Apa yang Membuat Pelanggan
Menyukai Kami?
www.UprightDecision.com Page 1
“Yummy Fancy Fiesta”:
Suatu Kisah Riset Pemasaran
ummy Fancy Fiesta”, atau sebut saja Yummy, adalah sebuah restauran (fiktif) dengan semboyan ”Saat paling lezat Anda hari ini …“ Manajer restauran, ibu Lily Williams, ingin mengetahui lebih jauh mengenai para pelanggannya, terutama penilaian mereka atas Yummy dan hal-hal apa yang membuat mereka suka atau tidak suka pada rumah makan tersebut.
Bulan lalu, konsultan Yummy mengadakan suatu survei dan memberikan laporan hasilnya. Laporan tersebut mencantumkan penilaian pelanggan pada Yummy. Tetapi Lily ingin mengetahui lebih pasti. Ia juga ingin memanfaatkan data survey tersebut untuk mengerti lebih banyak, a.l. apa yang menyebkan pelanggan menyukai / tidak menyukai Yummy. Ini adalah hal yang berguna bagi pemasaran Yummy. Survei bulan lalu tersebut dilakukan terhadap 50 pelanggan:
Variabel-Variabel Persepsi
Mula-mula, responden ditanyakan tentang persepsi mereka mengenai kinerja restauran.
1. Suasana yang Nyaman
2. Harga yang Kompetitif 3. Karyawan yang Kompeten
4. Makanan yang Lezat 5. Makanan yang Beraneka Ragam
6. Layanan yang Cepat Variabel-Variabel Klasifikasi
Kemudian, pewawancara mencatat pula Jenis Kelamin responden.
Akhirnya, pewawancara menanyakan atribut-atribut sikap/perilaku berikut: (kemauan untuk) Merekomendasikan kepada Teman
Tingkat Kepuasan
Penggunaan (frekuensi makan)
Setelah berdiskusi, Lily meminta kami untuk mencari tahu hal-hal berikut:
A. Karakteristik pelanggan (nilai variabel-variabel persepsi dan variabel-variabel klasifikasi) B. Segmentasi pelanggan kedalam grup pelanggan yang “berkenan” dan pelanggan yang
“tidak berkenan” berdasarkan sikap/perilaku mere
C. Variabel-variabel persepsi manakah yang paling berpengaruh dalam segmentasi tersebut?
D. Perbedaan-perbedaan sikap/perilaku antara pelanggan „wanita‟ dan „pria‟
Detail survei
Apendiks 1: Variabel-Variabel Surve
“Y
www.UprightDecision.com Page 2
A.
Karakteristik pelanggan (nilai variabel persepsi dan
variabel-variabel klasifikasi)
Variabel-variabel persepsi: x1 Suasana yang Nyaman x2 Harga yang Kompetitif x3 Karyawan yang Kompeten x4 Makanan yang Lezat x5 Makanan yang Beraneka Ragam x6 Layanan yang Cepat Skala: 1 – 10, nilai tengah: 5.5 Skala: 1 – 10, nilai tengah: 5.5 Skala: 1 – 10, nilai tengah: 5.5 Skala: 1 – 10, nilai tengah: 5.5 Skala: 1 – 10, nilai tengah: 5.5 Skala: 1 – 10, nilai tengah: 5.5 Rata-rata 3.62 2.22 8.02 5.48 2.86 6.80 Minimum 1 1 5 3 1 4 Maksimum 6 5 10 8 5 10 Variabel-variabel klasifikasi: x7 Jenis Kelamin x8 Merekomendasikan kepada Teman x9 Tingkat Kepuasan x10 Penggunaan 0 Wanita, 1 Pria Skala: 1 – 7, nilai tengah: 4 Skala: 1 – 7, nilai tengah: 4 0 Jarang, 1 Sering Rata-rata .40 4.68 4.78 .60 Minimum 0 3 3 0 Maksimum 1 7 7 1Hasil observasi terhadap 5o responden sampel:
Variabel-Variabel Persepsi:
a) Berkenaan dengan Suasana (x1), Harga makanan (x2), serta Variasi Makanan (x5) di Yummy, ke-50 pelanggan tersebut tidak menunjukkan persepsi yang positif. Hal ini bisa dilihat dari nilai rata-rata yang rendah.
b) Karyawan Yummy (x3) dinilai sangat kompeten dan Layanan (x6) mereka dianggap cepat. c) Rasa Makanan (x4) mereka anggap cukup.
Variabel-Variabel Klasifikasi (Jenis Kelamin dan Sikap/Perilaku): d) Kebanyakan pelanggan berJenis Kelamin (x7) wanita.
e) Mereka memiliki sedikit kecenderungan untuk Merekomendasikan (x8) Yummy kepada teman-teman mereka dan agak Puas (x9) dengan Yummy.
f) Kebanyakan pelanggan Menggunakan (x10) Yummy agak sering (dengan kata lain, mereka agak sering makan di sana).
Lily mengatakan, “Hal-hal ini serupa dengan hasil laporan konsultan yang melakukan wawancara.” “Dapatkah Anda memberikan informasi lebih?” ia bertanya. Kami tersenyum, ” Ya.”
Banyak perusahaan riset yang mengemukakan hasil observasi terhadap sampel seperti di atas dan berhenti di sini saja. Mereka tidak melakukan tes hal-hal mana dari hasil observasi yang signifikan dan berlaku bukan hanya untuk sampel (50 responden ) itu saja melainkan berlaku pula untuk keseluruhan populasi (semua pelanggan Yummy). UprightDecision berhati-hati dengan hal-hal seperti ini dan menyelidikinya secara seksama.
www.UprightDecision.com Page 3
Bagaimana menguji hasil-hasil observasi mana yang berlaku pada keseluruhan
populasi dan mana yang tidak?
Apendiks 2: Uji Signifikansi Perbedaan antara Rata-Rata dan antara Proporsi Grup Kami melakukan beberapa uji signifikansi dan menemukan bahwa semua hasil observasi
tersebut berlaku/dapat digeneralisasikan terhadap populasi (keseluruhan pelanggan Yummy), kecuali hal-hal berikut:
d) Bahwa Jenis Kelamin (x7) kebanyakan pelanggan adalah wanita, tidak dapat
digeneralisasikan. Dapat saja terjadi bahwa kebetulan ada lebih banyak wanita dalam sampel yang diambil.
e) Bahwa pelanggan Yummy Menggunakan (x10) restauran tersebut sedikit tinggi (mereka agak sering makan di sana), tidak dapat digeneralisasikan. Hal ini dapat saja terjadi pada sampel secara kebetulan.
www.UprightDecision.com Page 4
B.
Segmentasi pelanggan kedalam grup pelanggan yang “berkenan” dan
pelanggan yang “tidak berkenan” berdasarkan sikap/perilaku mereka
Lily ingin membedakan/mengelompokkan pelanggan yang „berkenan‟(atau „antusiastik‟) terhadap Yummy dan pelanggan yang ‟tidak berkenan‟(atau „tidak antusiastik‟). Pelanggan dikategorikan sebagai „berkenan‟ terhadap Yummy jikalau mereka:
1. Mau merekomendasikan Yummy kepada teman-teman mereka; diindikasikan oleh nilai yang tinggi untuk variabel klasifikasi Merekomendasikan kepada Teman (x8),
2. Puas dengan Yummy; diindikasikan oleh nilai yang tinggi untuk variabel klasifikasi Tingkat Kepuasan (x9),
3. Sering makan di Yummy; diindikasikan oleh nilai yang tinggi untuk variabel klasifikasi Penggunaan (x10).
Kami melakukan analisis klaster untuk mengklasifikasikan (memilih satu per satu) responden
ke dalam dua grup segmentasi berdasarkan atas apakah mereka „berkenan‟ atau „tidak berkenan‟ terhadap Yummy.
C.
Variabel-variabel persepsi manakah yang paling berpengaruh dalam
segmentasi tersebut?
Kemudian kami melakukan analisis diskriminan untuk mengetahui variabel-variabel persepsi manakah (dari variabel x1 sampai dengan x6) yang berguna secara signifikan dalam
pengklasifikasian responden ke dalam kedua segmen tersebut.
Melalui kedua teknik tersebut, kita dapat menemukan tambahan tinjauan mendalam yang berguna, yaitu variabel-variabel persepsi manakah yang sangat mempengaruhi pelanggan untuk memberikan nilai yang tinggi pada variabel-variabel sikap/perilaku. Banyak perusahaan riset yang tidak menemukan hasil yang berguna namun
„tersembunyi‟ seperti ini.
Bagaiamana mensegmentasikan pelanggan serta menemukan variabel-variabel
persepsi yang berpengaruh?
Apendiks 3: Analisis Klaster dan Analisis Diskrimina
Dua variabel persepsi paling berpengaruh terhadap pelanggan Yummy untuk menjadikan mereka „berkenan‟ terhadap Yummy:
1. Suasana yang Nyaman (x1) 2. Karyawan yang Kompeten (x3)
www.UprightDecision.com Page 5
D. Perbedaan-perbedaan sikap/perilaku antara pelanggan ‘wanita’ dan ‘pria’
Responden sebelumnya telah disegmentasikan ke dalam grup yang „berkenan‟ dan „tidak berkenan‟ terhadap Yummy.
Berdasarkan sampel yang terdiri dari 50 responden tersebut, dibuatlah bagan berikut ini. Dalam sampel tersebut, proporsi atau presentase pelanggan wanita dalam grup „berkenan‟ cukup tinggi (mencapai 76.7% dari pelanggan wanita) dan proporsi pelanggan pria dalam grup yang sama agak rendah (hanya 35% pelanggan pria).
Kami ingin mengetahui apakah hasil observasi ini berlaku terhadap keseluruhan populasi pelanggan Yummy. Kami melakukan uji signifukansi; dan hasilnya adalah ya. Proporsi/persentase
pelanggan wanita Yummy yang diklasifikasikan ke dalam grup „berkenan‟ adalah tinggi. Dengan kata lain, seorang pelanggan wanita mempunyai kemungkinan yang tinggi untuk menyukai Yummy. Kebalikannya berlaku bagi pelanggan pria.
Bagaimana menguji apakah pelanggan wanita lebih mungkin untuk berada dalam
grup „berkenan‟?
Apendiks 4: Distribusi Jenis Kelamin dalam Kedua Grup
www.UprightDecision.com Page 6 Untuk mengetahuinya, kami mencari tahu apakah pelanggan pria dan wanita menghasilkan nilai yang berbeda untuk variabel-variabel sikap/perilaku, yakni Merekomendasikan kepada Teman (x8), Tingkat Kepuasan (x9), dan Penggunaan (x10).
Nilai rata-rata Merekomendasikan kepada Teman (x8), Tingkat Kepuasan (x9), dan proporsi Penggunaan (x10) dari pelanggan wanita lebih tinggi (masing-masing besarnya adalah 4.97, 5.07, dan 76.7%), bila dibandingkan dengan nilai rata-rata dan proporsi dari pelanggan pria (masing-masing besarnya adalah 4.25, 4.35, dan 35%).
Seperti biasa, kami melakukan uji-uji untuk memastikan apakah penemuan-penemuan tersebut signifikan. Hasil uji-uji tersebut menunjukkan bahwa pelanggan wanita memberikan nilai yang lebih tinggi secara signifikan terhadap variabel-variabel sikap/perilaku. Oleh karenanya, penemuan-penemuan tersebut berlaku pula terhadap pelanggan-pelanggan Yummy lainnya (selain ke-50 pelanggan dalam sampel tersebut). Dengan kata lain, pelanggan wanita Yummy:
1. Memiliki kecenderungan untuk Merekomendasikan (x8) Yummy kepada temana-teman mereka.
2. Lebih Puas (x9) dengan Yummy. 3. Makan (x10) lebih sering di Yummy.
www.UprightDecision.com Page 7
Bagaimana mengetahui apakah pelanggan wanita benar-benar memiliki
sikap/perilaku yang lebih positif?
Apendiks 5: Sikap/Perilaku Berdasarkan Jenis Kelamin
Analisis kami pada bagian ini memberikan tambahan tinjauan mendalam bahwa pelanggan wanita merupakan grup pelanggan yang sungguh penting.
Perhatikan bahwa informasi yang berguna seperti ini lebih mungkin untuk ditemukan jika kita melakukan usaha-usaha analisis seperti didemonstrasikan sebelumnya di bagian ini.
ily puas dengan hasil riset tersebut. “Sangat berguna!” serunya. Ia melanjutkan, “Tidak hanya kami mengetahui pelanggan dengan lebih baik, kami pun mengetahui apa yang penting bagi mereka. Selebihnya, kami akan dapat mengarahkan upaya-upaya kami pada mereka dengan lebih tepat.” Ia pun mengatakan bahwa informasi yang didapatkan dari riset ini akan berguna antara lain untuk perencanaan promosi Yummy.
Catatan:
Data berdasarkan „Marketing Research within a Changing Information Environment‟ oleh Hair dan kawan-kawan dan mungkin saja kurang realistik. Dalam riset yang sebenarnya, kami menangani permasalahan seperti kualitas data, pengambilan sampel, dan sebagainya, sebelum melakukan analisis pada data untuk mendapatkan hasil dan menarik kesimpulan.
Jika Anda tetarik untuk mengetahui bagaimana caranya mendapatkan yang terbaik dari tantangan dan peluang usaha Anda saat ini, kunjungilah situs web kami atau kirimkan e-mail ke [email protected].
L
Pelanggan wanita Yummy cenderung untuk menyukai Yummy, hal ini sejalan dengan sikap/perilaku mereka yang lebih baik terhadap restauran.
www.UprightDecision.com Halaman A.1
Apendiks 1: Variabel-Variabel Survei
Contoh pertanyaan untuk wawancara, variael-variabelnya, serta cara mengkodekannya ditampilkan di bawah ini.
Variabel-Variabel Persepsi
Persepsi terhadap kinerja Yummy diukur sebagai berikut:
Berikut ini adalah karakteristik-karakteristik yang digunakan untuk mendskripsikan Yummy Fancy Fiesta. Menggunakan skala 1 sampai dengan 10, di mana 10 merepresentasikan “Sangat setuju” and 1 “Sangat tidak setuju,” sejauh manakah Anda setuju atau tidak setuju bahwa Yummy Fancy Fiesta memiliki:
x1–Suasana yang Nyaman
x2–Harga yang Kompetitif
x3–Karyawan yang Kompeten
x4–Makanan yang Lezat
x5–Makanan yang Beraneka Ragam
x6–Layanan yang Cepat
Sebagai contoh, jika seorang responden memberikan nilai 10 untuk Suasana yang Nyaman, hal ini mengindikasikan kesetujuan yang kuat; dengan kata lain, Yummy dianggap memiliki suasana yang sangat nyaman. Sebaliknya, jika seorang responden memberikan nilai 1 untuk Layanan yang Cepat, hal ini mengindikasikan ketidaksetujuan yang kuat; dengan kata lain, layanan Yummy dianggap sangat lamban.
Variabel-Variabel Klasifikasi
Data untuk variabel-variabel klasifikasi ditanyakan pada akhir survei. Kemudian respon yang didapatkan akan dikodekan sebagai berikut:
x7–Jenis Kelamin (0 = Wanita; 1 = Pria)
x8–Merekomendasikan kepada Teman (7 = Tentu akan merekomendasikan; 4 = Netral; 1 =
Tentu tidak akan merekomendasikan)
x9–Tingkat Kepuasan (7 = Sangat puas; 4 = Netral; 1 = Sangat tidak puas)
x10–Penggunaan (0 = Pelanggan ringan, yang dalam satu minggu tidak makan atau hanya satu kali makan di Yummy Fancy Fiesta; 1 = Pelanggan berat, yang dalam satu minggu makan di Yummy Fancy Fiesta dua kali atau lebih)
www.UprightDecision.com Halaman A.2
Apendiks 2: Uji Signifikansi Perbedaan antara Rata-Rata
dan antara Proporsi Grup
Kami melakukan uji t terhadap rata-rata variabel persepsi
X1-X6 dan juga variabel-variabel klasifikasi X8-X9. Karena
data masukan untuk variabel klasifikasi X7-Jenis Kelamin
and X10-Penggunaan berupa data kategori dikotomis, kami
melakukan uji binomial terhadap proporsi variabel-variabel tersebut.
Uji t terhadap rata-rata variabel persepsi X1-X6 dan variabel klasifikasi X8-X9
One-Sample Test Mean Test Value = 5.5 t df Sig. (2-tailed) Mean Difference 95% Confidence Interval of the Difference Lower Upper x1-Suasana yang Nyaman 3.62 -9.932 49 .000 -1.880 -2.26 -1.50 x2-Harga yang Kompetitif 2.22 -20.203 49 .000 -3.280 -3.61 -2.95 x3-Karyawan yang Kompeten 8.02 12.537 49 .000 2.520 2.12 2.92 x4-Makanan yang Lezat 5.48 -.125 49 .901 -.020 -.34 .30 x5-Makanan yang Beranrka Ragam 2.86 -21.773 49 .000 -2.640 -2.88 -2.40 x6-Layanan yang Cepat 6.80 5.518 49 .000 1.300 .83 1.77
Angka-angka dalam kolom Sig. (2-tailed) untuk semua variabel kurang dari .05 atau .10 (tergantung pada tingkat signifikansi yang ingin digunakan), kecuali untuk X4-Makanan yang Lezat.
Angka-angka tersebut menunjukkan bahwa rata-rata X1-Suasana yang Nyaman, X2-Harga yang Kompetitif,
X3-Karyawan yang Kompeten, X5-Makanan yang Beraneka Ragam, dan X6-Layanan yang Cepat,
secara meyakinkan atau secara signifikan berbeda dengan 5.5 (nilai tengah dari skala 1-10). Hanya rata-rata X4-Makanan yang Lezat yang tidak.
One-Sample Test Mean Test Value = 4 t df Sig. (2-tailed) Mean Difference 95% Confidence Interval of the Difference Lower Upper x8-Merekomendasikan kepada Teman 4.68 4.916 49 .000 .680 .40 .96 x9-Tingkat Kepuasan 4.78 5.782 49 .000 .780 .51 1.05
Angka-angka dalam kolom Sig. (2-tailed) kurang dari .05 atau .10. Angka-angka tersebut
menunjukkan bahwa rata-rata X8-Merekomendasikan kepada Teman dan X9-Tingkat Kepercayaan
www.UprightDecision.com Halaman A.3
Uji Binomial terhadap proporsi grup variabel klasifikasi X7-Jenis Kelamin dan X10-Penggunaan
Binomial Test
Mean Category N Observed
Prop. Test Prop. Asymp. Sig. (2-tailed) x7-Jenis Kelamin .40 Group 1 Wanita 30 .60 .50 .203 a Group 2 Pria 20 .40 Total 50 1.00 x10-Penggunaan .60 Group 1 Pelanggan ringan 20 .40 .50 .203 a Group 2 Pelanggan berat 30 .60 Total 50 1.00 a. Based on Z Approximation.
Angka-angka dalam kolom Asymp. Sig. (2-tailed) lebih dari .05 atau .10 (tergantung pada tingkat signifikansi yang ingin digunakan). Oleh karenanya, kita tidak dapat menyimpulkan bahwa
proporsi grup berbeda signifikan dari setengah (0.5), baik untuk variabel X7-Jenis Kelamin and X10
-Penggunaan.
www.UprightDecision.com Halaman A.4
Apendiks 3: Analisis Klaster dan Analisis Diskriminan
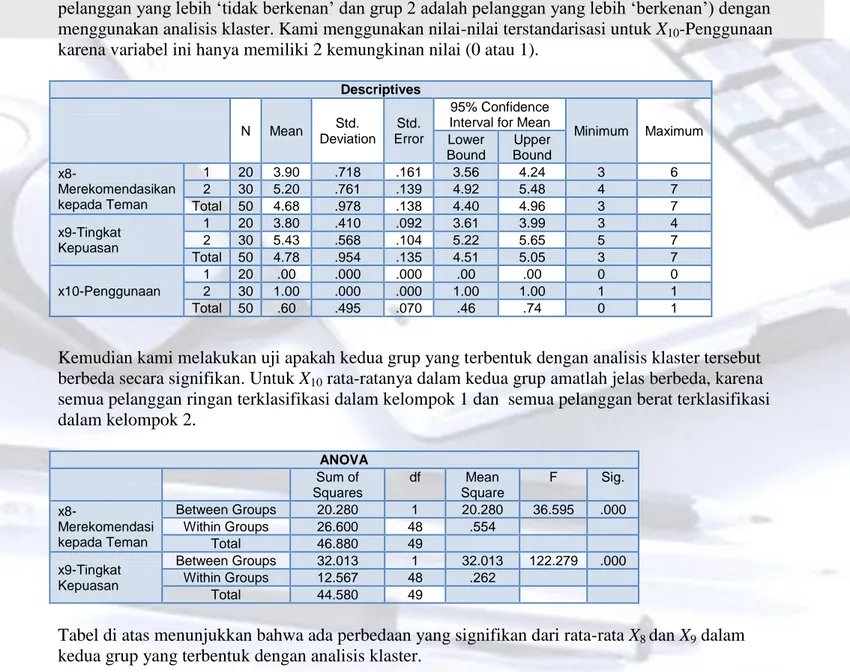
Di bawah ini adalah proses untuk menentukan variabel-variabel persepsi yang berpengaruh kuat. Mula-mula kami mengklaster (mengelompokkan) responden ke dalam dua grup (grup 1 adalah pelanggan yang lebih „tidak berkenan‟ dan grup 2 adalah pelanggan yang lebih „berkenan‟) dengan menggunakan analisis klaster. Kami menggunakan nilai-nilai terstandarisasi untuk X10-Penggunaan
karena variabel ini hanya memiliki 2 kemungkinan nilai (0 atau 1).
Descriptives N Mean Std. Deviation Std. Error 95% Confidence Interval for Mean
Minimum Maximum Lower Bound Upper Bound x8-Merekomendasikan kepada Teman 1 20 3.90 .718 .161 3.56 4.24 3 6 2 30 5.20 .761 .139 4.92 5.48 4 7 Total 50 4.68 .978 .138 4.40 4.96 3 7 x9-Tingkat Kepuasan 1 20 3.80 .410 .092 3.61 3.99 3 4 2 30 5.43 .568 .104 5.22 5.65 5 7 Total 50 4.78 .954 .135 4.51 5.05 3 7 x10-Penggunaan 1 20 .00 .000 .000 .00 .00 0 0 2 30 1.00 .000 .000 1.00 1.00 1 1 Total 50 .60 .495 .070 .46 .74 0 1
Kemudian kami melakukan uji apakah kedua grup yang terbentuk dengan analisis klaster tersebut berbeda secara signifikan. Untuk X10 rata-ratanya dalam kedua grup amatlah jelas berbeda, karena
semua pelanggan ringan terklasifikasi dalam kelompok 1 dan semua pelanggan berat terklasifikasi dalam kelompok 2. ANOVA Sum of Squares df Mean Square F Sig. x8-Merekomendasi kepada Teman Between Groups 20.280 1 20.280 36.595 .000 Within Groups 26.600 48 .554 Total 46.880 49 x9-Tingkat Kepuasan Between Groups 32.013 1 32.013 122.279 .000 Within Groups 12.567 48 .262 Total 44.580 49
Tabel di atas menunjukkan bahwa ada perbedaan yang signifikan dari rata-rata X8 dan X9 dalam
kedua grup yang terbentuk dengan analisis klaster.
Setelah itu kami ingin mengetahui bagaimana nilai-nilai variabel persepsi X1-X6 dalam kedua grup
ini. Kami melakukan analisis diskriminan dan mendapatkan hasil berikut:
Wilks' Lambda Test of Function(s) Wilks' Lambda Chi-square df Sig. 1 .446 37.498 3 .000
www.UprightDecision.com Halaman A.5 Classification Resultsa Ward Method Predicted Group Membership 1 2 Total Original Count 1 16 4 20 2 5 25 30 % 1 80.0 20.0 100.0 2 16.7 83.3 100.0 a. 82.0% of original grouped cases correctly classified.
Pada bagian akhir tabel Classification Results (Hasil Klasifikasi) tersebut dijelaskan bahwa kemampuan fungsi diskriminan untuk memprediksi keanggotaan grup adalah sebesar 82%.
Structure Matrix Function 1 x1-Nice Atmosphere .670 x3-Competent Employees .449 x6-Fast Servicea -.116 x2-Competitive Prices .111 x4-Delicious Fooda -.061
x5-Adequate Variety of Fooda -.003
Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions
Variables ordered by absolute size of correlation within function.
a. This variable not used in the analysis.
Berdasarkan tabel di atas, kami ingin mengidentifikasikan angka-angka di dalam kolom Function yang besarnya 0.30 atau lebih. Kami menemukan bahwa angka-angka untuk X1-Suasana yang
Nyaman dan X3-Karyawan yang Kompeten lebih besar dari .30 secara signifikan.
www.UprightDecision.com Halaman A.6
Apendiks 4: Distribusi Jenis Kelamin dalam Kedua Grup
Kami melakukan uji Chi-Square terhadap independensi distribusi jenis kelamin dalam kedua grup yang terbentuk dengan analisis klaster yang telah dilakukan.Group Number * Jenis Kelamin Crosstabulation
Jenis Kelamin Wanita Pria Total
Group Number
1
Count 7 13 20
Expected Count 12.0 8.0 20.0 % within Group Number 35.0% 65.0% 100.0% % within Gender 23.3% 65.0% 40.0% % of Total 14.0% 26.0% 40.0%
2
Count 23 7 30
Expected Count 18.0 12.0 30.0 % within Group Number 76.7% 23.3% 100.0% % within Gender 76.7% 35.0% 60.0% % of Total 46.0% 14.0% 60.0%
Total
Count 30 20 50
Expected Count 30.0 20.0 50.0 % within Group Number 60.0% 40.0% 100.0% % within Gender 100.0% 100.0% 100.0% % of Total 60.0% 40.0% 100.0%
Chi-Square Tests
Value df Asymp. Sig. (2-sided) Pearson
Chi-Square 8.681
a
1 .003
N of Valid Cases 50
a. 0 cells (.0%) have expected count less than 5. The minimum expected count is 8.00.
b. Computed only for a 2x2 table
Angka dalam kolom Asymp. Sig. (2-sided) kurang dari .05 atau .10 (tergantung pada tingkat signifikansi yang ingin dilakukan). Hasil uji Chi-Square memberitahukan kita bahwa X7-Jenis
Kelamin dalam kedua grup tersebut berbeda secara signifikan.
www.UprightDecision.com Halaman A.7
Apendiks 5: Sikap/Perilaku Berdasarkan Jenis Kelamin
Kami melakukan uji t terhadap rata-rata X8-Merekomendasikan kepada Teman dan X9-Tingkat Kepuasan, serta uji Chi-Square terhadap X10
-Penggunaan.
Uji t terhadap X8-Merekomendasikan kepada Teman dan Tingkat Kepuasan dengan X7-Jenis Kelamin sebagai Faktor
Independent Sample Tests
Levene's Test for
Equality of Variances t-test for Equality of Means
F Sig. t df Sig. (2-tailed) Mean Difference Std. Error Difference 95% Confidence Interval of the Difference Lower Upper x8-Merekomendasikan kepada Teman
Equal variances assumed 1.856 .179 2.696 48 .010 .717 .266 .182 1.251 Equal variances not assumed 2.896 47.894 .006 .717 .247 .219 1.214 x9-Tingkat Kepuasan Equal variances assumed 3.415 .071 2.775 48 .008 .717 .258 .197 1.236 Equal variances not assumed 2.624 33.048 .013 .717 .273 .161 1.272 Angka-angka dalam kolom Sig. (2-tailed) kurang .05 or .10 (tergantung pada tingkat signifikansi yang ingin digunakan). Hasil uji t tersebut
menunjukkan bahwa rata-rata X8-Merekomendasikan kepada Teman dan X9-Tingkat Kepuasan dalam kedua grup tersebut secara meyakinkan atau
secara signifikan berbeda.
Group Statistics Jenis Kelamin N Mean Std. Deviation Std. Error Mean x8-Merekomendasikan kepada Teman Wanita 30 4.97 1.033 .189 Pria 20 4.25 .716 .160 x9-Tingkat Kepuasan Wanita 30 5.07 .785 .143 Pria 20 4.35 1.040 .233
www.UprightDecision.com Halaman A.8
Uji Chi-Square terhadap X10-Penggunaan
Penggunaan * Jenis Kelamin Crosstabulation
Jenis Kelamin Wanita Pria Total
x10-Penggunaan Pelanggan ringan Count 7 13 20 Expected Count 12.0 8.0 20.0 % within Usage 35.0% 65.0% 100.0% % within Gender 23.3% 65.0% 40.0% % of Total 14.0% 26.0% 40.0% Pelanggan berat Count 23 7 30 Expected Count 18.0 12.0 30.0 % within Usage 76.7% 23.3% 100.0% % within Gender 76.7% 35.0% 60.0% % of Total 46.0% 14.0% 60.0% Total Count 30 20 50 Expected Count 30.0 20.0 50.0 % within Usage 60.0% 40.0% 100.0% % within Gender 100.0% 100.0% 100.0% % of Total 60.0% 40.0% 100.0% Chi-Square Tests
Value df Asymp. Sig. (2-sided) Pearson Chi-Square 8.681a 1 .003
N of Valid Cases 50
a. 0 cells (.0%) have expected count less than 5. The minimum expected count is 8.00.
b. Computed only for a 2x2 table
Angka-angka dalam kolom Asymp. Sig. (2-sided) kurang dari .05 or .10 (tergantung pada tingkat signifikansi yang ingin digunakan). Hasil uji Chi-Square menunjukkan bahwa X10-Penggunaan
dalam kedua grup tersebut secara meyakinkan atau secara signifikan berbeda.
Kembali ke bagian utama