83
Materi pada bab ini meliputi pengujian parameter pada model regresi, pemilihan model terbaik, asumsi-asumsi pada analisis regresi, serta penyimpangan- penyimpangan asumsi dan cara mengatasinya.
6.1. KOMPETENSI KHUSUS
Setelah mempelajari bab ini, mahasiswa diharapkan memiliki kompetensi sebagai berikut:
a. Dapat menduga parameter model regresi melalui pengujian parameter model regresi, baik secara serentak maupun individu
b. Mahasiswa mengetahui dan dapat menggunakan metode pemilihan model terbaik.
c. Mahasiswa dapat menguji asumsi-asumsi pada model regresi.
d. Mahasiswa dapat mengatasi penyimpangan pada model regresi.
6.2. URAIAN MATERI
Analisis regresi adalah analisis statistika yang bertujuan untuk memodelkan hubungan antara variabel independent dengan variabel dependent. Istilah regresi pertamakali dikenalkan oleh Francis Galton (1886) melalui artikelnya yang berjudul Regression Towards Mediocrity In Hereditary Stature, di dalam artikel ini Galton mengkaji hubungan antara tinggi badan anak dengan tinggi badan orang tua. Dari hasil kajian ini diperoleh informasi adanya hubungan antara tinggi badan anak dengan tinggi orang-tuanya.
Model yang menggambarkan hubungan antara variabel independent (X) dengan variabel dependent (Y) adalah:
( )
y= f x;β +ε
Hubungan antara variabel independent dengan variabel dependent dikatakan linear jika dapat dinyatakan dalam model:
84
0 1 1 2 2 p p
y=β +β x +β x + +L β x +ε
Dalam bentuk matriks, model regresi linear dapat ditulis dalam:
= +
y Xβ ε atau
11 1 0
1 1
21 2 1
2 2
1
1 1
1
p
p
n np p
n n
x ... x y
x ... x y
x ... x y
β ε
β ε
β ε
⎡ ⎤ ⎡ ⎤
⎡ ⎤ ⎡ ⎤
⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥
⎢ ⎥=⎢ ⎥ ⎢ ⎥+⎢ ⎥
⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎥
⎣ ⎦ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦
M M O M M
M M
Nilai vektor β dapat ditaksir dengan menggunakan metode kuadrat terkecil dengan cara :
( ) (
−1)
=
β X'X X'y dengan
0
1
p
β β β
⎡ ⎤⎢ ⎥
=⎢ ⎥⎢ ⎥
⎢ ⎥⎣ ⎦
β M ;
( )
1 1 1
2
1 1 1
1 1
2
1 1 1
n n
i pi
i i
n n
i i i pi
i i
n n
pi i pi pi
i i
n x ... x
x x ... x x
x x x x
= =
= =
= =
⎡ ⎤
⎢ ⎥
⎢ ⎥
⎢ ⎥
=⎢ ⎥
⎢ ⎥
⎢ ⎥
⎣ ⎦
∑ ∑
∑ ∑ ∑
∑ ∑ ∑
X'X M M O M
M
;
( )
1
1 1
1 n i i n
i i i
n pi i i
y x y ...
x y
=
=
=
⎡ ⎤
⎢ ⎥
⎢ ⎥
⎢ ⎥
=⎢ ⎥
⎢ ⎥
⎢ ⎥
⎣ ⎦
∑
∑
∑
X'Y
Pengujian terhadap vektor βdapat dilakukan dengan dua cara yaitu pengujian secara serentak dan pengujian secara individu.
6.2.1. Pengujian Parameter Regresi Pengujian secera serentak
Hipotesis :
0: H β 0 =
1: H β 0≠
85 Statistik Uji
Sumber
Variasi df Sum of Squares MS F
Regresi p
∑
(Yˆ−Y)2∑
(Yˆ−Y)2/psidual MS
gresi MS
Re .
Re .
Residual n-p-1
∑
(Y −Yˆ)2∑
(Y −Yˆ)2/(n−p−1)Total n-1
∑
(Y −Y)2Tolak Ho jika F >Fα, p , n p− −1.
Pengujian secara individu Hipotesis
0: j 0
H β =
1: j 0
H β ≠
Statistik uji: t=βˆj s
( )
βˆjTolak Ho jika t >tα 2 ; n -p-1
Kegiatan Praktikum
Tentukan model yang menggambarkan hubungan antara harapan hidup perempuan (Y) dengan pendapatan per-kapita dan kepadatan penduduk yang dinyatakan dalam:
( ) ( )
0 1 2
y=β +β ln gdp _ cap +β ln density
Penyelesaian :
a) Melakukan transformasi ln(gdp_cap) dan ln(density) dengan cara [klik transform+ compute]
86
b) Melakukan analisis regresi ;[klik+analyze+regression+linear]
87 dan hasilnya adalah :
Model Summary
.840a .706 .700 5.788
Model 1
R R Square
Adjusted R Square
Std. Error of the Estimate
Predictors: (Constant), ln_gdp, ln_dens a.
ANOVAb
8519.080 2 4259.540 127.141 .000a
3551.268 106 33.503
12070.349 108
Regression Residual Total Model 1
Sum of
Squares df Mean Square F Sig.
Predictors: (Constant), ln_gdp, ln_dens a.
Dependent Variable: Average female life expectancy b.
Coefficientsa
17.981 3.501 5.136 .000
.904 .388 .123 2.332 .022
6.150 .390 .831 15.766 .000
(Constant) ln_dens ln_gdp Model
1
B Std. Error Unstandardized
Coefficients
Beta Standardized
Coefficients
t Sig.
Dependent Variable: Average female life expectancy a.
Seluruh nilai sig.<5% sehingga harapan hidup perempuan dipengaruhi (Y) oleh kepadatan penduduk dan pendapatan per-kapita yang dinyatakan dalam model :
( ) ( )
17 981 6 150 0 904
y= , + , ln gdp _ cap + , ln density
6.2.2. Pemilihan Model Terbaik
Salah satu tujuan di dalam analisis regresi adalah untuk mendapatkan model terbaik yang menjelaskan hubungan antara variabel independent dengan variabel dependent, model terbaik adalah model yang seluruh koefisien regresinya berarti (significant) dan mempunyai kriteria model terbaik optimum. Beberapa kriteria
88
model terbaik dan metode untuk mendapatkannya disajikan pada Tabel 6.1. dan Tabel 6.2.
Tabel 6.1. Kriteria Model Terbaik pada Regresi
No Kriteria Formula Optimum
1 SSE
∑
ni=1(
yi−ˆyi)
2 Minimum2 MSE
(
1)
1( )
21
n
i i
i y ˆy
n p = −
− −
∑
Minimum3 R2
( )
( )
2 1
2 1
100
n i i n i i
ˆy y
%
y y
=
=
− ×
−
∑
∑
Maksimum4 Adjusted R2 1 1− −
(
R2) ( (
nn−−1p) )
Maksimum5 Cp Mallow SSE
(
n 2p)
MSE− − Minimum
6 AIC ln SSE n
( ) (
+ 2p n)
Minimum7 SBC ln SSE n
( ) (
+ p n ln n) ( )
MinimumTabel 6.2. Metode untuk Mendapatkan Model Terbaik
Metode Penjelasan Backward Mulai dengan model lengkap, kemudian variabel independent
yang ada dievaluasi, jika ada yang tidak significant dikeluarkan yang paling tidak significant, dilakukan terus menerus sampai tidak ada lagi variabel independent yang tidak significant
Forward Variabel independent yang pertama kali masuk ke dalam model adalah variabel yang mempunyai korelasi tertinggi dan significant dengan variabel dependent, variabel yang masuk kedua adalah variabel yang korelasinya dengan variabel dependent adalah tertinggi kedua dan masih significant, dilakukan terus menerus sampai tidak ada lagi variabel independent yang significant
StepSwise Gabungan antara metode forward dan backward, variabel yang pertama kali masuk adalah variabel yang korelasinya tertinggi dan significant dengan variabel dependent, variabel yang masuk kedua adalah variabel yang korelasi parsialnya tertinggi dan masih significant, setelah variabel tertentu masuk ke dalam model maka variabel lain yang ada di dalam model dievaluasi, jika ada variabel yang tidak significant maka variabel tersebut dikeluarkan
Best subset regression
Metode ini tersedia di dalam program paket MINITAB. Metode ini menyajikan k buah model terbaik untuk model dengan 1,2,…,p variabel independent.
89 Kegiatan Praktikum
Tentukan model terbaik yang menggambarkan hubungan antara harapan hidup perempuan (lifeexpf) dengan pendapatan perkapita (gdp_cap), persentase penduduk yang tinggal dikota (urban), persentase penduduk yang dapat membaca (literacy), banyaknya kematian per 1000 penduduk (death_rt), rata-rata banyaknya anak (fertility), konsumsi makanan per-hari (calories) dengan menggunakan metode stepwise dan best subset regression.
Penyelesaian :
a) Dengan bantuan SPSS permasalahan di atas dapat diselesaikan dengan cara [klik analyze+regression+linear]
atau melalui syntax berikut ini:
REGRESSION
/STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN
/DEPENDENT lifeexpf
/METHOD=STEPWISE gdp_cap calories literacy urban death_rt.
dan hasilnya adalah:
90
ANOVA
7229.894 1 7229.894 222.690 .000
2337.565 72 32.466
9567.459 73
8206.309 2 4103.154 214.028 .000
1361.150 71 19.171
9567.459 73
8906.744 3 2968.915 314.544 .000
660.716 70 9.439
9567.459 73
9017.788 4 2254.447 282.999 .000
549.672 69 7.966
9567.459 73
Regression Residual Total Regression Residual Total Regression Residual Total Regression Residual Total Model 1
2
3
4
Sum of
Squares df Mean Square F Sig.
Model Summary
.869a .756 .752 5.698
.926b .858 .854 4.378
.965c .931 .928 3.072
.971d .943 .939 2.822
Model 1 2 3 4
R R Square
Adjusted R Square
Std. Error of the Estimate
Predictors: (Constant), People who read (%) a.
Predictors: (Constant), People who read (%), Death rate per 1000 people
b.
Predictors: (Constant), People who read (%), Death rate per 1000 people, Gross domestic product / capita c.
Predictors: (Constant), People who read (%), Death rate per 1000 people, Gross domestic product / capita, Daily calorie intake
d.
91
Coefficientsa
36.226 2.275 15.924 .000
.430 .029 .869 14.923 .000
53.279 2.961 17.995 .000
.330 .026 .667 12.606 .000
-.966 .135 -.378 -7.137 .000
62.740 2.350 26.699 .000
.192 .024 .389 7.890 .000
-1.211 .099 -.474 -12.214 .000
.001 .000 .363 8.614 .000
54.214 3.143 17.252 .000
.172 .023 .347 7.456 .000
-1.136 .093 -.444 -12.178 .000
.000 .000 .252 5.170 .000
.004 .001 .186 3.734 .000
(Constant)
People who read (%
(Constant)
People who read (%
Death rate per 1000 people
(Constant)
People who read (%
Death rate per 1000 people
Gross domestic product / capita (Constant)
People who read (%
Death rate per 1000 people
Gross domestic product / capita Daily calorie intake Model
1
2
3
4
B Std. Error Unstandardized
Coefficients
Beta Standardized
Coefficients
t Sig.
Dependent Variable: Average female life expectancy a.
Sehingga model terbaiknya adalah :
( ) ( ) ( ) ( )
54 214 0 172 1 136 0 000 0 004
lifeexp= , + , literacy − , death_rt + , gdp_cap + , calorie dengan R2= 0.943
b) Dengan menggunakan best subset regression :[klik stat+regression+best subset]
sehingga diperoleh hasil sebagai berikut:
92 Response is LIFEEXPF
L C D I G A E T D L A U E P O T R R _ R H B A C I _ A C A E R Vars R-Sq R-Sq(adj) C-p S N Y P S T 1 75.6 75.2 225.8 5.6979 X 1 60.2 59.6 412.2 7.2752 X 1 59.8 59.3 416.2 7.3055 X 2 86.9 86.6 90.3 4.1981 X X 2 85.8 85.4 103.5 4.3686 X X 2 83.7 83.3 128.9 4.6816 X X 3 93.1 92.8 17.5 3.0711 X X X 3 92.1 91.7 30.1 3.2935 X X X 3 89.6 89.2 59.8 3.7688 X X X 4 94.3 93.9 5.5 2.8207 X X X X 4 93.5 93.1 15.1 3.0095 X X X X 4 92.5 92.1 26.2 3.2150 X X X X 5 94.4 94.0 6.0 2.8112 X X X X X
Dengan menggunakan criteria Cp-Mallows dan MSE terkecil diperoleh model terbaik yang mengandung variabel literacy, gdp_cap, calories dan death_rt, hasil ini sama dengan metode stepwise
6.2.3. Asumsi dalam Analisis Regresi
Model linear yang menggambarkan hubungan antara variabel independent dan variabel dependent adalah :
0 1 1 2 2 p p
y=β +β x +β x + +L β x +ε
Asumsi yang diperlukan untuk model ini adalah:
a. ε ~ N
(
0,σ2)
b. var
( )
εi =σ2 untuk semua i c. cov(
ε εi, j)
= untuk i≠j 0d. Antar variabel independen saling bebas
93
Asumsi-asumsi di atas kadang-kadang tidak dipenuhi, untuk mendeteksi dan mengatasi adanya masalah pelanggaran asumsi di atas dapat dilakukan langkah- langkah pada Tabel 6.3. berikut ini:
Tabel 6.3. Penyimpangan Asumsi pada Model Regresi dan Cara Mengatasinya
No. Masalah Deteksi Penyelesaian
1 Residual tidak Berdistribusi normal
Normal probability plot Uji kenormalan,
misalnya uji KS
Tranformasi variabel Regresi bootstrap
2 Hetroscedastivity
( )
i 2var ε ≠σ
Plot e dengan yˆ Uji Glesjer, White Uji Golfeld-Quandt
Transformasi variabel Weighted Least Squares
3 Autocorrelation
(
i j)
0cov ε ε, ≠ untuk i≠j
Plot e dengan yˆ Uji Durbin Watson ACF plot
Regresi beda, Regresi ratio, Memasukkan trend, Cochrane Orcutt, Hildreth-Lu,
Durbin, Prais-Winsten 4 Multicollinearity r X , X
(
i j)
tinggi,VIF > 10, X'X ≈0 R2 tinggi tetapi tidak ada yang significant
stepwise
Principal component reg.
Ridge regression
6.2.3.1. Heteroscedastisitas dan Normalitas
Heteroscedasticity adalah sifat residual yang mempunyai varians yang tidak homogen, atau :
i i
i σ σ ω
ε ) 2 2
var( = =
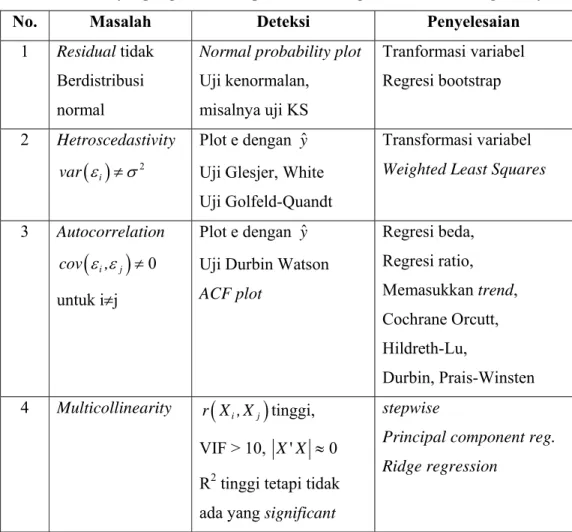
Untuk memeriksa sifat ini dapat dipergunakan scatter-plot antara residual yang sudah dibakukan dengan nilai yˆ , jika scatter plot membentuk gambar seperti pola sebelah kiri berikut maka varians residual masih dianggap konstan dan jika
94
membentuk pola seperi sebelah kanan maka varians residual cenderung tidak homogen.
(a) (b)
Gambar 6.1. Plot Untuk Uji Homogenitas Varians
Selain dengan menggunakan scatter-plot seperti di atas, keberadaan hetrocedasticity juga dapat diuji dengan menggunakan uji Glejser dengan cara meregresikan kuadrad atau harga mutlak residual dengan variabel independent, jika ada variabel independent yang significant maka varians residual cenderung tidak homogen, untuk mengatasi hal ini biasanya dilakukan transformasi dengan cara membagi seluruh nilai variabel dengan variabel yang significant, atau:
Jika e =k. x1. maka dilakukan transformasi sebagai berikut : 1 ...
1 3 3 1 2 2 1 1 1 1 0 1
+ +
+ +
= x
x x
x x
x x
x
y β β β β
atau
* ...
3 3
* 2 2
* 1 0 1
* = + x + x + x +
y β β β β
Koefisien regresi dari model ini kemudian ditaksir dengan menggunakan metode kuadrat terkecil sehingga diperoleh:
* ...
3 3
* 2 2
* 1 0 1
* =b +b x +b x +b x + y
Kemudian model ini dikembalikan ke variabel asal dengan menggandakan ruas kiri dan ruas kanan dengan x1 sehingga diperoleh :
3 ...
3 2 2 1 0
1+ + + +
=b b x b x b x y
95
Secara umum masalah heterocedasticity dapat diatasi dengan mengguna-kan metode weighted least-squares yaitu:
( )
1ˆ = -1 − -1
β X'Ω X XΩ y
dengan Ω adalah matriks diagonal dengan unsur diagonal adalah ωi
Selain dengan menggunakan uji Glejser, uji adanya heteroscedasticity dapat diuji dengan koefisien korelasi Spearman antara residual dengan variabel independent, jika korelasi ini significant maka cenderung terjadi kasus hetroscedasticity.
Koefisien korelasi Spearman dihitung dengan cara :
) 1 ( 1 6 2
2
− −
=
∑
n n
r D
dengan D adalah selisih rank antar dua variabel.
Kegiatan Praktikum :
Dengan menggunakan uji Glejser, periksalah adanya kasus heteroscedasticity untuk data berikut:
Year Saving Income Year Saving Income Year Saving Income
1 264 8777 12 950 17663 23 2105 29560
2 105 9210 13 779 18575 24 1600 28150
3 90 9954 14 819 19635 25 2250 32100
4 131 10508 15 1222 21163 26 2420 32500 5 122 10979 16 1702 22880 27 2570 35250 6 107 11912 17 1578 24127 28 1720 33500 7 406 12747 18 1654 25604 29 1900 36000 8 503 13499 19 1400 26500 30 2100 36200 9 431 14269 20 1829 27670 31 2300 38200 10 588 15522 21 2200 28300
11 898 16730 22 2017 27430
Penyelesaian :
Dengan bantuan MINITAB permasalahan di atas, dapat diselesaikan dengan cara:
96 MTB > regr 'saving' 1 'income';
SUBC> fits c11;
SUBC> resid c12.
dan hasilnya adalah:
The regression equation is saving = - 648 + 0.0847 income
Predictor Coef SE Coef T P Constant -648.1 118.2 -5.49 0.000 income 0.084665 0.004882 17.34 0.000 S = 247.6 R-Sq = 91.2% R-Sq(adj) = 90.9%
Untuk melakukan uji Glejser, dilakukan perintah : MTB > let c13=abs(c12)
MTB > name c13='abs_res'
MTB > regr 'abs_res' 1 'income'
The regression equation is
abs_res = - 7.7 + 0.00935 income
Predictor Coef SE Coef T P Constant -7.69 47.73 -0.16 0.873 income 0.009346 0.001972 4.74 0.000 S = 100.0 R-Sq = 43.6% R-Sq(adj) = 41.7%
Dari hasil uji Glejser ini, diperoleh informasi adanya hubungan antara variabel harga mutlak residual dengan variabel income sehingga terjadi kasus heteroscedasticity. Karena nilai harga mutlak residual sebanding dengan nilai income maka selanjutnya dilakukan analisis regresi untuk model :
(
saving income)
=β0+β1(
1income)
+εDengan bantuan MINITAB analisis regresi untuk model di atas dapat dilakukan dengan cara :
MTB > let c4=saving/income MTB > let c5=1/income MTB > name c4='y*' c5='x*' MTB > regr 'y*' 1 'x*';
97 SUBC> resid c21.
dan hasilnya adalah:
The regression equation is y* = 0.0881 - 723 x*
Predictor Coef SE Coef T P Constant 0.088139 0.004372 20.16 0.000 x* -722.50 72.36 -9.98 0.000 S = 0.01051 R-Sq = 77.5% R-Sq(adj) = 76.7%
Pengujian adanya heteroscedasticity dengan uji Glejser MTB > let c22=abs(c21)
MTB > name c22='absres'
MTB > regr 'absres' 1 'income' Hasil pengujian Glejser
The regression equation is
absres = 0.00793 +0.000000 income
Predictor Coef SE Coef T P Constant 0.007931 0.002608 3.04 0.005 income 0.00000003 0.00000011 0.31 0.760 S = 0.005465 R-Sq = 0.3% R-Sq(adj) = 0.0%
Nilai p untuk variabel income >5% sehingga tidak ada hubungan antara harga mutlak residual dengan income atau varians residual cenderung sudah homogen.
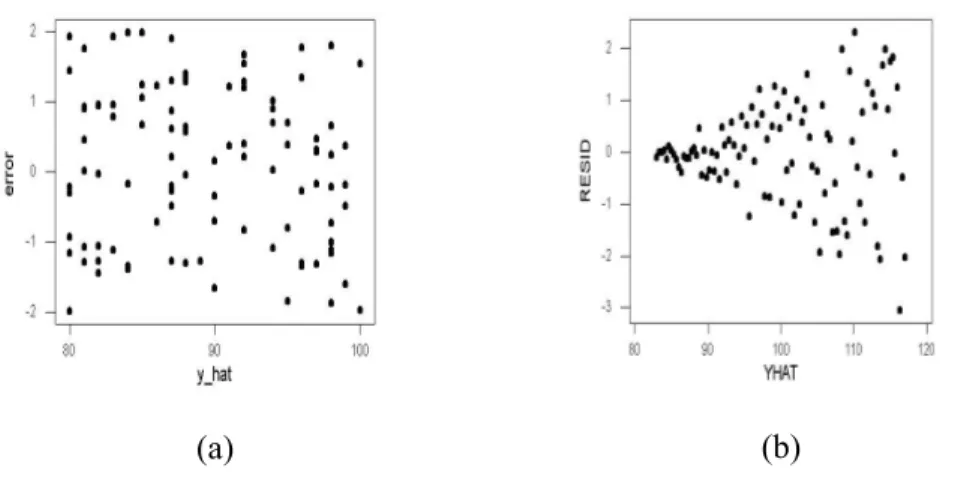
Sedangkan asumsi kenormalan residual dapat diuji dengan cara : MTB > %NormPlot C21;
SUBC> Kstest.
Hasil uji kenormalan dengan menggunakan uji Kolmogorov Smirnov adalah :
98
Gambar 6.2. Hasil Uji Kenormalan Data
Hasil pengujian Komogorov Smirnov, diperoleh hasil p-value>5% sehingga dapat diputuskan residual sudah berdistribusi normal.
Model yang menggambarkan hubungan antara saving dengan income setelah dilakukan transfromasi adalah:
y* = 0.0881 – 723 x*
atau
(
saving income)
=0 0881 723 1, −(
income)
Ruas kiri dan kanan digandakan dengan income maka diperoleh : 723 0 0881
saving= − + , income
6.2.3.2. Autokorelasi
Autocorrelation berarti ada hubungan antar residual atau residual bersifat tidak saling independent, kasus ini sering dijumpai pada data time series. Autocorrelation dapat dideteksi dengan metode-metode berikut ini:
a) Statistik uji Durbin-Watson :
∑
∑
=
= − −
= n
i i n
i
i i
e e e d
1 2 2
2 1) (
99
b) ACF plot, ada nilai r e ,e
(
t t k−)
melampaui batas 0±(
2 n)
maka residual tidak saling independentc) Statistik uji Ljung-Box
∑
= − += k
j j
j n n r
n Q
1 2
) 2
(
Tolak Ho atau residual saling independent jika Q>χα2;k.
pelanggaran asumsi model regresi, yaitu residual yang saling dependent dapat diatasi dengan:
a. Regresi beda
t t t t
t y x x
y − −1= β0+β1( − −1)+ε b. Regresi Nisbah
t t
t
t t
x x y
y =β +β +ε
−
− 1
1 0 1
1 0 1 1
t t t t t
y −ρ.y− =β +β( x −ρx− )+ ε
Kegiatan Praktikum
tahun export gdp tahun export gdp tahun export gdp 1970 102 255 1980 106 259 1990 112 268 1971 105 261 1981 106 258 1991 114 271 1972 105 261 1982 106 257 1992 113 269 1973 105 260 1983 106 257 1993 112 266 1974 104 257 1984 108 261 1994 114 270 1975 104 257 1985 108 261 1995 113 267 1976 106 261 1986 109 262 1996 117 276 1977 106 260 1987 110 264 1997 117 276 1978 105 257 1988 113 271 1998 117 276 1979 106 259 1989 113 271 1999 117 275
Tentukan model yang menggambarkan hubungan antara gdp dengan export dan periksa apakah residual sudah saling independent.
Penyelesaian
a. Penentuan model regresi dan pemeriksaan asumsi independent residual
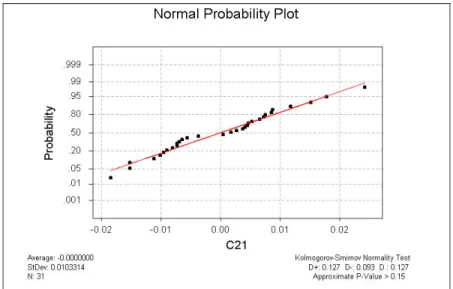
100 MTB > regr ‘gdp’ 1 ‘export’;
SUBC > resid c5.
The regression equation is gdp = 110 + 1.41 export
Predictor Coef SE Coef T P Constant 110.354 6.839 16.14 0.000 export 1.40664 0.06251 22.50 0.000
S = 1.549 R-Sq = 94.8% R-Sq(adj) = 94.6%
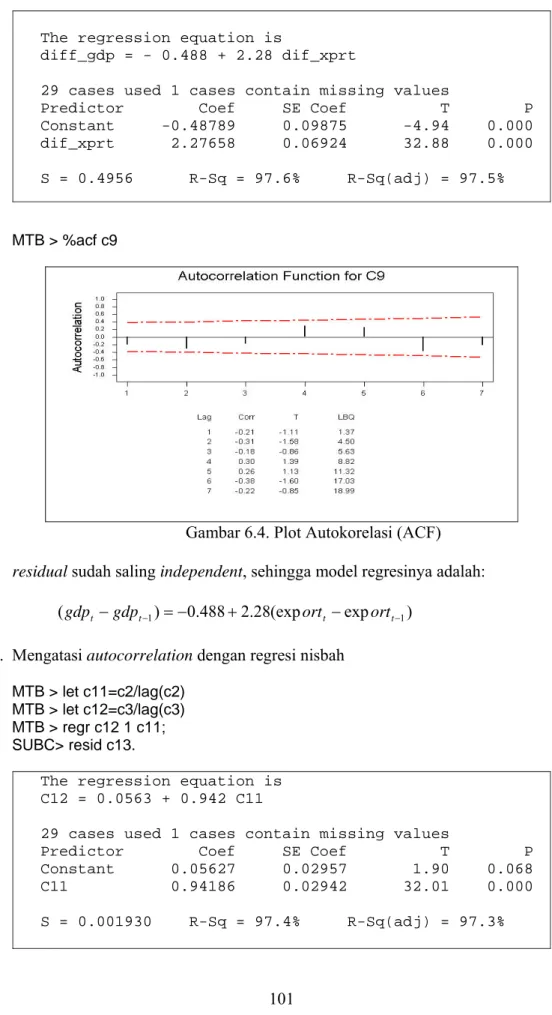
MTB > %acf c5
Gambar 6.3. Plot Autokorelasi (ACF)
Nilai autokorelasi residual keluar dari batas pada lag ke-1 sehingga residual tidak saling independent.
b. Mengatasi autocorrelation dengan regresi beda
MTB > diff 'export' c7 MTB > diff 'gdp' c8
MTB > name c7 'dif_xprt' c8 'diff_gdp' MTB > regr c8 1 c7;
SUBC> resid c9.
101 The regression equation is
diff_gdp = - 0.488 + 2.28 dif_xprt
29 cases used 1 cases contain missing values
Predictor Coef SE Coef T P Constant -0.48789 0.09875 -4.94 0.000 dif_xprt 2.27658 0.06924 32.88 0.000
S = 0.4956 R-Sq = 97.6% R-Sq(adj) = 97.5%
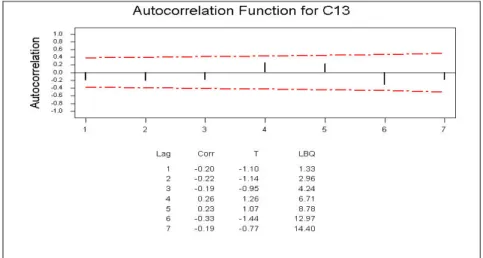
MTB > %acf c9
Gambar 6.4. Plot Autokorelasi (ACF) residual sudah saling independent, sehingga model regresinya adalah:
) exp (exp
28 . 2 488 . 0 )
(gdpt −gdpt−1 =− + ortt − ortt−1 c. Mengatasi autocorrelation dengan regresi nisbah
MTB > let c11=c2/lag(c2) MTB > let c12=c3/lag(c3) MTB > regr c12 1 c11;
SUBC> resid c13.
The regression equation is C12 = 0.0563 + 0.942 C11
29 cases used 1 cases contain missing values
Predictor Coef SE Coef T P Constant 0.05627 0.02957 1.90 0.068 C11 0.94186 0.02942 32.01 0.000
S = 0.001930 R-Sq = 97.4% R-Sq(adj) = 97.3%
102 MTB > %acf c13
Gambar 6.5. Plot Autokorelasi (ACF)
residual sudah saling independent, sehingga model regresinya adalah
1
1 exp
942 exp . 0 0563 . 0
−
−
+
=
t t
t t
ort ort gdp
gdp
6.2.3.3. Multikolinearitas
Multicollinearity adalah Adanya hubungan linear antar variabel independent.
Multicollinearity dapat dideteksi dengan cara berikut:
a. Variance Inflation Factor (VIF) yang tinggi, biasanya>10 b. korelasi antar variabel independent yang tinggi
c. X'X ≈0
d. R2 tinggi tetapi tidak ada variabel independent yang significant e. Koefisien korelasi dan koefisien regresi berbeda tanda
Multicollinearity dapat diatasi dengan metode berikut ini:
a. Mengeluarkan salah satu variabel independent yang berkorelasi tinggi dengan variabel independent yang lain. Pengeluaran variabel ini dapat dilakukan secara manual ataupun otomatis melalui metode stepwise.
b. Ridge Regression. Penaksiran koefisien parameter model regresi pada ridge regression adalah
103
( )
1ˆ = + k −
β X'X I X'y , untuk 0< < . k 1
c. Principal Component Regression (PCR). Langkah-langkah dari metode PCR adalah sebagai berikut:
• Melakukan pembakuan (pen-stadar-an) data :
s x z= x−
• Membangkitkan variabel baru yang saling independent
1 11 1 12 2 1
2 21 1 22 2 2
1 2 2
p p
p p
p p p pp p
w a x a x a x
w a x a x a x
w a x a x a x
= + + +
= + + +
= + + +
L L M
L atau
i = ′i
w a x, dengan a′i adalah eigen-vector dari eigen-value ke-i yang dihitung dari matriks korelasi antar variabel independent
• Melakukan regresi y dengan w dan mensubstitusi mundur ke dalam model asal, yaitu model y dengan x.
6.3. KEGIATAN PRAKTIKUM
1. Periksa adanya kasus multicollinearity pada pemodelan harapan hidup perempuan dengan pendapatan perkapita persentase penduduk yang tinggal di kota, persentase perempuan yang dapat membaca, persentase laki-laki yang dapat membaca di region Amerika Latin
2. Jika ada kasus multicollinearity, atasi dengan beberapa metode untuk mengatasi multicollinearity
Penyelesaian
a. Memilih data dari region Amerika Latin klik [ data+select cases+if ]
104
b. Memeriksa adanya kasus multicollinearity dengan menentukan matriks korelasi antar variabel independent, klik [analyze+correlate+bivariate]
Correlations
1 .550** .500* .833** .756**
.550** 1 .285 .617** .581**
.500* .285 1 .578** .542*
.833** .617** .578** 1 .956**
.756** .581** .542* .956** 1
Average female life expectancy
Gross domestic product / People living in cities (%)it Females who read (%) Males who read (%)
Average female life expectancy
Gross domestic product / capita
People living in cities
(%)
Females who read
(%)
Males who read (%)
Correlation is significant at the 0.01 level (2-tailed).
**.
Correlation is significant at the 0.05 level (2-tailed).
*.
105
Korelasi antar variabel independent cukup tinggi dan significant segingga ada kecenderungan terjadi kasus multicollinearity.
c. Memeriksa adanya kasus multicollinearity dengan VIF klik [analyze+regression+linear]
kemudian klik [statistics]
106
Coefficientsa
45.921 8.483 5.413 .000
.000 .001 .320 .753 1.640
.011 .068 .159 .875 1.525
-.273 .274 -.997 .334 11.573
.594 .238 2.498 .024 13.289
(Constant)
Gross domestic product / capita
People living in cities (%)
Males who read (%) Females who read (%)
B Std. Error Unstandardized
Coefficients
t Sig. VIF
Collinearity Statistics
Dependent Variable: Average female life expectancy a.
Ada variabel independent yang nilai VIF>10 dan tanda koefisien regresi untuk males who read negatif sedangkan koefisien korelasinya positif sehingga memang ada kasus multicollinearity.
d. Mengatasi multicollinearity dengan metode stepwise : klik [analyze + regression + linear + method stepwise]
Coefficientsa
39.013 5.077 7.684 .000
.406 .062 6.557 .000 1.000
(Constant)
Females who read (%) Model
1
B Std. Error Unstandardized
Coefficients
t Sig. VIF
Collinearity Statistics
Dependent Variable: Average female life expectancy a.
e. Mengatasi multicollinearity dengan ridge regression : klik [file + new + syntax]
107 klik [Run +All]
R-SQUARE AND BETA COEFFICIENTS FOR ESTIMATED VALUES OF K
K RSQ GDP_CAP URBAN LIT_FEMA LIT_MALE ______ ______ ________ ________ ________ ________
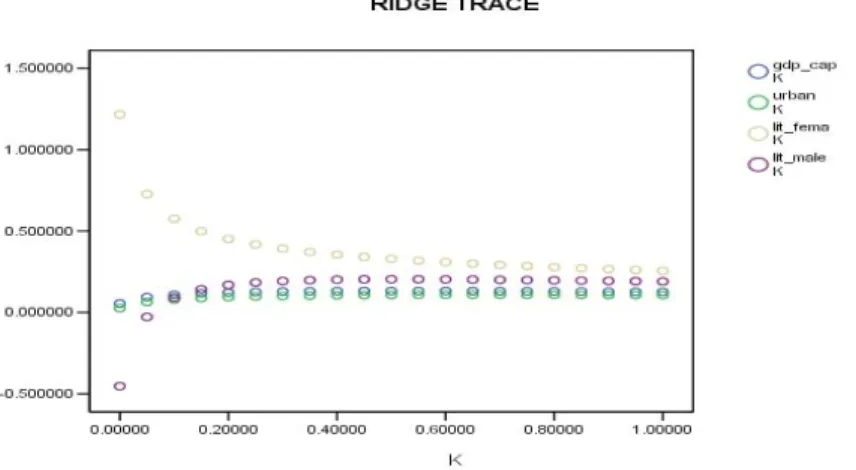
.00000 .71418 .054792 .026292 1.216924 -.453266 .05000 .69610 .094060 .064195 .727695 -.027707 .10000 .68316 .108722 .079079 .576309 .089996 .15000 .67496 .116972 .087904 .499551 .141542 .20000 .66894 .122256 .093883 .451628 .168551 .25000 .66400 .125810 .098171 .418018 .183994 .30000 .65966 .128228 .101326 .392635 .193180 .35000 .65564 .129847 .103668 .372467 .198665 .40000 .65182 .130880 .105402 .355839 .201821 .45000 .64811 .131470 .106666 .341745 .203441 .50000 .64445 .131719 .107560 .329540 .204016 .55000 .64083 .131700 .108158 .318790 .203861 .60000 .63722 .131470 .108517 .309190 .203186 .65000 .63360 .131071 .108681 .300520 .202137 .70000 .62999 .130537 .108683 .292617 .200817 .75000 .62637 .129895 .108551 .285355 .199298 .80000 .62273 .129165 .108309 .278639 .197636 .85000 .61909 .128365 .107975 .272392 .195871 .90000 .61544 .127509 .107564 .266551 .194033 .95000 .61179 .126608 .107088 .261068 .192146 1.0000 .60813 .125671 .106558 .255901 .190227
Besarnya k dipilih sedemikian hingga nilai koefisien regresinya dianggap sudah tidak berubah lagi, besarnya k yang memenuhi kriteria ini adalah k=0.35, pemilihan k ini juga dapat ditentukan berdasarkan gambar berikut:
108
Gambar 6.6. Iterasi pada Regresi Ridge
f. Mengatasi multicollinearity dengan principal component regression 1. Menentukan skor komponen (w1, w2,…)
MTB > PCA 'GDP_CAP' 'URBAN' 'LIT_MALE' 'LIT_FEMA';
SUBC> Coefficients c41-c44;
SUBC> Scores c51-c54.
Eigenanalysis of the Correlation Matrix
Eigenvalue 2.8278 0.7163 0.4141 0.0419 Proportion 0.707 0.179 0.104 0.010 Cumulative 0.707 0.886 0.990 1.000 Variable PC1 PC2 PC3 PC4 GDP_CAP -0.435 0.655 -0.616 0.049 URBAN -0.414 -0.755 -0.506 0.046 LIT_MALE -0.560 0.028 0.478 0.676 LIT_FEMA -0.571 0.022 0.368 -0.734
2. Meregresikan y dengan w
Hanya w1 yang eigen-value-nya >1 sehingga regresinya hanya dengan w1
MTB > regr 'lifeexpf' 1 'w1'
The regression equation is LIFEEXPF = 71.8 - 3.51 w1
Predictor Coef SE Coef T P Constant 71.7619 0.9930 72.26 0.000 w1 -3.5140 0.6051 -5.81 0.000
109
3. Menyatakan model regresi ke dalam variabel asal
71 8 3 51 1
y= , − , w
(
1 2 3 4)
71 8 3 51 0 435 0 414 0 560 0 571 y= , − , − . z − . z − . z − . z
1 2 3 4
71 8 1 53 1 45 1 97 2 00 y= , + , z + , z + , z + , z
4 3
2 1
4 3 4
2 3 2 1
1 1.45 1.97 2
53 . 1 8 . 71
x x
x
x s
x x s
x x s
x x s
x
y= + x − + − + − + −