TEORI DASAR NEURAL NETWORK (1)
Jaringan Syaraf Tiruan
Jaringan syaraf tiruan (JST) atau Artificial Neural Network (ANN) adalah
suatu model matematik atau komputasi untuk mensimulasikan struktur dan
fungsi dari jaringan syaraf dalam otak.
Terdiri dari :
• Node atau unit pemroses (penjumlah dan fungsi aktivasi) • Weight/ bobot yang dapat diatur
• Masukan dan Keluaran
Sifat :
• Adatif
Jaringan Syaraf Tiruan (JST)
Menirukan model otak manusia
Otak Manusia
JST
Soma
Node
Dendrites
Input/Masukan
Axon
Output/Keluaran
Synapsis
Weight/ Bobot
Model Neuron Tanpa Bias
Masukan / Input
Σ
p
1p
2p
i.
.
.
Penjumlahan
w
1w
2w
iBobot/Weight = bisa diatur
F(y)
n=Σp
i.w
iModel Neuron Dengan Bias
Masukan / Input
Σ
Bobot/Weight = bisa diatur
F(y)
n=Σp
i.w
ia=f(n)
Fungsi Aktivasi
Model Matematis
X = input/masukan I = banyaknya input
W = bobot/weight
Keluaran Penjumlah
à
n =
Σ
p
i
.w
i
• Jumlah semua Input (p
i) dikali bobot (w
i)
Output/Keluaran Neuron=
Fungsi Aktivasi
¨
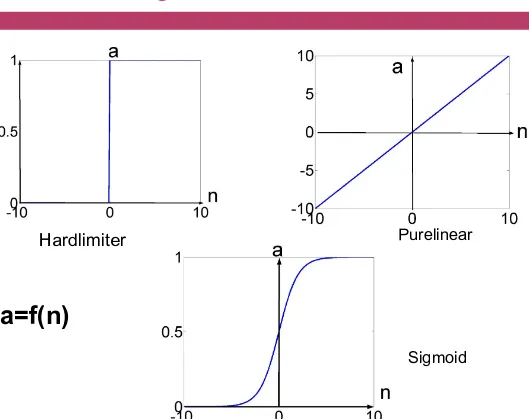
Beberapa fungsi aktivasi a=f(n)
¨
Hardlimit function
à
a =
¨
Linear Function
à
a = n
¨
Sigmoid Function
à
a = 1 /( 1+ e
-n
)
Grafik Fungsi Aktivasi
Hardlimiter Purelinear
Sigmoid
Kegunaan Aktivasi
Untuk pengambilan
keputusan biasanya
digunakan Hardlimit
Untuk pengenalan
pola/jaringan back
propagation
biasanya digunakan
sigmoid
Untuk
prediksi/aproksimasi
linear biasanya
Model McCulloch and Pitts
Neuron menghitung jumlah bobot dari setiap sinyal input dan
membandingkan hasilnya dengan nilai bias/threshold,
b
.
Jika input
bersih kurang dari threshold, output neuron adalah -1
. Tetapi,
jika
input bersih lebih besar dari atau sama dengan threshold, neuron
diaktifkan dan outputnya ditetapkan +1
(McCulloch and Pitts, 1943).
î
Fungsi aktivasi ini disebut
Fungsi Tanda
(Sign Function)
. Sehingga output aktual
dari neuron dapat ditunjukkan dengan:
Perceptron
Perceptron (Rosenblatt, 1958): JST training yang sederhana dipakaikan
prosedur algoritma training yang pertama kali. Terdiri dari neuron
tunggal dengan bobot synaptic yang diatur dan hard limiter.
Operasinya didasarkan pada model neuron McCulloch dan Pitts.
Jumlah input yang telah diboboti dipakaikan kepada hard limiter:
menghasilkan output +1 jika input positif dan -1 jika negatif à
mengklasifikasikan output ke dalam dua area A1 dan A2.
Proses Belajar
Target = Nilai yang diinginkan
Output = Nilai yang keluar dari neuron
Proses Compare (membandingkan) antara output dengan target
Target
Error digunakan untuk pembelajaran /mengatur bobot
Analog
Target
à
apa yang diinginkan
Input/masukan
à
Kekurangan dan kelebihan/potensi
Bobot
à
seberapa besar usaha
Output
à
hasil dari potensi AND kelemahan dikalikan dengan
usaha terhadap potensi OR kelemahan
Proses Belajar
Σ
p
1Masukan
w
1
F(y)
n=p
1.w
1a=f(n)
Proses Belajar jika masukan positif
keluaran a hrs dinaikan
untuk menaikan a maka
naikan nilai w1 karena
masukan positif
w1 next= w1 old + delta
w1
Proses Belajar jika masukan negatif
keluaran a hrs dinaikan
untuk menaikan a maka
turunkan nilai w1 karena
masukan negatif
w1 next= w1 old + (- delta
w1)
Proses Perceptron Belajar
Pada awalnya bobot dibuat kecil untuk menjaga jangan
sampai terjadi perbedaan yang sangat besar dengan target.
Bobot awal adalah dibuat random, umumnya dalam interval
[-0.5 – 0.5]
Keluaran adalah proses jumlah perkalian antara masukan
dengan bobot.
Jika terjadi perbedaan antara keluaran dengan target,
e(k)
= a(k) – t(k)
,
k
= iterasi ke- 1, 2, 3, maka:
Perceptron Learning Rule (Rosenblatt, 1960)
e(k) = a(k) – t(k), k = iterasi ke- 1, 2, 3, ….. • a(k) = keluaran neuron
• t(k) = target yang diinginkan • e(k) = error/kesalahan
w(k+1) = w(k) + Δw(k)
Δw(k) = kec belajar x masukan x error
• = ŋ x p(k) x e(k)
ŋ = learning rate à kecepatan belajar (0< ŋ ≤1)
ŋ besar belajar cepat à tidak stabil
Langkah Pembelajaran
Langkah
pertama :
Inisialisasi Awal
• Mengatur bobot w1, w2, ..., wn interval [-0.5 – 0.5], mengatur bias/threshold b, mengatur kec pembelajaran ŋ, fungsi aktivasi
Langkah kedua :
Menghitung
keluaran
• Mengaktifkan perceptron dengan memakai masukan p1(k), p2(k), ...,
pi(k) dan target yang dikehendaki t(k). Hitunglah output aktual pada iterasi ke-k = 1
• i adalah jumlah input perceptron dan step adalah fungsi aktivasi
Langkah ke tiga :
Menghitung error
• e(k) = t(k) – a(k) t(k) = target,a(t)=keluaran perceptron
Langkah ke
empat :
Mengatur Bobot
• Mengupdate bobot perceptron • wi(k+1) = wi(k) + Δwi(k)
• w(k+1)à bobot baru w(k)à bobot yg lalu
• Δwi(p) adalah pengkoreksian bobot pada iterasi k, yang dihitung dengan • Δwi(p) = ŋ x pi(k) x e(k)
Langkah ke
lima :
pengulangan
• Naikkan iterasi k
dengan 1 (k=k+1),
kembalilah ke langkah
ke dua dan ulangi
proses sampai keluaran
= target atau mendekati
target
Melatih Perceptron: Operasi OR
Variabel Input
OR
x
1x
2Fd
0
0
0
0
1
1
1
0
1
Fungsi OR
Σ
p
1p
2w
1
w
2
F(y)
n=Σpi.wi
a=f(n)
b
x1
x2
+
-Fd=target
Perceptron
Contoh Pembelajaran
1.
Langkah pertama : Inisialisasi Awal
n Mengatur bobot w1, w2 interval [-0.5 – 0.5],
w
1(1)=0.3
w2(1)
=0.1,mengatur bias/threshold b=0.2, mengatur kec pembelajaran ŋ =0.2,
fungsi aktivasi-> step
2.
Langkah kedua : Menghitung keluaran
n Mengaktifkan perceptron dengan memakai masukan p1(k), p2(k) dan
Contoh Pembelajaran
3.
Langkah ke tiga : Menghitung error
¤
e(k) = t(k) – a(k)
¤e(1) = 0 – 0 = 0
4.
Langkah ke empat : Mengatur Bobot
¤
Mengupdate bobot perceptron
¤wi(k+1) = wi(k) +
Δ
wi(k)
¤
w1(2) = 0.3(1) +
Δ
w1(1)
¤
Δ
w1(1) =
ŋ
x pi(1) x e(1) = 0.2 x 0 x 0 = 0
n
maka w1(2) = 0.3(1) + 0 = 0.3 (tidak berubah)
¤
wi(k+1) = wi(k) +
Δ
wi(k)
¤w2(2) = 0.3(1) +
Δ
w2(1)
¤
Δ
w2(1) =
ŋ
x pi(1) x e(1) = 0.2 x 0 x 0 = 0
Contoh Pembelajaran
5.
Langkah ke lima : pengulangan
n
Naikkan iterasi k dengan 1 (k=k+1), kembalilah ke langkah
Contoh Pembelajaran
l
K=2
w
1(2)= 0.3 w
2(2)=0.1, p
1(2)=0, p
2(2)=1
target(2)=Fd(2)=1
l
Hitung keluaran:
Contoh Pembelajaran
¨
Hitung error
¤
e(2)= target(2) - a(2) = 1 - 0 =1 (ada error)
¨
Mengatur Bobot
¤
Mengupdate bobot perceptron
n
wi(k+1) = wi(k) +
Δ
wi(k)
nw1(3) = 0.3(2) +
Δ
w1(2)
n
Δ
w1(2) =
ŋ
x p1(1) x e(1) = 0.2 x 0 x 1 = 0
n maka w1(3) = 0.3(1) + 0 = 0.3 (tidak berubah)
n
wi(k+1) = wi(k) +
Δ
wi(k)
nw2(3) = 0.3(2) +
Δ
w2(2)
n
Δ
w2(1) =
ŋ
x p2(1) x e(1) = 0.2 x 1 x 1 = 0.2
Multilayer Perceptron
Multi-Layer Perceptron adalah jaringan syaraf
tiruan feed-forward yang terdiri dari sejumlah
neuron
yang
dihubungkan
oleh
bobot-bobot
penghubung.
Neuron-neuron tersebut disusun dalam
lapisan-lapisan yang terdiri dari satu lapisan-lapisan input (input
layer), satu atau lebih lapisan tersembunyi (hidden
layer), dan satu lapisan output (output layer).
Multilayer Perceptron
Tidak ada batasan banyaknya hidden layer dan jumlah neuron pada setiap layernya.
Setiap neuron pada input layer terhubung dengan setiap neuron pada hidden layer. Demikian juga, setiap neuron pada hidden layer terhubung ke setiap neuron pada output layer.
Setiap neuron, kecuali pada layer input, memiliki input tambahan yang disebut bias.
Multilayer Perceptron
Kemudian, jaringan dilatih agar keluaran jaringan sesuai dengan pola pasangan masukan-target yang telah ditentukan.
Proses pelatihan adalah proses iteratif untuk menentukan bobot-bobot koneksi antara neuron yang paling optimal.
Kata back propagation yang sering dikaitkan pada MLP merujuk pada cara bagaimana gradien perubahan bobot dihitung.
Tahapan Dalam Penyelesaian Masalah Menggunakan Metode
Jaringan Syarat Tiruan Menggunakan Multilayer Percepteron
1.
Identifikasi masalah
¤ Tahap ini merupakan identifikasi masalah yang hendak diselesaikan dengan
jaringan syaraf tiruan, meliputi identifikasi jenis dan jumlah masukan serta keluaran pada jaringan.
2.
Menyiapkan training data set
¤ Training data set merupakan kumpulan pasangan data masukan-keluaran
berdasarkan pengetahuan yang telah dikumpulkan sebelumnya.
¤ Banyaknya data set harus mencukupi dan dapat mewakili setiap kondisi yang
hendak diselesaikan. Terbatasnya data set akan menyebabkan akurasi jaringan menjadi rendah.
3.
Inisialisasi dan pembentukan jaringan
¤ Tahap inisialisasi meliputi penentuan topologi, pemilihan fungsi aktivasi, dan
pemilihan fungsi pelatihan jaringan.
¤ Penentuan topologi adalah penentuan banyaknya hidden layer dan penentuan
Tahapan Dalam Penyelesaian Masalah Menggunakan Metode
Jaringan Syarat Tiruan Menggunakan Multilayer Percepteron
4.
Simulasi jaringan
¤
Simulasi jaringan dilakukan untuk melihat keluaran jaringan
berdasarkan masukan, bobot neuron dan fungsi aktivasinya.
5.
Pelatihan/training jaringan
¤
Sebelum melakukan pelatihan, dilakukan penentuan parameter
training terlebih dahulu, seperti penentuan jumlah iterasi, learning
rate, error yang diijinkan. Setelah itu dilakukan pelatihan yang
merupakan proses iteratif untuk menentukan bobot koneksi antar
neuron.
6.
Menggunakan jaringan untuk pengenalan pola
¤
Setelah pelatihan dilakukan, jaringan siap untuk digunakan untuk
Gradient Descent
Gradient descent (ascent) adalah algoritma optimasi orde
pertama.
Untuk menemukan minimum lokal dari fungsi menggunakan gradien
descent, diambil langkah sebanding dengan negatif dari gradien
(atau perkiraan gradien) dari fungsi pada titik sekarang.
Jika diambil langkah sebanding dengan gradien positif, maka
akan didapatkan maksimum lokal fungsi tersebut; prosedur ini
kemudian dikenal sebagai gradient ascent
Algoritma (maksimisasi)
¨
Mulai dari titik awal v
0¨
Bergerak dari v
0ke v
1dengan arah
Ñ
f(v
0) :
v
1= v
0+ t
0Ñ
f(v
0
)
dengan t
0adalah solusi dari masalah optimisasi
berikut:
max f(v
0+ t
0Ñ
f(v
0
) )
s.t t
0≥
0
¨
Langkah – langkah tersebut diulangi sampai
Algoritma (minimisasi)
¨
Mulai dari titik awal v
0¨
Bergerak dari v
0ke v
1dengan arah
Ñ
f(v
0) :
v
1= v
0- t
0Ñ
f(v
0
)
dengan t
0adalah solusi dari masalah optimisasi
berikut:
min f(v
0- t
0Ñ
f(v
0
) )
s.t t
0≥
0
¨
Langkah – langkah tersebut diulangi sampai
Contoh Soal
Gunakan metode steepest ascent untuk aproksimasi solusi dari
max 𝑧 = − 𝑥
(− 3
*− 𝑥
*− 2
*s.t
𝑥
(, 𝑥
*∈ 𝑅
*Dengan titik awal v
0= (1,1)
Jawab:
Ñ
f(x
1
, x
2) = (– 2(x
1– 3), – 2(x
2– 2))
Ñ
f(v
0
) =
Ñ
f(1,1) = (4,2)
Pilih t
0yang memaksimumkan
f(v
0+ t
0Ñ
f(v
0
) )
®
max f[(1,1)+t
0(4,2)]
®
max f[1+4t
0 ,
1+2t
0]
Contoh Soal
max 𝑧 = − 1 + 4𝑡
0− 3
*
− 1 + 2𝑡
0− 2
*
max 𝑧 = − −2 + 4𝑡
0*
− −1 + 2𝑡
0*
f ‘(t
0)=0
®
- 2(-2+4t
0
)4 -2(-1+2t
0)2 = 0
20 – 40 t
0= 0
t
0= 0.5
v
1= [(1,1)+0.5(4,2)] = (3,2)
Karena
Ñ
f(3, 2) = (0,0) maka iterasi dihentikan
Kesimpulan
Jaringan syaraf tiruan cocok digunakan untuk
menyelesaikan masalah yang tidak linier, yang
tidak dapat dimodelkan secara matematis.
Jaringan cukup belajar dari pasangan data
masukan dan target yang diinginkan, setelah
itu jaringan dapat mengenali pola yang mirip
dengan masukan ketika dilakukan pelatihan.
Kesimpulan
Bila data training cukup banyak dan konsisten, akurasi jaringan akan tinggi, sebaliknya bila data training tidak
memadai, akurasi jaringan rendah.
Selain data training, akurasi jaringan juga ditentukan oleh pemilihan topologi yang tepat.
Proses pembentukan jaringan sangat melelahkan, dilakukan secara terus menerus hingga diperoleh jaringan yang paling baik. Tetapi setelah jaringan yang optimal ditemukan, proses pengenalan pola dapat dilakukan secara cepat, lebih cepat