MODUL
STATISTIK PARAMETRIK
(PROGRAM SPSS)
DI SUSUN
OLEH
Dr. Nugroho Susanto, SKM, M.Kes
FAKULTAS ILMU KESEHATAN
PERTEMUAN 1
STATISTIK UNTUK UJI HIPOTESIS POPULASI YANG BERBEDA
A. PENGANTAR
Uji statistik untuk satu populasi dimaksudkan untuk melakukan pengujian hipotesis pada satu populasi. Pengujian hipotesis ini biasa sering disebut pengujian hipotesis deskriptif. Statistik parametrik yang dapat digunakan untuk menguji hipotesis deskriptif bila datanya berbentuk interval atau rasio adalah uji t-test 1 sampel.
Dalam pertemuan ini dibahas bagaimana mengaplikasikan uji statistik parametrik. Uji statistik parametrik antara lain uji one sample t test, independent t test, dependent t test dan uji anova. Yang penting diketahui sebelum pengunaan uji statistik adalah tipe sampel yang digunakan. Sampel yang akan dilakukan analisis, apakah sampel dependent atau sampel independent sehingga uji statistik yang digunakan mengikuti jenis/tipe sampelnya.
B. Uji one sampel t test Rumus
Rumus yang biasa digunakan adalah
n
s
t
0Contoh kasus
Suatu penelitian dilakukan di UGM terhadap 10 mahasiswa terhadap berat badan mahasiswa. Seorang peneliti menduga bahwa berat badan mahasiswa UGM = 50 kg.
3 46 4 62 5 64 6 47 7 59 8 44 9 50 10 67 Penyelesaian 1. Menentukan Hipotesis
Ho; Berat badan mahasiswa UGM adalah 50 Kg
Ha: Berat badan mahasiswa UGM tidak sama dengan 50 kg 2. Menentukan daerah penerimaan hipotesis
Alfa = 0,05 3. Perhitungan
n
s
t
010
27
,
9
50
57
t
9315
,
2
7
t
3878
,
2
t
4. Hasil T hitung > t tabel 5. Kesimpulan Ho ditolak.Suatu penelitian dilakukan di UGM terhadap 10 mahasiswa terhadap berat badan mahasiswa. Seorang peneliti menduga bahwa berat badan mahasiswa UGM = 50 kg.
Ujilah hipotesis peneliti tersebut dengan uji one sampel t test.
Berdasarkan hasil penelitian diperoleh hasil sebagai berikut: No BB MHS 1 68 2 63 3 46 4 62 5 64 6 47 7 59 8 44 9 50 10 67 Langkah penyelesaian
1. Buka menu lembar kerja SPSS 2. Buat variabel berat badan
3. Masukan data kasus diatas kedalam spss sehingga terlihat seperti gambar berikut:
4. Lakukan pengujian one sample t test dengan mengaktifkan menu ANALYZE, kemudian pilih compare means kemudian pilih one sampel t
5. Masukan dugaan yang diinginka kedalam kolom di
6. Kemudian klik OK sehingga hasil out put spss terlihat seperti gambar berikut:
Variable yang di uji
Tes yang diinginkan
7. interpretasi
hasil perhitungan uji t test sama dengan perhitungan secara manual. Untuk membandingkan apakah menerima atau menolak hipotesis nol dapat dilakukan dengan 2 cara yaitu:
a. Membandingkan nilai signifikasi hitung dengan nilai signifikansi yang ditetapkan oleh peneliti (misalnya; 0,01, 0,05 dan o,1).
b. Membandingkan nilai t hitung dengan t tabel
C. INDEPENDENT SAMPLE T TEST Pengantar
Uji independent sampel t test biasa digunakan pada penelitian dengan tipe sampel yang bersifat independent. Tipe sampel independent maksudnya adalah tipe sampel yang antara pengukuran satu variabel tidak terkait dengan variabel lain atau masing-masing pengukuran variabel bersifat independent.
Misalnya
Variabel umur dangan tekanan darah. Pengukuran variabel umur tidak terkait langsung dengan pengukuran tekanan darah atau sebaliknya.
Contoh kasus
Suatu penelitian dilakukan untuk mengetahui pebedaan tekanan darah antara laki-laki dan perempuan.
Hasil penelitian disajikan dalam tabel berikut:
No Jenis kelamin Tekanan darah Kode 1= laki-laki; 2 =perempuan 1 1 120 2 1 120 3 1 120 4 2 110 5 2 130 6 1 140 7 1 140 8 1 160
15 2 130
Buat hasil analisis sesuai format yang ada di journal berikut:
Sumber: Shavarage et al, 2007.
Penyelesaian dengan program spss 1. Buat lembar kerja baru spss
2. Buat variabel jenis kelamin dan tekanan darah dengan mengaktifkan menu variabel view.
3. Masukan data kasus diatas kedalam spss sehingga pada layar tampak gambar berikut:
4. Melakukan analisis dengan mengaktifkan menu ANALYZE, kemudian pilih
5. Kemudian masukan variabel jenis kelamin pada grouping variabel dan aktifkan menu defini group, seperti tampak pada layar berikut:
Uji yang diingikan
6. Setelah jenis kelamin dibuat grouping group 1 ketik 1 dan group 2 ketik 2, Kemudian klik continue untuk melanjutkan analisis.
7. Masukan variabel tekanan darah kedalam kolom sebelah kanan sehingga pada layar tampak gambar berikut:
8. Klik Ok untuk melihat hasil out put SPSS. Hasil out spss seperti disajikan pada gambar berikut:
Gruping jenis kelamin
Buat define variable jenis kelami
9. Interpretasi Hasil
Group Statistics
jenis kelamin N Mean Std. Deviation Std. Error Mean
tekanan darah laki-laki 9 133.33 13.229 4.410
perempuan 6 135.00 24.290 9.916
Independent Samples Test
Levene's Test for
Equality of Variances t-test for Equality of Means
F Sig. t df Sig. (2-tailed) Mean Differenc e Std. Error Difference 95% Confidence Interval of the Difference Lower Upper tekanan darah Equal variances assumed 1.082 .317 -.173 13 .865 -1.667 9.641 -22.495 19.161
Ringkasan table (sesuai journal) Variable Laki-laki mean±SD Perempuan mean±SD P Tekanan darah 133,33±13,22 135,00±24,29 0,865
D. DEPENDENT SAMPEL T TEST
Uji dependent sample t test biasa digunakan pada penelitian dengan tipe variabel penelitian dengan sampel yang bersifat dependent artinya satu pengukuran variabel berkaitan dengan pengukuran variabel lainya. Misalnya pengukuran suhu sebelum perlakukan dan setelah perlakukan.
Studi kasus
Suatu penelitian dilakukan untuk mengetahui dampak dari pemberian obat katapres terhadap penurunan tekanan darah pasien hipertensi. Berdasarkan hasil penelitian diperoleh hasil sebagai berikut:
No Sebelum Sesudah 1 140 120 2 140 120 3 160 120 4 140 110 5 180 130 6 130 140 7 130 120 8 160 130
Analisis hasil penelitian tersebut diatas dengan uji dependent sample t test kemudian Sajikan data tersebut diatas sesuai journal berikut:
Sumber: Ingram, J., 2005.
Langkah penyelesaian dengan program spss 1. Buka lembar kerja baru spss
2. Buat variabel sebelum dan sesudah seperti telihat pada gambar berikut:
3. Masukan data kasus diatas kedalam lembar kerja spss, sehingga pada layar tampak gambar berikut:
4. lakukan analisis data dengan mengaktifkan menu ANALYZE, kemudian pilih
5. Klik OK sehingga pada layar tampak gambar berikut:
6. Masukan variabel sebelum ke kolom sebelah kanan pada variabel 1 dan masukan variabel sesudah pada kolom sebelah kanan pada variabel 2 seperti terlihat pada gambar berikut:
Variable yang dianalisis
7. Kemudian klik OK untuk melihat hasil out put
Hasil out dalam versi windows
Paired Samples Statistics
Mean N Std. Deviation Std. Error Mean Pair 1 sebelum pemberian katapres 147.50 8 17.525 6.196
setelah pemberian katapres 123.75 8 9.161 3.239
Paired Samples Test
Paired Differences t df Sig. (2-tailed) Mean Std. Deviation Std. Error Mean 95% Confidence Interval of the Difference Lower Upper
Paired Samples Test Paired Differences t df Sig. (2-tailed) Mean Std. Deviation Std. Error Mean 95% Confidence Interval of the Difference Lower Upper Pair 1 sebelum pemberian katapres - setelah pemberian katapres 23.750 18.468 6.529 8.310 39.190 3.637 7 .008
8. Hasil table sesuai journal
Variable Sebelum pemberian katapres Setelah pemberian katapres t p Mean±SD Mean±SD Tekanan darah 147,50±17,52 123,75±9,16 3,637 0,008 9. Interpretasi Hasil
Hasil penelitian menunjukan bahwa terjadi penurunan tekanan darah yang signifikan antara sebelum pemberian katapres dan setelah pemberian katapres yang dapat dilihat dari nilai t dan p.
LATIHAN
Suatu penelitian dilakukan untuk mengetahui perbedaan tingkat kesembuahan penyakit diare antara pasien yang dirawat di rumah sakit A dan rumah sakit B. Tingkat kesembuhan penyakit didasarkan pada rata-rata lama dirawat dirumah sakit tersebut. Berdasarkan hasil penelitian diperoleh hasil sebagai berikut:
Rumah sakit A
Lama dirawat Rumah sakit B Lama dirawat 1 4 1 23 2 10 2 22 3 12 3 22 4 14 4 21 5 15 5 17 6 27 6 18 7 32 7 14 8 32 8 12 9 5 9 10 10 6 10 9 Pertanyaan....
1. Uji statistik apa yang tepat untuk menguji perbedaan tingkat kesebuhan pada penelitian tersebut diatas...? berikan alasannya...?
2. Setelah anda mengetahui uji statistik yang tepat untuk melakukan analisis penelitian tersebut.. kemudian lakukan analisis dan sajikan hasil analisis sesuai dengan format pada journal berikut:
PERTEMUAN 2
UJI HIPOTESIS KORELASIONAL
A. PENGANTAR
Riset korelasional dapat melibatkan hanya dua variable saja, tetapi juga dapat melibatkan lebih dari dua variable. Pada analisis korelasional dimaksudkan untuk mengetahui ada tidak hubungan antara dua variable atau lebih.
Pada prinsipnya ada dua sebutan korelasional yaitu korelasional positif dan korelasional negative. Korelasional positif jika didapatkan pada observasi skor-skor pada variabel satu tinggi, demikian pula pada skor-skor variabel satunnya juga tinggi atau skor-skor pada variabel satu rendah, demikian pula pada skor variabel satunnya juga rendah. Korelasional negatif jika skor-skor pada variabel satu tinggi, sedangkan skor-skor-skor-skor pada variabel satunya rendah atau sebaliknya.
Kekuatan hubungan sering dinyatakan dengan koefisien korelasi. Kekuatan hubungan yang dinyatakan dengan koefisien korelasi dapat berkisar antara -1 sampai +1. dimana mempunyai interpretasi jika nilai (0.6 sampau 1) atau – 0.6 sampai – 1) korelasi kuat, jika (0.4 sampai 0.6) atau (-0.4 sampai – 0.6) korelasi sedang (moderat), dan jika (0.0 sampai 0.4) atau (0.0 sampai -0.4) korelasi lemah.
Dua aspek yang penting pada analisis korelasi yaitu apakah data yang ada meyediakan bukti yang kuat ada kaitanya antara variable dalam populasi dalam sample, dan keduanya ada hubungan seberapa kuat hubungan antara vaariabel tersebut. Uji korelasi digunakan jika peneliti ingin mengetahui hubungan antara dua variable atau lebih. Jika data berdistribusi normal dapat dilakukan uji korelasi pearson dan jika data tidak berdistribusi normal dapat
mensyaratkan bahwa distribusi data normal dan variansi sama. Jika asumsi ini tidak terpenuhi sebaiknya digunakan analisis yang lain untuk menguji hipotesis yang bebentuk korelasio nal.
Skala data yang menyertai analisis korelasional biasanya dalam bentuk interval atau rasio.
Analisis korelasi pearson mengisyaratkan atau digunakan untuk membuktikan hipotesis yang sifatnya hubungan.
Rumus 2 2 y x xy rxy Dimana xy
r = Korelasi antar variabel x dan y
X = (Xi – x) Y = (Yi – Y)
2 2
2
2
i i i i i i i i xy y y n x x n y x y x n r Kasus KorelasiPermasalahan yang sering terjadi dalam penelitian adalah bahwa peneliti melupakan persyaratan untuk mengunakan analisis pearson. Jika dalam suatu penelitian diperoleh bahwa distribusi data tidak normal dan variansi tidak sama maka digunakan analisis yang lebih sederhana yaitu analisis kendall’s tau atau analisis spearman.
Contoh kasus
Suatu penelitian dilakukan di di Puskesmas gamping Sleman terhadap sepuluh subjek penelitian untuk mengetahui ada tidak nya hubungan antara kebiasaan makan sambal dengan kejadian diare. berdasarkan hasil
3 7 2 4 6 2 5 7 2 6 8 2 7 9 3 8 6 1 9 5 1 10 5 1 ∑=70 µ =7 ∑=20 µ=2 0 0 20 6 10 Data fiktif Jawab 2 2 y x xy rxy 6 . 20 10 xy r =0,9129
PRAKTEK ANALISIS KORELASI Aplikasi studi kasus korelasi Contoh kasus
Suatu penelitian dilakukan di di Puskesmas gamping Sleman terhadap sepuluh subjek penelitian untuk mengetahui ada tidak nya hubungan antara kebiasaan makan sambal dengan kejadian diare. berdasarkan hasil penelitian diperoleh hasil sebagai berikut:
No Frekuensi makan sambal Frekuensi kejadian diare (x-µ) X (Y-µ) y X2 Y2 Xy 1 8 3 2 9 3 3 7 2 4 6 2
Penyelesaian dengan program spss 2. Buka lebar kerja SPSS
3. Masukan data ke dalam format spss. Seperti terlihat pada gambar berikut:
4. Kemudian lakukan analisis data. Seperti pada gambar berikut:
5. Kemudian masukan data makan sambel dan diare pada kotak sebelah kanan dan pilih option pearson, seperti pada gambar berikut:
6. Kemudian hasil analisis tertampil sebagai berikut:
7. interpretasi data
LATIHAN Studi kasus
Seorang manajer kaos dagadu ingin mengetahui hubungan antara umur dengan kemampuan menghasilkan jumlah kaos (produksi kaos) dalam seminggu. Berdasarkan hasil penelitian diperoleh hasil sebagai berikut:
No Umur Jumlah kaos
1 45 130 2 50 135 3 51 140 4 53 145 5 54 150 6 57 155 7 58 160 8 60 165 9 61 170 10 62 175 11 64 180 12 63 175 13 66 185 14 67 190 15 68 195 16 69 200 17 70 205 18 71 210 19 72 210 20 73 215 Penyelesaian
1. Buka lembar kerja baru SPSS
2. Buat variable umur dan produksi kaos dalam lembar SPSS 3. Pemasukan data
Lakukan pengisian variable umur (sesuai data diatas)
Lakukan pengisian variable Tekanan darah (sesuai data diatas) 4. Mengisi data
5. Pengolahan data dengan SPSS
Selain menu analisis tampak menu option yang berisi karakteristik jenis analisis yang disertakan pada masing-masing uji statistik yang diinginkan.
Jika dirasa pilihan analisis dan menu sudah terpenuhi kemudia Tekan OK untuk melihat hasil analisis. Hasil analisis akan tampak pada menu out put SPSS.
Untuk lebih jelas kita pindahkan hasil analisis pada versi windows seperti pada point 6.
6. Hasil Analisis dan interpretasi
CORRELATIONS
/VARIABLES=produktivitas umur /PRINT=TWOTAIL NOSIG
/STATISTICS DESCRIPTIVES XPROD /MISSING=PAIRWISE .
Correlations
[DataSet0]
Descriptive Statistics
produksi kaos
Untuk melihat bagaimana mekanisme hubungan antara usia pekerja dengan produktivitas yang dihasilkan dengan analisis parametric (korelasi pearson) terlihat pada table berikut:
Correlati ons 1 ,991** ,000 13445,000 4047,000 707,632 213,000 20 20 ,991** 1 ,000 4047,000 1240,200 213,000 65,274 20 20 Pearson Correlation Sig. (2-tailed) Sum of Squares and Cross-products Cov ariance N
Pearson Correlation Sig. (2-tailed) Sum of Squares and Cross-products Cov ariance N
produksi kaos
usia pekerja
produksi kaos usia pekerja
Correlation is signif icant at the 0.01 lev el (2-tailed). **.
Hasil analisis korelasi pearson memberikan gambaran bahwa terdapat korelasi yang kuat antara usia pekerja dengan produktivitas kaos yang dihasilkan yang dibuktikan dengan hasil signifikansi.(Sig. (2-tailed) = 0.000. untuk menyimpulkan apakah hubungan antara variable umur pekerja dengan produktivitas dapat dilakukan dengan membandingkan hasil signifikansi dengan derajat kemaknaan yang diinginkan atau membandingkan hasil analisis korelasi pearson dengan table statistic.
Staement hipotesis:
Ho = tidak ada hubungan antara usia pekerja dengan produktivitas kaos yang dihasilkan.
Ha = ada hubungan antara usia pekerja dengan produktivitas kaos yang dihasilkan.
Standart yang digunakan
Kemaknaan α = 0.05 (kesalahan yang dapat diterima sebesar 5%) Signifikansi
Tanda ** menunjukan kemaknaan pada level 0.01. 0,991
menunjukan hasil analisis pearson
Ho ditolak Artinya
Ada hubungan antara usia pekerja dengan produktivitas kaos yang dihasilkan
NONPAR CORR
/VARIABLES=produktivitas umur /PRINT=BOTH TWOTAIL NOSIG /MISSING=PAIRWISE .
Nonparametric Correlations
[DataSet0] Correlati ons 1,000 ,995** . ,000 20 20 ,995** 1,000 ,000 . 20 20 1,000 ,999** . ,000 20 20 ,999** 1,000 ,000 . 20 20Correlation Coef f icient Sig. (2-tailed)
N
Correlation Coef f icient Sig. (2-tailed)
N
Correlation Coef f icient Sig. (2-tailed)
N
Correlation Coef f icient Sig. (2-tailed) N produksi kaos usia pekerja produksi kaos usia pekerja Kendall's tau_b Spearman's rho
produksi kaos usia pekerja
Correlation is signif icant at the 0.01 lev el (2-t ailed). **.
Pada analisis dengan non parametric (korelasi kendall’s tau_b dan Spearman’s rho) terlihat bahwa hasil analisis menunjukan signifikansi yang sama dengan uji korelasi pearson. Yang terpenting disini adalah pemilihan uji statistic yang diinginkan.
Kesimpulan menolak hipotesis dapat didasarkan pada taraf signifikansi yang diingikan atau dengan membandingkan hasil analisis korelasi (kendall’ tau_b
PERTEMUAN 3 ANALISIS REGRESI
A. PENGANTAR B. REGRESI LINIER
Regresi linier sering digunakan untuk melihat nila prediksi atau perkiraan yang akan datang. Apabila variable X dan Y mempunyai hubugan, maka nilai variable X yang sudah diketahui dapat digunakan untuk memperkirakan/menaksir Y. Ramalan pada dasarnya merupakan perkiraan mengenai terjadinnya sesuatu kejadian (nilai variable utuk waktu yang akan datang , seperti ramalan prosuksi 3 tahun yang akan datang, ramalan harga bulan depan, ramalan jumlah penduduk 10 tahun mendatang, ramalan hasil penjualan tahun depan).
Variable Y yang nilainya akan diramalkan disebut variable tidak bebas (dependent variable) sedangkan variable X yang nilainnya digunakan untuk meramalkan nilai Y disebut variable bebas (independent variable) atau variable peramal (predictor) dan sering kali disebut variable yang menerangkan (exsplanatory). Jadi jelas analisis korelasi ini memungkinkan kita untuk mengetahui sesuatu diluar hasil penyelidikan, misalnya dengan ramalan kita dapat mengetahui terjadinya suatu kejadian baik secara kualitatif (akan turun hujan, akan terjadi perang, akan lulus ujian) maupun kuantitatif (produksi padi akan mencapai 16 juta ton, indek harga 9 bahan pokok naik 10%, penerimaan devisa turun 5%) salah satu cara untuk melakukan peramalan adalah dengan mengunakan garis regresi.
Ilustrasi hubungan positif
X Pupuk Berat Badan Y Produksi Tekanan darah
1. Rumus regresi linier sederhana Y = a + b X
Diketahui.
Y = subjek dalam variable dependen yang diprediksikan a = Harga Y ketika harga X = 0 (harga constant)
b = Angka arah atau koefisien regresi, yang menunjukan angka peningkatan atau penurunan variabel independent yang didasarkan pada perubahan variabel independent.
X = Subjek pada variabel independen yang mempunyai nilai tertentu. Rumus a bX Y a x y
s
s
r
b
Keteranganr = Koefisien korelasi product moment antara variabel X dengan variabel Y. Sy = Simpangan baku variabel Y
Sx = Simpangan baku variabel X
Harga a dan b diperoleh dengan rumus:
2 2 2 i i i i iX
X
n
Y
X
X
X
Y
a
X
Jumlah aseptor
Harga suatu
barang
Y
Jumlah
kelahiran
Permintaan
barang darah
Suatu penelitian dilakukan di Rumah sakit A untuk mengetahui apakah ada hubungan antara frekuensi makan sambal setiap hari dengan kejadian buang air besar. Berdasarkan hasil penelitian diperoleh data sebagai berikut (data ilustrasi):
No Frek Sambal Frek diare
1 4 5 2 3 4 3 5 5 4 6 7 5 5 6 6 4 5 7 2 4 8 3 4 9 6 7 10 7 7 Pertanyaan
Seberapa besar konsumsi makan mampu memprediksi kejadian diare..? Penyelesaian
a. Menentukan Hipotesis
Ho = tidak Ada hubugan antara frekuensi makan sambal dengan kejadian diare.
Ha = ada hubungan antara kebiasaan makan sambal dengan kejadian diare.
b. Menentukan standar penerimaan ho Alfa = 0,05 c. Perhitungan Tabel bantu No Frek Sambal (Xi) Frek diare (Yi) Xi Yi Xi2 Yi2 1 4 5 20 16 25 2 3 4 12 9 16
5 5 6 30 25 36 6 4 5 20 16 25 7 2 4 8 4 16 8 3 4 12 9 16 9 6 7 42 36 49 10 7 7 49 49 49 ∑ Xi = 45 ∑ Yi = 54 ∑Xi Yi = 260 ∑ Xi2 = 225 ∑ Yi2 = 306 Y = a + b X
Mencari nilai a dan b
2 2 2 i i i i i i iX
X
n
Y
X
X
X
Y
a
245
225
*
10
260
45
225
54
a
...
a
2 2 i i i i i iX
X
n
Y
X
Y
X
n
b
245
225
*
10
54
45
260
*
10
b
Studi kasus
Suatu lembaga penelitian ingin mengetahui apakah terdapat hubungan yang positif antara pendapatan dengan konsumsi pangan para karyawan sebuah perusahaan industri. Riset dilakukan terhadap 20 karyawan sebuah perusahaan dimana ditanyakan mengenai pendapatan dan pengeluaran konsumsi pangan perbulan masing-masing diukur dalam ribuan. Data hasil penelitian sebagai berikut:
ID Pendapatan Pengeluaran ID Pendapatan Pengeluaran
1 900 400 11 700 340 2 800 350 12 1000 450 3 700 340 13 1200 500 4 700 350 14 1000 450 5 700 340 15 2000 700 6 1000 450 16 800 350 7 1200 500 17 700 340 8 1000 450 18 700 350 9 2000 700 19 700 340 10 1500 600 20 1000 450 Langkah-langkah penyelesaian
1. Buka lembar baru pada menu utama spss
2. Buat variabel pendapatan dan variabel pengeluaran
3. Masukan data pada tabel tesebut kedalam lembar kerja spss. Seperti tampak pada gambar berikut:
4. Kemudian lakukan analisis data. Dengan mengaktivkan analyze, kemudian pilih menu Regression, kemudian pilij Linier. Seperti tampak pada gambar berikut:
5. Kemudian masukan variabel pendapatan ke kolom variabel Independent dan variabel pengeluaran Dependent. Seperti tampak pada gambar berikut:
Dalam kotak ini tersedian beberapa menu antara lain statistik, option, plot. 6. Pada plot pilih sesuai tabel berikut:
Terlihat kolom X dan Y kosong kembali. Klik pada ZPRED dan masukan pada kolom Y, kemudian klik pada DEPENDENT dan masukan pada kolom X, kemudian antifkan NEXT.
Kemudian aktivkan pada Normal Probability Plot.
7. Pada statistik pilih seperti gambar berikut:
8. Hasil analisis dan interpretasi terlihat sebagai berikut:
REGRESSION
/DESCRIPTIVES MEAN STDDEV CORR SIG N /MISSING LISTWISE
/STATISTICS COEFF OUTS CI R ANOVA CHANGE /CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT pengeluaran /METHOD=ENTER pendapatan
/SCATTERPLOT=(*SDRESID ,*ZPRED ) (*ZPRED ,pengeluaran ) /RESIDUALS NORM(ZRESID) .
Regression
[DataSet0]
Descriptive Statistics
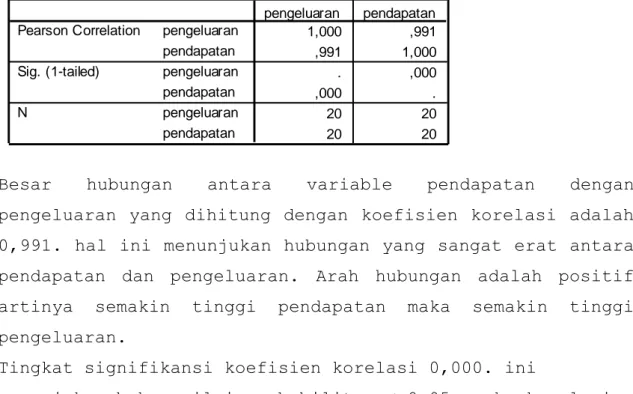
Correlati ons 1,000 ,991 ,991 1,000 . ,000 ,000 . 20 20 20 20 pengeluaran pendapatan pengeluaran pendapatan pengeluaran pendapatan Pearson Correlation Sig. (1-tailed) N pengeluaran pendapatan
Besar hubungan antara variable pendapatan dengan pengeluaran yang dihitung dengan koefisien korelasi adalah 0,991. hal ini menunjukan hubungan yang sangat erat antara pendapatan dan pengeluaran. Arah hubungan adalah positif artinya semakin tinggi pendapatan maka semakin tinggi pengeluaran.
Tingkat signifikansi koefisien korelasi 0,000. ini
menunjukan bahwa nilai probabilitas < 0.05. maka korelasi antara pendapatan dan pengeluaran sangat kuat.
Variabl es Entered/Removedb pendapata na . Enter Model 1 Variables Entered Variables Remov ed Method
All requested v ariables entered. a.
Dependent Variable: pengeluaran b.
Table ini menunjukan bahwa variable yang dimasukan adalah pendapatan dan tidak ada variable yang dikeluarkan.
Angka R square adalah 0,991. yang biasa disebut sebagai koefisien determinasi yang dalam hal ini berarti 99.1% pengeluaran dapat dijelaskan oleh variable pendapatan, sedangkan sisanya oleh sebab lain yang tidak termasuk dalam analisis ini. ANOVAb 247817,0 1 247816,964 978,646 ,000a 4558,036 18 253,224 252375,0 19 Regression Residual Total Model 1 Sum of
Squares df Mean Square F Sig.
Predictors: (Const ant), pendapatan a.
Dependent Variable: pengeluaran b.
Dari analisis anova didapatkan F hitung adalah 978,646 dengan tingkat signifikansi 0,000. artinya probabilitas jauh lebih kecil dari 0,05, maka model regresi dapat dipakai untuk memprediksikan pendapatan.
Coefficientsa 147,964 9,916 14,922 ,000 127,132 168,796 ,285 ,009 ,991 31,283 ,000 ,266 ,304 (Constant) pendapatan Model 1 B Std. Error Unstandardized Coeff icients Beta Standardized Coeff icients
t Sig. Lower Bound Upper Bound 95% Confidence Interv al for B
Dependent Variable: pengeluaran a.
Mengambarkan persamaan regresi: Y= 147,964 + 0,285X
Dimana
Y adalah pengeluaran X adalah pendapatan.
Konstanta sebesar 147,964 menyatakan bahwa jika tidak ada pendapatan pengeluaran sebesar 147,964.
Uji t menunjukan bahwa apakah pendapatan dapat memprediksikan pengeluaran untuk masa yang akan datang.
Residual s Stati sticsa
347,64 718,48 437,50 114,206 20 -,787 2,460 ,000 1,000 20 3,561 9,661 4,726 1,773 20 347,43 729,26 438,46 116,552 20 -26,170 24,150 ,000 15,489 20 -1,645 1,518 ,000 ,973 20 -1,701 1,625 -,027 1,044 20 -29,264 27,671 -,965 18,045 20 -1,804 1,709 -,035 1,076 20 ,001 6,053 ,950 1,782 20 ,001 ,623 ,094 ,187 20 ,000 ,319 ,050 ,094 20 Predicted Value St d. Predicted Value St andard Error of Predicted Value
Adjusted Predict ed Value Residual
St d. Residual St ud. Residual Delet ed Residual St ud. Deleted Residual Mahal. Distance Cook's Distance
Centered Lev erage Value
Minimum Maximum Mean St d. Dev iation N
Dependent Variable: pengeluaran a.
Nilai prediktiv value merupakan nilai perhitungan yang didasarkan pada nilai X.
Y= 147,964 + 0,285 X (400).
Residual merupakan selisih antara pendapatan yang sesunguhnya dengan pendapatan prediktif.
Pr
ob
1.0 0.8
Normal P-P Plot of Regression Standardized Residual Dependent Variable: pengeluaran
Nilai-nilai sebaran data terlihat pada sepanjang garis lurus. Hal ini menunjukan bahwa normalitas dapat terpenuhi.
Regression Standardized Predicted Value
3 2 1 0 -1 Regre ssi on St udentiz ed D el eted (Pr ess) Res idual 2 1 0 -1 -2 Scatterplot
Dependent Variable: pengeluaran
Jika model regresi layak untuk dipakai sebagai prediksi data akan berpencara disekitar angka nol (0 pada sumbu Y). data tersebut menunjukan bahwa sebaran data sekitar angka nol.
pengeluaran 700 600 500 400 300 R egr es si on St and ar di ze d Pr edi ct ed Va lue 3 2 1 0 -1 Scatterplot
Dependent Variable: pengeluaran
Jika model memenuhi syarat, sebaran data akan berada mulai dari kiri ke bawah lurus kea rah kanan atas. Terlihat sebaran data membentuk arah seperti yang dipersyaratkan.
C. REGRESI GANDA
Analisis regresi ganda biasa digunakan pada penelitian-penelitian yang bertujuan untuk melihat prediksi variabel independent terhadap variabel dependent yang mana variabel independent (bebas) terdiri dari 2 variabel atau lebih. Analisis regresi ganda merupakan analisis regresi yang digunakan untuk meramalkan faktor prediktor 2 atau lebih yang sekala datanya numerik.
Persamaan regresi untuk n predictor Y = a + b1X1 + b2X2 + b3X3... + bnXn Tabel penolong No X1 X2 Y X1Y X2Y X1X2 X12 X22 Jumlah ... .... .... .... ... .... .... ... Persamaan 2 1 1 1 X b X b an Y
2 2 1 2 1 1 1 1Y a X b X b X X X
2 2 2 2 1 2 2 2Y a X b X X b X X LatihanSuatu penelitian dilakukan untuk mengetahui hubungan antara lama dirawat dan lebar luka operasi dengan kejadian infeksi fraktur femur. Berdasarkan hasil penelitian didapatkan hasil sebagai berikut:
No Lama dirawat Lebar luka Grade infeksi
1 3 2 2 2 4 3 2 3 5 4 3 4 5 3 3 5 4 2 2 6 5 4 4 7 7 5 4 8 8 5 5 9 9 6 5
Langkah penyelesaian
D. REGRESI LOGISTIK
Regresi logistik biasa digunakan pada penelitian-penelitian yang skala datanya berbentuk kategorik/nominal. Regresi logistik mencoba menjelaskan variabel-variabel independent yang ikut berkontribusi terhadap variabel dependent. Pengunaan analisis regresi logistik menyaratkan hasil ukur variabel penelitian dalam bentuk kategorik.
Studi kasus
Suatu penelitian dilakukan untuk mengetahui hubungan antara pemberian ASI eksklusif terhadap kejadian ISPA pada balita. Adapun kerangka konsep penelitian disajikan dalam gambar berikut:
Variabel Bebas ASI Eksklusif Variabel perancu Status gizi Status Imunisasi Pendidikan ibu
Status sosial ekonomi
Variabel Terikat Kejadian ISPA
No Status ASI Status ISPA Status gizi Status imunisasi pendidika n Kode ; 1 = eksklusif; 2 = tidak eksklusif Kode ;1 = ISPA; 2 = tidak ISPA Kode ; 1 = Baik; 2 = buruk Kode ;1 = lengkap; 2 = tidak Kode ; 1 = rendah; 2 = tinggi 1 1 1 1 2 2 2 1 1 2 2 1 3 1 1 1 1 2 4 1 1 2 1 2 5 1 1 1 1 1 6 2 1 2 2 2 7 2 1 2 2 2 8 2 1 2 2 2 9 1 1 1 1 1 10 2 1 2 2 2 11 2 1 1 2 2 12 2 1 2 2 2 13 1 1 1 1 1 14 1 2 1 1 1 15 1 2 1 1 1 16 1 2 1 1 1 17 2 2 2 2 2 18 2 2 2 2 1 19 2 2 2 2 1 20 1 2 1 1 1 21 1 2 1 1 1 22 1 2 1 1 1 23 2 2 2 2 2 24 2 2 2 2 2 25 1 2 1 1 1 Pertanyaan
Lakukan analisis mengunakan program spss dengan uji statistik regresi logistik. Kemudian hasil analisis sajikan dalam bentuk tabel seperti pada journal berikut: