TINJAUAN PUSTAKA
Analisis gerombol dalam bidang riset pemasaran sering diistilahkan sebagai analisis segmentasi, merupakan alat statistika peubah ganda yang bertujuan untuk mengelompokkan n individu data ke dalam k gerombol, dengan k < n. Individu yang terletak dalam satu gerombol memiliki kemiripan sifat yang lebih besar dibandingkan dengan individu yang terletak dalam gerombol lain (Dillon & Goldstein 1984). Dengan demikian, sasaran analisis gerombol adalah mendapatkan gugus pengelompokkan yang meminimumkan keragaman di dalam gerombol dan sekaligus memaksimumkan keragaman antar gerombol (Garson 2006). Secara umum, metode penggerombolan dapat dibedakan ke dalam 3 kelompok, yaitu (1) metode penggerombolan berhirarki, (2) metode penggerombolan tak-berhirarki, dan (3) penggabungan kedua pendekatan metode penggerombolan, atau dikenal juga sebagai metode hybrid (Putri 2005).
Semakin rumitnya masalah yang dihadapi dalam menggerombolkan gugus data berdimensi besar dan banyaknya individu yang sangat besar, mendorong berkembangnya teknik-teknik penggerombolan baru yang dalam prosesnya dilakukan secara bertahap (pre clustering dan clustering). Metode-metode yang cukup dikenal dikalangan peneliti bidang pemasaran dan data mining diantaranya adalah, TwoStep
Cluster (Chiu et al. 2001), Latent Segment Analysis (Vermunt & Magidson 2000;
McCutcheon 1999, dan Bernstein et al. 2002), BIRCH (Zhang 1996), CLARANS,
CURE, dan DBscan (Strehl & Gosh 2002), serta Two Stage Clustering
(Lakshminarayan & Yu 2001). Pada penelitian ini, fokus evaluasi diarahkan pada metode TwoStep Cluster. Metode penggerombolan klasik, yaitu hirarki dan k-rataan dijadikan sebagai pembanding untuk mengevaluasi keakuratan metode TwoStep Cluster.
Metode Penggerombolan Berhirarki
Metode penggerombolan berhirarki digunakan apabila banyaknya gerombo l yang akan dibentuk belum diketahui dengan pasti di awal. Menurut Garson (2006), penggerombolan berhirarki cocok untuk ukuran data yang kecil (biasanya<250). Metode penggerombolan berhirarki dapat dibedakan menjadi dua yaitu metode penggabungan (agglomerative) dan metode pemecahan (divisive). Garson (2006) mengistilahkannya sebagai forward dan backward clustering. Pendekatan metode penggabungan berhiraki (agglomerative hierarchical) paling umum digunakan oleh para peneliti.
Metode berhirarki agglomerative dimulai dengan mengasumsikan bahwa setiap objek merupakan satu gerombol, selanjutnya secara bertahap dilakukan penggabungan pada objek-objek yang paling dekat. Proses ini berlanjut sampai semua sub grup bergabung menjadi satu gerombol. Sebaliknya, meto de divisive
diawali dengan asumsi semua objek berada dalam satu gerombol, kemudian objek-objek yang paling jauh dipisah dan membentuk satu gerombol lain. Proses tersebut berlanjut sampai semua objek masing- masing membentuk satu gerombol. Hasil pembentukan gerombol berhirarki beserta jarak penggabungannya dapat digambarkan dalam suatu dendogram.
Secara umum pembentukan dendogram dengan algoritma agglomerative adalah sebagai berikut (Johnson 1967) :
1. Mulai dengan N gerombol yang masing- masing hanya beranggotakan satu individu.
2. Gabungkan dua individu atau sub-gerombol yang memiliki jarak terdekat pada matrik jarak.
3. Hitung kembali jarak antar gerombol yang baru.
4. Ulangi langkah (2) dan (3) sampai (N-1) kali, sampai akhirnya semua objek bergabung menjadi satu gerombol.
Dalam metode penggerombolan berhirarki setiap langkah penggabungan gerombol diikuti dengan perbaikan matrik s jarak. Adenberg (1973), Dillon dan Goldstein (1984), serta Morrison (1990) memaparkan beberapa pilihan metode perbaik an jarak yang dapat digunakan pada langkah (3) di atas, yaitu :
a. Pautan tunggal (single linkage) b. Pautan lengkap (complete linkage)
c. Pautan rataan dalam kelompok (average linkage within the new group) d. Pautan rataan antar kelompok (average linkage between merged group) e. Centroid
f. Median g. Ward
Wijayanti (2002), dengan menggunakan metode simulasi, menunjukkan bahwa metode perbaikan jarak pautan rataan dalam kelompok memberikan nilai salah klasifikasi yang paling rendah diantara metode perbaikan jarak lainnya.
Metode penggerombolan berhirarki memungkinkan untuk digunakan pada gugus peubah kriteria penggerombolan yang semuanya berskala rasio, interval, ordinal, atau biner (Garson 2006). Untuk masing- masing jenis skala terdapat pilihan konsep jarak yang sesuai. Berbagai konsep jarak untuk data biner dibahas pada Digby dan Kempton (1987).
Metode Penggerombolan K-rataan
Metode k-rataan termasuk kedalam kelompok penggerombolan tak berhirarki. Menurut Garson (2006), penggerombolan dengan menggunakan metode k-rataan menggunakan konsep jarak Euclidian, sehingga peubah kriteria penggerombolan haruslah semuanya berskala rasio, interval, atau biner (true dichotomies). Untuk menggunakan metode penggerombolan k-rataan, pengguna (peneliti) harus menentukan terlebih dahulu banyaknya gerombol yang akan dibentuk secara apriori (Morrison 1990; dan Garson 2006). Pemilihan banyaknya gerombol (k) dapat ditentukan secara subjektif berdasarkan landasan teori dari masalah yang dianalisis atau melalui penelusuran data awal.
Titik pusat awal k buah gerombol dipilih secara acak pada pertama kali, selanjutnya dilakukan proses iterasi yang mana pada setiap iterasi dibentuk penggerombolan berdasarkan jarak Euclidian terdekat ke pusat gerombol. Jadi pada setiap iterasi pusat gerombol akan berubah. Proses iterasi akan berhenti bila rata-rata gerombol lebih kecil dari batas perubahan yang ditentukan, atau banyaknya iterasi telah melampaui batasan maksimum (Adenberg 1973). Secara umum, metode k-rataan menghasilkan tepat k gerombol yang memiliki perbedaan keragaman terbesar1). Garson (2006) mengemukakan bahwa metode k-rataan cocok untuk digunakan pada data berukuran besar (misal lebih dari 200 individu).
TwoStep Cluster
Algoritma TwoStep Cluster dikembangkan oleh Chiu, Fang, Chen, Wang, dan Jeris (2001) untuk analisis pada gugus data yang besar. Prosedurnya terdiri dari dua langkah (Chiu et al. 2001, SPSS 2004), yaitu :
1. Penggerombolan Awal (Pre-Clustering)
Tujuan penggerombolan awal (pre-clustering) adalah untuk memasukkan data matriks bar u dengan objek yang lebih sedikit pada langkah selanjutnya. Langkah penggerombolan awal menggunakan pendekatan penggerombolan secara sekuensial (Theodoridis & Koutroumbas 1999). Pendekatan ini menelusuri (scan) vektor data individu (record) satu per satu dan memutuskan apakah vektor data yang bersangkutan akan digabung dengan gerombol yang telah terbentuk sebelumnya atau memulai gerombol yang baru berdasarkan kriteria jarak yang telah ditetapkan.
___________________________________________ 1)
Prosedur tersebut diimplementasikan dengan membentuk Cluster Feature tree
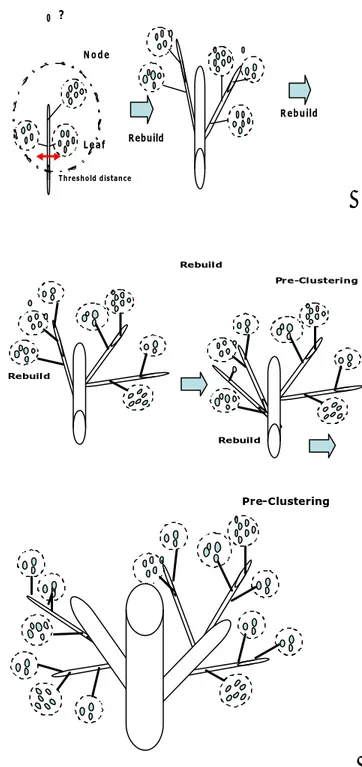
(Zhang et al. 1996), pada penulisan ini diterjemahkan sebagai “pohon ciri gerombol”. Pohon ciri gerombol terdiri dari beberapa tingkatan cabang (nodes) dan masing-masing cabang berisikan individu data (entries). Individu yang terdapat pada cabang yang berisikan individu rujukan disebut Leaf Entry, merepresentasikan anak-gerombol (sub-cluster) dari gerombol rujukan awal. Cabang-cabang yang bukan menjadi rujukan (non-leaf nodes) beserta individu di dalamnya akan mengarahkan vektor individu baru ke dalam cabang yang tepat secara cepat. Sebagai contoh, SPSS memberikan nilai default untuk banyaknya tingkat cabang maksimum (maximum
levels of nodes)=3 dan banyaknya entries per nodes maksimum 8 sehingga
banyaknya leaf entries maksimum sebanyak 83 = 512 anak-gerombol (SPSS Technical Guide 2001).
Suatu pohon ciri gerombol (CF tree) dengan informasi banyaknya individu pada pohon gerombol yang bersangkutan, nilai tengah dan ragam setiap peubah kontinu, serta frekuensi masing-masing kategori untuk peubah kategorik mencirikan setiap anak-gerombol (entries). Setiap vektor individu (record) yang berurutan, secara rekursif diarahkan untuk menemukan anak cabang terdekat, untuk menjadi daun pada pohon yang bersangkutan. Bila vektor individu yang bersangkutan terletak pada wilayah jarak penerimaan (threshold distance) dari dahan terdekat (leaf entry), dahan tersebut akan memasukkan individu yang bersangkutan menjadi anggota anak gerombol, kemudian merubah informasi pohon ciri gerombol dari dahan. Bila vektor individu terletak di luar wilayah jarak penerimaan, individu tersebut akan menjadi cikal bakal dahan yang baru pada cabang yang bersesuaian. Bila suatu cabang tidak lagi memiliki ruang untuk menambah daun baru (entries), maka cabang tersebut akan dipecah menjadi dua. Jika dimisalkan pada sebuah pohon, dari satu dahan kemudian membelah menjadi dua dahan. Individu- individu yang terdapat pada cabang sebelumnya akan dipecah menjadi 2 kelompok dengan menggunakan 2 titik rujukan yang paling berjauhan, kemudian individu lainnya akan disebarkan berdasarkan kriteria kedekatan. Proses ini akan berlanjut sampai seluruh individu terolah secara lengkap.
Jika CF tree berkembang melewati batas ukuran maksimum yang telah ditetapkan, maka CF tree yang telah ada akan dibangun ulang dengan cara meningkatkan kriteria ukuran penerimaan. CF tree yang melewati batas biasanya dikarenakan pada saat proses algoritma CF tree ini dijalankan, terbentuk daun entri yang beranggotakan pencilan (outlier). Pencilan pada analisis TwoStep Cluster
adalah data yang tidak dapat dimasukkan pada gerombol manapun. Pada saat CF tree
akan dibangun ulang, maka akan diperiksa daun entri yang berpote nsi sebagai pencilan. Daun entri yang terdeteksi beranggotakan pencilanmerupakan daun entri yang jumlah anggotanya kurang dari fraksi ukuran gerombol yang memiliki jumlah paling besar yang telah ditetapkan. Pada saat pembangunan ulang, daun entri yang berpotensi sebagai pencilan disimpan. Setelah CF tree dibangun ulang, maka satu per satu data dalam daun entri yang berpotensi sebagai pencilan dimasukkan ke dalam
CF tree yang baru tanpa mengubah ukuran CF tree tersebut. Jika masih ada data yang
tidak masuk ke dalam daun entri manapun, maka data tersebut dikatakan sebagai pencilan. Data-data yang dideteksi sebagai pencilan dimasukkan ke dalam satu gerombol.
Pada diagram algoritma CF tree yang disajikan pada Gambar 1, maksimum
depth dan maksimum nodes yang digunakan yaitu masing- masing 3, sehingga daun
entri (anak gerombol) yang terbentuk adalah sebanyak 33 atau 27 anak gerombol, sedangkan pada penelitian ini sesuai dengan default dari program SPSS maksimum
depth sama dengan 3 dan maksimum nodes 8.
Menurut Bacher, Wenzig, dan Vogler (2004), hasil penggerombolan awal bergantung pada urutan dari objek/individu yang disusun pada matriks data. Oleh karena itu, SPSS (2001:2) merekomendasikan untuk menggunakan urutan data secara acak.
? Rebuild Rebuild Node Leaf Threshold distance Pre-Clustering Rebuild Rebuild Rebuild Pre-Clustering
2. Penggerombolan Individu Objek ( Step 2 Cluster)
Pada tahap ini diterapkan model berbasiskan teknik hirarki. Sebagaimana halnya dengan teknik hirarki aglomeratif, hasil penggerombolan awal digabungkan dengan menggunakan cara bertatar (stepwise) sampai semua objek berada dalam satu gerombol. Berbeda dengan teknik -teknik hirarki aglomeratif, algoritma TwoStep
Cluster didasarkan pada suatu model statistik. Model dilandasi pada asumsi bahwa
peubah-peubah kontinu xj (j = 1,2,…,p) pada gerombol ke-i menyebar normal bebas stokastik dengan nilai tengah µij dan ragam
2
ij
σ , serta peubah-peubah kategorik aj pada gerombol ke-i mengikuti sebaran multinomial dengan peluang πijl, yang mana (jl) adalah indeks dari kategori ke l (l = 1,2,…,ml) dari peubah aj(j = 1,2,…,q).
3. Konsep Jarak
Terdapat dua konsep pengukuran jarak yang tersedia pada SPSS TwoStep
Cluster yaitu jarak Euclidean dan jarak log-likelihood. Bacher, Weinzig, dan Vogler
(2004) menyatakan bahwa ukuran jarak log-likelihood dapat diterapkan untuk atribut (peubah-peubah) campuran antara kategorik dan numerik.
Jarak log -likelihood antara dua kelompok i dan s didefinisikan sebagai berikut:
d(i,s)=ξi +ξs −ξi,s (1)
(
)
( )
− + − =∑
∑
∑
= = = p j m l ijl ijl q j j ij i i j n 1 1 1 2 2 ˆ log ˆ ˆ ˆ log 2 1 π π σ σ ξ (2)(
)
( )
− + − =∑
∑
∑
= = = p j m l sjl sjl q j j sj s s j n 1 1 1 2 2 ˆ log ˆ ˆ ˆ log 2 1 σ σ π π ξ (3)(
)
( )
− + − =∑
∑
∑
= = = p j m l jl s i jl s i q j j j s i s i s i j n 1 1 , , 1 2 2 , , , log ˆ ˆ ˆ log ˆ 2 1 π π σ σ ξ (4)Untuk penyingkatanξi,s dituliskan sebagai εv , yang dapat ditafsirkan sebagai
suatu jenis galat penyimpangan (dispersi) di dalam gerombol v (v = i,s,(i,s)). εv
terdiri dari dua komponen keragaman. Bagian pertama adalah ) ˆ ˆ log( 2 1 2 2 1 vj j p j v n σ +σ
−
∑
= yang mengukur total simpangan (keragaman) dari peubah kontinu xj di dalam gerombol v dan bagian kedua 1 mj1 ˆvjllog( ˆvjl)l q j v n ∑ = ∑= π π −
(entropy) mengukur dispersi pada peubah kategorik. Seperti halnya dengan teknik
hirarki aglomeratif, gerombol- gerombol dengan jarak terkecil d(i,s) digabungkan pada tiap langkah. Fungsi log -likelihood untuk langkah dengan k gerombol dituliskan sebagai:
∑
= = k v v k l 1 ξ (5) Fungsi lk bukan merupakan fungsi log-likelihood yang selengkapnya sebagaimana dituliskan pada persamaan sebelumnya. Fungsi ini dapat ditafsirkan sebagai dispersi di dalam gerombol (keragaman dalam gerombol). Bila hanya diperhatikan pada bagian peubah kategorik, lk adalah entropy dalam gerombol ke k.4. Penentuan Banyaknya Gerombol
Pada SPSS TwoStep Cluster, banyaknya gerombol dapat diperoleh secara otomatis. Dua tahap pendugaan diterapkan untuk menentukan banyaknya gerombol secara objektif. Tahap pertama menghitung besaran Kriteria Informasi Akaike (AIC) dan Kriteria Informasi Bayes (BIC). Kriteria Informasi Akaike untuk k buah gerombol dirumuskan sebagai :
AICk = −2lk +2rk (6)
yang mana rk adalah banyaknya parameter bebas.
Kriteria Informasi Bayes untuk k buah gerombol, dengan rumusan sebagai : BICk =−2lk+rklogn (7)
Menurut Chiu et al. (2001: 266) BICk atau AICk menghasilkan penduga awal yang baik bagi banyaknya gerombol maksimum. Banyaknya gerombol maksimum ditentukan sama dengan banyaknya gerombol yang memiliki rasio BICk/BIC1 yang pertama kali lebih kecil dari c1 (SPSS menetapkan c1 = 0,04 yang didasarkan atas studi simulasi) (SPSS Technical Support 2001).
Tahap kedua digunakan kriteria perubahan rasio jarak untuk k buah gerombol,
R(k) , yang didefinisikan sebagai :
k
k d
d k
R( )= −1/ (8)
yang mana dk-1 adalah jarak jika k buah gerombol digabungkan menjadi k-1 gerombol. Jarak dk dapat diperoleh dari hasil perhitungan sebagai berikut :
k k k l l d = −1− (9)
(
vlog v)
/2 v r n BICl = − atau lv =
(
2rv −AICv)
/2 untuk v=k, k-1 (10) Menurut Bacher, Wenzig, dan Vogler (2004), menggunakan BIC atau AIC menghasilkan jawaban ya ng berbeda. Sebagai catatan, SPSS menyediakan 2 pilihan kriteria, yaitu menggunakan BIC atau AIC. Banyaknya gerombol diperoleh berdasarkan ketentuan ditemukannya perbedaan yang nyata pada rasio perubahan gerombol. Rasio perubahan gerombol dihitung sebagai berikutR
( ) ( )
k1 /Rk2 (11) untuk dua nilai terbesar dari R(k) (k=1,2,…,kmax; kmax didapatkan dari langkah pertama).Jika rasio perubahan lebih besar daripada nilai batas c2 (SPSS menetapkan nilai c2 = 1,15 berdasarkan studi simulasi), banyaknya gerombol ditetapkan sama dengan
k1, selainnya banyak gerombol sama dengan maksimum {k1,k2}.
5. Langkah Penetapan Keanggotaan Gerombol dan Penanganan Pencilan
Tiap objek ditetapkan sebagai anggota dari gerombol terdekat secara deterministik berdasarkan ukuran jarak yang biasanya digunakan untuk mendapatkan gerombol. Bacher (2000) mengungkapkan bahwa penetapan keanggotaan gerombol
secara deterministik memungkinkan terjadinya penduga yang bias bagi profil gerombol, bila terjadi tumpang tindih (overlap) antar dua gerombol yang saling berdekatan. Kelompok data yang dapat mengakibatkan terjadinya bias dalam penetapan keanggotaan gerombol disebut sebagai pencilan (outlier) atau gangguan
(noise). Untuk menanggulangi hal ini, Bacher, Wenzig, dan Vogler (2004)
menyarankan agar pengguna SPSS menentukan nilai fraction of noise (opsi penanganan pencilan), misalnya 5 (=5%). Bila diyakini pada data tidak terdapat gangguan (penc ilan), maka pilihan penanganan pencilan dapat diabaikan.
Suatu dahan (pada tahapan penggerombolan awal) dianggap sebagai gerombol yang berpotensi sebagai pencilan bilamana banyaknya individu pada sub gerombol yang bersangkutan lebih sedikit dari persentase (proporsi) fraksi ukuran gerombol maksimum yang ditetapkan.
Pencilan atau gangguan (noise) diasumsikan menyebar mengikuti sebaran seragam. Untuk mendeteksi bahwa suatu individu dapat dinyatakan sebagai pencilan atau bukan, dilakukan perhitungan jarak log-likelihood dari titik yang bersangkutan ke sub gerombol terdekat yang bukan pencilan (closest non-noise cluster), dan jarak
log-likelihood bilamana titik tersebut dimasukkan sebagai pencilan. Langkah
berikutnya, memilih jarak log-likelihood terbesar dari kedua perhitungan tersebut. Langkah ini setara dengan memasukkan individu yang diduga sebagai pencilan ke sub gerombol terdekat yang bukan pencilan bilamana jarak log-likelihood lebih kecil dari titik kritis
C=log(V) (12) dimana : m k L R V =∏ ∏ (13) k
R = range dari peubah kontinu ke-k m
L = Banyaknya kategori untuk peubah kategori ke-m
Sub-sub gerombol yang telah diidentifikasi sebagai pencilan, pada tahap pra-penggerombolan (pre-clustering) tidak dilibatkan pada proses penentuan banyaknya gerombol maupun penetapan keanggotaan gerombol.