metode mana yang lebih baik digunakan untuk memilih istilah ekspansi yang akan ditambahkan pada kueri awal.
Lingkungan Implementasi
Perangkat lunak yang digunakan untuk penelitian yaitu:
1. Windows Vista Bussiness SP2 sebagai sistem operasi,
2. Strawberry-perl 5.10.1.0 sebagai interpreter bahasa pemrograman perl yang digunakan,
3. Apache xampp-win32-1.7.1 sebagai web server,
4. Notepad++ 5.8.2, dan
5. Microsoft Excell 2007 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem. Perangkat keras yang digunakan untuk penelitian meliputi:
1. Intel(R) Core(TM) 2 Duo CPU @2GHz, 2. RAM 2 GB,
3. Harddisk dengan kapasitas 160 GB.
HASIL DAN PEMBAHASAN Koleksi Dokumen Pengujian
Penelitian ini menggunakan 2000 buah dokumen yang berasal dari Laboratorium Temu Kembali Ilmu Komputer IPB. Deskripsi dari dokumen ini dapat dilihat pada Tabel 1. Tabel 1 Deskripsi dokumen pengujian
Uraian Nilai (byte)
Ukuran keseluruhan
dokumen 6.472.697
Ukuran rata-rata dokumen 3236 Ukuran dokumen terbesar 54.082 Ukuran dokumen terkecil 412
Contoh dari dokumen pengujian dapat dilihat pada Lampiran 2. Dokumen ini merupakan dokumen plain-text yang memilki struktur XML di dalamnya. Isi dari dokumen dikelompokan ke dalam tag-tag sebagai berikut:
<DOC></DOC>, tag ini mewakili keseluruhan dokumen. Tag ini melingkupi
beberapa tag-tag lain yang lebih spesifik di dalamnya.
<DOCNO></DOCNO>, tag ini menunjukkan ID dari dokumen. ID yang ada merupakan kombinasi dari nama sumber berita, tanggal berita, urutan berita dengan sumber dan tanggal yang sama.
<DATE></DATE>, menunjukkan tanggal dari berita
<AUTHOR></AUTHOR>, menunjukkan penulis dari berita tersebut.
<TEXT></TEXT>, tag ini menunjukkan isi dari dokumen.
Pengembangan Sistem 1. Pengindeksan
Modul paling awal yang dikerjakan dalam pengembangan sistem ini ialah modul pengindeksan dokumen. Pengindeksan dokumen yang dilakukan meliputi proses tokenisasi, pembuangan stopword, dan pembobotan dengan menggunakan metode pembobotan tf-idf.
Tokenisasi merupakan proses yang dilakukan untuk memecah isi dokumen menjadi token-token. Proses tokenisasi dilakukan berdasarkan langkah-langkah berikut:
Proses tokenisasi tidak dilakukan pada seluruh bagian dokumen, tetapi hanya pada bagian yang diapit oleh tag-tag
<TITLE><TITLE> dan <TEXT></TEXT>.
Gambar 2 menunjukkan ilustrasi bagian-bagian dokumen yang diproses.
Semua huruf dalam dokumen diubah menjadi huruf kecil. Penyeragaman ini dilakukan agar token yang sama namun memiliki besar kecil huruf yang berbeda tidak dianggap menjadi token-token yang berbeda.
Karakter-karakter yang akan yang akan dijadikan sebagai pemisah token didefinisikan dengan ekspresi regular berikut:
[\s+\/%,.\"\];()*<>&\':=`?\[!@]+
Selanjutnya pembuangan stopword dilakukan pada hasil tokenisasi dokumen. Hal ini bertujuan untuk menghilangkan kata-kata yang dianggap tidak penting seperti: kata sambung, kata keterangan, kata depan, kata ganti, kata dengan partikel (-lah, -kah, -pun), dan kata-kata tidak penting lainnya yang mempunyai frekuensi kemunculan tinggi.
Kata-kata tersebut dianggap tidak penting karena dianggap kurang bisa mencirikan dokumen yang mengandungnya. Sebagai
contoh: kata “adalah” merupakan kata yang tidak penting. Kata ini mungkin terdapat hampir di setiap dokumen sehingga tak dapat mencirikan dokumen tertentu.
Setelah dilakukan tokenisasi berikut pembuangan stopword, token-token yang dihasilkan akan diberi bobot tertentu. Metode pembobotan yang digunakan ialah metode pembobotan tf-idf. Pembobotan dilakukan dengan menggunakan lima fungsi utama dari program pengindeksan yang diberi nama Indexing.pl. Kelima fungsi utama tersebut antara lain:
Fungsi untuk mendapatkan frekuensi tiap token di dalam setiap dokumen (TF). Fungsi untuk mendapatkan jumlah
dokumen yang mengandung token tertentu (DF).
Fungsi untuk mendapatkan nilai IDF (Inverse document frequency) dari setiap token. Nilai IDF ini didapatkan dengan menggunakan rumus:
idft = log
dft N
dengan dft merupakan nilai df (jumlah
dokumen yang mengandung token tertentu) dan N merupakan jumlah dokumen yang ada dalam koleksi.
Fungsi untuk mendapatkan nilai tf-idf dari setiap token. Nilai tf-idf ini didapatkan dengan menggunakan rumus:
tf-idft = tft * idft
dengan tf merupakan frekuensi kemunculan kata dalam dokumen dan idf merupakan nilai invers document frequency dari kata tersebut.
Fungsi untuk mengetahui panjang dari masing-masing dokumen. Nilai ini diperlukan karena dokumen pengujian dimodelkan menjadi ruang vektor (vektor space model).
Nilai-nilai yang dihasilkan setiap fungsi disimpan dalam bentuk file hash dengan ekstension “.dat”. Dalam pemrograman perl file ini dapat langsung digunakan dengan menggunakan fungsi retrieve ().
Hash yang sebelumnya sudah dibuat akan disimpan di-memory. Jadi lebih mudah dan cepat untuk menggunakan hash berukuran besar dalam program yang berbeda. Sebagai contoh, jika ingin mendapatkan nilai IDF dari suatu kata, maka dapat digunakan cuplikan program yang ada pada Modul 1.
Modul 1
2. Penerjemahan Kamus Dwibahasa
Penerjemahan kamus dwibahasa dilakukan dengan tujuan mendapatkan istilah lain dengan makna yang sama atau berkaitan dengan kueri awal. Penerjemahan dilakukan dengan mengikuti Algoritme 1.
Algoritme 1
Untuk setiap kata dalam kueri lakukan:
Ambil hasil terjemahan dari kamus Indonesia-Inggris. Untuk setiap kata hasil penerjamahan, lakukan:
Ambil hasil terjemahan dari kamus Inggris-Indonesia.
# retrieve hasil pengindeksan my $indexingResult =
retrieve(„Stored
File/IndexingResult.dat‟) or die $!;
# nilai IDF hasil pengindeksan my %idfterm =
${$IndexingResult->{„idf‟}}; # nilai Idf untuk kata “tani” $tani_idf = $idfterm{“tani”} ; <DOC> <DOCNO>situshijau180603-002</DOCNO> <TITLE> Ditunggu, PP Pembebasan... ... .... </TITLE> <DATE>Kamis, 15 Februari 2001</DATE> <AUTHOR>Ely</AUTHOR> <TEXT> Pemerintah hendaknya segera... ... .... </TEXT> </DOC>
bagian dokumen yang digunakan untuk proses tokenisasi
Algoritme 1 merupakan algoritme yang sama yang digunakan oleh Sitohang (2009) dalam mendapatkan istilah ekspansi bagi penelitiannya. Selain menggunakan algoritme yang sama, penelitian ini juga menggunakan kamus yang sama untuk melakukan penerjemahan kueri awal.
Penerjemahan kueri akan dilakukan sebanyak pencarian yang dilakukan. Dengan demikian eksekusi kueri pada database juga akan dilakukan dalam jumlah yang sama. Penggunaan database untuk penerjemahan ini akan memperbanyak waktu yang dibutuhkan untuk melakukan pencarian. Jadi perlu dicari bentuk penerjemahan yang lebih baik untuk mengoptimalkan waktu pencarian.
Untuk membuatnya lebih efisien, penggunaan database akan digantikan dengan hash. Hal ini hampir serupa dengan penggunaan hash pada modul pengindeksan. Untuk melakukan penerjemahan hal yang perlu dilakukan hanyalah mengakses alamat dari hash tersebut. Contoh yang sederhana dari penggunaan hash ini dapat dilihat pada cuplikan program berikut:
$transpetani= $hK{„petani‟};
Cuplikan program ini akan mengembalikan hasil penerjemahan dengan kamus dwibahasa ke variabel $transpetani. Cara ini dianggap lebih efisien daripada harus melakukan eksekusi kueri pada tiap kata yang ingin diterjemahkan.
Untuk mengubah bentuk kamus yang berupa database menjadi bentuk hash digunakan sebuah program sederhana getHashKamus.pl. Program ini melakukan penerjemahan berdasarkan Algoritme 1. Hasil penerjemahan diberikan dalam bentuk array seperti ilustrasi pada Modul 2.
Modul 2
Hasil penerjemahan serupa yang dilakukan pada beberapa kata dalam kueri uji dapat dilihat pada Lampiran 3.
3. Penghitungan Peluang Bersyarat
Istilah-istilah baru yang didapatkan dari proses penerjemahan tidaklah dapat
digunakan semuanya. Penambahan istilah ekspansi yang terlalu banyak hanya akan mengurangi kinerja sistem temu kembali. Untuk itu diperlukan suatu ukuran untuk dapat memilih istilah ekspansi yang dapat digunakan. Ukuran yang digunakan dalam penelitian ini ialah peluang bersyarat kemunculan bersama antara kueri dan istilah ekspansinya. Peluang bersyarat ini akan menggambarkan suatu keterkaitan antara kata dalam kueri awal dan hasil terjemahannya. Ilustrasi penentuan nilai peluang bersyarat antara kata “hujan” dengan istilah hasil terjemahannya dapat dilihat pada Modul 3. Modul 3
Selanjutnya akan dipilih tiga istilah dengan nilai peluang bersyarat tertinggi serta nilai peluang bersyaratnya > 0. Hasilnya disimpan dalam sebuah file yang berisi hash dengan struktur yang dapat diilustrasikan pada Modul 4.
Modul 4
4. Pencarian Dokumen
Proses pencarian dokumen dilakukan sesuai dengan pilihan tindakan ekspansi yang dipilih oleh pengguna. Terdapat empat pilihan tindakan ekspansi di dalam sistem ini, di antaranya: pencarian tanpa melakukan ekspansi pada kueri, satu istilah ekspansi, dua istilah ekspansi, dan tiga istilah ekspansi. Masing-masing angka di atas menunjukkan jumlah istilah ekspansi yang ditambahkan pada tiap kata dalam kueri awal.
Hasil dari proses pencarian dokumen merupakan dokumen-dokumen yang dianggap memiliki kemiripan dengan kueri yang diberikan atau memiliki nilai ukuran kesamaan > 0. Pemeringkatan dokumen hasil pencarian juga dilakukan dan disajikan berdasarkan urutan menurun dari nilai ukuran kesamaannya. $hExp{hujan}[0]= musim $hExp{hujan}[0]= awan $hExp{hujan}{awan}= 0.9 $hExp{hujan}{megnhujani}= 0 $hExp{hujan}{menghujan}= 0 $hExp{hujan}{musim}=0.336 $hK{menyandang}[0]= mengangkat $hK{menyandang}[0]= membawa $hK{menyandang}[0]= memenangkan $hK{menyandang}[0]= menggotong $hK{menyandang}[0]= menerima $hK{menyandang}[0]= meloloskan
Pengujian Kinerja Sistem
1. Pengujian Presisi Pencarian Dokumen Proses evaluasi dalam penelitian ini menggunakan 30 kueri uji yang telah ada sebelumnya berikut dokumen-dokumen yang relevan dengannya. Pencarian dengan kueri uji ini dilakukan dengan tujuan mendapatkan nilai recall dan precision dari sistem. Nilai-nilai ini diukur dari setiap dokumen yang dihasilkan dari proses pencarian atau yang memiliki ukuran kesamaan > 0. Setelah didapatkan nilai-nilai recall dan precision-nya, interpolasi dilakukan untuk mendapatkan nilai average precision yang akan menggambarkan bagaimana kinerja dari sistem secara keseluruhan.
Pada tahap awal akan dihitung hasil pengujian untuk pencarian dokumen tanpa melakukan ekspansi (QE0). Gambar 3 merupakan grafik recall dan precision untuk hasil pencarian tanpa ekspansi dari ke-30 kueri uji yang ada.
Gambar 3 Grafik Nilai recall dan precision dari pencarian tanpa ekspansi (QE0)
Nilai recall dan precision dari pencarian tanpa ekspansi ini akan digunakan sebagai pembanding oleh pencarian yang menggunakan ekspansi, baik satu, dua, maupun pencarian yang menggunakan tiga buah ekspansi dari setiap kata dalam kueri awal. Nilai recall yang dihasilkan dari menu pencarian ini rata-rata sebesar 0,975. Nilai average precision (AVP) dari menu pencarian ini sebesar 0,530. Hal ini menunjukkan bahwa pencarian tanpa ekspansi yang dilakukan sistem ini rata-rata menemukembalikan 97,5% dokumen relevan dari semua dokumen relevan yang ada dalam koleksi dokumen.
Tiga kondisi pengujian selanjutnya yakni QE1, QE2, dan QE3 merupakan pengujian untuk pencarian yang dilakukan dengan
menambahkan istilah ekspansi pada kueri awal. Hasil dari masing-masing pengujian akan dibandingkan dengan pencarian tanpa ekspansi (QE0).
a. QE1 dibandingkan dengan QE0
QE1 merupakan kondisi pengujian dengan melakukan pencarian dokumen disertai dengan penambahan satu istilah ekspansi pada masing-masing kata dalam kueri awal. Istilah yang ditambahkan tidak lain adalah istilah terjemahan masing-masing kata yang memiliki nilai peluang bersyarat tertinggi.
QE1 menghasilkan pencarian dengan nilai recall rata-rata sebesar 0.982. Hal ini menunjukkan bahwa 98,2% dari total dokumen relevan yang ada dalam koleksi dokumen dihasilkan dari tiap pencarian dengan kueri uji. Nilai ini lebih tinggi 0,7% dibandingkan pencarian yang dilakukan tanpa penambahan istilah ekspansi.
Walaupun dapat meningkatkan nilai recall, pencarian dengan kondisi ini dapat menurunkan nilai presisi dari hasil pencarian. Nilai AVP dari kondisi pencarian ini ialah sebesar 0.487 atau 0.043 lebih rendah daripada nilai AVP yang dimiliki pencarian tanpa tambahan istilah ekspansi (QE0). Grafik perbandingan nilai presisi pencarian antara QE1 dan QE0 dapat dilihat pada Gambar 4.
Gambar 4 Grafik nilai recall dan precision pada pencarian QE1 dibandingkan dengan QE0
b. QE2 dibandingkan dengan QE0
Kondisi pengujian ini melakukan pencarian dengan menambahkan dua istilah ekspansi pada setiap kata dalam kueri awal. Hasil pencarian QE2 menghasilkan nilai recall rata-rata sebesar 0,982. Dengan melihat nilai recall yang dimilikinya dapat diketahui bahwa rata-rata 98,2% dari total dokumen
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 P re cis io n Recall 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 P re cis io n Recall QE0 QE1
relevan yang ada dalam koleksi dokumen dapat dihasilkan dari tiap pencarian.
Namun, seperti halnya QE1, penambahan dua istilah ekspansi pada setiap kata dalam kueri awal ini dapat pula menurunkan nilai presisi pencarian jika dibandingkan dengan pencarian tanpa ekspansi (QE0). Dengan kondisi pencarian QE2 terjadi penurunan nilai presisi menjadi 0.453. Penurunan ini malah lebih parah jika dibandingkan dengan QE1. Grafik perbandingan nilai presisi pancarian antara QE2 dengan QE0 dapat dilihat pada Gambar 5.
Gambar 5 Grafik nilai recall dan precision pada pencarian QE2 dibandingkan dengan QE0
c. QE3 dibandingkan dengan QE0
Seperti halnya QE2 dan QE1, QE3 juga melakukan pencarian yang disertai dengan penambahan istilah ekspansi pada setiap kata dalam kueri awal. Jumlah istilah yang ditambahkan pada kondisi pencarian QE3 ialah sebanyak tiga istilah ekspansi pada masing-masing kata dalam kueri awal. Hasil pencarian QE3 dapat memberikan nilai recall rata-rata sebesar 0.983.
Sebesar 98,3% dari total dokumen relevan dapat dikembalikan dengan kondisi pencarian QE3. Nilai ini lebih tinggi dibandingkan tiga kondisi pencarian lainnya yakni QE0, QE1, dan QE2. Walaupun demikian nilai presisi atau precision yang dihasilkan dari kondisi pencarian ini merupakan yang terendah dibandingkan dengan tiga kondisi pencarian lainnya. Nilai precision yang dihasilkan dari kondisi pencarian QE3 ialah sebesar 0.435. Grafik perbandingan nilai recall dan precision dari QE0 dan QE3 dapat dilihat pada Gambar 6.
Tabel 2 akan menampilkan nilai rata-rata recall dan AVP untuk masing-masing kondisi
pencarian QE0, QE1, QE2, dan QE3. Tabel 2 juga menunjukkan bahwa semakin banyak istilah ekspansi yang ditambahkan pada kueri awal maka semakin tinggi rata-rata nilai recall hasil pencariannya. Dapat pula dikatakan akan semakin banyak dokumen relevan yang ditemukembalikan pada hasil pencarian.
Meskipun banyak dokumen relevan yang ditemukembalikan, namun penurunan nilai precision dari hasil pencarian tetap terjadi. Hal ini dikarenakan penambahan istilah yang dilakukan mengakibatkan dokumen-dokumen yang tak relevan juga ikut ditemukembalikan oleh sistem. Dokumen-dokumen tak relevan ini sebagian menempati peringkat yang lebih tinggi daripada dokumen relevan yang ditemukembalikan sehingga nilai precision menjadi lebih rendah dibandingkan dengan pencarian yang tidak menggunakan penambahan istilah ekspansi.
Gambar 6 Grafik nilai recall dan precision pada pencarian QE3 dibandingkan dengan QE0
Tabel 2 Nilai recall dan AVP semua kondisi pencarian Kondisi Pencarian Nilai Recall Nilai AVP QE0 0.975 0.530 QE1 0.982 0.487 QE2 0.982 0.453 QE3 0.983 0.435
2. Pengujian Waktu Pencarian Dokumen Pengujian
Untuk setiap kueri pengujian yang ada dalam Lampiran 1, dilakukan pencarian sebanyak lima kali ulangan. Hasil yang diperolah yakni tidak ditemukannya pengaruh secara nyata dari banyaknya kata dalam kueri terhadap waktu yang dibutuhkan utnuk
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 P re cis io n Recall QE0 QE2 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 P re cis io n Recall QE0 QE3
melakukan sebuah pencarian. Hal ini tidak hanya berlaku untuk pencarian tanpa ekspansi (QE0), tetapi juga untuk pencarian yang dilakukan dengan menggunakan ekspansi (QE1, QE2, dan QE3).
Kelemahan Sistem
Salah satu kelemahan utama dari sistem yang dikembangkan yakni algoritme penerjemahan yang digunakan. Algoritme penerjemahan yang ada dalam penelitian ini terkadang menghasilkan istilah ekspansi yang terlihat seperti hanya diberi imbuhan dan bukan diterjemahkan. Pada Lampiran 3 dapat dilihat beberapa kata yang diterjemahkan menjadi kata awal yang hanya diberi imbuhan saja. Beberapa dari kata tersebut ditunjukkan pada Tabel 3.
Selain itu algoritme penerjemahan yang digunakan merupakan penerjemahan word-by-word atau penerjemahan kata-per-kata. Dengan penerjemahan seperti ini, dua kata yang merupakan frase akan dikenali sebagai dua kata terpisah tanpa ada keterkaitan. Untuk mengujinya, penulis memasukkan kata “rumah sakit”. Terjemahan yang diharapkan untuk kata ini ialah “hospital”. Lain halnya dengan hasil yang didapatkan dengan algoritme penerjemahan ini. Kata terjemahan yang dihasilkan ialah “house” dan “ill”. Jadi penerjemahan dilakukan secara terpisah untuk masing-masing kata “rumah” dan “sakit”. Tabel 3 Penerjemahan yang menghasilkan kata berimbuhan dari kata awal
kueri Istilah terjemahan pupuk Memupuk
harga Dihargai, menghargai, berharga
Tani Petani
Analisis Perbandingan Pemilihan Istilah Ekspansi
Penelitian ini menggunakan metode ekspansi kueri yang sama dengan ekspansi kueri yang dilakukan oleh Sitohang (2009). Namun penelitian ini memiliki beberapa perbedaan dalam hal metode pemilihan istilah ekspansi yang digunakan. Sitohang (2009) menggunakan nilai IDF sebagai ukuran utama untuk menentukan pemilihan istilah ekspansi yang akan ditambahkan pada kueri awal, sedangkan penelitian ini menggunakan peluang kejadian bersama antara dua istilah.
Penelitian Sitohang (2009) hanya menunjukkan 2 dari 30 kueri uji yang mengalami peningkatan nilai AVP setelah dilakukan ekspansi kueri terhadapnya. Peningkatan tersebut terjadi pada penambahan satu istilah ekspansi pada masing-masing kata pada kueri awal.
Pada penelitian ini keberhasilan kueri uji dalam meningkatkan nilai AVP terjadi pada setiap kondisi pengujian. QE1 menunjukkan bahwa 7 dari 30 kueri pengujian mengalami peningkatan AVP. QE2 menunjukkan bahwa 7 dari 30 kueri uji mengalami peningkatan nilai AVP dan kondisi pengujian QE3 menunjukkan bahwa 5 dari 30 kueri mengalami peningkatan nilai AVP. Perbandingan nilai AVP untuk tiap kondisi pengujian dapat dilihat pada Tabel 4.
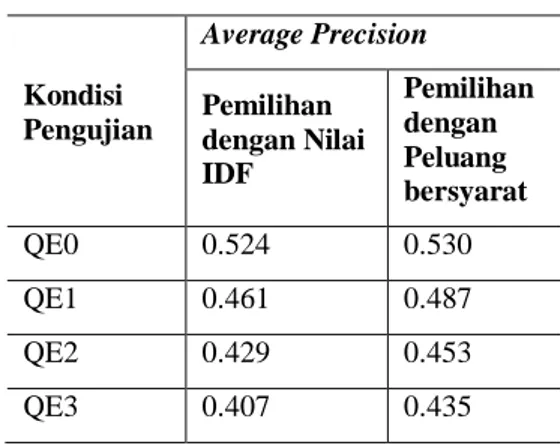
Tabel 4 Perbandingan nilai AVP dari kedua sistem Kondisi Pengujian Average Precision Pemilihan dengan Nilai IDF Pemilihan dengan Peluang bersyarat QE0 0.524 0.530 QE1 0.461 0.487 QE2 0.429 0.453 QE3 0.407 0.435
Pada Tabel 4 dapat dilihat bahwa pada tiap kondisi pengujian yang sama penggunaan peluang bersyarat memberikan hasil yang lebih tinggi. Pada pengujian QE0 sistem ini memiliki nilai AVP yang lebih tinggi daripada sistem yang dikembangkan dalam penelitian Sitohang (2009). Hal ini dapat disebabkan perlakuan tokenisasi yang berbeda pada saat proses pengindeksan dokumen. Selain itu penelitian ini juga menggunakan pembuangan stopword dengan daftar stopword yang berbeda.
Proses pengindeksan yang dilakukan Sitohang(2009) menghasilkan 23.775 istilah berbeda dari 1000 dokumen pengujian. Sementara penelitian ini menghasilkan 24.443 istilah berbeda dari penggunaan dokumen pengujian yang sama.
Hasil yang lebih tinggi juga terdapat pada nilai AVP pencarian yang menggunakan tambahan istilah ekspansi. Baik QE1, QE2,
maupun QE3 memperlihatkan bahwa ekspansi yang dilakukan pada penelitian ini memiliki hasil yang lebih baik daripada penelitian Sitohang (2009).
Penelitian ini menggunakan metode yang sama dalam mendapatkan istilah ekspansinya yakni dengan menggunakan metode penerjemahan kamus dwibahasa. Dengan metode ini kedua penelitian menghasilkan sejumlah istilah yang sama yang dapat ditambahkan ke dalam kueri awal. Kedua penelitian ini menjadi berbeda ketika akan memilih istilah mana saja yang akan ditambahkan ke dalam kueri. Sitohang (2009) memilih nilai IDF sebagai ukuran untuk memilih istilah terjemahan yang akan ditambahkan ke dalam kueri.
Nilai IDF merupakan nilai yang menunjukkan tingkat kepentingan suatu kata dalam koleksi. Semakin tinggi nilai IDF berarti semakin jarang kata itu muncul di banyak dokumen dan semakin mungkin kata itu dapat digunakan untuk mencirikan suatu dokumen. Dengan mengunakan nilai IDF sebagai pemilihan istilah ekspansi berarti mengambil istilah terjemahan yang merupakan kata terpenting untuk ditambahkan ke dalam kueri awal. Mengingat algoritme penerjemahan yang kurang baik digunakan dalam penelitiannya maka tingkat kepentingan kata menjadi kurang berarti.
Peluang bersyarat yang digunakan dalam penelitian ini dapat sedikit mengatasi masalah penerjemahan tersebut. Walaupun hasil terjemahan yang didapat kurang mencapai konsep kueri, namun dengan peluang bersyarat pencarian akan tetap berada pada sekitar kata yang memiliki keterkaitan dengan kueri awal.
Pengujian pada koleksi dokumen yang lebih besar
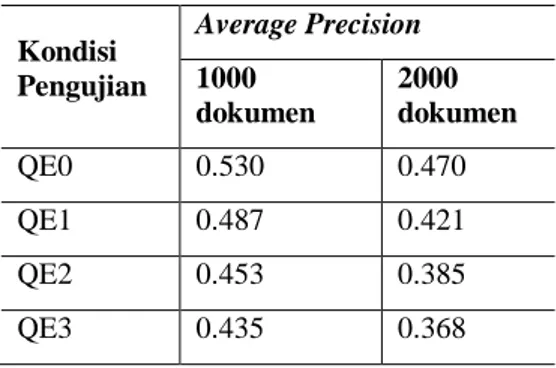
Pengujian ini menggunakan tambahan 1000 dokumen lagi pada koleksi dokumen sebelumnya. Total 2000 dokumen digunakan pada pengujian ini. Pengujian ini juga menggunakan kueri-kueri yang telah ditentukan dokumen-dokumen mana yang relevan dengannya. Ternyata sistem memperlihatkan penurunan presisi pencarian jika dilakukan penambahan dokumen terhadapnya. Tabel 5 di bawah ini akan memperlihatkan perbandingan nilai presisi sistem pada penggunaan 1000 dan 2000 dokumen.
Tabel 5 Perbandingan nilai presisi sistem pada penggunaan 1000 dan 2000 dokumen.
Kondisi Pengujian Average Precision 1000 dokumen 2000 dokumen QE0 0.530 0.470 QE1 0.487 0.421 QE2 0.453 0.385 QE3 0.435 0.368
KESIMPULAN DAN SARAN Kesimpulan
Hasil penelitian ini menunjukkan bahwa: 1. Ekspansi kueri yang dilakukan pada sistem
ini akan mengakibatkan menurunnya nilai presisi bila dibandingkan dengan pencarian tanpa melakukan ekspansi kueri. 2. Metode pemilihan istilah ekspansi dengan peluang bersyarat relatif lebih baik jika dibandingkan dengan penggunaan nilai IDF pada metode ekspansi yang sama, yakni metode penerjemahan kamus dwibahasa.
3. Banyaknya kata dalam kueri tidak memiliki pengaruh secara nyata terhadap waktu pencarian sistem.
Saran
Untuk penelitian-penelitian yang berkaitan dengan ekspansi kueri, disarankan untuk melakukan penelitian dengan:
1. Penggunaan koleksi dokumen yang lebih besar
2. Penggunaan metode pembobotan lainnya, seperti BM25.
DAFTAR PUSTAKA
Adisantoso J. 1997. Temu Kembali Infomasi Menggunakan Peluang Bersyarat. Tesis. Program Studi Ilmu Komputer Universitas Indonesia. Jakarta.
Aly AA. 2008. Using a Query Expansion Technique to Improve Document Retrieval. Information Technologies and Knowledge, vol. 2.
Baeza-Yates R, Riberio-Neito B. 1999. Modern Information Retrieval. New York, Adison Weasley.