3.1 Metode Penelitian
Dalam penulisan ini metode penelitian yang digunakan adalah metode studi kepustakaan dan studi laboratorium, di mana penulis mempelajari teori-teori teknik kompresi dari buku dan website, lalu kemudian merancang apilikasi pendukung untuk
membandingkan teknik kompresi data antara algoritma run length, huffman, dan half byte dalam hal ukuran hasil kompresi, waktu kompresi dan waktu dekompresi, di mana
dalam penelitian ini menggunakan 50 data berupa teks (.doc) yang dimampatkan dengan
masing-masing algoritma. Penelitian dilakukan dengan menggunakan langkah-langkah sebagai berikut :
● Perancangan aplikasi pendukung.
Dalam menguji hipotesis dibutuhkan data-data, oleh karena itu perlu dirancang sebuah aplikasi kompresi data antara algoritma run length, huffman dan half byte
dengan menggunakan bahasa pemrograman borland delphi 6. aplikasi ini memerlukan input berupa data yang berisi dari lokasi (path) dari data-data yang akan
dikompresi, kemudian melakukan proses kompresi pada data yang telah diinput dan
terakhir menghasilkan output berupa hasil kompresi, waktu kompresi, dan waktu
dekompresi.
● Melakukan uji coba aplikasi untuk mendapatkan data.
Pengujian aplikasi ini menggunakan 50 data teks (.doc). Dari pengujian ini akan
diukur hasil kompresi, waktu kompresi, dan waktu dekompresi. Waktu yang dibutuhkan untuk melakukan proses kompresi didapatkan dari komponen timer yang
ada pada borland delphi. Hasil kompresi berupa ukuran file data setelah proses
kompresi dilakukan dan persentase rasio, waktu kompresi serta waktu dekompresi. ● Menganalisis data yang telah didapatkan.
Hasil pengukuran yang telah didapatkan dari pengujian aplikasi akan diolah dengan menggunakan uji z jika distribusi data normal dan uji wilcoxon jika distribusi data
tidak normal untuk menguji perbedaan rata-rata hasil kompresi, waktu pemampatan, dan waktu dekompresi serta statistik deskriptif untuk memberikan deskripsi mengenai hasil kompresi, waktu kompresi, dan waktu dekompresi dari masing-masing algoritma. Uji z digunakan karena jumlah sampel yang digunakan cukup besar, yaitu : 50 buah. Uji z dapat dilakukan pada data yang memiliki sebaran normal, sedangkan untuk data yang tidak memilki sebaran normal, maka akan dilakukan uji nonparametrik, yaitu : uji wilcoxon. Untuk mengetahui normalitas
sebaran data, maka dilakukan uji kenormalan dengan menggunakan software SPSS,
sehingga dari hasil output software SPSS dapat diketahui normalitas data. Uji z dan
uji wilcoxon hanya dapat digunakan untuk menguji perbedaan pada 2 kelompok,
sehingga akan dilakukan pengujian antara algorima run length, huffman dan half byte yang meliputi ukuran hasil kompresi, waktu kompresi, dan waktu dekompresi.
Dalam penelitian ini akan dilakukan 9 pengujian, yaitu :
a. Uji terhadap hasil kompresi algoritma run length dan algoritma huffman.
b. Uji terhadap hasil kompresi algoritma run length dan algoritma half byte.
c. Uji terhadap hasil kompresi algoritma huffman dan algoritma half byte.
d. Uji terhadap waktu kompresi algoritma run length dan algoritma huffman.
e. Uji terhadap waktu kompresi algoritma run length dan algoritma half byte.
g. Uji terhadap waktu dekompresi algoritma run length dan algoritma huffman.
h. Uji terhadap waktu dekompresi algoritma run length dan algoritma half byte.
i. Uji terhadap waktu dekompresi algoritma huffman dan algoritma half byte.
3.2 Hipotesis
Melalui pengujian aplikasi dan menganalisis kinerja dari algoritma run length, huffman dan half byte yang meliputi hasil kompresi, waktu kompresi, dan waktu
dekompresi, maka akan digunakan uji hipotesis untuk membuktikan adanya perbedaan antara kedua algoritma tersebut dalam hal ukuran kompresi, waktu kompresi, dan waktu dekompresi. Hipotesis yang digunakan dalam penelitian ini adalah :
♦ ada perbedaan hasil pemampatan antara algoritma run length dengan algoritma huffman.
♦ ada perbedaan hasil pemampatan antara algoritma run length dengan half byte. ♦ ada perbedaan hasil pemampatan antara algoritma huffman dengan half byte.
♦ ada perbedaan waktu kompresi antara algoritma run length dengan algoritma huffman.
♦ ada perbedaan waktu kompresi antara algoritma run length dengan algoritma half byte.
♦ ada perbedaan waktu kompresi antara algoritma huffman dengan algoritma half byte. ♦ ada perbedaan waktu dekompresi antara algoritma run length dengan algoritma
huffman.
♦ ada perbedaan waktu dekompresi antara algoritma run length dengan algoritma half byte.
♦ ada perbedaan waktu dekompresi antara algoritma huffman dengan algoritma half byte.
Hipotesis dalam penelitian ini menyatakan bahwa ada perbedaan rata-rata antara kedua algoritma dilihat dari hasil kompresi, waktu kompresi, dan waktu dekompresi. Untuk menguji hipotesis tersebut digunakan uji z jika distribusi data normal dan uji
wilcoxon jika distribusi data tidak normal yang berdasarkan pada data-data statistik yang
dihasilkan dari hasil percobaan dengan menjalankan aplikasi yang dibuat terhadap 50 data teks. Dari hasil pengujian akan ditentukan apakah hipotesis yang ada dapat diterima.
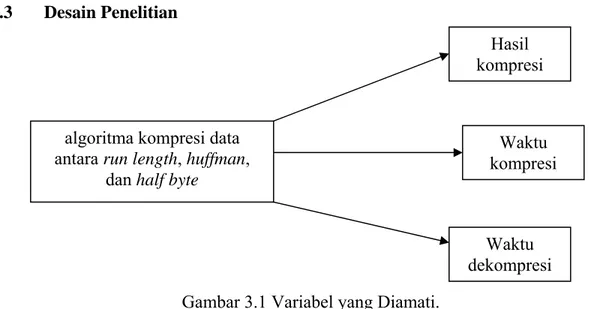
3.3 Desain Penelitian
Gambar 3.1 Variabel yang Diamati.
Pada penelitian ini terdapat tiga variabel yang diamati, yaitu hasil kompresi, waktu kompresi, dan waktu dekompresi. Dengan menggunakan teknik kompresi yang berbeda dari masing-masing algoritma kompresi data, maka akan didapatkan hasil yang berbeda pula yang meliputi tiga variabel yang diteliti. Pada penelitian ini yang merupakan variabel terikat atau tidak bebas adalah hasil kompresi, waktu kompresi, dan waktu dekompresi sedangkan yang merupakan variabel bebas adalah algoritma kompresi
Hasil kompresi Waktu kompresi Waktu dekompresi algoritma kompresi data
antara run length, huffman,
data antara run length, huffman dan half byte. Penelitian ini bertujuan untuk
membandingkan teknik kompresi dari algoritma run length, huffman dan half byte
terhadap tiga variabel terikat, yaitu hasil kompresi, waktu kompresi, dan waktu dekompresi.
3.4 Teknik Pengumpulan Data
Pada penelitian ini, pengumpulan data dilakukan dengan observasi langsung terhadap hasil percobaan, di mana data didapatkan dari hasil pengukuran dengan menggunakan aplikasi yang dibuat berdasarkan teknik kompresi atau pemampatan dengan algoritma run length, huffman dan half byte.
3.5 Teknik Analisis Data
Untuk menghitung rasio kompresi digunakan rumus sebagai berikut :
Ratio : 100% asli ukuran kompresi hasil ukuran ×
Sedangkan rumus untuk uji Z digunakan jika data berdistribusi normal adalah :
1 ) ( ) ( 2 2 2 − − =
∑
∑
n n x x S ; Z = ) / ( ) / ( ) ( 2 2 2 1 2 1 2 1 n s n s d x x o + − − = 1x nilai tengah sampel pertama
=
2
x nilai tengah sampel kedua
=
2 1
s ragam sampel pertama
=
2 2
s ragam sampel kedua
=
1
=
2
n jumlah sampel kedua
Rumus untuk digunakan pada uji wilcoxon jika data tidak berdistribusi normal adalah :
∑
= += n i i R w 1 4 ) 1 ( + = + n n w μ ; 24 ) 1 2 ( ) 1 ( 2 = + + + n n n w σ + + − = + w w hitung w Z σ μ ) ( +w = jumlah rank yang positif
Ri = rank pada di yang positif
μw+ = nilai tengah untuk rank perbedaan yang positif
σ2w+ = ragam untuk rank perbedaan yang positif n = jumlah total rank yang diamati
3.6 Perancangan Aplikasi
Dalam melakukan penelitian ini dibuat suatu aplikasi pendukung berupa aplikasi kompresi data dengan menggunakan bahasa pemrograman borland delphi 6. Melalui aplikasi ini akan dilakukan pemampatan atau kompresi terhadap data berupa teks dengan menggunakan algoritma run length, huffman dan half byte serta kemudian
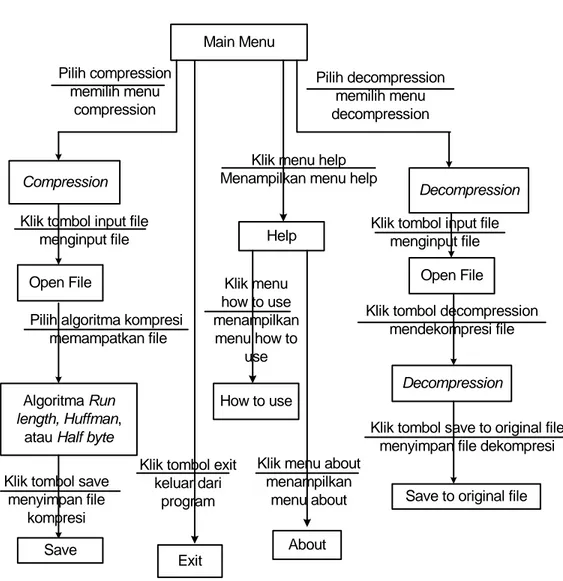
membandingkan ketiga algoritma tersebut dalam hal ukuran rasio pemampatan, waktu pemampatan, dan waktu dekompresi. Berikut adalah skema menu dari program aplikasi :
Gambar 3.2 Rancangan Menu Utama.
3.6.1 Perancangan Menu
Gambar 3.3 State Transition Diagram Aplikasi.
Main Menu Compression Pilih compression memilih menu compression Algoritma Run length, Huffman, atau Half byte
Pilih algoritma kompresi memampatkan file
Exit Klik tombol exit
keluar dari program
Save Klik tombol save
menyimpan file kompresi Decompression Pilih decompression memilih menu decompression Open File
Klik tombol input file menginput file
Open File Klik tombol input file
menginput file
Decompression
Klik tombol decompression mendekompresi file
Save to original file Klik tombol save to original file
menyimpan file dekompresi Help
Klik menu help Menampilkan menu help
How to use Klik menu how to use menampilkan menu how to use About Klik menu about
menampilkan menu about
Main Menu
3.6.1.1 Menu Compression
Gambar 3.4 Tampilan Menu Compression
Pada tampilan menu compression terdiri dari keterangan nama file, ukuran file,
waktu kompresi, pilihan compression dan decompression serta beberapa tombol dengan
fungsi sebagai berikut :
● Open file berfungsi untuk menginputfile yang akan dikompres.
● Run length berfungsi untuk memampatakan file dengan algoritma run length. ● Huffman berfungsi untuk memampatakan file dengan algoritma huffman. ● Half byte berfungsi untuk memampatkan file dengan algoritma half byte. ● Save berfungsi untuk menyimpan hasil kompresi.
● Exit berfungsi untuk menutup program aplikasi.
Proses untuk menggunakan menu ini dimulai dengan menginput sebuah file dan akan
kompresi yang terdiri atas tiga algoritma. Setelah itu akan muncul hasil berupa keterangan ukuran rasio dan waktu kompresi dari masing-masing algoritma yang dipilih serta dapat disimpan hasilnya dengan menekan tombol save.
3.6.1.2 Menu Decompression
Gambar 3.5 Tampilan Menu Decompression.
Pada tampilan menu decompression terdiri dari keterangan nama file, ukuran file, waktu dekompresi, pilihan compression dan decompression serta beberapa tombol
dengan fungsi sebagai berikut :
● Open file berfungsi untuk menginputfile yang akan didekompres. ● Decompress berfungsi untuk melakukan proses dekompresi file. ● save to original file berfungsi untuk menyimpan hasil dekompresi. ● Exit berfungsi untuk menutup program aplikasi.
Proses untuk menggunakan menu ini dimulai dengan menginput sebuah file dan akan
muncul keterangan nama file dan ukuran file yang telah dikompres. Kemudian menekan
tombol decompress. Setelah itu akan muncul hasil berupa keterangan ukuran file asli dan
waktu dekompresi dari masing-masing algoritma yang telah dipilih serta dapat disimpan hasilnya dengan menekan tombol save to original file.
3.6.2 Perancangan Modul
Implementasi program untuk masing-masing algoritma dapat dijelaskan melalui modul-modul yang digunakan dalam aplikasi ini, yaitu :
♦ Modul Run Length
Pertama yang dilakukan adalah dengan mencari karakter yang berulang lebih dari 3 kali pada suatu file yang diinput untuk kemudian diubah menjadi sebuah bit
penanda diikuti oleh sebuah bit yang memberikan informasi jumlah karakter yang
berulang dan kemudian diakhiri dengan karakter yang dikompres. File hasil pemampatan dengan algoritma Run Length harus ditandai pada awal datanya sehingga sewaktu
pengembalian ke file asli dapat dikenali apakah file tersebut benar merupakan hasil
pemampatan dengan algoritma ini. Pada program ini format pengenal file tersebut ditulis
pada byte pertama, kedua dan ketiga dengan karakter R, U, dan N. Kita dapat mengganti
format tersebut dengan karakter lain yang diinginkan, demikian juga dengan jumlahnya. Karakter berikutnya (keempat) berisi karakter bit penanda yang telah ditentukan
dengan mencari karakter dengan frekuensi kemunculan terkecil. Jika misalnya pada suatu filebit penandanya adalah X, maka 4 byte pertama isi file pemampatan adalah :
R U N X . . . Bit ke- 1 2 3 4 5 . . .
Karakter kelima dan seterusnya berisi hasil pemampatan dengan algoritma Run length seperti yang telah dijelaskan sebelumnya. Untuk lebih jelasnya berikut adalah
tahapan-tahapan dalam modul run length :
- Pertama memberikan pengenal file pada byte pertama, kedua, dan ketiga dengan
karakter R,U,N sehingga memudahkan dalam proses pengembalian ke file
semula.
- Membaca semua karakter yang terdapat pada file apakah terdapat deretan
karakter yang berulang lebih dari tiga karakter, jika memenuhi lakukan pemamapatan.
- Berikan bit penanda pada file pemampatan berupa 8 deretan bit untuk
manandakan bahwa karakter berikutnya adalah karakter pemampatan, sehingga memudahkan dalam pengembalian ke file aslinya. Pemilihan bit penanda ini
tidak boleh sama dengan karakter dalam file. Untuk menjaga agar hal tersebut
tidak terjadi, jika pada file asli terdapat karakter yang sama dengan bit penanda,
maka pada file pemampatan karakter tersebut ditulis sebanyak dua kali secara
berturutan. Pada saat pengembalian ke file asli, jika ditemukan bit penanda yang
berderetan sebanyak dua kali, hal itu berarti karakter tersebut bukan bit penanda,
tapi karakter asli dari file aslinya.
- Tambahkan deretan bit untuk menyatakan jumlah karakter yang sama berurutan.
- Selanjutnya dengan menambahkan deretan bit yang menyatakan karakter yang
♦ Modul Halfbyte
Modul ini dugunakan untuk melakukan proses kompresi dengan algoritma half byte. Metode ini melakukan kompresi dengan cara mengambil empat bit sebelah kiri
yang sering sama secara berurutan. Seperti pada algoritma run length, file hasil
pemampatan dengan algoritma halfbyte harus ditandai pada awal datanya sehingga
sewaktu pengembalian ke file asli dapat dikenali apakah file tersebut benar merupakan
hasil pemampatan dengan algoritma ini. Pada program ini format pengenal file tersebut
ditulis pada byte pertama, kedua dan ketiga dengan karakter H, A, dan L. Kita juga dapat
mengganti format tersebut dengan karakter lain yang diinginkan, demikian juga dengan jumlahnya.
Karakter berikutnya (keempat) berisi karakter bit penanda yang telah ditentukan
dengan mencari karakter dengan frekuensi kemunculan terkecil. Jika misalnya pada suatu file bit penandanya adalah Q, maka 4 byte pertama isi file pemampatan adalah :
H A L Q . . . Bit ke- 1 2 3 4 5 . . .
Karakter kelima dan seterusnya berisi hasil pemampatan dengan algoritma half byte
seperti yang telah dijelaskan sebelumnya. Untuk lebih jelasnya berikut adalah tahapan-tahapan dalam modul halfbyte :
- Pertama memberikan pengenal file pada byte pertama, kedua, dan ketiga dengan
karakter H,A,L sehingga memudahkan dalam proses pengembalian ke file
semula.
- Setelah itu melihat apakah terdapat deretan karakter yang 4 bit pertamanya sama
Berikan bit penanda pada file pemampatan, bit penanda disini berupa 8 deretan bit (1 byte) yang boleh dipilih sembarang asalkan digunakan secara konsisten
pada seluruh bit penanda pemampatan. Bit penanda ini berfungsi untuk menandai
bahwa karakter selanjutnya adalah karakter pemampatan sehingga tidak membingungkan pada saat mengembalikan ke file semula . Pemilihan bit
penanda diusahakan dipilih pada karakter yang paling sedikit jumlahnya terdapat pada file yang akan dimampatkan, sebab jika pada file asli ditemukan karakter
yang sama dengan bit penanda, terpaksa anda harus menulis karakter tersebut
sebanyak dua kali pada file pemampatan. Hal ini harus dilakukan untuk
menghindari kesalahan mengenali apakah bit penanda pada file pemampatan
tersebut benar-benar bit penanda atau memang karakter dari file yang asli. Untuk
menjaga agar hal tersebut tidak terjadi, jika pada file asli terdapat karakter yang
sama dengan bit penanda, maka pada file pemampatan karakter tersebut ditulis
sebanyak dua kali secara berturutan. Pada saat pengembalian ke file asli, jika
ditemukan bit penanda yang berderetan sebanyak dua kali, hal itu berarti karakter
tersebut bukan bit penanda, tapi karakter asli dari file aslinya. Pada kasus lain
dapat terjadi penggabungan 4 bit kanan menghasilkan sebuah karakter yang sama
dengan bit penanda sehingga diduga karakter itu adalah bit penutup. Untuk
menjaga agar hal tersebut tidak terjadi, jika terdapat penggabungan 4 bit kanan yang menghasilkan sebuah karakter yang sama dengan bit penanda, maka
deretan file tersebut tidak usah dimampatkan. Selain itu jika ditemukan kasus
jumlah karakter berurutan yang memiliki 4 bit pertama sama jumlahnya genap
- Tambahkan karakter pertama 4 bit kiri berurutan dari file asli.
- Gabungkan 4 bit kanan karakter kedua dan ketiga kemudian tambahkan ke file
pemampatan.
- Selanjutnya diakhiri dengan bit penanda pada file pemampatan. ♦ Modul Huffman
Pada modul ini dilakukan proses kompresi dengan menggunakan algoritma
huffman. Metode ini pada awalnya menghitung frekuensi kemunculan masing-masing
karakter dan kemudian diurutkan dari yang frekuensi terkecil sampai yang terbesar. Setelah itu dibuat pohon huffman berdasarkan frekuensi dari karakter yang ada, sehingga
diperoleh kode huffman. Seperti pada kedua algoritma sebelumnya, file hasil
pemampatan dengan algoritma huffman harus ditandai pada awal datanya sehingga
sewaktu pengembalian ke file asli dapat dikenali apakah file tersebut benar merupakan
hasil pemampatan dengan algoritma ini.
Pada program ini format pengenal file tersebut ditulis pada byte pertama, kedua
dan ketiga dengan karakter H, U, dan F. Kita juga dapat mengganti format tersebut dengan karakter lain yang diinginkan, demikian juga dengan jumlahnya.
Karakter keempat, kelima dan keenam berisi informasi ukuran file asli dalam byte, 3
karakter ini dapat berisi maksimal FFFFFF H atau 16.777.215 byte. Karakter ketujuh
berisi informasi jumlah karakter yang memiliki kode huffman atau dengan kata lain
jumlah karakter yang frekuensi kemunculannya pada file asli lebih dari nol, jumlah
tersebut dikurangi satu dan hasilnya disimpan pada karakter ke tujuh pada file
pemampatan. Misalnya suatu file dengan ukuran 3.000 byte dan seluruh karakter ASCII
terdapat pada file tersebut, jadi :
Karena 3.000 = BB8 H, maka : Karakter 4-6 : 000BB8
Karena seluruh karakter ASCII terdapat pada file tersebut, jadi jumlah karakter yang memiliki kode Huffman adalah 256 buah, 256-1=255 = FF H maka :
Karakter 7 : FF
Maka 7 byte pertama isi file pemampatan adalah :
H U F Chr (00H) Chr (0BH) Chr (B8H) Chr (FFH) . . . Bit ke- 1 2 3 4 5 6 7 8 . . .
Mulai dari karakter ke delapan berisi daftar kode huffman berturut-turut karakter (1 byte), kode huffman (2 byte) dan panjang kode Huffman (1 byte). 4 byte berturutan ini
diulang untuk seluruh karakter yang dikodekan. Selanjutnya file diisi hasil pemampatan
dengan algoritma huffman seperti yang telah dijelaskan sebelumnya.
Agar lebih jelas kita ulangi contoh sebelumnya, yaitu file yang berisi karakter
“PERKARA”. Jika file ini dimampatkan dengan metode huffman, maka file hasil
pemampatan akan kita dapatkan sebagai berikut : Karakter 1-3 : HUF = 48 55 46 H
Karena file tersebut berukuran 7 byte, jadi : Karakter 4-6 : 00 00 07 H.
Daftar kode huffman telah kita cari pada bab sebelumnya yaitu :
E = 010 K = 011 P = 00 A = 10 R = 11
Karena jumlah karakter yang memiliki kode huffman ada 5 buah, maka 5-1=4.
Karakter 7 : 04 H.
Karakter 8 : karakter E = 45 H.
Karena kode Huffman dari karakter E adalah 010, sedangkan tempat yang disediakan
sebanyak 2 byte maka karakter 9 dan 10 menjadi 00000000 00000010 B. Karakter 9 : 00000000 B = 00 H.
Karakter 10 : 00000010 B = 02 H.
Panjang kode Huffman dari karakter E adalah 3 bit (010), jadi :
Karakter 11: 03H.
Cara tersebut di atas diulang untuk karakter K, P, A dan R sehingga didapat : Karakter 12: karakter K = 4B H. Karakter 13: 00000000 B = 00 H. Karakter 14: 00000011 B = 03 H. Karakter 15: 03H. Karakter 16: karakter P = 50 H. Karakter 17: 00000000 B = 00 H. Karakter 18: 00000000 B = 00 H. Karakter 19: 02H. Karakter 20: karakter A = 41 H. Karakter 21: 00000000 B = 00 H. Karakter 22: 00000010 B = 02 H. Karakter 23: 02H. Karakter 24: karakter R = 52 H. Karakter 25: 00000000 B = 00 H.
Karakter 26: 00000011 B = 03 H. Karakter 27: 02H.
Selanjutnya pemampatan karakter-karakter “PERKARA” adalah : 0001011011101110. Jika kita potong-potong menjadi 8 bit tiap bagian akan menjadi :
00010110 = 16 H. 11101110 = EE H.
Jadi : Karakter 28 : 16 H. Karakter 29 : EE H.
File hasil pemampatan akan menjadi berukuran 29 byte yang dalam heksadesimal
berisi:
48 55 46 00 00 07 04 45 00 02 03 4B 00 03 03 50 00 00 02 41 00 02 02 52 00 03 02 16 EE
Jika kita bandingkan dengan file aslinya yang berukuran 7 byte, hasil ini bukan menjadi
lebih kecil, tapi malah menambah byte sebesar 29-7=22 byte. Hal ini wajar dalam file
yang berukuran sangat kecil seperti ini, tapi dalam file-file yang berukuran besar,
algoritma huffman ini sangat efektif. Untuk lebih jelasnya berikut adalah tahapan-tahapan
dalam modul huffman :
- Memberikan pengenal file pada byte pertama, kedua, dan ketiga dengan karakter
H,U,F, sehingga memudahkan dalam proses pengembalian ke file semula.
- Selanjutnya adalah menghitung frekuensi kemunculan masing-masing karakter dan mengurutkan dari terkecil sampai terbesar.
- Membuat huffman tree berdasarkan frekuensi kemunculan dari masing-masing
karakter untuk mencari kode huffman. Setelah itu berikan tanda bit 0 pada setiap
- Untuk mendapatkan kode huffman masing-masing karakter, ditelusuri karakter
tersebut dari node yang paling atas sampai ke node karakter tersebut dan susunlah bit-bit yang dilaluinya. Bit-bit yang dilalui itulah yang merupakan kode huffman. Kode-kode inilah yang menggantikan ukuran bit dari file semula.
♦ Modul Decompress
Modul ini digunakan untuk melakukan proses pengembalian file yang telah
dikompres menjadi file semula. Dalam modul ini proses pengembalian file dilakukan
dengan cara membaca algoritma yang digunakan dalam file yang telah dikompres. Jika
pada saat pembacaan file ditemukan format pengenal file RUN, maka file itu dikompres
dengan algoritma run length, jika dibaca format pengenal filenya adalah HAL, maka file
itu menggunakan algoritma half byte, dan jika dibaca format filenya adalah HUF, maka file tersebut menggunakan algoritma huffman. Setelah ditemukan pengenal filenya, baru
kemudian dilakukan proses dekompresi menurut algoritma yang terdapat pada file yang
telah dikompres tersebut. Untuk lebih jelasnya berikut adalah tahapan-tahapan untuk proses dekompresi dari masing-masing algoritma :
● Proses dekompresi untuk algoritma run length
- Pertama membaca pengenal file yang digunakan pada file yang telah dikompresi,
apakah menggunakan pengenal file berupa karakter R,U, dan N, jika memenuhi
baru dapat dilakukan proses berikutnya.
- Mengecek karakter pada hasil pemampatan satu-persatu dari awal sampai akhir, jika ditemukan bit penanda, lakukan proses pengembalian.
- Lihat karakter setelah bit penanda, konversikan ke bilangan desimal untuk
- Lihat karakter berikutnya, kemudian lakukan penulisan karakter tersebut sebanyak bilangan yang telah diperoleh pada karakter sebelumnya.
● Proses dekompresi untuk algoritma halfbyte
- Pertama membaca pengenal file yang digunakan pada file yang telah dikompresi,
apakah menggunakan pengenal file berupa karakter H,A, dan L, jika memenuhi
baru dapat dilakukan proses berikutnya.
- Lihat karakter pada hasil pemampatan satu-persatu dari awal sampai akhir, jika ditemukan bit penanda, lakukan proses pengembalian.
- Selanjutnya lihat karakter setelah bit penanda, tambahkan karakter tersebut pada file pengembalian.
- Lihat karakter berikutnya, jika bukan bit penanda, ambil 4 bit kanan dan kiri lalu
gabungkan dengan 4 bit kiri karakter di atasnya. Hasil gabungan tersebut
ditambahkan pada file pengembalian. Lakukan sampai ditemukan bit penanda. ● Proses dekompresi untuk algoritma huffman
- Pertama membaca pengenal file yang digunakan pada file yang telah dikompresi,
apakah menggunakan pengenal file berupa karakter H,U, dan F, jika memenuhi
baru dapat dilakukan proses berikutnya.
- Untuk proses pengembalian ke file aslinya, kita harus mengacu kembali kepada
kode huffman yang telah dihasilkan.
- Ambillah satu-persatu bit hasil pemampatan mulai dari kiri, jika bit tersebut
termasuk dalam daftar kode, lakukan pengembalian, jika tidak ambil kembali bit
3.7 Spesifikasi Perangkat Keras dan Perangkat Lunak 3.7.1 Spesifikasi Perangkat Keras
Perangkat keras yang digunakan adalah komputer dengan spesifikasi : ● Prosesor AMD Athlon XP 2100+ ≈ 1.76 Ghz
● Memori DDR 512 MB
● Harddisk dengan kapasitas 80 GB
3.7.2 Spesifikasi Perangkat Lunak
Perangkat lunak yang digunakan dalam penelitian ini adalah : ● Sistem operasi : Microsoft Windows XP Proffesional ● Bahasa pemrograman : Borland Delphi 6
● SoftwareSPSS versi 11