Perbandingan Teknik Pengklasteran Dalam Visualisasi Data Teks
Bahasa Indonesia
Praditya Kurniawan1, Ema Utami2, Andi Sunyoto3
1,2,3 STMIK AMIKOM Yogyakarta
e-mail: *1[email protected], 2[email protected], 3[email protected]
Abstrak
Pengklasteran merupakan salah satu teknik untuk melakukan analisis data pada data mining. Beberapa metode pengklasteran diantaranya adalah k-means dan single linkage. Setiap metode mempunyai karakteristik tersendiri dalam mengklasterkan data. Komparasi setiap metode dilakukan untuk melihat kemampuan setiap metode dalam mengklasterkan data. Penilaian yang dilakukan dalam komparasi ini menggunakan metode Silhouette Coefficient dan Purity. Selain itu pengujian setiap metode akan dilakukan dengan dua jenis data yang diambil dari sumber yang berbeda.
Dari pengujian yang dilakukan terhadap kedua metode, pada beberapa pengujian single link mempunyai hasil kualitas yang lebih baik daripada k-means. Hasil dari penelitian ini dapat dijadikan acuan untuk menentukan algoritma pengklasteran dalam data teks berbahasa Indonesia dan dapat dikembangkan lebih lanjut lagi dalam penerapan kasus sehari hari.
Kata kunci—Klaster, K-Means, Single Linkage, Bahasa Indonesia, Visualisasi
Abstract
Clustering is a technique to perform data analysis on data mining. Several clustering methods include k-means and single linkage. Each method has its own characteristics in mengklasterkan data. Comparison of each method was conducted to see the ability of each method in mengklasterkan data. Assessment is carried out in this comparative method Silhouette Coefficient and Purity. Besides testing each method will be conducted with two types of data taken from different sources.
From the tests performed on the second method, in some testing single linkage has a better quality results than k-means. The results of this study can be used as a reference for determining the clustering algorithms in the Indonesian language text data and can be developed further in the case of daily application.
Keywords— Clustering, K-means, Single Linkage, Indonesian Language, Visualization
1. PENDAHULUAN
lastering merupakan salah satu teknik dalam analisis data pada data mining. Teknik pengklasteran merupakan teknik pengelompokkan kumpulan data menjadi beberapa kelompok sehingga objek didalam satu kelompok mempunyai banyak kesamaan dan memiliki banyak perbedaan dengan objek kelompok lain[1].
Penelitian yang dilakukan Randy Handoyo[2] tentang pengklasteran menggunakan dokumen berbahasa Indonesia menghasilkan single linkage mempunyai nilai yang lebih baik. Dalam penelitian yang telah dilakukan dapat dikembangkan dengan jenis data yang berbeda. Heru Susanto[3] juga pernah melakukan pengklasteran dan analisis sentimen data dengan data twitter. Data twitter merupakan data teks yang mempunyai batas kata dan jumlahnya yang terus bertambah sehingga menarik untuk diteliti.
Berdasarkan penelitian yang dilakukan oleh Suwanto[4], penelitian bertema tentang pengklasteran data di Indonesia masih sedikit sehingga mempunyai peluang banyak untuk dilakukan penelitian.
2. METODE PENELITIAN
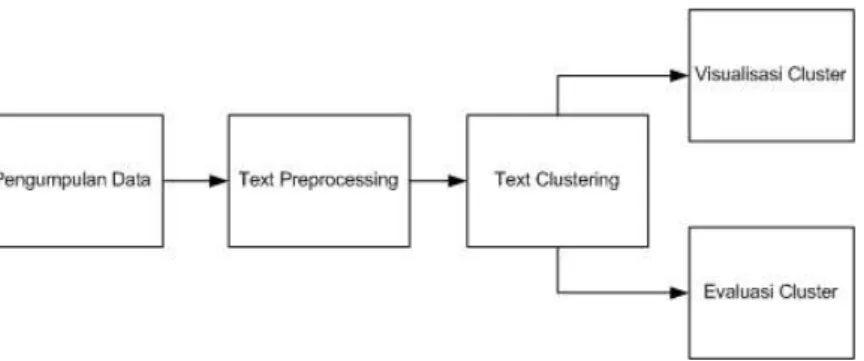
Pada bagian ini akan diuraikan langkah langkah yang dilakukan untuk melakukan penelitian. Secara umum langkah langkah penelitian dapat dilihat pada Gambar 22.
Gambar 22 Gambaran Alur Penelitian Secara Umum
2.1 Pengumpulan Data
Data yang akan digunakan dalam penelitian diambil dari beberapa sumber. Data pertama yang diambil adalah data teks berita. Sumber data teks berita dari berita online antaranews dengan memanfaatkan rss feed yang sudah disediakan tanpa menggunakan kategori tertentu (umum). Data kedua diambil dari twitter dengan memanfaatkan API yang sudah disediakan. Data twitter yang diambil hanya dari akun twitter milik @kompascom, @tempoco, dan @antaranews tanpa menggunakan filter tertentu.
2.2 Text Processing
Data yang sudah dikumpulkan harus melalui proses pembersihan teks. Fungsi dari text processing adalah menghilangkan kata yang tidak bermakna. Tahapan tahapan untuk melakukan pembersihan teks sebagai berikut.
1. Cleaning dan Case Folding
Cleaning merupakan proses penghapusan karakter angka, maupun tanda baca. Sedangkan case folding merubah semua karakter menjadi huruf kecil.
2. Tokenization
Tokenization merupakan tahapan untuk memecah kalimat menjadi per kata. 3. Stopword Removal
Stop word removal merupakan tahapan untuk menghapus kata yang tidak memiliki makna/ tidak berpengaruh.
4. Pembobotan
Untuk dapat mengklasterkan data teks, data teks tersebut harus diberi bobot sehingga dapat dilakukan perhitungan. Pembobotan yang digunakan adalah TF-IDF.
Pengklasteran teks menggunakan bahasa pemrograman PHP. Metode yang digunakan untuk mengklasterkan teks adalah k-means dan single linkage.
2.4 Evaluasi
Metode evaluasi yang digunakan dalam penelitian ini adalah silhouette coefficient dan purity. Perhitungan silhouette coefficient dapat dilihat pada persamaan (1)
(1)
Sedangkan perhitungan menggunakan purity dapat dilihat pada persamaan (2).
𝑃𝑢𝑟𝑖𝑡𝑦 (Ω, 𝐶) =
1𝑛
∑ max j (𝜔
𝑘 𝑘∩ 𝐶
𝑗)
(2)2.5 Visualisasi
Visualisasi digunakan untuk menampilkan hasil pengklasteran yang sudah dilakukan. Pada visualisasi ini menampilkan jumlah kata terbanyak pada setiap klaster yang dibentuk. Visualisasi menggunakan HTML dan javascript.
3. HASIL DAN PEMBAHASAN 3.1 Pengujian Dengan Menggunakan Data Teks Berita
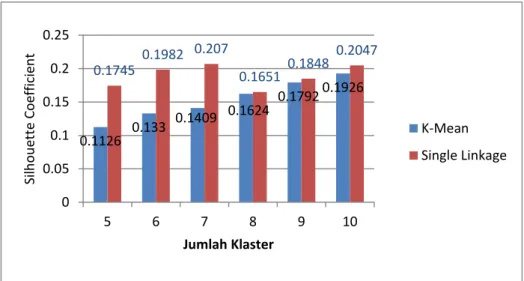
Setelah dilakukan pengklasteran data terhadap data twitter dan berita dilakukan evaluasi menggunakan silhouette coefficient dan purity. Hasil pengujian silhouette coefficient menggunakan 50 data berita antaranews dapat dilihat pada Gambar 23.
Gambar 23 Grafik Nilai SC pada Data Berita Antaranews
Dari hasil evaluasi menggunakan shilouette coefficient pengklasteran menggunakan metode single linkage lebih baik daripada k-means. Hal ini dapat dilihat pada pembentukan setiap klaster nilai sc (shilouette coefficient) dari single linkage lebih tinggi dari k-means. Walaupun secara keseluruhan klaster terbentuk belum cukup kuat (sc < 1). Nilai terbaik sc pada
0.1126 0.133 0.1409 0.1624 0.17920.1926 0.1745 0.1982 0.207 0.1651 0.1848 0.2047 0 0.05 0.1 0.15 0.2 0.25 5 6 7 8 9 10 Sil h o u ett e Coe ff ici en t Jumlah Klaster K-Mean Single Linkage
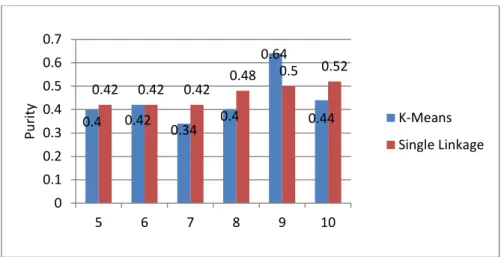
metode k-means terjadi saat pembentukan 10 klaster dengan nilai sc 0,1926. Sedangkan nilai terbaik metode single linkage terjadi saat pembentukan 7 klaster dengan nilai sc 0,207. Sedangkan hasil evaluasi menggunakan purity pada 50 data berita antaranews dapat dilihat pada Gambar 24
Gambar 24 Grafik Nilai Purity Pada Data Teks Berita
Dari hasil evaluasi menggunakan purity nilai purity single linkage dominan lebih tinggi daripada k-means. Namun pada pembentukan 6 klaster nilai purity k-means menyamai single linkage, bahkan pada pembentukan 9 klaster nilai purity k-means lebih tinggi dari single linkage. Hal ini dapat mengindikasikan jika k-means ada kemungkinan membentuk klaster yang lebih baik.
3.2 Pengujian Dengan Menggunakan Data Twitter
Hasil evaluasi silhouette coefficient pada pembentukan klaster dengan 50 data twitter dapat dilihat pada Gambar 25
Gambar 25 Grafik Nilai SC Pada Data Twitter
Dari evaluasi menggunakan silhouette coefficient pada penggunaan data twitter nilai sc Single linkage lebih tinggi daripada k-means. Nilai sc tertinggi untuk metode k-means adalah
0.4 0.42 0.34 0.4 0.64 0.44 0.42 0.42 0.42 0.48 0.5 0.52 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 5 6 7 8 9 10 Pu rity K-Means Single Linkage 0.1126 0.133 0.14090.1624 0.17920.1926 0.1745 0.1982 0.207 0.1651 0.1848 0.2047 0 0.05 0.1 0.15 0.2 0.25 5 6 7 8 9 10 Si lho u ett e C oe ff ic ie n t Jumlah Klaster K-Mean Single Linkage
0,1926 pada saat pembentukan 10 klaster. Sedangkan nilai sc tertinggi untuk single linkage adalah 0,207 saat pembentukan 7 klaster.
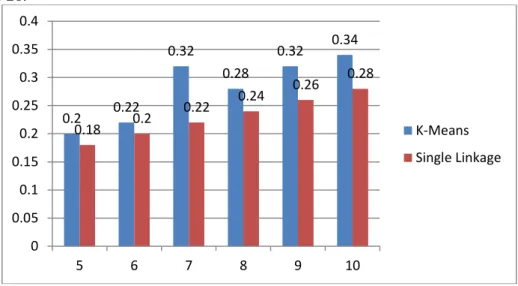
Hasil evaluasi menggunakan purity pada penggunaan 50 data twitter dapat dilihat pada Gambar 26.
Gambar 26 Grafik Nilai Purity Pada Data Twitter
Dari hasil evaluasi purity k-means mempunyai nilai purity yang lebih tinggi dibanding dengan single linkage. Nilai purity tertinggi pada metode k-means adalah 0,32 saat pementukan 7 klaster dan nilai terendah saat membentuk 5 klaster dengan nilai 0,2. Sedangkan nilai tertinggi untuk metode single linkage adalah 0,28 saat pembentukan 10 klaster dan nilai terendah saat pembentukan 5 klaster dengan nilai 0,18.
3.3 Visualisasi Data
Visualisasi data menggunakan HTML dengan Javascript sehingga dapat diakses menggunakan browser. Contoh visualisasi dengan menggunakan metode k-means dapat dilihat pada Gambar 27.
Gambar 27 Contoh hasil Visualisasi Dengan Metode K-Means
4. KESIMPULAN
Dari penelitian yang telah dilakukan dapat diambil kesimpulan sebagai berikut.
0.2 0.22 0.32 0.28 0.32 0.34 0.18 0.2 0.22 0.24 0.26 0.28 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 5 6 7 8 9 10 K-Means Single Linkage
1. Pada penggunaan data teks berita antaranews single linkage menghasilkan nilai SC dan purity yang lebih tinggi daripada k-means. Nilai SC tertinggi metode single linkage saat dilakukan pembentukan 7 klaster dengan nilai 0,207. Sedangkan nilai tertinggi metode k-means saat dilakukan pembentukan 10 klaster dengan nilai 0,192. Nilai purity tertinggi metode k-means saat membentuk 9 klaster dengan nilai 0,64. Sedangkan nilai tertinggi pada metode single linkage saat membentuk 10 kklaster dengan nilai 0,52.
2. Pada penggunaan data twitter metode k-means mempunyai indikasi dapat menghasilkan nilai SC dan Purity yang lebih tinggi daripada single linkage. Hal ini dapat dikarenakan penentuan titik centroid awal pada data mendekati data yang dominan.
5. SARAN
Berdasarkan penelitian yang telah dilakukan maka dalam upaya pengembangan dapat dikemukakan beberapa saran berikut:
1. Hasil dari pengklasteran dipengaruhi oleh hasil text processing yang dilakukan. Pemilihan metode dan library yang digunakan saat melakukan text processing akan mempengaruhi hasil pengklasteran yang dilakukan.
2. Penelitian ini menggunakan bahasa pemrograman PHP yang dapat digunakan pada hampir semua platform sehingga dapat dikembangkan lebih baik lagi dalam hal antarmuka.
UCAPAN TERIMA KASIH
Penulis mengucapkan terimakasih kepada STMIK Amikom Yogyakarta dan STMIK Dipanegara Makasar yang telah memberikan kesempatan mempublikasikan tulisan ini.
DAFTAR PUSTAKA
[1] Han, Jiawei & Kamber, Micheline., 2006, Data Mining: Concepts and Techniques, Second Edition, Morgan Kaufman Publishers, San Francisco
[2] Handoyo, Rendy dkk., 2014. Perbandingan Metode Clustering Menggunakan Metode Single Linkage dan K-Means Pada Pengelompokan Dokumen, Jurnal Teknik ITS
[3] Susanto, Heru, dkk., 2014, Visualisasi Data Teks Twitter Berbasis Bahasa Indonesia Menggunakan Teknik Pengklasteran, ITS Paper 2014
[4] Raharjo, Suwanto & Winarko, Edi., 2014. Klasterisasi, Klasifikasi, dan Peringkasan Teks Berbahasa Indonesia, Prosiding Seminar Ilmiah Nasional Komputer dan Sistem Intelijen