1. Pendahuluan
Pengenalan digit tulisan tangan atau handwritten digit recognition telah diketahui pemanfaatannya dalam beberapa aplikasi seperti pengenalan digit-digit penyusun kode pos pada sampul surat [3][4], pengenalan nilai angka yang tertulis pada surat berharga seperti cek atau giro[21], dan otomasi entry data dari formulir setelah form dropout dilakukan.[28][29] Terdapat sejumlah metode dalam handwritten character recognition yang offline. Dari sekian banyak metode tersebut tidak pernah disebut bahwa sebuah metode menjadi yang terbaik. Hal ini disebabkan kekurangan dan kelebihan yang ada pada masing-masing metode. Alasan utama masalah ini --hal mana membedakannya dengan optical character recognition (OCR) -- adalah inkonsistensi. Kenyataan
ini melahirkan suatu pemikiran bahwa menjadi mungkin untuk menghasilkan suatu metode gabungan
(multiple classifiers) dengan memanfaatkan sejumlah metode (individual classifiers) yang telah dikenal, sehingga performansi pengenalan yang memanfaatkan metode gabungan ini dapat ditingkatkan.
Pada prinsipnya semua metode yang digunakan untuk handwritten digit recognition dapat dikategorikan ke dalam 3 (tiga) respon yang berbeda. [14][25] Pada respon tipe 1 output yang dihasilkan menyebutkan bahwa glyph yang dikenali adalah kelas tertentu, tanpa dilengkapi atribut tambahan lainnya. Sebagai contoh untuk handwritten digit recognition maka output mungkin hanya menyebutkan secara sederhana bahwa “glyph ini adalah digit delapan”. Pada respon tipe 2 output yang dihasilkan kategori ini berupa ranking yang mungkin dari sebuah glyph.
Proceeding 2004 Asia Pasific Conference on ASET (Arts, Science, Engineering,
and Technology) for Human Resources Development via E&T and R&D.
Bandung, 5-8 Oktober 2004.
Multiple Classifiers Berbasis Tipe Respon untuk
Pengenalan Digit Tulisan Tangan
Kuswara Setiawan dan Gunawan
Jurusan Teknik Informatika
Sekolah Tinggi Teknik Surabaya
{kuswara, gunawan}@stts.edu
Abstrak:
Pada tulisan ini ditawarkan multiple classifier berbasis tipe respon untuk pengenalan digit tulisan tangan. Setiap metode yang akan berperan sebagai individual classifier menghasilkan output klasifikasi yang dapat dikategorikan ke dalam tiga respon yang berbeda. Pada tipe respon 1 output yang dihasilkan menyebutkan bahwa glyph yang dikenali adalah anggota kelas tertentu, tanpa dilengkapi atribut tambahan lainnya. Untuk tipe respon 2 output yang dihasilkan berupa ranking mulai dari kelas yang paling mirip. Sedangkan output tipe respon 3 adalah daftar probabilitas untuk masing-masing kelas. Untuk penggabungan respon tipe 1 dapat digunakan strategi voting Simple Majority Vote (SMV), Weighted Majority Vote (WMV), dan Dissenting-Weighted Majority Vote (DWMV). Penggabungan respon tipe 2 memanfaatkan aturan Borda Count, Black, dan Copeland. Sedangkan penggabungan respon tipe 3 memanfaatkan teknik averaging.Sebagai individual classifier digunakan tujuh representasi features: penskalaan sederhana glyph dalam ukuran tertentu; histogram yang mewakili semua garis baris, kolom, dan diagonal glyph; signature; moment description; character profile; convex deficiency dan neighborhood vector code, sedangkan klasifikasinya memanfaatkan backpropagation feed-forward neural network.
Melalui sejumlah percobaan dengan memanfaatkan digit-sets standard yang lazim digunakan untuk uji coba metode pengenalan digit tulisan tangan -- NIST Special Database 90, NIST 97, dan MNIST -- yang menyediakan hampir lima ratus ribu glyphs, performansi multiple classifiers yang ditawarkan dapat mencapai 98.4%.
Sebagai contoh output klasifikasinya mungkin menyebutkan: ”Glyph ini tampaknya seperti digit lima, tetapi mungkin juga sebuah digit tiga, dan sedikit mirip dengan digit dua”. Output respon tipe 3 adalah yang paling spesifik dari kedua respon sebelumnya, karena memberi tambahan atribut nilai
confidence dari kelas outputnya. Kedua tipe respon lainnya dapat dihasilkan oleh tipe respon ini.
2. Koleksi Datasets NIST
Penggunaan datasets yang standard untuk pengujian performansi sebuah sistem telah menjadi konvensi untuk publikasi metode baru dalam subdisiplin machine learning atau data mining. Demikian juga dengan metode-metode HCR yang dipublikasikan. Terdapat sejumlah datasets tulisan tangan yang menjadi konvensi untuk uji coba performansi sistem, misalnya CEDAR, CENPARMI, NIST, dan IAM.[2] Dikenal pula dataset lain seperti U.S. Zip Codes dari tim riset OCR Concordia yang berasal dari sampul-sampul surat yang disediakan oleh Kantor Pos Amerika Serikat. Datasets NIST digunakan oleh banyak metode handwritten digit recognition, terutama untuk pembuktian metode-metode terkemuka dengan performansi ketelitian di atas 90%. Dikenal 3 (tiga) varian datasets NIST yang berbeda, yaitu NIST90, NIST97, dan MNIST.
Dataset NIST90 diperoleh dari CD-ROM NIST Special Database 1 yang berlabel "Binary Images of Printed Digits, Alphas, and Text" yang memuat 2100 file kompresi berekstensi .pct. Setiap file berisi sebuah formulir tulisan tangan non-cursive, satu orang untuk sebuah formulir. Metode kompresi yang dipakai adalah CCITT group 4 yang dikhususkan untuk citra bilevel dan dapat mencapai rasio kompresi sekitar 5%. NIST97[7] diperoleh dari CD-ROM NIST Special Database 3 yang berlabel "Standard Reference Form-Based Handprint Recognition System (Release 2.0)." CD-ROM tersebut memuat tulisan tangan non-cursive yang tidak berbentuk kumpulan formulir lagi seperti NIST90, namun tetap dalam keadaan terkompres dengan metode yang sama. Ekstensi file dari data tulisan tangan tersebut adalah *.mis. Terdapat 4500 file .mis untuk ketiga kategori: digit, huruf besar, dan huruf kecil, sehingga setiap kategori memiliki 1500 file .mis. Untuk kategori digit secara rata-rata sebuah file memuat lebih dari 120 glyph digit. Setiap file .mis disertai dengan sebuah file *.cls yang memberikan informasi tentang jumlah tulisan tangan beserta semua label kelas tulisan tangan yang terdapat dalam file .mis terkait.
Obyek glyph tulisan tangan pada dataset MNIST[27] hanya berupa koleksi digit saja dan terdiri dari 2 file yang berisi 70.000 digit. File pertama khusus untuk keperluan training dan terdiri dari 60.000 digit, file kedua untuk testing sebanyak 10.000 digit. Kedua file tersebut tetap disertai dengan file
label yang serupa dengan struktur file .cls dataset NIST97. Scaling untuk semua glyph telah dilakukan pada dataset MNIST, sehingga semua glyph berukuran 20x20 pixel dengan mempertahankan
aspect ratio dan warna graylevel.
Dari ketiga jenis dataset NIST yang digunakan dalam penelitian ini, dirancang bentuk penyimpanan datasets yang seragam. Pendekatan yang digunakan adalah dengan membuat dua file untuk setiap formulir, yaitu file bitmap dan file log. File bitmap berisi gambar glyph dalam format Microsoft Windows Bitmap, dan file log berisi sebuah informasi jumlah glyph untuk file bitmap terkait, dan sejumlah informasi koordinat setiap glyph dalam bitmap. Pendekatan ini dapat dipandang sebagai bentuk kompromi antara ketiga NIST datasets yang tersedia.
(a)
123 {jumlah seluruh glyph} 10 {jumlah glyph digit 0} 0 0 29 31
29 0 32 22 61 0 26 18 87 0 35 31 122 0 32 27 154 0 36 32 190 0 32 25 222 0 40 31 262 0 33 42 295 0 35 35
17 {jumlah glyph digit 1} 0 42 18 33
18 42 17 26 35 42 18 27 :
:
(b)
Gambar 1
Contoh Penyimpanan Dataset sebuah Formulir (a) File Bitmap Glyph utuk Formulir 3821
(b) File Log untuk Formulir yang Sama
lowercase alphabet tidak tertutup untuk menggunakan prefix 'U' dan 'L', karena juga tidak tertutup kemungkinan bahwa datasets selain keluarga NIST dapat diintegrasikan ke dalam penyimpanan seperti ini. Sedangkan 4 digit yang mengikutinya adalah nomor formulir. Visualisasi kedua file untuk sebuah formulir dapat dilihat pada gambar 1, sedangkan tabel 1 menunjukkan rekapitulasi keseluruhan datasets NIST dengan total 496.599 glyph yang telah disimpan ke dalam format dan penamaan file yang baru. Berbeda dengan deskripsi yang disebutkan dalam dokumentasinya, tampak pada tabel tersebut bahwa terdapat beberapa formulir yang hilang walaupun dalam ukuran yang sangat kecil, 5 formulir dari NIST90 dan sebuah formulir dari NIST97.
Tabel 1
Rekapitulasi Ketiga Datasets NIST untuk Uji Coba Koleksi Datasets NIST90 NIST97 MNIST
Jumlah Formulir 2,095 1,499 700 Nomor Formulir 0-2099 2100-2599
dan 3100-4099
5000-5699
Jumlah Glyph '0' 25,520 17,392 6,903
Jumlah Glyph '1' 25,560 19,932 7,877
Jumlah Glyph '2' 24,697 17,941 6,990
Jumlah Glyph '3' 24,943 17,940 7,141
Jumlah Glyph '4' 23,915 17,605 6,824
Jumlah Glyph '5' 23,773 17,061 6,313
Jumlah Glyph '6' 25,084 17,809 6,876
Jumlah Glyph '7' 24,773 18,685 7,293
Jumlah Glyph '8' 24,569 17,550 6,825
Jumlah Glyph '9' 23,936 17,914 6,958
Jumlah Semua Glyph 246,770 179,829 70,000
3. Ekstraksi Feature
Tugas utama bagian ini adalah menunjukkan bagaimana perolehan feature vector yang mewakili ciri suatu glyph akan diumpankan ke dalam algoritma classifier. Dijelaskan setidaknya tujuh metode yang digunakan untuk ekstraksi feature. Dibandingkan dengan metode-metode lain yang dikenal hari ini, semua metode ekstraksi feature yang dijelaskan masih termasuk dalam kategori yang sangat sederhana. Masing-masing memberikan tekanan yang berbeda mengenai apa yang seharusnya diutamakan untuk diperhatikan dari sebuah glyph, seperti profile kiri dan kanan; bentuk area cekungan; deskripsi setiap cluster
glyph; dan lain sebagainya. Memperhatikan jumlah elemen feature vector yang berbanding lurus dengan waktu testing, pernyataan masalah yang berlaku umum pada setiap metode adalah bagaimana memperoleh feature vector dengan ukuran sekecil mungkin, dan dengan algoritma yang sesederhana mungkin, akan tetapi mampu mewakili sebuah glyph. Masalah selanjutnya bahwa representasi ini harus mencapai tingkatan performansi pengenalan yang
dikehendaki akan ditangani oleh individual dan multiple classifier yang digunakan.
Simple Normalization adalah metode yang paling sederhana. Dilakukan penskalaan (biasanya
shrinking) atas glyph original menjadi glyph ukuran n x n, sehingga feature vector berukuran n2
elemen. Pengkodean pixel hitam menjadi 1 dan pixel putih menjadi 0 dilakukan secara iteratif (row-major order)
untuk semua pixel.
Signature [14][20] menggunakan kumpulan segmen garis dari titik pusat ke setiap pixel tepi dari sebuah glyph sebagai feature vectornya. Feature vector berisi daftar nilai panjang semua garis tersebut. Apabila penelusuran pixel tepi dipandang sebagai sebuah putaran 360o
dengan nilai increment 1o
, maka akan dibutuhkan 360 elemen feature vector yang masing-masing mewakili 360 cluster yang berbeda secara berurutan. Proses dimulai dengan mendapatkan koordinat titik pusat (Cx,Cy), dimana Cx adalah pusat
kolom dan Cy adalah pusat barisnya. Untuk nilai N
yang menunjuk jumlah pixel hitam dari glyph G, dan kumpulan koordinat pixel hitam (X1,Y1), (X2,Y2), ...,
Untuk optimasi kecepatan proses, pencarian jarak pixel tepi terjauh dari titik pusat pada sebuah cluster tidak dilakukan secara iteratif cluster per cluster, melainkan dalam satu pass row-major order. Untuk nilai d yang merupakan besarnya sudut sebuahb cluster, penentuan nomor cluster sebuah pixel (Xi,Yi) dilakukan dengan formula:
NomorCluster
(
Y
i,
X
i) =
ArcTan(Yi−Cy,Xi−Cx)
d
Moment Description dapat dipandang sebagai perluasan metode signature dengan memodifikasi dan menambah feature baru yang diperoleh pada setiap clusternya. Jika untuk setiap cluster pada metode signature diambil sebuah feature saja, yaitu maksimum jarak pixel tepi ke titik pusat, maka pada metode moment description akan diambil 3 (tiga) feature sekaligus, yaitu: jumlah pixel hitam per cluster; akumulasi jarak semua pixel hitam ke titik pusat; dan nilai "ketebalan" kumpulan pixel hitam dalam sebuah cluster.
Proses thinning tidak diperlukan dalam metode ini, akan tetapi perolehan triple feature dalam setiap clusternya membutuhkan 2 (dua) iterasi secara row-major order untuk matriks glyph yang akan dikenali:
1. Iterasi pertama akan memperoleh koordinat titik pusat (Cx,Cy) glyph dengan rumus yang sama seperti metode signature. Pada iterasi ini jumlah pixel hitam setiap cluster (f1i) dapat langsung diperoleh dan sekaligus diperoleh pula akumulasi jarak semua pixel hitam ke titik pusat (f2i).
mendapatkan nomor cluster dari sebuah pixel juga tetap dilakukan. Dengan demikian pass pertama ini akan mendapatkan dua dari tiga feature yang dicari. Setelah iterasi pertama selesai dilakukan, dapat diperoleh himpunan nilai yang adalah rata-rata jarak semua pixel dalam sebuah cluster ke titikpusat glyph, atau f1i-f2i untuk semua cluster i.
2. Iterasi kedua dilakukan untuk memperoleh ketebalan kumpulan pixel hitam dalam sebuah glyph (f3i). Feature ini diperoleh dengan rumus:
f3i = f3i + (d(Pixel(y,x),Pixel(Cy,Cx))-) untuk i = 0,1,..., jumlah cluster-1,
dimana Pixel(y,x) adalah semua koordinat pixel hitam pada cluster i, Pixel(Cy,Cx) adalah koordinat titik pusat sebuah glyph, dan i adalah rata-rata jarak pixel
hitam ke titik pusat glyph untuk cluster i yang telah diperoleh pada iterasi sebelumnya. Dapat dilihat bahwa iterasi kedua ini mutlak diperlukan karena perhitungan d(Pixel(y,x),Pixel(Cy,Cx) membutuhkan yang harus diperoleh sebelumnya.
Direction Histogram mengasumsikan bahwa bagaimanapun simbol yang ditulis untuk sebuah digit sebenarnya hanyalah kumpulan ruas garis utama yang diletakkan pada posisi yang tepat di atas area penulisan. Jika semua ruas garis yang dimaksud hanya dikategorikan ke dalam empat arah yang berbeda: horizontal, vertikal, diagonal mayor ('\') dan diagonal minor ('/'), maka direction histogram berupaya untuk mengetahui pada lajur yang mana -- pada area penulisan -- ruas-ruas garis ini diletakkan. Untuk simbol digit '7' misalnya, dapat dijelaskan secara mudah bahwa kebanyakan penulis menggunakan 2 ruas garis utama: sebuah garis horizontal di lajur atas dan sebuah garis diagonal minor di lajur tengah untuk menulisnya. Karena yang akan diperoleh adalah informasi tentang ruas garis utama, tanpa memperhatikan serif ataupun ketebalan garis, metode ini memerlukan proses thinning. Proses ini dilakukan segera setelah proses penskalaan glyph. Dari glyph hasil thinning inilah keseluruhan feature vector didapatkan, yaitu dengan menghitung jumlah pixel yang terdapat untuk arah tertentu pada semua lajur yang mungkin. Untuk image berukuran n x n terdapat n lajur vertikal dan n garis horizontal, sedangkan untuk arah diagonalnya masing-masing memiliki 2n-1 lajur. Dengan demikian ukuran feature vector pada metode ini adalah n + n + (2n-1) + (2n-1) = 6n-2 elemen.
Neighborhood Vector Code [23][24] melakukan tiga tahap dalam memperoleh feature vectornya.
Tahap pertama adalah mengubah semua pixel hitam yang ada di glyph menjadi sebuah vector quadtuple yang secara berurutan menyimpan banyaknya jumlah pixel tetangga hitam yang ada di utara (atas), timur (kanan), selatan (bawah), dan barat (kiri) dari pixel hitam yang bersangkutan.
Tahap kedua melakukan pengkodean semua neighborhood vector yang terdapat dalam matriks menjadi sebuah nilai tunggal (C). Terdapat dua proses
yang harus dilakukan, yaitu penskalaan vector dan pengkodean vector. Pada bagian inilah permasalahan besarnya kemungkinan kode yang telah ditunjukkan sebelumnya akan diselesaikan. Jumlah kode diharapkan akan menjadi jauh lebih kecil, namun demikian keunikan setiap kode dipertahankan dengan cara memberikan kode yang sama untuk quadtuple yang mirip. Penskalaan vector berguna untuk membuat rentang nilai komponen neighborhood vector menjadi lebih kecil. Hal ini dapat dipandang sebagai normalisasi seperti pada metode-metode sebelumnya. Proses ini berguna untuk menurunkan rentang nilai C pada kondisi originalnya. Jangkauan dari nilai komponen neighborhood vector pada glyph berukuran L x L adalah 0 sampai dengan L-1. Proses ini diawali dengan memilih nilai L yang baru (L’) dan mendapatkan nilai b (konstanta rasio "kompresi" rentang) dengan rumus:
b
=
L
1 L
Setelah nilai b diperoleh, kemudian dapat dilakukan penskalaan dengan menerapkan rumus-rumus di bawah ini untuk setiap neighborhood vector yang ada:
V = N + S dengan skala baru yang lebih kecil dan memiliki jangkauan baru 0 sampai L’-1. Setelah dilakukan penskalaan vector, proses berlanjut ke pengkodean vector dengan memasukkan nilai tersebut ke dalam tiga persamaan di bawah untuk mendapatkan nilai C.
A = N’ * L’ + S’ – ( N’ * (N’-1) ) / 2 B = E’ * L’ + W’ – ( E’ * (E’-1) ) / 2 C = A * (L’² + L’) / 2 + B
Nilai C inilah yang digunakan sebagai kode baru untuk labeling (pelabelan) setiap neighborhood code dalam matriks. Dengan demikian ukuran feature vector adalah sama dengan jumlah jangkauan nilai C.
Tahap ketiga atau yang terakhir adalah menghitung frekuensi munculnya pada matriks neighborhood code untuk masing-masing nilai C.
Convex Deficiency [14] bekerja dengan mengolah daerah cekungan yang terjadi pada sebuah glyph. Terdapat lima jenis daerah cekungan, yaitu
hole (lubang), buka bawah, buka kanan, buka atas, dan buka kiri. Perlu dilakukan preprocessing
sederhana pada daerah-daerah cekungan sebuah glyph. Bila terdapat dua atau lebih daerah cekungan yang berlainan jenis dan terhubung secara
4-connected, maka kedua daerah tersebut digabung dan jenisnya mengikuti daerah yang luasnya terbesar.
Untuk setiap daerah cekungan yang terbentuk dihitung 6 nilai feature. Keenam nilai tersebut adalah luas (L), koordinat center of mass (Cx, Cy), dan
jumlah pixel yang membentuk daerah cekungan. Perhitungan M11, M20, M02 memerlukan pasangan nilai Cx dan Cy terlebih dahulu. Jika diketahui sepasang
vektor txi = | xi-Cx | dan tyi = | yi-Cx | untuk n pixel
image dalam glyph, maka:
M11 =
Untuk setiap jenis daerah cekungan disediakan dua slot nilai, artinya apabila terdapat lebih dari daerah cekungan dengan jenis yang sama, maka hanya dua cekungan dengan luas terbesar yang diambil. Cekungan dengan nilai luas terbesar menempati slot-1 dan cekungan dengan nilai terbesar kedua menempati slot-2. Bila hanya terdapat sebuah slot atau bahkan tidak ada cekungan jenis tertentu, maka seluruh elemen feature untuk slot yang kosong akan diganti dengan nilai 0
Dengan ketentuan tersebut maka panjang vektor feature untuk sebuah glyph bersifat fixed selalu selalu 60 elemen, dari 5 jenis cekungan x 2 slot x 6 feature, artinya panjang vektor tidak dipengaruhi ukuran glyph ataupun parameter lainnya.
Character Profile bekerja dengan memperhatikan posisi pixel terluar di sebelah kiri dan kanan dari glyph. Posisi pixel terluar diambil secara berurutan dari atas ke bawah dan disimpan dalam feature vector. Ukuran dari feature vector adalah 2n untuk n adalah tinggi dari glyph. Normalisasi pada feature vector dilakukan dengan membagi nilai tiap elemen dengan lebar glyph (n). Nilai tinggi dan lebar dari glyph adalah sama, karena ukuran glyph yang dipakai adalah n x n.
4. Generalisasi Classifier dengan
Backpropagation Neural Nets
Pemanfaatkan Backpropagation Feed-forward Neural Network (BPFFNN) sebagai individual classifier handwritten digit recognition memerlukan dua fase yang berbeda dengan memperhatikan bahwa BPFFNN adalah sebuah supervised classifier. Fase pertama adalah training yang berusaha untuk memperoleh pengetahuan dari training datasets, dan yang kedua adalah testing yang memanfaatkan pengetahuan hasil training untuk mengenali sebuah glyph dengan mengklasifikasikannya ke dalam salah satu dari 10 kelas output. Arsitektur yang digunakan adalah layer tunggal n-p-10 dengan nilai n yang tergantung metode ekstraksi featurenya. Tabel 2 menunjukkan jumlah node layer input untuk setiap metode.
Melalui sejumlah percobaan yang telah dilakukan dapat diketahui bahwa pemilihan representasi bipolar dan binary, penggunaan nilai learning rate yang optimal, inisialisasi bobot dengan Nguyen-Widrow, dan momentum tidak memiliki pengaruh yang signifikan terhadap proses pelatihan. Misalnya untuk penentuan learning-rate.
Tabel 2
Jumlah Node Input yang Dibutuhkan untuk Metode Ekstraksi Feature
Metode Jumlah Node Input yang Diperlukan
Simple Normalization n2, untuk n adalah ukuran penskalaan glyph
Signature jumlah cluster
Moment Desciption 3 x jumlah cluster
Direction Histogram 6n-2 Neighborhood Vector Code
Jangkauan nilai NVC, misalnya 100 untuk L’=4.
Convex Deficiency 60 Character Profile 2n
Fungsi aktivasi yang dilakukan pada sejumlah percobaan dapat menggunakan fungsi aktivasi bipolar sigmoid ataupun binary sigmoid tergantung dari representasi yang digunakan. Pada fungsi bipolar sigmoid nilai α yang optimal berada pada kisaran
α=0.01 ampai α=0.04. Pada fungsi binary sigmoid nilai α yang disarankan berada pada kisaran yang lebih besar, yaitu α=0.1 sampai α=0.4. Walaupun nilai optimal learning rate ini dapat diektahui, pengaruhnya terhadap proses training tidaklah signifikan.
Tabel 3
Performansi Terbaik Individual Classifier Berbasis BPFFNN
Metode Ekstraksi Feature Recognition Rate
Arsitektur BPFFNN
Simple Normalization 95.41% 400-40-10
Signature 94.09% 32-96-10
Moment Desciption 96.62% 96-72-10
Direction Histogram 95.36% 118-60-10
Neighborhood Vector Code 92.65% 225-75-10
Convex Deficiency 95.67% 60-120-10
Character Profile 95.49% 40-120-10
Pada tabel 3 ditunjukkan performansi terbaik BPFFNN untuk seluruh metode ekstraksi feature. Performansi ini diperoleh melalui training dan testing pada datasets MNIST yang menjadi datasets standard untuk ujicoba handwritten digit recognition. Dengan pengaturan parameter yang tepat, setiap metode membutuhkan tidak lebih dari 200 epoch untuk mencapai konvergen.
5. Multiple Classifier Berbasis Tipe
Respon
Semua metode yang digunakan untuk handwritten digit recognition dapat dikategorikan ke dalam tiga respon yang berbeda. Secara formal informasi yang dihasilkan dari berbagai algoritma classifier dapat dibagi menjadi tiga level:[25]
abstract level: sebuah classifier e menghasilkan sebuah label yang unik j, atau untuk beberapa per-luasan e menghasilkan J ⊂ Λ.
rank level: e meranking semua label anggota Λ da-lam sebuah queue dengan pilihan pertama yang terletak pada top.
measurement level: e melengkapi setiap label da-lam Λ dengan sebuah atribut baru yaitu nilai untuk mengukur level keanggotaan x dalam label.
Di antara ketiga level tersebut measurement level memuat jumlah informasi yang tertinggi dibandingkan kedua level lainnya. Dari atribut nilai yang diberikan pada setiap label, ranking untuk setiap label dalam Λ dapat diperoleh. Artinya measurement level dapat memberikan informasi yang sama dengan rank level. Dengan memilih label pada ranking tertinggi, maka informasi yang abstract level juga dapat diberikan measurement level. Pendekatan seperti inilah yang dilakukan untuk konversi antar tipe respon yang akan dijelaskan pada bagian berikutnya. Ketiga tipe respon tersebut selanjutnya disebut tipe respon 1, 2, dan 3 seperti telah dijelaskan pada awal tulisan ini.
Apapun tipe responnya, sebuah multiple classifier harus memenuhi ketiga syarat berikut:[15]
1. Respon multiple classifier haruslah salah satu hasil yang diberikan individual classifier, termasuk ketika terjadi kontradiksi di antaranya.
2. Individual classifier mungkin memiliki tipe respon yang berbeda, semuanya harus dapat digabungkan untuk menghasilkan sebuah respon tunggal yang koheren.
3. Multiple classifier harus memberikan hasil yang benar lebih sering dari setiap individual classifiernya.
Jika masing-masing individual classifiers memberikan tipe respon 1 karena seluruhnya hanya merupakan implementasi BPFFNN, cara penggabungan yang paling mudah dilakukan adalah dengan menggunakan strategi voting. Skema votingnya dapat diekspresikan dengan cara berikut: Ci(x) adalah hasil yang diberikan oleh classifier i untuk glyph x, di mana terdapat k classifier yang
berbeda dalam sistem. H(x,d) adalah fungsi yang menghasilkan berapa jumlah classifier yang mengklasifikasikan glyph x ke dalam kelas d, dimana d ∈ {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}.
Pertama kali dilakukan inisialisasi nilai voting untuk masing-masing pengenalan digit menjadi 0. Setelah itu, dihitung hasil pengenalan yang diberikan oleh setiap classifier. Hasil voting ini akan digunakan pada semua skema yang termasuk dalam kategori penggabungan tipe respon 1. Adapun multiple classifier untuk tipe respon 1 dibagi menjadi tiga skema yang berbeda, yaitu simple majority vote (SMV), weighted majority votes (WMV), dan dissenting-weighted majority vote (DWMV).
Simple Majority Vote (SMV) merupakan metode penggabungan tipe respon 1 yang paling sederhana. Simple majority votes memilih salah satu j (yang merupakan hasil pengenalan digit pada classifier), dimana H(x,j) merupakan nilai maksimum dari semua kelas j yang mungkin, dan diberikan syarat tambahan bahwa j lebih besar dari jumlah classifier / 2. Skema ini diekspresikan dengan:
E(x) =
{
j , jika max(H(x,i))=H(x,j) dan H(x,j)>k/2
reject , untuk kondisi lainnya
Keadaan reject adalah ketika classifier tidak dapat mengambil keputusan. Dalam pengambilan keputusan secara voting saat musyawarah mencapai mufakat tidak dapat dilakukan, sering kali disebutkan bahwa keputusan yang diambil adalah suara mayoritas yang dihitung dari "50 persen plus 1". Contoh konkrit adalah ketika terdapat lima pasang presiden dan wakil presiden yang dipilih secara langsung oleh rakyat, apabila masing-masing memperoleh 33%, 28%, 21%, 15%, 3%, maka belum ada yang terpilih sebagai presiden dan wakilnya karena belum ada yang menang mayoritas dengan 50 persen plus 1. Namun demikian ada pasangan terpilih jika salah satu pasangan telah memperoleh suara yang lebih dari 50%. Pada kasus ini classifiernya adalah jutaan rakyat yang memilih langsung.
Weighted Majority Votes (WMV) adalah generalisasi dari SMV dengan mengganti konstanta k/2 dengan konstanta k*α dimana 0 <= α <= 1. α disebut degree of flexibility dalam pengambilan keputusan penting untuk mendefinisikan berapa persen suara untuk dapat disebut sebagai mayoritas. Skema WMV dapat diekspresikan sebagai:
E(x) =
{
j , jika max(H(x,i))=H(x,j) dan H(x,j)>α*k
reject , untuk kondisi lainnya
performansi sistem akan diatur dengan menggunakan aspek-aspek lain, yaitu reliability dan acceptibility
sistem, melengkapi recognition rate yang digunakan pada tulisan ini.
Dissenting-Weighted Majority Vote (DWMV).
Dua metode sebelumnya, yaitu SMV dan WMV tidak menghitung kemungkinan perbedaan pendapat classifier satu dengan yang lain. Sebagai contoh, pada kasus A, terdapat 10 classifier, dengan 6 classifier menyatakan hasil pengenalan adalah '8', satu classifier menyatakan '5', satu classifier meyatakan '2', dan dua classifier lainnya gagal dalam mengenali digit (reject). Pada kasus B, dengan menggunakan 10 classifier yang sama, 6 classifier menyatakan hasil pengenalan digit adalah '8', sedangkan 4 classifier lainnya menyatakan '5'. Terlihat bahwa kedua kasus tersebut memang mendukung '8' sebagai outputnya, akan tetapi "kekuatan" keduanya dalam mengenali output '8' tidaklah sama. Cara untuk membedakan kekuatan dengan memperhitungkan selisih jumlah clsssifier terbesar adalah dengan cara menghitung max1 adalah jumlah classifier yang mendukung mayoritas klasifikasi j(max1= H(x,j)), dan max2 merupakan jumlah classifier yang mendukung klasifikasi ke-dua yang populer h(max2=H(x,h)), walaupun bukan yang terbesar. Skema DWMV ini dapat dimodelkan dengan:
E(x) =
{
j , jika max(H(x,i))=H(x,j) dan max1-max2>=α*k
reject , untuk kondisi lainnya
6. Uji Coba
Pengukuran performansi multiple classifier tipe respon 1 ini dilakukan dengan menggunakan sampel dari datasets NIST90 dan NIST97, dan seluruh data MNIST yang memang telah menjadi standard pengujian performansi handwritten digit recognition. Jumlah sampel untuk NIST90 dan NIST97 ditentukan pada kisaran 60000:10000 (training:testing) mengikuti pasangan jumlah yang digunakan oleh MNIST. Tidak ada pertimbangan khusus pada pemilihan kumpulan formulir yang digunakan selain masalah jumlah tersebut.
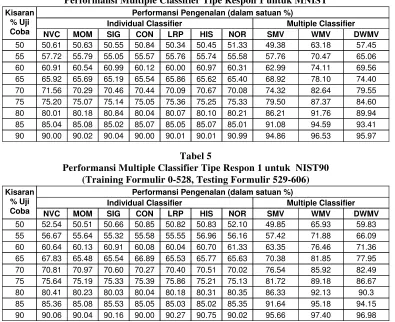
Walaupun sebuah hasil terbaik telah diperoleh, pengukuran dilakukan mulai dari tingkat ketelitian pada kisaran 50% sampai 90% dengan kenaikan 5% seperti ditunjukkan pada tabel 4, 5, dan 6 (seluruh tabel hasil percobaan disajikan pada halaman terakhir) untuk menunjukkan performansi multiple classifier pada recognition rate yang lebih rendah. Pada semua percobaan digunakan α=0.05. Dapat dihitung hasil percobaan dari ketiga datasets yang digunakan bahwa peningkatan performansi rata-rata sebesar 1.517% untuk SMV, 7.568% untuk WMV, dan 7.942% untuk DWMV. Peningkatan performansi ini dihitung berdasar performansi sebuah individual classifier yang terbaik, bukan dari rata-rata performansi individual classifiernya.
Untuk pengukuran pada datasets MNIST yang menjadi datasets standard ujicoba handwritten digit recognition, dengan menggunakan individual classifier dengan performansi terbaik seperti yang ditunjukkan pada tabel 3, maka performansi maksimal multiple classifier tipe respon 1 untuk masing-masing skema adalah:
97.72% untuk Simple Majority Vote (SMV) 98.42% untuk Weighted Majority Vote (WMV) 98.15% untuk Dissenting Weighted Majority Vote (DWMV)
Melalui sejumlah percobaan yang telah dilakukan dapat dilihat melalui tabel 4, 5, dan 6 bahwa ketiga syarat yang diberikan untuk sebuah multiple classifier untuk memperbaiki performansi individual classifier dapat dipenuhi.
Melengkapi ketiga skema multiple classifier tipe respon 1, untuk tipe-tipe respon lainnya sebenarnya juga terdapat beberapa skema yang berbeda. Sebagai contoh dikenal skema Borda, Black, dan Copeland untuk tipe respon 2, dan skema averaging techniques untuk tipe respon 3. Dikenal pula cara yang dapat dilakukan untuk konversi antar tipe respon ketika masing-masing individual classifier memiliki tipe respon yang berbeda. Namun demikian telah diketahui konversi ini memerlukan time complexity yang tinggi, terutama jika dilakukan dari tipe respon 1 ke tipe respon 2 dan 3, karena memerlukan pembentukan
confesion matrix. Beberapa percobaan pada sejumlah skema yang berbeda untuk tipe respon 2 dan 3 juga telah dilakukan, seperti ditunjukkan pada tabel 7, 8, dan 9. Sedangkan performansi maksimal berdasarkan individual classifier dengan performansi terbaik seperti ditunjukkan pada tabel 3 untuk beberapa skema tipe respon 2 dan 3 adalah:
97.85% untuk Borda Count 98.46% untuk Black 96.99% untuk Copeland
98.41% untuk Averaging Techniques
Namun demikian konversi tipe respon dari tipe 1 ke tipe 3, dan selanjutnya dari tipe 3 ke tipe 2 sebelumnya telah dilakukan untuk percobaan tersebut, sehingga hasilnya tidak menggambarkan performansi multiple classifier yang sesungguhnya.
7. Kesimpulan
Memperhatikan keseluruhan pembahasan tulisan ini dapat dilihat bahwa multiple classifier dari single classifier yang sederhana dapat dipertimbangkan sebagai alternatif solusi handwritten character recognition dengan performansi yang sama dengan sebuah single classifier dengan pendekatan yang lebih kompleks. Pencapaian recognition rate multiple classifier sampai 98.42% pada datasets standard MNIST menunjukkan bahwa sistem ini memiliki
Skema multiple classifier tipe respon 1 yang menggunakan komponen α atau degree of flexibility (WMV dan DWMV) memberikan performansi yang lebih baik dibanding Simple Majority Vote (SMV). Hal ini terjadi baik untuk performansi yang diatur pada kisaran 50% sampai 90%, ataupun performansi maksimal individual classifier dari kisaran 95% menjadi 98.4%.
Walaupun tersedia sejumlah cara konversi antar tipe respon sebuah single classifier, pendekatan konversi tidak akan membantu peningkatan performansi sistem. Konversi yang mekanismenya memerlukan time complexity tersendiri hanya diperlukan ketika secara alami individual classifier yang tersedia memang tergolong dalam respon tipe yang berbeda.
Pengembangan lanjut penelitian ini dapat dilakukan dengan sebuah hipotesis baru: "Apakah peningkatan performansi yang minimal sama dengan yang telah ditunjukkan dalam tesis ini juga dapat dilakukan untuk handwritten character recognition yang melibatkan karakter alfanumerik? Termasuk jika metode individual classifier untuk handwritten character recognition tersebut memiliki tipe respon 2 atau tipe repon 3 sehingga harus digunakan skema lainnya."
8. Kepustakaan
1. Behnke, Sven, Marcus Pfister dan Raúl Rojas. A Study on Combination Classifiers for Handwritten Digit Recognition. Free University of Berlin. Institute of Computer Science. Takustr. 9. Germany.
2. Bunke, Horst. Recognition of Cursive Roman Handwriting - Past, Present and Future. 2003. Departement of Computer Science, University of Bern. Switzerland.
3. Cohen E, Jonathan J. Hull dan Sargur N. Srihari.
Understanding Handwritten Text in a Structured Environment: Determining ZIP Codes from Addresses. 1991. World Scientific Series in Computer Science – Vol. 30: Character and Handwriting Recognition. World Scientific. USA. 4. Downton A.C, R.W.S. Tregidgo, dan E. Kabir.
Recognition and Verification of Handwritten and Hand-Printed British Postal Addresses. 1991. World Scientific Series in Computer Science – Vol. 30: Character and Handwriting Recognition. World Scientific. USA.
5. Erp, Merijn van dan Lambert Schomaker. 2000.
Variants of the Borda Count Method for Combining Ranked Classifier Hypotheses.
Proceeding of the 7th International Workshop on Frontiers in Handwriting Recognition. Amsterdam.
6. Fausett, Laurene. Fundamental of Neural Networks: Architectures, Algorithms, and
Applications. 1994. Prentice Hall. New Jersey. USA.
7. Garris, Michael D. et al. 1997. NIST Form-Based Handprint Recognition System (Release 2.0).
NISTIR 5959. National Institute od Standards and Technology. Gaithersburg, Maryland, USA. 8. Gunter, Simon. Multiple Classifier Systems in
Offline Cursive Handwriting Recognition. 2004. Disertasi. Universitat Bern.
9. Guyon I. Applications of Neural Networks to Character Recognition. 1991. World Scientific Series in Computer Science – Vol. 30: Character and Handwriting Recognition. World Scientific. USA.
10. Ho, Tin Kiam, Jonathan J. Hull dan Sargur N. Srihari. On Multiple Classifier Systems for Pattern Recognition.
11. Impedovo S, L. Ottaviano, dan S. Occhinegro. 1991. Optical Character Recognition – A Survey.
World Scientific Series in Computer Science – Vol. 30: Character and Handwriting Recognition. World Scientific. USA.
12. Kussul, Ernst dan Tatyana Baidyk. Improved Method of Handwritten Digit Recognition.
UNAM, Centro de Instrumentos, Cd.Universitaria, Mexico, D.F.
13. Liu, Cheng-Lin, Hiroshi Sako, dan Hiromichi Fujisawa. 2001. Performance Evaluation of Pattern Classifiers for Handwritten Character Recognition. International Journal on Document Analysis and Recognition (IJDAR). Springer-Verlag.
14. Parker, James R. 1993. Practical Computer Vision using C. John Wiley & Sons, Inc. USA.
15. Parker, James R. 1995. Voting Methods For Multiple Autonomous Agents. Laboratory for Computer Vision Department of Computer Science University of Calgary, Alberta, Canada. 16. Parker, James R. 1997. Algorithms for Image
Processing and Computer Vision. John Wiley & Sons, Inc. USA.
17. Parker, James R. 1997. Multiple/Parallel Handprinted Digit Recognition. Laboratory for Computer Vision Department of Computer Science University of Calgary, Calgary, Alberta, Canada.
18. Parker, James R. 1998. Multiple Sensors, Voting Methods and Target Value Analysis. Laboratory for Computer Vision Department of Computer Science University of Calgary, Calgary, Alberta, Canada.
19. Parker, James R. Vector Templates for Handprinted Symbol Recognition. PARKER 3rd International Conference Image Analysis & Grap. 20. Parker, James R. dan Zhang Zhou. 1998. Object
IASTED International Conference Signal and Image Processing. Las Vegas – Nevada USA. 21. Thien, Min Ha dan Horst Bunke, Model-Based
Understanding of Check Forms. 1994. World Scientific Series in Machine Perception and Artificial Intelligence - Vol. 16: Document Image Analysis. World Scientific. USA.
22. Tin Kiam Ho, Jonathan J. Hull, Sargur N. Srihari. 1994. Decision Combination in Multiple Classifier Systems. IEEE Transaction on Pattern Analysis and Machine Intelligence, Vol. 16 No. 1.
23. Tsang Ing Ren. Pattern Recognition and Complex Systems (Patroonherkenning en Complexe Systemen). September 2000. Disertasi Doktor Universiteit Antwerpen, Faculteit Wetenschappen. Antwerpen, Belanda.
24. Tsang Ing Jyh. Pattern Recognition, Neighborhood Codes, and Lattice Animals. 2000. Disertasi Doktor Universiteit Antwerpen, Faculteit Wetenschappen. Antwerpen, Belanda.
25. Xu, Lei, Adam Krzyzak dan Ching Y. Suen.
Method for Combining Multiple Classifiers and Their Applications to Handprinting Recognition.
IEEE Transaction on Systems, Man and Cybernetics, Vol. 22, No. 3, May/June 1992. 26. Xu, Lei, Adam Krzyzak dan Ching Y. Suen. 1994.
Associative Switch for Combining Multiple Classifiers. Journal of Artificial Neural Networks, 1(1), 77-100.
27. Yann LeCun. The MNIST Database of Handwritten Digits. NEC Research Institute, Princeton, New Jersey, USA. http://yann.lecun.com/ exdb/mnist.
28. Ye Xiangyun, Mohamed Cheriet, dan Ching Y. Suen, A Generic System to Extract and Clean Handwritten Data from Business Forms, Centre for Pattern Recognition and Machine Inteligence Concordia University.
Tabel 4
Performansi Multiple Classifier Tipe Respon 1 untuk MNIST Kisaran
% Uji Coba
Performansi Pengenalan (dalam satuan %)
Individual Classifier Multiple Classifier NVC MOM SIG CON LRP HIS NOR SMV WMV DWMV
50 50.61 50.63 50.55 50.84 50.34 50.45 51.33 49.38 63.18 57.45
55 57.72 55.79 55.05 55.57 55.76 55.74 55.58 57.76 70.47 65.06
60 60.91 60.54 60.99 60.12 60.00 60.97 60.31 62.99 74.11 69.56
65 65.92 65.69 65.19 65.54 65.86 65.62 65.40 68.92 78.10 74.40
70 71.56 70.29 70.46 70.44 70.09 70.67 70.08 74.32 82.64 79.55
75 75.20 75.07 75.14 75.05 75.36 75.25 75.33 79.50 87.37 84.60
80 80.01 80.18 80.84 80.04 80.07 80.10 80.21 86.21 91.76 89.94
85 85.04 85.08 85.02 85.07 85.05 85.07 85.01 91.08 94.59 93.41
90 90.00 90.02 90.04 90.00 90.01 90.01 90.99 94.86 96.53 95.97
Tabel 5
Performansi Multiple Classifier Tipe Respon 1 untuk NIST90 (Training Formulir 0-528, Testing Formulir 529-606) Kisaran
% Uji Coba
Performansi Pengenalan (dalam satuan %)
Individual Classifier Multiple Classifier NVC MOM SIG CON LRP HIS NOR SMV WMV DWMV
50 52.54 50.51 50.66 50.85 50.82 50.83 52.10 49.85 65.93 59.83
55 56.67 55.64 55.32 55.58 55.55 56.96 56.16 57.42 71.88 66.09
60 60.64 60.13 60.91 60.08 60.04 60.70 61.33 63.35 76.46 71.36
65 67.83 65.48 65.54 66.89 65.53 65.77 65.63 70.38 81.85 77.95
70 70.81 70.97 70.60 70.27 70.40 70.51 70.02 76.54 85.92 82.49
75 75.64 75.19 75.33 75.39 75.86 75.21 75.13 81.72 89.18 86.67
80 80.41 80.23 80.03 80.04 80.18 80.31 80.35 86.33 92.13 90.3
85 85.36 85.08 85.53 85.05 85.03 85.02 85.35 91.64 95.18 94.15
90 90.06 90.04 90.16 90.00 90.27 90.75 90.02 95.66 97.40 96.98
Tabel 6
Performansi Multiple Classifier Tipe Respon 1 untuk NIST97 (Training formulir 3100-3590, Testing formulir 3591-3674) Kisaran
% Uji Coba
Performansi Pengenalan (dalam satuan %)
Individual Classifier Multiple Classifier NVC MOM SIG CON LRP HIS NOR SMV WMV DWMV
50 50.12 51.85 51.26 50.48 50.01 51.54 50.93 51.17 65.54 59.54
55 55.31 55.18 55.16 55.20 55.19 55.93 55.55 55.81 69.99 64.60
60 61.39 60.49 60.79 61.44 60.96 60.98 60.74 62.67 75.15 70.97
65 66.66 65.55 65.67 66.50 65.49 65.16 65.58 69.25 80.09 76.51
70 71.37 70.31 70.27 70.36 70.39 70.31 70.63 75.10 84.31 81.38
75 75.34 75.19 75.00 75.27 75.07 75.30 75.15 80.79 87.82 85.60
80 80.57 80.02 81.35 80.04 80.05 80.17 80.08 86.02 91.16 89.62
85 85.09 85.93 85.45 85.02 85.66 85.88 86.46 90.98 94.62 93.71
90 90.04 90.11 90.05 90.15 90.08 90.01 90.08 94.17 96.37 95.66
Tabel 7
Performansi Multiple Classifier Tipe Respon 2 (Black, Borda, dan Copeland) dan 3 (Averaging Techniques) untuk Datasets MNIST
Kisaran % Uji Coba
Performansi Pengenalan (dalam satuan %)
Individual Classifier Multiple Classifier Tipe Respon 2 dan 3 NVC MOM SIG CON LRP HIS NOR Borda Black Copeland Averaging
50 50.61 50.63 50.55 50.84 50.34 50.45 51.33 39.36 60.55 45.7 51 55 57.72 55.79 55.05 55.57 55.76 55.74 55.58 55.7 69.87 54.24 62.29 60 60.91 60.54 60.99 60.12 60 60.97 60.31 63.79 72.61 64.4 66.55 65 65.92 65.69 65.19 65.54 65.86 65.62 65.4 70.49 77.4 71.92 73.09 70 71.56 70.29 70.46 70.44 70.09 70.67 70.08 78.05 80.71 75.86 78.43 75 75.2 75.07 75.14 75.05 75.36 75.25 75.33 82.12 86.77 78.98 84.32 80 80.01 80.18 80.84 80.04 80.07 80.1 80.21 87.46 91.59 86.62 90.59 85 85.04 85.08 85.02 85.07 85.05 85.07 85.01 92.21 94.59 90.82 94.43
Tabel 8
Performansi Multiple Classifier Tipe Respon 2 (Black, Borda, dan Copeland) dan 3 (Averaging Techniques) untuk Datasets NIST90 (Training formulir 0-528, Testing formulir 529-606)
Kisaran % Uji Coba
Performansi Pengenalan (dalam satuan %)
Individual Classifier Multiple Classifier Tipe Respon 2 dan 3 NVC MOM SIG CON LRP HIS NOR Borda Black Copeland Averaging
50 52.54 50.51 50.66 50.85 50.82 50.83 52.10 38.31 62.37 43.64 51.08 55 56.67 55.64 55.32 55.58 55.55 56.96 56.16 50.59 68.60 57.21 61.23 60 60.64 60.13 60.91 60.08 60.04 60.70 61.33 58.98 72.10 60.67 66.11 65 67.83 65.48 65.54 66.89 65.53 65.77 65.63 69.54 79.99 69.91 71.39 70 70.81 70.97 70.60 70.27 70.40 70.51 70.02 76.50 85.35 76.30 81.79 75 75.64 75.19 75.33 75.39 75.86 75.21 75.13 84.76 88.88 84.19 87.24 80 80.41 80.23 80.03 80.04 80.18 80.31 80.35 90.71 92.13 86.16 91.57 85 85.36 85.08 85.53 85.05 85.03 85.02 85.35 93.70 95.18 91.37 95.16 90 90.06 90.04 90.16 90.00 90.27 90.75 90.02 96.00 97.40 95.53 97.31
Tabel 9
Performansi Multiple Classifier Tipe Respon 3 (Black, Borda, dan Copeland) dan 3 (Averaging Techniques) untuk Datasets NIST97 (Training formulir 3100-3590, Testing formulir 3591-3674)
Kisaran % Uji Coba
Performansi Pengenalan (dalam satuan %)
Individual Classifier Multiple Classifier Tipe Respon 2 dan 3 NVC MOM SIG CON LRP HIS NOR Borda Black Copeland Averaging