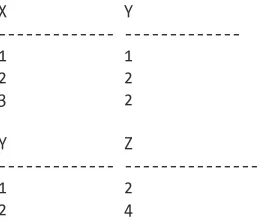
•Migratetothenew,ExtendedEventsframework •Automatetrackingofkeyperformanceindicators •Managestagedreleasesfromdevelopmenttoproduction •Designperformanceintoyourapplications
•AnalyzeI/Opatternsanddiagnoseresourceproblems •Backupandrestoreusingavailabilitygroups Don’tletyourdatabasemanageyou!Insteadturnto
andlearntheknowledgeandskillsyouneedtogetthemostfromMicrosoft’sflagship
iv
Contents at a Glance
About the Authors...xiv
About the Technical Reviewers ...xix
Acknowledgments ...xxi
Introduction ...xxiii
Chapter 1: Be Your Developer’s Best Friend ...1
Chapter 2: Getting It Right: Designing the Database for Performance ...17
Chapter 3: Hidden Performance Gotchas ...43
Chapter 4: Dynamic Management Views ...71
Chapter 5: From SQL Trace to Extended Events ...101
Chapter 6: The Utility Database ...135
Chapter 7: Indexing Outside the Bubble ...161
Chapter 8: Release Management ...197
Chapter 9: Compliance and Auditing ...221
Chapter 10: Automating Administration ...235
Chapter 11: The Fluid Dynamics of SQL Server Data Movement ...271
Chapter 12: Windows Azure SQL Database for DBAs ...293
Chapter 13: I/O: The Untold Story ...313
Chapter 14: Page and Row Compression ...335
Chapter 15: Selecting and Sizing the Server ...361
Chapter 16: Backups and Restores Using Availability Groups ...375
Chapter 17: Big Data for the SQL Server DBA ...395
Chapter 18: Tuning for Peak Load ...429
Contents
About the Authors...xiv
About the Technical Reviewers ...xix
Acknowledgments ...xxi
Introduction ...xxiii
Chapter 1: Be Your Developer’s Best Friend ...1
My Experience Working with SQL Server and Developers ...1
Reconciling Different Viewpoints Within an Organization ...2
Preparing to Work with Developers to Implement Changes to a System ...3
Step 1: Map Your Environment ...3
Step 2: Describe the New Environment ...5
Step 3: Create a Clear Document ...7
Step 4: Create System-Management Procedures ...7
Step 5: Create Good Reporting ...10
Ensuring Version Compatibility ...11
Setting Limits ...12
Logon Triggers ...12
Policy-Based Management ...15
Logging and Resource Control...15
Next Steps ...15
Chapter 2: Getting It Right: Designing the Database for Performance ...17
Requirements ...18
Table Structure ...20
vi
Why a Normal Database Is Better Than an Extraordinary One ...21
Physical Model Choices ...33
Design Testing ...40
Conclusion ...41
Chapter 3: Hidden Performance Gotchas ...43
Predicates ...43
Residuals ...59
Spills ...65
Conclusion ...70
Chapter 4: Dynamic Management Views ...71
Understanding the Basics ...71
Naming Convention ...72
Groups of Related Views ...72
Varbinary Hash Values ...73
Common Performance-Tuning Queries ...74
Retrieving Connection Information ...74
Showing Currently Executing Requests ...75
Locking Escalation ...77
Finding Poor Performing SQL ...78
Using the Power of DMV Performance Scripts ...80
Divergence in Terminology ...82
Optimizing Performance ...82
Inspecting Performance Stats ...85
Top Quantity Execution Counts ...86
Physical Reads ...87
Physical Performance Queries ...87
Locating Missing Indexes ...87
Partition Statistics ...92
System Performance Tuning Queries ...93
What You Need to Know About System Performance DMVs ...93
Sessions and Percentage Complete ...93
Conclusion ...99
Chapter 5: From SQL Trace to Extended Events ...101
SQL Trace ...101
Trace file provider ...107
Event Notifications ...110
Extended Events ...114
Events ...115
Predicates ...115
Actions ...116
Types and Maps ...116
Targets ...117
Sessions ...118
Built in Health Session ...121
Extended Events .NET provider ...123
Extended Events UI ...125
Conclusion ...133
Chapter 6: The Utility Database ...135
Start with Checklists ...136
Daily Checklist Items ...136
Longer-Term Checklist Items ...137
Utility Database Layout ...138
Data Storage ...138
Using Schemas ...140
Using Data Referential Integrity ...140
Creating the Utility Database ...140
Table Structure ...141
Gathering Data...143
System Tables ...143
Extended Stored Procedures ...143
CLR ...144
DMVs ...144
Storage ...144
Processors ...146
Error Logs ...148
Indexes ...149
Stored Procedure Performance ...151
Failed Jobs ...152
Reporting Services ...153
viii
AlwaysOn ...156
Managing Key Business Indicators ...156
Using the Data ...158
Automating the Data Collection ...158
Scheduling the Data Collection ...159
Conclusion ...160
Chapter 7: Indexing Outside the Bubble ...161
The Environment Bubble ...162
Identifying Missing Indexes ...162
Index Tuning a Workload ...170
The Business Bubble ...191
Index Business Usage ...191
Data Integrity ...193
Conclusion ...195
Chapter 8: Release Management ...197
My Release Management Process ...197
A Change Is Requested...198
Release Process Overview ...199
Considerations ...199
Documents ...207
Release Notes ...208
Release Plan Template and Release Plans ...212
Document Repository ...219
Conclusion ...219
Chapter 9: Compliance and Auditing ...221
Compliance ...221
Sarbanes-Oxley ...221
Health Insurance Portability and Accountability Act ...223
New Auditing Features in SQL Server 2012 ...224
Server-Level Auditing for the Standard Edition ...225
Audit Log Failure Options ...225
Maximum Rollover Files ...225
User-Defined Auditing ...225
Audit Filtering ...225
Server Audit ...226
Server Audit Specification ...228
Database Audit Specification ...230
Query the Audit File ...231
Pro Tip: Alert on Audit Events ...232
Conclusion ...234
Chapter 10: Automating Administration ...235
Tools for Automation ...235
Performance Monitor ...235
Dynamic Management Views ...237
SQL Server Agent ...238
Maintenance Plans ...252
SQL Server Integration Services ...259
PowerShell ...262
What to Automate ...263
Monitoring ...264
Backups and Restores ...267
Database Integrity ...269
Index Maintenance ...269
Statistics Maintenance ...270
Conclusion ...270
Chapter 11: The Fluid Dynamics of SQL Server Data Movement ...271
Why the Need for Replicating Data? ...271
SQL Server Solutions ...273
Replication ...274
Log Shipping ...278
Database Mirroring ...280
AlwaysOn ...282
Failover Clustering ...284
Custom ETL Using SQL Server Integration Services ...286
Bulk Copy Process ...287
Choosing the Right Deployment ...288
Keeping the Data Consistent ...290
x
Chapter 12: Windows Azure SQL Database for DBAs ...293
SQL Database Architecture ...294
Infrastructure ...294
Availability and Failover ...295
Hardware ...295
Differences with SQL Server ...296
Database Components ...296
Management Platform ...297
Security ...298
Other Important Information ...299
Federations ...300
Key Terms ...300
T-SQL Changes for Federations ...301
Federation Example ...302
Limitations ...303
Troubleshooting Performance Issues ...304
DMVs Available ...304
Execution Plans ...305
Performance Dashboard ...306
Related Services...308
Windows Azure SQL Reporting ...308
Windows Azure SQL Data Sync ...309
Import/Export Feature ...310
Cost of SQL Database ...311
Conclusion ...312
Chapter 13: I/O: The Untold Story ...313
The Basics ...314
Monitoring ...314
Considerations ...315
Tactical ...317
Code or Disk? ...321
Times Have Changed ...323
Getting to the Data ...324
Addressing a Query ...328
Conclusion ...334
Chapter 14: Page and Row Compression ...335
Before You Get Started ...336
Editions and Support ...336
What to Compress and How to Compress It ...337
Row Compression ...338
Page Compression ...341
What Do You Compress? ...346
Fragmentation and Logged Operations ...355
Conclusion ...359
Chapter 15: Selecting and Sizing the Server ...361
Understanding Your Workload ...361
SQL Server 2012 Enterprise Edition Consideration Factors ...362
Server Vendor Selection ...364
Server Form Factor Selection ...364
Server Processor Count Selection ...366
Dell 12th Generation Server Comparison ...366
Dell PowerEdge R320 ...366
Dell PowerEdge R420 ...367
Dell PowerEdge R520 ...367
Dell PowerEdge R620 ...367
Dell PowerEdge R720 ...368
Dell PowerEdge R720xd ...368
Dell PowerEdge R820 ...368
Dell Comparison Recap ...368
Processor Vendor Selection ...369
Processor Model Selection ...370
Memory Selection ...372
Conclusion ...373
Chapter 16: Backups and Restores Using Availability Groups ...375
Setting Up an Availability Group ...376
Configuring the Windows Server ...376
SQL Server Availability Group ...377
Backup Location ...383
Backup Priority ...384
Automating Backups on Availability Groups ...386
Maintenance Plans ...386
T-SQL Scripts ...388
Recovery on Availability Groups ...391
Conclusion ...392
Chapter 17: Big Data for the SQL Server DBA ...395
Big Data Arrives with Hadoop ...397
MapReduce: The Nucleus of Hadoop ...398
Hardware ...404
DBA As Data Architect ...405
Big Data for Analytics ...406
Using SQL Server with Hadoop ...407
The DBA’s Role ...407
Big Data in Practice ...408
Exporting from HDFS ...415
Hive ...416
Hive and Excel ...419
JavaScript ...420
Pig...423
Big Data for the Rest of Us ...425
Business Intelligence ...425
Big Data Sources ...425
Big Data Business Cases ...426
Big Data in the Microsoft Future ...427
Conclusion ...428
Chapter 18: Tuning for Peak Load ...429
Define the Peak Load ...429
Determine Where You Are Today ...431
Perform the Assessment ...433
Define the Data to Capture ...436
Analyze the Data...446
Analyzing Application-Usage Data ...446
Analyzing Configuration Data ...455
Analyzing SQL Performance Data ...458
Devise a Plan ...462
Conclusion ...463
■ ■ ■
Be Your Developer’s Best Friend
By Jesper Johansen
When asked to write a chapter for this book, I was in doubt about which subject to choose. Should I write about common problems I normally see? About how Microsoft SQL Server’s easy installation is at the same time a strength and a weakness? About how to fix the 10 most general problems with SQL Server
installation by querying a couple of dynamic management views (DMVs)? Or how about the Yet Another Performance Profiling (YAPP) method—a well-known performance method in the Oracle community that is just as usable in SQL Server with the implementation of Extended Events and DMVs that will show you what you are waiting for?
No. What really makes me tick is becoming friends with the developers by creating a good SQL Server environment and fostering an understanding of one another’s differences. Just think what can be
accomplished if both sides can live peacefully together instead of fighting every opposite opinion, digging the trenches even deeper and wider. Through fostering good relationships, I have seen environments move from decentralized development systems and standalone production databases to central solutions with easy access for developers, and calm uninterrupted nights for me. However, this does mean that you have to give up some sovereignty over your systems by relinquishing some of your admin power.
The main problem is focus. While the DBA thinks of space issues, data modeling, and the stability of everyday operations, the developers thinks of making things smarter, sexier, and shiny. To make the relationship work, we have to move through the entire palette of the system—standardization, accessibility, logging, information flow, performance information—all while ensuring that systems are stable and that developers know that they are not alone, and that DBAs still exist and decide things.
My Experience Working with SQL Server and Developers
After finishing my engineering studies, I started as a developer. I worked on CRM systems in DataEase under DOS and OS/2, and that combination gave me plenty of insight into the issues developers have with the DBA function. DataEase was the Microsoft Access of that time, and it had connectors to all the major databases (Oracle, SQL Server, and DB2). But most of the time, DBAs would not allow dynamic access to production data. Their resistance led to friction with the developers.
days before having TCP/IP on the mainframe, so we’re talking Systems Network Architecture (SNA) and IBM Communications Manager.
One day, my boss gave me responsibility for a new product called SQL Server. Why? Because I was the only one working with Windows.
My biggest problem was how to approach the current environment within the company. How many SQL Server databases did we already have? Which development groups were using it? Those were just some of the questions I had to grapple with.
I had to start from scratch. So I asked my DB/2 colleagues for help. After all, they had been working in these kind of environments for the last 15 years, handling systems with 15,000 concurrent users, 50,000 different programs, thousands of individual databases, and lots of data on every Danish citizen, such as taxes, pension funds, and other personal information. I wanted the benefit of their experience.
What I learned was that data modeling is a must. You need to have a naming standard for servers, for database objects, for procedures—for everything, actually. Starting the battle for naming standards and consistency took me on a six-year-long journey with developers, until most developers actually started to live safely. They came to understand that my requirements gave them more stable and consistent environments to develop on, made them more efficient, and got the job done faster for all.
Reconciling Different Viewpoints Within an Organization
The everyday battles between DBAs and developers mostly concern routine administrative tasks. Limitations on space allocations and limits to changes in production are perceived by developers as inhibiting innovation and stopping them from making a difference. They often see the DBA as someone who purposely limits them from doing their job. On the other hand, the admin group thinks that developers rarely plan ahead longer than the next drop-down box or the next screen, and that they never think in terms of the time period over which the software they build must run, which is often five to ten years or even longer.
The consequences of these differences are that developers create their own secret systems, move budget money out of reach of the DBA team, and generally do everything in their power to limit the admins in setting up the imaginary borders they believe are being set up. For example, often I would hear the sentence, “If you take away that privilege from me, I can no longer boot the machine at will.” The problem with that thinking is that well-configured SQL Server systems need no more restarts than any other type of systems.
So how do we get out of this evil spiral, and what are the benefits of doing so? Dialog is the way out, and the benefits are a controlled production environment, clearly defined ownership of databases, consistent environments patched correctly, lower cost of maintenance, possible license savings, and almost certainly fewer calls at 4:00 in the morning interrupting your sleep.
Remember, all change starts with one’s self, and it is far easier to change yourself than to change others. So get a hold of a piece of paper, divide it into a plus and a minus side, and start listing the good and bad things in your environment. For instance, it could be a plus that some developers have sysadmin privileges because they fix some things for themselves, but it could also be a minus because they meddle with things they are not supposed to meddle with and create objects without the knowledge of the DBA.
Preparing to Work with Developers to Implement Changes to a
System
To make progress, you have to prepare for it. Implementing change will not work if you make demands of the developers without preparing. The battle will be hard, but it will be worth fighting for, because in the end you’ll be eating cake with the developers while talking about the bad-old days with their unstable systems, anarchy, and crashes without backups.
Bring some good suggestions to the table. Do not approach developers without having anything to offer to make their lives easier. Think of yourself as a salesperson of stability and consistency—not even developers will disagree with those goals. As in any good marriage, however, the needs of both parties must be aired and acknowledged.
Put yourself in their place as well. Try to understand their work. You’ll find that most of their requests are actually not that bad. For example, a common request is to be able to duplicate the production environment in the development environment on the weekend to test new ideas in their software. Would you rather spend your weekend doing that work for them? Isn’t it preferable to facilitate having them do the work on their own so that you can be home with your family?
Listen to your developers. Ask them what they see as the biggest hurdles put in their way by the admin group. Your goal, ultimately, should be to create an environment that is good for the business. That means making everybody as happy as possible, easing the bureaucracy, and ensuring stable access for all.
A well-prepared environment can also lead to server consolidation, which in turn leads to saving power, simplifying patching, and ultimately less administrative effort. The money saved from having well-prepared environments can then be used for better things, such as buying Enterprise Edition or enabling Always On availability groups to provide an environment more resilient to failure.
By now, you are beginning to think that I am all talk. How can you get this process of working closely with developers started? The answer depends on how your business is structured. Following is a list of steps. Don’t start by doing everything at once. Keep it simple. Build on each success as you go along. Remember that the goal is to create a stable environment for all:
1. Make a map of your existing environment.
2. Create a description of what your new environment should look like.
3. Document your description in written form so that it is clear and convenient to pass on to management and vendors.
4. Create system-management procedures for most changes. 5. Create system reports to report on all those changes.
These are a good series of steps to follow. Don’t be too rigid, though. Sometimes you will need to divert from this sequence to make your business work. Adapt and do what is right for your business.
Step 1: Map Your Environment
Start by finding all the servers in your domain. Several free tools are available on the Internet to help you do this. Or maybe you already have the information in your Configuration Management Database (CMD) but you have never created reports on that data.
Try executing the following in a command prompt window: SQLCMD -L
This command will list all the available servers on your network that are visible. You can get much more detailed information using tools such as SQLPING, Microsoft Map, Quest Discovery Wizard, or other similar products. A benefit of these products is that they often provide information like version numbers or patch levels.
Once you find your servers, you need to find out whether they are actually still in use. Most likely, you will have servers that were used only during an upgrade, but no one thought to shut them down once the upgrade was complete. One place where I have seen this go horribly wrong was in an organization that forgot the old server was still running, so it no longer got patched. Along came the SLAMMER virus, and down went the internal network. Another project I was on, involved consolidating about 200 servers. We found we could actually just switch off 25 percent of them because they were not being used.
Following is a piece of code to help you capture information about logins so that you can begin to identify who or what applications are using a given instance. The code is simple, using the sysprocesses view available on most versions of SQL Server. Why not use audit trace? Because audit trace takes up a lot of space. You need only unique logins, and viewing logs of all login attempts from audit trace is not easy on the eyes.
First, create the following small table in the msdb database. I use msdb because it is available in all versions of SQL Server. The table will record unique logins.
CREATE TABLE msdb.dbo.user_access_log
CONSTRAINT DF_user_access_log_logdate DEFAULT (getdate()), CONSTRAINT PK_user_access_log PRIMARY KEY CLUSTERED (id ASC) )
Then run the following code to sample logins every 15 seconds. If you need smaller or larger
granularity, you can easily just change the WAITFOR part of the code. You can even make the code into a job that automatically starts when the SQL Server Agent starts.
nt_username, net_address ) SELECT distinct
DB_NAME(dbid) as dbname, SUSER_SNAME(sid) as dbuser, hostname,
When you begin this process of capturing and reviewing logins, you should create a small team consisting of a couple of DBAs and a couple of the more well-liked developers and system owners. The reason to include others, of course, is to create ambassadors who can explain the new setup to other developers and system owners. Being told something by your peers makes it that much harder to resist the changes or even refuse them. And these people also have a lot of knowledge about the business, how the different systems interact, and what requirements most developers have. They can tell you what would be a show-stopper, and catching those in the beginning of the process is important.
Step 2: Describe the New Environment
The next step is to describe your new environment or the framework in which you plan to operate. What should this description contain? Make sure to address at least the following items:
• Version of SQL Server The fewer SQL Server versions you have to support, the easier it is to keep systems up and running. You will have fewer requirements to run different versions of Windows Server, and the newer the version you keep, the easier it is to get support from Microsoft or the community at large. I have seen several shops running versions spanning the gamut from 7.0, 2000, 2005, 2008, 2008 R2 through to 2012. Why not just choose 2012? Having the latest version as the standard is also a good selling point to developers, because most of the exciting new features will then be available to them. You might not be able to get down to just one version, but work hard to minimize the number you are stuck with supporting.
try to think through how to explain why a certain feature will not be enabled—or instance, the use of globally unique identifiers (GUIDs) as primary keys. Developers tend to want to able to create the parent keys on their own, because it is then easier to insert into parent and child tables in the same transaction. In this case, SQL Server 2012’s new support for stored sequences can be an easy replacement for GUIDs created in an application.
• Editions Editions can be thought of as an extension of the feature set. How does the company look at using, say, the Express Edition? Should you use only Standard Edition, or do you need to use Enterprise Edition? Do you use Developer Edition in development and test environments and then use Standard Edition in production, which leaves you with the risk that the usage features in development cannot be implemented in production? How do you help developers realize what they can do and cannot do, and what advanced features they can actually use? Do you use policy-based management to raise an alarm whenever Enterprise Edition features are used? Or do you just periodically query the view sys.dm_db_persisted_sku_ features, which tells you how many Enterprise Edition features are in use?
• Naming standards Naming standards are a must. The lowest level should be on the server level, where you choose standard names for servers, ports, instances, and databases. Standardization helps to make your environment more manageable. Do you know which ports your instances use? Knowing this makes it a lot easier to move systems around and connect to different servers. Also, databases tend to move around, so remember that two different systems should not use the same database name. Prefix your databases with something application specific to make them more recognizable.
• Patching Version change is important to remember, because it is easily
overlooked. Overlook it, and you end up with a lot of old versions running in both production and development environments. Try and implement reasonable demands here. You could choose, for example, to say that development and test environments should be upgraded to the latest version every six months after release, and production environments get upgraded a maximum of three months after that upgrade. Also, you can require that service packs be implemented no later than three months after release.
• Privileges Privileges are very important to control. Some privileges might be acceptable in development and test environments, but not in production, which is OK. Just remember to write down those differences so that everybody is aware of them and the reasons why they exist. Start out by allowing developers dbo access to their own databases in development. That way, you do not constrain their work. If they crash something, they only ruin it for themselves. In production, users should get nothing beyond read, write, and execute privileges. You can implement wrapped stored procedures for people truly in need of other types of access. For example, many developers believe they should have dbo privileges, but they rarely need all the rights that dbo confers. Here, explicit grants of privilege can be offered as a replacement. If people want the ability to trace in production, you can wrap trace templates in stored procedures and offer access to the procedures.
Step 3: Create a Clear Document
Write everything down clearly. Create a single document you can hand to vendors, management, and new personnel to help them get up to speed.
I’ve often experienced systems going into production that did not adhere to our standards. These were primarily purchased applications that were bought without asking the IT department about demands related to infrastructure. Most of the time this happened because the rest of the business did not know about the standards IT had in place, and sometimes it happened because of the erroneous belief that our business could not make demands of the vendors. Here is where a piece of paper comes into play. Create a quick checklist so that people who buy applications can ask the vendor about what is needed to fit applications into your environment. Some possible questions that you might want to put to a vendor include the following:
• Do you support the latest release?
• Do you require sysdamin rights?
• What collation do you use?
When all the questions have been asked and answered, you have an actual possibility to see whether the vendor’s application is a realistic fit with your environment, or whether you should cancel the purchase and look for other possibilities. In most cases, when pressed on an issue, third-party vendors tend to have far fewer requirements than first stated, and most will make an effort to bend to your needs.
Step 4: Create System-Management Procedures
You will get into a lot of battles with your developers about rights. You’ll hear the argument that they cannot work independently without complete control. You can’t always give them that freedom. But what you can do is give them access to a helper application.
What I often found is that, as the DBA, I can be a bottleneck. Developers would create change requests. I would carry out the changes, update the request status, close the request, and then inform the required people. Often, it would take days to create a database because of all the other things I had to do. Yet, even though creating a database requires extensive system privileges, it is an easy task to perform. Why not let developers do these kind of tasks? We just need a way to know that our standards are followed— such as with the naming and placement of files—and and to know what has been done.
Logging is the key here. Who does what and when and where? For one customer, we created an application that took care of all these basic, but privileged, tasks. The application was web-based, the web server had access to all servers, and the application ran with sysadmin rights. Developers had access to run the application, not access to the servers directly. This meant we could log everything they did, and those developers were allowed to create databases, run scripts, run traces, and a lot more. What’s more, they could do those things in production. Granting them that freedom required trust, but we were convinced that 99.99 percent of the developers actually wanted to do good, and the last 0.01 percent were a calculated risk.
You don’t need an entire application with a fancy interface. You can just start with stored procedures and use EXECUTE AS. I’ll walk you through a simple example.
USE [master];
CREATE LOGIN [CreateDbUser] WITH PASSWORD=N'Allw@ysSq1', DEFAULT_DATABASE=[master], CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF;
DENY CONNECT SQL TO [CreateDbUser];
EXEC sp_addsrvrolemember
@loginame = N'CreateDbUser', @rolename = N'dbcreator';
USE [msdb]
CREATE USER [miracleCreateDb] FOR LOGIN [miracleCreateDb];
EXEC sp_addrolemember N'db_datareader', N'miracleCreateDb';
EXEC sp_addrolemember N'db_datawriter', N'miracleCreateDb'; GO
Next, create a table to log what the developers do with their newfound ability to create databases independently. The table itself is pretty simple, and of course, you can expand it to accommodate your needs. The important thing is that all fields are filled in so that you can always find who is the owner and creator of any given database that is created.
CREATE TABLE DatabaseLog
( [databasename] sysname PRIMARY KEY NOT NULL, [application] nvarchar(200) NOT NULL, [contact] nvarchar(200) NOT NULL, [remarks] nvarchar(200) NOT NULL, [creator] nvarchar(200) NOT NULL, [databaselevel] int NOT NULL, [backuplevel] int NOT NULL )
Then create a stored procedure for developers to invoke whenever they need a new database. The following procedure is straightforward. The create database statement is built in a few steps, using your options, and then the statement is executed. The database options are fitted to the standard, and a record is saved in the DatabaseLog table. For the example, I decided to create all databases with four equal-sized data files, but you can choose instead to create a USERDATA file group that becomes the default file group. Do whatever makes sense in your environment.
CREATE PROCEDURE [CreateDatabase] @databasename nvarchar(128), @datasize int = 100, @logsize int = 25,
@backuplevel int = 1
AS BEGIN
SET NOCOUNT ON;
EXECUTE AS Login = 'miracleCreateDb';
SET @DatafilesPerFilegroup = 4
SET @datasize = @datasize / @DatafilesPerFilegroup
SET AUTO_UPDATE_STATISTICS_ASYNC ON WITH NO_WAIT' + ';'+
PRINT 'Connection String : ' +
'Data Source=' + @@SERVERNAME +
This small example can easily be expanded to include the creation of standard users, default privilege assignments, and so on. As a small bonus, I returned the connection string to the database just created. That helps developers use the real drivers, and it helps ensure they include the application name, because there is nothing worse than to do diagnostics on a SQL Server instance in which all users are named “Joe” and the application is “Microsoft .Net Provider”.
As you can see, EXECUTE AS opens up a lot of options to create stored procedures that allow your developers to execute privileged code without having to grant the privileges to the developers directly.
Step 5: Create Good Reporting
Think globally by creating a general overview showing how a server is performing. What, for example, are the 35 most resource-consuming queries? List those in three different categories: most executions, most I/O, and most CPU usage. Combine that information with a list of significant events and the trends in disk usage.
But also think locally by creating the same type of overview for individual databases instead of for the server as a whole. Then developers and application owners can easily spot resource bottlenecks in their code directly and react to that. Such reports also give developers an easy way to continuously improve their queries without involving the DBA, which means less work for you.
In addition to including performance information, you can easily include information from log tables, so the different database creations and updates can be reported as well.
Finally, take care to clearly define who handles exceptions and how they are handled. Make sure nobody is in doubt about what to do when something goes wrong, and that everyone knows who decides what to do if you have code or applications that cannot support your framework.
Ensuring Version Compatibility
If you choose to consolidate on SQL Server 2012, you will no doubt discover that one of your key applications requires SQL Server 2008 to be supported from the vendor. Or you might discover that the application user requires sysadmin rights, which makes it impossible to have that database running on any of your existing instances.
You might need to make exceptions for critical applications. Try to identify and list those possible exceptions as early in the process as possible, and handle them as soon as you possible also. Most applications will be able to run on SQL Server 2012, but there will inevitably be applications where the vendor no longer exists, code is written in Visual Basic 3 and cannot directly be moved to Visual Basic 2010, or where the source has disappeared and the people who wrote the applications are no longer with the company. Those are all potential exceptions that you must handle with care.
One way to handle those exceptions is to create an environment in which the needed older SQL Server versions are installed, and they’re installed on the correct operating system version. Create such an environment, but do not document it to the outside world. Why not? Because then everyone will suddenly have exceptions and expect the same sort of preferential treatment. Support exceptions, but only as a last resort. Always try to fix those apparent incompatibilities.
Exceptions should be allowed only when all other options are tried and rejected. Vendors should not be allowed to just say, “We do not support that,” without justifying the actual technical arguments as to why. Remember you are the customer. You pay for their software, not the other way around.
Back when 64-bit Windows was new, many application vendors didn’t create their installation program well enough to be able to install it into a 64-bit environment. Sometimes they simply put a precheck on the version that did not account for the possibility of a 64-bit install. When 64-bit-compatible versions of applications finally arrived, it turned out that only the installation program was changed, not the actual application itself. I specifically remember one storage vendor that took more than a year to fix the issue, so that vendor was an exception in our environment. As soon as you create an exception, though, get the vendor to sign an end date for that exception. It is always good practice to revisit old requirements, because most of them change over time. If you do not have an end date, systems tend to be forgotten or other stuff becomes more important, and the exception lives on forever.
■
Tip
A very good reason to use compatibility mode instead of actually installing an instance on an older version is
that compatibility mode still provides access to newer administrative features, such as backup compression. For
example, SQL Server 2000 compatibility mode in SQL Server 2008 gave me the option to partition some really big
tables, even though partitioning was not supported in 2000. In checking with Microsoft, I was told that if the feature
works, it is supported.
Setting Limits
All is not well yet, though. You still have to set limits and protect data.
I’m sure you have experienced that a login has been misused. Sometimes a developer just happens to know a user name and password and plugs it into an application. That practice gives rise to situations in which you do not know who has access to data, and you might find that you don’t reliably know which applications access which databases. The latter problem can lead to production halts when passwords are changed or databases are moved, and applications suddenly stop working.
I have a background in hotel environments supporting multiple databases in the same instance, with each database owned by a different department or customer. (You can get the same effect in a
consolidation environment.) SQL Server lacks the functionality to say that Customer A is not allowed to access Customer B’s data. You can say that creating different database users solves the problem, but we all know that user names and passwords have a tendency to be known outside of the realm they belong in. So, at some point, Customer A will get access to Customer B’s user name and password and be able to see that data from Customer A’s location. Or if it’s not outside customers, perhaps internal customers or
departments will end up with undesired access to one another’s data.
Before having TCP/IP on the mainframe, it was common to use System Network Architecture (SNA) and Distributed Data Facility (DDF) to access data in DB2. DDF allowed you to define user and Logical Unit (LU) correlations, and that made it possible to enforce that only one user-id could be used from a specific location. When TCP/IP was supported, IBM removed this functionality and wrote the following in the documentation about TCP/IP: “Do you trust your users?”. So, when implementing newer technology on the old mainframe, IBM actually made it less secure.
Logon Triggers
The solution to the problem of not being able to restrict TCP/IP access to specific locations was to use a logon user exit in DB2. That exit was called Resource Access Control Facility (RACF). (It was the security implementation on the mainframe.) RACF was used to validate that the user and IP address matched and, if not, to reject the connection.
■
Caution
Be careful about LOGIN triggers. An error in such a trigger can result in you no longer being able to
connect to your database server or in you needing to bypass the trigger using the Dedicated Administrator
Connection (DAC).
Following is what you need to know:
• The logon trigger is executed after the user is validated, but before access is granted.
• It is in sys.dm_exec_connections that you find the IP address that the connection originates from.
• Local connections are called <local machine>. I don’t like it, but such is the case. Dear Microsoft, why not use 127.0.0.1 or the server’s own IP address?
• How to translate an IP address for use in calculations.
First, you need a function that can convert the IP address to an integer. For that, you can cheat a little and use PARSENAME(). The PARSENAME() function is designed to return part of an object name within the database. Because database objects have a four-part naming convention, with the four parts separated by periods, the function can easily be used to parse IP addresses as well.
Here’s such a function:
CREATE FUNCTION [fn_ConvertIpToInt]( @ip varchar(15) ) RETURNS bigint
WITH SCHEMABINDING BEGIN
RETURN (CONVERT(bigint, PARSENAME(@ip,1)) + CONVERT(bigint, PARSENAME(@ip,2)) * 256 + CONVERT(bigint, PARSENAME(@ip,3)) * 65536 + CONVERT(bigint, PARSENAME(@ip,4)) * 16777216) END
Next you need a table that can contain the names of users who need protection. The table will include Login Name and ip-ranges. The IP address is written in normal form (for example, 10.42.42.42), and at the same time in its integer value. It is the integer value that enables you to easily check whether an IP address falls within a given range. Following is a table that you might use:
CREATE TABLE [LoginsAllowed]
( [LoginName] [sysname] NOT NULL, [IpFromString] [varchar](15) NOT NULL, [IpToString] [varchar](15) NOT NULL,
[IpFrom] AS ([fn_ConvertIpToInt]([IpFromString])) PERSISTED, [IpTo] AS ([fn_ConvertIpToInt]([IpToString])) PERSISTED )
ALTER TABLE [LoginsAllowed] WITH CHECK
ADD CONSTRAINT [CK_LoginsAllowed_IpCheck] CHECK (([IpFrom]<=[IpTo]))
GO
[IpFrom] ASC, [IpTo] ASC )
Then create a user to execute the trigger. Grant the user access to the table and SERVER STATE. If you do not do this, the trigger will not have access to the required DMV. Here’s an example:
CREATE LOGIN [LogonTrigger] WITH PASSWORD = 'Pr@s1ensGedBag#' ;
DENY CONNECT SQL TO [LogonTrigger];
GRANT VIEW SERVER STATE TO [LogonTrigger];
CREATE USER [LogonTrigger] FOR LOGIN [LogonTrigger] WITH DEFAULT_SCHEMA=[dbo];
GRANT SELECT ON [LoginsAllowed] TO [LogonTrigger];
GRANT EXECUTE ON [fn_ConvertIpToInt] TO [LogonTrigger];
Now for the trigger itself. It will check whether the user logging on exists in the LOGIN table. If not, the login is allowed. If the user does exist in the table, the trigger goes on to check whether the connection comes from an IP address that is covered by that user’s IP range. If not, the connection is refused. Here is the code for the trigger:
CREATE TRIGGER ConnectionLimitTrigger ON ALL SERVER
WITH EXECUTE AS 'LogonTrigger' FOR LOGON
AS BEGIN
DECLARE @LoginName sysname, @client_net_address varchar(48), @ip bigint
SET @LoginName = ORIGINAL_LOGIN()
IF EXISTS (SELECT 1 FROM LoginsAllowed WHERE LoginName = @LoginName) BEGIN
SET @client_net_address=(SELECT TOP 1 client_net_address FROM sys.dm_exec_connections WHERE session_id = @@SPID)
-- Fix the string, if the connection is from <local host> IF @client_net_address = '<local machine>'
SET @client_net_address = '127.0.0.1'
SET @ip = fn_ConvertIpToInt(@client_net_address)
IF NOT EXISTS (SELECT 1 FROM LoginsAllowed WHERE LoginName = @LoginName AND @ip BETWEEN IpFrom AND IpTo) ROLLBACK;
When you test this trigger, have more than one query editor open and connected to the server. Having a second query editor open might save you some pain. The trigger is executed only on new connections. If there is a logical flaw in your code that causes you to be locked out of your database, you can use that spare connection in the second query editor to drop the trigger and regain access to your database. Or you need to make a DAC connection to bypass the trigger.
Policy-Based Management
Policy-based management (PBM) allows you to secure an installation or to monitor whether the
installation adheres to the different standards you have defined. PBM can be used in different ways. One customer I worked for had the problem of databases with enterprise features making it into production. This was a problem because the customer wanted to move to Standard Edition in the production environment. So they set up an enterprise policy to alert them whenever those features were used. They chose to alert rather than to block usage entirely because they felt it important to explain their reasoning to the developer instead of just forcing the decision.
Logging and Resource Control
If you need to log when objects are created, you probably also want to log whenever they are deleted. A procedure to drop a database, then, would perform the following steps:
1. DROP DATABASE 2. UPDATE DatabaseLog
When many resources are gathered in one place, as in consolidation environments, you need to control the usage of those resources to prevent one database from taking them all. There are two different levels to think about when you talk about resource control in SQL Server: resource usage across multiple instances, and by individual users in an instance.
One process (for example, a virus scan, backup agent, and so forth) could take all CPU resources on a machine and take away all CPU resources for all the other processes on that same server. SQL Server cannot guard itself against problems like that. But Windows can guard against that problem. Windows includes a feature called Windows System Resource Manager (WSRM), which is a not-well-known feature available starting with Windows Server 2008. When WSRM is running, it will monitor CPU usage and activate when usage rises above the 70 percent mark. You can create policies in which, when the resource manager is activated, you will allocate an equal share of CPU to all instances.
Next Steps
When all the details are in place, your target framework is taking shape, and your environment is slowly being created, you have to think about how to make your effort a success. Part of the solution is to choose the right developers to start with. Most would take the developers from the biggest or most important applications, but I think that would be a mistake. Start with the easy and simple and small systems, where you almost can guarantee yourself success before you begin. Then you will quietly build a good
■ ■ ■
Getting It Right: Designing the
Database for Performance
By Louis Davidson
Most of the topics in the book are related to admin tasks: indexing, performance tuning, hardware, backup, compression, and so forth. Many times, database administrators (DBAs) don’t have input into the design of the database they are responsible for. But even if you don’t have control over the design, it’s nice to know what a good design ought to look like—if for no other reason than you can be specific in your complaints when you are struggling with a piece of software.
In this chapter, I’ll present an overview of the entire process of designing a database system, discussing the factors that make a database perform well. Good performance starts early in the process, well before code is written during the definition of the project. (Unfortunately, it really starts well above of the pay grade of anyone who is likely to read a book like this.) When projects are hatched in the board room, there’s little understanding of how to create software and even less understanding of the unforgiving laws of time. Often the plan boils down to “We need software X, and we need it by a date that is completely pulled out of…well, somewhere unsavory.” So the planning process is cut short of what it needs to be, and you get stuck with the seed of a mess. No matter what part you play in this process, there are steps required to end up with an acceptable design that works, and that is what you as a database professional need to do to make sure this occurs.
In this chapter, I’ll give you a look at the process of database design and highlight many of the factors that make the goals of many of the other chapters of this book a whole lot easier to attain. Here are the main topics I’ll talk about:
• Requirements Before your new database comes to life, there are preparations to be made. Many database systems perform horribly because the system that was initially designed bore no resemblance to the system that was needed.
• Table Structure The structure of the database is very important. Microsoft SQL Server works a certain way, and it is important that you build your tables in a way that maximizes the SQL Server engine.
The process of database design is not an overly difficult one, yet it is so often done poorly. Throughout my years of writing, working, speaking, and answering questions in forums, easily 90 percent of the problems came from databases that were poorly planned, poorly built, and (perhaps most importantly) unchangeable because of the mounds of code accessing those structures. With just a little bit of planning and some knowledge of the SQL Server engine’s base patterns, you’ll be amazed at what you can achieve and that you can do it in a lot less time than initially expected.
Requirements
The foundation of any implementation is an understanding of what the heck is supposed to be created. Your goal in writing software is to solve some problem. Often, this is a simple business problem like creating an accounting system, but sometimes it’s a fun problem like shuffling riders on and off of a theme-park ride, creating a television schedule, creating a music library, or solving some other problem. As software creators, our goal ought to be to automate the brainless work that people have to do and let them use their brains to make decisions.
Requirements take a big slap in the face because they are the first step in the classic “waterfall” software-creation methodology. The biggest lie that is common in the programming community is that the waterfall method is completely wrong. The waterfall method states that a project should be run in the following steps:
• Requirements Gathering Document what a system is to be, and identify the criteria that will make the project a success.
• Design Translate the requirements into a plan for implementation.
• Implementation Code the software.
• Testing Verify that the software does what it is supposed to do.
• Maintenance Make changes to address problems not caught in testing.
• Repeat the process.
The problem with the typical implementation of the waterfall method isn’t the steps, nor is it the order of the steps, but rather it’s the magnitude of the steps. Projects can spend months or even years gathering requirements, followed by still more months or years doing design. After this long span of time, the programmers finally receive the design to start coding from. (Generally, it is slid under their door so that the people who devised it can avoid going into the dungeons where the programmers are located, shackled to their desks.) The problem with this approach is that, the needs of the users changed frequently in the years that passed before software was completed. Or (even worse) as programming begins, it is realized that the requirements are wrong, and the process has to start again.
As an example, on one of my first projects as a consultant, we were designing a system for a chemical company. A key requirement we were given stated something along the lines of: “Product is only sold when the quality rating is not below 100.” So, being the hotshot consultant programmer who wanted to please his bosses and customers, I implemented the database to prevent shipping the product when the rating was 99.9999 or less, as did the UI programmer. About a week after the system is shipped, the true
requirement was learned. “Product is only sold when the quality rating is not below 100…or the customer overrides the rating because they want to.” D’oh! So after a crazy few days where sleep was something we only dreamt about, we corrected the issues. It was an excellent life lesson, however. Make sure
shorten the amount of time between requirements gathering and implementation by shortening the entire process from gathering requirements to shipping software from years to merely weeks. (If you want to know more about Agile, start with their “manifesto” http://agilemanifesto.org/.) The critisisms of Agile are very often the exact opposite of the waterfall method: very little time is spent truly understanding the problems of the users, and after the words “We need a program to do…” are spoken, the coding is underway. The results are almost always predictably (if somewhat quicker…) horrible.
■
Note
In reality, Agile and Waterfall both can actually work well in their place, particularly when executed in the
right manner by the right people. Agile methodologies in particular are very effective when used by professionals
who really understand the needs of the software development process, but it does take considerable discipline to
keep the process from devolving into chaos.
The ideal situation for software design and implementent lies somewhere between spending no time on requirements and spending years on them, but the fact is, the waterfall method at least has the order right, because each step I listed earlier needs to follow the one that comes before it. Without
understanding the needs of the user (both now and in the future,) the output is very unlikely to come close to what is needed.
So in this chapter on performance, what do requirements have to do with anything? You might say they have everything to do with everything. (Or you might not—what do I know about what you would say?) The best way to optimize the use of software is to build correct software. The database is the foundation for the code in almost every business system, so once it gets built, changing the structure can be extremely challenging. So what happens is that as requirements are discovered late in the process, the database is morphed to meet new requirements. This can leave the database in a state that is hard to use and generally difficult to optimize because, most of the time, the requirements you miss will be the obscure kind that people don’t think of immediately but that are super-important when they crop up in use. The SQL Server engine has patterns of use that work best, and well-designed databases fit the requirements of the user to the requirements of the engine.
As I mentioned in the opening section of this chapter, you might not be the person gathering requirements, but you will certainly be affected by them. Very often (even as a production DBA who does no programming), you might be called on to give opinions on a database. The problem almost always is that if you don’t know the requirements, almost any database can appear to be correct. If the requirements are too loose, your code might have to optimize for a ridiculously wide array of situations that might not even be physically possible. If the requirements are too strict, the software might not even work.
Going back to the chemical plant example, suppose that my consulting firm had completed our part of the project, we had been paid, and the programmers had packed up to spend our bonuses at Disney World and the software could not be changed. What then? The user would then find some combination of data that is illogical to the system, but tricks the system into working. For example, they might enter a quality rating of 10,000 + the actual rating. This is greater than 100, so the product can ship. But now every usage of the data has to take into consideration that 10,000 and greater actually means that the value was the stored value minus 10,000 that the customer has accepted, and values under 100 are failed products that the user did not accept. In the next section, I’ll discuss normalization, but for now take my word for it that designing a column that holds multiple values and/or multiple meanings is not a practice that you would call good, making it more and more difficult to achieve adequate performance.
your tables, your goal will be to match your design to the version that is correct. Sure the first makes sense, but business doesn’t always make sense.
■
Note
In this short chapter on design and the effect on performance, I am going to assume you are acclimated to
the terminology of the relational database and understand the basics. I also will not spend too much time on the
overall process of design, but you should spend time between getting requirements and writing code visualizing the
output, likely with a data-modeling tool. For more information on the overall process of database design, might I
shamelessly suggest
Pro SQL Server 2012 Relational Database Design and Implementation
(Apress, 2012)? My goal
for the rest of this chapter will be to cover the important parts of design that can negatively affect your performance
of (as well as your happiness when dealing with) your SQL Server databases.
Table Structure
The engineers who work for Microsoft on the SQL Server team are amazing. They have built a product that, in each successive version, continues to improve and attempt to take whatever set of structures is thrown at them, any code that a person of any skill level throws at it, and make the code work well. Yet for all of their hard work, the fact remains that the heart of SQL Server is a relational database engine and you can get a lot more value by using the engine following good relational practices. In this section, I will discuss what goes into making a database “relational,” and how you can improve your data quality and database performance by just following the relational pattern as closely as possible.
To this end, I will cover the following topics:
• A Really Quick Taste of History Knowing why relational databases are what they are can help to make it clear why SQL Server is built the way it is and why you need to structuring your databases that way too.
• Why a Normal Database Is Better Than an Extraordinary One Normalization is the process of making a database work well with the relational engine. I will describe normalization and how to achieve it in a practical manner.
• Physical Model Choices There are variations on the physical structure of a database that can have distinct implications for your performance.
Getting the database structure to match the needs of the engine is the second most important part in the process of performance tuning your database code. (Matching your structure to the user’s needs being the most important!)
A Really Quick Taste of History
Following this paper, in the 1980s Codd presented 13 rules for what made a database “relational,” and it is quite useful to see just how much of the original vision persists today. I won’t regurgitate all of the rules, but the gist of them was that, in a relational database, all of the physical attributes of the database are to be encapsulated from the user. It shouldn’t matter if the data is stored locally, on a storage area network (SAN), elsewhere on the local area network (LAN), or even in the cloud (though that concept wasn’t quite the buzz worthy one it is today.) Data is stored in containers that have a consistent shape (same number of columns in every row), and the system works out the internal storage details for the user. The higher point is that the implementation details are hidden from the users such that data is interacted with only at a very high level.
Following these principles ensures that data is far more accessible using a high level language, accessing data by knowing the table where the data resided, the column name (or names), and some piece of unique data that could be used to identify a row of data (aka a “key”). This made the data far more accessible to the common user because to access data, you didn’t need to know what sector on a disc the data was on, or a file name, or even the name of physical structures like indexes. All of those details were handled by software.
Changes to objects that are not directly referenced by other code should not cause the rest of the system to fail. So dropping a column that isn’t referenced would not bring down the systems. Moreover, data should not only be treated row by row but in sets at a time. And if that isn’t enough, these tables should be able to protect themselves with integrity constraints, including uniqueness constraints and referential integrity, and the user shouldn’t know these constraints exist (unless they violate one, naturally). More criteria is included in Codd’s rules, including the need for NULLs, but this is enough for a brief infomercial on the concept of the relational database.
The fact is, SQL Server—and really all relational database management systems (RDBMSs) —is just now getting to the point where some of these dreams are achievable. Computing power in the 1980s was nothing compared to what we have now. My first SQL Server (running the accounting for a midsized, nonprofit organization) had less than 100 MB of disk space and 16 MB of RAM. My phone five years ago had more power than that server. All of this power we have now can go to a developer’s head and give him the impression that he doesn’t need to spend the time doing design. The problem with this is that data is addictive to companies. They get their taste, and they realize the power of data and the data quantity explodes, leading us back to the need of understanding how the relational engine works. Do it right the first time…. That sounds familiar, right?
Why a Normal Database Is Better Than an Extraordinary One
In the previous section, I mentioned that the only (desirable) method of directly accessing data in a relational database is by the table, row key, and column name. This pattern of access ought to permeate your thinking when you are assembling your databases. The goal is that users have exactly the right number of buckets to put their data into, and when you are writing code, you do not need to break down data any further for usage.As the years passed, the most important structural desires for a relational database were formulated into a set of criteria known as the normal forms. A table is normalized when it cannot be rewritten in a simpler manner without changing the meaning. This meaning should be more concerned with actual utilization than academic exercises, and just because you can break a value into pieces doesn’t mean that you have to. Your decision should be based mostly on how data is used. Much of what you will see in the normal forms will seem very obvious. As a matter of fact, database design is not terribly difficult to get right, but if you don’t know what right is, it is a lot easier to get things wrong.