setiap rumah tangga yang disurvey.
b. Survey mengenai barang atau jasa yang diperlukan bagi para pelaku bisnis yang akan memperdagangkan barang atau jasanya. Mereka ini mungkin pelaku bisnis yang bergerak pada bisnis distributor, pengecer atau pedagang besar.
c. Survey ini dilakukan bagi para rumah tangga umum mengenai keperluan rumah tangga, produk atau barang apa secara periodik diperlukan dan frekuensi pemenuhan yang dilakukan untuk masa-masa yang akan datang. Dari metode survey berdasar kelompok sasaran ini sebenarnya terkandung maksud dari surveyor bahwa barang dan jasa apa saja yang dibutuhkan, berapa frekuensi pemenuhan kebutuhan dan faktor-faktor apa saja yang pada umumnya yang mempengaruhi perilaku beli mereka ini. Sehingga secara tidak langsung perusahaan melihat peluang dan kendala apa saja yang bisa ditarik sebagai kepentingan bagi perusahaan atas hasil-hasil survey ini untuk memprediksi dan memperkirakan perilaku pasar dan konsumen perusahaan.
2. Sasaran Pengumpulan Data Kualitatif
Sasaran yang dituju dari pengumpulan data kualitatif ini kurang lebih sama dengan metode survey. Mereka antara lain para eksekutif, agen dan distributor, serta konsumen pada umumnya. Bahkan disini adalah sejumlah pihak yang dimintakan opini mereka, yakni para expert dibidangnya masing-masing, para konsultan manajemen dan bisnis yang relevan dengan maksud pengumpulan data dan opini ini.
barang atau jasa apa saja yang akan menjadi trend di masa dating, sumber-sumber potensi apa dan di mana, serta bagaimana sikap dan respon yang harus dikembangkan oleh perusahaan terhadap kecenderungan yang terjadi di pasar.
Metode Perkiraan Kuantitatif
1. Teknik dan Analisis Runtut Waktu
Pengertian runtut waktu sering dikonotasikan sebagai serangkaian waktu yang berurutan periodesasinya sepanjang periode di mana prakiraan permintaan diproyeksikan. Misalnya mingguan, bulanan, kuartalan dan tahunan, tergantung keinginan dari pihak-pihak yang melakukan prakiraan permintaan ini. Kalau diinginkan mingguan atau bulanan atau kuartalan dan tahunan maka periode prakiraan yang diinginkan adalah periode mingguan, biulanan, kuartalan, dan tahunan. Ini sesuai dengan kebutuhan periodik yang akan diharapokan hasilnya sebagai prediksi volume atau jumlah permintaan atau potensi pertumbuhan permintaan.
Perlu diperhatikan disini, bahwa klasifikasi waktu menurut sifat keruntutannya dapat dikelompokkan dalam empat kategori:
1. Trend Sekuler 2. Siklus Fluktuasi 3. Variasi Musim
4. Pengaruh Tak Teratur
a. Trend Sekuler
Kalau kecenderungan permintaan di tahun-tahun yang akan datang naik maka garis trend yang kita tarik cenderung menaik untuk tahun yang akan datang. Tetapi kalau kecenderungannya turun maka kita tarik garis trend menurun untuk tahun-tahun yang akan datang. Model penarikan garis semacam ini ada sejumlah data atau variabel lain ynag perlu kita jadikan sebagai data atau variabel pendukung serta asumsi yang bisa memperkuat kecenderungan garis yang telah dibuat.
b. Fluktuasi Siklus
Siklus perubahan atau naik turunnya volume permintaan selama tahun-tahun yang telah lalu dan yang akan dating,kita tarik kecenderungannya tentu disebabkan atau dipengaruhi oleh sejumlah faktor yang secara periodik dan tetap harus ada atau terjadi selam periode tahunan yang akan datang. Biasanya siklus bisa kita duga sebelumnya bahwa dengan datangnya permintaan yang meningkat pada periode tertentu sudah bisa kita prediksi kejadiannya. Begitu juga atas terjadinya penurunan permintaan oleh konsumen kita mesti dapat menduga sebelumnya pada periode tertentu selama tahun yang bersangkutan.
c. Metode Proyeksi Trend
Metode proyeksi trend ini merupakan metode yang paling sederhana dibanding dengan metode yang lainnya. Karena di dalam metode ini hanya dengan menarik garis lurus sesuai dengan kecenderungan data time series yang ada. Jika data time series yang dijadikan pijakan dalam menarik garis lurus ini ada kecenderungan meningkat, maka garis lurus yang ditarik cenderung naik sesuai dengan kecenderungan peningkatan yang terjadi atau yang akan terjadi. Rumus yang dipakai dalam menarik garis lurus ini adalah:
Di mana St merupakan nilai variabel yang akan diramal pada periode t. So adalah nilai estimasi dari time series (nilai konstanta dari fungsi forecast) pada tahun dasar. Dan b merupakan koefisien kecenderungan kemiringan garis forecast yang akan ditarik, atau angka absolut pertumbuhan atau penurunan per periode. Dan t merupakan lama waktu di mana time series dalam periode yang diramalkan.
d. Metode Variasi Musim
Melakukan prakiraan volume permintaan konsumen di waktu-waktu yang akan datang dapat didasarkan pada gelombang musiman yang melekat pada kultur budaya atau kebiasaan dari masyarakat. Tetapi dapat juga karena faktor sifat dan keadaan alam yang melekat pada iklim atau cuaca. Misalnya produksi musim semi, gugur, dan musim hujan bahkan musim kemarau. Sifat masyarakat yang menimbulkan musiman ini oleh karena faktor budaya dan kebiasaaan misalnya karena musim hari raya keagamaan. Pada saat itu biasanya masyarakat akan memiliki ajat yang cukup besar dalam melakukan pemenuhan konsumsi barang keperluan pesta dan sehari-hari. Maka dapat dipastikan pada periode ini permintaan akan kebutuhan dan keperluan konsumsi akan meningkat dalam jumlah yang cukup berarti.
Metode yang digunakan dalam forecasting adalah sebagai berikut :
1. Metode Rata-rata Bergerak
Kepentingan peramalan yang akan dipakai apakah dalam skup jangka pendek nilai ramalan yang diketahui atau dalam rentang waktu yang lebih panjang. Kalau menggunakan rentang waktu yang lebih pendek maka hasil rata-rata bergerak yang akan kita peroleh akan lebih mendekati kondisi sifat data yang sebenarnya dan rata-rata yang kita temukan terdistribusi atau tersebar pada kelompok data faktual. Sedangkan jika satuan waktu yang lebih panjang, rata-rata yang kita peroleh akan lebih mewakili sejumlah data yang lebih banyak dan beraneka macam fluktuasinya, sehingga rata-rata bergeraknya lebih tersebar dan kurang mewakili fakta sifat data yang tersebar tersebut. Terkecuali sifat data lebih homogen dan tidak terlalu fluktuatif.
Angka deviasi dapat diperoleh dengan cara mengurangi angka observasi dengan angka rata-rata bergerak. Sedangkan deviasi kuadrat adalah menguadratkan deviasi sehingga menghasilkan angka pada kolom deviasi kuadrat. Jumlah deviasi kuadrat ini akan kita pergunakan untuk menghitung penyimpangan atau tingkat error (istilah disini adalah Root Mean Square Error = RMSE) setiap pengelompokkan rata-rata bergerak ini. Dengan rumus sebagai berikut:
= ∑( ) (2)
Di mana:
RMSE = Root Mean Squre Error At = angka observasi
Ft = rata-rata bergerak yang dihasilkan per kelompok waktu
Metode eksponential smoothing ini merupakan metode yang lebih halus lagi daripada metode rata-rata bergerak. Jadi metode ini lebih hati-hati dalam memprediksi atau meramal permintaan yang akan terjadi di masa datang.
Apabila kita memperhatikan sifat data time series, maka ada kecenderungan bahwa metode rata-rata tertimbang akan lebih dipilih daripada metode rata-rata bergerak. Mengapa demikian, karena di dalam metode rata-rata tertimbang menyertakan faktor-faktor yang relevan yang menjadi penyebab tersebarnya data time series. Hal ini diimplementasikkan ke dalam prakiraan dari faktor terjadinya fluktuasi pada data time series kedalam risiko penyimpangan prakiraan, sehingga hasil prakiraan pada masing-masing prakiraan lebih kecil risiko fluktuasi penyimpangan. Dan angka rata-rata tertimbang tertentu yang dipilih merupakan komposisi persebaran atas terjadinya keakuratan dan risiko penyimpangan yang mungkin akan terjadi sebagai mendasari prakiraan yang dihasilkan. Demikian untuk perhitungan prakiraan berikutnya secara berjenjang dari prakiraan sebelumnya ke prakiraan selanjutnya di dalam periode yang diramalkan. Hal ini dimaksudkan untuk meratakan risiko penyimpangan sehingga risiko tersebut berada pada persebaran yang lebih merata keseluruhan periode yang diperkirakan.
Metode rata-rata tertimbang dilakukan dengan proses perhitungan sebagai berikut:
a. Menentukan angka tertimbang (weight) tertentu bagi data observasi dengan notasi w antara angka 0 s/d angka 1.;
b. Menambahkannya dengan angka tertimbang bagi data prakiraan dengan notasi (1-w).
c. Menghitung rata-rata keseluruhan dari data time series dengan rumusan
A1 + A2 + …...An dan notasinya = F1
d. Menghitung prakiraan dengan rumusan Ft+1 = wA + (1-w)F1
Di mana Ft+1 merupakan prakiraan pada periode kedua, w merupakan angka tertimbang yang dipilih, A merupakan data observasi, 1-w merupakan persebaran atau penghalusan, dan F1 merupakan prakiraan sebelumnya.
3. Metode Ekonometri
Metode ekonometri merupakan metode prediksi volume atau nilai dependen variabel dengan melibatkan berbagai faktor atau varibel independen yang relevan dan cukup signifikan mempengaruhi dependen variabel tersebut. Secara ekonomi dari model ekonometri ingin dilihat relevansinya pengaruh independen variabel terhadap dependen variabel. Bahkan juga ingin dilihat apakah antar variabel independent itu saling mempengaruhi dan berapa besar pengaruh terhadap dependen variabel. Juga ingin dilihat berapa tepat antara kebenaran statistik dikoreksi dengan kebenaran secara ekonomi.
memperoleh sesuatu yang lebih kecil dari penyebab yang hakiki pada hubungan antar variabel-variabel ini secara umum.
Terdapat empat tahapan yang termasuk didalam memformulasi forecast model ekonometrika ini.
1. Membangun suatu model teori. 2. Mengumpulkan data.
3. Memilih bentuk persamaan fungsi yang diestimasi. 4. Mengestimasi dan menginterpretasi hasil.
a. Membangun Model Teori
Dengan menggunakan metode ekonometri, pertama yang harus dilakukan adalah memformulasi model teori hubungan ekonomi. Model ini harus didasarkan pada nuansa teori ekonomi dan dinyatakan dalam bentuk fungsi matematik. Pada dasarnya membangun model termasuk menentukan variabel-variabel yang dimasukkan di dalam model dan jika ada teori yang rasional untuk memprediksi hubungan dan perilaku keterkaitan antar variabel. Sebagau contoh kita menginginkan untuk memprakirakan permintaan, maka hubungan antar harga dan kuantitas dapat menjadi dasar teori yang logis bagi suatu model. Suatu pernyataan matematik yang sederhana dalam hubungan antar variabel ini adalah:
Q = f(P) (3)
Namun satu hal bahwa hubungan antara harga dan kuantitas barang yang diminta oleh masyarakat ditunjukkan adanya hubungan dan respon negatif di dalam hubungan kedua faktor tersebut. Oleh karena itu pada model ekonometri ingin ditunjukkan model sejumlah faktor yang mempengaruhi volume permintaan.
Faktor yang harga mempengaruhi volume permintaan tersebut sebenarnya tidaklah lain yang juga ikut mempengaruhi permintaan, tetapi banyak faktor lain yang juga ikut mempengaruhi permintaan. Maka secara spesifik hubungan kausalistik permintaan itu dipengaruhi selain oleh harga, tetapi juga dipegaruhi oleh income per kapita (I), harga barang lain (Po), dan advertensi (A).
Karena itu model fungsi yang dikembangkan dalam persamaan ekonometri sebagimana ditunjukkan pada pembahasan estimasi permintaan yang dipengaruhi oleh sejumlah faktor atau variabel, seperti:
Qd = f (P, I, Po dan A) (4)
Yang secara ekonomi terbukti secara empiric bahwa fungsi permintaan (Qd) dipengaruhi P, I, Po dan A dirumuskan sebagai fungsi:
Qd = a – bP + cI + dPo + eA (5)
b. Mengumpulkan Data
Kegiatan mengumpulkan data dari faktor-faktor yang mempengaruhi permintaan yaitu harga, income, harga barang lain dan advertensi dilakukan oleh manajer anatara lain melaui survey di perusahaan, biro statistik umum, lembaga-lembaga konsultan manajemen. Survey juga dapat dilakukan langsung pada para pelaku usaha dan masyarakat konsumen selama periode tertentu menurut kebutuhan pengkajian dan peramalan permintaan dan potensi pasar yang akan dijadikan sebagai bahan informasi potensi dan peluang serta kendala pasar yang dihadapi oleh manajer perusahaan yang akan menyusun model atau metode ekonometri yang akan disusun.
c. Memilih dan Menetukan Fungsi Permintaan
Setelah data yang dikumpulkan tersebut diolah dalam komputer dan menghasilkan suatu print out atau tampilan parameter-parameter, uji kesalahan dan signifikansi serta layak dan tidaknya parameter tertsebut, baik secara statistik maupun secara ekonomi teori dari yang dihasilkan.
Jika telah meyakini bahwa fungsi permintan pada rumus (5) di atas dan terbukti signifikan semua parameter variabel yang terpilih tersebut, maka dapat kita pergunakan sebagai alat memforecasting atau meramal permintan di masa datang, dengan sejumlah asumsi yang perlu disertakan. Tidak ada variabel lain selain yang diprediksi mempengaruhi secara dominan terhadap permintaan.
harga barang pengganti, harga barang komplementer dan cita rasa atau kesukaan si konsumen.
d. Mengestimasi dan Menginterpretasi Hasil
Sebagai hasil dari pemilihan bentuk fungsi permintaan, maka kita akan jadikan ini sebagai fungsi yang dapat menjelaskan hal-hal berikut ini: a. Persamaan fungsi ini kita pilih untuk meramal berdasar pada teori
ekonomi.
b. Estimasi parameter dari persamaan linier ini mengindikasikan pengaruh perubahan variabel independen.
c. Demikian juga estimasi parameter, estimasi itu dapat kita jadikan sebagai bahan untuk menguji dan mengevaluasi gejala dan perilaku permintaan dipengaruhi variabel independen.
d. R2 merupakan nilai yang indikasinya adalah proporsi variasi pada variabel dependen dijelaskan oleh variabel independen.
2.5 Markov Chains
Pengelompokkan tipe populasi dari proses acak bisa digambarkan sebagai jika X adalah proses acak, maka populasi dari proses acak adalah semua nilai yang mungkin yang bisa dimasukkan dalam suatu proses contohnya
y X t y untukt TS : ( ) ,
titik-titik integer. Jika populasi dari S dari suatu proses acak X tidak dapat dihitung ( contoh S = ∞) maka X disebut Continuous Time Random Process perubahan state (discrete state) terjadi pada sembarang waktu.
Markov Chains merupakan proses acak di mana semua informasi tentang masa depan terkandung di dalam keadaan sekarang (yaitu orang tidak perlu memeriksa masa lalu untuk menentukan masa depan). Untuk lebih tepatnya, proses memiliki properti markov yang berarti bahwa bentuk ke depan hanya tergantung pada keadaan sekarang, dan tidak bergantung pada bentuk sebelumnya. Dengan kata lain, gambaran tentang keadaan sepenuhnya menangkap semua informasi yang dapat mempengaruhi masa depan dari proses evolusi. Suatu Markov Chains merupakan proses stokastik berarti bahwa semua transisi adalah probabilitas (ditentukan oleh kebetulan acak dan dengan demikian tidak dapat diprediksi secara detail, meskipun mungkin diprediksi dalam sifat statistik) (www.wikipedia.org).
Konsep Dasar Markov Chains
Apabila suatu kejadian tertentu dari suatu rangkaian eksperimentergantung dari beberapa kemungkinan kejadian , maka rangkaian eksperimen tersebut disebut Proses Stokastik. Proses stokastik merupakan suatu cara untuk mempelajari hubungan yang dinamis dari suatu tuntutan peristiwa atau proses yang kejadiannya bersifat tidak pasti. Ross (2000) mendefinisikan proses stokastik sebagai barisan peubah acak yang diberi indeks dengan urutan oleh parameter t dimana nilai t berubah-ubah sesuai dengan himpunan indeks T. Dengan demikian, untuk setiap t elemen dari T, V(t)adalah
peubah acak.
Proses stokastik pada dasarnya dikelompokkan berdasarkan sifat ruang parameter T, sifat ruang keadaan S, dan hubungan ketergantungan diantara peubah acak-peubah acak V(t). Berdasarkan sifat ruang parameter T, proses stokastik
digolongkan menjadi proses stokastik diskrit dan proses stokastik kontinu. Sering kali jika T diskrit, utnuk membedakan kita lebih baik menuliskan sebagai V(t).
Berdasarkan sifat ruang keadaan S, proses stokastik digolongkan menjadi proses stokastik dengan ruang keadaan diskrit dan menjadi proses stokastik dengan ruang keadaan kontinu. Berdasarkan hubungan ketergantungan diantara peubah acak-peubah acak V(t), proses stokastik dapat dibagi ke dalam beberapa tipe klasik
diantaranya proses stationer, proses renewal, martingales, point process dan proses markov. Sebagai contoh proses stokastik dengan ruang parameter diskrit dan ruang keadaan diskrit adalah banyaknya pengunjung yang datang ke suatu pertokoan pada hari ke-t. contoh proses stokastik dengan ruang parameter kontinu dan ruang keadaan kontinu adalah selang waktu antar kedatangan pengunjung ke suatu pertokoan pada waktu t sembarang.
Sebelum membahas mengenai rantai markov, perlu dijelaskan proses markov terlebih dahulu. Menurut Karlin dan Taylor (1975), proses markov adalah sebuah proses dengan sifat, diberikan nilai V(t), nilai V(t-1), tidak bergantung pada nilai V(u),
untuk setiap u<t. secara formal sebuah proses dikatakan markov jika memenuhi sifat markov yaitu :
dengan S=t+1-t
secara umum, peluang transisi juga merupakan fungsi dari selang waktu s. Jika peluang transisi satu langkah tidak tergantung pada variabel waktu, kita sebut rantai markov tersebut memiliki peluang stasioner. Secara umum rantai Markov yang biasa kita temui memiliki peluang transisi stasioner.
Berdasarkan ruang keadaan dan ruang parameternya, proses Markov dapat dikelompokkan sebagai berikut :
Ruang Parameter
Diskrit Kontinu
Ruang Keadaan
Diskrit Rantai markov parameter diskrit
Rantai markov parameter kontinu Kontinu Rantai markov parameter
diskrit
Rantai markov parameter kontinu
Gambar 2.4: Proses Markov
Sumber :Karlin dan Taylor (1975)
Jadi, rantai Markov adalah proses dengan ruang keadaan yang diskrit. Dalam rantai markov, salah satu hal yang menarik adalah kita dapat mempelajari perubahan keadaan pada proses. Untuk rantai Markov dengan ruang parameter diskrit peluang V(t), berada pada keadaan it+1bila diberikan V, berada pada keadaan it dinamakan
peluang transisi satu langkah dan dinotasikan dengan Pit,it+1.
Rantai Markov adalah suatu urutan dari variabel-variabel acak X1,X2,X3,...dengan sifat Markov yaitu, mengingat keadaan masa depan dan masa lalu
Nilai yang mungkin untuk membentuk XiS disebut ruang keadaan rantai.
Markov Chains adalah sebuah Proses Markov dengan populasi yang diskrit (dapat dihitung) yang berada pada suatu discrete state (position) dan diizinkan untuk berubah state pada time discrete.Ada beberapa macam variasi dari bentuk rantai markov
1. Continous Markov memiliki indeks kontinu.
2. Sisa rantai Markov homogen (rantai Markov stasioner) adalah proses di mana
untuk semua n. Probabilitas transisi tidak tergantung dari n.
3. Sebuah rantai Markov orde m di mana m adalah terbatas,
Dengan kata lain, keadaan selanjutnya tergantung pada keadaan m selanjutnya. Sebuah rantai (Y n) dari (X n) yang memiliki klasik Properti Markov sebagai
berikut: Biarkan Y n = (X n,X n -1,..., Xn - m 1 ), yang memerintahkan m-tupel dari
nilai-nilai X. Maka Y n adalah sebuah rantai Markov dengan ruang keadaan S m
dan memiliki klasik properti markov.
4. Sebuah aditif rantai markov order m di mana m adalah terbatas adalah
untuk semua n> m.
2.1.3.1Sifat-Sifat Pada Rantai Markov
ke keadaan lainnya. Dengan kata lain, ini menggambarkan peluang proses berada di satu keadaan bila diketahui keadaan proses pada satu waktu sebelumnya. Secara matematis, peluang transisi tersebut dapat ditulis sebagai berikut :
Pij = P(Vt+1 = j׀V = i)
dengan i dan j masing-masing tersebut penulisannya dapat dilakukan dalam berbagai cara seperti,
Akan tetapi, bentuk umum yang dipakai adalah persamaan yang paling kanan. Hal ini menguntungkan dengan menuliskan secara persamaan ini adalah dalam penerapan prinsip aljabar linear khususnya perkalian matriks. Dalam aljabar linear dua matriks misal Adan B dapat dikalikan jika banyaknya kolom pada matriks pertama (A) sama dengan banyaknya baris pada matriks kedua (B). Untuk menyelaraskan aturan perkalian dan persamaan Chapman-Kolmogorof, maka peluang transisi sebaikanya dituliskan sebagai matriks peluang transisi.
Selain peluang transisinya, rantai Markov juga ditentukan melalui distribusi peluangnya. Untuk rantai Markov dengan ruang parameter diskrit, distribusi peluang dari waktu ke-t atau πt adalah
πt
= {πtk : k = 1,2,…, n}
Dengan kata lain, distribusi peluang πt menyatakan proporsi dari keadaan proses di waktu t.
Persamaan Chapman-Kolmogorof menyatakan bahwa peluang transisi dari keadaan i ke j dalam t langkah sama dengan peluang transisi dari i ke seluruh n-keadaan dalam t-m langkah, kemudian dilanjutkan dengan transisi ke n-keadaan j dari n-keadaan tersebut dalam m langkah sisa. Dengan memanfaatkan Law of Total Probability dapat dibuktikan bahwa,
Untuk m=1 maka diperoleh
Tampak bahwa persamaan diatas merupakan perkalian antara baris dan kolom dari dua matriks. Bila P(t) adalah matriks peluang transisi t langkah maka,
P(t) = P(t-1) x P
Dengan menggunakan induksi diperoleh
P = (P x P x … x P) x P
= Pt-1 x P
= Pt
Seringkali, selain perhitungan distribusi peluang di waktu ke-t, perhitungan distribusi peluang setelah proses berjalan lama yaitu πt
memprediksi keadaan sistem setelah ia berjalan lama. Dengan kata lain, dapat dipelajari kelakuan dari sistem setelah ia stabil. Untuk menganalisa kelakuan tersebut, kita memerlukan pengetahuan mendasar tentang klasifikasi dari keadaan suatu rantai Markov.Berikut ini teorema yang dapat digunakan utnuk mencari distribusi limit dari suatu rantai Markov regular.
Teorema 1 Untuk P suatu matriks peluang transisi Markov regular dengan anggota ruang keadaan 1, 2, …, n, maka distribusi limit π = (π1, π2,…, πn).
Teorema 2 Ruang keadaan i dikatakan reccurent jika dan hanya jika, Dan ruang keadaan i dikatakan transient jika dan hanya jika
Dua sifat diatas merupakan contoh bagaimana sifat dari peluang transisi dan ruang keadaan akan mempengaruhi rantai Markov yang dibawanya. Beberapa definisi dan klasifikasi dari ruang keadaan dan matriks peluang transisi diperlukan untuk mengetahui berbagai macam kemungkinan mengenai sifat limit rantai Markov yang terkait.
Konsep komunikasi dalam rantai Markov sebagai berikut.Keadaan j dikatakan dapat dicapai (accessible) dari keadaan i jika terdapat bilangan bulat n ≥ 0 dimana Pnij>0. Dengan kata lain, terdapat peluang positif bahwa dalam berhingga transisi
keadaan j dan keadaan i. Jika keadaan j dapat dicapai dari keadaan i dan keadaan i dapat dicapai dari keadaaan j, maka i dan j dikatakan saling berkomunikasi maka Pnij
= 0 atau Pnji>0 untuk setiap n ≥ 0. Konsep mengenai relasi ekivalensi adalah sebagai
berikut :
a. Relasi i <—> j merupakan relasi ekuivalen
1. untuk setiap status i , berlaku i <—>i
3. jika i <—> j dan j <—> k maka i <—> k
b. Status-status suatu Rantai Markov dapat dipartisi kedalam kelas-kelas ekivalensi sehingga i <—> j, jika dan hanya jika i dan j berada dalam kelas ekivalensi yang sama.
c. Suatu Rantai Markov irreducible jika dan hanya jika didalamnya hanya terdiri atas tepat satu kelas ekivalensi.
d. Jika i<—> j, maka i dan j memiliki periode yang sama.
e. Untuk i<—> j, jika i recurrent maka juga j recurrent.
Konsep mengenai Irreducible dalam suatu rantai Markov. Jika {Xn}suatu rantai Markov, maka tepat salah satu kondisi berikut ini terjadi yaitu semua status adalah positif recurrent, atau semua status recurrent null, atau sstatus trancient.
Konsep mengenai Limiting Probability dalam rantai Markov. Definisi: πj(n)
adalah probabilitas suatu Rantai Markov { Xn}berada dalam status j pada step ke n.
Maka πj(n) = P[ Xn = j]
Distribusi awal (initial) dari masing-masing status 0, 1, 2, …… dinyatakan sebagaiπj(0) = P[ X0 = j], untuk j = 0, 1, 2, ……
Suatu rantai Markov memiliki distribusi probabilitas stasioner π = (π0, π1, π2, ....,
πn ) apabila terpenuhi persamaan π = πP asalkan setiap πi ≥ 0 dan ∑iπi =1.
Jika suatu rantai Markov homogen waktu (stasioner dari waktu ke waktu) yang irreducible, aperiodic, maka limit probabiltasnya
) (
lim jn
n
j
selalu ada dan independent dari distribusi probabilitas status awal π (0) = (π0(0) , π1(0) ,
π2(0), …..).
Jika seluruh status tidak positif recurrent (jadi seluruhnya recurrent null atau seluruhnya transient), maka πj = 0 untuk semua j dan tidak terdapat distribusi
BAB III
PENGENALAN MS. EXCEL DAN MATRIKS
Pendahuluan
Microsoft Excel atau Microsoft Office Excel adalah sebuah program aplikasi lembar kerja spreadsheet yang dibuat dan didistribusikan oleh Microsoft Corporation untuk sistem operasi Microsoft Windows dan Mac OS. Aplikasi ini memiliki fitur kalkulasi dan pembuatan grafik yang, dengan menggunakan strategi marketing Microsoft yang agresif, menjadikan Microsoft Excel sebagai salah satu program komputer yang populer digunakan di dalam komputer mikro hingga saat ini. Bahkan, saat ini program ini merupakan program spreadsheet paling banyak digunakan oleh banyak pihak, baik di platform PC berbasis Windows maupun platform Macintosh berbasis Mac OS, semenjak versi 5.0 diterbitkan pada tahun 1993. Aplikasi ini merupakan bagian dari Microsoft Office System, dan versi terakhir adalah versi Microsoft Office Excel 2007 yang diintegrasikan di dalam paket Microsoft Office System 2007 .
Dalam Microsoft Excel terdapat 4 komponen utama yaitu :
1. Row Heading
Row Heading (Kepala garis), adalah penunjuk lokasi baris pada lembar kerja yang aktif. Row Heading juga berfungsi sebagai salah satu bagian dari penunjuk sel (akan dibahas setelah ini). Jumlah baris yang disediakan oleh Microsoft Excel adalah 65.536 baris.
2. Column Heading
Column Heading
Column Heading (Kepala kolom), adalah penunjuk lokasi kolom pada lembar kerja yang aktif. Sama halnya dengan Row Heading, Column Heading juga berfungsi sebagai salah satu bagian dari penunjuk sel (akan dibahas setelah ini). Kolom di simbol dengan abjad A – Z dan gabungannya. Setelah kolom Z, kita akan menjumpai kolom AA, AB s/d AZ lalu kolom BA, BB s/d BZ begitu seterus sampai kolom terakhir yaitu IV (berjumlah 256 kolom). Sungguh suatu lembar kerja yang sangat besar, bukan. (65.536 baris dengan 256 kolom).
3. Cell Pointer
Cell Pointer (penunjuk sel), adalah penunjuk sel yang aktif. Sel adalah perpotongan antara kolom dengan baris. Sel diberi nama menurut posisi kolom dan baris. Contoh. Sel A1 berarti perpotongan antara kolom A dengan baris 1.
4. Formula Bar
Formula Bar, adalah tempat kita untuk mengetikkan rumus-rumus yang akan kita gunakan nantinya. Dalam Microsoft Excel pengetikkan rumus harus diawali dengan tanda ‘=’ . Misalnya kita ingin menjumlahkan nilai yang terdapat pada sel A1 dengan B1, maka pada formula bar dapat diketikkan =A1+B1 .
Menggerakkan Penunjuk Sel (Cell Pointer)
lebih baik menggunakan keyboard. Berikut daftar tombol yang digunakan untuk menggerakan pointer dengan keyboard :
Tombol Fungsi
← ↑ → ↓ Pindah satu sel ke kiri, atas, kanan atau bawah
Tab Pindah satu sel ke kanan Enter Pindah satu sel ke bawah Shift + Tab Pindah satu sel ke kiri Shift + Enter Pindah satu sel ke atas
Home Pindah ke kolom A pada baris yang sedang dipilih Ctrl + Home Pindah ke sel A1 pada lembar kerja yang aktif Ctrl + End Pindah ke posisi sel terakhir yang sedang digunakan PgUp Pindah satu layar ke atas
PgDn Pindah satu layar ke bawah Alt + PgUp Pindah satu layar ke kiri Alt + PgDn Pindah satu layar ke kanan
Ctrl + PgUp Pindah dari satu tab lembar kerja ke tab lembar berikutnya Ctrl + PgDn Pindah dari satu tab lembar kerja ke tab lembar sebelumnya
Format Worksheets
MENAMBAHKANBORDER DAN COLOR
Kita dapat menambahkan border pada lembar kerja kita. Caranya adalah dengan memblok terlebih dahulu cell yang akan kita beri border, kemudian klik tombol pada tab home
Kemudian pilihlah jenis border yang diinginkan.
Microsoft Excel 2007 menyediakan pula style border yang dapat langsung kita gunakan. Untuk menggunakannya klik tombol CELL STYLES pada tab home :
MERGE CELLS &ALLIGN CELL CONTENTS
Microsoft Excel juga menyediakan fasilitas merge cells dan memiliki fungsi yang sama seperti pada Microsoft word. Klik tombol berikut pada tab home.
o Menggunakan Rumus (Formula)
Rumus merupakan bagian terpenting dari Program Microsoft Excel , karena setiap tabel dan dokumen yang kita ketik akan selalu berhubungan dengan rumus dan fungsi. Operator matematika yang akan sering digunakan dalam rumus adalah ;
Lambang Fungsi
+ Penjumlahan
- Pengurangan
* Perkalian
/ Pembagian
^ Perpangkatan
% Persentase
Proses perhitungan akan dilakukan sesuai dengan derajat urutan dari operator ini, dimulai dari pangkat (^), kali (*), atau bagi (/), tambah (+) atau kurang (-).
o Menggunakan Fungsi
Fungsi sebenarnya adalah rumus yang sudah disediakan oleh Microsoft Excel, yang akan membantu dalam proses perhitungan. kita tinggal memanfaatkan sesuai dengan kebutuhan. Pada umumnya penulisan fungsi harus dilengkapi dengan argumen, baik berupa angka, label, rumus, alamat sel atau range. Argumen ini harus ditulis dengan diapit tanda kurung ().
Beberapa Fungsi yang sering digunakan:
1. Fungsi Average(…)
=AVERAGE(number1,number2,…), dimana number1, number2, dan seterusnya adalah range data yang akan dicari nilai rata-ratanya.
2. Fungsi Logika IF(…)
Fungsi ini digunakan jika data yang dimasukkan mempunyai kondisi tertentu. Misalnya, jika nilai sel A1=1, maka hasilnya 2, jika tidak, maka akan bernilai 0. Biasanya fungsi ini dibantu oleh operator relasi (pembanding) seperti berikut ;
Lambang Fungsi
= Sama dengan
< Lebih kecil dari
> Lebih besar dari
<= Lebih kecil atau sama dengan >= Lebih besar atau sama dengan <> Tidak sama dengan
3. Fungsi Max(…)
Fungsi ini digunakan untuk mencari nilai tertinggi dari sekumpulan data (range). Bentuk umum penulisannya adalah =MAX(number1,number2,…), dimana number1, number2, dan seterusnya adalah range data (numerik) yang akan dicari nilai tertingginya.
4. Fungsi Min(…)
5. Fungsi Sum(…)
Fungsi SUM digunakan untuk menjumlahkan sekumpulan data pada suatu range. Bentuk umum penulisan fungsi ini adalah =SUM(number1,number2,…). Dimana number1, number2 dan seterusnya adalah range data yang akan dijumlahkan.
6. Fungsi Left(…)
Fungsi left digunakan untuk mengambil karakter pada bagian sebelah kiri dari suatu teks. Bentuk umum penulisannya adalah =LEFT(text,num_chars). Dimana text adalah data yang akan diambil sebagian karakternya dari sebelah kiri, num_chars adalah jumlah karakter yang akan diambil.
7. Fungsi Mid(…)
Fungsi ini digunakan untuk mengambil sebagian karakter bagian tengah dari suatu teks. Bentuk umum pemakaian fungsi ini adalah
=MID(text,start_num,num_chars). Artinya mengambil sejumlah karakter mulai
dari start_num, sebanyak num_char.
8. Fungsi Right(…)
Fungsi ini merupakan kebalikan dari fungsi left, kalau fungsi left mengambil sejumlah karakter dari sebelah kiri, maka fungsi mengambil sejumlah karakter dari sebelah kanan teks.. Bentuk umum penulisannya adalah =RIGHT(text,num_chars). Dimana text adalah data yang akan diambil sebagian karakternya dari sebelah kanan, num_chars adalah jumlah karakter yang akan diambil.
9. Fungsi HLOOKUP dan VLOOKUP
Fungsi HLOOKUP dan VLOOKUP digunakan untuk membaca suatu tabel secara horizontal (VLOOKUP) atau secara vertikal (VLOOKUP). Bentuk umum penulisan fungsi ini adalah :
=VLOOKUP(Lookup_value, Table_array, Col_index_num,…)
Dari rumus diatas, dapat dilihat bahwa bedanya hanya pada nomor indeksnya saja, kalau kita pakai HLOOKUP, maka digunakan nomor indeks baris (Row_index_num), tapi kalu pakai VLOOKUP digunakan nomor indeks kolom (Col_index_num). Nomor indeks adalah angka untuk menyatakan posisi suatu kolom/baris dalam tabel yang dimulai dengan nomor 1 untuk kolom/baris pertama dalam range data tersebut.
o Menggunakan GRAFIK
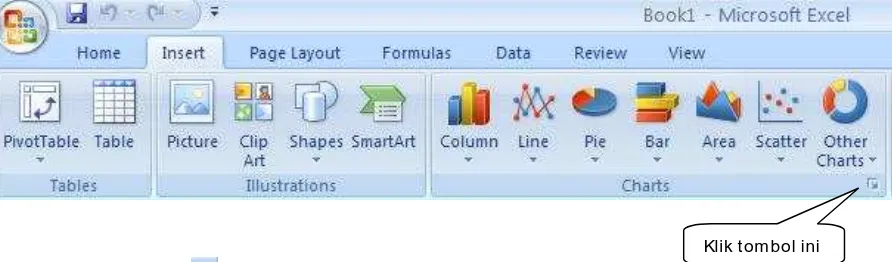
Salah satu fungsi unggul dalam Ms Excel 2007 adalah grafik dimana dapat melihat hasil tabel diubah menjadi ke dalam grafik dengan cepat. Dengan fungsi grafik para ilmuwan dapat menampilkan data mereka. Ms Excel menyediakan berbagai macam bentuk grafik yang mencakupi Line, XY, Column, Bar, Batang, Area, Stock, dan sebagainya. Grafik dapat dilihat dalam menu INSERT sebagai berikut.
Setelah klik tombol , maka akan muncul menu sebagai berikut :
Setelah masuk ke Insert Chart, maka silakan pilih jenis grafik yang anda inginkan sesuai selera anda. Jika sudah terpilih jenis Chart yang anda inginkan, silakan klik OK. Namun, karena membuat grafik perlu sebuah tabel data untuk menampilkan grafiknya.
OPERASI MATRIKS DALAM EXCEL