Implementasi Algoritma Association Rule Dan K-Means Sebagai Sistem
Rekomendasi Produk Pada Website Penjualan Online
Teguh Iman Hermanto
Teknik Informatika, Sekolah Tinggi Teknik Wastukancana Email : [email protected]
Abstrak
Penelitian ini membahas tentang pengolahan data transaksi pembelian dan data pelanggan untuk menghasilkan sebuah informasi yang dapat membantu pengambilan keputusan dalam meningkatkan penjualan dengan memberikan sistem penawaran barang. Penelitian ini didasarkan adanya masalah pada sistem penjualan online yang belum memiliki sistem penawaran barang yang sesuai dengan karakteristik pembeli. Metode yang digunakan pada penelitian ini adalah pengolahan data transaksi pembelian menggunakan algoritma Association Rule dan pengolahan data pelanggan menggunakan K-Means clustering. Pengolahan data transaksi dilakukan dengan menentukan nilai support dan confidence sebagai nilai kepastian dari pola data pembelian yang dihasilkan. Pengolahan data pelanggan dilakukan dengan menentukan nilai Recency, Frequency, dan Monetary sebagai variabel untuk menentukan segmentasi pelanggan. Hasil dari penelitian ini adalah pengolahan data menggunakan algoritma Association Rule dengan nilai optimal confidence dan support sebesar 8% dan pengolahan data pelanggan menggunakan algoritma K-Means dengan nilai below zeros sebanyak 2 pelanggan, nilai migrator sebanyak 6 pelanggan, nilai most growable sebanyak 97 pelanggan, dan nilai most valuable sebanyak 31 pelanggan.
Kata kunci : Association Rule, Confidence, Support, K-Means clustering, RFM
1. Pendahuluan
Peningkatan kebutuhan informasi yang dapat digunakan sebagai sistem pengambilan keputusan bisnis sangatlah dibutuhkan oleh para manager pemilik perusahaan. Seorang manager membutuhkan sebuah sistem yang dapat mengolah sekumpulan data yang tersimpan di dalam media penyimpanan untuk dijadikan sebuah pengetahuan baru yang dapat mendukung sebuah keputusan bisnis (Wen dkk., 2012). Bisnis cerdas sangat dibutuhkan dalam sebuah sistem yang sedang dimplemenasikan di dalam menunjang sebuah kegiatan bisnis di dalam sebuah perusahaan. Tujuan bisnis cerdas adalah untuk mengolah data yang sangat banyak menjadi memiliki nilai bisnis melalui laporan analistik. Oleh karena itu diperlukan sebuah sistem yang mampu memilah dan memilih data, sehingga dapat diperoleh informasi yang berguna bagi penggunanya (Cakir dan Aras, 2012).
Bisnis cerdas dapat diterapkan dalam sebuah sistem penjualan online sehingga manager dapat mengetahui banyak informasi yang digunakan sebagai pendukung keputusan dalam mengelola perusahaan. Kecerdasan bisnis yang diterapkan dapat dikembangkan sesuai dengan kebutuhan manager dalam mengelola perusahaan (Liao dkk., 2012).
Penelitian ini dilakukan dengan membangun sebuah sistem penjualan online dengan fitur analisis keranjang pasar yang dapat menemukan aturan asosiatif dengan memanfaatkan data tranasaksi terkait dengan daftar pembelian produk yang dibeli oleh
33
konsumen. Dari hasil analisis asosiasi inilah terbentuk sebuah aturan yang digunakan sebagai alat untuk merekomendasikan barang sesuai dengan kebutuhan customer.
2. Kerangka Teori 2.1 Association Rule
Analisis asosiasi atau Association Rules didefinisikan sebagai suatu proses untuk menemukan semua aturan asosiatif yang memenuhi syarat minimum untuk support dan syarat minimum confidence pada database. Metodologi dasar analisis Apriori terbagi menjadi dua tahap, yaitu :
a. Analisa Pola Frekuensi Tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan persamaan 2.1 berikut :
( ) (2.1)
Pada persamaan2.1 menjelaskan bahwa nilai support diperoleh dengan cara mencari jumlah transaksi yang mengandung nilai A (satu item) dibagi dengan jumlah keseluruhan transaksi. Sedangkan nilai support dari 2-item diperleh dari rumus berikut :
( ) √( ) ( ) ( ) b. Analisa pembentukan aturan asosiasi
( )
(2.2)
Pada persamaan 2.2 menjelaskan bahwa nilai support diperoleh dengan cara mencari jumlah transaksi yang mengandung A dan B (item pertama bersamaan dengan item lain) dibagi dengan jumlah keseluruhan transaksi. c. Pembentukan aturan asosiatif
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan assosiatif yang memenuhi syarat minimum untuk nilai confidence dengan menghitung nilai confidence aturan assosiatif A
B Nilai confidence dari aturan A
B diperoleh dari persamaan berikut:( )
( )
Persamaan 2.3 menjelaskan bahwa nilai confidence diperoleh dengan cara mencari jumlai transaksi yang mengandung A dan B dibagi dengan jumlah transaksi yang mangandung nilai A.
2.2 Algoritma K-Means
Algoritma K-Means pertama kali dipublikasikan oleh Stuart Lloyd pada tahun 1984 dan merupakan algoritma clustering yang banyak digunakan. Algoritma K-Means bekerja dengan mensegmentasi objek yang ada kedalam kelompok atau yang disebut dengan segmen sehingga objek yang berada dalam masing-masing kelompok lebih serupa satu sama lain dibandingkan dengan objek dalam kelompok yang berbeda.
K-Means bekerja dengan pendekatan Top-Down karena memulai dengan segmentasi yang sudah ditentukan terlebih dahulu (Myatt, 2007). Sehingga hasil data sebuah segmen tidak mungkin tercampur antara satu segmen dengan segmen lainnya (Xu dan Wunsch, 2009). Pendekatan ini juga mempercepat proses komputasi untuk data dalam jumlah besar.
Perhitungan jarak antar titik dengan menggunakan Euclidean distance dapat dilakukan pada titik dalam satu dimensi, dua dimensi, maupun 3 dimensi. Formula Jarak antar dua titik dalam satu, dua dan tiga dimensi secara berurutan ditunjukkan pada persamaan berikut ini. (2.4) √( ) ( )
(2.5) √( ) ( ) (2.6) 34 2.3 Segmentasi Pelanggan
Segmentasi merupakan proses mengidentifikasi dan memilah-milah konsumen kedalam kelompok-kelompok pembeli yang dirasa memiliki kebutuhan atau keinginan atas produk atau jasa yang diberikan (Kotler, 2004)
Don Pepper dan Martha Roger dalam bukunya “Managing Customer Relationship : A Strategic Framework”. Melakukan kategorisasi pelanggan sebagai berikut:
a. Most Valuble Customer (MVC), yaitu pelanggan dengan nilai paling tinggi bagi perusahaan. Pelanggan yang termasuk dalam kategori ini adalah pelanggan yang seharusnya menjadi perhatian perusahaan. Hal ini dikarenakan pelanggan kategori MVC memberikan keuntungan terbesar bagi perusahaan.
b. Most Growable Customer, yaitu pelanggan yang tanpa disadari memiliki potensi besar.
c. Below Zeros, yaitu pelanggan yang memberikan keuntungan lebih sedikit daripada biaya untuk memberikan pelayanan.
d. Migrators, yaitu pelanggan yang berada pada posisi diantara below zeros dan most growable customer dan perlu dianalisis agar dapat diketahui kategori asalnya (Pepper & Roger, 2004).
2.4 RFM model
Sebuah model untuk segmentasi pelanggan dapat diusulkan menjadi sebuah model, yaitu RFM model, yang dapat digunakan untuk mengukur customer value. Disebutkan pula bahwa analisis RFM merupakan salah satu cara yang dapat digunakan untuk mengetahui pelanggan-pelanggan potensial. Model RFM diaplikasikan secara luas pada database pemasaran dan merupakan tool yang umum digunakan untuk membangun strategi pemasaran. (Wei, 2010).
RFM berdasarkan segmentasi pelanggan menghasilkan kemampuan segmentasi antara 75% sampai 85%. Berikut ini adalah penjelasan mengenai RFM menurut Cheng dan Chen (2009):
1. Recency, yaitu kapan transaksi terakhir dilakukan 2. Frequency, tingkat keseringan pelanggan
melakukan transaksi. Misalkan sekali transaksi tiap bulan, atau 2 kali dalam satu tahun
3. Monetary, besarnya nilai transaksi yang dilakukan Penerapkan RFM analysis untuk menentukan segmentasi pelanggan pada salah satu perusahaan elektronik penyedia power supply. Sementara itu, D. Christodoulakis melakukan penelitian mengenai penerapan RFM untuk menentukan customer value dari pelanggan e-banking.
3. Metodologi
3.1 Prosedur Penelitian
Prosedur penelitian pada penelitian ini dimulai dengan mengidentifikasi masalah, kemudian dilanjutkan dengan studi pustaka, pengumpulan data, dan pengolahan data. Pada pengolahan data, terdapat dua proses pengolahanyaitu pengolahan data pelanggan menggunakan K-Means Clustering dan pengolahan data transaksi menggunakan Apriori Algorithm.hasil dari dua pengolahan berupa segmentasi pelanggan dan kumpulan aturan asosiasi pembelian produk yang divisualisasikan dalam bentuk dashboard, seperti pada Gambar 3.1 berikut :
Identifikasi masalah
Pengumpulan Data
Data Mining
K-Means Clustering
Association Rule
Segmentasi Pelanggan Analisis Pembelian Aturan Asosiasi Pembelian Dashboard
Gambar 3.1 Prosedur Penelitian
Pada proses data mining terdapat dua proses pengolahan data, yaitu data pelanggan menggunakan algoritma K-Means clustering dan data transaksi pembelian menggunakan algoritma Apriori. Data pelanggan yang diolah menggunakan algoritma K-Means Clustering menghasilkan sebuah data segmentasi pelanggan yang berfungsi untuk membagi kategori pelanggan sesuai dengan metode RFM (Recency, Frequency, dan Monetary). Data transaksi pembelian yang diolah menggunakan algoritma Apriori berfungsi untuk menghasilkan sebuah pola transaksi pembelian yang dilakukan oleh konsumen sehingga sistem penjualan dapat melakukan rekomendasi produk yang akan dibeli konsumen sesuai data pola transaksi yang dihasilkan.
4. Hasil dan Pembahasan 4.1 Hasil Pembentukan Asosiasi
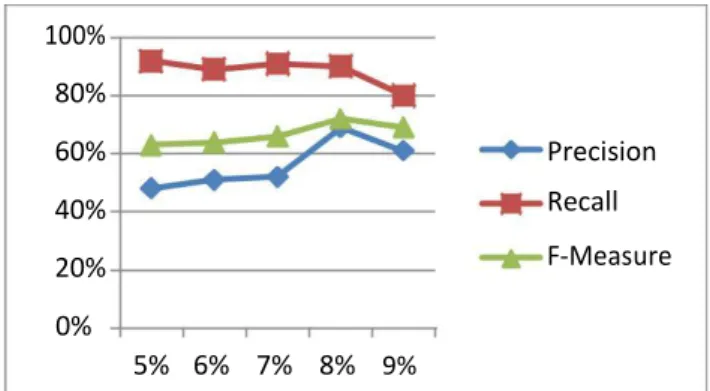
Pada pengujian analisis asosiasi dilakukan proses pengujian pada data transaksi penjualan barang menggunakan lima kali perbandingan nilai support dan nilai confidence sebesar 5%, 6%, 7%, 8%, dan 9% (Hsu dkk., 2004). Hasil pengolahan data transaksi melalui beberapa tahap yaitu pembentukan kandidat itemset dan pengukuran frequent itemset.Untuk grafik hasil pengujian performa analisis asosasi dapat dilihat pada Gambar 4.1. 35 100% 80% 60% Precision 40% Recall 20% F-Measure 0% 5% 6% 7% 8% 9%
Gambar 4.1 Hasil Pengukuran Performa Asosiasi
4.2 Hasil Pembentukan Segmentasi
Pada pengujian analisis clustering menggunakan metode RFM ditemukan 4 cluster yaitu migrator, most growble, below zeros, dan most valuable. Masing-masing cluster terdapat data pelanggan yang masuk ke dalam cluster tersebut yang nantinya tabel cluster akandihitung nilai precision dan nilai recall untuk mengetahui performa dari masing-masing cluster. Hasil dari pengolahan segmentasi pelanggan dapat dilihat pada Gambar 4.2.
Gambar 4.2 Hasil Segmentasi Pelanggan 5. Kesimpulan
Berdasarkan dari proses pengolahan data transaksi menggunakan metode association rule dan proses pengolahan segmentasi data pelanggan menggunakan metode K Means clustering dapat disimpulkan penerapan metode asosiasi dalam mengolah data transaksi yang dilakukan oleh pelanggan dapat membantu sistem dalam membentuk pola frequent itemset yang berfugsi untuk sistem penawaran barang agar dapat meningkatkan penjualan barang ke konsumen. Penerapan metode K-menas clustering dalam mengolah data pelanggan berdasarkan recency, frequancy, dan monetary dapat membentuk sebuah cluster atau pengelompokan pelanggan menjadi empat kelompok yaitu migrator, most growable, below zeros, dan most valuable. Pengelompokan pelanggan dapat membantu sistem untuk mempelajari intensitas
pelanggan dalam melakukan transaksi pembelian pada sistem penjualan online.
Daftar Pustaka
Ahn, K., 2012, Effective Product Assignment Based on Association Rule Mining in Retail. Expert System With Applications, 12551-12556.
Berry, M., J., dan Linoff, G., S., 2004, Data Mining Techniques For
Marketing, Sales, Customer Relationship Management Second Editon, Wiley Publishing.
Cakir, O., & Aras, 2012, A Recomendation Engine by Using Association Rules, Procedia – Social and Behavioral Sciences
62, 452 – 456.
Deypir, M., dan Sadreddini, M., H., 2012, A Dynamic Layout of Sliding Window for Frequent Itemset Mining Over Data Streams, The Journalof System and Software 85, 746-759. Dongwon, L., Park, S., H., dan Moon, S., 2013, Utility-Based
Association Rule Minin : A Marketing Solution for Cross-Selling, Expert Systems With Applications 40, 2715-2725. Hsu, P., Y., Chen, Y., L., dan Ling, C., C., 2004, Algorithms for
mining association rules in bag databases, Information Sciences 166 31-47.
Kim, Y, S, & Yum B., J., 2011, Recomender Systembased On Click Stream Data Using Association Rule Mining, Expert systems
with applications 38, 13320-13327.
Kuo, R., J., Chao, C., M., dan Chiu, Y., T., 2011, Application of Particle Swarm Optimization to Association Rule Mining.
Applied Soft Computing 11, 326–336.
Larose, D., T., 2005, Discovering Knowledge in Data: an
Introduction to Data Mining, John Willey & Sons.
Liao, S., H., Chu, P., H., Chen, Y., J., dan Chang C., C., 2012, Mining Customer Knowledge for Exploring Online Group Buying Behavior, Expert System With Applications 39, 3708-3716.
Pepper, D., dan Roger, M., 2004, managing customer relationship, John Willey & Sons, Inc.
Roy, D., K., dan Sharma., L., K., 2010, Genetic K-Means Clustering Algorithm for Mixed Numeric and Categorical Data Sets,
International Journal of Artificial Intelegence & Applications (IJAIA) vol.1, 2333-9721.
Shweta, T., Bharadwaj, K., K., 2012, Enhanced New User Recomendations Based on Quantitative Association Rule Mining. Procedia Computer science 10, 102-109.
Taniar, D., Rahayu, W., Lee, V., Daly, O., 2008, Exception Rules in Association Rule Mining, Applied Mathematics and
Computation 205, 735–750.
Turban, E., Aronson, J., E., Liang, T., P., 2005, Decision support
system and intelligent systems, Andi Offset.
Vipin Kumar, V., Tan, P., N., Steinbach, M., 2006, Introduction to
Data Mining Edisi 1, Pearson Education.
Voditel, P., P., & Deshpande, U., 2013, A Stock Market Portofolio Recomender System Based on Association Rule Mining.
Applied Soft Computing 13, 1055 – 1063.
Wei, J., T., Lin, S., Yen.,dan Wu, H., H., 2010, A review of the
application of RFM model, African Journal ofBusiness
Management Vol. 4(19), Pp. 4199-4206.
Wen, C., H., Liao, S., H., Chang, W., L., Hsu, P., Yu., 2012, Mining Shopping Behavior In The Taiwan Luxury Products Market,
Expert System With Applications 39, 11257-11268.
Witten, I., H., Eibe, F., dan Hall, M., A., 2011, Data mining:
Practical Machine Learning Tools and Techniques 3rd Edition,
Elsevier.