4
LANDASAN TEORI DAN TINJAUAN PUSTAKA
Bab ini berisi tentang penguraian teori-teori yang dikategorikan menjadi teori umum dan teori khusus yang mendukung penelitian ini. Teori-teori umum mencakup definisi musik, definisi genre musik dan fitur musik berdasarkan konten (Content Based). teori-teori khusus yang mencakup metode pengenalan pola itu sendiri seperti pemrosesan sinyal digital, ekstraksi fitur, dan algoritma Support Vector Machine yang akan diimplementasikan ke dalam sistem serta berisi tinjauan pustaka yang mencakup penelitian terkait yang pernah dilakukan.
2.1 Teori – Teori Umum
pada subbab ini akan membahas teori-teori umum terkait definisi musik, genre musik dan fitur musik content-based.
2.1.1 Definisi Musik
Dalam kamus besar bahasa Indonesia, musik adalah suatu bidang/seni untuk menyusun nada dalam urutan dan relasi temporal untuk menghasilkan komposisi (suara) yang mempunyai kesatuan kesinambungan nada atau suara yang telah disusun demikian rupa sehingga berisi irama, lagu, dan keharmonisan. selain itu juga dalam musik terdapat fitur yang menjadi ciri tertentu dalam sebuah genre musik.
2.1.2 Definisi Genre
Menurut Kamus Besar Bahasa Indonesia genre adalah jenis, tipe, atau kelompok sastra atas dasar bentuknya.. Menurut penelitian dari Giri bahwa genre musik adalah label yang digunakan oleh manusia untuk mengelompokkan dan mendeskripsikan dunia musik yang luas. Musik yang berada pada genre yang sama biasanya memiliki kemiripan karakteristik tertentu yang terkait dengan instrument, struktur ritmis, dan pitch (nada) musik [5].
2.1.3 Fitur Musik (Content Based)
Menurut penelitian dari Scaringella, fitur – fitur musik dapat dibagi menjadi 3 jenis, timbre, melody/harmony, dan rhythm.[6]
1. Timbre
Timbre didefinisikan dalam sejumlah daftar pustaka seperti fitur pengenalan yang memperbaiki dua suara dengan nada (pitch) yang sama dan kenyaringan (loudness) terdengar berbeda. seperti suara manusia atau bunyi alat musik. Distribusi spektral dianalisis sebagai fitur karakteristik timbre melalui perhitungan sinyal dalam domain waktu. Fitur ini juga bersifat global dalam arti mengintegrasikan informasi semua sumber dan instrumen secara bersamaan. Namun fitur ini di ringkas kedalam fitur tingkat rendah dalam penelitiannya untuk mengkategorikan suatu genre. Adapun kategori fitur timbre tersebut adalah :
a. Fitur Temporal : fitur ini dihitung dari frame sinyal pada audio dan terdiri dari (zero-crossing rate, linear prediction coefficients, etc.). b. Fitur Energi : fitur ini mengacu pada konten yang terdapat pada sinyal
musik dan terdiri dari (Root Mean Square energy dari frame signal, energi dari komponen harmonic dari kekuatan spectrum, energy dari bagian noise yang ada di kekuatan spektrum ).
c. Fitur spektral : fitur ini untuk mendeskripsikan bentuk dari spektrum yang ada di frame sinyal dan terdiri dari (centroid, spread, skewness, kuortosis, slope, roll-off frequency, variation, Mel-Frequency Ceptral Coefficients MFCCs).
d. Fitur Perseptual : fitur ini dihitung menggunakan model dari human earring process (relative specific loudness, sharpness, spread).
2. Melodi/Harmoni
Melodi didefinisikan sebagai sekumpulan nada yang terdengar saling berurutan serta berirama dan mengatakan suatu gagasan, sedangkan keserasian dikatakan sebagai campuran nada, yaitu paduan bunyi nyanyian atau permainan musik yang mempergunakan dua nada atau lebih yang berbeda tinggi nadanya dan dibunyikan secara serentak. Dan menurut
penelitian dari scaringella, melodi dan harmoni digambarkan menggunakan fitur audio tingkat menengah.
3. Rhythm
Rhythm (ritme) didefinisikan seperti susunan terstruktur dari suara musik, terutama fitur ini bersesuaian dengan panjang durasi dan fokus terhadap periodik. Fitur ini memicu pada tingkat emosional manusia.
2.2 Teori-Teori Khusus
Teori khusus yang mencakup metode pengenalan pola itu sendiri seperti pemrosesan sinyal digital, ekstraksi fitur, dan algoritma Support Vector Machine.
2.2.1 Pemrosesan Sinyal Digital
Pemrosesan sinyal digital merupakan tahapan yang mencakup metode yang digunakan untuk mengekstrak atau mengolah data file audio (dataset) supaya menjadi file yang berisi masukan (input) yang akan digunakan untuk proses pembelajaran (training) dan klasifikasi.
a. Dataset Audio
Untuk melakukan proses pengklasifikasian suatu genre, maka dibutuhkan sampel audio yang akan diolah. Dalam hal ini menggunakan file audio dari dataset GTZAN. Dataset ini terdiri atas dan 10 sample jenis genre dan 100 audio untuk setiap genre, sehingga terdapat 1000 potongan audio. Dataset ini juga akan digunakan pada saat melakukan proses input. Data audio masing-masing memiliki properti seperti durasi rata-rata yaitu 30 detik, sampling rate 22050, bitrate 353 kbps. Sampling rate adalah banyaknya nilai yang diambil setiap detiknya.[7]
b. Ekstraksi Fitur Audio
Ekstraksi fitur/ciri adalah suatu proses untuk mendapatkan ciri khusus atau yang paling mendukung dalam sebuah sinyal audio yang dalam hal ini file musik. Tahap ini akan menghasilkan data fitur audio untuk setiap jenis genre musik yang sudah melalui tahap frame. Ada dua tipe fitur yang dihitung dalam setiap frame dimana fitur pertama adalah perceptual features, composed of total power, subband powers, brightness, bandwith,
dan pitch dan yang kedua adalah MFCC. [9]Hal ini akan sangat berguna untuk ke tahap selanjutnya yaitu proses klasifikasi. Metode yang sudah pernah dilakukan dalam mengekstraksi fitur audio pada beberapa penelitian yaitu, ekstraksi fitur musical surfaces dan fitur rythm, ekstraksi fitur MFCC, dan dengan teknik Content-Based. Proses ekstraksi menjadi sangat penting karena merupakan langkah awal untuk mendapatkan data yang berguna pada saat proses training dan testing.
c. Principal Component Analysis (PCA)
Principal component analysis adalah perpaduan data linear dari sejumlah fitur awal data secara geometrik merupakan sistem koordinat baru yang didapatkan berdasarkan rotasi sistem semula.[21]. cara ini berguna jika data yang memiliki jumlah fitur atau variabel yang besar dan saling berkorelasi antar fiturnya perhitungan metode ini berdasarkan pada perhitungan nilai eigen vector dan eigen value yang merupakan suatu penyebaran dari dataset. Tujuan utama dari metode ini adalah mengurangi jumlah fitur menjadi lebih sedikit tanpa harus banyak kehilangan informasi yang ada pada data. Dengan metode ini, fitur sejumlah n akan dikurangi menjadi k fitur baru baru (principal component) dengan jumlah k lebih sedikit dari n fitur. fitur hasil dari reduksi dinamakan dengan principal component atau disebut juga dengan faktor. Langkah-langkah dalam penerapan principal component analysis adalah sebagai berikut :
1. Menghitung matriks kovarian dengan menggunakan persamaan dibawah ini.
(2.1)
2. Menghitung nilai eigen dengan dengan menggunakan persamaan berikut.
(A-λІ) = 0 (2.2)
3. Setelah itu, menghitung nilai eigen vektor dengan persamaan
[A-λІ] [X] = [0] (2.3)
4. Mencari variabel baru (principal component) dengan cara mengalikan variabel asli dengan matriks vektor eigen.
5. Sedangkan variansi yang dapat dijelaskan oleh variabel baru ke-I tergantungan dengan kontribusi pi, dari masing-masing nilai eigen yang dihitung dengan persaman dibawah ini.
ρI=
X 100% (2.4)
d. Klasifikasi Genre
Klasifikasi genre musik merupakan tahap akhir dari seluruh pemrosesan sinyal digital yang nantinya akan berguna dalam menentukan garis yang memisahkan dari beberapa kelas yang berbeda, sesuai dengan ekstraksi fitur yang telah dilakukan sebelumnya. Keseluruhan proses yang dilakukan akan dilakukan proses pelatihan data sehingga hasil akhir dari proses pelatihan tersebut adalah sebuah model pemisah yang memisahkan beberapa kelas jenis genre yang berbeda. Terdapat banyak sekali algoritma yang telah digunakan dalam proses klasifikasi, seperti K-NN, LVQ, GMM dan CNN.
2.3 Algoritma Support Vector Machine (SVM)
Support Vector Machine (SVM) merupakan teknik algortima supervised learning, baik dalam proses klasifikasi maupun teknik regresi. SVM menemukan solusi global optimal, oleh karena itu SVM selalu mencapai solusi yang sama untuk setiap running. Kelebihan metode SVM dari metode klasifikasi lainnya, antara lain: generalisasi, curse of dimensionality, dan feasibility. Generalisasi adalah kemampuan suatu metode untuk proses klasifikasi data yang tidak termasuk dalam fase pembelajaran. Curse of dimensionality didefinisikan sebagai masalah yang banyak ditemui suatu metode pattern recognition pada proses penentuan variasi parameter dikarenakan jumlah data sampel yang sedikit jika dibandingkan dimensi suatu ruang vektor data tersebut. jika Semakin tinggi dimensi suatu suatu ruang vektor informasi yang diolah, semakin banyak jumlah data yang diperlukan dalam proses pembelajaran. SVM membuktikan bahwa tingkat generalisasi yang diperoleh tidak dipengaruhi oleh dimensi dari input vektor. Hal ini merupakan alasan kenapa SVM menjadi salah satu metode/ cara yang paling tepat dipakai
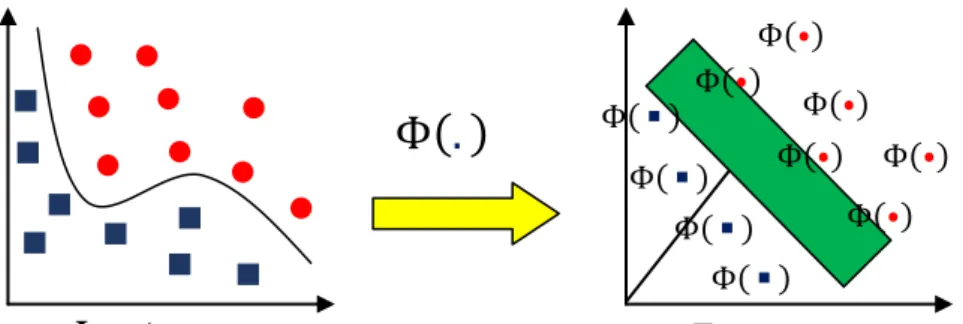
untuk memecahkan permasalahan jumlah berdimensi yang tinggi, dalam keterbatasan sampel data yang ada .[10] Pada Gambar 2.1, terdapat banyak kemungkinan pengklasifikasian secara linier yang dapat memisahkan suatu data, tetapi akan hanya ada satu yang memaksimalkan nilai margin (memaksimalkan jarak di antara itu dan titik data terdekat dari masing-masing kelas). Penggolong linier ini disebut pemisah hyperplane optimal. Secara intuitif, mengharapkan batasan ini untuk menggeneralisasi juga menentang batas-batas lain yang mungkin.
2.3.1 SVM Pada Linerarly Separable Data
Linearly separable data merupakan jenis suatu data yang dapat dipisahkan secara linier. Misalkan { 1, … , } adalah data set dan 1 ∈{+1, -1} adalah kelas dari data , untuk i = 1,2,3, ..., n, dimana n adalah merupakan jumlah banyaknya data. Sedangkan w adalah bobot vektor pada data, dan b adalah bias pada data.
Xi.w+b=-1 Xi.w+b=-0 Xi.w+b=1 Support Vector Kelas 2 Class 2 Bidang Pemisah Bidang Pembatas Kelas 2 Bidang Pembatas Kelas 1
Gambar 2. 1 Pemisah Hyperplane Optimal
Gambar 2. 2 Alternatif bidang pemisah (kiri) dan bidang pemisah terbaik degan margin m terbesar (kanan).
Diasumsikan kedua kelas -1 dan 1 dapat terpisah secara sempurna oleh fungsi pemisah ( hyperplane) berdimensi d, yang didefinisikan sebagai berikut :
(2.5)
Setiap data pelatihan memiliki nilai , dimana data latih dengan nilai ≥0 merupakan support vector yang dapat mempengaruhi fungsi keputusan. Setelah solusi permasalahan quadratic programming ini ditemukan(nilai ), maka kelas dari data xi dapat ditentukan berdasarkan nilai dari fungsi keputusan.
(2.6)
Dimana adalah support vector, ns = jumlah support vector, dan adalah data yang akan diklasifikasikan.
Contoh kasus persoalan memisahkan data secara linier dengan 2 buah kelas dapat dilihat pada gambar dibawah ini :
Tabel 2. 1 Soal Kasus Linear Pada SVM X1 X2 kelas
1 1 1
1 -1 -1
-1 1 -1
-1 -1 -1
Karena terdapat 2 fitur (x1 dan x2 ), maka nilai w juga akan memiliki 2 fitur (w1 dan w2). Rumus yang digunakan untuk meminimalkan nilai margin adalah sebagai berikut : (2.7) Dengan syarat : (2.8) W.| x + b = 0
Sehingga mendapatkan beberapa persamaan berikut :
1.
2. –
3.
4.
Dari keempat persamaan diatas, tujuannya adalah untuk mendapatkan nilai w1, w2, dan b (bias). Selanjutnya dari persamaan tersebut dilakukan substitusi.
a. Menjumlahkan persamaan (1) dan (2)
2w2 = 2 Maka w2 = 1
b. Menjumlahkan persamaan (1) dan (3)
2w1 = 2 Maka w1 = 1
c. Menjumlahkan persamaan (2) dan (3)
-2 b = 2
Sehingga didapatkan persamaan hyperplane : 1. w1x1 + w2x2 +b = 0
2. x1 + x2 -1 = 0 3. x2 = 1 –x1
visualisasi garis hyperplane (sebagai fungsi klasifikasi) : w1x1 + w2x2+b = 0
x1 + x2 - 1 = 0 x2 = 1- x1 selanjutnya
Tabel 2. 2 Hasil Persamaan SVM x1 x2 = 1- x1 -2 3 -1 2 0 1 1 0 2 -1
2.3.2 SVM Pada Nonlinearly Separable Data
SVM pada Nonlineary Seperable Data adalah suatu pendekatan yang dapat dilakukan untuk data yang tidak dapat dipisahkan secara linier yaitu dengan
1 1 1,5 -1 -1 1,1 1,-1 1,-1 -1,1 -0,5 0,5 -0,5 0,5
mentranformasikan data ke dalam dimensi ruang fitur (feature space) sehingga dapat dipisahkan secara linier pada feature space. [11] untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linier formula SVM harus dimodifikasi karena tidak akan ada solusi yang ditemukan. oleh karena itu, kedua bidang pembatas harus diubah sehingga lebih fleksibel. cara lain untuk proses mengklasifikasikan data yang tidak dapat dipisahkan secara linier adalah mentransformasikan data ke dalam dimensi ruang fitur (feature space) sehingga dapat dipisahkan secara linier pada feature space.
2.3.2.1 Kernel SVM
Salah satu cara untuk mengatasi permasalahan data yang tidak dapat di pisahkan secara linear adalah dengan mengubah data ke ruang dimensi yang lebih tinggi, yang disebut ruang kernel, dimana data akan terpisah secara linear. Pada gambar 2.3 merupakan ilustrasi data yang tidak dapat dipisahkan secara linear, maka di transformasikan ke dalam ruang dimensi yang lebih tinggi (feature space). Pada kasus linear tentu sangat berbeda, pemisah linear berbentuk sebuah garis untuk memisahkan data antar kelas, tetapi untuk kasus non-linear akan membentuk sebuah bidang untuk memisahkan data antar kelas. Ada beberapa fungsi kernel dalam SVM yang umum digunakan, antara lain yaitu liniear kernel, polynomial, dan RBF (Radial Basis Function). Namun dalam penelitian ini akan menggunakan fungsi kernel RBF.
a. Radial Basis Function (RBF) kernel 2 ] (2.7) Input space
Φ
Φ Φ Φ Φ Φ Φ Φ Φ Feature space Φ Φb. Linier
(2.8)
c. Polynomial
(2.9)
d. tangent hyperbolic (sigmoid)
(2.10)
Dalam beberapa kasus, nilai beberapa parameter akan dirtentukan sendiri oleh user (pemakai). Misalnya dalam polynomial, p bisa diberi nilai 2, 3 atau nilai lain berupa bilangan positif. Dalam kernel RBF, nilai degree bisa diberi nilai bilangan rill positif.
2.4 Tinjauan Pustaka
Beberapa penilitian tentang klasifikasi genre musik dengan menggunakan fitur permukaan musik dan ritme telah banyak dilakukan dengan menggunakan algoritma KNN,CNN, Gaussion Mixture Model, dan SVM seperti yang akan dijelaskan dibawah ini.
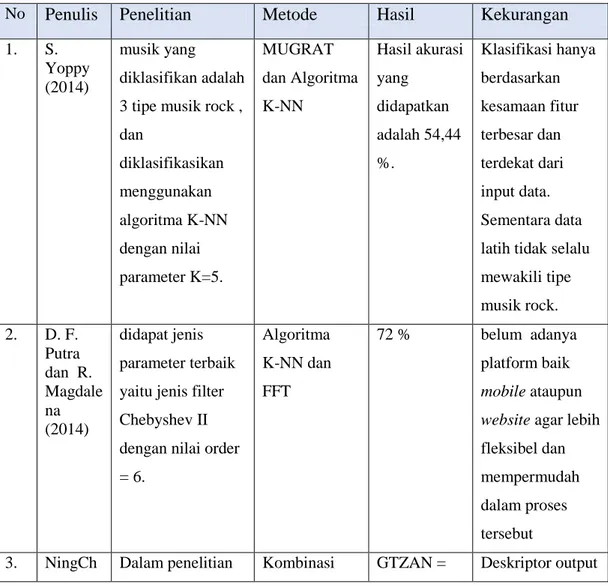
Penelitian tentang klasifikasi genre musik dilakukan menggunakan algoritma K-NN dan metode MUGRAT untuk proses ekstraksi fitur. musik yang diklsifikasikan adalah 3 tipe musik rock. Dalam penelitian tersebut menggunakan nilai parameter k adalah 5. Teknik pengumpulan data yang digunakan adalah dengan mendownload data internet dengan format mp3 lalu dikonversi kedalam format wav dengan sampling rate 8000 Hz. 12 lagu yang menjadi data training, dimana masing-masing tipe musik rock memiliki 30 lagu sehingga total ada 90 lagu. Nilai akurasi yang didapatkan pada klasifikasi ini mencapai 54,44 % . tetapi kurangnya kriteria dari fitur khusus untuk jenis musik tertentu, sehingga pengklasifikasian fitur hanya didasarkan pada kesamaan fitur terbesar dan terdekat, sehingga akurasi yang didapatkan masih kecil.[12]
Penelitian genre musik menggunakan algoritma KNN dan FFT sebagai metode pengambilan ciri juga pernah dilakukan. Dalam pengujian tersebut, didapat jenis
parameter terbaik yaitu jenis filter Chebyshev II dengan nilai order = 6. Jenis genre yang diklasifikasikan ada 3 yaitu pop, rock, dan dance. Jumlah data latih 50 untuk tiap-tiap genre, dan 50 data uji untuk tiap tiap genre dengan nilai k=5 jenis distance cosine mendapatkan akurasi tertinggi sebesar 72 % .kekurangan klasifikasi genre pada penelitian ini adalah belum adanya platform baik mobile ataupun website agar lebih fleksibel dan mempermudah dalam proses tersebut.[13]
Penelitian juga dilakukan dengan menggunakan algoritma kombinasi CNNS dan LSTM, serta menggunakan berbagai macam jenis dataset dalam berbagai eksperimenya. Diantaranya adalah GTZAN memiliki spesifikasi (1000 audio track, durasi 30 detik, 10 Genres). Ballroom Dataset memiliki spesifikasi (698 audio track, durasi 30 detik, 8 Genres), Soundtrack dataset memiliki spesfikasi (470 kutipan musik film, durasi 15-30 detik, masing-masing kutipan terdiri dari 5 emosi diskrit (marah, takut, sedih, bahagia, lembut). Dimana hasil perbandingan performa masing–masing dataset dengan menggunakan algoritma tersebut sangatlah berbeda. Dengan menggunakan algoritma CNN pada dataset GTZAN didapatkan nilai akurasi sebesar 51.70 % dan 59,30% menggunakan LTSM, hasil yang diperoleh dari Ballroom dataset menghasilkan akurasi sebesar 81,79% menggunakan CNN dan 64,00% LTSM. Serta hasil dari Soundtrack dataset sebesar 52,00% menggunakan CNN dan 64,00% dengan LTSM.[14]
Penelitian tentang klasifikasi genre musik menggunakan content-based music juga pernah dilakukan. Dalam penelitian tersebut menggunakan algoritma SVM. Fitur timbral digunakan dalam ekstraksi audio tersebut. Dimana fitur timbral yang digunakan terdiri dari 2 jenis yaitu MFCC dan Log Energy. Jenis genre yang diklasifikasikan ada 9. Data lagu tersebut terdapat 400 lagu. Rata-rata akurasi yang didapatkan adalah 86% dengan menggunakan exponential radial basis kernel function. namun platform yang digunakan untuk proses klasifikasi belum ada. [15]
Penelitian yang berjudul simulasi dan analisis klasifikasi genre musik berbasis SVM juga pernah dilakukan, dalam penelitian tersebut mengklasifikasikan 5 genre lagu dan lebih cenderung melakukan pengujian ataupun analisis terhadap
pengaruh 4 tipe filter dan orde filter, banyak data latih dan uji, pengaruh kernel option dan nilai Epsilon pada algoritma SVM terhadap akurasi output sistem. dan pengujian terhadap fitur musik yang sangat mempengaruhi atau mewakili terhadap klasifikasi jenis genre tidak dibahas. Kesimpulan hasil yang dapat diambil adalah setelah melakukan pengujian terhadap 5 genre lagu, metode kalsifikasi SVM-OAA memiliki akurasi tertingi mencapai 85,6 % dengan 50 jumlah data latih dan 50 data uji untuk setiap genre dan menggunakan parameter jenis kernel polynomial, kernel option kernel option 1, nilai epsilon 10-1 dan nilai C=10. Dan metode klasifikasi SVM-OAO mencapai akurasi sebesar 86,4 % dengan komposisi filter dan parameter kernel option yang sama dengan SVM-OAA. Perlu diketahui bahwa OAA atau One-Against- All adalah sebuah metode klasifikasi yang dibangun sejumlah k SVM binary dan contohnya untuk persoalan klasifikasi 5 buah jumlah kelas digunakan 5 buah SVM binary. Sedangkan OAO atau One-Against-One adalah menggunakan 5 buah SVM binary untuk 5 buah kelas.[3]
Penelitian lain yang berjudul klasifikasi genre musik menggunakan metode SVM. Dalam penelitian tersebut, sama seperti sebelumnya bahwa tidak terlalu membahas dalam sisi ekstraksi fitur sehingga fitur yang paling mewakili terhadap klasifikasi genre musik. Hasil akurasi mencapai 92,5 % dengan perbandingan 90% (360 data audio) data latih dan 10 % (40 data audio) data uj untuk scenario pengaruh banyak nya data latih, dan untuk skenario pengujian metode SVM dengan mengklasifikasikan 4 genre lagu menggunakan model RBF akurasi mencapai 84,5% dengan parameter gamma=0.001, C=10 dan untuk model polynomial sebesar 85,5% dengan menggunakan parameter gamma=0.001, C=10, epsilon=1, degree=1. Dalam penelitian tersebut juga terdapat beberapa saran yang salah satunya adalah pengembangan metode ekstraksi ciri musik lain yang dapat meningkatkan akurasi dan telah menarik kesimpulan bahwa semakin banyak banyak data latih maka nilai akurasi akan semakin akurat.[16]
Penelitian juga pernah dilakukan dengan menggunakan algoritma ANN (Artificial Neural Network) namun dengan menggunakan beberapa metode optimasi. Metode optimasi dan ANN backpropagation diimplementasikan menggunakan
MATLAB ver. 7.0 dari MathWorks Inc. Dalam program tersebut telah menyediakan berbagai macam tools dengan algoritma dan fungsi bawaan untuk pengoptimalan algoritma ANN. Algoritma ANN paling banyak terdiri dari 2 lapisan tersembunyi (hidden layer) dengan neuron sebanyak yang telah disediakan oleh metode pengoptimalan dan 1 lapisan keluaran (output layer) terdiri dari 1 neuron. Lapisan tersembunyi (hidden layer) menggunakan fungsi sigmoid tangen hiperbolik yang dikompilasi dengan input dari ANN, sedangkan lapisan keluaran (output layer) menggunakan fungsi transfer linier agar bisa menghasilkan sepuluh nilai yang dapat dilihat berbeda, sebanyak data audio genre yang ada dalam dataset. Nilai akurasi dalam proses klasifikasi yang didapatkan adalah 81 %. [17]
Analisis penggunaan algoritma genetika untuk klasifikasi genre musik dalam rangka meningkatkan performa juga pernah dilakukan terhadap algoritma JST Backpropagation. Dimana pada penelitian sebelumnya menggunakan algoritma JST Backpropagation mendapatkan nilai akurasi 67 %. lalu digunakan algoritma genetika dengan menggunakan ciri konten frekuensi yang digunakan dalam algoritma JST. dimana parameter jumlah generasi 100, jumlah populasi 50, jumlah crossover 0,6 dan peluang permutasi 0,01. Sehingga algoritma genetika dapat meningkatkan akurasi menjadi 85,55 %. [18]
Penilitian klasifikasi genre musik menggunakan kombinasi algoritma Learning Vector Quantization (LVQ) dan Self Organizing Map (SOM) juga pernah dilakukan.akurasi tertinggi dihasilkan oleh masing-masing classifier diperoleh pada nilai learning rate yang berbeda. Dimana akurasi tertinggi dari classifier LVQ diperoleh pada saat bernilai 0,1 yaitu 52,87 %. selanjutnya kombinasi LVQ dan SOM dengan learning rate 0.35 yaitu 54,2 %. lalu menggunakan learning rate 0.4 yaitu 53,93 %. serta saat learning rate bernilai 0,15 mendapat akurasi sebesar 54,23 %.[19]
Berdasarkan pemaparan dari penelitian terkait diatas, algoritma SVM telah banyak sekali dilakukan tetapi tidak terlalu berfokus terhadap metode ekstraksi fitur ataupun membahas ciri musik lain yang menjadi salah satu faktor juga dalam meningkatkan akurasi seperti yang sudah di sarankan dalam penelitian ini [16],
serta banyaknya data latih juga akan sangat mempengaruhi dalam mengkaslifikasi suatu jenis genre tertentu, pada penelitian sebelumnya data audio untuk data latih dan uji masih sedikit antara 100 sampai 400 lagu, jenis genre yang masih kurang bervariatif serta platform yang digunakan dalam mengklasifikasi masih kurang ataupun belum ada. Sehingga untuk penelitian ini menggunakan algoritma SVM sebagai metode untuk pengklasifikasian serta beberapa fitur lain yang lebih dominan dalam mewakili suatu jenis genre lain dengan harapan nilai akurasi dapat bertambah.[6], menggunakan 10 jenis genre musik dengan total 1000 data audio agar lebih bervariatif, Serta membangun platform berbasis website agar lebih fleksibel dan mempermudah dalam mengklasifikasikan suatu lagu.
Tabel 2. 3 Rangkuman Penelitian Terkait
No Penulis Penelitian Metode Hasil Kekurangan 1. S.
Yoppy (2014)
musik yang diklasifikan adalah 3 tipe musik rock , dan diklasifikasikan menggunakan algoritma K-NN dengan nilai parameter K=5. MUGRAT dan Algoritma K-NN Hasil akurasi yang didapatkan adalah 54,44 %. Klasifikasi hanya berdasarkan kesamaan fitur terbesar dan terdekat dari input data. Sementara data latih tidak selalu mewakili tipe musik rock. 2. D. F. Putra dan R. Magdale na (2014) didapat jenis parameter terbaik yaitu jenis filter Chebyshev II dengan nilai order = 6. Algoritma K-NN dan FFT 72 % belum adanya platform baik mobile ataupun website agar lebih
fleksibel dan mempermudah dalam proses tersebut
No Penulis Penelitian Metode Hasil Kekurangan en, (2017) ini menggunakan beberapa dataset untuk dibandingkan. hasil akurasi yang didapatkan. Diantaranya GTZAN (1000 audio track, 10 genres), Ballroom (698 audio track, 8 genre), Soundtrack dataset (470 kutipan musik film, terdiri dari 5 emosi diskrit (marah, takut, sedih, bahagia, lembut)). CNN dan LSTM CNN (51,70%), LTSM (59,30%), Ballroom= CNN (81,79%), LTSM (64,00%), Soundtrack CNN (52,00 %), LTSM(64,00 %). dari CNN tidak dapat digabungkan secara efisien. 4. S. H. Chen and S. H. Chen (2009) Menggunakan fitur timbral seperti MFCC dan Log Energy untuk metode ekstrasi fiturnya. SVM dengan menggunakan exponential radial basis kernel function. Hasil akurasi 86 %. Platform yang digunakan belum ada. 5 I. G. A. D. Wintara (2017) - SVM-OAA yang dibangun sejumlah k model SVM binary dengan k jumlah kelas. - SVM-OAO dibangun dengan SVM –OAA parameter kernel polynomial dan SVM – OAO kernel polynomial SVM-OAA 85,6% dan SVM-OAO 86,4% Sisi metode ekstraksi fitur yang tidak dijelaskan.
No Penulis Penelitian Metode Hasil Kekurangan jumlah k (k-1)/2 buah model 6 E. J. Santosa, (2017) -Pengujian metode SVM dengan 2 Model yaitu RBF dan polynomial. -RBF dengan parameter C=10 dan gamma 0.0001. -Polynomial dengan nilai parameter C=10, gamma=001, Degree 1, Coeficient 1. SVM model RBF dan SVM model polynomial Model RBF 84,5% dan model polynomial 85,5 % -metode ekstraksi ciri yang kurang bervariasi 7. P. S. Stergiop oulos and O. B. Efremid es Metode optimasi dan ANN backpropagation diimplementasikan menggunakan MATLAB ver. 7.0 dari MathWorks Inc. ANN Bacpropagati on dan metode pengoptimalan lain. Hasil akurasi 81%. Harus lebih memperhatikan fungsi ambang batas serta berbagai jenis jaringan neural dan berbagai cara untuk mengekstrak vector fitur. 8 . A. Alvarad o Díaz (2016) Analisis penggunaan algoritma genetika untuk meningkatkan Algoritma Genetika 85,55 % -
No Penulis Penelitian Metode Hasil Kekurangan performansi dalam klasifikasi genre berbasis JST Backpropagation. 9 M. R. Fansuri (2011) Kombinasi algoritma LVQ dan SOM berdasarkan fitur entropi koefisien wavelet. learning rate bernilai 0,15 Kombinasi LVQ dan SOM. 54,23 % -