TUGAS AKHIR
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik
Program Studi Teknik Elektro
Oleh:
Nama : Yosef Morris NIM : 015114006
PROGRAM STUDI TEKNIK ELEKTRO
JURUSAN TEKNIK ELEKTRO
FAKULTAS TEKNIK
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
FINAL PROJECT
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Teknik Degree
In Electrical Engineering Study Program
By:
Name : Yosef Morris Student Number: 015114006
ELECTRICAL ENGINEERING STUDY PROGRAM
DEPARTMENT OF ELECTRICAL ENGINEERING
FACULTY OF ENGINEERING
SANATA DHARMA UNIVERSITY
“Saya menyatakan dengan sesungguhnya bahwa tugas akhir yang saya tulis ini tidak memuat karya atau bagian karya orang lain,
kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.”
Yogyakarta, Juli 2007
Kupersembahkan karya tulis ini kepada :
Tuhan Yesus Kristus,
Bapak dan Ibu
Tercinta,
Kedua saudaraku Connery dan Hillary,
Titik dan Cindy,
“Barangsiapa
setia
pada
perkara
‐
perkara
kecil,
ia
setia
juga
pada
perkara
‐
perkara
besar.
Dan
barangsiapa
tidak
benar
dalam
perkara
‐
perkara
kecil,
ia
tidak
benar
juga
dalam
perkara
‐
perkara
adalah file dengan format windows bitmap dan keluarannya adalah file dengan format text.
Arsitektur jaringan syaraf tiruan yang digunakan adalah Backpropagation.
Jaringan terdiri dari tiga lapisan, yaitu lapisan input (input layer) yang terdiri dari 600 neuron, lapisan tersembunyi (hidden layer) yang terdiri dari 100 neuron dan lapisan output (output layer) yang terdiri dari satu neuron.
Jaringan harus dilatih terlebih dahulu agar bisa mengenali pola-pola karakter yang terdapat pada data masukan. Parameter yang digunakan untuk melatih jaringan adalah target, error target, learning rate, dan maximum epoch.
Untuk mengenali pola karakter yang terdapat pada data masukan, program akan menganalisa gambar terlebih dahulu. Langkah selanjutnya adalah memisahkan karakter-karakter yang terdapat pada data masukan dan mengubahnya menjadi matriks dengan ukuran 30 x 20. Setelah itu program akan melakukan komputasi terhadap matriks dengan data-data hasil pelatihan jaringan, sehingga didapat sebuah nilai keluaran. Nilai tersebut merupakan kode desimal dari karakter ASCII, dan program akan mengubah kode tersebut menjadi karakter ASCII. Jenis font yang digunakan adalah Arial, Courier New, danTimes New Roman. Dari tiga jenis font yang digunakan, Courier New adalah jenis font yang dapat dikenali dengan baik.
This final project’s aim to make the simulation program of character recognition that uses the artificial neural network technology. The input for the program is file with the windows bitmap format and the output’s is file with the text format.
The architecture of artificial neural network that used is Backpropagation. The network consists three layers, which is input layer that consisted by 600 neurons, hidden layer consisted by 100 neurons and output layer that consisted by one neuron.
The network has to be trained first so that it can recognize the character patterns on input data. The parameters that are use to train the network are target, error target, learning rate, and maximum epoch.
To recognize the character pattern on input data, the program will analyze the image first. The next step is separate the characters on input data and then convert it to be 30 x 20 matrix. After that, program will compute the matrix with the data’s of network training results, so that will result an output value. This value represents the decimal code of ASCII character, and program will convert the code to ASCII character. The font type that used is Arial, Courier New, and Times New Roman. From three-font type that used, Courier New is font type that can be recognized better.
Syukur dan terima kasih kepada Tuhan Yesus Kristus atas segala rahmat dan
karunia-Nya sehingga tugas akhir dengan judul “Pengenalan Karakter Berbasis
Jaringan Syaraf Tiruan” ini dapat diselesaikan dengan baik.
Selama menulis tugas akhir ini, penulis menyadari bahwa ada begitu banyak
pihak yang telah memberikan bantuan dengan caranya masing-masing, sehingga
tugas akhir ini bisa diselesaikan. Oleh karena itu penulis ingin mengucapkan
terima kasih kepada:
1. Kedua orang tua yang tercinta atas doa, kesabaran dan dukungan baik
secara moril ataupun materil.
2. Bapak Ir. Greg. Heliarko, SJ., B.ST., MA., M.Sc, selaku dekan fakultas
teknik.
3. Bapak Damar Wijaya, S.T., M.T., selaku dosen pembimbing yang telah
dengan sabar membimbing, memberi semangat dan saran yang membantu
penulis dalam menyelesaikan tulisan ini.
4. Seluruh dosen teknik elektro dan laboran yang telah banyak memberikan
pengetahuan kepada penulis selama kuliah.
5. Kedua adikku Connery dan Hillary atas dukungan dan pengertiannya.
6. Bapak A.M. Yoesro sekeluarga atas bantuan dan dukungan yang
diberikan.
7. Thitik tercinta dan Cindy yang nakal atas kesabaran, doa dan
10.Teman-teman kost Flamboyan: Funny, Anenk, Umay, Ike dan Dian atas
bantuan dan kebersamaannya.
11.Teman-teman yang sudah lulus: Leo, Koko, Nesty, Jimboy, Christ dan
Frankie.
12.Teman-teman IPKMS: Mr. Bene dan Telly.
13.Berbagai pihak yang tidak bisa penulis sebutkan satu-persatu atas bantuan,
bimbingan, kritik dan saran.
Dengan rendah hati penulis menyadari bahwa tugas akhir ini masih jauh dari
sempurna, oleh karena itu berbagai kritik dan saran untuk perbaikan tugas akhir
ini sangat diharapkan. Akhir kata, semoga tugas akhir ini dapat bermanfaat bagi
semua pihak. Terima kasih.
Yogyakarta, Juni 2007
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN... iv
HALAMAN PERNYATAAN KEASLIAN KARYA ... v
HALAMAN PERSEMBAHAN ... vi
HALAMAN MOTO ... vii
INTISARI ... viii
ABSTRACT ... ix
KATA PENGANTAR... x
DAFTAR ISI... xii
DAFTAR GAMBAR... xv
DAFTAR TABEL ... xx
BAB I 1
PENDAHULUAN... 1
I.1 Judul... 1
I.2 Latar Belakang... 1
I.3 Batasan Masalah dan Spesifikasi Perangkat Lunak... 4
I.4 Tujuan Penelitian ... 5
I.5 Manfaat Penelitian ... 5
II. 2 JST... 9
II.2.1 Sejarah JST... 10
II.2.2 Model Neuron Pada JST... 11
II.2.3 Fungsi Aktivasi Pada JST... 13
II.3 Backpropagation... 17
II.3.1 Bias ... 19
II.3.2 Parameter-Parameter Pada Backpropagation... 21
II.3.3 Pelatihan Jaringan... 23
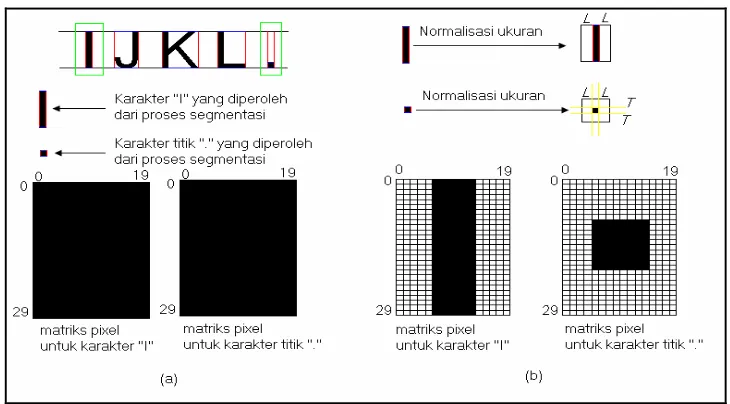
II.4 Pengenalan Karakter... 43
II.4.1 Segmentasi... 43
II.4.2 Normalisasi Ukuran... 47
II.4.3 Matriks Pixel... 49
BAB III 52
PERANCANGAN PERANGKAT LUNAK ... 52
III.1 Perancangan JST ... 53
III.2 Diagram Alir Program... 55
III.2.1 Diagram Alir Pelatihan Jaringan... 55
III.2.1.1 Diagram Alir Subrutin Analisa Gambar ... 55
III.2.1.2 Diagram Alir Inisialisasi Jaringan... 64
III.2.2.1 Diagram Alir Inisialisasi Jaringan... 69
III.2.2.2 Diagram Alir Untuk Mencari Keluaran Jaringan... 71
III.3 Tampilan Program... 72
BAB IV 78
HASIL DAN PEMBAHASAN ... 78
IV.1 Pengujian Tampilan program... 78
IV.2 Menentukan Jumlah Hidden Neuron... 82
IV.3 Pengujian Program... 84
IV.3.1 Pengujian Program Dengan Variasi Nilai Error target dan Nilai Learning rate... 84
IV.3.2 Pengujian Program Secara Keseluruhan... 88
IV.3.2.1 Pengujian Program Untuk Font Arial ... 89
IV.3.2.2 Pengujian Program Untuk Font Courier New ... 98
IV.3.2.3 Pengujian Program Untuk Font Times New Roman ... 99
BAB V 103
KESIMPULAN DAN SARAN ... 103
V.1 Kesimpulan ... 103
V.2 Saran... 103
Anatomi sebuah neuron pada jaringan syaraf biologis [9] ... 8
Gambar 2. 2 Blok diagram JST secara umum [4] ... 9
Gambar 2. 3 Sebuah jaringan sederhana [3]... 12
Gambar 2. 4 Grafik keluaran Threshold Function [3]... 14
Gambar 2. 5 Grafik keluaran Symetric Hard Limit Function [5] ... 14
Gambar 2. 6 Grafik keluaran sigmoid function... 15
Gambar 2. 7 Grafik keluaran Piecewise Linear Function [3] ... 16
Gambar 2. 8 Grafik keluaran Identitiy Function... 16
Gambar 2. 9 Struktur dasar jaringan Backpropagation [16] ... 17
Gambar 2. 10 Arsitektur Backpropagation... 18
Gambar 2. 11 Jaringan yang ditambah bias... 19
Gambar 2. 12 Arah sinyal dalam backpropagation [3] ... 23
Gambar 2. 13 Arsitektur Backpropagation tanpa bias... 27
Gambar 2. 14 Grafik hasil pelatihan pada jaringan yang tidak menggunakan bias ... 33
Gambar2.15 Arsitektur Backpropagation dengan bias... 34
Gambar2.16 Hasil pelatihan dengan menambahkan bias pada jaringan ... 40
Gambar2.17 Hasil pelatihan dengan nilai learning rate=10... 42
Gambar2.18 Hasil pelatihan dengan nilai learning rate = 70 ... 42
Gambar2.19 Contoh hasil pemisahan baris karakter ... 44
Gambar2.24 Matriks pixel dengan ukuran 30 x 20 [7]... 50
Gambar2.25 Hubungan antara matriks pixel dengan JST [20] ... 51
Gambar3.1 Diagram blok pelatihan jaringan...52
Gambar3.2 Diagram blok pengenalan karakter... 52
Gambar3.3 Diagram blok perancangan JST... 53
Gambar3.4 Grafik hubungan antara jumlah hidden neuron , akurasi dan waktu pelatihan [2] ... 54
Gambar3. 5 Rancangan Jaringan ... 55
Gambar3. 6 Diagram alir pelatihan jaringan ... 56
Gambar3. 7 Diagram alir pemisahan baris karakter ... 57
Gambar3.8 Diagram alirsegmentasi ... 58
Gambar3.9 Diagram alir segmentasi (sambungan) ... 59
Gambar3.10 Diagram alir Cari Atas... 60
Gambar3.11 Diagram alir Cari Bawah ... 61
Gambar3.12 Diagram alirNormalisasi Ukuran... 61
Gambar3.13 Contoh hasil proses sampling pixel... 62
Gambar3.14 Diagram aliruntuk membuat matriks pixel... 63
Gambar3.15 Diagram alir Inisialisasi Jaringan ... 64
Gambar3.16 Diagram alir untuk memodifikasi bobot jaringan... 65
Gambar3.21 Diagram alir Inisialisasi Jaringan dengan nilai bobot didapat dari
file jaringan ... 70
Gambar3.22 Diagram alir untuk mencari keluaran jaringan ... 71
Gambar3.23 Hubungan antara user dengan komputer ... 72
Gambar3.24 Rancangan tampilan utama program ... 73
Gambar3.25Tab Training... 76
Gambar3.26Tab Training Results... 76
Gambar3.27 Rancangan Form About... 77
Gambar 4. 1 Tampilan awal program saat pertama kali dijalankan ... 78
Gambar 4. 2 Tampilan program jika Tab Training dipilih... 79
Gambar 4. 3 Tampilan form About... 79
Gambar 4. 4 Tampilan form help... 80
Gambar 4. 5 Kotak dialog yang ditampilkan jika Button Load Image atau Button Load Trainer ditekan ... 81
Gambar 4. 6 Data pelatihan untuk menguji jaringan dengan jumlah hidden neuron 100 ... 83
Gambar 4. 7 Hasil pelatihan jaringan dengan jumlah hidden neuron 100 ... 83
Gambar 4. 8 Data pelatihan untuk font Arial... 84
Gambar 4. 9 Data pelatihan untuk font Courier New ... 85
Gambar 4. 14 Data pelatihan font Courier New ... 88
Gambar 4. 15 Data pelatihan font Times New Roman... 89
Gambar 4. 16 Hasil pelatihan untuk font Arial setelah peltihan berjalan selama 2 jam 5 menit 56 detik... 89
Gambar 4. 17 Hasil pelatihan untuk font Arial setelah pelatihan berjalan selama 3 jam 12 menit 30 detik... 90
Gambar 4. 18 Data pelatihan dengan huruf kapital untuk font Arial ... 90
Gambar 4. 19 Data pelatihan dengan huruf kecil untuk font Arial... 91
Gambar 4. 20 Hasil pelatihan setelah proses berjalan selama 1 jam 18 menit 38 detik... 91
Gambar 4. 21 Hasil pelatihan setelah proses berjalan selama 1 jam 48 menit 8 detik... 92
Gambar 4. 22 Karakter yang memiliki bentuk yang sama ... 92
Gambar 4. 23 Data pelatihan yang tidak terdiri dari karakter-karakter yang
memiliki bentuk yang sama ... 93
Gambar 4. 24 Hasil pelatihan untuk data masukan yang tidak terdiri dari
karakter-karakter yang memiliki bentuk yang sama ... 93
program ... 96
Gambar 4. 28 Data masukan untuk font Arial ... 97
Gambar 4. 29 Hasil pengujian program untuk font Arial ... 97
Gambar 4. 30 Hasil pelatihan jaringan untuk font Courier New ... 98
Gambar 4. 31 Data masukan untuk font Courier New ... 98
Gambar 4. 32 Hasil pengujian program untuk font Courier New ... 99
Gambar 4. 33 Hasil pelatihan jaringan untuk font Times New Roman... 100
Gambar 4. 34 Data masukan untuk font Times New Roman ... 100
Gambar 4. 35 Hasil pengujian program untuk font Times New Roman ... 101
Gambar 4. 36 Data masukan untuk font Times New Roman dengan penambahan spasi diantara setiap karakter ... 102
DAFTAR TABEL
Tabel 2. 1 Tabel kebenaran logika XOR ... 27
Tabel 2. 2 Inisialisasi nilai bobot antara input layer dan hidden layer... 28
Tabel 2. 3 Inisialisasi nilai bobot antara inputlayer dan hidden layer... 28
Tabel 2. 4 Nilai bobot antara inputlayer dan hiddenlayer hasil pelatihan dengan pola pertama (x1 = 1, x2 = 1, dan d = 0)... 31
Tabel 2. 5 Nilai bobot antara hiddenlayer dan ouputlayer hasil pelatihan dengan pola pertama (x1 = 1, x2 = 1, dan d = 0)... 31
Tabel 2. 6 Bobot antara inputlayer dan hiddenlayer hasil pelatihan pada epoch
pertama... 32
Tabel 2. 7 Nilai bobot antara hiddenlayer dan outputlayer hasil pelatihan pada
epoch pertama ... 32
Tabel 2. 8 Hasil pengujian jaringan menggunakan bobot pada epoch pertama ... 32
Tabel 2. 9 Hasil pengujian jaringan menggunakan bobot pada epoch ke-11.432 34
Tabel 2. 10 Inisialisasi nilai bobot antara inputlayer dan hiddenlayer... 35
Tabel 2. 11 Inisialisasi nilai bobot antara inputlayer dan hiddenlayer... 35
Tabel 2. 12 Nilai bobot antara inputlayer dan hiddenlayer hasil pelatihan dengan pola pertama (x1 = 1, x2 = 1, dan d = 0)... 38
Tabel 2. 13 Nilai bobot antara hidden layer dan ouputlayer hasil pelatihan
dengan pola pertama (x1 = 1, x2 = 1, dan d = 0) ... 38
Tabel 2. 15 Nilai bobot antara hiddenlayer dan ouputlayer hasil pelatihan
dengan pola pertama (x1 = 1, x2 = 1, dan d = 0) ... 39
Tabel 2. 16 Hasil pengujian jaringan menggunakan bobot pada epoch pertama . 39
Tabel 2. 17 Hasil pengujian jaringan menggunakan bobot pada epoch ke-6.546 41
Tabel 4. 1 Hasil pengujian program untuk variasi nilai error target... 85
Tabel 4. 2 Hasil pengujian program untuk variasi nilai learning rate... 86
I.1 Judul
Pengenalan Karakter Berbasis Jaringan Syaraf Tiruan (Character
Recognition Based on Artificial Neural Networks).
I.2 Latar
Belakang
Sering dijumpai begitu banyak karakter-karakter ASCII (American
Standards Code for Information Interchange) yang disimpan di dalam
komputer menggunakan format file gambar, misal hasil scanner dan hasil
foto. File gambar yang terdapat pada sistem operasi Windows®, biasanya disimpan menggunakan format WindowsBitmap (.bmp), Joint Photographic
Experts Group (.JPEG), Graphics Interchange Format (.GIF) dan lain-lain
[1], [2].
Karakter-karakter ASCII yang disimpan menggunakan format file
gambar, tidak bisa langsung diolah menggunakan teks editor. Hal ini
disebabkan oleh perbedaan format file teks dengan format file gambar. File
yang bisa diolah menggunakan teks editor adalah file yang menggunakan
format teks. Pada sistem operasi Windows®, file teks disimpan menggunakan format word document (.doc), rich text format (.rtf) dan text
Jika ingin mengolah karakter-karakter ASCII yang terdapat pada file
gambar menggunakan teks editor, karakter-karakter tersebut harus diketik
lagi. Hal ini tentu saja tidak praktis, karena membuang banyak waktu dan
tenaga. Maka dari itu, dibutuhkan perangkat lunak yang bisa mengkonversi
karakter-karakter ASCII yang terdapat pada file gambar, menjadi
karakter-karakter ASCII yang bisa diolah menggunakan teks editor.
Agar karakter ASCII yang terdapat pada file gambar bisa dikonversi,
pola karakter harus dikenali terlebih dahulu. Untuk mengenali
pola-pola karakter yang ada pada file gambar, dibutuhkan metode ataupun
teknologi yang tepat untuk melakukan fungsi tersebut. Ada beberapa
teknologi dan metode yang bisa melakukan proses pengenalan pola (pattern
recogniton), antara lain metode Statistik, metode Sintaktik dan teknologi
Jaringan Syaraf Tiruan (JST). Metode Statistik adalah metode yang
membandingkan data masukan dengan sekumpulan data yang ada, kemudian
keluarannya adalah data yang memiliki selisih terkecil dengan data
masukannya. Metode Sintaktik adalah metode yang mengenali pola dengan
cara membandingkan struktur pola masukan, dengan struktur pola yang
sudah ada. Contoh penerapan Metode Sintaktik adalah untuk mengecek
tatabahasa (grammar) formal, karena tatabahasa formal memiliki aturan dan
standar yang baku. JST adalah teknologi yang dikembangkan dengan
mengambil prinsip dan cara kerja jaringan syaraf biologis. Proses
pengenalan pola, dilakukan dengan cara mengalikan dan menjumlahkan
sinyal masukan dengan bobot-bobot jaringan sehingga terbentuk sebuah
Jaringan syaraf tiruan membutuhkan proses pelatihan agar bisa mengenali
pola-pola masukan [3], [4], [5].
Dari semua metode atau teknologi yang disebutkan di atas, yang sering
digunakan pada proses pengenalan pola, khususnya pengenalan karakter
adalah JST. Teknologi ini tergolong mudah karena tidak membutuhkan
perhitungan-perhitungan statistik yang rumit. Selain itu, jaringan yang
dibuat bisa dilatih untuk mengenali pola-pola agar sesuai dengan target yang
diharapkan. Pelatihan jaringan adalah salah satu kelebihan JST
dibandingkan dengan teknologi yang lain.
Pengenalan karakter menggunakan JST pernah dilakukan oleh
Shashank Araokar, seorang mahasiswa Jurusan Elektronik dan
Telekomunikasi Universitas Mumbai India. Shashank Araokar membuat
sebuah perangkat lunak yang bisa mengenali pola-pola karakter yang
terdapat pada file gambar yang memiliki format bitmap. Aplikasi yang
dibuat hanya bisa mengenali satu karakter saja. Hasil yang didapat tidak
berupa karakter-karakter ASCII, tetapi hanya menunjukkan berapa persen
karakter yang menjadi masukannya bisa dikenali sebagai karakter ASCII [6],
[7].
Penulis akan melakukan pengembangan pada aplikasi yang telah
dibuat oleh Shashank Araokar. Aplikasi yang dirancang mampu mengenali
lebih dari satu karakter dalam sebuah file yang menjadi masukan.
Parameter-parameter yang dibutuhkan untuk pelatihan jaringan juga dapat diatur oleh
user, sehingga user bisa melihat pengaruh parameter-parameter yang
disimpan ke dalam sebuah file dengan format text (txt). Dengan adanya
perangkat lunak ini, diharapkan bisa membantu orang-orang yang ingin
mengolah teks yang disimpan menggunakan format file gambar.
I.3 Batasan Masalah dan Spesifikasi Perangkat Lunak
Pada pelaksanaan dan penyusunan karya ilmiah ini akan dibatasi oleh
beberapa hal, yaitu
1. File masukan untuk sistem terdiri dari karakter ASCII yang terdapat
pada keyboard, kecuali karakter petik ganda (“) dan karakter pipe ( | ).
2. File masukan tidak hanya terdiri dari karakter-karakter disjoint
(karakter yang tidak menyambung, seperti i, =, !, ?, :, dan ;).
3. Jenis font yang digunakan adalah Arial, Courier New, dan Times New
Roman dengan ukuran minimal adalah 36 pt.
4. Font style yang digunakan adalah regular (normal) dan tidak
menggunakan font effect subscript dan superscript.
5. Tidak bisa digunakan pada karakter-karakter yang bertindihan
(ortogonal) dan karakter yang bersentuhan (touch).
6. File masukan terdiri dari dua warna, yaitu warna hitam dan warna
putih. Karakter berwarna hitam dan background berwarna putih.
7. Hanya bisa digunakan untuk mengenali karakter yang memiliki
bentuk yang sama persis dengan karakter yang dilatih.
8. Jumlah iterasi (epoch) maksimum yang digunakan untuk proses
Sedangkan spesifikasi perangkat lunak yang akan dibuat adalah
sebagai berikut
1. Format file gambar yang dijadikan masukan untuk sistem adalah
windowsbitmap (.bmp).
2. Format file yang digunakan untuk menyimpan hasil adalah text (.txt)
dan menggunakan huruf Microsoft Sans Serif dengan ukuran 12 pt
(ukuran font yang sering digunakan adalah 12 pt).
3. Arsitektur jaringan yang digunakan adalah Backpropagation.
4. Algoritma pelatihan yang digunakan adalah algoritma
Backpropagation.
5. Bahasa pemrograman yang digunakan adalah Visual C#.
I.4
Tujuan Penelitian
Tujuan penelitian ini adalah untuk membuat sebuah perangkat lunak
menggunakan JST untuk mengenali pola-pola karakter yang terdapat pada
file gambar yang memiliki format windowsbitmap (.bmp).
I.5 Manfaat
Penelitian
Hasil karya ilmiah ini bermanfaat bagi mahasiswa yang ingin
mempelajari JST dan proses pelatihan yang menggunakan algoritma
Backpropagation. Selain itu, hasil penelitian ini juga akan bermanfaat bagi
orang yang ingin mengembangkan dan mengaplikasikan JST ke tahap yang
I.6 Sistematika
Penulisan
Sistematika penulisan yang digunakan dalam karya ilmiah ini adalah
sebagai berikut:
BAB I PENDAHULUAN
Bab ini berisi judul, latar belakang penulisan, batasan masalah dan
spesifikasi perangkat lunak, tujuan penelitian, manfaat penelitian
dan sistematika penulisan.
BAB II DASAR TEORI
Bab ini berisi teori JST, teori Backpropagation dan algoritma
pelatihan jaringan serta teori pengenalan karakter.
BAB III PERANCANGAN PERANGKAT LUNAK
Bab ini berisi perancangan tampilan program, flow chart program,
cara kerja program, dan cara-cara menentukan
parameter-parameter yang digunakan.
BAB IV HASIL DAN PEMBAHASAN
Bab ini berisi pembahasan data yang didapat.
BAB V PENUTUP
Bab ini berisi kesimpulan akhir dan saran-saran yang berguna
untuk mengatasi segala kekurangan dalam karya ilmiah ini yang
Kecerdasan Buatan (Artificial Intelligence), merupakan bagian dari
teknologi komputer yang dikembangkan untuk membuat perangkat lunak
(software) dan perangkat keras (hardware) yang bisa bekerja seperti otak manusia
[8]. Salah satu teknologi yang mendukung sistem kecerdasan buatan adalah JST,
yang dibuat dengan mengambil prinsip dan cara kerja jaringan syaraf biologis.
JST adalah sebuah teknologi yang berwujud algoritma dan perhitungan
matematis, yang bisa diimplementasikan ke dalam perangkat keras ataupun
perangkat lunak.
II.1 Jaringan
Syaraf
Biologis
Otak manusia memiliki struktur yang sangat kompleks dan memiliki
kemampuan yang luar biasa. Manusia memiliki 1012 neuron dan 6 x 1018 sinapsis,
sedangkan dalam sebuah neuron diperkirakan ada 103 sampai 104 sinapsis [3], [9].
Neuron adalah suatu komponen dalam jaringan syaraf yang berfungsi untuk
mengolah sinyal-sinyal yang diterima, sedangkan sinapsis adalah bagian yang
menangani proses interaksi antara neuron satu dengan neuron yang lain [10].
Dengan jumlah yang begitu banyak, otak manusia mampu mengenali pola,
melakukan perhitungan, dan mengontrol organ-organ tubuh yang lain dengan
Setiap neuron pada jaringan syaraf biologis bekerja karena ada pengaruh
dari neuron lain. Namun ada neuron yang bekerja bukan karena pengaruh neuron
lain, neuron tersebut adalah input neuron (reseptor). Input neuron bekerja karena
ada pengaruh rangsangan dari luar (suhu, tekanan, gesekan), kemudian keluaran
neuron ini yang membuat neuron-neuron lain bekerja .
Neuron memiliki 3 bagian penting, yaitu dendrit, soma dan axon. Dendrit
berfungsi untuk menerima sinyal-sinyal yang dikirim oleh neuron lain.
Sinyal-sinyal tersebut dimodifikasi (dikuatkan atau dilemahkan) oleh suatu bagian yang
disebut sinapsis. Kemudian sinyal-sinyal tersebut dijumlahkan oleh soma.
Penjumlahan yang dilakukan oleh soma berfungsi menguatkan sinyal-sinyal yang
diterima. Jika sinyal-sinyal yang telah dijumlahkan oleh soma cukup kuat dan
telah melebihi batas ambang (threshold), maka sinyal tersebut akan diteruskan ke
neuron-neuron lain melalui axon [9 - 11]. Anatomi sebuah neuron pada jaringan
syaraf biologis ditunjukkan pada Gambar 2.1.
Gambar 2. 1Anatomi sebuah neuron pada jaringan syaraf biologis [9]
Karena jumlah neuron dalam jaringan syaraf biologis sangat banyak, maka
Pertama, masih bisa mengenali pola-pola masukan yang sedikit berbeda dengan
pola-pola yang diterima sebelumnya. Kedua, masih mampu bekerja dengan baik
walaupun ada sebuah ataupun sekelompok neuron mengalami gangguan.
II. 2 JST
Pada dasarnya, JST terdiri dari elemen-elemen sederhana yang bekerja
secara paralel, yang prinsip dan cara kerjanya sama dengan jaringan syaraf
biologis [4]. Tujuan pembuatan teknologi ini adalah untuk mengatasi
masalah-masalah komputasi yang sulit jika dikerjakan dengan perhitungan biasa.
Secara garis besar, diagram blok JST ditunjukkan pada Gambar 2.2. Nilai
error pada diagram blok tersebut, digunakan untuk mengatur nilai-nilai bobot
pada sinapsis agar keluaran jaringan sama dengan nilai target. Bobot adalah suatu
nilai yang menunjukkan kemampuan sinapsis dalam menguatkan sinyal yang
melewatinya. Semakin besar nilai bobot sebuah sinapsis, semakin besar pula
amplitudo sinyal yang dihasilkan. Pengaturan nilai-nilai bobot pada sinapsis
dilakukan pada proses pelatihan (training) yang akan dibahas pada bagian
Pelatihan Jaringan.
II.2.1 Sejarah JST
Era perkembangan JST dimulai pada tahun 1943 oleh McCulloch-Pitts.
Warren S. McCulloch adalah seorang ahli psikologi syaraf yang telah 20 tahun
berusaha mengimplementsikan proses-proses yang terjadi di dalam jaringan syaraf
manusia ke dalam sebuah sistem perhitungan logika. Kemudian pada tahun 1942,
Walter Pitts, seorang matematikawan, bergabung dengan penelitian yang
dilakukan oleh McCulloch. McCulloch dan Pitts mendefinisikan
perhitungan-perhitungan logika yang terjadi dalam jaringan syaraf manusia, dan
mengimplementasikan menggunakan operasi-operasi logika untuk melakukan
fungsi logika sederhana. Fungsi aktivasi yang digunakan adalah Threshold
Function [9], [10], [12], [13]. Threshold Function akan dibahas pada bagian
Fungsi Aktivasi
Perubahan besar selanjutnya dalam sejarah JST terjadi pada tahun 1949,
dengan diterbitkan sebuah buku yang berjudul The Organization of Behaviour.
Penulis buku tersebut adalah Donald Hebb, seorang ahli psikologi dari Universitas
McGill. Di dalam buku tersebut, Hebb menuliskan konsep pelatihan untuk
merubah bobot sinapsis pada jaringan. Hebb adalah orang yang pertama kali
mengemukakan ide pelatihan jaringan. Hebb juga secara rinci menyebutkan
bahwa jaringan di dalam otak terus menerus melakukan perubahan pada sinapsis
setiap kali mempelajari sesuatu yang baru [10], [13] .
Pada tahun 1958, Frank Rossenblatt dari Cornell Aeronautical Laboratory,
memperkenalkan dan mulai mengembangkan jaringan yang disebut Perceptron.
model McCulloch-Pitts dan model Hebb. Perceptron adalah suatu arsitektur
jaringan yang hanya terdiri dari input layer dan output layer, tetapi nilai-nilai
bobot diubah melalui proses pelatihan jaringan, seperti yang dikemukakan oleh
Hebb [9], [10], [13].
Pada tahun 1960, Widrow dan Hoff mengembangkan pelatihan perceptron
yang ditemukan oleh Rossenblatt. Mereka memperkenalkan aturan pelatihan
jaringan yang lebih dikenal dengan aturan Delta atau Aturan Kuadrat Rata-Rata
Terkecil [9], [12]. Aturan ini akan mengubah bobot pada jaringan perceptron
apabila keluaran yang dihasilkan tidak sesuai dengan target yang diinginkan
berdasarkan nilai selisih yang diperoleh antara masukan dan target [4].
Pada tahun 1986, Rumelhart mengembangkan perceptron menjadi
Backpropagation. Backpropagation adalah suatu arsitektur jaringan yang terdiri
dari lapisan-lapisan perceptron sehingga sering juga disebut sebagai Multilayer
Perceptron. Teknologi perceptron yang dikembangkan oleh McCulloch, Pitts,
Rossenbalt, Widrow dan Hoff hanya memiliki satu layer (single layer). Teknologi
yang ditemukan oleh Rumelhart memungkinkan jaringan diproses melalui
beberapa layer, yang mampu memecahkan persoalan yang tidak bisa diselesaikan
dengan satu layer [9].
II.2.2 Model Neuron Pada JST
Neuron merupakan komponen utama penyusun JST. Jumlah neuron pada
JST menentukan unjuk kerja sebuah jaringan. Semakin banyak neuron yang ada
Unjuk kerja sebuah jaringan dilihat dari kemampuan untuk mengenali pola-pola
masukan. Sebuah neuron memiliki 3 elemen penting, yaitu [9]:
1. Himpunan unit-unit yang dihubungkan dengan jalur koneksi (sinapsis).
Jalur-jalur tersebut memiliki bobot yang berbeda-beda. Bobot yang
bernilai positif akan menguatkan sinyal yang melewatinya dan bobot yang
bernilai negatif akan melemahkan sinyal-sinyal yang melewatinya.
2. Unit penjumlah (linear combiner)
Unit ini berfungsi untuk menjumlahkan sinyal-sinyal masukan yang
sudah dikalikan dengan bobot sinapsis. Gambar 2.3 menunjukkan sebuah
jaringan sederhana yang di dalamnya terdapat unit penjumlah dengan
masukan x1, x2, x3 dan bobot sinapsis w11, w12, w13.
Gambar 2. 3 Sebuah jaringan sederhana [3]
Besarnya nilai keluaran unit penjumlah adalah u=x1w11+x2w12+x3w13.
Tapi ada sejumlah buku yang menuliskan u sebagai net [3], [9], [14].
Persamaan matematis nilai keluaran unit penjumlah dinyatakan dengan [3]
i p
j ji
j
j u w x
net = =
∑
=1 ...(2.1)
dengan uj atau netj adalah nilai keluaran unit penjumlah ke-j, wjiadalah nilai
bobot sinapsis antara input neuron ke-i dengan unit penjumlah ke-j, xi
adalah sinyal masukan ke-i, p adalah jumlah unit penjumlah.
3. Fungsi aktivasi (activation function)
Fungsi aktivasi hanya terdapat pada neuron-neuron, khususnya pada
output layer dan hidden layer seperti yang akan dibahas pada bagian
selanjutnya. Fungsi aktivasi berfungsi untuk membatasi amplitudo keluaran
hidden layer dan output layer. Input neuron tidak memiliki fungsi aktivasi,
karena input neuron bekerja bukan karena pengaruh neuron lain.
Pada JST, amplitudo keluaran sebuah jaringan memiliki rentang 0
sampai 1 untuk bipolar, -1 sampai 1 untuk unipolar, dan adapula yang
memiliki rentang dari –a sampai a, dengan a adalah sembarang bilangan
riil. Fungsi aktivasi dinotasikan dengan f (x), F(x) atau φ(.) [3], [4], [9],
[10], [15].
II.2.3 Fungsi Aktivasi Pada JST
Fungsi aktivasi yang sering digunakan antara lain Threshold Function atau
Hard Limit Function, Symetric Hard Limit Function, Sigmoid Function, Piecewise
Linear Function, Identitiy Function(Purelin Function) [4], [9], [10].
1. Threshold Function (Hard Limit Function)
Nilai ambang fungsi ini adalah 0. Nilai keluaran fungsi ini dinyatakan
( )
⎩ ⎨ ⎧ < ≥ = 0 x jika , 0 0 x jika , 1 x f ...(2.2)Grafik keluaran threshold function ditunjukkan pada Gambar 2.4
-50 -40 -30 -20 -10 0 10 20 30 40 50
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Gambar 2. 4 Grafik keluaran Threshold Function [3]
2. Symetric Hard Limit Function
Nilai ambang untuk fungsi ini adalah 0. Nilai keluaran fungsi ini dinyatakan
dengan [4]
( )
⎩ ⎨ ⎧ < − ≥ = 0 x jika , 1 0 x jika , 1 x f ...(2.3)Grafik keluaran symetric hard limit function ditunjukkan pada Gambar 2.5
-50 -40 -30 -20 -10 0 10 20 30 40 50 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1
3. Sigmoid Function
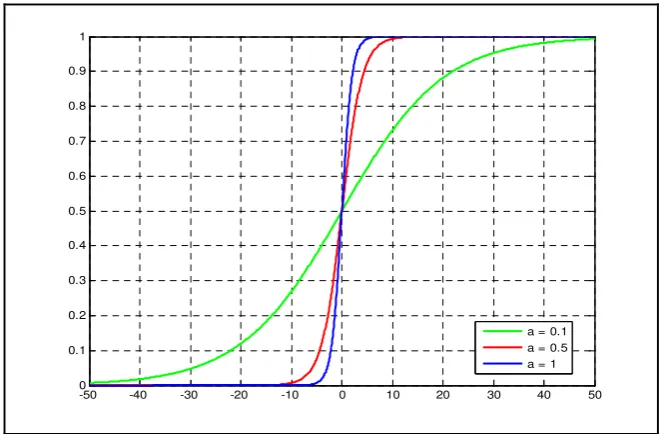
Nilai keluaran fungsi ini adalah [3]
( )
) exp( 1 1 ax x f − + = ...(2.4)dengan a adalah sebuah parameter yang berfungsi untuk menentukan
kecuraman (slope) pada sigmoid function. Bentuk sinyal keluaran yang
berbeda-beda, akan didapat dengan mengubah-ubah nilai a seperti yang
ditunjukkan pada Gambar 2.6.
-50 -40 -30 -20 -10 0 10 20 30 40 50 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
a = 0.1 a = 0.5 a = 1
Gambar 2. 6 Grafik keluaran sigmoid function
4. Piecewise Linear Function
Nilai keluaran fungsi ini dinyatakan dengan [10]
( )
⎪ ⎩ ⎪ ⎨ ⎧ ≤ > > ≥ = 0 jika , 0 1 0 jika , 1 jika , 1 x x x x x f ...(2.5)-3 -2 -1 0 1 2 3 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Gambar 2. 7 Grafik keluaran Piecewise Linear Function [3]
5. Identity Function (Purelin Function)
Nilai keluaran fungsi ini dinyatakan dengan [9]
( )
x xf = ...(2.6)
Identitiy function merupakan fungsi aktivasi yang bisa memberikan nilai
keluaran berupa sembarang bilangan riil. Grafik keluaran Identity Function
(Purelin Function) ditunjukkan pada Gambar 2.8
-50 -40 -30 -20 -10 0 10 20 30 40 50 -50
-40 -30 -20 -10 0 10 20 30 40 50
II.3
Backpropagation
Backpropagation atau Multilayer Perceptron merupakan arsitektur
jaringan yang memiliki jumlah layer lebih dari 1 [10]. Layer tambahan tersebut
disebut hidden layer karena bukan merupakan bagian input layer ataupun output
layer. Struktur dasar jaringan backpropagation ditunjukkan pada Gambar 2.9
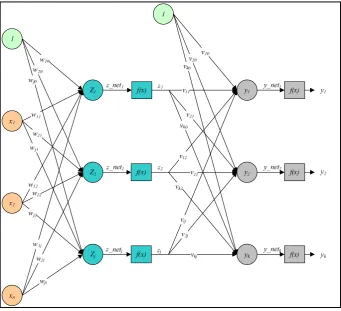
Gambar 2. 9 Struktur dasar jaringan Backpropagation [16]
Sinyal masukan yang diterima oleh input layer akan diteruskan ke hidden
layer. Setelah diproses, sinyal tersebut akan diteruskan ke output layer untuk
mendapatkan nilai keluaran. Arsitektur Backpropagation yang memiliki sebuah
hidden layer ditunjukkan pada Gambar 2.10. Dua buah neuron yang nilainya
selalu 1 pada Gambar 2.10 disebut sebagai bias dan akan dibahas pada bagian
Gambar 2. 10 Arsitektur Backpropagation
Pemrosesan sinyal di dalam backpropagation dibagi dua, yaitu, propagasi
maju dan propagasi mundur. Pada tahap propagasi maju, sinyal masukan akan
merambat menuju output layer melalui hidden layer. Bobot-bobot sinapsis pada
jaringan tidak mengalami perubahan selama proses ini berlangsung. Hasil yang
didapat akan dibandingkan dengan suatu nilai target. Nilai target adalah suatu
nilai yang diberikan pada proses pelatihan jaringan dan menjadi acuan bagi
jaringan untuk memodifikasi bobot-bobot sinapsis. Jika antara nilai target dan
nilai keluaran yang diperoleh selama proses propagasi maju memiliki selisih,
maka sinyal selisih (error signal) akan dikirim menuju input layer. Error signal
II.3.1
Bias
Bias adalah sebuah neuron yang nilainya selalu bernilai 1 dan bukan
merupakan fungsi aktivasi [10]. Bias berfungsi untuk mengurangi jumlah epoch
pada pelatihan. Sebuah jaringan sederhana dengan penambahan sebuah bias
ditunjukkan pada Gambar 2.11
Gambar 2. 11 Jaringan yang ditambah bias
Nilai keluaran unit penjumlah ke-j (netj) yang didapat karena pengaruh
penambahan bias, dinyatakan dengan
i i
j bw xw x w xw
net = 10+ 1 11+ 2 12+ 1 ...(2.7)
karena nilai b selalu 1, maka persamaan (2.7) bisa ditulis menjadi
i i
j w xw x w xw
net = 10 + 1 11+ 2 12 + 1 ...(2.8)
Persamaan (2.8) dapat disederhanakan menjadi [1]
i p
j ji
j
j w w x
net = +
∑
=1
0 ...(2.9)
dengan netj adalah nilai keluaran unit penjumlah ke-j, wj0 adalah bobot bias
sinapsis antara input neuron ke-i dengan unit penjumlah ke-j, i = 1, 2, 3,...;, p
adalah jumlah unit penjumlah.
Keluaran hidden neuron (zj) pada Gambar 2.10, dicari menggunakan
persamaan (2.10), (2.11) dan (2.12). Keluaran unit penjumlah pada hidden neuron
dinyatakan dengan i ji j j j j i i i i x w x w x w w net z x w x w x w w net z x w x w x w w net z + + + = + + + = + + + = 2 2 1 1 0 2 2 22 1 21 20 2 1 2 12 1 11 10 1 _ _ _ ...(2.10)
Persamaan umum untuk persamaan (2.10) adalah
∑
= + = p j i ji jj w w x
net z
1 0
_ ...(2.11)
dengan p adalah jumlah neuron pada hidden layer.
Secara keseluruhan, keluaran hidden layer (zj) adalah
(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + = =∑
= p j i ji j jj f z net f w w x
z
1 0
_ ...(2.12)
dengan zj adalah keluaran hidden neuron, f adalah fungsi aktivasi, dan p adalah
jumlah neuron pada hidden layer. Nilai keluaran unit penjumlah pada output
neuron adalah y_net1, y_net2, dan y_netk, dan dinyatakan dengan
j kj k k k k j j j j z v z v z v v net y z v z v z v v net y z v z v z v v net y + + + = + + + = + + + = 2 2 1 1 0 2 2 22 1 21 20 2 1 2 12 1 11 10 1 _ _ _ ...(2.13)
Persamaan umum untuk persamaan (2.13) adalah
∑
= + = l j j kj kk v v z
net y
1 0
Nilai keluaran jaringan adalah
(
)
⎟⎟⎠ ⎞ ⎜⎜
⎝ ⎛
+ =
=
∑
=
l
j j kj k
k
k f y net f v v z
y
1 0
_ ...(2.15)
dengan y_netk adalah keluaran unit penjumlah pada output neuron ke-k, zj adalah
keluaran hidden neuron ke-j, vkj adalah bobot antara hidden neuron ke-j dengan
output neuron ke-k, dan l adalah jumlah output neuron.
II.3.2 Parameter-Parameter Pada
Backpropagation
Ada beberapa parameter penting yang sangat berpengaruh dalam proses
pelatihan jaringan. Parameter-parameter tersebut adalah epoch, learning rate,
momentum, dan error target.
1. Epoch
Epoch adalah satu siklus pelatihan yang melibatkan semua pola masukan,
walaupun jaringan belum mengenali semua pola [9]. Agar jaringan bisa
mengenali semua pola, maka semua pola masukan tersebut diolah lagi pada
epoch selanjutnya. Semakin banyak epoch yang dilakukan, semakin baik pula
hasil yang akan didapat. Untuk kasus yang kompleks, jumlah epoch yang
diperlukan sangat banyak, sehingga waktu yang dibutuhkan untuk melatih
jaringan juga akan lama. Sehingga jumlah epoch perlu dibatasi.
2. Learning rate (
α
)Learning rate adalah suatu parameter yang menentukan seberapa cepat
perubahan yang terjadi pada bobot-bobot sinapsis [9]. Semakin besar learning
cepat, sehingga waktu yang dibutuhkan untuk melatih jaringan akan sedikit.
Nilai learning rate sebaiknya dipilih dengan nilai yang kecil, yaitu antara 0
sampai 1, walaupun sebenarnya tidak ada batasan yang pasti untuk nilai ini.
Jika nilai learning rate terlalu besar, maka perubahan bobot-bobot sinapsis
akan terlalu cepat. Akibatnya adalah jaringan tidak akan pernah bisa
mengenali pola sesuai dengan targetnya. Selain itu nilai error jaringan juga
bisa menjadi sangat besar atau tak terhingga sehingga proses pelatihan tidak
bisa dilanjutkan lagi.
3. Momentum (
μ
)Momentum adalah suatu parameter yang berfungsi untuk menghindari
perubahan bobot yang signifikan akibat data yang diberikan sangat berbeda
dengan data sebelumnya (outliner) [9]. Perubahan nilai bobot tidak hanya
didasarkan pada pola yang dimasukkan saat itu, tetapi juga perubahan bobot
akibat pola sebelumnya. Penambahan parameter ini sangat berguna pada
permasalahan yang kompleks. Namun untuk kasus yang sederhana,
penambahan momentum membuat pelatihan jaringan lebih lama, sedangkan
hasil yang didapat akan sama dengan pelatihan tanpa momentum.
4. Error target
Error target merupakan parameter terpenting dalam pelatihan sebuah
jaringan. Error target adalah nilai selisih antara masukan dengan target
jaringan yang diharapkan. Secara ideal, nilai error yang diharapkan adalah 0.
Semakin kecil nilai error target, semakin banyak jumlah pola yang bisa
(
∑
=
−
= N
k
k
k y
d N E
1
2
1
)
...(2.16)
dengan E adalah nilai error antara masukan dan target, N adalah jumlah pola
masukan, yk adalah nilai keluaran output neuron ke-k, dk adalah target output
neuron ke-k.
II.3.3 Pelatihan Jaringan
Pelatihan jaringan berfungsi untuk mengubah nilai-nilai bobot sinapsis
agar sinyal masukan yang diberikan sesuai dengan targetnya. Tujuan utama proses
pelatihan adalah meminamalisasi error antara target dan keluaran jaringan [17].
Pada Backpropagation, perubahan bobot sinapsis dilakukan pada tahap propagasi
mundur. Gambar 2.12 memperlihat arah sinyal yang ada pada Backpropagation.
Gambar 2. 12 Arah sinyal dalam backpropagation [3]
Pelatihan jaringan memerlukan 3 tahap, yaitu tahap propagasi maju, tahap
propagasi mundur, dan tahap modifikasi bobot. Tahap propagasi maju dan
bobot adalah tahap yang dikerjakan setelah tahap propagasi mundur selesai, dan
proses modifikasi bobot dikerjakan secara bersamaan.
Pelatihan jaringan backpropagation menggunakan algoritma sebagai
berikut [9], [12]:
1. Semua bobot diinisialisasi dengan bilangan acak kecil.
2. Jika kondisi penghentian belum terpenuhi (error target belum tercapai
atau jumlah epoch belum sama dengan jumlah epoch maksimum)
langkah 3 – 10 dilakukan.
3. Untuk setiap pasang data pelatihan, langkah 4 – 9 dilakukan.
Tahap propagasi maju
4. Menghitung keluaran neuron di hidden layer menggunakan persamaan
(2.11) dan (2.12).
5. Menghitung keluaran neuron di output layer menggunakan persamaan
(2.14) dan (2.15).
Tahap propagasi mundur
6. Menghitung faktor kesalahan di output layer menggunakan persamaan
(
k k) (
k)
k = d −y f' y_net
δ ...(2.17)
dengan δk adalah faktor kesalahan pada output neuron ke-k, dk adalah
target output neuron ke-k, yk adalah keluaran output neuron ke-k, f’
adalah turunan pertama fungsi aktivasi pada output layer, dan y_netk
adalah keluaran unit penjumlah di output layer, k=1,2,3,...,l; dengan l
7. Menghitung faktor perubahan bobot antara hidden layer dan output layer
menggunakan persamaan
j k
kj z
v =αδ
Δ ...(2.18)
dengan Δvkj adalah faktor perubahan bobot antara hidden layer dan
output layer, α adalah learning rate, δk faktor kesalahan pada output
neuron ke-k, zj adalah keluaran hidden neuron ke-j, k=1,2,3,...l; dengan
l adalah jumlah output neuron, j=1,2,3,...p; dengan p adalah jumlah
hidden neuron.
Jika jaringan menggunakan bias, maka faktor perubahan bobot pada bias
dinyatakan dengan
b vkj =αδk
Δ ...(2.19)
dengan k=1,2,3...p; dengan p adalah jumlah hidden neuron, j=0.
8. Menghitung faktor kesalahan pada hidden layer menggunakan
persamaan
∑
=
= l
k kj k
j v
net 1
_ δ
δ ...(2.20)
dengan δ_netj adalah faktor kesalahan pada unit penjumlah di hidden layer, δk adalah faktor kesalahan pada output neuron ke-k, vkj adalah
bobot antara hidden neuron ke-j dengan output neuron ke-k, dan l adalah
jumlah output neuron.
(
j)
j
j δ_net f' z_net
dengan δj adalah faktor kesalahan pada hidden neuron ke-j, f’ adalah turunan pertama fungsi aktivasi pada hidden layer, dan z_netj adalah
keluaran unit penjumlah pada hidden neuron ke-j.
9. Menghitung faktor perubahan bobot antara input layer dan hidden layer
menggunakan persamaan
i j
ji x
w =αδ
Δ ...(2.22)
dengan adalah faktor perubahan bobot antara input neuron ke-i
dengan hidden neuron ke-j, ji
w Δ
α adalah learning rate, δj faktor kesalahan
pada hidden neuron ke-j, dan xi adalah nilai masukan pada input neuron
ke-i.
Jika jaringan menggunakan bias, maka faktor perubahan bobot pada bias
dinyatakan dengan
b wji =αδj
Δ ...(2.23)
dengan j=1,2,3,...,p; dengan p adalah jumlah hidden neuron, i=0.
Tahap perubahan bobot
10.Menghitung perubahan bobot menggunakan persamaan
kj kj
kj baru v lama v
v ( )= ( )+Δ ....(2.24)
(
)
ji(
)
jiji baru w lama w
w = +Δ ...(2.25)
Jika proses pelatihan menggunakan momentum, maka perubahan bobot
baru akan terjadi pada iterasi ketiga, sehingga persamaan untuk
( )
t+1 =w( )
t + x +(
w( )
t −w( )
t−1)
wji ji αδj i μ ji ji ...(2.26)
(
t+1)
=v( )
t + z +(
v( )
t −v( )
t−1)
vkj kj αδk j μ kj kj ...(2.27)
dengan t adalah waktu pelaksanaan iterasi, μ adalah momentum, α
adalah learning rate dan xi adalah sinyal input pada input neuronke-i.
Contoh 1 Penggunaan Backpropagation tanpa bias untuk mengenali fungsi logika XOR
Persoalan:
Gunakan arsitektur jaringan seperti yang ditunjukkan pada Gambar 2.13
untuk mengenali fungsi logika XOR, dengan learning rate = 0.2 dan error target
0.01, fungsi aktivasinya adalah sigmoid. Tabel kebenaran fungsi logika XOR
ditunjukkan pada Tabel 2.1
Gambar 2. 13 Arsitektur Backpropagation tanpa bias
Tabel 2. 1 Tabel kebenaran logika XOR
x1 x2 d (target)
Penyelesaian:
Langkah 1: Semua bobot diinisialisasi dengan bilangan acak kecil, seperti yang ditunjukkan pada Tabel 2.2 dan Tabel 2.3
Tabel 2. 2 Inisialisasi nilai bobot antara input layer dan hidden layer
Z1 Z2 Z3
x1 w11 = 0.2 w21 = -0.1 w31 = 0.5
x2 w12 = 0.1 w22 = 0.6 w32 = -0.2
Tabel 2. 3 Inisialisasi nilai bobot antara inputlayer dan hidden layer
y Z1 v11 = 0.3
Z2 v12 = 0.7
Z3 v13 = -0.7
Langkah 4: Menghitung keluaran hidden layer Untuk pola I: x1 = 1, x2 = 1, dan d = 0
∑
= = 2 1 _ j i jij w x
net z
( )
( )
( )
( )
( )
1 0.2( )
1 0.3 5 . 0 2 . 0 5 . 0 _ 5 . 0 1 6 . 0 1 1 . 0 6 . 0 1 . 0 _ 3 . 0 1 1 . 0 1 2 . 0 1 . 0 2 . 0 _ 2 1 3 2 1 2 2 1 1 = − = − = = + − = + − = = + = + = x x net z x x net z x x net z( )
( )
Langkah 5: Menghitung keluaran jaringan
∑
= = l j j kjk v z
net y 1 _
(
)
(
)
(
)
2060 . 0 5744 . 0 7 . 0 6225 . 0 7 . 0 5744 . 0 3 . 0 7 . 0 7 . 0 3 . 0_ 1 1 2 3
= − + = − +
= z z z
net y
(
)
5513 . 0 1 1 2060 . 0 2060 . 0 1 = + = = = − e f y yLangkah 6: Menghitung faktor kesalahan di output layer
(
k k) (
k)
k = d − y f' y_net
δ
Turunan fungsi aktivasinya adalah f'
( )
x = f( )
x[
1− f(
x)
]
(lihat Lampiran 1), dan karena hanya ada satu neuron pada output layer,maka δk =
(
dk −yk) (
f y_netk) (
[
1− y_netk)
]
=(
dk −yk) (
yk 1−yk)
dk = 0; nilai target untuk x1 = 1 dan x2 = 1
(
0−0.5513)(
0.5513)
[
1−0.5513]
=−0.1364=
k δ
Langkah 7: Menghitung faktor perubahan perubahan bobot antara hidden layer
dan output layer
j k
kj z
v =αδ Δ
(
)(
)
(
)(
)
Langkah 8: Menghitung faktor kesalahan di hidden layer
∑
= = l k kj k j v net 1 _ δδ , dengan l adalah jumlah output neuron
kj k j v net δ δ_ =
( )
( )
(
0.7)
0.0955 1364 . 0 _ 0955 . 0 7 . 0 1364 . 0 _ 0490 . 0 3 . 0 1364 . 0 _ 13 2 12 2 11 1 = − − = = − = − = = − = − = = v net v net v net k k k δ δ δ δ δ δbesarnya faktor kesalahan hidden layer adalah
(
j) (
j) (
j)
(
(
j)
)
j
j =δ_net f' z_net = δ _net f z_net 1− f z_net
δ
(
j) (
j j)
j = δ _net z 1−z
δ
(
) (
)
(
)(
)
(
) (
)
(
)(
)
(
_) (
1)
0.0955(
0.5744)(
1 0.5744)
0.0233 0224 . 0 6225 . 0 1 6225 . 0 0955 . 0 1 _ 1 . 0 5744 . 0 1 5744 . 0 0490 . 0 1 _ 3 3 3 3 2 2 2 2 1 1 1 1 = − = − = − = − − = − = − = − − = − = z z net z z net z z net δ δ δ δ δ δLangkah 9: Menghitung faktor perubahan bobot antara input layer dengan hidden layer
i j
ji x
w =αδ Δ
( )(
)( )
( )(
)( )
( )(
0.2 0.0233)( )
1 0.0047 0045 . 0 1 0224 . 0 2 . 0 02 . 0 1 1 . 0 2 . 0 1 3 31 1 2 21 1 1 11 − = − = = Δ − = − = = Δ − = − = = Δ x w x w x w αδ αδ αδ( )(
)( )
( )(
)( )
Langkah 10: Menghitung semua perubahan bobot
kj kj
kj baru v lama v
v ( )= ( )+Δ
(
)
(
)
(
0.0157)
-0.7157 7 . 0 ) ( ) ( ) ( 6830 . 0 0170 . 0 7 . 0 ) ( ) ( ) ( 2843 . 0 0157 . 0 3 . 0 ) ( ) ( ) ( 13 13 13 13 12 12 12 12 11 11 11 11 = − + − = ⇒ Δ + = = − + = ⇒ Δ + = = − + = ⇒ Δ + = baru v v lama v baru v baru v v lama v baru v baru v v lama v baru v ji jiji baru w lama w
w ( )= ( )+Δ
(
)
(
)
(
0.0047)
0.4953 5 . 0 ) ( ) ( ) ( 1045 . 0 0045 . 0 1 . 0 ) ( ) ( ) ( 1800 . 0 02 . 0 2 . 0 ) ( ) ( ) ( 31 31 31 31 21 21 21 21 11 11 11 11 = − + = ⇒ Δ + = − = − + − = ⇒ Δ + = = − + = ⇒ Δ + = baru w w lama w baru w baru w w lama w baru w baru w w lama w baru w(
)
(
)
(
0.0047)
0.2047 2 . 0 ) ( ) ( ) ( 5955 . 0 0045 . 0 6 . 0 ) ( ) ( ) ( 0800 . 0 02 . 0 1 . 0 ) ( ) ( ) ( 32 32 32 32 22 22 22 22 12 12 12 12 − = − + − = ⇒ Δ + = = − + = ⇒ Δ + = = − + = ⇒ Δ + = baru w w lama w baru w baru w w lama w baru w baru w w lama w baru wTabel 2. 4 Nilai bobot antara inputlayer dan hiddenlayer hasil pelatihan dengan pola pertama (x1 = 1, x2 = 1, dan d = 0)
Z1 Z2 Z3
x1 w11 = 0.18 w21 = -0.1045 w31 = 0.4953
x2 w12 = 0.08 w22 = 0.5955 w32 = -0.2047
Tabel 2. 5 Nilai bobot antara hiddenlayer dan ouputlayer hasil pelatihan dengan pola pertama (x1 = 1, x2 = 1, dan d = 0)
y Z1 v11 = 0.2843
Z2 v12 = 0.6830
Z3 v13 = -0.7157
dengan cara yang sama, nilai bobot pada epoch pertama ditunjukkan pada Tabel
Tabel 2. 6 Bobot antara inputlayer dan hiddenlayer hasil pelatihan pada epoch pertama
Z1 Z2 Z3
x1 w11 = 0.1999 w21 = -0.1003 w31 = 0.5003
x2 w12 = 0.0998 w22 = 0.5994 w32 = -0.1995
Tabel 2. 7 Nilai bobot antara hiddenlayer dan outputlayer hasil pelatihan pada epoch
pertama
y Z1 v11 = 0.2976
Z2 v12 = 0.6973
Z3 v13 = -0.7023
Hasil pengujian jaringan pada epoch pertama diperlihatkan pada Tabel 2.8
Tabel 2. 8 Hasil pengujian jaringan menggunakan bobot pada epoch pertama
x1 x2 d (target)
keluaran jaringan (y)
1 1 0 0.5502 1 0 1 0.5144 0 1 1 0.5720 0 0 0 0.5365
nilai error pada epoch pertama dicari mengunakan persamaaan (2.16)
(
) (
) (
) (
)
[
]
[
]
0.2524 0095 . 1 4 1 5365 . 0 0 5720 . 0 1 5144 . 0 1 5502 . 0 0 41 2 2 2 2
= = − + − + − + − = E
karena E > error target, proses pelatihan diulangi lagi. Dengan bantuan perangkat
lunak MATLAB®, jumlah epoch yang dibutuhkan untuk mencapai error target
Source code:
>> x=[1 1 0 0 ; 1 0 1 0]; >> t=[0 1 1 0];
>> net=newff(minmax(x),[3,1],{'logsig','logsig'},'traingd'); >> net.biasConnect=[0;0];
>> net.IW{1,1}=[0.2 0.1;-0.1 0.6;0.5 -0.2]; >> net.LW{2,1}=[0.3 0.7 -0.7];
>> net.trainparam.goal=.01; % nilai error target >> net.trainparam.lr=0.2; % nilai learning rate >> net.trainparam.epochs=100000; % nilai epoch maksimum >> net=train(net,x,t)
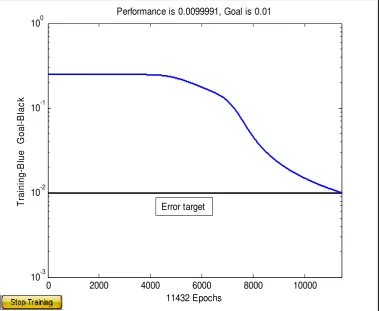
Grafik hasil pelatihan diperlihatkan pada Gambar 2.14. Dari Gambar 2.14, terlihat
bahwa jumlah epoch yang dibutuhkan untuk mencapai error target sebesar 0.01
adalah 11.432 epoch.
0 2000 4000 6000 8000 10000 10-3
10-2 10-1 100
11432 Epochs
T
ra
ini
ng
-B
lue
G
oal
-B
la
c
k
Performance is 0.0099991, Goal is 0.01
Error target
Hasil pengujian jaringan pada epoch ke-11.432 diperlihatkan pada Tabel 2.9
Tabel 2. 9 Hasil pengujian jaringan menggunakan bobot pada epoch ke-11.432
x1 x2 d (target)
keluaran jaringan (y)
1 1 0 0.0679 1 0 1 0.9057 0 1 1 0.9062 0 0 0 0.1330
(
) (
) (
) (
)
[
]
[
]
0.01 0.0400 4
1
1130 . 0 0 9062 . 0 1 9057 . 0 1 0679 . 0 0 4
1 2 2 2 2
= =
− + −
+ −
+ −
=
E
Contoh 2 Penggunaan Backpropagation dengan bias untuk mengenali fungsi logika XOR
Persoalan:
Gunakan arsitektur jaringan seperti yang ditunjukkan pada Gambar 2.15
untuk mengenali fungsi logika XOR, dengan learning rate = 0.2 dan error target
0.01, fungsi aktivasinya adalah sigmoid. Tabel kebenaran fungsi logika XOR
ditunjukkan pada Tabel 2.1
Penyelesaian:
Langkah 1: Semua bobot diinisialisasi dengan bilangan acak kecil, seperti yang ditunjukkan pada Tabel 2.10 dan Tabel 2.11
Tabel 2. 10 Inisialisasi nilai bobot antara inputlayer dan hiddenlayer
Z1 Z2 Z3
b w10 = -0.3 w20 = -0.8 w30 = -0.1
x1 w11 = 0.2 w21 = -0.1 w31 = 0.5
x2 w12 = 0.1 w22 = 0.6 w32 = -0.2
Tabel 2. 11 Inisialisasi nilai bobot antara inputlayer dan hiddenlayer
y
b v10 = 0.9
Z1 v11 = 0.3
Z2 v12 = 0.7
Z3 v13 = -0.7
Langkah 4: Menghitung keluaran hidden layer Untuk pola I: x1 = 1, x2 = 1, dan d = 0
∑
= + = 2 1 0 _ j i ji jj w w x
net z
( )
( )
( )
( )
( )
1 0.2( )
1 0.2 5 . 0 1 . 0 2 . 0 5 . 0 _ 3 . 0 1 6 . 0 1 1 . 0 8 . 0 6 . 0 1 . 0 _ 0 1 1 . 0 1 2 . 0 3 . 0 1 . 0 2 . 0 _ 2 1 30 3 2 1 20 2 2 1 10 1 = − + − = − + = − = + − + − = + − + = = + + − = + + = x x w net z x x w net z x x w net z( )
(
)
( )( )
0.5498Langkah 5: Menghitung keluaran jaringan
∑
= + = l j j kj kk v v z
net y 1 0 _
( )
(
)
(
0.9631 5498 . 0 7 . 0 4256 . 0 7 . 0 5 . 0 3 . 0 9 . 0 7 . 0 7 . 0 3 . 0_ 1 10 1 2 3
= − + + =
)
− + +=v z z z
net y
(
)
0.7237 1 1 9631 . 0 9631 . 0 1 = + = = = − e f y yLangkah 6: Menghitung faktor kesalahan di output layer
(
) (
) (
[
)
]
(
k k) (
k k)
k k k k k y y y d net y net y f y d − − = − − = 1 _ 1 _ δ
dk = 0; nilai target untuk x1 = 1 dan x2 = 1
(
0−0.7237)(
0.7237)
[
1−0.7237]
=−0.1447=
k δ
Langkah 7: Menghitung faktor perubahan perubahan bobot antara hidden layer
dan output layer
j k
kj z
v =αδ Δ
(
)( )
(
)(
)
(
0.1447)(
0.5498)
-0.0159 2 . 0 -0.0123 4256 . 0 1447 . 0 2 . 0 -0.0145 5 . 0 1447 . 0 2 . 0 1 13 2 12 1 11 = − = = Δ = − = = Δ = − = = Δ z v z v z v k k k αδ αδ αδ b vk =αδkΔ 0
(
0.1447)( )
1 0.0289 2. 0
10 = = − =−
Langkah 8: Menghitung faktor kesalahan di hidden layer
∑
= = l k kj k j v net 1 _ δδ , dengan l adalah jumlah output neuron
( )
( )
(
0.7)
0.1013 1447 . 0 _ -0.1013 7 . 0 1447 . 0 _ -0.0434 3 . 0 1447 . 0 _ 13 2 12 2 11 1 = − − = = = − = = = − = = v net v net v net k k k δ δ δ δ δ δbesarnya faktor kesalahan hidden layer adalah
(
j) (
j j)
j = δ _net z 1−z
δ
(
) (
)
( )(
)
(
) (
)
(
)(
)
(
_) (
1)
0.1013(
0.5498)(
1 0.5498)
0.0251 0.0248 4256 . 0 1 4256 . 0 1013 . 0 1 _ 0.0109 5 . 0 1 5 . 0 0434 . 0 1 _ 3 3 3 3 2 2 2 2 1 1 1 1 = − = − = − = − − = − = − = − − = − = z z net z z net z z net δ δ δ δ δ δLangkah 9: Menghitung faktor perubahan bobot antara input layer dengan hidden layer
i j
ji x
w =αδ Δ
( )(
)( )
( )(
)( )
( )(
0.2 0.0251)( )
1 0.0050 0.0050 1 0248 . 0 2 . 0 0.0022 1 0109 . 0 2 . 0 1 3 31 1 2 21 1 1 11 = = = Δ − = − = = Δ − = − = = Δ x w x w x w αδ αδ αδ( )(
)( )
( )(
)( )
( )(
0.2 0.0251)( )
1 0.0050 0050 . 0 1 0248 . 0 2 . 0 0022 . 0 1 0109 . 0 2 . 0 2 3 32 2 2 22 2 1 12 = = = Δ − = − = = Δ − = − = = Δ x w x w x w αδ αδ αδ b wj =αδjΔ 0
( )(
)( )
( )(
)( )
( )(
0.2 0.0251)( )
1 0.0050 0.0050 1 0248 . 0 2 . 0 0.0022 1 0109 . 0 2 . 0 3 30 2 20 1 10 = = = Δ − = − = = Δ − = − = = Δ b w b w b w αδ αδ αδkj kj
kj baru v lama v
v ( )= ( )+Δ
(
)
(
)
(
)
(
0.0159)
-0.7159 7 . 0 ) ( ) ( ) ( 0.6877 0123 . 0 7 . 0 ) ( ) ( ) ( 0.2855 0145 . 0 3 . 0 ) ( ) ( ) ( 0.8711 0289 . 0 9 . 0 ) ( ) ( ) ( 13 13 13 13 12 12 12 12 11 11 11 11 11 10 10 10 = − + − = ⇒ Δ + = = − + = ⇒ Δ + = = − + = ⇒ Δ + = = − + = ⇒ Δ + = baru v v lama v baru v baru v v lama v baru v baru v v lama v baru v baru v v lama v baru v ji jiji baru w lama w
w ( )= ( )+Δ
(
)
(
)
(
0.0050)
-0.0950 1 . 0 ) ( ) ( ) ( -0.8050 0050 . 0 8 . 0 ) ( ) ( ) ( -0.3022 0022 . 0 3 . 0 ) ( ) ( ) ( 30 30 31 30 20 20 21 20 10 10 11 10 = + − = ⇒ Δ + = = − + − = ⇒ Δ + = = − + − = ⇒ Δ + = baru w w lama w baru w baru w w lama w baru w baru w w lama w baru w(
)
(
)
![Gambar 2. 9 Struktur dasar jaringan Backpropagation [16]](https://thumb-ap.123doks.com/thumbv2/123dok/1550425.2047386/38.595.206.417.258.537/gambar-struktur-dasar-jaringan-backpropagation.webp)