Pada bab ini berisikan kerangka pemikiran dan metode yang digunakan dalam penelitian berdasarkan literatur dan jurnal yang berhubungan dengan penerapan Big Data sebagai suatu implementasi di Institusi ANRI. Pembahasan mengenai kerangka pemikiran dijelaskan pada sub bab 3.1.
3.1 Kerangka Pemikiran
Penerapan Big Data melalui Hadoop memerlukan tahapan-tahapan dalam implementasi. Mulai dari tahap analisa informasi sistem IT yaitu dengan melakukan pemrosesan dan melakukan pencarian yang nantinya dapat dirancang melalui portfolio aplikasi. Berikut ini merupakan kerangka pemikiran dari penelitian ini, sebagai berikut:
Start
Pengumpulan Data
Observasi Wawancara
Implementasi di Hadoop Software
Analisa Hasil
Kesimpulan dan Saran
Gambar 3.1. Kerangka Pemikiran
48
3.2 Tahap Penelitian
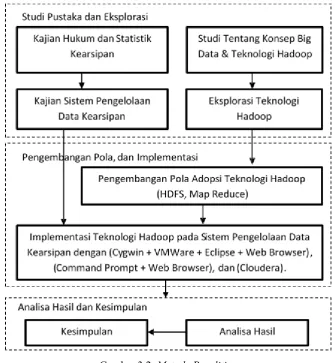
Metode yang digunakan dalam penelitian ini berdasarkan literatur dan jurnal yang berhubungan dengan penerapan Big Data sebagai suatu implementasi di Institusi Arsip Nasional RI dengan pendekatan Hadoop Framework. Adapun tahap pengumpulan data dilakukan melalui studi pustaka dan studi kasus. Pada metode penelitian berisi tahapan-tahapan, sebagai berikut:
Gambar 3.2. Metode Penelitian
A. Studi Pustaka dan Eksplorasi
Studi pustaka mencakup:
2. Kajian Sistem Pengelolaan data kearsipan, yaitu dengan melakukan penelitian mengenai sistem yang berjalan di ANRI.
3. Studi Konsep Big Data dan teknologi Hadoop, yaitu dengan melakukan riset dan implementasi bagaimana Big Data dengan Hadoop dapat berjalan, melakukan konfigurasi Hadoop pada Intitusi ANRI.
4. Sharing pengalaman teknologi Hadoop dari beberapa sumber yang diperoleh, kemudian melakukan eksplorasi tentang teknologi Hadoop, dengan cara menyiapkan kebutuhan konfigurasi lingkungan Hadoop dan turunannya. Melakukan dokumentasi mengenai proses instalasi dan melakukan monitoring terhadap kinerjanya pada sistem di Browser), dan (Layanan Big Data dengan Cloudera).
Pada Tahap ini, melakukan perancangan sistem yang dibuat. Perancangan Sistem implementasi teknologi Hadoop terdiri dari tahap-tahapan sebagai berikut:
a) Arsitektur Sistem.
50
Gambar 3.3. Arsitektur Sistem
Sumber:
https://www.academia.edu/8146931/Analisis_Performansi_Hadoop_Cluster_Mu lti_Node_pada_Komputasi_Dokumen
Berdasarkan gambar 3.3 diatas, dapat dijelaskan pada server pusat yang diindetifikasi dengan alamat IP mengirim suatu tindakan untuk melakukan jobtracker/namenode dari PC 1, PC 2, PC 3. Untuk melakukan tindakan jobtracker pada PC 2, dan PC 3 melakukan switch hub yang telah di konfigurasi di server pusat.
b) Skenario Pengujian Map Reduce.
Gambar 3.4. Proses Kinerja Map Reduce
Berdasarkan gambar 3.4 diatas, dapat dijelaskan pada server client mempunyai 2 tugas, yaitu membuat jobtracker dan menulis/write Tasktracker.
Pada alur ketika submit job, mengolah data HDFS terdistribusi dan membuat jobtracker. Kemudian menulis atau melakukan input file melalui tasktracker (melalui proses maping dan reduce) sehingga menghasilkan suatu output file.
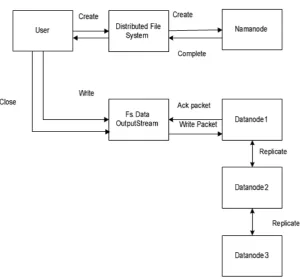
c) Skenario Pengujian HDFS.
52
Gambar 3.5. Proses Kinerja Write pada HDFS
Berdasarkan gambar 3.5 diatas, dapat dijelaskan pada server client mempunyai 2 tugas, yaitu membuat/create namenode dan menulis/write Datanode.
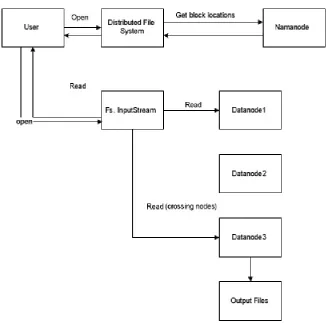
Gambar 3.6. Proses Kinerja Read pada HDFS
Berdasarkan gambar 3.6 diatas, dapat dijelaskan pada server client mempunyai 2 tugas, yaitu membuat open dan read.
54
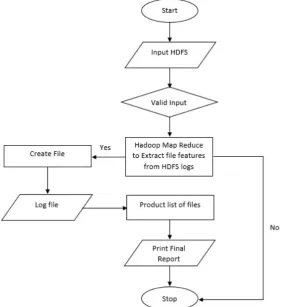
d) Skenario Pengujian Multi Node Cluster.
Gambar 3.7. Proses Pengujian Multi Node
Berdasarkan gambar 3.7 diatas, menjelaskan proses pengujian Multi Node Cluster, sebagai berikut:
C. Analisa Hasil dan Kesimpulan
Pada tahapan ini melakukan analisa hasil uji coba sehingga menghasilkan suatu kesimpulan apakah pola dan hasil implementasi telah menjawab persoalan yang ada dan memberikan hasil yang diharapkan.
Pembahasan berikutnya adalah mengenai metode pengumpulan data terkait dengan penelitian. Metode pengumpulan data dan sumber data dijabarkan pada sub bab 3.3.
3.3 Metode Pengumpulan Data dan Sumber Data 3.3.1 Data Primer
Data primer di dapat melalui observasi, wawancara dengan pimpinan dan staff di Institusi Arsip Nasionl RI. Hal ini mengartikan sumber data yang diperoleh berisfat langsung, berasal dari sumber asli. Data primer berupa opini yang bersifat subjektif (orang) baik secara individu atau kelompok, hasil observasi terhadap suatu benda (fisik), kejadian atau kegiatan dan hasil pengujian.
3.3.2 Data Sekunder
Data sekunder merupakan data pendukung terhadap penelitian yang dilakukan yang berupa data yang di dapat dari literatur yang berhubungan. Pada penelitian ini, menggunakan teknik pengumpulan data yang bersifat kualitatif sebagai suatu perencanaan dan sebagai pelaksanaan pengumpulan data terkait yang berupa observasi, wawancara dan dokumnetasi.
1. Observasi
56
2. Wawancara
Merupakan teknik pengumpulan data yang dilakukan secara langsung dengan menggunakan pertanyaan lisan dan tertulis, dimana memerlukan adanya kontak atau hubungan antara peneliti dengan subjek, dalam hal penelitian ini dengan responden di Institusi ANRI yang terdiri dari Pimpinan, anggota kantor, anggota lapangan. Data-data yang diperoleh sebagian besar merupakan data deskriptif, tetapi pengumpulan data dapat dirancang untuk menjelaskan sebab dan akibat atau mengungkapkan ide-ide perihal penelitian yang dilakukan ini.
Teknik wawancara yang dilakukan ini diperlukan peneliti agar dapat berkomunikasi dengan responden. Data yang dikumpulkan umumnya dapat berupa masalah tertentu yang bersifat kompleks, sensitive, dan kontroversial. Teknik ini dilakukan dengan tujuan membantu responden yang kurang familiar dengan teknik kuesioner.
Kegiatan teknik wawancara dengan pengumpulan data melakukan pertemuan langsung dan memberikan pertanyaan kepada pimpinan dan user yang terkait dengan implementasi pemanfaatan TI/SI pada Institusi ANRI.
Pembahasan berikutnya adalah metode evaluasi penelitian yang dijabarkan pada sub bab 3.4.
3.4 Metode Evaluasi Penelitian
Selanjutnya kesimpulan sementara dirumuskan secepatnya mungkin menjadi kesimpulan-kesimpulan yang kokoh, kuat dan mengandung makna sebelum data tersebut terhimpun. Kesimpulan tersebut bertujuan untuk menjawab pertanyaan pertanyaan penelitian serta dapat dijadikan sebagai temuan-temuan penelitian yang bermanfaat.
Analisis data yang digunakan dalam penelitian ini terbagi dalam dua bagian yaitu analisis fungsional dan analisis non fungsional. Analisis fungsional dilakukan untuk mengetahui apakah penelitian ini sudah menjawab permasalahan pada Instansi. Analisis non fungsional dilakukan untuk mengetahui spesifikasi kebutuhan untuk sistem baik hardware maupun software. Analisis fungsional dan non fungsional dijabarkan dalam tabel, sebagai berikut:
Tabel 3.1. Analisis Fungsional
Analisis Fungsional
Admin & IT Operasional
No. Permasalahan
1 Seringnya terjadi gangguan dalam menagkses data di penyimpanan / terjadi server down.
2 Lambatnya penanganan provider ketika terjadi gangguan, dan tidak tersedianya fitur keamanan yang jelas bila terjadi masalah pada sistem seperti fitur DRP.
Pihak Manajemen Instansi
No. Permasalahan
1 Anggaran biaya pada Sistem menambah kapasitas penyimpanan, maupun saat terjadi maintenance.Cloud Computing yang mahal, terutama ketika
2 Perlunya pembatasan akses antar sub divisi untuk meminimalkan resiko pengaksesandata yang sifatnya “sensitive dokumen”.
Pada tabel 3.1 diatas, dapat dijelaskan sebagai berikut:
58
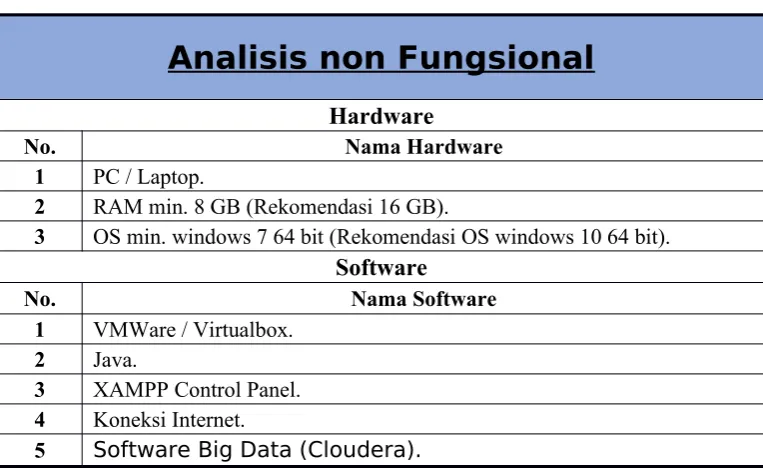
2 RAM min. 8 GB (Rekomendasi 16 GB).
3 OS min. windows 7 64 bit (Rekomendasi OS windows 10 64 bit). Software
5 Software Big Data (Cloudera).
Pada 3.2 diatas, dapat dijelaskan sebagai berikut: