EVENT DETECTIONPADA MICROBLOGGING TWITTER DENGAN
ALGORITMA DBSCAN (STUDI KASUS: BANJIR)
Skripsi
Diajukanuntuk memenuhi sebagian dari Syarat untuk memperoleh Gelar Sarjana Komputer
Program Studi Ilmu Komputer
OLEH: RENDY 0807646
PROGRAM STUDI ILMU KOMPUTER
FAKULTAS PENDIDIKAN MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS PENDIDIKAN INDONESIA
Event Detection
pada
Microblogging
Twitter dengan Algoritma DBSCAN
(Studi Kasus: Banjir)
Oleh Rendy
Sebuah skripsi yang diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana pada Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam
© Rendy 2013
Universitas Pendidikan Indonesia Juni 2013
Hak Cipta dilindungi undang-undang.
LEMBAR PENGESAHAN
EVENT DETECTION PADA MICROBLOGGING TWITTER DENGAN
ALGORITMA DBSCAN (STUDI KASUS: BANJIR)
Oleh : RENDY 0807646
Disetujui dan Disahkan oleh :
Pembimbing I Pembimbing II
Yudi Wibisono, M.T NIP 197507072003121003
Rosa Ariani Sukamto, M.T NIP198109182009122003
Mengetahui,
Ketua Program Studi Ilmu Komputer
ABSTRAK
Twitter merupakan sebuah situs microblogging yang populer dibandingkan dengan situs microblogging lainnya. Twitter mampu mengirimkan pesan pendek 140 karakter. Isi dari pesan yang dikirim atau dinamakan tweet umumnya berisi laporan mengenai kejadian sehari-hari. Pada skripsi ini, penulis memfokuskan penelitian untuk mendeteksi adanya banjir melalui Twitter. Teknik yang dapat digunakan untuk memanfaatkan hal tersebut salah satunya dengan teknik clustering. Clustering dapat mengelompokan tweet yang memiliki kemiripan isi
ke dalam kelompok-kelompok. Metode pengelompokan tweet yang digunakan yaitu metode Density-based Clustering dengan Algoritma DBSCAN. Metode Density-based Clustering melakukan pengelompokkan berdasarkan tingkat
kepadatan dari suatu tweet. Cluster akan dipisahkan berdasarkan area yang memiliki kepadatan tinggi dengan area yang memiliki kepadatan rendah. Setiap cluster merepresentasikan satu event. Dari setiap event yang terdeteksi diambil
informasi mengenai lokasi banjir dan deskripsi banjir tersebut menggunakan Named Entity Recognition (NER). Deteksi event menggunakan algoritma
DBSCAN memberikan hasil yang baik, terbukti dengan nilai evaluasi cluster yang besar (0.86) dari data sebanyak 5354 tweet dengan jumlah event yang terdeteksi sebanyak 24 event.
EVENT DETECTION IN TWITTER MICROBLOGGING USING DBSCAN
ALGORITHM
(CASE STUDY: FLOOD)
ABSTRACT
Twitter is the popular microblogging site's than others. Twitter allows user
to send short messages contains 140 characters. The Twitter post, called tweets,
typically contains about real-life events. In this paper, the authors focus on the
study to detect flooding through Twitter. The technique can be used is clustering.
Clustering can group tweets that have similar contents into groups. The authors
uses based Clustering with DBSCAN algorithm to group tweets.
Density-based clustering methods perform clustering Density-based on the density of a tweet.
Clusters are separated by areas that have a high density area with a low density.
Each cluster represents a single event. Each of detected event, extract information
about the location and description of the flood using Named Entity Recognition
(NER). Event detection using DBSCAN gives good results as evidenced by the
large cluster evaluation value (0.86) of 5354 tweets with 24 number of events
detected.
Keywords: Event Detection, Clustering, DBSCAN, Twitter, Named Entitiy
DAFTAR ISI
ABSTRAK ... Error! Bookmark not defined. ABSTRACT ... Error! Bookmark not defined.
KATA PENGANTAR ... Error! Bookmark not defined. UCAPAN TERIMA KASIH ... Error! Bookmark not defined. DAFTAR ISI ... vi DAFTAR TABEL ... Error! Bookmark not defined. DAFTAR GAMBAR ... Error! Bookmark not defined. BAB I PENDAHULUAN ... Error! Bookmark not defined. 1.1. Latar Belakang ... Error! Bookmark not defined. 1.2. Rumusan Masalah ... Error! Bookmark not defined. 1.3. Batasan Masalah ... Error! Bookmark not defined. 1.4. Tujuan Penelitian ... Error! Bookmark not defined. 1.5. Definisi Operasional ... Error! Bookmark not defined. 1.6. Sistematika Penulisan ... Error! Bookmark not defined. BAB II TINJAUAN PUSTAKA ... Error! Bookmark not defined. 2.1. Twitter dan Twitter API ... Error! Bookmark not defined.
2.2. Text Mining ... Error! Bookmark not defined.
2.3. Event Detection ... Error! Bookmark not defined.
2.4. Clustering ... Error! Bookmark not defined.
2.5. Named Entity Recognition ... Error! Bookmark not defined.
3.2. Metode Penelitian ... Error! Bookmark not defined. 3.3. Alat dan Bahan Penelitian ... Error! Bookmark not defined. BAB IV HASIL PENELITIAN DAN PEMBAHASANError! Bookmark not defined.
BAB I PENDAHULUAN
1.1. Latar Belakang
Twitter merupakan sebuah situs microblogging yang populer dibandingkan dengan situs microblogging lainnya. Hal ini terlihat dari jumlah pengguna Twitter yang mencapai 105 juta pada April 2010 dengan jumlah posting 55 juta tweet per hari (Jackoway, dkk., 2011). Twitter merupakan social media yang digunakan oleh banyak orang untuk dapat terhubung dengan orang-orang disekelilingnya dan seluruh dunia melalui komputer dan perangkat mobile.
Twitter sebagai salah satu situs microblogging mampu mengirimkan pesan pendek (140 karakter) tentang apa yang mereka lakukan, apa yang ada di sekeliling mereka, kejadian yang sedang terjadi, dan hal lainnya yang dapat dilihat oleh semua orang. Pesan tersebut biasanya disebut dengan tweet. Twitter dikategorikan sebagai microblogging service. Microblogging merupakan sebuah bentuk blog dimana penggunanya dapat mengirimkan sebuah pesan teks (status update) yang singkat.
Indonesia merupakan negara ketiga penghasil tweet terbesar dengan jumlah enam juta tweet per hari (Wibisono, 2012). Ini bisa menjadi potensi informasi yang sangat besar untuk dimanfaatkan. Twitter pun dapat dimanfaatkan untuk mendeteksi adanya bencana karena sifatnya yang real-time dan on-location update. Misalnya, ketika terjadi bencana banjir, maka orang-orang akan mengirim
sebuah pesan melalui Twitter tentang apa yang sedang terjadi terjadi di sekelilingnya.
3
Dalam hal ini, informasi atau kejadian yang terdapat pada Twitter dapat diidentifikasi, sehingga nantinya informasi tersebut akan bermanfaat untuk dikonsumsi. Dengan adanya cara tersebut dapat membantu menemukan kejadian yang sudah terjadi, sedang terjadi, atau mungkin yang akan terjadi.
Twitter menyediakan banyak kumpulan tweetdengan banyak variasi penulisan kata didalamnya. Banyak sekali kata-kata yang jarang (noise) ditemui dalam bahasa Indonesia baku seperti singkatan kata, bahasa gaul, dan karakter-karakter yang tidak bermakna (Rangrej, dkk. 2011). Hal tersebut menjadi kendala dalam penentuan event detection sehingga harus dilakukan pemrosesan awal terlebih dahulu untuk mengurangi noise sehingga informasi yang didapat dari kumpulan tweet merupakan informasi yang bermanfaat.
Penelitian ini melakukan analisis tweet dengan keyword “banjir" untuk diproses lebih lanjut sehingga menghasilkan informasi yang dapat bermanfaat dan digunakan sebaik-baiknya, misalkan mengetahui kejadian banjir yang umum terjadi pada rentang waktu tertentu. Metode yang dipakai dalam penelitian ini, yaitu density-based clustering dengan algoritma DBSCAN. Density-based clustering akan melakukan clustering berdasarkan tingkat kepadatan dari suatu
kumpulan data. Karakteristik dari density-based clustering ini sangat cocok digunakan untuk menemukan adanya event dari suatu kumpulan data tanpa terbatas berapa event yang ingin dideteksi. Selain itu, algoritma DBSCAN sangat cocok digunakan pada data yang memiliki banyak noise(Gaonkar, 2013). Banjir ini dijadikan sebagai objek penelitian karena merupakan salah satu bencana alam terbesar di Indonesia selain gempa bumi.Tahun 2013, Badan Nasional Penanggulangan Bencana (BNPB) mencatat banjir sebagai bencana yang paling sering terjadi di Indonesia dengan jumlah sebanyak 4261 bencana.
4
1.2. Rumusan Masalah
Merujuk dari latar belakang di atas, ada beberapa permasalahan yang timbul dalam melakukan identifikasi bencana:
a. Bagaimana algoritma DBSCAN dapat membantu mendeteksi adanya event melalui Twitter?
b. Bagaimana melakukan pengambilan informasi dari setiap event berdasarkan kumpulan tweet yang terbentuk sehingga dapat menyimpulkan dimana lokasi adanya event?
1.3. Batasan Masalah
Untuk memfokuskan penelitian yang akan dilakukan ada beberapa batasan masalah, yaitu sebagai berikut.
a. Penulis hanya menggunakan Twitter sebagai sumber data.
b. Bencana yang dideteksi dalam penelitian ini difokuskan pada bencana banjir. c. Penulis tidak mendeteksi kejadian berdasarkan kesamaan kata yang
bersinonim dengan banjir, misalkan genangan air atau aliran air.
d. Data tweet yang diambil tidak real-time, melainkan hasil pengumpulan dalam jangka waktu tertentu (Januari – Februaru 2012 dan Januari 2013).
e. Data lokasi banjir tidak diambil dari data geotagging di Twitter, melainkan diambil dari hasil ekstraksi informasi yang ada pada tweet.
f. Penulis menggunakan data kumpulan sinonim yang dibuat secara manual berdasarkan data tweet yang ada berdasarkan asumsi yang sering muncul. 1.4. Tujuan Penelitian
Tujuan dari penelitian yang akan dilakukan yaitu.
a. Dapat mendeteksi adanya banjir berdasarkan tweet dengan metode density-based clustering menggunakan algoritma DBSCAN.
5
1.5. Definisi Operasional
Di dalam penelitian ini ada beberapa istilah yang umum digunakan. Diantaranya sebagai berikut.
1. Eps adalah input paramater untuk algoritma DBSCAN yang digunakan untuk
menentukan radius dari suatu cluster.
2. MinPts adalah input parameter untuk algoritma DBSCAN yang digunakan
untuk menentukan nilai minimum point suatu cluster di dalam radius eps.
3. Noise adalah data yang tidak masuk ke dalam cluster manapun. Noise dalam
algoritma DBSCAN merupakan titik yang memiliki kepadatan rendah sehingga jarak point tersebut terhadap point lain jauh.
4. Tweet adalah pesan yang dituliskan pada Twitter.
5. Clustering adalah proses pengelompokkan kumpulan data ke dalam
kelompok-kelompok yang memiliki kemiripan.
6. Event Detection adalah proses identifikasi adanya suatu event.
7. Named Entitiy Recognition adalah teknik pengenalan entitas dari data teks
untuk mengenali informasi seperti nama, lokasi, waktu, organisasi. 1.6. Sistematika Penulisan
Sistematikan penulisan proposal skripsi ini adalah sebagai berikut. BAB I PENDAHULUAN
Bab ini berisi latar belakang, rumusan masalah, batasan masalah, tujuan penelitian yang akan dilakukan, dan sistematikan penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini berisi penjelasan tentang teori-teori dan konsep algoritma yang digunakan dalam penelitian.
BAB III METODOLOGI PENELITIAN
6
BAB IV HASIL PENELITIAN DAN PEMBAHASAN
Bab ini berisi uraian tentang hasil penelitian dan pembahasan terhadap hasil penelitian yang dilakukan
BAB V KESIMPULAN DAN SARAN
BAB III
METODOLOGI PENELITIAN
3.1. Desain Penelitian
Desain penelitian merupakan tahapan yang akan dilakukan oleh penulis untuk memberikan gambaran serta kemudahan dalam melakukan penelitian. Berikut tahapan penelitian yang digunakan:
Gambar 3. 1 Desain Penelitian
1) Pengumpulan data
Data yang digunakan diambil dari situs jejaring sosial Twitter. Tweet yang saat ini penulis dapatkan ada lebih dari 250.000 tweet terkait dengan banjir. Data tersebut didapatkan dengan cara melakukan crawling dengan memanfaatkan Twitter Search API. Data diambil dari bulan Januari 2012 sampai Februari 2012 dan bulan Januari 2013.
2) Preproccessing
32
a) Cleaning, yaitu proses membersihkan data tweetdari kata yang tidak
diperlukan untuk mengurangi noise. Beberapa contoh kata yang dihilangkan adalah hashtag (#), username (@username), dan url. Selain penghapusan kata, dilakukan penghapusan tanda baca seperti koma (,) dan titik (.).
b) Case Folding, yaitu penyeragaman bentuk huruf, sehingga data hanya
menjadi huruf latin dari a sampai z.
c) Tokenizing, yaitu proses memecah sebuah kalimat menjadi kata.
3) Pembobotan
Pada tahap ini akan dilakukan konversi data teks menjadi data vektor menggunakan Vectore Space Model. Sebuah data tweet, dinyatakan dalam model vector-space. Semua kata yang terkandung dalam tweetdidaftarkan, dinyatakan dengan {f1,f2,...,fm} yang merupakan daftar kata. Setiap kata akan
dihitung nilai TF-IDF sebagai representasi dari kata. 4) Pembelajaran dan Klasifikasi
Pada tahap ini akan digunakan algoritma clustering DBSCAN untuk melakukan pengelompokkan tweet ke dalam sejumlah event.
5) Evaluasi
Pada tahap ini akan dilakukan uji kualitas hasil cluster dari kinerja DBSCAN menggunakan overall similarity.
6) Postprocessing
Pada tahap ini akan dilakukan pengambilan informasi dari tweet yang terbentuk pada setiap cluster.
3.2. Metode Penelitian
Untuk lebih jelasnya, metode penelitian yang dilakukan dijelaskan dalam sub-bab berikut:
3.2.1. Proses Pengumpulan Data
Data yang digunakan dalam penelitian ini merupakan data yang diambil dari
33
Januari – Februari 2012 dan Januari 2013. Data hasil crawl ini dimasukkan ke database untuk diproses lebih lanjut.
3.2.2. Proses Pengembangan Perangkat Lunak
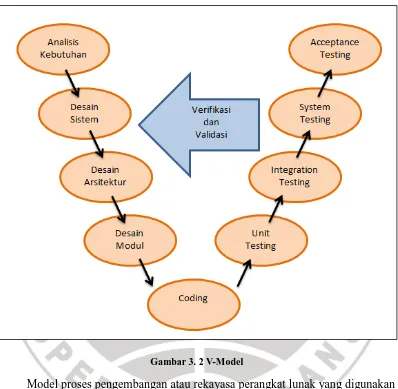
Gambar 3. 2 V-Model
Model proses pengembangan atau rekayasa perangkat lunak yang digunakan dalam penelitian ini adalah V Model. V Model merupakan perbaikan dari model waterfall(Balaji, 2012).
1. Analisis Kebutuhan, tahap pengumpulan data dan informasi terkait dengan metode yang akan digunakan dan berbagai kebutuhan penunjang lain untuk mendapatkan gambaran aplikasi. Pada tahap ini dilakukan pengumpulan data tweet dengan keyword banjir dan menentukan algoritma apa yang digunakan
34
2. Desain Sistem, tahap pembuatan desain rekayasa sistem yang akan dibuat sesuai dengan analisa kebutuhan. Pada tahap ini dibuat desain dari sistem yang akan dikembangkan untuk event detection (lihat gambar 3.1).
3. Desain Arsitektur/Program, tahap pembuatan desain rekayasa struktur program, dan algoritma. Pada tahap ini ditentukan modul apa saja yang akan dibuat untuk melakukan event detection, yaitu modul preprocessing, modul pembobotan, modul, clustering, modul postprocessing.
4. Desain Modul, tahap pembuatan modul-modul program hasil implementasi dari tahap Desain Arsitektur/Program. Tahap ini membuat programmer dapat melakukan pemecahan unit-unit yang masing-masing unitnya memiliki fungsi yang sama. Pada tahap ini dibuat kerangka prosedur atau fungsi pada setiap modul.
5. Coding, tahap pembuatan aplikasi yang merupakan tindak lanjut dari
perancangan program untuk mengolah data menjadi informasi berupa kode-kode program.
6. Unit Testing, tahap pengujian terhadap aplikasi yang telah dibuat. Jika terdapat
kekurangan maka tahap ini berhubungan dengan tahap Desain Arsitektur/Program.Pada tahap ini diuji apakah ada task yang terlewat atau tidak ketika melakukan event detection.
7. Integration Testing, tahap melakukan integrasi dari modul-modul yang
terpisah menjadi satu kesatuan yang utuh. Pada tahap ini setiap modul yang telah dibuat diuji fungsionalitasnya melalui antarmuka sistem.
8. System Testing, tahap pengujian sistem. Jika terdapat kekurangan maka tahap
ini berhubungan dengan tahap Desain Sistem. Pada tahap ini dilakukan pengujian keseluruhan sistem dari mulai tahap preprocessing sampai postprocessing (ekstraksi informasi).
9. Acceptance Testing, tahap pengujian yang bersifat menyeluruh, yakni berupa
35
3.3. Alat dan Bahan Penelitian
Alat yang digunakan dalam penelitian ini adalah seperangkat komputer yang dilengkapi perangkat keras dan perangkat lunak pendukung. Sedangkan bahan yang digunakan adalah data yang diambil melalui microblogging Twitter.
3.3.1. Alat Penelitian
Dalam penelitian ini digunakan perangkat keras komputer dengan spesifikasi sebagai berikut:
1. Processor Intel Core 2 Solo
2. Memori 4 GB RAM
3. Hardisk berkapasitas 320 GB
4. Monitor 14” dengan resolusi 1366x768 pixel
5. Mouse dan Keyboard
Adapun perangkat lunak yang digunakan adalah 1. Microsoft Windows 7 Ultimate
2. Netbeans 6.8
stopword dan kumpulan kata sinonim yang diambil library TweetMining
BAB V
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Adapun kesimpulan akhir dari penelitian Event Detection pada Microblogging Twitter dengan Algoritma DBSCAN:
1. Algoritma DBSCAN membantu mendeteksi adanya event dengan cara mengelompokkan sebuah data berdasarkan tingkat kepadatannya sehingga cluster akan dipisahkan dengan data-data dengan tingkat kepadatan yang
rendah. DBSCAN membutuhkan dua parameter input untuk melakukan clustering, yaitu eps dan MinPts. Kedua parameter tersebut sangat berpengaruh terhadap hasil cluster. Sebuah cluster hasil dari DBSCAN ini merepresentasikan sebuah event yang ingin dideteksi sehingga satu cluster berarti satu event.
2. Pengambilan informasi event dapat dilakukan dengan teknik Named Entity Recognition (NER). Implementasi NER yang digunakan yaitu
pemanfaatan regular expression (regex). Regex akan mengambil informasi dengan mencocokan pola string tertentu dengan data hasil cluster. Jika terdapat kecocokan, maka dapat diambil informasi mengenai
lokasi dan deskripsi dari event yang terdeteksi. 5.2. Saran
Untuk pengembangan lebih lanjut, saran-saran yang diberikan pada penelitian ini:
53
2. Perlu dilakukan penelitian lebih lanjut dengan menggunakan algoritma lain dari metode density-based clustering dan membandingkan hasilnya dengan algoritma DBSCAN.
3. Perlu dilakukan penelitian lebih lanjut untuk mengambil informasi dari setiap cluster (ekstraksi informasi) sehingga data nama dan lokasi kejadian suatu eventlebih presisi, misalnya dengan menggunakan teknik NER berdasarkan pembelajaran mesin (machine learning).
DAFTAR PUSTAKA
Balaji, S., Murugaiyan, M.S., 2012. Waterfall vs V-Model vs Agile: A Comparative Study on SDLC. International Journal of Information Technology and
Business Management Vol 2 No. 1
Chincor, N. 1998. MUC-7 Named Entity Task Definition. Proceedings of the Seventh Message Understanding Conference (MUC-7). Morgan Kaufmann Ester, M., Kriegel, H.P., dkk. 1996. A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. 2nd International
Conference on Knowledge Discovery and Data Mining.
Even, Y., Zohar. 2002. Introduction To Text Mining. [Online]. Tersedia di: http://www.docstoc.com/docs/25443990/Introduction-to-Text-Mining diakses pada 16 Februari 2012
Gaonkar, N.M., Sawant, K. 2013. AutoEpsDBSCAN: DBSCAN with Eps Automatic for Large Dataset. International Journal of Advance Computer
Theory and Engineering Volume 2. ISSN (Print): 2319-2526
Feinerer, I., Hornik, K., dkk. 2008. Text Mining Infrastructure. Journal of Statistic Software Volume 25
Han, J., Kamber, M. 2006. Data Mining: Concept and Techniques (Second Edition). San Francisco: Morgan Kaufmann Publishers.
Huang, J.Z., Michael Ng., dkk. 2006. Text Clustering: Algorithms, Semantics, and Systems. PAKDD Tutorial
Kerman, M.C., dkk. 2009. Event Detection Challenges, Methods, and Applications in Natural and Artificial Systems. 14th International
xii
Kumar, V., Steinbach, M., dkk 2003. Challenges of Clustering High Dimensional Data: Density based Subspace Clustering Algorithms. International
Journal of Computer Applications (0975-8887) Volume 63
Meier, M. ____. Named Entity Recognition Pipeline. Projektgruppe Information Driven Software Engineering.
Nugroho, A.S., Witarto, A.B., dkk. 2003. Support Vector Machine: Teori dan
Aplikasinya dalam Bioinformatika. [Online]. Tersedia di:
http://ilmukomputer.com diakses pada 6 Februari 2012
Rangrej, A., Kulkarni, S., dkk. 2011. Comparative Study of Clustering Techniques for Short Text Document. WWW 2011 - Poster
Sakaki, T., Okazaki, M., dkk. 2010. Earthquake Shakes Twitter Users: Real-time
Event Detection by Social Sensors. [Online]. Tersedia di:
http://ymatsuo.com/papers/www2010.pdf diakses pada 3 Februari 2012 Saraswati, N.W.S. 2011. Tesis: Text Mining Dengan Metode Naive Bayes
Classifier dan Support Vector Machines Untuk Sentiment Analysis.
[Online]. Tersedia di: http://pps.unud.ac.id/thesis/pdf_thesis/unud-209-236721286-tesis.pdf diakses pada 6 Februari 2012
Sayyadi, H., Matthew, H., dkk. 2009. Event Detection and Tracking in Social
Steams. [Online]. Tersedia di:
www.cs.umd.edu/.../9-sayyadi-EventDetection_KeyGraph_ICWSM09.pdf diakses pada 3 Februari 2012 Steinbach, M., Kumar, V., dkk (2000). A Comparison of Document Clustering
Techniques. Journal of Citerseerx. 1-20.
Sun, Y. 2012. Event Detection Tutorial for Twitter Project. [Online]. Tersedia di: https://wiki.engr.illinois.edu/download/attachments/200016061/Tutorial+o n+Event+Detection+for+Twitter+Project.pptx diakses pada 4 Januari 2013 Wibisono, Y. 2011. Sistem Analisis Opini Microblogging Berbahasa Indonesia.
xiii
_____________________. (2010). Document Preprocessing. [Online]. Tersedia: