LANDASAN TEORI
2.1 Teori Dasar Kompresi
Pada dasarnya data apapun sebenarnya adalah merupakan rangkaian bit 0 dan 1. Yang membedakan antara suatu data tertentu dengan data yang lain adalah ukuran dari rangkaian bit dan bagaimana 0 dan 1 itu ditempatkan dalam rangkaian bit tersebut. Misalnya data berupa teks dan data yang berupa gambar, dalam data teks suatu rangkaian bit tertentu mewakili satu karakter, sedangkan dalam data gambar suatu rangkaian bit mewakili suatu warna dalam satu pixel. Semakin kompleks suatu data, ukuran rangkaian bit yang diperlukan semakin panjang, dengan demikian ukuran keseluruhan data juga semakin besar.
Dalam penyimpanan dan pengiriman data komputer, selain isi dari data tersebut parameter yang tidak kalah pentingnya adalah ukurannya. Kerap kali data yang disimpan dalam suatu media penyimpanan berukuran sangat besar sehingga memerlukan tempat yang lebih banyak dan tidak efisien. Apalagi bila data tersebut akan dikirim, semakin besar ukurannya, waktu yang diperlukan untuk pengiriman akan lebih lama. Untuk itu, diperlukan kompresi data (data compression) untuk memperkecil ukuran suatu data tanpa merubah isi atau informasi yang terkandung dalam data tersebut.
Ada banyak sekali teori dan metode untuk kompresi data. Salah satu teori yang cukup sederhana adalah dengan menggunakan kode Huffman (Huffman coding). Dalam enkoding kode Huffman, digunakan konsep struktur data pohon biner (binary tree). Teori kode Huffman ini sendiri tidak hanya ada satu, tetapi ada beberapa variasi, optimasi, dan kombinasinya. Dalam ilmu sains komputer kompresi data adalah seni dalam merepresentasikan sumber data digital dan lainnya ke dalam bentuk yang lebih compact (kecil). Istilah lain dari kompresi data adalah pemampatan data.
8
Berikut ini beberapa defenisi dari kompresi data:
a. Kompresi berarti memampatlkan/mengecilkan ukuran.
b. Kompresi data adalah proses mengkodekan informasi menggunakan bit atau informasi bearing unit yang lain yang lebih rendah dari pada representasi data yang tidak terkodekan dengan suatu sistem enkoding tertentu.
2.2 Kompresi Data
Data tidak hanya disajikan dalam bentuk teks, tetapi juga dapat berupa gambar, audio (bunyi, suara, musik) dan video. Keempat macam data tersebut sering disebut dengan multimedia. Pada umumnya representasi data digital membutuhkan memori yang besar, disisi lain kebanyakan data misalnya citra (image) mengandung duplikasi. Duplikasi ini dapat berarti dua hal. Pertama, besar kemungkinan suatu pixel dengan pixel lain tetangganya memiliki intensitas yang sama, sehingga penyimpanan setiap pixel memboroskan tempat. Kedua, citra banyak mengandung bagian (region) yang sama, sehingga bagian yang sama ini tidak perlu dikodekan berulang kali. Saat ini, kebanyakan aplikasi menginginkan representasi dengan memori yang lebih sedikit. Pemampatan data atau kompresi data (data compression) bertujuan meminimalkan kebutuhan memori untuk merepresentasikan data digital. Prinsip umum yang digunakan pada proses kompresi adalah mengurangi duplikasi data sehingga memori untuk merepresentasikan menjadi lebih sedikit daripada representasi data digital semula.
Data digital yang telah dikompresi dapat dikembalikan ke bentuk data digital semula (dekompresi) dimana hal ini tergantung pada aplikasi software yang mendukung kompresi tersebut. Ketika suatu aplikasi mampu ‘menghilangkan’ atau mengkompresi data yang tidak dibutuhkan maka aplikasi tersebut juga mampu mengembalikan data yang dihilangkan tersebut sehingga menjadi data digital semula (dekompresi) namun terdapat juga suatu aplikasi yang dapat mengkompresi namun ketika dekompresi dapat menggunakan aplikasi lain contohnya aplikasi winzip dengan aplikasi winrar.
Contoh software sound forge yang digunakan untuk mengkompresi data digital namun hasil yang didapat malah ukuran yang dihasilkan lebih besar daripada ukuran data digital semula dimana hal ini dapat terjadi karena terdapat informasi-informasi yang tidak dikenali software ini sehingga terjadi penambahan informasi oleh software ini sehingga ukuran menjadi lebih besar. Bila dibandingkan dengan software permainan atau games terdapat informasi yang lebih banyak dikompresi karena terdapat informasi yang bisa dikompresi.
Image atau citra yang ditransmisikan sepanjang world wide web (www) merupakan salah satu contoh mengapa kompresi data diperlukan.
Ada empat pendekatan yang digunakan pada kompresi suatu data, yaitu: 1. Pendekatan statistik.
Kompresi didasarkan pada frekuensi kemunculan derajat keabuan pixel didalam seluruh bagian. Contoh metode : Huffman Coding.
2. Pendekatan ruang.
Kompresi didasarkan pada hubungan spasial antara pixel-pixel di dalam suatu kelompok yang memiliki derajat keabuan yang sama dalam suatu daerah gambar atau data. Contoh metode : Run-Length Encoding.
3. Pendekatan kuantisasi
Kompresi dilakukan dengan mengurangi jumlah derajat keabuan yang tersedia. Contoh metode : kompresi kuantisasi (CS&Q).
4. Pendekatan fraktal
Kompresi dilakukan pada kenyataan bahwa kemiripan bagian-bagian didalam data atau citra atau gambar dapat dieksploitasi dengan suatu matriks transformasi.
Contoh metode : Fractal Image Compression. 2.3 Metode Kompresi Data
Metode pemampatan data atau kompresi data dapat dikelompokan dalam dua kelompok besar yaitu metode lossless dan metode lossy (Sutoyo, 2009). yaitu: 1. Metode lossless.
10
memungkinkan data yang asli dapat disusun kembali dari data kompresi. Lossless data kompresi digunakan dalam berbagai aplikasi seperti format ZIP dan GZIP. Lossless juga sering digunakan sebagai komponen dalam teknologi kompresi data lossy. Kompresi Lossless digunakan ketika sesuatu yang penting pada kondisi asli. Beberapa format gambar seperti PNG atau GIF hanya menggunakan kompresi lossless, sedangkan yang lainnya sperti TIFF dan MNG dapat menggunakan metode lossy atau lossless.
Metode lossless menghasilkan data yang identik dengan data aslinya, hal ini dibutuhkan untuk banyak tipe data, contohnya: executable code, word processing files, tabulated numbers dan sebagainya. Misalnya pada citra atau gambar dimana metode ini akan menghasilkan hasil yang tepat sama dengan citra semula, pixel per pixel sehingga tidak ada informasi yang hilang akibat kompresi. Namun ratio kompresi (rasio kompresi yaitu, ukuran file yang dikompresi dibanding yang tak terkompresi dari file) dengan metode ini sangat rendah. Metode ini cocok untuk kompresi citra yang mengandung informasi penting yang tidak boleh rusak akibat kompresi, misalnya gambar hasil diagnosa medis. Contoh metode lossless adalah metode run-length, Huffman, delta dan LZW.
Kebanyakan program kompresi lossless menggunakan dua jenis algoritma yang berbeda: yang satu menghasilkan model statistik untuk input data, dan yang lainnya memetakan data input ke rangkaian bit menggunakan model ini dengan cara bahwa “probable” data akan menghasilkan output yang lebih pendek dari “improbable” data. algoritma encoding yang utama yang dipakai untuk menghasilkan rangkaian bit adalah huffman coding dan arithmatic coding.
2. Metode lossy
Lossy kompresi adalah suatu metode untuk mengkompresi data dan men-dekompresinya, data yang diperoleh mungkin berbeda dari yang aslinya tetapi cukup dekat perbedaaanya. Lossy kompresi ini paling sering digunakan untuk kompres data multimedia (suara atau gambar diam). Sebaliknya, kompresi lossless diperlukan untuk data teks dan file, seperti catatan bank, artikel teks dan lainnya.
Format kompresi lossy mengalami generation loss yaitu jika melakukan berulang kali kompresi dan dekompresi file akan menyebabkan kehilangan kualitas secara progresif. hal ini berbeda dengan kompresi data lossless. ketika pengguna yang menerima file terkompresi secara lossy (misalnya untuk mengurangi waktu download) file yang diambil dapat sedikit berbeda dari yang asli di-level bit ketika tidak dapat dibedakan oleh mata dan telinga manusia untuk tujuan paling praktis.
Metode ini menghasilkan rasio kompresi yang lebih besar daripada metode lossless. Misal terdapat image asli berukuran 12,249 bytes, kemudian dilakukan kompresi dengan JPEG kualitas 30 dan berukuran 1,869 bytes berarti image tersebut 85% lebih kecil dan rasio kompresi 15%. Contoh metode lossy adalah metode CS&Q (coarser sampling and/or quantization), JPEG, dan MPEG.
Ada dua skema dasar lossy kompresi :
a. Lossy transform codec, sampel suara atau gambar yang diambil, di potong kesegmen kecil, diubah menjadi ruang basis yang baru, dan kuantisasi. hasil nilai kuantisasi menjadi entropy coded.
b. Lossy predictive codec, sebelum dan/atau sesudahnya data di-decode digunakan untuk memprediksi sampel suara dan frame picture saat ini. kesalahan antara data prediksi dan data yang nyata, bersama-sama dengan informasi lain digunakan untuk mereproduksi prediksi, dan kemudian dikuantisasi dan kode.
Dalam beberapa sistem kedua teknik digabungkan, dengan mengubah codec yang digunakan untuk mengkompresi kesalahan sinyal yang dihasilkan dari tahapan prediksi.
Keuntungan dari metode lossy atas lossless adalah dalam beberapa kasus metode lossy dapat menghasilkan file kompresi yang lebih kecil dibandingkan dengan metode lossless yang ada, ketika masih memenuhi persyaratan aplikasi. Metode lossy sering digunakan untuk mengkompresi suara, gambar dan video. karena data tersebut dimaksudkan kepada human interpretation dimana pikiran dapat dengan mudah “mengisi bagian-bagian yang kosong” atau melihat kesalahan masa lalu sangat kecil atau inkonsistensi. Idealnya lossy adalah
12
kompresi transparan, yg dapat diverifikasi dengan tes ABX. Sedangkan lossless digunakan untuk mengkompresi data untuk diterima ditujuan dalam kondisi asli seperti dokumen teks. Lossy akan mengalami generation loss pada data sedangkan pada lossless tidak terjadi karena data yang hasil dekompresi sama dengan data asli.
2.3 Format Data Waveform Audio
Secara umum data audio digital memiliki karakteristik yang dapat dinyatakan dengan parameter-parameter berikut:
a. Laju sampel (sampling rate) dalam sampel/detik, misalnya 22050 atau 44100 sampel/detik.
b. Jumlah bit tiap sampel, misalnya 8 atau 16 bit. c. Jumlah kanal, yaitu 1 untuk mono dan 2 untuk stereo.
Parameter-parameter tersebut menyatakan setting yang digunakan oleh ADC (Analog-to-Digital Converter) pada saat data audio direkam. Biasanya laju sampel juga dinyatakan dengan satuan Hz atau kHz. Sebagai gambaran, data audio digital yang tersimpan dalam CD audio memiliki karakteristik laju sampel 44100 Hz, 16 bit per sampel, dan 2 kanal (stereo), yang berarti setiap satu detik suara tersusun dari 44100 sampel, dan setiap sampel tersimpan dalam data sebesar 16-bit atau 2 byte. Laju sampel selalu dinyatakan untuk setiap satu kanal. Jadi misalkan suatu data audio digital memiliki 2 kanal dengan laju sampel 8000 sampel/detik, maka sesungguhnya di dalam setiap detiknya akan terdapat 16000 sampel.
Sebagaimana telah dijelaskan sebelumnya bahwa untuk stream data audio menggunakan header berupa struktur PCMWAVEFORMAT. PCM merupakan singkatan dari Pulse Coded Modulation, yaitu suatu metode yang digunakan untuk mengkonversikan sinyal audio dari bentuk analog ke bentuk digital.
Adapun struktur dari PCMWAVEFORMAT adalah sebagai berikut: typedef struct {WAVEFORMAT wf;WORD wBitsPerSample;}
Field wf merupakan struktur WAVEFORMAT yang berisi keterangan umum mengenai format data audio. Field wBitsPerSample menunjukkan banyaknya bit per sample.
Adapun struktur data dari WAVEFORMAT adalah sebagai berikut: typedef struct {WORD wFormatTag; WORD nChannels; DWORD nSamplesPerSec; DWORD nAvgBytesPerSec; WORD nBlockAlign;} WAVEFORMAT;
Keterangan mengenai field-field dari struktur WAVEFORMAT ini dapat dilihat pada tabel 2.1.
Tabel 2.1
Field-field pada struktur data WAVEFORMAT
Field Keterangan
wFomatTag Menunjukkan type format data dan memiliki nilai WAVE_FORMAT_PCM.
nChannels Menunjukkan banyaknya kanal yang ada di dalam data waveform audio. Untuk mono menggunakan satu kanal sedangkan untuk stereo menggunakan dua kanal.
nSamplesPerSec Menunjukkan besarnya sample rate dalam sample per detik.
nAvgBytesPerSec Menunjukkan rata-rata laju transfer data, dalam byte per detik. Misalnya untuk PCM 16-bit stereo pada 44.1 kHz, nAvgBytesPerSec bernilai 176400 ( 2 kanal * 2 byte per sample * 44100 ).
nBlockAlign
Menunjukkan banyaknya byte yang digunakan untuk satu buah sample. Misalnya untuk PCM 16-bit mono, nBlockAlign akan bernilai 2.
2.4 Audio MP3
MPEG (Moving Picture Expert Group)-1 audio layer III atau yang lebih dikenal dengan MP3, adalah salah satu dari pengkodean dalam digital audio dan juga merupakan format kompresi audio yang memiliki sifat “menghilangkan”. Istilah menghilangkan yang dimaksud adalah kompresi audio ke dalam format mp3 menghilangkan aspek-aspek yang tidak signifikan pada pendengaran manusia untuk mengurangi besarnya file audio.
Sejarah mp3 dimulai dari tahun 1991 saat proposal dari Phillips (Belanda), CCET (Perancis), dan Institut für Rundfunktechnik (Jerman) memenangkan proyek untuk DAB (Digital Audio Broadcast). Produk mereka Musicam (akan lebih dikenal dengan layer 2) terpilih karena kesederhanaan, ketahanan terhadap kesalahan, dan perhitungan komputasi yang sederhana untuk melakukan pengkodean yang menghasilkan keluaran yang memiliki kualitas tinggi. Pada akhirnya ide dan teknologi yang digunakan dikembangkan menjadi MPEG-1 audio layer 3.
MP3 adalah pengembangan dari teknologi sebelumya sehingga dengan ukuran yang lebih kecil dapat menghasilkan kualitas yang setara dengan kualitas CD. Spesifikasi dari layer-layer sebagai berikut:
1. Layer 1: paling baik pada 384 kbit/s
2. Layer 2: paling baik pada 256...384 kbit/s, sangat baik pada 224...256 kbit/, baik pada 192...224 kbit/s
3. Layer 3: paling baik pada 224...320 kbit/s, sangat baik pada 192...224 kbit/s, baik pada 128...192 kbit/s
Kompresi yang dilakukan oleh mp3 seperti yang telah disebutkan diatas, tidak mempertahankan bentuk asli dari sinyal input. Melainkan yang dilakukan adalah menghilangkan suara-suara yang keberadaannya kurang/tidak signifikan bagi sistem pendengaran manusia. Proses yang dilakukan adalah menggunakan model dari sistem pendengaran manusia dan menentukan bagian yang terdengar bagi sistem pendengaran manusia. Setelah itu sinyal input yang memiliki domain waktu dibagi
menjadi blok-blok dan ditransformasi menjadi domain frekuensi. Kemudian model dari sistem pendengaran manusia dibandingkan dengan sinyal input dan dilakukan proses penyaringan yang menghasilkan sinyal dengan range frekuensi yang signifikan bagi sistem pendengaran manusia. Proses diatas adalah proses konvolusi dua sinyal yaitu sinyal input dan sinyal model sistem pendengaran manusia. Langkah terakhir adalah kuantisasi data, dimana data yang terkumpul setelah penyaringan akan dikumpulkan menjadi satu keluaran dan dilakukan pengkodean dengan hasil akhir file dengan format mp3.
Proses pengkompresian MP3 dapat menghasilkan keluaran yang hampir setara dengan aslinya disebabkan oleh kelemahan dari sistem pendengaran manusia yang dapat dieksploitasi. Berikut adalah beberapa kelemahan dari sistem pendengaran manusia yang digunakan dalam pemodelan:
1. Terdapat beberapa suara yang tidak dapat didengar oleh manusia (diluar jangkauan frekuensi 30-30.000 Hz).
2. Terdapat beberapa suara yang dapat terdengar lebih baik bagi pendengaran manusia dibandingkan suara lainnya.
3. Bila terdapat dua suara yang dikeluarkan secara simultan, maka pendengaran manusia akan mendengar yang lebih keras sedangkan yang lebih pelan akan tidak terdengar.
Kepopuleran dari mp3 yang sampai saat ini belum tersaingi disebabkan oleh beberapa hal. Pertama mp3 dapat didistribusikan dengan mudah dan hampir tanpa biaya, walaupun sebenarnya hak paten dari mp3 telah dimiliki dan penyebaran mp3 seharusnya dikenai biaya. Walaupun begitu, pemilik hak paten dari mp3 telah memberikan pernyataan bahwa penggunaan mp3 untuk keperluan perorangan tidak dikenai biaya. Keuntungan lainnya adalah kemudahaan akses mp3, dimana banyak software yang dapat menghasilkan file mp3 dari CD dan keberadaan file mp3 yang bersifat ubiquitos (kosmopolit).
Pada perbandingan kualitas suara antara beberapa format kompresi audio hasil yang dihasilkan bervariasi pada bitrate yang berbeda, perbandingan berdasarkan codec yang digunakan. Pada 128 kbit/s, LAME MP3 unggul sedikit dibandingkan
8
dengan Ogg Vorbis, AAC, MPC and WMA Pro. Kemudian pada 64 kbit/s,AAC-HE dan mp3pro menjadi yang teratas diantara codec lainnya. Dan untuk diatas 128 kbit/s tidak terdengar perbedaan yang signifikan. Pada umumnya format mp3 sekarang menggunakan 128 kbit/s dan 192 kbit/s sehingga hasil yang dihasilkan cukup baik. 2.5 Arithmatic Coding
Algoritma arithmatic coding melakukan penggantian satu deretan simbol input dengan sebuah bilangan floating point. Semakin panjang dan semakin kompleks pesan yang dikodekan, akan semakin banyak bit yang diperlukan untuk keperluan tersebut. Output dari pengkodean arithmatic encoding adalah satu angka yang lebih kecil dari angka 1 dan lebih besar atau sama dengan 0. Angka ini secara unik daoat dapat didekoding sehingga menghasilkan deretan simbol yang dipakai untuk menghasilkan angka tersebut. Untuk menghasilkan angka output tersebut, tiap simbol yang akan di-encode diberi satu set nilai probabilitas. Contohnya andaikan string “ABBABABACAACDDD” akan di-encode, maka akan didapatkan tabel probabilitas seperti Tabel 2.1.
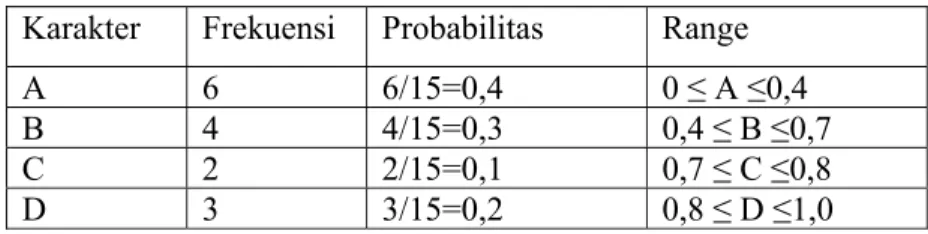
Tabel 2.1 Tabel Probabilitas
Karakter Frekuensi Probabilitas A 6 6/15=0,4 B 4 4/15=0,3 C 2 2/15=0,1 D 3 3/15=0,2
Setelah probabilitas tiap karakter diketahui, tiap simbol/karakter akan diberikan range tertentu yang nilainya berkisar antara 0 dan 1, sesuai dengan probabilitas yang ada. Dalam hal ini tidak ada ketentuan urutan penentuan segmen, asalkan antara encoder dan decoder melakukan hal yang sama. Selanjutnya akan diperoleh tabel Range Probabilitas seperti Tabel 2.2.
Tabel 2.2 Tabel Range Probabilitas Karakter Frekuensi Probabilitas Range
A 6 6/15=0,4 0 ≤ A ≤0,4
B 4 4/15=0,3 0,4 ≤ B ≤0,7
C 2 2/15=0,1 0,7 ≤ C ≤0,8
D 3 3/15=0,2 0,8 ≤ D ≤1,0
Satu hal yang perlu dicatat dari tabel ini adalah tiap karakter melingkupi range yang disebutkan, kecuali bilangan yang tinggi. Jadi, huruf/simbol “D” sesungguhnya mempunyai range mulai dari 0,8 sampai dengan 0,9999… Selanjutnya, untuk melakukan proses encoding, algoritma berikut dipakai.
1. Set low = 0,0 (kondisi awal) 2. Set high = 1.0 (kondisi awal) 3. While (simbol input masih ada) do 4. Ambil simbol input.
5. CR = high – low.
6. High = low + CR*high_range(simbol) 7. Low = low + CR*low_range(simbol) 8. End while
9. Cetak low
Disini “low” adalah output dari proses pengkodean aritmatik.
Untuk string “ABBABABACAACDDD” di atas, pertama kita ambil karakter pertama, yaitu “A”.
Low = 0,0 (kondisi awal) High = 1,0 (kondisi awal) CR = high – low
= 1 – 0 = 1
10
Low_range (A) = 0,0
Kemudian, didapat nilai-nilai berikut. High = low + CR*high_range (A)
= 0 + 1 * 0,4
= 0,4
Low = low + CR*low_range (A) = 0 + 1 * 0
= 0
Kemudian, karakter kedua “B” diambil dan diperoleh: Low = 0 (hasil perhitungan dari karakter A)
High = 0,4 (hasil perhitungan dari karakter A) CR = high – low
CR = 0,4 – 0 CR = 0,4
High_range (B) = 0,7 Low_range (B) = 0,4
Kemudian, didapatkan nilai-nilai berikut. High = low + CR * high_range (B)
= 0 + 0,4 * 0,7 High = 0,28
Low = low + CR * low_range (B) = 0 + 0,4 * 0,4
Low = 0,16
Kemudian, karakter ketiga “B” diambil sehingga diperoleh: Low = 0,16 High = 0,28 RC = high – low = 0,28 – 0,16 RC = 0,12 High_range (B) = 0,7 Low_range (B) = 0,4
Kemudian, nilai-nilai berikut didapatkan. High = low + CR * high_range (B)
= 0,16 + 0,12 * 0,7 High = 0,244
Low = low + CR * low_range (B) = 0,16 + 0,12 * 0,4
Low = 0,208
Demikian selanjutnya untuk perhitungan karakter yang lainya sehingga diperoleh tabel Hasil Encoding seperti pada Tabel 2.3.
Tabel 2.3 Hasil Encoding
No Huruf Low High CR
Awal 0,0 1,0 1,0 1 A 0,0 0,4 1,0 2 B 0,16 0,28 0,4 3 B 0,208 0,244 0,12 4 A 0,208 0,2224 0,036 5 B 0,21376 0,21808 0,0144 6 A 0,21376 0,215488 0,00432 7 B 0,2144512 0,2149696 0,001728 8 A 0,2144512 0,21465856 0,0005184 9 C 0,214596352 0,214617088 0,000020736 10 A 0,214596352 0,2146046464 0,0000020736 11 A 0,214596352 0,21459966976 0,00000082944 12 C 0,214598674432 0,214599006208 0,000000331776 13 D 0,2145989398528 0,214599006208 0,0000000331776 14 D 0,21459899293696 0,214599006208 0,00000000663552 15 D 0,214599003553792 0,214599006208 0,000000001327104 Dari proses ini, nilai low untuk data terakhir adalah:
Low = 0, 214599003553792.
12
Untuk melakukan decoding, algoritma berikut digunakan. 1. Ambil encoded-symbol (ES).
2. Do
3. Cari range dari simbol yang melingkupi ES. 4. Cetak simbol
5. RC = high_range – low_range 6. ES = ES – low_range
7. ES = ES / CR 8. Until simbol habis
2.6 Windows API (Application Programming Interface)
Windows API adalah sekumpulan fungsi-fungsi eksternal yang terdapat dalam file-file perpustakaan Windows (library windows) atau file-file library lainnya yang dapat digunakan dalam pembanguna program. Fungsi ini dapat menangani semua yang berhubungan dengan Windows seperti pengaksesan disk, interface printer, grafik Windows, kotak dialog, Windows shell, memainkan musik dan sebagainya (Hadi, 2007).
Pada pemrograman Visual Basic, untuk bisa memutar sebuah file suara (WAV) atau file musik (MP3) harus menggunakan Windows API yaitu file winmm.dll. File ini terlebih dahulu dideklarasikan atau dikenalkan ke bahasa pemrograman yang sedang digunakan dengan cara sebagai berikut.
Declare Function mciSendString Lib “winmm.dll” alias _ “mciSendStringA”(ByVal lpstrCommand As String, ByVal lpstrReturnString As _ String,ByVal uReturnString as String,ByVal uReturnLength as long,byVal _ hwdnCallBack as long) As Long.
Keterangan :
1. Declare merupakan fungsi reserved word, kata yang telah baku disediakan oleh Visual Basic untuk menyatakan pendeklarasian prosedur API.
2. Function merupakan fungsi untuk menghasilkan suatu nilai sebagai hasil dari sebuah aksi.
3. mciSendStringA merupakan sebuah nama fungsi yang terdapat pada suatu file pustaka prosedur (*.dll). Setelah penulisan nama fungsi ini, proses harus dilanjutkan dengan nama file pustaka prosedur dimana fungsi tersebut berada. 4. Lib “winmm” adalah tempat untuk memberitahukan Visual Basic letak fungsi
mciSendStringA berada, yaitu pada library sistem. File winmm.dll disebut sebagai pustaka prosedur karena di dalamnya terdapat puluhan bahkan ratusan macam fungsi. Penulisan string “32” pada beberapa pustaka sistem prosedur, mengacu pada terminologi Win32-Based Application, yaitu sebuah teknologi sistem operasi berbasis 32-bit yang dikembangkan oleh Microsoft dan telah digunakan hampir semua pengguna Windows saat ini. Untuk generasi terbaru, Microsoft telah mengeluarkan teknologi 64-bit, dan sebelumya microsoft telah mengeluarkan sistem operasi berbasis 16-bit. Pada lingkungan Windows 16-bit, pustaka prosedur sistem tidak memiliki string “32” atau “16”.
5. (ByVal uFlags As Long, ByVal dwReserved As Long) merupakan argumen atau parameter yang memerlukan nilai tertentu yang bersifat tetap atau sebuah variabel asli yang tidak bisa diubah).
6. As Long merupakan pendeklarasian tipe nilai yang dikembalikan fungsi API. 2.7 Visual Basic 6.0
Visual Basic 6.0 dirilis tahun 1998, bersama Microsoft Visual Studio 6.0 dan meraih penghargaan PC Magazine untuk kategori “Best of 1997” Award Winner dan PC Winner dan PC/Computing MVP Award. Visual Basic dikembangkan dari bahasa Quick Basic yang berjalan di atas sistem operasi DOS. Versi awal diciptakan oleh Alan Cooper yang kemudian menjualnya ke Microsoft dan mengambil alih pengembangan produk dengan memberi nama sandi “Thunder”. Akhirnya Visual Basic menjadi bahasa pemrograman utama di lingkungan Windows. (Dewobroto, 2003).
14
Visual Basic merupakan bahasa pemrograman yang berorientasi objek (Object Oriented Programming / OOP). OOP adalah pemrograman yang terdiri dari beberapa objek yang berkomunikasi atau berhubungan dan melakukan suatu aksi dalam suatu kejadian (event), sehingga istilah objek banyak digunakan dalam pemrograman Visual Basic ini. Objek-objek digambarkan pada layar dan melakukan properti terhadap objek yang digambarkan lalu menuliskan metode-metode terhadap objek tersebut sesuai dengan tujuan program.
Pada pemrograman Visual Basic, perancangan program dimulai dengan perencanaan dan pendefenisian tujuan program, lalu merancang keluaran dan media hubungan dengan pemakai, dan langkah terakhir adalah penulisan kode program tersebut. Visual Basic menyediakan IDE (Integrated Development Environment) sebagai lingkungan tempat bekerja untuk menghasilkan program aplikasi pada Visual Basic. Komponen-komponen IDE terdiri dari control menu, baris menu, toolbar, toolbox, form window, form layout window, properties window, project explorer, kode window, object window dan event window. Yang mana setiap komponen memiliki tujuan dan kegunaan masing-masing.
Visual Basic memiliki beberapa jenis form. Dalam perancangan ini form yang digunakan adalah form induk (MDI Form) dan form anak (MDI Child). MDI singkatan dari Multiple Document Interface. MDI dirancang untuk program aplikasi yang membutuhkan banyak form. MDI Form adalah jenis form yang berfungsi sebagai pusat pengaturan form-form lain atau disebut form induk karena dapat menampilkan form lain di dalamnya.
2.7.1 Integrated Development Integration (IDE)
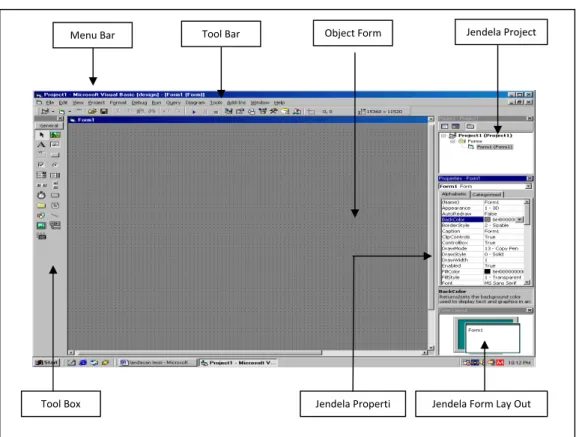
Integrated Development Intergration adalah bidang kerja, tempat bekerja untuk menghasilkan program aplikasi. Setelah berhasil membuka Visual Basic pada layar, maka pemakai akan berhadapan dengan lingkungan IDE (Alam, 2002), seperti pada Gambar 2.1 yang berisi beberapa komponen-komponen antara lain :
1. Main Menu
Baris menu terletak pada baris atas pada IDE. Menu ini merupakan kumpulan perintah-perintah yang dikelompokkan dalam kriteria operasi yang dihasilkan. 2. Tool Bar
Tool bar terdiri atas beberapa tombol untuk mengendalikan tampilan, seperti mengatur pemunculan jendela Properties, Project dan Form Layout.
3. Form
Form adalah pusat dari pengembangan aplikasi Visual Basic, atau sebagai tempat dimana objek atau komponen akan diletakkan, seperti tombol label, command Button image, picture dan lainnya. Form dapat diumpamakan sebagai panel yang berisi sekumpulan tombol-tombol yang dapat diberi perintah atau kode.
4. Window Code
Window code adalah jendela yang mengandung kode-kode program yang merupakan instruksi untuk aplikasi Visual Basic, pada window code terdapat dua fasilitas utama yaitu pemilihan object dan prosedur tempat penulisan kode program yang berada diantara Code Private dan End Sub.
5. Tool Box
Tool Box adalah penyimpanan kontrol digunakan pada program yang dipasangkan pada form seperti Label. Setiap kontrol di tambakan ke form dan menjadi object yang dapat dibuat kode program.
6. Project Explorer
Project Explorer adalah jendela yang mengandung semua file yang terdapat pada aplikasi Visual Basic, yang digunakan pada proses pemrograman dan menyediakan akses ke file tersebut. Pada Project Explorer tersebut ditampilkan semua file yang terdapat pada Project yang sedang aktif atau terbuka.
7. Property Windows
Property Window adalah jendela yang semua mengandung semua informasi mengenai objek yang terdapat pada aplikasi program. Property adalah sifat dari sebuah object misalnya namanya, warna, ukuran, posisi, atau sebagainya.
16
8. Form Layout
Form Layout adalah Jendela yang menggambarkan posisisi dari form yang ditampilkan pada layar monitor.
9. Immediate Window
Immediate Window berguna untuk mencoba beberapa instruksi pada program window ini. Pada saat menguji program, window ini biasa digunakan sebagai window debug.
Tampilan Visual Basic merupakan suatu lingkungan yang besar yang terdiri dari beberapa bagian, yang mana bagian ini memiliki sifat yaitu :
1. Floating, dapat digeser ke posisisi mana saja, untuk menggeser elemen ke layar Visual Basic, dilakukan dengan cara mengklik dan menahan tombol mause pada judul (Title Bar) element tersebut, lalu menggeser ke posisi yang diinginkan.
Gambar 2.1 Menu Utama Visual Basic 6.0
Tool Bar Jendela Project Tool Box Object Form Jendela Form Lay Out Jendela Properti Menu Bar
2. Sizeable, dapat diubah-ubah ukurannya seperti halnya mengubah ukuran jendela pada windows. Untuk mengubah ukuran elemen atau jendela dilakukan dengan mengklik dan menahan tombol mouse pada sisi (Border) jendela tersebut. Lalu mengubah ukurannya sesuai dengan yang diinginkan.
3. Dockable, dapat menempel pada bagian lain yang berdekatan. Untuk menepelkan layar Visual Basic ke elemen lainnya, cukup menempelkan sisi elemen tersebut ke sisi yang diinginkan.
2.7.2 Variabel dan Tipe Data
Variabel adalah tempat didalam komputer yang diberi nama sebagai pengenal dan dideklarasikan untuk menampung data informasi dan sesuai dengan data yang ditampung maka variabel yang mempunyai tipe data yang sesuai dengan isinya.
Dalam Visual Basic 6.0 tipe data digolongkan dalam tujuh kategori yaitu Numeric, String, Boolean, Data Objek, Byte dan Variant. Tipe data Numeric dibedakan atas 5 jenis yaitu Integer, Long, Single, Double, Currency, masing-masing tipe data memiliki batas tersendiri dapat dilihat pada tabel jangkauan tipe data seperti pada Tabel 2.4.
Tipe Jangkauan Ukuran Keterangan Integer 32,768 s/d 32.767 2 byte Untuk mendeklarasikan
bilangan bulat Long -2,147,483,648 s/d
2,147,648,
4 byte Sama dengan integer tetapi jangkauannya lebih besar. Single (Negatif) –3.4038230e38
s/d –1.401298e45 (Positif) 1.4012980e38 s/d
3.403823e38
4 byte Menyimpan suatu nilai floating point single precision. Doble (Negatif) -1.797669313486232e308 s/d -4.94065645841247e324 (Positif) 8 byte
Sama halnya dengan single tetapi memiliki ketelitian yang lebih tinggi.
18 4.94065645841247e324 s/d 1.79769313486232e308 Currency - 922,337,203,685,477,5808 s/d 922,337,203,685,477,5807
8 byte Menyimpan suatu nilai skalar
String 0 s/d 2e32 karakteer 1 byte/karakt
er
Bersama untuk menampung sederetan karakter
Boolean True/False 2 byte Berguna untuk melakukan pengujian
Date 1 Jan 100 s/d 31 Des 1999 8 byte Menyatakan tanggal dan watu (jam, menit, detik) Object Refrensi objek 4 byte Tipe data yang bisa dipakai
untuk menggantikan objek-objek pada visual basic 6.0
Byte 0 s/d 255 1 byte
Variant Null, Error, Numerik dengan Tipe Doble, Karakter Teks, Obyek atau Array
16 byte Untuk hal-hal khusus seperti keadaan darurat sewaktu lupa menuliskan tipe data atau keadaan yang bersifat sementara.