5
BAB 2
TINJAUAN PUSTAKA
2.1. Information Retrieval
2.1.1 Definisi
Information Retrieval System atau Sistem Temu Balik Informasi merupakan
bagian dari computer science tentang pengambilan informasi dari
dokumen-dokumen yang didasarkan pada isi dan konteks dari dokumen-dokumen-dokumen-dokumen itu
sendiri. Menurut Gerald J. Kowalski di dalam bukunya “Information Storage and Retrieval Systems Theory and Implementation ”, sistem temu balik informasi adalah suatu sistem yang mampu melakukan penyimpanan, pencarian, dan
pemeliharaan informasi. Informasi dalam konteks ini dapat terdiri dari teks
(termasuk data numerik dan tanggal), gambar, audio, video, dan objek multimedia
lainnya. Tujuan dari sistem IR adalah memenuhi kebutuhan informasi pengguna
dengan me-retrieve semua dokumen yang mungkin relevan, pada waktu yang
sama me-retrieve sesedikit mungkin dokumen yang tidak relevan. Sistem IR yang
baik memungkinkan pengguna menentukan secara cepat dan akurat apakah isi
dari dokumen yang diterima memenuhi kebutuhannya. Agar representasi
dokumen lebih baik, dokumen -dokumen dengan topik atau isi yang mirip
dikelompokkan bersama-sama (Gerald J. Kowalski, 2000).
Model Information Retrieval adalah model yang digunakan untuk
melakukan pencocokan antara term-term dari query dengan term - term dalam
document collection, Model yang terdapat dalam Information retrieval terbagi
dalam 3 model
6
2. Algebratic model, model merepresentasikan dokumen dan query sebagai
vektor atau matriks similarity antara vektor dokumen dan vektor query yang
direpresentasikan sebagai sebuah nilai skalar. Contoh model ini ialah vektor
space model (model ruang vektor) dan latent semantic indexing (LSI).
3. Probabilistic model, model memperlakukan proses pengambilan dokumen
sebagai sebuah probabilistic inference. Contoh model ini ialah penerapan
teorema bayes dalam model probabilistic (Hiemstra, 2009)
2.1.2 Arsitektur Information Retrieval
Ada dua pekerjaan yang ditangani oleh sistem ini, yaitu melakukan pre-processing
terhadap database dan kemudian menerapkan metode tertentu untuk menghitung
kedekatan (relevansi atau similarity) antara dokumen di dalam database
yang telah di preprocess dengan query pengguna.
Pada tahapan preprocessing , sistem yang berurusan dengan dokumen
semi-structured biasanya memberikan tag tertentu pada term-term atau bagian
dari dokumen, sedangkan pada dokumen tidak terstruktur proses ini dilewati dan
membiarkan termt anpa imbuhan tag. Query yang dimasukkan pengguna
dikonversi sesuai aturan tertentu untuk mengekstrak term-term penting yang
sejalan dengan term-term yang sebelumnya telah diekstrak dari dokumen dan
menghitung relevansi antara query dan dokumen berdasarkan pada term-term
tersebut. Sebagai hasilnya, sistem mengembalikan suatu daftar dokumen terurut
sesuai nilai kemiripannya dengan query pengguna. Setiap dokumen (termasuk
query) direpresentasikan menggunakan model bag-of-words yang mengabaikan
urutan dari kata kata di dalam dokumen, struktur sintaktis dari dokumen dan
kalimat. Dokumen ditransformasi ke dalam suatu “tas“ berisi kata-kata independen. Term disimpan dalam suatu database pencarian khusus yang ditata
sebagai sebuah inverted index . Index ini merupakan
konversi dari dokumen asli yang mengandung sekumpulan kata ke dalam daftar
kata yang berasosiasi dengan dokumen terkait dimana kata-kata tersebut muncul.
7
untuk mendapatkan retrieve document dari collection documents yang ada melalui
pencarian query yang diinputkan user.
Sistem temu-kembali teks (teks retrieval) adalah sistem penemuan
kembali informasi dalam bentuk dokumen dengan mengukur kemiripan
(similarity) antara informasi yang tersimpan dalam basis data dengan query yang
dimasukkan oleh pengguna (Baeza & Ribeiro, 1998:19). Teknik pencarian
informasi pada sistem Information Retrieval berbeda dengansistem pencarian
pada sistem manajemen basisdata (DBMS) . Dalam sistem temu kembali terdapat
dua bagian utama yaitu bagian pengindeksan (indexing) dan pencarian
(searching). Kedua bagian tersebut memiliki peran penting dalam proses temu
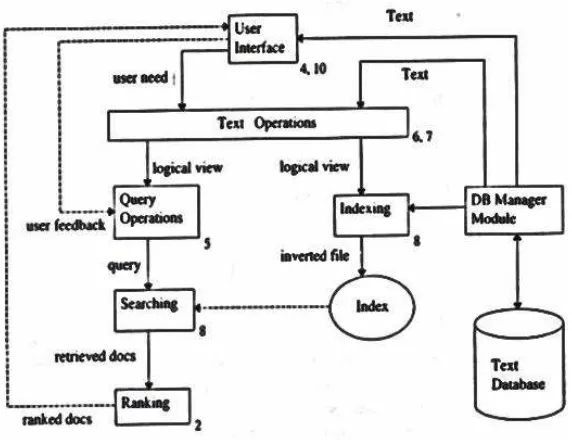
kembali informasi seperti pada gambar dibawah ini:
Gambar 2.1 Arsitektur Information Retrieval
Sumber : (Baeza & Ribeiro, 1999)
8
fungsi optimisasi, meskipun jangkauan permasalahan yang telah diaplikasikan
oleh genetika algoritma sangat luas, yaitu :
1. Al Biles menggunakan algoritma genetika untuk memfilter bagian yang baik
dan buruk untuk improvisasi jazz.
2. Militer menggunakan algoritma genetika untuk mengembangkan persamaan
untuk mendapatkan perbedaan di antara perputaran radar.
3. Perusahaan-perusahaan menggunakan algoritma genetika untuk
memprediksikan pasar bursa.
Kebanyakan sistem AI simbolis adalah sangat statis. Biasanya digunakan
hanya untuk memecahkan satu masalah khusus, dikarenakan arsitekturnya
didesain sesuai dengan permasalahan yang ada. Jadi, jika permasalahan dirubah,
maka sistem-sistem tersebut akan kesulitan untuk beradaptasi, dikarenakan solusi
yang didapat tidak tepat atau kurang efisien. Algoritma genetika dibentuk untuk
mengatasi permasalahan ini (Sastry, 2004).
Sebuah algoritma genetika berfungsi mula-mula dengan menghasilkan
himpunan dari solusi-solusi yang mungkin untuk masalah yang ada. Kemudian
dilakukan evaluasi pada masing-masing solusi dan menentukan tingkat Fitness
(ketahanan) untuk setiap himpunan solusi. Solusi-solusi tersebut kemudian
menghasilkan solusi-solusi yang baru. Solusi-solusi parent yang lebih fit adalah
yang memiliki kemungkinan besar untuk reproduksi, sedangkan yang kurang
memiliki kemungkinan kecil untuk reproduksi. Pada intinya, solusi-solusi
berevolusi dari waktu ke waktu. Dengan cara ini, dapat dikembangkan skop ruang
pencarian pada suatu titik di mana bisa didapatkan solusi. Algoritma genetika bisa
sangat efisien bila diprogram secara tepat.
2.2.1. Pengertian Dasar Metode Algoritma Genetika
Algoritma genetika pertama kali dikembangkan oleh John Holland dari
Universitas Michigan pada tahun 1975. John Holland menyatakan bahwa setiap
masalah yang berbentuk adaptasi (alami maupun buatan) dapat diformulasikan
kedalam terminologi genetika. Algoritma genetika adalah simulasi dari proses
9
Algoritma genetika mengikuti prosedur atau tahap-tahap yang
menyerupai proses evolusi, yaitu adanya proses seleksi, crossover dan
mutasi. Pada setiap generasi, himpunan baru dari deretan individu dibuat
berdasarkan kecocokan pada generasi sebelumnya (Goldberg, 1989).
Keberagaman pada evolusi biologis adalah variasi dari kromosom dalam
individu organisme. Variasi kromosom ini akan mempengaruhi laju reproduksi
dan tingkat kemampuan organisme untuk tetap hidup (Kristanto, 2004).
Teknik pencarian yang dilakukan algoritma genetika dari himpunan
solusi secara acak disebut dengan populasi. Sedangkan setiap individu
dalam populasi disebut kromosom. Kromosom berevolusi dalam suatu proses
iterasi yang berkelanjutan yang disebut generasi. Pada setiap generasi,
kromosom akan dievaluasi berdasarkan fungsi fitness (Gen & Cheng, 1997).
Setelah beberapa generasi, maka algoritma genetika akan konvergen pada
kromosom terbaik yang diharapkan merupakan solusi optimal (Goldberg, 1989).
Pendekatan yang diambil oleh algoritma genetika adalah dengan
menggabungkan secara acak berbagai pilihan solusi terbaik didalam suatu
populasi untuk mendapatkan individu baru (offspring) yaitu pada suatu kondisi
yang memaksimalkan kecocokan yang disebut fitness. Algoritma genetika
adalah algoritma pencarian heuristik yang didasarkan atas mekanisme evolusi
biologis.
Algoritma genetika merupakan algoritma pencarian yang
berdasarkan pada seleksi alam dan genetika alam. Algoritma ini berguna
untuk masalah yang memerlukan pencarian yang efektif dan efisien, dan
dapat digunakan secara meluas untuk aplikasi bisnis, pengetahuan, dan
dalam ruang lingkup teknik. Algoritma genetika ini dapat digunakan untuk
10
chromosome itu mewakili sebuah solusi untuk masalah yang akan
dihadapi. Sebuah chromosome biasanya simbolnya string hal ini
diperuntukkan bagi bilangan biner dan untuk floating point yang dipakai
adalah bilangan real. Untuk masalah tiga variabel maka chromosome akan
tersusun atas tiga gen demikian pula kalau permasalahannya melibatkan lima
variabel, maka didalam satu chromosome juga akan terdapat lima gen.
Chromosome terbentuk setiap generasi dan kemudian dievaluasi
menggunakan beberapa ukuran fitness. Untuk generasi yang baru,
chromosome baru terbentuk oleh proses yang dinamakan proses seleksi .
Setelah proses seleksi itu berlangsung chromosome yang baru terbentuk itu
akan mengalami proses reproduksi dimana didalam proses reproduksi ini
chromosome tadi akan daproses dalam dua tahap yaitu crossover dan
mutasi. Kadua tahap proses itu akan membuat offspring. Untuk proses
crossover , offspring yang terbentuk merupakan penggabungan dari
chromosome yang sebelumnya, sedangkan untuk mutasi offspring yang
terbentuk merupakan hasil perubahan mutasi dari gen atau mutasi pada bit.
Generasi baru terbentuk oleh seleksi menurut nilai fitness dari
keseluruhan chromosome , beberapa parent dan offspring dipilih agar
menjaga ukuran populasi tetap. Chromosome yang memiliki nilai fitness yang
besar memiliki peluang yang lebih besar untuk terpilih. Setelah beberapa
generasi, Algoritma Genetika ini akan mengumpulkan chromosome terbaik,
yang membantu untuk mewakili solusi yang optimal untuk masalah itu.
Ada 2 mekanisme yang menghubungkan Algoritma Genetika dengan
masalah yang ingin diselesaikan yaitu cara pengkodean /encoding
penyelesaian untuk masalah pada chromosome dan fungsi evaluasi yang
mengembalikan ukuran harga dari setiap chromosome dalam konteks dari
masalah itu. Teknik untuk mengkodekan penyelesaian bermacam-macam dari
masalah ke masalah dan dari Algoritma Genetika ke Algoritma Genetika .
Populasi disusun dari bermacam-macam individu, setiap individu
11
string), dan fitness (fungsi obyektif). Fungsi evaluasi adalah penghubung
antara Algoritma Genetika dan masalah yang akan diselesaikan. Fungsi
evaluasi mengambil sebuah chromosome sebagai input dan
mengembalikan nomor atau daftar dari nomor yang merupakan ukuran
dari chromosome pada masalah yang akan diselesaikan. Fungsi evaluasi
mempunyai aturan yang sama dalam Algoritma Genetika yang berkecimpung
dalam evolusi alam (Suyanto, 2005).
Inisialisasi dilakukan secara random atau acak. Rekombinasi
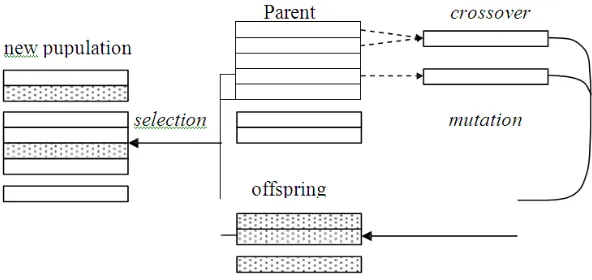
termasuk di dalamnya crossover / kawin silang dan mutasi untuk
munghasilkan offspring / keturunan. Kenyataannya ada dua operasi pada
Algoritma Genetika
- Operasi genetika yaitu crossover dan mutasi
- Operasi evolusi yaitu seleksi
Operasi genetika meniru proses turun menurun dari gen untuk
membentuk offspring pada setiap generasi. Operasi evolusi meniru proses
dari Darwinian evolution untuk membentuk populasi dari generasi ke
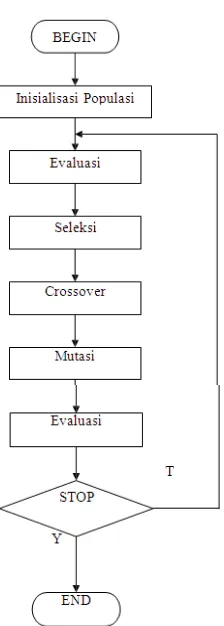
generasi. Blok diagram untuk proses algoritma genetika diberikan pada Gambar
12
Gambar 2.2 Proses Algoritma Genetika
Sumber : (Mitchell, 1996).
Pada algoritma genetika ini terdapat beberapa definisi penting yang harus
dipahami sebelumnya, yaitu :
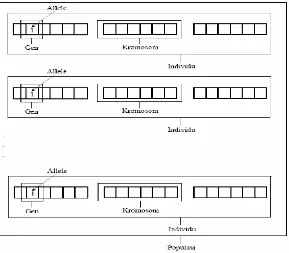
a) Gen : merupakan nilai yang menyatakan satuan dasar yang membentuk
suatu arti tertentu dalam satu kesatuan gen yang dinamakan kromosom.
b) Kromosom/Individu : merupakan gabungan dari gen-gen yang membentuk
nilai tertentu dan menyatakan solusi yang mungkin dari suatu permasalahan.
c) Populasi : merupakan sekumpulan individu yang akan diproses bersama
dalam satu satuan siklus evolusi.
d) Fitness menyatakan seberapa baik nilai dari suatu individu yang didapatkan.
e) Seleksi merupakan proses untuk mendapatkan calon induk yang baik.
f) Crossover merupakan proses pertukaran atau kawin silang gen-gen dari dua
13
g) Mutasi merupakan proses pergantian salah satu gen yang terpilih dengan
nilai tertentu.
h) Generasi merupakan urutan iterasi dimana beberapa kromosom tergabung. i) Offspring merupakan kromosom baru yang dihasilkan
Gambar 2.3 Individu dalam Algoritma Genetika
Sumber : (Mitchell, 1996).
2.2.2 Operator Algoritma Genetika
Sama seperti suatu penyelesaian umum lainnya, Algoritma Genetika
mempunyai operator-operator yang secara berurutan dipakai untuk
14
A. Seleksi
Tiga dasar pokok yang tergabung di dalam fase seleksi dalam metode
Algoritma Genetika yaitu: (a) Sampling space; (b). Sampling mechanism; (c).
Selection probability
a. Sampling Space
Prosedur seleksi yang menghasilkan populasi baru untuk generasi selanjutnya
berdasarkan pada baik semua parent atau offspring atau bagian dari
mereka. Inilah yang memimpin masalah dari sampling space. Sebuah sampling
space dikarakteristikkan oleh dua faktor yaitu size (ukuran) dan ingredient
(bahan) yang menunjuk pada parent dan offspring. Pop_size menunjuk pada
ukuran dari populasi dan off_size menunjuk pada ukuran dari offspring
yang dihasilkan pada setiap generasi. Regular sampling space memiliki ukuran
dari pop_size dan berisi semua offspring dengan sebagian dari parent. Enlarge
sampling place memiliki okoran dari pop_size + off_size dan berisi semua
parent dan offspring.
- Regular sampling space: pada waktu terjadi crossover dan mutasi itulah
maka akan dilahirkan offspring. Parent digantikan oleh offspring atau
keturunannya segera setelah kelahirannya. Pergantian secara langsung ini
dinamakan generational repacement. Karena operasi genetika buta dalam
alam, offspring mungkin lebih buruk dibandingkan dengan parent.
Strategi pergantian setiap parent dengan offspring secara langsung
akan menyebabkan beberapa chromosome yang memiliki peluang yang
besar akan hilang dari proses evolusi . Ada beberapa ide untuk
mengatasi masalah ini . Holland mengusulkan ketika setiap offspring
lahir, offspring itu akan menggantikan secara random chromosome yang
dipilih dari populasi sekarang. Dalam model crowding, ketika offspring
lahir, satu parent yang dipilih akan mati. Parent yang mati itu dipilih
dengan ciri seperti parent yang mirip offspring yang baru, kemiripan
ini diperoleh dengan menggunakan kesamaan bit per bit untuk menghitung
15
parent yang terpilih untuk rekombinasi, populasi yang baru terbentuk
oleh pergantian parent dengan offspring yang terbentuk. Michalewics
memberikan deskripsi pada Algoritma Genetika sederhana dimana
offspring dalam setiap generasi akan menggantikan parent untuk
generasi tersebut segera setelah kelahirannya, generasi yang baru
dibentuk oleh roulette wheel selection. Gambar 2.1 berikut ini adalah
merupakan seleksi yang dilakukan pada regular sampling space (Suyanto,
2005).
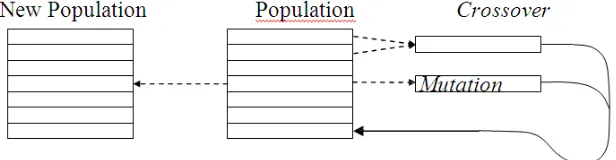
Gambar 2.4 Seleksi berdasarkan pada Regular Sampling Space
Sumber :( Suyanto, 2005).
- Enlarge sampling space: ketika seleksi dilakukan pada enlarge sampling
space, baik parent dan offspring mempunyai kesempatan untuk berkompetisi
dengan tujuan untuk bertahan. Untuk sebuah kasus khusus adalah seleksi ( + ). Stategi ini digunakan dalam srategi evolusi. Dengan stategi ini, parent dan offspring berkomperisi untuk kelangsungan hidupnya dan terbaik keluar dari offspring dan old parent dipilih sebagai parent pada
16
Gambar 2.5. Seleksi Dilakukan Pada Enlarge Sampling Space
Sumber :( Suyanto, 2005).
B. Crossover
Pada crossover terjadi ketika parent bertukar bagian dari gen
pembentuknya. Dalam Algoritma Genetika, crossover menggabungkan
materi genetika dari kedua chromosome parent menjadi dua anak. Crossover
yang dipakai untuk bilangan real adalah Arithmetic Crossover.
Prosedur untuk memilih parent mana yang akan mengalami proses crossover :
- Tentukan probabilitas crossover.
- Bangkitkan bilangan random 0 sampai 1 sebanyak i (jumlah chromosome
dalam satu populasi).
- Bandingkan bilangan random itu dengan probabilitas crossover
- Parent terpilih bila bilangan r yang ke-i kurang atau sama dengan
probabilitas crossover (Pc).
- Bila parent yang terpilih jumlahnya hanya satu maka proses ini diulang
sampai jumlah parent lebih dari satu
Arithmetic Chrossover
Proses selanjutnya setelah melakukan pemilihan Chromosome adalah
melakukan Arithmetic Crossover yang dikerjakan untuk kondisi bilangan real
17
• Bangkitkan bilangan random antara 0 dan 1
• Offspring1 = (parent1 x random) + (parent2 x (1-random)). • Offspring2 = (parent1 x (1-random)) + (parent2 x random)).
One-Point Crossover
Sedangkan untuk bilangan biner, pada proses crossover ada perbedaan.
Untuk bilangan biner prosedur pemilihan chromosome sama dengan proses
pemilihan chromosome seperti pada bilangan real. Untuk biner prosesnya
adalah:
• Total bit merupakan banyaknya bit dalam satu populasi.
• Bangkitkan bilangan random antara 1 sampai total bit-1. Ini merupakan titik crossover, misalnya ditemukan nilai randomnya m.
• Pertukarkan bit yang ke (m +1) sampai total bit dari parent dengan bit yang ke (m+1) sampai ke total bit dari parent 2.
C. Mutasi
Proses mutasi adalah proses yang bertujuan untuk mengubah salah satu atau
lebih bagian dari chromosome. Untuk bilangan floating ini memakai
Nonuniform Mutation atau yang dikenal sebagai Dynamic Mutation. Mutasi ini
didesain untuk dapat mentuning dengan baik dengan tujuan mencapai tingkat
ketelitian yang tinggi. Prosedur untuk menentukan gen mana yang akan dimutasi
adalah :
1. Tentukan probabilitas mutasi.
2. Tentukan banyaknya random yang diperoleh dari banyaknya jumlah
chromosome dalam satu populasi x banyaknya gen dalam satu chromosome
18
5. Bila kurang dari probabilitas mutasi (Pm) maka gen tersebut yang akan
dipilih untuk dimutasi.
6. Gen yang terpilih kemudian dihitung sehingga dapat diketahui gen tersebut
berada pada chromosome nomor berapa dan pada gen yang nomor berapa.
2.3 Algoritma Umum pada Algoritma Genetika
Berikut ini algoritma yang umum pada algoritma genetika yaitu dengan
memberikan tahapan mulai dari pembentukan kromosom sampai pada solusi yang
terbaik :
2.3.1 Membentuk Model Kromosom.
Kromosom pada algoritma genetika merupakan suatu solusi yang mungkin yang
dibentuk oleh gen-gen. Atau dapat disebutkan bahwa kromsom merupakan string
yang terbentuk oleh gen-gen yang merupakan bit (0 dan 1).
Contoh kromosom : 01101010110101101
Model kromosom yang dibentuk tergantung dari kasus/permasalahan yang
dihadapi. Sebagai contoh, diberikan persamaan :
a + b * c - d * e = 100
Pada persamaan tersebut dicari nilai variabel a, b, c, d, dan e agar mendapatkan
100. Diandaikan nilai maksimum untuk setiap variabel adalah 15, berarti dalam
representasi biner terdapat empat bit untuk setiap variabel. Karena terdapat lima
variabel, maka panjang kromosom adalah 20 bit. Misalkan pada suatu
solusi/kromosom nilai variabel a adalah 10(10102), variabel b adalah 5(01012),
variabel c adalah 14(11102), variabel d adalah 2(00102), dan variabel e adalah
9(10012), maka kromosom pada solusi tersebut adalah :
19
2.3.2 Membentuk Populasi Awal Secara Acak.
Populasi merupakan kumpulan dari kromosom atau solusi. Agar dapat berevolusi
dan menghasilkan solusi yang tepat pada suatu generasi, maka harus memiliki
nenek moyang. Nenek moyang tersebutlah yang merupakan populasi awal yang
dibentuk secara acak.Jumlah populasi awal tersebut tidak memiliki patokan,
sesuai dengan permasalahan yang ada dan kemampuan komputer. Contoh
populasi awal untuk kasus di atas :
01101101101010010111 (a=6, b=13, c=10, d=9, e=7)
01011010110101101010 (a=5, b=10, c=13, d=6, e=10)
11011011110010100100 (a=13, b=11, c=12, d=10, e=4)
01011010001010100110 (a=5, b=10, c=2, d=10, e=6)
11011011110110101111 (a=13, b=11, c=13, d=10, e=15)
2.3.3 Mengevaluasi Fitness Untuk Setiap Kromosom.
Tujuan dari tahap ini adalah untuk mendapatkan nilai fitness yang akan berguna
dalam seleksi kromosom untuk generasi berikutnya. Sebagai contoh, dalam
kehidupan di alam tertutup (gua, bawah tanah), makhluk yang mengandalkan
penglihatan (contoh: singa, kuda, gajah, dll.) akan memiliki nilai ketahanan yang
rendah, karena kesulitan navigasi dalam lingkungan yang gelap. Maka, akan kecil
kemungkinan makhluk tersebut dapat bertahan dan memiliki generasi berikutnya.
Akan tetapi, untuk makhluk lainnya seperti kelelawar akan memiliki nilai
ketahanan yang tinggi karena kelelawar memiliki kemampuan pancaran
supersonik sehingga dapat melakukan navigasi dalam lingkungan yang gelap.
Evaluasi fitness tergantung pada kasus ataupun permasalahan yang
dihadapi. Untuk contoh di atas, worst case scenario ataupun hasil yang paling
melenceng jauh dari nilai yang diharapkan(100) adalah jika a=0, b=0, c=0, d=15,
e=15 dengan hasil –325. Nilai fitness merupakan selisih dari 325 dengan jarak antara 100 (nilai yang diharapkan) dengan nilai yang didapatkan dengan
20
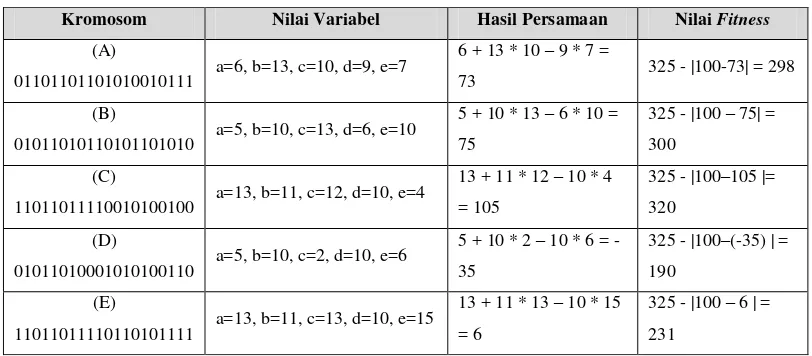
Tabel 2.1. Perhitungan nilai fitness
2.3.4 Penentuan Populasi Generasi Berikutnya.
Penentuan populasi pada generasi berikutnya didasarkan pada nilai
fitness/ketahanan. Kromosom yang memiliki nilai ketahanan yang lebih
tinggi(dalam analogi biologis, yaitu lebih mampu bertahan dalam lingkungan)
akan memiliki kemungkinan yang lebih tinggi untuk memiliki kopiannya pada
generasi berikutnya, sedangkan yang memiliki nilai ketahanan yang lebih rendah
(dalam analogi biologis, yaitu kurang mampu bertahan dalam lingkungan) akan
memiliki kemungkinan yang lebih rendah untuk memiliki kopiannya pada
generasi berikutnya. Penentuan tersebut biasanya dikenal dengan istilah seleksi.
Biasanya, jumlah populasi pada generasi berikutnya adalah sama dengan jumlah
populasi pada generasi sebelumnya, yaitu populasi dari sebelumnya telah hilang
dan sepenuhnya digantikan dengan populasi yang baru. Dengan kata lain, jumlah
populasi untuk setiap generasi adalah sama.
Terdapat banyak cara seleksi, salah satunya adalah dengan metode roda
rolet. Metode ini merupakan suatu cara seleksi kromosom yang proporsional pada
nilai fitness tersebut. Cara ini tidak menjamin bahwa kromosom yang memiliki
nilai fitness tertinggi dapat bertahan ke generasi berikutnya, melainkan memiliki
kemungkinan yang tinggi.
Pada cara ini, diandaikan nilai fitness total direpresentasikan oleh diagram
lingkaran ataupun roda rolet. Kemudian, dipasangkan setiap potongan pada roda
tersebut pada setiap anggota populasi/kromosom. Ukuran dari potongan tersebut
Kromosom Nilai Variabel Hasil Persamaan Nilai Fitness
(A)
01101101101010010111 a=6, b=13, c=10, d=9, e=7
6 + 13 * 10 – 9 * 7 =
73 325 - |100-73| = 298
(B)
01011010110101101010 a=5, b=10, c=13, d=6, e=10
5 + 10 * 13 – 6 * 10 =
75
325 - |100 – 75| =
300
(C)
11011011110010100100 a=13, b=11, c=12, d=10, e=4
13 + 11 * 12 – 10 * 4
= 105
325 - |100–105 |=
320
(D)
01011010001010100110 a=5, b=10, c=2, d=10, e=6
5 + 10 * 2 – 10 * 6 =
-35
325 - |100–(-35) | =
190
(E)
11011011110110101111 a=13, b=11, c=13, d=10, e=15
13 + 11 * 13 – 10 * 15
= 6
325 - |100 – 6 | =
21
proporsional pada nilai fitness dari kromosom, yaitu semakin tinggi nilai fitness
maka memiliki potongan yang semakin besar pada roda/lingkaran tersebut.
Kemudian, untuk memilih kromosom pada generasi berikutnya dilakukan dengan
melemparkan bola(atau mengambil nilai acak) pada lingkaran/rolet tersebut.
Potongan lingkaran tempat bola tersebut berhenti(atau nilai acak yang didapat)
diambil untuk generasi berikutnya. Hal ini dilakukan beberapa kali sebanyak
jumlah populasi yang diharapkan.
Pada contoh sebelumnya, nilai fitness total adalah : 298 + 300 + 320 + 190 + 231
= 1339. Maka, besarnya potongan untuk masing-masing kromosom adalah :
298/1339 * 100 % = 22 %
300/1339 * 100 % = 22 %
320/1339 * 100 % = 25 %
190/1339 * 100 % = 14 %
231/1339 * 100 % = 17 %
Jika diberikan penomoran pada lingkaran tersebut : 0 s/d 22 adalah untuk
kromosom A, 22.1 s/d 44 (22+22) untuk kromosom B, 44.1 s/d 69 (44+25) untuk
kromosom C, 69.1 s/d 83 (69+14) untuk kromosom D, 83.1 s/d 100 (83+17).
Kemudian dilakukan pengambilan nilai acak dengan jangkauan 0 s/d 100
sebanyak 5 kali, maka :
42 : berada pada wilayah B
83 : berada pada wilayah D
33 : berada pada wilayah B
11 : berada pada wilayah A
60 : berada pada wilayah C
Maka, populasi pada generasi berikutnya adalah :
01011010110101101010 (kromosom B)
01011010001010100110 (kromosom D)
01011010110101101010 (kromosom B)
22
2.3.5 Melakukan Crossover dan Mutasi.
Crossover berarti melakukan pertukaran gen-gen di antara kromosom.Pada
biologis, crossover adalah hibridasi antara jenis yang berbeda.Mutasi adalah
perubahan gen-gen pada kromosom, yaitu perubahan bit-bit dari 0 ke 1 ataupun
sebaliknya dari 1 ke 0. Untuk melakukan crossover, perlu ditentukan konstanta pc,
yaitu konstanta yang menyatakan besarnya peluang untuk melakukan
crossover.Nilai pc tersebut biasanya adalah sebesar 0.7.Iterasi dilakukan pada tiap
kromosom dan dilakukan pengambilan nilai acak di antara 0 s/d 1 pada tiap
kromosom. Jika nilai acak yang dihasilkan adalah <= pc, maka kromosom tersebut
terpilih untuk dilakukan crossover, sedangkan jika > pc, maka tidak dilakukan
crossover pada kromosom tersebut.
Pada saat dilakukan crossover, dilakukan pengambilan nilai acak posisi gen
pada kromosom untuk menentukan gen-gen mana saja yang ditukar.Dalam hal ini,
terdapat dua teknik, yaitu 1-point crossover dan 2-point crossover.
Pada 1-point crossover, nilai acak posisi gen yang diambil(misalkan n) hanya
satu saja. Kemudian dilakukan pertukaran gen dari kromosom pertama dengan
kromosom kedua, yaitu dari gen ke-1 hingga gen ke-n. Sebagai contoh, jika
terdapat dua kromosom :
01101101010110101101
11011011010100100101
Kemudian nilai acak(n) yang dihasilkan adalah 7, maka kromsom-kromosom hasil
crossover adalah sebagai berikut :
11011011010110101101 01101101010100100101
Pada 2-pointcrossover, nilai acak posisi gen yang diambil adalah dua buah (m dan
n). Pertukaran gen dari kedua buah kromosom adalah dengan menukarkan gen
ke-m hingga gen ke-n pada kedua buah kroke-mosoke-m tersebut. Sebagai contoh, jika
terdapat dua kromosom :
01101101010110101101
11011011010100100101
Dan nilai acak yang dihasilkan adalah 6 dan 15, maka kromosom-kromosom
23
01101011010100101101
11011101010110100101
Pada mutasi, dilakukan inversi nilai bit, yaitu bit 0 ke bit 1 ataupun bit 1
ke bit 0. Untuk melakukan mutasi, perlu ditentukan konstanta pm, yaitu konstanta
yang menyatakan peluang terjadinya mutasi.Nilai pm biasanya diset pada sangat
rendah, misalnya 0.01, sesuai pada kehidupan biologis nyata di mana sangat kecil
kemungkinan terjadinya mutasi pada keadaan standar.Iterasi dilakukan pada setiap
gen pada setiap kromosom dan mengambil nilai acak 0 s/d 1. Jika nilai acak yang
dihasilkan adalah <= pm, maka pada gen/bit tersebut dilakukan inversi, dan
sebaliknya jika > pm, tidak dilakukan apa-apa.
Misalkan terdapat suatu kromosom :
01101101010110101101
Dilakukan iterasi pada tiap bit dan dilakukan pengambilan nilai acak 0 s/d
1 :
Bit ke-1 : 0.180979788303375
Bit ke-2 : 0.64313793182373
Bit ke-3 : 0.517344653606415
Bit ke-4 : 0.0501810312271118
Bit ke-5 : 0.172802269458771
Bit ke-6 : 0.0090474414825439
Bit ke-7 : 0.225485235254974
Bit ke-8 : 0.128151774406433
Bit ke-9 : 0.581712305545807
Bit ke-10 : 0.173850536346436
Bit ke-11 : 0.2264763712883
Bit ke-12 : 0.518977284431458
24
Bit ke-18 : 0.167530059814453
o Bit ke-19 : 0.874832332134247
o Bit ke-20 : 0.0878018701157
Maka kromosom hasil mutasi adalah sebagai berikut :
0110111101011010110
2.3.6 Evaluasi Generasi Berikutnya.
Pada tahap ini, dilakukan evaluasi pada keseluruhan populasi generasi yang baru,
apakah sudah mencapai solusi yang diharapkan atau belum. Jika belum, maka
kembali ke langkah (c) dan dilakukan berulang-ulang hingga didapatkan solusi
yang diharapkan.Teknik evaluasi pada tahap ini tergantung pada kasus yang
dihadapi.
Untuk contoh yang diberikan sebelumnya, algoritma ini akan berhenti jika
pada salah satu kromosom pada populasi yang baru dapat menghasilkan nilai 100
pada persamaan tersebut. Sebagai contoh, jika pada generasi yang baru salah satu
kromosom adalah 10001010110001000111 (a=8, b=10, c=12, d=4, e=7). Jika
dimasukkan pada persaman tersebut : 8 + 10 * 12 – 4 * 7 = 100. Maka kromosom ini adalah solusi yang diharapkan, dan algoritma genetika berhenti pada tahap ini.
2.4 Fungsi Cosine Similarity
Cosine similarity adalah ukuran kesamaan antara duadari vektor n dimensi
dengan mencari kosinus antar dimensi. Sebagai contoh diberikan dua vektor dari
atribut X dan Y, dengan similaritas θ dilambangkan dengan menggunakan titik produk dan besarnya sebagai.
Pada rumus 2.1 dibawah ini diperlihatkan rumus untuk mengukur nilai similaritas
cosine coefficient antar 2 dokumen. Sedang untuk himpunan dapat digunakan
rumus 2.2, dimana Y X adalah jumlah kata yang muncul di dokumen X dan
dokumen Y, |X| adalah jumlah kata yang ada di dokumen X. (Basuki, 2003)
25
∑ √∑ ∑
………….. 2.1
Rumus 2.2 Rumus untuk menghitung cosine coefficient dalam format himpunan
| | | | ………..2.2
X ∩ Y adalah jumlah terms yang ada di X dan Y |X| adalah umlah term yang ada di X
2.5 POSI Formulation
Jika dalam datu database dijumpai sejumlah j dokumen/paper dimana setiap
dokumen/paper memiliki kata kunci (k) terhadap I dimana I,j adalah integer, maka
perhitungan untuk kemiripan antara sejumlah kata kunci (keyword) tersebut dapat
dihitung dengan POSI Formulation.
Misalkan dokumen/paper1 disebut sebagai dokumen1, paper 2 disebut
sebagai dokumen2 sampai dengan dokumenj disebut dengan dokumenj.
Kromosom (kata kunci)1 disebut dengan k1, kromosom2 disebut dengan K2 dengan
kromosomi disebut dengan Ki
Untuk menguji persentasi kemiripan antara kata kunci (keyword) terhadap
dokumen dapat dihitung dengan menggunakan perhitungan Percentage of
Similarity (POSI) formulation. Proses yang dilakukan adalah bahwa proses GA
telah menghasilkan kata kunci solusi. Kemudian kata kunci ini akan dibandingkan
dengan data yang ada pada database pada kolom judul tulisan, kata kunci
26
Formula yang digunakan dapat dilihat seperti pada formula 2.3 berikut ini.
n
∑
ki dj1
Sim (k,d)= --- ...(2.3)
K total
Dimana Sim (k,d) = Nilai Kemiripan.
kidj = jumlah masing-mading nilai kata kunci (i dan j = 0, 1,2,3,,,n, n
adalah integer)
Ktotal= jumlah total dari semua kata kunci solusi yang terdiri dari judul,
abstrak dan kata kunci.
2.6. Teks Mining
2.6.1.Pengertian Teks Mining
Teks mining, yang juga disebut sebagai Text Data Mining (TDM) atau Knowledge
Discovery in Text (KDT), secara umum mengacu pada proses ekstraksi informasi
dari dokumen-dokumen teks tak terstruktur (unstructured). Teks mining dapat
didefinisikan sebagai penemuan informasi baru dan tidak diketahui sebelumnya
oleh komputer, dengan secara otomatis mengekstrak informasi dari
sumber-sumber teks tak terstruktur yang berbeda. Kunci dari proses ini adalah
menggabungkan informasi yang berhasil diekstraksi dari berbagai sumber
(Tan,1999).
Tujuan utama teks mining adalah mendukung proses knowledge discovery
pada koleksi dokumen yang besar. Pada prinsipnya, teks mining adalah bidang
ilmu multidisipliner, melibatkan information retrieval (IR), text analysis,
information extraction (IE), clustering, categorization, visual ization, database
technology, natural language processing (NLP), machine learning, dan data
mining. Dapat pula dikatakan bahwa teks mining merupakan salah satu bentuk
27
Teks mining mencoba memecahkan masalah information overload
dengan menggunakan teknik-teknik dari bidang ilmu yang terkait. Teks mining
dapat dipandang sebagai suatu perluasan dari data mining atau
knowledge-discovery in database (KDD), yang mencoba untuk menemukan pola-pola
menarik dari basis data berskala besar. Namun teks mining memiliki potensi
komersil yang lebih tinggi dibandingkan dengan data mining, karena kebanyakan
format alami dari penyimpanan informasi adalah berupa teks. Teks mining
menggunakan informasi teks tak terstruktur dan mengujinya dalam upaya
mengungka dalam teks.
Perbedaan mendasar antara teks mining dan data mining terletak pada
sumber data yang digunakan. Pada data mining, pola diekstrak dari basis data
yang terstruktur, sedangkan di teks mining, pola diekstrak dari data tekstual
(natural language). Secara umum, basis data didesain untuk program dengan
tujuan melakukan pemrosesan secara otomatis, sedangkan teks ditulis untuk
dibaca langsung oleh manusia (Hearst, 2003)
2.6.2.Ruang Lingkup Teks Mining
Teks mining merupakan suatu proses yang melibatkan beberapa area teknologi.
Namun secara umum proses-proses pada teks mining mengadopsi proses data
mining. Bahkan beberapa teknik dalam proses teks mining juga menggunakan
teknik-teknik data mining. Ada empat tahap proses pokok dalam teks mining,
yaitu pemrosesan awal terhadap teks (text preprocessing), transformasi teks (text
transformation), pemilihan fitur (feature selection), dan penemuan pola (pattern
discovery). (Even, 2002).
a. Text Preprocessing
Tahap ini melakukan analisis semantik (kebenaran arti) dan sintaktik (kebenaran
susunan) terhadap teks. Tujuan dari pemrosesan awal adalah untuk
mempersiapkan teks menjadi data yang akan mengalami pengolahan lebih lanjut.
28
b. Text Transformation
Transformasi teks atau pembentukan atribut mengacu pada proses untuk
mendapatkan representasi dokumen yang diharapkan. Pendekatan representasi
dokumen yang lazim bag of words (vector space model). Transformasi teks
sekaligus juga melakukan pengubahan kata-kata ke bentuk dasarnya dan
pengurangan dimensi kata di dalam dokumen. Tindakan ini diwujudkan dengan
menerapkan stemming dan menghapus stopwords.
c. Feature Selection
Pemilihan fitur (kata) merupakan tahap lanjut dari pengurangan dimensi pada
proses transformasi teks. Walaupun tahap sebelumnya sudah melakukan
penghapusan kata-kata yang tidak deskriptif (stopwords), namun tidak semua
kata-kata didalam dokumen memiliki arti penting. Oleh karena itu, untuk
mengurangi dimensi, pemilihan hanya dilakukan terhadap katakata yang relevan
yang benar-benar merepresentasikan isi dari suatu dokumen. Ide dasar dari
pemilihan fitur adalah menghapus kata-kata yang kemunculannya di suatu
dokumen terlalu sedikit atau terlalu banyak. Algoritma yang digunakan pada teks
mining, biasanya tidak hanya melakukan perhitungan pada dokumen saja, tetapi
juga pada feature.
Empat macam feature yang sering digunakan:
1. Character, merupakan komponan individual, bisa huruf, angka, karakter
spesial dan spasi, merupakan block pembangun pada level paling tinggi
pembentuk semantik feature, seperti kata, term dan concept. Pada umumnya,
representasi character-based ini jarang digunakan pada beberapa teknik
pemrosesan teks.
2. Words, merupakan gabungan dari beberapa huruf atau gabungan huruf dan
angka
3. Terms, merupakan single word dan multiword phrase yang terpilih secara
langsung dari corpus. Representasi term-based dari dokumen tersusun dari
subset term dalam dokumen.
4. Concept, merupakan feature yang digenerate dari sebuah dokumen secara
29
d. Pattern Discovery
Pattern discovery merupakan tahap penting untuk menemukan pola atau
pengetahuan (knowledge) dari keseluruhan teks. Tindakan yang lazim dilakukan
pada tahap ini adalah operasi teks mining, dan biasanya menggunakan
teknik-teknik data mining. Dalam penemuan pola ini, proses teks mining dikombinasikan
dengan proses-proses data mining. Masukan awal dari proses teks mining adalah
suatu data teks dan menghasilkan keluaran berupa pola sebagai hasil interpretasi
atau evaluasi. Apabila hasil keluaran dari penemuan pola belum sesuai untuk
aplikasi, dilanjutkan evaluasi dengan melakukan iterasi ke satu atau beberapa
tahap sebelumnya. Sebaliknya, hasil interpretasi merupakan tahap akhir dari
proses teks mining dan akan disajikan ke pengguna dalam bentuk visual. (Even,
2002)
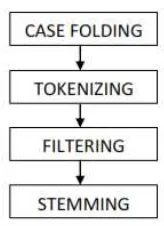
2.6.3. Ekstraksi Dokumen
Teks yang akan dilakukan proses teks mining, pada umumnya memiliki beberapa
karakteristik diantaranya adalah memiliki dimensi yang tinggi, terdapat noise pada
data, dan terdapat struktur teks yang tidak baik. Cara yang digunakan dalam
mempelajari suatu data teks, adalah dengan terlebih dahulu menentukan fitur-fitur
yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen. Sebelum
menentukan fitur-fitur yang mewakili, diperlukan tahap preprocessing yang
dilakukan secara umum dalam teks mining pada dokumen, yaitu case folding,
tokenizing, filtering, stemming, tagging dan analyzing. Gambar 2.6 adalah tahap
30
2.6.3.1 Case folding dan Tokenizing
Case folding adalah mengubah semua huruf dalam dokumen diterima. Karakter
selain huruf dihilangkan dan dianggap delimiter. Tahap tokenizing / parsing
adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya.
Gambar 2.7 adalah proses tokenizing: (Triawati, 2009)
Gambar 2.7 Proses Tokenizing
Sumber (Triawati, 2009)
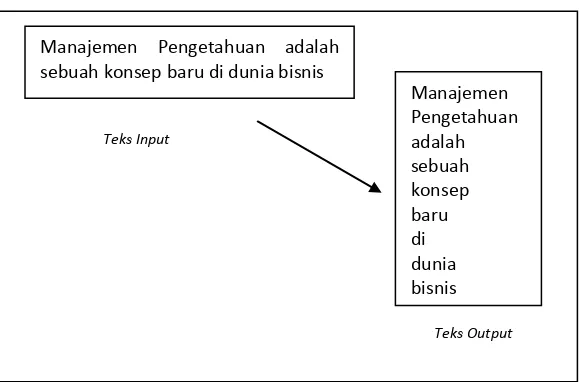
2.6.3.2 Filtering
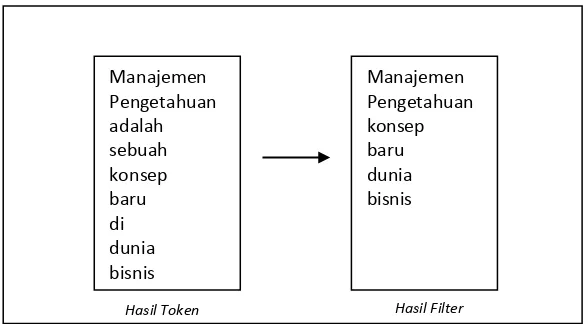
Filtering adalah tahap mengambil kata-kata penting dari hasil token. Bisa
menggunakan algoritma stoplist (membuang kata yang kurang penting) atau
wordlist (menyimpan kata penting). Stoplist / stopword adalah kata-kata yang
tidak deskriptif yang dapat dibuang dalam pendekatan bag of words. Contoh
stopwords seterusnya. Contoh dari tahapan ini dapat dilihat pada gambar 2.8
(Triawati, 2009)
Manajemen Pengetahuan adalah sebuah konsep baru di dunia bisnis
Teks Input
Manajemen Pengetahuan adalah sebuah konsep baru di dunia bisnis
31
Gambar 2.8 Proses Filtering
Sumber (Triawati, 2009)
2.7. String Matching (Pencocokan String/Kata)
String matching atau pencocokan string adalah suatu metode yang digunakan
untuk menemukan suatu keakuratan/hasil dari satu atau beberapa pola teks yang
diberikan. String matching merupakan pokok bahasan yang penting dalam ilmu
komputer karena teks merupakan adalah bentuk utama dari pertukaran informasi
antar manusia, misalnya pada literatur, karya ilmiah, halaman web dsb.
(Hulbert-Helger,2007).
String matching digunakan dalam lingkup yang bermacammacam, misalnya pada
pencarian dokumen, pencocokan DNA sequences yang direpresentasikan dalam
bentuk string dan juga string matching dapat dimanfaatkan untk mendeteksi
adanya plagiarisme dalam karya seseorang.
String-matching fokus pada pencarian satu, atau lebih umum, semua kehadiran
32
2.8Penelitian Terdahulu
Adapun penelitian yang terdahulu terkait dengan penelitian yang dikerjakan terdiri
dari penelitian bidang information retrieval dalam bidang pengujian kemiripan
dokumen dengan berbagai metode lainnya antara lain Pengembangan Aplikasi
Pendeteksi Plagiarisme Menggunakan Metode Latent Semantic Analysis (LSA),
Studi Kasus Plagiarisme Karya Ilmiah Berbahasa Indonesia. Bertujuan untuk
menguji dan mendeteksi plagiat dokumen oleh Ardiansyah, Adryan Tahun 2011.
Metode yang digunakan dalam penelitian ini adalah metode LSA yaitu dengan
menguji dengan melakukan analisys semantic.
Kemudian pada tahun 2012 penelitian tentang kemiripan dokumen yang
berjudul Deteksi Kemiripan Isi Dokumen Teks Menggunakan Algoritma
Levenshtein Distance. Teknik Informartika, Fakultas Sains dan Teknologi,
Universitas Islam Negeri Maulana Malik Ibrahim, Malang. Oleh Hendri Winoto
Tahun 2012. Algoritma yang digunakan adalah Levenshtein Distance. Untuk
penelitian yang lain salah mengukur kesamaan paragraph dengan vector space
model yang bertujuan untuk mendeteksi kesamaan dokumen yang diteliti oleh
Taufiq M. Isa, Taufik Fuadi Abidin tahun 2013 dengan judul Mengukur Tingkat
Kesamaan Paragraf Menggunakan Vector Space Model untuk Mendeteksi
Plagiarisme, Seminar Nasional dan ExpoTeknik Elektro, Jurusan Matematika,
FMIPA, Universitas Syiah Kuala.
2.9Kontribusi Penelitian
Adapun kontribusi penelitian yang dilakukan adalah:
1. Menambah salah satu cara untuk mengukur kemiripan dokumen berbasis teks
dalam sebuah pusat data yang terdiri dari dokumen jurnal dan karya ilmiah
lainnya.
2. Membuat clustering dalam database server untuk mempercepat proses
pengukuran kemiripan menggunakan fungsi SQL.
3. Aplikasi yang dirancang berbasis GUI yang dapat dipergunakan secara
33
4. Menggunakan referensi untuk menambah kata kunci dalam melakukan
kompetisi kata kunci.
5. Dokumen yang akan diuji dapat berupa karya ilmiah lainnya yang memiliki