TEKNOLOGI PENGENALAN DAN PENSINTESA UCAPAN
BAHASA INDONESIA PADA SISTEM INFORMASI
BERBASIS MICROSOFT SPEECH API
Stephanus Priyowidodo
AMIK HARAPAN MEDAN
Abstrak
Seiring dengan cepatnya kemajuan teknologi perangkat komputer, membuka peluang baru bagi perkembangan teknologi pengenalan ucapan ( speech recognition ) dan pensintesa ucapan ( speech synthesizer ). Perangkat komputer yang ukurannya semakin kecil dan ringan kelak dapat membantu siapa saja dalam memperoleh informasi dari berbagai sumber hanya dengan menggunakan ucapan. Sistem ucapan juga dapat disambungkan ke serangkaian perangkat elektronik lain, seperti perangkat sensor, perangkat hiburan dan sistem penerangan. Selain itu, teknologi pengenalan dan pensintesa ucapan dapat diaplikasikan pada robot humanoid sehingga robot dapat berkomunikasi dengan manusia atau sesama robot melalui ucapan. Permasalahannya adalah kurangnya penelitian pengenalan ucapan dan pensintesa ucapan bahasa Indonesia. Makalah ini membahas topik pengenalan ucapan dan pensintesa ucapan bahasa Indonesia menggunakan engine Microsoft Speech Application Programming Interface (SAPI).
Kata kunci : pengenalan ucapan, sintesa ucapan, speech recognition, speech synthesizer, SAPI
1. Pendahuluan
Bagaimana menurut Anda apabila Anda dan komputer bisa saling berkomunikasi melalui ucapan? Memerintah komputer untuk melakukan sesuatu yang Anda inginkan, seperti membacakan laporan, menampilkan grafik, menghidupkan lampu, memutar lagu kesukaan, membesarkan kecilkan volume sampai membacakan berita. Tentu itu semua akan menjadi pengalaman yang menyenangkan.
Pengenalan dan pensintesa ucapan saat ini banyak diaplikasikan pada robot humanoid. Beberapa robot humanoid yang dapat diperintah melalui ucapan seperti ASIMO dan HRP dari Jepang, Hubo dari Korea dan beberapa robot humanoid lain. Robot-robot tersebut dapat melakukan tugas sesuai perintah yang diucapkan dan menjawab sejumlah pertanyaan dalam bentuk sintesa ucapan.
Pengenalan ucapan adalah proses konversi dari sinyal yang diucapkan menjadi serangkaian kata atau kalimat dengan algoritma yang telah diimplementasi pada aplikasi komputer. Performansi sistem pengenalan ucapan selalu dispesifikasikan dalam bentuk kecepatan pengenalan dan akurasinya. Beberapa aplikasi sangat sensitif terhadap tingkat akurasi pengenalan ucapan misalnya alat dikte otomatis. Akurasi pada umumnya berkisar antara 98% sampai 99%.
Saat ini pengenalan ucapan menggunakan teknologi, metoda dan algoritma yang kompleks. Salah satu metoda yang banyak digunakan pada
sistem pengenalan ucapan adalah Hidden Markov Models (HMM) [3]. Pendekatan lain untuk pengenalan ucapan adalah teknologi neural network atau dalam bahasa Indonesia disebut Jaringan Syaraf Tiruan (JST). Teknologi ini memiliki tingkat akurasi pengenalan ucapan yang sangat tinggi dan dapat mengenal ucapan berkualitas rendah, data yang kabur (noise) dan pembicara yang berbeda-beda. Pengenalan ucapan dengan teknologi JST banyak digunakan untuk mengenal fonem. Meski memiliki keakuratan yang tinggi, teknik ini harus dilatih terus-menerus.
Penelitian perihal pengenalan ucapan pada komputer masih terus dilakukan. Beberapa engine pengenal ucapan sudah diperkenalkan secara umum, seperti Dragon Speech Recognition, CMU Sphinx, engine Nuance Communications dan Microsoft Speech API.
Pensintesa ucapan merupakan proses terbalik dari pengenalan ucapan. Teks yang akan diucapkan oleh komputer dikonversi menjadi suara fonem dimulai dari karakter awal sampai karakter akhir. Hasil akhirnya berupa sinyal suara digital yang selanjutnya disuarakan lewat loudspeaker. Proses pensintesa ucapan lebih sederhana bila dibandingkan dengan proses pengenalan ucapan. Beberapa engine pensintesa ucapan diantaranya DECtalk, MBROLA, eSpeak dan Microsoft Speech API.
Interface (SAPI) pada sistem operasi Microsoft Windows.
2. Microsoft Speech API (SAPI)
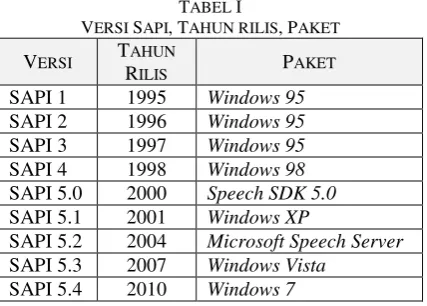
Secara umum SAPI dapat dianggap sebagai antar-muka yang terdapat diantara aplikasi dan speech engine (pengenalan dan pensintesa suara). Pada SAPI versi 1 sampai 4 aplikasi dapat langsung mengakses speech engine, sedangkan pada SAPI 5 komunikasi langsung antara aplikasi dan speech engine diberi batasan. Aplikasi dan speech engine berbicara lewat komponen run-time sapi.dll. Tabel I berisi versi, tahun rilis dan jenis paket SAPI.
2.1 SAPI versi 1 sampai versi 4
SAPI versi 1 dirilis untuk pertama sekali pada tahun 1995 dan mendukung sistem operasi Windowss 95 dan Windows NT 3.51. Pada versi ini SAPI berisikan Direct Speech Recognition dan Direct Text To Speech tingkat rendah di mana aplikasi dapat langsung mengendalikan speech engine. Versi 2 dirilis tahun 1996 dan versi 3 tahun 1997, saat itu SAPI memiliki kemampuan pengenalan ucapan terus-menerus yang terbatas.
SAPI 4 dirilis pada tahun 1998. Pada versi ini SAPI telah memiliki komponen-komponen diantaranya objek-objek tingkat tinggi untuk memerintah dan mengendalikan pengenalan ucapan, objek tingkat tinggi untuk diktasi secara terus-menerus, objek pensintesa suara, objek untuk aplikasi speech via telepon dan objek-objek lainnya.
2.2 SAPI versi 5.x
SAPI 5 dirilis pada tahun 2000 dengan perubahan konsep yakni aplikasi dan speech engine didesain terpisah, komunikasi antara keduanya dilakukan lewat run-time sapi.dll. Dengan demikian speech engine-nya menjadi lebih independen. Pada versi 5 SAPI telah mendukung continous dictation dan command/control.
SAPI 5.2 2004 Microsoft Speech Server SAPI 5.3 2007 Windows Vista
SAPI 5.4 2010 Windows 7
Sistem pengenalan ucapan pada SAPI memiliki prinsip kerja seperti gambar 1. Suara
pengguna yang diterima mikrofon dikonversi menjadi sinyal digital. Suara digital ini umumnya di-sampling pada frekwensi 11 Khz dengan format 16 bit. Sinyal yang masih baku ini selanjutnya dianalisa frekuensinya untuk diambil informasi fonem di dalamnya. Engine pengenal ucapan memiliki database suara-ke-fonem yang telah didefinisikan sebelumnya.
Gambar 1, Sistem Pengenalan Ucapan
Susunan fonem yang telah diperoleh dari proses sebelumnya dicari kesamaannya pada database kata. Setelah semua bagian fonem berhasil diperoleh, engine akan mengeluarkan hasil konversi fonem berupa teks. Namun demikian tidak semua suara digital dapat dikenali dengan mudah. Kata yang sama yang diucapkan oleh dua orang dapat diartikan berbeda oleh engine. Hal ini bisa terjadi disebabkan oleh perbedaan warna suara, noise dan gangguan lain. Solusinya adalah melatih ulang engine agar dapat mengenal berbagai perbedaan.
Sistem pensintesa ucapan lebih sering disebut text-to-speech (TTS). Prinsip kerja umum sistem pensintesa ucapan terlihat seperti gambar 2. Teks yang akan diucapkan mulanya dianalisa untuk dinormalisasi, singkatan dan istilah dinormalisasi menjadi teks terbaca, misalnya singkatan “dr.” akan diubah menjadi “dokter”, “computer” menjadi
Kalimat yang telah dinormalisasi selanjutnya dikenakan proses prosody. Prosody adalah bagian ilmu bahasa yang mempelajari tentang irama, intonasi, stres dan atribut yang terkait, seperti marah, takut, sedih, gembira, heran dan terkejut[1]. Hasil akhirnya berupa teks yang telah dinormalisasi dan telah diberi parameter prosody.
Selanjutnya proses mengubah teks menjadi fonem berdasarkan kamus pengucapan. Daftar fonem-fonem yang telah tersusun selanjutnya diambil suara-suara digital-nya dari database fonem-ke-suara dan selanjutnya diucapkan melalui loudspeaker.
Sampai saat ini engine SAPI hanya mendukung pengenalan ucapan dan pensintesa ucapan dalam tiga bahasa yakni bahasa Inggris, Simplified Chinese dan Jepang. Bahasa lainnya, termasuk bahasa Indonesia, belum didukung oleh SAPI.
3. Teknis Microsoft SAPI 5.x
3.a. Pengenalan Ucapan
SAPI versi 5.x mendukung dua jenis pengenalan ucapan, dictation (dikte) dan command and control (komando dan kendali) [4]. Sangat penting untuk memahami perbedaan antara keduanya.
- Dictation
Dictation mengacu pada jenis pengenalan ucapan di mana komputer mendengarkan apa yang di katakan dan mencoba untuk menerjemahkannya ke dalam teks. SAPI melakukan hipotesa terhadap semua kata yang didengar. Setiap bagian kata yang dihipotesa dianggap ada hubungannya dengan kata-kata yang diterima sebelum dan sesudahnya. Hasil akhir hipotesa akan mengembalikan keluaran berupa teks yang dikenal dan mengembalikan hasilnya ke aplikasi. Semua proses terjadi otomatis di dalam engine SAPI.
- Command and Control (CnC)
CnC digunakan untuk mengendalikan aplikasi berdasarkan aturan tata bahasa (grammar) yang telah ditentukan dan masing-masing aturan memiliki respon yang telah diprogram. Dalam mengembangkan aplikasi yang menggunakan CnC, programmer harus mendefinisikan tata bahasa, aturan dan respon aplikasi terhadap aturan yang dikenal [2].
SAPI belum mendukung bahasa Indonesia, karena itu teknik dictation tidak dapat diterapkan untuk kata-kata berbahasa Indonesia. Namun untuk CnC masih ada cara agar bahasa Indonesia dapat dikenal oleh SAPI 5.x.
Memperkenalkan kata atau kalimat bahasa Indonesia ke dalam engine SAPI 5.x membutuhkan kecermatan dan ujicoba. Data fonem yang akan kita
gunakan sebagai dasar fonem dari kata yang akan diperkenalkan adalah data fonem bahasa Inggris. Fonem bahasa Inggris pada SAPI 5.x terdiri atas 42 fonem yakni : silence (tanda diam), ae, ax, ah, aa, ao, ey, eh, uh, er, y, iy, ih, ix, w, uw, ow, aw, oy, ay, h, r, l, s, z, sh, ch, jh, zh, th, dh, f, v, d, t, n, k, g, ng, p, b, m. Sebagai contoh, kata “halo”, harus diperkenalkan sebagai urutan fonem “h aa l ow”, kata “bagus”urutan fonemnya “b aa g uw s s”.
Dari hasil penelitian dan ujicoba diperoleh tabel fonem dan contoh kata seperti pada tabel II.
TABEL II
FONEM DAN KATA BAHASA INDONESIA
NO FONEM CONTOH KATA
1 silence (tidak ada)
2 ae aestika
3 ax senang
4 ah merah
5 aa baik, bagus,
6 ao kakao
7 ey hemat, medan
8 eh september
9 uh patuh
10 er terakhir
11 y yakin
12 iy kiri, miring
13 ih terimakasih
14 ix matriks, helix
15 w waktu
16 uw ulang, baru
17 ow roster, monster
18 aw kacau, awas
19 oy amboi
20 ay ayam, balai
21 h hampir, tujuh
22 r rumah, harus, dengar
23 l lima, selasa, hasil
24 s satu, puasa, panas
25 z zamrut
26 sh sholat
27 ch catur
28 jh jauh, jam
29 zh (lihat z)
30 th semut
31 dh (lihat d)
32 f final
33 v variasi
34 d desa, sedia
35 t tanah, kiamat
36 n nada, dimana, bukan
37 k kecil, bekerja, batik
38 g gerak, begitu
39 ng siang, mengantuk
40 p pasti, tiap
41 b besar, kabar
Berdasarkan tabel II, dapat di-create engine baru yang secara otomatis mengubah kata atau kalimat bahasa Indonesia menjadi urutan fonem yang sesuai. Kata atau kalimat yang telah diubah menjadi fonem selanjutnya diperkenalkan ke SAPI 5.x melalui objek SpLexicon method AddPronunciation. Objek SpLexicon dapat mengakses langsung ke bagian SAPI 5.x yang berisi kata atau kalimat yang dikenal.
3.b. Pensintesa Ucapan
Engine SAPI 5.x telah didesain sedemikian rupa sehingga untuk mengucapkan kata atau kalimat hanya dibutuhkan perintah satu baris yakni SpVoice.Speak. Namun yang menjadi masalah adalah SAPI tidak mendukung bahasa Indonesia sehingga perintah SpVoice.Speak normal menjadi tidak begitu berguna. Kalimat dalam bahasa Indonesia akan diucapkan sesuai dengan cara baca bahasa yang didukung oleh sistem operasi. Bila sistem operasi mendukung bahasa Inggris maka kalimat “apa kabar” akan diucapkan “aopekaber”. Bagi pendengar, ucapan yang tidak sesuai dari yang seharusnya akan sulit dimengerti. Ada beberapa solusi yang dapat dilakukan untuk memperbaiki kualitas ucapan bahasa Indonesia yang dihasilkan oleh SAPI.
Solusi pertama adalah dengan mengubah fonem yang akan diucapkan oleh SAPI menjadi fonem yang seharusnya. SAPI 5.x menyediakan fungsi pengucapan menggunakan simbol-simbol fonem, sehingga kalimat “Apa kabar?” dapat diganti dengan simbol fonem seperti “aa p aa k aa b aa r ?”. Contoh lainnya, kalimat “Konferensi Nasional Sistem Informasi” secara normal akan diucapkan oleh SAPI dengan urutan fonem “k aa n f er ax n s iy n ae s iy ax n ae l s ih s t eh m ih n f ao r m aa s iy”, ucapan tersebut sulit dimengerti. Berdasarkan tabel II dapat di-create urutan fonem baru yang bila didengar akan lebih mudah dimengerti yakni, “k ow n f eh r eh n s iy n ah s iy ow n ah l s iy s t ax m iy n f ow r m ah s iy”.
Solusi kedua adalah dengan menggunakan engine selain Microsoft, misalnya eSpeak [7]. eSpeak menghasilkan ucapan kalimat yang lebih baik dibandingkan ucapan asli SAPI. eSpeak merupakan speech engine tidak berbayar yang banyak digunakan oleh aplikasi, diantaranya NVDA dan Google Translate. Setelah meng-install eSpeak, daftar suara pada SAPI properties Windows akan bertambah dengan suara dari eSpeak. Tambahkan kode negara Indonesia pada saat instalasi yakni ‘id’ agar eSpeak mendukung ucapan dalam bahasa Indonesia.
Dengan menggunakan perintah SAPI SpVoice.Speak yang normal eSpeak akan menghasilkan ucapan kata atau kalimat dalam bahasa Indonesia dengan kualitas lebih baik.
Solusi ketiga adalah dengan menambahkan eSpeak dan MBROLA pada SAPI 5.x. Solusi ini merupakan solusi terbaik. MBROLA adalah Multi-Band Resynthesis OverLap-Add, proyek database diphone berbagai bahasa dari Faculte Polytechnique de Mons, TCTS Lab, Belgia [8]. Database diphone MBROLA untuk bahasa Indonesia diberi nama ID1[5].Solusi ini menggabungkan kemampuan SAPI 5.x, engine eSpeak dan database diphone MBROLA ID1, menghasilkan ucapan kata atau kalimat dalam bahasa Indonesia dengan sangat baik [9].
4. Pengujian
4.a. Pengujian Pengenalan Ucapan
Pengujian terhadap sistem pengenalan ucapan dilakukan terhadap 10 orang dengan mengucapkan 30 kalimat berbeda kepada komputer. Dari hasil pengujian diambil jumlah kalimat yang dikenali dan tidak dikenali oleh komputer. Hasil pengujian sistem pengenalan ucapan menggunakan SAPI dapat dilihat pada tabel III.
TABEL III
Dari hasil pengujian di atas diperoleh prosentase rata-rata kalimat yang dikenali oleh komputer adalah 89.33%.
4.b. Pengujian Pensintesa Ucapan
Pengujian terhadap sistem pensintesa ucapan dilakukan dengan memperdengarkan ucapan 20 kalimat yang dihasilkan oleh komputer kepada 5 orang yang berbeda. Ucapan kalimat yang diperdengarkan dihasilkan oleh sistem pensintesa ucapan yang berbeda yakni dengan sistem pengucapan SAPI, SAPI dengan tambahan eSpeak serta SAPI dengan tambahan eSpeak dan MBROLA. Kemudian diambil jumlah ucapan kalimat yang mudah dimengerti dari masing-masing sistem pengucapan.
TABEL IV
PENGUJIAN SISTEM PENSINTESA UCAPAN
Orang
ke SAPI
SAPI + eSpeak
SAPI + eSpeak + MBROLA
1 11 13 18
2 10 11 20
3 14 10 19
4 13 15 20
5 12 15 20
60.00% 64.00% 97.00%
Dari hasil pengujian terhadap sistem pensintesa ucapan di atas diperoleh bahwa pengucapan kalimat dengan sistem SAPI yang ditambah dengan eSpeak dan MBROLA lebih mudah dimengerti.
5. Kesimpulan
Dari pembahasan sebelumnya perihal pengenalan ucapan dan pensintesa ucapan dapat disimpulkan :
1. Pengenalan ucapan SAPI dikte (dictation) tidak dapat dipergunakan pada bahasa Indonesia karena dukungan SAPI terbatas hanya pada bahasa Inggris, Cina dan Jepang.
2. Pengenalan ucapan SAPI CnC dapat dipergunakan agar komputer dapat mengenali kata atau kalimat dalam bahasa Indonesia dengan persyaratan konversi kata atau kalimat menjadi fonem SAPI dilakukan dengan tepat. 3. Pensintesa ucapan SAPI untuk bahasa
Indonesia harus dilakukan dengan cara mengkonversi kalimat yang akan diucapkan menjadi urutan fonem-fonem yang didukung oleh SAPI.
4. Penambahan engine eSpeak dan database diphone MBROLA akan meningkatkan secara drastis kualitas ucapan yang akan dihasilkan oleh SAPI.
Daftar Pustaka:
[1]
[2]
[3]
[4]
[5]
[6]
[7] [8] [9]
Breazeal, Cynthia, 2002, Emotive Qualities in Lip-Synchronized Robot Speech, MIT Media Lab.
Dunn, Michael, 2007, Pro Microsoft Speech Server 2007 – Developing Speech Enabled Applications with .NET, Apress.
Holmes, John, and Holmes, Wendi, 2001, Speech Synthesis and Recognition, Taylor & Francis.
Microsoft, 2001, Microsoft Speech SDK SAPI 5.1, Microsoft Corp.
Priyowidodo, Stephanus, and Irwan, Dedi, 2010, Speech Synthesizer Bahasa Indonesia Berbasis Diphone MBROLA, Proceeding SNIKOM 2010 Universitas Sumatera Utara. Rozak, Mike, 1996, Talk to Your Computer and Have It Answer Back with the Microsoft Speech API, Microsoft Systems Journal. http://espeak.sourceforge.net/