KOMPARASI METODE UNDERSAMPLING UNTUK
KLASIFIKASI TEKS UJARAN KEBENCIAN
Naufal Azmi Verdikha
1), Teguh Bharata Adji
2), Adhistya Erna Permanasari
3)Teknologi Informasi, Departemen Teknik Elektro dan Teknologi Informasi,
Fakultas Teknik, Universitas Gadjah Mada
Jl. Grafika No 2, Kampus UGM, Yogyakarta, 55281
1
[email protected],
2[email protected],
3[email protected]
ABSTRAK
Jaringan media sosial telah menjadi sebuah wadah dimana hampir setiap orang di penjuru dunia saling berbagi pikiran. Kemudahan yang diberikan oleh jaringan media sosial dapat memberikan kebebasan penggunanya untuk saling berbagi pikiran. Namun, kebebasan yang tidak terkontrol dapat menyebabkan penggunanya untuk menyerang seseorang atau sebuah organisasi menggunakan ujaran kebencian. Sistem klasifikasi teks sangat dibutuhkan untuk mengatasi masalah ujaran kebencian yang terdapat di jaringan media sosial. Akan tetapi, ujaran kebencian yang terdapat di jaringan media sosial susah ditemukan. Hal ini membuat distribusi data sampel pada data latih untuk sistem klasifikasi teks menjadi tidak seimbang. Salah satu metode untuk mengatasi data latih yang tidak seimbang yaitu dengan metode undersampling. Penelitian ini bertujuan untuk membandingkan metode-metode undersampling yang digunakan untuk klasifikasi teks ujaran kebencian, dengan manfaat agar pihak lain dapat menggunakan metode
undersampling yang terbaik menurut penelitian ini. Penelitian ini menggunakan sebuah dataset tweet ujaran
kebencian yang terbagi dalam tiga kelas, yaitu kelas rasisme, kelas seksisme, dan kelas data tweet yang bukan termasuk rasisme dan seksisme. Penelitian ini menggunakan metode pembobotan kata TF-IDF dan metode klasifikasi Support Vector Machines (SVM). Hasil penelitian menunjukkan bahwa metode
undersampling Instances Hardness Threshold meningkatkan nilai evaluasi klasifikasi terbesar
dibandingkan metode undersampling yang lain.
Kata kunci : Klasifikasi Teks, Ujaran Kebencian, Tweet, Undersampling, Support Vector Machines. ABSTRACT
Social network has become a place where people from every corner of the world has sharing their minds. The convenience provided by social network can give users a freedom to share. However, unrestricted freedom can cause users to attack someone or an organization using hate speech. A text classification is needed to address the problem of hate speech in social network. But hate speech text sample in social network is difficult to get. This problem make the distribution of sample data in the training data of the text classification system to be unbalanced. One of the methods to overcome the unbalanced training data is by undersampling method. This research aims to compare undersampling methods used for hate speech classification, with benefit that others can use the best undersampling method according to this study. This research used a tweet hate speech dataset that is divided into three classes: racism, sexism and class of tweet that does not belong to racism and sexism. This research using TF-IDF weighting method and Support Vector Machines (SVM) for the classifier. The results of this research show that Instances Hardness Threshold method get the highest evaluation performance of the classification than the other undersampling methods.
Keywords : Text Classification, Hate Speech, Tweet, Undersampling, Support Vector Machines.
1. PENDAHULUAN
Jaringan media sosial semakin memberikan kebebasan penggunanya untuk saling berbagi pikiran. Kebebasan pengguna yang tidak terkontrol dapat memudahkan penggunanya untuk menyerang seseorang atau organisasi lain menggunakan bahasa yang penuh kebencian atau disebut ujaran kebencian. Hal ini tentu saja dapat membahayakan sesorang atau organisasi yang telah menjadi korban ujaran kebencian
tersebut. Jaringan media sosial seperti Twitter dan Facebook telah menerapkan kebijakan bahwa penggunanya tidak boleh mendukung kekerasan terhadap atau secara langsung menyerang atau mengancam pengguna lain atas dasar ras, suku, asal negara, orientasi seksual, jenis kelamin, identitas jenis kelamin, hubungan keagamaan, usia, ketidakmampuan fisik, atau penyakit. Cara penerapan kebijakan dalam menghapus konten ujaran kebencian masih dianggap kurang mampu untuk mengatasi masalah tersebut (Davidson, dkk., 2017).
Sistem klasifikasi teks diyakini mampu mengatasi masalah ujaran kebencian yang terdapat di jaringan media sosial. Akan tetapi, ujaran kebencian yang terdapat di jaringan media sosial susah ditemukan. Hal ini membuat distribusi data sampel untuk data latih menjadi tidak seimbang (imbalanced data). Klasifikasi pada imbalanced data akan cenderung mengabaikan kelas yang memiliki jumlah sampel yang lebih sedikit (kelas minoritas) dan cenderung fokus ke kelas yang memiliki jumlah sampel yang lebih besar (kelas mayoritas). Kecenderungan ini akan berpengaruh buruk terhadap kinerja dari sebuah sistem klasifikasi tersebut. Walaupun sistem klasifikasi mempunyai nilai akurasi yang tinggi, tetapi sistem sebagian besar hanya mengklasifikasi dengan benar pada kelas mayoritas. Oleh karena itu nilai akurasi tidak bisa dijadikan sebuah nilai evaluasi untuk klasifikasi pada imbalanced data.
Menurut Estabrooks, dkk(2004), solusi pendekatan untuk mengatasi masalah imbalanced data terbagi dua, yaitu solusi pendekatan internal dan solusi pendekatan eksternal. Solusi pendekatan internal dilakukan dengan cara membuat sebuah algoritma baru atau memodifikasi algoritma yang sudah ada untuk memperkecil tingkat kesalahan (error rate). Solusi pendekatan eksternal dilakukan dengan merubah jumlah sampel (resampling) yang ada pada dataset sebelum diproses kedalam algoritma klasifikasi. Untuk beberapa kasus tertentu, solusi pendekatan internal cukup efektif dalam mengatasi masalah imbalanced
data, akan tetapi solusi ini membuat algoritma tersebut menjadi lebih spesifik. Hal ini menjadi sebuah
masalah dikarenakan beberapa dataset memiliki karakteristik yang berbeda-beda dimana beberapa dataset tersebut dapat diklasifikasikan lebih baik oleh algoritma klasifikasi yang lain. Disisi lain, solusi pendekatan eksternal tidak bergantung kepada algoritma klasifikasi yang digunakan, oleh karena itu solusi pendekatan eksternal lebih serba guna dibandingkan solusi pendekatan internal.
Pada dasarnya solusi pendekatan eksternal terbagi menjadi dua, yaitu oversampling dan undersampling.
Oversampling bekerja dengan cara menambah data sampel yang ada pada kelas minoritas dengan cara
membuat replika data sampel tersebut sehingga distribusi data sampel menjadi lebih seimbang. Sebaliknya,
undersampling bekerja dengan cara mengurangi data sampel yang ada pada kelas mayoritas dengan cara
menyeleksi data sampel tersebut sehingga distribusi data sampel menjadi lebih seimbang. Pada penelitian Drummond dan Holte (2003), menunjukkan bahwa metode undersampling memiliki performa yang lebih unggul dibandingkan dengan metode oversampling.
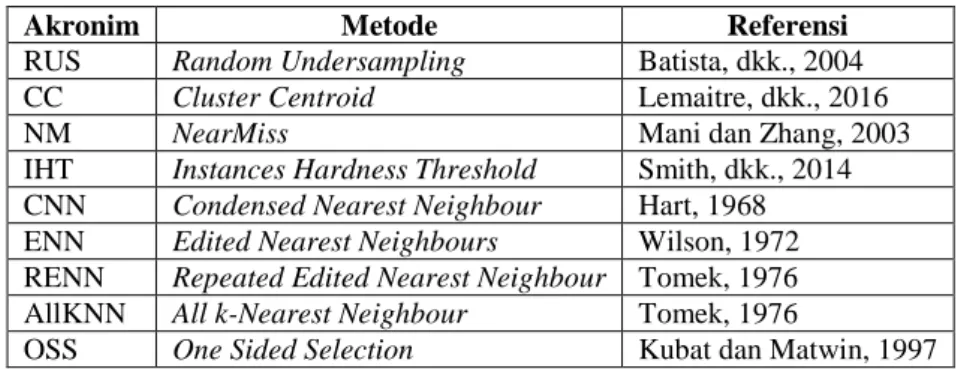
Penelitian ini bertujuan untuk membandingkan metode-metode undersampling yang telah disediakan oleh salah satu modul bahasa pemrograman Python : imbalanced-learn yang telah dibuat oleh Lemaitre, dkk., pada tahun 2016. Berikut ini adalah tabel akronim dan referensi untuk metode-metode undersampling yang digunakan dalam penelitian ini :
Tabel 1.1 Tabel akronim dan referensi metode-metode undersampling
Akronim Metode Referensi
RUS Random Undersampling Batista, dkk., 2004
CC Cluster Centroid Lemaitre, dkk., 2016
NM NearMiss Mani dan Zhang, 2003
IHT Instances Hardness Threshold Smith, dkk., 2014 CNN Condensed Nearest Neighbour Hart, 1968 ENN Edited Nearest Neighbours Wilson, 1972 RENN Repeated Edited Nearest Neighbour Tomek, 1976
AllKNN All k-Nearest Neighbour Tomek, 1976
Metode-metode undersampling tersebut akan digunakan untuk menyeimbangkan Dataset Tweet
Hatespeech yang telah dikumpulkan dan diberikan label sebelumnya oleh Waseem dan Hovy pada tahun
2016. Dataset tersebut berisi sekumpulan data tweet yang berlabelkan rasisme, seksisme dan bukan yang termasuk keduanya. Penelitian ini menggunakan metode pembobotan kata TF-IDF dan metode klasifikasi
Support Vector Machines (SVM). Hasil klasifikasi tersebut dievaluasi menggunakan nilai F1, Geometric Mean (Geo), dan Index of Balanced Accuracy (IBA).
2. METODE PENELITIAN Pengambilan Data
Dataset yang digunakan penelitian ini berasal dari penelitian Waseem dan Hovy pada tahun 2016. Dataset
berisi tweet ujaran kebencian berlabelkan racism (rasisme), sexism (seksisme) dan none (bukan termasuk rasisme dan seksisme). Pengambilan data tweet dilakukan dengan menggunakan salah satu crawler tweet Python: Tweepy.
Pra Proses
Dataset yang telah terkumpul kemudian diproses untuk menghilangkan beberapa fitur. Hal ini dilakukan
untuk meningkatkan performa dari classifier (Prayogo dan Mubarok, 2016). Berikut ini adalah tahapan dari pra proses :
1. Menghapus data tweet yang error pada saat pengambilan data.
2. Menghapus atribut tweet seperti Retweet (‘RT’), hashtag (‘#’), tagging (‘@’), emoticon, link URL. 3. Menghapus karakter non-alfanumerik.
4. Case Folding : mengubah semua huruf besar menjadi huruf kecil.
5. Tokenizing : memisahkan kalimat-kalimat di tweet menjadi kata-kata tungal (unigram). Bag of Words (BOW)
Fitur yang dihasilkan dari pra proses kemudian direpresentasikan dalam bentuk Bag of Words (BOW). Representasi ini berbentuk matrik berdimensi besar, dimana baris matrik merupakan dokumen tweet dan kolom matrik merupakan fitur berupa kata-kata unik. Bentuk matrik BOW dapat dilihat pada gambar berikut :
Komponen baris (𝐷1, 𝐷2, … , 𝐷𝑛) menunjukkan dokumen tweet ke-1 sampai dengan dokumen tweet ke-n.
Komponen kolom (𝑇1, 𝑇2, … , 𝑇𝑛) menunjukkan term atau fitur kata-kata unik yang bersumber dari
dokumen-dokumen tweet yang diproses. Perpotongan antara baris dan kolom menunjukkan keberadaan dan bobot suatu fitur didalam dokumen tweet tersebut (Wenando, 2017).
Undersampling
Penelitian ini menggunakan metode undersampling pada saat fitur berbentuk BOW. Penelitian ini menggunakan salah satu modul bahasa pemrograman Python : imbalanced-learn (Lemaitre, dkk., 2016). Berikut adalah tabel parameter metode-metode undersampling yang digunakan :
Tabel 2.1 Parameter metode
Metode Parameter
RUS (ratio='auto', return_indices=False, random_state=None, replacement=False) CC (ratio='auto', random_state=0, estimator=None, voting='auto', n_jobs=1)
Gambar 2.1 Matrik BOW
NM (ratio='auto', return_indices=False, random_state=0, version=2, size_ngh=None, n_neighbors=3, ver3_samp_ngh=None, n_neighbors_ver3=3, n_jobs=1)
IHT (estimator= RandomForestClassifier(), ratio='auto', return_indices=False, random_state=0, cv=5, n_jobs=1, **kwargs)
CNN (ratio='auto', return_indices=False, random_state=0, size_ngh=None, n_neighbors=None, n_seeds_S=1, n_jobs=1)
RENN (ratio='auto', return_indices=False, random_state=0, size_ngh=None, n_neighbors=3, max_iter=100, kind_sel='all', n_jobs=1)
AllKNN (ratio='auto', return_indices=False, random_state=0, size_ngh=None, n_neighbors=3, kind_sel='all', allow_minority=False, n_jobs=1)
OSS (ratio='auto', return_indices=False, random_state=0, size_ngh=None, n_neighbors=None, n_seeds_S=1, n_jobs=1)
Term Frequency – Inverse Document Frequency (TF-IDF)
Setelah melalui tahap undersampling, fitur yang berbentuk BOW tersebut diubah kedalam bentuk Term
Frequency – Inverse Document Frequency TF-IDF. Nilai Term Frequency (TF) didapatkan dari nilai
frekuensi kemunculan fitur t pada dokumen d.
𝑇𝐹𝑡,𝑑= 𝑓(𝑡, 𝑑) (2.1)
Nilai Inverse Document Frequency (IDF) dapat dihitung dari logaritma banyaknya dokumen N dibagi banyaknya dokumen 𝐷𝐹𝑡 yang mengandung fitur t.
𝐼𝐷𝐹𝑡= log ( 𝑁
𝐷𝐹𝑡) (2.2)
Merujuk pada penelitian Zhang, dkk., (2011) nilai TF-IDF (𝑊𝑡) didapatkan dengan mengalikan nilai TF
(persamaan (2.1)) dengan nilai IDF (persamaan(2.2)).
𝑊𝑡= 𝑇𝐹𝑡,𝑑 × 𝐼𝐷𝐹𝑡 (2.3)
Klasifikasi
Pada klasifikasi teks, dataset dipisahkan ke dalam dua bagian, yaitu training set dan testing set. Metode klasifikasi yang digunakan pada penelitian ini adalah Support Vector Machines (SVM). Dikarenakan
dataset mempunyai tiga kelas atau multi-class, SVM pada penelitian ini menggunakan kernel linier dengan
strategi one-vs-rest. Untuk detail lebih lanjut tentang penggunaan linier SVM dapat merujuk pada penelitian Keerthi, dkk,. (2008). Implementasi klasifikasi linier SVM pada penelitian ini menggunakan salah satu modul Python: sklearn.svm.LinearSVC, dengan parameter: (penalty=’l2’, loss=’squared_hinge’, dual=True, tol=0.0001, C=1.0, multi_class=’ovr’, fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000).
Evaluasi
Berikut adalah evaluasi yang digunakan pada penelitian : 1. Imbalance Ratio (IR)
Imbalance Ratio (IR) adalah sebuah nilai rasio dari sebuah dataset (Puig dan Mansilla, 2009). Nilai ini
didapatkan dengan membagi jumlah data sampel kelas mayoritas dengan jumlah data sampel kelas minoritas. Jika nilai IR semakin mendekati satu, maka dataset akan semakin seimbang.
2. Geometric Means (Geo)
Geometric Mean (Geo) adalah salah satu metode evaluasi untuk mengukur performa klasifikasi pada imbalance data. Metode evaluasi ini diajukan oleh Kubat dan Matwin (1997) dalam mengevaluasi
metode undersampling OSS pada penelitian mereka. Nilai evaluasi ini mengindikasikan keseimbangan antara performa klasifikasi pada kelas mayoritas dan kelas minoritas. Jika terdapat performa buruk dalam memprediksi kelas minoritas, maka nilai Geo akan rendah, walaupun sampel didalam kelas mayoritas diklasifikasikan secara benar (berlaku juga untuk sebaliknya). Berikut adalah cara mendapatkan nilai Geo dari sebuah confussion matrix :
Tabel 2.2 Confusion matrix
Predictive positive Predicted negative Actual positive True positive (TP) False negative (FN) Actual negative False positive (FP) True negative (TN)
𝐺𝑒𝑜 = √ 𝑇𝑃
𝑇𝑃+𝐹𝑁× 𝑇𝑁
𝑇𝑁+𝐹𝑃 (2.4)
3. HASIL DAN PEMBAHASAN
Setelah mengalami proses pengambilan data dan pra proses, beberapa sampel dibeberapa kelas mengalami sejumlah pengurangan dari dataset asli. Hal ini disebabkan oleh beberapa faktor seperti terdapat tweet yang error dan faktor pra proses. Berikut ini adalah tabel dataset setelah mengalami proses pengambilan data dan pra proses:
Tabel 3.1 Dataset Kelas Jumlah Sampel
racism 1.923
sexism 3.119
none 10.701
Total 15.743
Dari tabel 3.1 dapat dilihat bahwa kelas none memiliki jumlah sampel lebih besar daripada kelas lainnya. Hal ini menunjukkan bahwa dataset adalah data yang tidak seimbang (imbalanced data). Metode klasifikasi pada umumnya akan cenderung fokus pada kelas none dan akan cenderung mengabaikan kelas sexism dan
racism.
Hasil token (kata tunggal) yang diperoleh dari proses tokenizing pada tahap pra proses berjumlah 15.312 token. Hasil ini membuat matrik BOW berdimensi berukuran tinggi, yaitu 15.743 × 15.312.
Berikut ini adalah hasil evaluasi klasifikasi menggunakan metode klasifikasi linier SVM sebelum dan setelah menggunakan metode undersampling :
Tabel 3.2 Hasil Evaluasi
Data IR Geo Std 5,56 0,78 RUS 1,00 0,66 CC 1,00 0,83 NM 1,00 0,85 IHT 1,16 0,93 CNN 2,50 0,77 RENN 33,36 0,85 AllKNN 4,27 0,82 OSS 5,54 0,79
Pada tabel 3.2 menunjukkan hasil evaluasi metode klasifikasi dimana data Std adalah dataset sebelum menggunakan metode undersampling. Pada hasil evaluasi menunjukkan bahwa tidak semua metode
menaikkan performa klasifikasi. Metode RUS mendapatkan nilai Geo terendah (0,66) dibandingkan metode lainnya, hal ini dikarenakan metode RUS menyeleksi sampel data kelas yang akan dikurangi secara acak, walaupun dataset sudah seimbang (IR = 1). Metode RENN memiliki nilai Geo diatas rata-rata (0,85), akan tetapi dataset menjadi lebih tidak seimbang (IR = 33,36), hal ini dikarenakan metode RENN menyeleksi terlalu banyak data sampel yang akan dikurangi pada kelas none ( berkurang 4.330 data sampel) dan kelas
sexism (berkurang 2.928 data sampel). Metode IHT memiliki nilai Geo tertinggi (0,93) dan memiliki dataset yang hampir seimbang (IR = 1,16), hal ini membuat metode IHT menjadi metode yang terbaik pada
penelitian ini.
4. PENUTUP
Penelitian ini menyajikan perbandingan metode-metode undersampling untuk mengatasi masalah
imbalanced data pada klasifikasi ujaran kebencian. Dengan menggunakan metode pembobotan kata
TF-IDF dan metode klasifikasi SVM, tidak semua metode undersampling dapat mengatasi masalah imbalanced
data tersebut. Walaupun metode RUS dapat menyeimbangkan dataset, akan tetapi metode RUS mengalami
penurunan performa klasifikasi. Keadaan sebaliknya terjadi pada metode RENN, dimana metode ini dapat menaikkan performa klasifikasi tetapi dataset bertambah jauh dari keadaaan seimbang dikarenakan banyaknya data sampel yang berkurang pada kelas yang bukan kelas mayoritas. Metode IHT memiliki kenaikan performa klasifikasi yang lebih unggul dibandingkan metode undersampling yang lainnya dan dengan metode IHT, dataset menjadi lebih seimbang. Oleh karena itu, metode IHT dapat mengatasi masalah imbalanced data untuk klasifikasi teks ujaran kebencian.
Untuk penelitian lebih lanjut, dibutuhkannya analisa penggunaan metode-metode undersampling khususnya penggunaan metode IHT untuk klasifikasi teks pada imbalanced data dalam bidang lain agar dapat mengetahui batasan-batasan metode IHT dalam mengatasi masalah imbalanced data.
5. DAFTAR PUSTAKA
[1]. Davidson, T., Warmsley, D., Macy, M., Weber, I. 2017. Automated Hate Speech Detection and the Problem of Offensive Language. Proceedings of the 11th International AAAI Conference on Web and Social Media. 512-515.
[2]. Estabrooks, A., Jo, T., Japkowicz, N. 2004. A Multiple Resampling Method for Learning from Imbalanced Data Sets. Computational Intelligence. Vol. 20. Hal. 18-36.
[3]. Chris Drummond dan Robert C. Holte. 2000. Exploiting the Cost in Sensitivity of Decision Tree Splitting Criteria. Proceedings of the 17th International Conference on Machine Learning. Hal. 239– 246.
[4]. Lemaitre, G., Nogueira, F., Aridas, C. 2016.Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. Journal of Machine Learning Research. Vol. 18. No. 17. Hal. 1-5.
[5]. Batista, G., Prati, R., Monard, M. 2004. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data. ACM SIGKDD Explorations Newsletter - Special issue on learning from imbalanced datasets. Vol. 6. Hal. 20-29.
[6]. Zhang, Jianping dan Mani, Inderjeet. 2003. kNN Approach to Unbalanced Data Distributions: A Case Study involving Information Extraction. ICML. Hal. 42-48.
[7]. Smith, M., Martinez, T., Giraud-Carrier, C. 2014. An instance level analysis of data complexity. Machine Learning. Vol. 95. Hal. 225-256.
[8]. Hart, P. 1968. The condensed nearest neighbor rule (Corresp.). IEEE Transactions on Information Theory. Vol. 14. Hal. 515-516.
[9]. Wilson, Dennis L. 1972. Asymptotic Properties of Nearest Neighbor Rules Using Edited Data. IEEE Transactions on Systems, Man and Cybernetics. Vol. 2. Hal. 408-421.
[10]. Tomek, Ivan. 1976. An Experiment with the Edited Nearest-Neighbor Rule. IEEE Transactions on Systems, Man, and Cybernetics. Vol. 6. Hal. 448-452.
[11]. Kubat, Miroslav dan Matwin, Stan. 1997. Addressing the Curse of Imbalanced Training Sets: One Sided Selection. ICML. Vol. 97. Hal. 179-186.
[12]. Waseem, Zeerak dan Hovy, Dirk. 2016. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. Proceedings of the NAACL Student Research Workshop. Hal. 88-93.
[13]. Prayogo, A.H., Mubarok, M.S, Adiwijaya. 2016. Identifikasi Parafrasa pada Dokumen Teks Bahasa Indonesia Menggunakan Bayesian Networks. Indosc 2016. Hal. 207-218.
[14]. Wenando, Febby.A. 2017. KLASIFIKASI TEKS UNTUK MENDETEKSI PEMAHAMAN MAHASISWA DALAM PROSES PRIOR KNOWLEDGE ACTIVATION. Tesis Master of Engineering. Universitas Gadjah Mada. Yogyakarta.
[15]. Zhang, W., Yoshida, T., Tang, X. 2011. A comparative study of TF*IDF, LSI and multi-words for text classification. Expert Systems with Applications. Vol. 38. Hal. 2758-2766.
[16]. Keerthi, S., dkk. 2008. A Sequential Dual Method for Large Scale Multi-Class Linear SVMs. Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. Hal. 408-416.