7 BAB II KAJIAN PUSTAKA 2.1 Visi Komputer
Visi komputer dapat didefinisikan sebagai suatu proses pengenalan objek yang menarik di dalam suatu citra, dan dapat didefinisikan sebagai deduksi logis otomatis terhadap properti objek tiga dimensi dari satu atau beberapa citra. Tugas-tugas seperti pengidentifikasian tanda tangan, pengidentifikasian tumor pada suatu citra regsonansi magnetik, pengenalan objek pada citra satelit, pengidenifikasian wajah, penempatan sumber daya mineral dari suatu citra, penghasilan gambaran tiga-dimensi dari potongan citra dua dimensi, dan pengenalan suatu kode ZIP, dianggap berada dalam ruang lingkup visi komputer. Manusia memiliki kemampuan untuk menguraikan tulisan tangan yang ceroboh, mengenal dan mengklasifikasikan citra, mengidentifikasikan citra yang terhalang sebagian pada lingkungan yang noisy, mengidentifikasikan objek dengan orientasi dan skala yang berbeda, serta kedalaman persepsi. Pengembangan sistem visi komputer untuk melaksanakan tugas-tugas seperti ini membutuhkan proses yang kompleks. Biasanya, untuk setiap aplikasi yang diberikan, keseluruhan tugas tidak dapat dilaksanakan pada sebuah tahapan tunggal. Oleh karena itu, sistem visi komputer seringkali dibagi ke dalam beberapa tahapan, dan setiap tahapan melaksanakan satu fungsi atau lebih. Sistem visi komputer tertentu terdiri dari tahapan-tahapan seperti perolehan citra, preprocessing, pengekstraksian fitur, penyimpanan objek secara asosiatif, pengaksesan suatu basis pengetahuan, dan pengenalan.
Visi komputer meliputi pengolahan citra dan pengenalan pola. Pengolahan citra berkaitan dengan manipulasi dan analisis gambar. Sub-area utama pada pengolahan citra, yaitu:
a. Digitisasi dan kompresi
b. Enhancement, restorasi, dan rekonstruksi c. Pencocokan
d. Pendeskripsian dan pengenalan
Digitisasi adalah proses pengkonversian gambar menjadi bentuk diskrit, dan kompresi mencakup coding efisien atau pendekatan gambar digital untuk menghemat tempat penyimpanan atau kapasitas channel. Teknik perbaikan dan restorasi berkaitan dengan peningkatan kualitas dari citra dengan kontras yang rendah, blur, ataupun noisy. Teknik pencocokan dan pendeskripsian berkaitan dengan perbandingan dan pelapisan gambar yang satu dengan gambar yang lainnya, pembagian gambar menjadi beberapa bagian, serta pengukuran hubungan antara bagian-bagian tersebut (Kulkarni, 2001, p1).
Salah satu tantangan utama dalam merancang algoritma pengolahan citra adalah dalam memahami kriteria yang digunakan untuk menaksir hasil yang diharapkan. Hal ini termasuk pengukuran sensitivitas parameter, kekuatan algoritma, dan keakuratan hasil. Secara umum, evaluasi kinerja meliputi pengukuran beberapa kelakuan pokok dari suatu algoritma yang dapat mencapai keakuratan, kekuatan, atau ekstensibilitas. Hal ini memungkinkan penekanan karakteristik intrinsik dari suatu algoritma dan penaksiran keuntungan serta batasan-batasannya (Manohar et al, p1).
Pengenalan pola berkaitan dengan identifikasi objek dari citra atau pola yang diamati. Pada pengenalan pola konvensional, sebuah vektor observasi dipetakan terlebih dahulu terhadap sebuah bidang fitur. Teknik pengenalan pola tertentu meliputi fungsi
diskriminan, serta metode parametrik dan nonparametrik statistik. Selama 30 tahun ini, banyak teknik digital yang telah dikembangkan untuk tugas-tugas pengolahan citra dan pengenalan pola, serta digunakan pada aplikasi-aplikasi seperti visi robot, pengenalan karakter, pengenalan pembicaraan, penginderaan jauh, pengintaian militer, pengidentifikasian tanda tangan, diagnosis citra medis, pendeteksian sumber daya mineral, dan survei geologi.
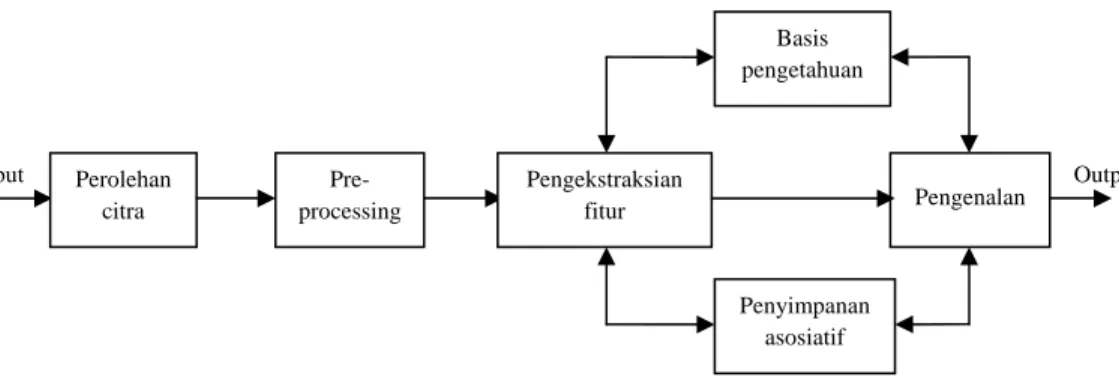
Berbagai langkah di dalam sebuah sistem visi komputer dapat dilihat pada Gambar 2.1. Sistem terdiri dari enam tahap: perolehan citra, preprocessing, pengekstrasian fitur, penyimpanan asosiatif, basis pengetahuan,dan pengenalan. Tahap-tahap ini pada dasarnya dibagi ke dalam tiga tingkatan pengolahan, yaitu tingkat rendah, menengah, dan tinggi. Langkah pertama adalah perolehan citra, yaitu langkah untuk memperoleh sebuah citra digital. Citra yang dimaksud adalah sebuah fungsi intensitas cahaya dua dimensi , , dimana dan adalah koordinat spasial dan nilai pada titik , sebanding dengan tingkat keterangan atau keabuan citra pada titik tersebut. Citra digital adalah citra , yang koordinat spasial dan keterangannya telah didigitisasikan. Citra digital dapat dianggap sebagai sebuah matriks dimana setiap baris dan kolom mengidentifikasikan sebuah titik pada citra, dan nilai elemen matriks tersebut merepresentasikan tingkat keabuan pada titik tersebut. Elemen pada array digital disebut elemen gambar atau piksel. Tahap perolehan citra adalah mengenai pengambilan citra oleh suatu sensor. Sensor yang dimaksud dapat berupa sebuah kamera atau sebuah
scanner. Sifat sensor dan citra yang dihasilkan ditentukan oleh aplikasinya.
Setelah sebuah citra digital didapatkan, maka langkah selanjutnya adalah
preprocessing, yang sebanding dengan pengolahan visi awal atau pengolahan tingkat
keabuan, penapisan noise, isolasi daerah, perbaikan geometris, restorasi, rekonstruksi, dan segmentasi. Teknik perbaikan citra dapat diklasifikasikan ke dalam dua metode, yaitu domain spasial dan domain frekuensi. Metode domain spasial didasarkan pada manipulasi langsung terhadap nilai keabuan pada piksel di dalam suatu citra. Metode domain frekuensi didasarkan pada modifikasi transformasi Fourier pada suatu citra. Pada teknik manipulasi skala keabuan, perbaikan pada setiap titik di dalam citra mungkin hanya bergantung pada nilai keabuan titik tersebut, atau mungkin bergantung pada nilai keabuan titik tersebut dan sekitarnya. Kategori ini termasuk dalam pemrosesan titik. Pendekatan dimana perbaikan pada setiap piksel bergantung pada nilai keabuan piksel tersebut dan piksel-piksel di sekitarnya menggunakan penutup (masks) atau jendela (windows) yang mendefinisikan piksel sekitarnya. Terdapat banyak implementasi piranti keras dan piranti lunak untuk mengimplementasikan teknik perbaikan tersebut.
Sistem penglihatan manusia membutuhkan variabilitas dalam pencahayaan. Tahap preprocessing pada suatu sistem pengenalan mesin mungkin berkaitan dengan persepsi keterangan seperti permasalahan restorasi dan rekonstruksi citra. Sistem perolehan citra pada prakteknya tidaklah sempurna. Sistem ini memiliki resolusi terbatas. Metode restorasi citra berkaitan dengan penafsiran citra asli dari citra yang telah rusak. Teknik restorasi memperbaiki kerusakan sistem yang mungkin telah dialami oleh suatu citra.
Tingkat pengolahan selanjutnya adalah tingkat menengah. Pengolahan pada tingkat ini berusaha untuk membangun sebuah koalisi bukti (tokens) yang didapatkan pada pengolahan tingkat rendah dan untuk mengekstraksi entitas-entitas yang penting. Salah satu teknik pengolahan tingkat menengah yang terkenal adalah pengekstraksian fitur, yang terdiri dari pemetaan sebuah vektor observasi ke dalam bidang fitur. Tujuan
utama dari pengekstraksian fitur adalah untuk mengurangi data dengan mengukur fitur-fitur tertentu yang membedakan pola inputan. Untuk mengekstraksi fitur-fitur, dapat dilakukan dengan memilih sebuah subset dari vektor input yang diamati, atau dapat dilakukan dengan mentransformasikan vektor observasi inputan menjadi sebuah vektor fitur menggunakan beberapa fungsi dasar ortogonal. Pada beberapa aplikasi, vektor observasi didapatkan dengan melakukan sampling terhadap citra inputan yang merepresentasikan data yang terkorelasi dengan baik. Untuk pengurangan dimensi saat menyimpan suatu informasi, vektor observasi dipetakan ke dalam sebuah domain bidang fitur. Data di dalam domain yang telah ditransformasikan kemudian dapat disusun berdasarkan derajat kepentingan dari isi dan kualitas pola yang diperoleh.
Dalam 30 tahun ini, banyak sekali teknik yang telah dikembangkan untuk mengekstraksi fitur, di antaranya: transformasi Fourier, invarian waktu (moment
invariant), distribusi Wigner, transformasi Hough, polinomial ortogonal, fungsi Gabor,
dan lain-lain. Masalah pengenalan objek invarian seringkali dilakukan pada tahap pengekstraksian fitur, karena untuk mengingat perbedaan skala, translasi, dan rotasi pada suatu citra, sistem pengenalan harus dilatih menggunakan contoh-contoh latihan dengan jumlah yang besar. Untuk mendapatkan fitur invarian, properti dari transformasi Fourier sering digunakan. Sistem penglihatan manusia juga sensitif terhadap variasi tekstural pada permukaan objek. Fitur tekstur sering digunakan untuk mengenali objek. Secara umum, tekstur dikenal sebagai dasar persepsi. Terdapat banyak metode statistik dan struktural seperti model jaringan syaraf untuk menganalisis fitur. Metode statistik untuk menganalisis fitur didasarkan pada hubungan antara nilai keabuan piksel-piksel di dalam suatu citra. Tahap pengekstraksian fitur juga berkaitan dengan pengekstraksian fitur tekstur.
Tiga tahap terakhir – tahap asosiatif, basis pengetahuan, dan pengenalan – termasuk ke dalam pengolahan tingkat tinggi. Ingatan manusia seringkali dapat mengingat informasi lengkap dari informasi parsial atau petunjuk-petunjuk yang halus. Penyimpanan asosiatif adalah suatu penyimpanan di mana alamat setiap data didasarkan pada isi data tersebut (content-addressable). Kemampuan untuk mendapatkan suatu representasi internal atau untuk menyimpulkan sebuah representasi yang kompleks dari suatu bagian membentuk dasar penyimpanan asosiatif. Fungsi dasar penyimpanan asosiatif adalah untuk menyimpan pasangan pola asosiatif melalui sebuah proses pengorganisasian sendiri (self-orginizing) dan untuk memproduksi sebuah pola tanggapan yang sesuai pada presentasi pola stimulus yang sama. Penyimpanan asosiatif juga berguna untuk pengenalan objek invarian.
Tahap pengenalan berkaitan dengan proses pengklasifikasian. Tahap ini memberikan sebuah label kepada sebuah objek berdasarkan informasi yang disediakan oleh deskriptornya. Teknik klasifikasi konvensional dikelompokkan ke dalam dua teknik: supervised dan unsupervised. Pada cara supervised, classifiers belajar dengan bantuan training sets. Sedangkan pada cara unsupervised, classifier belajar tanpa bantuan training sets. Metode statistik dan classifiers jaringan saraf berhasil digunakan di dalam beberapa masalah pengenalan. Namun, dalam prakteknya, terdapat beberapa masalah, dimana metode statistik tidak sesuai dan metode deskriptif lebih sesuai. Metode deskriptif seringkali didasarkan pada peraturan klasifikasi yang memetakan vektor fitur input ke dalam kategori output. Peraturan klasifikasi dalam hal ini dapat disimpan di dalam basis pengetahuan. Interaksi antara basis pengetahuan dan modul lain di dalam sebuah sistem pengenalan dapat dilihat pada Gambar 2.1. Basis pengetahuan berinteraksi tidak hanya dengan tahap pengektraksian fitur dan pengenalan, tetapi juga
dengan penyimpanan asosiatif. Seringkali pengetahuan dasar mengenai sebuah objek juga dapat dimasukkan (encoded) ke dalam basis pengetahuan. Basis pengetahuan mungkin saja sesederhana daerah terperinci dari suatu citra, dimana informasi yang menarik diketahui keberadaannya, sehingga membatasi pencarian yang harus dilakukan untuk mencari informasi tersebut. Basis pengetahuan juga bisa kompleks. Rancangan suatu sistem pengenalan mesin perlu mencakup semua tahap pengolahan sebelumnya.
Gambar 2.1 Sistem visi komputer
Visi komputer dapat dideskripsikan sebagai suatu deduksi otomatis terhadap struktur atau properti tiga dimensi dari satu atau beberapa citra dua dimensi dan pengenalan objek dengan bantuan dari properti-properti tersebut. Citra yang dimaksud dapat bersifat monokrom ataupun berwarna, dan dapat diambil dari satu atau beberapa kamera. Properti struktural yang akan dideduksi tidak hanya berupa properti geometris, tetapi juga properti material. Properti geometris meliputi bentuk, ukuran, dan lokasi objek, sedangkan properti material meliputi keterangan atau kegelapan suatu permukaan, warnanya, dan teksturnya. Tujuan dari suatu sistem visi komputer adalah untuk menyimpulkan keadaan fisik dari citra yang noisy ataupun berambigu. Visi komputer sulit direalisasikan karena formasi citra adalah suatu pemetaan many-to-one. Berbagai
Output Input Perolehan citra Pre-processing Pengekstraksian fitur Basis pengetahuan Penyimpanan asosiatif Pengenalan
objek dengan properti geometris dan material yang berbeda dapat memiliki citra yang identik. Sistem visi komputer kompleks dan seringkali diimplementasikan dengan beberapa modul. Pendekatan modular mempermudah pengontrolan dan pengawasan kinerja sistem. Berbagai tahapan atau modul dari suatu sistem visi dapat diimplementasikan menggunakan metode statistik konvensional, jaringan saraf, teknik logika fuzzy, dan algoritma genetika. Biasanya jumlah tahapan dalam suatu sistem visi dan kompleksitasnya bergantung pada sistem aplikasi yang sedang dirancang. Aplikasi visi komputer meliputi otomatisasi pada jalur perakitan, penginderaan jauh, robotika, komunikasi komputer dan manusia, alat bantu untuk tunanetra, dan lain-lain.
Gambar 2.2 Sistem visi komputer
Salah satu pendekatan yang mengimplementasikan sistem visi komputer adalah dengan mengemulasi sistem penglihatan manusia. Permasalahan dengan pendekatan ini adalah bahwa sistem penglihatan manusia sangat kompleks dan tidak dimengerti dengan baik. Sistem penglihatan manusia yang melampaui mata manusia terpotong-potong dan spekulatif. Oleh karena itu, pada saat ini, tidak mungkin dapat mengemulasi sistem penglihatan manusia secara persis. Namun, studi mengenai sistem biologis memberikan petunjuk-petunjuk untuk mengembangkan sistem visi komputer. Visi komputer berkaitan dengan masalah pengolahan tingkat rendah dan tingkat tinggi, seperti maslaah kognitif. Tahapan pada sistem visi komputer ditunjukkan pada Gambar 2.2. Pengolahan
Output
Pengolahan tingkat tinggi Input Perolehan citra Pre-processing Pengekstraksian fitur Pengenalan Pengolahan awal
awal atau pengolahan tingkat rendah berkaitan dengan pengolahan pada retina, sedangkan pengolahan tingkat tinggi berkaitan dengan pemakaian kognitif dari pengetahuan (Kulkarni, 2001, pp8-11).
Visi komputer adalah transformasi data dari sebuah citra atau video menjadi sebuah keputusan atau representasi baru. Semua transformasi dilakukan dengan menetapkan beberapa tujuan tertentu. Data input mungkin berupa informasi kontekstual seperti “kamera dipasang di dalam sebuah mobil” atau “laser range finder mengindikasi adanya suatu objek dalam jarak 1 meter”. Keputusan yang didapatkan mungkin berupa “terdapat seseorang pada layar ini” atau “ada 14 sel tumor pada bagian ini”. Representasi baru dapat diartikan sebagai pengubahan sebuah citra berwarna menjadi sebuah citra keabuan atau penghilangan gerakan kamera dari sederetan citra (Bradski dan Kaehler, 2008, p2).
2.2 Sistem Penglihatan Manusia
Sistem penglihatan manusia kompleks dan meliputi pengolahan pada mata dan pengenalan pada otak. Sistem visi komputer dirancang untuk menjalankan tugas-tugas spesifik dan sistem ini harus sama dengan sistem penglihatan biologis. Sistem penglihatan biologis menarik para ahli, sebagaimana studi terhadap sistem tersebut berguna dalam merancang sistem visi komputer.
Pada dasarnya, sebuah sistem visi komputer berkaitan dengan deduksi permukaan dan properti objek tiga dimensi dari citra dua dimensi. Sistem ini meliputi pendeteksian pinggiran (edge), segmentasi, dan pengekstrasian fitur menggunakan tekstur, bayangan, stereo, gerakan, dan pengenalan. Sebuah sistem visi komputer, seperti sistem perekayasaan lainnnya, memiliki dua komponen – piranti keras dan piranti lunak
– dan terdiri dari tahapan seperti perolehan citra, preprocessing, pengekstraksian fitur, penyimpanan objek secara asosiatif, pengaksesan basis pengetahuan, dan pengenalan. Komponen piranti lunak dari sistem visi berkaitan dengan algoritma dan implementasi tahapan-tahapan tersebut. Berbagai metode seperti metode statistik konvensional, jaringan syaraf, teknik logika fuzzy, algoritma genetika, atau teknik syaraf fuzzy, dapat digunakan untuk mengimplementasikan berbagai tahap pada sistem visi komputer. Komponen piranti keras dari sistem visi komputer berkaitan dengan peralatan pencitraan seperti digitizers, scanners, kamera, dan peralatan display, serta perekam film, alat penyimpanan, dan sebuah komputer. Untuk mengolah citra pada komputer digital, citra tersebut harus didigitisasikan terlebih dahulu. Citra digital biasanya didapatkan dari kamera digital (Kulkarni, 2001, pp28-29).
2.3 Persepsi
Persepsi memiliki subjek yang sangat luas dan kompleks. Para peneliti beragumentasi bahwa melihat hanyalah suatu aksi mekanis. Sistem penglihatan manusia sensitif terhadap stimulus seperti titik, garis, bentuk, warna, arah, tekstur, skala, dan gerakan. Stimulus ini hanya merepresentasikan karakteristik fisik dan tidak dapat mendefinisikan apa yang dipersepsikan oleh otak. Kanizsa (1979) berpendapat bahwa persepsi penglihatan bukanlah bagian integral dari apa yang disebut dengan kecerdasan. Beliau mendefinisikan persepsi sebagai suatu proses, yang dimulai dengan input panca indera dan menuju ke dunia fenomenal yang koheren dan signifikan, dimana seseorang dapat berkelakuan dengan aman dan sesuai. Istilah persepsi mencegah pemisahan perbedaan antara penglihatan dengan pemikiran. Dalam persepsi, sulit untuk memutuskan titik dimana aspek panca indera berakhir dan proses kejiwaan dimulai.
Sebuah pemikiran mungkin digunakan untuk melaksanakan proses-proses seperti pengkategorisasian, pemahaman hubungan, dan pertimbangan oleh induksi dan deduksi. Sistem penglihatan manusia mengalami banyak ketidaksesuaian dalam pembuatan kesimpulan. Pada pengolahan informasi visual, otak manusia melampaui informasi yang diberikan. Ada dua cara untuk melakukannya, yaitu membuat sebuah identifikasi dan membuat sebuah kesimpulan.
Tujuan dari visi komputer adalah untuk menyimpulkan keadaan dunia fisik dari citra dunia yang noisy dan berambigu. Peneliti visi komputer tidak mengemulasi penglihatan manusia dengan mudah, karena apa yang diketahui mengenai sistem penglihatan manusia melampaui mata adalah sangat spekulatif. Sebagai tambahan, kekeliruan penglihatan manusia didemonstrasikan secara luas oleh adanya ilusi, ketidak-konsistenan, dan ambiguitas. Sistem visi komputer juga dapat dipekerjakan atau dirancang untuk melaksanakan tugas-tugas yang melampaui penglihatan manusia.
Dondis (1973) membagi tiga tingkatan mengenai otak manusia dalam memahami informasi visual, yaitu representasional, abstrak, dan simbolis. Tingkat representasional berkaitan dengan laporan langsung. Mata melaporkan sebuah laporan visual mengenai apa yang ada di depannya. Tingkat ini berkaitan dengan karakteristik fisik dari objek, seperti bentuk, warna, tekstur, keterangan, skala, dan lain-lain. Abstraksi berkaitan dengan pereduksian dari semua yang dilihat menjadi elemen visual dasar dan memutuskan pemahaman dari pesan visual. Abstraksi menyampaikan arti pokok dari pengalaman substansi yang dialami panca indera secara langsung kepada susunan syaraf. Tingkat tertinggi pengolahan informasi visual di dalam sistem penglihatan manusia adalah tingkat simbolis. Simbol adalah semua hal, mulai dari sebuah gambar sederhana, hingga sebuah sistem yang sangat kompleks dari arti yang dilampirkan,
seperti bahasa atau angka. Dewasa ini, hanya sedikit yang mengetahui tentang tigkat abstrak dan simbolis. Singkat kata, dapat dikatakan bahwa representasi adalah apa yang kita lihat dan kita kenal dari lingkungan, abstraksi adalah reduksi dari kejadian visual menjadi elemen dasar dari komponen visual, dan simbolisme adalah dunia dari sistem
coded yang diciptakan sewenang-wenang oleh otak.
Marr (1982) menyatakan bahwa retina dan lapisan visual ada untuk mewujudkan sebuah variasi dari modul-modul yang memanfaatkan isyarat sperti tekstur, warna, gerakan, bayangan, dan aspek stereoskopis dari layar. Ada beberapa modul yang berbeda, seperti modul bayangan, modul tekstur, modul warna, dan lain-lain. Modul-modul ini terlihat beroperasi hampir secara terpisah antara satu dengan lainnya. Hasilnya hanya terintegrasi pada akhir persepsi visual. Hal menarik ke dua yang ditemukan oleh Marr adalah cara modul-modul menyelesaikan ambiguitas dua dimensi dari sebuah citra dengan membuat asumsi pasti mengenai kenyataan fisik. Sebagai contoh, beberapa asumsi yang dipakai dalam persepsi adalah bahwa ukuran suatu objek di dalam citra digunakan untuk menafsir jarak objek tersebut dari pengamat, semakin jauh suatu objek, semakin kecil citranya, dan bentuk dari suatu objek berubah karena perspektif pengamat yang berubah (Kulkarni, 2001, pp38-39).
2.4 Peralatan Input-Output
Sebuah diagram skematis dari sistem visi komputer ditunjukkan pada gambar 2.3. Kamera pada sebuah sistem visi komputer memiliki peran yang sama dengan mata pada sistem penglihatan manusia. Secara umum, kamera menghasilkan citra-citra optik pada sebuah film. Tanggapan film terhadap energi cahaya yang ada tidak semuanya linear. Resolusi suatu film umum adalah 40 garis/mm, yang berarti bahwa sebuah citra
1400 x 1400 mungkin didigitisasikan dari sebuah film dengan slide 35 mm. Digitizers dapat diklasifikasikan secara luas ke dalam dua bentuk: digitizer mekanik dan flying spot
scanner. Pada digitizer mekanik, film dan sebuah rakitan penginderaan ditransportasikan
secara mekanis melewati satu sama lainnya sementara rekaman dibuat. Di sini, sebuah film disusun di atas sebuah drum, yang berputar dengan kecepatan yang konstan, dan sinar laser men-scan film tersebut. Sinar cahaya dimodulasi sesuai dengan nada (tone) citra. Sinyal analog kemudian didigitisasikan untuk menghasilkan citra digital. Pada
flying spot scanner, sebuah layar difokuskan pada permukaan fotosensitif, yang di-scan
oleh berkas elektron. Kamera televisi adalah peralatan yang menarik untuk aplikasi visi komputer. Sama seperti cara retina menerima citra, citra terbalik dari suatu objek dipetakan ke permukaan fotosensitif pada kamera. Citra pada permukaan fotosensitif lalu ditransformasikan ke dalam citra digital, yang kemudian diproses lebih lanjut.
Gambar 2.3 Diagram skematis dari sistem visi komputer
Peralatan lain yang digunakan dalam formasi citra terdiri dari fotosensor
solid-state yang dikenal sebagai charge-coupled devices (CCDs). CCDs menyerupai
MOSFET (metal-oxide semiconductor field-effect transistor) dan dapat dianggap sebagai sebuah array monolitis dari kapasitor MOS dengan jarak yang sangat dekat yang membentuk sebuah shift register (Kulkarni, 2001, p40).
Objek Sistem pencitraan Display Pemrosesan komputer Sampling dan kuantisasi
2.5 Sampling dan Kuantisasi
Sebuah citra dapat direpresentasikan oleh sebuah fungsi kontinu , , dimana , adalah sebuah nilai keabuan pada titik , . Agar dapat mengolah citra pada komputer digital, citra tersebut harus didigitisasikan terlebih dahulu. Proses digitisasi meliputi sampling dan kuantisasi. Suatu citra perlu di-sample pada titik array diskrit . Sampling meliputi dua pilihan, yaitu tessellation, atau pelapisan bidang dengan pola spasial dari titik sampling, dan interval sampling. Berbagai tessellations telah dipelajari, seperti segi empat, segi tiga, dan segi enam. Tessellation segi empat adalah yang paling umum. Interval sampling ditentukan dengan menggunakan teorema
sampling. Teorema sampling menyatakan bahwa terdapat kemungkinan untuk
merekonstruksi fungsi dari sample diskritnya apabila tingkat sampling minimal sama dengan atau lebih besar dari dua kali frekuensi sinyal tertinggi. Teorema sampling dapat ditingkatkan menjadi fungsi dua dimensi.
Tahapan setelah sampling adalah kuantisasi. Pertanyaan yang timbul pada tahap ini misalnya berapa banyak tingkat diskrit yang harus dipilih untuk merepresentasikan suatu nilai keabuan. Semakin tinggi jumlah tingkat diskrit, semakin baik representasinya. Namun, jumlah bit yang dibutuhkan untuk merepresentasikan suatu citra meningkat berdasarkan jumlah tingkat diskrit. Biasanya, citra dikuantisasi pada tingkat diskrit 256 sehingga setiap piksel dapat direpresentasikan dengan 1 byte. Dengan tingkat diskrit 256, 0 merepresentasikan warna hitam, 255 merepresentasikan warna putih, dan nilai-nilai di antaranya merepresentasikan warna abu-abu.
Tingkat sampling sangat penting bagi citra dengan detil-detil yang kecil. Pada citra yang sedikit bervariasi, penting untuk memiliki kuantisasi yang baik, tetapi
sampling boleh kasar. Sedangkan layar dengan detil yang banyak butuh sampling yang
baik, namun kuantisasi boleh kasar (Kulkarni, 2001, p45).
2.6 Teknik Preprocessing
Teknik preprocessing berkaitan dengan pengolahan awal dan meliputi teknik-teknik seperti koreksi geometris dan radiometris, perbaikan, kompresi data, penapisan, pendeteksian tepi, perhitungan orientasi permukaan, dan lain-lain. Tidak ada sistem pencitraan yang sempurna di dalam prakteknya, dan citra selalu mengalami degradasi atau blur. Pada perbaikan citra, dilakukan manipulasi terhadap citra untuk meningkatkan kualitas citra tersebut. Pada dasarnya, teknik perbaikan adalah prosedur heuristik. Teknik-teknik perbaikan yang sering digunakan adalah stretching, ekualisasi histogram, penghilangan noise, penapisan, dan perbaikan tepi. Pada kebanyakan masalah praktis, nilai keabuan pada citra jatuh di antara rentang yang sempit, dan oleh karena itu, kebanyakan citra praktis tidak menunjukkan kontras yang baik. Pada stretching kontras, setiap piksel dalam citra input diberikan sebuah nilai keabuan baru. Nilai keabuan pada citra yang telah ditransformasikan menyebar ke seluruh rentang keabuan dari 0 (hitam) hingga 255 (putih).
Tujuan dari perestorasian citra adalah untuk meningkatkan kualitas citra tersebut. Restorasi adalah suatu proses yang berusaha untuk memperbaiki atau merekonstruksi citra asli dari sebuah citra yang diamati atau terdegradasi dengan menggunakan beberapa pengetahuan pokok mengenai fenomena degradasi. Pada restorasi, sebuah sistem pencitraan dibuat dan proses inverse diaplikasikan untuk memperbaiki citra aslinya (Kulkarni, 2001, p47).
2.7 Pengekstraksian Fitur dan Pengenalan
Kemampuan untuk mengenali pola adalah dasar visi komputer. Istilah pola di sini adalah sebuah deskripsi struktural dan kuantitatif dari suatu objek. Secara umum, satu atau beberapa deskriptor membentuk pola. Bidang pola berkorespondensi dengan sebuah pengukuran atau sebuah bidang observasi. Vektor pola terkadang dirujuk sebagai vektor observasi. Vektor pola seringkali berisi informasi yang berlebih-lebihan. Oleh karena itu, vektor pola dipetakan ke sebuah vektor fitur. Sistem pengenalan pola biasanya mempertimbangkan akan dipetakan terlebih dahulu ke vektor fitur manakah sebuah bidang fitur. Vektor fitur digunakan untuk memutuskan termasuk kelas manakah suatu sample input. Tujuan dari pengekstraksian fitur adalah untuk mengurangi data dengan memperoleh fitur atau properti pasti yang membedakan pola input.
Salah satu pendekatan yang terkenal untuk merepresentasikan batasan-batasan adalah tanda tangan. Salah satu cara sederhana untuk menghasilkan tanda tangan adalah dengan memetakan jarak dari pusat ke batasan sebagai suatu fungsi dari suatu sudut. Pemetaan ini mengurangi representasi batasan menjadi sebuah fungsi satu dimensi yang dapat didigitisasikan menjadi sebuah vektor. Deskriptor seperti kode rantai (chain code) dan rasio area dengan keliling digunakan untuk mengkarakterisasi bentuk.
Scanner digunakan untuk mendapatkan citra. Salah satu scanner yang digunakan
dalam penginderaan jauh adalah thematic mapper (TM). Jenis scanner ini memperoleh citra dalam tujuh pita spektrum yang berkorespondensi dengan rentang spektrum dari infrared ke ultraviolet. Citra spektrum penginderaan jauh digunakan pada berbagai aplikasi, di antaranya adalah pertanian, kehutanan, sumber daya mineral, hidrologi, geografi, perpetaan, meteorologi, dan pengintaian militer (Kulkarni, 2001, p54).
2.8 Deteksi Wajah
Citra berisi wajah manusia adalah pusat dari interaksi antara manusia dengan komputer. Banyak penelitian yang telah dilakukan menggunakan citra wajah, termasuk pengenalan wajah, penjejakan wajah, perkiraan pose, pengenalan ekspresi, dan pengenalan gestur. Kebanyakan metode-metode mengenai topik ini mengasumsikan wajah manusia di dalam sebuah citra atau sederetan citra telah diidentifikasi dan dilokalisasikan. Untuk membangun sistem otomatis yang mengekstraksi informasi dari citra berisi wajah manusia, penting untuk mengembangkan algoritma yang kuat dan efisien untuk mendeteksi wajah manusia. Diberikan sebuah citra tunggal atau sederetan citra, tujuan dari pendeteksian wajah adalah untuk mengidentifikasi dan melokasikan semua wajah manusia tanpa memperhatikan posisi, skala, orientasi, pose, dan kondisi pencahayaannya. Hal ini merupakan masalah yang menantang karena wajah manusia merupakan objek yang tidak kaku dengan tingkat variabilitas yang tinggi dalam hal ukuran, bentuk, warna, dan tekstur (Yang, 2000, p3).
Pendeteksian wajah pada citra merupakan suatu langkah penting menuju interaksi manusia dan komputer berbasis visi yang cerdas. Pendeteksian wajah ini merupakan langkah awal dalam berbagai penelitian di bidang pengolahan wajah, termasuk pengenalan wajah, perkiraan pose, dan pengenalan ekspresi. Berbagai teknik telah diusulkan untuk mendeteksi wajah di dalam citra maupun video (Manohar et al, p4).
Tugas pendeteksian wajah semakin banyak dibutuhkan pada dunia modern. Hal ini dikarenakan perkembangan sistem keamanan sebagai jawaban untuk melawan terorisme. Sebagai tambahan, algoritma ini telah banyak digunakan dalam antarmuka
pengguna interaktif, industri periklanan, layanan hiburan, coding video, dan lain-lain (Degtyarev dan Seredin, p1).
Pendeteksian wajah merupakan suatu tugas yang penting dalam visi komputer. Pendeteksian wajah biasanya dijalankan sebagai langkah preprocessing untuk analisis wajah yang lebih jauh, terutama untuk pengenalan. Kesulitan intrinsik dalam pendeteksian wajah adalah kenyataan bahwa adanya wajah merupakan kejadian langka di dalam citra, dan juga classifier yang sangat baik mungkin menghasilkan hasil palsu dalam jumlah yang sangat besar dikarenakan banyaknya pengujian yang harus dilakukan pada citra berdimensi standar (Destrero, 2006, p5).
Pendeteksian wajah adalah mengenai pencarian ada atau tidaknya wajah di dalam suatu citra (biasanya dalam skala keabuan), dan jika ada, maka akan dikembalikan lokasi dan isi setiap wajah pada citra tersebut. Hal ini adalah langkah pertama di dalam sistem-sistem otomatis yang menganalisa informasi yang terdapat di dalam wajah (seperti identitas, jenis kelamin, ekspresi, umur, ras, dan pose). Jika beberapa sistem terdahulu bekerja menggunakan wajah-wajah frontal, saat ini telah banyak dikembangkan sistem yang mampu mendeteksi wajah yang dirotasikan secara in-plane ataupun out-of-plane dengan baik.
Kemajuan teknologi computing telah memudahkan pengembangan modul visi
real-time yang berinteraksi dengan manusia dalam beberapa tahun terakhir ini. Ada
banyak contoh, terutama dalam bidang biometrik dan interaksi manusia dengan komputer sebagaimana informasi yang ada di dalam suatu wajah perlu dianalisis agar sistem dapat bertindak dengan sesuai. Untuk sistem-sistem biometrik yang menggunakan wajah sebagai modul input non-intrusif, penting sekali untuk melokasikan wajah pada layar sebelum algoritma pengenalan dapat diaplikasikan. Suatu antarmuka
pengguna berbasis visi yang cerdas harus dapat memberitahukan fokus perhatian pada penggunanya agar dapat ditanggapi dengan sesuai. Agar aplikasi seperti kosmetik digital dapat mendeteksi fitur wajah dengan akurat, wajah perlu dilokasikan dan diregister terlebih dahulu untuk mempermudah pengolahan lebih lanjut. Telah terbukti bahwa pendeteksian wajah memiliki peran yang penting dan kritis dalam keberhasilan suatu sistem pengolahan wajah.
Masalah pendeteksian wajah merupakan masalah yang menantang, karena perlu mencatat setiap variasi penampilan yang mungkin, yang disebabkan oleh perubahan pencahayaan, fitur wajah, penghalang, dan lain-lain. Sebagai tambahan, suatu sistem pendeteksian wajah harus dapat mendeteksi wajah yang muncul dengan rotasi in-plane, skala, dan pose yang berbeda-beda. Meskipun demikian, kemajuan luar biasa telah dibuat selama dekade terakhir ini dan telah ada banyak sistem yang menunjukkan kinerja real-time yang menakjubkan. Kemajuan algoritma ini juga telah memberikan kontribusi yang signifikan dalam mendeteksi objek-objek lain seperti manusia/pejalan kaki, dan mobil (Yang, p1).
Pendeteksian wajah adalah suatu metode untuk mencari semua wajah yang mungkin pada lokasi yang berbeda-beda dan dengan ukuran yang berbeda pula di dalam suatu citra. Pendeteksian wajah memiliki banyak aplikasi visi komputer. Pendeteksian wajah meliputi banyak tantangan penelitian, seperti skala, rotasi, pose, dan variasi pencahayaan. Teknik yang digunakan untuk pendeteksian wajah telah diteliti selama bertahun-tahun dan banyak kemajuan yang diusulkan dalam literatur. Kebanyakan metode pendeteksian wajah mendeteksi wajah frontal dengan kondisi pencahayaan yang baik. Menurut Yang G. Dan Huang T.S. (1997), metode-metode ini dapat
dikategorisasikan ke dalam empat jenis, yaitu: knowledge-based, appearance-based,
feature invariant, dan template matching.
Metode knowledge-based menggunakan aturan human-coded untuk menggambarkan fitur wajah, seperti dua mata yang simetris, satu hidung di tengah, dan satu mulut di bawah hidung. Metode feature invariant mencoba mencari fitur wajah yang invarian terhadap pose, kondisi pencahayaan, atau rotasi. Warna kulit, edges, dan bentuk, termasuk ke dalam kategori ini. Metode template matching mengkalkulasi korelasi antara suatu citra pengujian dan templates wajah yang telah dipilih sebelumnya. Kategori terakhir, appearance-based, mengadopsi teknik pembelajaran mesin untuk mengekstraksi fitur diskriminatif dari set latih yang telah diberi label sebelumnya. Metode eigenfaces, support vector machines, jaringan syaraf, statistical classifiers, dan pendeteksian wajah Viola Jones berbasis AdaBoost termasuk dalam kelas ini. Metode
appearance-based memperoleh hasil yang sangat baik dalam hal keakuratan dan
kecepatan (Anila dan Devarajan, 2010, p54).
Secara dasar (Rasolzadeh, 2008), ada empat pendekatan berbeda dalam permasalahan deteksi wajah, yaitu:
1. Metode berbasis pengetahuan: Aturan didapatkan berdasarkan pengetahuan manusia mengenai fitur terdefinisi dari wajah sesorang manusia. Mayoritas dari aturan-aturan ini membahas tentang hubungan antar fitur.
2. Metode invarian fitur: algoritma dirancang untuk mencari fitur struktural dari wajah yang invarian terhadap masalah umum mengenai pose, halangan, ekspresi, kondisi citra, dan pengrotasian.
3. Metode pencocokan template: dengan suatu set sample yang diberikan, sebuah set pola wajah standar yang serupa dapat dihasilkan. Hubungan antara citra sample dan
set pola yang telah didefinisikan dapat dihitung dan digunakan untuk menarik kesimpulan.
4. Metode berbasis penampilan: mirip dengan metode pencocokan template. Tujuannya adalah untuk mendapatkan keakuratan yang lebih tinggi dengan variasi yang lebih besar pada data latih.
2.9 Pendeteksian Objek Viola Jones
Kerangka kerja pendeteksian objek Viola Jones adalah kerangka kerja pendeteksian objek pertama yang memberikan tingkat pendeteksian objek secara
real-time. Kerangka kerja ini diusulkan pada tahun 2001 oleh Paul Viola dan Michael Jones
dalam makalah mereka yang berjudul Robust Real-Time Object Detection. Makalah tersebut mendeskripsikan sebuah kerangka kerja pendeteksian objek visual, yang mampu mengolah citra dengan sangat cepat dan memberikan tingkat pendeteksian yang tinggi. Terdapat tiga kontribusi utama dalam kerangka kerja pendeteksian objek Viola Jones (Kumar et al, 2010, p889).
Kontribusi pertama adalah suatu representasi citra baru yang disebut dengan citra integral. Citra integral memungkinkan evaluasi fitur yang sangat cepat. Seperti Papageorgiou et al., Viola Jones menggunakan suatu kumpulan fitur yang mirip dengan fungsi Haar Basis. Agar dapat menghitung fitur-fitur tersebut dengan cepat pada berbagai skala, Viola Jones memperkenalkan suatu representasi citra integral. Citra integral dapat dihitung menggunakan sedikit operasi per piksel. Setelah citra integral dihitung, maka fitur Haar-like juga dapat dihitung pada berbagai skala dan tempat dalam waktu yang konstan.
Kontribusi ke dua dalam Viola Jones adalah metode untuk membangun suatu
classifier dengan memilih sedikit fitur penting menggunakan algoritma AdaBoost. Di
dalam setiap citra sub-window, jumlah total fitur Haar-like sangat banyak, jauh lebih besar dari pada jumlah piksel. Agar klasifikasi dapat berjalan dengan cepat, proses pembelajaran harus menyisihkan sejumlah besar fitur yang ada, dan fokus pada sejumlah kecil fitur-fitur penting. Penyeleksian fitur pada metode Viola Jones didapatkan dari modifikasi sederhana terhadap AdaBoost. Setiap tahapan pada proses boosting, yang memilih sebuah classifier lemah baru, dapat dilihat sebagai proses penyeleksian fitur. AdaBoost menyediakan sebuah algoritma pembelajaran yang efektif dan batas-batas yang kuat terhadap kinerja generalisasi.
Kontribusi ke tiga adalah metode untuk menggabungkan classifier yang lebih kompleks secara berturut-turut di dalam suatu struktur cascade (bertingkat) yang meningkatkan kecepatan detektor secara dramatis dengan memfokuskan perhatian pada daerah-daerah yang menjanjikan di dalam citra. Pemrosesan yang lebih kompleks hanya akan dijalankan pada daerah-daerah yang menjanjikan ini.
Sub-windows yang tidak ditolak oleh classifier terdahulu akan diproses oleh
sederetan classifier lainnya, di mana setiap tingkatan akan sedikit lebih kompleks dibandingkan tingkatan sebelumnya. Jika suatu classifier menolak sub-window, maka tidak akan ada proses lebih lanjut untuk sub-window tersebut.
Cascade deteksi wajah memiliki 32 classifiers, dengan total lebih dari 80.000
operasi. Namun, struktur bertingkat ini mampu mendeteksi dalam waktu yang sangat cepat. Pada set data yang sulit, berisi 507 wajah dan 75 juta sub-window, wajah terdeteksi menggunakan sekitar 270 instruksi mikroprosesor per sub-window. Sebagai
perbandingan, sistem ini lebih cepat 15 kali dari pada implementasi sistem pendeteksian yang dibuat oleh Rowley et al (Viola dan Jones, 2001, pp1-2).
Walupun dapat dilatih untuk mendeteksi variasi dari kelas-kelas objek, pada dasarnya, sistem pendeteksian objek Viola Jones dimotivasi oleh permasalahan pendeteksian wajah. Algoritma ini diimplementasikan pada OpenCV sebagai cvHaarDetectObjects() (Anonym 1).
2.9.1 Fitur
Fitur Haar-like adalah fitur citra digital yang digunakan di dalam pengenalan objek. Sejumlah fitur Haar-like mewakili wilayah persegi pada citra dan menjumlahkan semua piksel pada daerah tersebut. Jumlah yang didapatkan digunakan untuk mengkategorisasikan citra. Pada citra sample 20x20, terdapat lebih dari 40.000 fitur, yang harus diseleksi menjadi 200 fitur baik (Podolsky dan Frolov, p2).
Sistem pendeteksian objek Viola Jones mengklasifikasikan citra berdasarkan nilai dari fitur-fitur sederhana. Ada beberapa alasan untuk menggunakan fitur dan bukan piksel. Salah satu alasan utamanya adalah bahwa fitur dapat meng-encode pengetahuan domain ad-hoc yang sulit dipelajari menggunakan data latih dengan jumlah yang terbatas. Alasan lainnya adalah bahwa sistem berbasis fitur beroperasi lebih cepat dari pada sistem berbasis piksel.
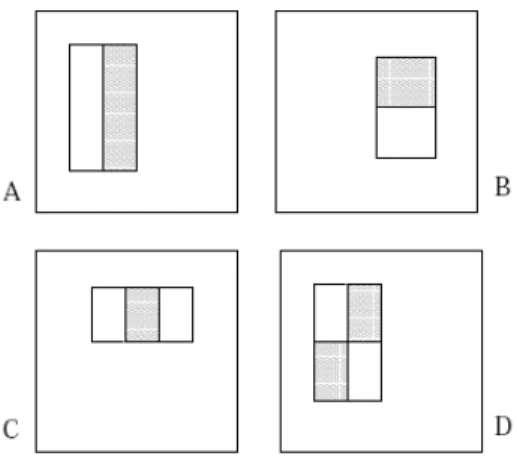
Fitur sederhana yang digunakan mirip dengan fitur dasar Haar yang digunakan oleh Papageorgiou et al. Viola Jones menggunakan tiga jenis fitur. Nilai dari sebuah fitur dua-persegi adalah selisih jumlah piksel di antara kedua daerah persegi tersebut. Setiap daerah tersebut memiliki bentuk serta ukuran yang sama, dan berbatasan secara horizontal ataupun secara vertikal. Nilai dari sebuah fitur tiga-persegi adalah hasil
pengurangan antara jumlah piksel pada kedua persegi yang berada di luar dengan jumlah piksel pada persegi yang berada di tengah. Sedangkan nilai dari sebuah fitur empat-persegi adalah selisih antara setiap pasangan diagonal empat-persegi (Viola dan Jones, 2001, p3).
Gambar 2.4 Fitur persegi Haar-like
2.9.2 Citra Integral
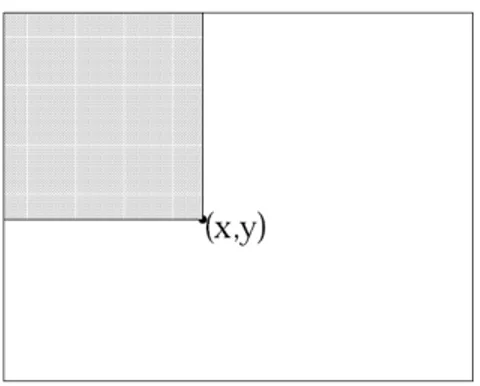
Fitur persegi dapat dihitung dengan cepat menggunakan suatu representasi citra yang disebut citra integral. Nilai citra integral pada titik , adalah jumlah piksel yang ada di atas dan di sebelah kiri titik tersebut.
, ′, ′
′ , ′
Di mana , adalah citra integral dan , adalah citra asli.
, , 1 ,
, 1, ,
Gambar 2.5 Nilai citra integral pada titik (x,y) adalah jumlah semua piksel yang berada
di atas dan di kiri titik tersebut
Dengan menggunakan citra integral, jumlah dari setiap persegi dapat dihitung dengan menggunakan empat referensi array. Perbedaan antara jumlah dua persegi dapat dihitung dengan delapan referensi. Fitur dua persegi dapat dihitung dengan enam referensi array, delapan untuk fitur tiga persegi, dan sembilan untuk fitur empat persegi (Viola dan Jones, 2001, pp4-5).
Gambar 2.6 Nilai citra integral pada lokasi 1 adalah jumlah piksel pada persegi . Nilai
pada lokasi 2 adalah , pada lokasi 3 adalah , dan pada lokasi 4 adalah
Gambar 2.7 Citra integral
2.9.3 Fungsi Klasifikasi Pembelajaran
Detektor dengan resolusi dasar 24x24 memiliki jumlah fitur persegi sebanyak 45.396. Jumlah ini jauh lebih besar dari pada jumlah piksel. Walaupun setiap fitur dapat dihitung dengan sangat efisien, namun menghitung keseluruhan set merupakan sesuatu yang sangat mahal. Berdasarkan penelitian yang dilakukan Viola dan Jones, sangat sedikit dari fitur-fitur ini dapat dikombinasikan untuk membentuk suatu classifier yang efektif. Tantangan utamanya adalah pencarian fitur-fitur tersebut.
Viola Jones menggunakan suatu bentuk variasi dari AdaBoost untuk memilih fitur-fitur dan untuk melatih classifier. Pada bentuk aslinya, algoritma pembelajaran
AdaBoost digunakan untuk meningkatkan kinerja klasifikasi terhadap suatu algoritma
pembelajaran sederhana (misalnya perceptron sederhana). Hal ini dilakukan dengan menggabungkan sekumpulan fungsi klasifikasi lemah untuk membentuk sebuah
classifier yang lebih kuat. Dalam hal ini, algoritma pembelajaran sederhana disebut
sebagai sebuah pembelajar lemah. Sebagai contoh, algoritma pembelajaran perceptron mencari ke sejumlah perceptron yang mungkin dan mengembalikan perceptron dengan
kesalahan klasifikasi terendah. Pembelajar ini disebut lemah karena fungsi klasifikasi yang terbaik sekalipun tidak dapat mengklasifikasikan data latih dengan baik.
Agar dapat ditingkatkan, pembelajar lemah dipanggil untuk menyelesaikan sederetan masalah pembelajaran. Setelah tahap pertama pembelajaran, data-data akan diberi bobot kembali untuk memperjelas kesalahan klasifikasi yang dilakukan oleh
classifier lemah sebelumnya. Classifier kuat akhir akan mendapatkan bentuk perceptron,
sebuah kombinasi berbobot dari classifiers lemah yang diikuti dengan sebuah threshold. Dengan menggambarkan suatu analogi antara classifier lemah dengan fitur-fitur,
AdaBoost merupakan suatu prosedur yang efektif untuk mendapatkan sejumlah kecil
fitur-fitur baik dengan variasi yang signifikan. Salah satu metode praktis untuk menyelesaikan analogi ini adalah dengan membatasi pembelajar lemah terhadap sejumlah fungsi klasifikasi yang masing-masing bergantung pada sebuah fitur tunggal. Untuk mendukung tujuan ini, algoritma pembelajaran lemah dirancang untuk memilih sebuah fitur persegi yang dapat memisahkan data positif dan negatif dengan paling baik. Untuk setiap fitur, pembelajar lemah menentukan fungsi klasifikasi threshold yang optimal sedemikian rupa sehingga jumlah minimum kesalahan klasifikasi bisa didapatkan.
Dalam prakteknya, tidak ada fitur yang dapat melaksanakan tugas klasifikasi dengan kesalahan yang rendah. Fitur yang diseleksi pada proses awal memiliki tingkat kesalahan antara 0.1 dan 0.3. Fitur yang diseleksi pada tahap selanjutnya, dengan tugas yang semakin sulit, memiliki tingkat kesalahan antara 0.4 dan 0.5.
Tabel 2.1 Algoritma boosting untuk mempelajari sebuah query secara online
• Diberikan citra , , … , , di mana 0,1 untuk data negatif dan positif berturut-turut.
• Inisialisasikan bobot , , untuk 0,1 berturut-turut, di mana
dan adalah jumlah negatif dan positif berturut-turut. • Untuk 1, … , :
1. Normalisasikan bobot,
, ∑ ,
,
sehingga adalah distribusi probabilitas.
2. Untuk setiap fitur, , latih sebuah classifier yang dibatasi agar menggunakan sebuah fitur tunggal. Kesalahan dievaluasi sehubungan
dengan , ∑ | |.
3. Pilih classifier, , dengan kesalahan terendah . 4. Perbaharui bobot:
, ,
di mana 0 jika data diklasifikasi dengan benar, 1 jika sebaliknya, dan .
• Classifier kuat akhir-nya adalah:
1 0
1 2
di mana
Penelitian awal yang dilakukan oleh Viola Jones menunjukkan bahwa classifier yang dibentuk dari 200 fitur memiliki hasil yang masuk akal. Dengan angka pendeteksian 95%, classifier tersebut mendapatkan 1 positif palsu dari 14084 data latih.
Untuk masalah pendeteksian wajah, fitur persegi awal yang diseleksi oleh AdaBoost memiliki peran penting dan mudah diinterpretasikan. Fitur pertama yang diseleksi tampaknya fokus pada properti bahwa wilayah mata biasanya lebih gelap dari pada wilayah hidung dan pipi. Fitur ini relatif lebih besar dibandingkan dengan
sub-window pendeteksian, dan mungkin sedikit kurang sensitif terhadap ukuran dan lokasi
wajah. Fitur ke dua yang diseleksi bergantung pada properti bahwa mata lebih gelap dari pada daerah hidung yang memisahkan kedua mata.
Gambar 2.8 Fitur pertama dan ke dua yang diseleksi oleh AdaBoost
Secara ringkas, classifier 200-fitur membuktikan bahwa boosted classifier yang dibuat dari fitur persegi merupakan teknik yang efektif untuk pendeteksian objek. Untuk
masalah pendeteksian, hasil ini menarik tetapi tidak cukup untuk beberapa tugas dunia nyata. Untuk masalah komputasi, classifier ini mungkin lebih cepat dari pada sistem lain yang telah dipublikasikan, membutuhkan 0.7 detik untuk men-scan sebuah citra 384x288 piksel. Namun sayangnya, teknik paling mudah untuk meningkatkan kinerja pendeteksian, dengan menambahkan fitur pada classifier, akan langsung meningkatkan waktu komputasi (Viola dan Jones, 2001, pp6-9).
2.9.4 Attentional Cascade
Cascade classifier adalah suatu pohon keputusan degenerasi, dimana pada setiap
tahap, sebuah classifier dilatih untuk mendeteksi hampir semua objek yang menarik (contoh: wajah frontal) sembari menolak suatu fraksi tertentu dari pola bukan objek. AdaBoost merupakan suatu algoritma pembelajaran untuk meningkatkan kinerja klasifikasi terhadap suatu algoritma pembelajaran sederhana. AdaBoost menggabungkan sekumpulan fungsi klasifikasi lemah untuk membentuk suatu classifier yang kuat (Podolsky dan Frolov, p2).
AdaBoost merupakan singkatan dari Adaptive Boosting, yaitu suatu algoritma pembelajaran mesin yang dirumuskan oleh Yoav Freund dan Robert Schapire. AdaBoost merupakan suatu meta-algorithm, dan dapat digunakan bersamaan dengan banyak algoritma pembelajaran lain untuk meningkatkan kinerjanya. AdaBoost bersifat adaptif, dimana classifiers berikutnya dibangun untuk mendukung data-data yang mengalami kesalahan klasifikasi oleh classifier sebelumnya. AdaBoost sensitif terhadap data yang
noisy dan outliers. Dalam beberapa hal, AdaBoost menjadi kurang rentan terhadap
masalah overfitting, jika dibandingkan dengan algoritma pembelajaran pada umumnya (Anonym 2).
Boosted classifier yang lebih kecil dan efisien, yang dapat dibangun, menolak
banyak sub-window negatif ketika mendeteksi hampir semua data positif. Classifiers sederhana digunakan untuk menolak mayoritas sub-window sebelum classifiers yang lebih kompleks dipanggil untuk mendapatkan tingkat positif palsu yang rendah.
Tahap-tahap pada cascade dibuat dengan melatih classfiers menggunakan AdaBoost. Dimulai dengan classifier kuat dua fitur, filter wajah yang efektif bisa didapatkan dengan mengatur threshold classifier kuat untuk meminimalkan negatif palsu. Threshold awal AdaBoost, ∑ , dirancang untuk mendapatkan tingkat kesalahan yang rendah pada data latih. Threshold yang lebih rendah menghasilkan tingkat deteksi yang lebih tinggi dan tingkat positif palsu yang lebih tinggi. Berdasarkan hasil percobaan, classifier dua-fitur dapat disesuaikan untuk mendeteksi 100% wajah dengan tingkat positif palsu sebesar 40%.
Kinerja pendeteksian dari classifier dua-fitur jauh dari sistem deteksi objek yang bisa diterima. Meskipun begitu, classifier tersebut dapat mengurangi secara signifikan jumlah sub-window yang membutuhkan pengolahan lebih lanjut dengan operasi-operasi yang sangat sedikit:
1. Evaluasi fitur-fitur perseginya (membutuhkan antara 6 hingga 9 referensi array per fitur).
2. Hitung classifier lemah untuk setiap fitur (membutuhkan satu operasi threshold per fitur).
3. Gabungkan classifiers lemahnya (membutuhkan sebuah perkalian per fitur, sebuah penambahan, dan sebuah threshold).
Sebuah hasil positif dari classifier pertama memicu evaluasi classifier ke dua yang juga telah disesuaikan untuk mendapatkan tingkat pendeteksian yang sangat tinggi. Sebuah hasil positif dari classifier ke dua memicu classifier ke tiga, dan selanjutnya. Sebuah hasil negatif menyebabkan penolakan langsung terhadap sub-window tersebut.
Struktur cascade merefleksikan kenyataan bahwa di dalam setiap citra, mayoritas
sub-window yang ada adalah negatif. Karena itulah, cascade berusaha menolak negatif
sebanyak mungkin pada tahapan seawal mungkin.
Seperti pohon keputusan, classifiers berikutnya dilatih menggunakan data-data yang telah melewati semua tahapan sebelumnya. Hasilnya, classifier ke dua akan menghadapi tugas yang lebih sulit dari pada yang pertama (Viola dan Jones, 2001, pp11-12).
Gambar 2.9 Gambaran skematis sebuah cascade pendeteksian
Pendeteksian objek Viola Jones merupakan suatu classifier kuat yang dibentuk dari beberapa classifier lemah. Classifier lemah ini memungkinkan pengolahan yang cepat, yaitu hanya dengan melakukan penjumlahan bobot pada fitur-fitur persegi.
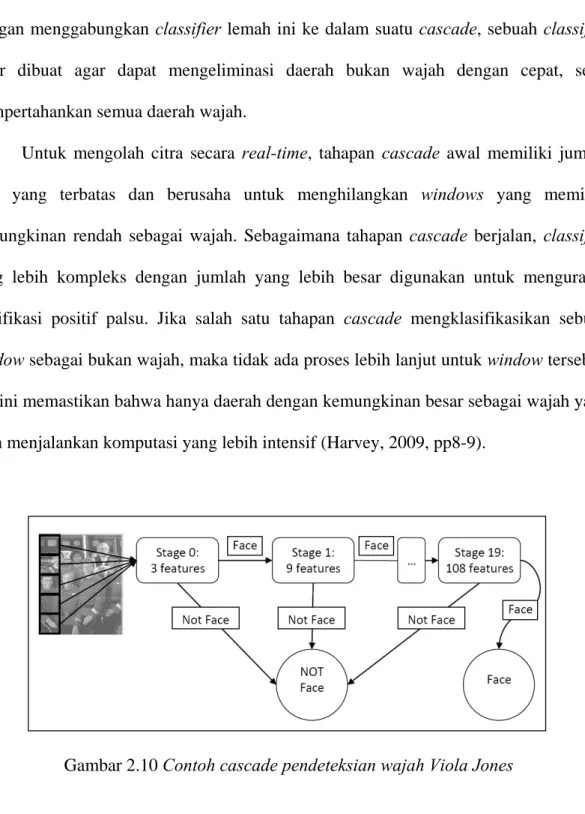
Dengan menggabungkan classifier lemah ini ke dalam suatu cascade, sebuah classifier akhir dibuat agar dapat mengeliminasi daerah bukan wajah dengan cepat, serta mempertahankan semua daerah wajah.
Untuk mengolah citra secara real-time, tahapan cascade awal memiliki jumlah fitur yang terbatas dan berusaha untuk menghilangkan windows yang memiliki kemungkinan rendah sebagai wajah. Sebagaimana tahapan cascade berjalan, classifier yang lebih kompleks dengan jumlah yang lebih besar digunakan untuk mengurangi klasifikasi positif palsu. Jika salah satu tahapan cascade mengklasifikasikan sebuah
window sebagai bukan wajah, maka tidak ada proses lebih lanjut untuk window tersebut.
Hal ini memastikan bahwa hanya daerah dengan kemungkinan besar sebagai wajah yang akan menjalankan komputasi yang lebih intensif (Harvey, 2009, pp8-9).
Gambar 2.10 Contoh cascade pendeteksian wajah Viola Jones
2.9.5 Melatih Cascade Classifiers
Diberikan sebuah cascade classifiers yang telah dilatih, jumlah positif palsu pada
di mana adalah jumlah positif palsu pada cascaded classifier, adalah jumlah
classifiers, dan adalah jumlah positif palsu pada classifier ke . Tingkat
pendeteksiannya adalah:
di mana adalah tingkat pendeteksian pada cascaded classifier, adalah jumlah
classifier, dan adalah tingkat pendeteksian pada classifier ke .
Diberikan tujuan konkrit dari tingkat pendeteksian dan positif palsu secara keseluruhan, angka target dapat ditentukan untuk setiap tahap pada proses cacscade. Jumlah fitur yang dievaluasi ketika men-scan citra asli membutuhkan proses probabilistik. Setiap sub-window yang diberikan akan diproses ke bawah melalui
cascade, satu classifier pada satu waktu, sampai diputuskan apakah sub-window
tersebut negatif atau, sub-window tersebut lolos dari setiap pengujian dan diberi label positif. Jumlah fitur yang diharapkan dievaluasi adalah:
di mana adalah jumlah fitur yang diharapkan dievaluasi, adalah jumlah classifier, adalah jumlah positif pada classifier ke , dan adalah jumlah fitur pada classifier ke .
Prosedur pembelajaran AdaBoost hanya digunakan untuk meminimalkan kesalahan, dan bukan dirancang secara spesifik untuk mendapatkan tingkat pendeteksian yang tinggi. Salah satu skema yang sederhana dan sangat konvensional untuk mengatasi
kesalahan ini adalah dengan mengatur threshold perceptron yang dihasilkan AdaBoost. Semakin tinggi threshold, semakin sedikit positif palsu, dan semakin rendah tingkat pendeteksian. Semakin rendah threshold, semakin banyak positif palsu dan semakin tinggi tingkat pendeteksian. Namun pada saat ini, belum jelas, apakah dengan mengatur
threshold dapat mempertahankan jaminan pelatihan dan generalisasi yang diberikan oleh
AdaBoost.
Pada umunya, classifier dengan fitur yang lebih banyak akan mendapatkan tingkat pendeteksian yang lebih tinggi dan jumlah positif palsu yang lebih sedikit. Tetapi
classifier dengan fitur yang lebih banyak membutuhkan waktu komputasi yang lebih
banyak pula.
Sebuah framework yang sangat sederhana digunakan untuk menghasilkan sebuah
classifier efektif yang sangat efisien. Algoritmanya dapat dilihat pada tabel 2.2 (Viola
dan Jones, 2001, pp12-14).
Tabel 2.2 Algoritma latihan untuk membangun sebuah cascaded detector
• Pengguna memilih nilai untuk , jumlah maksimum positif palsu yang dapat diterima, dan , tingkat minimum pendeteksian yang dapat diterima per
layer.
• Pengguna memilih target keseluruhan tingkat positif palsu, . • himpunan data positif
• himpunan data negatif
• 1.0; 1.0
• Selama - 1 - 0; - Selama 1
Gunakan dan untuk melatih sebuah classifier dengan fitur sebanyak menggunakan AdaBoost.
Evaluasi current cascaded classifier pada validasi yang diatur untuk menentukan dan .
Kurangi threshold untuk classifier ke hingga current cascaded
classifier memiliki tingkat pendeteksian minimal (hal ini
juga mempengaruhi . -
- Jika maka evaluasi current cascaded detector pada himpunan citra bukan-wajah dan berikan pendeteksian palsu pada himpunan .
Gambar 2.11 Contoh citra wajah frontal yang digunakan untuk melatih sistem
Gambar 2.12 Hasil pendeteksian wajah Viola Jones
2.10 OpenCV
OpenCV adalah sebuah library open source untuk visi komputer yang bisa didapatkan dari http://SourceForge.net/projects/opencvlibrary. Library ini ditulis dengan bahasa C dan C++, serta dapat dijalankan dengan Linux, Windows, dan Mac OS X. OpenCV dirancang untuk efisiensi komputasional dan dengan fokus yang kuat pada aplikasi real-time.
Salah satu tujuan OpenCV adalah untuk menyediakan infrastruktur visi komputer yang mudah digunakan yang membantu orang-orang dalam membangun aplikasi-aplikasi visi yang sophisticated dengan cepat. Library pada OpenCV berisi lebih dari 500 fungsi yang menjangkau berbagai area dalam permasalahan visi, meliputi inspeksi produk pabrik, pencitraan medis, keamanan, antarmuka pengguna, kalibrasi kamera, visi stereo, dan robotika. Karena visi komputer dan pembelajaran mesin seringkali berkaitan, OpenCV juga memiliki Machine Learning Library (MLL). Sublibrary ini berfokus pada pengenalan pola statistik dan clustering. MLL sangat berguna untuk tugas-tugas visi yang berada dalam misi inti OpenCV, tetapi MLL cukup umum digunakan untuk permasalahan pembelajaran mesin.
Lisensi open source pada OpenCV telah distrukturisasi sehingga pengguna dapat membangun produk komersial menggunakan seluruh bagian pada OpenCV. Tidak ada kewajiban untuk meng-open source produk tersebut atau untuk memberikan peningkatan ke domain publik. Sebagian karena peraturan lisensi liberal ini, maka terdapat komunitas pengguna dalam jumlah yang sangat besar, termasuk di dalamnya orang-orang dari perusahaan besar (seperti IBM, Microsoft, Intel, SONY, Siemens, dan Google) serta pusat-pusat penelitian (seperti Stanford, MIT, CMU, Cambridge, dan INRIA).
Sejak peluncuran pertamanya pada Januari 1999, OpenCV telah digunakan pada banyak aplikasi, produk, dan usaha-usaha penelitian. Aplikasi-aplikasi ini meliputi penggabungan citra pada peta web dan satelit, image scan alignment, pengurangan noise pada citra medis, sistem keamanan dan pendeteksian gangguan, sistem pengawasan otomatis dan keamanan, sistem inspeksi pabrik, kalibrasi kamera, aplikasi militer, serta kendaraan udara tak berawak, kendaraan darat, dan kendaraan bawah air. OpenCV juga
telah digunakan untuk pengenalan suara dan musik, dimana teknik pengenalan visi diaplikasikan pada citra spektogram suara (Bradski dan Kaehler, 2008, pp1-2).
OpenCV adalah singkatan dari Open Computer Vision, yaitu library open source yang dikhususkan untuk melakukan pengolahan citra. Tujuannya adalah agar komputer mempunyai kemampuan yang mirip dengan cara pengolahan visual pada manusia.
Library ini dibuat untuk bahasa C/C++ sebagai optimasi aplikasi real-time. OpenCV
memiliki API (Application Programming Interface) untuk pengolahan tingkat tinggi maupun tingkat rendah. Pada OpenCV juga terdapat fungsi-fungsi siap pakai untuk
me-load, menyimpan, serta mengakuisisi gambar dan video.
Library OpenCV (Mukhlas, 2010, p10) memiliki fitur-fitur sebagai berikut:
- Manipulasi data gambar (mengalokasi memori, melepaskan memori, menduplikasi gambar, mengatur serta mengkonversi gambar)
- Image/Video I/O (bisa menggunakan kamera yang sudah didukung oleh library ini) - Manipulasi matriks dan vektor, serta terdapat juga routines aljabar linear (products,
solvers, eigenvalues, SVD)
- Pengolahan citra dasar (penapisan, pendeteksian tepi, sampling dan interpolasi, konversi warna, operasi morfologi, histogram, piramida citra)
- Analisis struktural - Kalibrasi kamera - Pendeteksian gerakan - Pengenalan objek
- GUI dasar (menampilkan gambar/video, mengontrol mouse/keyboard, scrollbar) - Image labelling (garis, kerucut, poligon, penggambaran teks)
Libraries OpenCV menyediakan banyak algoritma visi komputer dasar, dengan
keuntungan bahwa fungsi-fungsi tersebut telah diuji dengan baik dan digunakan oleh para peneliti di seluruh dunia. Libraries OpenCV juga menyediakan sebuah modul untuk pendeteksian objek yang menggunakan algoritma Viola Jones (Augusto, 2006, p4).