3 METODE
Metode penelitian metafile penyusun struktur digraf menggunakan algoritme Document Index Graph (DIG) terdiri atas beberapa tahapan yaitu tahap analisis masalah dan studi literatur dari penelitian terkait, tahap praproses data, tahap implementasi algoritme, tahap pembangkitan metafile, tahap representasi digraf dan tahap analisis output hasil pengelompokan. Metode penelitian dapat dilihat pada Gambar 5.
Mulai Analisa Masalah Studi Literatur Penelitian terkait Tokenisasi Stop-word removal Stemming Penetapan nilai jarak intercluster Penetapan nilai jarak intracluster Penetapan jumlah dokumen Konfigurasi Verteks dan Edge
Struktur digraf untuk dokumen tunggal Struktur digraf untuk dokumen gabungan Identifikasi klusterisasi yang dihasilkan Selesai
Praproses data Implementasi
Document Index Graph Pembangkitan Metafile
Representasi Digraf
Analisis hasil klusterisasi
Gambar 5 Metode penelitian
Perlakuan pada penelitian ini adalah: jumlah dokumen yang digunakan untuk dokumen latih dan dokumen uji, term frequency threshold sebagai batas frekuensi kemunculan kata yang akan digunakan untuk pengelompokan dan output metafile yang dihasilkan. Faktor dan level penelitian ini ditampilkan pada Tabel 1.
Tabel 1 Faktor dan level penelitian
Faktor Level
Jumlah Dokumen Pengujian algoritme dilakukan pada 20 dokumen uji dan 50-100 dokumen latih Stemming Analisis Masalah Studi Literatur Penelitian Terkait Analisis hasil Clustering Konfigurasi
Pengukuran nilai precision, recall dan accuracy dilakukan pengujian terhadap 20, 25, 50 dan 100 dokumen latih
Term Frequent Threshold Batas kemunculan kata pada dokumen minimal 20 kali
Output metafile Menggunakan format bahasa DOT untuk penyusunan struktur digraf untuk
dokumen tunggal dan dokumen
gabungan
Analisis Masalah dan Studi Pustaka
Pada tahap ini dilakukan analisis dan studi pustaka terhadap permasalahan yang dihadapi. Permasalahan tersebut yaitu mengenai peningkatan volume data pada dokumen web yang berkembang saat ini meskipun format dokumen yang ditemukan telah terstruktur dengan baik. Fenomena tersebut dapat diatasi dengan melakukan teknik text mining dengan melakukan proses pengelompokan terhadap dokumen-dokumen web dengan merujuk pada pola-pola dan keterkaitan isi dalam dokumen-dokumen tersebut. Pengelolaan informasi dengan text mining memberikan gambaran dari topik dalam satu set besar dokumen tanpa harus membaca isi dokumen satu per satu. Hal ini dapat dilakukan dengan pengelompokan.
Pencarian dan pembelajaran mengenai literatur yang berkaitan dengan penelitian, yang dilakukan yaitu menerapkan algoritme pengelompokan yang mudah difahami baik secara input, proses maupun output. Salah satu algoritme yang telah dikembangkan dari penelitian sebelumnya adalah algoritme Document Index Graph (DIG). Literatur tersebut dapat berupa buku, jurnal, dan media yang dapat dibuktikan kebenarannya.
Tahap Praproses Data
Tahap praproses data mengubah bentuk asli data tekstual ke dalam struktur dokumen yang siap untuk proses data mining, dan telah dapat mengidentifikasi fitur teks yang paling signifikan yang dapat menentukan perbedaan di antara kategori-kategori tertentu (Srividhya 2010). Dengan kata lain, tahap ini adalah proses penggabungan sebuah dokumen baru ke dalam sistem temu kembali informasi dan menentukan fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen.
Data penelitian yang digunakan untuk pengujian pengelompokan menggunakan data REUTERS-21578. Data tersebut merupakan koleksi dari dokumen-dokumen yang pernah ditulis di REUTERS newswire (format SGML) pada tahun 1987. Dokumen-dokumen tersebut memiliki karakteristik data kategorikal dan disusun kembali dan dilakukan pengindeksan dalam beberapa kategori oleh para staf di Reuters (UCI KDDI Archive, 1999). Data berisi 21578 dokumen berita yang terbagi dalam 9603 data training, 3299 dokumen uji, dan 8676 dokumen yang tidak digunakan. Dokumen terdiri
atas 5 atribut yakni TOPICS, LEWISSPLIT, CGISPLIT, OLDID, NEWID. Pada kasus kategorisasi teks, data REUTERS-21578 terdiri atas 5 kategori berdasarkan isi dokumen yakni Exchange, Orgs, People, Places, Topics.
Tahapan praproses data dalam konteks text mining adalah sebagai berikut (Srividhya 2010) :
Stop-word removal. Menghilangkan kata-kata yang sering digunakan tapi tidak memuat informasi yang signifikan (the, of, and, to)
Stemming. Proses ini akan mencari kata dasar dari sebuah kata (user, used, users -> USE)
Document index. Teknik pencarian keyword yang tepat dari setiap dokumen (pemodelan graf). Salah satu metode document index adalah term weighting. Term weighting adalah pembobotan kata pada setiap kemunculannya di setiap dokumen dan menunjukkan pentingnya kata tersebut (menghitung bobot node di setiap edge).
Dimentional reduction. Menentukan jumlah dokumen yang di dalamnya terdapat kata yang sering muncul dan menghilangkan kata yang jarang muncul. Jika kata yang muncul tidak melebihi n dokumen yang ditetapkan sebagai nilai threshold maka kata tersebut dapat dihilangkan.
Implementasi Algoritme Document Index Graph (DIG)
DIG merupakan algoritme pembangun digraf. Digraf yang dibangun merupakan graf berarah. Arah digraf menunjukkan struktur kalimat. Digraf yang dibangun merupakan komponen dari :
1. Node. Node berisi kata unik dari setiap kalimat dalam dokumen.
2. Edge. Merupakan penghubung antarnode. Pada edge terdapat informasi berupa nomor edge, posisi kata tersebut dalam kalimat dan dalam dokumen.
3. Path. Node pada digraf berisi informasi tentang kata unik dalam sebuah dokumen. Jalur atau path yang dibentuk oleh node dan edge merupakan representasi dari sebuah kalimat tertentu.
Algoritme Document Index Graph sebagai berikut (Hammouda 2004) : 1. Proses satu per satu kalimat pada setiap dokumen.
2. Setiap kata yang belum ada di dalam kumpulan digraf, maka akan ditambahkan sebagai node.
3. Jika kata sudah ada dalam kumpulan digraf, maka buat edge baru. 4. Untuk setiap kata yang bertetangga,hubungkan dengan edge.
5. Untuk mendapatkan matching phrase, buat daftar data dokumen-dokumen yang mempunyai edge yang serupa ke dalam sebuah tabel.
6. Jika matching phrase berikutnya mempunyai edge yang merupakan kelanjutan dari edge sebelumnya, maka gabungkan pada matching phrase sebelumnya.
7. Jika kata yang muncul tidak melebihi n dokumen yang ditetapkan sebagai nilai threshold maka kata tersebut dapat dihilangkan
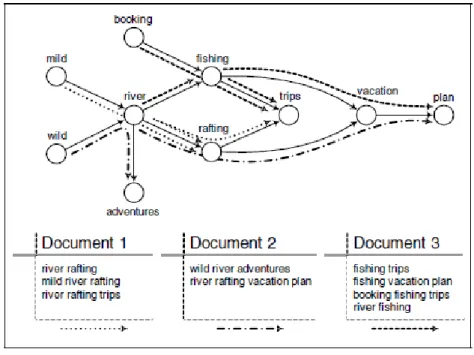
Ilustrasi pembentukan digraf menggunakan algoritme DIG pada dokumen di bawah ini dapat dijelaskan dengan contoh isi dokumen dan gambar berikut :
Dokumen a : river rafting, mild river rafting, river rafting trips
Dokumen b : wild river adventures, river rafting vacation plan
Dokumen c : fishing trips, fishing vacation plan, booking fishing trips, river rafting Struktur digraf yang terbentuk dari ketiga dokumen di atas ditampilkan pada Gambar 6.
Gambar 6 Ilustrasi Document Index Graph (Hammouda 2004)
Proses dimentional reduction dilakukan dengan melakukan penetapan nilai document frequency threshold (relevant and irrelevant threshold) yang ditambahkan pada implementasi algoritme DIG tersebut sehingga mempengaruhi hasil pengelompokan yang terbentuk nantinya.
Cluster yang terbentuk dari implementasi algoritme DIG akan dicocokkan dengan hasil penelitian Lewis (1997). Pengujian pengelompokan dokumen dilakukan pada jumlah dokumen tertentu. Pengujian dilakukan dengan mencari kata-kata yang memiliki frekuensi kemunculan dokumen lebih dari 20 kali. Pengujian menghasilkan komposisi kategori yang muncul untuk selanjutnya ditentukan kelompok atau kategorinya (Lewis 1997). Komposisi kategorisasi teks ditampilkan pada Gambar 7.
Pembangkitan metafile penyusun struktur digraf
Metafile penyusun struktur digraf adalah sebuah bentukan output dari hasil implementasi algoritme DIG dengan penerapan dimentional reduction dan menghasilkan bentukan cluster dari dokumen yang diproses. Metafile berisi informasi tentang struktur node dan edge yang saling terhubung dalam sebuah path. Penentuan struktur digraf dibedakan dengan pewarnaan sesuai dengan jalur path yang terbentuk dari hasil implementasi algoritme tersebut. Adapun beberapa informasi yang terkandung di dalam metafile tersebut sebagai berikut :
digraph {
graph[fontname,fontsize,style,nodesep=3] node [style=filled fillcolor="gray80"] "vertex =>Term Frequency" ... ;
}
Representasi digraf menggunakan metafile penyusun digraf
Representasi digraf divisualisasikan dengan menggunakan aplikasi Graphviz menggunakan lingkungan pemrograman PHP sehingga input untuk representasi digraf tersebut yakni metafile menggunakan bahasa pemrograman PHP. Output penelitian adalah bentukan digraf yang berisi hasil pengelompokan dokumen dengan batasan nilai document frequency threshold dan jumlah dokumen yang akan diuji.
Analisis hasil pengelompokan berdasarkan pengujian
Penelitian ini melakukan pengujian untuk pengelompokan hasil implementasi algoritme DIG dengan menentukan nilai-nilai batasan sebagai berikut :
1. Batasan jumlah dokumen. Jumlah dokumen yang diuji mencakup 10 dan 20 dokumen newswire REUTERS-21578 berkategori LEWISSPLIT yakni PUBLISHED-TEST.
2. Batasan nilai document frequency threshold. Membatasi kata-kata yang memiliki nilai Term Frequency (TF) yang tinggi akan tetapi tidak relevan terhadap isi dokumen.
3. Batasan nilai relevant words. Membatasi kata-kata yang memiliki nilai TF relatif kecil sehingga proses pengelompokan kata menjadi lebih sederhana.
4. Pembangkitan struktur digraf. Memberikan pilihan untuk pembangkitan struktur digraf secara keseluruhan atau masing-masing dokumen. Penentuan tersebut akan mempengaruhi kompleksnya penggambaran digraf pada aplikasi.
Berdasarkan pengujian yang dilakukan dilakukan analisis hasil pengelompokan dengan menghitung nilai persentase precision, recall dan accuracy untuk memberikan penjelasan seberapa efektif kinerja/kualitas dari metode DIG yang digunakan dengan menggunakan data newswire REUTERS.