Pengantar Pengolahan
Data Statistik
Menggunakan SPSS 22
Statistika
Statistika adalah ilmu yang mempelajari bagaimana
merencanakan, mengumpulkan, menganalisis,
menginterpretasi, dan mempresentasikan data.
Statistika (
statistics
) berbeda dengan statistik
(
statistic
).
Populasi dan
Sampel
Populasi
adalah keseluruhan objek yang dibatasi oleh
kriteria tertentu.
Sampel
adalah sebagian objek yang diambil dari
populasi dengan menggunakan cara-cara tertentu.
Syarat suatu sampel:
Sampel mewakili populasi yang diwakili
Sampel tidak boleh subjektif, dalam pemilihannya harus
Analisis
Statistik
Secara garis besar, analisis data statistic dibagi menjadi
dua kelompok, yaitu:
Statistik deskriptif: Adalah analisis yang memberikan
gambaran secara umum mengenai karakteristik data seperti mean, median, mode, varian dan range.
Statistik inferensi: Adalah membuat inferensi terhadap data
yang diolah, seperti untuk perkiraan dan pengambilan
Statistik
Inferensi
Statistika
Inferensi
Parametrik
Statistika
Parametrik
Statistika parametrik mempertimbangkan jenis
sebaran (distribusi) data, yaitu apakah data menyebar
normal atau tidak.
Statistika parametrik menetapkan adanya
syarat-syarat tertentu (asumsi-asumsi) tentang variabel
random atau populasi yang merupakan sumber sampel
penelitian.
Statistika
Non-Parametrik
Statistika non-parametrik adalah statistika bebas
sebaran, artinya tidak mensyaratkan bentuk sebaran
parameter populasi.
Jenis Data
Statistik
Dalam ilmu statistic, jenis data dibedakan menjadi 4
bagian, yaitu:
Jenis Data
Statistik:
Nominal
Digunakan untuk mengklasifikasikan informasi/data.
Contoh:
Data jenis kelamin, yaitu laki-laki dan Perempuan.
Biasanya, saat analisis data, tipe data seperti ini dilambangkan dengan bilangan numerik (angka).
Laki-laki dilambangkan dengan angka 1, sedangkan
perempuan dilambangkan dengan angka 0.
Jenis Data
Statistik:
Ordinal
Digunakan untuk mengklasifikasikan serta memiliki
tingkatan.
Tipe data ordinal lebih tinggi daripada nominal karena
kemampuannya untuk membentuk tingkatan.
Contoh:
Jabatan di dalam perusahaan yang terdiri dari karyawan,
manager, direktur utama.
Misal, karyawan dilambangkan dengan 1, manager dengan 2,
dan direktur utama dengan 3.
Pada tipe data ini, angka 1 dianggap lebih rendah dari angka
2, dst.
Bisa saja karyawan dilambangkan dengan angka 1, tetapi
manager angka 3 dan direktur utama dengan angka 10. Tipe data ini tidak mensyaratkan jarak yang sama antar angka
yang digunakan sebagai lambang. Yang perlu diperhatikan
Jenis Data
Statistik:
Interval
Memiliki poin jarak objektif dalam keteraturan kategori
peringkat, tapi jarak yang tercipta sama antar
masing-masing angka.
Contoh Data Variabel :
Umur 20-30 tahun = 1
Umur 31-40 tahun = 2
Umur 41-50 tahun = 3
Suhu 0-50 Celsius = 1
Suhu 51-100 Celsius = 2
Jenis Data
Statistik: Rasio
Memiliki kemampuan dari ketiga tipe data
sebelumnya, dan angka nol dianggap mutlak.
Contoh:
Jenis Data
Statitik
Computing : Nominal Ordinal Interval Ratio
frequency distribution. Yes Yes Yes Yes
median and percentiles. No Yes Yes Yes
add or subtract. No No Yes Yes
mean, standard deviation, standard error
of the mean. No No Yes Yes
SPSS
SPSS adalah sebuah program aplikasi yang memiliki
kemampuan analisis statistik cukup tinggi serta sistem
manajemen data pada lingkungan grafis dengan
menggunakan menu-menu deskriptif dan kotak-kotak
dialog yang sederhana sehingga mudah untuk
Input Data
Ada 3 cara untuk input/memasukkan data:
Impor data dari spreadsheet, MS. Excel
Impor dari file notepad (.txt)
Membuat file
SPSS yang
baru
Ketika memasukkan data SPSS yang baru, ada 2
tampilan yaitu
data
view dan
variable
view.
Data view mirip dengan Excel, namun ada beberapa
perbedaan, yaitu:
Baris pada SPSS adalah merupakan kasus.
Pada setiap baris sel di halaman SPSS mewakili satu kasus atau observasi.
Data View
Variable View
Variable view digunakan untuk memasukkan informasi atribut
variabel:
Name: nama variable
Type: jenis variabel (numerik, tanggal, nominal,teks/string, dsb).
Width: lebar kolom dalam tampilan data view. Secara otomatis/default biasanya berisi 8 (delapan) karakter.
Decimals: jumlah digit di belakang koma.
Label: penjelasan lebih lanjut dari nama variabel, misalnya: dalam nama variabel berisi RESID, kemudian labelnya diisikan dengan RESPONDENT IDENTITY.
Values: nilai variabel, misalnya: 1= laki-laki, 0=perempuan
Missing: perlakuan untuk nilai yang kosong
Columns: lebar kolom
Align: rata kiri, rata kanan atau tengah.
Label Data
Label data digunakan untuk memberikan keterangan
penjelas dari data.
Statistik Deskriptif
HATCO
HATCO adalah perusahaan yang menjualbahan
–
bahan kebutuhan produksi kepada perusahaan lain.
Berikut ini adalah langkah-langkah untuk menghasilkan statistik deskriptif:
Klik ANALYZE >>DESCRIPTIVE STATISTIC >> DESCRIPTIVES
Berikut ini adalah langkah-langkah untuk menghasilkan statistik deskriptif:
Kemudian klik OPTIONS… hingga muncul kotak dialog DESCRIPTIVES: OPTIONS, kemudian beri tanda
Berikut ini adalah langkah-langkah untuk menghasilkan statistik deskriptif:
Statistik Inferensi
Uji Kualitas
Data
:
Uji Validitas
Untuk melakukan Uji Validitas item pertanyaan Variabel X1 adalah dengan langkah: klik Analyze, pilih Correlate, dan klik Bivariate.
Uji Kualitas
Data
:
Uji Kualitas
Data
:
Uji Realibilitas
Misalnya menguji Reliabilitas untuk Variabel X1: klik Analyze, pilih Scale, klik
Reliability Analysis….
Setelah tampil kotak Reliability Analysis, pindahkan item-item pertanyaan X1 dan Variabel X1 ke kotak Items kemudian klik tanda panah dan klik Statistics
Uji Kualitas
Data
:
Uji Realibilitas
Ceklist kotak item dan scan if item deleted
Uji Kualitas
Data
:
Uji Asumsi
Klasik
Uji asumsi klasik. Tujuan pengujian ini adalah untuk memperoleh
hasil atau nilai yang tidak bias atau estimator linear tidak bias yang terbaik (Best Linear Unbiased Estimator/BLUE).
Uji asumsi klasik tersebut yaitu:
Uji Normalitas
Uji Multikolinearitas
Uji Autokorelasi
Uji Normalitas
Uji Normalitas
• Centang pilihan Unstandardized pada bagian Residuals, kemudian
pilih Continue dan pada tampilan awal pilih tombol OK, akan menghasilkan variabel baru bernama Unstandardized Residual (RES_1).
• Selanjutnya Analyze>>Descriptive Statistics >>Descriptives akan muncul tampilan sebagai berikut.
Uji Normalitas
• Centang pilihan Unstandardized pada bagian Residuals, kemudian pilih Continue dan pada tampilan awal pilih tombol OK, akan
menghasilkan variabel baru bernama Unstandardized Residual (RES_1).
• Selanjutnya Analyze>>Descriptive Statistics >>Descriptives akan muncul tampilan sebagai berikut.
Uji
Autokorelasi
Uji autokorelasi digunakan untuk mengetahui ada atau tidaknya korelasi antara anggota–anggota serangkaian observasi yang
tersusun dalam rangkaian waktu atau yang tersusun dalam rangkaian ruang.
Hasil dari output SPSS menunjukkan nilaiDurbin-Watson (DW) hitung sebesar 1,984, sedangkan pada tabel DW diperoleh nilai dU (Upper Durbin-Watson) sebesar 1.7887. Model regresi dinyatakan tidak
terdapat permasalahan autokorelasi apabila nilaiDurbin-Watson (DW) terletak diantara dU dan 4-dU. Angka DW hitung pada model
penelitian ini berada diantara DW tabel dengan menggunakan derajat kepercayaan 95% danα 5% yaitu 1.7887 < DW hitung < 2,2113. Dapat disimpulkan tidak terjadi autokorelasi atau tidak terdapat
Uji Hipotesis:
Koefisien
Determinasi
Koefisien Determinasi (R2) berfungsi untuk melihat sejauh mana
keseluruhan variabel independen dapat menjelaskan variabel dependen
Terdapat nilai Adjusted R Square yaitu sebesar 0,704 atau 70,4%.
Uji Hipotesis:
Analisis
Regresi
Berganda
Maka dapat dibentuk model persamaan regresi berganda sebagai
berikut:
Y= - α + β1X1 + β2X2 + e
Keterangan:
Y = Kinerja Karyawan
X1= Kompensasi
X2= Displin
β = Koefisien Regresi X1dan X2
α = Konstanta
Uji Hipotesis:
Uji Parsial (t)
Pengaruh Kompensasi terhadap Kinerja Karyawan
H1= Kompensasi berpengaruh positif dan signifikan terhadap kinerja karyawan.
Pada tabel diatas terdapat nilai t hitung yaitu 7,457 dan tingkat signifikansi sebesar 0.000. Nilai signifikansi tersebut lebih kecil dari 0.05 dan nilai t hitung (7,457) lebih besar dari t tabel (1,651). Hal tersebut mengindikasikan bahwa kompensasi berpengaruh signifikan secara parsial terhadap kinerja karyawan. Pada tabel diatas terdapat nilai koefisien (β) yaitu positif, artinya pengaruh yang diberikan oleh variabel tersebut adalah positif. Dapat
disimpulkan bahwa kompensasi berpengaruh positif dan
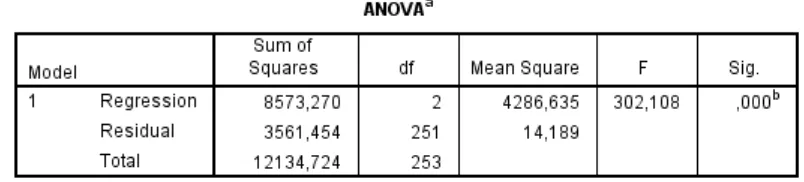
Uji Hipotesis:
Uji Simultan (f)
Diperoleh nilai F hitung sebesar 302,108 yang lebih besar dari F tabel sebesar 3.04 .
Hal tersebut mengindikasikan bahwa kompensasi dan disiplin