BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang serta penelitian sebelumnya yang berhubungan dengan permasalahan file undelete dan algoritma Aho-Corasick.
2.1. Forensik Digital
Menurut The American Heritage (2000), forensik adalah penggunaan ilmu pengetahuan dan teknologi untuk melakukan investigasi dan memperoleh fakta atau bukti yang dapat dipergunakan dalam pengadilan atau hukum. Dalam bidang komputer, digital dapat diartikan representasi data dalam bentuk kode biner (1 dan 0). Forensik digital adalah cabang dari ilmu forensik yang mencakup pemulihan dan investigasi material yang ditemukan dalam perangkat digital yang sering berkaitan dengan kejahatan dalam bidang komputer (Reith, et al. 2002). Forensik digital memiliki tujuan untuk mengidentifikasi barang bukti digital dengan metode ilmiah sehingga dapat dipergunakan untuk membantu proses investigasi (Carrier, 2001). Pengaplikasian forensik digital sangat beragam. Namun, pengaplikasian yang paling umum adalah untuk mendukung atau menyanggah sebuah hipotesis dalam pengadilan kasus kriminal atau sipil (sebagai bagian dari proses penemuan elektronik). Forensik digital selain dipergunakan untuk mengidentifikasi barang bukti langsung dari sebuah kejahatan, juga dapat dipergunakan untuk menghubungkan barang bukti dengan tersangka tertentu, memastikan alibi atau pernyataan, menentukan modus, mengidentifikasi sumber (sebagai contoh, dalam kasus hak cipta), atau autentikasi dokumen (Casey, 2009). Forensik digital dapat dibagi menjadi beberapa cabang sesuai dengan perangkat digital yaitu: forensik komputer, forensik jaringan, analisis data forensik dan forensik perangkat mobile. Secara umum, proses forensik mencakup pengambilalihan perangkat, akusisi data, analisis media digital dan pembuatan laporan menjadi sebuah barang bukti yang kolektif (Adams, 2012).
2.2. File
Berdasarkan GNU version of the Collaborative International Dictionary of English (2008), file komputer atau biasanya disebut dengan file adalah kumpulan data dalam media penyimpanan digital yang disimpan sebagai sebuah unit yang dapat dipergunakan untuk penyimpanan, pembacaan, dan pengindeksan data digital serta dapat diakses dengan menggunakan program komputer berdasarkan nama file. Sebuah
file dapat berisi program instruksi atau data yang dapat berupa informasi numerik, teks
atau grafis. Format sebuah file ditentukan oleh isi dari file tersebut karena sebuah file merupakan wadah untuk menyimpan data. Pada beberapa platform, format biasanya ditentukan oleh filename extension yang menentukan bagaimana byte harus diatur sehingga dapat diinterpretasikan.
File format adalah sebuah cara standar bagaimana informasi mengalami encoding (perubahan menjadi bentuk kode tertentu) untuk kemudian disimpan dalam file komputer. Setiap file format didesain untuk tipe data tertentu, misalnya file teks
(.TXT) hanya dapat berisi karakter sesuai dengan standar format (ASCII, UTF-8 atau MIME) dan file citra PNG dapat menyimpan citra bitmap dengan kompresi data yang
lossless. File format juga menyimpan informasi tentang metode encoding yang
dipergunakan file tersebut. Misalnya sebuah file teks TXT dapat disimpan dengan metode encoding ASCII (atau sering dikenal sebagai ANSI) maupun UTF-8. File teks dengan metode encoding ANSI hanya dapat menyimpan maksimal 256 karakter ASCII sedang metode encoding UTF-8 dapat menyimpan 1.112.064 karakter termasuk karakter dari bahasa lain. Oleh karena itu, apabila file teks yang berisi karakter Unicode disimpan dengan metode encoding ANSI maka karakter tersebut akan kehilangan format karakter Unicode. Sebagai contoh, karakter “ÿ” adalah karakter Unicode yang apabila disimpan dengan encoding ANSI akan menjadi karakter “y”.
Filename extension adalah sebuah metode yang dipergunakan oleh banyak
sistem operasi untuk menentukan format dari sebuah file berdasarkan akhir dari nama
file tersebut – untaian karakter yang mengikuti tanda titik terakhir. Sebagai contoh
sebuah file dokumen HTML dikenal dengan nama file yang diakhiri .HTML ataupun .HTM.
File dapat dibagi menjadi tiga bagian yaitu:
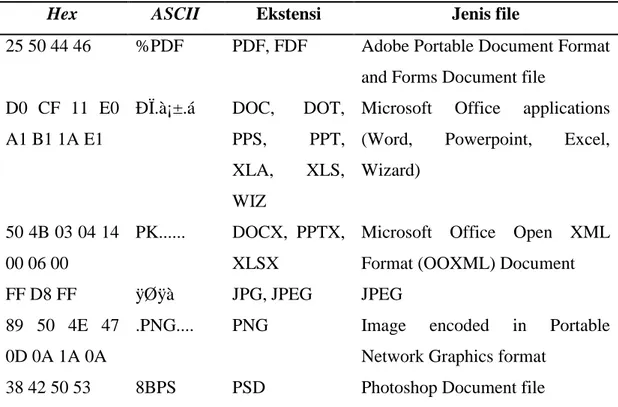
1. Header adalah bagian awal file dimana terdapat file signature atau dikenal juga sebagai magic bytes. Signature merupakan penanda yang diberikan di awal file sehingga sistem operasi dapat mengenali jenis file tersebut. Daftar dari file
signature beberapa file dapat dilihat pada Tabel 2.1.
2. Body adalah konten dari file yang berbentuk informasi atau data yang tersimpan dalam file tersebut.
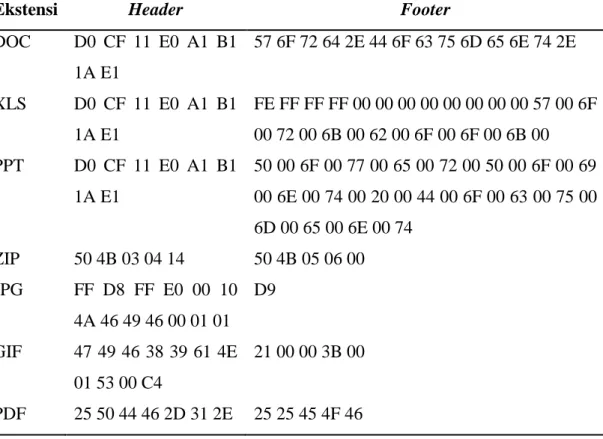
3. Footer (tail) adalah bagian penutup file yang menjadi penanda akhir dari file tersebut seperti pada Tabel 2.2 yang diadaptasi dari Tyagi (2004).
Tabel 2.1. Daftar file signature pada header untuk beberapa jenis file
Hex ASCII Ekstensi Jenis file
25 50 44 46 %PDF PDF, FDF Adobe Portable Document Format and Forms Document file
D0 CF 11 E0 A1 B1 1A E1 ÐÏ.ࡱ.á DOC, DOT, PPS, PPT, XLA, XLS, WIZ
Microsoft Office applications (Word, Powerpoint, Excel, Wizard)
50 4B 03 04 14 00 06 00
PK... DOCX, PPTX, XLSX
Microsoft Office Open XML Format (OOXML) Document FF D8 FF ÿØÿà JPG, JPEG JPEG
89 50 4E 47 0D 0A 1A 0A
.PNG.... PNG Image encoded in Portable Network Graphics format
38 42 50 53 8BPS PSD Photoshop Document file
2.2.1 Pemulihan file yang telah terhapus
Pemulihan file adalah proses yang dilakukan untuk memulihkan file yang telah terhapus sehingga dapat dipergunakan sebagai barang bukti digital. Proses untuk memulihkan file dalam bidang forensik digital dibagi menjadi tiga yaitu:
1. Undelete
Undelete adalah proses untuk memulihkan file yang telah terhapus dari file system. File yang dapat dipulihkan dengan proses undelete adalah file yang reference-nya
terhapus dari MFT. Dengan kata lain, entry pada MFT untuk file tersebut telah diberikan flag yang bernilai deleted yang mengakibatkan cluster yang ditempati
file tersebut menjadi unallocated space. Pemulihan file dengan proses undelete
dapat dilakukan dengan cara membaca entry pada MFT dan mencari file dengan
flag bernilai deleted lalu mengambil isi dari cluster-cluster yang ditunjuk oleh entry tersebut dan menyatukannya menjadi sebuah file kembali. Metode ini
merupakan metode yang memiliki kemungkinan terbesar dalam memulihkan file dengan baik namun bergantung pada tipe file system.
2. File carving
File carving atau biasa disebut dengan carving adalah proses ekstraksi
sekumpulan data dari kumpulan data yang lebih besar (Beek, 2011). File yang dipulihkan pada proses ini mengalami proses “carving” dari unallocated space menggunakan nilai header dan footer yang spesifik. Berbeda dengan proses
undelete yang memanfaatkan metadata yang diperoleh dari Master File Table (MFT) untuk proses pemulihan, proses carving bekerja dengan data mentah pada
media penyimpanan dan mengabaikan struktur file system (Beek, 2011). Dalam metode carving, header dan footer yang berbentuk untaian string bertipe byte dibaca dari database. Header dan footer berbentuk pola tertentu seperti pada Tabel 2.2. Setelah itu pencarian akan dilakukan pada image dari drive untuk mencari kemunculan dari header dan footer. Proses ini bertujuan menentukan lokasi awal dan akhir dari sebuah file dalam image dan kemudian melakukan proses penggandaan untaian byte yang ditemukan dalam segmen tersebut menjadi file-file sesuai dengan struktur dari file yang ingin dipulihkan.
File carving adalah metode yang sangat handal karena file didapatkan dari
data mentah dalam image tanpa menghiraukan file system. File masih mungkin didapatkan walaupun metadata dari file system telah rusak. Kerusakan pada
metadata dari file system biasanya disebabkan karena proses format dan perubahan
tipe file system (misalnya dari FAT32 menjadi NTFS) (Richard & Roussev, 2005). Walaupun metode pemulihan file dengan file carving merupakan metode yang handal, proses carving yang melakukan rekonstruksi file dari segmen yang dibatasi oleh tempat ditemukannya header dan footer memiliki kelemahan seperti hanya dapat dilakukan terhadap file yang contiguous dan menghasilkan banyak
sebagai sebuah file yang kriterianya memenuhi kriteria file yang ingin direkonstruksi namun bukan file yang sebenarnya ingin diperoleh. File carving juga memerlukan ukuran ruang penyimpanan yang besar karena jumlah false
positive yang dihasilkan. Dengan menerapkan in-place file carving maka ukuran
media penyimpanan yang dilakukan dapat dikurangi karena metadata dapat dibuat kembali tanpa harus menggandakan isi file (Richard et al., 2007).
Tabel 2.2. Daftar header dan footer untuk beberapa jenis file
Ekstensi Header Footer
DOC D0 CF 11 E0 A1 B1 1A E1 57 6F 72 64 2E 44 6F 63 75 6D 65 6E 74 2E XLS D0 CF 11 E0 A1 B1 1A E1 FE FF FF FF 00 00 00 00 00 00 00 00 57 00 6F 00 72 00 6B 00 62 00 6F 00 6F 00 6B 00 PPT D0 CF 11 E0 A1 B1 1A E1 50 00 6F 00 77 00 65 00 72 00 50 00 6F 00 69 00 6E 00 74 00 20 00 44 00 6F 00 63 00 75 00 6D 00 65 00 6E 00 74 ZIP 50 4B 03 04 14 50 4B 05 06 00 JPG FF D8 FF E0 00 10 4A 46 49 46 00 01 01 D9 GIF 47 49 46 38 39 61 4E 01 53 00 C4 21 00 00 3B 00 PDF 25 50 44 46 2D 31 2E 25 25 45 4F 46 3. Recovery
Istilah recovery dipergunakan secara umum untuk menjelaskan tentang pemulihan
file. Akan tetapi, recovery secara khusus dapat diartikan sebagai proses
penyelamatan dan penanganan data media penyimpanan yang rusak, corrupted atau saat media tersebut tidak dapat diakses secara normal. Istilah ini juga dipergunakan dalam forensik dimana data yang dienkripsi atau disembunyikan dipulihkan.
Pemulihan file merupakan salah satu proses yang dilakukan dalam pengumpulan barang bukti dalam forensik digital. Pada file system berjenis NTFS, proses pada saat file yang terhapus dipulihkan lebih handal karena entry MFT untuk
setiap file memiliki daftar cluster yang dialokasikan untuk penyimpanan file tersebut. Oleh karena itu, file yang telah mengalami fragmentasi masih mungkin untuk dipulihkan (Casey, 2011).
2.3. Disk Imaging
Proses pembuatan image dari sebuah drive atau disk imaging adalah proses pembuatan duplikat dari sebuah media penyimpanan. Berbeda dengan proses menggandakan file, pada proses ini media penyimpan dibaca secara langsung (bit per bit) tanpa menggunakan file system. Proses ini juga menggandakan data yang tidak berhubungan dengan file seperti data boot sector. Karena cara kerja disk imaging tersebut, maka setiap bagian dari media penyimpanan akan dibaca sehingga dihasilkan sebuah image yaitu duplikat dari media penyimpanan yang isinya persis sama dengan media penyimpanan yang sebenarnya (Leaver, 2007). Proses disk imaging sangat penting untuk membuat drive sekunder sehingga dapat mencegah pemakaian media penyimpanan lebih lanjut yang dapat mengakibatkan terjadinya proses penimpaan oleh data baru yang dapat mengurangi tingkat keberhasilan proses pemulihan file.
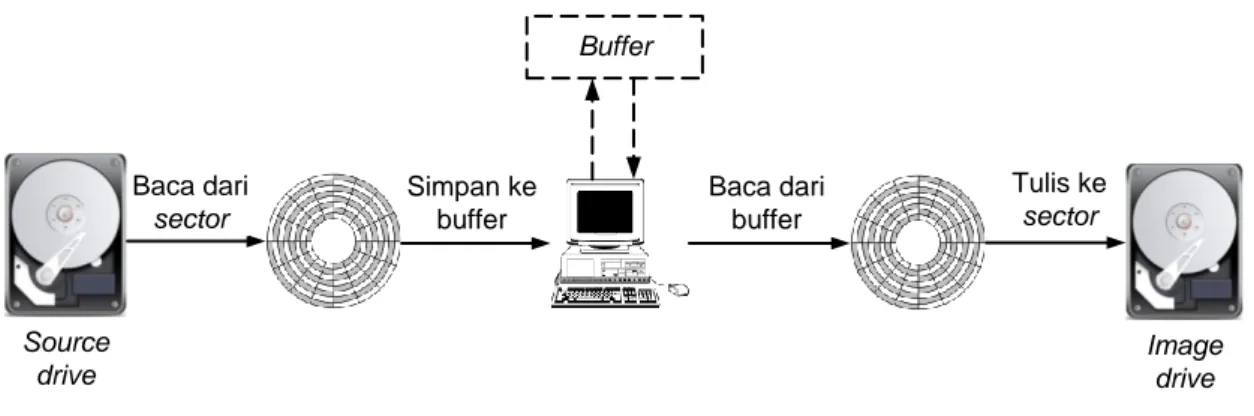
Proses disk imaging menggandakan isi setiap sector pada source drive (media penyimpanan asal) ke sector lain pada image drive (media penyimpanan hasil penggandaan) seperti yang terlihat pada Gambar 2.1.
Source drive Image drive Baca dari sector Simpan ke buffer Buffer Tulis ke sector Baca dari buffer
Gambar 2.1. Proses disk imaging
Pertama, sector pada media penyimpanan akan dibaca secara low level sehingga diperoleh isi sector tersebut berupa untaian bilangan hexadecimal. Selanjutnya,
untaian bilangan hexadecimal tersebut akan disimpan dalam sebuah buffer. Isi pada
buffer tersebut kemudian akan dituliskan pada sector yang ada pada image drive.
Proses ini berulang secara terus menerus sampai semua sector yang ada pada source
drive digandakan. Sector adalah unit penyimpanan fisik terkecil dalam disk magnetik
maupun disk optikal dan memiliki ukuran 512 byte.
2.4. File System NTFS
NTFS atau New Technology File System adalah file system yang dikembangkan oleh Microsoft serta memiliki dukungan yang lebih baik untuk metadata dan penggunaan struktur data yang lebih lanjut untuk meningkatkan performa, kehandalan, dan penggunaan lokasi penyimpanan. File system ini dirancang untuk dapat secara cepat melakukan operasi file seperti operasi baca, tulis, dan pencarian serta operasi tingkat lanjut seperti pemulihan file system pada hard disk yang berukuran sangat besar. Proses format untuk file system dengan jenis NTFS akan menghasilkan beberapa file
metadata atau metafile seperti $MFT (Master File Table), $BitMap, $LogFile dan
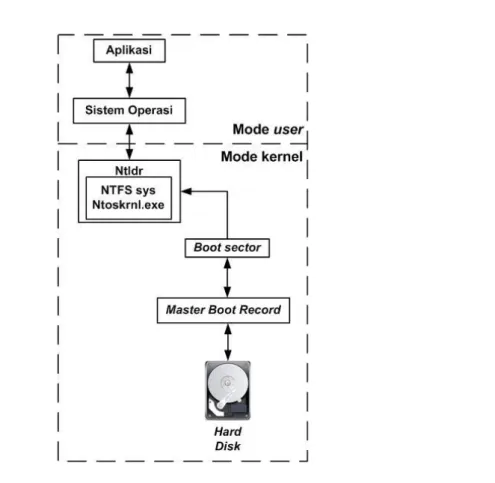
lain-lain yang berisi informasi tentang file dan folder dalam file system NTFS tersebut. Gambar 2.2 menunjukkan bagaimana aplikasi berkomunikasi dengan hard disk pada file system berjenis NTFS. Tabel 2.3 berisi penjelasan tentang masing-masing komponen arsitektur NTFS yang terdapat pada Gambar 2.2. Gambar 2.2 dan Tabel 2.3 diadaptasi dari Microsoft (2003).
Tabel 2.3. Komponen Arsitektur NTFS
Komponen Deskripsi
Hard disk Media penyimpanan, dapat terdiri dari satu atau lebih partisi.
Boot sector Bagian yang diinisialisasi dan menyimpan informasi susunan
volume media penyimpanan dan struktur file system serta boot code yang memuat Ntldr.
Master Boot Record Berisi kode yang dapat dijalankan dan dimuat oleh BIOS
sistem ke dalam memori. Kode ini memindai MBR untuk mencari partition table (tabel partisi) untuk menentukan partisi mana yang aktif atau partisi mana yang diinisialisasi.
Tabel 2.3. Komponen Arsitektur NTFS (lanjutan)
Komponen Deskripsi
Ntldr.dll Mengalihkan CPU ke mode protected, memulai file system, dan kemudian membaca isi dari file Boot.ini. Informasi ini menentukan pilihan startup dan pilihan boot menu
Ntfs.sys System file driver untuk NTFS.
Ntoskrnl.exe Mengekstraksi informasi system device driver mana yang akan dimuat dan urutan memuat.
Kernel mode Mode pemrosesan yang memungkinkan kode untuk memperoleh akses langsung ke semua perangkat keras dan memori dalam sistem.
User mode Mode pemrosesan dimana aplikasi berjalan.
Gambar 2.2. Arsitektur NTFS
Partisi file system berjenis NTFS memiliki struktur yang sederhana seperti terlihat pada Gambar 2.3 berdasarkan adaptasi dari Schwarz (2009). Pada awal file
MFT dari dua MFT yang ada dalam file system NTFS (salah satunya merupakan MFT yang dipergunakan file system dan yang lainnya merupakan salinan dari MFT tersebut). MFT umumnya dialokasikan sebesar 12,5% dari ukuran partisi, namun nilai ini dapat diubah untuk mendukung file system.
Partisi dengan file system berjenis NTFS Boot
sector
Master File
Table Data dalam file system
Duplikat Master File
Table Sector dengan
nomor logical 0
Gambar 2.3. Struktur file system NTFS
Gambar 2.4 memperlihatkan contoh isi dari boot sector (sector dengan nomor
logical 0). Bagian boot sector sebagian besar terdiri dari kode boot strap.
EB 52 90 4E 54 46 53 20 20 20 20 00 02 08 00 00 00 00 00 00 00 F8 00 00 3F 00 FF 00 3F 00 00 00 00 00 00 00 80 00 00 00 A0 72 73 00 00 00 00 00 00 00 04 00 00 00 00 00 02 00 00 00 00 00 00 00 F6 00 00 00 01 00 00 00 1D AD D8 C0 E5 D8 C0 76 00 00 00 00 FA 33 C0 8E D0 BC 00 7C FB 68 C0 07 1F 1E 68 66 00 CB 88 16 0E 00 66 81 3E 03 00 4E 54 46 53 75 15 B4 41 BB AA 55 CD 13 72 0C 81 FB 55 AA 75 06 F7 C1 01 00 75 03 E9 DD 00 1E 83 EC 18 68 1A 00 B4 48 8A 16 0E 00 8B F4 16 1F CD 13 9F 83 C4 18 9E 58 1F 72 E1 3B 06 0B 00 75 DB A3 0F 00 C1 2E 0F 00 04 1E 5A 33 DB B9 00 20 2B C8 66 FF 06 11 00 03 16 0F 00 8E C2 FF 06 16 00 E8 4B 00 2B C8 77 EF B8 00 BB CD 1A 66 23 C0 75 2D 66 81 FB 54 43 50 41 75 24 81 F9 02 01 72 1E 16 68 07 BB 16 68 70 0E 16 68 09 00 66 53 66 53 66 55 16 16 16 68 B8 01 66 61 0E 07 CD 1A 33 C0 BF 28 10 B9 D8 0F FC F3 AA E9 5F 01 90 90 66 60 1E 06 66 A1 11 00 66 03 06 1C 00 1E 66 68 00 00 00 00 66 50 06 53 68 01 00 68 10 00 B4 42 8A 16 0E 00 16 1F 8B F4 CD 13 66 59 5B 5A 66 59 66 59 1F 0F 82 16 00 66 FF 06 11 00 03 16 0F 00 8E C2 FF 0E 16 00 75 BC 07 1F 66 61 C3 A0 F8 01 E8 09 00 A0 FB 01 E8 03 00 F4 EB FD B4 01 8B F0 AC 3C 00 74 09 B4 0E BB 07 00 CD 10 EB F2 C3 0D 0A 41 20 64 69 73 6B 20 72 65 61 64 20 65 72 72 6F 72 20 6F 63 63 75 72 72 65 64 00 0D 0A 42 4F 4F 54 4D 47 52 20 69 73 20 6D 69 73 73 69 6E 67 00 0D 0A 42 4F 4F 54 4D 47 52 20 69 73 20 63 6F 6D 70 72 65 73 73 65 64 00 0D 0A 50 72 65 73 73 20 43 74 72 6C 2B 41 6C 74 2B 44 65 6C 20 74 6F 20 72 65 73 74 61 72 74 0D 0A 00 8C A9 BE D6 00 00 55 AA 1 2 4 5 6 3 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F 0000 0001 0002 0003 0004 0005 0006 0007 0008 0009 000A 000B 000C 000D 000E 000F 0010 0011 0012 0013 0014 0015 0016 0017 0018 0019 001A 001B 001C 001D 001E 001F Offset
Susunan boot sector pada Gambar 2.4 ditunjukkan pada Tabel 2.4 berdasarkan adaptasi dari Microsoft (2003), Schwarz (2009), dan Wilkinson (2012).
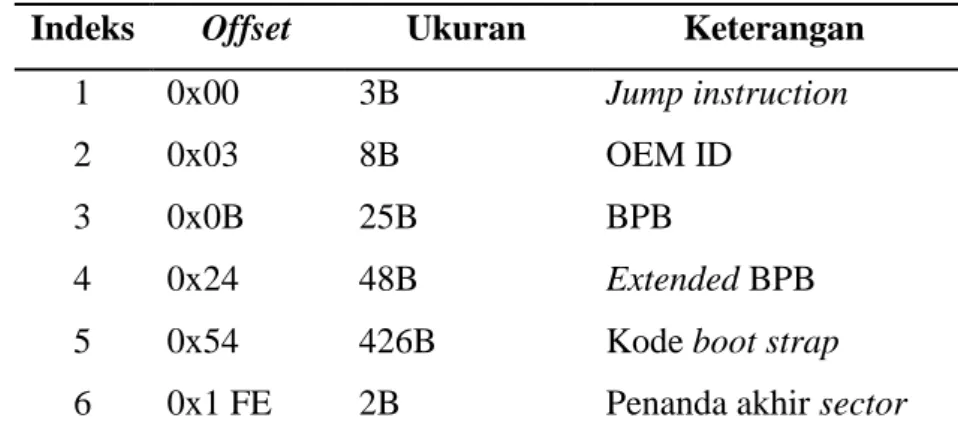
Tabel 2.4. Susunan boot sector pada file system NTFS
Indeks Offset Ukuran Keterangan
1 0x00 3B Jump instruction
2 0x03 8B OEM ID
3 0x0B 25B BPB
4 0x24 48B Extended BPB
5 0x54 426B Kode boot strap 6 0x1 FE 2B Penanda akhir sector
Kode boot strap dalam boot sector memiliki informasi penting yang tersimpan dalam BPB dan extended BPB seperti ukuran byte per sector, jumlah sector per
cluster, cluster tempat MFT dan salinan MFT berada, jumlah total sector, dan
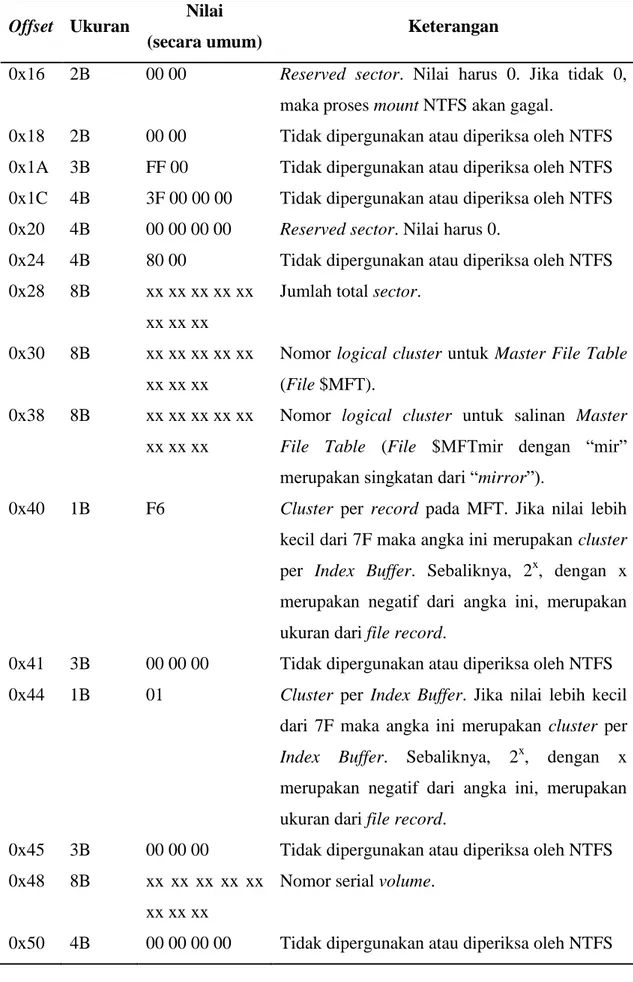
informasi penting lainnya. BIOS Parameter Block (BPB) adalah struktur data yang terdapat dalam boot sector yang memberikan informasi tentang susunan parameter fisik dalam volume penyimpanan data. Susunan informasi dalam BPB dapat dibagi seperti pada Tabel 2.5 berdasarkan adaptasi dari Schwarz (2009) dan Microsoft (2003).
Tabel 2.5. Susunan informasi dalam BPB
Offset Ukuran Nilai
(secara umum) Keterangan
0x0B 2B 00 02 Ukuran byte per sector. Umumnya 512 byte 0x0D 1B 08 Jumlah sector per cluster.
0x0E 2B 00 00 Reserved sector. Nilai harus 0. Jika tidak 0,
maka proses mount NTFS akan gagal.
0x10 3B 00 00 00 Reserved sector. Nilai harus 0. Jika tidak 0,
maka proses mount NTFS akan gagal.
0x13 2B 00 00 Reserved sector. Nilai harus 0. Jika tidak 0,
maka proses mount NTFS akan gagal.
0x15 1B F8 Jenis media penyimpanan (media descriptor). F8: hard disk, F0: floppy berkepadatan tinggi.
Tabel 2.5. Susunan informasi dalam BPB (lanjutan)
Offset Ukuran Nilai
(secara umum) Keterangan
0x16 2B 00 00 Reserved sector. Nilai harus 0. Jika tidak 0,
maka proses mount NTFS akan gagal.
0x18 2B 00 00 Tidak dipergunakan atau diperiksa oleh NTFS 0x1A 3B FF 00 Tidak dipergunakan atau diperiksa oleh NTFS 0x1C 4B 3F 00 00 00 Tidak dipergunakan atau diperiksa oleh NTFS 0x20 4B 00 00 00 00 Reserved sector. Nilai harus 0.
0x24 4B 80 00 Tidak dipergunakan atau diperiksa oleh NTFS 0x28 8B xx xx xx xx xx
xx xx xx
Jumlah total sector.
0x30 8B xx xx xx xx xx xx xx xx
Nomor logical cluster untuk Master File Table (File $MFT).
0x38 8B xx xx xx xx xx xx xx xx
Nomor logical cluster untuk salinan Master
File Table (File $MFTmir dengan “mir”
merupakan singkatan dari “mirror”).
0x40 1B F6 Cluster per record pada MFT. Jika nilai lebih
kecil dari 7F maka angka ini merupakan cluster per Index Buffer. Sebaliknya, 2x, dengan x merupakan negatif dari angka ini, merupakan ukuran dari file record.
0x41 3B 00 00 00 Tidak dipergunakan atau diperiksa oleh NTFS 0x44 1B 01 Cluster per Index Buffer. Jika nilai lebih kecil
dari 7F maka angka ini merupakan cluster per
Index Buffer. Sebaliknya, 2x, dengan x merupakan negatif dari angka ini, merupakan ukuran dari file record.
0x45 3B 00 00 00 Tidak dipergunakan atau diperiksa oleh NTFS 0x48 8B xx xx xx xx xx
xx xx xx
Nomor serial volume.
Tidak semua informasi dalam BPB dan extended BPB merupakan informasi yang penting. Beberapa informasi penting yang dapat diperoleh dari BPB adalah ukuran byte untuk setiap sector, jumlah sector dalam setiap cluster, dan alamat cluster MFT. Informasi yang tersimpan dalam BPB dibaca secara little endian, yaitu sebuah sistem dimana least significant bit menempati alamat terkecil dalam memori. Contoh, pada Gambar 2.4 nilai pada offset 0x0B sebanyak 2B merepresentasikan ukuran sector dalam file system. Nilai pada offset ini adalah 00 02. Jika dibaca dengan menggunakan sistem little endian, nilai ini menjadi 02 00, dimana apabila nilai ini diubah menjadi desimal maka akan menjadi 512. Angka ini merupakan ukuran setiap sector yang dimiliki oleh partisi ini yaitu sebesar 512 byte.
Berdasarkan Gambar 2.4 diperoleh bilangan heksadesimal yang merupakan BPB dan extended BPB dari offset 0x0B sampai dengan 0x4F sebagai berikut:
Offset 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F 0000 ………00 02 08 00 00 0001 00 00 00 00 00 F8 00 00 3F 00 FF 00 3F 00 00 00 0002 00 00 00 00 80 00 00 00 A0 72 73 00 00 00 00 00 0003 00 00 04 00 00 00 00 00 02 00 00 00 00 00 00 00 0004 F6 00 00 00 01 00 00 00 1D AD D8 C0 E5 D8 C0 76 Beberapa informasi penting yang dapat diperoleh dari BPB dan extended BPB sesuai dengan boot sector pada Gambar 2.4 dan susunan informasi dalam BPB pada Tabel 2.5 seperti yang diberikan dalam Tabel 2.6.
Tabel 2.6. Informasi yang diperoleh dari BPB
Offset Ukuran Nilai Keterangan
0x0B 2B 00 02 Dibaca secara little endian menjadi 0x 02 00. Nilai 02 00 (heksadesimal) sama dengan 512 (desimal). Dengan demikian ukuran per sector adalah 512 byte.
0x0D 8B 08 00 00 00 00 00 00 00
Nilai ini sama dengan 8 (desimal). Dengan demikian, jumlah sector dalam setiap cluster adalah 8.
Tabel 2.6. Informasi yang diperoleh dari BPB (lanjutan)
Offset Ukuran Nilai Keterangan
0x15 1B F8 Jenis media penyimpanan adalah hard disk karena F8 merupakan media descriptor untuk
hard disk.
0x28 8B A0 72 73 00 00 00 00 00
Jumlah total sector adalah 0x 73 72 A0 = 7.565.984 sector.
0x30 8B 00 00 04 00 00 00 00 00
MFT dimulai pada cluster 0x 4 00 00 = 262.144 atau sector 1.048.576. Ini merupakan pengalamatan logical, dan untuk memperoleh pengalamatan physical, maka angka ini harus ditambahkan dengan jumlah dari total sector sebelumnya jika hard disk memiliki lebih dari satu partisi. Jika hard disk hanya terdiri dari satu partisi, maka alamat logical dari sebuah sector akan sama dengan alamat physical. Karena hard
disk yang dipergunakan hanya terdiri dari satu
partisi maka alamat physical sama dengan alamat logical.
0x38 8B 02 00 00 00 00 00 00 00
Salinan MFT berada pada cluster 0x 2 = 32 (secara logical).
0x40 1B F6 Terdapat 0x F6 = 246 cluster per record pada MFT.
0x44 1B 01 Terdapat satu cluster per index buffer. 0x48 8B 1D AD D8
C0 E5 D8 C0 76
Nomor serial volume adalah 76 C0 D8 E5 C0 D8 AD 1D.
Dalam file system NTFS, pengorganisasian hard disk dilakukan berdasarkan ukuran cluster (allocation unit size). Cluster merupakan satuan pengalokasian tempat penyimpanan untuk file dan direktori. Untuk mengurangi manajemen struktur data yang berlebihan, file system tidak melakukan alokasi berdasarkan sector namun berdasarkan cluster. Sebuah cluster dapat terdiri dari satu atau beberapa sector.
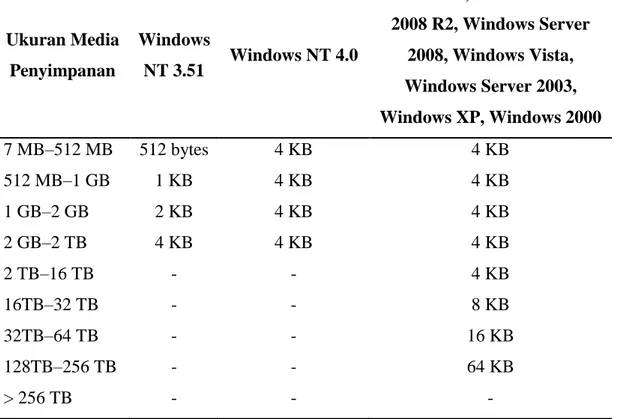
Ukuran cluster merepresentasikan ukuran terkecil yang dapat dipergunakan untuk menyimpan file. Ukuran cluster untuk file system berjenis NTFS yang sering ditemukan adalah 4KB atau 4096 byte (cluster yang tersusun dari 8 buah sector, 8 * 512 byte = 4096 byte = 4 KB). Ukuran cluster pada file system NTFS bervariasi dari 512 byte (1 sector) sampai 64 KB (128 sector), namun variasi ukuran cluster selain bergantung pada ukuran media penyimpanan juga bergantung pada jenis sistem operasi seperti terlihat pada Tabel 2.7 berdasarkan adaptasi dari Microsoft (2013). Semakin besar ukuran cluster pada file system media penyimpanan akan mengurangi tingkat fragmentasi file namun akan berdampak pada peningkatan jumlah slack space dan demikian pula sebaliknya.
Tabel 2.7. Daftar ukuran cluster pada file system NTFS
Ukuran Media Penyimpanan
Windows
NT 3.51 Windows NT 4.0
Windows 7, Windows Server 2008 R2, Windows Server 2008, Windows Vista, Windows Server 2003, Windows XP, Windows 2000 7 MB–512 MB 512 bytes 4 KB 4 KB 512 MB–1 GB 1 KB 4 KB 4 KB 1 GB–2 GB 2 KB 4 KB 4 KB 2 GB–2 TB 4 KB 4 KB 4 KB 2 TB–16 TB - - 4 KB 16TB–32 TB - - 8 KB 32TB–64 TB - - 16 KB 128TB–256 TB - - 64 KB > 256 TB - - - 2.4.1. File Fragmentation
Penggunaan cluster dalam media penyimpanan memberikan keuntungan berupa reduksi tingkat fragmentasi dalam file system. File fragmentation atau fragmentasi adalah suatu keadaan media penyimpanan dimana file dibagi menjadi bagian-bagian yang lebih kecil dan tersebar di berbagai bagian dalam media penyimpanan. Fragmentasi merupakan proses yang umum terjadi saat disk sering dipergunakan
untuk membuat, menghapus dan mengubah file. Oleh karena itu, sistem operasi harus menyimpan bagian dari sebuah file dalam cluster yang tidak berurutan. Proses fragmentasi tidak kasat mata oleh user namun dapat memperlambat kecepatan akses data karena pencarian harus dilakukan ke semua bagian media penyimpanan untuk menghasilkan sebuah file.
Penyebab utama terjadinya fragmentasi adalah saat file yang tersimpan dalam media penyimpanan dihapus sehingga mengakibatkan terbentuknya cluster kosong yang siap ditempati oleh file lain. Apabila ukuran cluster tersebut tidak cukup untuk menampung seluruh isi file, maka file akan dibagi menjadi beberapa bagian untuk ditempatkan di cluster-cluster kosong yang ada. Saat file yang ada mengalami penambahan isi file yang mengakibatkan ukuran file bertambah, sering kali tidak mungkin untuk melakukan proses penulisan di bagian akhir file yang berpotensi menyebabkan proses fragmentasi. Penyebab fragmentasi dapat dilihat pada Gambar 2.5.
Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 Cluster 7 Cluster 8
File 1 File 2 File 2 File 2 File 3 File 4 File 5 File 6
File 2 File 2 File 2 File 5
(1)
(2)
(3)
File X File 2 File 2 File 2 File X File X File 5 File X
(4)
Gambar 2.5. Penyebab terjadinya fragmentasi
Sebuah media penyimpanan yang masih belum berisi akan diisi dengan 5 buah
file dengan ukuran yang berbeda (kondisi nomor (1)). Kemudian saat file dengan
ukuran yang bervariasi menempati media penyimpanan, cluster yang ada menjadi terisi. Saat cluster yang kosong berurut, maka file juga akan tersusun secara berurut
(kondisi nomor (2)). Saat file dihapus, maka cluster yang semula menampung file tersebut menjadi kosong dan media penyimpanan mengalami fragmentasi (kondisi nomor (3)). File system dapat melakukan proses defragmentasi segera setelah proses penghapusan, namun proses defragmentasi akan berdampak pada performa pada waktu yang tidak dapat diperkirakan. Oleh karena itu, secara umum, cluster kosong akan dibiarkan dan ditandai pada MFT sebagai cluster yang siap dipergunakan. Saat
file baru akan dimasukkan ke media penyimpanan yang telah mengalami proses
fragmentasi, maka file tersebut akan terbagi menjadi beberapa bagian untuk menempati cluster kosong yang tersedia (kondisi nomor (4)).
Pada Gambar 2.6, sebuah file berukuran 16KB akan disimpan dalam sebuah
hard disk dengan file system berjenis NTFS dan cluster berukuran 4KB. File
berukuran 16KB tersebut akan dibagi menjadi beberapa bagian (fragment) sesuai dengan ukuran cluster dan akan ditempatkan di cluster-cluster yang kosong sehingga mengakibatkan terjadinya fragmentasi.
File 1
Fragment
file 1 File lain File lain File lain
Fragment file 1
Fragment
file 1 File lain
Fragment file 1
16KB
Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 Cluster 7 Cluster 8
Cluster berukuran 4KB
Gambar 2.6. Proses fragmentasi sebuah file untuk menempati cluster kosong Ukuran cluster yang lebih besar diperlukan untuk mengurangi tingkat fragmentasi file sehingga waktu akses data dapat ditingkatkan,
2.4.2. Slack Space
Karena cluster merupakan ukuran alokasi paling kecil yang dipergunakan untuk menyimpan sebuah file dalam media penyimpanan, maka apabila sebuah file yang
kecil disimpan dalam cluster yang besar maka akan mengakibatkan munculnya slack
space. Slack space adalah bagian dari hard drive yang tidak sepenuhnya digunakan
oleh file yang sedang dialokasikan di cluster tersebut dan dapat berisi data dari file yang sebelumnya terhapus (Hoog, 2008). Gambar 2.6 menunjukkan perbedaan ukuran sebenarnya sebuah file dan ukuran file tersebut dalam hard disk. Sebagai contoh, file yang berukuran 940 byte hanya akan menempati 2 sector dalam hard disk (2 sector = 2 * 512 byte = 1024 byte – cukup untuk menampung file tersebut). Akan tetapi, karena file system melakukan manajemen bukan berdasarkan sector namun berdasarkan cluster, maka file tersebut akan menempati sebuah cluster (berukuran 4KB). Karena file hanya memerlukan 940 byte untuk dipergunakan sebagai tempat penyimpanan, maka sisa ruang alokasi yang tidak dipergunakan akan diisi oleh file
system dengan bit 1 atau 0 atau sisa cluster tidak akan diubah sama sekali.
Size :
Size on disk 1 byte (1 byte)4.00 KB (4,096 bytes)
Gambar 2.7. Contoh slack space
Gambar 2.8 menunjukkan bagaimana sebuah file yang seharusnya hanya memerlukan 5 sector sebagai tempat penyimpanan menggunakan sebuah cluster berukuran 4 KB dan sisa cluster yang tidak dipergunakan (slack space) berdasarkan adaptasi dari Hoog (2008).
File.txt
File.txt
Ukuran : 2542 byte
File.txt File.txt File.txt Slack space
Slack space
Slack space
Cluster berukuran 4KB (4096 byte) Slack space. Diisi oleh sistem operasi. F il e .t x t
Gambar 2.8. Ilustrasi manajemen penyimpanan file dan slack space
2.5. Master File Table (MFT)
Master File Table atau MFT adalah sebuah file yang menyimpan informasi tentang semua file dan direktori yang ada dalam file system. Dalam MFT terdapat paling sedikit satu record untuk setiap file dan direktori dalam volume logical NTFS. Informasi yang rinci seperti jenis file, ukuran, tanggal dan waktu pembuatan, tanggal dan waktu perubahan terakhir, dan identitas pembuat file disimpan dalam entry MFT atau di luar MFT namun dideskripsikan dalam entry MFT.
Karena MFT menyimpan informasi tentang semua file, MFT juga menyimpan informasi tentang file MFT itu sendiri. Sebanyak 16 record pertama MFT dipergunakan untuk menyimpan file metadata yang dipergunakan untuk mendeskripsikan file MFT. Record yang berisi informasi tentang MFT dirincikan pada Tabel 2.8 yang diadaptasi dari Schwarz (2009) dan Wilkinson (2012).
Tabel 2.8. Daftar record berisi informasi tentang MFT
Record Nama Metafile Keterangan
0 $MFT Self reference ke MFT (MFT itu sendiri). Berisi file record untuk setiap file dan folder.
1 $MFTMirr Backup empat record pertama FILE MFT.
Memungkinkan akses ke MFT jika terjadi
Tabel 2.8. Daftar record berisi informasi tentang MFT (lanjutan)
Record Nama Metafile Keterangan
2 $LogFile Membantu menjaga konsistensi file system jika terjadi system error. Berisi informasi yang dapat dipergunakan oleh file system NTFS untuk melakukan pemulihan sistem dengan cepat.
3 $Volume Informasi volume (nama volume, nomor volume, dan lain-lain).
4 $AttrDef Mendefinisikan atribut file yang didukung. 5 . (dot) Direktori root.
6 $BitMap Representasi bit dari cluster yang bebas atau digunakan dalam volume.
7 $Boot Boot sector dalam volume. Berisi BPB untuk proses mount dan kode bootstrap loader.
8 $BadClus Daftar cluster yang rusak atau buruk dalam volume. 9 $Secure Security descriptor untuk semua file.
10 $UpCase Tabel karakter huruf kapital UNICODE untuk
sorting.
11 $Extend Untuk penambahan yang bersifat opsional seperti
quota, data reparse point, dan pengenal objek.
12 – 15 - Reserved.
2.5.1. Record MFT
Setiap record untuk file dan folder yang disimpan dalam MFT berukuran 1 KB. Atribut file disimpan dalam MFT. Selain atribut file, setiap file record berisi informasi tentang lokasi blok data file. Atribut untuk file yang kecil seluruhnya akan tersimpan dalam MFT. Entry MFT menyerupai record basis data dengan banyak field yang bersifat opsional. Struktur record MFT seperti yang diberikan pada Gambar 2.9 yang diadaptasi dari Schwarz (2009).
Master File Table
Entry
header Atribut 1 Atribut 2 Atribut 3
Sisa space Sebuah record MFT
Header atribut
Gambar 2.9. Struktur record MFT
Gambar 2.10 menunjukkan struktur record MFT untuk file berukuran kecil berdasarkan adaptasi dari Schwarz (2009). Secara umum, file yang ukurannya mendekati 900B tersimpan sepenuhnya dalam entry MFT.
Informasi standar
Nama file atau
direktori Data atau indeks
Ruang penyimpanan yang tidak dipergunakan
Gambar 2.10. Record MFT untuk file berukuran kecil
Struktur data untuk entry pada MFT seperti yang diberikan pada Tabel 2.9 yang diadaptasi dari Schwarz (2009). Entry MFT secara umum terdiri dari:
1. Informasi standar yang berisi timestamp cara akses dan jumlah link.
2. Daftar atribut berisi lokasi semua record atribut yang tidak sesuai atau tidak dapat dimasukkan dalam record MFT.
3. Nama file diberikan dalam versi panjang dan pendek (DOS readable). Nama file versi pendek memiliki format 8.3 case insensitive khusus. Nama versi panjang dapat terdiri dari 255 karakter Unicode.
4. Object ID (hanya dimiliki beberapa file).
5. Logged Tool Stream yang hanya dipergunakan oleh EFS. 6. Reparse point yang dipergunakan oleh perangkat mounted.
7. Index root yang dipergunakan untuk implementasi folder dan indeks lain.
8. Index allocation yang dipergunakan untuk implementasi struktur B-tree untuk
folder berukuran besar dan indeks berukuran besar lain.
9. Bitmap yang dipergunakan untuk implementasi struktur B-tree untuk folder berukuran besar dan indeks berukuran besar lain.
Tabel 2.9. Struktur data entry dalam MFT
Offset Ukuran Sistem
Operasi Keterangan
0x00 – 0x03 4 Magic number “FILE”.
0x04 – 0x05 2 Offset ke update sequence.
0x06 – 0x07 2 Jumlah entry dalam fixup array. 0x08 – 0x0f 8 $LogFile Sequence Number (LSN). 0x10 – 0x11 2 Sequence number.
0x12 – 0x13 2 Jumlah hard link.
0x14 – 0x15 2 Offset ke atribut pertama.
0x16 – 0x17 2 Flag, jika 0x01: record yang sedang
digunakan, 0x02: direktori.
0x18 – 0x1b 4 Ukuran entry MFT yang dipergunakan. 0x1c – 0x1f 4 Ukuran entry MFT yang dialokasikan. 0x20 – 0x27 8 File reference ke record FILE dasar.
0x28 – 0x29 2 ID atribut selanjutnya.
0x2a – 0x2b 2 XP Menyelaraskan dengan batas 4B. 0x2c – 0x2f 4 XP Jumlah record MFT ini.
0x30 – 0x1000 Atribut dan nilai fixup.
2.5.2. LSN (Log Sequence Number), alamat file reference
LSN atau Log Sequence Number adalah sebuah nilai sebesar 64 bit yang dipergunakan sebagai logging area dalam entry MFT untuk metafile $LogFile. Log file terdiri dari dua bagian utama yaitu restart area dan logging area (Carrier, 2005). Logging area dibagi menjadi pengalamatan dengan MFT entry value sebesar 48 bit dengan entry pertama memiliki alamat 0 dan nomor urut (sequence number) sebesar 16 bit yang bertambah saat entry dialokasikan. Logging area yang terdiri dari entry value dan
sequence number juga dapat disebut sebagai file reference. Gambar 2.11 menujukkan
contoh pengalamatan file reference yang diadaptasi dari Carrier (2005) dan Schwarz (2009). Nilai sequence number akan berubah jika terjadi transaksi file system seperti: 1. Pembuatan file atau direktori baru.
2. Perubahan konten dari file atau direktori. 3. Perubahan nama file atau direktori.
4. Perubahan data file atau direktori yang tersimpan dalam entry MFT seperti ID pengguna, pengaturan keamanan, dan lain-lain.
Entry MFT $LogFIle
Logging area Restart area
64 bit
Sequence number Entry number
0040 0000 0000 0012
16 bit
Entry value
48 bit
File reference
Gambar 2.11. Alamat file reference
File reference mempermudah untuk mengetahui apakah file system mengalami
kerusakan (corrupt).
2.5.3. Atribut entry MFT
Atribut entry MFT dapat dinyatakan dengan bebas. Setiap atribut diawali oleh header atribut. Header atribut memberikan informasi mendasar tentang atribut tersebut seperti jenis atribut, ukuran, dan nama. Setiap atribut memiliki header berukuran 16 byte, lokasi dan ukuran konten sebesar 56 byte, dan konten yang ukurannya bervariasi. Gambar 2.12 merupakan contoh struktur dari record MFT baik untuk record dengan atribut yang bersifat resident maupun non-resident berdasarkan adaptasi dari Carrier (2005) dan Schwarz (2009).
Gambar 2.12. Contoh struktur record MFT
Jenis atribut untuk MFT terdapat dalam $AttrDef. Secara standar, informasi tentang jenis atribut yang terdapat dalam record MFT seperti pada Tabel 2.10 berdasarkan adaptasi dari Carrier (2005) dan Schwarz (2009).
Tabel 2.10. Jenis atribut MFT secara standar
Nilai Jenis Atribut Keterangan
0x10 STANDARD_INFORMATION Informasi umum seperti flag, waktu akses terakhir, waktu penulisan, dan waktu pembuatan serta pemilik file dan ID keamanan.
0x20 $ATTRIBUTE_LIST Daftar tempat dimana atribut lain dapat ditemukan.
0x30 $FILE_NAME Nama file dalam Unicode serta waktu akses terakhir, waktu penulisan, dan waktu pembuatan.
0x40 $VOLUME_VERSION Informasi volume (Windows NT). 0x40 $OBJECT_ID Penanda berukuran 16 byte yang unik
untuk file atau direktori (untuk Windows setelah Windows 2000+). 0x50 $SECURITY_DECRIPTOR Kontrol akses dan keamanan dari file.
Tabel 2.10. Jenis atribut MFT secara standar (lanjutan)
Nilai Jenis Atribut Keterangan
0x60 $VOLUME_NAME Nama volume.
0x70 $VOLUME_INFORMATION Versi file system dan flag lainnya.
0x80 $DATA Isi file.
0x90 $INDEX_ROOT Simpul akar dari pohon indeks.
0xA0 $INDEX_ALLOCATION Simpul dari pohon indeks dengan akar $INDEX_ROOT.
0xB0 $BITMAP Bitmap untuk file $MFT dan untuk
pengindeksan.
0xC0 $SYMBOLIC_LINK Informasi soft link (Windows NT). 0xC0 $REPARSE_POINT Data tentang reparse point,
dipergunakan sebagai soft link pada Windows 2000+.
0xD0 $EA_INFORMATION Dipergunakan sebagai backward compactibility untuk aplikasi OS/2
(HPFS).
0xE0 $EA Dipergunakan sebagai backward
compactibility untuk aplikasi OS/2
(HPFS). 0xF0 $PROPERTY_SET
0x100 $LOGGED_UTILITY_STREAM Berisi kunci dan informasi untuk atribut yang terenkripsi (Windows 2000+).
Atribut untuk record MFT dapat tersimpan seluruhnya dalam record tersebut (resident) maupun disimpan di luar record (non-resident). Struktur data 16 B pertama atribut bernilai sama baik untuk atribut resident maupun non-resident seperti pada Tabel 2.11 berdasarkan adaptasi dari Schwarz (2009). Setelah 16 B, maka stuktur data atribut resident akan berbeda dengan atribut non-resident karena atribut non-resident harus mendeskripsikan cluster konsekutif yang ditempati.
Tabel 2.11. Struktur data 16 B pertama atribut record MFT untuk record
resident maupun non-resident
Offset Ukuran Keterangan
0x00 4 Penanda jenis atribut
0x04 4 Panjang atribut (menentukan lokasi atribut selanjutnya) 0x08 1 Non-resident flag
0x09 1 Panjang nama 0x0a 2 Offset nama
0x0c 2 Flags
Perbedaan struktur data atribut resident dan non-resident seperti pada Tabel 2.12 dan 2.13 yang diadaptasi dari Schwarz (2009).
Tabel 2.12. Struktur data atribut resident
Offset Ukuran Keterangan 0x0e 2 Penanda atribut 0x10 4 Ukuran konten 0x15 2 Offset konten
Tabel 2.13. Struktur data atribut non-resident
Offset Ukuran Keterangan
0x0e 2 Penanda atribut
0x10 8 Nomor cluster virtual awal dari runlist 0x18 8 Nomor cluster virtual akhir dari runlist 0x20 2 Offset dari runlist
0x22 2 Ukuran unit kompresi 0x24 4 Tidak dipergunakan
0x28 8 Ukuran yang dialokasikan untuk atribut konten
0x30 8 Ukuran sebenarnya untuk atribut konten 0x38 8 Ukuran inisialisai untuk atribut konten
Offset dihitung dari awal atribut sampai akhir atribut (awal atribut memiliki nilai
0x00) dan bukan merupakan offset dari keseluruhan record.
2.6. Metadata
Metadata dapat secara literal diartikan sebagai “data tentang data”. Metadata atau
yang sering disebut dengan metacontent didefiniskan juga sebagai data yang memberikan informasi tentang satu atau lebih aspek dari sebuah data seperti:
1. Tujuan pembuatan data. 2. Fungsi data.
3. Waktu dan tanggal pembuatan.
4. Pembuat data (creator atau author, dimana istilah author biasanya dipergunakan untuk data berbentuk dokumen atau teks sedangkan istilah creator dipergunakan untuk jenis lainnya).
5. Lokasi dalam jaringan komputer dimana data dibuat. 6. Penggunaan standar.
Misalnya, sebuah citra digital bisa memiliki metadata yang berisi tentang ukuran citra, kedalaman warna, kapan citra tersebut dibuat, dan informasi lainnya. Demikian juga
metadata dokumen dapat berisi informasi tetang pembuat (author) dokumen tersebut,
panjang dokumen, kapan dokumen tersebut ditulis, dan ringkasan singkat dokumen tersebut.
Dalam proses undelete, diperlukan metadata dari file yang telah dihapus.
Metadata ini mengandung informasi seperti nama file dalam MFT, flag yang
menandakan apakah file telah dihapus dari file system, lokasi file dalam hard drive, ukuran file, dan lain-lain serta diperoleh dengan mengakses MFT. Metadata yang diperoleh dari MFT ini dapat dipergunakan untuk memulihkan file yang terhapus.
2.7. Algoritma Aho-Corasick
Algoritma Aho-Corasick adalah algoritma pencarian string atau sering juga pencocokan string (string matching algorithm) yang ditemukan oleh Alfred V. Aho dan Margaret J. Corasick (Aho & Corasick, 1975). Algoritma ini merupakan algoritma penyesuaian kamus yang menempatkan elemen dalam kumpulan string yang
terhingga. Algoritma ini menyesuaikan semua pola secara bersamaan. Kompleksitas algoritma ini adalah O(n + m + z), dengan n merupakan banyak pola, m merupakan panjang dari teks yang digunakan dalam pencarian, dan z merupakan jumlah output yang sesuai atau jumlah kemunculan pola.
Algoritma Aho-Corasik pertama-tama akan membuat mesin automata yang menyerupai trie dengan link tambahan diantara node internal dari keyword atau pola yang ada. Link tambahan ini memungkinkan transisi yang cepat saat terjadi kegagalan dalam proses pencocokan pola sehingga automata dapat berpindah ke cabang trie yang lain yang memiliki prefix yang mirip. Dengan adanya link tambahan tersebut, automata dapat berpindah saat proses pencocokan pola tanpa diperlukannya
backtracking. Trie adalah struktur data ordered tree yang dipergunakan untuk
menyimpan set yang dinamis atau array assosiatif dimana kunci yang ada biasanya berupa string. Sebuah trie memiliki berbagai kelebihan dibandingkan dengan binary
tree (Bentley & Sedgewick, 1998) dan dapat juga dipergunakan untuk menggantikan
tabel hash.
2.7.1.Konstruksi Keyword Trie
Algoritma Aho-Corasick didasarkan pada keyword trie. Keyword trie untuk himpunan pola P adalah trie dengan akar K dimana:
1. Setiap edge K dinamakan dengan sebuah karakter.
2. Dua edge yang keluar dari sebuah simpul memiliki nama yang berbeda. 3. Untuk setiap XP terdapat sebuah simpul v dengan L(v)=X.
4. Label L(v) dari setiap daun v adalah sama dengan X P.
Konstruksi keyword trie untuk himpunan pola P = {P1, …, Pk} dimulai dari
simpul akar atau awal, dengan memasukkan setiap pola Pi satu per satu dengan aturan:
1. Mulailah dari simpul akar dengan mengikuti path yang dinamakan dengan karakter dari Pi.
2. Jika path berakhir sebelum Pi, maka lanjutkan dengan menambah edge baru dan
simpul untuk setiap karakter Pi.
3. Simpan pengenal (identifier) i dari Pi pada simpul terminal dari path.
Pi adalah elemen ke-i dari himpunan P. Proses konstruksi keyword trie memerlukan
Sebagai contoh, terdapat himpunan pola P = {he, she, his, hers}. Keyword trie yang terbentuk dari himpunan pola P seperti yang diberikan pada Gambar 2.13 dengan state terminal dilambangkan dengan lingkaran ganda berdasarkan adaptasi dari Vilo (2008). 0 1 8 6 h e r s i s 3 4 5 s h e NOT {h,s}
P = {he, she, his, hers}
2
9
7
Gambar 2.13. Contoh keyword trie
2.7.2.Pencarian dalam Keyword Trie
Pencarian sebuah untaian string X dimulai dari simpul akar (root) atau awal mengikuti
path yang diberikan label karakter dari X. Jika penelusuran path berhenti pada simpul
dengan identifier atau dengan kata lain berhenti pada simpul terminal, maka X adalah
keyword dalam kamus atau trie. Sebaliknya, jika penelusuran path berhenti sebelum
akhir dari string X, maka string tersebut tidak ditemukan dalam kamus.
Selanjutnya keyword trie diubah menjadi automata untuk mendukung pencocokan linear-time dengan setiap simpul dalam keyword trie menjadi state dalam automata dan simpul akar menjadi state awal atau state 0. Lalu, untuk menentukan perpindahan state dalam automata, ditambahkan tiga fungsi:
1. Fungsi goto, g(q, a) menghasilkan state yang dituju dari state saat itu (q) setelah menerima input karakter a.
a. Jika edge (q, v) diberikan label a, maka g(q, a) = v.
b. g(0, a) = 0 untuk setiap a yang tidak diberikan sebagai label untuk edge yang keluar dari state awal. Automata tetap berada pada state awal jika menerima input berupa karakter yang tidak dikenal.
c. Lainnya g(q, a) = Ø
2. Fungsi failure f(q) untuk q ≠ 0 untuk state saat tidak ditemukan kecocokan. f(q) adalah simpul yang diberikan label longest proper suffix w dari L(v) dengan w merupakan prefix dari pola tertentu.
3. Fungsi output out(q) memberikan string yang dikenal saat memasuki sebuah state. Perubahan keyword trie menjadi automata dan penambahan fungsi akan menambahkan transisi pada keyword trie dari satu simpul ke simpul lain seperti pada Gambar 2.14 yang diadaptasi dari Vilo (2008).
0 1 8 6 h e r s i s 3 4 5 s h e NOT {h,s} 2 9 7
Gambar 2.14. Contoh automata dari keyword trie dengan penambahan fungsi-fungsi transisi
Automata pada Gambar 2.14 dapat dirincikan seperti pada Tabel 2.14 berdasarkan suffix link.
Tabel 2.14. Daftar kecocokan pola pada automata dan suffix link
Path Ada dalam kamus Suffix Link
() Tidak (h) Tidak () (he) Ya () (her) Tidak () (hers) Ya (s) (hi) Tidak () (his) Ya (s) (s) Tidak () (sh) Tidak (h) (she) Ya (he)
Output yang mungkin dihasilkan oleh state terminal automata seperti dirincikan pada
Tabel 2.15.
Tabel 2.15. Output yang dihasilkan oleh state terminal
State Output Keterangan
2 he
5 she, he Karena state 4 dan 5 memiliki suffix link ke state 1 dan 2 serta ”he” merupakan longest proper suffix dari “she”.
7 his 9 her
2.8. Penelitian Terdahulu
Penelitian yang sebelumnya sudah pernah dilakukan tentang pemulihan file yang terhapus adalah proses pemulihan file dengan algoritma Boyer-Moore (Richard, et al., 2007), pendekatan proses carving untuk memulihkan file multimedia (Yoo, et al., 2011), dan rekonstruksi forensik untuk file mp3 (Sajja, 2010).
Richard, et al. (2007) melakukan penelitian untuk memulihkan file yang terhapus dengan metode carving menggunakan algoritma Boyer-Moore. Hasil
penelitiannya menunjukkan bahwa proses carving memerlukan resource berupa waktu yang lama dan kapasitas penyimpanan yang sangat besar. Proses carving dengan
target disk berukuran 8 GB menghasilkan lebih dari 1,1 juta file dengan ukuran total
melebihi 250 GB dan jumlah false positive yang sangat besar. Selain itu, algoritma Boyer-Moore yang diterapkan dinilai masih kurang optimal untuk proses pencocokkan header dan footer dari file (O(mn)).
Sajja (2010) melakukan penelitian untuk melakukan rekonstruksi pada
fragment dari file MP3 dengan Variable Bit Rate (VBR). Metode yang diajukan
mampu meningkatkan keberhasilan dalam menemukan fragment yang benar dari file yang akan direkonstruksi. Persentase peningkatan untuk file MP3 dengan kualitas tinggi sebesar 49,20 – 69,42%, untuk file dengan kualitas menengah sebesar 1,80 – 3,75%, dan untuk file dengan kualitas rendah sebesar 41,32 – 100,00 %. Peningkatan keberhasilan dalam menemukan fragment dari file akan meningkatkan performa proses carving.
Yoo, et al. (2011) melakukan penelitian dengan mengajukan metode carving untuk file multimedia. Metode yang diajukan dapat melakukan pemulihan file multimedia berjenis MP3, AVI, dan WAV secara sempurna untuk file-file yang dialkokasi secara kontinu. Walaupun file dialokasikan secara diskontinu, file masih dapat diverifikasi setelah proses pemulihan karena karakteristik yang dimiliki oleh file multimedia. Pemulihan untuk file yang disimpan pada file system berjenis NTFS yang mengalami kompresi lebih sulit dilakukan. Namun, file multimedia yang tersimpan pada file system NTFS yang mengalami kompresi masih dapat dipulihkan dengan metode carving untuk file multimedia.
Tabel 2.16. Daftar penelitian terdahulu
Nama Metode Keterangan
Richard, et al. (2007)
Carving dengan
algoritma Boyer-Moore
Carving pada target disk sebesar 8 GB menghasilkan jumlah file sebanyak 1,1 juta
file dengan jumlah false positive yang besar. Algoritma Boyer-Moore kurang optimal
untuk proses pencocokkan header dan footer dari file (O(mn)).
Tabel 2.16. Daftar penelitian terdahulu (lanjutan)
Nama Metode Keterangan
Sajja (2010) Variable Bit Rate (VBR)
Rekonstruksi pada fragment dari file MP3.
Meningkatkan keberhasilan untuk menemukan fragment dari file MP3 dengan benar.
Yoo, et al. (2011)
Carving untuk file multimedia.
Untuk file multimedia dengan jenis AVI, WAV, dan MP3.
Dapat melakukan pemulihan file secara baik untuk file dengan alokasi yang kontinu.
File yang diskontinu masih dapat diverifikasi setelah pemulihan.
Pemulihan lebih sulit dilakukan pada file