iv
Puji syukur penulis panjatkan ke hadiran Allah SWT. yang telah melimpahkan segala rahmat dan hidayah-Nya, sehingga tersusunlah Skripsi yang berjudul “ANALISIS DATA MINING UNTUK PREDIKSI PERPANJANGAN KONTRAK MENGGUNAKAN METODE NAÏVE BAYES”.
Skripsi tersusun dalam rangka melengkapi salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi Pelita Bangsa.
Penulis sungguh sangat menyadari, bahwa penulisan Skripsi ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari berbagai pihak. Sudah selayaknya, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada:
a. Bapak Dr. Ir. Suprianto, M.P selaku Ketua STT Pelita Bangsa
b. Bapak Aswan S. Sunge, S.E., M.Kom. selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
c. Bapak Drs. Muhtajuddin Danny S.Kom., M.Kom. selaku Pembimbing Utama dan Bapak Windi, S.Pd., M.M. yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
d. Seluruh Dosen STT Pelita Bangsa yang telah membekali penulis dengan wawasan dan ilmu di bidang teknik informatika.
e. Seluruh staf STT Pelita Bangsa yang telah memberikan pelayanan terbaiknya kepada penulis selama perjalanan studi jenjang Strata 1.
f. Rekan-rekan mahasiswa STT Pelita Bangsa, khususnya angkatan 2014, yang telah banyak memberikan inspirasi dan semangat kepada penulis untuk dapat menyelesaikan studi jenjang Strata 1.
g. Ibu dan Ayah tercinta yang senantiasa mendo’akan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
v
terdapat dalam Skripsi ini dan berharap semoga Skripsi ini dapat memberikan manfaat bagi khasanah pengetahuan Teknologi Informasi di lingkungan STT Pelita Bangsa khususnya dan Indonesia pada umumnya.
Bekasi, 24 September 2018
vi
PERSETUJUAN ... i
PENGESAHAN ... ii
PERNYATAAN KEASLIAN PENELITIAN ... iii
KATA PENGANTAR ... iv
DAFTAR ISI ... vi
DAFTAR TABEL ... x
DAFTAR GAMBAR ... xii
DAFTAR LAMPIRAN ... xiii
ABSTRACT ... xiv ABSTRAK ... xv BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Identifikasi Masalah ... 2 1.3 Rumusan Masalah ... 3 1.4 Batasan Masalah... 3
1.5 Tujuan dan Manfaat ... 3
1.5.1 Tujuan ... 3
1.5.2 Manfaat ... 4
vii
2.1 Kajian Pustaka ... 6
2.2 Dasar Teori ... 9
2.2.1 Data Mining ... 9
2.2.2 Pengelompokkan Data mining ... 10
2.2.3 Tahap-Tahap Data mining ... 11
2.2.4 Tugas Tugas Data Mining ... 12
2.3 Naive Bayes ... 12
2.3.1 Persamaan Metode Naive Bayes ... 16
2.3.2 Alur Metode Naïve Bayes ... 17
2.4 Karyawan ... 20
2.4.1 Pengertian Kinerja Karyawan ... 21
2.5 CRISP-DM (Cross-Industry Standard Process for Data Mining) ... 21
2.6 Analisis Data ... 22
BAB III METODE PENELITIAN... 18
3.1 Objek Penelitian ... 18
3.1.1 Profil Perusahaan ... 18
3.1.2 Tujuan Perusahaan ... 18
3.1.3 Visi dan Misi ... 23
3.1.4 Struktur Organisasi ... 23
viii
3.4.1 Populasi ... 24
3.4.2 Sample ... 24
3.5 Sumber Data ... 24
3.6 Metode Pengumpulan Data ... 26
3.7 Rancanga Penelitian ... 27
3.8 Instrumen Penelitian... 28
3.8.1 Kebutuhan Perangkat Lunak (Software) ... 28
3.8.2 Kebutuhan Perangkat Keras (Hardware) ... 29
3.9 Jenis Penelitian ... 30
3.10 Teknik Analisis Data ... 30
3.11 Tahapan Penelitian ... 34
BAB IV ... 37
4.1 Hasil ... 37
4.4.1 Penentuan Atribut... 37
4.2 Perhitungan Naïve Bayes ... 39
4.2.1 Perhitungan Probabilitas Kelas ... 44
4.2.2 Menghitung Probabilitas Masing-masing Atribut ... 44
4.2.3 Menghitung Probabilitas Akhir Untuk Setiap Kelas ... 47
4.2.4 Kasus Perhitungan Naïve Bayes ... 47
ix
4.3.2 Proses Training dan Testing ... 51
4.3.3 Hasil Performance Vector ... 52
4.4 Pembahasan ... 53
4.4.1 Evaluasi (Evaluation) ... 53
4.4.2 AUC (Area Under Curve) ... 55
4.4.3 Hasil Klasifikasi Class ... 56
4.2.4 Penyebaran (Deployment) ... 57
4.4.2 Hasil Analisa Naïve Bayes Prediksi Tidak ... 59
4.4.2 Hasil Analisa Naïve Bayes Prediksi Ya ... 60
BAB V PENUTUP ... 61
5.1 Kesimpulan ... 61
5.2 Saran ... 61
DAFTAR PUSTAKA ... 63
x
Tabel 3. 1 Keterangan Atribut ... 31
Tabel 3. 2 Atribut Penelitian ... 33
Tabel 4. 1 Atribut yang digunakan ... 37
Tabel 4. 2 Bobot Nilai ... 38
Tabel 4. 3 Atribut Kelas ... 39
Tabel 4. 4 Atribut Ketelitian ... 39
Tabel 4. 5 Atribut Kreativitas... 40
Tabel 4. 6 Atribut Tanggung Jawab ... 40
Tabel 4. 7 Atribut Kerjasama ... 41
Tabel 4. 8 Atribut Pencapaian Tujuan... 41
Tabel 4. 9 Atribut Inisiatif ... 42
Tabel 4. 10 Atribut Kehadiran ... 42
Tabel 4. 11 Atribut Inovasi ... 43
Tabel 4. 12 Atribut Loyalitas ... 43
Tabel 4. 13 Probabilitas Kelas ... 44
Tabel 4. 14 Probabilitas Ketelitian ... 44
Tabel 4. 15 Probabilitas Kreativitas ... 45
Tabel 4. 16 Probabilitas Tanggung Jawab ... 45
Tabel 4. 17 Probabilitas Kerjasama ... 45
Tabel 4. 18 Probabilitas Pencapaian Tujuan ... 45
Tabel 4. 19 Probabilitas Inisiatif ... 46
xi
Tabel 4. 22 Probabilitas Loyalitas ... 46 Tabel 4. 23 Kasus Perhitungan Naive Bayes ... 47 Tabel 4. 24 Confusion Matrix ………54
xii
Gambar 2. 1Alur Metode Naive Bayes ... 19
Gambar 3. 1 Struktur Organisasi ... 23
Gambar 3. 2 Rancangan Penelitian ... 27
Gambar 3. 3 Siklus CRIPS-DM ... 30
Gambar 3. 4 Tahap Penelitian ……….36
Gambar 4. 1 Cross Validation ... 50
Gambar 4. 2 Proses Training dan Testing ... 51
Gambar 4. 3 Accuracy... 52
Gambar 4. 4 Precision ... 53
Gambar 4. 5 Recall ... 53
Gambar 4. 6 Kurva ROC ... 55
xiii
Tabel Data Training 1 ... 69 Tabel Data Testing 1 ... 80
xiv
Determining the extension of a contract to a company is very important, given that if there is a decision-making error it will have an impact on the company's loss.The use of the data mining classification algorithm approach will be applied to determine the prediction of employee contract extension so that the contract extension process can be in accordance with company standards. In this study the author uses the Naïve Bayes Algorithm to determine the prediction of employee contract extension. The author also uses the Rapidminer 7.6 support application for testing the accuracy of the system that is made. The test was carried out by preparing 419 training data and testing data as many as 210 randomly selected data. The testing data will be analyzed using the Rapidminer 7.6 support application. The test results produced an accuracy of 93.33% with an error percentage of 6.67%.
xv
Penentuan perpanjangan kontrak pada sebuah perusahaan adalah hal yang sangat penting, mengingat jika terjadi kesalahan pengambilan keputusan maka akan berdampak pada kerugian perusahaan. Penggunaan pendekatan algoritma klasifikasi data mining akan diterapkan untuk menentukan prediksi perpanjangan kontrak karyawan sehingga proses perpanjangan kontrak karyawan bisa sesuai dengan standar perusahaan. Dalam pernelitian ini penulis menggunakan Algoritma Naïve Bayes untuk menentukan prediksi perpanjangan kontrak karyawan. Penulis juga menggunakan aplikasi pendukung Rapidminer 7.6 untuk pengujian akurasi terhadap sistem yang buat. Pengujian dilakukan dengan menyiapkan data training sebanyak 419 data dan data testing sebanyak 210 data yang dipilih secara random. Data testing tersebut akan dianalisa menggunakan aplikasi pendukung Rapidminer 7.6. Hasil pengujian menghasilkan akurasi 93.33% dengan persentase error 6.67%.
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Sumber daya manusia adalah faktor yang paling menentukan dalam pencapaian tujuan perusahaan. Karena sumber daya manusia termasuk unsur dari kekuatan yang memiliki daya saing yang baik, untuk itu sumber daya manusia dituntut menjadi lebih profesional dalam kerjanya demi kemajuan dan pencapaian tujuan perusahaan di Indonesia khususnya agar bisa bersaing dalam era globalisasi ini. (Anindita, Herawati, & Niaga, 2017)
Stewart, (1998, hal. 125-126) menyatakan bahwa penilaian kinerja karyawan merupakan salah satu butir dari delapan butir pemberdayaan. Jika proses pemberdayaan melalui training telah dilaksanakan, pentinglah memantau perkembangan dan menilai hasilnya. Pemantau dan penilaian dilakukan secara terus menerus sehingga menjadi sebagian ciri manajemen yang dijalankan, baik penilai maupun yang dinilai dengan mempertimbangkan sasaran-sasaran dan standar-standar yang telah ditetapkan, dipenuhi dan dicermati.(Abadi & Latifah, 2016)
Pada penelitian sebelumnya di PT. Capella Dinamik Nusantara Takengon suatu perusahaan yang bergerak di bidang penjualan sepeda motor merk Honda. PT. Capella Dinamik Nusantara, selama ini hanya menggunakan keputusan pimpinan langsung dalam melakukan penilaian kinerja karyawan. Pimpinan pun terkadang sulit dalam menilai kinerja masing-masing karyawan karna kurang
jelasnya kriteria penilaian karyawan. Penilaian karyawan hanya di lakukan sebagai referensi pimpinan saja, sehingga karyawan kurang termotivasi dalam menunjukkan kinerja terbaik mereka.(Safitri, Waruwu, & Mesran, 2017)
Berdasarkan uraian latar belakang diatas maka dibutuhkan suatu cara atau metode yang dapat memprediksi perpanjangan kontrak karyawan mengikuti penelitian yang telah ada sebelumnya (Pauziah, 2017), yaitu membahas tentang “ Analisis penentuan karyawan terbaik menggunakan metode algoritma naive bayes (studi kasus pt. Xyz) peneliti diatas menerapkan metode Naive Bayes dengan tujuan dapat memberikan inspirasi dan masukan bagi pihak perusahaan tersebut untuk dapat memanfaatkan metode algoritma naïve bayes yang dapat membantu dalam pengambilan keputusan pada penentuan karyawan terbaik..maka dari itu judul penelitian yang akan diambil yaitu “Analisa Data Mining Untuk Memprediksi Perpanjangan Kontrak Karyawan Menggunakan Metode Naive Bayes". Penelitian ini menggunakan algoritma naive bayes classifier sebagai salah satu algoritma klasifikasi data mining untuk memprediksi perpanjangan kontrak dengan akurat.
1.2 Identifikasi Masalah
Berdasarkan latar belakang yang telah disampaikan diatas, maka daftar masalah yang dijadikan acuan dalam penelitian ini adalah :
1. Belum diterapkan analisis yang objektif untuk memprediksi perpanjangan kontrak.
2. Hasil keputusan penilaian perpanjang kontrak karyawan belum dapat dinilai tingkat keakuratannya.
1.3 Rumusan Masalah
Berdasarkan pada latar belakang dan identifikasi masalah yang sudah dikemukaakan diatas, rumusan masalah pada penelitian ini adalah :
1. Bagaimana mendapatkan hasil analisa yang objektif untuk memprediksi perpanjangan kontrak karyawan?
2. Bagaimana penggunaan metode naïve bayes untuk memprediksi perpanjngan kontrak karyawan dengan tingkat akurasi sempurna ?
1.4 Batasan Masalah
Berdasarkan penjelasan diatas maka penulis membatasi ruang lingkup penelitian sebagai berikut :
1. Algoritma yang digunakan adalah algoritma Naïve Bayes.
2. Data yang diambil yaitu data karyawan yang akan habis masa kontraknya. 3. Penelitian ini hanya membahas tentang prediksi perpanjangan kontrak
karyawan dengan metode naïve bayes.
1.5 Tujuan dan Manfaat 1.5.1 Tujuan
1. Menerapkan metode naive bayes untuk memprediksi perpanjangan kontrak karyawan.
2. Mengetahui hasil prediksi perpanjangan kontrak karyawan dengan melihat akurasi Algoritma naïve bayes agar proses perpanjangan kontrak karyawan sesuai standar perusahaan.
1.5.2 Manfaat
Penelitian ini dilakukan dengan harapan memberi manfaat diantaranya 1. Bagi penulis
a. Dapat menambah wawasan tentang metode data mining khususnya klasifikasi naïve bayes.
b. Menjadi referensi bagi peneliti berikutnya. 2. Bagi Perusahaan
a. Sebagai salah satu alternatif untuk membantu perusahaan terutama departemen HRD (Human resource departement) dalam menentukan perpanjangan kontrak karyawan.
b. Menghindari manipulasi data maupun cara yang subyektif dari pengambil keputusan agar karyawan juga merasa keputusan yang diperoleh sudah sesuai data yang benar.
3. Bagi Institusi
Diharapkan dapat menjadi bahan pembelajaran dan referensi bagi peneliti yang akan melakukan penelitian lebih lanjut dengan topik yang berhubungan dengan judul penelitian diatas.
1.6 Sistematika Penulisan
Dalam penelitian ini penulis membagi beberapa bab untuk mempermudah dalam penyusunan dan mempermudah pembaca untuk memahaminya, berikut pembagian bab tersebut :
BAB I PENDAHULUAN
Bab ini meliputi uraian mengenai latar belakang masalah, identifikasi masalah, batasan masalah, rumusan masalah, tujuan dan manfaat penelitian, dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Dalam bab ini menjelaskan tentang hal-hal yang berkaitan dengan teori konsep model data mining, teori yang berkaitan dengan penelitian, konsep aplikasi dan peralatan pendukungnya.
BAB III METODE PENELITIAN
Bab ini meliputi uraian mengenai objek penelitian, teknik pengumpulan data dan model data mining.
BAB IV HASIL DAN PEMBAHASAN
Bab ini penulis menguraikan masalah pokok dari objek penulisan penelitian, bagaimana menerapkan sebuah model data mining kedalam suatu sistem untuk memprediksi perpanjangan kontrak karyawan.
BAB V PENUTUP
Pada bab ini meliputi uraian mengenai kesimpulan dan koreksi beserta saran-saran untuk peneliti yang akan melakukan penelitian berikutnya.
6
BAB II
TINJAUAN PUSTAKA
2.1 Kajian Pustaka
Dibawah ini adalah beberapa penelitian tentang Data mining ataupun mendekati penelitian yang digunakan sebagai referensi.
1. Sistem Pendukung Keputusan Pemilihan Karyawan Berprestasi Dengan Menggunakan Metode Analytical Hieararchy Process (Safitri et al., 2017). Berdasarkan proses analisa, perancangan dan implementasi pada penggunaan sistem pendukung keputusan pemilihan karyawan berprestasi di PT. Capella Dinamik Nusantara Takengon dapat diambil kesimpulan bahwa aplikasi ini dibangun untuk memudahkan dalam pengambilan keputusan karyawan berprestasi dengan cepat dan lebih baik berdasarkan data yang telah diproses. Dengan adanya proses pemilihan karyawan berprestasi di PT. Capella Dinamik Nusantara Takengon ini dapat membantu pihak perusahaan dalam memilih karyawan berprestasi yang tepat guna dijadikan bahan pertimbangan dalam proses pemilihan karyawan berprestasi di perusahaan. Dengan menerapkan metode AHP sehingga perusahaan dapat mengetahui nilai bobot karyawan beprestasi dan dapat memberikan hasil penilaian.
2. Sistem Pendukung Keputusan Menentukan Kelayakan Pengangkatan Karyawan Tetap Menggunakan Metode Analytic Hierarchy Process Dan Weighted Product (Saepudin, Abdillah, & Yuniarti, 2017).
Berdasarkan uraian mengenai penerapan metode Analytical Hierarchy Process dan Weighted Product dalam sistem pendukung keputusan menentukan kelayakan karyawan tetap, dari hasil pengujian terhadap data karyawan kontrak yang dikembangkan mengunakana model Anlytical Hierarchy Process dan Weighted Product dapat disimpulkan bahwa perhitungan telah dengan benar, sehingga perhitungan ini dapat digunakan untuk membantu PT. Kwanglim Yh Indah dalam menentukan kelayakan pengangkatan karyawan kontrak menjadi tetap.
3. Sistem Klasifikasi Kinerja Satpam Menggunakan Metode Naїve Bayes Classifier (Wibowo & Hartati, 2016).
Pada jurnal tersebut, peneliti menarik kesimpulan telah dibangun sistem klasifikasi kinerja satpam menggunakan metode Naive Bayes Classifier, dibuat dengan konsep Computer Based Test yang berisi pertanyaan-pertanyaan untuk mengetahui kinerja baik, cukup, buruk dari masing-masing satpam berdasarkan kemampuan, kepribadian dan ketrampilan menggunakan aplikasi Embarcadero Delphi 2010 dengan engine basis data MySQL.Pengujian metode Naive Bayes Classifier untuk klasifikasi kinerja satpam menggunakan 39 data uji menghasilkan prosentase kebenaran sebesar 92,31% dengan prosentase kinerja baik sebesar 20,51%, kinerja cukup sebesar 71,79%, dan kinerja buruk sebesar 7,69%.
4. Penerapan Data mining Untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier (Ridwan, Suyono, & Sarosa, 2013).
Dari hasil penelitian dapat disimpulkan bahwa : pengujian pada data mahasiswa angkatan 2005- 2009 mining NBC menghasilkan nilai precision, recall, dan accuracy masing-masing 83%, 50%, dan 70%. Penentuan data training dapat mempengaruhi hasil pengujian, karena pola data training tersebut akan dijadikan sebagai rule untuk menentukan kelas pada data testing. Sehingga besar atau kecilnya prosentase tingkat precision, recall, dan accuracy dipengaruhi juga oleh penentuan.
5. Analisis Penentuan Karyawan Terbaik Menggunakan Metode Algoritma Naive Bayes (Studi Kasus Pt. Xyz)(Pauziah, 2017).
Berdasarkan penelitian yang dilakukan penulis dapat diambil kesimpulan adanya bentuk dan fungsi aplikasi yang dapat dipakai untuk perusahaan- perusahaan, yang bisa digunakan untuk menghitung layak atau tidaknya seorang karyawan menjadi karyawan terbaik di perusahaan tersebut. Berdasarkan hasil dari semua penelitian dan metode yang digunakan diatas terbukti penggunaan metode Naive Bayes memiliki banyak kelebihan didalam hal prediksi dengan tingkat akurasi yang baik , oleh karena itu metode Naive Bayes dipilih untuk digunakan dalam penelitian ini.
2.2 Dasar Teori 2.2.1 Data Mining
Pramudiono mengungkapkan Data Mining adalah analisis otomatis dari data
yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaanya.(C, Baskoro, Ambarwati, & Wicaksana, 2013)
Data mining adalah proses bisnis untuk menjelajahi sejumlah besar data untuk menemukan pola yang bermakna dan beraturan (Darmawan, Kustian, Rahayu, & Tabebuya, 2018).
Data mining didefinisikan sebagai proses menemukan pola-pola dalam data. Proses ini otomatis atau seringnya semiotomatis. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi. Data yang dibutuhkan dalam jumlah besar (Lumbantoruan, 2015).
Data mining adalah serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu basis data. Informasi yang dihasilkan diperoleh dengan cara mengekstrasi dan mengenali pola yang pentingatau menarik dari data yang terdapat pada basis data. Data mining terutama digunakan untuk mencari pengetahuan yang terdapat dalam basis data yang besar sehingga sering disebut Knowledge Discovery Databases (KDD)(Anindita et al., 2017).
2.2.2 Pengelompokkan Data mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Tampubolon et al., 2013).
1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari data untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menentukan keterangan atau fakta bahwa siapa yang tidak cukup professional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelesan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variable target estimasi lebih kearah numerik dari pada kearah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel predikasi. Sebagai contoh akan dilakukan estimasi tekanan darah
s
istolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam predikasi nilai dari hasil akan ada dimasa mendatang. Contoh prediksi bisnis dan penelitian adalah:
a) Prediksi harga beras dalam tiga bulan yang akan datang.
b) Prediksi persentasi kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori , yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
5. Pengklusteran (Clustering)
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain.
6. Asosiasi
Tugas asosiasi dalam Data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
2.2.3 Tahap-Tahap Data mining
Tahapan Data mining adalah sebagai berikut (Triuli , Novianti Abdul, 2015).
1) Pembersihan data (data cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten.
2) Integrasi data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru.
3) Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semua dipakai, hanya data yang sesuai untuk dianalisis yang diambil dari database. Karena tidak semua tabel digunakan maka perlu dilakukan pembersihan data agar data yang akan diolah benar-benar relevan dengan yang dibutuhkan.
4) Transformasi data (Data Transformation).
Data digabung ke dalam format yang sesuai untuk diproses dalam Data mining. Transformasi data merupakan proses pengubahan atau penggabungan data ke dalam format yang sesuai.
5) Proses mining merupakan proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dari data.
2.2.4 Tugas Tugas Data Mining
Fayyad mengungkapkan Tugas-tugas data mining bisa dikelompokan ke dalam enam kelompok berikut ini (Dr. Suyanto, S.T., 2017)
Klasifikasi : men-generalisasi struktur yang diketahui untuk diaplikasikan pada data-data baru.
Klasterisasi : mengelompokan data , yang tidak diketahui label kelasnya, ke dalam sejumlah kelompok tertentu sesuai dengan ukuran kemiripannya.
Regresi : menemukan suatu fungsi yang memodelkan data dengan galat (kesalahan prediksi) seminimal mungkin.
Deteksi anomali : mengidentifikasi data yang tidak umum, bisa berupa outlier (pencilan), perubahan atau deviasi yang mungkin sangat penting dan perlu investigasi lebih lanjut.
Pembelajaran aturan asosiasi atau pemodelan keberuntungan : mencari antar relasi antar variabel.
Perangkuman : menyediakan representasi data yang lebih sederhana, meliputi visualisasi dan pembuatan laporan.
2.3 Naive Bayes
Bayesian classification adalah pengklasifikasian statistik yang dapat digunakan untuk memprediski probabilitas keanggotaan suatu class. Bayesian classification didasarkan pada teorema Bayes yang memiliki kemampuan klasifikasi serupa dengan decesion tree dan neural network. Bayesian
classification terbukti memiliki akurasai dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar(Jananto, 2013).
Bayes merupakan teknik klasifikasi berbasis probabilistic sederhana yang berdasar pada penerapan teorema Bayes (aturan Bayes) dengan asumsi independensi yang kuat (Naïve) dengan kata lain Naive Bayes Classifier. Model yang digunakan adalah model fitur independen. Dalam Bayes terutama Naive Bayes Classifier, maksud independen yang kuat dalam fitur adalah bahwa sebuah fitur pada data tidak berkaitan dangan ada atau tidaknya fitur lain pada data yang sama (Via, Nugroho, & Syafrizal, 2015).
2.3.1 Persamaan Metode Naive Bayes
Bentuk umum atau persamaan dari teorema Bayes adalah : ( | ) ( | ) ( )
( ) Keterangan :
X : Data dengan class yang belum diketahui H : Hipotesa data X merupakan suatu cass spesifik
P(H|X): Probabilitas hipotesis H berdasar kondisi X (posteriori probability)
P(H) : Probabilitas hipotesis H (prior probability)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H P(X) : Probabilitas X
Untuk menjelaskan metode Naive Bayes, perlu diketahui bahwa proses klasifikasi memerlukan sejumlah petunjuk untuk menentukan kelas apa yang
cocok bagi sample yang dianalisis tersebut. Karena itu, metode Naive Bayes di atas disesuaikan sebagai berikut:
(𝐶|𝐹1…𝐹𝑛) = (𝐶) (𝐹 𝐹𝑛|𝐶) (𝐹 𝐹𝑛)
Di mana Variabel C merepresentasikan kelas, sementara variabel “F1 ... Fn” merepresentasikan karakteristik petunjuk yang dibutuhkan untuk melakukan klasifikasi. Maka rumus tersebut menjelaskan bahwa peluang masuknya sampel karakteristik tertentu dalam kelas C (Posterior) adalah peluang munculnya kelas C (sebelum masuknya sampel tersebut, seringkali disebut prior), dikali dengan peluang kemunculan karakteristik-karakteristik sampel pada kelas C (disebut juga likelihood), dibagi dengan peluang kemunculan karakteristik-karakteristik sampel secara global (disebut juga evidence). rumus di atas dapat pula ditulis secara sederhana sebagai berikut:
Posterior
=
Nilai Evidence selalu tetap untuk setiap kelas pada satu sampel. Nilai dari posterior tersebut nantinya akan dibandingkan dengan nilai-nilai posterior kelas lainnya untuk menentukan ke kelas apa suatu sample akan diklasifikasikan. Penjabaran lebih lanjut rumus Naïve Bayes tersebut dilakukan dengan menjabarkan (𝐶|𝐹1,…,) menggunakan aturan perkalian sebagai berikut:
(𝐶|𝐹1,…,𝐹𝑛= (𝐶) (𝐹1,…,𝐹𝑛|𝐶) = (𝐶) (𝐹1|𝐶) (𝐹2,…,𝐹𝑛|𝐶,𝐹1) = (𝐶) (𝐹1|𝐶) (𝐹2|𝐶,𝐹1 ) (𝐹3,…,𝐹𝑛|𝐶,𝐹1,𝐹2
= (𝐶) (𝐹1|𝐶) (𝐹2|𝐶,𝐹1 ) (𝐹3|𝐶,𝐹1,𝐹2) (𝐹4,…,𝐹𝑛|𝐶,𝐹1,𝐹2,𝐹3) = (𝐶) (𝐹1|𝐶) (𝐹2|𝐶,𝐹1) (𝐹3|𝐶,𝐹1,𝐹2)… (𝐹𝑛|𝐶,𝐹1,𝐹2,𝐹3,…,𝐹𝑛−1)
Dapat dilihat bahwa hasil penjabaran tersebut menyebabkan semakin banyak dan semakin kompleksnya faktor - faktor syarat yang mempengaruhi nilai probabilitas, yang hampir mustahil untuk dianalisa satu persatu. Akibatnya, perhitungan tersebut menjadi sulit untuk dilakukan. Di sinilah digunakan asumsi independensi yang sangat tinggi (naif), bahwa masing-masing petunjuk (F1,F2...Fn) saling bebas (independen) satu sama lain. Dengan asumsi tersebut, maka berlaku suatu kesamaan sebagai berikut:
(𝐹𝑖|𝐹 𝑗) = ( ) ( )
=
( ) ( ) ( )=
(𝐹𝑖) untuk I ≠ j, sehingga (𝐹𝑖 | 𝐶, 𝐹𝑗) = (𝐹𝑖|𝐶)Dari persamaan di atas dapat disimpulkan bahwa asumsi independensi naif tersebut membuat syarat peluang menjadi sederhana, sehingga perhitungan menjadi mungkin untuk dilakukan. Selanjutnya, penjabaran P(F1,…,Fn | C) dapat disederhanakan menjadi seperti berikut
P(F Fn | C) P(F | C) P(F2 | C) P(Fn | C) P(F Fn | C) =
∏
( 𝐹𝑖 | 𝐶)Dengan kesamaan di atas, persamaan teorema bayes dapat dituliskan sebagai berikut
P(F Fn | C) =
( )
∏
( 𝐹𝑖 | 𝐶)Persamaan di atas merupakan model dari teorema Naïve Bayes yang selanjutnya akan digunakan dalam proses klasifikasi dokumen data. Adapun Z adalah mempresentasikan evidence yang nilainya konstan untuk semua kelas pada satu sample.
2.3.2 Alur Metode Naïve Bayes
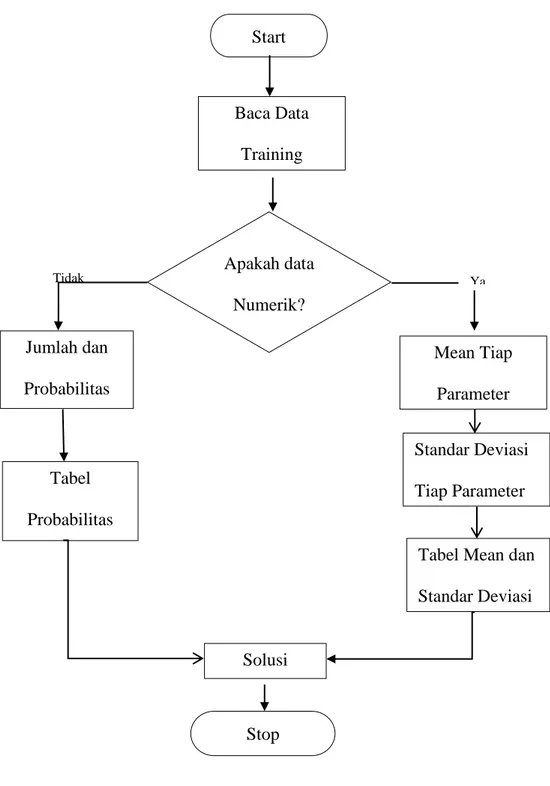
Alur metode Naïve Bayes adalah sebagai berikut(Saleh, 2015): 1. Baca data training
2. Hitung jumlah dan probabilitas, namun apabila data numerik maka :
a. Cari nilai mean dan standar deviasi dari masing masing parameter yang merupakan data numerik.
Adapun persamaan yang digunakan untuk menghitung nilai rata-rata hitung (mean) dapat dilihat sebagai berikut :
µ
=
∑atau
µ =
dimana:µ:
Rata-rata hitung (mean)Nilai sampel ke-i
𝑛:
Jumlah sampleDan persamaan untuk menghitung nilai simpangan baku (standar deviasi) dapat dilihat sebagai berikut:
σ
=
√
∑ ( ) dimana:σ:
Standar deviasi:
Nilai x ke-iµ:
Rata-rata hitung𝑛:
Jumlah sampleb. Cari nilai probabilistik dengan cara menghitung jumlah data yang sesuai dari kategori yang sama dibagi dengan jumlah data pada kategori tersebut.
3. Mendapatkan nilai dalam tabel mean, standart deviasi dan probabilitas. 4. Solusi kemudian dihasilkan.
Gambar 2. 1Alur Metode Naive Bayes Start Apakah data Numerik? Baca Data Training Mean Tiap Parameter Standar Deviasi Tiap Parameter
Tabel Mean dan Standar Deviasi Jumlah dan Probabilitas Tabel Probabilitas Solusi Stop T Tidak Ya
2.4 Karyawan
Pengertian karyawan kontrak adalah karyawan yang bekerja pada suatu instansi dengan kerja waktu tertentu yang didasari atas suatu perjanjian atau kontrak dapat juga disebut dengan Perjanjian Kerja Waktu Tertentu (PKWT), yaitu perjanjiann kerja yang didasarkan suatu jangka waktu yang diadakan untuk paling lama 2 tahun dan hanya dapat diperpanjang 1 kali untuk jangka waktu maksimal 1 tahun (Undang-Undang RI ketenagakerjaan 2003 dalam pasal 59 ayat 1).(Mallu, 2015). Karyawan merupakan faktor pendukung dalam sebuah perusahaan atau instansi, karena dengan adanya karyawan yang memiliki standar kualifikasi perusahaan maka produktivitas perusahaan pasti akan tetap terjaga dan semakin meningkat. Proses pemilihan karyawan berprestasi merupakan proses yang rumit dan memerlukan pertimbangan – pertimbangan yang cermat. Untuk memperoleh informasi yang cepat dan akurat akan prestasi kinerja karyawan yang tepat (memenuhi kriteria yang diharapkan), dibutuhkan suatu proses otomatisasi dengan menggunakan teknologi. Oleh karena itu kebutuhan sebuah sistem yang berbasis komputer dirasa sangat perlu guna memenuhi tuntutan akan kebutuhan informasi.(Abadi & Latifah, 2016).
Karyawan adalah tiap orangyang mampu melaksanakan pekerjaan, baik di dalam maupun di luar hubungan kerja guna menghasilkan jasa atau barang untuk memenuhi kebutuhan masyarakat (Safitri et al., 2017).
2.4.1 Pengertian Kinerja Karyawan
Beberapa pengertian kinerja karyawan yang dikemukakan beberapa pakar lain dikutip dari (Anindita et al., 2017) dapat disajikan berikut ini :
Menurut Stolovitch, Kinerja karyawan adalah seperangkat hasil yang dicapai dan merujuk pada tindakan pencapaian serta pelaksanaan suatu pekerjaan yang diminta.
Menurut Rivai, Kinerja karyawan adalah kesediaan orang atau sekelompok orang untuk melakukan suatu kegiatan dan menyempurnakannya sesuai dengan tanggung jawabnya dengan hasil seperti yang diharapkan.
Menurut Schemerhorn Kinerja karyawan sebagai kualitas dan kuantitas dari pencapaian tugas – tugas, baik yang dilakukan oleh individu, kelompok maupun perusahaan.
2.5 CRISP-DM (Cross-Industry Standard Process for Data Mining)
CRISP-DM atau Cross-Industry Standard Process for Data Mining merupakan standar yang dikembangkan pada tahun 1996 yang ditujukan untuk proses analisis suatu industry sebagai strategi pemecahan masalah dari bisnis. CRISP-DM tidak menentukan standar atau karakteristik tertentu karena setiap data yang akan dianalisis akan diproses kembali pada fase-fase di dalamnya.(Imtiyaz, Zain Muhammad , Nasrun Muhammad, 2015).
2.6 Analisis Data
Analisis dalam perpanjangan kontrak karyawan meliputi : a. Penentuan atribut
Data yang dibutuhkan untuk mencari atribut perpanjangan kontak karyawan adalah data karyawan yang masa kerjanya akan habis setahun sebelumnya. Semua data-data diperoleh dari bagian Staff Personalia. Kemudian menguji data untuk diambil sampel secara acak. atribut tersebut meliputi ketelitian, kretifitas, tanggung jawab, kerjasama, pencapaian tujuan, inisiatif, kehadiran, inovasi, loyalitas.
b. Penentuan Sampel
Untuk menentukan jumlah sampel yang akan digunakan dalam sistem data yang diambil dari data tahun sebelumnya sejumlah 628 data.
c. Penggunaan Metode
Metode yang digunakan dalam penelitian ini yaitu naive bayes . Pemilihan metode ini dikarenakan relatif mudah digunakan karena tidak ada perkalian matrik atau optimasi numerik, lebih efisien apabila digunakan untuk memprediksi dalam jumlah yang sangat besar, dan memiliki tingkat keakurasian yang relatif tinggi dalam hasil prediksi. Metode naive bayes juga sering disebut dengan algoritma HMAP (Hypothesis Maximum Apriori Probability) yang merupakan penyederhanaan dari metode bayes.
23
BAB III
METODE PENELITIAN
3.1 Objek Penelitian 3.1.1 Profil Perusahaan
PT.Armstrong Industri Indonesia berdiri semenjak tahun 1995 yang beralamat di Kawasan Industri EJIP Plot-1 A-3 Cikarang Selatan Bekasi merupakan perusahaan yang bergerak dibidang manufacturing. Perusahaan ini merupakan anak dari perusahaan PT. Armstrong Vietnam. Memiliki sekitar kurang lebih 950 orang pegawai dalam menjalankan bisnis usahanya. PT. Armstrong Industri Indonesia memiliki produk-produk berupa : Plastic film, tape, foam, expanded foam, serta cork.
3.1.2 Tujuan Perusahaan
1. Menyediakan pelayanan terbaik dan produk-produk berkualitas tinggi untuk para pelanggan, dengan tidak menggunakan bahan baku dibawah standar serta tidak memproduksi dan mengirimkan produk tidak memenuhi standar kualitas.
2. Melaksanakan tata kelola perusahaan yang baik, dengan menekankan kepada karawan pentingnya untuk menerapkan prinsip etika tinggi, dan terus menjaga kesehatan dan keselamatan kerja melalui cara kerja yang baik.
3.1.3 Visi dan Misi 1. Visi
Menjadi perusahaan global yang memberikan produk dan layanan berkualitas tinggi kepada pelanggan dengan biaya minimum.
2. Misi
1. Menjaga efisiensi dalam proses produksi sehingga dapat menciptakan harga yang bersaing produk sejenis.
2. Menjaga mutu produk dengan kontrol produksi yang profesional dan berusaha terus menerus meningkatkan mutu produk.
3.1.4 Struktur Organisasi
Struktur organisasi adalah suatu susunan dan hubungan antara tiap bagian serta posisi yang ada pada suatu organisasi atau perusahaan dalam menjalankan kegiatan operasional untuk mencapai tujuan yang diinginkan. Struktur organisasi menggambarkan dengan jelas pemisah kegiatan pekerjaan antara satu dengan yang lain dan bagaimana hubungan aktivitas dan fungsi dibatasi.
3.3 Tempat dan Waktu Penelitian
Penelitian dilaksanakan di PT. Armstrong Industri Indonesia yang beralamat di Kawasan Industri EJIP Plot-1 A-3 Cikarang Selatan Bekasi. Adapun waktu yang digunakan untuk melakukan penelitian ini dimulai selama 12 hari terhitung 2 Juli 2018 sampai 17 Juli 2018.
3.4 Populasi dan Sampel Penelitian 3.4.1 Populasi
Popuasi dalam penelitian ini adalah karyawan yang akan habis masa kontraknya di PT. Armstrong Industri Indonesia
3.4.2 Sample
Sampel dalam penelitian ini adalah data karyawan yang habis kontrak di periode Juli tahun 2017 sampai Agustus tahun 2018 dengan atribut Ketelitian, kretifitas, tanggung jawab, kerjasama, pencapaian tujuan, inisiatif, kehadiran, inovasi, loyalitas. Sample data berjumlah 629 karyawan.
3.5 Sumber Data
1. Data Primer
Yaitu data yang diambil langsung dari obyek penelitian. Data primer diperoleh dengan cara melakukan pengamatan langsung (observasi) dan melakukan tanya jawab pada pihak yang bersangkutan (wawancara). Data primer yang dipakai yaitu data laporan perpanjangan kontrak berupa softcopy , kemudian melakukan tanya jawab kepada Staff personalia yang menangani perpanjangan kontrak karyawan.
2. Data Sekunder
Yaitu data yang mendukung penelitian yang didapat dari buku referensi dan jurnal ilmiah yang berkaitan dengan penelitian. Adapun hal yang berkaiatan di dalamnya adalah data sejarah perusahaan, data visi misi perusahaan, dan data pustaka yang digunakan sebagai acuan landasan teori.
3.6 Metode Pengumpulan Data
Untuk mendapatkan data-data yang dapat menunjang penelitian ini, peneliti menggunakan beberapa metode pengumpulan data sebagai berikut:
1. Observasi
Observasi dilakukan langsung di PT. Armstrong Industri Indonesia yang beralamat di Kawasan Industri EJIP Plot-1 A-3 Cikarang Selatan Bekasi. 2. Wawancara
Wawancara dilakukan dengan Kepala bagian personalia yang menangani perpanjangan kontrak karyawan.
3. Studi Pustaka
Penulis melakukan studi kepustakaan melalui literatur-literatur atas referensi-referensi yang ada di perpustakaan dan internet.
3.7 Rancanga Penelitian
Rancangan dalam penelitian dibuat agar langkah-langkah dalam penelitian tidak keluar dari pokok pembahasan dan mudah dipahami, urutan langkah-langkah dibuat secara sistematis sehingga dapat dijadikan pedoman yang jelas dan mudah untuk menyelesaikan permasalahan yang ada.
Gambar 3. 2 Rancangan Penelitian
Data Data karyawan habis kontrak Naive Bayes Metode Penelitian
Dapat memprediksi perpanjangan kontrak karyawan dengan cepat dan akurat
Hasil
Proses analisis untuk prediksi perpanjangan kontrak karyawan belum menerapkan metode naïve bayes sehingga memerlukan waktu
yang lama
Masalah
Penerapan data mining menggunakan metode Naïve bayes
3.8 Instrumen Penelitian
Instrumen penelitian berfungsi sebagai alat bantu dalam mengumpulkan data-data yang dibutuhkan dalam sebuah penelitan. Penyusunan instrumen seperti halnya mengevaluasi, karena dengan mengevaluasi peneliti dapat memperoleh data dari objek yang diteliti, dan hasil yang didapatkan bisa diukur memakai standar yang sebelumnya telah ditentukan oleh peneliti.
Didalam penulisan dan penelitian ini penulis membutuhkan beberapa instrumen antara lain adalah perangkat keras maupun perangkat lunak untuk menunjang penyelesaiann penelitian.
Berikut ini adalah spesifikasi perangkat keras dan perangkat lunak yang dibutuhkan, diantaranya :
3.8.1 Kebutuhan Perangkat Lunak (Software)
Didalam sebuah penelitian peneliti memerlukan sebuah penunjang perangkat lunak komputer yang diperuntukkan untuk melakukan penelitian ini adalah sebagai berikut ini :
a. Sistem Operasi
Pada penelitian ini penulis menggunakan sistem operasi yang digunakan adalah Microsoft Windows 10 64 bit.
b. Rapid Miner Studio 7.6
Framework yang akan digunakan untuk melihat hasil akurasi dari algoritma yang digunakan terhadap dataset yang sedang diteliti.
c. Microsoft Office Word 2010
d. Microsoft Office Excel 2010
Software ini digunakan sebagai media penulisan dan pengolahan dataset, data training dan data testing.
e. Micrososft Visual Basic 6
Sofware ini digunakan untuk membuat sistem pendukung keputusan.
3.8.2 Kebutuhan Perangkat Keras (Hardware)
Didalam sebuah penelitian peneliti memerlukan sebuah penujang perangkat keras komputer yang diperuntukkan untuk melakukan penelitian ini adalah sebagai berikut ini :
a. Laptop dengan spesifikasi sebagai berikut
- Prosesor Intel(R) Celeron(TM) CPU 1007U 1.50GHz - Harddisk 250 GB
- RAM 2GB
- Layar Monitor 11” - Mouse
b. Printer dengan spesifikasi -Cannon IP2700
3.9 Jenis Penelitian
Dalam penelitian ini menggunakan jenis penelitian deskriptif. Dimana penelitian ini bertujuan untuk memecahkan masalah yang ada pada saat ini, pada penelitian ini kasus yang diambil adalah karyawan yang masa kerjanya akan habis. Jenis penelitian deskriptif mempunyai ciri-ciri sebagai berikut :
a. Berpusat pada penyelesaian masalah pada masa sekarang, dan pada masalah yang aktual.
b. Data yang terkumpul terlebih dulu disusun, dijelaskan dan dianalisa karena metode ini sering disebut metode analitik.
3.10 Teknik Analisis Data
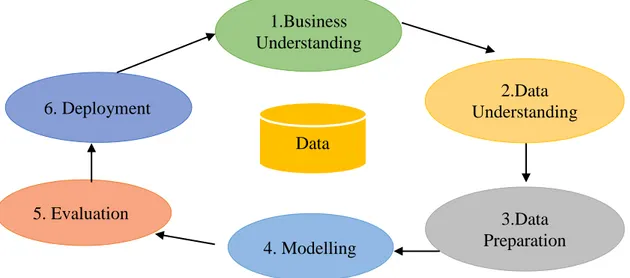
Pada penelitian ini menggunakan metodologi pengembangan data mining CRISP-DM (Cross Standart Industries for Data Mining) yaitu merupakan standar yang ditujukan untuk proses analisis suatu industry sebagai strategi pemecahan masalah dari bisnis., yang memiliki siklus hidup terdiri dari 6 tahap.
Gambar 3. 3 Siklus CRIPS-DM Sumber : ((North, n.d.)) Data 2.Data Understanding 3.Data Preparation 4. Modelling 5. Evaluation 6. Deployment 1.Business Understanding
1. Business Understanding
Pada tahapan pertama peneliti mencoba untuk memahami permasalahan yang ada dalam memprediksi perpanjangan kontrak karyawan pada PT. Armstrong Industri Indonesia. Sehingga dapat menentukan tujuan dan pola yang akan didapatkan dengan data mining.
Faktor dalam penentuan kelayakan karyawan diperpanjang biasanya terdapat pada salah satu atribut yang mempunyai faktor terbesar dalam menentukan hasil kelayakan , dimana atribut berperan dalam menentukan Layak atau Tidak nya Karyawan diperpanjang kontraknya.
2. Data Understanding (Pemahaman Data)
Pada tahap ini peneliti melakukan pemahaman terhadap data yang dibutuhkan untuk kemudian mengambil data yang relevan dan memiliki keterkaitan, adapun data yang digunakan yaitu ketelitian, kretifitas, tanggung jawab, kerjasama, pencapaian tujuan,inisiatif, kehadiran, inovasi, loyalitas
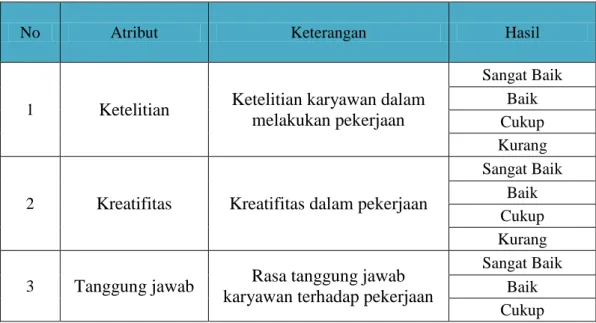
Tabel 3. 1 Keterangan Atribut
No Atribut Keterangan Hasil
1 Ketelitian Ketelitian karyawan dalam melakukan pekerjaan
Sangat Baik Baik Cukup Kurang
2 Kreatifitas Kreatifitas dalam pekerjaan
Sangat Baik Baik Cukup Kurang 3 Tanggung jawab Rasa tanggung jawab
karyawan terhadap pekerjaan
Sangat Baik Baik Cukup
Kurang
4 Kerjasama Kerjasama dalam pekerjaan
Sangat Baik Baik Cukup Kurang
5 Pencapaian tujuan Kerjasama dalam pekerjaan
Sangat Baik Baik Cukup Kurang
6 Inisiatif Inisiatif karyawan dalam pekerjaan
Sangat Baik Baik Cukup Kurang
7 Kehadiran Baik buruknya absensi karyawan
Sangat Baik Baik Cukup Kurang
8 Inovasi Inovasi karyawan untuk
perusahaan
Sangat Baik Baik Cukup Kurang
9 Loyalitas Loyalitas karyawan
Sangat Baik Baik Cukup Kurang
3. Data Preparation (Pengolahan Data)
Pada tahap ini peneliti mengolah data yang didapat dengan beberapa tahapan seperti melakukan pembersihan terhadap data / data cleaning, melakukan integrasi data / data integration, melakukan pemilihan data / data selection dan transformasi pada data / data transformation. Pada tahapan pengolahan data, data yang telah diperoleh dari Staff Personalia akan diolah terlebih dahulu sebelum melalui tahap prediksi yaitu melalui beberapa proses antara lain :
a) Tahap pertama menentukan data yang akan diolah, dibawah ini merupakan tabel atribut yang digunakan dalam penelitian.
Tabel 3. 2 Atribut Penelitian
No Atribut Type Proses
1 Ketelitian Char Digunakan
2 Kreatifitas Char Digunakan 3 Tanggung jawab Char Digunakan
4 Kerjasama Char Digunakan
5 Pencapaian
tujuan Char Digunakan
6 Inisiatif Char Digunakan
7 Kehadiran Char Digunakan
8 Inovasi Char Digunakan
9 Loyalitas Char Digunakan
b) Tahap Kedua melakukan konversi data, data dengan atribut yang telah dipilih kemudian dikonversikan untuk memudahkan proses data mining, karena data akan diproses dengan tools bantu data mining yang digunakan yaitu Rapid Miner Studio 7.6.
4. Modeling (Pemodelan)
Pada tahap ini peneliti menentukan teknik data mining yang digunakan untuk mengolah data yang telah disiapkan sebelumnya. Teknik yang dilakukan yaitu dengan klasifikasi menggunakan algoritma Naïve Bayes Classifier (NBC). Data yang sudah melalui proses pengolahan kemudian akan di analisa menggunakan tools Rapid Miner. Dua langkah yang dilakukan pada tahap ini ialah:
a) Perhitungan Naïve Bayes secara manual, data yang akan digunakan dalam perhitungan Naïve Bayes secara manual diambil 1 sampel data, data yang diambil secara acak oleh peneliti dari total 50 data.
b) Penerapan Naïve Bayes menggunakan Rapid Miner, impelementasi dengan menggunakan Rapid Miner bertujuan untuk memudahkan dalam pemrosesan data yang berjumlah besar serta mengetahui tingkat akurasi terhadap data dan metode yang digunakan.
5. Evaluation (Evaluasi)
Melakukan pengujian terhadap model-model yang bertujuan untuk mendapatkan hasil dengan akurasi sempurna. Pada tahap evaluasi, akan diketahui apakah hasil dari tahap pemodelan dapat menjawab tujuan yang telah ditetapkan pada fase pertama sehingga diharapkan mendapat informasi atau pola yang berguna sebagai rekomendasi upaya mendiagnosa penyakit pneumonia di Puskesmas Cimalaka.
6. Deployment (Penyebaran)
Pembentukan model selanjutnya melakukan analisa dan pengukuran pada tahap sebelumnya, pada tahap ini diterapkan model atau rule yang paling akurat dan selanjutnya dapat digunakan untuk mengevaluasi data baru.
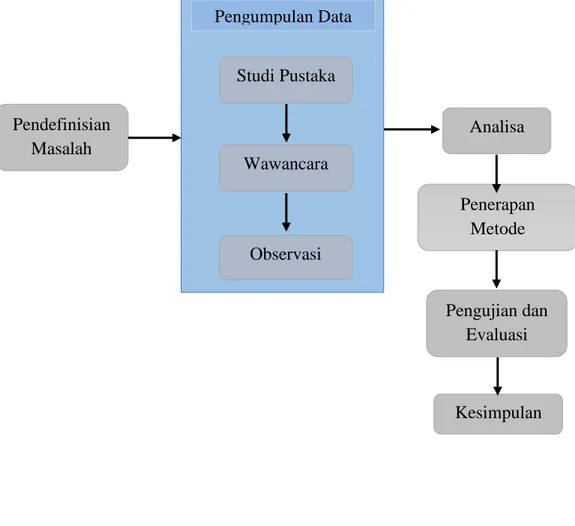
3.11 Tahapan Penelitian
Pada tahap penelitian di awali dengan pendefinisian masalah hingga metode yang akan di gunakan. Dibawah ini adalah tahapan sebagai berikut :
2. Studi Pustaka : Pengumpulan data yaitu berupa literatur buku, jurnal nasional maupun internasional, kemudian penelitian yang pernah di lakukan peneliti sebelumnya.
3. Wawancara : Melakukan proses wawancara tanya jawab kepada Kepala Personalia.
4. Observasi : Pengamatan langsung proses kegiatan yang ada.
5. Analisa : Melakukan analisa pada hasil observasi, wawancara dan penelitian sebelumnya.
6. Penerapan Metode : Metode yang digunakan yaitu Naïve Bayes Classifier (NBC).
7. Pengujian dan Evaluasi: Melakukan pengujian data menggunakan Rapid Miner Studio 7.6 dan mengevaluasinya.
Gambar 3. 4 Tahap Penelitian Pendefinisian Masalah Analisa Penerapan Metode Pengujian dan Evaluasi Kesimpulan Studi Pustaka Wawancara Observasi Pengumpulan Data
37
BAB IV
HASIL DAN PEMBAHASAN
4.1 Hasil
4.4.1 Penentuan Atribut
Dalam menentukan karyawan layak atau tidak diperpanjang kontraknya ada beberapa atribut yang digunakan pihak PT. Armstrong Industri Indonesia. Tidak hanya atribut yang bersifat objektif, tetapi kriteria yang bersifat subjektif. Berdasarkan wawancara oleh pihak PT. Armstrong Industri Indonesia khususnya bagian Staff personalia.
Atribut yang digunakan sebagai penilaian dalam perpanjangan kontrak karyawan adalah :
Tabel 4. 1 Atribut yang digunakan
No Atribut Nilai 1 Ketelitian A B C D 2 Kreatifitas A B C D 3 Tanggung jawab A B C D 4 Kerjasama A B C
D 5 Pencapaian tujuan A B C D 6 Inisiatif A B C D 7 Kehadiran A B C D 8 Inovasi A B C D 9 Loyalitas A B C D
Tabel 4. 2 Bobot Nilai
No Keterangan Bobot Nilai
1 Sangat
Baik A
2 Baik B
3 Cukup C
4.2 Perhitungan Naïve Bayes
Data yang digunakan sebagai data training adalah sebanyak 419 data (lampiran 1) yang diambil dari data karyawan habis kontrak periode Juli 2017-Agustus 2018 yang sudah ditentukan kelayakannya. Sedangkan untuk data testing yang akan ditentukan kelayakannya berjumlah 50 data (lampiran 2).
Tabel 4. 3 Atribut Kelas
Dari tabel diatas menjelaskan bahwa karyawan yang Layak perpanjang kontraknya yaitu sebanyak 157 karyawan sedangkan 262 karyawan Tidak layak perpanjang kontraknya.
1. Ketelitian
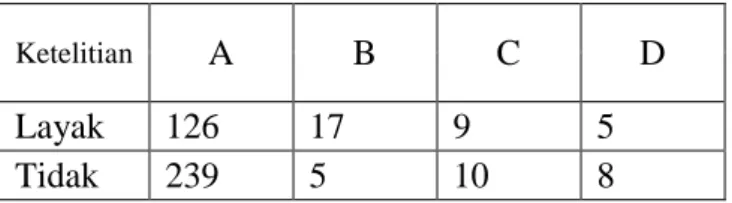
Tabel 4. 4 Atribut Ketelitian
Ketelitian A B C D
Layak 126 17 9 5
Tidak 239 5 10 8
Tabel diatas menjelaskan bahwa karyawan dengan Ketelitian = “A” terdapat 126 Layak dan 239 Tidak , Ketelitian = “B” terdapat 17 Layak dan 5 Tidak , Ketelitian = “C” terdapat 9 Layak dan 10 Tidak, Ketelitian =”D” terdapat 5 Layak dan 8 Tidak
Kelas
Layak Tidak
2. Kreativitas
Tabel 4. 5 Atribut Kreativitas
Kreatifitas A B C D
Layak 96 37 16 8
Tidak 30 80 102 50
Tabel diatas menjelaskan bahwa karyawan dengan Kreativitas = “A” terdapat 96 Layak dan 30 Tidak , Kreativitas = “B” terdapat 37 Layak dan 80 Tidak , Kreativitas = “C” terdapat 16 Layak dan 102 Tidak, Kreativitas =”D” terdapat 8 Layak dan 50 Tidak.
3. Tanggung Jawab
Tabel 4. 6 Atribut Tanggung Jawab
Tanggung
Jawab A B C D
Layak 61 70 20 6
Tidak 81 17 72 92
Tabel diatas menjelaskan bahwa karyawan dengan Tanggung jawab = “A” terdapat 61 Layak dan 81 Tidak , Tanggung jawab = “B” terdapat 70 Layak dan 17 Tidak , Tanggung jawab = “C” terdapat 20 Layak dan 72 Tidak, Tanggung jawab =”D” terdapat 6 Layak dan 92 Tidak.
4. Kerjasama
Tabel 4. 7 Atribut Kerjasama
Kerjasama A B C D
Layak 92 53 4 8
Tidak 118 13 64 67
Tabel diatas menjelaskan bahwa karyawan dengan Kerjasama = “A” terdapat 92 Layak dan 118 Tidak , Kerjasama = “B” terdapat 53 Layak dan 13Tidak , Kerjasama = “C” terdapat 4 Layak dan 64 Tidak, Kerjasama =”D” terdapat 8 Layak dan 67 Tidak.
5. Pencapaian tujuan
Tabel 4. 8 Atribut Pencapaian Tujuan
Pencapaian
tujuan A B C D
Layak 101 41 11 4
Tidak 150 12 49 51
Tabel diatas menjelaskan bahwa karyawan dengan Pencapaian Tujuan = “A” terdapat 101 Layak dan 150 Tidak , Pencapaian Tujuan = “B” terdapat 41 Layak dan 12 Tidak , Pencapaian Tujuan = “C” terdapat 11 Layak dan 49 Tidak, Pencapaian Tujuan =”D” terdapat 4 Layak dan 51 Tidak.
6. Inisiatif
Tabel 4. 9 Atribut Inisiatif
Inisistif A B C D
Layak 120 26 6 5
Tidak 180 11 33 38
Tabel diatas menjelaskan bahwa karyawan dengan Inisiatif = “A” terdapat 120 Layak dan 180 Tidak , Inisiatif = “B” terdapat 26 Layak dan 11 Tidak , Inisiatif = “C” terdapat 6 Layak dan 33 Tidak, Inisiatif =”D” terdapat 5 Layak dan 38 Tidak.
7. Kehadiran
Tabel 4. 10 Atribut Kehadiran
Kehadiran A B C D
Layak 127 20 6 4
Tidak 198 10 24 30
Tabel diatas menjelaskan bahwa karyawan dengan Kehadiran = “A” terdapat 127 Layak dan 198 Tidak , Kehadiran = “B” terdapat 20 Layak dan 10 Tidak , Kehadiran = “C” terdapat 6 Layak dan 24 Tidak, Kehadiran =”D” terdapat 4 Layak dan 30 Tidak.
8. Inovasi
Tabel 4. 11 Atribut Inovasi
Inovasi A B C D
Layak 134 10 7 6
Tidak 212 11 16 23
Tabel diatas menjelaskan bahwa karyawan dengan Inovasi = “A” terdapat 134 Layak dan 212 Tidak , Inovasi = “B” terdapat 10 Layak dan 11 Tidak , Inovasi = “C” terdapat 7 Layak dan 16 Tidak, Inovasi =”D” terdapat 6 Layak dan 23 Tidak.
9. Loyalitas
Tabel 4. 12 Atribut Loyalitas
Loyalitas A B C D
Layak 135 11 6 5
Tidak 211 13 16 22
Tabel diatas menjelaskan bahwa karyawan dengan Loyalitas = “A” terdapat 135 Layak dan 211 Tidak , Loyalitas = “B” terdapat 11 Layak dan 13 Tidak , Loyalitas = “C” terdapat 6 Layak dan 16 Tidak, Loyalitas =”D” terdapat 5 Layak dan 22 Tidak.
4.2.1 Perhitungan Probabilitas Kelas
Tahap pertama perhitungan penentuan layak tidak perpanjang kontrak dengan metode naïve bayes adalah dengan mencari probabilitas dari masing-masing kelas. Untuk perpanjangan kontrak karyawan akan ditentukan 2 kelas yaitu kelas “Layak”dan “Tidak ”. Cara perhitungannya adalah dengan mencari jumlah data yang “Layak” dan “Tidak” dari total keseluruhan data training, lalu membaginya dari total keseluruhan data. Hasil perhitungan tersebut dapat dilihat pada tabel berikut :
Tabel 4. 13 Probabilitas Kelas
4.2.2 Menghitung Probabilitas Masing-masing Atribut
Cara mencari probabilitas suatu atribut adalah dengan membandingkan atribut dari data testing dengan atribut dari data training. Berapa jumlah atribut dengan kelas “Layak” yang berada pada data training, kemudian bagi dengan probabilitas kelas “Layak”. Begitu juga dengan mencari probabilitas untuk kelas “Tidak”.
1. Ketelitian
Tabel 4. 14 Probabilitas Ketelitian
Ketelitian A B C D Layak 126/157 17/157 9/157 5/157 Tidak 239/262 5/262 10/262 8/262 Kelas Layak Tidak Layak 157/419 Tidak 262/419
2. Kreativitas
Tabel 4. 15 Probabilitas Kreativitas
Kreatifitas A B C D
Layak 96/157 37/157 16/157 8/157 Tidak 30/262 80/262 102/262 50/262
3. Tanggung Jawab
Tabel 4. 16 Probabilitas Tanggung Jawab
Tanggung
Jawab A B C D
Layak 61/157 70/157 20/157 6/157 Tidak 81/262 17/262 72/262 92/262
4. Kerjasama
Tabel 4. 17 Probabilitas Kerjasama
Kerjasama A B C D
Layak 92/157 53/157 4/157 8/157 Tidak 118/262 13/262 64/262 67/262
5. Pencapaian tujuan
Tabel 4. 18 Probabilitas Pencapaian Tujuan
Pencapaian
tujuan A B C D
Layak 101/157 41/157 11/157 4/157 Tidak 150/262 12/262 49/262 51/262
6. Inisiatif
Tabel 4. 19 Probabilitas Inisiatif
Inisistif A B C D
Layak 120/157 26/157 6/157 5/157 Tidak 180/262 11/262 33/262 38/262
7. Kehadiran
Tabel 4. 20 Probabilitas Kehadiran
Kehadiran A B C D
Layak 127/157 20/157 6/157 4/157 Tidak 198/262 10/262 24/262 30/262
8. Inovasi
Tabel 4. 21 Probabilitas Inovasi
Inovasi A B C D
Layak 134/157 10/157 7/157 6/157 Tidak 212/262 11/262 16/262 23/262
9. Loyalitas
Tabel 4. 22 Probabilitas Loyalitas
Loyalitas A B C D
Layak 135/157 11/157 6/157 5/157 Tidak 211/262 13/262 16/262 22/262
4.2.3 Menghitung Probabilitas Akhir Untuk Setiap Kelas
Untuk menghitung probabilitas akhir pada setiap kelas, perlu menggunakan data training yang terdapat pada tabel 4.1 dan mengubahnya menjadi nilai yang sudah ditentukan pada proses 4.2.2 sesuai dengan atribut masing-masing. Lalu dari masing-masing atribut dan nilai probabilitas kelas, dikalikan.
Dari kedua hasil yang sudah ditentukan pada tiap kelas, bandingkan nilai yang paling tinggi. Jika kelas layak bernilai paling tinggi, maka hasilnya “Layak”. Begitu pula sebaliknya.
4.2.4 Kasus Perhitungan Naïve Bayes
Untuk memudahkan dalam pemahaman perhitungan Naïve Bayes secara manual akan dibuat studi kasus sebagai berikut dengan rulenya berupa data training pada lampiran :
Tabel 4. 23 Kasus Perhitungan Naive Bayes Ketelitian Kreativitas Tanggung
Jawab Kerjasama
Pencapaian
Tujuan Inisiatif Kehadiran Inovasi Loyalitas Status
C A A C C A D A A ?
Data Testing : X = (Ketelitian=” C”, Kreatifitas=”A”, Tanggung Jawab=” A”, Kerjasama =”C”, Pencapaian Tujuan=”C”, Inisiatif=”A”, Kehadiran=”A”, Inovasi=” A”, Loyalitas=” A”).
a. Tahap 1 Menghitung Jumlah Kelas atau Prediksi. P(Ci)
P(Layak)= 157/419= 0.3747 P(Tidak )= 262/419 = 0.6252
b. Tahap 2 menghitung jumlah kasus yang sama dengan kelas yang sama P(X|Ci)
P (Ketelitian= “C” | Layak)=9/157= 0.057 P(Ketelitian= “C” | Tidak)= 10/262= 0.038 P(Kreatifitas= “A” | Layak)= 96/157 = 0.611 P(Kreatifitas= “ A” | Tidak )= 30/262= 0.114 P(Tanggung Jawab= “A” | Layak)= 61/157 = 0.388 P(Tanggung jawab= “A” | Tidak)= 81/262= 0.309 P(Kerjasama= “C” | Layak)= 4/157 = 0.025 P(Kerjasama = “C” | Tidak)= 64/262 = 0.244
P(Pencapaian Tujuan= “C” | Layak)= 11/157= 0.070 P(Pencapaian Tujuan= “C” | Tidak)= 49/262= 0.187 P(Inisiatif= “A” | Layak)= 120/157= 0.764
P(Inisiatif= “A” | Tidak)= 180/262= 0.687 P(Kehadiran= “A” | Layak)= 127/157=0.808 P(Kehadiran= “A” | Tidak)= 198/262= 0.755 P(Inovasi= “A” | Layak)= 134/157= 0.853 P(Inovasi= “A” | Tidak )= 212/262 = 0.809 P(Loyalitas= “A” | Layak)= 135/157= 0.859
P(Loyalitas= “A” | Tidak)= 211/262= 0.805
c. Tahap 3 mengalikan semua hasil atribut “LAYAK” dan “TIDAK”
P(X|Layak) = 0.057 x 0.611 x 0.388 x 0.025 x 0.070 x 0.764 x 0.808 x 0.853 x 0.859= 0.0001069
P(X|Tidak Layak) = 0.038 x 0.114 x 0.309 x 0.244 x 0.187 x 0.687 x 0.755 x 0.809 x 0.805 = 0.0000206
d. Tahap 4 membandingkan nilai kelas “LAYAK” dan TIDAK LAYAK”. P(X|Ci)*P(Ci)
P(X|Layak)*P(Layak)=0.3747 x 0.00001069 = 0.00000400
P(X|Tidak Layak)*P(Tidak Layak)=0.6252 x 0.0000206 = 0.0001287 Jadi, untuk Ketelitian=” C”, Kreatifitas=”A”, Tanggung Jawab=” A”, Kerjasama =”C”, Pencapaian Tujuan=”C”, Inisiatif=”A”, Kehadiran=”A”, Inovasi=” A”, Loyalitas=” A”, masuk kelas “TIDAK ”.
4.3 Implementasi Klasifikasi Naïve Bayes pada Rapid Miner
Berikut adalah tahapan analisis data mining dengan metode naive bayes menggunakan Rapid Miner 7.6.
4.3.1 Proses Validasi
Proses validasi yaitu melakukan analisis berbagai model dan memilih model dengan prediksi terbaik, pada gambar 4.1 merupakan proses validasi, dimana operator read excel dimasukan dimasukan dan dihubungkan dengan operator Cross Validation. Proses data training dan testing berada di dalam proses validation.
4.3.2 Proses Training dan Testing
Proses training yaitu melakukan proses pelatihan data pada model Naive Bayes, sedangkan proses testing yaitu melakukan pengujian data yang akan menghasilkan grafik dan pola.
Pada gambar 4.2 dijelaskan bahwa proses training dilakukan dengan memasukan model Naive Bayes pada blok training dan dihubungkan dengan blok testing pada operator apply model dan performance.
4.3.3 Hasil Performance Vector
Proses klasifikasi menggunakan Rapid Miner dengan metode Naive Bayes yang digunakan untuk mendiagnosa pneumonia diperoleh nilai Accuracy, Precision dan Recall.
a) Accuracy
Dengan mengetahui jumlah data yang di klasifikasikan secara benar maka dapat diketahui akurasi hasil prediksi yaitu 80.43%.
Gambar 4. 3 Accuracy
b) Precision
Precision adalah jumlah data yang True Layak (jumlah data Layak yang dikenali secara benar sebagai Layak) dibagi dengan jumlah data yang dikenali sebagai Layak, sedangkan jumlah data yang True Tidak (jumlah data tidak yang dikenali secara benar sebagai tidak) dibagi dengan jumlah data yang dikenali sebagai tidak, dari hasil pengujian nilai precision yaitu 82.85% untuk class Layak dan 75.86% untuk class Tidak.
Gambar 4. 4 Precision c) Recall
Recall adalah jumlah data yang True Positive di bagi dengan jumlah data yang sebenarnya Positive (True Positive + False Negatif ), sedangkan True Negatif di bagi dengan jumlah data yang sebenarnya Negatif (True Negatif + False Positive ), untuk nilai Recall yaitu 97.10% pada Class Positif dan nilai Class Negatif yaitu 99.24%
Gambar 4. 5 Recall
4.4 Pembahasan
4.4.1 Evaluasi (Evaluation)
Pada tahap ini melakukan pengecekan terhadap setiap atribut dan model yang sudah dibangun, kemudian melakukan evaluasi terhadap hasil dengan melakukan analisis dari setiap variable output atau karakteristik informasi yang dihasilkan oleh model data mining pada tabel 4.20 dibawah ini adalah hasil confusion matrix dari Rapid Miner.
Tabel 4. 24 Confusion Matrix Accuracy: 80,43 %
true TIDAK true LAYAK class precision
pred.TIDAK 227 47 82.85% pred.Layak 35 110 75.86% class recall 86.64% 70.06% a) Accuracy Accuracy = ( ) ( ) = ( ) ( )
=
= 0.8043 x 100 =80,43 % b) Precision Precision (Positive) = ( )=
( )=
= 0,7586 x 100 = 75,86 % Precision (Negatif) = ( )
=
( )=
= 0,82846 x 100 = 82,85 % c) Recall Recall(Positive) = ( )
=
( )=
= 0.7586 x 100 = 75.86% Recall (Negatif) = ( )=
( )=
= 0.82846 x 100 = 82.85%4.4.2 AUC (Area Under Curve)
Selain Confusion Matrix, kurva Receiver Operating Characteristic (ROC) dihasilkan oleh Rapid Miner, kurva tersebut dapat dilihat pada gambar dibawah ini.
Gambar 4. 6 Kurva ROC
Kurva ROC digunakan untuk mengekspresikan data dari Confusion Matrix. Garis horizontal mewakili nilai False Positive (FP) dan garis vertikal mewakili nilai True Positive (TP). Dari gambar 4.6 dapat diketahui bahwa nilai Area Under Curve (AUC) model algoritma Naive Bayes adalah 0.890, hal ini menunjukan bahwa model algoritma Naive Bayes memperoleh hasil “good classification“”.
4.4.3 Hasil Klasifikasi Class 4.4.3.1 Simple Distribution Model
Menganalisa tabel data karyawan dalam memprediksi perpanjangan kontrak dengan metode Naive Bayes dapat menghasilkan 2 class utama.
Gambar 4. 7 Simple Distribution Model
Hasil klasifikasi dari data karyawan dengan menggunakan metode Naive Bayes membagi 2 class klasifikasi yaitu class LAYAK dan class TIDAK, untuk nilai class LAYAK yaitu (0.375) dan nilai class TIDAK yaitu (0.625).
4.2.4 Penyebaran (Deployment)
Dalam penerapan pada sistem yang dibuat, data training yang dimasukan adalah sebanyak 419 record, sistem ini hanya diterapkan dengan alur algoritma Naive Bayes, berikut adalah tampilan dari aplikasi yang dibuat dengan Visual Basic 6.0.
4.4.2 Hasil Analisa Naïve Bayes Prediksi Tidak
Halaman ini menampilkan hasil “Tidak”dari analisa berupa perhitungan probabilitas tiap atribut, probabilitas kelas dan hasil kelayakan perpanjangan kontrak karyawan.
4.4.2 Hasil Analisa Naïve Bayes Prediksi Ya
Halaman ini menampilkan hasil “Ya”dari analisa berupa perhitungan probabilitas tiap atribut, probabilitas kelas dan hasil kelayakan perpanjangan kontrak karyawan.