TRANSLITERASI NAMA JALAN BERAKSARA
JAWA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Kasih Handoyo
135314064
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
TRANSLITERATION OF JAVANESE STREET
NAMES
THESIS
Submitted in Partial Fulfillment of The Requirements for The Degree of Sarjana Komputer
In Informatics Engineering Study Program
By:
Kasih Handoyo
135314064
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
vii
ABSTRAK
Bangsa Indonesia merupakan bangsa yang multikultural. Salah satu budaya yang sangat terkenal adalah karya tulis dari suku Jawa yang ditulis menggunakan aksara Jawa. Aksara Jawa inilah yang menjadi ciri khas dan tradisi orang Jawa dalam mengembangkan tradisi tulis-menulis mereka. Seiring dengan perkembangan zaman, aksara Jawa mulai dipertanyakan keberadaannya. Pada generasi saat ini hanya beberapa orang saja yang dapat memahami ataupun membaca aksara Jawa. Sejak berkembangnya teknologi pengenalan pola dan pemrosesan citra maka dapat dibuat suatu sistem yang secara otomatis akan mengenali dan menerjemahkan karakter dari suatu citra ke dalam tulisan dalam bahasa lain yang sering disebut dengan pengenalan aksara atau character recognition.
Pada penelitian ini akan dibangun sebuah prototype sistem yang mampu mengenali dan membaca tulisan beraksara Jawa dengan objek nama-nama jalan yang ada di Yogyakarta dalam bentuk citra digital kemudian menerjemahkannya ke dalam tulisan latin. Tahap awal dalam penelitian ini adalah data acquisition. Citra nama jalan diambil menggunakan kamera smartphone sejumlah 130 gambar. Tahap selanjutnya adalah preprocessing. Preprocessing yang dikerjakan adalah cropping,
grayscaling, binarization, segmentation dan resizing. Metode yang dipakai dalam
proses segmentation menggunakan projectionprofile. Data yang sudah siap untuk diolah kemudian masuk ke tahap feature extraction and selection. Ektraksi yang dipakai pada penelitian ini adalah ICZ-ZCZ (Image Centroid and Zone-Zone
Centroid and Zone). Model klasifikasi yang dipakai dalam penelitian ini adalah
template matching. Model ini bekerja dengan mengukur kedekatan atau kesamaan
(similarity) antar objek. Data citra yang digunakan untuk pembuatan template
sejumlah 100 data. Proses selanjutnya adalah postprocessing, yaitu proses untuk mengelompokkan suku kata agar membentuk kata atau kalimat yang memiliki arti. Hal tersebut perlu dilakukan karena karakter penulisan aksara Jawa adalah tanpa spasi.
Tahapan terakhir adalah evaluation, yaitu menguji performa sistem yang direpresentasikan dengan nilai tingkat akurasi. Pengujian dilakukan dengan 2 macam test case, yang pertama data uji yang diambil dalam keadaan normal dan data uji yang bervariasi. Berdasarkan pengujian yang telah dilakukan, tingkat akurasi yang dihasilkan oleh sistem menggunakan pembagian 4 zona secara horizontal sebesar 93.33% untuk data normal dan 86.67% untuk data yang bervariasi sedangkan untuk pembagian 4 zona secara horizontal dan vertikal memiliki tingkat akurasi 76.67% untuk data normal dan 70% untuk data yang bervariasi.
viii
ABSTRACT
Indonesia is a multicultural nation. One of the most well-known on their culture is the Javanese scripts which is written in Javanese character. The Javanese Character become tradition and identity for Javanese people to envole their literacy. At this time the existance of Javanese character begun to be inquired. Only few of this generation today could understand and read the Javanese script. The envolving technology of pattern recognition and image processing can make a system that automated to recognize and translate a character from centain image to other languages which usually called by character recognition.
In this research will build a system prototype which able to recognize and read the Javanese script on the street names of Yogyakarta in the digital image to Roman lettering. The first step in this research is data acquisition. The street names of Yogyakarta image is taken by smartphone camera as many as 130 images. The next step is preprocessing. The preprocessing method are cropping, grayscaling, binarization, segmentation and resizing. The method is used for segmentation is projection profile. Data which is already to be processed then continue to the next step, it is feature extraction and selection. Extraction method that will be used are ICZ-ZCZ (Image Centroid and Zone-Zone Centroid and Zone). In this research we used template matching for classification model. This model works by counting the similarity between the objects. The number of data to make a template is 100. The next step is postprocessing, that is process which groups the syllables to make meaning word or sentences. This is should be done because characteristic of Javanese character is written without spacing between their character.
The final step is evaluation, that is to test the performance of the system which is represented by accuration value. The evaluation process is divided into 2 test case, the first one is dataset taken in normal condition and the second one is dataset in many kind of variances. Based on the testing, the accuracy that can be obtained in 4 horizontal zones is 93.33% for nomal dataset and 86.67% for variance dasatet then in 4 vertical-horizontal zones is 76.67% for normal dataset and 70% for variance dataset.
ix
KATA PENGANTAR
Puji dan syukur saya panjatkan kehadirat Tuhan Yesus Kristus oleh karena berkat dan kasih-Nya sehingga tugas akhir saya yang berjudul “Transliterasi Nama Jalan Beraksara Jawa” dapat diselesaikan dengan baik dan tepat waktu. Tugas akhir ini merupakan salah satu persyaratan yang wajib ditempuh pada Program Studi Teknik Informatika Universitas Sanata Dharma untuk memperoleh gelar Sarjana Komputer. Selama persiapan proposal dan penyusunan tugas akhir ini saya mendapat banyak dukungan dan bantuan dari berbagai pihak sehingga saya menyampaikan terima kasih kepada:
1. Ibu Dr. Anastasia Rita Widiarti, M.Kom. selaku dosen pembimbing skripsi yang telah bersedia memberikan arahan, masukan, motivasi serta kekuatan dalam pekerjaan saya selama menyelesaikan skripsi.
2. Keluarga saya tercinta yang selalu memberikan dukungan motivasi dan doa sehingga saya selalu bersemangat dalam mengerjakan dan menyelesaikan tugas akhir ini selama 1 semester.
3. Bapak Albertus Agung Hadhiatma, S.T., M.T. selaku dosen pembimbing akademik yang memberikan saran serta penghiburan selama proses pengerjaan tugas akhir.
4. Bapak Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan Teknologi.
5. Saudara Rismanto dan saudari Sekar Mirah yang telah meluangkan waktu, tenaga dan pikiran untuk membantu saya dalam mengambil gambar nama-nama jalan yang berada di Kota Yogyakarta.
6. Seluruh dosen Teknik Informatika Universitas Sanata Dharma yang telah mendidik, memberikan ilmu pengetahuan dan pengalaman yang berharga untuk bekal dalam mengerjakan tugas akhir saya ini.
xi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vi
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 4
1.3 Tujuan ... 4
1.4 Batasan Masalah ... 4
1.5 Manfaat ... 5
1.6 Metodologi Penelitian ... 5
1.7 Sistematika Penulisan ... 6
BAB II LANDASAN TEORI ... 8
2.1 Aksara Jawa ... 8
2.2 Pemrosesan Citra Digital ... 13
2.2.1 Citra Berwarna ... 13
xii
3.3.1 Observasi ... 32
3.3.2 Studi Literatur ... 33
3.4 Tahap Penelitian... 33
3.4.1 Identifikasi Masalah ... 33
3.4.2 Studi pustaka ... 33
3.4.3 Pengumpulan Data ... 34
3.4.4 Pengolahan Data... 34
3.4.5 Perancangan Alat Uji ... 40
3.4.6 Implementasi ... 40
3.5 Desain Alat Uji ... 43
3.6 Pengujian (Testing) ... 44
3.7 Pengukuran Akurasi Sistem ... 44
BAB IV HASIL DAN ANALISA ... 45
4.1 Data Acquisition ... 45
4.2 Preprocessing ... 46
4.2.1 Cropping ... 46
4.2.2 Grayscaling ... 47
4.2.3 Binarization ... 47
4.2.4 Image Segmentation ... 48
4.2.5 Resizing ... 52
4.3 Feature Extraction and Selection ... 53
4.4 Pembuatan Template Database ... 57
4.5 Classification... 61
4.6 Postprocessing... 64
4.7 Evaluation ... 67
BAB V PENUTUP ... 87
5.1 KESIMPULAN ... 87
5.2 SARAN ... 88
DAFTAR PUSTAKA ... 90
xiii
DAFTAR GAMBAR
Gambar 2.1 Aksara Jawa Legena ... 8
Gambar 2.2 Sandhangan Swara ... 9
Gambar 2.3 Sandhangan Panyigeg Wanda ... 10
Gambar 2.4 Sandhangan Wyanjana ... 10
Gambar 2.5 Sandhangan Pangkon ... 11
Gambar 2.6 Aksara Pasangan ... 11
Gambar 2.7 Penulisan Aksara Apel Batu ... 12
Gambar 2.8 Aksara Rekan ... 12
Gambar 2.9 Warna RGB dalam Ruang Berdimensi Tiga ... 14
Gambar 2.10 Citra Biner “Para” ... 21
Gambar 2.11 Projection Profile dari Citra Aksara Pa dan Ra ... 22
Gambar 2.12 Pembagian Zona dan Perhitungan Jarak (ICZ) ... 25
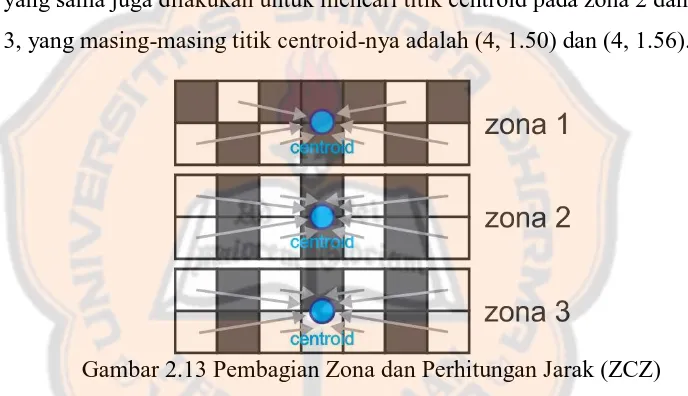
Gambar 2.13 Pembagian Zona dan Perhitungan Jarak (ZCZ) ... 26
Gambar 2.14 Aksara Iredha ... 29
Gambar 2.15 Aksara Modhang ... 29
Gambar 2.16 Aksara Pajeksan ... 30
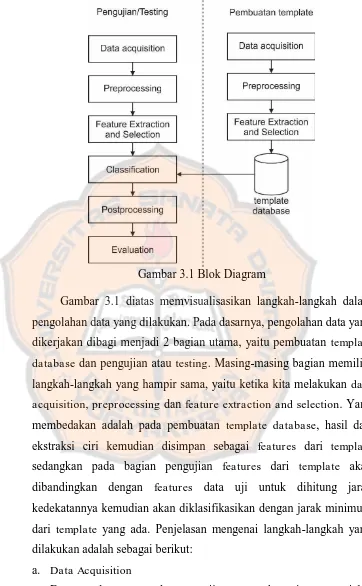
Gambar 3.1 Blok Diagram ... 35
Gambar 3.2 Preprocessing Modules ... 36
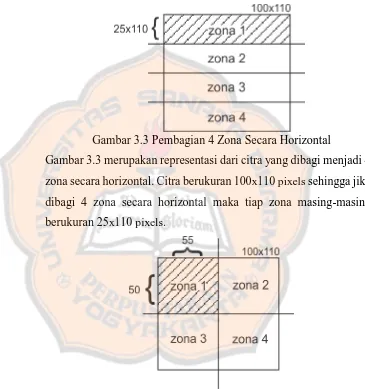
Gambar 3.3 Pembagian 4 Zona Secara Horizontal ... 38
Gambar 3.4 Pembagian 4 Zona Secara Vertikal-Horizontal ... 38
Gambar 3.5 Desain Interface Sistem ... 43
Gambar 4.1 Citra Jalan Pajeksan ... 45
Gambar 4.2 Pemotongan Citra Jalan Pajeksan ... 46
Gambar 4.3 Citra Abu-Abu Jalan Pajeksan ... 47
Gambar 4.4 Citra Biner Jalan Pajeksan... 48
Gambar 4.5 Projection Profile dari Citra Jalan Pajeksan ... 50
Gambar 4.6 Citra Biner Jalan Langensari ... 51
Gambar 4.7 Projection Profile dari Citra Jalan Langensari ... 51
Gambar 4.8 Citra Jalan Pajeksan Hasil Resizing ... 52
Gambar 4.9 Nilai Features dari Citra Jalan Pajeksan ... 56
Gambar 4.10 Citra Jalan Menteri Supeno ... 57
Gambar 4.11 Hasil Cropping Citra Jalan Menteri Supeno ... 58
Gambar 4.12 Citra Abu-Abu Aksara Su ... 58
Gambar 4.13 Citra Biner Aksara Su ... 59
Gambar 4.14 Pembuatan Kombinasi Aksara untuk Template Database ... 61
Gambar 4.15 Feature Database dari Template beserta Label ... 61
Gambar 4.16 Nilai Feature pada Template Pertama ... 62
Gambar 4.17 Nilai Jarak Feature Objek Pertama... 63
Gambar 4.18 Hasil Klasifikasi Citra Jalan Pajeksan ... 64
Gambar 4.19 Hasil Postprocessing ... 67
xiv
DAFTAR TABEL
Tabel 4.1 Tabel Hasil Pengujian Menguunakan 4 Zona Secara Horizontal ... 67 Tabel 4.2 Tabel Kesalahan Transliterasi Tiap Aksara ... 71 Tabel 4.3 Tabel Nilai Jarak Citra Uji dengan Template ... 72 Tabel 4.4 Tabel Hasil Pengujian Menggunakan 4 Zona Secara Vertikal dan
Horizontal ... 73 Tabel 4.5 Tabel Kesalahan Transliterasi Tiap Aksara Menggunakan 4 Zona Secara Vertikal dan Horizontal ... 76 Tabel 4.6 Tabel Hasil Pengujian Menggunakan 4 Zona Secara Horizontal ... 79 Tabel 4.7 Tabel Hasil Pengujian Menggunakan 4 Zona Secara Vertikal dan
1
BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
Bangsa Indonesia merupakan bangsa yang majemuk. Memiliki wilayah yang terbentang dari Sabang sampai Merauke serta terdiri dari banyak suku, ras, agama, bahasa dan budaya menjadikan bangsa Indonesia sebagai bangsa yang multikultural. Hal inilah yang menyebabkan bangsa Indonesia memiliki kekayaan budaya dan memiliki kekhasan untuk setiap daerahnya. Salah satu budaya yang sangat terkenal adalah karya tulis dari suku Jawa yang ditulis menggunakan aksara Jawa. Aksara Jawa inilah yang menjadi ciri khas dan tradisi orang Jawa dalam mengembangkan tradisi tulis-menulis mereka. Saat ini suku Jawa yang paling banyak berada di Yogyakarta sehingga sampai saat ini kita bisa merasakan nuansa budaya Jawa yang ada di Yogyakarta.
Seiring dengan perkembangan zaman, aksara Jawa mulai dipertanyakan keberadaannya. Pada generasi saat ini hanya beberapa orang saja yang dapat memahami ataupun membaca aksara Jawa. Bahkan orang Jawa sekalipun, khususnya yang ada di Yogyakarta belum tentu bisa memahami ataupun membaca Aksara Jawa padahal aksara Jawa merupakan warisan budaya Indonesia yang patut kita jaga dan lestarikan. Hal ini yang menjadi keprihatinan penulis karena akan membuat budaya tulis dengan aksara Jawa menjadi luntur dan menghilang ditengah-tengah masyarakat Jawa sendiri. Sejak berkembanganya teknologi pengenalan pola dan pemrosesan citra maka dapat dibuat suatu sistem yang secara otomatis akan mengenali dan menerjemahkan karakter dari suatu citra kedalam tulisan dalam bahasa lain yang sering disebut dengan pengenalan aksara atau character recognition
(Mahto et al., 2015). Definisi pengenalan pola adalah suatu disiplin ilmu sains yang mempunyai tujuan pada pengklasifikasian objek kedalam beberapa kelas atau kategori. Pengenalan pola merupakan bagian integral dalam sistem mesin cerdas (machine intelligence) yang dibuat untuk membuat sebuah keputusan (Theodoridis dan Koutroumbas, 2009). Sedangkan menurut Gonzales dan Woods (2008) pemrosesan citra meliputi suatu proses yang memiliki input dan output berupa image (citra) dan sebagai tambahan meliputi juga proses yang mengekstraksi atribut dari citra hingga sampai pada pengenalan masing-masing objek. Pengenalan aksara atau character
recognition termasuk dalam bidang ilmu pengenalan pola yang melibatkan
pemrosesan citra didalamnya.
kumpulan aksara yang ada. Tingkat akurasi yang dihasilkan adalah sebesar 85.9% hingga 94.82%. Setelah melalui tahap preprocessing maka citra nama jalan siap untuk diekstrak cirinya. Ekstraksi ciri diperlukan untuk memperoleh informasi penting dari objek dengan mereduksi dimensi data. Penelitian tentang ekstraksi ciri pengenalan tulisan tangan angka dari 4 script
yang terkenal dari India Selatan berbasis zona, yaitu menggunakan metode ICZ (Image Centroid and Zone) dan ZCZ (Zone Centroid and Zone) telah dikerjakan oleh Rajashekararadhya dan Ranjan (2005) untuk pengenalan pola angka tulisan tangan dengan aksara Kannada, Telugu, Tamil dan Malayalam. Dari penelitian tersebut disimpulkan bahwa ekstraksi ciri berbasis zona (zone
based) menghasilkan pengenalan yang baik meskipun beberapa tahap
preprocessing tidak dikerjakan seperti filtering, smoothing. Tingkat akurasi
yang dihasilkan sebesar 99% untuk aksara Kannada dan Telugu serta masing-masing didapat 98% untuk aksara Tamil dan 95% untuk aksara Malayalam. Sampai saat ini terdapat 4 model pengenalan pola yang umum digunakan, yaitu template matching, statistical classification, syntactic or structural
matching, dan neural network (Jain et al., 2000). Dari keempat pendekatan
Berdasarkan dari penelitian yang sudah ada dan tingkat akurasi yang diperoleh oleh penelitian sebelumnya maka penulis ingin menerapkan metode
projection profile untuk tahap preprocessing dan ekstraksi ciri menggunakan
ICZ-ZCZ (image centroid and zone-zone centroid and zone) pada penelitian yang dilakukan namun menggunakan objek yang berbeda, yaitu citra nama-nama jalan beraksara Jawa di Kota Yogyakarta. Penelitian ini akan mengenali dan menerjemahkan citra aksara Jawa berupa tulisan nama-nama jalan yang ada di Yogyakarta menggunakan pendekatan template matching. Melalui pengenalan pola ini citra hasil segmentasi akan diekstrak cirinya menggunakan metode ICZ-ZCZ kemudian dengan template database aksara yang dibuat akan dihitung kemiripan antar kedua objek sehingga citra nama jalan yang dimasukkan akan dibandingkan dan menghasilkan suatu informasi yaitu terjemahan dari aksara Jawa. Dengan adanya penelitian ini diharapkan orang akan terbantu dalam mengenal aksara Jawa, disamping itu juga dapat mengenal tempat-tempat yang ada di Yogyakarta dan ikut serta dalam melestarikan budaya Indonesia, khususnya budaya Jawa.
1.2 Rumusan Masalah
Berapakah persentase keberhasilan yang diperoleh dalam proses pengenalan nama jalan beraksara Jawa?
1.3 Tujuan
Mengetahui performa sistem yang ditunjukkan dengan persentase nilai kebenaran atau akurasi sistem yang mampu dihasilkan untuk mengkonversi citra aksara Jawa menjadi tulisan latin.
1.4 Batasan Masalah
Batasan masalah yang ada dalam penelitian ini adalah sebagai berikut: 1. Pengenalan pola ini menggunakan input berupa sebuah citra aksara Jawa
pengambilan gambar sekitar 50 cm dari tiang serta waktu pengambilan gambar di pagi atau siang hari.
2. Objek diambil satu arah saja dengan posisi tegak lurus terhadap kamera. 3. Objek yang diamati merupakan pengenalan nama-nama jalan beraksara
Jawa yang ada di Yogyakarta.
4. Output yang dihasilkan berupa terjemahan dalam huruf latin.
5. Jumlah data uji yang digunakan sekitar 30 citra nama-nama jalan beraksara Jawa di Yogyakarta.
6. Aksara Jawa yang akan dikenali berupa aksara pokok (nglegena), aksara pengubah bunyi (sandhangan) dan aksara penutup konsonan (pasangan) serta aksara rekan.
1.5 Manfaat
Manfaat yang dapat diperoleh melalui penelitian ini adalah sebagai berikut: 1. Membantu menerjemahkan citra tulisan nama jalan beraksara Jawa di
Yogyakarta secara otomatis melalui prototype sistem yang dibuat. 2. Ikut serta dalam melestarikan budaya Jawa khususnya tradisi
tulis-menulis menggunakan aksara Jawa.
1.6 Metodologi Penelitian
1. Studi Literatur
Pada tahap ini semua hal-hal yang mendukung penelitian dipelajari melalui buku-buku referensi ataupun jurnal yang berkaitan dengan pengenalan aksara (character recognition).
2. Pengumpulan Data
Pada tahap ini data tentang citra nama jalan beraksara Jawa di Yogyakarta dikumpulkan untuk digunakan sebagai bahan dalam penelitian. Data dikumpulkan dengan melakukan pengamatan langsung di daerah Kota Yogyakarta kemudian nama-nama jalan yang ditulis menggunakan aksara Jawa diambil gambarnya menggunakan kamera
3. Perancangan Sistem
Pada tahap ini akan dibangun sebuah sistem yang dipakai sebagai alat uji untuk mengetahui tingkat akurasi dari algoritma yang digunakan.
4. Pembuatan Sistem
Pada tahap ini sistem mulai dibangun berdasarkan rancangan yang telah dibuat.
5. Pengujian
Sistem diuji performanya dengan menghitung tingkat akurasi yang dihasilkan dalam pengenalan nama-nama jalan beraksara Jawa.
6. Pembuatan Laporan
Pada tahap ini dilakukan penyusunan laporan penelitian berdasarkan tahapan dan proses yang telah dikerjakan dan didukung oleh teori-teori yang dipakai.
1.7 Sistematika Penulisan
Pada proposal ini terbagai dalam 5 bab utama, yaitu: 1. Bab I Pendahuluan
Bagian ini berisi mengenai latar belakang tugas akhir, rumusan masalah, tujuan, batasan masalah, metodologi penelitian dan sistematika penulisan.
2. Bab II Landasan Teori
Bagian ini berisi tentang teori yang berkaitan dengan topik tugas akhir. 3. Bab III Metode Penelitian
4. Bab IV Hasil dan Analisa
Bagian ini menjelaskan tentang implementasi dari konsep yang sudah dibuat dan memaparkan hasil analisis terhadap langkah-langkah yang sudah dikerjakan. Semua langkah percobaan dipaparkan secara rinci dan disertai dengan capture dari output proses atau tahapan yang dilakukan. 5. Bab V Penutup
8
BAB II
LANDASAN TEORI
2.1 Aksara Jawa
Sebelum dikenalnya carakan atau yang sekarang disebut dengan hanacaraka, pada zaman dahulu orang telah menggunakan aksara yang lebih tua beredarnya yang dikenal dengan aksara Jawa Kuno atau Kawi (Rochkyatmo, 1996). Aksara Jawa atau yang lebih kita kenal dengan hanacaraka diperkirakan dibuat dan berkembang mulai abad 16 pada era setelah Brawijaya V, sekitar zaman kerajaan Demak. Manuskrip menggunakan aksara Jawa baru muncul pada awal abad 17. Aksara Jawa merupakan turunan dari aksara Brahmi dan Pallawa yang ketika itu banyak digunakan untuk menuliskan bahasa Sansekerta.
Pada dasarnya aksara Jawa terdiri dari 20 aksara pokok (nglegena) yang bersifat kesukukataan (sylabic). Sifat penulisan aksara Jawa yang lain seperti ditulis dari kiri ke kanan (abugida) dan ditulis secara bersambung tanpa spasi antar kata (scriptio continua). Selain aksara pokok (nglegena), aksara Jawa memiliki kelompok aksara kapital (murda), aksara vokal (swara), aksara rekaan (rekan), pengubah bunyi (sandhangan), penutup konsonan
(pasangan), penutup suku kata (sigeg), angka (wilangan) dan tanda baca.
Menurut Hadiprijono (2013) aksara Jawa yang terdiri dari 20 aksara, yaitu dari aksara ha sampai nga adalah sebagai berikut:
Gambar 2.1 merupakan aksara dasar atau pokok yang berjumlah sebanyak 20 aksara. Aksara pokok atau sering disebut legena memiliki arti aksara wuda
(telanjang) sebab belum diikuti dengan sandhangan. Selain aksara pokok, aksara Jawa juga terdiri dari 12 aksara sandhangan. Aksara sandhangan
adalah aksara yang dipakai untuk mengubah bunyi dari aksara yang diikutinya. Secara khusus, aksara sandhangan tersebut dibagi ke dalam 4 jenis, yaitu 5 sandhangan swara, 3 sandhangan penyigeg wanda, 3
sandhangan wyanjana dan sandhangan pangkon. Untuk sandhangan swara
terdiri dari 5 aksara, yaitu sebagai berikut:
Gambar 2.2 Sandhangan Swara
Gambar 2.2 merupakan kumpulan dari sandhangan swara, yaitu terdiri dari
wulu, suku, taling, taling-tarung dan pepet. Masing-masing sandhangan
mempunyai karakteristik tersendiri dalam mengubah bunyi suatu aksara yang diikutinya, yaitu wulu akan membuat suku kata menjadi bunyi vokal /i/, suku
si dan ji. Selanjutnya, sandhangan paniyegeg wanda terdiri 3 aksara sebagai berikut:
Gambar 2.3 Sandhangan Panyigeg Wanda
Gambar 2.3 adalah sandhangan panyigeg wanda yang terdiri dari layar,
wigyan dan cecak. Sigeg artinya pembuat konsonan atau penutup suku kata
sedangkan wanda artinya suku kata. Fungsi sandhangan layar akan memberikan bunyi /r/, wignyan akan memberi bunyi /h/ dan cecak akan memberikan bunyi /ng/ pada suku kata yang diikutinya. Contoh pada Gambar 2.3 untuk membentuk kata “gajah” maka dapat ditulis dengan aksara ga dan
ja kemudian diberi sandhangan wignyan yang akan memberi konsonan atau akhiran h. Jenis sandhangan berikutnya adalah sandhangan wyanjana yang terdiri dari 3 aksara seperti gambar di bawah ini.
Gambar 2.4 Sandhangan Wyanjana
Gambar 2.4 adalah contoh dari sandhangan wyanjana yang terdiri dari cakra,
keret dan pengkal. Sandhangan wyanjana merupakan penanda dari gugus
pada masing-masing aksara yang diikutinya. Sebagai contoh pada Gambar 2.4 untuk membentuk kata “putra” maka dapat ditulis dengan aksara pa yang diberi suku lalu aksara ta yang diberi cakra. Terakhir, sandhangan pangkon
adalah sebagai berikut:
Gambar 2.5 Sandhangan Pangkon
Gambar 2.5 adalah sandhangan pangkon. Fungsi pangkon adalah sebagai penutup suku kata atau membentuk konsonan pada suku kata yang berada di depannya. Sebagai contoh, ketika ingin membentuk kata “tangan” maka dapat ditulis dengan aksara ta, nga dan na yang diberi pangkon sehingga menjadi konsonan n.
Selain aksara pokok, dalam penulisan aksara Jawa juga terdapat aksara
pasangan. Jumlah dan bunyi aksara pasa ngan sama seperti aksara legena,
yaitu berjumlah 20 dan terdiri dari ha sampai nga. Berikut ini adalah contoh dari aksara pasangan.
Gambar 2.6 Aksara Pasangan
Gambar 2.6 adalah contoh dari aksara pasangan. Hanya terdapat 3 aksara saja yang ditulis sejajar dengan aksara legena, yaitu pasangan ha, pasangan sa
dan pasangan pa, selain itu penulisan pasangan ditulis di bawah aksara
Gambar 2.7 Penulisan Aksara Apel Batu
Gambar 2.7 merupakan sebuah contoh penulisan aksara Jawa menggunakan
pasangan. Jika dibaca maka bunyi dari aksara tersebut adalah “apel batu.”
Secara sederhana, terdapat 5 buah suku kata, 4 suku kata tersusun dari aksara legena dan sisanya merupakan aksara pasangan. Untuk membentuk kata “apel” maka diperlukan aksara ha, pa yang diberi sandhangan pepet
dan la. Penggunaan pangkon harus diletakkan di akhir suku kata sehingga untuk membentuk konsonan /l/ maka pada aksara la diberi pasangan untuk menyambung ke suku kata berikutnya, yaitu ba. Selanjutnya untuk membentuk suku kata tu menggunakan aksara ta yang diberi sandhangan
suku.
Selain dari 20 suku kata dari ha sampai nga terdapat pula aksara untuk mengakomodasi kata yang tidak bisa memenuhi penulisan dengan aksara pokok. Aksara tersebut terdiri dari 5 buah yang disebut dengan aksara rekan
Berikut adalah kelima aksara rekan yang dapat dilihat melalui gambar di bawah ini.
Gambar 2.8 Aksara Rekan
Gambar 2.8 merupakan kumpulan aksara rekan. Dengan adanya aksara rekan
2.2 Pemrosesan Citra Digital
Sebuah citra dapat didefinisikan sebagi fungsi dua dimensi, f(x, y), x
dan y merupakan koordinat spatial dan amplitudo dari f dengan pasangan koordinat (x, y) disebut intensitas citra atau gray level pada titik tersebut. Ketika x, y dan nilai amplitudo dari f adalah terbatas (finite), bernilai diskrit maka suatu citra dapat disebut sebagai citra digital (digital image). Citra digital ini terbentuk dari angka yang terbatas dan dapat diukur (finite) dari setiap elemennya yang memiliki lokasi dan nilai tertentu. Elemen-elemen tersebut sering kita sebut dengan picture elements, image elements, pels, dan
pixels. Pemrosesan yang terkait dengan citra digital ini dapat didefinisikan
sebagai suatu proses yang memiliki input dan output berupa image (citra) dan sebagai tambahan meliputi juga proses yang mengekstraksi atribut dari citra hingga sampai pada pengenalan masing-masing objek.(Gonzales dan Woods, 2008).
Menurut Kadir dan Susanto (2012) secara umum terdapat tiga jenis citra yang sering digunakan dalam pemrosesan citra yaitu citra berwarna, citra berskala keabuan dan citra biner (citra hitam putih).
2.2.1 Citra Berwarna
Citra berwarna merupakan jenis citra yang mempunyai 3 komponen warna, yaitu komponen merah (red), komponen hijau
(green) dan komponen biru (blue) sehingga sering disebut dengan citra
RGB (Red Green Blue). Setiap komponen R (merah), G (hijau) dan B (biru) memiliki ukuran 8 bit, yaitu berkisar antara 0 sampai dengan 255. Secara umum, jumlah variasi warna yang dapat dihasilkan dari perpaduan citra RGB adalah (2b)3, dengan b adalah jumlah bits disetiap
Gambar 2.9 Warna RGB dalam Ruang Berdimensi Tiga
Gambar 2.9 merupakan representasi dari RGB color cube (kubus warna RGB) dengan 3 simpul utama yaitu warna primer (red, green, blue) dan warna sekunder (cyan, magenta and yellow).
2.2.2 Citra Berskala Keabuan
Citra berskala keabuan atau sering disebut dengan citra grayscale
merupakan representasi citra yang memiliki gradasi warna hitam dan putih sehingga menghasilkan efek warna keabuan. Intensitas warna yang dimiliki citra grayscale adalah 8 bit, yaitu berskala sekitar antara 0 sampai 255. Intensitas 0 menyatakan warna hitam dan intensitas 255 menyatakan warna putih sehingga intensitas antara 0 sampai 255 menghasilkan wana keabuan.
2.2.3 Citra Biner
Citra biner merupakan jenis citra yang memiliki intensitas 0 atau 1. Intensitas 0 menyatakan warna hitam dan intensitas 1 warna menyatakan putih. Seringkali citra biner disebut juga sebagai citra black
2.3 Pengenalan Pola
Definisi pengenalan pola adalah suatu disiplin ilmu sains yang mempunyai tujuan pada pengklasifikasian objek ke dalam beberapa kelas atau kategori. Objek tersebut bergantung pada pengaplikasiannya, seperti citra, sinyal maupun tipe objek lainnya yang ingin diklasifikasi. Pengenalan pola merupakan bagian integral dalam sistem mesin cerdas (machine
intelligence) yang dibuat untuk membuat sebuah keputusan (Theodoridis dan
Koutroumbas, 2009). Suatu sistem dapat dikatakan sebagai sistem pengenalan pola jika terdiri dari beberapa komponen seperti data acquisition, preprocessing, feature extraction, feature selection, model selection and
training, serta evaluation (Polikar, 2006). Di beberapa kajian penelitian
tentang character recognition terdapat sebuah proses atau komponen yang dilakukan sebelum ke tahap evaluation, yaitu postprocessing (Patil dan Srinivasan, 2013).
Pengertian dari data acquisition adalah suatu proses bagaimana cara kita memperoleh data, cara mengukur data tersebut dan berapa jumlah data yang diperlukan. Data yang kita dapatkan berasal dari lingkungan sekitar yang kemudian kita ubah kedalam bentuk digital sehingga dapat diolah oleh komputer.
Komponen selanjutnya adalah preprocessing, yaitu proses ketika data yang sudah diperoleh (acquired data) dikondisikan sedemikian sehingga siap diolah untuk tahap selanjutnya dengan tujuan agar permasalahan mengenai pengenalan pola dapat dengan mudah diselesaikan. Hal-hal yang biasanya dilakukan dalam tahap preprocessing yaitu outlier removal, data
normalization, treating missing data, dll (Theodoridis dan Koutroumbas,
2009).
Definisi dari feature extraction adalah mengekstrak atau mengambil fitur-fitur penting dari objek untuk mengurangi dimensi data. Secara singkat, tujuan dari feature extraction adalah menemukan jumlah kecil dari fitur objek
(subset) yang mampu membedakan dengan objek lainnya dan yang paling
(dimensionality reduction) di dalam pengenalan pola atau bisa dikatakan sebuah feature set kecil tetapi sangat informatif secara signifikan dapat mengurangi kompleksitas dari algoritma yang digunakan untuk proses klasifikasi, waktu dan beban memory untuk menjalankan algoritma.
Komponen selanjunya adalah feature selection yaitu menyeleksi atau memilih subset fitur dari set (himpunan) fitur yang telah diidentifikasi sebelumnya menggunakan algoritma yang digunakan pada tahap feature
extraction. Pemilihan fitur ini didasarkan pada pencarian subset fitur yang
mengarah pada performa generalisasi terbaik dari kinerja classifier ketika dilatih dengan subset tersebut.
Model selection and training adalah komponen yang dipenuhi setelah
data diperoleh lalu melalui tahap preprocessing, kemudian ektraksi fitur dan pemilihan fitur yang unik atau informatif dari objek tersebut sehingga telah siap untuk memilih classifier dan algoritma pelatihan (training)yang sesuai. Proses klasifikasi dapat dikatakan pemilihan fungsi aproksimasi yang mampu memetakan suatu masukan (input) kedalam informasi pada sebuah class yang sesuai. Ketika proses klasifikasi ini dikatakan sebagai suatu fungsi aproksimasi maka berbagai alat matematika (mathematical tools) seperti algoritma optimasi dapat digunakan. Menurut Jain et al., (2000) algoritma atau pendekatan yang umum digunakan untuk proses klasifikasi adalah
template matching, statistical classification, syntactic or structural matching,
dan neural network.
maka hanya berupa susunan kata, tanpa ada arti atau informasi dari barisan suku kata yang ada.
Bagian komponen terakhir, yaitu setelah postprocessing selesai sering disebut sebagai evaluation. Performa kinerja dari classifier perlu dievaluasi menggunakan data baru untuk menghitung tingkat kebenaran atau akurasi yang dihasilkan oleh classifier. Pertama, dataset terlebih dahulu harus dipisah antara data untuk training dan testing. Terkait dengan pembagian dataset
untuk memisah data training dan data testing menjadi penting karena data
testing harus independent dari data training agar mampu membentuk model
yang relatif tepat untuk membentuk prediksi data baru yang akan datang. Namun di sisi lain ada perhatian khusus mengenai data yang dipakai untuk
training dan testing yang harus diperhatikan seperti jika sebagian kecil dari
data yang digunakan untuk testing maka perkiraan dari performa generalisasi dari classifier mungkin tidak dapat diandalkan (unreliable), sedangkan jika sebagian besar data dipakai untuk testing maka berakibat pada sedikitnya data latih (training)atau sering disebut dengan poor training.
2.4 Data Acquisition
Data acquisition merupakan suatu proses yang kita kerjakan untuk
memperoleh data, cara mengukur data tersebut dan berapa jumlah data yang diperlukan. Data tersebut bisa diperoleh dengan memotret menggunakan kamera, sensor satelit, atau menggunakan sensor lainnya. Data yang kita dapatkan berasal dari lingkungan sekitar yang kemudian kita ubah kedalam bentuk digital sehingga dapat diolah oleh komputer.
2.5 Preprocessing
2.5.1 Cropping
Cropping pada sebuah citra merupakan proses yang dilakukan
koordinat untuk melakukan proses pemotongan yaitu koordinat awal dan koordinat akhir. Koordinat awal merupakan titik pojok kiri atas citra yang akan dipotong sedangkan koordinat akhir merupakan titik pojok kanan bawah citra yang akan dipotong. Tiap-tiap pixel yang ada pada koordinat tersebut menjadi sebuah citra baru yang merupakan hasil dari pemotongan citra yang dilakukan.
2.5.2 Grayscaling
Citra grayscale atau citra keabu-abuan memiliki nuansa warna abu-abu yang berada diantara warna hitam dan putih. Citra graysclace
direpresentasikan dengan variasi nilai intensitas tertentu yang berada dalam interval 0 hingga 255. Proses grayscaling mengubah citra berwarna yang memiliki 3 komponen warna R, G dan B menjadi 1 komponen warna dengan memberikan sebuah nilai bobot kepada 3 komponen R, G dan B kemudian dijumlahkan untuk memperoleh intensitas warna abu-abu. Persamaan yang umum dipakai untuk mengubah citra berwarna menjadi citra grayscale menggunakan standar NTSC (National Television System Committee) yang dapat dinyatakan sebagai berikut:
, = . , + . � , + . ∗ , (2.1)
Dengan:
g(x,y) = citra yang akan dikonversi menjadi grayscale
R(x,y) = nilai pixel pada lokasi (x,y) untuk komponen R
G(x,y) = nilai pixel pada lokasi (x,y) untuk komponen G
B(x,y) = nilai pixel pada lokasi (x,y) untuk komponen B
2.5.3 Binarization
Binarization merupakan sebuah proses untuk mengubah citra
grayscale menjadi citra hitam putih. Citra perlu diubah kedalam format
binary karena informasi mengenai warna tidak dibutuhkan, selain itu
citra dipisahkan menjadi 2 komponen, yaitu komponen pertama adalah objek dari citra, kemudian yang lainnya adalah background. Untuk mengkonversi citra grayscale menjadi citra biner sekaligus memisahkan antara objek dan background maka dilakukan proses pengecekan nilai setiap nilai pixel terhadap nilai ambang atau sering disebut dengan pengambangan intensitas atau thresholding. Menurut Kadir dan Susanto (2012) nilai ambang ditentukan dengan terlebih dahulu melihat histogram citra dan dipilih nilai untuk ambang pada bagian lembah. Secara matematis, thresholding atau pengambangan intensitas dapat dinyatakan melalui persamaan:
, = { ,, >≤ (2.2)
Dengan:
g(x,y) = citra hasil segmentasi atau citra biner
f(x,y) = citra masukan
(x,y) = titik (x,y) pada citra
T = nilai thresholding (nilai ambang)
Dalam penerapannya, nilai 1 atau 0 pada persamaan 2.2 dapat saling ditukarkan posisinya.
2.5.4 Image Segmentation
Segmentasi citra merupakan suatu metode yang dilakukan untuk memperoleh objek-objek yang terkandung di dalam citra atau membagi suatu citra menjadi beberapa daerah yang memiliki kemiripan atribut antara objek atau daerah pada citra (Kadir et.al., 2012).
Penelitian yang telah dilakukan oleh Widiarti et al. (2014) tentang
Preprocessing Model of Manuscript in Javanese Characters
pixel objek secara vertikal untuk memperoleh informasi tentang pixel
garis yang memiliki kelompok pixel tertentu yang merupakan representasi dari suatu objek (karakter). Persamaan dari vertical
projection dapat ditulis sebagai berikut:
��[ ] = ∑ [ , ] =
(2.3) Dengan:
Pv = vektor Pv pada baris ke-i
S = citra masukan berupa citra biner
R,C = ukuran baris dan kolom citra
Hasil dari vertical projection yaitu menemukan line image suatu objek sehingga langkah selanjutnya adalah segmentasi karakter. Segmentasi karakter dilakukan untuk memperoleh setiap objek karakter yang terkandung dalam citra. Proses yang dikerjakan untuk melakukan segmentasi karakter adalah menerapkan horizontal projection untuk mendapatkan informasi posisi pixel yang memungkinkan kita potong untuk memperoleh karakter tersebut. Persamaan horizontal projection
adalah sebagai berikut:
�ℎ[ ] = ∑ [ , ] �
=
(2.4)
Dengan:
Ph = vektor Ph pada kolom ke-j S = citra masukan berupa citra biner
R,C = ukuran baris dan kolom citra
(karakter). Persamaan dari vertical projection dapat dilihat pada persamaan 2.3. Misalnya kita memiliki sebuah citra biner aksara Jawa
pa dan ra dalam satu bagian.
Gambar 2.10 Citra Biner “Para”
Gambar 2.10 merupakan contoh representasi citra aksara pa dan ra. Dengan melakukan vertical projection pada Gambar 2.10 maka kita akan menjumlahkan nilai setiap pixel pada semua baris di setiap kolomnya untuk mengetahui letak garis pada masing-masing aksara. Pada citra biner, komponen yang berwarna hitam mempunyai nilai pixel
0 dan komponen putih mempunyai nilai pixel 1, sehingga dapat kita peroleh matriks proyeksi vertikalnya adalah [ 0 5 1 5 1 5 1 5 0 1 1 6 1 1 5 0 ]. Dengan hasil yang diperoleh dapat disimpulkan bahwa jika nilai pada matriks sama dengan 0 berarti pada kolom tersebut tidak terdapat objek, sebaliknya jika nilai pada matrik lebih dari 0 maka menandakan pada kolom tersebut terdapat objek. Dengan kata lain, dapat kita katakan bahwa pada citra tersebut terdapat 2 objek, yaitu objek pertama terletak pada kolom ke-2 sampai ke-8 sedangkan objek kedua terletak pada kolom ke-10 sampai ke-15.
Setelah melakukan proyeksi secara vertikal lalu dilanjutkan dengan proyeksi horizontal. Proyeksi horizontal (horizontal projection) dilakukan untuk mengetahui batas atas dan batas bawah pada objek agar secara tepat dapat dipisahkan atau dipotong. Persamaan dari horizontal
projection dapat dilihat pada persamaan 2.4. Prinsip kerja dari
horizontal projection adalah menjumlahkan pixel masing-masing baris
dapat kita peroleh matriks proyeksi horizontalnya adalah [ 0 6 7 6 6 6 7 0 ]. Berdasarkan hasil dari matriks tersebut dapat disimpulkan bahwa batas paling atas pada objek tersebut berada pada baris ke-2 dan batas paling bawah berada pada baris ke-7. Secara visual, hasil dari
projection profile (vertical dan horizontal projection) dapat dinyatakan
sebagai berikut:
Gambar 2.11 Projection Profile dari Citra Aksara Pa dan Ra
Gambar 2.11 adalah representasi citra hasil projection profile terhadap Gambar 2.10. Gambar sebelah kiri adalah aksara pa dan sebelah kanan adalah aksara ra yang telah tersegmentasi dengan baik. Dengan
projection profile maka kita dapat memisahkan masing-masing aksara
yang menyusun sebuah kata pada citra nama jalan. 2.5.5 Resizing
Resizing atau mengubah ukuran citra merupakan sebuah cara
untuk mengubah dimensi citra dengan ukuran tertentu sehingga informasi pixel dari citra tersebut juga berubah. Sebagai contoh, ketika ukuran citra diperkecil maka informasi pixel yang tidak dibutuhkan akan dihilangkan sedangkan ketika ukuran citra diperbesar maka akan ditambahkan informasi pixel baru untuk memperoleh ukuran citra yang lebih besar.
2.6 ICZ-ZCZ
zona merupakan nilai rerata dari jarak semua pixel di zona tersebut. Hasil dari ekstraksi ciri ICZ akan menghasilkan n fitur dari objek tersebut.
ZCZ merupakan kependekan dari Zone Centroid and Zone. Ekstraksi ciri ZCZ bekerja dengan membagi citra menjadi n zona kemudian masing-masing zona dihitung titik centroid-nya masing-masing. Setelah didapatkan titik centroid kemudian menghitung jarak semua pixel di zona tersebut dengan titik centroid. Total nilai jarak yang diperoleh di tiap zona merupakan rerata semua jarak yang dihasilkan. Langkah tersebut diulang sebanyak n
zona yang ada sehingga hasil dari ekstraksi ciri ZCZ menghasilkan n fitur. Perbedaan yang mendasar dari ekstraksi ciri ICZ dan ZCZ adalah penghitungan centroid dan pembagian zona yang dilakukan. ICZ bekerja dengan mencari titik centroid-nya terlebih dahulu kemudian citra dibagi kedalam n zona yang sama sehingga akan didapatkan satu titik centroid
Dalam penghitungan jarak antara centroid dengan nilai pixel yang ada di dalam zona menggunakan perhitungan jarak Euclidean distance dengan rumus seperti pada persamaan 2.7.
Misalkan terpadat sebuah citra aksara pa seperti Gambar 2.11. Pinsip kerja dari ekstraksi ciri menggunakan ICZ adalah sebagai berikut. Langkah pertama adalah mencari titik centroid-nya. Citra masukkan untuk proses ektraksi ciri adalah citra biner, sehingga objek dari citra memiliki representasi nilai 1, atau bagian yang berwarna putih. Dengan demikian nilai xi dan yi
adalah 1 sedangkan untuk nilai pi tergantung dari sumbu mana yang akan kita
cari, jika sumbu x maka nilai pi merupakan nilai koordinat objek pada sumbu x sedangkan jika sumbu y maka nilai pi merupakan nilai koordinat objek pada
sumbu y. Berdasarkan persamaan 2.5 dan 2.6 ketika suatu bilangan dikalikan 1 akan menghasilan bilangan itu sendiri maka secara sederhana kita cukup menjumlahkan nilai koordinat pada masing-masing sumbu untuk seriap pixel
objeknya. Titik centroid untuk � dan � dapat dihitung dengan:
� = + + + + + + + + + + + + + + + + + + + + + + = =
� = + + + + + + + + + + + + + + + + + + + + + + = = .
Dengan hasil yang diperoleh maka pusat massa (centroid) objek tersebut berada di titik (4, 3.82). Setelah titik centroid diperoleh maka objek tersebut kita bagi menjadi beberapa zona. Untuk mempermudah perhitungan kita bagi menjadi 3 zona secara horizontal. Jika citra sudah dibagi kedalam 3 zona kemudian menghitung jarak antara masing-masing pixel yang ada disetiap zona terhadap titik centroid-nya. Total nilai jarak yang ada disetiap zona merupakan nilai rerata dari jarak semua pixel di zona tersebut. Hasil dari ekstraksi ciri ICZ akan menghasilkan 3 fitur dari objek tersebut, sesuai dengan jumlah pembagian zona yang diberikan. Adapun persamaan yang digunakan untuk menghitung nilai jarak adalah menggunakan euclidean
Gambar 2.12 Pembagian Zona dan Perhitungan Jarak (ICZ)
Gambar 2.12 merupakan representasi pembagian zona menggunakan ICZ yang dibagi menjadi 3 zona sama besar secara horizontal pada citra aksara pa. Perhitungan untuk fitur pada zona 1 adalah sebagai berikut:
= √ − + − . = .
= √ − + − . = .
= √ − + − . = .
= √ − + − . = .
= √ − + − . = .
= √ − + − . = .
= . + . + . + . + . + . = .
euclidean distance. Total nilai jarak yang ada disetiap zona merupakan nilai rerata dari jarak semua pixel di zona tersebut. Hasil dari ekstraksi ciri ZCZ akan menghasilkan 3 fitur dari objek tersebut, sesuai dengan jumlah pembagian zona yang diberikan.
Adapun titik centroidxc dan yc pada zona 1 adalah sebagai berikut:
� = + + + + + = =
�= + + + + + = = .
Dengan demikian maka titik centroid pada zona 1 adalah (4, 1.67). Proses yang sama juga dilakukan untuk mencari titik centroid pada zona 2 dan zona 3, yang masing-masing titik centroid-nya adalah (4, 1.50) dan (4, 1.56).
Gambar 2.13 Pembagian Zona dan Perhitungan Jarak (ZCZ)
Gambar 2.13 merupakan representasi pembagian zona menggunakan ZCZ yang dibagi menjadi 3 zona sama besar secara horizontal pada citra aksara pa. Perhitungan untuk fitur pada zona 1 adalah sebagai berikut:
= √ − + − . = .
= √ − + − . = .
= √ − + − . = .
= √ − + − . = .
= √ − + − . = .
= √ − + − . = .
Berdasarkan hasil perhitungan diatas maka ciri atau fitur dari zona 1 adalah 2.06. Cara yang sama juga berlaku untuk mencari nilai ciri atau fitur pada zona 2 dan zona 3 sehingga diperoleh fitur zona ke 2 adalah 2.08 serta zona 3 adalah 1.90. Jika digabung akan menghasilkan 3 fitur, yaitu [ 3.01 2.11 2.66 ]. Setelah didapatkan masing-masing 3 fitur menggunakan metode ICZ dan ZCZ lalu fitur tersebut digabungkan sehingga menjadi 6 fitur yang merepresentasikan citra tersebut sehingga dapat ditulis [ 3.01 2.11 2.66 2.06 2.08 1.90 ].
2.7 Template Matching
Model klasifikasi yang digunakan dalam penelitian ini adalah menggunakan template matching. Pendekatan template matching dipilih karena paling mudah untuk diterapkan dan sesuai dengan karakteristik data yang akan dikenali. Prinsip pendekatan template matching untuk klasifikasi adalah mengukur kedekatan atau kesamaan (similarity) antar objek atau
entities yang diperbandingkan. Objek yang diperbandingkan adalah data uji
yang akan dikenali dengan database template yang sudah disimpan. Ketika suatu objek baru yang ingin dikenali dibandingkan dengan database template
kemudian diperoleh nilai kesamaan yang relatif besar maka secara langsung objek baru tersebut dapat diklasifikasikan atau dikenali sesuai dengan
template pembandingnya. Secara umum rumus yang biasa digunakan untuk
mengukur jarak antar 2 objek adalah menggunakan euclidean distance. Adapun rumus euclidean distance dapat ditulis sebagai berikut:
, = √∑ −
�
=
(2.7)
Dengan:
d(x,y) = jarak antara vektor objek x dan y
n = jumlah dimensi objek
Nilai jarak antar objek yang besar menandakan bahwa kedua objek tersebut relatif tidak mirip, sebaliknya jika nilai jarak antar objek bernilai kecil maka kedua objek tersebut relatif mirip (memiliki kesamaan). Sebagai contoh, diberikan sebuah objek A memiliki nilai feature [6 4 3 8 9 4 5 2] dan objek B memiliki nilai feature [4 5 8 2 2 4 2 9] sedangkan terdapat sebuah template C dengan nilai feature [1 8 6 4 4 5 6 4]. Untuk mencari objek mana yang memiliki kemiripan dengan objek C maka berdasarkan nilai feature masing-masing objek dapat dihitung jaraknya sebagai berikut:
=
√ − + − + − + − + − + − + − + − =
√ = .
=
√ − + − + − + − + − + − + − + − =
√ = .
Cara diatas merupakan perhitungan yang biasa kita lakukan untuk menghitung nilai jarak menggunakan euclidean distance. Untuk menyingkat proses perhitungan, kita dapat melakukan hal yang berbeda tetapi dengan hasil yang sama menggunakan perhitungan matriks. Cara tersebut adalah sebagai berikut:
= [ − ]
= [ − − − − − − − − ]
= [ − − − − − ]
=√ ∗ ′ =√ + + + + + + + =√ = .
= [ − ]
= [ − − − − − − − − ]
= [ − − − − − ]
=√ ∗ ′ =√ + + + + + + + =√ = .
bahwa objek B memiliki kemiripan dengan objek C dibandingkan dengan objek A.
2.8 Postprocessing
Proses postprocessing dilakukan untuk mengelompokkan suku kata agar membentuk kata atau kalimat yang memiliki arti. Hal tersebut perlu dilakukan karena karakter penulisan aksara Jawa adalah tanpa spasi sehingga jika tidak dikelompokkan maka hanya berupa susunan kata, tanpa ada arti dari barisan suku kata tersebut. Namun sebelum dilakukan proses pengelompokan kita juga harus mengetahui tentang aturan-aturan dalam penulisan aksara Jawa karena sering kali tidak hanya ditulis dengan aksara legena tetapi ditambah dengan sandhangan dan pasangan. Sebagai contoh, perhatikan penulisan aksara berikut ini.
Gambar 2.14 Aksara Iredha
Gambar 2.14 di atas jika dibaca bunyinya “iredha.” Aksara tersebut disusun oleh 3 aksara legena, pertama, yaitu ha diberi sandhangan yang letaknya diatas aksara ha berupa wulu sehingga jika dibaca menjadi hi atau i. Aksara kedua ra diberi sandhangan berupa taling di depannya sehingga menjadi re
dan yang terakhir adalah aksara dha. Jika semua aksara digabungkan maka dibaca “iredha.”
Gambar 2.15 Aksara Modhang
dibaca menjadi mo. Aksara kedua dha diberi sandhangan berupa cecak di atasnya sehingga menjadi dhang. Jika semua aksara digabungkan maka dibaca “modhang.”
Gambar 2.16 Aksara Pajeksan
Gambar 2.16 di atas jika dibaca bunyinya “pajeksan.” Aksara tersebut disusun oleh 4 aksara legena dan 1 aksara pasangan.Aksara pertama, yaitu pa lalu aksara kedua yaitu ja diberi sandhangan yang terletak di atasnya berupa pepet
sehingga jika dibaca menjadi je. Aksara ketiga yaitu ka. Setalah aksara ka
terdapat aksara pasangan sa sehingga aksara di depannya yaitu ka akan berubah menjadi mati atau konsonan k. Aksara terakhir yaitu na diberi
pangkon sehingga menjadi mati atau konsonan n. Jika semua aksara
digabungkan maka dibaca “pajeksan.”
Berdasarkan beberapa contoh diatas maka dapat dirangkum menjadi aturan penulisan menggunakan aksara Jawa dipengaruhi oleh aksara yang lainnya, aksara tersebut dapat berupa sandhangan maupun pasangan. Ketika diberi sebuah pasangan maka aksara asli (legena) akan berubah bunyinya. Terdapat pengecualian untuk sandhangan berupa pangkon yaitu digunakan sebagai sigeg (konsonan penutup suku kata) untuk aksara yang berada di depannya. Aksara legena jika diberi sebuah pasangan maka aksara yang di depan atau di atasnya akan menjadi konsonan atau mati.
2.9 Evaluation
dibandingkan dengan jumlah semua objek yang secara umum menggunakan rumus seperti dibawah ini.
32
BAB III
METODE PENELITIAN
3.1 Bahan Riset/Data
Penelitian ini menggunakan bahan sebuah citra nama jalan beraksara Jawa sebagai input yang akan diproses ke tahap pengenalan aksara. Objek citra nama jalan beraksara Jawa ini diperoleh dengan mengambil foto nama-nama jalan yang berada di Kota Yogyakarta. Jumlah citra nama-nama jalan yang dipakai dalam penelitian ini sebanyak 130 gambar yang dibagi menjadi 30 gambar untuk data uji dan 100 gambar untuk data template.
3.2 Peralatan Penelitian
Spesifikasi perangkat keras yang digunakan dalam pembuatan
prototype sistem pengenalan nama jalan beraksara Jawa ini yaitu sebuah
komputer dengan prosesor Intel Core i5, kapasitas memory sebesar 6 GB dan ruang penyimpanan (hardisk)sebesar 500 GB.
Perangkat lunak yang dipakai dalam proses pembuatan prototype
sistem pada penelitian ini adalah Matlab versi 7.10. Pemilihan Matlab sebagai alat untuk membangun prototype sistem karena dukungan toolbox yang lengkap dan cocok dipakai dalam pengolahan data berupa matriks.
3.3 Metode Pengumpulan Data
3.3.1 Observasi
3.3.2 Studi Literatur
Studi literatur merupakan sarana untuk memperoleh informasi yang digunakan untuk mencari topik dan teori-teori yang terkait dengan penelitian yang akan dikerjakan. Teori yang sudah ada dan berbagai penelitian sejenis yang pernah dilakukan akan digunakan sebagai acuan dan pedoman dalam melakukan penelitian saat ini. Sumber-sumber yang dapat dijadikan bahan referensi antara lain buku-buku atau jurnal yang berkaitan dengan pembahasan yang akan diteliti.
3.4 Tahap Penelitian
3.4.1 Identifikasi Masalah
Tahap awal dalam penelitian ini adalah merumuskan masalah dengan melihat kondisi yang ada disekitar yaitu membuat sebuah sistem yang mampu menerjemahkan kata yang ditulis menggunakan aksara Jawa. Data mengenai kata dalam aksara Jawa diambil dari nama-nama jalan yang ada di Yogyakarta. Rumusan permasalahan yang akan diselesaikan adalah mengukur kemampuan sistem dalam menerjemahkan tulisan menggunakan aksara Jawa menjadi tulisan latin yang direpresentasikan dengan tingkat akurasi yang dihasilkan oleh sistem.
3.4.2 Studi pustaka
sehingga penelitian yang akan dikerjakan dapat diselesaikan dan dapat dipertanggungjawabkan kebenarannya.
3.4.3 Pengumpulan Data
Pengumpulan data menjadi unsur yang penting dalam penyelesaian tugas akhir karena digunakan untuk memperoleh informasi atau data yang berguna untuk penelitian yang sedang dikerjakan. Data yang diperoleh nantinya akan diamati dan diolah secara mendalam sesuai dengan prosedur dan teori yang sudah dirumuskan. Data yang digunakan untuk penelitian ini bersumber dari hasil mengambil foto objek nama-nama jalan yang ada di wilayah Yogyakarta. Jarak pengambilan gambar nama jalan kurang lebih 50 cm dari tiang jalan. Objek nama jalan yang dipilih merupakan nama jalan yang ditulis menggunakan aksara Jawa.
Teknik yang digunakan dalam mengumpulkan data penelitian ini adalah teknik observasi. Teknik ini umumnya sering dipakai didalam penelitian kualitatif. Observasi pada dasarnya melakukan suatu kegiatan menggunakan panca indera kita, bisa berupa penglihatan, penciuman, pendengaran untuk memperoleh informasi yang dibutuhkan dalam menjawab masalah pada penelitian yang sedang dikerjakan. Dengan menggunakan observasi ini maka data dapat diperoleh secara riil gambaran suatu peristiwa yang berada dilapangan. 3.4.4 Pengolahan Data
Gambar 3.1 Blok Diagram
Gambar 3.1 diatas memvisualisasikan langkah-langkah dalam pengolahan data yang dilakukan. Pada dasarnya, pengolahan data yang dikerjakan dibagi menjadi 2 bagian utama, yaitu pembuatan template
database dan pengujian atau testing. Masing-masing bagian memiliki
langkah-langkah yang hampir sama, yaitu ketika kita melakukan data
acquisition, preprocessing dan feature extraction and selection. Yang
membedakan adalah pada pembuatan template database, hasil dari ekstraksi ciri kemudian disimpan sebagai features dari template
sedangkan pada bagian pengujian features dari template akan dibandingkan dengan features data uji untuk dihitung jarak kedekatannya kemudian akan diklasifikasikan dengan jarak minimum dari template yang ada. Penjelasan mengenai langkah-langkah yang dilakukan adalah sebagai berikut:
a. Data Acquisition
dengan resolusi 10 megapixels (4096 x 2304 pixels). Jarak pengambilan gambar sekitar 50 cm dari tiang nama jalan. Pengambilan gambar dilakukan dengan 2 versi, yang pertama data diambil pada keadaan normal, artinya kondisi pencahayaan cukup terang pada waktu pagi hingga siang hari dan sudut pengambilan gambar tegak lurus terhadap papan nama jalan. Versi kedua, untuk membuat data uji bervariasi maka sebagian gambar diambil pada keadaan tidak normal, artinya pengambilan gambar dilakukan dengan pencahayaan yang minim/gelap pada waktu malam hari dan
angle/sudut pengambilan gambar sembarang atau tidak tegak lurus
terhadap papan nama jalan. Format gambar yang digunakan adalah JPG. Bahan yang digunakan untuk pembuatan template adalah citra aksara Jawa nglegena, sandhangan dan pasangan yang divariasikan. Data yang dipakai untuk membuat template harus
independent terhadap data uji agar mampu membentuk model yang
relatif tepat untuk membentuk prediksi data baru yang akan datang.
b. Preprocessing
Sebelum data diekstrak cirinya maka data tersebut harus disiapkan sedemikian sehingga data tersebut siap untuk diolah. Adapun tahapan yang dilakukan pada preprocessing adalah sebagai berikut:
Gambar 3.2 merupakan tahapan dalam proses preprocessing.
Secara berurutan, proses tersebut adalah cropping, grayscaling,
binarization, dan image segmentation, resizing. Proses cropping
dilakukan secara manual menggunakan photoshop untuk mendapatkan citra nama jalan yang ditulis dengan aksara Jawa saja. Proses grayscaling dan binarization diperlukan untuk mengubah citra dari berwarna menjadi citra abu-abu lalu dari citra abu-abu diubah menjadi citra hitam-putih atau citra biner. Kedua proses tersebut menggunakan toolbox pada Matlab yaitu fungsi
rgb2gray() dan fungsi im2bw(). Langkah selanjutnya adalah proses segmentation yaitu proses untuk memisahkan tiap karakter yang menyusun tulisan nama jalan secara otomatis menggunakan metode projection profile. Proses terakhir adalah resizing yaitu mengubah ukuran citra agar memiliki ukuran yang sama untuk mempermudah proses ekstraksi ciri dan klasifikasi. Dengan menggunakan toolbox dari Matlab yaitu imresize() citra diubah ukurannya menjadi 100x110 pixels. Pemilihan ukuran tersebut berdasarkan hasil percobaan untuk mendapatkan ukuran citra terbaik tanpa kehilangan informasi/detail penting dari citra.
c. Feature Extraction and Selection
Ekstraksi ciri dan pemilihan ciri yang tepat dan sesuai dengan karakteristik objeknya merupakan hal yang sangat berpengaruh terhadap kemampuan sistem untuk mengklasifikasikan objek. Ekstraksi ciri akan mengambil informasi yang penting dari objek sehingga mempermudah dalam proses klasifikasi. Selain itu ektraksi ciri dilakukan untuk mengurangi dimensi data sehingga beban memory lebih sedikit, running time relatif lebih cepat dan mengurangi kompleksitas algoritma untuk proses klasifikasi. Ektraksi yang dipakai pada penelitian ini adalah ICZ-ZCZ (Image
Centroid and Zone-Zone Centroid and Zone). Untuk pembagian
yang menguji model pembagian zona terbaik sehingga pada penelitian ini citra dibagi ke dalam 4 zona. Pembagian 4 zona ini diuji menggunakan 2 model yaitu citra dibagi menjadi 4 zona secara horizontal dan vertikal-horizontal. Berikut ini adalah representasi citra ketika dibagi menjadi 4 zona.
Gambar 3.3 Pembagian 4 Zona Secara Horizontal
Gambar 3.3 merupakan representasi dari citra yang dibagi menjadi 4 zona secara horizontal. Citra berukuran 100x110 pixels sehingga jika dibagi 4 zona secara horizontal maka tiap zona masing-masing berukuran 25x110 pixels.
Gambar 3.4 Pembagian 4 Zona Secara Vertikal-Horizontal Gambar 3.4 merupakan representasi dari citra yang dibagi menjadi 4 zona secara vertikal dan horizontal. Citra berukuran 100x110 pixels
sehingga jika dibagi 4 zona maka setiap zona secara vertikal-horizontal masing-masing berukuran 50x55 pixels. Jumlah feature
feature dan ekstraksi ZCZ memiliki keluaran 4 nilai features. Pada prinsipnya ekstraksi ciri ICZ-ZCZ merupakan gabungan dari ekstraksi ciri ICZ dan ZCZ sehingga dengan pembagian 4 zona maka menghasilkan nilai 8 nilai features dari objek.
d. Pembuatan Template Database
Data yang sudah melalui tahap preprocessing dan feature extraction
and selection akan menghasilkan keluaran berupa ciri dari objek
tersebut. Ciri dari setiap objek yang dijadikan sebagai template
disimpan ke database ciri untuk membuat template database. Citra yang digunakan untuk pembuatan template database sebanyak 100 citra yang independen terhadap citra data uji (testing).
e. Classification
Tahap klasifikasi akan menghitung jarak minimum antara template
dengan data uji sehingga data uji yang memiliki kemiripan paling besar akan diklasifikasikan sesuai dengan template-nya. Untuk mengukur kedekatan antar objek yang diperbandingkan menggunakan rumus jarak euclidean distance.
f. Postprocessing
Pada tahap ini, kumpulan aksara Jawa yang diperoleh dari hasil klasifikasi akan diproses lagi untuk dicek apakah sudah sesuai dengan aturan dalam penulisan aksara atau belum. Jika belum maka akan dibetulkan sesuai dengan kaidah yang berlaku. Jika kata yang membentuk sudah sesuai dengan aturan penulisan aksara Jawa maka akan dikelompokkan menjadi 2 hingga 3 kata, sesuai dengan kata yang menyusun nama jalan yang berada di Kota Yogyakarta.
g. Evaluation
pencahayaan cukup terang dan angle/sudut pengambalian gambar tegak lurus dengan papan nama jalan. Case kedua data yang diambil divariasikan dengan data yang diambil dengan kondisi tidak normal, artinya gambar diambil dengan pencahayaan mini,/gelap
dan angle/sudut pengambilan gambar tidak tegak lurus dengan
papan nama jalan. Dari 2 test case tersebut masing-masing akan dibandingkan hasil akurasinya menggunakan pembagian 4 zona secara horizontal dan 4 zona secara vertikal-horizontal. Semakin tinggi tingkat akurasi yang dihasilkan maka semakin baik performa sistem dalam mengklasifikasikan suatu objek.
3.4.5 Perancangan Alat Uji
Kebutuhan fungsional dari prototype sistem yang akan dibuat adalah sistem mampu menerjemahkan kata dalam aksara Jawa menjadi tulisan latin. Input yang dimasukkan kedalam sistem berupa citra nama jalan beraksara Jawa kemudian akan memberikan output berupa terjemahan tulisan latinnya. Sistem dibuat menggunakan Matlab
sebagai tool untuk membangun alat uji. 3.4.6 Implementasi
Pada tahap implementasi, tahapan pengolahan data dan perancangan alat uji akan diimplementasikan menjadi sebuah code
dengan memanfaatkan Matlab sebagai tools untuk membuat prototype
sistem. Sebagai dasar atau alur pemikiran dalam menerjemahkan langkah penelitian menjadi sebuah code maka masing-masing tahapan dapat dituliskan menjadi sebuah algoritmasebagai berikut:
a. Projection Profile
Vertical Projection
Step 1: inisialisasi citra masukan inImage adalah berupa citra biner, vert
adalah vektor hasil vertical
projection
Step 3: inisialisasi matrik bernilai 0 (zeros) berdimensi 1 x panjang kolom citra masukan
Step 4: lakukan perulangan i=2 sampai panjang matriks v_proj-1, jika ya lakukan dengan 0, jika ya maka objek terletak pada kolom ke i+1, simpan letak objek ke variable v_line, jika tidak ke step 7
Step 7: Cek apakah v_proj ke i-1 tidak sama dengan 0, jika ya maka objek terletak pada kolom ke i-1, simpan letak objek ke variable v_line
Step 8: nilai vert sama dengan v_line Step 9: selesai
Horizontal Projection
Step 1: inisialisasi citra masukan inImage adalah berupa citra biner, horz
adalah vektor hasil horizontal
projection
Step 4: lakukan perulangan i=2 sampai panjang matriks h_proj-1, jika ya lakukan dengan 0, jika ya maka objek terletak pada baris ke i+1, simpan letak objek ke variable h_line, jika tidak ke step 7
Step 7: Cek apakah h_proj ke i-1 tidak sama dengan 0, jika ya maka objek terletak pada baris ke i-1, simpan letak objek ke variable h_line
b. Ekstraksi ciri ICZ-ZCZ
Step 1: mencari koordinat centroid citra
input
Step 2: membagi citra ke dalam n daerah yang sama
Step 3: menghitung jarak centroid dengan pixel citra yang ada pada daerah
Step 6: cari koordinat centroid untuk setiap daerah
Step 7: menghitung jarak centroid dengan pixel citra yang ada pada daerah tersebut
Step 8: hitung rerata jarak pada daerah tersebut
Step 9: ulangi langkah 7-8 sampai semua daerah yang ada. Jika sudah lanjut ke step 10
Step 10: Simpan hasil perhitungan jarak
sebagai ciri dari objek tersebut
c. Pengukuran jarak antara data uji dengan template
Step 1: inisialisasi variabel temp = selisih fitur template baris pertama dengan fitur objek
Step 2: hitung jarak pada step 1, simpan ke variabel mind_dist
Step 3: inisialisasi variabel min_idx = 1
Step 4: inisialisasi n = jumlah template
Step 5: lakukan perulangan untuk n=2 sampai panjang database template, jika ya lakukan step 6 sampai 10, jika tidak ke step 11
Step 6: inisialisasi temp_2 = selisih fitur template ke n dengan fitur objek, lalu Step 7: hitung jarak pada step 6, simpan ke
variabel dist
Step 8: Jika dist kurang dari min_dist maka ke step 9, jika tidak ke step 5
Step 9: nilai min_dist sama dengan dist Step 10: nilai min_idx = n
Step 11: selesai
d. Proses postprocessing
Step 2: lakukan perulangan dari i=1 sampai width, lakukan step 4 sampai 10, jika tidak ke step 11
Step 3: jika i lebih dari 3 dan i kurang dari width, lakukan step 4, jika tidak ke step 10
Step 4: jika string ke i adalah taling, lanjut ke step 5, jika tidak ke step 6
Step 5: jika string ke i+1 adalah tarung, ubah string terakhir menjadi berakhiran o Step 6: ubah string string ke i+1 menjadi
berakhiran e
Step 7: cek apakah string i+1 adalah pasangan_ha, jika ya maka string ke i dijadikan konsonan, jika tidak ke step 8
Step 8: cek apakah string i+1 adalah pasangan_sa, jika ya maka string ke i dijadikan konsonan, jika tidak ke step 9
Step 9: cek apakah string i+1 adalah pasangan_pa, jika ya maka string ke i dijadikan konsonan, jika tidak ke step 10
Step 10 : gabungkan nilai string ke i ke variabel finalString
Step 11: selesai
3.5 Desain Alat Uji
Prototype sistem pengenalan pola kata beraksara Jawa yang akan
dibangun memiliki desain interface seperti pada gambar dibawah ini.
Secara garis besar, desain interface sistem pada Gambar 3.3 dibagi menjadi 3 bagian penting, yaitu header untuk meletakkan judul, kemudian body sebagai bagian untuk meletakkan fungsi utama dari sistem dan terakhir footer untuk memberikan informasi tambahan diluar fungsi utama mengenai sistem yang dibuat.
3.6 Pengujian (Testing)
Pada tahap pengujian, citra nama jalan akan digunakan sebagai input
untuk sistem untuk diterjemahkan dari aksara Jawa ke huruf latin. Jumlah pengujian yang dilakukan sebanyak 30 kali yang sesuai dengan jumlah bahan citra yang diperoleh. Dari 30 citra masukan akan dihitung berapa banyak hasil terjemahan yang benar kemudian menghitung tingkat akurasi sistem dalam menerjemahkan aksara Jawa ke huruf latin.
3.7 Pengukuran Akurasi Sistem
Kemampuan sistem dalam menerjemahkan kata dalam bentuk aksara Jawa menjadi tulisan latin harus bisa diukur dengan menghitung nilai akurasinya. Cara mengukur tingkat akurasi yaitu dengan membandingkan objek yang dikenali dengan benar oleh sistem dengan jumlah data testing
45
BAB IV
HASIL DAN ANALISA
Pada bab ini akan diuraikan masing-masing tahapan dari transliterasi nama jalan beraksara Jawa. Secara umum tahapan yang dikerjakan seperti pada Gambar 3.1 tentang blok diagram yang dibagi menjadi 6 bagian, yaitu data acquisition,
preprocessing, featureextraction and selection, classification, postprocessing dan
evaluation. Untuk tahapan dalam pembuatan template terdapat sedikit perbedaan
yang hanya terdiri dari 4 proses, yaitu setelah proses feature extraction and
selection dilanjutkan ke tahap pembuatan database template.
4.1 DataAcquisition
Data berupa citra nama jalan yang digunakan pada penelitian ini diambil menggunakan kamera smarthpone dengan resolusi sebesar 4096 x
2304 pixels. Data citra yang diambil sebanyak 130buah yang dibagi menjadi 100 citra untuk data template dan 30 citra untuk data uji. Waktu pengambilan citra pada waktu pagi atau siang hari dengan pencahayaan cukup terang. Daerah tempat pengambilan citra berada di daerah Kota Yogyakarta.