BAB II
Dasar Teori
Bab ini membahas teori-teori yang mendukung penulisan tesis. Teori ini mencakup teori tentang data mining secara umum, concept drift, data streams, ensemble classifier, streaming ensemble algorithm, dan paradigma pengembangan perangkat
lunak menggunakan unified process.
II.1 Data Mining
II.1.1 Pengantar Data Mining
Menurut [HAN01], data mining dapat diartikan sebagai proses pengekstraksian atau
“mining” (menambang) pengetahuan dari data berskala besar. Pengertian yang lain
lagi menurut [TAN06], yaitu data mining adalah proses dari mengotomatisasikan
penemuan informasi yang berguna pada basis data berskala besar (basis data dengan
volume isi data yang sangat besar).
Tidak semua penemuan informasi yang berguna dikategorikan sebagai data mining.
Sebagai contoh, melakukan query suatu data individu menggunakan database management system atau mencari suatu web page berdasarkan kriteria suatu query
tertentu dengan memanfaatkan search engine merupakan tugas yang berhubungan
dengan information retrieval. [TAN06]
Proses data mining dapat diterapkan pada berbagai jenis repositori. Jenis tersebut
adalah basis data relasional, gudang data (data warehouse), basis data transaksional, flat files, basis data berorientasi object, basis data spasial, dan basis data multimedia
dan text. Penerapan dan teknik mining untuk tiap jenis wadah penampung data dapat
berbeda. [HAN01]
Sebelum dilakukannya proses data mining, terlebih dahulu harus ditentukan tugas data mining. Penentuan ini didasarkan atas jenis pola yang ingin didapatkan dari data
yang ada. Tugas data mining menurut [TAN06] secara umum dibagi menjadi dua
1. Tugas predictive
Tujuan dari tugas ini adalah untuk memprediksi nilai suatu atribut berdasarkan nilai-nilai dari atribut yang lainnnya. Atribut yang diprediksi dikenal dengan istilah target atau dependent variable, sedangkan atribut yang digunakan
untuk membuat prediksi dikenal sebagai explanatory atau independent variables.
2. Tugas descriptive
Tujuan dari tugas ini adalah untuk memperoleh pola (correlations, trends, clusters, trajectories,dan anomalies) yang merangkum relasi pokok pada data.
Tugas descriptive data mining biasanya exploratory dan secara sering
membutuhkan teknik postprocessing untuk memvalidasi dan menjelaskan
hasilnya.
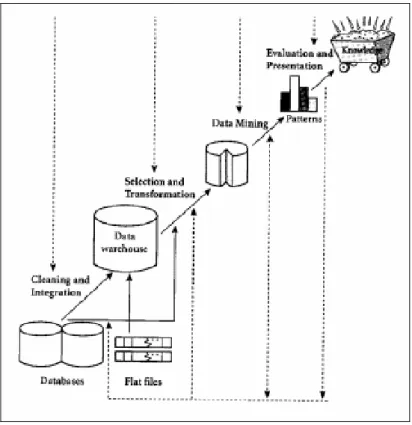
Banyak orang memperlakukan data mining sebagai sinonim dari Knowledge Discovery in Databases (KDD). Namun ada juga yang melihat data mining sebagai
bagian yang inti dari proses sebuah KDD. Knowledge discovery sebagai sebuah
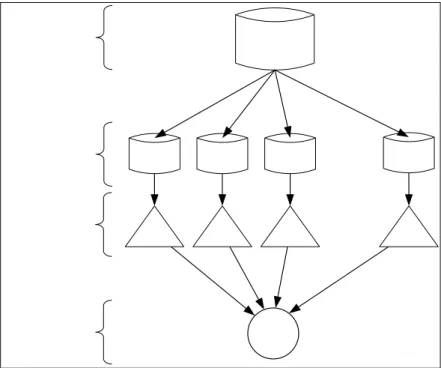
proses digambarkan pada Gambar II.1 dan terdiri dari beberapa rangkaian iterasi sebagai berikut: [HAN01]
1. Data cleaning (menghilangkan noise dan data yang tidak konsisten)
2. Data integration (sumber data yang berbeda-beda dikombinasikan)
3. Data selection (data yang sesuai dengan tugas analisis diambil dari basis data)
4. Data transformation (data ditransformasikan atau dikonsolidasi ke bentuk
yang sesuai untuk mining)
5. Data mining (proses inti dimana teknik-teknik diaplikasikan sebagai upaya
untuk mengekstraksi pola)
6. Pattern evaluation (mengidentifikasi pola penting yang merepresentasikan
dasar pengetahuan dari sebuah ukuran kepentingan)
7. Knowledge presentation (teknik visualisasi dan representasi pengetahuan
Gambar II.1. Proses KDD
II.1.2 Penjelasan Konsep, Instans, dan Atribut
Masukan yang diterima pada proses data mining merupakan dalam bentuk konsep,
instans dan atribut. Konsep merupakan hal yang ingin dipelajari. Hasil keluaran yang didapatkan dari sebuah skema pembelajaran disebut sebagai concept description
(deskripsi dari konsep). Instans atau disebut juga sebagai contoh adalah hal-hal yang
ingin diklasifikasi, diasosiasikan, atau dikelompokkan. Setiap instans merupakan
contoh individu dan independen dari konsep yang ingin dipelajari. Setiap instans
dikarakteristikkan dengan nilai-nilai dari sekumpulan atribut atau disebut juga sebagai fitur, yang telah ditentukan. Atribut dapat berupa numerik (disebut juga atribut kontinu) maupun nominal (disebut juga atribut kategori). [WIT05]
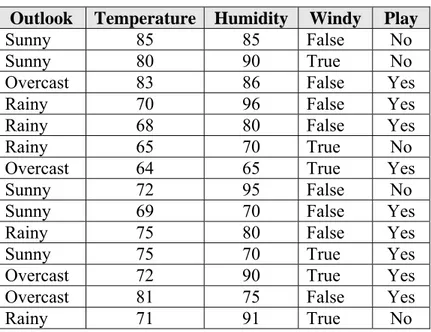
Pada Tabel II.1 merupakan contoh data mengenai apakah seseorang akan melakukan suatu permainan olah raga atau tidak sesuai dengan keadaan cuaca. Pada tabel tersebut, konsepnya adalah apakah seseorang akan melakukan suatu permainan olah raga atau tidak (ditandakan dengan kolom Play). Instans dalam tabel tersebut merupakan tiap baris data. Atribut pada tabel tersebut adalah Outlook (bertipe nominal), Temperature (bertipe numerik), Humidity (bertipe numerik), dan Windy (bertipe nominal).
Tabel II.1. Data Bermain Olah Raga Sesuai dengan Cuaca
Outlook Temperature Humidity Windy Play
Sunny 85 85 False No
Sunny 80 90 True No
Overcast 83 86 False Yes
Rainy 70 96 False Yes
Rainy 68 80 False Yes
Rainy 65 70 True No
Overcast 64 65 True Yes
Sunny 72 95 False No
Sunny 69 70 False Yes
Rainy 75 80 False Yes
Sunny 75 70 True Yes
Overcast 72 90 True Yes
Overcast 81 75 False Yes
Rainy 71 91 True No
II.1.3 Klasifikasi sebagai Salah Satu Tugas Data Mining
Klasifikasi adalah proses dari mencari suatu himpunan models (atau fungsi) yang
dapat mendeskripsikan dan membedakan kelas-kelas data atau konsep-konsep, dengan tujuan dapat menggunakan model tersebut untuk memprediksi kelas dari suatu objek dimana kelasnya belum diketahui. [HAN01]
Dalam studi literatur yang lain dijelaskan bahwa klasifikasi merupakan data mining
dengan tugas predictive yang bertujuan untuk membangun sebuah model untuk
variabel target sebagai sebuah fungsi yang terdiri atas variabel-varabel explanatory.
Variabel target atau disebut juga sebagai variabel bergantung adalah atribut yang
ingin diprediksi, sedangkan variabel explanatory atau disebut juga sebagai variabel
bebas adalah atribut-atribut yang digunakan untuk melakukan prediksi. Teknik klasifikasi yang digunakan untuk klasifikasi dapat berupa decision tree classifier, bayesian classifier, ensemble classifier, nearest neighbour classifier, dan lain
sebagainya. Masing-masing classifier memiliki algoritma pembelajarannya
masing-masing. [TAN06]
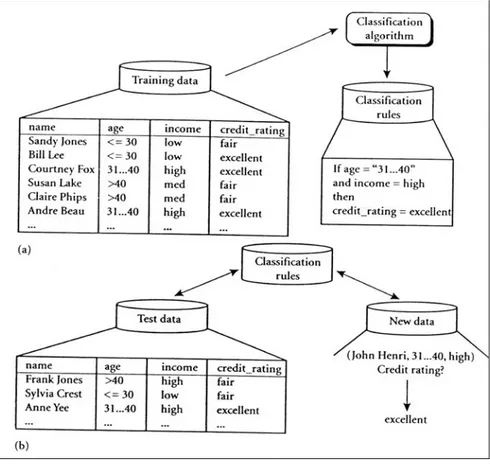
Klasifikasi merupakan proses dua tahap, Gambar II.2 mengilustrasikan tahapan pada klasifikasi. Pada tahap pertama, sebuah model dibangun berdasarkan training data
(data pelatihan), yang mendeskripsikan definisi yang telah ditetapkan mengenai himpunan kelas data atau konsep. Model tersebut dibangun dengan cara menganalisis
tuples pada database yang terdeskripsikan berdasarkan atributnya. Tiap tuple
diasumsikan dimiliki oleh kelas yang telah didefinisikan sebelumnya. Data tuples
tersebut dianalisis untuk membangun model secara kolektif membentuk training data set. Tiap tuples yang digunakan pada training set dikenal juga sebagai training samples,dipilih secara acak dari populasi sample. Dikarenakan tiap label kelas (class label) pada training sample telah disediakan maka tahapan ini dikenal juga dengan supervised learning. Hasil pada tahap ini direpresentasikan sebagai aturan klasifikasi, decision tree, atau formula matematika. [HAN01]
Pada tahap kedua, model digunakan untuk mengklasifikasikan data tuples yang baru
atau objek dimana label kelasnya belum diketahui. Pada tahap ini akurasi model diukur. Akurasi dari sebuah model dihitung dari presentase sampel pengujian yang diklasifikasi secara benar oleh model. Pengujian ini dilakukan dengan data yang berbeda dari training data (data pelatihan) yaitu data pengujian, hal ini disebabkan
karena model yang dipelajari cenderung untuk overfit pada data (memasukkan
anomali yang terdapat pada data kedalam model), yang dapat disebabkan oleh noise
ataupun kurangnya training data. Jika akurasi dari model dapat diterima, maka model
tersebut dapat digunakan untuk mengklasifikasi data tuples maupun objek-objek yang
Gambar II.2. Proses Pembangunan Model Klasifikasi
II.2 Data Streams
Dengan meningkatnya kemajuan dalam bidang hardware dan software dalam
beberapa tahun ini telah memungkinkan untuk memperoleh hasil pengukuran data yang berbeda-beda pada bidang-bidang ilmu yang ada. Pengukuran ini dihasilkan secara terus-menerus dan laju pertambahan data yang semakin cepat. Contohnya adalah sensor pada networks, web logs, dan computer network traffic. [GAB05]
Mining data streams merupakan evolusi dari data mining dimana proses mining pada
awalnya pada data yang bersifat tetap (tidak bertambah) menjadi yang bersifat stream
(terus menerus bertambah). Hal ini mengakibatkan perlunya penyesuaian pada metode-metode yang ada sehingga miningdata streams ini dapat diatasi.
Secara singkat mining data streams menyangkut pengekstraksian struktur
pengetahuan yang direpresentasikan dalam model dan pola-pola pada data streams.
Penelitian akan mining data streams telah menarik banyak perhatian karena tingkat
kepentingannya yang tinggi akan pengaplikasiannya dan meningkatnya generation
bervariasi dari aplikasi yang ilmiah sampai dengan aplikasi finansial atau bisnis. [GAB05]
II.3 Concept Drift
Pada dunia nyata konsep umumnya tidak stabil dan dapat berubah terhadap waktu. Sering kali perubahan ini membuat model yang telah kita bangun diatasnya tidak konsisten dengan perubahan yang ada. Masalah ini dikenal sebagai concept drift,
dimana akan memperumit tugas dalam learning sebuah model dari data dan
membutuhkan pendekatan yang khusus. [TSY04]
Konsep yang ingin dipelajari sering kali bergantung pada hidden context. Contohnya
pada peramalan cuaca, aturan peramalan cuaca yang digunakan dapat berbeda secara radikal sesuai dengan musimnya. Contoh lainnya yaitu konsep mild weather (angin
dan hujan) dapat berbeda di Siberia dan di Central Afrika. [WID96]
Perubahan pada concept drift dapat terjadi secara mendadak (dikenal juga dengan revolutionary drift), maupun secara gradual (dikenal juga dengan evolutionary drift).
Perubahan gradual dapat dibagi menurut laju perubahannya, yaitu perubahan lambat
atau perubahan sedang. [TSY04]
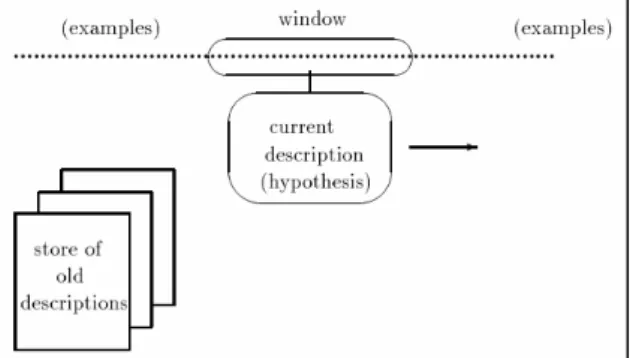
Terdapat sebuah pendekatan yang dapat diambil untuk menangani permasalahan
concept drift ini yaitu dengan cara hanya menyimpan “jendela” yang berisi
instans-instans dan hipotesis-hipotesis yang dipercaya saja. Diilustrasikan pada Gambar II.3. Untuk memperluas pendekatan ini, asumsikan concept descriptions disimpan dan
digunakannya ketika timbul konteks yang sebelumnya pernah ada di masa lampau [WID96]
Gambar II.3. Concept descriptions yang baru dan lama dan sebuah “jendela” yang bergerak berdasarkan stream dari data examples
II.4 Ensemble Classifier
II.4.1 Pengantar Ensemble Classifier
Metode ensemble atau dikenal juga dengan metode classifier combination, merupakan
teknik yang dapat digunakan untuk meningkatkan akurasi dari klasifikasi pada data mining. Sebuah metode ensemble mengkonstruksi suatu himpunan base classifiers
yang dibangun dari blok-blok training data, dan melakukan klasifikasi dengan cara voting terhadap hasil prediksi yang dibuat oleh masing-masing base classifier,
kemudian mengagregasikan hasil prediksi tersebut untuk menghasilkan klasifikasi secara keseluruhan, ilustrasinya dapat dilihat pada Gambar II.4. [TAN06]
Gambar II.4. Gambaran Umum Ensemble
II.4.2 Metode untuk Mengkonstruksi Sebuah Ensemble Classifier
Ide dasar dari metode ensemble adalah untuk mengkonstruksi beberapa classifier dari
data asal dan kemudian mengagregasi hasil prediksinya saat akan mengklasifikasi contoh yang belum diketahui hasilnya. Ensemble classifiers dapat dikonstruksi
melalui beberapa cara yaitu: [TAN06]
1. Mengkonstruksi sebuah ensemble classifier dengan memanipulasi training data
Pada pendekatan ini, beberapa training data dibuat dengan resampling data
asli menurut suatu distribusi sampling tertentu. Distribusi sampling
dilakukan berulang kali maka hasilnya selalu bervariasi. Sebuah classifier
kemudian dibangun dari tiap training data menggunakan suatu algoritma learning (pembelajaran) tertentu. Bagging dan boosting merupakan dua contoh
metode ensemble yang memanipulasi training data.
2. Mengkonstruksi sebuah ensemble classifier dengan memanipulasi fitur input
Pada pendekatan ini, suatu himpunan bagian dari fitur input (atribut dari suatu
tabel beserta datanya) dipilih untuk membentuk tiap training data. Himpunan
bagian tersebut dapat dipilih secara acak atau berdasarkan rekomendasi dari
domain experts. Dari beberapa penelitian telah ditunjukkan bahwa pendekatan
ini bekerja sangat baik pada data sets yang memiliki fitur redudansi yang
tinggi. Random forest merupakan metode ensemble yang memanipulasi fitur input dan menggunakan decision tree sebagai base classifier-nya.
3. Mengkonstruksi sebuah ensemble classifier dengan memanipulasi label kelas
Metode ini dapat digunakan jika jumlah dari kelas cukup banyak. Training data ditransformasikan menjadi suatu permasalahan kelas biner, cara yang
dilakukan adalah dengan secara acak melakukan partisi terhadap label kelas sehingga menjadi dua himpunan terpisah A0 dan A1. Training data dimana
label kelasnya dimiliki oleh himpunan A0 ditugaskan kepada kelas 0, dan
sisanya yang dimiliki oleh himpunan A1 ditugaskan kepada kelas 1. Training
data yang telah dilabel ulang kelasnya tersebut kemudian digunakan untuk
melatih sebuah base classifier. Dengan mengulang-ulang proses label ulang
kelas tersebut dan tahapan pembangunan model berkali-kali, maka diharapkan akan diperoleh suatu ensemble dari base classifier. Jika test data (data
pengujian) dihadirkan, tiap base classifier Ci digunakan untuk
memprediksikan kelas labelnya. Jika test data diprediksikan sebagai kelas 0
maka semua kelas yang dimiliki oleh kelas A0 akan menerima vote (suara).
Sebaliknya juga, jika diprediksikan sebagai kelas 1 maka semua kelas yang dimiliki oleh kelas A1 akan menerima vote. Seluruh vote dicatat dan kelas
yang menerima vote terbanyak menjadi hasil dari test data tersebut. Contoh
metode yang menggunakan pendekatan ini adalah error-correcting output coding
4. Mengkonstruksi sebuah ensemble classifier dengan memanipulasi algoritma learning
Banyak algoritma learning dapat dimanipulasi dengan suatu cara dimana jika
algoritma tersebut diterapkan berkali-kali pada suatu training data maka akan
menghasilkan model yang berbeda-beda. Sebagai contoh, suatu artificial neural network dapat menghasilkan model yang berbeda-beda dengan
mengubah topologi network-nya atau inisialisasi weight-nya dari
keterhubungan antar neuron.
Ketiga cara pertama diatas merupakan metode umum yang dapat diaplikasikan pada
classifier apapun, dan untuk cara yang keempat bergantung pada tipe classifier yang
digunakan.
II.5 Streaming Ensemble Algorithm (SEA) II.5.1 Pendahuluan SEA
SEA merupakan suatu algoritma yang dibuat untuk menangani masalah concept drift
dan data streams pada klasifikasi di data mining. Teknik SEA ini berdasar pada
metode ensemble dan dikembangkan untuk menangani kedua permasalahan yang
telah disebutkan. [STR01]
Pembangunan SEA didasarkan atas empat kriteria pemikiran pembangunan algoritma untuk metode predictive dalam skala besar dari [FAY96] :
1. Iterative
Algoritma harus beroperasi dengan model iteratif, membaca blok-blok data pada suatu waktu tertentu dibandingkan dengan membaca seluruh data tersebut pada awal algoritma.
2. Single pass
Algoritma hanya boleh melakukan satu kali pass pada data.
3. Limited memory
Dibutuhkan suatu jumlah memory yang konstan untuk struktur data yang
digunakan pada algoritma, dan sebaiknya tidak membesar sesuai dengan ukuran data.
4. Any-time learning
Algoritma harus menyediakan solusi yang baik bila algoritma diberhentikan ditengah jalan sebelum ditemukannya suatu kesimpulan.
II.5.2 Metode SEA
Pseudocode dari SEA yang telah dibangun adalah sebagai berikut: [STR01]
01: while more data points are available
02: ··read d points, creating training set D
03: ··build classifier Ci using D
04: ··evaluate classifier Ci-1 on D
05: ··evaluate all classifier in ensemble E on D
06: ··if E not full
07: ····insert Ci-1
08: ··else if Quality(Ci-1) > Quality(Ej) for some j
09: ····replace Ej with Ci-1
10: ··end
11: end
Dalam pseudocode tersebut yang dikerjakan adalah sebagai berikut. Classifier
individu dibangun dari suatu himpunan bagian dari data, dibaca secara berurutan dalam blok-blok. Komponen dari classifier dikombinasikan menjadi sebuah ensemble
dengan suatu ukuran yang tetap. Saat ensemble telah penuh, maka classifier baru akan
ditambahkan jika memenuhi suatu kriteria kualitas tertentu, berdasar pada kemampuan estimasi untuk meningkatkan performansi dari ensemble. [STR01]
Base classifier yang digunakan pada SEA oleh W. Nick Street dan YongSeog Kim
adalah Quinlan C4.5. Parameter operasional dari C4.5 ini adalah apakah suatu tree
akan di-prune atau tidak. Kunci performansi dari algoritma ini adalah metode yang
digunakan untuk menentukan apakah suatu base classifier baru dapat ditambahkan
pada ensemble, dan apakah suatu baseclassifier dapat dihilangkan. [STR01]
Kriteria kualitas yang digunakan pada SEA adalah sebagai berikut:
1. Jika kedua ensemble E dan baseclassifier baru T adalah benar, maka kualitas
dari T ditingkatkan menjadi 1 - | P1 – P2 |. Maksud dari ini adalah jika vote
ditutup, base classifier baru tersebut mendapatkan nilai kualitas yang tinggi,
dikarenakan dapat secara langsung mempengaruhi votes pada masa
2. Jika T adalah benar namun E tidak benar maka kualitas ditingkatkan menjadi 1
- | P1 – PC |.
3. Jika prediksi T tidak benar (tidak perlu lagi memperdulikan hasil dari E), maka
kualitas diturunkan menjadi 1 - | PC – PT |.
Dimana:
P1 = Persentase dari top vote-getter
P2 = Persentase dari second-highest vote-getter
PC = Persentase dari kelas yang benar
PT = Persentase dari prediksi dari baseclassifier baru T
Beberapa hal yang diperoleh dari penelitian SEA oleh W. Nick Street dan YongSeog Kim adalah: [STR01]
1. Memperbesar ukuran dari ensemble menghasilkan hasil dengan generalisasi
yang lebih baik, yaitu sekitar 20 atau 25 base classifier.
2. Pruning tree individu menghasilkan akurasi ensemble yang menurun,
walaupun akurasi dari tiap tree individu meningkat.
3. Variasi sederhana dari metode “voting terbesar” memiliki efek yang kecil atau
tidak memiliki efek dalam masalah akurasi ensemble. Memberikan bobot pada votes berdasarkan akurasi base classifier atau memberikan bobot pada nilai confidence dari tiap base classifier, dapat menghasilkan peningkatan yang
tidak konsisten dan kecil efeknya untuk masalah akurasi ensemble.
4. Penelitian dengan metode “gated voting”, dimana anggota ensemble
melakukan vote hanya pada kasus dimana mereka dapat memprediksikannya
dengan benar. Metode ini juga menghasilkan peningkatan yang tidak konsisten terhadap metode “voting terbesar”.
II.6 Backpropagation sebagai Base Classifier
Sebuah base classifier merupakan suatu teknik klasifikasi yang dapat digunakan
sebagai dasar terbentuknya ensemble. SEA yang diajukan oleh W. Nick Street dan
YongSeog Kim menggunakan C4.5 sebagai base classifier-nya. Pada tesis ini backpropagation akan digunakan sebagai base classifier-nya.
Backpropagation merupakan suatu jenis jaringan saraf tiruan yang dapat digunakan
untuk mengklasifikasi data. Backpropagation menerapkan metode gradient descent,
yaitu dimana penyesuaian-penyesuaian dilakukan pada jaringan sehingga memperkecil error dalam mengklasifikasi data. Untuk informasi yang lebih lengkap
mengenai backpropagation beserta algoritmanya dapat dilihat pada [DHA04].
Beberapa penjelasan istilah dalam backpropagation yaitu [DHA04]:
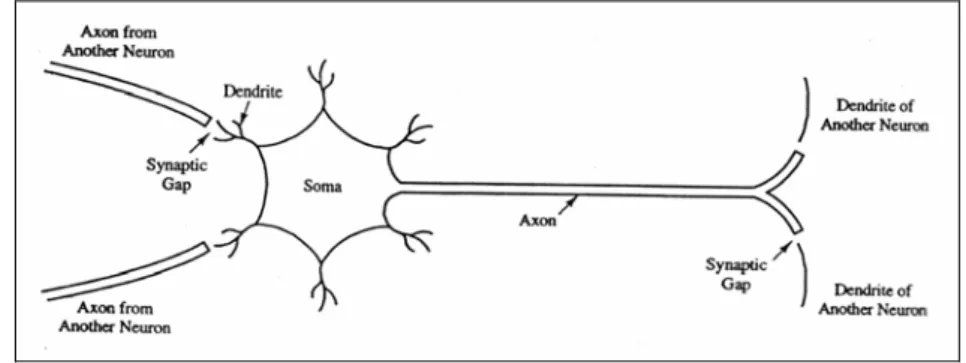
1. Neuron merupakan sel terkecil dari jaringan otak saraf manusia, ditunjukkan
pada Gambar II.5.
2. Bobot merupakan synaptic gap dan berfungsi sebagai bobot untuk
memperkuat sinyal atau memperlemah.
3. Masukan neuron merupakan dendrite dan berfungsi memberikan sinyal
masukan
4. Fungsi aktivasi merupakan soma dan berfungsi mengolah sinyal yang masuk
5. Keluaran neuron merupakan axon dan berfungsi mengeluarkan sinyal keluaran
Gambar II.5. Neuron pada Manusia
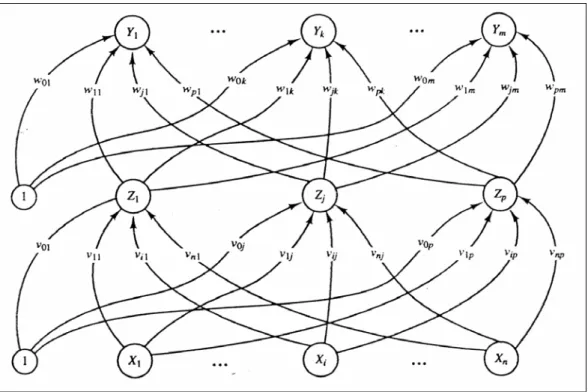
Backpropagation memiliki arsitektur dengan minimal satu layer untuk hidden layer,
dapat dilihat pada Gambar II.6 yaitu pada layer Z. Untuk layer masukan ditunjukkan
dengan X pada Gambar 3.1, layer keluaran ditunjukkan dengan layer Y pada Gambar
3.1. Hidden layer dapat memiliki bias, dimana bias menyerupai bobot pada koneksi
antar neuron namun dengan nilai keluaran neuron-nya selalu 1. Untuk bobot dari layer masukan ke hidden layer ditunjukkan dengan v, dan untuk bobot dari hidden layer ke layer keluaran ditunjukkan dengan w. [DHA04]
Gambar II.6. Arsitektur Backpropagation
II.7 Paradigma Pengembangan PL Menggunakan Unified Process
Unified process merupakan paradigma pengembangan yang menggunakan pendekatan
iteratif (pengulangan). Dalam tiap iterasi terdiri dari langkah-langkah pengembangan suatu perangkat lunak, ditunjukkan pada Gambar II.7. Dalam tiap iterasi dilakukan sedikit requirements, analysis, design, implementation, dan testing. Pada tiap iterasi
masukannya adalah berdasarkan iterasi sebelumnya, hal ini terus dilakukan sampai mendekati produk final. [KRO03]
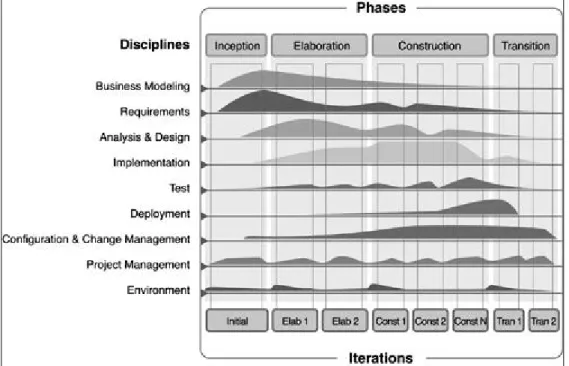
Pada awal iterasi umumnya titik beratnya lebih pada requirements, analysis, dan design. Kemudian pada iterasi akhir titik beratnya lebih pada implementation dan testing. Keterangan mengenai apa yang dikerjakan pada tiap iterasi ditunjukkan pada
Gambar II.8. Dalam unified process terdapat 4 tahapan yaitu Inception, Elaboration, Construction, dan Transition. Masing-masing tahapan tersebut memiliki fokus-fokus
bagian yang berbeda-beda. [KRO03]
Gambar II.8. Keterangan Tahapan Pengembangan pada Unified Process
Dalam memodelkan pengembangan perangkat lunak, unified process menggunakan
bahasa pemodelan Unified Modeling Language (UML). Langkah pertama yang
dikerjakan dalam unified process ini adalah pembuatan use-case. Use-case ini
menggambarkan tingkah laku fungsionalitas dari sistem dilihat dari sisi user, sehingga
apa yang dikembangkan ini dapat sesuai dengan apa yang dibutuhkan oleh user.
Hubungan use-case ke model rekayasa perangkat lunak ditunjukkan pada Gambar
II.9. Use-case akan digunakan pada analysis dan design, implementation, dan test.
Gambar II.9. Keterhubungan Use-Case ke Model Rekayasa Perangkat Lunak
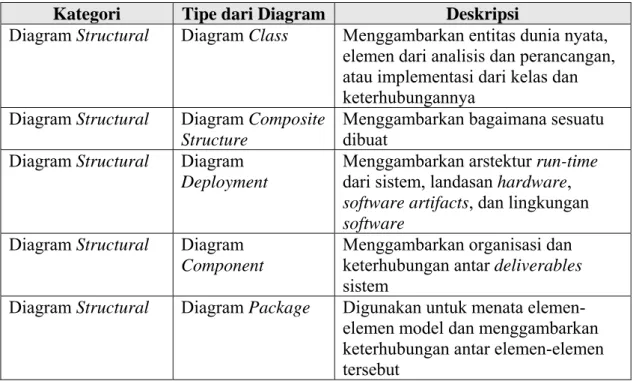
Dalam UML terdapat beberapa diagram yang dapat digunakan sebagaimana ditunjukkan pada Tabel II.2. Diagram structural menggambarkan fitur-fitur yang
tidak berubah dari waktu ke waktu. Diagram behavioral menggambarkan bagaimana
sistem menanggapi permintaan. Diagram interaction merupakan sebuah tipe diagram behavioral, namun penekanannya pada pertukaran message antar objects dan
bagaimana mencapai tujuannya. [CHO03]
Tabel II.2. Diagram pada UML
Kategori Tipe dari Diagram Deskripsi
Diagram Behavioral Diagram Use-Case Menggambarkan servis apa saja yang
dapat diminta seorang aktor pada sebuah sistem
Diagram Behavioral Diagram Activity Menggambarkan data flow dan control flow dari tingkah laku antar objects
Diagram Behavioral Diagram State Machine
Menggambarkan life cycle dari sebuah object, atau sequences dari sebuah object kemana saja, atau yang harus
didukung oleh sebuah interface
Diagram Interaction Diagram Overview Menggambarkan skenario interaksi
yang berbeda-beda untuk sebuah
collaboration (suatu kumpulan object
yang bekerja sama untuk mencapai tujuan) yang sama
Diagram Interaction Diagram Sequence Berfokus pada pertukaran message
antar sebuah kelompok objects,
beserta urutannya Diagram Interaction Diagram
Communication
Berfokus pada message antar sebuah
kelompok objects dan relasi yang
pokok dari objects
Diagram Interaction Diagram Timing Menggambarkan perubahan dan relasi
pada waktu nyata atau sistem
embedded
Diagram Structural Diagram Object Menggambarkan objects beserta
Kategori Tipe dari Diagram Deskripsi
Diagram Structural Diagram Class Menggambarkan entitas dunia nyata,
elemen dari analisis dan perancangan, atau implementasi dari kelas dan keterhubungannya
Diagram Structural Diagram Composite Structure
Menggambarkan bagaimana sesuatu dibuat
Diagram Structural Diagram Deployment
Menggambarkan arstektur run-time
dari sistem, landasan hardware, software artifacts, dan lingkungan software
Diagram Structural Diagram Component
Menggambarkan organisasi dan keterhubungan antar deliverables
sistem
Diagram Structural Diagram Package Digunakan untuk menata
elemen-elemen model dan menggambarkan keterhubungan antar elemen-elemen tersebut