commit to user
i
REGRESI ROBUST DENGAN METODE CONSTRAINED M ESTIMATION
PADA PRODUKSI PADI SAWAH DI JAWA TENGAH
oleh
IDA YUSWARA DYAH PITALOKA M0108046
SKRIPSI
ditulis dan diajukan untuk memenuhi sebagian persyaratan memperoleh gelar Sarjana Sains Matematika
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SEBELAS MARET SURAKARTA
commit to user
iii
MOTO
“Sesungguhnya bersama kesulitan ada kemudahan”
(QS. Al-Insyiroh : 6).
“Barang siapa menempuh jalan untuk memperoleh ilmu, maka Allah akan
memudahkan baginya jalan menuju surga”
commit to user
iv
PERSEMBAHAN
Skripsi ini kupersembahkan khusus untuk
Kedua orangtuaku tercinta yang selelu mendoakan yang terbaik untukku,
commit to user
v
ABSTRAK
Ida Yuswara Dyah Pitaloka, 2012. REGRESI ROBUST DENGAN METODE
CONSTRAINED M ESTIMATION PADA PRODUKSI PADI SAWAH DI
JAWA TENGAH, FMIPA, Universitas Sebelas Maret Surakarta.
Jawa Tengah merupakan provinsi penyangga padi sawah nasional. Produksi padi sawah dapat dipengaruhi oleh faktor luas panen, produktivitas, dan luas pengairan. Hubungan produksi padi sawah dan faktor-faktor tersebut dapat dimodelkan dengan analisis regresi, namun terdapat tujuh data pencilan pada data-data produksi padi dan faktor-faktor tersebut. Regresi robust dengan metode
constrained M estimation dapat digunakan untuk mengatasi adanya data pencilan. Tujuan dari penelitian ini untuk menyusun model regresi robust dengan metode
constrained M estimation pada produksi padi sawah di Jawa Tengah. Hasil
penelitian menunjukkan bahwa model regresinya adalah 283520 5,70 5016 dengan i adalah kabupaten di provinsi Jawa Tengah, adalah luas panen dan adalah produktivitas. Ini berarti bahwa faktor yang berpengaruh terhadap produksi padi sawah di Jawa Tengah adalah luas panen dan produktivitas.
commit to user
vi
ABSTRACT
Ida Yuswara Dyah Pitaloka, 2012. ROBUST REGRESSION WITH
CONSTRAINED M ESTIMATION METHOD IN WET LAND PADDY PRODUCTION IN CENTRAL JAVA, FMIPA, Universitas Sebelas Maret Surakarta.
Central Java is a province of the national rice buffer. Wet land paddy production can be influenced by factors in harvested area, productivity, and extensive irrigation. The relationship between wet land paddy production and these factors can be modeled with regression analysis, but there are seven outliers in the data of wet land paddy production data and factors. A robust regression with constrained M estimation method can be used to address the existence of data outliers. The purpose of this research is to find the robust regression model by the method of constrained M estimation in wet land paddy production in Central Java. The results showed that the regression model is 283520 5,70 5016 with i is the district in Central Java province, is the harvested area and is productivity. It means that factor influence in wet land paddy production in Central Java is the harvested area and productivity.
commit to user
vii
KATA PENGANTAR
Puji syukur kehadirat Allah SWT yang dengan siraman rahmat dan
hidayah-Nya telah memberi kekuatan pada penulis dalam menyusun skripsi ini.
Penulis menyadari bahwa tanpa bantuan dan dukungan dari pihak lain, tidak
mungkin dapat menyelesaikan skripsi ini. Untuk itulah pada kesempatan ini
penulis menyampaikan rasa terima kasih kepada
1. Ibu Dra. Yuliana Susanti, M.Si. dan Bapak Drs. Pangadi, M.Si., selaku dosen
Pembimbing I dan Pembimbing II yang telah memberikan bimbingan dan
pengarahan sehingga dapat diselesaikannya penyusunan tugas akhir ini,
2. semua pihak yang membantu penyusunan skripsi ini.
Semoga skripsi ini dapat bermanfaat bagi pembaca.
Surakarta, Juli 2012
commit to user
viii
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN PENGESAHAN ... ii
MOTO ... iii
PERSEMBAHAN ... iv
ABSTRAK ... v
ABSTRACT ... vi
KATA PENGANTAR ... vii
DAFTAR ISI ... viii
DAFTAR TABEL ... x
DAFTAR GAMBAR ... xi
I. PENDAHULUAN 1
1.1Latar Belakang ... 1
1.2 Perumusan Masalah ... 2
1.3 Tujuan Penelitian ... 3
1.4 Manfaat Penelitian ... 3
II. LANDASAN TEORI 4
2.1Tinjauan Pustaka ... 4
2.1.1 Model Regresi Linier ... 5
2.1.2 Metode Kuadrat Terkecil ... 5
2.1.3 Pengujian Asumsi Analisis Regresi ... 6
2.1.4 Pencilan ... 10
2.1.5 Pengujian Kriteria Statistik ... 11
2.1.6 Regresi Robust ... 13
2.1.7 Estimasi-CM ... 14
2.2 Kerangka Pemikiran ... 15
commit to user
ix
IV. HASIL DAN PEMBAHASAN 17
4.1Data ... 17
4.2Deteksi Pencilan ... 18
4.3Model Kuadrat Terkecil ... 19
4.3.1 Uji Asumsi Normalitas ... 19
4.3.2 Uji Asumsi Homoskedastisitas ... 20
4.3.3 Uji Asumsi Bebas Autokorelasi ... 21
4.3.4 Uji Asumsi Bebas Multikolinearitas ... 22
4.4Model Regresi Robust dengan Estimasi-CM ... 22
V. KESIMPULAN DAN SARAN 5.1 Kesimpulan ... 28
5.2 Saran ... 28
DAFTAR PUSTAKA ... 29
commit to user
x
DAFTAR TABEL
Halaman
Tabel 4.1. Hasil uji TRES dan 19
Tabel 4.2. Hasil uji multikolinearitas 22
Tabel 4.3. Nilai tiap iterasi pada estimasi-CM dengan empat
koefisien
23
Tabel 4.4. Hasil uji t pada estimasi-CM untuk tiga variabel
independen
25
Tabel 4.5. Nilai tiap iterasi pada estimasi-CM dengan tiga
koefisien
26
Tabel 4.6. Hasil uji t pada estimasi-CM untuk dua variabel
independen
commit to user
xi
DAFTAR GAMBAR
Halaman
Gambar 2.1. Pola yang memenuhi asumsi homoskedastisitas 7
Gambar 2.2. Pola-pola heteroskedastisitas 8
Gambar 2.3. Statistik d Durbin-Watson 9
Gambar 4.1. Plot antara produksi padi sawah ( ) dan luas panen ( ) 17
Gambar 4.2. Plot antara produksi padi sawah ( ) dan produktivitas
( )
17
Gambar 4.3. Plot antara produksi padi sawah ( ) dan luas pengairan
teknis ( )
18
Gambar 4.4. Plot probabilitas sisaan 20
Gambar 4.5. Plot kuadrat sisaan dengan estimasi Y 21
commit to user
1
BAB I PENDAHULUAN
1.1Latar Belakang Masalah
Jawa Tengah merupakan salah satu provinsi penyangga padi nasional.
Kebutuhan padi setiap tahun selalu meningkat sebagai akibat dari peningkatan
jumlah penduduk. Produksi padi sawah provinsi Jawa Tengah tahun 2010 sebesar
9,86 juta ton Gabah Kering Giling (GKG), naik 479,46 ribu ton atau 5,11%
dibandingkan produksi padi sawah Tahun 2009. Peningkatan produksi padi sawah
tahun 2010 selain disebabkan adanya kenaikan luas panen seluas 71,62 ribu ha
atau 4,31% juga disebabkan oleh kenaikan produktivitas padi sawah sebesar 0,43
kwintal/ha atau 0,76% (Badan Pusat Statistik, 2011). Selain itu, produksi padi
bergantung dari adanya pengairan yang baik. Menurut Sutawan (2001) air
merupakan salah satu unsur yang sangat penting dalam produksi pangan seperti
halnya padi. Jika air tidak tersedia maka produksi pangan akan terhenti. Salah satu
jenis pengairan adalah pengairan teknis, yaitu jenis pengairan dimana saluran
pemberi terpisah dari saluran pembuang agar penyediaan dan pembagian air ke
dalam lahan sawah dapat sepenuhnya diatur dan diukur dengan mudah. Mudakir
(2007) menunjukkan bahwa luas pengairan teknis berpengaruh positif terhadap
produksi padi sawah. Oleh karena itu, luas panen, produktivitas dan luas
pengairan teknis berpengaruh terhadap produksi padi sawah.
Produksi padi sawah dapat diprediksi menggunakan analisis regresi untuk
mengetahui hubungan antara variabel dependen yaitu produksi padi sawah dan
variabel independen yaitu luas panen, produktivitas dan luas pengairan teknis.
Analisis regresi merupakan teknik statistika yang digunakan untuk menyelidiki
dan memodelkan hubungan antara variabel dependen dan variabel independen.
Dalam analisis regresi harus dipenuhi asumsi-asumsi, yakni asumsi normalitas,
homoskedastisitas, bebas autokorelasi dan bebas multikolinearitas (Gujarati,
1978). Jika asumsi-asumsi tersebut tidak dipenuhi, maka estimator yang
dihasilkan tidak lagi merupakan estimator tak bias linier terbaik (best linear
commit to user
regresi linear, misalnya sisaan tidak berdistribusi normal atau sisaan tidak
menyebar secara acak. Salah satu penyebabnya terdapat data outlier (pencilan),
yaitu pengamatan yang sangat berbeda dengan pengamatan yang lain, mungkin
nilainya terlalu besar atau lebih kecil (Kartika, 1985). Data pencilan tidak boleh
dibuang karena dimungkinkan data pencilan tersebut mengandung informasi yang
penting. Oleh karena itu, diperlukan suatu metode agar tidak membuang informasi
tersebut, salah satu di antaranya dengan menggunakan metode yang bersifat
robust yakni regresi robust. Diharapkan dengan regresi robust tersebut nilai
estimasinya tidak banyak dipengaruhi oleh perubahan kecil dalam data.
Regresi robust merupakan metode regresi yang digunakan ketika terdapat
beberapa pencilan yang berpengaruh pada model. Metode ini merupakan alat
penting untuk menganalisis data yang dipengaruhi oleh pencilan sehingga
dihasilkan model yang robust atau resistance terhadap pencilan. Menurut Arslan
et al. (2002), salah satu estimasi regresi robust adalah estimasi constrained M
(estimasi-CM) yang pertama kali dikembangkan oleh Mendes dan Tyler pada
tahun 1995.
Metode estimasi-CM memiliki nilai breakdown point hingga 0,5 (Kent
and Tyler, 2001). Breakdown point adalah salah satu cara untuk mengukur
ke-robust-an suatu estimator (Yohai, 1987). Breakdown point merupakan proporsi
minimal dari banyaknya pencilan dibandingkan keseluruhan data yang dapat
ditangani sebelum pengamatan tersebut mempengaruhi model. Selain itu, metode
estimasi-CM ini dapat menangani pencilan pada variabel dependen dan variabel
independennya. Metode ini menggunakan nilai pembobot dengan fungsi Tukey’s
biweight untuk mendapatkan estimator.
1.2Perumusan Masalah
Berdasarkan latar belakang masalah dapat dirumuskan suatu permasalahan
yaitu bagaimana menyusun model regresi robust dengan metode estimasi-CM
commit to user
1.3Tujuan PenelitianTujuan dalam penelitian ini adalahmenyusun model regresi robust dengan
metode estimasi-CM produksi padi sawah di Jawa Tengah.
1.4Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini yakni dapat menambah
commit to user
4
BABII
LANDASAN TEORI
Ada dua subbab yang dibahas pada landasan teori ini, yaitu tinjauan
pustaka dan kerangka pemikiran. Tinjauan pustaka berisi pengertian-pengertian
yang berhubungan dengan pembahasan model estimasi regresi robust dengan
estimasi-CM. Kerangka pemikiran berisi langkah dan arah penelitian untuk
mencapai tujuan.
2.1Tinjauan Pustaka
Metode estimasi dalam regresi robust sebelum estimasi-CM yakni
estimasi-M, least trimmed square (LTS), dan least median square (LMS) (Chen,
2002). Metode estimasi-M pertama kali diperkenalkan oleh Huber pada tahun
1973. Estimasi-M merupakan metode regresi robust yang sering digunakan dan
dipandang baik untuk mengestimasi parameter yang disebabkan oleh -outlier
dan memiliki breakdown point 1/ . Metode estimasi LMS merupakan metode
high breakdown point yang diperkenalkan pertama kali oleh Rousseeuw pada
tahun 1984. LMS adalah modifikasi dari metode kuadrat terkecil biasa. Modifikasi
yang dilakukan dengan mengubah operator jumlah menjadi median. Parameter
dapat diestimasi dengan cara meminimumkan median dari kuadrat sisaan.Metode
estimasi LTS merupakan metode high breakdown point yang diperkenalkan
pertama kali oleh Rousseeuw pada tahun 1984. LTS merupakan suatu metode
pendugaan parameter regresi robust untuk meminimumkan jumlah kuadrat h
sisaan (fungsi objektif).
Kelemahan dari ketiga metode tersebut bahwa ketiganya hanya dapat
mengestimasi parameter yang disebabkan oleh pencilan pada variabel independen
dengan breakdown point lebih kecildari 0,5 sehingga dikembangkanlah
estimasi-CM.
Teori-teori yang relevan dan mendukung yang digunakan dalam penelitian
meliputi model regresi linear berganda, metode kuadrat terkecil, asumsi analisis
commit to user
2.1.1. Model Regresi Linear Berganda
Model regresi adalah model yang memberikan gambaran mengenai
hubungan antara variabel independen dengan variabel dependen (Sembiring,
2003). Bentuk umum dari model regresi linear berganda adalah
… , 1,2, … , 2.1 dengan
: harga variabel dependen pada pengamatan ke-i
, , , … , : parameter koefisien regresi
, , … , : variabel independen pada pengamatan ke-i
: sisaan ke-i dengan ~ 0, : banyaknya pengamatan
: banyaknya variabel independen.
2.1.2 Metode Kuadrat Terkecil (MKT)
Metode kuadrat terkecil pada prinsipnya adalah meminimumkan jumlah
kuadrat sisaan (JKS) yang dirumuskan sebagai
JKS ∑ ∑ … . 2.2
Cara untuk meminimumkan (2.2), dicari turunan JKS secara parsial terhadap
, 0, 1, 2, … , dan disamakan dengan nol sehingga diperoleh
commit to user
…
…
…
… . 2.4
Jika disusun dalam bentuk matriks maka persamaan (2.4) menjadi
2.5 dengan
,
1 1
1
, .
Penyelesaian persamaan (2.5) diperoleh dengan mengalikan kedua sisinya dengan
invers dari , sehingga estimator adalah
.
2.1.3 Pengujian Asumsi Analisis Regresi
Pengujian untuk mengetahui apakah model regresi memenuhi asumsi
regresi atau tidak sangat diperlukan pada model regresi. Uji asumsi tersebut ada
empat.
1. Normalitas
Analisis regresi linear mengasumsikan bahwa sisaan ( ) berdistribusi
normal. Menurut Gujarati (1978) pada regresi linear klasik diasumsikan bahwa
commit to user
Cara untuk menguji asumsi kenormalan adalah dengan uji
Kolmogorov-Smirnov. Uji ini didasarkan pada nilai D yang didefiniikan sebagai
max| | , 1, 2, . . , ,
dengan adalah fungsi distribusi frekuensi kumulatif relatif dari
distribusi teoritis di bawah , adalah distribusi frekuensi kumulatif
pengamatan sebanyak sampel, adalah sisaan berdistribusi normal.
Selanjutnya, nilai ini dibandingkan dengan nilai kritis dengan signifikansi
(tabel Kolmogorof-Smirnov). Jika nilai > atau , maka
asumsi kenormalan tidak dipenuhi.
2. Homoskedastisitas
Asumsi penting dalam analisis regresi adalah variasi sisaan ( ) pada
setiap variabel independen adalah homoskedastisitas. Asumsi ini dapat ditulis
sebagai
i =1, 2,…n.
Pengujian homoskedastisitas yaitu dengan melihat pola tebaran sisaan
( ) terhadap nilai estimasi . Jika tebaran sisaan bersifat acak (tidak
membentuk pola tertentu) maka dikatakan bahwa variansi sisaan homogen
(Draper dan Smith, 1998).
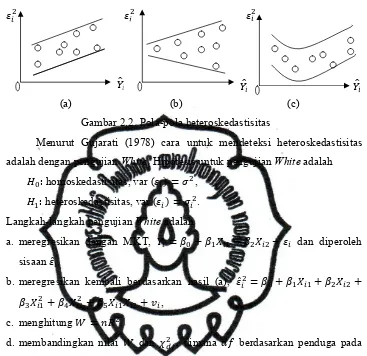
Gujarati (1978) menggambarkan beberapa plot sisa terhadap seperti
pada Gambar 2.1 dan Gambar 2.2. Jika hasil plot mirip pola pada Gambar 2.1,
maka asumsi homoskedastisitas dipenuhi karena titik-titik tersebar rata atau
tidak membentuk pola tertentu. Pada Gambar 2.2 (a) sampai (c) terlihat
membentuk pola tertentu, artinya terjadi heteroskedastisitas.
commit to user
(a) (b) (c)
Gambar 2.2. Pola-pola heteroskedastisitas
Menurut Gujarati (1978) cara untuk mendeteksi heteroskedastisitas
adalah dengan pengujian White. Hipotesis untuk pengujian White adalah
: homoskedastisitas, var ( , : heteroskedastisitas, var ( . Langkah-langkah pengujian White adalah
a. meregresikan dengan MKT, dan diperoleh
sisaan ̂,
b. meregresikan kembali berdasarkan hasil (a), ̂
,
c. menghitung ,
d. membandingkan nilai dan , dimana berdasarkan penduga pada
(b). jika , maka ditolak.
3. Bebas multikolinearitas
Menurut Montgomery dan Peck (1992), kolinearitas terjadi karena
terdapat korelasi yang cukup tinggi di antara variabel independen. Variance
inflation factor (VIF) merupakan salah satu cara untuk mengukur besar
kolinearitas dan didefinisikan sebagai 1 1
dengan 1,2, … , dan adalah banyaknya variabel independen.
adalah koefisien determinasi yang dihasilkan dari regresi variabel independen
dengan variabel independen lain . Nilai VIF menjadi semakin
commit to user
Jika nilai VIF lebih dari 10, multikolinearitas memberikan pengaruh yang
serius pada pendugaan metode kuadrat terkecil.
4. Bebas autokorelasi
Asumsi penting dari regresi linear adalah bahwa tidak ada autokorelasi
antara serangkaian pengamatan yang diurutkan menurut waktu. Kebebasan
antar sisaan dapat dideteksi secara grafis dan empiris. Pendeteksian
autokorelasi secara grafis yaitu dengan melihat pola tebaran sisaan terhadap
urutan waktu. Jika tebaran sisaan terhadap urutan waktu tidak membentuk
suatu pola tertentu atau bersifat acak maka dapat disimpulkan tidak ada
autokorelasi antar sisaan (Draper dan Smith, 1998).
Pengujian secara empiris dilakukan dengan menggunakan statistik uji
Durbin-Watson. Adapun rumusan matematis uji Durbin-Watson adalah:
∑ ∑
Kaidah keputusan dalam uji Durbin-Watson adalah sebagai berikut.
a. : 0 vs : 0. Menolak pada tingkat signifikansi jika
yang berarti terdapat autokorelasi positif.
b. : 0 vs : 0. Menolak pada tingkat signifikansi jika
4 yang berarti terdapat autokorelasi negatif.
c. : 0 vs : 0. Menolak pada tingkat signifikansi 2 jika
dan 4 yang berarti terdapat autokorelasi negatif ataupun
positif.
d. Untuk uji DW dapat dilihat pada Gambar 2.3.
H0 diterima
2 4 4 Gambar 2.3. Statistik d Durbin-Watson
commit to user
2.1.4 Pencilan (Outlier)Terkadang pada beberapa kasus ditemukan adanya data yang jauh dari
pola kumpulan data keseluruhan yang didefinisikan sebagai data pencilan.
Menurut Chen (2002) terdapat 3 kelas masalah yang dapat menggunakan teknik
regresi robust, yaitu
1. masalah dengan pencilan yang terdapat pada variabel (variabel dependen),
2. masalah dengan pencilan yang terdapat pada variabel (variabel independen),
dan
3. masalah dengan pencilan yang terdapat pada keduanya yaitu pada variabel
(variabel dependen) dan variabel (variabel independen).
Permasalahan yang muncul akibat adanya pencilan adalah
1. sisaan yang besar dari model yang terbentuk 0,
2. variansi dari data akan menjadi lebih besar, dan
3. estimasi interval akan memiliki rentang yang lebih besar.
Menurut Draper dan Smith (1998), metode yang digunakan dalam
mengidentifikasi pencilan terhadap variabel adalah studientized deleted residual
(TRES) yang didefinisikan sebagai
1 1
dengan adalah prediksi dari bila pengamatan ke- tidak diikutsertakan,
adalah jumlah variabel independen, adalah banyaknya pengamatan dan
adalah simpangan baku beda ( ), 1, 2, … , , , ,
′ ′ , 1.
Hipotesis untuk menguji adanya pencilan adalah
: Pengamatan ke- bukan pencilan,
: Pengamatan ke- merupakan pencilan.
Kriteria pengujian yang melandasi keputusan adalah ditolak jika | |
commit to user
Metode yang digunakan dalam mengidentifikasi pencilan terhadap
variabel adalah nilai pengaruh (leverage point). Nilai Pengaruh ( ) dari
pengamatan , menunjukkan besarnya peranan terhadap dan
didefinisikan sebagai
′ ′ , 1, 2, … , ,
dengan = [ 1 … ] adalah vektor baris yang berisi nilai – nilai dari
variabel independen dalam pengamatan ke- . Nilai berada diantara 0 dan 1,
∑ dengan 1 dan ∑ / . Jika lebih besar dari 2 dengan
2 2 ∑ 2 ,
maka pengamatan ke- dikatakan pencilan terhadap .
2.1.5 Pengujian Kriteria Statistik
Gujarati (1978) menyatakan bahwa uji signifikansi merupakan prosedur
yang digunakan untuk menguji kebenaran atau kesalahan dari hasil hipotesis nol
dari sampel. Ide dasar yang melatarbelakangi pengujian signifikansi adalah uji
statistik (estimator) dari distribusi sampel dari suatu statistik di bawah hipotesis
nol. Keputusan untuk mengolah dibuat berdasarkan nilai uji statistik yang
diperoleh dari data yang ada.
Uji statistik terdiri dari pengujian koefisien regresi secara bersama-sama
(uji F), pengujian koefisien regresi parsial (uji t), dan pengujian koefisien
determinasi Goodness of fit test R .
1. Pengujian Signifikansi Simultan (Uji F)
Uji F dilakukan untuk mengetahui apakah variabel-variabel independen
secara keseluruhan signifikan secara statistik dalam mempengaruhi variabel
dependen. Jika nilai F lebih besar dari nilai F tabel, maka variabel-variabel
independen secara keseluruhan berpengaruh terhadap variabel dependen.
Hipotesis yang digunakan adalah
commit to user
Nilai hitung dirumuskan sebagai
/
/ 1
dimana
jumlah parameter yang diestimasi termasuk konstanta jumlah observasi
Kriteria pengujian yang digunakan pada tingkat signifikansi 5% dinyatakan
sebagai
a. diterima dan ditolak apabila F< F tabel atau p-value > yang
artinya variabel independen secara serentak atau bersama-sama tidak
mempengaruhi variabel dependen secara signifikan,
b. ditolak dan diterima apabila F hitung > F tabel atau p-value <
yang artinya variabel independen secara serentak dan bersama-sama
mempengaruhi variabel yang dijelaskan secara signifikan.
2. Pengujian Signifikansi Parameter Individual (Uji t)
Uji signifikansi parameter individual (uji t) dilakukan untuk melihat
signifikansi dari pengaruh variabel independen terhadap variabel dependen
secara individual dan menganggap variabel lain konstan. Hipotesis yang
digunakan adalah
: 0, 1, 2, … , ,
: 0, 1, 2, … , .
Nilai t hitung dapat divari dengan rumus
dimana
parameter yang diestimasi, nilai pada hipotesis,
standar error .
commit to user
a. jika t-hitung > t-tabel atau p-value < , maka ditolak. Artinya salah
satu variabel independen mempengaruhi variabel dependen secara
signifikan.
b. jika t-hitung < t-tabel atau p-value > , maka diterima. Artinya salah
satu variabel independen tidak mempengaruhi variabel dependen secara
signifikan.
3. Koefisien Determinasi
Gujarati (1978) menyatakan bahwa koefisien determinasi pada
intinya mengukur seberapa jauh kemampuan suatu model dalam menerangkan
variasi variabel dependen. Nilai adalah antara nol dan satu. Nilai yang
kecil (mendekati nol) berarti kemampuan satu variabel dalam menjelaskan
variabel dependen sangat terbatas. Nilai yang mendekati satu berarti
variabel-variabel independen memberikan hampir semua informasi dibutuhkan untuk
memprediksi variabel dependen.
Kelemahan mendasar penggunaan determinasi adalah bias terhadap
jumlah variabel independen yang dimasukkan ke dalam model. Setiap
penambahan satu variabel pasti meningkat tidak peduli apakah variabel
tersebut berpengaruh secara signifikan terhadap variabel dependen. Oleh
karena itu, banyak peneliti menganjurkan untuk menggunakan adjusted pada
saat mengevaluasi model regresi terbaik. Nilai koefisien determinasi diperoleh
dengan rumus
Asumsi regresi klasik sering tidak dipenuhi dalam memprediksi model
regresi, misal tidak dipenuhinya asumsi kenormalan atau asumsi
homoskedastisitas. Pelanggaran tersebut dapat dikarenakan adanya pencilan.
commit to user
sisaan tidak normal (Draper dan Smith, 1998). Analisis regresi robust merupakan
alternatif dari MKT. Seringkali transformasi tidak akan menghilangkan atau
melemahkan pengaruh dari pencilan yang akhirnya estimasi menjadi bias dan
estimasi parameter menjadi tidak valid. Oleh karena itu, sangat tepat jika
menggunakan metode regresi robust yang tahan terhadap pengaruh pencilan
sehingga menghasilkan estimasi yang lebih baik.
2.1.7 Estimasi-CM
Estimasi-CM diperkenalkan pertama kali oleh Mendes dan Tyler pada
Tahun 1995 yang memiliki breakdown point min , 1 atau 50% ketika
0,5 (Arslan et al., 2002). Breakdown point adalah ukuran umum proporsi dari pencilan yang dapat ditangani sebelum pengamatan tersebut mempengaruhi
model. Masalah estimasi-CM adalah menentukan global minimum dari fungsi
objektif
, log
dengan “ ” adalah rata-rata nilai aritmatik dan ∑ untuk
1, 2, … , dan 0, 1, … , , dimana , 0, dan subjek constraint
dan adalah jumlah pengamatan.
Dalam kasus ini, bersifat terbatas, fungsi tidak turun untuk 0
dengan 0 dan didefinisikan sebagai fungsi pembobot Tukey’s beweight
2 2 6 , | | 1 1
6, | | 1.
commit to user
′ 1 , | | 1
0, | | 1
dengan dan 4. Sisaan awal yang digunakan pada estimasi-CM adalah sisaan yang diperoleh dari MKT. Kemudian dengan mencari pembobot untuk melakukan iterasi dengan MKT terboboti secara iterasi yang disebut iteratively reweighted least square (IRLS) hingga mencapai konvergen. Adapun pembobot IRLS adalah
Berdasarkan tinjauan pustaka, dapat dibuat kerangka pemikiran bahwa
asumsi regresi klasik sering tidak dipenuhi dalam menentukan nilai parameter
regresi, misal tidak dipenuhinya asumsi kenormalan atau asumsi
homoskedastisitas. Hal ini terjadi karena pada suatu data terdapat observasi pada
variabel dependen maupun independen yang mengandung pencilan sehingga
mengakibatkan sisaan tidak berdistribusi normal atau sisaan tidak menyebar
secara acak. Oleh karena itu, dalam melakukan estimasi parameter tidak bisa
membuang data pencilan tersebut ataupun menggunakan metode yang biasa
digunakan yaitu MKT.
Penyelesaian masalah tersebut adalah harus digunakannya suatu metode
yang kekar terhadap adanya pencilan yaitu dengan menggunakan regresi robust.
Regresi robust yang digunakan adalah estimasi-CM yang meminimumkan fungsi
objektif dengan fungsi pembobot Tukey’s biweight. Fungsi pembobot ini
digunakan untuk mendapatkan nilai pembobot yang digunakan dalam perhitungan
MKT terbobot. Kemudian melakukan iterasi sampai diperoleh kekonvergenan
commit to user
16
BAB III
METODE PENELITIAN
Data yang digunakan dalam penelitian ini adalah produksi padi sawah
sebagai variabel dependen , sedangkan luas panen , produktivitas ,
dan luas pengairan teknis sebagai variabel independen. Data diambil
sebanyak 35 kabupaten dan kota di Jawa Tengah dari Buku Jawa Tengah Dalam
Angka 2011. Langkah-langkah yang digunakan dalam penelitian ini yaitu
1. eksplorasi data,
2. mendeteksi adanya pencilan,
3. menduga koefisien regresi dengan MKT yang akan digunakan sebagai
nilai awal untuk menentukan koefisien regresi robust debgan
estimasi-CM,
4. menguji asumsi klasik regresi linier,
5. menduga koefisien regresi dengan estimasi-CM dengan langkah
a. memperoleh nilai awal dan menghitung sisaan awal yang
diperoleh dari MKT pada langkah 3 kemudian dihitung untuk
mendapatkan nilai ,
b. menghitung nilai pembobot ,
c. menggunakan MKT terbobot untuk mendapatkan penduga kuadrat
terkecil terbobot ′ ′ ,
d. menjadikan sisaan langkah (c) sebagai sisaan awal langkah (b)
sehingga diperoleh nilai dan pembobot yang baru, dan
e. melakukan iterasi hingga konvergen dan diperoleh , , … ,
yang merupakan estimasi-CM,
commit to user
17
BAB IV
HASIL DAN PEMBAHASAN
4.1Data
Bab ini menyajikan hasil analisis data sekunder produksi padi sawah di
Jawa Tengah Tahun 2010 yang diperoleh dari Badan Pusat Statistik. Data tersebut
meliputi produksi padi sawah sebagai variabel dependen , luas panen ,
produktivitas padi sawah dan luas pengairan teknis sebagai variabel
independen.
Adapun plot tiap variabel independen dengan variabel dependen disajikan
pada gambar –gambar berikut untuk mengetahui hubungan linier antara
masing-masing variabel independen dan variabel dependen.
140000
commit to user
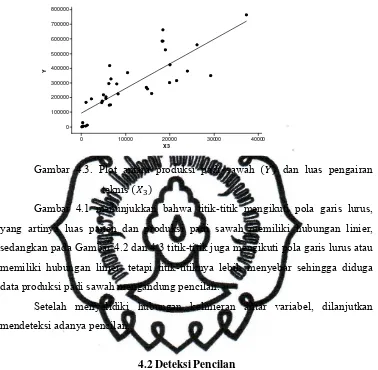
Gambar 4.3. Plot antara produksi padi sawah dan luas pengairan
teknis
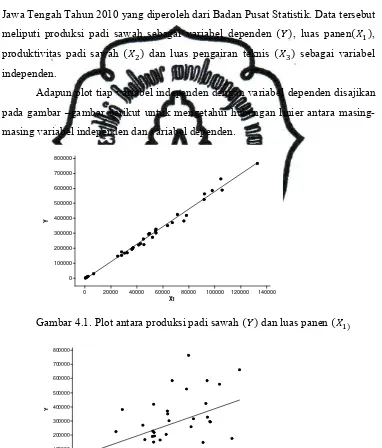
Gambar 4.1 menunjukkan bahwa titik-titik mengikuti pola garis lurus,
yang artinya luas panen dan produksi padi sawah memiliki hubungan linier,
sedangkan pada Gambar 4.2 dan 4.3 titik-titik juga mengikuti pola garis lurus atau
memiliki hubungan linier, tetapi titik-titiknya lebih menyebar sehingga diduga
data produksi padi sawah mengandung pencilan.
Setelah menyelidiki hubungan kelinieran antar variabel, dilanjutkan
mendeteksi adanya pencilan.
4.2Deteksi Pencilan
Berdasar statistik uji untuk mengetahui pencilan terhadap yaitu TRES
dengan menarik kesimpulan menolak apabila nilai TRES > maka
diperoleh kesimpulan seperti pada Tabel 4.1 bahwa pengamatan ke 15, 27, 31 dan
33 merupakan pencilan terhadap variabel .
Berdasar statistik uji untuk mengetahui pencilan terhadap yaitu hii yang
dengan menarik kesimpulan menolak apabila nilai > 2 / maka diperoleh
kesimpulan seperti pada Tabel 4.1 bahwa pengamatan ke 1, 28 dan 33 merupakan
pencilan terhadap variabel . Nilai TRES dan secara lengkap ada pada
commit to user
Tabel 4.1. Hasil uji TRES dan
Pengamatan TRES ttabel 2k /n
1 0.260026 > 0,2286
15 3.50196 > 2,042
27 -2.15301 < -2,042
28 0.259067 > 0,2286
31 2.18431 > 2,042
33 3.66633 > 2,042 0.235876 > 0,2286
4.3Model Kuadrat Terkecil
Koefisien regresi dari metode kuadrat terkecil digunakan pada penelitian
ini sebagai nilai awal yang akan digunakan untuk menduga koefisien regresi
dengan estimasi-CM. Model regresi dengan metode kuadrat terkecil adalah
239519 5,73 4285 0,216 , 1, 2, … , 35 (4.1)
dengan
: estimasi produksi padi sawah (ton) di kabupaten ke-i
: luas panen (ha) di kabupaten ke-i
: produktivitas padi sawah (kwintal/ha) di kabupaten ke-i
: luas pengairan teknis (ha) di kabupaten ke-i.
Adapun langkah-langkah dan hasil MKT terdapat pada Lampiran 2.
Selanjutnya dilakukan uji asumsi klasik untuk melihat apakah model yang diteliti
memenuhi asumsi klasik atau tidak. Hasil uji asumsi klasik ada empat.
4.3.1 Uji Asumsi Normalitas
Pengujian kenormalan digunakan untuk mengetahui apakah sisaan
berdistribusi normal atau tidak. Plot kenormalan untuk sisaan dari model produksi
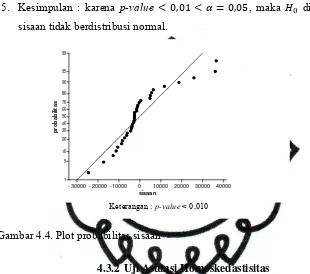
padi sawah disajikan pada Gambar 4.4.
Gambar 4.4 menunjukkan pola penyebaran sisaan tidak mengikuti pola
garis lurus, ini berarti asumsi kenormalan pada sisaan tidak dipenuhi. Pengujian
kenormalan dapat juga digunakan uji Kolmogorof-Smirnov sebagai berikut.
commit to user
: sisaan tidak berdistribusi normal. 2. Dipilih α 0,05.
3. Daerah kritis: H ditolak jika p-value 0,05.
4. Statistik uji : hasil menunjukkan pada Gambar 4.4 bahwa p-value < 0,010.
5. Kesimpulan : karena p-value 0,01 0,05, maka ditolak artinya
sisaan tidak berdistribusi normal.
40000
Gambar 4.4. Plot probabilitas sisaan
4.3.2 Uji Asumsi Homoskedastisitas
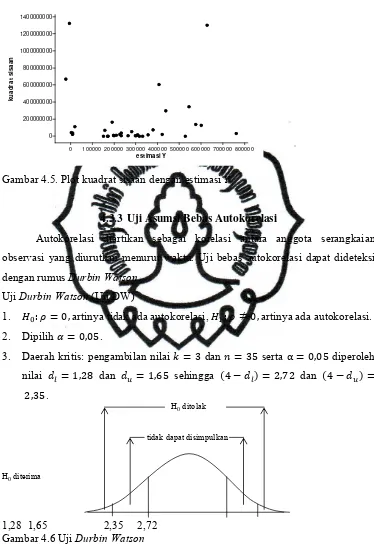
Pendeteksian homoskedastisitas dapat dilakukan dengan melihat pola plot.
Plot kesamaan variansi untuk data sisaan pada model produksi padi sawah di Jawa
Tengah disajikan pada gambar 4.5.
Gambar 4.5 menunjukkan bahwa variansi sisaan dari satu pengamatan ke
pengamatan yang lain tidak berpola acak yang mengindikasikan bahwa variansi
sisaan tidak konstan sehingga dapat disimpulkan asumsi homoskedastisitas tidak
dipenuhi. Selain itu, dapat dilakukan uji White. Jika nilai , maka sisaan
mengandung masalah heteroskedastisitas. Hasil pengujian menunjukkan bahwa
35 0,867 30,345 dan nilai , ; 16,92. Karena nilai , ; ,
maka disimpulkan bahwa asumsi homoskedastisitas tidak dipenuhi (Lampiran 3).
commit to user
Gambar 4.5. Plot kuadrat sisaan dengan estimasi
4.3.3 Uji Asumsi Bebas Autokorelasi
Autokorelasi diartikan sebagai korelasi antara anggota serangkaian
observasi yang diurutkan menurut waktu. Uji bebas autokorelasi dapat dideteksi
dengan rumus Durbin Watson.
Uji Durbin Watson (Uji DW)
1. : 0, artinya tidak ada autokorelasi, : 0, artinya ada autokorelasi.
2. Dipilih 0,05. Gambar 4.6 Uji DurbinWatson
4. Statistik uji: hasil menunjukkan bahwa nilai 1,98150 .
commit to user
5. Kesimpulan : berdasarkan hasil diperoleh nilai 1.98150 berada
pada posisi 1,65 maka tidak ditolak. Artinya, asumsi
bebas autokorelasi pada model produksi padi sawah di Jawa Tengah Tahun
2010 dipenuhi.
4.3.4 Uji Asumsi Bebas Multikolinearitas
Pengujian multikolinearitas bertujuan untuk mengetahui ada tidaknya
hubungan linear antara variabel independen. Pendeteksian adanya
mutikolinearitas dapat dilakukan dengan melihat nilai VIF. Hasil uji
multikolinearitas dapat dilihat pada Tabel 4.2.
Tabel 4.2. Hasil uji multikolinearitas
Variabel independen VIF Keterangan
(Luas panen) 3.330 < 10 Tidak terdapat multikolinearitas
(Produktivitas padi sawah) 1.153 < 10 Tidak terdapat multikolinearitas
(Luas pengairan teknis) 3.145 < 10 Tidak terdapat multikolinearitas
Tabel 4.2 menunjukan bahwa nilai VIF untuk semua variabel independen,
baik variabel luas panen , produktivitas padi sawah , dan luas pengairan
teknis adalah lebih kecil dari 10, sehingga dapat disimpulkan bahwa asumsi
bebas multikolinearitas dipenuhi.
Berdasarkan pengujian asumsi klasik pada model produksi padi sawah di
Jawa Tengah tahun 2010 menggunakan analisis regresi diperoleh bahwa asumsi
normalitas dan asumsi homoskedastisitas telah dilanggar sehingga diperlukan
penanganan terhadap pelanggaran asumsi-asumsi tersebut agar diperoleh model
regresi yang tepat di antaranya dengan menggunakan regresi robust estimasi-CM.
4.4Model Regresi Robust dengan Estimasi-CM
Proses perhitungan estimasi-CM secara iterasi diawali dengan menentukan
estimasi koefisien regresi yang diperoleh dari MKT yaitu =
( 239519: 5,73 ; 4285; 0,216) kemudian berdasarkan langkah-langkah menduga
commit to user
dan
. Proses iterasi menggunakan MKT terboboti dilanjutkan denganmenghitung nilai dan menghitung pembobot yang baru dan dilakukan
pendugaan parameter secara berulang-ulang sampai konvergen. Koefisien regresi
tiap iterasi ditunjukkan pada Tabel 4.3.
Tabel 4.3. Nilai tiap iterasi pada estimasi-CM dengan empat koefisien
iterasi
Tabel 4.3 menunjukkan kekonvergenan koefisien regresi . Koefisien
konvergen ke nilai -285356, koefisien konvergen ke nilai 5,72, koefisien
regresi konvergen ke nilai 5047, dan koefisien konvergen ke nilai -0,07.
Berdasarkan hasil yang diperoleh dapat ditulis model regresi robust dengan
commit to user
R2adjusted = 99,8% dan s = 8829,31. Interpretasi model yaitu sebesar 99,8%
produksi padi sawah dapat diterangkan oleh variabel luas panen, produktivitas
padi sawah, dan luas pengairan teknis, sedangkan sebesar 0,2 % diterangkan oleh
variabel yang lain. Setiap peningkatan satu ha luas panen dan satu kwintal/ha
produktivitas padi sawah di kabupaten ke-i akan meningkatkan produksi padi
sawah di Jawa tengah di kabupaten ke-i masing-masing sebesar 5,72 ton dan 5047
ton, setiap peningkatan satu ha luas pengairan teknis di kabupaten ke-i akan
menurunkan produksi padi sawah di kabupaten ke-i sebesar 0,070 ton.
Uji serentak digunakan untuk mengetahui apakah variabel-variabel
independen secara keseluruhan signifikan dalam mempengaruhi variabel
independen.
1. 0, 1,2,3
(luas panen, produktivitas padi sawah atau luas pengairan teknis tidak
berpengaruh secara signifikan terhadap produksi padi sawah).
0, untuk suatu 1,2,3
(paling tidak ada salah satu di antara luas panen, produktivitas padi sawah atau
luas pengairan teknis berpengaruh secara signifikan terhadap produksi padi
sawah).
2. Dipilih 0,05.
3. Daerah kritis: ditolak jika 0,05.
4. Statistik uji : hasil menunjukkan bahwa nilai 0,000.
5. Kesimpulan : karena 0,000 0,05 maka ditolak.
Artinya, paling tidak ada salah satu di antara luas panen, produktivitas padi
sawah atau luas pengairan teknis berpengaruh secara signifikan terhadap
produksi padi sawah.
Selanjutnya dilakukan uji parsial untuk mengetahui signifikansi atau
pengaruh masing-masing variabel independen terhadap model regresi yang
commit to user
Tabel 4.4. Hasil uji t pada estimasi-CM untuk tiga variabel independen
Variabel Kesimpulan
Luas panen 0,000 0,05 Signifikan Produktivitas padi sawah 0,000 0,05 Signifikan Luas pengairan teknis 0,881 0,05 Tidak signifikan
Tabel 4.4 menunjukkan bahwa luas panen dan produktivitas padi sawah
adalah signifikan dalam mempengaruhi jumlah produksi padi sawah di Jawa
Tengah, sedangkan luas pengairan teknis tidak berpengaruh signifikan.
Karena variabel luas pengairan teknis tidak berpengaruh signifikan
terhadap produksi padi sawah, maka variabel tersebut dikeluarkan dari model,
kemudian diregresikan kembali dengan estimasi-CM antara variabel produksi padi
sawah dengan luas panen dan produktivitas dengan regresi robust dengan metode
estimasi-CM. Koefisien regresi konvergen ditunjukkan pada Tabel 4.5.
Tabel 4.5 menunjukkan koefisien regresi telah konvergen. Koefisien
konvergen ke nilai -283520, koefisien konvergen ke nilai 5,7, dan koefisien
konvergen ke nilai 5016, sehingga diperoleh model regresi robust dengan
estimasi-CM yaitu 283520 5,70 5016 dengan adjusted= 99,8%
dan s = 8684,51. Interpretasi model yaitu sebesar 99,8% produksi padi sawah
dapat diterangkan oleh variabel luas panen dan produktivitas, sedangkan sebesar
0,2% diterangkan oleh variabel lain. Setiap peningkatan satu ha luas panen di
kabupaten ke-i dan satu kwintal/ha produktivitas di kabupaten ke-i akan
meningkatkan produksi padi sawah di Jawa Tengah pada kabupaten ke-i
masing-masing sebesar 5,70 ton dan 5016 ton.
Kemudian untuk mengetahui apakah variabel-variabel independen
berpengaruh terhadap variabel dependen dilakukan uji serentak pada model
regresi robust estimasi-CM.
1. 0, 1,2
(luas panen atau produktivitas padi sawah tidak berpengaruh secara signifikan
terhadap produksi padi sawah).
0, untuk suatu 1,2
(paling tidak ada salah satu di antara luas panen atau produktivitas padi sawah
commit to user
2. Dipilih 0,05.
3. Daerah kritis: ditolak jika 0,05.
4. Statistik uji : hasil menunjukkan bahwa nilai 0,000.
5. Kesimpulan : karena 0,000 0,05 maka ditolak.
Artinya paling tidak ada salah satu luas panen atau produktivitas padi sawah
yang berpengaruh secara signifikan terhadap produksi padi sawah.
Tabel 4.5. Nilai tipa iterasi pada estimasi-CM dengan tiga koefisien
iterasi
Selanjutnya dilakukan uji parsial untuk mengetahui signifikansi atau
pengaruh masing-masing variabel independen terhadap model regresi yang
commit to user
Tabel 4.6. Hasil uji t pada estimasi-CM untuk dua variabel independen
Variabel Kesimpulan
Luas panen 0,000 0,05 Signifikan Produktivitas padi sawah 0,000 0,05 Signifikan
Tabel 4.6. menunjukkan bahwa luas panen dan produktivitas padi sawah
mempengaruhi jumlah produksi padi sawah di Jawa Tengah.
Berdasarkan analisis di atas, berarti upaya pemerintah dalam meningkatkan
produksi padi sawah di jawa Tengah adalah dengan menambah luas panen yaitu
dengan penambahan luas lahan sawah. Selain itu, pemerintah juga dapat
meningkatkan produktivitas padi sawah, misalnya dengan cara penggunaan
commit to user
28
BAB V PENUTUP
5.1 Kesimpulan
Berdasarkan hasil pembahasan, dapat ditarik dua kesimpulan.
1. Model regresi robust dengan metode estimasi-CM dalam memprediksi
produksi padi sawah di Jawa Tengah adalah
283520 5,70 5016 , 1, 2, … , 35
dengan adjusted= 99,8%. Interpretasi model yaitu sebesar 99,8% produksi
padi sawah dapat diterangkan oleh variabel luas panen dan produktivitas,
sedangkan sebesar 0,2% diterangkan oleh variabel lain. Setiap peningkatan satu
ha luas panen di kabupaten ke-i dan satu kwintal/ha produktivitas di kabupaten
ke-i akan meningkatkan produksi padi sawah di kabupaten ke-i di Jawa Tengah
masing-masing sebesar 5,70 ton dan 5016 ton.
2. Variabel independen yang berpengaruh dalam model regresi robust
menggunakan estimasi-CM dalam memprediksi produksi padi sawah di Jawa
Tengah adalah variabel luas panen dan produktivitas. Sedangkan variabel luas
pengairan teknis tidak berpengaruh signifikan.
5.2 Saran
Bagi peneliti yang tertarik dengan estimasi-CM, dapat melanjutkan