PROCEEDING
SEMINAR NASIONAL
TEKNOLOGI INFORMASI DAN APLIKASINYA
2012
“Aplikasi Teknologi Informasi dalam Menunjang
Pelestarian Budaya Nasional dan Pengembangan Sektor
Pariwisata”
Bali, 9 Oktober 2011
Diselenggarakan Oleh :
Program Studi Teknik Informatika
Jurusan Ilmu Komputer
Universitas Udayana
KATA PENGANTAR
Puji syukur kita panjatkan kehadirat Tuhan Yang Maha Esa, atas terselesainya
penyususnan
Proceeding
SNATIA 2012 ini. Buku ini memuat naskah hasil penelitian dari
berbagai bidang kajian yang telah di
review
oleh pakar dibidangnya dan telah
dipresentasikan dalam acara Seminar SNATIA 2012 pada tanggal 9 Oktober 2012 di
Universitas Udayana kampus Bukit Jimbaran, Badung, Bali.
Kegiatan SNATIA 2012 merupakan yang pertama kali diadakan, dan akan menjadi
agenda tahunan Program Studi Teknik Informatika, Jurusan Ilmu Komputer, Universitas
Udayana. SNATIA 2012 mengambil tema “Aplikasi Teknologi Informasi dalam
Menunjang Pelestarian Budaya Nasional dan Pengembangan Sektor Pariwisata”, dengan
pembicara utama seminar yang terdiri dari pakar peneliti dibidang teknologi informasi,
pembicara dari praktisi pariwisata Bali, dan pembicara dari Dinas Kebudayaan Propinsi
Bali.
Meskipun kegiatan seminar dan pendokumentasian naskah dalam
proceeding
ini telah
dipersiapkan dengan baik, namun kami menyadari masih banyak kekurangannya. Untuk
itu panitia mohon maaf yang sebesar-besarnya, dan juga mengucapkan terimakasih atas
kepercayaan dan kerjasamanya dalam kegiatan ini. Kritik dan saran perbaikan sangat
diharapkan untuk penyempurnaan di masa mendatang, yang dapat dikirimkan melalui
[email protected]
.
Kepada semua pihak yang terlibat, baik langsung maupun tidak langsung dalam
penyelenggaraan seminar, dan penyusunan
proceeding
SNATIA 2012, panitia
mengucapkan terima kasih.
Denpasar, 9 Oktober 2012
Panitia SNATIA 2012
Ketua Pelaksana
DAFTAR ISI
Kata Pengantar
Daftar Isi
Analisis Dan Implementasi Algoritma Learning Vector Quantization (Lvq) Dalam Pengenalan Ekspresi Wajah
Kadek Dian Trisnadewi, I Wayan Santiyasa, I Made Widiartha ... 1 Analisis Kualitas Voip Pada Jaringan Yang Menggunakan Active Queue ManagementRandom
Early Detection (Red)
I Dewa Made Bayu Atmaja Darmawan ... 6 Analisis Sistem Firewall Pada Jaringan Komputer Menggunakan Iptables Untuk Meningkatkan
Keamanan Jaringan ( Studi Kasus : Jaringan Komputer Jurusan Matematika Fakultas Mipa Universitas Udayana)
I Wayan Supriana, I Wayan Santiyasa, Cokorda Rai Adi Pramartha ... 13 Ekstraksi Tepi Dengan Menggunakan Fuzzy Spatial Filtering Dan Slicing Intensity
I Gede Aris Gunadi, Retantyo Wardoyo ... 22 Evaluasi Cluster Menggunakan Metode Prototype-Based Cohesion And Separation Dan Silhouette
Coefficient Pada Implementasi Algoritma Som
Gusti Ayu Vida Mastrika Giri, Kadek Cahya Dewi ... 29 Group Decision Support System Dengan Menggunakan Metode Analytical Hierarchy Process
(Ahp) Dan Borda Dalam Penentuan Lokasi Bank Dan Pimpinan Cabang Yang Tepat
Desak Made Dwi Utami Putra ... 34 Identifikasi Lagu Menggunakan Algoritma K-Nearestneighbours – Cosine Similarity(KNNCS)
I Gede Suta Lascarya Astawa, Agus Muliantara, Kadek Cahya Dewi... 42 Kompresi Citra Fraktal Dengan Algoritma Genetika Adaptif
Putu Indah Ciptayani1, Zulfahmi Indra2 ... 46 Mobile Information System Untuk Mengidentifikasidefisiensi Unsur Hara Pada Daun
Asti Dwi Irfianti, Endang Sulistyaningsih ... 51 Model Rekayasa Perangkat Lunak Berbasis Komponen (Component-Based Software Engineering)
Herri Setiawan, Edi Winarko... 57 Model Sistem Pendukung Keputusan Kelompok Dengan Metode Multiplicative Exponent
Weighting
Muhammad Syaukani, Sri Hartati ... 65 Optimasi Distribusi Pupuk Bersubsidi Dengan Menggunakan Algoritma Genetika (Studi Kasus:
Kab. Jombang Jawa Timur)
Perancangan Dan Implementasi Aplikasi Web Service(Studi Kasus : Sim Perpustakaan Dengan Simak F.Mipa Universitas Udayana)
Made Agung Raharja ... 78 Perancangan Dan Implementasi Rekam Medis Berbasis Mobile
Ida Bagus Made Mahendra, Ida Bagus Gede Dwidasmara, Putu Praba Santika ... 88 Pengalokasian Sumber Daya Dalam Sistem Pendukung Keputusan
Rita Wiryasaputra .... ... 95 Perancangan Dan Implementasi Customer Information Gathering Menggunakan Model Ruang
Vektor Dan Perluasan Query
Sang Gede Suriadnyana, I Made Widiartha, I Gede Santi Astawa ... 101 Perancangan Dan Implementasi Sistem Pencarian Buku Menggunakan Algoritma Pemetaan
Transaksi
Wayan Gede Suka Parwita, Ngurah Agus Sanjaya Er, Luh Gde Astuti ... 107 Pengembangan Cost Driver Model Cocomo Ii Dengan Modifikasi Nilai Atribut Analysis
Capability Untuk Estimasi Usaha Perangkat Lunak
Sri Andayani, L. Anang Setiyo ... 111 Prototype Sistem Penyeberangan Jalanbagi Penyandang Tuna Netra Berbasis Rfid( Radio
Frequency Identification )
I Made Widhiwirawan ... 119 Review Of Ontology-Based Question Answering System
Eka Karyawati, Azhari S. N. ... 126 Resiko Proyek Teknologi Informasi
Herri Setiawan, Ashari SN ... 134 Sistem Pendukung Keputusan Untuk Pembelian Rumah Menggunakan Analytical Hierarchy
Process (Ahp)
Standy Oei, Riah Ukur Ginting ... 140 Vanet Untuk Solusi Komunikasi Data Di Kawasan Pariwisata Bali
I Komang Ari Mogi,Waskitho Wibisono ... 146 Visualisasi Cluster Menggunakan Smoothed Data Histograms (Sdh) Pada Audio Clustering Lagu
Daerah Indonesia Menggunakan Self Organizing Map (Som)
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2012
107 Jurusan Ilmu Komputer, FMIPA, Universitas Udayana
PERANCANGAN DAN IMPLEMENTASI SISTEM PENCARIAN BUKU MENGGUNAKAN ALGORITMA PEMETAAN TRANSAKSI
Wayan Gede Suka Parwita, Ngurah Agus Sanjaya ER, Luh Gde Astuti
Program Studi Teknik Informatika
Jurusan Ilmu Komputer Fakultas MIPA, Universitas Udayana
ABSTRAK
Pemanfaatan kaidah asosiasi untuk proses pencarian sangat jarang diterapkan. Konteks pemanfaatan kaidah asosiasi dalam pencarian adalah untuk mengetahui kemungkinan seorang pengguna mencari data bersamaan dengan pencarian data lainnya.
Pencarian frequentItemset pada algoritma pemetaan transaksi dilakukan secara depth-first. Algoritma ini bekerja dengan memetakan dan meringkas daftar TIDs dari masing-masing itemset ke dalam suatu daftar interval menggunakan suatu pohon transaksi dan menghitung nilai support dari masing-masing itemset dengan menggunakan irisan dari daftar interval tersebut. Frequentitemset didapat dalam urutan depth-first pada pembangunan suatu pohon lexicographic.
Sumber data yang digunakan ada 2 yaitu data pencarian dan juga data peminjaman. Data pencarian disimpan saat user melakukan pencarian buku. Dari hasil penelitian, sistem yang dibangun menghasilkan aturan asosiatif yang sama dengan hasil yang didapat oleh aplikasi ARMADA 1.4.
Kata Kunci : Kaidah Asosiasi, Pemetaan Transaksi, Frequent Itemset.
Pendahuluan
Dengan jumlah data yang semakin besar, tentunya penggunaan sistem tanpa suatu proses pencarian tidak akan efektif. Umumnya proses pencarian menggunakan proses perhitungan otomatis (counter) untuk menghitung peringkat dari kepopuleran suatu data.
Pola asosiasi menjadi salah satu fungsionalitas yang paling menarik dalam penggalian data. Terlebih lagi sejak diperkenalkannya frequent itemsets pada tahun 1993 oleh Agrawal dkk., kaidah asosiasi mendapatkan banyak perhatian dalam bidang eksplorasi pengetahuan dan data mining, khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frekuensi tinggi (frequent pattern mining). Kaidah asosiasi adalah teknik data mining untuk menemukan aturan assosiatif antara suatu kombinasi item pada tabel data transaksional. Pola asosiasi akan memberikan gambaran mengenai hubungan antara item pada tabel. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang dan confidence (nilai kepastian).
Pemanfaatan kaidah asosiasi untuk proses pencarian sangat jarang diterapkan. Konteks pemanfaatan kaidah asosiasi untuk pencarian adalah diketahui seberapa besar kemungkinan seorang pengguna mencari data bersamaan dengan pencarian data lainnya. Dengan pemanfaatan kaidah asosiasi, maka pencarian buku yang saling berkaitan sangat mungkin dilakukan, sehingga pengguna aplikasi akan mudah menentukan buku mana yang sebaiknya digunakan. Persoalan-persoalan yang telah disebutkan di atas menyebabkan penulis merasa tertarik untuk membangun suatu sistem pencarian menggunakan kaidah asoasiasi dengan algoritma pemetaan transaksi. Sistem Pencarian Buku berbasis Web ini akan dirancang dan diimplementasikan di Perpustakaan Universitas Udayana.
Kaidah Asosiasi
Kaidah asosiasi adalah teknik mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Fungsi kaidah asosiasi seringkali disebut dengan “market basket analysis”. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support yaitu persentase kombinasi item tersebut dalam basis data dan confidence yaitu kuatnya hubungan antar item dalam aturan assosiatif. Aturan asosiasi yang didefinisikan pada basket data, digunakan untuk keperluan promosi, desain katalog, segmentasi customer dan target pemasaran. Secara tradisional, aturan asosiasi digunakan untuk menemukan trend bisnis dengan menganalisa transaksi customer, dan dapat digunakan secara efektif pada bidang Web Mining.
Algoritma yang paling populer dikenal sebagai Apriori dengan paradigma generate and test, yaitu pembuatan kandidat kombinasi item yang mungkin berdasar aturan tertentu lalu diuji apakah kombinasi item tersebut memenuhi syarat support minimum. Kombinasi item yang memenuhi syarat tersebut disebut frequent Itemset, yang nantinya dipakai untuk membuat aturan-aturan yang memenuhi syarat confidence minimum (Agrawal dan R. Srikant,1994).
Pemetaan Transaksi
2012
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
Jurusan Ilmu Komputer, FMIPA, Universitas Udayana 108
interval menggunakan suatu pohon transaksi dan menghitung nilai support dari masing-masing itemset dengan menggunakan irisan dari daftar interval tersebut. Frequentitemset didapat dalam urutan depth-first pada pembangunan suatu pohon lexicographic.
Langkah-langkah algoritma pemetaan transaksi ada empat yaitu (Song dan Rajasekaran, 2006) : 1. Amati seluruh basis data dan identifikasi semua frequent 1-itemset.
2. Buat pohon transaksi dan hitung support untuk setiap simpul.
3. Buat daftar interval transaksi. Gabungkan interval jika memungkinkan.
4. Buat pohon lexicographic dalam urutan depth-first. Ketika memproses suatu simpul maka penghitungan support dari kandidat dilakukan dengan irisan interval. Jika support melebihi minsup maka kandidat dikeluarkan sebagai luaran. Ketika koefisien kompresi dari suatu simpul kurang dari 2 maka irisan yang digunakan adalah irisan TIDs.
Desain Sistem
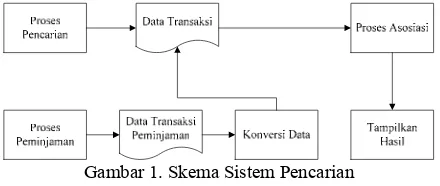
. Sumber data yang masuk ada 2 yaitu data pencarian dan juga data peminjaman. Data peminjaman akan ditransformasikan terlebih dahulu untuk menyesuaikan bentuk dari data transaksi. Selanjutnya data transaksi tersebut akan dijadikan data untuk melakukan proses asosiasi. Data pada data proses disesuaikan kebutuhannya untuk proses asosiasi. Pada proses asosiasi, data diolah untuk menemukan kombinasi item yang saling berkaitan. Lalu data hasil asosiasi ditampilkan. Gambar 1 merupakan skema rancangansistem
Gambar 1. Skema Sistem Pencarian
Transformasi data hanya akan dilakukan pada saat user melakukan peng-update-an data transaksi. Update data akan dilakukan dari hari update data transaksi terakhir yang tersimpan dalam tabel konfig sampai hari saat transformasi data dilakukan.
Pada saat transformasi data dilakukan, satu data transaksi pada data peminjaman akan diseleksi berdasarkan id anggota dan juga tanggal peminjaman. Ini dilakukan untuk mengetahui item apa saja yang tergabung dalam transaksi tersebut. Setelah data transaksi tersebut didapatkan, maka id buku dalam data transaksi tersebut akan diurutkan lalu selanjutnya dimasukkan ke dalam tabel transaksi.
Penambahan data dilakukan jika user menekan link pada hasil pencarian yang telah ditampilkan sebelumnya. Data transaksi didapatkan dari penggabungan sejumlah link yang ditekan. Ini dimungkinkan dengan menggunakan kata kunci pencarian sebagai alat ukur bahwa data tersebut merupakan satu transaksi. Misalkan kata kunci yang dimasukkan adalah “komputer”, maka link yang ditekan saat kata kunci ini digunakan dianggap satu transaksi. Saat kata kunci diubah, maka data tersebut dianggap baru, walaupun sebelumnya kata kunci tersebut sudah pernah digunakan. Hal ini disebabkan adanya kemungkinan user yang menggunakan sistem bukanlah user yang sama. Setelah memastikan apakah data tersebut adalah satu transaksi, maka pada penekanan link selanjutnya data akan langsung diurut. Jadi data hasil penambahan data pencarian ini merupakan daftar transaksi yang sudah diurut.
Hasil Pengujian
Data pengujian yang digunakan adalah data berupa tabel transaksi yang berisi sebanyak 10 transaksi dengan 20 item. Item tersebut merupakan deret huruf yang disusun sedemikian rupa agar semua kemungkinan dalam algoritma dapat diuji. Penggunaan data uji ini dilakukan untuk memudahkan dalam pengujian implementasi algoritma ke dalam program untuk menentukan benar atau salahnya implementasi algoritma terebut. Sedangkan pada saat pengujian hasil keluaran, data transaksi yang digunakan adalah data transaksi yang disertakan dalam aplikasi ARMADA 1.4. Data transaksi ini memiliki 203 baris data. Penggunaan data transaksi ini dilakukan karena keterbatasan dari perangkat uji yang digunakan. Isi kedua data ini dapat dilihat pada lampiran data transaksi.
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2012
109 Jurusan Ilmu Komputer, FMIPA, Universitas Udayana
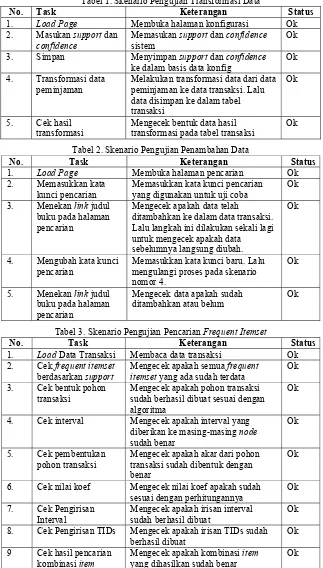
Tabel 1. Skenario Pengujian Transformasi Data
No. Task Keterangan Status
1. Load Page Membuka halaman konfigurasi Ok 2. Masukan support dan
confidence
Memasukan support dan confidence sistem
Ok
3. Simpan Menyimpan support dan confidence ke dalam basis data konfig
Ok
4. Transformasi data peminjaman
Melakukan transformasi data dari data peminjaman ke data transaksi. Lalu data disimpan ke dalam tabel transaksi
Ok
5. Cek hasil transformasi
Mengecek bentuk data hasil transformasi pada tabel transaksi
Ok
Tabel 2. Skenario Pengujian Penambahan Data
No. Task Keterangan Status
1. Load Page Membuka halaman pencarian Ok 2. Memasukkan kata
kunci pencarian
Memasukkan kata kunci pencarian yang digunakan untuk uji coba
Ok
3. Menekan link judul buku pada halaman pencarian
Mengecek apakah data telah
ditambahkan ke dalam data transaksi. Lalu langkah ini dilakukan sekali lagi untuk mengecek apakah data sebelumnya langsung diubah.
Ok
4. Mengubah kata kunci pencarian
Memasukkan kata kunci baru. Lalu mengulangi proses pada skenario nomor 4.
Ok
5. Menekan link judul buku pada halaman pencarian
Mengecek data apakah sudah ditambahkan atau belum
Ok
Tabel 3. Skenario Pengujian Pencarian FrequentItemset
No. Task Keterangan Status
1. Load Data Transaksi Membaca data transaksi Ok 2. Cek frequentitemset
berdasarkan support
Mengecek apakah semua frequent itemset yang ada sudah terdata
Ok
3. Cek bentuk pohon transaksi
Mengecek apakah pohon transaksi sudah berhasil dibuat sesuai dengan algoritma
Ok
4. Cek interval Mengecek apakah interval yang diberikan ke masing-masing node sudah benar
Ok
5. Cek pembentukan pohon transaksi
Mengecek apakah akar dari pohon transaksi sudah dibentuk dengan benar
Ok
6. Cek nilai koef Mengecek nilai koef apakah sudah sesuai dengan perhitungannya
Ok
7. Cek Pengirisan Interval
Mengecek apakah irisan interval sudah berhasil dibuat
Ok
8. Cek Pengirisan TIDs Mengecek apakah irisan TIDs sudah berhasil dibuat
Ok
9 Cek hasil pencarian kombinasi item
Mengecek apakah kombinasi item yang dihasilkan sudah benar
Ok
Pengujian ini menunjukkan bahwa fungsi perangkat lunak telah bekerja sesuai dengan spesifikasi dan kebutuhan fungsi karena seluruh kasus uji yang dilakukan sudah berhasil dilewati.
2012
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
Jurusan Ilmu Komputer, FMIPA, Universitas Udayana 110
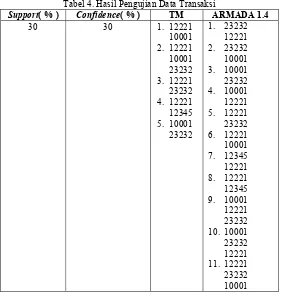
Tabel 4. Hasil Pengujian Data Transaksi
Support( % ) Confidence( % ) TM ARMADA 1.4
30 30 1. 12221
10001 2. 12221 10001 23232 3. 12221 23232 4. 12221 12345 5. 10001 23232 1. 23232 12221 2. 23232 10001 3. 10001 23232 4. 10001 12221 5. 12221 23232 6. 12221 10001 7. 12345 12221 8. 12221 12345 9. 10001 12221 23232 10. 10001 23232 12221 11. 12221 23232 10001
Dari tabel di atas dapat dilihat bahwa sistem yang dibuat memiliki kombinasi item dengan jumlah yang berbeda. Ini disebabkan karena pada algoritma pemetaan transaksi tidak memasukkan ulang itemset yang memiliki item dengan kombinasi yang sama. Dengan demikian kombinasi item yang sama tidak dituliskan kembali. Hal ini merupakan salah satu keunggulan dari algoritma pemetaan transaksi. Sehingga waktu komputasi dapat dikurangi dengan adanya pengurangan pengecekan kombinasi item yang sama. Proses ini dilakukan pada pohon lexicographic pada saat pembacaan hasil dari pencarian kombinasi item. Jika item dengan kombinasi yang sama dianggap satu transaksi maka hasil pemrosesan antara sistem yang dibuat dengan aplikasi ARMADA 1.4 dapat dikatakan sama. Dengan demikian sistem yang dibuat telah berhasil mencari hubungan asosiatif antara kombinasi item.
Kesimpulan
Berdasarkan uji coba yang dilakukan, maka kesimpulan yang dapat diambil dari penelitian ini adalah : 1. Sistem yang dibangun dibagi menjadi tiga bagian yaitu proses transformasi data peminjaman, proses
penambahan data pencarian dan proses pencarian menggunakan algoritma pemetaan transaksi. Proses transformasi data peminjaman terdapat pada halaman konfigurasi yang digunakan juga untuk pengaturan
support dan confidence. Proses penambahan data pencarian dilakukan saat user menekan link pada daftar buku yang dicari. Proses ini langsung menambahkan data pada tabel transaksi secara otomatis. Proses pencarian menggunakan algoritma pemetaan transaksi dilakukan pada halaman pencarian buku.
2. Sistem yang dibuat dalam penelitian ini telah berhasil membuat sistem pencarian buku berdasarkan kaidah asosiasi dengan menggunakan algoritma pemetaan transaksi. Setelah perbandingan dilakukan, sistem yang dibangun menghasilkan aturan asosiatif yang sama dengan aplikasi ARMADA 1.4.
Saran
Untuk memaksimalkan kinerja sistem, penyesuaian support dan confidence untuk setiap data sangat dibutuhkan. Oleh karena itu, diperlukan penelitian lebih lanjut dalam penggunaan algoritma yang mencari
support dan juga confidence secara dinamis.
Daftar Pustaka
Agrawal,R. dan Srikant, R., 1994. Fast Algorithms for Mining Association Rules. Proc. 20th Int’l Conf. Very Large Data Bases, pp. 487-499.
Aliyuana, 2009. Teknik Pengujian Perangkat Lunak (Software Testing Techniques). Yogyakarta : Universitas Gunadarma.