i TESIS – PM 147501
PENENTUAN INTERVAL WAKTU PERAWATAN
PENCEGAHAN PADA PERALATAN
GAS
COMPRESSION SYSTEM
DI PT PERTAMINA HULU
ENERGI
EKWAN HARDIYANTO NRP. 9115201703
DOSEN PEMBIMBING
Ir. Bobby Oedy P. Soepangkat, M.Sc., Ph.D.
DEPARTEMEN MANAJEMEN TEKNOLOGI BIDANG KEAHLIAN MANAJEMEN INDUSTRI
FAKULTAS BISNIS DAN MANAJEMEN TEKNOLOGI INSTITUT TEKNOLOGI SEPULUH NOPEMBER
iii
PENENTUAN INTERVAL WAKTU PERAWATAN
PENCEGAHAN PADA PERALATAN
GAS COMPRESSION
SYSTEM
DI PT PERTAMINA HULU ENERGI
Nama : Ekwan Hardiyanto NRP : 9115201703
Pembimbing : Ir. Bobby Oedy P. Soepangkat, M.Sc., Ph.D.
ABSTRAK
PT Pertamina Hulu Energi (PHE) saat ini mengelola lapangan Offshore North West Java (ONWJ). Lapangan tersebut telah beroperasi sejak tahun 1971 sampai sekarang, sehingga peralatan yang digunakan sudah relatif tua. Salah satu metode pengangkatan minyak di lapangan tersebut adalah dengan menggunakan metode gas lift. Metode ini memanfaatkan tekanan gas yang dihasilkan oleh Gas Compression System (GCS). Gas bertekanan tersebut diinjeksikan ke dalam annulus
(ruang antara tubing dan casing) dan kemudian ke dalam tubing produksi. Unit GCS memiliki 5 sistem utama, yaitu suction and discharge scrubber, turbin gas, kompresor, interstage cooler dan support and others. Data kegagalan yang diperoleh menunjukkan bahwa kelima bagian tersebut memiliki komponen-komponen dengan tingkat kegagalan yang tinggi. Oleh karena itu, sebagai langkah awal akan ditentukan interval waktu perawatan pencegahan (Tp) dari kelima bagian unit GCS dengan laju biaya perawatan pencegahan yang minimum, dan juga mampu menghasilkan keandalan (R) dan ketersediaan (A) yang memenuhi persyaratan perusahaan.
Ada tiga langkah yang ditempuh untuk menentukan Tp yang optimum. Langkah pertama adalah melakukan pengumpulan, pengolahan, penentuan distribusi dan parameter dari data waktu antar kegagalan (TBF) dan waktu perbaikan (TTR). Langkah berikutnya adalah melakukan iterasi waktu operasi (Ti) dan Tp untuk menentukan laju biaya perawatan minimum, keandalan dan ketersediaan. Iterasi ini diterapkan untuk setiap bagian utama dari GCS yang tersusun secara seri. Tp dengan laju biaya pemeliharaan terendah ditetapkan Tpoptimum.
Dari penelitian ini diperoleh nilai Tp, R dan A yang bervariasi pada masing-masing sistem dengan laju biaya sebesar USD 612.339/day. Nilai optimum Tp pada sistem suction & discharge scrubber adalah 400 jam, dengan R dan A sebesar 0.972 dan 0.99. Nilai optmum Tp pada sistem kompresor sebesar 1200 jam, dengan R dan A
iv
v
DETERMINATION OF PREVENTIVE MAINTENANCE TIME
INTERVAL OF GAS COMPRESSION SYSTEM EQUIPMENT AT
PERTAMINA HULU ENERGI
By : Ekwan Hardiyanto
Student Identity Number : 9115201703
Supervisor : Ir. Bobby Oedy P. Soepangkat, M.Sc., Ph.D.
ABSTRACT
PT. Pertamina Hulu Energi (PHE) is working on Offshore North West Java (ONWJ) block. It has been operating since 1971 until now, so it can be said that the equipments are relatively old. One of the methods to lift the crude oil from this field is by using gas lift. This method exploits the gas pressure which produced by Gas Compression System (GCS). This compressed gas is injected into annulus (space between tubing and casing) then inserted to tubing production. This high compressed gas causing the aeration process which impacted to the decreasing of fluid weight in tubing column production. This process causing pressure at reservoir that can push the fluid from well to production facility on the surface. GCS has 5 main parts, they are suction & discharge scrubber, gas turbine, compressor, interstage cooler and support & others. From the downtime data taken, those five parts have components with high failing rate. By those explained reason, this research is aimed to determine the time interval for preventive maintenance (Tp) for those five parts with minimum maintenance cost, reliability and availability value set by the company.
There were three steps to determine the optimum Tp. The first step was
collected data and obtain the best distributuion of time between failures (TBF) and time to repair (TTR). The second step was to iterate the operating time (Ti) and Tp to
determine the minimum preventive maintenance cost rate, reliability and availability. This iteration was applied to parts of GCS that prosseses a series system. Tp at the
lowest rate of preventive maintenance costs was an optimum Tp.
The optimum Tp for suction & discharge scrubber is 400 hours with
reliability and availability is 0.972 and 0.99. The optimum Tp for compressor is 1200
hours with reliability and availability is 0.974 and 0.994. The optimum Tp for gas
turbine is 1600 hours with reliability and availability is 0.975 and 0.987. The optimum Tp for fin fan cooler is 220 hours with reliability and availability is 0.997 and 0.97.
The optimum Tp for support and others is 2000 hours with reliability and availability
is 0.994 and 0.96.
vi
vii
KATA PENGANTAR
Penulis mengucapkan syukur kepada Allah SWT, atas segala limpahan rahmat dan hidayahnya, penulis dapat menyelesaikan tesis ini sesuai dengan harapan. Tesis ini disusun guna memenuhi persyaratan kelulusan akademis bagi Mahasiswa Strata-2 (S2) pada Program Studi Magister Manajemen Teknologi bidang keahlian Manajemen Industri, Institut Teknologi Sepuluh Nopember, Surabaya.
Tentunya juga tesis ini tidak akan pernah terwujud tanpa adanya bantuan dari berbagai pihak yang meluangkan waktu, tenaga dan pikirannya untuk terselesaikannya proses penyelesaian tesis ini. Saya ucapkan terima kasih yang sebesar-besarnya kepada:
1. Ir. Bobby Oedy P. Soepangkat, M.Sc., Ph.D, selaku dosen pembimbing atas waktu, ide, pengarahan, kesabaran, serta bimbingan selama pengerjaan tesis. 2. Dr. Ir. Mokh. Suef, MSc(Eng), selaku ketua program studi MMT-ITS.
3. PT. Pertamina Hulu Energi yang telah membantu dalam pengumpulan data kerusakan komponen pada Gas Compression System.
4. Bapak, ibu dan istri atas doa, perhatian, nasehat, dorongan yang selalu diberikan selama ini, serta pengertiannya dalam memberikan dukungan moril tak terhingga, terutama di masa-masa sulit.
5. Terima kasih secara khusus kepada teman-teman seperjuangan di Program Studi MMT-ITS kelas kerja sama Pertamina Hulu Energi angkatan 2015.
Penulis menyadari bahwa tesis ini masih jauh dari kata sempurna. Penulis berharap bahwa penelitian ini dapat menjadi acuan untuk melakukan penelitian lebih lanjut. Segala kritik dan saran sangat diharapkan oleh penulis demi kesempurnaan tesis ini dikemudian hari.
viii
ix
DAFTAR ISI
LEMBAR PENGESAHAN ... i
ABSTRAK ... iii
ABSTRACT ... v
KATA PENGANTAR ... vii
DAFTAR ISI ... ix
DAFTAR GAMBAR ... xiii
DAFTAR TABEL ... xv
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Perumusan Masalah ... 8
1.2.1 Batasan Penelitian ... 8
1.2.2 Asumsi-asumsi ... 9
1.3 Tujuan Penelitian ... 9
1.4 Manfaat Penelitian ... 9
1.5 Sistematika Penulisan Laporan ... 10
BAB 2 TINJAUAN PUSTAKA ... 11
2.1 Konsep Dasar Perawatan ... 11
2.2 Jenis Perawatan... 11
2.2.1 Perawatan Pencegahan (Preventive Maintenance) ... 12
2.2.2 Perawatan Perbaikan (Corrective Maintenance) ... 13
2.3 Konsep-Konsep Perawatan ... 13
2.3.1 Konsep Breakdown dan Downtime ... 13
2.3.2 Konsep Keandalan (Reliabliity) ... 15
2.3.3 Konsep Keterawatan (Maintainability) ... 17
2.4 Pemodelan Keandalan Sistem ... 17
2.4.1 Sistem Seri ... 17
2.4.2 Sistem Paralel ... 18
x
2.4.4 Kombinasi Seri dan Paralel ... 19
2.5 Laju Kegagalan ... 19
2.6 Mean Time Between Failure (MTBF) ... 20
2.7 Mean Time to Failure (MTTF) ... 20
2.8 Mean Time to Repair (MTTR) ... 20
2.9 Konsep Kesiapan (Availability) ... 20
2.10 Analisis Variansi ... 20
2.11 Uji F ... 22
2.12 Uji Asumsi Residual ... 23
2.13 Distribusi Data Kegagalan dan Maintainability ... 23
2.13.1Distribusi Data Kegagalan ... 24
2.13.2Distribusi Data Maintainability ... 26
2.14 Pengujian Distribusi ... 28
2.15 Laju Biaya Perawatan Pencegahan ... 30
2.16 Optimasi Interval Waktu Perawatan Pencegahan ... 31
2.17 Posisi Penelitian ... 34
BAB 3 METODE PENELITIAN ... 37
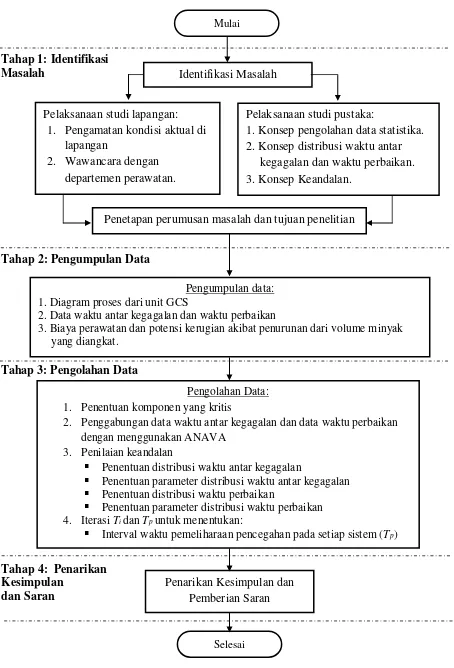
3.1 Studi Lapangan dan Identifikasi Masalah ... 37
3.2 Studi Pustaka ... 37
3.3 Perumusan Masalah dan Tujuan Penelitian ... 39
3.4 Pengumpulan Data ... 39
3.5 Pengolahan Data ... 39
3.6 Penarikan Kesimpulan dan Saran ... 40
BAB 4 PENGOLAHAN DATA ... 43
4.1 Pengolahan Data Antar Waktu Kegagalan dan Waktu Perbaikan ... 43
4.2 Pengolahan Data Antar Waktu Kegagalan dan Waktu Perbaikan ... 47
4.3 Penentuan Parameter Keandalan Setiap Sistem ... 48
4.4 Penentuan Parameter Maintainability Setiap Sistem ... 50
BAB 5 PENENTUAN INTERVAL WAKTU PERAWATAN PENCEGAHAN YANG OPTIMUM... 53
xi
BAB 6 ANALISIS KERUSAKAN PERALATAN ... 67
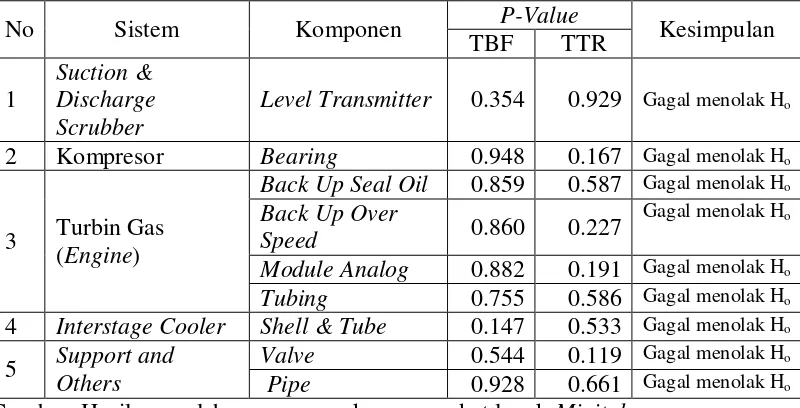
6.1 Analisis Kerusakan Komponen ... 67
6.1.1 Level Transmitter ... 67
6.1.2 Bearing... 68
6.1.3 Back Up Seal Oil... 69
6.1.4 Back Up Over Speed ... 70
6.1.5 Modul Analog ... 71
6.1.6 Tubing ... 72
6.1.7 Shell & Tube ... 73
6.1.8 Valve ... 73
6.1.9 Pipe ... 74
BAB 7 KESIMPULAN DAN SARAN ... 77
6.1 Kesimpulan ... 77
6.2 Saran ... 78
xii
xiii
DAFTAR GAMBAR
Gambar 1.1 Diagram alir Gas Compression System ... 2
Gambar 1.2 Diagram Alir Stage GCS ... 2
Gambar 1.3 Diagram Alir Proses Kerja Turbin Gas ... 3
Gambar 1.4 Blok Diagram Kegagalan Komponen dengan Frekuensi Tinggi ... 7
Gambar 2.1 Laju kerusakan mesin/bathtub curve. ... 14
Gambar 2.2. Tipikal Fungsi Densitas Kegagalan ... 17
Gambar 2.3. Blok Diagram Sistem Seri ... 18
Gambar 2.4 Blok Diagram Sistem Paralel. ... 18
Gambar 2.5. Blok Diagram Kombinasi Sistem dan Paralel ... 19
Gambar 2.6 Alur Iterasi Ti dan TpSecara Berurutan Sesuai dengan Pola Perawatan Pencegahan Multi Komponen ... 32
Gambar 2.7 Pengaruh Tp Terhadap Laju Biaya Perawatan Pencegahan ... 33
Gambar 3.1 Diagram Alir Penelitian ... 38
Gambar 3.2 Diagram Alir Pengolahan Data dengan Perangkat Lunak Weibul++6 ... 41
Gambar 3.3 Diagram Alir Iterasi Tidan Tpuntuk komponen ... 42
Gambar 4.1 Plot ACF untuk Data Back Up Seal Oil. ... 44
Gambar 4.2 Plot Residual Versus Observation Order. ... 45
Gambar 4.3 Plot Uji Distribusi Normal. ... 45
Gambar 5.1 Pengaruh Tp terhadap Laju Biaya Perawatan pada Sistem Suction & Discharge Scrubber ... 58
Gambar 5.2 Pengaruh Tp terhadap Keandalan pada Sistem Suction & Discharge Scrubber ... 58
Gambar 5.3 Pengaruh Tp terhadap Ketersediaan pada Sistem Suction & Discharge Scrubber ... 59
Gambar 5.4 Pengaruh Tp terhadap Laju Biaya Perawatan pada Sistem Kompresor ... 60
Gambar 5.5 Pengaruh Tp terhadap Keandalan pada Sistem Kompresor ... 60
xiv
Gambar 5.7 Pengaruh Tp terhadap Laju Biaya Perawatan pada Sistem Turbin Gas
(Engine) ... 61
Gambar 5.8 Pengaruh Tp terhadap Keandalan pada Sistem Turbin Gas (Engine) ... 61
Gambar 5.9 Pengaruh Tp terhadap Ketersediaan pada Sistem Turbin Gas (Engine) ... 62
Gambar 5.10 Pengaruh Tp terhadap Laju Biaya Perawatan pada Sistem Fin Fan Cooler ... 63
Gambar 5.11 Pengaruh Tp terhadap Keandalan pada Sistem Fin Fan Cooler ... 63
Gambar 5.12 Pengaruh Tp terhadap Ketersediaan pada Sistem Fin Fan Cooler .. 63
Gambar 5.13 Pengaruh Tp terhadap Laju Biaya Perawatan pada Sistem Support and Others ... 64
Gambar 5.14 Pengaruh Tp terhadap Keandalan pada Sistem Support and Others ... 64
Gambar 5.15 Pengaruh Tp terhadap Ketersediaan pada Sistem Support and Others ... 65
Gambar 6.1 Level Transmitter. ... 67
Gambar 6.2 Bearing. ... 68
Gambar 6.3 Back Up Seal Oil. ... 69
Gambar 6.4 Back Up Over Speed. ... 70
Gambar 6.5 Module Analog. ... 71
Gambar 6.6 Tubing. ... 72
Gambar 6.7 Shell & Tube. ... 73
Gambar 6.8 Valve. ... 74
xv
DAFTAR TABEL
Tabel 1.1 Frekuensi Kegagalan, Jumlah Downtime dan Biaya Perawatan GCS
dari tahun 2012-2016 ... 4
Tabel 1.2 Kegagalan Komponen Unit GCS ... 5
Tabel 2.1 Tabel Analisis Variansi ... 21
Tabel 4.1 TBF dan TTR Komponen Back Up Seal Oil ... 43
Tabel 4.2 Hasil ANAVA Unit GCS dari Data Waktu antar Kegagalan dan Waktu Perbaikan Komponen di Setiap Sistem dengan Tingkat Signifikansi 5% ... 46
Tabel 4.3 Pemilihan Distribusi Data Antar Waktu Kegagalan pada Sistem Suction and Discharge Scrubber. ... 48
Tabel 4.4 Parameter Keandalan Waktu antar Kegagalan. ... 48
Tabel 4.5 Fungsi Padat Peluang Waktu antar Kegagalan. ... 49
Tabel 4.6 Fungsi Keandalan Waktu antar Kegagalan Sub-Sub Unit. ... 50
Tabel 4.7 Parameter Maintainability Setiap Sistem. ... 50
Tabel 4.8 Fungsi Padat Peluang Waktu Perbaikan Setiap Sistem. ... 51
Tabel 4.9 Fungsi Maintainability Waktu Perbaikan Setiap Sistem. ... 52
Tabel 5.1 Komponen Biaya Perbaikan dan Perawatan Pencegahan (dalam USD) ... 55
Tabel 5.2 Perhitungan Ti untuk Setiap Sistem unit GCS. ... 55
Tabel 5.3 Perhitungan Tiuntuk setiap sistem unit GCS. ... 56
Tabel 5.4 Waktu gagal (Tf)untuk setiap sistem unit GCS pada N = 2 dengan bilangan acak 0.002. ... 57
Tabel 5.5 Hasil Penentuan Tp Optimum pada Sistem Suction & Discharge Scrubber ... 58
Tabel 5.6 Hasil Penentuan Tp Optimum pada Sistem Kompresor ... 59
Tabel 5.7 Hasil Penentuan TpOptimum pada Sistem Turbin Gas (Engine) ... 61
Tabel 5.8 Hasil Penentuan Tp Optimum pada Sistem Fin Fan Cooler ... 62
xvi
1
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Kebutuhan minyak di Indonesia mencapai 1.6 juta barel oil/hari, sedangkan produksi nasional saat ini hanya 830 ribu barel oil/hari (BP, 2016). Hal tersebut menuntut semua perusahaan yang bergerak di hulu migas untuk bekerja lebih efektif dan efisien. Keandalan peralatan merupakan salah satu kunci dalam mencapai target tersebut. PT Pertamina Hulu Energi (PHE) saat ini mengelola lapangan Offshore North West Java (ONWJ) yang terbentang dari Kepulauan Seribu sampai dengan pantai utara Cirebon. Target produksi lapangan tersebut pada tahun 2015 sebesar 40 ribu BOPD. Lapangan ONWJ telah beroperasi sejak tahun 1971 sampai sekarang, sehingga peralatan yang digunakan sudah relatif tua. Sistem perawatan yang lebih baik sangat diperlukan untuk mengantisipasi terjadinya kehilangan volume minyak yang diangkat akibat kegagalan fungsi peralatan. Proses pengangkatan minyak dari perut bumi dilakukan oleh PT PHE ONWJ melalui dua metode, yaitu:
1. Electrical Submersible Pump (ESP)
ESP adalah pompa sentrifugal yang daya angkatnya (lifting head) dapat diatur melalui variable speed drive (VSD). Pompa ESP dirancang untuk tenggelam dalam fluida di dalam lubang sumur dan berpenggerak motor induksi listrik.
2. Gas Compression System (GCS)
Sistem GCS bekerja dengan menginjeksikan gas bertekanan tinggi ke dalam
annulus (ruang antara tubing dan casing) dan kemudian ke dalam tubing produksi. Gas bertekanan tinggi tersebut menyebabkan terjadinya proses aerasi (aeration) yang mengakibatkan berkurangnya berat jenis fluida dalam kolom tubing produksi. Proses tersebut menyebabkan tekanan reservoir
2
Gambar 1.1 menunjukkan unit GCS yang berfungsi merubah gas bertekanan rendah (±40 psi) menjadi gas bertekanan tinggi (±600 psi). Unit GCS terdiri dari 2 tahapan utama, yaitu 1st stage dan 2nd stage yang bekerja secara seri.
Gambar 1.1 Diagram alir Gas Compression System (Data Internal Perusahaan, 2016)
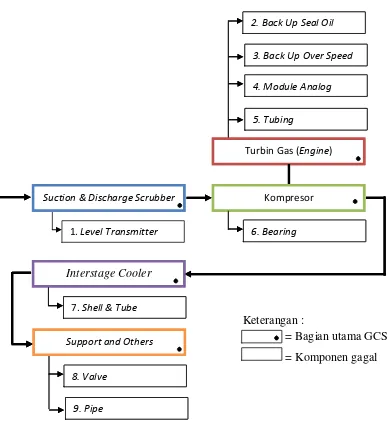
Pada masing-masing stage, unit GCS dapat dibagi menjadi 5 bagian utama seperti ditunjukkan pada Gambar 1.2, yaitu:
Gambar 1.2 Diagram Alir Stage unit GCS (Data Internal Perusahaan, 2016)
Fungsi dari setiap bagian utama adalah sebagai berikut: 1. Suction and Discharge Scrubber
Bagian ini berfungsi sebagai pemisah antara gas dan fluida berdasarkan prinsip gravitasi. Pada suction scrubber gas hasil pemisahan akan dikompresi oleh kompresor hingga mencapai tekanan yang diinginkan, sedangkan pada discharge scrubber gas hasil pemisahan akan disalurkan ke sumur minyak.
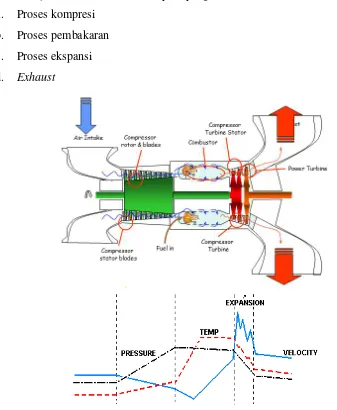
2. Turbin Gas (Engine)
Bagian ini berfungsi sebagai penggerak utama kompresor. Turbin gas mengubah energi kimia hidrokarbon dalam bahan bakar gas (methana CH4, ethana
3
Gas hasil reaksi ini sangat potensial untuk diubah menjadi energi mekanik. Turbin gas bekerja berdasarkan siklus Brayton yang terdiri dari:
a. Proses kompresi b. Proses pembakaran c. Proses ekspansi d. Exhaust
Gambar 1.3 Diagram Alir Proses Kerja Turbin Gas (Solar, 1970)
4
dengan bahan bakar gas pada ruang bakar. Perpaduan udara dan bahan bakar tersebut akan bertemu dengan nyala api dari pemantik. Temperatur gas yang keluar dari ruang bakar tersebut dikendalikan dengan suhu maksimal sebesar 1190˚F. Energi panas inilah yang ditransformasikan ke dalam bentuk energi kinetik, dimana gas akan mengalir dengan kecepatan yang lebih tinggi, sedangkan tekanan secara transient akan cenderung menurun.
3. Kompresor
Bagian ini berfungsi untuk meningkatkan tekanan gas dari sumur gas berdasarkan prinsip kecepatan.
4. Interstage Cooler (Pendingin)
Bagian ini berfungsi menurunkan temperatur gas akibat kenaikan tekanan pada kompresor.
5. Support and Others
Bagian ini berupa peralatan pendukung seperti jaringan pipa, valve, filter,
dan peralatan lainnya.
Berdasarkan data internal perusahaan nilai kegagalan dari unit GCS masih sangat tinggi. Hal tersebut mengakibatkan downtime yang menyebabkan menurunya volume minyak yang diangkat. Tabel 1.1 menunjukkan frekuensi kegagalan, jumlah downtime, dan biaya perawatan dari tahun 2012-2016.
Tabel 1.1 Frekuensi Kegagalan, Jumlah Downtime dan Biaya Perawatan GCS dari tahun 2012-2016.
No Tahun Frekuensi
Kegagagalan
Downtime
(Jam)
Biaya Perawatan Kerugian akibat penurunan
volume minyak
1 2012 230 3312 Rp38.998.543.247 Rp12.886.475.160
2 2013 76 14565 Rp12.886.475.160 Rp56.670.142.121
3 2014 213 8159 Rp36.116.042.225 Rp31.745.395.782
4 2015 204 12513 Rp34.590.012.272 Rp48.686.130.337
5 2016 193 9542 Rp32.724.864.551 Rp37.126.432.964
Sumber: PHE ONWJ (2016)
5
Tabel 1.1 berfluktuasi dan jauh lebih besar dari pada anggaran biaya perawatan pencegahan yang telah ditetapkan.
Unit GCS merupakan peralatan pengangkatan minyak yang digunakan secara terus menerus, sehingga keandalan peralatan tersebut semakin menurun. Menurunnya keandalan dari unit GCS tersebut ditandai dengan banyaknya komponen-komponen gagal pada setiap bagian dari unit GCS. Tabel 1.2 menunjukkan data kegagalan komponen-komponen dari unit GCS. Data tersebut disajikan berdasarkan urutan bagian, sistem dan komponen yang gagal.
Tabel 1.2 Kegagalan Komponen unit GCS
Bagian Frekuensi Kegagalan Komponen
2016 2015 2014 2013 2012 TOTAL
A SUCTION AND DISCHARGE SCRUBBER
6
Tabel 1.2 Kegagalan Komponen unit GCS (lanjutan)
B.5 ACCESSORIES
7
ditunjukkan pada Tabel 1.2 dapat diketahui komponen-komponen kritis dari unit GCS, yakni komponen dengan frekuensi kegagalan tinggi (>20). Gambar 1.4 menunjukkan blok diagram dari komponen-komponen dengan frekuensi kegagalan yang tinggi pada setiap bagian unit GCS.
Keterangan :
= Bagian utama GCS = Komponen gagal
Gambar 1.4 Blok Diagram Kegagalan Komponen Komponen dengan Frekuensi Tinggi (PHE ONWJ, 2016)
Selama ini penentuan interval waktu kegiatan perawatan pencegahan dilakukan berdasarkan rekomendasi yang dibuat oleh manufaktur dari unit GCS. Kondisi peralatan yang sudah tua memerlukan penjadwalan perawatan pencegahan yang lebih efektif untuk mencegah kegagalan komponen tersebut.
8
Keuntungan dari perawatan pencegahan adalah dapat meminimalkan downtime
dan menurunkan tingkat kegiatan pekerjaan yang bersifat darurat (Campbell dan Jardine, 1973).
Sejauh ini, ada beberapa metode penentuan interval waktu perawatan pencegahan yang sudah diketahui dan diimplementasikan. Salah satunya adalah dengan melakukan optimasi interval waktu pemeliharaan pencegahan (Jardine, 1970). Rakhmad (2011) melakukan iterasi Ti dan Tp untuk meningkatkan keandalan sistem minimum hingga 74%, dan penghematan biaya pemeliharaan juga dapat ditingkatkan menjadi 139,9 USD/hari dari 145,7 USD/hari. Sutanto (2011) melakukan optimasi laju biaya pemeliharaan pencegahan sehingga didapatkan penghematan laju biaya pemeliharaan pencegahan pada packer PT ISM Bogasari sebesar 14,6%. Dengan mengacu pada penelitian sebelumnya penelitian mengenai penentuan interval waktu perawatan pencegahan pada unit
Gas Compression System berdasarkan pada komponen-komponen yang gagal belum pernah dilakukan.
Berdasarkan latar belakang yang telah dijelaskan, maka akan dilakukan penentuan interval waktu perawatan pencegahan dari unit GCS dengan laju biaya perawatan pencegahan yang minimum, serta keandalan dan ketersediaan yang memenuhi persyaratan perusahaan.
1.2 Perumusan Masalah
Berdasarkan latar belakang masalah yang telah dijelaskan, maka rumusan masalah pada tesis ini adalah bagaimana menentukan interval waktu perawatan pecegahan dari unit GCS pada anjungan lepas pantai Mike-Mike, yang dapat meminimalkan laju biaya perawatan pencegahan, serta memenuhi keandalan dan ketersediaan yang dipersyaratkan oleh perusahaan.
1.2.1 Batasan Penelitian
Agar penelitian ini terarah dan fokus, maka diberlakukan batasan-batasan masalah sebagai berikut:
9
2. Data kegagalan komponen yang digunakan hanya data dari unit GCS dalam kurun waktu 1 Januari 2012-31 Desember 2016.
3. Biaya yang digunakan untuk perhitungan hanya biaya perawatan dan penggantian suku cadang.
4. Tidak membahas kegagalan akibat proses di luar sistem.
1.2.2 Asumsi-asumsi
Adapun asumsi-asumsi yang diberlakukan pada tesis ini adalah sebagai berikut:
1. Suku cadang yang diganti memiliki spesifikasi sama. 2. Kegagalan akibat kesalahan desain awal diabaikan.
3. Kemampuan teknisi dianggap sama dan sesuai dengan standar yang ditetapkan.
4. Kesalahan pengoperasian oleh operator diabaikan.
5. Usaha perbaikan dianggap mampu mengembalikan kondisi peralatan sama seperti kondisi sebelumnya.
6. Peralatan tanpa catatan kerusakan dianggap memiliki keandalan sebesar satu.
1.3 Tujuan Penelitian
Berdasarkan permasalahan yang telah disebutkan, maka tujuan dari tesis ini adalah menentukan interval waktu perawatan pencegahan dari unit GCS anjungan lepas pantai Mike-Mike, yang dapat meminimalkan laju biaya perawatan pencegahan, serta memenuhi keandalan dan ketersediaan yang dipersyaratkan oleh perusahaan.
1.4 Manfaat Penelitian
Adapun hasil dalam penelitian tesis ini diharapkan dapat berguna dan menjadi:
1. Dasar kebijakan Departemen Perawatan PT PHE ONWJ dalam menentukan pola perawatan dari unit GCS.
10
3. Dasar pengembangan metode penentuan inteval waktu perawatan pencegahan pada penelitian mendatang.
1.5 Sistematika Penulisan Laporan
BAB 1 PENDAHULUAN
Berisi latar belakang penelitian, perumusan masalah, tujuan penelitian, manfaat penelitian serta batasan masalah dan asumsi-asumsi yang diguanakan dalam penelitian.
BAB 2 TINJAUAN PUSTAKA
Berisi referensi pustaka dan teori dasar yang digunakan untuk penelitian yang akan dilakukan.
BAB 3 METODE PENELITIAN
Berisi metode penelitian atau langkah-langkah dalam memecahkan masalah.
BAB 4 PENGOLAHAN DATA DAN PENILAIAN
KEANDALAN
Berisi pemodelan sistem, analisis variansi untuk data waktu antar kegagalan dan waktu perbaikan dan penentuan distribusi waktu antar kegagalan dan
maintanability serta penentuan parameter keandalan.
BAB 5 PENENTUAN INTERVAL WAKTU PERAWATAN
PENCEGAHAN
Berisi hasil optimasi interval waktu perawatan pencegahan dan jumlah tenaga kerja yang dapat meminimalkan laju biaya pemeliharaan pencegahan, serta keandalan dan ketersediaan pada interval waktu pemeliharaan pencegahan yang optimum.
BAB 5 KESIMPULAN DAN SARAN
11
BAB 2
TINJAUAN PUSTAKA
Perawatan pencegahan merupakan hal yang sangat penting dalam manajemen perawatan. Tepatnya pelaksanaan perawatan pencegahan dapat mengurangi angka kerusakan dan downtime peralatan. Berkurangnya angka tersebut dapat meningkatkan keandalan (reliability) dan tingkat kesiapan peralatan (availability).
2.1 Konsep Dasar Perawatan
Ada beberapa pengertian perawatan yang diungkapkan oleh para ahli, diantaranya:
a. Perawatan berarti suatu kombinasi dari setiap tindakan yang dilakukan untuk menjaga atau mempertahankan kualitas peralatan agar tetap dapat berfungsi dengan baik seperti dalam kondisi sebelumnya (Stephens, 2004).
b. Perawatan merupakan suatu kegiatan yang diarahkan pada tujuan untuk menjamin kelangsungan fungsional suatu sistem produksi sehingga dari sistem itu diharapkan menghasilkan output sesuai yang dikehendaki (Gasperz, 1992).
c. Peralatan merupakan suatu konsepsi dari semua aktivitas yang diperlukan untuk menjaga atau mempertahankan kualitas peralatan agar tetap berfungsi dengan baik seperti dalam kondisi sebelumnya (Supandi, 1990).
2.2 Jenis Perawatan
12
2.2.1 Perawatan Pencegahan (Preventive Maintenance)
Perawatan pencegahan adalah perawatan yang dilakukan secara terjadwal, umumnya secara periodik dimana sejumlah kegiatan seperti inspeksi, perbaikan, penggantian, pembersihan, pelumasan, penyesuaian dan penyamaan (Ebeling, 1997). Pengertian lain perawatan pencegahan adalah kegiatan perawatan yang dilakukan untuk mencegah timbulmya kerusakan dan menemukan kondisi yang menyebabkan fasilitas atau mesin produksi mengalami kerusakan pada waktu melakukan produksi (Assauri, 1999).
Pelaksanaan perawatan pencegahan sangat penting terutama untuk peralatan atau mesin yang dianggap sebagai unit yang kritikal. Terdapat beberapa kategori unit yang kritikal (Tampubolon, 2004), diantaranya:
a. Fasilitas atau peralatan yang berhubungan dengan keselamatan dan kesehatan kerja.
b. Fasilitas yang akan mempengaruhi kualitas produk yang dihasilkan. c. Fasilitas yang akan menyebabkan terhentinya seluruh proses produksi. d. Fasilitas dengan nilai investasi yang tinggi.
Dalam pelaksanaan perawatan pencegahan dapat dibedakan menjadi dua macam (Assauri, 2008), yaitu:
a. Perawatan Rutin
Perawatan rutin adalah kegiatan perawatan dan perawatan yang dilakukan secara rutin. Sebagai contoh kegiatan pengecekan visual, pembersihan, pelumasan dan pengujian mesin.
b. Perawatan Periodik
Perawatan periodik adalah kegiatan perawatan yang dilakukan secara periodik atau dalam jangka waktu tertentu, misalnya setiap satu bulan. Pelaksanaan perawatan periodik juga dapat dilakukan berdasarkan jumlah jam kerja mesin (running hours).
Beberapa manfaat dari perawatan pencegahan antara lain (Assauri, 2008):
a. Memperkecil overhaul (turun mesin).
13
c. Mengurangi biaya kerusakan atau penggantian mesin.
d. Memperkecil kemungkinan terjadinya produk-produk yang rusak. e. Meminimalkan persediaan suku cadang.
f. Memperkecil munculnya gaji tambahan yang diakibatkan adanya kerusakan.
g. Menurunkan biaya satuan dari produk pabrik.
2.2.2 Perawatan Perbaikan (Corrective Maintenance)
Perawatan perbaikan adalah kegiatan perawatan yang dilakukan setelah mesin atau fasilitas produksi mengalami kerusakan atau gangguan sehingga tidak dapat berfungsi dengan baik (Patrick, 2001). Perawatan perbaikan dapat dihitung dengan mean time to tepair (MTTR) dimana time to repair terdiri dari 3 kelompok (Patrick, 2001), yaitu:
a. Waktu persiapan
Merupakan waktu yang dibutuhkan untuk menemukan orang untuk mengerjakan perbaikan, waktu tempuh menuju lokasi dan membawa peralatan uji.
b. Waktu perawatan aktual
Merupakan waktu sebenarnya yang digunakan untuk melakukan perbaikan meliputi waktu yang dibutuhkan untuk mempelajari dan memetakan kerusakan, serta waktu yang dibutuhkan untuk melakukan dokumentasi terhadap perbaikan yang telah dilakukan.
c. Waktu tunggu
Merupakan waktu yang dibutuhkan untuk menunggu datangnya komponen dari mesin yang diperbaiki.
2.3 Konsep-Konsep Perawatan
2.3.1 Konsep Breakdown dan Downtime
14
Karakteristik kegagalan atau kerusakan pada mesin sehubungan dengan waktu dapat dilihat Gambar 2.1 sebagai berikut:
Gambar 2.1 Laju kerusakan mesin/bathtub curve (Wilkins, 2002)
Grafik tersebut sering disebut sebagai bathtub curve, terbagi menjadi tiga daerah kerusakan, yaitu:
a. Burn in Zone (Early Life)
Daerah ini adalah periode permulaan beroperasinya suatu komponen atau sistem yang masih baru (sehingga keandalanya masih 100%), dengan periode waktu yang pendek. Pada kurva ditunjukkan bahwa laju kerusakan yang awalnya tinggi kemudian menurun dengan bertambahnya waktu, atau diistilahkan sebagai decreasing failure rate (DFR). Kerusakan yang terjadi umumnya disebabkan karena proses manufacturing atau fabrikasi yang kurang sempurna.
b. Useful Life Time Zone
Periode ini mempunyai laju kerusakan yang paling rendah dan hampir konstan yang disebut constant failure rate (CFR). Kerusakan yang terjadi bersifat
15
failure rate-nya adalah konstan, persamaan keandalan yang digunakan adalah sebagai berikut:
(2.1)
Jika persamaan tersebut diterapkan pada sistem atau komponen yang masih baru, maka tingkat keandalannya diasumsikan pada pada keadaan 100% atau R0 = 100%. Untuk komponen atau sistem yang sudah tidak baru lagi, atau
sudah pernah mengalami maintenance, persamaannya dapat ditulis sebagai berikut:
(2.2)
Dengan:
R = nilai keandalan/reliability (%)
M = nilai keandalan setelah dilakukan perawatan/maintainability (%)
λ = laju kerusakan/failure rate c. Wear Out Zone
Periode ini adalah periode akhir masa pakai komponen atau sistem. Pada periode ini, laju kerusakan naik dengan cepat dengan bertambahnya waktu, yang disebut dengan istilah increasing failure rate (IFR). Periode ini berakhir saat keandalan komponen atau sistem ini mendekati nol, dimana kerusakan yang terjadi sudah sangat parah dan tidak dapat diperbaiki kembali.
2.3.2 Konsep Keandalan (Reliabliity)
16
distribusi kumulatif ini dikenal sebagai fungsi distribusi kegagalan kumulatif
(cumulative failure distribution function) atau disingkat distribusi kegagalan kumulatif (cumulative failure distribution). Distribusi kegagalan kumulatif ini biasanya dilambangkan dengan F(t).
Jika R(t) menyatakan fungsi keandalan dari suatu komponen atau suatu sistem sebagai fungsi waktu maka hubungan antara fungsi keandalan R(t) dan distribusi kegagalan kumulatif atau fungsi ketidakandalan F(t) dihubungkan oleh sebuah formula di bawah ini (Ebeling, 1997).
R(t) = 1 - F(t) (2.3)
Fungsi distribusi probabilitas merupakan turunan dari distribusi probabilitas kumulatif. Dalam terminologi keandalan fungsi distribusi probabilitas ini disebut dengan fungsi densitas kegagalan (failure density function). Fungsi densitas kegagalan ini, yang dinotasikan dengan f(t), dapat diturunkan baik dari fungsi ketidakandalan maupun fungsi keandalan seperti pada formula di bawah ini (Ebeling, 1997).
f(t) = =
(2.4)
Sebaliknya fungsi ketidakandalan maupun fungsi keandalan dapat diperoleh dari fungsi densitas kegagalan seperti yang dituliskan dalam
formulasi di bawah ini (Ebeling, 1997).
F(t) = (2.5)
dan
R(t) = 1 - F(t) = 1 -
= (2.6)
17
sedang keandalan diwakili daerah di bawah kurva dengan interval dari t sampai tak hingga.
Gambar 2.2. Tipikal Fungsi Densitas Kegagalan (Shankar, 2013)
Penilaian terhadap keandalan suatu sistem dapat didekati dengan dua metode, antara lain:
a. Analisis kuantitatif
Secara kuantitatif dapat dibedakan menjadi dua, yaitu: 1. Component level (physics of failure, statistics)
2. System level (fault tree analysis, markov analysis)
b. Analisis Kualitatif
Secara kulitatif dapat dibedakan menjadi tiga, yaitu: 1. Intangible decision matrix
2. Critical Analysis
3. failure mode effect analysis (FMEA)
2.3.3 Konsep Keterawatan (Maintainability)
Keterawatan adalah probabilitas suatu komponen atau sistem yang rusak untuk dapat diperbaiki dan kembali beroperasi dalam jangka waktu tertentu yang dalam pelaksanaannya sesuai dengan prosedur yang berlaku (Ebeling, 1997).
2.4 Pemodelan Keandalan Sistem
Terdapat beberapa pemodelan keandalan sistem, diantaranya:
2.4.1 Sistem Seri
Suatu sistem dikatakan memiliki pemodelan seri jika semua komponen saling terikat untuk membuat sistem berhasil beroperasi dan hanya satu kegagalan
18
komponen yang diperlukan untuk membuat sistem gagal. Blok diagram sistem seri dapat ditunjukkan pada Gambar 2.3 berikut:
Gambar 2.3. Blok Diagram Sistem Seri (Ebeling, 1997)
Dengan menganggap bahwa semua komponen bersifat independent, maka dapat diperoleh persamaan (Ebeling, 1997):
= Probabilitas semua sistem berfungsi = R1 . R2….Rn
= (2.7)
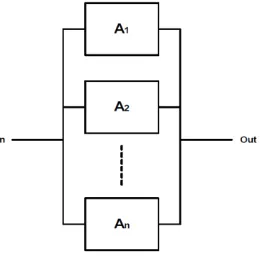
2.4.2 Sistem Paralel
Dalam sistem paralel semua komponen membuat sistem sukses yang berbeda, atau dengan kata lain diperlukan lebih dari komponen gagal untuk membuat sistem gagal. Blok diagram seperti pada Gambar 2.3 berikut:
Gambar 2.4 Blok Diagram Sistem Paralel (Ebeling, 1997)
Dengan menganggap semua komponen bekerja independent, maka dapat diperoleh persamaan (Ebeling, 1997):
= Probabilitas semua komponen gagal = P(A1 gagal) P(A2 gagal)… P(An gagal)
= (1-R1) . (1-R2)….(1-Rn)
19
2.4.3 Sistem Paralel dengan m Sukses dari n Unit
Dalam sistem ini terdapat sejumlah n komponen yang akan sukses hanya jika terdapat sejumlah m komponen suskses, persamaan untuk sistem ini sebagai berikut:
Rm/n =
(2.9)
(2.10)
2.4.4 Kombinasi Seri dan Paralel
Salah satu contoh sistem kombinasi adalah sebagai berikut:
Gambar 2.5. Blok Diagram Kombinasi Sistem dan Paralel (Ebeling, 1997) Nilai keandalan system yang tersusun seri dan paralel dapat dihitung dengan menggunakan persamaan berikut (Ebeling, 1997):
Rx = [1-(1-R1)(1-R2)], Ry = Rx(R3), Rz = R4(R5)
Rs = [1-(1-Ry)(1-Rz)](R6) (2.11)
2.5 Laju Kegagalan
Adalah rasio jumlah kegagalan dalam selang watu tertentu dengan total waktu operasi komponen atau sistem. Laju kegagalan dapat dirumuskan sebagai berikut (Ebeling, 1997):
λ
=
(2.12)Keterangan:
20 T = Total waktu kegagalan
2.6 Mean Time Between Failure (MTBF)
MTTBF adalah waktu rata-rata antar kegagalan berlaku untuk komponen/sistem yang dapat diperbaiki (Ebeling, 1997).
MTBF =
, atau (2.13)
MTBF = = (2.14)
2.7 Mean Time to Failure (MTTF)
MTTF dalah rata-rata antar kegagalan yang berlaku untuk komponen/sistem yang tidak dapat diperbaiki (Ebeling, 1997).
MTTF = (2.15)
2.8 Mean Time to Repair (MTTR)
MTTR adalah waktu yang diperlukan untuk memulihkan suatu sistem dari sebuah kegagalan (Ebeling, 1997).
MTTR =
,atau (2.16)
MTTR = (2.17)
2.9 Konsep Kesiapan (Availability)
Kesiapan (availability) adalah keadaan siap suatu mesin/peralatan baik dalam jumlah (kuantitas) maupun kualitas sesuai dengan kebutuhan yang digunakan untuk melaksanakan proses operasi. Kesiapan (availability) tersebut dapat digunakan untuk menilai keberhasilan atau efektifitas dari kegiatan perawatan yang telah dilakukan (Ebeling, 1997).
(2.18) =
(2.19)
2.10 Analisis Variansi
21
hanya dua buah. Dengan demikian, ANAVA dapat dipandang sebagai teknik t-tes yang diperluas. Analisis ini dilakukan dengan menguraikan seluruh variansi atas bagian-bagian yang diteliti. Pada tahap ini, akan dilakukan pengklasifikasian hasil eksperimen secara statistik sesuai dengan sumber variasi sehingga dapat mengidentifikasi kontribusi faktor. Dengan demikian akurasi perkiraan model dapat ditentukan. Analisis variansi pada matriks ortogonal dilakukan berdasarkan perhitungan jumlah kuadrat untuk masing-masing kolom. Analisis variansi digunakan untuk menganalisis data percobaan yang terdiri dari satu faktor atau lebih dengan satu level atau lebih (Montgomery, 2009). Perhitungan ANAVA untuk satu faktor yang dipilih secara tetap (fixed) ditunjukkan pada Tabel 2.1 dan meliputi derajat bebas (db), jumlah kuadrat (sum of square, SS), kuadrat tengah (mean of square, MS) dan fhitung.
Tabel 2.1 Analisis Variansi
Sumber Variasi Db SS MS Fhitung
Faktor A νA SSA MSA FA
Error νerror SSerror MSerror
22
SSE = Jumlah kuadrat error
= SST - SSA (2.27)
N = Jumlah total percobaan
nAi = Jumlah total pengamatan faktor A
2.11 Uji F
Uji F digunakan dengan tujuan untuk menunjukkan bukti adanya perbedaan pengaruh masing-masing faktor dalam percobaan (Soejanto, 2009). Uji F dilakukan dengan membandingkan variansi yang disebabkan oleh masing-masing faktor dengan variansi error. Variansi error adalah variansi setiap individu dalam pengamatannya timbul karena faktor-faktor yang tidak dapat dikendalikan. Hipotesis yang digunakan dalam pengujian ini adalah :
H0 : μ1= μ2= μ3= ... = μk
H1 : Sedikitnya ada satu pasangan μyang tidak sama
Kegagalan menolak H0 mengindikasikan tidak adanya pengaruh faktor A
terhadap respon, sedangkan penolakan H0 mengindikasikan adanya pengaruh
23
Bila menggunakan perangkat komputasi statistik, kegagalan menolak H0
dilakukan jika P-value lebih besar daripada α (tingkat signifikansi). Kegagalan menolak H0 juga dilakukan apabila nilai Fhitung lebih besar dari dua (Park, 1996). 2.12 Uji Asumsi Residual
Pada analisis variansi terdapat asumsi bahwa residual bersifat bebas satu sama lain (independen), mempunyai mean nol dan variansi konstan (identik), serta berdistribusi normal. Pemeriksaan asumsi IIDN~(0, ) digunakan untuk mengetahui residual yang dihasilkan setelah melakukan percobaan sudah memenuhi ketiga asumsi tersebut. Residual didefinisikan sebagai (Montgomery, 2009):
A. Uji Asumsi Residual Independen
Uji independen digunakan untuk menjamin bahwa pengamatan telah dilakukan secara acak, yang berarti antar pengamatan tidak ada korelasi (independen). Pemeriksaan asumsi ini dilakukan dengan menggunakan plot auto correlation function (ACF). Residual bersifat independen jika nilai korelasi berada dalam interval ±
.
B. Uji Asumsi Residual Identik
Pemeriksaan residual identik dilakukan untuk melihat apakah residual memenuhi asumsi identik. Suatu data dikatakan identik apabila plot residualnya menyebar secara acak dan tidak membentuk suatu pola tertentu. Nilai variansnya rata-rata sama antara varians satu dengan yang lainnya. Hal ini dilakukan dengan memeriksa plot terhadap Ῡl(secara visual).
C. Uji Asumsi Distribusi normal
Pemeriksaan residual berdistribusi normal dilakukan untuk melihat apakah residual memenuhi asumsi berdistribusi normal, apabila plot residualnya
2
24
cenderung mendekati garis lurus (linier). Kolmogorov-Smirnov normality test
digunakan pada pengujian kenormalan residual. Hipotesis yang digunakan adalah: H0 : Residual berdistribusi normal.
H1 : Residual tidak berdistribusi normal.
Gagal menolak H0 apabila P-value > α.
2.13 Distribusi Data Kegagalan dan Maintainability
Pengolahan data keandalan dan maintainability dapat dilakukan dengan beberapa jenis distribusi kontinyu, diantaranya adalah distribusi eksponensial,
Weibull, normal, dan lognormal. Parameter-parameter distribusi yang diperoleh dapat digunakan untuk menentukan: fungsi padat peluang/probability density function (pdf), keandalan R(t), laju kegagalan f(t), MTBF dan MTTR.
2.13.1 Distribusi Data Kegagalan
A.Distribusi Weibull 2 Parameter
Fungsi padat peluang (pdf) dari distribusi Weibull 2 parameter adalah (Ebeling, 1997):
(2.33)
Dengan:
f(T) > 0, t > 0, > 0, β > 0
= parameter skala (scale parameter) = parameter bentuk (shape parameter)
Jika distribusi kerusakan suatu komponen mengikuti distribusi Weibull 2 parameter, maka fungsi keandalannya adalah:
R(t) = 1 –F(t) = exp (2.34)
Laju kegagalan pada distribusi Weibull 2 parameter dihitung dengan persamaan:
(2.35)
25
MTBF = Г ( (2.36)
Nilai Γ menunjukkan nilai fungsi gamma yang dapat diperoleh dari Tabel fungsi gamma atau dihitung dengan bantuan perangkat lunak Microsoft Excel.
B.Distribusi Weibull 3 Parameter
Fungsi padat peluang (pdf) dari distribusi Weibull 3 parameter adalah (Ebeling, 1997):
(2.37)
Dengan:
η = parameter skala (scale parameter), η > 0 β = parameter bentuk (shape parameter) γ = parameter lokasi (location parameter)
Jika γ = 0 maka diperoleh distribusi Weibull dengan 2 parameter. Jika distribusi kegagalan suatu komponen mengikuti distribusi Weibull 3 parameter, maka fungsi keandalannya adalah:
R(t) = 1 –F(t) = exp – (2.38)
Laju kegagalan pada distribusi Weibull 3 parameter dihitung dengan persamaan:
(2.39)
Persamaan rata-rata waktu antar kegagalan pada distribusi Weibull 3 parameter adalah:
MTBF = Г ( (2.40)
Nilai Γ menunjukkan nilai fungsi gamma yang dapat diperoleh dari Tabel fungsi gamma atau dihitung dengan bantuan perangkat lunak Microsoft Excel.
C.Distribusi Lognormal
Fungsi padat peluang (pdf) dari distribusi lognormal adalah (Ebeling, 1997):
26
Jika distribusi kegagalan suatu komponen mengikuti distribusi lognormal, maka fungsi keandalannya adalah:
(2.42)
Laju kegagalan pada distribusi lognormal dihitung dengan persamaan:
(2.43)
Persamaan rata-rata waktu antar kegagalan pada distribusi lognormal parameter adalah:
(2.44)
2.13.2 Distribusi Data Maintainability
A.Distribusi Weibull 2 Parameter
Fungsi padat peluang (pdf) dari distribusi Weibull 2 parameter adalah (Ebeling, 1997):
(2.45)
dengan
f(T) ≥ 0, t ≥ 0, η > 0, β > 0,
η = parameter skala (scale parameter)
β = parameter bentuk (shape parameter)
Jika data waktu perbaikan berdistribusi Weibull 2 parameter, maka fungsi
maintainability dari data tersebut adalah:
M(t) = 1- exp (2.46)
Persamaan rata-rata waktu perbaikan pada distribusi Weibull 2 parameter adalah:
MTTR = Г ( (2.47)
Nilai Γ menunjukkan nilai fungsi gamma yang dapat diperoleh dari Tabel fungsi gamma atau dihitung dengan bantuan perangkat lunak Microsoft Excel.
B.Distribusi Weibull 3 Parameter
27
(2.48)
dengan
η = parameter skala (scale parameter), η > 0
β = Parameter bentuk (shape parameter)
γ = parameter lokasi (location parameter)
Jika data waktu perbaikan berdistribusi Weibull 3 parameter, maka fungsi
maintainability dari data tersebut adalah:
M(t) = 1 –exp – (2.49)
Persamaan rata-rata waktu perbaikan pada distribusi Weibull 3 parameter adalah:
MTTR = Г ( (2.50)
Nilai Γ menunjukkan nilai fungsi gamma yang dapat diperoleh dari Tabel fungsi gamma atau dihitung dengan bantuan perangkat lunak Microsoft Excel.
C.Distribusi Lognormal
Waktu perbaikan dari suatu komponen (t) diasumsikan memiliki distribusi lognormal, bila nilai ln(t) mengikuti distribusi normal dengan nilai
rata-rata μ dan variansinya adalah . Fungsi padat peluang (pdf) dari distribusi lognormal adalah (Ebeling, 1997):
(2.51)
Jika data waktu perbaikan berdistribusi lognormal, maka fungsi
maintainability dari data tersebut adalah:
(2.52)
Rata-rata waktu perbaikan pada distribusi lognormal adalah:
(2.53)
2.14 Pengujian Distribusi
28 1. Average Goodness of Fit (AvGOF)
Untuk menganalisis kesesuaian data dapat dimanfaatkan uji goodness of fit (kesesuaian) antara distribusi frekuensi hasil pengamatan dengan distribusi frekuensi yang diharapkan. Uji goodness of fit berdasarkan pada uji Kolmogorov– Smirnov, yang beranggapan bahwa distribusi variabel yang sedang diuji bersifat kontinu dan sampel diambil dari populasi sederhana.
Nilai AvGOF didapatkan dari uji Kolmogorov-Smirnov (KS) dengan membandingkan distribusi empiris data dengan distribusi teoritis tertentu yang dihipotesiskan. Pada prinsipnya jika nilai KS lebih kecil maka akan lebih baik. Persamaan untuk menghitung parameter KS adalah (Reliasoft, 2005):
(2.54)
dengan
= fraksi kumulatif jumlah data kegagalan hasil observasi pada (t) terhadap total (t) pengamatan.
= fraksi kumulatif jumlah kegagalan hasil dari perhitungan jenis distribusi yang diharapkan pada (t) terhadap total (t) perhitungan.
Hipotesa yang digunakan adalah:
H0: data mengikuti suatu distribusi kontinu tertentu
H1: data mengikuti suatu distribusi kontinu yang lain
Jika Dn < Dkritis, maka H0 gagal ditolak, dengan Dkritis bisa didapatkan dari Tabel uji KS yang tersedia di buku statistik. Pada perangkat lunak Weibull++6, nilai AvGOF adalah selisih dari nilai data aktual dan data yang dihasilkan dari referensi distribusi yang dimiliki perangkat lunak Weibull++6 (Reliasoft, 2005). Sehingga semakin kecil AvGOF maka semakin baik distribusi yang diuji dibandingkan dengan yang lain.
2. Average of Plot (AvPlot)
AvPlot didasarkan pada normalized index dari uji plot fit. Hasil uji ditunjukkan dalam AvPlot index yang merupakan normalisasi dari koefisien
29
AvPlot index didapatkan dengan melakukan normalisasi dari koefisien korelasi di atas. Ketentuan yang dipakai adalah jika semakin kecil nilai AvPlot, maka distribusi yang diuji akan lebih baik daripada yang lain.
3. Nilai dari Likelihood Function Ratio (LKV)
LKV adalah suatu metode untuk menentukan jenis distribusi dari suatu data dengan cara membandingkan kemiripan dari dua model. Uji ini berdasarkan pada likelihood ratio, yang menggambarkan berapa kali terdapat kecocokan suatu kelompok data terhadap karakteristik suatu model. Likelihood ratio diukur berdasarkan nilai logaritmanya sehingga sering disebut log-likelihood ratio. Persamaan log-likelihood adalah (Reliasoft, 2005):
(2.56)
Nilai maksimum dari persamaan 2.54 didapatkan dengan menurunkan persamaan tersebut secara parsial dan kemudian disamakan dengan nol.
30
Weibull++6 dilakukan pemeringkatan yang didasari oleh pembobotan dari masing-masing ketiga pengujian distribusi. Hasil pembobotan yang mempunyai nilai terendah dari distribusi tersebut menunjukkan distribusi yang terbaik untuk data waktu antar kegagalan dan lama waktu perbaikan yang dimaksud. Distribusi terbaik inilah yang akan digunakan untuk menghitung nilai keandalan dan
maintainability secara kuantitatif.
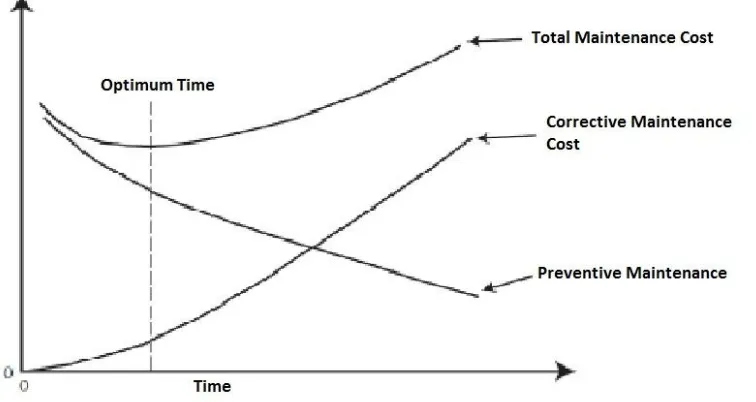
2.15 Laju Biaya Perawatan Pencegahan
Biaya-biaya yang muncul untuk perawatan sangat berkaitan dengan usaha optimasi interval waktu perawatan. David (2011) menyatakan bahwa ada tiga kegiatan perawatan, yaitu:
1. Inspeksi
2. Perawatan pencegahan 3. Perawatan prediktif
Perawatan pencegahan dapat dilakukan jika laju kegagalan semakin tinggi, dimana pada kurva bathtub ditunjukkan dengan distribusi Weibull yang mempunyai nilai β > 1. Daerah ini juga disebut dengan nama wear out area
(daerah keusangan). Kegagalan peralatan atau sistem yang terjadi di daerah ini dapat dicegah dengan perawatan pencegahan (Jardine, 1970). Persamaan untuk laju biaya perawatan pencegahan adalah:
(2.58)
(2.59)
Dengan,
= total biaya per unit waktu
= biaya perawatan terencana/pencegahan = biaya perbaikan kerusakan
= interval waktu antar perawatan pencegahan
31
2.16 Optimasi Interval Waktu Perawatan Pencegahan
Keandalan dan maintainability alat atau sistem dapat diiterasi dengan menggunakan random number yang dihasilkan dari fungsi RAND () di perangkat lunak Microsoft Excel. Fitur ini dapat digunakan untuk menghasilkan bilangan acak antara 0 dan 1. Sebagai contoh, suatu keandalan dari sub sub sistem (i) yang data waktu antar kegagalannya (ti) mengikuti distribusi Weibull 3 parameter (persamaan 2.32), dapat disusun ulang dengan membuat keandalan atau R(ti) menjadi variabel bebas dan ti sebagai variabel tidak bebas:
R(t) = 1 –F(t) = exp – (2.60)
(2.61)
Dalam hubungannya dengan waktu perawatan, maka selanjutnya notasi diganti dengan notasi .Kriteria yang digunakan untuk menyatakan bahwa sub-sub sistem akan sukses atau gagal adalah:
1. Sistem sukses bila > atau 2. Sistem gagal bila < .
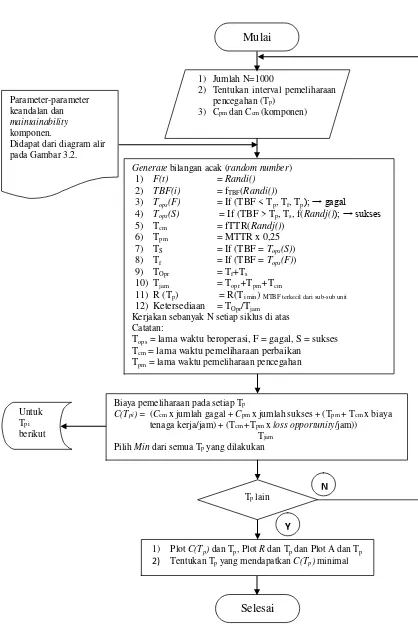
Dengan menentukan interval waktu perawatan pencegahan ( ) dan jumlah iterasi sebanyak n bilangan acak yang diinginkan, maka keandalan sub-sub sistem dihitung dengan persamaan berikut (Barringer, 1997):
n = Jumlah percobaan keseluruhan
Iterasi untuk maintainability dilakukan dengan mensubsitusi variabel
maintainability dengan random number antara 0 dan 1. Contoh model
32
(2.63)
adalah lama waktu perbaikan atau perawatan yang dianggap sudah
termasuk waktu-waktu untuk logistik, administrasi dan perbaikannya sendiri. Jika kegiatan yang dilakukan adalah perbaikan dari kerusakan, maka waktu yang digunakan adalah . Waktu yang digunakan untuk perawatan pencegahan adalah . Iterasi dan dilakukan dengan cara berurutan seperti yang diilustrasikan pada Gambar 2.6 dan dengan menggunakan langkah-langkah sebagai berikut (Giani, 2006):
1. Penetapan parameter-parameter keandalan yang akan digunakan. 2. Penetapan nilai pertama dari .
3. Penentuan dua kelompok random number, Rand1() untuk iterasi dan
Rand2() untuk iterasi .
4. Jika > , maka sub sub sistem tidak mengalami kerusakan atau = , namun tetap dilakukan perawatan pencegahan selama . 5. Jika < , maka sub sub sistem mengalami kerusakan atau = ,
sehingga harus dilakukan perbaikan selama .
6. Pengulangan langkah 3 sampai 5 sesuai dengan jumlah total run yang digunakan.
7. Pengulangan langkah 2 sampai 6 dengan nilai yang berbeda-beda. 8. Pembuatan kurva laju biaya perawatan dan seperti yang diilustrasikan
pada Gambar 2.7.
33
Gambar 2.7 Pengaruh Terhadap Laju Biaya Perawatan Pencegahan (Jardine, 1970)
Dengan melakukan iterasi angka acak untuk mendapatkan
, maka diperoleh ketersediaan dari sub sub sistem tersebut dan
laju biaya perawatan pencegahan, sesuai dengan persamaan berikut (Laggoune, 2009):
(2.64)
(2.65)
(2.66)
(2.67)
dengan
i = Subskrip (i) untuk sub sub sistem
= Interval waktu perawatan pencegahan sub sistem r = Subskrip (r) untuk run
= Lama perbaikan sub sub sistem (i) run (i) N = Total percobaan
= Lama operasi sub sistem = + +
34
s = Superskrip (s), indikator sukses = Keandalan sub sistem
= Biaya perawatan pencegahan sub sub sistem (i)
= Ketersediaan sub sistem
= Biaya perbaikan sub sub sistem (i)
= Laju biaya perawatan pencegahan sub sistem
= Waktu hidup sub sub sistem (i) pada run ke (r)
= Biaya loss opportunity = Biaya tenaga kerja perjam
2.17 Posisi Penelitian
Rakhmad (2011) melakukan penelitian yang berjudul “Optimasi Interval
Waktu Perawatan Pencegahan pada Sistem Pemasok Bahan Bakar Turbin Gas.” Tujuan dari penelitian ini adalah untuk meningkatkan keandalan sistem. Hasil dari optimasi ini adalah keandalan sistem meningkat hingga 74% dan penghematan biaya perawatan juga dapat ditingkatkan menjadi 139,9 USD/hari dari 145,7 USD/hari.
Sutanto (2011) melakukan penelitian yang berjudul “Optimalisasi
Interval Waktu Penggantian Komponen Mesin Packer Tepung Terigu Kemasan 25 kg di PT. X.” Penelitian ini bertujuan untuk menentukan interval waktu optimal untuk preventive maintenance pada sub unit mesin packer. Hasil dari penelitian ini adalah didapatkannya waktu optimal untuk melakukan preventive maintenance dengan laju biaya terendah dan dapat menghemat biaya perawatan hingga 14,6%.
Fesa (2017) melakukan penelitian yang berjudul “Penentuan Interval Waktu Perawatan dan Jumlah Tenaga Kerja Pada Peralatan Sub Unit RKC 3 di PT. X Pabrik Tuban. Hasil dari penelitian ini adalah interval waktu perawatan adalah 155,97 hari dengan laju biaya perawatan sebesar Rp. 33.100/jam.
35
waktu perawatan dan laju biaya perawatan pada unit yang menjadi obyek penelitian.
36
37
BAB 3
METODE PENELITIAN
Metode penelitian mengandung suatu proses yang terstruktur dan memerlukan aturan serta langkah-langkah tertentu dalam pelaksaannya. Langkah-langkah dasar yang dilakukan untuk mencapai tujuan ini adalah sebagai berikut:
1. Studi lapangan dan identifikasi masalah 2. Studi pustaka
3. Perumusan masalah dan tujuan penelitian 4. Pengambilan data
5. Pengolahan data
6. Penarikan kesimpulan dan saran
Langkah-langkah tersebut dapat dilihat pada diagram alur penelitian yang ditunjukkan pada Gambar 3.1.
3.1 Studi Lapangan dan Identifikasi Masalah
Sistem yang menjadi obyek penelitian adalah unit GCS. Data kegagalan komponen diperoleh dari data failure and down time unit GCS. Selain itu, untuk memperkaya data dilakukan pengambilan data work order (WO) atau list pekerjaan yang dilakukan oleh pihak luar. Kedua data tersebut diperoleh dari Departemen Perawatan.
3.2 Studi Pustaka
38
Gambar 3.1 Diagram Alir Penelitian Selesai 1. Penentuan komponen yang kritis
2. Penggabungan data waktu antar kegagalan dan data waktu perbaikan dengan menggunakan ANAVA
3. Penilaian keandalan
Penentuan distribusi waktu antar kegagalan
Penentuan parameter distribusi waktu antar kegagalan Penentuan distribusi waktu perbaikan
Penentuan parameter distribusi waktu perbaikan 4. Iterasi Ti dan Tp untuk menentukan:
Interval waktu pemeliharaan pencegahan pada setiap sistem (Tp)
Penarikan Kesimpulan dan 1. Pengamatan kondisi aktual di
lapangan
2. Wawancara dengan departemen perawatan.
Pelaksanaan studi pustaka:
1. Konsep pengolahan data statistika. 2. Konsep distribusi waktu antar
kegagalan dan waktu perbaikan. 3. Konsep Keandalan.
Penetapan perumusan masalah dan tujuan penelitian
Pengumpulan data: 1. Diagram proses dari unit GCS
2. Data waktu antar kegagalan dan waktu perbaikan
3. Biaya perawatan dan potensi kerugian akibat penurunan dari volume minyak yang diangkat.
39
3.3 Perumusan Masalah dan Tujuan Penelitian
Setelah melakukan studi lapangan, identifikasi masalah dan studi pustaka, maka tahap selanjutnya adalah merumuskan pokok permasalahan yang dihadapi dan tujuan yang akan dicapai dalam penelitian ini.
3.4 Pengumpulan Data
Pengumpulan data dilakukan pada 6 anjungan minyak lepas pantai yang memiliki GCS dengan karakteristik dan usia yang sama. Keenam anjungan tersebut adalah Mike-Mike, Echo, Bravo, Lima, Foxtrot, dan KLA. Sumber data yang digunakan adalah data failure anddown time dari unit GCS dan work order
untuk periode 1 Januari 2012–31 Desember 2016. Data yang diperlukan pada penentuan interval waktu perawatan pencegahan meliputi:
1. Data waktu antar kegagalan komponen, waktu perbaikan, dan potensi kerugian perusahaan yang diperoleh dari Departemen Perawatan. 2. Biaya perawatan yang dibutuhkan.
3.5 Pengolahan Data
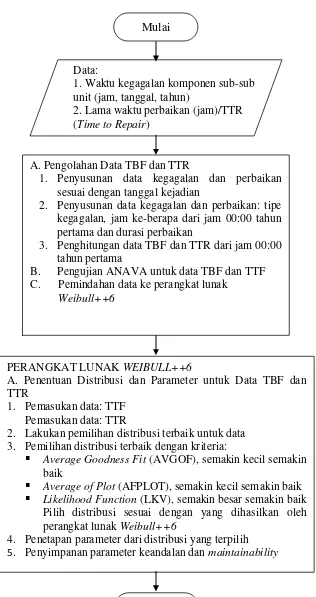
Pada tahap ini, dilakukan konversi data downtime dan work order dari
shutdown investigation report menjadi data watu antar kegagalan (TBF) dan waktu perbaikan (TTR). Selanjutnya, dilakukan penggabungan data TBF dan TTR pada 6 anjungan minyak lepas pantai dengan menggunakan ANAVA. Tujuan dari dilakukannya ANAVA adalah untuk mendapatkan jumlah data kegagalan masing-masing komponen sebanyak lebih atau sama dengan 20 data. Langkah berikutnya adalah menentukan jenis distribusi data, fungsi padat peluang untuk kegagalan, laju kegagalan, keandalan peralatan, dan fungsi padat peluang untuk pemeliharaan dengan bantuan perangkat lunak Weibull++6. Alur pengolahan data dengan perangkat lunak Weibull++6 ditunjukkan pada Gambar 3.2. Iterasi Ti dan Tp digunakan untuk menentukan interval waktu pemeliharaan pencegahan dan jumlah tenaga kerja yang mempunyai laju biaya minimum. Pada iterasi tersebut digunakan random number generator yang terdapat pada perangkat lunak
40
sub unit dihitung dari fungsi keandalan sub-sub unit yang memiliki mean time between failure (MTBF) terendah.
3.6 Penarikan Kesimpulan dan Saran
41
Gambar 3.2 Diagram Alir Pengolahan Data dengan Perangkat Lunak Weibul++6
Data:
1. Waktu kegagalan komponen sub-sub unit (jam, tanggal, tahun)
2. Lama waktu perbaikan (jam)/TTR (Time to Repair)
2. Lakukan pemilihan distribusi terbaik untuk data 3. Pemilihan distribusi terbaik dengan kriteria:
Average Goodness Fit (AVGOF), semakin kecil semakin baik
Average of Plot (AFPLOT), semakin kecil semakin baik Likelihood Function (LKV), semakin besar semakin baik
Pilih distribusi sesuai dengan yang dihasilkan oleh perangkat lunak Weibull++6
4. Penetapan parameter dari distribusi yang terpilih
5. Penyimpanan parameter keandalan dan maintainability
Selesai Mulai
A. Pengolahan Data TBF dan TTR
1. Penyusunan data kegagalan dan perbaikan sesuai dengan tanggal kejadian
2. Penyusunan data kegagalan dan perbaikan: tipe kegagalan, jam ke-berapa dari jam 00:00 tahun pertama dan durasi perbaikan
3. Penghitungan data TBF dan TTR dari jam 00:00 tahun pertama
B. Pengujian ANAVA untuk data TBF dan TTF C. Pemindahan data ke perangkat lunak
42
Selesai
1) Plot C(Tp) dan Tp, Plot R dan Tp dan Plot A dan Tp
2) Tentukan Tp yang mendapatkan C(Tp) minimal Tp lain
Generate bilangan acak (random number)
1) F(t) = Randi()
Kerjakan sebanyak N setiap siklus di atas Catatan:
Tops = lama waktu beroperasi, F = gagal, S = sukses
Tcm = lama waktu pemeliharaan perbaikan
Tpm = lama waktu pemeliharaan pencegahan
Biaya pemeliharaan pada setiap Tp
C(Tpi) = (Ccm x jumlah gagal + Cpm x jumlah sukses + (Tpm + Tcm x biaya
43
BAB 4
PENGOLAHAN DATA
4.1 Pengolahan Data Antar Waktu Kegagalan dan Waktu Perbaikan
Komponen penyebab kegagalan pada masing-masing bagian telah ditunjukkan pada Gambar 1.4, sehingga dapat dihitung waktu antar kegagalan atau time between failure (TBF) dan waktu perbaikan atau time to repair (TTR) dari masing-masing komponen. Dalam pengolahan data telah ditetapkan frekuensi minimum kegagalan adalah 20 data kegagalan, akan tetapi data yang dimiliki belum memenuhi kriteria tersebut. Oleh karena itu, dilakukan analisis variansi (ANAVA) untuk menggabungkan data TBF dan TTR dari anjungan lain yakni Mike-Mike, Echo, Bravo, Lima, Foxtrot, dan KLA. Asumsi-asumsi yang digunakan untuk menggabungkan data tersebut adalah:
1. Memiliki konfigurasi rangkaian yang sama. 2. Memiliki tipe dan jenis komponen yang sama.
3. Memiliki parameter operasi dan waktu operasi yang sama. 4. Memiliki perlakuan pemeliharaan yang sama.
Penggabungan data TBF dan TTR dilakukan berdasarkan hasil ANAVA. Apabila data TBF dan TTR dari keenam anjungan tersebut dapat dianggap berasal dari populasi yang sama, maka dapat dilakukan penggabungan data. Tabel 4.1 menunjukkan data TBF dan TTR pada komponen back up seal oil pada anjungan Mike-Mike, Echo, Bravo, Lima, Foxtrot, dan KLA.
Tabel 4.1 TBF dan TTR Komponen Back Up Seal Oil.
44
Tabel 4.1 TBF dan TTR Komponen Back Up Seal Oil (lanjutan).
Sumber: PHE ONWJ (2016).
Setelah melakukan uji ANAVA, langkah selanjutnya adalah uji asumsi residual. Berikut merupakan hasil pengujian terhadap residual dari data TBF dan TTR dari komponen back up seal oil.
A. Uji Independen
Pengujian independen pada penelitian ini dilakukan dengan menggunakan
auto correlation function (ACF). Berdasarkan plot ACF yang ditunjukkan pada Gambar 4.1 tidak ada nilai ACF pada setiap lag yang berada di luar dari batas interval. Hal ini membuktikan bahwa tidak ada korelasi antar residual sehingga residual bersifat independen.
(a) TBF (b) TTR
Gambar 4.1 Plot ACF untuk Data Back Up Seal Oil.
B. Uji Identik
Uji residual identik pada penelitian ini dilakukan secara visual, yaitu dengan menggambarkan plot antara residual dan observation order seperti ditunjukkan pada Gambar 4.2. Plot tersebut menunjukkan bahwa data tersebar secara acak dan tidak membentuk pola tertentu. Hal ini menunjukkan bahwa asumsi residual bersifat identik terpenuhi.
LIMA (4) FOXTROT (5) KLA (6)
TBF TTR TBF TTR TBF TTR
12397.0 3.8 9651.0 3.4 15617.0 3.2
13211.0 2.9 10487.0 3.0 12471.0 3.3
552.0 3.4 12142.0 3.4 14128.0 3.1
45
(a) TBF (b) TTR
Gambar 4.2 Plot Residual Versus Observation Order. C. Uji Kenormalan
Pengujian asumsi residual normal (0, σ2) dilakukan melalui uji
Kolmogorov-Smirnov. Hipotesis yang digunakan adalah: H0: Residual berdistribusi normal
H1: Residual tidak berdistribusi normal
H0 ditolak jika P-Valuelebih kecil dari pada α = 0,05. Gambar 4.3 menunjukkan
pengujian pada komponen back up seal oil dengan uji Kolmogorov-Smirnov.
(a) TBF (b) TTR
Gambar 4.3 Plot Uji Distribusi Normal.
P-Value > 0,150 yang berarti lebih besar dari α= 0,05. Oleh karena itu dapat disimpulkan bahwa H0 gagal ditolak atau residual berdistribusi
normal untuk TBF dan TTR.
Mean bernilai sebesar 7,27 x 10-14 untuk TBF dan 8,88 x 10-17untuk TTR yang berarti mendekati nol.
Variansi residual adalah sebesar 0,0133 untuk TBF dan 0,014 untuk TTR. Dengan demikian asumsi residual berdistribusi normal dengan nilai mean