Analisis
Cluster
Studi Kasus: Kabupaten Jepara Jawa Tengah
Disusun untuk Memenuhi Tugas Mata Kuliah Metode Analisis Perencanaan
(TKP 342)
Dosen Pengampu:
Dr. Iwan Rudiarto
Widjanarko, S.T., M.T.
Sri Rahayu, S.Si, M.Si
Anang Wahyu Sejati, S.T., M.T.
Disusun oleh:
Izzah Khusna
21040113140123
Kelas A- 2013
JURUSAN PERENCANAAN WILAYAH DAN KOTA
FAKULTAS TEKNIK UNIVERSITAS DIPONEGORO
SEMARANG
2015
1. Pendahuluan
Seringkali sebagai seorang planner memiliki kesulitan dalam melakukan perencanaan terhadap suatu wilayah maupun kota karena wilayah atau kota tersebut terdiri dari beragam karakteristik, baik dari segi topografi, bahaya geologi, tingkat aksesibilitas, hingga ketersediaan sarana dan prasarana. Perencana tersebut harus bisa mengklasifikasikan atau mengelompokkan wilayah satu dengan wilayah lainnya yang memiliki kemiripan dan membentuk kelompok lain jika tidak memiliki kemiripan dengan kelompok sebelumnya. Hal ini ditujukan agar perencanaan yang hendak dilakukan terhadap tiap-tiap kelompok wilayah tersebut bisa sesuai dan seimbang (no missing plan). Jadi, dapat diartikan bahwa dalam melakukan suatu perencanaan, kita tidak bisa sembarang menentukan keputusan karena setiap wilayah (atau kelompok wilayah) membutuhkan penanganan yang berbeda-beda sehingga perencanaannya pun harus berberbeda-beda.
Salah satu alat yang bisa membantu mengambil keputusan adalah Analisis Cluster. Analisis cluster adalah teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek/cases berdasarkan karakteristik yang dimilikinya. Analisis cluster mengklasifikasi objek sehingga setiap objek yang memiliki sifat yang mirip (paling dekat kesamaannya) akan mengelompok ke dalam satu cluster (kelompok) yang sama (Hidayat, 2014). Karena tujuan analisis cluster adalah mengelompokkan obyek berdasarkan kesamaan karakteristik diantara obyek-obyek tersebut, maka secara logika, cluster yang baik memiliki ciri sebagai berikut:
1. Homogenitas Internal: kesamaan yang tinggi antar anggota dalam satu cluster ( within-cluster).
2. Heterogenitas Eksternal: perbedaan yang tinggi antar cluster yang satu dengan cluster yang lainnya (between-cluster).
Beberapa manfaat dari analisis cluster adalah: eksplorasi data pengubah ganda, reduksi data, stratifikasi sampling, prediksi keadaan obyek. Berbeda dengan teknik multivariat lainnya, analisis ini tidak mengestimasi set variabel secara empiris, sebaliknya menggunakan set variabel yang ditentukan oleh peneliti itu sendiri. Fokus dari analisis cluster adalah membandingkan objek berdasarkan set variabel, hal inilah yang menyebabkan para ahli mendefinisikan set variabel sebagai tahap kritis dalam analisis cluster. Set variabel cluster adalah suatu set variabel yang mempresentasikan karakteristik yang dipakai objek-objek. (Ulwan, 2014)
Anggota cluster untuk tiap penyelesaian/solusi tergantung pada beberapa elemen prosedur dan beberapa solusi yang berbeda dapat diperoleh dengan mengubah satu elemen atau lebih. Solusi cluster secara keseluruhan bergantung pada variabel-variabel yang digunakan sebagai dasar untuk menilai kesamaan. Penambahan atau pengurangan variabel-variabel yang relevan dapat mempengaruhi substansi hasi analisisi cluster. Langkah pengelompokkan dalam analisis cluster mencakup tiga hal:
a. Mengukur kesamaan/similarity jarak b. Membentuk cluster secara hierarkis c. Menentukan jumlah cluster
Adapun metode pengelompokkan dalam analisis cluster meliputi: A. Metode Hierarki
Teknik pengelompokkan yang membentuk konstruksi hirarki atau berdasarkan tingkatan tertentu seperti struktur pohon, sehingga proses pengelompokkan dilakukan secara bertingkat atau bertahap. Dalam metode hirarki cluster terdapat dua tipe dasar
yaitu aglomeratif (pemusatan) dan divisif (penyebaran). Berikut adalah penjelasan keduanya:
1) Metode Aglomeratif
Dalam metode aglomeratif, setiap obyek atau observasi dianggap sebagai sebuah cluster tersendiri. Dalam tahap selanjutnya, dua cluster yang mempunyai kemiripan digabungkan menjadi sebuah cluster baru demikian seterusnya. Proses berlangsung erus sampai akhirnya terbentuk satu cluster yang terdiri atas semua objek. Dalam aglomeratif ada tujuh metode yang digunakan berdasarkan prinsip kemiripan antar objek dalam bentuk jarak, antara lain:
a. Single Linkage
Prinsip yang digunakan adalah aturan jarak minimum dalam pembentukan cluster b. Complete Linkage
Merupakan kebalikan dari pendekatan single linkage. Prinsip yang digunakan adalah aturan jarak maksimum/terjauh objek
c. Average Linkage Between Group Method
Jarak antara dua cluster yang digunakan adalah jarak rata-rata antara semua pasangan objek yang mungkin dari dua buah cluster
d. Average Linkage Within-Group Method
Merupakan variasi UPGMA. Perbedaannya terletak pada cara pembentukan cluster sehingga jarak rata-rata antar cluster adalah yang terkecil. Metode ini memperhitungkan jarak rata-rata semua pasangan objek yang terdapat dalam dua cluster.
e. Ward’s Error Sum of Squares Method
Pembentukan cluster yang didasari oleh hilangnya informasi akibat penggabungan objek antar cluster.
f. Centroid Method
Jarak antara dua buah cluster sebgai jarak antara rataan tiap cluster (centroid) terhadap variabel
g. Median Method
Mirip dengan centroid, perbedaannya adalah perhitungan rataan tiap cluster tidak memperhitungkan ukuran suatu cluster.
2) Metode Divisif
Metode divisif merupakan kebalikan dari metode sebelumnya, yaitu beranjak dari sebuah cluster besar yang terdiri dari semua obyek atau observasi. Selanjutnya, obyek atau observasi yang paling tinggi nilai ketidakmiripannya kita pisahkan demikian seterusnya sehingga akan terdapat n buah cluster yang berisikan hanya satu objek atau n buah cluster yang diinginkan.
B. Metode Non-Hirarki
Kebalikan dari metode hirarki, metode non-hirarki tidak meliputi proses treelike construction. Justru menempatkan objek-objek ke dalam cluster sekaligus sehingga terbentuk sejumlah cluster tertentu. Langkah pertama adalah memilih sebuah cluster sebagai inisial cluster pusat, dan semua objek dalam jarak tertentu ditempatkan pada cluster yang terbentuk. Kemudian memilih cluster selanjutnya dan penempatan dilanjutkan sampai semua objek ditempatkan. Objek-objek bisa ditempatkan lagi jika jaraknya lebih dekat pada cluster lain daripada cluster asalnya. Metode non-hirarki
berkaitan dengan K-means clustering. Terdapat tiga pendekatan yang digunakan untuk menempatkan masing-masing observasi pada satu cluster, antara lain:
a. Sequential Threshold
Metode Sequential Threshold memulai dengan pemilihan satu cluster dan menempatkan semua objek yang berada pada jarak tertentu ke dalamnya. Jika semua objek yang berada pada jarak tertentu telah dimasukkan, kemudian cluster yang kedua dipilih dan menempatkan semua objek yang berjarak tertentu ke dalamnya. Kemudian cluster ketiga dipilih dan proses dilanjutkan seperti yang sebelumnya.
b. Parallel Threshold
Merupakan kebalikan dari pendekatan yang pertama yaitu dengan memilih sejumlah cluster secara bersamaan dan menempatkan objek-objek kedalam cluster yang memiliki jarak antar muka terdekat. Pada saat proses berlangsung, jarak antar muka dapat ditentukan untuk memasukkan beberapa objek ke dalam cluster-cluster. Juga beberapa variasi pada metode ini, yaitu sisa objek-objek tidak dikelompokkan jika berada di luar jarak tertentu dari sejumlah cluster.
c. Optimization
Metode ketiga adalah serupa dengan kedua metode sebelumnya kecuali bahwa metode ini memungkinkan untuk menempatkan kembali objek-objek ke dalam cluster yang lebih dekat.
2. Studi Kasus
Kabupaten Jepara memiliki 16 kecamatan yang baik secara fisik maupun non-fisik memiliki karakteristik yang berbeda-beda. Seiring berkembangnya sektor industri dan jasa membuat jumlah penduduk semakin bertambah dan kebutuhan hidup yang meningkat. Sayangnya ketersediaan sarana dan prasarana tampaknya belum cukup memadai. Oleh karena itulah, untuk merencanakan pembangunan sarana dan prasarana di tiap-tiap kecamatan, salah saunya diperlukan analisis cluster yang akan membantu pengelompokkan kecamatan yang sekiranya membutuhkan penanganan yang sama dan berbeda.
Variabel yang digunakan untuk pengelompokkan adalah luas wilayah, kepadatan penduduk, jumlah sarana pendidikan, dan laju pertumbuhan PDRB Atas Dasar Harga Berlaku. Berikut adalah data yang akan diolah:
Tabel I.1
Variabel Analisis Cluster Kabupaten Jepara (Tahun 2013) KECAMATAN Luas Wilayah(km²)
Kepadatan Penduduk (jiwa/km) Sarana Pendidikan Laju Pertumbuhan PDRB ADHB (%) KEDUNG 43.06 1728 79 9.25 PECANGAAN 35.88 2266 85 11.03 KALINYAMATAN 23.7 2604 77 12.67 WELAHAN 27.64 2603 81 12.11 MAYONG 65.04 1332 114 14.17 NALUMSARI 56.97 1250 95 13.16 BATEALIT 88.88 925 106 13.1 TAHUNAN 38.91 2815 105 9.33 JEPARA 24.67 3438 101 11.98 MLONGGO 42.4 1946 100 11.71 PAKIS AJI 60.55 959 74 10.39 BANGSRI 85.35 1150 143 11.94
KEMBANG 108.12 623 104 11.25
KELING 123.12 488 119 12.67
DONOROJO 108.64 499 102 10.68
KARIMUNJAWA 71.2 127 23 11.3
Total 1004.13 24753 1508 186.74
Sumber: Jepara Dalam Angka 2014 (Bappeda Kabupaten Jepara, 2014) dan BPS Kabupaten Jepara, 2014
Karena jenis data diatas merupakan data rasio, maka pada pengolahannya nanti akan diubah menjadi data ordinal, kecuali jumlah sarana pendidikan yang tetap menggunakan data rasio. Jumlah sarana pendidikan merupakan hasil penjumlahan sekolah mulai dari TK, SD/MI, SMP/MTs, SMA/MA/SMK, dan Perguruan Tinggi/Akademik baik yang berstatus negeri maupun swasta. Sedangkan laju pertumbuhan PDRB merupakan hasil rata-rata keseluruhan sektor di Kabupaten Jepara.
Berikut adalah klasifikasi yang digunakan untuk selanjutnya diolah di software SPSS: Tabel I.2
Klasifikasi Variabel Analisis Cluster Klasifikasi Luas Wilayah (km²)
Kecil < 50 Sedang 50 sampai 100 Besar >100 Klasifikasi LP PDRB ADHB Lambat < 9.04 Sedang 9.05 sampai 11.10 Cepat >11.10
3. Hasil dan Pembahasan
Berikut merupakan hasil dan pembahasan analisis cluster yang diolah menggunakan bantuan software SPSS 17.0. Melalui pembahasan ini akan diketahui kesamaan/similarity jarak dari masing-masing kecamatan dan berapa banyak klaster yang dihasilkan terhadap kecamatan-kecamatan yang ada di Kabupaten Jepara serta interpretasi mengenai hasil klaster:
Case Processing Summarya
Cases
Valid Missing Total
N Percent N Percent N Percent
16 100.0 0 .0 16 100.0
a. Average Linkage (Between Groups)
Berdasarkan tabel diatas dapat diketahui bahwa data yang digunakan dapat diproses dan diketahui oleh program (tidak ada yang missing/terlewatkan). Jumlah data yang terproses merupakan total keseluruhan kecamatan yang ada di Kabupaten Jepara, yaitu sebanyak 16 kecamatan. Hal ini berarti rangkaian analisis yang dilakukan dapat dikatakan valid 100% karena keseluruhan data berhasil diproses dan terdeteksi oleh program.
Klasifikasi Kepadatan Penduduk
Rendah < 1000
Sedang 1000 sampai 2000
Mengukur kesamaan/sim
ili arity jarak
Melalui tabel diatas proximity matrix, dapat diketahui jarak antar kecamatan yang ada. Tabel ini berfungsi sebagai langkah awal dalam menentukan klaster yang nantinya akan dibentuk. Sebagai contoh:
1. Kecamatan Kedung memiliki jarak paling dekat yaitu sebesar 6.000 dengan Kecamatan Kalinyamatan dan Welahan; 2. Terdekat kedua yaitu sebesar 27.000 dengan Kecamatan Pakis Aji;
3. Terdekat ketiga yaitu sebesar 37.000 dengan Kecamatan Pecangaan.
Jadi, kemungkinan besar, kelima kecamatan (Kedung, Kalinyamatan, Welahan, Pakis Aji, dan Pecangaan) ini akan membentuk satu klaster. Begitu seterusnya dan berlaku di semua kecamatan.
Proximity Matrix
Case
Squared Euclidean Distance 1:KEDUN
G 2:PECANGAAN 3:KALIN
YAMAT
AN 4:WELAHAN 5:MAYONG 6:NALUMSARI 7:BATEALIT 8:TAHUNAN 9:JEPARA 10:MLONGGO AJI 11:PAKIS 12:BANGSRI 13:KEMBANG 14:KELING 15:DONOROJO 16:KARI MUNJA WA 1:KEDUNG .000 37.000 6.000 6.000 1227.000 258.000 732.000 677.000 486.000 442.000 27.000 4098.000 631.000 1606.000 534.000 3139.000 2:PECANGAAN 37.000 .000 65.000 17.000 844.000 103.000 447.000 400.000 257.000 227.000 126.000 3367.000 370.000 1165.000 297.000 3850.000 3:KALINYAMATAN 6.000 65.000 .000 16.000 1371.000 326.000 846.000 785.000 576.000 530.000 15.000 4358.000 737.000 1772.000 634.000 2921.000 4:WELAHAN 6.000 17.000 16.000 .000 1091.000 198.000 630.000 577.000 400.000 362.000 55.000 3846.000 537.000 1452.000 450.000 3369.000 5:MAYONG 1227.000 844.000 1371.000 1091.000 .000 361.000 65.000 84.000 171.000 197.000 1602.000 841.000 102.000 27.000 147.000 8282.000 6:NALUMSARI 258.000 103.000 326.000 198.000 361.000 .000 122.000 103.000 38.000 26.000 443.000 2304.000 83.000 578.000 52.000 5185.000 7:BATEALIT 732.000 447.000 846.000 630.000 65.000 122.000 .000 7.000 30.000 38.000 1025.000 1370.000 5.000 170.000 18.000 6889.000 8:TAHUNAN 677.000 400.000 785.000 577.000 84.000 103.000 7.000 .000 17.000 27.000 966.000 1447.000 10.000 205.000 17.000 6730.000 9:JEPARA 486.000 257.000 576.000 400.000 171.000 38.000 30.000 17.000 .000 2.000 735.000 1766.000 17.000 332.000 10.000 6089.000 10:MLONGGO 442.000 227.000 530.000 362.000 197.000 26.000 38.000 27.000 2.000 .000 679.000 1850.000 21.000 366.000 10.000 5931.000 11:PAKIS AJI 27.000 126.000 15.000 55.000 1602.000 443.000 1025.000 966.000 735.000 679.000 .000 4763.000 902.000 2027.000 785.000 2602.000 12:BANGSRI 4098.000 3367.000 4358.000 3846.000 841.000 2304.000 1370.000 1447.000 1766.000 1850.000 4763.000 .000 1523.000 578.000 1684.000 14401.00 0 13:KEMBANG 631.000 370.000 737.000 537.000 102.000 83.000 5.000 10.000 17.000 21.000 902.000 1523.000 .000 225.000 5.000 6562.000 14:KELING 1606.000 1165.000 1772.000 1452.000 27.000 578.000 170.000 205.000 332.000 366.000 2027.000 578.000 225.000 .000 290.000 9217.000 15:DONOROJO 534.000 297.000 634.000 450.000 147.000 52.000 18.000 17.000 10.000 10.000 785.000 1684.000 5.000 290.000 .000 6243.000 16:KARIMUNJAWA 3139.000 3850.000 2921.000 3369.000 8282.000 5185.000 6889.000 6730.000 6089.000 5931.000 2602.000 14401.000 6562.000 9217.000 6243.000 .000 This is a dissimilarity matrix
2 1
Membentuk klaster
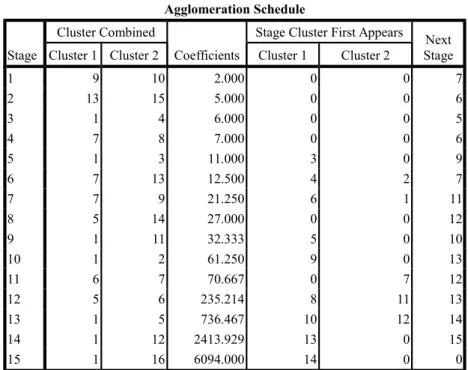
Agglomeration Schedule Stage
Cluster Combined
Coefficients
Stage Cluster First Appears Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 9 10 2.000 0 0 7 2 13 15 5.000 0 0 6 3 1 4 6.000 0 0 5 4 7 8 7.000 0 0 6 5 1 3 11.000 3 0 9 6 7 13 12.500 4 2 7 7 7 9 21.250 6 1 11 8 5 14 27.000 0 0 12 9 1 11 32.333 5 0 10 10 1 2 61.250 9 0 13 11 6 7 70.667 0 7 12 12 5 6 235.214 8 11 13 13 1 5 736.467 10 12 14 14 1 12 2413.929 13 0 15 15 1 16 6094.000 14 0 0
Tabel Agglomeration Schedule akan menganalisis lebih lanjut menegenai pembentukan klaster setelah jarak berhasil diukur. Sebagai contoh:
1. Pada tahap/stage 1, kecamatan 9 (Jepara) dan kecamatan 10 (Mlonggo) merupakan yang paling mirip sehingga keduanya akan menjadi satu kelompok (klaster) terlebih dahulu. Tahap tidak berhenti sampai disitu, selanjutnya lihat kolom next stage, terlihat stage 7 menjadi kelanjutan dari stage 1;
2. Pada stage 7, kecamatan 7 (Batealit) mirip dengan kecamatan 9 yang artinya kecamatan 7 masuk ke dalam kelompok sebelumnya. Jadi anggota kelompok pertama kini adalah kecamatan 9 (Jepara), kecamatan 10 (Mlonggo), dan kecamatan 7 (Batealit);
3. Begitu seterusnya hingga kolom next stage terselesaikan (menjumpai angka 0);
Berdasarkan cara pembentukan klaster oleh tabel Agglomeration Schedule diketahui bahwa indikator utamanya adalah jarak. Jarak didapatkan dari analisis luas wilayah, kepadatan penduduk, jumlah sarana pendidikan, dan laju PDRB yang sebelumnya diolah. Melalui perhitungan diatas dapat diartikan bahwa Kecamatan Jepara, Mlonggo, Batealit (dan anggota kelompok lain yang belum disebutkan langkah pencariannya) memiliki kemiripan dari segi luas wilayah, kepadatan penduduk, jumlah sarana pendidikan, atau laju PDRB ADHB-nya.
Langkah diatas baru menghasilkan satu kelompok, tidak ada salahnya jika kita mencoba mencari kelompok baru. Sebagai contoh:
1. Pada stage 3, kecamatan 1 (Kedung) ternyata memiliki kemiripan dengan kecamatan 4 (Welahan), lanjut stage 5;
2. Kecamatan 1 mirip dengan kecamatan 3 (Kalinyamatan), lanjut stage 9; 3. Kecamatan 1 mirip dengan kecamatan 11 (Pakis Aji), lanjut stage ke 10;
4. Kecamatan 1 mirip dengan kecamatan 2 (Pecangaan). Jadi anggota kelompok baru adalah Kecamatan Kedung, Welahan, Kalinyamatan, Pakis Aji, dan Pecangaan.
Stage tidak dilanjutkan ke stage 13 karena coefficients yang dihasilkan di stage 13 sangat besar, hal ini berarti stage 13 sudah bukan bagian dari pembentukan kelompok kecamatan 1 dan harus membentuk kelompok (klaster) baru lagi.
Menentukan jumlah klaster
Cluster Membership
Case 4 Clusters 3 Clusters 2 Clusters
1:KEDUNG 1 1 1 2:PECANGAAN 1 1 1 3:KALINYAMATAN 1 1 1 4:WELAHAN 1 1 1 5:MAYONG 2 1 1 6:NALUMSARI 2 1 1 7:BATEALIT 2 1 1 8:TAHUNAN 2 1 1 9:JEPARA 2 1 1 10:MLONGGO 2 1 1 11:PAKIS AJI 1 1 1 12:BANGSRI 3 2 1 13:KEMBANG 2 1 1 14:KELING 2 1 1 15:DONOROJO 2 1 1 16:KARIMUNJAWA 4 3 2
Berdasarkan tabel Cluster Membership diatas klaster terhadap kecamatan-kecamatan di Kabupaten Jepara terdiri dari 3 macam klaster, yaitu 2 klaster, 3 klaster, 4 klaster. Jika terbentuk 2 klaster, maka anggota klaster 1 terdiri dari Kecamatan Kedung hingga Donorojo, sedangkan anggota klaster 2 adalah Kecamatan, Karimun Jawa. Jika terbentuk 3 klaster, maka anggota klaster 1 terdiri dari Kecamatan Kedung, Pecangaan, Kalinyamatan, Welahan, Mayong, Nalumsari, Batealit, Tahunan, Jepara, Mlonggo, Pakis Aji, Kembang, Keling, dan Donorojo. Sedangkan anggota klaster 2 adalah Kecamatan Bangsri. Jika terbentuk 4 klaster maka anggota klaster 1 terdiri dari Kecamatan Kedung, Pecangaan, Welahan, Kalinyamatan, dan Pakis Aji. Anggota klaster 3 adalah Kecamatan Bangsri, anggota klaster 4 adalah Kecamatan Karimun Jawa, sedangkan anggota klaster 2 adalah sisanya.
Melalui hasil analisis diatas diketahui bahwa Kecamatan Karimun Jawa menjadi satu-satunya kecamatan yang paling tidak memiliki kemiripan diantara kecamatan lainnya. Berdasarkan letak geografisnya, Kecamatan Karimun Jawa memang terpisah dengan kecamatan lain, bahkan lepas dari pulau jawa, namun secara administratif ia masuk ke bagian Kabupaten Jepara. Karena letaknya yang jauh dari peradaban pusat kegiatan mengakibatkan tidak banyak penduduk yang tinggal disana, kecuali penduduk asli. Karena kepadatan penduduk yang kurang padat, ketersediaan sarana dan prasarana disana juga jauh lebih rendah dibandingkan sarana dan prasarana yang ada di kecamatan lainnya. Hal inilah yang menyebabkan Kecamatan Karimun Jawa tidak bisa bergabung dengan klaster lain dan membentuk klaster bagi dirinya sendiri. Meskipun tidak memiliki kemiripan dengan kecamatan, Kecamatan Karimun Jawa berhasil melakukan laju pertumbuhan PDRB yang cepat dari komoditi unggulannya di sektor pariwisata bahari. Kecamatan yang paling tidak mirip kedua adalah Kecamatan Bangsri. Hal ini kemungkinan besar diakibatkan jumlah sarana pendidikannya yang melampaui jumlah kecamatan lain meskipun kepadatan penduduknya adalah sedang. Meskipun secara kualitas tidak dapat disebutkan yang terbaik, namun sarana pendidikan di Kecamatan Bangsri seringkali diminati oleh masyarakat dari kecamatan lain sehingga jumlah sarananya menjadi banyak.
Dendogram
Proses aglomerasi kemudian ditampilkan secara grafis dalam bentuk dendogram. Dendogram merupakan grafik yang berfungsi untuk mempermudah cara pembacaan pembentukan klaster yang dihasilkan, meskipun demikian hasil yang ditampilkan juga sama dengan tabel Cluster Membership. Berikut merupakan dendogram yang dihasilkan oleh analisis SPSS terhadap kecamatan di Kabupaten Jepara:
* * * * * * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * * * * Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25 Label Num +---+---+---+---+---+ JEPARA 9 -+ MLONGGO 10 -+ KEMBANG 13 -+ DONOROJO 15 -+ BATEALIT 7 -+ TAHUNAN 8 -+---+ NALUMSARI 6 -+ | MAYONG 5 -+ | KELING 14 -+ +---+ KEDUNG 1 -+ | | WELAHAN 4 -+ | | KALINYAMATAN 3 -+ | +---+ PAKIS AJI 11 -+---+ | | PECANGAAN 2 -+ | | BANGSRI 12 ---+ | KARIMUNJAWA 16 ---+ Anggota
klaster 2 Terbentuktiga
klaster: Anggota klaster 1 Terbentuk dua klaster: Anggota klaster 1 Anggota klaster 1 (empat klaster)
Anggota klaster 3 Anggota klaster 2 Anggotaklaster 2
Anggota klaster 4 Anggota klaster 3
4. Kesimpulan
Melalui analisis yang telah dilakukan dengan bantuan software SPSS dapat disimpulkan bahwa dari 16 kecamatan yang ada, Kecamatan Karimun Jawa merupakan kecamatan yang paling tidak memiliki kemiripan dengan kecamatan lain. Selanjutnya ada Kecamatan Bangsri yang juga tidak memiliki kemiripan dengan lainnya ketika terbentuk 3 klaster. Keduanya kemudian membentuk dua klaster yang berbeda (memisahkan diri dari kecamatan lain) ketika program memerintahkan terbentuknya 3 klaster atau 4 klaster. Untuk Kecamatan Kedung, Welahan, Pecangaan, Pakis Aji, dan Kalinyamatan memiliki kemiripan yang paling banyak sehingga mereka membentuk satu klaster, sedangkan 9 kecamatan sisanya (Kecamatan Jepara, Mlonggo, Kembang, Donorojo, Batealit, Tahunan, Nalumsari, Mayong, dan Keling) membentuk satu klaster lain karena saling memiliki kesamaan karakteristik.
Dengan demikian, hal ini mengindikasikan bahwa Kecamatan Karimun Jawa membutuhkan penanganan perencanaan yang berbeda dan tidak bisa disamakan dengan kecamatan lainnya. Hal ini berbanding lurus dengan keadaan lapangan dimana saat ini oleh pemerintah daerah menjadikan Kecamatan Karimun Jawa lebih condong pada sektor pariwisata, bukan sektor industri, perdagangan, dan jasa seperti kecamatan pada umumnya. Sedangkan klaster lain seperti Kecamatan Bangsri juga membutuhkan perencanaan yang tidak sama dengan kecamaran lain karena perbedaan karakteristik yang cukup signifikan (terlihat dari banyaknya sarana pendidikan). Adanya pengelompokan karakteritik ini kemudian akan mempermudah perencana dalam melakukan perencanaan didalamnya, sebab pada umumnya kesamaan karakteristik akan menghasilkan perencanaan dan menanganan kebijakan yang relatif sama.
5. Daftar Pustaka
B.J. Prayudho. 2008. Analisis Cluster dalam bentuk .pdf. Diunduh pada hari Selasa, 14 April 2015.
Hidayat, Anwar. 2014. Analisis Cluster dalam statistikian.com. Diakses pada hari Selasa, 21 April 2015.
Ulwan, M. Nashihun. 2014. Cara Analisis Cluster Metode Hirarkis dengan SPSS dalam portal-statistik.com. Diakses pada hari Selasa, 21 April 2015.
Jepara, Mlonggo, Kembang, Donorojo, Batealit, Tahunan, Nalumsari, Mayong, dan Keling Bangsri Kedung, Welahan, Pecangaan, Pakis Aji Kalinyamatan Karimun Jawa
6. Lampiran
1. Buka jendela baru software SPSS, buka tab variable view dan ketik nama data apa saja yang akan di-input. Berikut adalah beberapa data yang akan diolah beserta setting -annya:
2. Masukkan data yang digunakan dari Microsoft Excel ke dalam software SPSS untuk diolah.
3. Karena data masih dalam bentuk rasio, maka yang harus dilakukan adalah mengklasifikasikan data tersebut menjadi data ordinal.
4. Klik Transform→Record Into Same Variables dan kemudian sesuaikan klasifikasi masing-masing seperti yang sudah diatur. Data yang diklasifikasi hanya Luas Wilayah, Kepadatan Penduduk, dan Laju Pertumbuhan PDRB, untuk Jumlah Sarana Pendidikan tidak perlu diklasifikasi.
Klasifikasi untuk data Luas wilayah: 1: Kecil 2: Sedang 3: Besar
5. Setelah selesai proses klasifikasi, tentukan nilai data ordinal yang tadi dimasukkan/buat ke kolom values (tab variable view). Kemudian kembali ke tab data view
6. Selanjutnya adalah proses inti: mengklasterkan kecamatan-kecamatan yang ada di kabupaten Jepara. Klik analyze→classify→Hierarchical Cluster
Klasifikasi untuk data Kepadatan Penduduk. 1: Sedikit
2: Sedang 3: Padat
Klasifikasi untuk data Laju Pertumbuhan PDRB ADHB. 1: Lambat 2: Sedang 3: Cepat
7. Muncul koak dialog dari hierarchical cluster analysis. Pindahkan data Luas Wilayah, Kepadatan Penduduk, Jumlah Sarana Pendidikan, dan Laju Pertumbuhan PDRB dari kotak kiri ke kotak kanan atas (kolom Variables) dan data Kecamatan dari kotak kiri ke kotak kanan bawah (kolom Label Cases By). Untuk lebih jelasnya dapat diperhatikan gambar di bawah ini:
8. Klik option statistic, plots, dan method-nya dan atur seperti berikut: (option Save tidak perlu diatur)
9. Setelah semuanya telah diatur, maka tinggal klik OKdan tunggu hingga jendela output SPSS keluar menampilkan hasil analisis cluster. (Pastikan pada kotak Cluster yang dipilih adalah Cases dan kotak Display dicentang semua)
10.Muncul jendela output menampilkan hasil analisis:
Merupakan pengaturan berapa jumlah cluster yang diinginkan. Pada kesempatan kali ini user
menentukan jumlah cluster minimal adalah 2