2
BAB II
LANDASAN TEORI
2.1. Landasan Teori
2.1.1. Algoritma K-Nearest Neighbor
Algoritma K-Nearest Neighbor (K-NN) adalah suatu metode yang menggunakan algoritma supervised [8]. K-NN dapat digunakan untuk mengklasifikasikan suatu data baru ke dalam kelompok data dengan cara mencari tetangga terdekat dari data tersebut. Dalam pencarian tetangga terdekat pada algoritma K-NN ini, diperlukan nilai yang disebut dengan K untuk membatasi jumlah data yang dapat disebut sebagai tetangga terdekat bagi data baru tersebut. Dalam pengklasifikasian dua kelas, nilai K yang digunakan dalam perhitungan algoritma K-NN harus merupakan nilai yang ganjil untuk menghindari kebingungan apabila hasil dari data yang terpilih sebagai tetangga terdekat memiliki kelompok data yang berbeda namun dengan nilai euclidean
distance yang sama. K-NN adalah algoritma yang efektif dan efisien jika data
training berjumlah besar, tahan terhadap data yang noisy, dan mudah diimplementasikan untuk permasalahan multi-class [9].
2.1.2. Euclidean Distance
Euclidean distance adalah suatu teori pengukuran jarak yang terpakai dalam
algoritma K-Nearest Neighbor. Rumus dari euclidean distance sendiri dapat dilihat pada persamaan 2.1 [1].
𝑑𝑖𝑠𝑡(𝑥, 𝑦) = √∑(𝑥𝑖 − 𝑦𝑖)2 𝑛
𝑖=1
(2.1)
Dalam K-NN, euclidean distance melakukan perhitungan dengan cara menghitung selisih antara semua variabel data baru dengan semua variabel data yang berperan sebagai tetangga terdekat. Hasil selisih yang diperoleh dari
setiap variabel data tersebut dijumlahkan kemudian diakarkan untuk mendapatkan hasil akhir perhitungan nilai euclidean distance.
2.1.3. Confusion Matrix
Confusion matrix adalah sebuah metode yang dapat digunakan untuk
mengevaluasi performa dari suatu algoritma pada proses klasifikasi [8].
Confusion matrix terdiri atas 4 istilah yang merepresentasikan hasil klasifikasi,
yaitu True Positive (TP) yang merupakan data positif yang terdeteksi benar,
True Negative (TN) yang merupakan data negatif yang terdeteksi benar, False Positive (FP) yang merupakan data negatif yang terdeteksi sebagai data positif,
dan False Negative (FN) yang merupakan data positif yang terdeteksi sebagai data negatif. Gambaran mengenai confusion matrix dapat dilihat pada gambar 2.1 [10].
Gambar 2.1 Confussion Matrix
Keterangan:
TP = Nilai True Positive TN = Nilai True Negative FP = Nilai False Positive FN = Nilai False Negative
Berdasarkan nilai TP, TN, FP, dan FN yang ada pada confusion matrix, dapat diperoleh nilai akurasi, presisi, dan recall yang dapat digunakan untuk menghitung performa dari suatu algoritma pada proses klasifikasi. Adapun rumus dari akurasi, presisi, dan recall adalah sebagai berikut :
1. Akurasi
Akurasi adalah perhitungan evaluasi yang dilihat dari tingkat kedekatan nilai prediksi dengan nilai yang sebenarnya atau tingkat kebenaran prediksi [11]. Rumus akurasi dapat dilihat pada persamaan 2.2 [10].
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁 (2.2)
Keterangan:
TP = Nilai True Positive TN = Nilai True Negative FP = Nilai False Positive FN = Nilai False Negative
2. Presisi
Presisi adalah perhitungan evaluasi yang menunjukkan ketepatan hasil prediksi [11]. Rumus presisi dapat dilihat pada persamaan 2.3 [10].
𝑃𝑟𝑒𝑠𝑖𝑠𝑖 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑃 (2.3)
Keterangan:
TP = Nilai True Positive FP = Nilai False Positive
3. Recall
Recall adalah perhitungan evaluasi yang menunjukkan tingkat sensitifitas
terhadap bagian data yang relevan [11]. Rumus Recall dapat dilihat pada persamaan 2.4 [10].
𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁 (2.4)
Keterangan:
TP = Nilai True Positive FN = Nilai False Negative
4. F1-Score
F1-Score disebut F-Score atau F-Measure. F1-Score menunjukkan
keseimbangan antara presisi dan recall. Rumus F1-Score dapat dilihat pada persamaan 2.5 [10]. 𝐹1 − 𝑆𝑐𝑜𝑟𝑒 = 2 ∗ 𝑃𝑟𝑒𝑠𝑖𝑠𝑖 ∗ 𝑅𝑒𝑐𝑎𝑙𝑙 𝑃𝑟𝑒𝑠𝑖𝑠𝑖 + 𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃 𝑇𝑃 +12 (𝐹𝑃 + 𝐹𝑁) (2.5) Keterangan:
TP = Nilai True Positive FP = Nilai False Positive FN = Nilai False Negative
2.1.4. Min-Max
Min-Max adalah suatu teknik yang digunakan dalam melakukan normalisasi data. Normalisasi Min-Max akan memberikan hasil dengan skala nilai 0 sampai dengan 1 [12]. Normalisasi Min-Max diperlukan agar setiap parameter memiliki bobot yang sama. Rumus normalisasi Min-Max dapat dilihat pada persamaan 2.6 [13].
𝑋∗ = 𝑋 − min (𝑋)
max(𝑋) − min (𝑋) (2.6)
Keterangan:
X* = Nilai X baru (hasil normalisasi)
X = Nilai X mula-mula (nilai yang akan dinormalisasi) min (X) = Nilai terkecil dari keseluruhan X
max (X) = Nilai terbesar dari keseluruhan X
2.1.5. Data Cleaning
Data cleaning merupakan bagian dalam preprocessing yang dilakukan untuk
melakukan pengecekan adanya kesalahan-kesalahan data [14]. Adapun kesalahan-kesalahan data tersebut disebabkan oleh beberapa hal.
1. Incompleteness, dalam data yang diperoleh masih terdapat kekurangan atribut, atau nilai-nilai atributnya, atau hanya mengandung agregat saja. 2. Noise, masih ada ketidaksesuaian atau masih ada ketimpangan dan kesalahan dari sebenarnya, yaitu nilai yang diharapkan, seperti adanya nilai-nilai yang outlier.
3. Inconsistence, di mana adanya perbedaan dan ketidakcocokan dalam penggunaan kode atau nama.
Dalam hal ini, data cleaning berperan dalam melakukan pengisian untuk data yang hilang, menghaluskan data-data yang terganggu, mengidentifikasi data
outliers dan kemudian menghapusnya, serta menyelesaikan ketidakkonsistenan [12]. Penanganan terhadap missing value dapat dilakukan dengan dua cara, yaitu dengan mengabaikan atau menghapus data yang memiliki missing value, dan mengisi missing value dengan nilai yang paling mungkin [15].
2.1.6. Identifikasi Outliers
Outliers adalah suatu titik data yang terpisah jauh dari data-data yang lainnya.
dan hasil klasifikasi [16]. Outliers dapat ditemukan dengan menggunakan metode rentang interkuartil (IQR). Nilai IQR diperoleh dari selisih antara nilai kuartil bawah (Q1) dengan nilai kuartil atas (Q3) pada sekumpulan data yang akan dicari outliers-nya. IQR dapat digunakan untuk mengidentifikasi outliers dengan menetapkan batas sesuai dengan nilai k untuk batas kuartil atas dan batas kuartil bawah. Nilai k yang biasa digunakan adalah 1.5, namun dalam beberapa kasus nilai k yang digunakan adalah 3 untuk menemukan nilai
outliers yang ekstrim [17]. Dalam identifikasi outliers menggunakan nilai
k=1.5, maka setiap nilai yang berada di bawah Q1 – 1.5 * IQR (Lower Bound) dan berada di atas Q3 + l.5 * IQR (Upper Bound) merupakan outliers dan akan dihilangkan dari dataset [16]. Adapun rumus dalam pencarian nilai Q1, Q3, IQR, Lower Bound, dan Upper Bound secara umum dapat dilihat pada persamaan 2.7, 2.8, 2.9, 2.10 dan 2.11.
𝑄1 = 1
4 (𝑛 + 1) (2.7)
Keterangan:
Q1 = Nilai kuartil bawah n = Jumlah data
𝑄3 = 3
4 (𝑛 + 1) (2.8)
Keterangan:
Q1 = Nilai kuartil bawah n = Jumlah data
𝐼𝑄𝑅 = 𝑄3 − 𝑄1 (2.9)
Keterangan:
IQR = Nilai interkuartil Q3 = Nilai kuartil atas
Q1 = Nilai kuartil bawah
𝐿𝑜𝑤𝑒𝑟 𝐵𝑜𝑢𝑛𝑑 = 𝑄1 − (1.5 ∗ 𝐼𝑄𝑅) (2.10)
Keterangan:
Lower Bound = Batas bawah
Q1 = Nilai kuartil bawah IQR = Nilai interkuartil
𝑈𝑝𝑝𝑒𝑟 𝐵𝑜𝑢𝑛𝑑 = 𝑄3 + (1.5 ∗ 𝐼𝑄𝑅) (2.11)
Keterangan:
Upper Bound = Batas atas
Q1 = Nilai kuartil bawah IQR = Nilai interkuartil
2.1.7. DIM
DIM atau Data Induk Mahasiswa adalah istilah yang digunakan di Institut Teknologi Sumatera yang merujuk pada data yang diisikan oleh calon mahasiswa baru yang berfungsi untuk memperoleh data diri mahasiswa sekaligus sebagai penentu besaran Uang Kuliah Tunggal (UKT) mahasiswa ketika telah resmi menjadi mahasiswa di Institut Teknologi Sumatera [18]. Data DIM yang diisikan oleh mahasiswa baru antara lain meliputi data diri mahasiswa, data keluarga, data penanggung jawab, data darurat, kebutuhan khusus, kartu pendaftaran, KTP orang tua, kartu keluarga (KK), jumlah tanggungan, tagihan listik 3 bulan terakhir, PBB rumah, penghasilan penanggung jawab, penghasilan ayah, penghasilan ibu, foto aset, STNK kendaraan, tagihan telepon, tagihan PAM, pembayaran kredit orang tua, pengeluaran makan, pengeluaran kesehatan, pendapatan tambahan orang tua, dan status rumah.
2.1.8. UKT
Uang Kuliah Tunggal (UKT) merupakan sistem yang diterapkan dalam pembiayaan perkuliahan yang harus ditanggung oleh mahasiswa Perguruan Tinggi Negeri yang berada di bawah Kementerian Riset, Teknologi, dan Pendidikan Tinggi (Kemenristek Dikti) yang harus dibayar oleh mahasiswa setiap semester [1]. UKT biasanya dibagi menjadi beberapa golongan dan penentuannya didasarkan pada kondisi kemampuan keluarga mahasiswa yang dapat dilihat dari hasil pengisian DIM. Di ITERA sendiri, UKT untuk semua program studi dibagi menjadi 8 golongan. Umumnya, golongan I dikenai biaya sebesar 500.000, golongan II sebesar 1.000.000, golongan III sebesar 2.000.000, golongan IV sebesar 3.500.000, golongan V sebesar 5.000.000, golongan VI sebesar 6.500.000, golongan VII sebesar 8.000.000, dan golongan VIII sebesar 9.500.000. Namun untuk beberapa program studi, memiliki biaya yang berbeda pada golongan VIII. Misalnya program studi Teknik Informatika yang dikenai biaya golongan VIII sebesar 9.000.000, program studi Teknologi Pangan dan program studi Rekayasa Kehutanan yang dikenai biaya golongan VIII sebesar 9.344.000, serta beberapa program studi lain yang juga dikenai biaya golongan VIII dengan nilai yang berbeda dari umumnya.
2.1.9. PHP
PHP atau Hypertext Preprocessor adalah bahasa pemrograman yang dapat digunakan dalam melakukan pemrograman web agar sebuah halaman web menjadi dinamis [19]. PHP merupakan bahasa pemrograman server-side, yang berarti pengolahannya dilakukan dari sisi server. PHP juga merupakan bahasa pemrograman yang bersifat open source, artinya bahasa pemrograman ini dapat digunakan secara bebas dan gratis.
2.1.10. HTML
HTML atau Hypertext Markup Language adalah suatu bahasa standar yang digunakan untuk membuat halaman website yang nantinya dapat diakses dan ditampilkan melalui sebuah browser [20]. HTML adalah bahasa yang sifatnya
pemrograman web memiliki fungsi yang berdampak pada tampilan sebuah website untuk membuat halaman web menjadi lebih baik dan nyaman untuk dilihat, seperti mengubah ukuran font dari suatu tulisan, mengubah warna tulisan, mengatur paragraf, dan fungsi-fungsi lainnya. HTML tidak didesain untuk dekstop publishing, tetapi didesain sebagai bahasa pengkodean untuk
world wide web. HTML menawarkan beberapa kemampuan untuk
menampilkan dokumen melalui berbagai macam sistem komputer [21].
2.1.11. MySQL
MySQL adalah sebuah sistem manajemen basis data server yang berfungsi untuk mengelola dan mengolah data agar lebih terstruktur, mudah diatur, dan mudah untuk dilakukan modifikasi [19]. Dengan menggunakan MySQL, pengguna dapat dengan mudah melakukan pengelompokan data dalam satu tabel, menambah data baru, mengedit dan menghapus sebuah data, serta menyilangkan dua buah tabel yang berbeda untuk memperoleh data yang diinginkan. Penggunaan MySQL biasanya dilakukan di dalam phpMyAdmin yang dilengkapi dengan user interface sehingga dapat memberikan kemudahan kepada pengguna dalam melakukan pengelolaan dan pengolahan data. MySQL juga bersifat open source, sehingga dapat digunakan oleh semua pihak secara gratis.
2.1.12. Laravel
Laravel adalah salah satu framework yang dapat digunakan untuk melakukan pemrograman web yang bersifat open source [22]. Pada laravel, setiap bagian dari pemrograman web dipisahkan ke dalam folder yang berbeda sesuai dengan fungsinya, seperti folder untuk controller, folder untuk layouts, folder untuk
routes, dan lain sebagainya. Pembagian file ke dalam beberapa folder ini
membuat pengerjaan proyek menjadi lebih terstruktur sehingga memudahkan pengguna dalam melakukan pekerjaannya. Selain memiliki peran dalam hal kerapian, laravel juga memiliki beberapa fitur yang dapat membantu memudahkan dan mempercepat pengerjaan web bagi pengguna, seperti fitur untuk melakukan migrasi secara langsung, fitur untuk membuat menu register dan login secara otomatis, dan fitur-fitu lainnya. Laravel juga dikenal sebagai
framework yang dapat memberikan informasi kesalahan secara jelas apabila
terjadi kekeliruan dalam penulisan kode program.
2.2. Tinjauan Studi
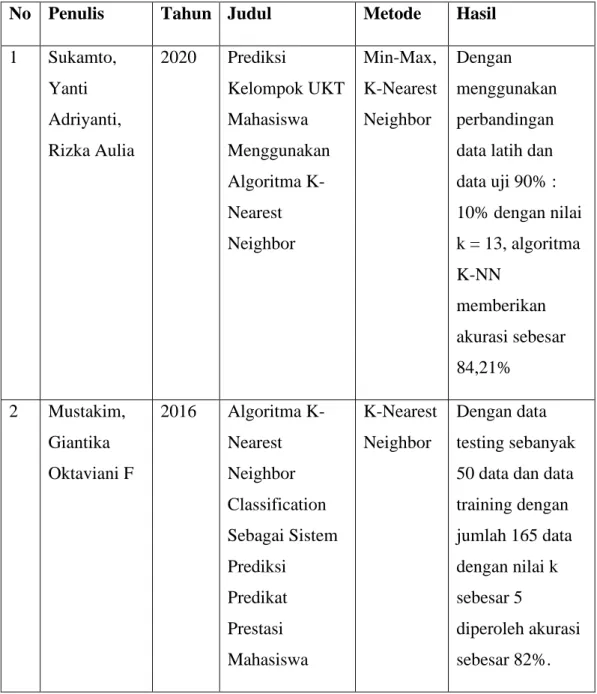
Adapun beberapa penelitian terdahulu yang memiliki hubungan dengan topik yang dikerjakan oleh penulis dapat dilihat pada Tabel 2.1 berikut.
Tabel 2.1 Tinjauan Studi
No Penulis Tahun Judul Metode Hasil
1 Sukamto, Yanti Adriyanti, Rizka Aulia 2020 Prediksi Kelompok UKT Mahasiswa Menggunakan Algoritma K-Nearest Neighbor Min-Max, K-Nearest Neighbor Dengan menggunakan perbandingan data latih dan data uji 90% : 10% dengan nilai k = 13, algoritma K-NN memberikan akurasi sebesar 84,21% 2 Mustakim, Giantika Oktaviani F 2016 Algoritma K-Nearest Neighbor Classification Sebagai Sistem Prediksi Predikat Prestasi Mahasiswa K-Nearest Neighbor Dengan data testing sebanyak 50 data dan data training dengan jumlah 165 data dengan nilai k sebesar 5 diperoleh akurasi sebesar 82%.
No Penulis Tahun Judul Metode Hasil 3 Denni Kurniawan, Ade Saputra 2019 Penerapan K-Nearest Neighbour Dalam Penerimaan Peserta Didik Dengan Sistem Zonasi K-Nearest Neighbor Dengan melakukan pengujian nilai K dari rentang 1-10, diperoleh nilai K terbaik 5 yang menghasilkan akurasi sebesar 83,36% dengan data latih sebanyak 35 dan data uji sebanyak 15 4 Richard Emmanuel Johanes, Edy Santoso, Suprapto 2020 Implementasi Algoritma K-Nearest Neighbor Untuk Klasifikasi Deteksi Penyakit Anjing K-Nearest Neighbor
Dengan data uji sebanyak 50 dan menggunakan nilai K=1 dan K=3 diperoleh hasil akurasi yang sama yaitu 88% 5 Herlambang Brawijaya, Samudi, Slamet Widodo 2019 Komparasi Algoritma K-Nearest Neighbor dan Naiive Bayes pada Pengobatan Penyakit Kutil K-Nearest Neighbor, Naive Bayes Hasil pengujian menunjukkan bahwa model K-NN memiliki hasil akurasi terbaik sebesar 90%, sedangkan Naive Bayes memberikan
No Penulis Tahun Judul Metode Hasil Menggunakan Cryotheraphy akurasi sebesar 86,67% 6 Wilda Imama Sabilla, Tesa Eranti Putri 2017 Prediksi Ketepatan Waktu Lulus Mahasiswa dengan K-Nearest Neighbor dan Naïve Bayes Classifier (Studi Kasus Prodi D3 Sistem Informasi Universitas Airlangga) K-Nearest Neighbor, Naive Bayes Classifier Hasil pengujian menunjukkan bahwa hasil akurasi terbaik didapatkan dari metode K-NN dengan akurasi sebesar 98,7%, sedangkan akurasi tertinggi yang didapatkan dari Naive Bayes Classifier sebesar 80.9% 7 Noor Basha, Ashok Kumar P S, Gopal Krishna C, Venkatesh P 2019 Early Detection of Heart Syndrome Using Machine Learning Technique K-NN, Random Forest, Support Vector Machine, Decision Tree, Naive Bayes Dengan data sebanyak 88 data, diperoleh akurasi menggunakan algoritma KNN sebesar 85%, Decision Tree sebesar 82%, Random Forest sebesar 81%, Naive Bayes sebesar 80%, dan
No Penulis Tahun Judul Metode Hasil SVM sebesar 82% 8 Mega Luna Suliztia, Achmad Fauzan 2019 Comparing Naive Bayes, K-Nearest Neighbor, And Neural Network Classification Methods Of Seat Load Factor In Lombok Outbound Flights Naive Bayes, K-Nearest Neighbor, Neural Network Dengan menggunakan 47 data, Naive Bayes memberikan akurasi sebesar 70%, K-NN dengan K=5 memberikan akurasi sebesar 89%, dan Neural Network memberikan akurasi sebesar 79% 9 Bhagyalaxmi Jena, Anita Mohanty, Subrat Kumar Mohanty 2020 Gender Recognition of Speech Signal using KNN and SVM K-NN, SVM Dengan menggunakan 300 data (data training 60%, data uji 40%), diperoleh hasil akurasi K-NN sebesar 87.5% dan SVM sebesar 80%.
Penelitian yang berjudul “Prediksi Kelompok UKT Mahasiswa Menggunakan Algoritma K-Nearest Neighbor” adalah penelitian yang dilakukan untuk melakukan prediksi UKT mahasiswa Universitas Riau khususnya pada program studi S1 Sistem Informasi FMIPA. Dalam penentuan kelompok UKT, penelitian ini menggunakan algoritma K-NN dengan kriteria yang digunakan dalam penentuan golongan UKT antara lain adalah penghasilan kotor, penanggung uang kuliah, jumlah tanggungan dalam kartu keluarga, status tempat tinggal, keadaan dinding tempat tinggal, keadaan atap tempat tinggal, total luas kepemilikan lahan, dan biaya pemakaian listrik sebulan. Data latih yang digunakan sebanyak 168 data dan data uji yang digunakan sebanyak 19 data. Hasil penelitian menggunakan nilai k sebesar 13 ini menunjukan nilai akurasi sebesar 84,21%. [1].
Penelitian yang berjudul “Algoritma K-Nearest Neighbor Classification Sebagai Sistem Prediksi Predikat Prestasi Mahasiswa” menggunakan atribut jenis kelamin, jenis tanggal, umur, jumlah SKS, dan jumlah jenis mutu untuk dapat memprediksi predikat prestasi mahasiswa dengan algoritma K-NN. Mahasiswa yang datanya digunakan sebagai data testing dalam penelitian ini adalah mahasiswa program studi Sistem Informasi angkatan 2014/2015, sedangkan yang digunakan sebagai data training berasal dari mahasiswa angkatan 2012/2013. Penelitian ini menggunakan data latih sebanyak 165 data dan data uji sebanyak 50 data dengan nilai k sebesar 5. Akurasi yang diperoleh dari hasil penelitian ini sebesar 82% [8]. Penelitian yang berjudul “Penerapan K-Nearest Neighbour Dalam Penerimaan Peserta Didik Dengan Sistem Zonasi” adalah penelitian menggunakan algoritma K-NN yang dilakukan untuk membantu pihak sekolah menetapkan peserta didik yang akan diterima atau tidak berdasarkan sistem zonasi yang menjadi ketetapan dari Permendikbud. Penelitian ini menggunakan data latih sebanyak 35 dan data uji sebanyak 15. Dalam penelitian ini dilakukan pengujian nilai K dari rentang 1-10 dan diperoleh hasil bahwa nilai K sebesar 5 adalah nilai K terbaik yang dapat memberikan hasil akurasi sebesar 83,36% [23].
Penelitian yang berjudul “Implementasi Algoritma K-Nearest Neighbor Untuk Klasifikasi Deteksi Penyakit Anjing” adalah penelitian menggunakan algoritma K-Nearest Neighbor yang dilakukan untuk mendeteksi penyakit pada anjing. Penyakit
anjing yang digunakan sebagai hasil klasifikasi terbagi menjadi 5 jenis, yaitu
Demodicosis, Dermatofitosis, Scabiosis, Otis, dan Helminthiasis, sedangkan gejala
penyakit yang digunakan sebagai atribut dalam perhitungan algoritma ada 23 jenis. Penelitian ini menggunakan data uji sebanyak 50 dengan percobaan nilai K bernilai 1 dan 3 memberikan hasil akurasi yang sama, yaitu sebesar 88% [24].
Penelitian yang berjudul “Komparasi Algoritma K-Nearest Neighbor dan Naiive Bayes pada Pengobatan Penyakit Kutil Menggunakan Cryotheraphy” adalah penelitian yang dilakukan untuk membandingkan performa dari algoritma K-NN dengan Naiive Bayes terhadap pengobatan penyakit kutil menggunakan cryotheraphy. Penelitian ini memberikan hasil bahwa K-NN dengan nilai k=1 memberikan nilai akurasi terbaik sebesar 90% dibandingkan dengan Naive Bayes yang memberikan akurasi sebesar 86,67% [25].
Penelitian yang berjudul “Prediksi Ketepatan Waktu Lulus Mahasiswa dengan K-Nearest Neighbor dan Naïve Bayes Classifier (Studi Kasus Prodi D3 Sistem Informasi Universitas Airlangga)” adalah penelitian yang dilakukan untuk memprediksi ketepatan waktu lulus mahasiswa dengan menggunakan 2 jenis algoritma, yaitu K-NN dan Naive Bayes Classifier. Penlitian ini memberikan hasil bahwa K-NN memberikan akurasi terbaik sebesar 98,7%, sedangkan akurasi tertinggi yang didapat dari Naive Bayes sebesar 80,9% [26].
Penelitian yang berjudul “Early Detection of Heart Syndrome Using Machine Learning Technique” adalah penelitian yang membandingkan berbagai algoritma dalam memprediksi sindrom terkait jantung pada pasien. Atribut yang digunakan adalah age (usia), sex (jenis kelamin), Cp (chest pain type), chol (serum cholestoral
in mg/dl), FBS (fasting blood sugar), Restecg (resting electrocardiographic), Thalach (maximum heart rate achieved), Exang (exercise induced angina), Old Peak (ST depression), Slope (the slope of the peak), Ca (number of major vessels),
dan Thal. Penelitian ini menggunakan 88 data dan memberikan hasil akurasi K-NN sebesar 85%, Decision Tree sebesar 82%, Random Forest sebesar 81%, Naive Bayes sebesar 80%, dan SVM sebesar 82% [27].
Penelitian yang berjudul “Comparing Naive Bayes, K-Nearest Neighbor, And Neural Network Classification Methods Of Seat Load Factor In Lombok Outbound
Flights” adalah penelitian yang dilakukan untuk mengklasifikasikan Seat Load
Factor yang merupakan persentase keterisian pesawat, dan juga ukuran dalam
menentukan nilai keuntungan pada penerbangan suatu maskapai. Penelitian ini menggunakan 4 atribut yang mempengaruhi, yaitu jumlah penumpang, harga tiket, rute, dan waktu penerbangan. Hasil dari penelitian ini adalah perbandingan klasifikasi algoritma Naive Bayes, K-NN, dan Neural Network dimana Naive Bayes memberikan akurasi sebesar 70%, K-NN dengan K=5 memberikan akurasi sebesar 89%, dan Neural Network memberikan akurasi sebesar 79% [28].
Penelitian yang berjudul “Gender Recognition of Speech Signal using KNN and SVM” adalah penelitian yang dilakukan untuk mengklasifikasikan suara ke dalam suatu kelas (laki-laki atau perempuan) dengan menggunakan 2 jenis algoritma yang akan dibandingkan, yaitu algoritma K-NN dan SVM. Atribut yang digunakan dalam penelitian ini adalah Short-Time Average Magnitude (STAM), Short-Time
Average Energy (STE), Mean, Variance, and Standart Deviation, Average Power density, Mean frequency, dan Median frequency. Penelitian menunjukkan hasil