LAMPIRAN 9
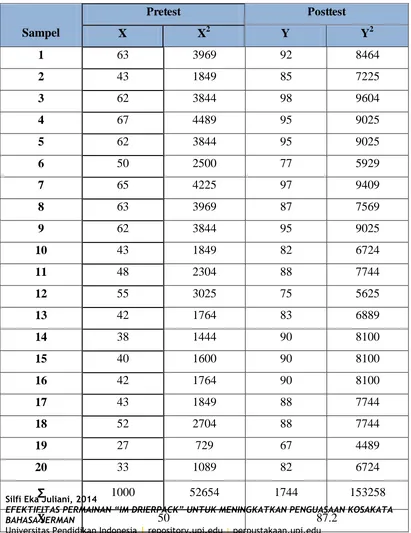
Tabel 4
Data Pretest dan Posttest
Sampel
Pretest Posttest
X X2 Y Y2
1 63 3969 92 8464
2 43 1849 85 7225
3 62 3844 98 9604
4 67 4489 95 9025
5 62 3844 95 9025
6 50 2500 77 5929
7 65 4225 97 9409
8 63 3969 87 7569
9 62 3844 95 9025
10 43 1849 82 6724
11 48 2304 88 7744
12 55 3025 75 5625
13 42 1764 83 6889
14 38 1444 90 8100
15 40 1600 90 8100
16 42 1764 90 8100
17 43 1849 88 7744
18 52 2704 88 7744
19 27 729 67 4489
Kategori Penilaian menurut Arikunto (2008:245)
Angka 100 Keterangan
80-100 Baik sekali
66-79 Baik
56-65 Cukup
40-55 Kurang
30-39 Gagal
LAMPIRAN 10
Uji Normalitas Data Pretest (X) dan Posttest (Y)
A.Uji Normalitas Data X (Pretest)
Sebelum melakukan pengujian normalitas data X, terlebih dahulu diperlukan
data-data sebagai berikut:
Banyak data (n) = 20
Jumlah skor (Ʃx) = 1000
Jumlah kuadrat skor (Ʃ 2) = 52654
Untuk mencari rata-rata/mean (� ) digunakan rumus:
� = Ʃ
�
= 1000 20
= 50
S 11.81881 7.8847
Max 67 98
Untuk mencari simpangan baku (s) digunakan rumus:
Untuk menghitung proporsi Zi,Z2,Z3... yang ke Zi
S (Zi) =
� � � �, 2,… � �� �
�
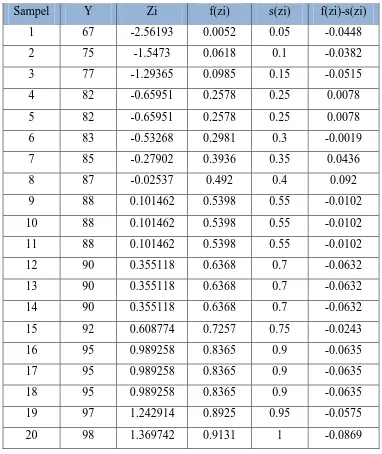
Tabel 5
Uji Normalitas Data Pretest
7 43 -0.59228 0.2776 0.4 -0.1224
8 43 -0.59228 0.2776 0.4 -0.1224
9 47 -0.25383 0.4013 0.45 -0.0487
10 48 -0.16922 0.4364 0.5 -0.0636
11 50 0 0 0.55 -0.55
12 52 0.169222 0.5636 0.6 -0.0364
13 55 0.423055 0.6628 0.65 0.0128
14 62 1.015331 0.8438 0.8 0.0438
15 62 1.015331 0.8438 0.8 0.0438
16 62 1.015331 0.8438 0.8 0.0438
17 63 1.099942 0.8621 0.9 -0.0379
18 63 1.099942 0.8621 0.9 -0.0379
19 65 1.269164 0.8965 0.95 -0.0535
20 67 1.438385 0.9236 1 -0.0764
Dari tabel di atas diperoleh Lhitung= 0,1224. Dengan jumlah sampel (n) = 20 dan pada taraf nyata � = 0,05 diperoleh Ltabel = 0,190. Dengan demikian tampak
bahwa Lhitung < Ltabel. Hal ini berarti data X berdistribusi normal. Artinya hasil
penelitian berlaku untuk seluruh populasi. Untuk lebih jelas perhatikan tabel berikut
ini:
Hasil Uji Normalitas Tes
Lhitung Ltabel Tafsiran
0,1224 0,190 Normal
Penghitungan Ltabel diperoleh dengan cara:
B.Uji Normalitas Data Y (Posttest)
Untuk mencari rata-rata/mean (X) digunakan rumus:
X=Ʃy
�
= 1744 20 = ,
Untuk mencari simpangan baku (s) digunakan rumus:
S = n. Ʃy
S (Zi) =� � � �, 2,… � �� �
�
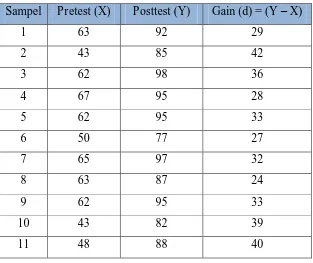
Tabel 6
Uji Normalitas data Posttest
Sampel Y Zi f(zi) s(zi) f(zi)-s(zi)
1 67 -2.56193 0.0052 0.05 -0.0448
2 75 -1.5473 0.0618 0.1 -0.0382
3 77 -1.29365 0.0985 0.15 -0.0515
4 82 -0.65951 0.2578 0.25 0.0078
5 82 -0.65951 0.2578 0.25 0.0078
6 83 -0.53268 0.2981 0.3 -0.0019
7 85 -0.27902 0.3936 0.35 0.0436
8 87 -0.02537 0.492 0.4 0.092
9 88 0.101462 0.5398 0.55 -0.0102
10 88 0.101462 0.5398 0.55 -0.0102
11 88 0.101462 0.5398 0.55 -0.0102
12 90 0.355118 0.6368 0.7 -0.0632
13 90 0.355118 0.6368 0.7 -0.0632
14 90 0.355118 0.6368 0.7 -0.0632
15 92 0.608774 0.7257 0.75 -0.0243
16 95 0.989258 0.8365 0.9 -0.0635
17 95 0.989258 0.8365 0.9 -0.0635
18 95 0.989258 0.8365 0.9 -0.0635
19 97 1.242914 0.8925 0.95 -0.0575
20 98 1.369742 0.9131 1 -0.0869
Lhitung < Ltabel. Hal ini berarti data X berdistribusi normal. Artinya hasil penelitian berlaku untukseluruh populasi. Untuk lebih jelas perhatikan tabel berikut ini:
Hasil Uji Normalitas Tes
Lhitung Ltabel Tafsiran
0,0869 0,195 Normal
Penghitungan Ltabel diperoleh dengan cara:
Diketahui n = 20, berdasarkan tabel uji lilifors n = 20 adalah 0,190.
LAMPIRAN 11
Uji Homogenitas Varians Data X dan Y
Untuk menguji data homogenitas varians data digunakan rumus:
�= �
� =
�� ��� �� �
�� ��� �����
Berdasarkan pengujian normalitas, diketahui bahwa besar simpangan baku atau
standar deviasi (S) dan varians (S2) pretest dan posttest adalah sebagai berikut:
Tabel 7.
Besar Varians Data Pretest dan Posttest
LAMPIRAN 12
Uji Signifikansi Perbedaan Rata-Rata Nilai Pretest (X) dan Posttest (Y)
Untuk menguji signifikansi perbedaan rata-rata nilai X dan Y digunakan rumus
hitung Uji-t sebagai berikut:
= �
Ʃ� (� −2 1)
Dengan keterangan:
Md = mean dari perbedaan antara Pretest (X) dan Posttest (Y)
Xd = deviasi masing-masing subjek (d – Md) Ʃ 2 = jumlah kuadrat deviasi
n = subjek pada sampel
df = atau db adalah n – 1
Perhitungan dalam tabel disajikan sebagai berikut:
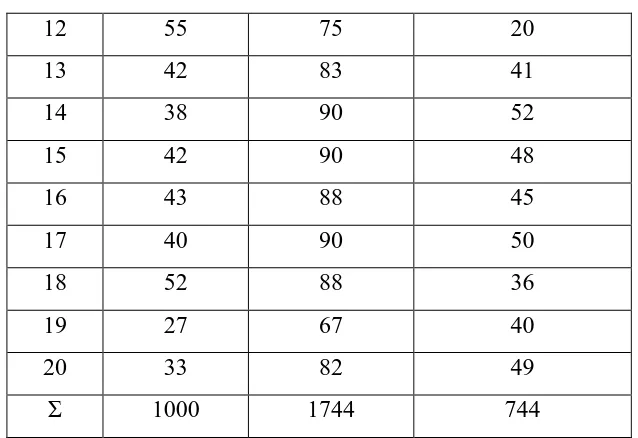
Tabel 8
Distribusi Nilai Pretest, Posttest dan Gain Siswa
Sampel Pretest (X) Posttest (Y) Gain (d) = (Y – X)
1 63 92 29
2 43 85 42
3 62 98 36
4 67 95 28
5 62 95 33
6 50 77 27
7 65 97 32
8 63 87 24
9 62 95 33
10 43 82 39
12 55 75 20
13 42 83 41
14 38 90 52
15 42 90 48
16 43 88 45
17 40 90 50
18 52 88 36
19 27 67 40
20 33 82 49
Σ 1000 1744 744
Untuk mengetahui deviasi masing-masing subjek, maka terlebih dahulu dicari
mean dari perbedaan pretest dan posttest dengan rumus sebagai berikut:
� = Ʃ
�
=744 20
= ,
Dari perhitungan di atas, diketahui mean dari pretest dan posttest sebesar 37,2.
Kemudian dicari jumlah kuadrat deviasi masing-masing subjek (Ʃ 2 ) yang
disajikan dalam tabel berikut:
Tabel 9
Jumlah Kuadrat Deviasi
Sampel d Xd= (d-Md) X2d
1 29 -8.2 67.24
2 42 4.8 23.04
3 36 -1.2 1.44
4 28 -9.2 84.64
6 27 -10.2 104.04
7 32 -5.2 27.04
8 24 -13.2 174.24
9 33 -4.2 17.64
10 39 1.8 3.24
11 40 2.8 7.84
12 20 -17.2 295.84
13 41 3.8 14.44
14 52 14.8 219.04
15 48 10.8 116.64
16 45 7.8 60.84
17 50 12.8 163.84
18 36 -1.2 1.44
19 40 2.8 7.84
20 49 11.8 139.24
Σ Σ d=744 Σ X2
d= 1547.2
Berdasarkan tabel di atas, dapat diketahui data sebagai berikut:
n = 20 Σd = 744 Md = 37,2 Σx2d = 1547,2 dk = 20–1= 19
Jadi nilai t adalah:
= �
Ʃ� � −2 1
= 37,2
1547,2 20 (20−1)
= 37,2 4,0716
Mencari dengan �= 0,05 dan dk = 19 ; 0,95 33 = 1,729. Jika
ℎ� �� = 18,4 > = 1,729. Dengan demikian terdapat perbedaan rata-rata
yang signifikan antara hasil pretest dan posttest.
LAMPIRAN 13
Analisis Pengujian Hipotesis
Adapun kriteria penerimaan hipotesis penelitian ini adalah sebagai berikut:
H0 : μ SsP = μ SbP
H1 : μ SsP > μ SbP
Keterangan:
μ SsP : kemampuan kosakata bahasa Jerman setelah diterapkannya perlakuan
permainan im Dreierpack (posttest) dalam pembelajaran.
μ SbP : kemampuan kosakata bahasa Jerman sebelum diterapkannya perlakuan
permainan im Dreierpack (pretest) dalam pembelajaran.
H0 : hasil posttest sama dengan hasil pretest, artinya tidak terdapat peningkatan
hasil belajar siswa dalam meningkatkan kosakata bahasa Jerman setelah
mendapat perlakuan dengan teknik permainan im Dreierpack
H1 : hasil posttest setelah perlakuan lebih besar dari hasil pretest, artinya
terdapat peningkatan hasil belajar siswa dalam meningkatkan kosakata
bahasa Jerman setelah mendapat perlakuan dengan teknik permainan im Dreierpack
Berdasarkan perhitungan di atas, diperoleh ℎ� �� = 18,4 sedangkan =
1,729. Maka dapat disimpulkan bahwa ℎ� �� > , maka artinya H1 diterima
dan H0 ditolak. Hal ini menunjukan bahwa kemampuan akhir siswa lebih baik