7 BAB II
TINJAUAN PUSTAKA
2.1 Big Data
Big data merujuk kepada suatu kumpulan data besar yang dapat disimpan,
diteliti, dibagikan, divisualisasikan, dan dianalisis, dengan kapasitas volume besar, kecepatan tinggi, yang membutuhkan berbagai bentuk inovasi dalam pemrosesan informasi untuk meningkatkan wawasan dan pengambilan keputusan.
Big data diciptakan untuk menangani volume dari kumpulan data yang biasanya
besar, tersebar, belum sempurna, belum pasti, kompleks atau dinamis, yang berasal dari berbagai sumber yang mandiri. Sumber utama big data adalah berasal dari berikut ini (Kharat & Bhise, 2015).
Arsip
Arsip terutama dikelola oleh organisasi, untuk menunjukkan fungsi dari orang tertentu atau fungsi-fungsi organisasisehingga membutuhkan sistem dengan kemampuan pemrosesan yang tinggi.
Media
User menghasilkan berbagai gambar, video, audio, live stream, podcast,
dan bentuk media lainnya yang berkontribusi dalam membentuk big data. Berbagai aplikasi bisnis
Data yang besar dapat dihasilkan dari berbagai aplikasi bisnis sebagai bagian dari manajemen proyek, otomatisasi pemasaran, produktivitas,
8
customer relation management (CRM), enterprise resourse planning
(ERP), Google Docs, dan sebagainya yang termasuk dalam big data. Web publik
Banyak organisasi dibawah penanganan sektor pemerintahan, ekonomi, sensus, saham, bank, Wikipedia, dan sebagainya menggunakan web untuk berkomunikasi. Data-data tersebut berkontribusi dalam big data.
Media sosial
Dewasa ini pengguna bergantung dalam media sosial seperti Twitter, LinkedIn, Facebook, Instagram, Tumblr, YouTube, Google+, dan sebagainya untuk bertukar konten yang dihasilkan pengguna. Data-data tersebut berkontribusi dalam big data.
2.2 Media Sosial
Media sosial adalah sebuah media online dimana para penggunanya dapat dengan mudah berpartisipasi dalam arti seseorang akan dengan mudah berbagi informasi, menciptakan konten atau isi yang ingin disampaikan kepada orang lain,
member komentar terhadap masukan yang diterimanya dan seterusnya (Utari,
2011). Semua dapar dilakukan dengan cepat dan tak terbatas. Beberapa tipe dari media sosial adalah sebagai berikut (Kaplan & Haenlein, 2010):
1. Collaboration project
Pada proyek kolaborasi ini, website mengizinkan usernya untuk dapat mengubah, menambah, ataupun membuang konten-konten yang ada di website ini.
9 2. Micro blogs
User lebih bebas dalam mengekspresikan sesuatu di blog ini
seperti bercerita ataupun mengkritik kebijakan pemerintah. 3. Content community
Para pengguna website saling membagikan konten-konten media baik seperti video, ebook, gambar, dan lain-lain.
4. Social networking sites
Pada situs jejaring ini, aplikasi yang mengizinkan user untuk dapat terhubung dengan cara membuat informasi pribadi sehingga dapat terhubung dengan orang lain.
5. Virtual game world
Pada dunia virtual ini yang dapat merepresentasikan lingkungan 3D, dimana user bisa muncul dalam bentuk avatar-avatar diinginkan serta berinteraksi dengan orang lain selayaknya di dunia nyata.
6. Social virtual world
Pada dunia virtual yang dimana penggunanya merasa hidup di dunia virtual, sama seperti virtual game world, berinteraksi dengan yang lain. Pada penelitan ini peneliti memilih jenis media sosial content community karena berdasarkan penjelasan yang dipaparkan diatas, media sosial Instagram memiliki karakteristik yang sama dengan jenis content community, yaitu pengguna media sosial tersebut dapat membagikan konten media. Dalam Instagram konten yang dapat dibagikan adalah gambar dan video.
10 2.2.1 Instagram
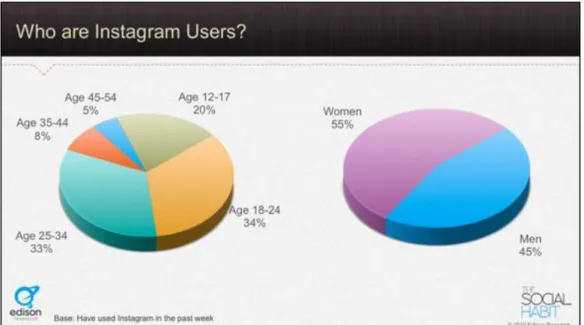
Gambar 2.1 Pengguna Instagram berdasarkan Usia dan Jenis Kelamin Sumber: Pringle, Pinterest Versus Instagram: Which One is Best For Your
Brand? (2014)
Disusun dari dua kata, yaitu “Insta” dan “Gram”. Arti dari kata pertama diambil dari istilah “Instan” atau serba cepat/mudah. Namun dalam sejarah penggunaan kamera foto, istilah “Instan” merupakan sebutan lain dari kamera Polaroid, yaitu jenis kamera yang bisa langsung mencetak foto beberapa saat setelah membidik objek. Sedangkan kata “Gram” diambil dari “Telegram” yang maknanya dikaitkan sebagai media pengirim informasi yang sangat cepat. Maka Instagram adalah sebagai media untuk membuat foto dan mengirimkannya dalam waktu yang sangat cepat. Tujuan tersebut sangat dimungkinkan oleh teknologi internet yang menjadi basis aktivitas dari media sosial ini.
11
Semakin banyak orang yang menyadari bahwa Instagram merupakan alat promosi yang sangat ampuh. Kecenderungan para pengguna internet ialah lebih tertarik pada bahasa visual. Dibandingkan dengan media sosial lainnya, Instagram lebih memaksimalkan fiturnya untuk komunikasi melalui gambar atau foto. Ketika bahasa visual mendominasi dunia internet, dari situlah para pelaku bisnis bisa memanfaatkan peluang yang terhampar di depan mata (Febian, 2015).
Aplikasi Instagram memiliki lima menu utama yang semuanya terletak dibagian bawah, yaitu sebagai berikut (Atmoko, 2012):
1. Home
Halaman utama menampilkan linimasa foto-foto terbaru dari sesama pengguna yang telah diikuti.
2. Comments
Foto-foto yang ada di Instagram bisa dikomentari dengan kolom komentar.
3. Explore
Explore merupakan tampilan dari foto-foto popular yang paling banyak
disukai para pengguna Instagram. 4. Profile
Dihalaman profil kita bisa mengetahui secara detail mengenai informasi pengguna, baik itu diri kita maupun orang lain sesama pengguna.
5. News feed
Fitur ini menampilkan notifikasi terhadap berbagai aktivitas yang dilakukan oleh pengguna Instagram.
12
Selain itu menurut Atmoko (2012) ada beberapa bagian yang sebaiknya diisi agar foto yang kita unggah lebih informatif. Bagian-bagian tersebut yaitu:
1. Judul
Membuat judul atau caption foto lebih bersifat untuk memperkuat karakter atau pesan yang ingin disampaikan pada foto tersebut.
2. Hashtag
Hashtag adalah suatu label berupa suatu kata yang diberi awalan simbol
bertanda pagar (#). Fitur pagar ini penting karena sangat memudahkan penggunna untuk menemukan foto-foto di Instagram dengan label tertentu. 3. Lokasi
Instagram memaksimalkan teknologi ini dengan menyediakan fitur lokasi. Sehingga setiap foto yang diunggah akan menampilkan lokasi dimana pengambilannya.
Instagram juga merupakan jejaring sosial. Karena disini kita bisa berinteraksi dengan sesama pengguna. Ada beberapa aktivitas yang dapat kita lakukan di Instagram, yaitu:
1. Follow
Adanya follow memungkinkan kita untuk mengikuti atau berteman dengan pengguna lain yang kita anggap menarik untuk diikuti.
2. Like
Jika menyukai foto yang ada di linimasa, jangan segan-segan untuk memberi like. Pertama dengan menekan tombol like dibagian bawah
13
caption yang bersebelahan dengan komentar. Kedua, dengan double tap
(mengetuk dua kali) pada foto yang disukai. 3. Komentar
Sama seperti like komentar adalah bagian dari interaksi namun lebih hidup dan personal. Karena lewat komentar, pengguna mengungkapkan pikirannya melalui kata-kata. Kita bebas memberikan komentar apapun terhadap foto, baik itu saran, pujian atau kritikan.
4. Mentions
Fitur ini memungkinkan kita untuk memanggil pengguna lain. Caranya adalah dengan menambahkan tanda arroba (@) dan memasukan akun Instagram dari pengguna tersebut
2.3 Data Mining
Data mining adalah bagian interdisipliner ilmu komputer yang melibatkan proses secara komputasional untuk menemukan pola dari kumpulan data besar. Tujuan dari proses analisis berkelanjutan ini adalah untuk mengekstraksi informasi dari suatu kumpulan data dan mengubahnya menjadi struktur yang dimengerti untuk penggunaan yang lebih lanjut. Metode yang digunakan merupakan hubungan dari kecerdasan buatan, pembelajaran mesin, statistika, sistem basis data, dan kecerdasan bisnis. Data mining adalah tentang menyelesaikan permasalahan dengan menganalisis data yang sudah ada dalam basis data (Jain & Srivastava, 2013).
14
Mengekstraksi, mengubah, dan memuat data transaksi ke dalam sistem data warehouse.
Menyimpan dan mengatur data di dalam sistem basis data multidimensi. Menyediakan akses data kepada pakar analis bisnis dan pakar teknologi
informasi.
Menganalisis data dengan aplikasi perangkat lunak.
Menyajikan data ke dalam format yang berguna, seperti dalam bentuk grafik atau tabel.
Tugas data mining dapat diklasifikasikan ke dalam dua kategori – deskriptif dan prediktif. Tugas deskriptif adalah mengkarakterisasi sifat umum dari data dalam basis data. Tugas prediktif menampilkan kesimpulan dari data saat ini yang bertujuan untuk membuat prediksi. Berbagai macam metodologi dari data
mining adalah neural network, decision trees, genetic algorithm, rule of extraction, dan lain-lain (Jain & Srivastava, 2013).
2.3.1 Penerapan Data Mining
Secara prinsip data mining dapat diterapkan pada banyak jenis data, seperti
relational database, data warehouse, transactional, dan object-relational database. Pola data yang menarik juga dapat diambil dari jenis repository
informasi yang lain termasuk spatial, time-series, sequence, text, multimedia,
legacy database, data stream, dan world wide web. Tetapi teknik data mining bisa
15
2.3.2 Komponen-komponen dan Tahapan Data Mining
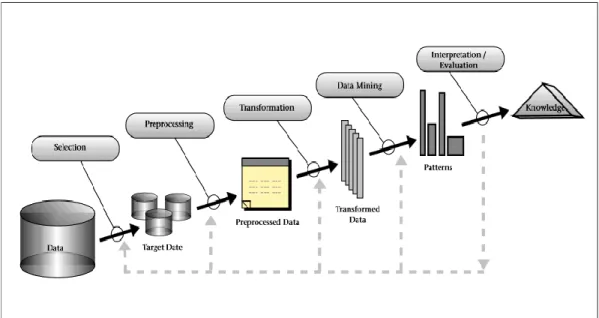
Gambar 2.2 Proses Knowledge Discovery in Databases Sumber: Fayyad, Piatetsky-Shapiro, dan Smyth (1996)
KDD atau Knowledge Discovery in Database adalah keseluruhan proses untuk mengkonversi data mentah menjadi suatu pengetahuan yang bermanfaat (Han, Kamber, & Pei, 2001). Knowledge discovery sebagai suatu proses diperlihatkan pada Gambar 2.2 dan berikut penjelasannya:
a. Data selection: untuk mengambil data yang sesuai untuk keperluan analisis.
b. Preprocessing: pada langkah ini dilakukan proses-proses pendahuluan meliputi pemilihan dan pemindahan data yang tidak berguna (data
cleaning), penggabungan sumber data (data integration), menampilkan
16
berasal dari data mentah dan hasilnya akan menjadi data yang nantinya siap untuk diolah dengan data mining.
c. Data transformation: untuk mentransformasikan data ke dalam bentuk yang lebih sesuai untuk di-mining. Langkah ini meliputi penentuan fitur penting untuk merepresentasikan data bergantung pada tujuan, dan menggunakan reduksi dimensionalitas atau metode-metode transformasi untuk mengurangi banyaknya variabel efektif di bawah pertimbangan, atau menemukan representasi invariant bagi data.
d. Data mining: proses terpenting untuk dimana metode tertentu diterapkan untuk menghasilkan data pattern dan merupakan pencarian pola dalam bentuk representasi tertentu seperti Decision Tree, Neural Network, Rule
Induction, Bayesian Network, K-means Clustering, dll. Sebelum data mining dilakukan, terlebih dahulu perlu dipilih sebuah data mining task,
selanjutnya dipilih sebuah representasi model yang sesuai dengan task tersebut, dan kemudian ditentukan algoritma untuk menentukan model. Pemilihan sebuah data mining task disesuaikan dengan tujuan proses KDD yang telah ditentukan di awal. Data mining task antara lain:
Klasifikasi: memetakan (mengklasifikasikan) data ke dalam satu atau beberapa kelas yang sudah didefinisikan sebelumnya.
Regresi: memetakan sebuah item data pada sebuah variable prediksi nilai nyata.
Clustering: memetakan data ke dalam satu atau beberapa kelas kategori (atau cluster) dimana kelas-kelas tersebut harus ditentukan
17
dari data, tidak seperti klasifikasi dimana kelas didefinisikan sebelumnya.
Peringkasan: menemukan sebuah deskripsi kompak bagi sebuah subset data.
Pemodelan kebergantungan: menemukan model yang menggambarkan kebergantungan signifikan di antara variable.
Deteksi perubahan dan deviasi: mencari perubahan yang paling signifikan dalam data dari pengukuran atau nilai normal sebelumnya. e. Pattern evaluation: untuk mengidentifikasi apakah interesting patterns
yang sudah didapatkan sudah cukup mewakili knowledge berdasarkan perhitungan tertentu.
f. Knowledge presentation: untuk merepresentasikan knowledge yang sudah didapatkan sudah cukup mewakili knowledge berdasarkan perhitungan tertentu.
2.3.3 Data Mining dalam Media Sosial
Media sosial memiliki data yang dihasilkan oleh para pengguna dalam jumlah besar yang dapat dimanfaatkan untuk data mining. Data mining dalam media sosial dapat memperkuat penggunaan media sosial dan meningkatkan pelayanan dalam urusan komersil. Sebagai contoh, teknik data mining dapat mengidentifikasi sentimen pengguna sebagai persiapan antisipatif untuk mengembangkan sistem petunjuk untuk bidang bisnis dengan produk yang
18
spesifik dan bahkan untuk membuat jaringan pertemanan baru atau menghubungkan berbagai komunitas dengan kepentingan tertentu.
Ahli pemasaran sedang mencari cara untuk memanfaatkan hal tersebut untuk kepentingan tim penjualan dan iklan mereka. Cukup banyak jenis deteksi pola yang biasanya digunakan dalam data mining media sosial termasuk:
sequential patterns, association learning, clustering, classification, regression, deviation detection, dan summarization. (Pippal, Batra, Krishna, Gupta, & Arora,
2014).
2.4 Text Mining
Text mining adalah salah satu bidang khusus dari data mining. Atau bisa
disebut juga data mining dengan input data berupa teks. Text mining dapat didefinisikan sebagai suatu proses menggali informasi dimana seorang user berinteraksi dengan sekumpulan dokumen menggunakan alat analisis yang merupakan komponen dalam data mining yang salah satunya adalah klasifikasi (Feldman & Sanger, 2007).
Text mining mengacu pada proses pengambilan informasi berkualitas
tinggi dari teks. Informasi berkualitas tinggi biasanya diperoleh melalui peramalan pola dan kecenderungan melalui sarana seperti pembelajaran pola statistik. Text
mining biasanya melibatkan proses penataan input, menentukan menentukan pola
dalam data terstruktur, dan akhirnya mengevaluasi dan menginterpretasi output. ‘Berkualitas tinggi’ dibidang text mining biasanya mengacu kepada beberapa kombinasi relevansi, kebaruan, dan interestingness (Saraswati, 2011).
19
Pendekatan manual text mining secara intensif dalam laboratorium pertama muncul pada pertengahan 1980-an, namun kemajuan teknologi telah memungkinkan ranah tersebut untuk berkembang selama dekade terakhir. Text
mining adalah bidang interdisipliner yang mengacu pada pencarian pencarian
informasi, penambangan data, pembelajaran mesin, statistik, dan komputasi linguistik. Dikarenakan kebanyakan informasi (perkiraan umum mengatakan lebih dari 80%) saat ini disimpan sebagai teks, text mining diyakini memiliki potensi nilai komersial tinggi (Bridge, 2011).
2.4.1 Penerapan Text Mining
Menurut Saraswati (2011), saat ini text mining telah mendapat perhatian dalam berbagai bidang:
1. Aplikasi keamanan.
Banyak paket perangkat lunak text mining diperlukan terhadap aplikasi keamanan, khususnya analisis plain text seperti berita internet. Hal ini juga mencakup studi enkripsi teks.
2. Aplikasi biomedis.
Berbagai aplikasi text mining dalam literature biomedis telah disusun. Salah satu contohnya adalah PubGene yang mengkombinasikan
text mining biomedis dengan visualisasi jaringan sebagai sebuah layanan
internet. Contoh lain text mining adalah GoPubMed.org. Kesamaan semantic juga telah digunakan oleh sistem text mining, yaitu,
20 3. Perangkat lunak dan apllikasi.
Departemen riset dan pengembangan perusahaan besar, termasuk IBM dan Microsoft, sedang meneliti teknik text mining dan mengembangkan program untuk lebih mengoptimatisasi proses pertambangan dan analisis. Perangkat lunak text mining juga sedang diteliti oleh perusahaan yang berbeda yang bekerja di bidang pencarian dan pengindeksan secara umum sebagai cara untuk meningkatkan performansinya.
4. Aplikasi media online.
Text mining sedang digunakan oleh perusahaan media besar,
seperti perusahaan Tribune, untuk menghilangkan ambigu informasi dan untuk memberikan pembaca dengan pengalaman pencarian yang lebih baik, yang meningkatkan loyalitas pada site dan pendapatan. Selain itu, editor diuntungkan dengan mampu berbagi, mengasosiasi dan properti paket berita, secara signifikan meningkatkan peluang untuk enguangkan konten.
5. Aplikasi pemasaran.
Text mining juga mulai digunakan dalam pemasaran, lebih spesifik
dalam analisis manajemen hubungan pelanggan. 6. Sentiment analysis.
Sentiment analysis mungkin melibatkan analisis dari review film
21
semacam ini mungkin memerlukan kumpulan data berlabel atau label dari efektifitas kata-kata.
Sentiment analysis pada dasarnya mencari berbagai macam opini di
dalam konten dan mengambil sentimen pada opini-opini tersebut (Donkor, 2016). Pendapat adalah ekspresi yang terdiri dari dua komponen utama:
Sasaran (yang biasa disebut sebagai “topik” oleh kebanyakan alat analisis media sosial);
Sentimen pada sasaran/topik.
Analisis semacam ini mungkin memerlukan kumpulan data berlabel atau label dari efektifitas kata-kata. Sebuah sumber daya untuk efektifitas kata-kata telah dibuat untuk WordNet.
7. Aplikasi akademik.
Masalah text mining penting bagi penerbit yang memiliki database besar untuk mendapatkan informasi yang memerlukan pengindeksan untuk pencarian. Hal ini terutama berlaku dalam ilmu sains, dimana informasi yang sangat spesifik sering terkandung dalam teks tertulis. Oleh karena itu, inisiatif telah diambil seperti Nature’s proposal untuk Open Text Mining
Interface (OTMI) dan Health’s common Journal Publishing untuk Document Type Definition (DTD) yang akan memberikan isyarat semantik
pada mesin untuk menjawab pertanyaan spesifik yang terkandung dalam teks tanpa menghilangkan barrier penerbit untuk akses publik.
22 2.4.2 Tahapan Text Mining
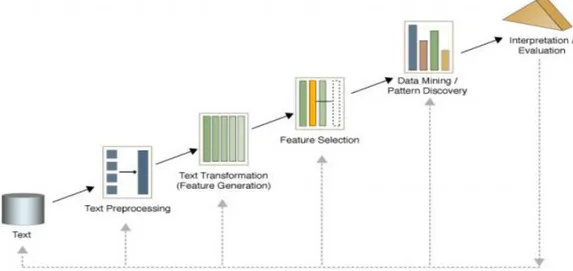
Berdasarkan ketidakaturan struktur data teks, maka proses text mining memerlukan beberapa tahap awal yang pada intinya adalah mempersiapkan agar teks menjadi lebih terstruktur. Tahapan text mining dapat dilihat pada Gambar 2.3.
Gambar 2.3 Tahap-tahap dalam Text Mining Sumber: Even-Zohar, Introduction to Text Mining (2002).
Seperti terlihat pada gambar, terdapat lima tahap dalam melakukan text
mining, yaitu:
1. Text preprocessing, pada tahap ini dilakukan proses pembersihan teks dengan cara membuang kata-kata tidak terpakai seperti header, signature, dan lain-lain. Selain pembersihan teks, dilakukan juga restrukturasi untuk tahapan selanjutnya.
2. Text transformation, pada tahap ini dilakukan pengolahan teks dengan cara memisah-misahkan tiap kata, menghilangkan imbuhan, dan melakukan proses penghilangan stopwords atau stopwords removal. Stopwords adalah
23
kata yang tidak relevan yang banyak muncul pada sebuah teks (Budhi, Gunawan, & Yuwono, 2006).
3. Feature selection, pada tahapan ini dilakukan penghilangan dimensi kata, yaitu membuang kata-kata yang tidak penting.
4. Data mining/pattern discovery, pada tahap ini dilakukan proses data
mining untuk mendapatkan pengetahuan baru pada teks. Tahapan ini dapat
dilakukan dengan teknik-teknik data mining seperti classification.
5. Interpretation/Evaluation, hasil dari proses mining akan diinterpretasikan ke dalam bentuk tertentu untuk kemudian dilakukan proses evaluasi.
2.5 Klasifikasi Dokumen
Klasifikasi merupakan proses identifikasi objek ke dalam sebuah kelas, grup ataupun kategori tertentu berdasarkan prosedur, karakteristik serta definisinya (Tan, Steinbach, & Kumar, 2006).
Gambar 2.4 Proses klasifikasi dengan memasukan nilai atribut x ke dalam kelas label y
Gambar 2.4 menunjukkan garis besar proses klasifikasi dilakukan, dimana dokumen input-an yang akan diklasifikasi memiliki nilai atribut x, kemudian
24
dengan menggunakan model klasifikasi yang telah ditentukan akan menghasilkan nilai y sebagai kelas keluaran proses klasifikasi.
Secara umum, proses klasifikasi dapat dilakukan dalam dua tahap, yaitu proses belajar dari data pelatihan dan klasifikasi kasus baru. Pada proses belajar, algoritma klasifikasi mengolah data pelatihan untuk menghasilkan sebuah model. Setelah model diuji dan dapat diterima, pada tahap klasifikasi, model tersebut digunakan untuk memprediksi kelas dari kasus baru untuk membantu proses pengambilan keputusan. Kelas yang dapat diprediksi adalah kelas-kelas yang sudah terdefinisi pada data pelatihan. Karena proses klasifikasi kasus baru cukup sederhana, penelitian lebih banyak ditujukan untuk memperbaiki teknik-teknik pada proses belajar.
2.6 Naïve Bayes Classifier (NBC)
Naïve Bayes merupakan salah satu metode machine learning yang
menggunakan perhitungan peluang. Konsep dasar yang digunakan oleh Naïve
Bayes adalah Teorema Bayes, yaitu melakukan klasifikasi dengan melakukan
perhitungan nilai peluang 𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗), yaitu peluang kategori 𝑐𝑖 jika diketahui dokumen 𝑑𝑗. Klasifikasi dilakukan untuk menentukan kategori 𝑐 ∈ 𝐶 dari suatu dokumen 𝑑 ∈ 𝐷 dimana 𝐶 = (𝑐1, 𝑐2, 𝑐3, … , 𝑐𝑖) dan 𝐷 = (𝑑1, 𝑑2, 𝑑3, … , 𝑑𝑗). Penentuan dari kategori sebuah dokumen dilakukan dengan mencari nilai maksimum dari 𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗) pada 𝑃 = (𝑝(𝐶 = 𝑐𝑖 | 𝐷 = 𝑑𝑗 | 𝑐 ∈ 𝐶 𝑑𝑎𝑛 𝑑 ∈ 𝐷). Nilai peluang 𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗) dapat dihitung dengan persamaan (Mitchell, 2005):
25
𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗) = 𝑃(𝐶 = 𝑐𝑖 ∩ 𝐷 = 𝑑𝑗) 𝑃(𝐷 = 𝑑𝑗)
= 𝑝(𝐷 = 𝑑𝑗 | 𝐶 = 𝑐𝑖) × 𝑝(𝐶 = 𝑐𝑖) 𝑃(𝐷 = 𝑑𝑗)
𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗) yaitu nilai peluang dari kemunculan dokumen 𝑑𝑗 jika diketahui dokumen tersebut berkategori 𝑐𝑖. 𝑝(𝐶 = 𝑐𝑖) adalah nilai peluang kemunculan kategori 𝑐𝑖, dan 𝑝(𝐷 = 𝑑𝑗) adalah nilai peluang kemunculan dokumen 𝑑𝑗.
Naïve Bayes menganggap sebuah dokumen sebagai kumpulan dari
kata-kata yang menyusun dokumen tersebut, dan tidak memerhatikan urutan kemunculan kata pada dokumen. Sehingga perhitungan peluang 𝑝(𝐷 = 𝑑𝑗 | 𝐶 = 𝑐𝑖) dapat dianggap sebagai hasil perkalian dari peluang kemunculan kata-kata pada dokumen 𝑑𝑗. Perhitungan peluang 𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗) dapat dituliskan sebagai berikut:
𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗) = ∏ 𝑝(𝑤𝑘 𝑘|𝐶 = 𝑐𝑖) × 𝑝(𝐶 = 𝑐𝑖) 𝑝(𝑤1, 𝑤2, 𝑤3, … , 𝑤𝑘, … , 𝑤𝑛)
dengan ∏𝑘𝑝(𝑤𝑘|𝐶 = 𝑐𝑖) adalah hasil perkalian dari peluang kemunculan semua kata pada dokumen 𝑑𝑗.
Proses klasifikasi dilakukan dengan membuat model probabilistik dari dokumen latih, yaitu dengan menghitung nilai 𝑝(𝑤𝑘|𝑐). Untuk 𝑤𝑘𝑗 diskrit dengan 𝑤𝑘𝑗 ∈ 𝑉 = (𝑣1, 𝑣2, 𝑣3, … , 𝑣𝑚) maka 𝑝(𝑤𝑘|𝑐) dicari untuk seluruh kemungkinan nilai 𝑤𝑘𝑗 dan didapatkan dengan melakukan perhitungan (Mitchell, 2005):
𝑝(𝑤𝑘 = 𝑤𝑘𝑗|𝑐) =𝐷𝑏(𝑤𝑘=𝑤𝑘𝑗.𝐶)
26 dan
𝑝(𝑐) = 𝐷𝑏(𝑐)
|𝐷|
dengan 𝐷𝑏(𝑤𝑘 = 𝑤𝑘𝑗. 𝐶) adalah fungsi yang mengembalikan jumlah dokumen 𝑏 pada kategori 𝑐 yang memiliki nilai kata 𝑤𝑘 = 𝑤𝑘𝑗. 𝐷𝑏(𝑐) adalah fungsi yang mengembalikan jumlah dokumen 𝑏 yang memiliki kategori 𝑐, dan |𝐷| adalah jumlah seluruh dokumen latih. Persamaan 𝐷𝑏(𝑤𝑘 = 𝑤𝑘𝑗. 𝐶) seringkali dikombinasikan dengan Laplaction Smoothing untuk mencegah persamaan mendapatkan nilai 0, yang dapat mengganggu hasil klasifikasi secara keseluruhan. Sehingga persamaan 𝐷𝑏(𝑤𝑘 = 𝑤𝑘𝑗, 𝑐) dilakukan sebagai (Mitchell, 2005):
𝑝(𝑤𝑘 = 𝑤𝑘𝑗|𝑐) =𝐷𝑏(𝑤𝑘= 𝑤𝑘𝑗, c) + 1 𝐷𝑏(𝑐) + |𝑉|
dengan |𝑉| merupakan jumlah kemungkinan nilai dari 𝑤𝑘𝑗. Pemberian kategori dari sebuah dokumen dilakukan dengan memilih nilai 𝑐 yang memiliki nilai 𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗) maksimum, dan dinyatakan dengan:
𝑐∗ = arg 𝑚𝑎𝑥
𝑐∈𝐶 𝑝Π𝑘 𝑝(𝑤𝑘|𝐶) × 𝑝(𝑐)
Kategori 𝑐∗ yaitu kategori yang memiliki nilai 𝑝(𝐶 = 𝑐𝑖 |𝐷 = 𝑑𝑗) maksimum. Nilai 𝑝(𝐷 = 𝑑𝑗) tidak memengaruhi perbandingan karena untuk setiap kategori nilainya akan sama. Berikut gambaran proses klasifikasi dengan Naïve Bayes:
27
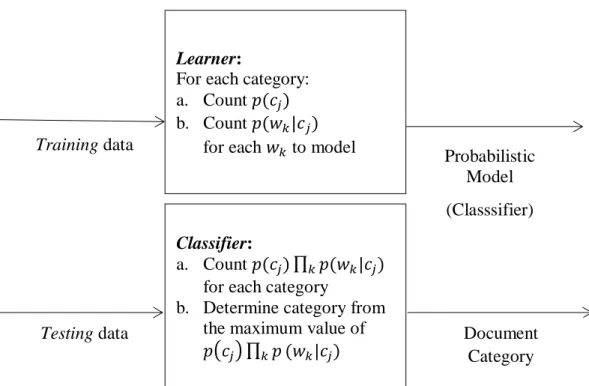
Gambar 2.5 Tahapan proses klasifikasi dokumen dengan algoritma Naïve Bayes
2.7 Hubungan Kepribadian dengan Penggunaan Jejaring Sosial
Sebuah teknologi pada hakikatnya diciptakan untuk membuat hidup manusia menjadi semakin mudah dan nyaman, tuntutan kebutuhan pertukaran informasi yang cepat, peranan teknologi komunikasi menjadi sangat penting, teknologi sangat bermanfaat dalam memudahkan manusia untuk mencapai sesuatu yang diinginkan secara efisisen dalam waktu yang singkat. Munculnya media jejaring sosial berbanding terbalik dengan frekuensi komunikasi tatap muka antar pribadi yang dilakukan baik pada individu dengan tipe kepribadian ekstrovert dan introvert. Intensitas komunikasi menggunakan jejaring sosial yang berlebihan dapat menjadi candu karena kesenangan yang ditawarkan, seseorang dengan intensitas komunikasi tinggi dalam menggunakan jejaring sosial maka semakin
Learner:
For each category: a. Count 𝑝(𝑐𝑗) b. Count 𝑝(𝑤𝑘|𝑐𝑗)
for each 𝑤𝑘 to model
Classifier:
a. Count 𝑝(𝑐𝑗) ∏ 𝑝(𝑤𝑘 𝑘|𝑐𝑗) for each category
b. Determine category from the maximum value of 𝑝(𝑐𝑗) ∏ 𝑝𝑘 (𝑤𝑘|𝑐𝑗)
Training data
Probabilistic Model (Classsifier)
Testing data Document
28
rendah intensitas komunikasi tatap muka pada komunikasi antarpribadi (Risti, 2015).
Komunikasi berfungsi untuk menghubungkan dan mengajak orang lain untuk mengerti apa yang kita sampaikan, apabila penerima berita mengerti benar mengenai pesan yang disampaikan pengirim pesan, maka dapat disebut sebagai komunikasi yang efektif, jika tidak, maka terjadi kesalahan pesan atau disebut
miscomunication. Terdapat lima unsur dalam proses komunikasi yang terdiri dari
adanya pengirim berita, penerima berita, adanya berita yang dikirimkan, adanya media atau alat pengirim berita serta adanya sistem yang digunakan untuk menyatakan berita (Sarwono, 2012).
Komunikasi menggunakan media jejaring sosial dijadikan sarana pengganti proses komunikasi secara tatap muka. Penggunaan komunikasi media jejaring sosial dapat menimbulkan ketidaksepahaman terhadap makna dan tujuan pesan yang disampaikan dalam berkomunikasi, hal ini dikarenakan komunikasi melalui jejaring sosial tanpa disertai dengan bahasa nonverbal, padahal komunikasi nonverbal dapat membantu menekankan beberapa bagian dari pesan verbal (Devito, 1997).
Dalam pemanfaatan penggunaan media jejaring sosial, pengguna cenderung memiliki karakteristik yang berbeda. Hal ini dikarenakan setiap orang memiliki pengalaman, motif, sikap dan tipe kepribadian yang relatif berbeda dalam penggunaan jejaring sosial. Kepribadian bersifat unik dan konsisten sehingga dapat digunakan untuk membedakan antara individu satu dengan lainnya. Terkait dengan perbedaan tipe kepribadian, Jung menggolongkan
29
kepribadian menjadi dua yaitu tipe kepribadian ekstrovert dan introvert (Suryabrata, 2002).
Kepribadian dalam bahasa Inggris disebut dengan istilah personality, istilah ini berasal dari bahasa latin yaitu persona yang berarti topeng, topeng digunakan dalam pertunjukan drama untuk mewakili karakteristik kepribadian tertentu, berdasarkan penjelasan tersebut kepribadian diartikan sebagai seseorang yang nampak di hadapan orang lain (Irwanto, 1989).
Kepribadian merupakan karakteristik seseorang yang menyebabkan munculnya konsistensi perasaan, pemikiran dan perilaku. Menurut Allport, kepribadian didefinisikan sebagai organisasi dinamis dari sistem psikofisik individu yang menentukan penyesuaian dirinya terhadap lingkungan (Friedman & Schustack, 2008).
2.8 Five Factor Model
Setelah beberapa dekade, cabang psikologi kepribadian memperoleh suatu pendekatan taksonomi kepribadian yang dapat diterima secara umum yaitu dimensi “Big Five Personality”. Dimensi Big Five pertama kali diperkenalkan oleh Goldberg pada tahun 1981. Dimensi ini tidak mencerminkan perspektif teoritis tertentu, tetapi merupakan hasil dari analisis bahasa alami manusia dalam menjelaskan dirinya sendiri dan orang lain. Taksonomi Big Five bukan bertujuan untuk mengganti sistem yang terdahulu, melainkan sebagai penyatu karena dapat memberikan penjelasan sistem kepribadian secara umum (John & Srivastava, 1999).
30
Big Five disusun bukan untuk menggolongkan individu ke dalam satu
kepribadian tertentu, melainkan untuk menggambarkan sifat-sifat kepribadian yang disadari oleh individu itu sendiri dalam kehidupannya sehari-hari. Pendekatan ini disebut Goldberg sebagai Fundamental Lexical (Language)
Hypothesis; perbedaan individu yang paling mendasar digambarkan hanya dengan
satu istilah yang terdapat pada setiap bahasa (dalam Pervin, 2005). Big Five
Personality atau yang juga disebut dengan Five Factor Model oleh Costa &
McRae dibuat berdasarkan pendekatan yang lebih sederhana. Disini, peneliti berusaha menemukan unit dasar kepribadian dengan menganalisa kata-kata yang digunakan orang pada umumnya, yang tidak hanya dimengerti oleh para psikolog, namun juga orang biasa (Pervin, Cervone, & John, 2005).
Seperti yang telah dijelaskan sebelumnya, bahwa big five personality terdiri dari lima tipe atau faktor. Terdapat beberapa istilah untuk menjelaskan kelima faktor dengan istilah berikut:
1. Neuroticism (N) 2. Extraversion (E)
3. Openness to New Experience (O) 4. Agreeableness (A)
5. Conscientiousness (C)
Untuk lebih mudah mengingatnya, istilah-istilah tersebut di atas disingkat menjadi OCEAN (Pervin, Cervone, & John, 2005).
Dari hasil penelitian Costa dan McRae (1985;1992) disebutkan bahwa
perasaan-31
perasaan negatif, seperti kecemasan, kesedihan, mudah marah, dan tegang.
Openness to Experience menjelaskan keluasan, kedalaman, dan kompleksitas dari
aspek mental dan pengalaman hidup. Extraversion dan Agreeableness merangkum sifat-sifat interpersonal, yaitu apa yang dilakukan seseorang dengan dan kepada orang lain. Conscientiousness menjelaskan perilaku pencapaian tujuan dan kemampuan mengendalikan dorogan yang diperlukan dalam kehidupan sosial (Pervin, Cervone, & John, 2005).
Menurut Costa & McRae (Pervin, Cervone, & John, 2005), setiap dimensi dari Big Five terdiri dari 6 (enam) faset atau subfaktor. Faset-faset tersebut adalah:
1. Extraversion terdiri dari:
Gregariousness (suka berkumpul) Activity level (level aktivitas) Assertiveness (asertif)
Excitement seeking (mencari kesenangan) Positive emotions (emosi yang positif) Warmth (kehangatan)
2. Agreeableness terdiri dari:
Straightforwardness (berterusterang) Trust (kepercayaan)
Altruism (mendahulukan kepentingan orang lain) Modesty (rendah hati)
Tendermindedness (berhati lembut) Compliance (kerelaan)
32 3. Conscientiousness terdiri dari:
Self-discipline (disiplin) Dutifulness (patuh) Competence (kompetensi) Order (teratur)
Deliberation (pertimbangan)
Achievement striving (pencapaian prestasi) 4. Neuroticism terdiri dari:
Anxiety (kecemasan)
Self-consciousness (kesadaran diri) Depression (depresi)
Vulnerability (mudah tersinggung) Impulsiveness (menuruti kata hati) Angry hostility (amarah)
5. Openness to new experience terdiri dari: Fantasy (khayalan) Aesthetics (keindahan) Feelings (perasaan) Ideas (ide) Actions (tindakan) Values (nilai-nilai)
33 2.9 Unified Modeling Language (UML)
Unified Modeling Language (UML) adalah sekumpulan model konvensi
yang digunakan untuk menentukan atau menggambarkan sebuah sistem perangkat lunak dalam kaitannya dengan objek (Whitten, 2004).
UML dapat digunakan untuk membuat model untuk semua jenis aplikasi perangkat lunak. Dimana aplikasi tersebut dapat berjalan pada perangkat keras, sistem operasi dan jaringan apapun, serta ditulis dalam bahasa pemrograman apapun. Tetapi karena UML juga menggunakan class dan operations dalam konsep dasarnya, maka UML lebih cocok untuk penulisan perangkat lunak dalam bahasa-bahasa pemrograman berorientasi objek seperti C++, Java, C#, VB.Net, atau Delphi.
Pada UML dikenal beberapa diagram, diantaranya sebagai berikut: 1. Use case diagram
Use case diagram menggambarkan fungsionalitas yang diharapkan
dari sebuah sistem. Sebuah use case merepresentasikan sebuah interaksi antara actor dengan sistem. Seorang/sebuah aktor adalah sebuah entitas manusia atau mesin yang berinteraksi dengan sistem untuk melakukan pekerjaan-pekerjaan tertentu.
2. Activity diagram
Activity diagram menggambarkan berbagai alur aktivitas dalam
sistem yang sedang dirancang, bagaimana masing-masing alur berawal,
34
diagram juga menggambarkan proses paralel yang mungkin terjadi pada beberapa eksekusi.
3. Sequence diagram
Sequence diagram menggambarkan interaksi antar objek di dalam
dan di sekitar sistem (termasuk pengguna, display, dan sebagainya berupa
message yang digambarkan terhadap waktu. Sequence diagram terdiri
antar dimensi vertikal (waktu) dan dimensi horizontal (onjek-onjek yang terkait).
4. Class diagram
Class adalah sebuah spesifikasi yang jika diinstansiasi akan
menghasilkan sebuah objek dan merupakan inti dari pegembangan dan desain berorientasi objek. Class menggambarkan keadaan (atribut/properti) suatu sistem, sekaligus menawarkan layanan untuk memanipulasi keadaan tersebut (metoda/fungsi). Class diagram menggambarkan struktur dan deskripsi class, package, dan objek beserta hubungan satu sama lain seperti containment, perwarisan, asosiasi, dan lain-lain.
5. Component diagram
Component diagram menggambarkan struktur dan hubungan antar
komponen piranti lunak, termasuk ketergantungan (dependency) diantaranya. Komponen perangkat lunak adalah modul berisi code, baik berisi source code maupun binary code, baik library maupun executeable, baik yang muncul pada compile time, link time, maupun run time.
35
Umumnya komponen terbentuk dari beberapa class atau package, tapi dapat juga dari komponen-komponen yang lebih kecil. Komponen dapat juga berupa interface, yaitu kumpulan layanan yang disediakan sebuah komponen untuk komponen lain.
2.10 Microsoft Access
Microsoft Access (atau Microsoft Office Access) adalah sebuah program
aplikasi berbasis basis data computer relasional yang ditujukan untuk kalangan rumahan dan perusahaan kecil dan menengah. Aplikasi ini merupakan anggota dari beberapa aplikasi Microsoft Office, selain tentunya Microsoft Word,
Microsoft Excel, dan Microsoft PowerPoint. Aplikasi ini merupakan mesin basis
data Microsoft Jet Database Engine, dan juga menggunakan tampilan grafis yang intuitif sehingga memudahkan penggunaan.
Microsoft Access dapat menggunakan data yang disimpan di dalam format Microsoft Access, Microsoft Jet Database Engine, Microsoft SQL Server, Oracle Database, atau semua kontainer basis data yang mendukung standar ODBC. Para
pengguna atau programmer yang mahir dapat menggunakannya untuk mengembangkan perangkat lunak aplikasi yang kompleks, sementara para
programmer yang kurang mahir dapat menggunakannya untuk mengembangkan
perangkat lunak aplikasi sederhana. Access juga mendukung teknik-teknik pemrograman berorientasi objek (PBO/OOP), tetapi tidak dapat digolongkan ke dalam perangkat bantu pemrograman berorientasi objek (Wikipedia, Microsoft Access, 2012).
36 2.11 Bahasa Pemrograman C#
C# (dibaca: C sharp) merupakan sebuah bahasa pemrograman yang berorientasi objek yang dikembangkan oleh Microsoft sebagai bagian dari inisiatif kerangka .NET Framework. Bahasa pemrograman ini dibuat berbasiskan bahasa C++ yang telah dipengaruhi oleh aspek-aspek ataupun fitur bahasa yang terdapat pada bahasa-bahasa pemrograman lainnya seperti Java, Delphi, Visual Basic, dan lain-lain) dengan beberapa penyederhanaan. Menurut standar ECMA-334 C#
Language Specification, nama C# terdiri atas sebuah huruf Latin C (U+0043)
yang diikuti oleh tanda pagar yang menandakan angka # (U+0023). Tanda pagar # yang digunakan memang bukan tanda kres dalam seni musik (U+266F), dan tanda pagar # (U+0023) tersebut digunakan karena karakter kres dalam seni musik tidak terdapat di dalam keyboard standar (Wikipedia, C Sharp, 2011).
Standar European Computer Manufacturer Association (ECMA) mendaftarkan beberapa tujuan desain dari bahasa pemrograman C#, sebagai berikut:
Bahasa pemrograman C# dibuat sebagai bahasa pemrograman yang bersifat bahasa pemrograman general-purpose (untuk tujuan jamak), berorientasi objek, modern, dan sederhana.
Bahasa pemrograman C# ditujukan untuk digunakan dalam mengembangkan komponen perangkat lunak yang mampu mengambil keuntungan dari lingkungan terdistribusi.
Portabilitas programmer sangatlah penting, khususnya bagi programmer yang telah lama menggunakan bahasa pemrograman C dan C++.
37
Dukungan untuk internasionalisasi (multi-language) juga sangat penting. C# ditujukan agar cocok digunakan untuk menulis program aplikasi baik
dalam sistem klien-server (hosted system) maupun sistem embedded (embedded system), mulai dari perangkat lunak yang sangat besar yang menggunakan sistem operasi yang canggih hingga kepada perangkat lunak yang sangat kecil yang memiliki fungsi-fungsi terdedikasi.
Meskipun aplikasi C# ditujukan agar bersifat 'ekonomis' dalam hal kebutuhan pemrosesan dan memori komputer, bahasa C# tidak ditujukan untuk bersaing secara langsung dengan kinerja dan ukuran perangkat lunak yang dibuat dengan menggunakan bahasa pemrograman C dan bahasa rakitan.
Bahasa C# harus mencakup pengecekan jenis (type checking) yang kuat, pengecekan larik (array), pendeteksian terhadap percobaan terhadap penggunaan Variabel-variabel yang belum diinisialisasikan, portabilitas kode sumber, dan pengumpulan sampah (garbage collection) secara otomatis.
2.12 Microsoft Visual Studio
Microsoft Visual Studio merupakan perangkat lunak lengkap (suite) yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dalam bentuk aplikasi
console, aplikasi Windows, ataupun aplikasi Web. Visual Studio mencakup
38
(umumnya berupa MSDN Library). Kompiler yang dimasukkan ke dalam paket
Visual Studio antara lain Visual C++, Visual C#, Visual Basic, Visual Basic .NET, Visual InterDev, Visual J++, Visual J#, Visual FoxPro, dan Visual SourceSafe.
Microsoft Visual Studio dapat digunakan untuk mengembangkan aplikasi dalam native code (dalam bentuk bahasa mesin yang berjalan di atas Windows) ataupun managed code (dalam bentuk Microsoft Intermediate Language di atas .NET Framework). Selain itu, Visual Studio juga dapat digunakan untuk mengembangkan aplikasi Silverlight, aplikasi Windows Mobile (yang berjalan di atas .NET Compact Framework) (Wikipedia, Microsoft Visual Studio, 2011).