Load Balancing Distributed Inverted Files
Mauricio Marin
Carlos Gomez
Yahoo! Research Santiago, Chile
[email protected] [email protected]
ABSTRACT
This paper present a comparison of scheduling algorithms applied to the context of load balancing the query traffic on distributed inverted files. We implemented a number of algorithms taken from the literature. We propose a novel method to formulate the cost of query processing so that these algorithms can be used to schedule queries onto pro-cessors. We avoid measuring load balance at the search en-gine side because this can lead to imprecise evaluation. Our method is based on the simulation of a bulk-synchronous parallel computer at the broker machine side. This simu-lation determines an optimal way of processing the queries and provides a stable baseline upon which both the broker and search engine can tune their operation in accordance with the observed query traffic. We conclude that the sim-plest load balancing heuristics are good enough to achieve efficient performance. Our method can be used in practice by broker machines to schedule queries efficiently onto the cluster processors of search engines.
Categories and Subject Descriptors
H.3.3 [Information Storage and Retrieval]: Information Search and Retrieval—Search process
General Terms
Algorithms, Performance
Keywords
Inverted Files, Parallel and Distributed Computing
1.
INTRODUCTION
Cluster based search engines use distributed inverted files [10] for dealing efficiently with high traffic of user queries. An inverted file is composed of a vocabulary table and a set of posting lists. The vocabulary table contains the set of relevant terms found in the text collection. Each of these
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
WIDM’07, November 9, 2007, Lisboa, Portugal.
Copyright 2007 ACM 978-1-59593-829-9/07/0011 ...$5.00.
terms is associated with a posting list which contains the document identifiers where the term appears in the collec-tion along with addicollec-tional data used for ranking purposes. To solve a query, it is necessary to get the set of documents associated with the query terms and then perform a ranking of these documents in order to select the topKdocuments as the query answer.
The approach used by well-known Web search engines to the parallelization of inverted files is pragmatic, namely they use the document partitioned approach. Documents are evenly distributed onP processors and an independent inverted file is constructed for each of the P sets of doc-uments. The disadvantage is that each user query has to be sent to theP processors and it can present imbalance at posting lists level (this increases disk access and interproces-sor communication costs). The advantage is that document partitioned indexes are easy to maintain since insertion of new documents can be done locally and this locality is ex-tremely convenient for the posting list intersection opera-tions required to solve the queries (they come for free in terms of communication costs). Intersection of posting lists is necessary to determine the set of documents that contain all of the terms present in a given user query.
Another competing approach is the term partitioned index in which a single inverted file is constructed from the whole text collection to then distribute evenly the terms with their respective posting lists onto the processors. However, the term partitioned inverted file destroys the possibility of com-puting intersections for free in terms of communication cost and thereby one is compelled to use strategies such as smart distribution of terms onto processors to increase locality for most frequent terms (which can be detrimental for overall load balance) and caching. However, it is not necessary to broadcast queries to all processors (which reduces commu-nication costs) and latency disk costs are smaller as they are paid once per posting list retrieval per query, and it is well-known that in current cluster technology it is faster to transfer blocks of bytes through the interprocessors network than from Ram to Disk. Nevertheless, the load balance is sensitive to queries referring to particular terms with high frequency, making it necessary to use posting lists caching strategies to overcome imbalance in disk accesses.
factors affecting the performance of query processing. The balance of interprocessors communication depends on the balance of these two components. From empirical evidence we have observed thatmoderate imbalance in communica-tion is not detrimental to performance, good balance in doc-ument ranking is always relevant whereas good balance in disk accesses is crucial in ranking methods requiring inter-section of posting lists.
When a given problem of sizeNis being solved onP pro-cessors, optimal load balance for many applications tends to be achieved when there is sufficient slackness, namelyN/P
is large enough. Slackness is also useful to hide overheads and other inefficiencies such as poor scalability. Given the size of the Web, current search engines are operating under a huge slackness since the number of processors at data cen-ters is similar to the average rate of queries per second. In this context, document partitioned inverted files are work-ing fine but this does not imply they make an efficient use of computational resources and does not guarantee the same scenario at larger query traffics demanding the use of more and more processors. We have observed that even at large slackness, sudden imbalance can produce unstable behavior such as communication buffers saturation (which in our case implies a program crash).
Some work has been done on the problem of load bal-ancing query traffic on inverted files. They apply simple heuristics such as the least loaded processor first or the round-robin strategy [7]. However, from the literature on parallel computing we can learn a number of more sophisti-cated strategies for static and dynamic scheduling of tasks onto processors. It is not clear whether those strategies are useful in this particular application of parallel computing, namely whether they can have a significant impact in im-proving performance under high query traffic situations. Yet previous work applies these heuristics at the search engine side without considering the actual factors leading to imbal-ance. This because the scheduling decisions are not built upon a cost model which be independent of the current op-eration of the search engine.
Queries arrive to the processors from a receptionist ma-chine that we call thebroker. In this paper we study the case in which the broker is responsible for assigning the work to the processors. Jobs badly scheduled onto the processors can result in high imbalance. To this end the broker uses a scheduling algorithm. For example, a simple approach is to distribute the queries uniformly at random onto the proces-sors in a blind manner, namely just as they arrive to the bro-ker they are scheduled in a circular round-robin manner. A more sophisticated scheduling strategy demands more com-puting power from the broker so in our view this cost should by paid only if load balance improves significantly. Notice that the proposals of this paper can be extended to the case of two or more broker machines by simple composition.
The key point in the use of any scheduling algorithm is the proper representation of the actual load imposed onto the processors. For the distributed inverted files case we need to properly represent the cost of disk accesses and doc-ument ranking and (very importantly) their relationship. A method for this purpose is the main contribution of this pa-per along with an evaluation of the effectiveness of a number of scheduling algorithms in the distributed inverted files con-text. Our method can be used by search engines to schedule user queries efficiently which together with the scheduling
strategy found to be most efficient in this paper can be con-sidered as a practical and new strategy for processing queries in search engines.
Most implementations of distributed inverted files reported so far are based on the message passing approach to paral-lel computing in which we can see combinations of multi-threaded and computation/communication overlapped sys-tems. Artifacts such as threads are potential sources of over-heads and can produce unpredictable outcomes in terms of running time. Yet another source of unpredictable behavior are the accesses to disk used to retrieve the posting lists. Namely, runs are too dependent on the particular state of the machine and its fluctuations and thereby predicting cur-rent load balance to perform proper job scheduling can be involved and inaccurate. An additional complication related to measurement and control is that a corrective action in a part of the system can affect the measures taken in another part and this can be propagated circularly.
We think that what is needed is a way to measure load balance that is independent of the current operation of the search engine. We propose a precise and stable way to mea-sure load balance and perform job scheduling. We do this by letting the broker simulate a bulk-synchronous parallel (BSP) computer [8] and take decisions based on its cost model. It is known that this well-structured form of par-allel computation allows a very precise evaluation of the costs of computation and communication. For a fully asyn-chronous multithreaded search engine, the broker simulates a BSP machine and takes decisions on where to route queries whereas the processors also simulate a BSP machine in or-der to tune their operation (thread activity) to the pace set by the BSP machine. These simulations are simple and overheads are very low. Certainly the asynchronous search engine can be replaced by an actual BSP search engine in which case the simulation is an actual execution at the clus-ter side.
The BSP cost model provides an architecture indepen-dent way to both measure load balance and relate the costs of posting list fetching and document ranking. It has been shown elsewhere [8] that a BSP machine is able to simulate any asynchronous computation to within small constant fac-tors, so the simulated BSP computer is expected to work efficiently if scheduling is effected properly. This provides a stable setting for comparing scheduling algorithms.
The BSP model of parallel computing [9] is as follows. In BSP the computation is organized as a sequence of su-persteps. During a superstep, the processors may perform computations on local data and/or send messages to other processors. The messages are available for processing at their destinations by the next superstep, and each superstep is ended with the barrier synchronization of the processors. The underlying communication library ensures that all mes-sages are available at their destinations before starting the next superstep.
2.
PARALLEL QUERY PROCESSING
The broker simulates the operation of a BSP search engine that is processing the queries. The method employed by the BSP machine is as follows. Query processing is divided in “atoms” of size K, where K is the number of documents presented to the user as part of the query answer. These atoms are scheduled in a round-robin manner across super-steps and processors. The asynchronous tasks are givenK
sized quanta of processor time, communication network and disk accesses. These quanta are granted during superteps, namely they are processed in a bulk-synchronous manner.
As all atoms are equally sized then the net effect is that no particular task can restrain others from using the resources. This because (i) computing the solution to a given query can take the processing of several atoms, (ii) the search engine can start the processing of a new query as soon as any query is finished, and (iii) the processors are barrier synchronized and all messages are delivered in their destinations at the end of each superstep. It is not difficult to see that this scheme is optimal provided that we find an “atom” packing strategy that produces optimal load balance and minimizes the total number of supersteps required to complete a given set of queries (this is directly related to the critical path for the set of queries).
The simulation assumes that at the beginning of each su-perstep the processors get into their input message queues both new queries placed there by the broker and messages with pieces of posting lists related to the processing of queries which arrived at previous supersteps. The processing of a given query can take two or more supersteps to be com-pleted. The processor in which a given query arrives is called therankerfor that query since it is in this processor where the associated document ranking is performed.
Every query is processed using two major steps: the first one consists on fetching a K-sized piece of every posting list involved in the query and sending them to the ranker processor. In the second step, the ranker performs the actual ranking of documents and, if necessary, it asks for additional
K-sized pieces of the posting lists in order to produce the
Kbest ranked documents that are passed to the broker as the query results. We call thisiterations. Thus the ranking process can take one or more iterations to finish. In every iteration a new piece ofK pairs (doc id, frequency) from posting lists are sent to the ranker for every term involved in the query. At a given interval of time, the ranking of two or more queries can take place in parallel at different processors along with the fetching of K-sized pieces of posting lists associated with new queries.
3.
SCHEDULING FRAMEWORK
The broker uses the BSP cost model to evaluate the cost of its scheduling decisions. The cost of a BSP program is the cumulative sum of the costs of its supersteps, and the cost of each superstep is the sum of three quantities: w,h G
andL, wherewis the maximum of the computations per-formed by each processor,his the maximum of the messages sent/received by each processor with each word costingG
units of running time, andLis the cost of barrier synchroniz-ing the processors. The effect of the computer architecture is included by the parametersGandL, which are increasing functions ofP. Like in communication, the average cost of each access to disk can be represented by a parameterD.
The broker performs the scheduling maintaining two win-dows which account for the processors work-load through the supersteps. One window is for the ranking operations ef-fected per processor per superstep and the another is for the posting list fetches from disk also per processor per super-step. In each window cell we keep the count of the number of operations of each type.
To select the ranker processor for a given query we have two phases. In the first one the cost of list fetches is reflected in the window in accordance with the type of inverted file (document or term partitioning). In the second step the ranking of document is reflected in the window, every de-cision on where to perform the ranking has an impact in the balance of computation and communication. It is here where a task scheduling algorithm is employed. Each alter-native is evaluated with the BSP cost model. The windows reflect the history of previous queries and iterations, and their effect is evaluated with the BSP cost model.
The optimization goal for the scheduling algorithms is as follows. We set an upper limit to the total number of list fetches allowed to take place in each processor and superstep (we use 1.5RwhereR is the average). Notice that we can-not change the processor where the list fetching is to take place but we can defer it one or more supersteps to avoid imbalance coming from these operations. This has an effect in the other window since this also defers the ranking of those documents which provides the combinations that the scheduling algorithms are in charge to evaluate and select from.
The optimization goal is to achieve an imbalance of about 15% in the document ranking operation. Imbalance is mea-sured via efficiency, which for a measureX is defined by the ratio average(X)/maximum(X)≤1, over theP processors. All this is based on the assumption that the broker is able to predict the number of iterations demanded by every query. This requires cooperation from the search engine. If it is a BSP search engine then the solution is simple since the broker can determine what queries were retained for further iterations from the answers coming from the search engine. For instance, for a query requiring just one iteration the an-swer must arrive in two supersteps of the search engine. To this end, the answer messages indicate the current superstep of the search engine and the broker update its own superstep counter taking the maximum from these messages.
For fully multi-threaded asynchronous search engines it is necessary to collect statistics at the broker side for queries arriving from the search engine. Data for most frequent query terms is kept cached whereas other terms are given 1 iteration initially. If the search engine is implemented using the round-robin query processing scheme described in the previous section, then the exact number of iterations per query can be calculated for each query. For asynchronous search engines using any other form of query processing, the broker can predict how those computations could have been done by a BSP search engine from the response times for the queries sent to processing. This is effected as follows.
The broker predicts the operation of the hypothetical BSP engine every Nq completed queries by assuming thatQ =
q P new queries are received in each superstep. For this period of ∆ units of time, the observed value of Qcan be estimated using the G/G/∞ queuing model. LetS be the sum of the differences δq= [DepartureTime – ArrivalTime]
between the arrival of the queries and the end of their com-plete processing. Then the averageqfor the period is given by S/∆. This because the number of active servers in a G/G/∞model is defined as the ratio of the arrival rate of events to the service rate of events (λ/µ). Ifnqueries are received by the processor during the interval ∆, then the arrival rate is λ = n/∆ and the service rate isµ = n/S. Then the total number of supersteps for the period is given byNq/Qand the average running time demanded by every
superstep isδs= ∆Q / Nq, so that the number of iterations
for any queryiis given byδqi/δs.
4.
EVALUATION OF SCHEDULING
ALGORITHMS
We studied the suitability of the proposed method by eval-uating different scheduling algorithms using actual imple-mentations of the document and term partitioned inverted files. Our BSP windowing simulation based scheme allows a comparison of well-known algorithms under the same con-ditions.
Under circular allocation of queries to processors, the load balance problem is equivalent to the case of balls thrown uniformly at random into a set ofP baskets. As more balls of sizeKare thrown into the baskets, it is more likely that the baskets end up with a similar number of balls. In each superstep the broker throwsQ=q P new queries onto the processors. However, it is not clear the effect of balls coming from previous supersteps as a result of queries requiring two or more iterations. The number of iterations depends on the combined effect of the specific terms that are present in the query and the respective lengths of the posting lists. This makes a case for exploring the performance of well-known scheduling algorithms for this context.
The scheduling algorithms evaluated are dynamic and static ones [5, 6, 1, 3, 2, 4]. In some cases we even gave them the advantage of exploring the complete query log used in our experiment in order to formulate a schedule of the queries. In others we allowed them to take batches ofq P queries to make the scheduling. We define makespan as the maximum amount of work performed by any processor.
The algorithms evaluated are the following: [A1] Round-robin, namely distribute circularly the queries onto the pro-cessors; [A2] Graham algorithm (least loaded processor), every time a taskjarrives, we select the least load proces-sor as the ranker; [A3] Limit algorithm, every time a task
jarrives, the makespan is computed as the maximum work load in each machine. Then a processori is selected in a way to minimize the difference between the makespan and the work load of the processor i plus the running time of the new taskj, if there is no such machine, the least loaded processor is selected; [A4] Optimal limit algorithm, like A3 but in this case the limit isS(L(i))/PwhereL(i) is the work load of the processori, andSis the sum over all processors; [A5] LPT (longest processing time), the tasks are ordered by decreasing order of their processing time and then exe-cute the LLP in that order; [A6] FFD (first-fit decreasing), the optimal makespan is set as we mentioned before. The tasks are ordered in decreasing order and are assigned in that order. Each task is assigned to a processor avoiding to exceed the optimal makespan. If there is not such machine, the task is assigned in the LLP way; [A7] BFD (best-fit de-creasing), like FFD but the task is assigned to a processor
where the difference between the optimal makespan and the work load in that processor plus the running time of the task, is minimum. If there is no such machine, the LLP strategy is performed.
The results were obtained using a 12GB sample of the Chilean Web taken from the www.todocl.cl search engine. We also used a smaller sample of 2GB to increase the effect of imbalance. Queries were selected at random from a set of 127,000 queries taken from the todocl log and iterations for every query finished with the topK= 1024 documents. The experiments where performed on a 32-nodes cluster with dual processors (2.8 GHz). We used BSP, MPI and PVM realizations of the document and term partitioned inverted files. The scheduling algorithms were executed to gener-ate the queries injected in each processor during the runs. The BSP search engine does not perform any load balance strategy so that its performance relies on the proper assign-ment of queries to its processors. In every run we process 10,000 queries ineach processor. That is the total number of queries processed in each experiment reported below is 10,000P. Thus running times are expected to grow withP
due to theO(logP) effect of the inter-processors communi-cation network.
The following figures show running times for the BSP real-izations of the document and term partitioned inverted files. These are results from actual executions on the 32-nodes cluster. We used the BSP simulation at the broker machine side to schedule the queries onto the processing nodes (pro-cessors). Below we compare predictions made from the BSP simulations with the observations in the actual BSP search engine.
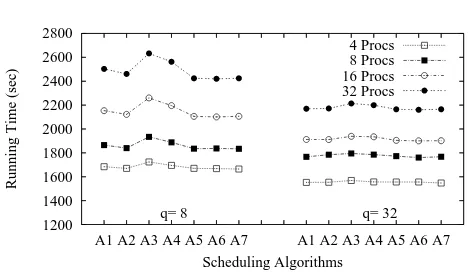
The figures 1 and 2 show that the strategies A1, A2, A5, A6 and A7 achieve similar performance. A3 and A4 show poor performance. These are results for an actual query log submitted by real users. In most cases queries contain one or two terms. To see if the same holds for more terms per query we artificially increased the number of terms by us-ing composite queries obtained by packus-ing together several queries selected uniformly at random from the query log to achieve an average of 9 terms per query. This can represent a case in which queries are expanded by the search engine to include related terms such as synonyms. The results are presented in figures 3 and 4 and also show that A1, A2, A5, A6 and A7 achieve similar performance.
The same is observed in figures figures 5 and 6 for compos-ite queries containing 34 terms. Among all the algorithms considered, A1 is the simplest to implement and its efficiency is outstanding.
Notice that the performance of the document partitioned index becomes very poor compared to the performance of the term partitioned index for queries with large number of terms. Its performance is highly degraded by the broadcast operations required to copy larger queries in each processor and its consequences such as increased disk activity. Also running times for low query traffic indicated by q= 8 are larger than the case of high query trafficq= 32. This is ex-plained by the balls thrown into baskets situation described in the first part of this section. Imbalance is larger with low query traffic and it has a significant impact in running time which the scheduling algorithms cannot solve completely. However, the comparative performance among the schedul-ing algorithms remains unchanged.
100
Figure 1: Document partitioned inverted index.
100
Figure 2: Term partitioned inverted index.
algorithms behave practically the same. This because the slacknessN/P (with P=4) is large enough and overall ba-lance is good. In this case scheduling is almost unneces-sary. However, for a relatively larger number of processors the slackness is small and the scheduling algorithms have to cope with a significant imbalance from the balls and baskets problem.
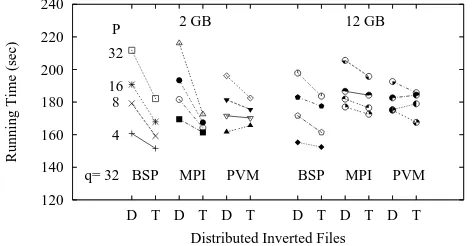
Finally figure 7 shows results obtained using strategy A1 for two asynchronous message passing realizations of in-verted files implemented using the message passing PVM and MPI communication libraries. The results are similar to the BSP inverted file which is clear evidence that the BSP cost model is a good predictor of actual performance. We used these asynchronous realizations of inverted files to test our model to predict the execution of an associated BSP search engine at the broker side. The results were an almost perfect prediction of the number of supersteps and iterations per query. Most time differences were below 1% with some cases in which the difference increased to no more than 5%. This because under steady state query traffic theG/G/∞ model is a remarkably precise predictor of the average num-ber of queries per superstep.
200
Figure 3: Document partitioned inverted index (large number of terms per query).
200
Figure 4: Term partitioned inverted index (large number of terms per query).
1200
1200
Figure 6: Term partitioned inverted index (very large number of terms per query).
5.
SCHEDULING FOR RESPONSE TIMES
The decomposition of the query processing task in the so-called round-robin quanta of sizeKcan be exploited at the broker side to schedule ranking and disk access opera-tions in a way that it gives more priority to queries requir-ing few iterations. The case shown in the previous sections was intended to optimize query throughput. In this sec-tion we adapt our method to improving response time of small queries. The difference here is that new queries are injected in the current superstep only when the same num-ber of current queries have finished processing. We describe the method in the context of the document partitioned in-dex.
We assume an index realization in which it is necessary to perform the intersection of the posting lists for the query terms and then perform a ranking of the top-K results ob-tained in each processor. In this case disk accesses and intersections are well balanced across processors, and it is necessary to determine the processor (ranker) in which the ranking for a given query is effected. We propose a strategy that both improves the load balance of the ranking process and prevent small queries from being delayed by queries re-quiring a larger number of disk accesses.
The broker maintains a vocabulary table indicating the total number of disk accesses required to retrieve the posting list of each term. For an observed average arrival rate ofQ
queries per unit time the broker can predict the operation of a BSP computer and take decisions about where to schedule ranking of queries.
During a simulated superstep the broker gives to each query a chance to make a disk access to retrieve K pairs (doc ids, freq) of their posting lists. In the case of terms appearing in two or more queries the broker grants only one access and cache the retrieved data to let this bucket of sizeKbe used by the other queries without requiring extra disk accesses. Disk accesses are granted in a circular man-ner among the available queries until reaching a sufficient number of rankings which ensures an efficiency above 0.8 for this process. Thus small queries pass quickly through these rounds of disk accesses. The efficiency is calculated considering that the rankings are scheduled with the “least loaded processor first” load balancing heuristic [4].
120
BSP MPI PVM BSP MPI PVM
q= 32
Figure 7: Scheduling A1 on asynchronous inverted files; D stands for the document partitioned index and T for term partitioned index.
As described in the previous section, the efficiency is cal-culated as the ratio average(X)/maximum(X) whereX is the cost each ranking and the average and maximum values are calculated considering the given distribution of rankings onto theP processors (for simplicity we consider that is cost is linear with the number of terms). Also in practice it is convenient to wait for efficiency above 0.8 and a total num-ber of rankings to be scheduled of (Q/4)P or more. This to avoid an excessive increase in the number of supersteps.
The figure 8 shows efficiencies predicted by the broker by different values ofQwithP = 32 and figure 9 shows the ac-tual efficiencies achieved by the respective BSP search engine for the caseQ= 32 andP= 4, 8, 16 and 32 processors. This figure also shows the efficiencies of the fetch+intersection and communication tasks. The figures show that the broker is able to predict well the actual load balance of the docu-ment partitioned index. The resulting scheduling of queries to rankers leads to an almost perfect load balance forQ=32 andP= 4, 8, 16 and 32.
The figure 10 shows the average response time for queries requiring from 1 to 19 disk accesses for P= 32 and Q= 32. The curves Q/2 and Q/4 show the case in which the broker waits for that number of pending rankings before scheduling them onto theP processors. The curve labeled
Rshows a case in which the broker waits until allQqueries injected in the superstep get their ranking pending. As ex-pected the caseRgives the same average response time to all queries independently of the number of disk accesses they require. Also Q/4 provides better results confirming the shorter queries are given more preference than the other two cases.
6.
CONCLUDING REMARKS
0 0.2 0.4 0.6 0.8 1 1.2
0 50 100 150 200 250
Eficiency
SStep
Q=32 16 8 4
Figure 8: Predicted efficiencies in the round-robin document partitioned index.
1.0
1.0
1.0
0 10 20 30 40 50
Efficiency
Supersteps
Ranking Comm Fetch
Figure 9: Actual efficiencies in the round-robin doc-ument partitioned index.
actly the same conditions. The BSP cost model ensures that the cost evaluation is not disconnected from reality. Our method separates the cost of list fetching from document ranking which makes these two important factors affecting the total running time independent each other in terms of scheduling. This means that the broker does not need to be concerned with the ratio disk to ranking costs when deciding to which processor send a given query.
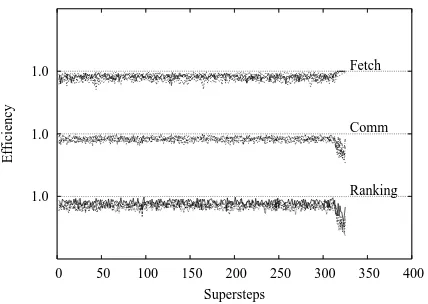
For search engines handling typical user queries the round-robin strategy with limitR to the number of disk accesses per processor per superstep is sufficient to achieve efficient performance. For example, the figures 11 and 12 show the near-optimal efficiencies achieved across supersteps by the list fetching, communication and document ranking oper-ations in the execution using A1 shown in figures 1 and 2. This explains the efficient performance produced by this strategy since all critical performance metrics are well bal-anced. Our results also show that a bad scheduling strat-egy can indeed degrade performance significantly. The least loaded processor first heuristic should work better for queries with large number of terms but we did not observe this in-tuition for artificially enlarged queries. For large number of terms per query we also observed that the bad performer algorithms tend to equal the good ones for high traffic of queries (q= 32) whereas for low traffic (q= 8) they become even more inefficient than in the case of few terms per query.
0 0.2 0.4 0.6 0.8 1 1.2
0 5 10 15 20
Query Cost
Number of Fetches R
Q/2 Q/4
Figure 10: Query cost in the round-robin document partitioned index.
Our results also show that the proposed BSP simulation method at the broker side is useful to reduce running times. Notice that this method allows the scheduling of ranking operations in a round-robin fashion but this is effected con-sidering the limits to the number of disk accesses per pro-cessor per superstep. That is, the broker maintains several supersteps of round-robin scheduled rankings, each at dif-ferent stage of completeness depending on the new queries arriving at the broker machine and the queries currently under execution in the cluster processors. The upper lim-its to the number of disk operations ensure that this costly process is kept well-balanced and round-robin scheduling en-sures that the efficiency of the also costly ranking operations is kept over 80%. We think that this strategy is fairly more sophisticated than having a broker machine blindly schedul-ing queries in a circular manner onto the processors. In this sense, this paper proposes a new and low cost strategy for load balancing distributed inverted files. Our results show that this strategy is able to cause efficient performance in both bulk-synchronous and message-passsing search engines.
Acknowledgment: This paper has been partially funded by Fondecyt project 1060776.
7.
REFERENCES
[1] J. L. Bentley, D. S. Johnson, F. T. Leighton, C. C. McGeoch, and L. A. McGeoch. Some unexpected expected behavior results for bin packing. InSTOC, pages 279–288, 1984.
[2] O. J. Boxma. A probabilistic analysis of the lpt scheduling rule. InPerformance, pages 475–490, 1984. [3] E. G. Coffman, Jr., M. R. Garey, and D. S. Johnson.
Approximation algorithms (ed. D. Hochbaum), chapter Approximation algorithms for bin packing - a survey. PWS, 1997.
1.0
1.0
1.0
0 50 100 150 200 250 300 350 400
Efficiency
Supersteps
Ranking Comm Fetch 4
32
4
32
4
32
Figure 11: Document partitioned index: Efficiencies in disk accesses, communication and ranking withy -axis values from 0 to 1.
1.0
1.0
1.0
0 50 100 150 200 250 300 350 400
Efficiency
Supersteps
Ranking Comm Fetch
Figure 12: Term partitioned index: Efficiencies in disk accesses, communication and ranking with y -axis values from 0 to 1.
[5] D. S. Johnson, A. J. Demers, J. D. Ullman, M. R. Garey, and R. L. Graham. Worst-case performance bounds for simple one-dimensional packing algorithms. SIAM J. Comput., 3(4):299–325, 1974. [6] F. T. Leighton and P. W. Shor. Tight bounds for
minimax grid matching, with applications to the average case analysis of algorithms. InSTOC, pages 91–103, 1986.
[7] A. Moffat, W. Webber, and J. Zobel. Load balancing for term-distributed parallel retrieval.29th annual international ACM SIGIR conference on Research and development in information retrieval, pages 348–355, 2006.
[8] D. Skillicorn, J. Hill, and W. McColl. Questions and answers about BSP. Technical Report PRG-TR-15-96, Computing Laboratory, Oxford University, 1996. Also in Journal of Scientific Programming, V.6 N.3, 1997. [9] L. Valiant. A bridging model for parallel computation.
Comm. ACM, 33:103–111, Aug. 1990.