Fakultas Ilmu Komputer
Universitas Brawijaya
1667
Klasifikasi Luka pada Jaringan Payudara Berbasis Spektra Impedansi
Listrik Menggunakan Fuzzy k-Nearest Neighbor
Sandya Ratna Maruti1, Imam Cholissodin2, Heru Nurwasito3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1nduk.sandya@gmail.com, 2imamcs@ub.ac.id, 3heru@ub.ac.id
Abstrak
Penyakit payudara umumnya terjadi pada wanita dengan insiden penyakit meningkat setiap tahun. Angka kematian pada penderitanya hingga 40% keatas dan cenderung pada wanita muda modern. Karena itu deteksi penyakit payudara dan diagnosis di awal tahap menjadi masalah yang paling penting dalam kedokteran. Keadaan physiopathology jaringan payudara manusia dapat terlihat dengan Electrical
Impedance Spectral (EIS) sehingga dapat dilakukan klasifikasi. Tujuan penelitian ini adalah
mengklasifikasikan luka pada jaringan payudara dan mengetahui akurasi menggunakan metode Fuzzy
k-Nearest Neighbor (FKNN). Dataset berjumlah 105 data, dari dataset UCI-Repository dengan 9
parameter masukan yang didapat dari impedansi listrik meliputi I0, PA500, HFS, DA, AREA, A/DA, MAX IP, DR dan P. Sedangkan keluarannya merupakan kondisi luka payudara yaitu jaringan kelenjar
(glandular tissue), jaringan ikat (connective tissue), jaringan adiposa (adipose tissue), mastopathy, fibro-adenoma dan karsinoma (carcinoma). Pengujian FK-NN menghasilkan nilai terbaik yaitu nilai
m=2, persentase data training=60% dan k = 3. Hasil metode ini mampu mengklasifikasikan 28 data
testing sesuai dengan kelas aktual dan 14 data testing yang tidak sesuai dengan kelas aktualnya dari total
42 data testing. Tingkat akurasinya adalah 66.6666667%.
Kata kunci: Luka jaringan payudara, Electrical Impedance Spectral, klasifikasi, Fuzzy k-Nearest Neighbor.
Abstract
Breast disease generally occurs in women with increased incidence of disease each year. The mortality rate for the sufferer is up to 40% and above and tends to be in modern young women. Therefore breast cancer detection and early diagnosis of the stage become the most important problem in medicine. The physiopathology state of human breast tissue can be seen with Electrical Impedance Spectral (EIS) so that it can be classified. The aim of this research is to classify the wound on breast tissue and to know the accuracy using Fuzzy k-Nearest Neighbor (FKNN) method. The dataset consists of 105 data, from the UCI-Repository dataset with 9 input parameters obtained from electrical impedance including I0, PA500, HFS, DA, AREA, A / DA, MAX IP, DR and P. While the output is a condition of breast injury that is glandular tissue, connective tissue, adipose tissue, mastopathy, fibro-adenoma and carcinoma. The FKNN test yields the best value of m = 2, the percentage of training data = 60% and k = 3. The result of this method is able to classify 28 data testing in accordance with the actual class and 14 data testing which is not in accordance with the actual class of total 42 data testing. The accuracy rate is 66.6666667%.
Keywords: Breast tissue injury, Electrical Impedance Spectral, classification, Fuzzy k-Nearest Neighbor.
1. PENDAHULUAN
Penyakit payudara umumnya terjadi pada wanita dengan insiden penyakit meningkat setiap tahun. Angka kematian pada penderitanya hingga 40% keatas, dan penyakit tersebut cenderung terjadi pada orang yang lebih muda. Penyakit ini mengancam kesehatan wanita
modern. Karena itu deteksi penyakit payudara
dan diagnosis di awal tahap menjadi salah satu masalah yang paling penting dalam kedokteran (Bandyopadhyay, 2013).
Dalam kaitannya dengan kanker payudara, kanker payudara mengacu pada ganasnya tumor yang telah dikembangkan dari sel-sel atau jaringan pada payudara. Lebih dari 50% wanita
menderita kanker payudara berada pada kelompok usia 25 sampai 50 tahun. Kanker payudara juga dapat berkembang pada pria tetapi kondisinya langka (Nagpal, 2015).
Keadaan physiopathology jaringan payudara manusia dapat terlihat dengan impedansi listrik karakteristik spektral. Spektrum karakteristik pada jaringan payudara dapat membedakan keadaan jaringan payudara. Artinya dapat dibuat diagnosis penyakit payudara untuk pasien (Chang, 2015).
Sebagian metode klasifikasi kanker diusulkan terkait dengan data mining atau daerah
soft computing seperti analisis tetangga terdekat,
analisis jaringan back-propagation, analisis logika Fuzzy. Sebagian besar metode bekerja dengan baik pada masalah kelas biner dan tidak memberikan hasil baik pada masalah multi-kelas (Nagpal, 2015).
K-Nearest Neighbor Classifier (KNN)
adalah salah satu algoritma klasifikasi yang sederhana. KNN classifier telah telah menjadi patokan algoritma klasifikasi yang baik (Mahmoud, 2015). K-NN termasuk algoritma
supervised learning dimana hasil dari query instance yang baru diklasifikasikan berdasarkan
mayoritas dari kategori pada K-NN atau bekerja berdasarkan jarak terpendek dari query instance ke training sample untuk menentukan K-NN nya. Klasifikasinya menggunakan voting terbanyak diantara klasifikasi dari k obyek (Maghfiroh, 2014).
Algoritma Fuzzy K-Nearest Neighbor (FKNN) bertujuan untuk meningkatkan kinerja KNN konvensional dengan memperkenalkan konsep fuzzy (Yang, 2014). Fuzzy K-Nearest Neighbor (FKNN) melakukan prediksi dengan mencari nilai tetangga terdekat kemudian menggunakan basis nilai keanggotaan data
testing dari setiap kelas dengan mengambil nilai
keanggotaan terbesar sebagai hasil akhir prediksi (Wisdarianto, 2013). Keuntungannya adalah nilai-nilai keanggotaan vektor seharusnya memberikan tingkat jaminan pada hasil klasifikasi. FK-NN (fuzzy k-nearest neighbor) merupakan salah satu proses yang penting dari ekstraksi ciri. Proses ini menghitung derajat keanggotaan fuzzy dengan menghitung jarak antara vektor antar kelas maupun dalam kelas (Prasetyo, 2012).
Dalam kaitannya Fuzzy K-Nearest Neighbor dengan klasifikasi luka pada jaringan
payudara beserta akurasinya, klasifikasi dilakukan dengan masukan 9 parameter yang didapat dari impedansi listrik meliputi I0
(Impedivity ohm di frekuensi nol), PA500 (sudut fase di 500 KHz), HFS (kemiringan tinggi frekuensi sudut fase), DA (jarak impedansi antara ujung spectral), AREA (daerah di bawah spektrum), A/DA (daerah dinormalisasi oleh DA), MAX IP (maksimum spektrum), DR (jarak antara I0 dan bagian nyata dari titik frekuensi maksimum) dan P (panjang kurva spectral). Sedangkan keluaran perangkat lunak yang merupakan kondisi luka pada jaringan payudara yaitu jaringan kelenjar (glandular tissue), jaringan ikat (connective tissue), jaringan adiposa (adipose tissue), mastopathy, fibro-adenoma, dan karsinoma (carcinoma). 2. TINJAUAN PUSTAKA
2.1. Jaringan Payudara
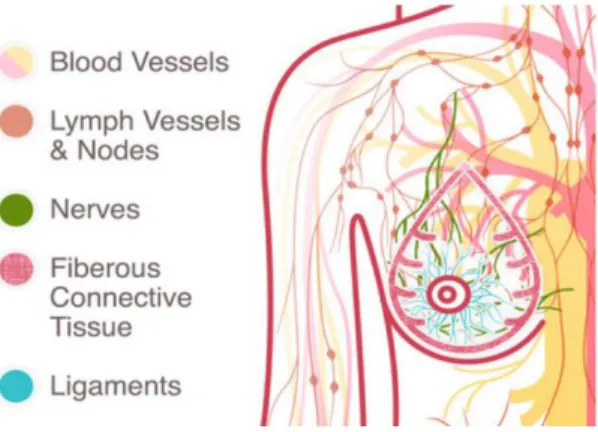
Didalam payudara terdapat glandular (kelenjar), fatty (lemak) dan connective tissue (jaringan ikat). Kelenjar getah bening yang disebut rantai mamaria internal mulai terdapat pada pusat dada (Dense, 2017). Bagian kelenjar payudara dibagi menjadi beberapa bagian yang disebut lobus. Dalam setiap lobus ada bagian kecil, yang disebut lobulus, yang menghasilkan susu. Mirip dengan bagaimana sistem peredaran darah mendistribusikan elemen seluruh tubuh, sistem getah bening mengangkut sel pelawan penyakit dan cairan. Kelompok kelenjar getah bening berbentuk kacang tetap di daerah seluruh sistem getah bening dan bertindak sebagai filter dengan membawa sel-sel abnormal dari jaringan sehat (National Breast Cancer Foundation, 2017). Sistem getah bening pada payudara dapat dilihat pada Gambar 1.
Gambar 1. Sistem Getah Bening Payudara
2.1.1 Luka Jaringan Payudara
Para peneliti membagi kondisi jaringan payudara menjadi 6 kelompok antara lain jaringan kelenjar (glandular tissue), jaringan
ikat (connective tissue), jaringan adiposa
(adipose tissue), mastopathy, fibro-adenoma,
dan karsinoma (carcinoma). Keenam kelompok dapat dibagi menjadi dua kelompok, yang pertama tiga kelompok adalah jaringan normal dan yang lainnya adalah jaringan luka. Dua pertama (mastopathy dan fibro-adenoma) dari kondisi jaringan luka tergolong penyakit yang jinak, dan yang terakhir adalah penyakit ganas
(carcinoma) (Chang, 2015).
2.2. Electrical Impedance Spectroscopy Electrical Impedance Spectroscopy (EIS)
adalah suatu metode yang dapat digunakan untuk mengukur kompleks sifat impedansi listrik dari material. Tegangan atau dikenal dengan arus frekuensi dan amplitudo diterapkan seluruh sistem dan respon dari arus dan tegangannya dicatat. Perbedaan fase dan besarnya stimulus terapan dan respon digunakan untuk menentukan impedansi kompleks pada frekuensi. Hasilnya sering ditampilkan dalam plot Nyquist, yang menunjukkan resistif dan komponen reaktif dari impedansi pada masing-masing frekuensi yang diukur. Gambar 2 menunjukkan karakteristik melengkung pada petak Nyquist untuk RC sirkuit yang sederhana.
Gambar 2. Plot Nyquist untuk RC Circuit Sederhana
2.3. Data Mining
Istilah data mining digunakan untuk menguraikan penemuan pengetahuan didalam
database. Data mining itu sendiri didefinisikan
sebagai proses ekstraksi dan identifikasi informasi atau pola yang penting dan pengetahuan dalam basis data dengan ukuran yang besar dengan menggunakan teknik statistik, matematik, kecerdasan buatan, dan
machine learning (Amri, 2013). 2.4. Klasifikasi
Pengertian klasifikasi yaitu suatu pengelompokan objek ke dalam beberapa kelompok berdasarkan variabel yang diamati. Klasifikasi juga dapat diartikan sebagai salah satu teknik yang digunakan dalam melakukan prediksi terhadap kelas atau properti dari sebuah data. Proses klasifikasi dimulai dari
pengumpulan data kemudian akan dibuat aturan yang mana akan menmisahan beberapa bagian data menjadi ke dalam proses klasifikasi (Mujiasih, 2011).
2.5. Normalisasi
Teknik normalisasi bisa disebut teknik pemetaan skala atau tahap pra pengolahan. Di mana peneliti bisa menemukan rentang baru dari satu rentang yang ada. Hal ini dapat membantu untuk prediksi atau peramalan dengan banyak keluaran. Salah satu proses normalisasi dapat menggunakan normalisasi Min-Mix. Normalisasi Min-Max adalah teknik sederhana di mana teknik khusus dapat sesuai dengan data dalam batas yang telah ditentukan (Patro, 2015). Fungsi untuk menghitung Min-Max normalization dapat menggunakan persamaan 1:
𝑉𝑖(𝑖) = ( 𝑉(𝑖)−min(𝑉(𝑖))
max(𝑉(𝑖))−min(𝑉(𝑖))) ∗ (𝐵𝐴 − 𝐵𝐵) + 𝐵𝐵 (1)
Dimana,
𝑉𝑖(𝑖) = Hasil normalisasi data ke-i 𝑉(𝑖) = Data ke-i yang belum dinormalisasi
min(𝑉(𝑖)) = Nilai minimum dari semua data dimana data ke-i berada
max(𝑉(𝑖)) = Nilai maksimum dari semua data dimana data ke-i berada
𝐵𝐴 = Batas atas interval 𝐵𝐵 = Batas bawah interval 2.6. K-Nearest Neighbor
Algoritma k-nearest neighbor (k-NN) adalah salah satu metode yang sering digunakan yang merupakan instance-based learning dan tergolong supervised learning, dimana proses klasifikasi untuk record baru yang belum diklasifikasi dilakukan dengan menyimpan data
training terlebih dahulu kemudian hasilnya
dapat ditemukan dengan membandingkan tingkat kemiripan yang paling banyak terhadap
data training. Pada algoritma ini yang harus
dipertimbangkan adalah nilai k, karena pemilihan nilai k yang terlalu kecil menyebabkan sensitif terhadap noise, k terlalu besar juga dapat menyebabkan neighborhood dapat mencakup titik-titik dari kelas lain, sehingga dilakukan pemilihan dengan meminimalkan estimasi error pengklasifikasian. Untuk mendapatkan hasil klasifikasi dengan menggunakan metode k-nearest neighbor hal
pertama yang dilakukan adalah mencari nilai jarak yaitu mengukur seberapa dekat jarak antara
data training dengan data testing. Metode yang
dapat digunakan untuk menentukan jarak dapat dengan menggunakan metode euclidean distance. Adapun rumus dari metode Euclidean distance dapat dilihat pada Persamaan 2 (Putri,
2015). ∥ 𝑥 − 𝑥𝑗 ∥= (∑ |𝑁𝑖 − 𝑁𝑖𝑗| 2 𝑛 𝑖−1 ) 1 2 (2) Dimana norm x dikurangi xj (||𝑥 − 𝑥𝑗||) adalah nilai jarak euclidean antara data testing 𝑥 dan tetangga terdekat atau data training ke-j (𝑥𝑗). Sedangkan 𝑁i adalah nilai data testing pada atribut ke-i dan 𝑁i𝑗 nilai data training kej pada atribut ke-i. Sedangkan n adalah jumlah keseluruhan atribut dan i adalah index ke-i. 2.7. Fuzzy K-Nearest Neighbor
Algoritma fuzzy k-nearest neighbor dasarnya adalah menetapkan nilai keanggotaan atau
membership sebagai fungsi pola jarak atau
kesamaan dari sejumlah himpunan k-NN dan pemberian nilai keanggotaan tetangga pada kelas tertentu (Prasetyo, 2014).
Untuk menentukan nilai keanggotaan kelas pada data testing x dengan menggunakan metode Euclidean distance antara data testing x dan tetangga terdekat 𝑥𝑗 ke-j dihitung dengan menggunakan Persamaan 3 (Chen at all, 2011).
( 1) / 1 / 1 ) ( 1 ) 1 /( 2 1 ) 1 /( 2
m x x x x u x u K j m j K j m j ij i (3)Dimana (𝑥) adalah nilai keanggotaan data
testing x pada kelas ke-i, 𝑢𝑖𝑗 adalah nilai keanggotaan tetangga ke-j pada kelas ke-i, 𝑖=1, 2, … , 𝑐 𝑑𝑎𝑛 𝑗=1,2, …,𝑘 dengan c adalah nilai kelas dan k adalah nilai tetangga terdekat. Parameter kekuatan fuzzy m adalah bobot pangkat yang digunakan untuk menentukan seberapa banyak jarak tertimbang ketika mengkalkulasi kontribusi tiap tetangga sebagai nilai keanggotaan dan nilai tersebut biasanya sebagai berikut 𝑚 ∈(1, +∞). Sedangkan norm x dikurangi xj (||𝑥 − 𝑥𝑗||) adalah jarak Euclidean. 2.8. Evaluasi
Evaluasi dilakukan untuk mengetahui
tingkat akurasi dari hasil klasifikasi dengan menghitung data testing yang kelasnya diklasifikasi secara tepat oleh sistem. Presentase akurasi dapat diperoleh dengan persamaan 4 (Rahayu, 2013) :
𝑎𝑘𝑢𝑟𝑎𝑠𝑖 =𝑗𝑢𝑚𝑙𝑎ℎ 𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 𝑏𝑒𝑛𝑎𝑟
𝑗𝑢𝑚𝑙𝑎ℎ 𝑡𝑜𝑡𝑎𝑙 𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 ∗ 100% (4)
Mengadaptasi dari tabel kategori pengklasifikasian dari Mohanty at all 2011, nilai akurasi dibawah 60% termasuk “fail (gagal)”, 61%-70% termasuk “poor (rendah)”, 71%-80% termasuk “fair (sama)”, 81%-90% termasuk “good (baik)” dan 91%-100% termasuk “excellent (paling baik)”.
3. METODOLOGI
Metodologi yang digunakan dalam penelitian ini dilakukan dengan tahapan-tahapan seperti studi literature, analisis data penelitian, analisis dan perancangan sistem, implementasi hasil, pengujian dan analisis serta yang terakhir adalah evaluasi dan analisis tingkat akurasi dari sistem berdasarkan pada hasil output yang dihasilkan. Diagram alurnya seperti pada Gambar 3. Mulai Studi literatur Pengumpulan data Analisis dan perancangan sistem Implementasi sistem
Pengujian dan analisis sistem
Evaluasi dan analisis hasil
Selesai
4. PERANCANGAN Mulai Data EIS Normalisasi FKNN Hasil prediksi Selesai Persentase Data
Gambar 4. Diagram Alir Sistem
Perancangan pada Gambar 4 diatas menggambarkan diagram alir proses keseluruhan sistem. Proses klasifikasi diawali dengan memasukkan data yang didapatkan dari hasil impedansi listrik spektra sesuai dengan atribut yang tersedia. Data dinormalisasikan dan dibagi menjadi data training dan data testing sesuai dengan kebutuhan user kemudian diproses menggunakan metode FKNN sehingga diperoleh hasil klasifikasi luka pada jaringan payudara.
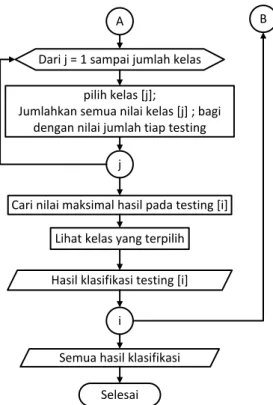
FKNN Mulai
Data training dan data testing Inisialisasi m dan k
Hasil hitung jarak E.D. Sorting E.D.
Dari i = 1 sampai jumlah data testing Jumlahkan nilai data tiap testing
Hitung jarak euclidean distance
Pangkatkan (-2/(m-1)) Pilih data sejumlah k
A B
pilih kelas [j];
Jumlahkan semua nilai kelas [j] ; bagi dengan nilai jumlah tiap testing
j
Dari j = 1 sampai jumlah kelas
Cari nilai maksimal hasil pada testing [i]
Hasil klasifikasi testing [i] Lihat kelas yang terpilih
i
Semua hasil klasifikasi Selesai
A B
Gambar 5. Diagram Alir Proses FKNN
Pada Gambar 5 dijelaskan diagram alir proses FK-NN. Data hasil pembagian data dengan konsep persentase data training dan data
testing digunakan sebagai inputan untuk proses
hitung jarak dengan euclidean distance yaitu jarak antara data testing dengan data training yang kemudian hasilnya digunakan dalam proses FKNN. Secara rinci langkah-langkahnya adalah sebagai berikut:
1. Inisialisasi nilai k dan m.
2. Hitung jarak dengan euclidean distance dengan Persamaan 2.3.
3. Urutkan hasil penghitungan jarak dengan
euclidean distance yaitu dari nilai terkecil ke
nilai terbesar.
4. Ambil data hasil pengurutan sejumlah k untuk tiap-tiap data testing.
5. Pangkatkan hasil dengan (-2/(m-1)) untuk proses penghitungan nilai keanggotaan terhadap kelas.
6. Hitung jumlah nilai data untuk tiap-tiap
testing yang sudah terpilih berdasarkan k
7. Hitung nilai keanggotaan tiap kelas dengan Persamaan 2.4. Dengan cara menjumlahkan nilai dari tiap kelas pada tiap testing kemudian bagi dengan nilai jumlah tiap testing (poin 6)
8. Cari nilai maksimal pada nilai tiap kelas yang terhitung pada tiap testing untuk mengetahui hasil klasifikasi.
9. Kelas dari nilai maksimal yang terpilih merupakan hasil dari klasifikasi.
10. Kumpulkan semua hasil dari klasifikasi tiap
data testing.
5. PENGUJIAN DAN PEMBAHASAN Pada pengujian ini digunakan data sebanyak 105 data breast tissue yang terdiri dari 21 data carcinoma (car), 15 data fibro-adenoma(fad), 18 data mastopati (mas), 15 data glandular (gla), 14 data connective (con) dan 22 data adipose (adi). Dimana data ini dibagi menjadi 3 kelompok data sesuai nilai K yang ditentukan. Pengujian dilakukan sebanyak 3 model pengujian yaitu :
1. Pengujian untuk mengetahui pengaruh nilai
m yang digunakan.
2. Pengujian untuk mengetahui pengaruh nilai
k yang digunakan.
3. Pengujian terhadap pembagian data training dan data testing untuk mengetahui
pengaruh persentase data training dalam mendapatkan hasil akurasi terbaik.
5.1. Analisis Hasil Pengujian Pengaruh Nilai
m terhadap Rata-rata Akurasi
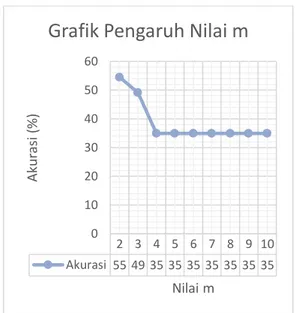
Berdasarkan pada pengujian terhadap pengaruh nilai m yang ditunjukkan pada Gambar 6, terlihat bahwa nilai m=2 memberikan nilai rata-rata akurasi tertinggi yaitu 54.5498069%, nilai k default adalah 1 sampai jumlah data
training.
Pada pengujian nilai m, nilai m pada proses klasifikasi FKNN tidak berpengaruh secara langsung terhadap hasil akurasi, namun berpengaruh pada nilai derajat keanggotaan tiap-tiap data testing terhadap masing-masing kelas. Variabel m merupakan bobot pangkat pada FKNN yang digunakan untuk menentukan seberapa besar jarak tertimbang ketika menghitung kontribusi tiap tetangga pada nilai keanggotaan.
Nilai m yang semakin besar akan membuat nilai keanggotaan semakin rendah, sehingga berpengaruh pada penentuan hasil kelas prediksi, dimana kelas prediksi tersebut yang mempengaruhi akurasi. Hal ini dikarenakan nilai
m menentukan berapa banyak bobot jarak antara
masing-masing tetangga ke nilai keanggotaan.
Gambar 6. Grafik Hasil Rata-rata Akurasi Pengujian Nilai m
5.2. Analisis Hasil Persentase Data training terhadap Rata-rata Akurasi
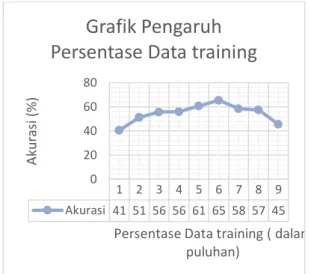
Berdasarkan pada pengujian terhadap pengaruh persentase datalatih dan data testing terlihat bahwa persentase terbaik adalah 60%
data training dan 40% data testing yaitu
65.49508692%. Didapat dengan nilai m terpilih adalah 2 dengan menggunakan nilai k default yaitu k=1 sampai jumlah data training.
Proses pembagian data dilakukan pada pengujian ini untuk mengoptimalkan seluruh data, karena semua data dapat menjadi data
testing dan data training. Nilai persentase yang
digunakan pada proses FKNN mempengaruhi banyaknya solusi yang dihasilkan. Sehingga semakin banyak variasi, semakin banyak pula solusi yang didapatkan serta dapat menghasilkan nilai akurasi yang lebih beragam, sehingga dapat diambil nilai akurasi yang tertinggi.
Dari Gambar 7 grafik dapat dilihat secara garis besar akurasi semakin meningkat dari data
training 10% sampai puncaknya dengan
persentase data training 60% kemudian menurun. Akan tetapi apabila diperhatikan dengan membagi persentase menjadi 2 kelompok yaitu <50% dan >50% maka akurasi dari pengaruh persentase data training ini lebih baik apabila jumlah data training lebih besar dari data testing.
2 3 4 5 6 7 8 9 10 Akurasi 55 49 35 35 35 35 35 35 35 0 10 20 30 40 50 60 Ak u ras i (%) Nilai m
Gambar 7. Grafik Hasil Akurasi Pengujian Persentase Data Training
5.3. Analisis Hasil Pengujian Pengaruh Nilai
k terhadap Rata-rata Akurasi
Pada pengujian nilai k, nilai k sangat berpengaruh pada hasil akurasi karena nilai derajat keanggotaan pada klasifikasi FKNN berdasarkan pada jumlah tetangga pada k, selain itu karena adanya jarak kedekatan terhadap tetangga terdekatnya. Nilai k yang kecil atau besar tidak terlalu menurunkan akurasi karena adanya pengaruh nilai keanggotaan tetangga terdekat ke-j terhadap kelas ke-i pada klasifikasi FKNN, dimana nilai keanggotaan yang bernilai maksimum yang digunakan sebagai penentu kelas prediksi.
Berdasarkan pada pengujian terhadap pengaruh nilai k yang ditunjukkan pada Gambar 8, terlihat bahwa nilai akurasi cenderung mengalami naik turun yang signifikan. Akurasi hanya memiliki sedikit kelompok nilai. Pada pengujian ini, didapatkan akurasi memiliki 2 nilai yaitu 64.2857143% dimiliki oleh k= 1,2,5,7-12,14-18,24-40 serta 66.6666667% dimiliki oleh k=3,4,6,13,19-23, 41-63.
Gambar 8. Grafik Hasil Rata-rata Akurasi Pengujian Nilai k (m=2, data training 60% )
6. KESIMPULAN
Berdasarkan pengujian yang telah dilakukan menghasilkan nilai terbaik yaitu nilai m=2 pada pengujian pertama. Persentase data
training=60% pada pengujian kedua. Dan k =
3,4,6,13,19-23, 41-63 pada pengujian ketiga. Dengan memilih nilai m=2, data training = 60%, k=3 dan data uji=42 data, metode FKNN menghasilkan kelas klasifikasi Carcinoma (car) dengan persentase kebenaran 54.55%.
Fibro-Adenoma (fad) dengan persentase kebenaran
28.57%. Mastopathy (mas) dengan persentase kebenaran 57.14%. Glandular (gla) dengan persentase kebenaran 83.33%. Conective (con) dengan persentase kebenaran 100%. Adipose (adi) dengan persentase kebenaran 100%.
Tingkat akurasinya adalah 66.6666667% dan termasuk dalam kategori akurasi yang “poor” atau “rendah”. Sehingga dapat disimpulkan bahwa metode FKNN kurang cocok untuk diaplikasikan dalam klasifikasi luka pada jaringan payudara dengan dataset dari UCI
repository.
Saran yang diberikan untuk penelitian lebih lanjut adalah penggunakan database untuk data yang lebih besar, penggunakan data studi kasus nyata di rumah sakit atau laboratorium yang menyediakan dataset hasil perhitungan atribut pada impedansi listrik berbasis spektra. Diperlukan optimisasi metode guna mendapatkan akurasi yang tinggi atau solusi yang lebih baik. Pada proses FKNN disarankan menggunakan jumlah data yang sama atau seimbang pada setiap kelas data training maupun data testing, guna mendapatkan hasil yang lebih akurat dan meminimalisir adanya dominasi kelas pada data training.
DAFTAR PUSTAKA
Amri, M., Khoiril., 2013.Penerapan Data Mining untuk Menentukan Kriteria Calon Nasabah Potensial pada AJB BumiPutera 1912 Palembang.Skripsi Program Studi Teknik Informatika. Fakultas Ilmu Komputer. Universitas Bina Darma.
Chang, Liu., Chang Tiantian, Li Changxing., 2015. Breast Tissue Classification based on Electrical Impedance Sectroscopy. International Conference on Industrial Technology and Management Science (ITMS).
Dense Breast Tissue - What It Is and What It Means About Cancer Risk diakses pada tanggal 8 Januari 2017 dari
1 2 3 4 5 6 7 8 9 Akurasi 41 51 56 56 61 65 58 57 45 0 20 40 60 80 Ak u ras i ( % )
Persentase Data training ( dalam puluhan)
Grafik Pengaruh
Persentase Data training
63 64 65 66 67 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 Ak u ras i (%) Nilai k
http://www.healthline.com/health/dense-
breast-tissue-what-it-and-cancer-risk#Overview1
Maghfiroh, Nurul., Candra Dewi, Nurul Hidayat. , 2014. Implementasi Algoritma Fuzzy K-Nearest Neighbor (F-KNN) untuk Mengetahui Tingkat Resiko Penyakit Gagal Ginjal. Filkom Universitas Brawijaya Malang.
Mahmoud, Hamdi A dkk., 2015. Cattle Classi fications System using Fuzzy K- Nearest Neighbor Classifier. Informatics, Electronics & Vision (ICIEV).
Mujiasih, Subekti., 2011. Jurnal Meteorologi dan Geofisika, Pemanfaatan Data Mining untuk Perkiraan Cuaca Vol 12, No 2 Hal 189-195.
Nagpal, Rashmi., Rashmi Shrivas. ), 2015. Cancer Classification Using Elitism PSO Based Lezy IBK on Gene Expression Data. International Journal of Scientific and Technical Advancements (IJSTA. ISSN : 2454-1532.
National Breast Cancer Foundation - Breast Anatomy diakses pada tanggal 9 januari
2017 dari
http://www.nationalbreastcancer.org/breast -anatomy
Patro, S.Gopal Krishna., Kishore Kumar sahu, 2015. Normalization: A Preprocessing Stage. Cornell University Library.
Prasetyo, Eka., 2012. Fuzzy K-NN In Every Class Untuk Klasifikasi Data. Universitas Pembangunan Nasional.
Putri, Ika Retno., 2015. Optimasi Metode Adaptive Fuzzy K-Nearest Neighbor dengan Particle Swarm Optimization untuk Klasifikasi Status Sosial Ekonomi Keluarga. Filkom Iniversitas Brawijaya. Malang.
Rahayu, Sri., 2013. Sistem pakar untuk mendiagnosa penyakit gagal ginjal dengan menggunakan metode bayes. Medan : Pelita Informatika Budi Darma, Volume : IV, Nomor: 3 Volume : IV.
Wisdariyanto, Ardhy., 2013. Penerapan Metode Fuzzy K-Nearest Neighbor (FKNN) untuk Pengklasifikasian Spam Email. Skripsi. Malang.
Yang, Jinn-Min., 2014. A novel interval type-2 fuzzy k-nearest neighbor classifier for remotely sensed hyperspectral image classification. IEEE.