METODE ADAPTIVE-SECTING DIVISIVE CLUSTERING DENGAN
PENDEKATAN GRAF HUTAN YANG MINIMUM
Achmad Maududie1), Wahyu Catur Wibowo2)
1)
Program Studi Sistem Informasi, Universitas Jember
2)
Fakultas Ilmu Komputer, Universitas Indonesia
Email : [email protected]1), [email protected]2)
Abstrak
Pengelompokkan obyek dalam sejumlah grup
(kelompok) dalam proses clustering tidak hanya memperhatikan algoritma clustering yang digunakan, namun juga indeks validitas clustering yang digunakan yang menunjukkan kualitas hasil clustering. Salah satu usaha untuk meningkatkan kualitas tersebut adalah membagi cluster hasil yang memiliki diameter terlalu besar. Artikel ini mengenalkan metode pembagian cluster yang tidak hanya dapat membagi cluster menjadi dua sub cluster (bisecting), namun dimungkinkan tiga atau lebih. Metode ini didasarkan pada pendekatan graf hutan yang minimum yang dinamakan Adaptive-secting Divisive Clustering Minimum Forest Graph (ADCMFG). Dari hasil eksperimen didapatkan bahwa metode ADCMFG mampu membagi dua atau lebih cluster target dengan hasil kinerja yang baik. Hal ini ditunjukkan dari
hasil evaluasi yang dilakukan (menggunakan
Compactess-separation Criterion) yang menyatakan adanya perbaikan indeks dari cluster hasil yang didapat, yaitu; 0,127 menjadi 0,106 untuk dataset 1, 0,190 menjadi 0,071 untuk dataset 2, dan 0,205 menjadi 0,069 untuk dataset 3. Disamping itu, pendekatan ini juga mampu melakukan reposisi elemen ke dalam cluster yang lebih tepat seperti yang ditunjukkan dalam hasil clustering pada dataset 3.
Kata kunci: clustering, adaptive-secting, graf hutan yang minimum.
1. Pendahuluan
Tujuan utama proses clustering adalah mengelompokkan seluruh obyek dalam sejumlah grup (kelompok) obyek berdasarkan tingkat kedekatan (proximity) obyeknya [1, p. 8], [2, p. 3], [3, p. 269], [4, p. 1499] yang dipresentasikan dalam indeks kesamaan (similarity) dan ketidaksamaan (dissimilarity) [1, p. 11], [2, p. 5]. Selain pemilihan algoritma clustering yang tepat, clustering juga memperhatikan kualitas hasil yang diperoleh dengan melakukan evaluasi terhadap beberapa indikator atau yang dikenal sebagai proses validitas clustering. Salah satu contoh metode validitas clustering yang digunakan dalam algoritma clustering yang berbasis nilai tengah (center-based clustering algorithm) adalah
Compactness-separation criterion (CSC) yang
dikenalkan oleh Ray dan Tury (1999) [2, p. 37]. Semakin kecil indeks CSC maka semakin kompak dan terdistribusi cluster yang dihasilkan.
Hasil clustering yang memiliki cluster dengan elemen yag memiliki diameter atau sum of square error (SSE) terlalu besar biasanya memberikan indeks CSC menjadi besar yang berarti cluster yang dihasilkan adalah cluster yang relatif tidak kompak atau memiliki separasi antar cluster yang terlalu dekat. Problem semacam ini biasanya diselesaikan dengan menambah jumlah cluster yang dihasilkan dengan cara membagi cluster dengan diameter besar menjadi dua sub cluster atau yang dikenal dengan bisecting divisive clustering. Meskipun sering menjawab problem yang muncul, namun bisecting hanya membagi sebuah cluster menjadi dua, sehingga apabila cluster yang dimaksud harus dibagi menjadi lebih dari dua sub-cluster maka proses bisecting harus dilakukan lebih dari satu kali. Selain itu, proses bisecting hanya dapat dilakukan dalam satu cluster saja pada satu waktu.
25,64 14,48 25,67 11,63 8,02 16,57 10,72 6,53 10,46 8,20 5,45 12,50 5,06 6,06 10,03 10,72 6,53 10,46 8,36 a. Cluster yang akan dipisah b. Hasil bisecting pertama c. Hasil bisecting kedua
Gambar 1. Contoh Proses Bisecting untuk
Menghasilkan Tiga Sub Cluster
Artikel ini menawarkan pendekatan baru yang fokus pada proses pemisahan cluster yang bersifat adaptif, yiatu dapat memisahkan sebuah cluster menjadi dua atau lebih sub-cluster dalam satu proses. Selain itu pendekatan ini diharapkan dapat melakukan pemisahan pada lebih dari satu cluster secara serempak seperti dalam Gambar 2. Kualitas hasil clustering yang didapat dievaluasi menggunakan CSC. Indeks CSC dalam hasil
clustering setelah dilakukan pembagian akan
Gambar 2. Contoh Hasil Adaptive Bisecting Clustering 2. Pembahasan
Compactness-Separation Criterion
Hingga saat ini telah banyak metode validitas clustering yang dikembangkan, baik menggunakan kriteria internal, eksternal, dan relatif [2, p. 299]. Validasi dengan kriteria
internal fokus mengukur seberapa kompak
(compactness) cluster yang dihasilkan baik yang ditunjukkan oleh homogenitas intra-cluster, separasi inter-cluster, atau kombinasi keduanya [3, p. 273] hanya menggunakan data internal [2, p. 303], [3, p. 273]. Metode Compactness-separation Criterion (CSC) adalah
salah satu metode validitas clustering yang
menggunakan kriteria internal. Dalam metode ini terdapat dua nilai penting yang harus dihitung, yaitu intra-cluster (Mintra) dan inter-cluster (Minter). Nilai Mintra
dihitung menggunakan WCSS (within-cluster sum of
squares), yaitu mengukur rerata jarak setiap obyek
terhadap centroid dari cluster masing-masing, sedangkan
nilai Minter ditentukan oleh jarak terpendek antar
centroidnya [2, p. 37].
... (1)
... (2) dengan n adalah jumlah obyek, zi adalah centroid dari
cluster Ci.
Dari Persamaan (1) dan (2) maka indeks validitas (V) dapat dihitung sebagai berikut [2, p. 37].
... (3)
Adaptive-secting Divisive Clustering
Pada prinsipnya, metode pembagian cluster yang dikenalkan berbasis pada graf hutan yang minimum
(ADCMFG), memiliki 8 tahapan proses seperti dalam Gambar 3.
ALGORITMA ADCMFG
Input: Cluster target, jumlah cluster target t Output: Sub Cluster
1. Hitung rerata jarak setiap elemen terhadap
centroidnya ( ) di setiap cluster target dan rerata dari rerata jarak setiap elemen terhadap centroidnya
2. Pilih elemen yang memiliki jarak lebih besar dari
rerata jaraknya ( )
3. Bangkitkan graf hutan yang minimum dari semua elemen yang terpilih berdasarkan jarak terdekatnya dengan ketentuan jarak terdekatnya tidak boleh melebihi
4. Bangkitkan centroid awal (initial centroid) yang dibentuk dari rerata tiap komponen graf hutan 5. while terdapat jarak antar centroid awal yang lebih
kecil dari lakukan
6. Gabungkan dua centroid awal terdekat yang
memiliki jarak lebih dari dengan
menggunakan rerata kedua inisial centroid tersebut
7. end while
8. Lakukan clustering terhadap cluster yang akan dibagi menggunakan centroid awal yang terbentuk dengan.
Gambar 3. Algoritma ADCMFG
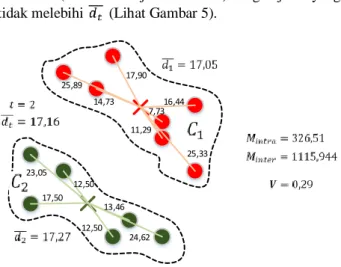
Sebagai ilustrasi, dalam Gambar 4 terdapat dua cluster dari hasil proses clustering dengan masing-masing rerata jarak elemen terhadap centroidnya adalah 17,05 untuk cluster 1 dan 17,27 untuk cluster 2. Dari kedua cluster tersebut didapat indeks CSC sebesar 0,29. Apabila kedua cluster tersebut dianggap sebaga cluster target (t = 2), maka dari kedua cluster tersebut diseleksi elemen-elemen yang memiliki jarak lebih besar dari masing-masing jarak reratanya. Dengan elemen-elemen yang terseleksi tersebut disusun sebuah graf hutan yang minimum (berdasarkan jarak terdekat) dengan jarak yang
tidak melebihi (Lihat Gambar 5).
12,50 17,50 17,90 25,89 14,73 16,44 7,73 11,29 25,33 13,46 12,50 24,62 23,05
Gambar 4. Contoh Hasil Proses Clustering 23,05 17,50 17,90 25,89 25,33 24,62 15,00 15,81 x2 x3 x4 x5 x6 x1
a. Hasil seleksi elemen
( )
b. Graf hutan yang minimum (dengan empat komponen)
Gambar 5. Contoh Hasil Pembangkitan Graf Hutan
yang Minimum
Dalam Gambar 5b terlihat bahwa graf hutan yang minimum memiliki empat komponen (tree) dengan dua diantaranya tidak memiliki sisi (hanya terbentuk dari sebuah simpul), yaitu pada simpul x5 dan x6 karena
jarak terdekat ke simpul lainnya melebihi . Dari setiap komponen graf hutan yang terbentuk dibangkitkan centroid awal dari nilai tengah setiap komponen. Apabila jarak antar dua centroid awal terdekatnya kurang dari , maka kedua centroid awal tersebut digabungkan dengan mengambil reratanya.
... (4) 15,00 15,81 x2 x3 x4 x5 x6 x1 a. Pembangkitan Centroid
awal (tanda silang)
b. Centroid awal
(tanda silang)
Gambar 6. Contoh Pembangkitan Centroid Awal Apabila tidak ada jarak antar centroid awal yang kurang
dari maka lakukan proses clustering dengan
menggunakan centroid awal yang telah terbentuk tersebut.
Gambar 7. Contoh Hasil Pembagian Cluster Dalam Gambar 7 terlihat bahwa masing-masing cluster dibagi menjadi dua sub cluster secara bersamaan, sehingga terbentuk empat cluster. Apabila indeks CSC hasil pembagian cluster tersebut dibandingkan dengan sebelum dibagi maka hasil pembagian memiliki indeks yang lebih baik.
Hasil eksperimen
Dalam eksperimen, pendekatan Adaptive-secting
Divisive Clustering Minimum Forest Graph (ADCMFG)
diuji dengan menggunakan tiga dataset sintetik yang berdimensi dua (lihat Gambar 8). Hasil clustering dari setiap dataset tersebut telah ditentukan cluster mana yang murupakan cluster target, sehingga metoda
ADCMFG difokuskan untuk melakukan proses
pembagian cluster target. Indeks CSC hasil pembagian cluster di tiap dataset akan dibandingkan dengan indeks CSC cluster sebelum dibagi.
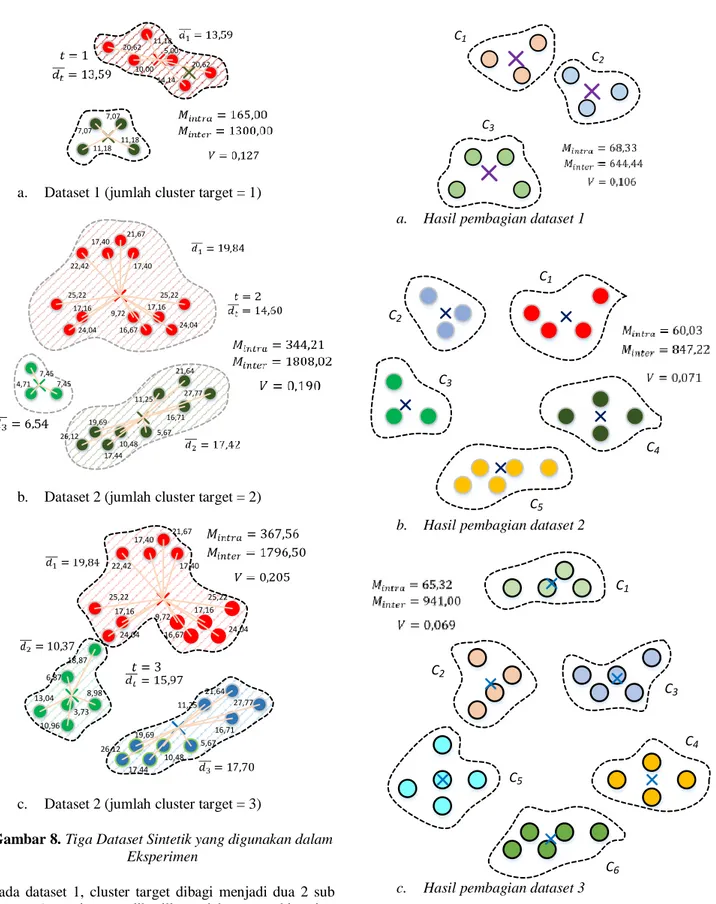
Dari ketiga dataset sitetik yang digunakan, hasil pembagian setiap dataset dapat dilihat dalam Tabel 1. Tabel 1. Hasil Pembagian Dataset
Dataset Status
Indeks CSC Jml.
cluster Mintra Minter V
1 Awal 2 165,00 1300,00 0,127 Akhir 3 68,33 644,44 0,106 2 Awal 3 344,21 1808,02 0,190 Akhir 5 60,03 847,22 0,071 3 Awal 3 367,56 1796,50 0,205 Akhir 6 65,32 941,00 0,069
Dalam Tabel 1 terlihat bahwa hasil pembagian cluster mendapatkan indeks CSC yang lebih kecil dibandingkan sebelum dibagi. Hal ini berarti bahwa hasil pembagian cluster pada ketiga dataset tersebut memberikan cluster yang lebih kompak dan lebih terdistribusi.
11,18 20,62 10,00 5,00 14,14 20,62 7,07 7,07 11,18 11,18
a. Dataset 1 (jumlah cluster target = 1)
21,67 22,42 17,40 17,40 25,22 17,16 24,04 9,72 16,67 17,16 24,04 25,22 7,45 7,45 4,71 19,69 26,12 17,44 10,48 5,67 11,25 16,71 27,77 21,64
b. Dataset 2 (jumlah cluster target = 2)
21,67 22,42 17,40 17,40 25,22 17,16 24,04 9,72 16,67 17,16 24,04 25,22 19,69 26,12 17,44 10,48 5,67 11,25 16,71 27,77 21,64 18,87 6,87 3,73 8,98 10,96 13,04
c. Dataset 2 (jumlah cluster target = 3)
Gambar 8. Tiga Dataset Sintetik yang digunakan dalam
Eksperimen
Pada dataset 1, cluster target dibagi menjadi dua 2 sub cluster (seperti yang dihasilkan oleh proses bisecting divisive clustering). Namun demikian, pada dataset 2 dan 3, cluster target dibagi menjadi lebih dari dua sub cluster (lihat Gambar 9).
C2
C1
C3
a. Hasil pembagian dataset 1
C2
C1
C3
C5
C4
b. Hasil pembagian dataset 2
C2 C1 C3 C5 C4 C6
c. Hasil pembagian dataset 3
Gambar 9. Hasil Pembagian Cluster
menggunakan metode ADCMFG
Dalam Gambar 9c terlihat bahwa pembagian cluster dengan metode ADCMFG tidak hanya mempu membagi cluster menjadi sejumlah sub cluster, namun juga dapat
3. Kesimpulan
Dari hasil eksperimen dapat disimpulkan bahwa metode
yang diperkenalkan (Adaptive-secting Divisive
Clustering Minimum Forest Graph) mampu membagi
cluster target menjadi dua atau lebih sub cluster. Disamping itu, metode ini juga mampu melakukan reposisi elemen cluster ke cluster yang sesuai. Disamping itu, hasil evaluasi menggunakan
Compactess-separation Criterion menunjukkan indeks yang baik
dibandingkan dengan cluster yang belum dilakukan pembagian, yaitu; 0,127 menjadi 0,106 untuk dataset 1, 0,190 menjadi 0,071 untuk dataset 2, dan 0,205 menjadi 0,069 untuk dataset 3. Untuk penelitian selanjunya, metode ini sebaiknya diuji dengan struktur data yang lain dan bila perlu dataset uji memiliki dimensi yang lebih besar.
Daftar Pustaka
[1] A. K. Jain, Algorithms for clustering data. Englewood Cliffs, N.J: Prentice Hall, 1988.
[2] G. Gan, Data clustering: theory, algorithms, and applications. Philadelphia, Pa. : Alexandria, Va: SIAM, Society for Industrial and Applied Mathematics ; American Statistical Association, 2007.
[3] L. Rokach, “A survey of Clustering Algorithms,” in Data Mining
and Knowledge Discovery Handbook, O. Maimon and L.
Rokach, Eds. Boston, MA: Springer US, 2010.
[4] D. Cheng, R. Kannan, S. Vempala, and G. Wang, “A divide-and-merge methodology for clustering,” ACM Trans. Database Syst., vol. 31, no. 4, pp. 1499–1525, Dec. 2006.
[5] A. K. Jain, M. N. Murty, and P. J. Flynn, “Data clustering: a review,” ACM Comput. Surv., vol. 31, no. 3, pp. 264–323, Sep. 1999.
[6] M. E. Celebi, H. A. Kingravi, and P. A. Vela, “A comparative study of efficient initialization methods for the k-means clustering algorithm,” Expert Syst. Appl., vol. 40, no. 1, pp. 200– 210, Jan. 2013.
[7] X. Wu, V. Kumar, J. Ross Quinlan, J. Ghosh, Q. Yang, H. Motoda, G. J. McLachlan, A. Ng, B. Liu, P. S. Yu, Z.-H. Zhou, M. Steinbach, D. J. Hand, and D. Steinberg, “Top 10 algorithms in data mining,” Knowl. Inf. Syst., vol. 14, no. 1, pp. 1–37, Jan. 2008.
[8] S. S. Khan and A. Ahmad, “Cluster center initialization algorithm for K-modes clustering,” Expert Syst. Appl., vol. 40, no. 18, pp. 7444–7456, Dec. 2013.
[9] K. Liao, G. Liu, L. Xiao, and C. Liu, “A sample-based hierarchical adaptive K-means clustering method for large-scale video retrieval,” Knowl.-Based Syst., vol. 49, pp. 123–133, Sep. 2013.