KLASIFIKASI JENIS UJARAN KEBENCIAN PADA CUITAN BAHASA INDONESIA BERDASARKAN SANKSI PIDANA MENGGUNAKAN
GLOVE EMBEDDINGS DAN MULTINOMIAL NAÏVE BAYES
LENNY BR LUMBAN TOBING 171402119
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2021
KLASIFIKASI JENIS UJARAN KEBENCIAN PADA CUITAN BAHASA INDONESIA BERDASARKAN SANKSI PIDANA MENGGUNAKAN
GLOVE EMBEDDINGS DAN MULTINOMIAL NAÏVE BAYES
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
LENNY BR LUMBAN TOBING 171402119
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2021
PERNYATAAN
KLASIFIKASI JENIS UJARAN KEBENCIAN PADA CUITAN BAHASA INDONESIA BERDASARKAN SANKSI PIDANA MENGGUNAKAN GLOVE
EMBEDDING DAN MULTINOMIAL NAIVE BAYES
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 31 Juni 2021
LENNY BR LUMBAN TOBING 171402119
UCAPAN TERIMA KASIH
Dengan memanjatkan puji dan syukur kepada Tuhan yang Maha Esa, karena atas berkat dan kasih-Nya yang memberikan kesehatan sehingga penulis dapat menyelesaikan penyusunan skripsi ini yang berjudul “Klasifikasi Jenis Ujaran Kebencian Pada Cuitan Bahasa Indonesia Berdasarkan Sanksi Pidana Menggunakan Metode Glove Embedding Dan Multinomial Naïve Bayes“ sebagai salah satu syarat untuk memperoleh gelar Sarjana pada Program Studi S1 Teknologi Informasi, Fakultas Ilmu Komputer dan Teknologi Informasi, Universitas Sumatera Utara.
Dalam penyusunan skripsi ini tidak terlepas dari berbagai kendala yang dihadapi. Penulis tidak dapat menyelesaikan penyusunan skripsi ini apabila tidak disertai oleh doa, dukungan, dan semangat dari seluruh pihak yang terlibat dalam masa perkuliahan dan penyusunan skripsi ini sampai selesai. Adapun pada kesempatan ini penulis ingin mengucapkan terimakasih kepada:
1. Keluarga penulis, Ayah Willer Lumban Tobing dan Ibu Delvina Br Sinaga, yang telah memberikan kasih sayang, doa, dukungan, dan semangat kepada penulis hingga saat ini, begitu juga dengan abang penulis Chardo Lumban Tobing dan Jarudi Lumban Tobing yang juga senantiasa memberikan doa, dukungan, dan semangat kepada penulis.
2. Bapak Dr. Muryanto Amin, S.Sos., M.Si selaku Rektor Universitas Sumatera Utara.
3. Ibu Dr. Maya Silvi Lydia, M.Sc selaku Dekan Fasilkom-TI USU.
4. Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc selaku Ketua Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
5. Ibu Sarah Purnamawati, ST., M.Sc., selaku Sekretaris Program Studi S1 Teknologi Informasi Universitas Sumatera Utara dan Dosen Pembimbing I dan juga Ibu Ade Sarah Huzaifah,S.Kom.M,Kom. selaku Dosen Pembimbing II yang telah meluangkan waktu untuk membimbing, memberikan masukan, kritik, dan saran kepada penulis.
6. Bapak Dani Gunawan , ST., MT selaku Dosen Pembanding I, dan Bapak Ivan Jaya, S,Si.,M.Kom selaku Dosen Pembanding II yang telah memberikan kritik dan saran untuk membantu penyempurnaan skripsi .
7. Seluruh Dosen Program Studi S1 Teknologi Informasi yang telah memberikan ilmu dan mengajari penulis selama perkuliahan.
8. Staff dan pegawai akademik Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara yang telah membantu penulis memenuhi kelengkapan administrasi untuk menyelesaikan studi.
9. Sahabat dan teman-teman seperjuangan penulis semasa kuliah Arnesa Julia Damanik, Grace Sella Ginting, Sophia Nola, Jessie Gabriella Silalahi, dan Fani Theresa yang telah banyak menolong dan sama-sama berjuang juga saling memberikan dukungan, doa, dan semangat di masa perkuliahan sampai selesai penyusunan skripsi ini.
10. Sahabat penulis yang menemani mulai dari masa SMP, Praycilia Elisabeth , Siska Triamenda Ginting , Rut Yuliana ,Kevin Simarmata , Sonia Simarmata , Phila Delphia Tindaon , Anggie Mayang Sembiring , Septian Budi dan Septian Deva Sinaga yang telah memberikan semangat dan juga dukungan kepada penulis hingga penyusunan skripsi selesai.
11. Abangku, Sahat Gebima Sihotang dan Aldo Stepanus Simarmata yang telah banyak sekali membantu penulis juga memberikan doa, dukungan serta semangat dari semasa kuliah hingga selesai penyusunan skripsi.
12. Kakak dan abang penulis selama masa perkuliahan, Bora Sejati, Sutan Mahalel Ritonga, dan Gebriel Juliendi Sitorus, yang memberikan dukungan dan semangat kepada penulis.
13. Semua pihak yang terlibat langsung maupun tidak langsung yang tidak dapat penulis tuliskan satu persatu yang telah membantu dalam penyelesaian skripsi ini.
Medan , 31 Juni 2021
Penulis
ABSTRAK
Penyebaran ujaran kebencian yang dilakukan secara daring telah menyebabkan beberapa negara menerapkan undang - undang yang melarang ujaran kebencian untuk memaksa warga negaranya menahan diri dari perilaku tersebut. Sosial media sebagai sarana secara online untuk menyatakan ekspresi dan emosi terhadap sejumlah momen dan peristiwa yang terjadi sehingga data yang diperoleh melalui user dapat dianalisis.
Penelitian ini bertujuan untuk melakukan klasifikasi twit mana saja yang mengandung ujaran kebencian berdasarkan motif motif tertentu, dengan pendekatan ini maka dapat disimpulkan tidak pidana yang dilakukan berdasarkan undang undang. Klasifikasi ujaran kebencian melalui twit bahasa Indonesia menggunakan metode Multinomial Naïve Bayes. Penelitian menggunakan 2500 dokumen twit yang di-crawling pada media sosial twitter berdasarkan 4 jenis klasifikasi. Untuk melakukan klasifikasi perlu adanya tahapan preprocessing terlebih dahulu yaitu casefolding, punctual removal, normalization, stopword removal, stemming dan tokenization. Penelitian ini juga menggunakan pembobotan kata dengan Glove Embedding terhadap tiap twit dalam dataset dan dilakukan kalkulasi terhadap nilai probabilitas dengan algoritma Multinomial Naïve Bayes untuk menentukan nilai probabilitas dari hasil tiap label yang diberikan, nilai probabilitas tertinggi akan menjadi hasil klasifikasi terhadap jenis ujiaran kebencian pada twit. Klasifikasi ujaran kebencian dengan Glove Embeding dan Multinomial Naïve Bayes akan menghasilkan akurasi sebesar 92%.
Kata Kunci: klasifikasi ujaran kebencian, Glove Embedding, Multinomial Naïve Bayes, Confussion Matrix
CLASSIFICATION OF HATE SPEECH IN INDONESIAN TWIT BASED ON CRIMINAL SANCTIONS USING GLOVE EMBEDDING AND
MULTINOMIAL NAVE BAYES
ABSTRACT
The spread of hate speech online has led to several countries implementing laws that prohibit hate speech to force their citizens to refrain from such behavior. Through this tweet the source of the data obtained can be analyzed, considering that users are more likely to express the level of emotion towards each event in a post or tweet. This study aims to classify which tweets contain hate speech based on certain motives, with this approach it can be concluded no crime committed in accordance with the articles in the law. The classification of hate speech through Indonesian tweets uses the Multinomial Naïve Bayes method. This study uses 2500 data crawled on Twitter social media based on 4 types of classification. To perform the classification, it is necessary to have several preprocessing stages which is casefolding, punctual removal, normalization, stopword removal, stemming and tokenization. This study also uses word embedding with Glove Embedding for each tweet in the dataset and each words will represent the number of the value which carried out on the probability value with the Multinomial Naïve Bayes algorithm to determine the probability value of the results of each given label, the highest probability value will be the result of the classification of the type of hate speech on tweets. Hate speech classification with Glove Embeding and Multinomial Naïve Bayes will produce an accuracy of 92%.
Keyword: hatespeech classification, Glove Embedding, Multinomial Naïve Bayes, Confussion Matrix
DAFTAR ISI
Hal.
PERSETUJUAN i
PERNYATAAN ii
UCAPAN TERIMAKASIH iii
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR TABEL ix
DAFTAR GAMBAR x
BAB 1 PENDAHULUAN 1
1.1. Latar Belakang 1
1.2. Rumusan Masalah 3
1.3. Tujuan Penelitian 3
1.4. Batasan Masalah 4
1.5. Manfaat Penelitian 4
1.6. Metodologi Penelitian 4
1.7. Sistematika Penulisan 5
BAB 2 LANDASAN TEORI 7
2.1. Ujaran Kebencian 7
2.2. Text Preprocessing 8
2.3. Word Embedding 8
2.4. Multinomial Naïve Bayes 9
2.5. Penelitian Terdahulu 12
2.6. Perbedaan Penelitian 14
BAB 3 ANALISIS DAN PERANCANGAN 15
3.1. Arsitektur Umum 15
3.2. Data 16
3.3. Preprocessing 16
3.3.1. Case Folding 17
3.3.2. Punctuation Removal 17
3.3.3. Normalization 18
3.3.4. Stemming 19
3.3.5. Stopword Removal 20
3.3.6. Tokenization 20
3.4. GloVe Embedding 21
3.5. Multinomial Naïve Bayes 23
3.6. Perancangan Sistem 26
3.6.1. Rancangan Halaman Beranda 26
3.6.2. Rancangan Halaman Training 27
3.6.3. Rancangan Halaman Testing 28
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM 30
4.1. Implementasi Sistem 30
4.1.1. Spesifikasi Perangkat keras dan Perangkat lunak 30
4.1.2. Implementasi Rancangan Antarmuka 30
4.2. Metode Evaluasi 34
BAB 5 KESIMPULAN DAN SARAN 39
5.1. Kesimpulan 39
5.2. Saran 39
DAFTAR PUSTAKA 40
DAFTAR TABEL
Hal
Tabel 2.1. Penelitian Terdahulu 9
Tabel 3.1. Jumlah Data Uji dan Latih 15
Tabel 3.2. Penerapan Proses Case Folding 15
Tabel 3.3. Penerapan Proses Punctuation Removal 16
Tabel 3.4. Penerapan Proses Normalization 17
Tabel 3.5. Penerapan Proses Stemming 17
Tabel 3.6. Penerapan Proses Stopword Removal 18
Tabel 3.7. Penerapan Proses Tokenization 19
Tabel 3.8. Nilai Bobot Kata pada Glove Embedding 21
Tabel 3.9. Kata Berdasarkan Kelas
Tabel 4.1. Keterangan Non Hate Speech Confusion Matrix 33 Tabel 4.2. Keterangan Hate Speech Golongan Confusion Matrix 34 Tabel 4.3. Keterangan Hate Speech Agama Confusion Matrix 35 Tabel 4.4. Keterangan Hate Speech Ras Confusion Matrix 35
Tabel 4.5. Evaluasi 36
DAFTAR GAMBAR
Hal.
Gambar 2.1. Contoh Data Mentah 7
Gambar 3.1. Arsitektur Umum 14
Gambar 3.2. Kamus Normallisasi 18
Gambar 3.3. Vektor dari Kata Benci 22
Gambar 3.4. Rancangan Halaman Beranda 26
Gambar 3.5. Rancangan Halaman Training 27
Gambar 3.6. Rancangan Halaman Testing (1) 28
Gambar 3.7. Rancangan Halaman Testing (2) 29
Gambar 4.1. Tampilan Halaman Utama 31
Gambar 4.2. Halaman Training 31
Gambar 4.3. Hasil Proses Halaman Training 32
Gambar 4.4. Halaman Testing 33
Gambar 4.5. Hasil Proses Halaman Testing 33
Gambar 4.6. Informasi Hasil Testing 34
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Ujaran kebencian merupakan suatu penyampaian yang diutarakan baik secara lisan atau tulisan terhadap suatu golongan, SARA untuk menyampaikan bentuk kebencian dengan kesengajaan untuk mempermalukan, menghina dan merusak nama baik untuk target tertentu (Munir, et al., 2018). Penyebaran ujaran melalui daring telah menjadi pantauan dan masalah serius di beberapa negara. Penerapan undang - undang yang melarang ujaran kebencian dilakukan untuk memaksa warga negaranya menahan diri dari perilaku tersebut. Negara-negara seperti Jerman, Amerika Serikat, Prancis dan Indonesia memiliki undang - undang yang melarang ujaran kebencian.
Bentuk layanan dengan microblogging web seperti twitter dapat digunakan sebagai media untuk analisis berdasarkan ujaran yang diberikan melalui twit secara langsung berdasarkan perisitiwa yang ditentukan. Ekspresi yang dilampiaskan melalui sosial media terhadap peristiwa terkait secara lisan atau tulisan dapat diteliti dan dianalisa berdasarkan tingkat bentuk ujaran dan emosi yang ditulis (Burnap &
Williams, 2014). Dengan demikian maka akan dapat klasifikasi twit mana saja yang memiliki beberapa makna terhadap ujaran kebencian dan juga twit mana saja yang memiliki dasar terhadap motif tertentu.
Negara Indonesia memberlakukan sanksi yang berbeda untuk setiap orang yang melakukan ujaran kebencian. Berdasarkan pembagian bentuk kejahatan, ujaran kebencian merupakan kejahatan formal. Adapun tindakan formal ialah bentuk tindak pidana yang sudah dilakukan berdasarkan pasal yang berlaku dalam undang undang sehingga pihak tersangka yang melakukan ujaran kebencian (hate speech) dipidana karena perbuatan nya sendiri, yaitu : tidak ujaran kebencian terhadap suatu agama yang dikenakan berdasarkan pasal 165A KUHP, tindak ujaran kebencian terhadap suku dan golongan tertentu baik secara lisan atau tulisan yang akan dikenakan berdasarkan pasal 156 KUHP dan 157 KUHP dan bentuk tindakan ujaran kebencian terhadap ras dan etnis tertentu baik secara lisan ataupun tulisan berdasarkan pasal 16 UU Nomor 40 tahun 2008, Penghapusan Diskriminasi Ras dan Etnis (Kadiyarsa et al, 2020). Dalam menentukan sanksi dibutuhkan seorang ahli, dan penentuan pasal
dibutuhkan waktu yang lama, untuk itu dibutuhkan pendekatan untuk melakukan otomatisasi klasifikasi ujaran kebencian.
Penelitian mengenai mengenai ujaran kebencian sudah dilakukan beberapa penelitian, salah satunya ialah penelitian yang berjudul Hate Speech on Twitter: A Pragmatic Approach to Collect Hateful and Offensive Expressions and Perform Hate Speech Detection (Watanabe. et al., 2018). Dalam penelitian ini, penulis mengusulkan pendekatan baru untuk mendeteksi ujaran kebencian di Twitter. Pendekatan yang diusulkan menggunakan metode Random Forest untuk mendeteksi ujaran kebencian yang dibantu dengan ekstraksi fitur yaitu fitur unigram, fitur sentiment-based dan fitur semantik untuk mengklasifikasikan tweet menjadi ujaran kebencian, menyinggung, dan bukan ujaran kebencian. Penelitian ini menghasilkan akurasi sebesar 87.4%. Selanjutnya penelitian yang berjudul Using Convolutional Neural Networks to Classify Hate-Speech (Gambäck. et al., 2017). Pada penelitian ini penulis melakukan eksperimen dengan sistem untuk klasifikasi teks ujaran kebencian Twitter berdasarkan Convolutional Neural Network deep-learning . Klasifikasi menetapkan setiap tweet ke salah satu dari empat kategori yang telah ditentukan: rasisme, seksisme, keduanya (rasisme dan seksisme) dan tidak keduanya. Dua model Convolutional Neural Networks dibuat berdasarkan set vektor input yang berbeda yang digunakan untuk pelatihan dan klasifikasi. Vektor kata berdasarkan informasi semantik dibangun menggunakan unsupervised strategy, word2vec, dan dibandingkan dengan garis dasar vektor yang dibuat secara acak. Selain itu, dua model Convolutional Neural Networks (CNN) akan dilatihkan pada karakter 4-gram, juga kombinasi vektor kata dan karakter n-gram. Penelitian ini menghasilkan akurasi sebesar 85.66%. Penelitian selanjutnya berjudul Analysis Text of Hate Speech Detection using Recurrent Neural Network (Saksesi et al., 2018). Penelitian ini melakukan deteksi pada ujaran kebencian berbahasa indonesia, dimana data yang dipakai adalah data tweet yang diambil dari Twitter menggunakan Twitter API sebanyak 1235 record. Penelitian ini menggunakan Word2vec sebagai word embedding, lalu data akan dilanjutkan dan diolah menggunakan metode Long Short- Term Memory (LSTM) Recurrent Neural Network dan menghasilkan akurasi yang tinggi yaitu sebesar 91%.
Dalam penelitian ini, penulis akan menggunakan GloVe embeddings yaitu Global Vektors for Word Representation sebagai metode untuk ekstraksi fitur. GloVe
embedding bekerja baik dengan menangkap maksud kata, terbukti di dalam penelitian yang berjudul Word Embedding Comparison for Indonesian Language Sentiment Analysis oleh (Immaduddin. et al., 2019), GloVe melampaui kinerja word2vec dengan menghasilkan akurasi sebesar 95%. Penulis akan menggunakan metode Multinomial Naïve Bayes sebagai metode untuk mengklasifikasi ujaran kebencian. Multinomial Nave Bayes merupakan salah satu turunan klasifikasi berasal dari Bayesian teori untuk mencari nilai probabilitas terhadap tiap aspek yang mempengaruhi label.
Algoritma ini memiliki keunggulan yang lebih baik seperti perhitungan dan pemodelan lebih efektif dan mudah untuk diimplementasikan untuk struktur yang sederhana maupun yang lebih kompleks (Taheri, 2013). Penelitian oleh (Abbas et al., 2019) dengan judul Multinomial Naive Bayes Classification Model for Sentiment Analysis menunjukkan bahwa algoritma yang digunakan mampu mengklasifikasikan teks dengan akurasi sebesar 93%.
Berdasarkan dari penjelasan yang diberikan, Maka penelitian ini diberi judul
“KLASIFIKASI JENIS UJARAN KEBENCIAN PADA TWIT BAHASA INDONESIA BERDASARKAN SANKSI PIDANA MENGGUNAKAN GLOVE EMBEDDING DAN MULTINOMIAL NAÏVE BAYES”.
1.2. Rumusan Masalah
Seiring dengan meningkatnya pengguna twitter semakin meningkat pula terjadinya ujaran kebencian terhadap pengguna lain pada platform tersebut. Ujaran kebencian dapat dibedakan menjadi beberapa jenis berdasarkan sanksi pidananya. Penentuan jenis ujaran kebencian biasanya harus dilakukan oleh tenaga ahli dengan teliti dan memakan waktu dan tenaga yang lebih lama maka, perlu dilakukan pendekatan secara otomatis untuk melakukan klasifikasi ujaran kebencian.
1.3. Tujuan Penelitian
Penelitian dilakukan dengan tujuan untuk melakukan klasifikasi jenis ujaran kebencian pada twit bahasa indonesia berdasarkan sanksi pidana menggunakan GloVe embeddings dan Multinomial Naive Bayes.
1.4. Batasan Masalah
Batasan masalah diberikan untuk memusatkan masalah kepada rincian yang jelas agar penelitian dapat dilakukan dengan baik. Adapun batasan yang dimiliki adalah sebagai berikut:
1. Penentuan klasifikasi berdasarkan kata yang diberikan emoji, angka dan karakter spesial tidak memilki pengaruh dan dihilangkan.
2. Tiap dokumen di-crawling melalui twitter 3. Data berupa teks dengan format .csv
4. Ujaran kebencian yang dibahas berdasarkan sanksi pidana pada kitab undang - undang hukum pidana sebagai berikut :
a. Tindak ujaran kebencian terhadap suatu agama yang berdasarkan Pasal 165A KUHP.
b. Tindak ujaran kebencian terhadap suku tertentu berdasarkan Pasal 156 KUHP.
c. Tindak ujaran kebencian terhadap golongan tertentu berdasarkan Pasal 157 KUHP.
d. Tindak ujaran kebencian berdasarkan ras dan etnis yang berdasarkan Pasal 16 UU Nomor 40 tahun 2008 tentang Penghapusan Diskriminasi Ras dan Etnis.
1.5. Manfaat Penelitian
Penelitian dilakukan guna untuk mendapatkan manfaat yang akan dicapai sebagai berikut:
1. Kinerja GloVe embeddings dan Multinomial Naive Bayes dapat diketahui pada klasifikasi ujaran kebencian berdasarkan sanksi pidana.
2. Membantu praktisi hukum untuk mengklasifikasikan jenis ujaran kebencian
1.6. Metode Penelitian
Untuk mewujudkan proses penelitian terhadap tahapan – tahapan yang harus dilakukan dalam penelitian antara lain:
1. Studi Literatur
Dalam tahapan ini penulis mengumpulkan informasi dan referensi yang terkait dari jurnal, buku panduan dan sumber referensi lainnya berkaitan dengan algoritma Multinomial Naive Bayes, Word Embedding, Text Processing dan UU mengenai ujaran kebencian
2. Analisis Permasalahan
Dalam tahap ini penulis melakukan analisa terhadap permasalahan upaya mendapat konsep metode Multinomial Naive Bayes dan mendapatkan faktor yang dapat membantu dalam penyelesaian masalah dalam penelitian.
3. Perancangan
Tahapan ini akan dilakukan berdasarkan studi literatur dan analisis yang sudah dilakukan. Rancangan desain antar muka, dataset dan arsitektur umum akan dibuat sesuai tujuan penelitian.
4. Implementasi
Dalam tahap ini, dilakukan implementasi yang menerapkan hasil yang sesuai baik dalam perancangan arsitektur dan desain antarmuka sistem.
5. Pengujian
Setelah dilakukannya implementasi maka, dilakukan pengujian performa pada metode Multinomial Naive Bayes sebagai tolak ukur dan evaluasi
6. Penyusunan Laporan
Tahapan terakhir yang melakukan penulisan laporan untuk memberikan informasi secara detail mengenai penelitian yang sudah dilakukan
1.7. Sistematika Penulisan
Beberapa tahapan dalam sistematika penulisan skripsi digunakan ke dalam lima bagian utama antara lain:
Bab 1: Pendahuluan
Bab pendahuluan terdiri dari latar belakang permasalahan, rumusan masalah, tujuan penelitian yang ingin dicapai, manfaat dari penelitian, metodologi yang diterapkan dan sistematika penulisan.
Bab 2: Landasan Teori
Pada bab ini berisi teori sebagai landasan untuk memahami pengetahuan yang mendasar yang menjadi permasalahan dalam penelitian ini. Sehingga mempermudah
pemahaman mengenai teori cara kerja penelitian seperti GloVe Embeddings dan Multinomial Naïve Bayes .
Bab 3: Analisis dan Perancangan
Bab 3 merupakan buah pikir untuk melakukan Analisa dan perancangan dengan GloVe Embedding dan metode Multinomial Naïve Bayes untuk melakukan berbagai klasifikasi jenis ujaran kebencian melalui media sosial twitter. Bab ini juga membahas lebih rinci mengenai alur arsitektur umum dari sistem yang dibangun .
Bab 4: Implementasi dan Pengujian
Bab ini merupakan bentuk implementasi berdasarkan analisis dan rancangan yang sudah dilakukan pada bab sebelumnya. Setelah implementasi sudah dilakukan maka akan dilakukan pengujian untuk melihat tolak ukur sebagai bentuk evaluasi berdasarkan penelitian yang sudah dilakukan dengan menggunakan metode yang digunakan.
Bab 5: Kesimpulan dan Saran
Bab 5 merupakan bab akhir yang menarik kesimpulan dan saran berdasarkan penelitian yang sudah dilakukan. Bab yang dibahas akan mencari rangkuman dan aspek yang perlu diperhatikan untuk pengembangan untuk penelitian selanjutnya.
BAB 2
LANDASAN TEORI 2.1. Ujaran Kebencian
Ujaran kebencian adalah perbuatan, sikap dan tindakan secara langsung maupun tidak langsung terhadap seseorang atau suatu kelompok yang mengandung kebencian berdasarkan sesuatu yang melekat pada orang atau kelompok tersebut. Umumnya ujaran lebih sering diutarakan pada media sosial khususnya dalam platform twitter.
Peraturan yang mengatur tentang ujaran kebencian pada media sosial terdapat dalam UU ITE Nomor 11 Tahun 2008 Area pada kotak merah merupakan contoh ujaran kebencian pada platform twitter dapat dilihat pada gambar 2.1.
Gambar 2.1. Contoh Data Mentah
Menurut Polri dalam Surat Edaran No: SE/6/X/2015 tentang Penanganan Ujaran Kebencian (SE Polri), hal yang dapat dikatakan sebagai ujaran kebencian adalah melakukan tindakan pencemaran nama baik secara lisan atau tulisan, melakukan penghinaan dan penistaan, memberikan efek ketidaknyamanan dan tidak menyenangkan serta melakukan penyebaran berita hoax yang memberikan pengaruh yang bersifat provokasi dan menghasut oleh pihak tertentu. Tindakan ujaran kebencian juga memiliki tujuan yang akan memberikan dapat terhadap golongan, SARA dan kelompok tertentu yang dapat dirugikan,
Dalam penelitian klasifikasi terhadap ujaran kebencian maka akan diberi 5 jenis tindak pidana berdasarkan (Kadiyarsa et al., 2020) seperti bentuk tindakan ujaran kebencian terhadap suatu agama baik secara lisan atau tulisan berdasarkan pasal 165A KUHP, pasal 165 KUHP yang merupakan tindakan ujaran kebencian terhadap suku tertentu, tindak kebencian terhadap golongan tertentu baik secara lisan atau tulisan berdasarkan pasal 175 KUHP dan tindak ujaran kebencian terhadap ras dan etnis yang dilakukan secara lisan atau tulisan akan dilakukan tindak pidana berdasarkan pasal 16 UU Nomor 40 tahun 2008, Penghapusan Diskriminasi Ras dan Etnis.
2.2. Text Preprocessing
Text Preprocessing adalah proses penyeleksian data yang memudahkan penelitian dan menjadi data yang lebih terstruktur. Tahapan ini dilakukannya proses pembersihan data yang di crawl dan belum diolah yang akan diubah menjadi data yang lebih baik dan dimengerti oleh mesin untuk mendapatkan performa yang lebih baik dalam klasifikasi. Data diambil dari twitter api banyak memiliki hashtag serta karakter khusus yang tidak memiliki makna akan mengurangi kinerja algoritma untuk itu text preprocessing dilakukan. Beberapa tahapan proses text processing adalah punctuation removal, case folding, stemming,, stopword removal, normalization ,dan tahapan terakhir tokenization.
2.3. Word Embedding
Word embedding merupakan model untuk memetakan serangkaian kata atau frasa dalam kosakata ke dalam bentuk vektor yang berisi angka atau bilangan. Word embedding berfungsi sebagai representasi kata dalam bentuk angka. Dalam natural language processing, suatu kata harus diubah ke dalam bentuk vektor yang berisi nilai numerik agar dapat dilakukan perhitungan matematis.
Salah satu jenis word embedding adalah GloVe (Global Vektors for Word Representation) merupakan unsupervised learning algorithm yang menentukan nilai vektor sebagai representasi pada tiap kata dalam dokumen. GloVe Embedding juga memperhatikan semantik antar kata berdasarkan matriks pada kemunculan kata secara bersamaan untuk mendapatkan nilai sebagai representasi kata.
2.4 Multinomial Naive Bayes
Multinomial Naive Bayes merupakan salah bayesian yang melakukan perhitungan nilai probabilitas berdasarkan kemunculan frekuensi pada dokumen. Perhitungan tidak memperhatikan terhadap urutan kata dalam dokumen (positional independence) sehingga tidak memerlukan metode semantic yang bergantung terhadap kata selanjutnya
Penentuan nilai probabilitas berdasarkan nilai prior pada sebuah kelas dan conditional tiap kata yang ditentukan nilai bobotnya berdasarkan pembobotan glove embedding dalam sebuah kelas yang menentukan nilai terbesar untuk mendapatkan hasil kemungkinan yang terbaik dalam tiap kelas.
𝑃(𝐶𝑗|𝑊𝑗) = 𝐶𝑜𝑢𝑛𝑡(𝑊𝑖, 𝐶𝑗)
((∑𝑤∈𝑉𝐶𝑜𝑢𝑛𝑡(𝑊, 𝐶𝑗)) + |𝑣| ) 2.1
Keterangan :
𝑃(𝐶𝑗|𝑊𝑗) = Conditional Probability
𝐶𝑜𝑢𝑛𝑡(𝑊𝑖, 𝐶𝑗) = Jumlah nilai term conditional W pada kelas j 𝐶𝑜𝑢𝑛𝑡(𝑊, 𝐶𝑗) = Jumlah total nilai term pada kelas j
2.5. Confussion Matrix
Confusion Matrix merupakan salah satu metode evaluasi yang umumnya digunakan untuk proses penentuan tolak ukur terhadap pemodelan klasifikasi pada algoritma yang digunakan. Metode evaluasi menunjukkan hasil precision, recall, F-measure, dan accuracy berdasarkan jumlah nilai label diprediksi dan label aktual yang diberikan. Untuk mendapatkan hasil classification report maka, dibutuhkan persamaan tabulasi confusion matrix ditunjukkan sebagai berikut:
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃𝑇
𝑇𝑃𝑇 + 𝐹𝑃𝑇 2.2
Keterangan :
TPR = True Positive Twit, representasikan kelas yang diprediksi sesuai FPR = False Positive Twit, tweet yang negatif yang diprediksi nilai positif
𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃𝑇
𝑇𝑃𝑇 + 𝐹𝑁𝑇 2.3 Keterangan :
TPR = True Positive twit, representasikan kelas yang diprediksi sesuai
FNR = False Negative kelas, nilai tweet positif ulasan yang diprediksi nilai negatif 𝐹 − 𝑀𝑒𝑎𝑠𝑢𝑟𝑒 = 2 × 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑅𝑒𝑐𝑎𝑙𝑙
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑅𝑒𝑐𝑎𝑙𝑙 2.4 Keterangan :
Precision = Hasil nilai kalkulasi precision Recall = Hasil nilai kalkulasi Recall
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃𝑇 + 𝑇𝑁𝑇
𝑇𝑃𝑇 + 𝐹𝑃𝑇 + 𝑇𝑁𝑇 + 𝐹𝑁𝑇 2.5 Keterangan :
TPR = True Positive Tweet, representasikan kelas yang diprediksi sesuai
TNR = True Negative Tweet, representasikan kelas negatif yang sesuai diprediksi FPR = False Positive Tweet, nilai kelas negatif ulasan yang diprediksi nilai postif FNR = False Negative Tweet, nilai tweet positif ulasan yang diprediksi nilai negative
2.6. Penelitian Terdahulu
Beberapa penelitian telah dilakukan mengenai Klasifikasi Jenis Ujaran Kebencian Pada Cuitan Tweet Bahasa Indonesia atau tentang implementasi Multinomial Naïve Bayes dan GloVe Embedding. Penelitian oleh (Watanabe. et al., 2018) yang berjudul Hate Speech on Twitter: A Pragmatic Approach to Collect Hateful and Offensive Expressions and Perform Hate Speech Detection. Dalam penelitian ini, penulis mengusulkan pendekatan baru untuk mendeteksi ujaran kebencian di Twitter.
Pendekatan yang diusulkan menggunakan metode Random Forest untuk mendeteksi ujaran kebencian yang dibantu dengan ekstraksi fitur yaitu fitur unigram, fitur sentiment-based dan fitur semantik untuk mengklasifikasikan tweet menjadi ujaran kebencian, menyinggung, dan bukan ujaran kebencian. Penelitian ini menghasilkan akurasi sebesar 87.4%.
Selanjutnya penelitian oleh (Gambäck. et al., 2017) yang berjudul Using Convolutional Neural Networks to Classify Hate-Speech. Pada penelitian ini penulis melakukan eksperimen dengan sistem untuk klasifikasi teks ujaran kebencian Twitter berdasarkan Convolutional Neural Network deep-learning. Klasifikasi menetapkan setiap tweet ke salah satu dari empat kategori yang telah ditentukan: rasisme, seksisme, keduanya (rasisme dan seksisme) dan tidak keduanya.
Dua model Convolutional Neural Networks dibuat berdasarkan set vektor input yang berbeda yang digunakan untuk pelatihan dan klasifikasi. Vektor kata berdasarkan informasi semantik dibangun menggunakan unsupervised strategy, word2vec, dan dibandingkan dengan garis dasar vektor yang dibuat secara acak.
Selain itu, dua model Convolutional Neural Networks (CNN) akan dilatihkan pada karakter 4-gram, juga kombinasi vektor kata dan karakter n-gram. Penelitian ini menghasilkan akurasi sebesar 85.66%.
Penelitian oleh Saksesi et al. (2018) dalam penelitiannya yang berjudul Analysis Text of Hate Speech Detection using Recurrent Neural Network. Penelitian ini melakukan deteksi pada ujaran kebencian berbahasa indonesia, dimana data yang dipakai adalah data
tweet yang diambil dari Twitter menggunakan Twitter API sebanyak 1235 record.
Penelitian ini menggunakan Word2vec sebagai word embedding, lalu data akan dilanjutkan dan diolah menggunakan metode Long Short-Term Memory (LSTM) Recurrent Neural Network dan menghasilkan akurasi yang tinggi yaitu sebesar 91%.
Penelitian oleh Immaduddin et al. (2019) dalam penelitiannya yang berjudul Word Embedding Comparison for Indonesian Language Sentiment Analysis.
Penelitian ini membandingkan beberapa metode embedding, yaitu word2vec CBOW, word2vec skip gram, doc2vec dan glove dalam kasus analisis sentimen dari data review hotel berbahasa Indonesia. Di proses klasifikasi, penulis menggunakan Long Short-Term Memory (LSTM). Hasil yang diperoleh menunjukkan bahwa metode GloVe embedding memiliki akurasi terbaik di antara metode yang lain yaitu 95,52%.
Metode word2vec dan skip gram mendapat akurasi terendah yaitu 91.81%.
Penelitian lainnya yaitu (Abbas. et al., 2019) dalam penelitian yang berjudul Multinomial Naive Bayes Classification Model for Sentiment Analysis ini penulis menyajikan kerangka klasifikasi teks. Untuk Analisis Sentimen berdasarkan Algoritma klasifikasi Multinomial Naïve Bayes (MNB) dan Metode TF-IDF.
Motivasi utama dari penelitian ini adalah untuk mengembangkan konsep kerangka kerja yang berorientasi pada algoritma Multinomial Naive Bayes dan modul TF-IDF.
Review dan perbandingan beberapa pengklasifikasi Naive Bayesian modern dilakukan berdasarkan kemampuannya untuk mengklasifikasikan sejumlah besar dokumen teks secara efisien. Penelitian ini menghasilkan akurasi sebesar 93.1%.
Rincian singkat penelitian yang telah dilakukan dapat dilihat pada Tabel 2.1
Tabel 2.1 Penelitian Terdahulu No Nama
Peneliti
Metode Judul Keterangan
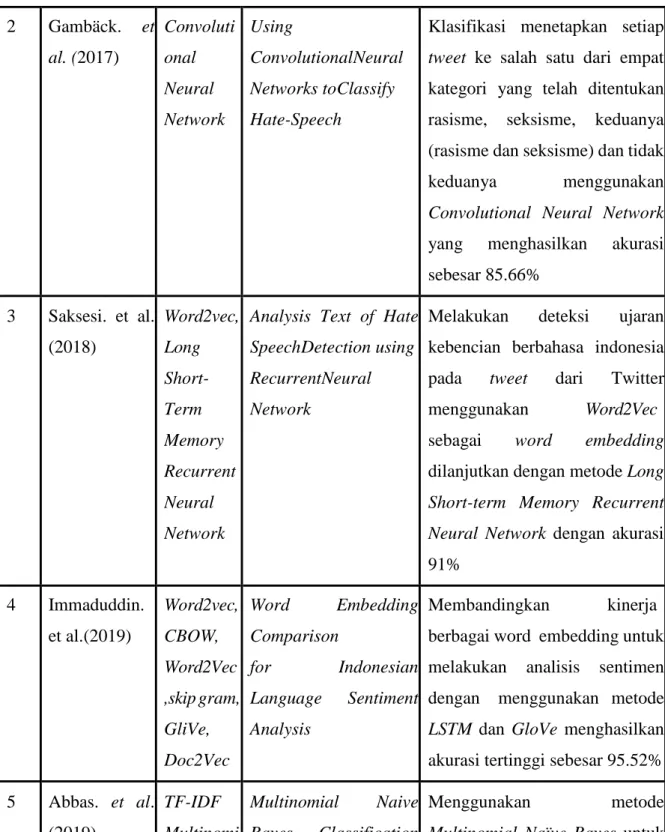
1 Watanabe et al.(2018)
Random Forest
Hate Speech on Twitter:
A Pragmatic Approach to Collect Hateful and Offensive Expressions and Perform Hate Speech
Menggunakan ekstraksi fitur unigram, sentiment-based untuk membedakan kalimat yang mengandung konteks negatif, dan semantik dengan metode Random Forest yang menghasilkan akurasi sebesar 87.4%
Tabel 2.1 Penelitian Terdahulu (Lanjutan) 2 Gambäck. et
al. (2017)
Convoluti onal Neural Network
Using
Convolutional Neural Networks to Classify Hate-Speech
Klasifikasi menetapkan setiap tweet ke salah satu dari empat kategori yang telah ditentukan rasisme, seksisme, keduanya (rasisme dan seksisme) dan tidak keduanya menggunakan Convolutional Neural Network yang menghasilkan akurasi sebesar 85.66%
3 Saksesi. et al.
(2018)
Word2vec, Long Short- Term Memory Recurrent Neural Network
Analysis Text of Hate Speech Detection using Recurrent Neural Network
Melakukan deteksi ujaran kebencian berbahasa indonesia pada tweet dari Twitter menggunakan Word2Vec sebagai word embedding dilanjutkan dengan metode Long Short-term Memory Recurrent Neural Network dengan akurasi 91%
4 Immaduddin.
et al. (2019)
Word2vec, CBOW, Word2Vec ,skip gram, GliVe, Doc2Vec
Word Embedding Comparison
for Indonesian Language Sentiment Analysis
Membandingkan kinerja berbagai word embedding untuk melakukan analisis sentimen dengan menggunakan metode LSTM dan GloVe menghasilkan akurasi tertinggi sebesar 95.52%
5 Abbas. et al.
(2019)
TF-IDF Multinomi al Naive Bayes
Multinomial Naive Bayes Classification Model for Sentiment Analysis
Menggunakan metode
Multinomial Naïve Bayes untuk melakukan analisis sentimen dengan ekstraksi fitur TF-IDF.
Penelitian ini menghasilkan akurasi sebesar 93.1%
2.6 Perbedaan Penelitian
Dalam penelitian ini terdapat perbedaan dengan penelitian sebelumnya yang dijelaskan sebelumnya. Penelitian sebelumnya belum ada penelitian yang menggunakan metode Multinomial Naïve Bayes untuk klasifikasi Hatespceeh pada Twitter Selain itu pada penelitian terdahulu belum ada yang melakukan klasifikasi Hatespeech berdasarkan Undang - Undang dan membaginya ke dalam beberapa kelas seperti : Non-Hatespeech , Hatespeech terhadap agama , hatespeech terhadap golongan , dan hatespeech terhadap suku dan ras . Hal lain yang membedakan adalah dalam penelitian sebelumnya belum ada yang menggunakan Glove Embedding sebagai Word Embedding , dimana penelitian sebelumnya menggunakan TF-IDF dan n-gram
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
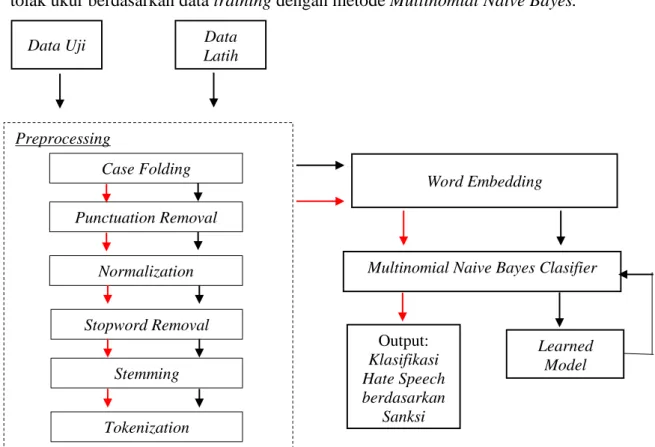
3.1. Arsitektur Umum
Untuk mendapatkan penyelesaian masalah pada penelitian dibutuhkan beberapa tahapan untuk mendapatkan kesimpulan yang sesuai, yaitu : pengumpulan data terkait, data yang akan digunakan akan di-crawling melalui platform twitter dan diimpor berformat .csv untuk mempermudah proses dalam modeling data dan proses komputasi. Data yang sudah dikumpulkan akan dipreproses melalui 6 tahapan yang terdiri dari punctuation removal, Normalization, Stopword Removal, Case Folding, Stemming, Tokenization. Data akan diberikan nilai bobot vektor untuk menentukan hasil pemodelan selanjutnya berdasarkan angka dari tiap kata dalam dokumen. Setiap kata memiliki nilai yang berbeda berdasarkan corpus yang sudah dilakukan pre- trained mengenai kata kata ujaran kebencian. Data pilihan yang diproses kemudian proses selanjutnya dilakukan pemodelan berdasarkan data training dan menentukan tolak ukur berdasarkan data training dengan metode Multinomial Naive Bayes.
Gambar 3.1 Arsitektur Umum Preprocessing
Word Embedding
Multinomial Naive Bayes Clasifier
Learned Model Output:
Klasifikasi Hate Speech berdasarkan
Sanksi pidana Punctuation Removal
Normalization
Stopword Removal Stemming Case Folding
Tokenization
Data Uji Data
Latih
3.2. Data
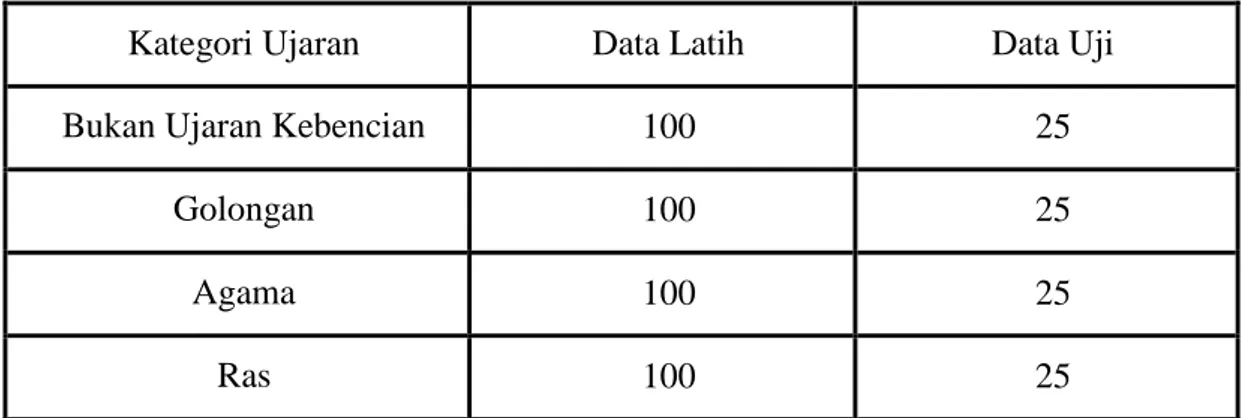
Input data akan diambil dari data yang di-crawling. Data mengenai ujaran pada user diambil mulai dari tahun 2020 - 2021 melalui media sosial twitter. Data yang di- crawling terdapat banyak opini yang tidak memiliki konteks yang sesuai dengan label klasifikasi sehingga total data yang dapat digunakan sebanyak 500 ujaran. Data yang sudah terkumpul akan dibagi berdasarkan data latih dan data uji dengan perbandingan 8:2, sehingga mendapatkan jumlah data latih sebanyak 400 dan total 100 data uji.
Ujaran yang digunakan akan dilabel berdasarkan pakar hukum yang memberikan parameter sebagai acuan untuk membuktikan bahwa cuitan yang dilakukan pada user dapat sesuai dengan konteks klasifikasi. Jumlah data berdasarkan kategori dapat diperhatikan pada Tabel 3.1.
Tabel 3.1. Jumlah Data Uji dan Latih
Kategori Ujaran Data Latih Data Uji
Bukan Ujaran Kebencian 100 25
Golongan 100 25
Agama 100 25
Ras 100 25
3.3. Preprocessing
Preprocessing merupakan tahap awal untuk proses pembersihan data yang dapat dimengerti oleh mesin. Data yang akan dibersihkan akan lebih mudah diproses serta menghasilkan hasil yang lebih akurat. Untuk mendapatkan data yang baik perlu dilakukan beberapa proses antara lain Punctuation Removal, Normalization, Stopword Removal, Case Folding, Stemming, Tokenization
3.3.1. Case Folding
Case Folding merupakan proses penyederhanaan kata pada kalimat. Proses ini dilakukan dengan huruf kapital menjadi huruf kecil, menghilangkan angka yang tidak diperlukan, menghapus emoji atau tanda baca, serta menghilangkan karakter spesial dan spasi yang berlebih yang tidak memiliki makna. Proses penyederhanaan mendapatkan kata - kata yang lebih seragam, sehingga teks yang tidak penting dapat dihapus untuk mendapatkan nilai vektor nantinya serta hasil probabilitas yang lebih baik pada kinerja algoritma yang digunakan.
Tabel 3.2. Penerapan proses Case Folding
Kalimat sebelum Case Folding Setelah Case Folding USER USER : DASAR CINA!!! Sampah bgt
kelakuan lo ajg, mau lo siapanya nggak berhak memukul orang ye,,, DIA juga manusia begek bgt dah. Mending balek ke
negara asal lo !!
@satriya;URLtwitter.com/dhakwy@123hdj a/
user user : dasar cina!!! sampah bgt kelakuan lo ajg, mau lo siapanya nggak berhak memukul orang ye,,, dia juga manusia begok bgt dah.
mending balek ke negara asal lo !!
@satriya;urltwitter.com/dhakwy@12 3hdja/
3.3.2. Punctuation Removal
Proses Punctuation Removal merupakan proses awal digunakan untuk menghindari adanya kegagalan pada proses klasifikasi pada penelitian. Proses ini digunakan untuk menghilangkan missing value atau attribute pada sebuah data, menghapus tanda baca atau simbol, serta menghilangkan duplikasi pada dataset. Noise pada data akan berdampak pada nilai vektor yang akan ditetapkan pada word embedding sehingga akan mengakibatkan nilai yang tidak sesuai dalam proses akhirnya, Contoh pada sebuah data twitter dimana dalam hasil crawl umumnya terdapat url yang tidak diperlukan dan akan mempengaruhi konteks dan makna sebenarnya dalam data, kalimat yang tidak mengandung kecocokan menyebabkan data yang tidak konsisten.
Tabel 3.3. Penerapan proses Punctuation Removal
Sebelum Punctuation Removal Setelah Punctuation Removal user user : dasar cina!!! sampah bgt kelakuan
lo ajg mau lo siapanya nggak berhak memukul orang ye,,, dia juga manusia begok bgt dah.
mending balek ke negara asal lo !!
@satriya;urltwitter.com/dhakwy@123hdja/
user user dasar cina sampah bgt kelakuan lo ajg mau lo siapanya nggak berhak memukul orang ye dia juga manusia begok bgt dah. mending balek ke negara asal lo
3.3.3. Normalization
Normalization proses menormalisasikan data menjadi kata yang lebih terstruktur.
Proses ini memperhatikan berdasarkan dua hal penting yaitu struktur kalimat dan kosakata. Struktur kalimat yang lebih spesifik akan mudah diproses dikarenakan mencapai objek berdasarkan kata kerja atau kata sifat yang sesuai dengan konteks dan kosakata yang akan digunakan untuk korpus perlu diminimalisir, sehingga variasi kata yang lebih sedikit memperoleh hasil yang lebih baik.
Normalisasi pada penelitian ini menggunakan kamus normalisasi dengan format .csv dari (Ibrohim & Budi, 2019) dengan sedikit penambahan yang dilakukan untuk menyesuaikan dengan data pada penelitian ini. Kamus normalisasi berisi kata yang tidak normal diikuti dengan kata yang seharusnya. Pada gambar 3.2 ditunjukkan gambaran kamus normalisasi.
Gambar 3.2 Kamus Normalisasi
Kata – kata yang tidak normal pada data akan dideteksi dengan membandingkan kata pada data dengan kata yang tidak normal pada korpus, selanjutnya akan diganti dengan kata yang normal yang ada pada kamus normalisasi. Jadi, kata seperti “ajg”
akan diubahkan menjadi “anjing”, “blh” menjadi “boleh” dan kata - kata typo yang tidak sesuai dalam Bahasa Indonesia. Tabel 3.4 menunjukkan penerapan proses normalisasi.
Tabel 3.4. Penerapan proses Normalization
Sebelum Normalization Setelah Normalisation dasar cina sampah bgt kelakuan lo ajg
mau lo siapanya nggak berhak memukul orang ye dia juga manusia begok bgt dah. mending balek ke negara asal lo
dasar cina sampah banget kelakuan kamu anjing mau kamu siapanya tidak berhak memukul orang ya dia juga manusia bodoh banget dah. mending balik ke negara asal kamu
3.3.4. Stemming
Stemming adalah tahapan reduksi kata imbuhan menjadi kata dasar yang memiliki makna yang sama. Dalam tahapan ini semua kata bentuk imbuhan akan dihilangkan dan diubah menjadi root atau dasar yang digunakan. Contoh imbuhan antara lain Inflection Suffixes (“-kah”, “mu”, “ku”, “-nya”), imbuhan turunan (“-i”, “-an”, “kan”), imbuhan awalan (“di”, “ke”, “be”). Tiap penggunaan imbuhan tersebut akan dihapus untuk mendapatkan variasi kata yang lebih akurat tanpa harus menghilangkan makna pada kata itu sendiri.
Tabel 3.5. Penerapan proses Stemming
Sebelum Stemming Setelah Stemming
dasar cina sampah banget kelakuan kamu anjing mau kamu siapanya tidak berhak memukul orang ya dia juga manusia bodoh banget dah. mending balik ke negara asal kamu
dasar cina sampah banget laku kamu anjing mau kamu siapa tidak berhak memukul orang ya dia juga manusia bodoh banget dah. mending balik ke negara asal kamu
3.3.5. Stopword Removal
Stopword Removal merupakan proses penyaringan kata hubung yang tidak digunakan.
Kata hubung tidak akan mempengaruhi arti dari sebuah kalimat sehingga sangat berpengaruh untuk membatasi variasi yang digunakan dalam korpus nantinya. Hal ini mempermudah proses klasifikasi dikarenakan hasil penyaringan tersebut menghasilkan kata - kata objektif yang sesuai konteks sehingga dalam proses pemodelan dengan data latih akan lebih mudah diketahui ciri dari tiap kalimat berdasarkan konteks yang dilabel. Kata hubung dalam bahasa indonesia hanya memperjelas konteks yang hanya dipahami oleh manusia untuk mengerti pembahasan yang dibaca. Penelitian ini menggunakan library Natural Language Toolkit (NLTK) yang menyediakan daftar stopword untuk Bahasa Indonesia.
Tabel 3.6. Penerapan proses Stopword Removal
3.3.6. Tokenization
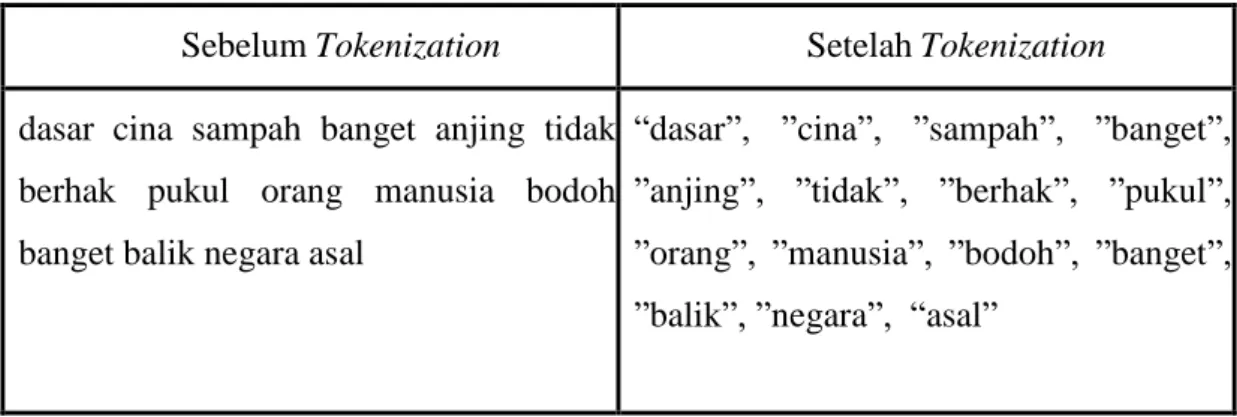
Tokenization merupakan tahap akhir dalam preprocessing dengan melakukan pemotongan tiap kata dalam kalimat. Kata yang dipotong disebut token yang akan dipisahkan berdasarkan tiap frasa yang dibatasi spasi atau white space. Tokenization bertujuan untuk memisahkan kata secara bertahap untuk dilakukan proses penentuan nilai bobot yang akan dilakukan pada proses word embedding dimana tiap token nantinya akan diberi nilai berdasarkan corpus yang sudah disediakan.
Sebelum Stopword Removal Setelah Stopword Removal dasar cina sampah banget laku kamu
anjing mau sudah kamu siapa tidak berhak pukul orang ya dia juga manusia bodoh banget dah. mending balik ke negara asal kamu.
dasar cina sampah banget anjing tidak berhak pukul orang manusia bodoh banget balik negara asal
Tabel 3.7. Penerapan proses Tokenization
Sebelum Tokenization Setelah Tokenization dasar cina sampah banget anjing tidak
berhak pukul orang manusia bodoh banget balik negara asal
“dasar”, ”cina”, ”sampah”, ”banget”,
”anjing”, ”tidak”, ”berhak”, ”pukul”,
”orang”, ”manusia”, ”bodoh”, ”banget”,
”balik”, ”negara”, “asal”
3.4. GloVe Embedding
Pennington et al. (2014) telah menyediakan model GloVe embedding yang telah di- training dengan 6 milyar tokens dan menghasilkan 400.000 kosa kata dengan vektor berukuran 300 dimensi. Model yang disediakan berupa kosa kata dalam bahasa inggris yang diambil dari Wikipedia 2014 dan Gigaword 5.
Model yang telah dibuat oleh Pennington et al. (2014) tidak dapat dipakai dalam penelitian ini karena model yang dibuat adalah kosa kata berbahasa Inggris, sementara penelitian ini meneliti kata dalam bahasa Indonesia. Untuk itu, peneliti membangun GloVe model berbahasa Indonesia dengan menggunakan corpus Wikipedia Indonesia.
Wikipedia Indonesia menyediakan corpus yang berisi artikel Wikipedia berbahasa Indonesia. Kata yang diperoleh dari corpus Wikipedia Indonesia adalah sebanyak 555.139.395 tokens.
Pennington et al. (2014) menyediakan library dalam bahasa C dengan format bash untuk membangun model GloVe dengan corpus yang dikehendaki. Library diperoleh dari https://github.com/stanfordnlp/GloVe dan selanjutnya akan digunakan untuk melatih 555.139.395 tokens. Model yang didapat menghasilkan 377.000 kosa kata dengan vektor berukuran 300 dimensi. Berikut adalah contoh vektor dari kata benci.
Gambar 3.3 Vektor dari kata benci
De Boom et al. (2016) memanfaatkan word embedding untuk algoritma yang bukan neural network seperti Support Vektor Machine, Random Forest, atau Multinomial Naïve Bayes dengan mendapatkan nilai rata – rata berdasarkan vektor yang telah dilatih sebelumnya.
Langkah – langkah penerapan glove embedding pada penelitian ini adalah sebagai berikut:
1. Setiap vektor yang terdapat pada corpus glove embedding akan dicari nilai rata- ratanya. Jadi, seperti vektor pada kata “benci” yang berjumlah 300 dimensi
seperti pada gambar 3.2 yaitu [-0.040585, 0.175509, 0.396089, … , -0.200268]
akan diubah menjadi nilai rata-ratanya yaitu [0.004093536666666669]. Jadi corpus dalam glove embedding telah diubah menjadi {‘benci’ : 0.004093536666666669}. Contoh nilai bobot rata-rata glove embedding dapat dilihat pada Tabel 3.8.
2. Selanjutnya, setiap kata pada data akan diubah menjadi nilai bobot rata – rata yang terdapat pada corpus glove sebelumnya. Contoh : [“usir”,”cina”,”bodoh”]
akan diubah menjadi [0.026133436666666673, 0.01109466, 0.02048942]
Tabel 3.8. Nilai Bobot Kata pada Glove Embedding
Kata Nilai Bobot
Cina 0.01109466
Bodoh 0.02048942
Sipit 0.02011886
Jelek 0.03688525
Hitam 0.00932232
Kriting 0.00052089
Kadrun 0.02150773
Anjing 0.02518231
kafir 0.00991176
sampah 0.05375832
3.5. Multinomial Naive Bayes
Pada tahap akhir dilakukan implementasi berdasarkan pemodelan yang sudah dilakukan pada Multinomial Naive bayes. Tahap ini dilakukan dengan cara mencari nilai probabilitas tertinggi dari tiap kelas, dengan menghitung tiap token yang sudah diberi nilai pada sebuah kalimat. Untuk hasil klasifikasi yang tepat diperlukan pembagian data testing dan data training dengan perbandingan 2:8, data training digunakan untuk melatih algoritma Multinomial Naive Bayes untuk mendapatkan ciri berdasarkan konteks kalimat yang sudah dilabel sebelumnya dan data testing untuk mengetahui performa terhadap kinerja algoritma yang sudah dilatih sebelumnya. Data latih yang sudah diberi nilai pada Glove Embedding selanjutnya akan diproses dengan Multinomial Naive Bayes. Untuk menentukan hasil jenis ujaran kebencian berdasarkan
6 klasifikasi dilakukan perhitungan berdasarkan nilai prior, conditional dan likelihood dimana conditional probability berdasarkan jumlah kata variasi yang ada dalam sebuah dokumen yang sudah disediakan (Manning, et al., 2009).
Tiap kata dalam dokumen yang diberikan nilai terhadap tiap token akan dimodelkan menjadi proses klasifikasi selanjutnya bedasarkan ujaran kebencian.
Ujaran kebencian akan diukur berdasarkan kata yang sesuai dari nilai hasil terbesar berdasarkan tiap kemunculan kata pada prior dan likelihood. Penentuan nilai klasifikasi dapat dilihat pada contoh tabel 3.8.
Tabel 3.9. Kata berdasarkan kelas
Data latih No Kata Kelas
d1 Cina, bodoh, sipit, jelek Ras (R) d2 Hitam, jelek, bodoh, kriting Ras (R) d3 kadrun, bodoh, anjing Agama (A) d4 kafir, bodoh, sampah Agama (A) Uji data d5 Kadrun, bodoh, anjing, kafir,
hitam
?
Pada tabel diatas merupakan contoh data latih yang sudah di label berdasarkan tiap kelas. Tiap token merepresentasikan kelas tersebut akan menjadi acuan pada hasil akhir untuk menentukan jenis ujaran kebencian pada data uji (d5). Prior ditentukan berdasarkan jumlah kelas x pada total keseluruhan data, pada dapat kita tentukan P(R) dan P(A) dengan tiap data berjumlah 2 dokumen P(R)= (d1, d2) dan P(A) P(A)= (d1, d2). Perhitungan dapat dikalkulasi dengan membagi dokumen terhadap P(x) terhadap seluruh total data yang dapat kita lihat sebagai berikut:
𝑃(𝑅) = 2
4 𝑃(𝐴) = 2 4
Selanjutnya kita akan mencari nilai likelihood berdasarkan tiap kata yang ada pada P(R) dan P(A) lalu menambahkan total vocabulary size untuk nilai multinomial terhadap kata unik dalam kelas.