isprsarchives XL 2 W1 87 2013
Teks penuh
Gambar
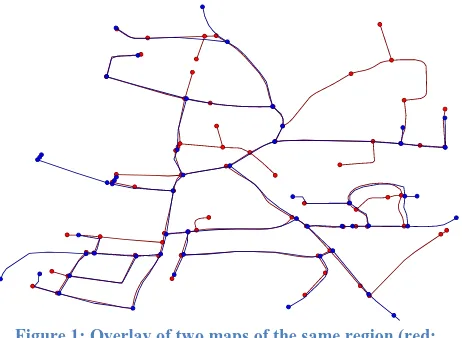
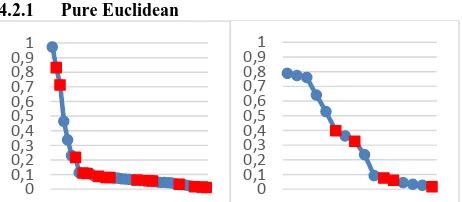
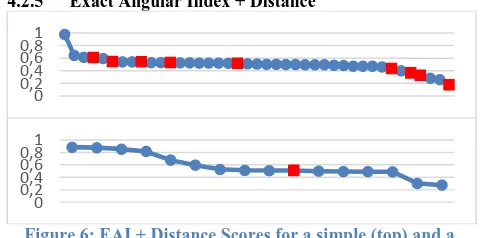
Garis besar
Dokumen terkait
A calibrated model at this scale can be used for various analyses such as cross-boundary water analysis, assessment of nitrate loads gener- ated in various countries; quantification
Universitas Negeri
Interaksi antara beberapa varietas padi gogo (Oriza sativa L.) dengan ketebalan tanah mineral pada lahan gambut berpengaruh nyata terhadap bobot kering tajuk tanaman dan bobot
produksi lateks harian dapat meningkat khususnya pada klon yang responsif. Pemberian stimulan berpengaruh terhadap fisiologis tanaman karet antara lain: 1). membuat
Pelaksanaan program penelitian Panel Petani Nasional (PATANAS) erat hubungannya dengan kelangkaan persediaan data tentang pedesaan di Indonesia selama ini, terutama dalam
Tujuan penelitian ini adalah menge- tahui: (1) penerapan pembelajaran model learning community pada Matakuliah Metodologi Penelitian yang optimum, (2) prestasi
Penyebab pembusukan dan kerusakan bahan pangan yang paling utama adalah mikroorganisme dan pelbagai perubahan enzimatis maupun nonenzimatis yang terjadi setelah panen,
Ketentuan dalam lampiran angka IV mengenai Surat Perjalanan Republik Indonesia dari Peraturan Pemerintah Nomor 75 Tahun 2005 tentang Jenis dan Tarif atas Jenis Penerimaan Negara
