1
Abstrak— Metode regularization telah banyak diaplikasikan pada pengenalan pola yang bertujuan untuk menghasilkan klasifikasi data. Penelitian ini menggunakan metode Discriminatively
Regularized Least Squares Classification (DRLSC) dimana
pengklasifikasian datanya berdasarkan informasi discriminative yang dipengaruhi oleh jumlah data-data yang terdekat berdasarkan metode K Nearest Neighbor dan regularization
parameter. Untuk meningkatkan keakurasian dari metode DRLSC,
penelitian ini mengoptimasi jumlah data-data yang terdekat sebelum membangun matrix Laplacian dan regularization
parameter berdasarkan error terkecil. Metode yang digunakan
adalah penggabungan Algoritma Genetika dan Particle Swarm
Optimization (GAPSO). Data yang digunakan untuk uji coba adalah
database UCI, yaitu IRIS, WINE, dan LENSA. Berdasarkan hasil uji coba untuk mengoptimasi metode DRLSC maka nilai fitness yang dihasilkan metode GAPSO lebih baik jika dibandingkan Algoritma Genetika (GA) dan Particle Swarm Optimization (PSO) dengan selisih nilai fitness 7.3e-008 hingga 0,025.
Kata Kunci : Desain Klasifikasi, Discriminatively Regularized Least
Square Classification, Algoritma genetika, Particle Swarm Optimization, Pengenalan Pola.
I. PENDAHULUAN
Metode DRLSC mengklasifikasikan data-data secara
discriminative berdasarkan intraclass dan interclass sehingga
cenderung menghasilkan keakurasian yang lebih baik dibandingkan metode regularization sebelumnya (Xue, 2009).
DRLSC sangat dipengaruhi oleh jumlah tetangga terdekat setiap
data sebanyak K pada metode KNN dan regularization
parameter (
η
). Berdasarkan hal ini maka perlu adanya penentuan secara otomatis pada jumlah tetangga terdekat pada setiap data (K) danη
. Metode Algoritma genetika telah banyak digunakan dalam mengoptimasi dengan menggunakan operatorcrossover dan mutasi sehingga dalam mencari search point
memiliki karakteristik mencari pola baru yang diharapkan agar memiliki nilai fitness yang lebih baik. Pada Particle Swarm
Optimization (PSO), dalam mencari search point berdasarkan
nilai fitness yang terbaik dengan resultan posisi point saat ini dengan nilai yang akan dicapai. Sehingga karakteristik pada pencarian nilai pada PSO berdasarkan satu nilai point yang memiliki fitness terbaik, sedangkan pada Algoritma Genetika pencarian nilai dilakukan oleh seluruh kromosom dengan menggunakan operator Algoritma Genetika (Sivanandam,
2008). Untuk menggabungkan karakteristik dari kedua metode optimasi ini, maka dibangun pengembangan optimasi yang merupakan penggabungan dari kedua metode dikenal dengan istilah GAPSO. Penelitian ini mengoptimasikan parameter K dan
η
dengan GAPSO berdasarkan error terkecil dari hasil pengklasifikasian secara otomatis.
II.PENGKLASIFIKASIAN DRLSC
Langkah-langkah pada pengklasifikasian DRLSC
sebagaimana Gambar 1.
Gambar.1.Diagram Alir pengklasifikasian metode DRLSC Parameter yang dioptimasi adalah parameter K yang terdapat pada proses pengelompokan data dengan metode KNN dan regularization parameter yang terdapat pada proses penghitungan S
η
.OPTIMASI METODE DISCRIMINATIVELY REGULARIZED LEAST SQUARE
DENGAN ALGORITMA GENETIKA DAN
PARTICLE SWARM OPTIMIZATION UNTUK PENGKLASIFIKASIAN
Ariadi Retno Tri Hayati Ririd
1)Agus Zainal Arifin
2)Anny Yuniarti
3)1,2,3
Jurusan Teknik Informatika, Institut Teknologi Sepuluh Nopember Kampus ITS, Sukolilo, Surabaya 60111
2
Pengklasifikasian DRLSC dimulai dari pengelompokan data dengan metode KNN hingga menentukan kelas data berdasarkan hasil output.2.1K Nearest Neighbor
K Nearest Neighbor digunakan untuk menentukan hubungan
antara data. Pada setiap data
x
i maka dicari K data yang memiliki jarak yang terdekat kemudian dibangun edge yang menghubungkan datax
i dengan K data. K data yang terdekat disimpan pada variabel ne(i)={ 1,..., k}i
i x
x . Berikut adalah algoritma dari KNN (Duda, 2001; Song, 2007; Liu, 2004): 1. Menentukan nilai K.
2. Menghitung jarak data pada setiap data training dengan eucledian.
3. Mendapatkan K data yang memiliki jarak terdekat.
Penghitungan jarak pada metode KNN dengan eucledian antara vektor
x
i dan vektorx
j dengan rumus sebagaimana persamaan 1. 2 1 1 2 2)
(
)
(
)
(
)
,
(
−
=
−
−
=
∑
= D i j i j i T i j ix
x
x
x
x
x
x
x
d
(1) dimanax
i adalah data ke-i danx
j adalah data ke-j,d
(
x
i,
x
j)
adalah jarak kedua data. Semakin mirip kedua data, maka nilai dari jarak kedua data semakin kecil. Sebaliknya semakin besar hasil dari
d
(
x
i,
x
j)
maka semakin tinggi perbedaan karakteristik antara kedua data vektor.2.2Membedakan new dan neb
Setelah mendapatkan K data terdekat pada setiap data,
dilanjutkan dengan dua pembagian kelompok data dari K data terdekat pada setiap data. Pembagian ini berdasarkan data-data yang terkelompokkan berdasarkan kelasnya (new) atau data-data yang terkelompokkan tidak termasuk dalam kelasnya (neb) sebagaimana persamaan berikut:new(i)={
j i
x
|jikax
ijdanx
i kelas yang sama, 1≤j≤K}neb(i)={
j i
x
|jikax
ijdanx
i kelas yang berbeda, 1≤j≤K} (2)Jika seluruh K tetangga terdekat terkelompokkan pada new maka jumlah neb data tersebut bernilai 0. Seluruh anggota pada new dan neb merupakan anggota dari ne pada setiap data. Hasil pengelompokan dari new dan neb akan menjadi dasar yang sangat penting untuk membangun keterhubungan data-data sebagai dasar dari matrix Laplacian.
2.3 Membangun matrix Gw dan Gb
Dasar dalam membangun matrik Laplacian adalah membangun matrik weight berdasarkan new yaitu Gw dan berdasarkan neb yaitu Gb dengan menggunakan konsep matrix
adjacency (Xue, 2009). Konsep dari matrix adjacency dalam
pemberian bobot untuk matrix dari graph Gw dan Gb adalah sebagai berikut:
(3)
Matrix adjacency yang telah dibangun menunjukkan
hubungan keterkaitan antara data-data. Setelah membangun Gw dan Gb, maka dilanjutkan dengan membangun matrik Laplacian.
2.4Matrik Laplacian
Matrik Laplacian dibangun berdasarkan matrik Gw dan Gb. Persamaan untuk membangun matrik Laplacian sebagaimana berikut: w w w
D
G
L
=
−
b b bD
G
L
=
−
(4) dimanaD
w adalah matrix diagonal yang elemen diagonalnya adalah jumlah seluruh j elemen dari Gw. Sedangkan Db merupakan matrix diagonal yang elemen diagonalnya adalah jumlah seluruh j elemen dari Gb. Nilai pada elemen-elemen diagonal merupakan penjumlahan dari data-data yang terdapat pada Gw dan Gb berdasarkan kolomnya pada setiap baris.2.4 Least Square
Konsep dari penghitungan Least Square adalah mendapatkan solusi dari vektor C yang memenuhi persamaan AC=B,
ATAC~=ATB (5) Pada penyelesaian matrik invers dibutuhkan matrik square, sehingga dilakukan pendekatan ATA
≈
A
. C~ adalah solusiLeast Squares dengan melakukan invers (Duda, 2001;
Grodzevich, 2005; Jia, 2008; Rifkin, 2007) sebagaimana persamaan berikut:
C~=(ATA)-1ATB (6)
Jika hasil dari invers ATA adalah matrik singular (mendekati nilai nol), maka digunakan pseudoinverse
berdasarkan singular value decomposition(Rifkin, 2007; Bartolli,2000). Konsep dasar dari penghitungan pseudoinverse adalah singular value decomposition (svd). Jika terdapat matrix
G berukuran matrix [NxM], dengan menggunakan singular value decomposition akan didapatkan nilai matrix U [u1,u2,…uN]
yang merupakan left singular vektor dari matrix G dan nilai
matrix V [v1,v2,…vM] yang merupakan nilai right singular
3
2.5 PenghitunganS
ηS
η adalah parameter yang bertujuan memberikan informasipada data-data pembelajaran mengenai informasi yang terdapat pada matrix Laplacian sebagaimana persamaan 7.
(
)
[
]
T b wL
X
L
X
S
η=
η
−
1
−
η
(7) dimana η adalah regularization parameter dan X adalahkumpulan dari data-data x. Jika data diproyeksikan berdasarkan kernel, maka perlu pembangunan matrik kernel dengan cara data diproyeksikan kedalam fungsi kernel kemudian dilanjutkan dengan penyelesaian persamaan linier (Xue, 2009). Penelitian ini menggunakan gaussian kernel (Xue, 2009). Persamaan 8 adalah persamaan untuk kernel gaussian.
−
−
=
2 22
exp
)
,
(
σ
j i j ix
x
x
x
K
(8)dimana σ adalah variabel varian. Setelah didapatkan nilai dari hasil perhitungan
S
η, dilanjutkan dengan penghitungan nilai bias (b) dan parameter Langrange Multiplier (γ
) sebagai dasar dalam mendapatkan nilai bobot dari metode DRLSC.2.6 Penghitungan b dan
γ
Kelebihan dari metode DRLSC adalah dapat mengklasifikasikan data secara multiclass (pada waktu bersamaan dapat mengklasifikasikan data-data dengan kelas yang berbeda) tanpa mengklasifikasikannya pada beberapa pengklasifikasian binary class. Persamaan multiclass
sebagaimana persamaan 9.
[
]
[
Y
]
I
b
N N T N N0
1
1
0
=
+
Ω
ηγ
(9) dimana( )
[ ]
[
]
NxN N T N T N i T j ij=
x
S
x
=
=
I
∈
R
Ω
+,
,...,
,
1
,...,
1
1
,
1 ,η
γ
γ
γ
η Imerupakan matrik identitas,
0
c=
[
0
,...,
0
]
T,
Y
=
[
y
1,...,
y
N]
, N adalah jumlah data pembelajaran dan, (.)+ adalah invers dari matrik.Untuk pengklasifikasian multiclass, maka pada label kelas dibangun secara vektor dengan tujuan dapat mengatasi permasalahan multiclass. Jika data
x
i termasuk pada kelas k maka target kelas merupakan yi=[0,...,1,...,0]T ∈ Rc, dimanakelas ke-k bernilai 1 dan yang lain bernilai 0.
2.7 Penghitungan Hasil Keluaran
Setelah mendapatkan nilai b dan
γ
, maka dilanjutkan dengan penghitungan bobot (w) berdasarkan persamaan 10.i N i i
S
x
w
+ =∑
=
1)
(
ηγ
(10) Sesuai dengan persamaan diatas, maka w adalah penjumlahandari hasil perkalian dari Langrange multipliers, invers dari η
S
dan, data ke-i sejumlah N data. Setelah mendapatkan nilai w dan bias, maka hasil keluaran untuk pengklasifikasian multiclass sebagaimana persamaan 11.b
x
w
x
f
=
T+
)
(
(11) dimana w∈Rnxc, b∈RcHasil dari pengklasifikasian dari metode DRLSC digunakan sebagai dasar dari penghitungan fitness pada metode Optimasi Algoritma Genetika dan Particle Swarm Optimization.
3. GAPSO
Penelitian ini mengimplementasikan penggabungan dua metode optimasi yaitu Algoritma Genetika dan Particle Swarm
Optimization dengan istilah GAPSO.
Konsep dasar dari PSO yaitu mengembangkan simulasi sekumpulan burung dalam ruang dimensi XY (dua dimensi) direpresentasikan dengan partikel berdasarkan informasi posisi dan kecepatan (velocity). Setiap partikel mengetahui nilai terbaiknya (Pbest) dan posisinya (x). Selanjutnya, setiap particle mengetahui nilai terbaik didalam seluruh data (Gbest). Pada Gambar 2 menggambarkan konsep desain sistem untuk menggabungkan kedua metode.
Gambar 2. Diagram pengklasifikasian metode GA dan PSO Berikut adalah algoritma dari metode GAPSO (Kao, 2008): 1. Inisialisasi random populasi sebanyak N data.
2. Evaluasi dan ranking evaluasi fitness pada setiap N individu, dimana fungsi fitness pada penelitian ini
, 1 2 )) ( ( 1 ) ( = ∑N y− f x N MSE Error MeanSquare
4
berdasarkan mean square error, sebagaimana persamaan 12 (Dondeti, 2005; Coletti, 1999).
dimana yadalah nilai target yang diinginkan, f(x)adalah hasil keluaran dari pengklasifikasian data.
3. Algoritma genetika dengan menggunakan real code operator
GA, dari N/2 data terbaik.
3.1Seleksi dari N data pilih N/2 data dengan fitness terbaik. 3.2 Crossover N/2 data sebagaimana persamaan 13.
3.3 Mutasi dengan pengaruh fungsi gaussian terhadap nilai random. Probabilitas mutasi sebesar 0.2 sebagaimana persamaan 14. ' * (1 ) 1 2 , 1 2 ,..., 2 , 1 1 ) 1 ( * ' N i x i x i x N i i x i x i x = − + = − = + − + = α α α α (13) (14) 4. Setelah pembelajaran dengan metode crossover dan mutasi,
maka dilanjutkan dengan pembelajaran PSO. Operasi yang digunakan pada pembelajaran PSO untuk penentuan velocity pada pembelajaran GAPSO sebagaimana persamaan 15.
(
),
old id gd New idcxrandx
p
x
V
=
−
(15) dimana nilai c adalah 2, rand adalah nilai random antara 0 dan 1,gd
p
adalah nilai Gbest. Pada pembelajaran GAPSO pada penelitian ini tidak menggunakan velocity lama untuk memperbarui nilai velocity, hal ini berpengaruh positif sehingga menuju nilai optimal lebih terarah dan lebih cepat. Hal ini disebabkan karena pada pada metode GAPSO, dapat terjadi kemungkinan data dari PSO menjadi data pembelajaran padaGA yang tidak membutuhkan informasi nilai velocity
sebelumnya. Dari hasil pembelajaran GA ini diperoleh generasi baru yang tidak dipengaruhi oleh nilai velocity sebelumnya. Dengan demikian, maka penggunaan velocity sebelumnya dapat memperlambat kearah nilai optimal jika terjadi kemungkinan nilai dari data PSO pada generasi berikutnya digunakan sebagai pembelajaran pada metode GA.
Setelah pembelajaran dengan metode GA dilanjutkan dengan metode PSO, maka dilakukan analisa fitness dalam penelitian ini Mean Square Error dari pengklasifikasian DRLSC untuk mengetahui error yang telah dicapai oleh pembelajaran
GAPSO. Penentuan iterasi berhenti dalam penelitian ini
menggunakan maksimum iterasi. Sebelum memasuki optimasi pada PSO, maka perlu adanya konversi nilai dari kromosom sebagaimana persamaan 16 (Saruhan, 2004):
x=rb+(ra-rb)g, (16) dimana rb adalah batas bawah dan ra adalah batas atas dengan g
adalah gen dari kromosom.
IV. HASIL UJI COBA DAN ANALISA
Setiap uji coba yang dilakukan pada ke-3 dataset akan dibandingkan pada empat metode yaitu tanpa optimasi, dengan metode GA, metode PSO, dan optimasi dengan GAPSO.
Tabel 1. Hasil Pembelajaran Data IRIS Metode Fitness %Uji Coba Σ iterasi K ita Tanpa Optimasi 1,1e-004 93,33% 24 104 6 GA 1,1e-004 93,33% 27 129,65 6 PSO 1,1e-004 93,33% 13 56,54 6 GAPSO 1,1e-004 93,33% 13 85,41 6
Berdasarkan hasil percobaan pada Tabel 1, hasil pembelajaran pada ketiga metode optimasi dan tanpa optimasi menghasilkan parameter K dan η yang sama, sehingga fitness pada ke-4 parameter memiliki nilai yang sama.
Tabel 2. Hasil Pembelajaran Data WINE Metode Fitness %Uji Coba Σ iterasi K η
Tanpa Optimasi 0,076 93,33% 24 175,32 2 GA 4,2e-004 93,33% 30 254,45 17 PSO 4,7e-006 93,33% 17 140,11 2 GAPSO 8,9e-010 93,33% 50 558,55 2
Hasil yang diperoleh berdasarkan Tabel 2, nilai fitness terkecil diperoleh oleh metode GAPSO.
Tabel 3. Hasil Pembelajaran Data LENSA Metode Fitness %Uji
Coba Σ iterasi K Η Tanpa Optimasi 0,005 92,31% 2 0,17 2 GA 0,0186 92,31% 11 1,7 2 PSO 2,6e-005 92,31% 17 3,68 5 GAPSO 1,9e-006 92,31% 13 3,03 2
Sebagaimana pada hasil percobaan pada Tabel 3, hasil
fitness yang didapatkan pada GAPSO memiliki nilai terbaik
dibandingkan ke-2 metode optimasi dan tanpa optimasi.
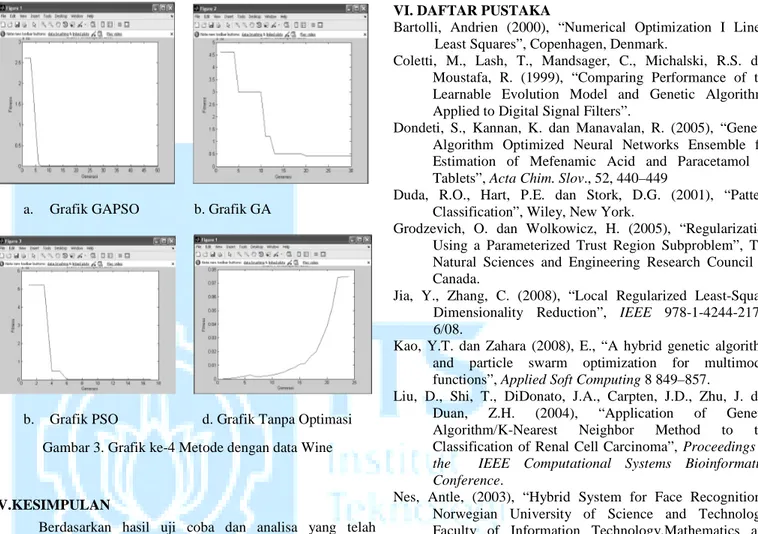
Berdasarkan analisa pada seluruh uji coba maka kecenderungan metode GAPSO menghasilkan nilai fitness yang lebih kecil jika dibandingkan metode GA ataupun PSO. Metode
GAPSO sejak iterasi pertama hingga konvergen memiliki
kecenderungan menghasilkan nilai fitness yang lebih kecil jika dibandingkan dengan metode GA ataupun PSO sendiri pada setiap iterasinya. Hal ini dipengaruhi oleh hasil pembelajaran dari metode Algoritma Genetika mempengaruhi data pembelajaran pada metode PSO pada setiap iterasinya.
Semakin banyak jumlah iterasi untuk mencapai konvergen dengan data pembelajaran yang sama pada metode (12)
5
GAPSO memiliki kecenderungan menghasilkan nilai fitness
yang terkecil dibandingkan metode optimasi GA ataupun PSO untuk data yang sama.
a. Grafik GAPSO b. Grafik GA
b. Grafik PSO d. Grafik Tanpa Optimasi
V.KESIMPULAN
Berdasarkan hasil uji coba dan analisa yang telah dilakukan maka dapat diuraikan beberapa kesimpulan, yaitu:
• Pada penelitian ini mampu mendapatkan parameter K dan η
secara otomatis dengan menerapkan metode optimasi
GAPSO.
• Metode GAPSO yang diterapkan untuk mengoptimasi metode DRLSC memiliki kecenderungan mampu menghasilkan nilai fitness yang lebih baik jika dibandingkan metode optimasi GA ataupun PSO sendiri dan tanpa optimasi.
• Pada metode GAPSO, semakin banyak jumlah iterasi untuk mencapai konvergen akan menghasilkan nilai fitness yang lebih baik jika dibandingkan metode GA ataupun PSO dengan data yang sama.
Pada penelitian ini masih terdapat kelemahan ketika proses pembelajaran KNN membutuhkan waktu yang lama karena menggunakan dimensi sebenarnya, untuk mengatasi hal ini perlu adanya penelitian pengurangan dimensi untuk mempercepat proses komputasi ketika pada pembelajaran KNN.
VI. DAFTAR PUSTAKA
Bartolli, Andrien (2000), “Numerical Optimization I Linear Least Squares”, Copenhagen, Denmark.
Coletti, M., Lash, T., Mandsager, C., Michalski, R.S. dan Moustafa, R. (1999), “Comparing Performance of the Learnable Evolution Model and Genetic Algorithms Applied to Digital Signal Filters”.
Dondeti, S., Kannan, K. dan Manavalan, R. (2005), “Genetic Algorithm Optimized Neural Networks Ensemble for Estimation of Mefenamic Acid and Paracetamol in Tablets”, Acta Chim. Slov., 52, 440–449
Duda, R.O., Hart, P.E. dan Stork, D.G. (2001), “Pattern Classification”, Wiley, New York.
Grodzevich, O. dan Wolkowicz, H. (2005), “Regularization Using a Parameterized Trust Region Subproblem”, The Natural Sciences and Engineering Research Council of Canada.
Jia, Y., Zhang, C. (2008), “Local Regularized Least-Square Dimensionality Reduction”, IEEE 978-1-4244-2175-6/08.
Kao, Y.T. dan Zahara (2008), E., “A hybrid genetic algorithm and particle swarm optimization for multimodal functions”, Applied Soft Computing 8 849–857.
Liu, D., Shi, T., DiDonato, J.A., Carpten, J.D., Zhu, J. dan Duan, Z.H. (2004), “Application of Genetic Algorithm/K-Nearest Neighbor Method to the Classification of Renal Cell Carcinoma”, Proceedings of
the IEEE Computational Systems Bioinformatics Conference.
Nes, Antle, (2003), “Hybrid System for Face Recognition”, Norwegian University of Science and Technology, Faculty of Information Technology,Mathematics and Electrical Engineering, Department of Computer and Information Science, Division of Intelligent Systems / Image Processing
Rifkin, R. M. dan Lippert, R. A. (2007), “Notes on Regularized Least Squares”, Computer Science and Artificial
Intelligence Laboratory Technical Report ,
MIT-CSAIL-TR-2007-025
Saruhan, H. (2004), “Genetic Algorithms: An Optimization Technique”, TEKNOLOJĐ, Volume 7, Issue 1, 105-114. Sivanandam, S.N. dan Deepa, S.N. (2008), “Introduction to
Genetic Algorithms”, Springer-Verlag Berlin Heidelberg. Song, Y., Huang, J, Zhou, D., Zha, H. dan Giles, C. L. (2007),
“IKNN: Informative K-Nearest Neighbor Pattern Classification”, Springer-Verlag Berlin Heidelberg. Xue, H., Chen, S. dan Yang, Q. (2009), “Discriminatively
Regularized Least-Squares Classification”, Science Direct, Pattern Recognition 42 93 – 104.