Analisis Pengolahan
Text File
pada Hadoop Cluster
dengan Memperhatikan Kapasitas
Random Access
Memory (RAM)
Analysis of text file processing on Hadoop Cluster regard to Random Access Memory (RAM) Capacity
Tugas Akhir
Diajukan untuk memenuhi sebagian dari syarat untuk memperoleh gelar Sarjana Ilmu Komputasi
Fakultas Informatika Universitas Telkom
Irvan Nur Aziz 1107110001
Fakultas Informatika
Universitas Telkom
Bandung
2015
Lembar Pernyataan
Dengan ini saya menyatakan bahwa Tugas Akhir dengan judul “Analisis Pengolahan Text File pada Hadoop Cluster dengan Memperhatikan Kapasitas Random Access Memory (RAM)”beserta seluruh isinya adalah benar-benar karya saya sendiri dan saya tidak melakukan penjiplakan atau pengutipan dengan cara-cara yang tidak sesuai dengan etika keilmuan yang berlaku dalam masyarakat keilmuan. Atas pernyataan ini, saya siap menanggung resiko/sanksi yang dijatuhkan kepada saya apabila kemudian ditemukan adanya pelanggaran terhadap etika keilmuan dalam karya saya ini, atau ada klaim dari pihak lain terhadap keaslian karya saya ini.
Bandung, 5 Agustus 2015 Yang membuat pernyataan,
Lembar Pengesahan
Analisis Pengolahan Text Filepada Hadoop Cluster dengan Memperhatikan Kapasitas Random Access Memory (RAM)
Analysis of text file processing on Hadoop Cluster regard to Random Access Memory (RAM) Capacity
Irvan Nur Aziz NIM :1107110001
Telah disetujui dan disahkan sebagai Tugas Akhir Program Studi Sarjana Ilmu Komputasi
Fakultas Informatika Universitas Telkom Bandung, 5 Agustus 2015 Menyetujui Pembimbing I Pembimbing II Fitriyani, S.Si, MT. NIP. 10830595-1
Kemas Rahmat Saleh W, St., M.Eng NIP.06830335-1
Abstrak
Implementasi Hadoop cluster untuk pengolahan data secara terdistribusi dalam skala besar sudah menjadi tren saat ini. Hadirnya hadoop cluster sangat membantu dalam bidang pengolahan data, banyak perusahaan yang mengimplementasikan hadoop cluster seperti facebook, yahoo, dan amazon. Hal ini didasari oleh kelebihan hadoop yang dapat memiliki performansi tinggi dengan menggunakan hardware sederhana.
Pada dasarnya pengimplementasian Hadoop cluster didasari pada kecepatan pengolahan data skala besar dengan menggunakan hardwareyang standar namun dapat memiliki performansi yang baik.
Tujuan dari penelitian ini adalah mengimplementasikan hadoop cluster dengan menggunakan benchmark wordcount sebagai tools untuk mengetahui tingkat performansi dari jenis text file dengan memperhatikan kapasitas Random Access Memory (RAM) .Jenis-jenis file textyang ajan diujicoba adalah doc, pdf, csv, xlsx dan txt.
Waktu ujicoba yang dihasilkan dari jenis-jenis text file tersebut menunjukan urutan tingkat performansi terbaik dimulai dari jenis text file csv, txt, xlsx, pdf dan yang terakhir adalah jenis file doc. Waktu peningkatan performansi dari semua jenis file tidak mengalami peningkatan yang sama dengan peningkatan kapasitas RAM, pada saat kapasitas RAM ditingkatkan menjadi 100% hasil percobaan menunjukan performansi dari jenis file doc mengalami peningkatan sebesar 4,58%, file pdf sebesar 7,57%, file csv sebesar 8,87%, file xlsx sebesar 8,35% dan filetxt sebesar 12,82%.
Abstract
Nowadays, Implementation of Hadoop clusters for distributed processing of data on a large scale has become a trend. The presence of cluster hadoop very helpful in the field of data processing, some companies are implementing hadoop cluster such as facebook, yahoo and amazon. It is based on the hadoop excess which can have high performance by using simple hardware.
The aim of this research is to implement hadoop cluster by using Wordcount benchmarks as tools to determine the level of performance of this text file type regard to Random Access Memory (RAM) capacity. The types of text files that will be tested is the doc, pdf, csv, xlsx and .txt.
Time trials resulting from the types of the text file showing the best performance level sequence starting from the csv, txt, xlsx, pdf, and doc. The performance enhancement time of all kinds of text files are not proportional with the capacity of RAM, when the RAM capacity increased to 100% of the performance results of the experiment showed doc file increased by 4.58%, pdf file increased by 7.57%, csv file increased by 8.87%, xlsx file increased by 8,35% and txt file increased by 12.82%.
Kata Pengantar
Puji syukur kehadirat Allah SWT yang senantiasa memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan Tugas Akhir dengan judul “Analisis Pengolahan Text File pada Hadoop Cluster dengan Memperhatikan Kapasitas Random Access Memory (RAM)”.Tugas Akhir ini disusun sebagai salah satu syarat yang harus dipenuhi untuk menyelesaikan pendidikan tahap sarjana di Program Studi Sarjana Ilmu Komputasi, Fakultas Informatika Universitas Telkom.
Penulis menyadari bahwa Tugas Akhir ini masih jauh dari kesempurnaan yang disebabkan oleh keterbatasan pengetahuan yang dimiliki oleh penulis. Untuk itu saran dan kritik yang bersifat membangun dari pembaca sangat penulis harapkan demi perbaikan di masa yang akan datang. Dengan segala kerendahan hati, penulis berharap Tugas Akhir ini dapat dikembangkan ke arah yang lebih baik dan bermanfaat bagi pembaca dan penulis khususnya, serta bagi dunia pendidikan pada umumnya.
Bandung, 5 Agustus 2015
Lembar Persembahan
Alhamdulillaahirabbil ‘alamin penulis panjatkan kehadirat Allah SWT karena telah melimpahkan ilmu yang bermanfaat sehingga saya dapat menyelesaikan Tugas Akhir ini dengan sebaik-baiknya. Tidak lupa juga sholawat serta salam kepada Nabi Muhammad SAW.
Saya mengucapkan banyak terimakasih kepada orang-orang yang telah membantu dan memberikan kelancaran pada saya untuk menyelesaikan Tugas Akhir ini, baik yang terlibat secara langsung maupun yang tidak. Ucapan terimakasih tesebut saya ucapkan kepada :
1 Kedua orang tua saya, Ayah Ir.Darmono dan Ibu Euis Susilawati yang senantiasa dan selalu mendoakan saya, memberi semangat dihari-hari kuliah sampai dengan pengerjaan tugas akhir ini. Adik-adik saya Ikhsan Muhamad Arif dan Amanda Amalia yang senantiasa menjadi pemicu semangat saya untuk segera menyelesaikan tugas akhir ini agar saya dapat menjadi panutan yang baik. Keluarga besar saya yang selalu memberikan dukungan untuk dapat segera menyelesaikan tugas akhir ini. Semoga kesehatan dan keberkahan selalu menyertai ayah, ibu, adik-adik dan keluarga besar saya. 2 Ibu Fitriyani, S.Si, MT. selaku pembimbing I yang selalu membantu saya
dalam setiap kesulitan pada tahapan-tahapan pengerjaan tugas akhir, dan memberikan solusi atas permasalahan pada tugas akhir ini serta Bapak Kemas Rahmat Saleh W, St., M.Eng selaku dosen pembimbing II yang juga selalu membantu saya dalam pengerjaan tugas akhir ini. Semoga kebahagiaan, kesehatan dan kesuksesan selalu menyertai ibu dan bapak.
3 Ibu Sri Suryani P.,S.Si.,M.Si selaku dosen wali yang membimbing saya sejak saya memulai perkulihan dikampus ini, selalu memberi solusi saat saya mengalami kesulitan selama perkuliahan dan memberi saya nasihat agar dapat menjadi lebih baik dalam menjalani perkuliahan. Semoga kebahagiaan, kesehatan dan kesuksesan selalu menyertai ibu.
4 Seluruh dosen Ilmu Komputasi Fakultas Informatika Telkom University yang dengan ikhlas telah memberikan ilmunya. Semoga ilmu ini bisa bermanfaat dan menjadi amal jariah untuk bapak ibu semua.
5 Teman-teman IK-35-01, teman sekelas, teman seperjuangan dari semester pertama sampai sekarang. Terimakasih telah menjadi teman yang senantiasa selalu membantu selama ini, semoga tali silaturahmi kita akan tetap dapat terjaga dengan baik.
6 Pihak yang belum disebutkan diatas, saya sadar manusia merupakan mahluk sosial yang tidak bisa hidup sendiri, namun saling tergantung satu sama lain.
Daftar Isi
LEMBAR PERNYATAAN ...II LEMBAR PENGESAHAN ... III ABSTRAKSI ... IV ABSTRACT... V KATA PENGANTAR... VI LEMBAR PERSEMBAHAN...VII DAFTAR ISI... VIII DAFTAR GAMBAR... X DAFTAR TABEL ... XI 1. PENDAHULUAN...1 1.1 LATAR BELAKANG...1 1.2 PERUMUSAN MASALAH...2 1.3 BATASAN MASALAH...2 1.4 TUJUAN...2 1.5 METODOLOGI PENELITIAN...3 1.6 SISTEMATIKA PENULISAN...3 2. DASAR TEORI ...4 2.1 CLUSTER COMPUTER...4 2.2 HADOOP CLUSTER...4 2.3 MAPREDUCE...6 2.3.1 Map Procedure...6 2.3.2 Reduce Procedure...7
2.3.3 Contoh Proses Hadoop Cluster...8
2.4 HADOOP DISTRIBUTE FILE SYSYTEM (HDFS)...9
2.5 CLOUDERA...11
2.6 WORDCOUNT...11
2.7 RANDOM ACCESS MEMORY (RAM)...11
2.8 JENIS-JENIS TEXT FILE...11
2.9 CENTOS...12
3. PERANCANGAN SISTEM...13
3.1 GAMBARAN UMUM SISTEM...13
3.2 PREPARATION...14
3.3 NETWORKING...14
3.4 INSTALASI HADOOP...15
3.4.1 Persyaratan ...15
3.4.2 Jaringan ...15
3.4.3 Konfigurasi Secure Shell (SSH)...16
3.4.4 Instalasi Hadoop ...16
3.4.5 Konfigurasi Instalasi...17
3.4.6 Cek Instalasi Hadoop...18
4. PERCOBAAN SISTEM DAN ANALISIS ...19
4.1 GAMBARAN UMUM SISTEM...19
4.1.1 Tujuan Percobaan...19 4.2 PERSIAPAN DATA...19 4.2.1 Pemilihan Data ...19 4.2.2 Pembagian Data...20 4.3 SKENARIO PERCOBAAN...20 4.4 PROSES PERCOBAAN...20 4.4.1 Transfer File...21 4.4.2 Eksekusi File...23 4.5 HASIL PERCOBAAN...25
4.5.1 Hasil Percobaan Tahap Pertama...25
4.5.2 Hasil Percobaan Tahap Kedua ...26
4.5.3 Hasil Percobaan Tahap Ketiga ...28
4.5.4 Hasil Percobaan Tahap Keempat ...30
4.5.5 Konfigurasi Instalasi...32
4.5.6 Cek Instalasi Hadoop...35
4.5.7 Cloudera Manager ...40 5. PENUTUP ...41 5.1 KESIMPULAN...41 5.2 SARAN...41 DAFTAR PUSTAKA...42 LAMPIRAN...43
Daftar Gambar
Gambar 2.1 Map Architecture...6
Gambar 2.2 Pseudo-code of Map Procedure...6
Gambar 2.3 Reduce Architecture...7
Gambar 2.4 Pseudo-code of Reduce Procedure...7
Gambar 2.5 Wordcount...8
Gambar 2.6 Arsitektur Menyimpan Data...9
Gambar 2.7 Arsitektur Membaca Data ...10
Gambar 3.1 Gambaran Umum Sistem ...13
Gambar 3.2 Arsitektur Cluster...14
Gambar 3.3 Cloudera Manager Login...18
Gambar 4.1Transfer File Via FileZila Site Manager...21
Gambar 4.2 Transfer File To Master Node...21
Gambar 4.3 Transfer File Master Node To HDFS...22
Gambar 4.4 JarFile Directory...23
Gambar 4.5 Jar File Execution...23
Gambar 4.6 Jar File Output...23
Gambar 4.7 Kondisi Cluster(RAM 2GB) ...24
Gambar 4.8 Kondisi Cluster (RAM 4GB) ...26
Gambar 4.9 Kondisi Cluster(RAM 8GB) ...28
Gambar 4.10 Kondisi Cluster(RAM 16GB) ...30
Gambar 4.11 Grafik Pembanding dengan Kapasitas RAM 2GB...32
Gambar 4.12 Grafik Pembanding dengan Kapasitas RAM 4GB...33
Gambar 4.13 Grafik Pembanding dengan Kapasitas RAM 8GB...34
Gambar 4.14 Grafik Pembanding dengan Kapasitas RAM 16GB...34
Gambar 4.15 Grafik Pembanding FileDoc ...35
Gambar 4.16 Grafik Pembanding FilePdf ...36
Gambar 4.17 Grafik Pembanding FileCsv...37
Gambar 4.18 Grafik Pembanding FileXlsx ...38
Gambar 4.19 Grafik Pembanding FileTxt ...39
Daftar Tabel
Tabel 4.1 Pembagian Data ...20
Tabel 4.2 Hasil PercobaanFileDoc (RAM 2GB) ...24
Tabel 4.3 Hasil PercobaanFilePdf (RAM 2GB) ...25
Tabel 4.4 Hasil PercobaanFileCsv (RAM 2GB) ...25
Tabel 4.5 Hasil PercobaanFileXlsx (RAM 2GB) ...25
Tabel 4.6 Hasil PercobaanFileTxt (RAM 2GB) ...25
Tabel 4.7 Hasil PercobaanFileDoc (RAM 4GB) ...26
Tabel 4.8 Hasil PercobaanFilePdf (RAM 4GB) ...27
Tabel 4.9 Hasil PercobaanFileCsv (RAM 4GB) ...27
Tabel 4.10 Hasil PercobaanFileXlsx (RAM 4GB) ...27
Tabel 4.11 Hasil PercobaanFileTxt (RAM 4GB) ...27
Tabel 4.12 Hasil Percobaan File Doc (RAM 8GB) ...28
Tabel 4.13 Hasil Percobaan FilePdf (RAM 8GB) ...29
Tabel 4.14 Hasil Percobaan FileCsv (RAM 8GB) ...29
Tabel 4.15 Hasil Percobaan FileXlsx (RAM 8GB) ...29
Tabel 4.16 Hasil Percobaan FileTxt (RAM 8GB) ...29
Tabel 4.17 Hasil Percobaan FileDoc (RAM 16GB) ...30
Tabel 4.18 Hasil Percobaan FilePdf (RAM 16GB) ...31
Tabel 4.19 Hasil Percobaan FileCsv (RAM 16GB) ...31
Tabel 4.20 Hasil Percobaan FileXlsx (RAM 16GB) ...31
1. PENDAHULUAN
1.1 Latar Belakang
Perkembangan teknologi terus berkembang pesat dari tahun ke tahun hal ini karena permintaan dan kebutuhan masyarakat yang semakin banyak, mulai dari penelitian, pekerjaan, hingga hiburan. Salah satu sektor teknologi yang terkena dampak dari perkembangan yang sangat pesat ini adalah sektor data elektronik, ukuran data-data elektronik yang dimiliki oleh perusahaan sebelumnya hanya gigabyte hingga terabyte namun saat ini sudah mengalami peningkatan yang sangat signifikan, data yang dimiliki perusahaan sudah mencapai ukuran petabyte. Dengan data sebesar itu maka diperlukan metode pengolahan data yang optimal dan tempat penyimpanan yang juga sangat besar.
Adakalanya aplikasi yang dibuat membutuhkan komputer dengan sumber daya yang tinggi sebagai lingkungan implementasi dan biasanya harga untuk komputer dengan sumber daya yang tinggi tidaklah murah sedangkan untuk komputer dengan spesifikasi yang tidak terlalu tinggi akan kurang reliable dalam menangani data yang begitu besar (Venner, 2009) [4].
Untuk melakukan komputasi dengan data yang sangat besar, Google memberikan suatu metode yang dinamakan MapReduce. MapReduce melakukan komputasi dengan membagi beban komputasi dan diproses secara paralel atau bersama-sama (Dean, 2004) [4].
Terinspirasi oleh adanya Google File System (GFS) yang dikembangkan oleh Google yang digunakan untuk mengolah data mentah dengan jumlah yang sangat besar maka apache membuat framework berbasis java yang diberi nama Hadoop. Hadoop diciptakan oleh Doug Cutting dan Mike Cafarella pada tahun 2005.
Hadoop adalah sebuah framework berbasis java. Hadoop bekerja secara terdistribusi dengan 2 buah proses utama yaitu MapReduce dan Hadoop Distributed File System(HDFS). Hadoop memiliki kelebihan dapat secara cepat dan optimal didalam mengolah data yang sangat besar dengan kualitas hardware yang standar.
Random access memory (RAM) adalah memori tempat penyimpanan sementara pada komputer saat komputer dijalankan. RAM berfungsi untuk mempercepat pemprosesan data pada komputer, semakin besar ukuran RAM pada komputer maka pemprosesan data akan semakin cepat.
Text file merupakan dokumen yang biasanya digunakan untuk media pengolahan kata pada perangkat komputer. Terdapat berbagai macam jenis file yang dapat dibedakan berdasarkan formatnya.
Maka pada tugas akhir ini akan dilakukan analisis pengolahan text file pada hadoop cluster dengan memperhatikan kapasitas (RAM).
1.2 Perumusan Masalah
Berdasarkan latar belakang yang diuraikan diatas, maka rumusan masalah tugas akhir ini adalah
1. Bagaimana implementasi hadoop cluster berbasispersonal computer (pc)?
2. Berapa besar peningkatan performansi hadoop cluster jika spesifikasi RAM ditingkatkan?
3. Bagaimana perbandingan performansi pengolahan text fileuntuk setiap jenis file pada hadoop cluster?
1.3 Batasan Masalah
Untuk mendapatkan hasil yang spesifik sesuai dengan yang diinginkan, dalam penelitian ini ditentukan batasan masalah sebagai berikut:
1. Hardware yang dianalisis adalah RAM.
2. Kapasitas RAM yang digunakan 2 Gigabyte, 4 Gigabyte, 8 Gigabyte dan 16 Gigabyte.
3. Jumlah Komputer yang digunakan sebanyak 3 buah. 4. Menggunakan operating systemCentos.
5. Menggunakan Wordcountsebagai aplikasi benchmark.
6. Jenis fileyang digunakan untuk proses uji coba adalah jenis file doc, pdf, csv, xlsx dan txt
1.4 Tujuan
Adapun tujuan dari penelitian tugas akhir ini adalah: 1. Mengimplementasikan hadoop cluster.
2. Mengetahui berapa kali lipat peningkatan performansi hadoop cluster jika spesifikasi RAM ditingkatkan.
3. Mengetahui perbandingan performansi pengolahan text file untuk setiap jenis file pada hadoop cluster.
1.5 Metodologi Penelitian
1. Studi Literatur
Merupakan tahap pencarian referensi dan literatur yang berhubungan tahap, yang berhubungan dengan tujuan penelitian Tugas Akhir 2. Hipotesis Awal
Merupakah tahap pengambilan intisari dan studi literatur untuk siap diimplementasikan, termasuk penentuan metode yang digunakan untuk menyelesaikan percobaan.
3. Implementasi
Merupakan tahap pembangunan Hadoop cluster. 4. Analisis dan Percobaan
Merupakan tahap analisis kinerja dari sistem yang dibangun, yang akan diukur dari hasil pemprosesan data.
5. Kesimpulan
Merupakan pengambilan kesimpulan dari penelitian tugas akhir yang mengacu dari analisa pada tahap sebelumnya.
1.6 Sistematika Penulisan
Sistematika penulisan laporan Tugas Akhir ini terdiri atas lima bab yang disusun sebagai berikut:
BAB I Pendahuluan
Berisi latar belakang, tujuan penelitian, rumusan masalah, batasan masalah, metodologi penelitian dan sistematika penulisan.
BAB II Dasar Teori
Berisi teori-teori yang mendukung dan mendasari penulisan laporan Tugas Akhir.
BAB III Perancangan dan Implementasi Sistem
Berisi urutan proses perancangan dan implementasi sistem Hadoop Cluster dengan menggunakan Cloudera Manager. BAB IV Percobaan Sistem dan Analisis
Berisi penjelasan tentang skenario percobaan sistem dan analisis terhadap hasil penelitian yang telah dilakukan. BAB V Kesimpulan dan Saran
Berisi kesimpulan dari analisa yang telah dilakukan dan saran untuk penelitian selanjutnya.
2. DASAR TEORI
2.1 Cluster Computer
Cluster Computer merupakan kumpulan atau gabungan dari dua buah komputer atau lebih yang digabungkan menjadi satu bagian melalui sebuah jaringan berupa interkoneksi atau Local Area Network (LAN). Secara fungsional gabungan dari komputer menjadi satu bagian namun secara fisik komputer-komputer terpisah satu dengan lainya. Pemanfaatan cluster biasanya untuk mendukung sebuah pekerjaan yang membutuhkan sumberdaya komputer dengan spesifikasi tinggi.
Cara kerja dari sebuah cluster computer adalah dengan menggabungkan sumberdaya yang dimiliki masing-masing komputer, jika pada cluster terdapat 5 buah komputer dengan spesifikasi masing-masing processor pada komputer adalah 7 coremaka clustertersebut memiliki sumberdaya sebesar 35 core.
2.2 Hadoop cluster
Hadoop merupakan salah satu framework berbasis java milik apache yang diciptakan oleh Doug Cutting dan Mike Cafarella pada tahun 2005. Hadoop berfungsi untuk mengolah data skala besar (Big Data) dengan kecepatan berkali-kali lipat dibandingkan dengan metode konvensional, tidak hanya data dengan ukuran Gigabyte dan Terabyte yang dapat diolah, namun data dengan ukuran Petabytedapat diolah oleh Hadoop.
Framework Apache Hadoop tersusun dari 4 modul berikut:
1 Hadoop Common – berisi libraries dan utilities yang dibutuhkan oleh
modul Hadoop lainnya.
2 Hadoop Distributed File System (HDFS) – sebuah distributed file-system.
3 Hadoop YARN – sebuah platform resource-management yang
bertanggung jawab untuk mengelola resources dalam clusters dan
scheduling.
4 Hadoop MapReduce – sebuah model programminguntuk pengelolaan data
skala besar.
Seiring dengan perkembangan dunia teknologi dan informasi kini hadoop
memiliki pengembangan dibidang perangkat lunak yang dikenal sebagai hadoop
ecosystem, berikut ini merupakan beberapa produk dari hadoop ecosystem dan kegunaanya:
1. Pig,adalah scripting platform untuk pengembangan dan eksekusi job Hadoop. Pig memberikan pengalaman development yang lebih mudah dibandingkan pemrograman MapReduceberbasis pemrograman Java. Pig umumnya digunakan dalam kebutuhan pengolahan data mentah untuk menjadi data matang kebutuhan analitik selanjutnya baik menggunakan Hive maupun Mahout.
2. Hive, service Data Warehouse yang mengakses langsung file-file yang tersimpan dalam HDFS, dan juga diset untuk mengakses langsung berbagai table HBase. Hive memberikan pengalaman development yang lebih familiar karena menggunakan sintaks SQL yang sudah dikenal umum. Umumnya Hive digunakan untuk kebutuhan analisis data lebih lanjut yang sebelumnya yang sudah matang diproses oleh Pig atupun Mahout.
3. Mahoutadalah library Machine Learning (ML) –berbasis pemrograman Java– yang teruji kompatibel dengan platform komputasi MapReduce Hadoop untuk pemrosesan analitik prediktif (predictive analytic)
4. Hueadalah server web portal yang dapat mengakses langsung Hadoop. Hue dapat digunakan untuk meregistrasi job Hadoop, monitor proses eksekusinya dan me-review hasilnya.
5. HBase,database terdistribusi untuk menampung Big data secara terstruktur dalam suatu table sangat besar. HBase juga terinspirasi oleh pengembangan Google BigTable.
6. Sqoop memungkinkan integrasi data antara RDBMS ataupun database NoSQL lainnya dengan Hadoop.
7. Flume, untuk mengakuisisi sumber data berbasis logfiles secarareal-time. 8. Avro, suatu kontainer untuk menampung kumpulan data berukuran kecil
dalam satu file binary besar yang kompak, terstruktur skema-datanya & ringan untuk diproses lebih lanjut oleh MapReduce.
9. Oozie, untuk kebutuhan pengelolaan job scheduling & kontrol prosesworkflowdari serangkaian MapReduce Jobyang saling terkait. 10.Zookeeper, high-performance service untuk koordinasi pelbagai aplikasi
terdistribusi yang berjalan di atas Hadoop [10].
Hadoop bekerja dengan prinsip membagi-bagi skala data berukuran besar menjadi beberapa bagian kecil dan kemudian memproses data-data potongan kecil tersebut secara paralel.
Hadoop dapat bekerja pada sebuah komputer atau lebih (cluster). cluster adalah 2 buah komputer atau lebih yang saling terhubung melalui sebuah jaringan. Maka Hadoop sering dikenal dengan istilah Hadoop cluster karena proses kerjanya pada sebuah cluster.
Hadoop memiliki 2 proses utama: 1. MapReduce
2.3 MapReduce
MapReduce pertama kali dikenalkan oleh Jeffrey Dean dan Sanjay Ghemawat dari Google,Inc. MapReduce adalah model pemograman terdistribusi yang digunakan untuk melakukan pengolaha data digunakan pengolahan data besar (Ghemawat, 2004). Mapreduce membagi input data menjadi beberapa potongan data, masing-masing ditugaskan sebagai map task yang dapat memproses data secara pararel.MapReduce didalam prosesnya dibantu oleh Jobtracker dan Tasktrackersehingga proses dapat berjalan dengan baik. MapReduce memiliki 2 tahapan utama, yaitu Mapdan Reduce.
2.3.1 Map Procedure
Berikut ini merupakan gambaran arsitektur dari prosedur Mappada proses MapReduce.
Gambar 2.1 Map Architecture
Pada proses ini jobtrackermenerima atau membaca data masukan dalam bentuk pasangan key/value yang kemudian dipecah-pecah dengan ukuran tertentu, setelah dipecah-pecah data dibagikan kepada tasktracker untuk di proses dan disimpan didalam tempat-tempat penyimpanan yang tersedia secara terdistribusi. Output dari proses map ini adalah pasangan key/value.
Map memiliki identitas value dan key yang disebut dengan pasangan intermediate, yang berguna sebagai alamat ketika dalam proses reduce. Secara singkat prosedur mapdapat dituliskan dengan pseudo-code sebagai berikut:
Gambar 2.2 Pseudo-code of Map Procedure
Data Reduce
Map
Map
Map Input
MapProcess(FileName, file- contents); For eachword infile – contents;
2.3.2 Reduce Procedure
Berikut ini merupakan gambaran arsitektur dari prosedur Mappada proses MapReduce.
Gambar 2.3 Reduce Architecture
Pada proses ini jobtracker menerima permintaan data kemudian memanggil para tasktracker (penyimpan data yang diminta) sesuai dengan pasangan intermediate <value,key>. setelah itu data-data dari tasktracker dikumpulkan menjadi satu secara terdistribusi untuk memberi jawaban dari data yang diminta.
Secara singkat prosedur Reduce dapat dituliskan dengan pseudo-codesebagai berikut:
Gambar 2.4 Pseudo-code of Reduce Procedure Output Data Reduce Map Map Map ReduceProcess(word, values);sum = 0 For eachvalueinvalues; sum = sum + value Output(word.sum);
2.3.3 Contoh Proses Hadoop Cluster
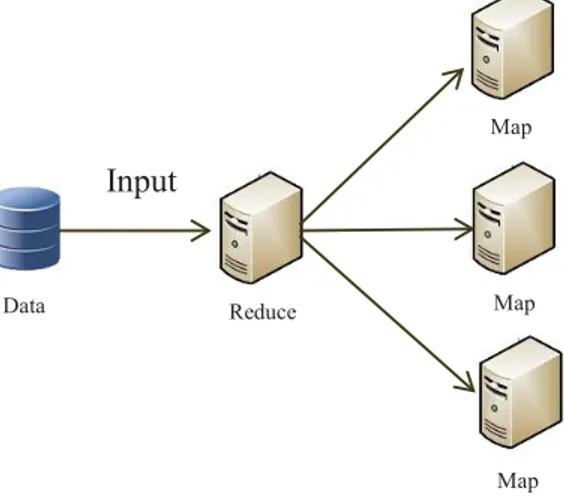
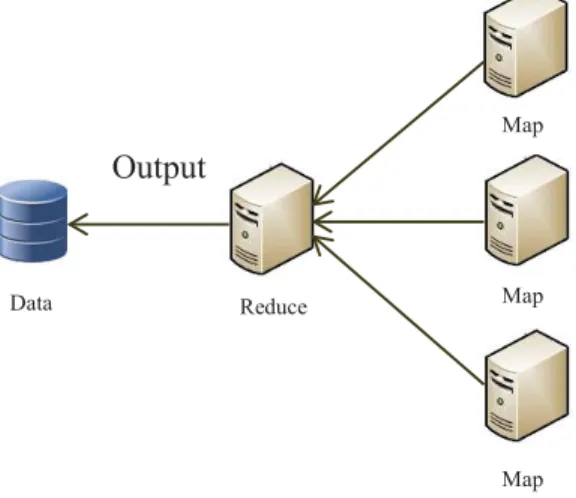
Berikut ini merupakan gambaran dari proses hadoop cluster pada aplikasi benchmark wordcount.
Gambar 2.5 Wordcount [12]
Aplikasi benchmark wordcount pada hadoop merepresentasikan prinsip kerja hadoop secara terdistribusi yaitu dengan memecah data menjadi beberapa bagian kecil kemudian memprosesnya.
Pada gambar diatas terdapat beberapa paraggraf yang mengandung kata-kata sebagai masukan, kemudian proses map pada hadoop cluster memecah paragraph berdasarkan kata-kata dan memberi nilai 1 untuk masing-masing kata. Setelah paragraph terpecah menjadi kata-kata maka selanjutnya dilakukan proses reduce untuk mengelompokan kata-kata yang sama menjadi satu dan menjumlahkan setiap nilai kata dalam satu kelompok. Sehingga jika sebuah data dimasukan pada aplikasi benchmark wordcount maka aplikasi ini dapat menghitung berapa banyak jumlah kata pada data tersebut berdasarkan kata-kata yang sama.
2.4
Hadoop Distributed File System (HDFS)
Hadoop Distributed File System (HDFS) adalah file sistem terdistribusi yang berasal dari Hadoop. File sistem terdistribusi adalah file sistem yang bekerja dengan cara menyimpan data dengan membagi-bagi data kedalam ukuran tertentu dan menempatkan pada tempat penyimpanan yang berbeda di dalam sebuah cluster. Potongan-potongan data yang dibagi menjadi beberapa bagian disebut dengan HDFS blok. HDFS memiliki 2 buah komponen utama, yaitu NameNodedan DataNode.
NameNode adalah sebuah komputer yang berperan sebagai kepala pada cluster, sedangkan DataNode merupakan komputer-komputer yang berperan sebagai anak buah pada cluster. Keberhasilan proses distribusi file sistem pada HDFS ini ditentukan oleh kinerja dari 2 buah komponen utama diatas.
Sebagai kepala, NameNodebertugas untuk mengatur penempatan data-data yang masuk untuk ditempatkan pada blok-blok yang tersedia pada cluster dan bertanggung jawab atas data-data tersebut. Sedangkan DataNode bertugas untuk menjaga blok-blok data yang sudah terisi data dan melaporkan kondisinya secara berkala kepada NameNode, kondisi ini disebut dengan Heartbeat.
HDFS memiliki 2 buah prosedur, yaitu menyimpan data dan membaca data. 1. Prosedur menyimpan data
Untuk prosedur menyimpan data harus ada sebuah komputer clientyang terhubung dengan sebuah Hadoop cluster.
Gambar 2.6 Arsitektur Menyimpan Data
Langkah-Langkah prosedur menyimpan data sebagai berikut: A. Usermemasukan perintah masukan pada komputer client B. Komputer client berkomunikasi dengan NameNode
memberitahu bahwa ada data yang akan disimpan dan menanyakan lokasi blok-blok tempat menyimpan data.
C. Komputer client mendapat jawaban dari NameNode berupa B D C E HDFS Client A NameNode DataNode
D. Komputer client langsung berkomunikasi dengan DataNode untuk memasukan data-data pada lokasi blok-blok yang sudah diatur NameNode. Data sudah otomatis terbelah-belah sesuai dengan ukuran yang di setting sehingga dapat langsung menempati blok-blok yang sudah ditentukan.
E. DataNodememberikan laporan kepada NameNodebahwa data-data telah masuk dan menempati blok-blok yang sudah ditentukan oleh NameNode.
2. Prosedur Membaca data
Untuk prosedur membaca data harus ada sebuah komputer clientyang terhubung dengan sebuah Hadoop cluster.
Gambar 2.7 Arsitektur Membaca Data
Langkah-Langkah prosedur membaca data sebagai berikut:
A. User memasukan perintah untuk mengambil data pada komputer client.
B. Komputer client berkomunikasi dengan NameNode untuk menanyakan alamat DataNode penyimpan data yang diinginkan.
C. Komputer client mendapat jawaban dari NameNode berupa lokasi blok-blok tempat penyimpanan data yang inginkan. D. Komputer client secara langsung berhubungan dengan
DataNode untuk mengakses lokasi blok-blok tempat penyimpanan data yang diinginkan.
E. DataNode akan memberikan data yang diinginkan dan data secara otomatis akan ditampilkan pada layar komputer client.
E C D B HDFS Client A NameNode DataNode
2.5 Cloudera
Cloudera merupakan pelopor dari berdirinya sebuah hadoop distribusi didalam dunia teknologi, hadoop distribusi itu sendiri merupakan sebuah software yang menambahkan tools-tools serta konfigurasi khusus pada hadoop. Cloudera didirikan oleh orang-orang yang memiliki kontribusi didalam terciptanya hadoop apache, saat ini cloudera memiliki beberapa versi dari mulai versi gratis sampai versi berbayar.
2.6
Wordcount
Wordcount merupakan salah satu benchmark tools yang dimiliki oleh hadoop yang berfungsi untuk melakukan perhitungan jumlah kata-kata yang sama dalam sebuah dokumen dengan skala besar.
2.7
Random Access Memory (RAM)
RAM adalah memori tempat penyimpanan sementara pada komputer pada saat dijalankan. RAM bekerja dengan menyimpan dan menyuplai data-data yang dibutuhkan processor secara cepat untuk nantinya akan diolah oleh processordan menjadi sebuah informasi. RAM berfungsi untuk mempercepat pemrosesan data pada komputer. RAM memiliki ukuran yang disebut dengan kapasitas RAM, mulai dari 512 Megabyte, 1 Gigabyte hingga 8 Gigabyte, dan tidak menutup kemungkinan kapasitas RAM akan terus bertambah besar seiring dengan kebutuhan. Semakin besar kapasitas pada RAM makan Pemprosesan pada komputer akan semakin cepat
2.8 Jenis-Jenis
Text File
Text file merupakan dokumen yang biasanya digunakan untuk media pengolahan kata pada perangkat komputer. Terdapat berbagai macam jenis file yang dapat dibedakan berdasarkan formatnya. Berikut ini merupakan beberapa jenis text file:
1. Doc
Doc adalah sebuah ekstensi file yang digunakan pada dokumen pengolah kata biasanya digunakan pada Microsoft Word. Pada tahun 1990-an Microsoft memilih menggunakan ekstensi *.doc pada pengolah kata Microsoft Word.
2. Portable Document Format (pdf)
PDF (Portable Document Format) adalah sebuah format berkas yang dibuat oleh Adobe System pada tahun 1993 untuk keperluan pertukaran dokumen digital. Format PDF digunakan untuk merepresentasikan dokumen dua dimensi yang meliputi teks, huruf, citra dan grafik vektor dua dimensi.
3. Csv
Comma Separated Values (CSV) adalah suatu format data dalam basis data di mana setiap record dipisahkan dengan tanda koma (,) atau titik koma (;). Selain sederhana, format ini dapat dibuka dengan berbagai text-editorseperti Notepad, Wordpad, bahkan MS Excel.
4. Xlsx
Xlsx adalah jenis ekstensi file yang berasal dari software Microsoft Excel, dibuat oleh Microsoft Corporation. Biasa digunakan untuk memperhitungkan, mempresentasi data, menganalisa dll.
5. Txt
Txt adalah jenis ekstensi yang merupakan format mendasar dari teks file. Untuk membuat dan membuka file ini dapat digunakan notepad, wordpad , ataupuntext editor lainnya [9].
2.9 Centos
CentOS Linux adalah platform yang stabil, dapat diprediksi, dikelola dan reproduceable berasal dari sumber Red Hat Enterprise Linux (RHEL). CentOS Linux telah menjadi sumber distribusi komunitas karena bersifat opensourceHat. Dengan demikian, CentOS Linux bertujuan untuk menjadi fungsional kompatibel dengan RHEL.
3. PERANCANGAN SISTEM
3.1 Gambaran Umum Sistem
Perancang memberikan gambaran bagaimana merancang sebuah sistem sampai dengan proses kerja pada sistem. Perancangan sistem dibagi menjadi 3 buah tahap utama. Tahap pertama adalah menyiapkan komponen-komponen hardware pendukung, kedua adalah instalasi hadoop cluster (Cloudera Manager), ketiga adalah pengolahan data pada hadoop cluster.
Perancangan sistem dimulai dengan pemilihan hardware dengan spesifikasi tertentu sesuai dengan kebutuhan cluster, spesifikasi pada setiap komputer didalam cluster harus memiliki spesifikasi yang sama agar cluster dapat berjalan dengan baik.
Tahap selanjutnya adalah proses networking, networking dilakukan pada komputer-komputer yang akan digabungkan menjadi sebuah cluster agar setiap komputer dapat terhubung kedalam sebuah jaringan dan dapat saling berkomunikasi satu dengan lainnya.
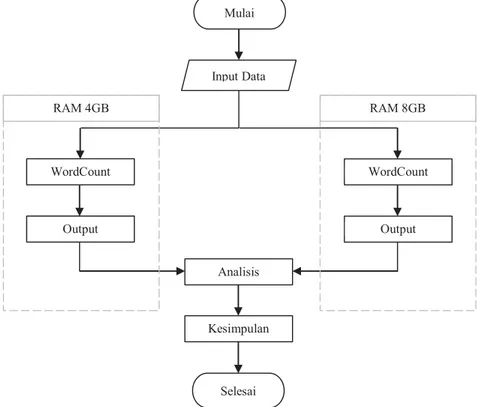
Tahap selanjutnya adalah instalasi hadoop dengan menggunakan Cloudera Manager, jika tahap instalasi hadoop sudah selesai maka proses selanjutnya adalah pengolahan data menggunakan fitur dari hadoop yaitu wordcount dengan menggunakan sebuah dokumen sebagai masukan. Setelah wordcount dilakukan didapatkan hasil berupa sebuah data yang selanjutnya akan dianalisis. Ilustrasi dapat dilihat pada gambar dibawah ini
Gambar 3.1 Gambaran Umum Sistem Analisis Kesimpulan Selesai Mulai Input Data WordCount Output RAM 4GB WordCount Output RAM 8GB
3.2
Preparations
Pada tahap preparationsdilakukan pengumpulan komponen-komponen hardware yang akan dibentuk menjadi sebuah cluster, komponen-komponen tersebut diantaranya :
1. 3 buah komputer dengan spesifikasi yang sama, pada perancangan sistem ini perancang menggunakan spesifikasi komputer sebagai berikut:
a. Processor Core i3
b. RAM 2GB, RAM 4GB, RAM 8GB dan RAM 16GB c. Operating System: Centos
2. Switch 3. Kabel LAN
3.3
Networking
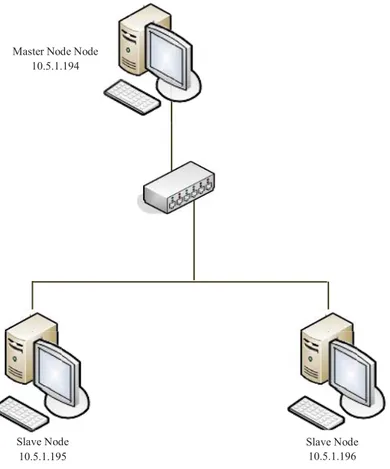
Pada tahap networking dilakukan proses penggabungan komponen-komponen yang sudah disiapkan pada tahap sebelumnya kedalam sebuah jaringan, sehingga setiap komputer terhubung satu dengan lainnya. Berikut ini merupakan gambaran dari networkingpada cluster yang akan dibangun.
Gambar 3.2 Arsitektur Cluster Slave Node
10.5.1.195 Master Node Node
10.5.1.194 e
Slave Node 10.5.1.196 Sl N d
3.4 Instalasi Hadoop
Pada tahap instalasi hadoop perancang menggunakan Cloudera Manager sebagai hadoop distribusi, pemilihan ini atas pertimbangan banyaknya pengguna Cloudera Manager pada saat ini serta sumber referensi yang lebih banyak dibandingkan dengan hadoop distribusi lainya seperti HortonWorks, MapR dll. Versi Cloudera yang digunakan dalam perancangan sistem ini adalah versi 5.2.0.
Berikut ini adalah tahapan-tahapan utama untuk membangun Hadoop Cluster:
3.4.1 Persyaratan
Berikut ini merupakan beberapa persyaratan sebelum melakukan instalasi hadoop cluster:
1. Installjava pada Master Nodedan Slave Node. Untuk mengistal java pada komputer
Ketikan perintah java-version pada terminal untuk mengetahui apakah java sudah terinstall dengan baik pada komputer.
2. Pastikan Sel Linuxdalam keadaan disable.
Ketikan perintah more /etc/selinux/config untuk memastikan Sel linux sudah dalam keadaan disable.
3. Pastikan IPTABLESdalam keadaan disablemelalui chkconfig ketikan perintah iptables –L –v –n untuk memastikan IPTABLESsudah dalam keadaan disable.
3.4.2 Jaringan
Untuk memudahkan proses instalasi sampai dengan proses penggunaan hadoop cluster maka IP (Internet Protocol) pada Master Node dan seluruh Slave Node dibuat menjadi IP Static, ini berfungsi agar kita tidak perlu lagi melakukan setting IP jika Master Node atau Slave Nodemati atau direstart.
Setelah memastikan seluruh IP pada Master Node dan Slave Node adalah IP Static kemudian edit file /etc/hosts pada Master Node dan Slave Nodedengan mengetikan perintah cat /etc/hosts.Tambahkan IP dan hostnamekomputer-komputer lain pada masing-masing komputer agar setiap komputer dapat melakukan komunikasi.
3.4.3 Konfigurasi Secure Shell (SSH)
Lakukan konfigurasi SSH pada Master Node dan Slave Nodeagar dapat mengendalikan node-nodeatau mentransfer fileantara node.
Berikut ini adalah langkah-langkah untuk melakukan konfigurasi SSH:
1. Masuk sebagai root pada Centos dengan mengetikan perintah su pada terminal.
2. Install open ssh serverdan clientdengan mengetikan perintah yum –y install openssh-server openssh-clients.
3. Setelah proses instalasi selesai lakukan konfigurasi pada
sshd_config dengan mengetik perintah cat
/etc/ssh/sshd_config.
4. Ganti PermitRootLogin yang semula “YES” ubah menjadi “NO”
5. Ganti PermitEmptyPassword yang semula “YES” ubah menjadi “NO”
6. Buat user authentication untuk komputer-komputer agar dapat mengakses ssh server. Contoh: AllowUser Master Node.
7. Savessh_config.
8. Restart sshd dengan mengetikan perintah /etc/ini.d/sshd restart.
3.4.4 Instalasi Hadoop
Pada tahap instalasi hadoop dibagi menjadi 2 bagian : 1. Instalasi Master Node
Instalasi Master Node ini adalah proses instalasi Cloudera Hadoop Package Server.
Komponen-komponen yang harus diinstal pada Master Node sebagai berikut:
a. jdk-6u31-linux-amd64.rpm (jika java belum terinstal pada komputer) b. oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm c. cloudera-manager-daemons-5.2.0 1.cm520.p0.60.el6.x86_64.rpm d. cloudera-manager-agent-5.2.0-1.cm520.p0.60.el6.x86_64.rpm e. cloudera-manager-server-5.2.0-1.cm520.p0.60.el6.x86_64.rpm f. cloudera-manager-server-db-2-5.2.0 1.cm520.p0.60.el6.x86_64.rpm
Ketik perintah yum –nogpgcheck localinstall <nama_package> untuk menginstal packagediatas
2. Instalasi Slave Node
Instalasi Slave Node ini adalah proses instalasi Cloudera Hadoop Package Agent.
Komponen-komponen yang harus diinstal pada Slave Node sebagai berikut:
a. jdk-6u31-linux-amd64.rpm (jika Java belum terinstal pada komputer) b. oracle-j2sdk1.7-1.7.0+update67-1.x86_64.rpm c. cloudera-manager-daemons-5.2.0-1.cm520.p0.60.el6.x86_64 .rpm d. cloudera-manager-agent-5.2.0-1.cm520.p0.60.el6.x86_64.rpm
Ketik perintah yum –nogpgcheck localinstall <nama_package> untuk menginstal packagediatas
Langkah selanjutnya setelah kedua tahapan diatas telah dilakukan adalah menyalin cloudera manager pada directory master dengan mengetikan perintah cp <versi cloudera manager> /opt/cloudera/parcels-repo. Kemudian ketikan perintah chmod 640 <versi cloudera manager> dan chown <versi cloudera manager>sebagai permission untuk instalasi cloudera manager. 3.4.5 Konfigurasi Instalasi
Pada tahapan ini dilakukan konfigurasi-konfigurasi pada komponen yang sudah diinstal pada Master Node dan Slave Node. Untuk memulai proses konfigurasi kita dapat mengubah file config cloudera agent dengan mengetikan perintah cat /etc/cloudera-scm-agent/config.ini.
Setelah terbuka halaman config.ini ganti server_host dengan hostname atau IP dari komputer yang akan dijadikan sebagai Master Nodepada cluster, contoh didalam perancangan sistem menggunakan hostnameMaster maka sever_hostdiisi dengan server_host=Master.
Lakukan langkah pergantian host_server disemua komputer yang akan digunakan sebagai Slave Node pada cluster. Setelah pergantian selesai maka langkah selanjutnya adalah restart cloudera-scm agent dengan mengetikan perintah service cloudera-scm-agent start, lakukan ini pada seluruh komputer yang telah dilakukan pergantian pada server_host.
3.4.6 Cek Instalasi Hadoop
Pada tahapan ini dilakukan pengecekan pada seluruh service-service packageyang telah diinstal sebelumnya pada Master Nodedan Slave Node, hal ini perlu dilakukan untuk memastikan seluruh package sudah benar-benar terinstal dengan baik agar proses selanjutnya berjalan dengan lancar.
Berikut ini merupakan proses pengecekan pada instalasi hadoop: 1. Proses pengecekan service package yang dilakukan pada
Master Nodediantaranya sebagai berikut: a. Cloudera-scm-server
b. Cloudera-scm-server-db c. Cloudera-scm-agent
2. Sedangkan proses pengecekan service packageyang dilakukan pada Slave Nodeadalah cloudera-scm-agent.
Untuk proses pengecekan status dapat dilakukan dengan mengetikan perintah service<nama_service> status.
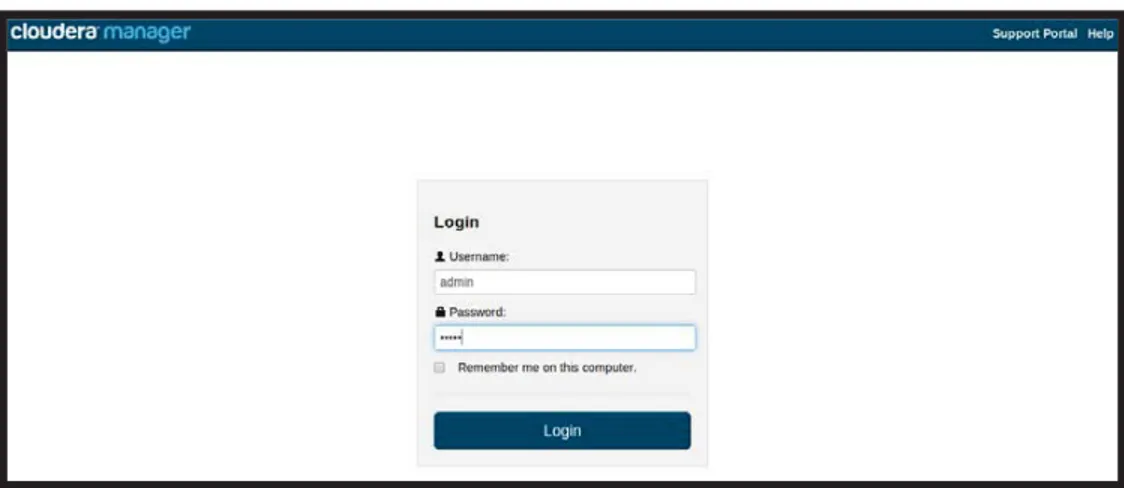
3.4.7 Cloudera Manager
Pada tahapan ini merupakan tahap untuk membuka halaman login dari cloudera manager, jika seluruh pengecekan service sudah selesai dan tidak ada masalah maka proses untuk membuka halaman login cloudera manager dapat langsung dilakukan dengan mengetikan <IP_Master Node>:7180 pada browser. Untuk username dan password defaultadalah admin
Gambar 3.3 Cloudera Manager Login
4. PERCOBAAN SISTEM DAN ANALISIS
4.1 Percobaan Sistem
Percobaan merupakan tahap uji coba terhadap sistem yang sudah dibangun, percobaan dibutuhkan untuk mengetahui apakah sistem telah berjalan dengan lancar dan siap untuk digunakan. Dan analisis diperlukan untuk mendapatkan kesimpulan dari hasil ujicoba yang dilakukan pada sistem yang sudah melewati tahapan percobaan, didalam tugas akhir ini analisis difokuskan pada pengaruh RAM, sehingga yang menjadi parameter utama yang diperhatikan didalam analisis adalah RAM.
Pada tahapan percobaan sistem dan analisis ini akan menjelaskan bagaimana skenario percobaan dilakukan sampai dengan pengambilan hasil percobaan.
4.1.1 Tujuan Percobaan
Berikut ini merupakan tujuan dari tahapan percobaan sistem dan analisis:
1. Mengetahui kondisi sistem setelah selesai proses pembangunan.
2. Mengetahui pengaruh perubahan kapasitas RAM terhadap kinerja sistem.
3. Mengetahui perbandingan performansi pengolahan text file untuk setiap jenis file terhadap kinerja sistem.
4.2 Persiapan Data
Persiapan data merupakan tahapan pengumpulan data-data yang akan digunakan pada proses percobaan sistem, tahapan ini sangat penting untuk mempercepat proses pengolahan data nantinya setelah pembangunan sistem selesai.
4.2.1 Pemilihan Data
Data-data yang dipilih untuk proses percobaan ini berupa beberapa jenis file yang berbasis text, jenis-jenis file yang akan diproses pada percobaan sistem adalah sebagai berikut:
A. Doc B. Pdf C. Csv D. Xlsx E. Txt
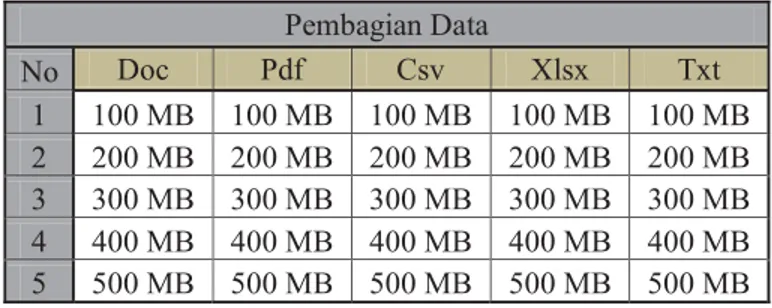
4.2.2 Pembagian Data
Pada proses pembagian data, data pada setiap file dibagi menjadi 5 bagian yang berbeda-beda ukuran (100MB, 200MB, 300MB, 400MB, 500MB) dan disesuaikan untuk kepentingan selanjutnya yaitu skenario percobaan sistem. Berikut ini merupakan tabel pembagian data.
Pembagian Data No Doc Pdf Csv Xlsx Txt 1 100 MB 100 MB 100 MB 100 MB 100 MB 2 200 MB 200 MB 200 MB 200 MB 200 MB 3 300 MB 300 MB 300 MB 300 MB 300 MB 4 400 MB 400 MB 400 MB 400 MB 400 MB 5 500 MB 500 MB 500 MB 500 MB 500 MB
Tabel 4.1 Pembagian Data
Pembagian data diatas didapatkan dengan cara menggabungkan beberapa filekedalam sebuah foldersehingga pada foldertersebut berisikan
beberapa filedengan ukuran yang diinginkan.
4.3 Skenario Percobaan
Skenario percobaan merupakan gambaran bagaimana cara percobaan sistem akan dilakukan. Dalam tugas akhir ini percobaan dilakukan berdasarkan parameter utama yaitu kapasitas RAM, skenario percobaan pada sistem dibagi menjadi 4 buah tahapan utama, berikut ini merupakan tahapan utama dari skenario percobaan:
1. Proses percobaan sistem dengan menggunakan kapasitas RAM 2GB. 2. Proses percobaan sistem dengan menggunakan kapasitas RAM 4GB. 3. Proses percobaan sistem dengan menggunakan kapasitas RAM 8GB. 4. Proses percobaan sistem dengan menggunakan kapasitas RAM 16GB. Pada setiap tahapan dilakukan proses percobaan menggunakan skenario tabel pembagian data, setiap ukuran data pada file dilakukan proses percobaan sebanyak 3 kali dan akan diambil nilai rata-rata dari ke-3 proses percobaan tersebut, hal ini dilakukan agar dapat menghasilkan hasil yang optimal.
4.4 Proses Percobaan
Proses percobaan dilakukan dengan melakukan percobaan data-data dengan skenario percobaan yang telah dibuat sebelumnya.
4.4.1 Transfer File (data-data)
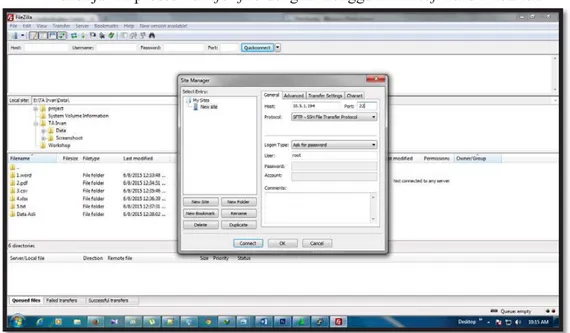
Langkah pertama pada proses percobaan adalah transfer file, transfer file dilakukan untuk menempatkan data-data yang berada pada local disk kedalam directory sistem (hadoop cluster). Gambar 4.2 dan 4.3 menunjukan proses transfer filedengan menggunakan software FileZila.
Gambar 4.1 Transfer File Via FileZila Site Manager
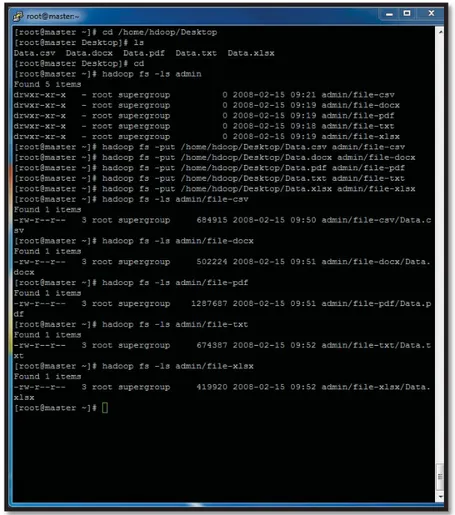
Setelah file berada pada Master Node maka tahap selanjutnya adalah copy file kedalam HDFS directorydengan mengetikan perintah hadoop fs –put <Master Node_Directory> <Target_HDFS_Directory>. Berikut ini merupakan copy file kedalam HDFS yang perancang lakukan pada tahap percobaan sistem.
Gambar 4.3 Transfer File Master Node To HDFS
Sebelum melakukan transfer file perancang terlebih dahulu membuat folder khusus pada directory HDFS sebagai tempat untuk file yang akan ditransfer, folder-folderyang dibuat oleh perancang diantaranya sebagai berikut: 1. Admin/File-csv 2. Admin/File-docx 3. Admin/File-pdf 4. Admin/File-txt 5. Admin/File-xlsx
4.4.2 Eksekusi File (data-data)
Proses eksekusi filedilakukan dimulai dengan tahapan mengakses file jar yang terletak pada directory /opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce.Berikut ini merupakan gambaran akses file jar.
Gambar 4.4 Jar File Directory
Setelah berada pada jar file directory proses selanjutnya adalah eksekusi file jar dengan data-data yang telah dicopy pada directory HDFS dengan mengetikan perintah hadoop jar <jarfile> <classname> <input_dir> <output_dir>. Berikut ini merupakan gambaran eksekusi file jar.
Gambar 4.5 Jar File Execution
Pada tahapan eksekusi jar perancang menambahkan perintah >& 1.word-100-f.txt pada baris akhir yang berguna agar output dari hasil eksekusi disimpan didalam file .txt. berikut ini merupakan contoh hasil outputdari eksekusi data menggunakan file jar.
4.5 Hasil Percobaan
Hasil percobaan merupakan kumpulan CPU time spent dari setiap output-output fileyang dihasilkan dari proses eksekusi data menggunakan filejar dengan skenario percobaan.
4.5.1 Hasil Percobaan Tahap Pertama
Pada tahap pertama dilakukan proses percobaan pada sistem dengan menggunakan kapasitas RAM pada setiap komputer sebesar 2GB. Gambar 4.7 menunjukan bahwa kapasitas RAM pada cluster sebesar 2GB
Gambar 4.7 Kondisi Cluster(RAM 2GB)
Berikut ini merupakan hasil percobaan pada tahap pertama: A. FileDoc File Doc No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 38.86 59.14 100.47 116.77 134.44 2 Percobaan 2 (Second) 39.21 59.15 101.53 117.65 135.07 3 Percobaan 3 (Second) 39.69 60.17 100.06 116.53 136.1 Rata-Rata (Second) 39.25 59.49 100.69 116.98 135.20
B. FilePdf File Pdf No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 29.56 58.22 85.97 113.42 130.38 2 Percobaan 2 (Second) 30.05 58.29 84.79 112.8 129.27 3 Percobaan 3 (Second) 29.53 60.99 85.13 112.54 131.5 Rata-Rata (Second) 29.71 59.17 85.30 112.92 130.38
Tabel 4.3 Hasil PercobaanFilePdf (RAM 2GB) C. FileCsv File Csv No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 20.15 26.4 38.09 47.09 56.62 2 Percobaan 2 (Second) 19.61 26.64 37.47 48.25 55.47 3 Percobaan 3 (Second) 20.55 26.34 38.12 47.28 57.49 Rata-Rata (Second) 20.10 26.46 37.89 47.54 56.53
Tabel 4.4 Hasil PercobaanFileCsv (RAM 2GB) D. FileXlsx File Xlsx No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 28.39 56.56 77.9 100.77 122.32 2 Percobaan 2 (Second) 28.14 59.2 78.32 102.92 123.14 3 Percobaan 3 (Second) 29.25 58.04 78.42 101.78 122.96 Rata-Rata (Second) 28.59 57.93 78.21 101.82 122.81
Tabel 4.5 Hasil PercobaanFileXlsx (RAM 2GB)
E. FileTxt File Txt No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 23.18 43.82 68.47 96.19 118.38 2 Percobaan 2 (Second) 23.14 49.14 67.43 96.11 119.84 3 Percobaan 3 (Second) 22.52 48.08 69.63 96.7 116.99 Rata-Rata (Second) 22.95 47.01 68.51 96.33 118.40
4.5.2 Hasil Percobaan Tahap Kedua
Pada tahap kedua dilakukan proses percobaan pada sistem dengan menggunakan kapasitas RAM 4GB, Berikut ini merupakan hasil percobaan pada tahap kedua. Gambar 4.8 menunjukan bahwa kapasitas RAM pada cluster sebesar 4GB
Gambar 4.8 Kondisi Cluster(RAM 4GB)
Berikut ini merupakan hasil percobaan pada tahap pertama: A. FileDoc File Doc No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 37.98 57.81 99.23 114.6 133.43 2 Percobaan 2 (Second) 38.43 58.59 101.01 114.67 134.46 3 Percobaan 3 (Second) 38.59 57.99 99.93 115.26 135.18 Rata-Rata (Second) 38.33 58.13 100.0567 114.84 134.36
B. File Pdf File Pdf No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 27.21 57.62 82.81 109.95 128.92 2 Percobaan 2 (Second) 26.68 57.55 84.39 109.73 127.73 3 Percobaan 3 (Second) 26.4 57.22 84.42 109.98 128.07 Rata-Rata (Second) 26.76 57.46 83.87 109.89 128.24
Tabel 4.8 Hasil PercobaanFilePdf (RAM 4GB) C. FileCsv File Csv No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 18.2 25.04 37.53 45.52 51.68 2 Percobaan 2 (Second) 18.18 26.62 37.21 43.25 54.37 3 Percobaan 3 (Second) 18.27 25.81 35.1 43.95 53.11 Rata-Rata (Second) 18.22 25.82 36.61 44.24 53.05
Tabel 4.9 Hasil PercobaanFileCsv (RAM 4GB) D. FileXlsx File Xlsx No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 25.61 56.28 76.16 98 122.25 2 Percobaan 2 (Second) 25.14 55.97 79.87 99.13 119.42 3 Percobaan 3 (Second) 25.87 57.64 76.07 99.82 119.67 Rata-Rata (Second) 25.54 56.63 77.37 98.98 120.45
Tabel 4.10 Hasil PercobaanFileXlsx (RAM 4GB)
E. FileTxt File Txt No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 21.52 40.08 59.24 83.79 117.2 2 Percobaan 2 (Second) 20.63 41.94 62.62 81.64 115.86 3 Percobaan 3 (Second) 21.15 41.13 61.23 81.12 115.72 Rata-Rata (Second) 21.10 41.05 61.03 82.18 116.26
4.5.3 Hasil Percobaan Tahap Ketiga
Pada tahap ketiga dilakukan proses percobaan pada sistem dengan menggunakan kapasitas RAM pada setiap komputer sebesar 8GB. Gambar 4.9 menunjukan bahwa kapasitas RAM pada cluster sebesar 8GB
Gambar 4.9 Kondisi Cluster(RAM 8GB)
Berikut ini merupakan hasil percobaan pada tahap pertama: A. FileDoc File Doc No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 36.18 57.12 94.99 110.28 131.71 2 Percobaan 2 (Second) 37.14 57.1 97.53 110.12 130.47 3 Percobaan 3 (Second) 37.28 55.49 95.91 109.85 131.1 Rata-Rata (Second) 36.87 56.57 96.14 110.08 131.09
B. FilePdf File Pdf No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 26.82 50.59 81.4 98.11 122.67 2 Percobaan 2 (Second) 26.88 50.03 82.13 98.09 123.9 3 Percobaan 3 (Second) 26.53 50.52 81.17 98.51 122.34 Rata-Rata (Second) 26.74 50.38 81.57 98.24 122.97
Tabel 4.13 Hasil PercobaanFilePdf (RAM 8GB) C. FileCsv File Csv No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 16.71 24.36 36.29 42.16 52.31 2 Percobaan 2 (Second) 17 25.06 36.24 41.89 50.12 3 Percobaan 3 (Second) 16.88 25.77 35 41.91 51.82 Rata-Rata (Second) 16.86 25.06 35.84 41.99 51.42
Tabel 4.14 Hasil PercobaanFileCsv (RAM 8GB) D. FileXlsx File Xlsx No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 25.08 48.55 73.65 91.18 116.99 2 Percobaan 2 (Second) 25.22 48.41 73.57 91.46 117.38 3 Percobaan 3 (Second) 24.43 48.02 73.02 91.61 117.29 Rata-Rata (Second) 24.91 48.33 73.41 91.42 117.22
Tabel 4.15 Hasil PercobaanFileXlsx (RAM 8GB)
E. FileTxt File Txt No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 18.11 32.07 47.63 66.4 104.84 2 Percobaan 2 (Second) 19.61 32.66 47.7 66.78 107.49 3 Percobaan 3 (Second) 18.54 33.29 47.04 64.21 109.44 Rata-Rata (Second) 18.75 32.67 47.46 65.80 107.26
4.5.4 Hasil Percobaan Tahap Keempat
Pada tahap keempat dilakukan proses percobaan pada sistem dengan menggunakan kapasitas RAM 16GB, Berikut ini merupakan hasil percobaan pada tahap kedua. Gambar 4.10 menunjukan bahwa kapasitas RAM pada cluster sebesar 16GB
Gambar 4.10 Kondisi Cluster(RAM 16GB)
Berikut ini merupakan hasil percobaan pada tahap pertama: A. FileDoc File Doc No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 36.48 56.92 85.54 96.67 116.68 2 Percobaan 2 (Second) 36.84 55.87 85.15 96.21 116.57 3 Percobaan 3 (Second) 36.14 56.12 85.2 96.98 116.24 Rata-Rata (Second) 36.49 56.30 85.30 96.62 116.50
B. File Pdf File Pdf No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 25.52 48.61 75.61 89.51 101.79 2 Percobaan 2 (Second) 25.25 48.86 75.53 88.66 101.2 3 Percobaan 3 (Second) 25.72 48.17 75.99 89.11 103.33 Rata-Rata (Second) 25.50 48.55 75.71 89.09 102.11
Tabel 4.18 Hasil PercobaanFilePdf (RAM 16GB) C. FileCsv File Csv No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 12.62 20.93 31.62 37.36 48.91 2 Percobaan 2 (Second) 13.1 20.64 31.37 37.21 48.04 3 Percobaan 3 (Second) 12.76 21.46 31.87 37.66 48.18 Rata-Rata (Second) 12.83 21.01 31.62 37.41 48.38
Tabel 4.19 Hasil PercobaanFileCsv (RAM 16GB) D. FileXlsx File Xlsx No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 20.11 45.35 64.64 85.37 98.85 2 Percobaan 2 (Second) 20.27 45.03 64.45 85.55 98.17 3 Percobaan 3 (Second) 20.42 45.24 64.74 85.65 99.86 Rata-Rata (Second) 20.27 45.21 64.61 85.52 98.96
Tabel 4.20 Hasil PercobaanFileXlsx (RAM 16GB)
E. FileTxt File Txt No Scenario 100MB 200MB 300MB 400MB 500MB 1 Percobaan 1 (Second) 13.51 26.5 34.18 51.37 80.89 2 Percobaan 2 (Second) 13.05 26.68 34.33 51.49 82.86 3 Percobaan 3 (Second) 13.18 27.82 34.82 51.94 82.81 Rata-Rata (Second) 13.25 27 34.44 51.60 82.19
4.5.5 Hasil Percobaan Berdasarkan Kapasitas RAM
Hasil percobaan ini memuat 5 buah grafik dari 5 buah jenisfileyang berbeda, hasil percobaan ini berfungsi untuk mengetahui bagaimana pengaruh jenis fileterhadap performansi sistem.
A. Hasil Percobaan dengan Kapasitas RAM 2GB
Hasil percobaan dengan kapasitas RAM 2GB file doc menjadi file dengan waktu eksekusi paling lambat, hal ini dikarenakan karakteristik file doc yang dapat mengandung semua tipe data sedangkan jenis filepdf yang memiliki karakteristik dengan doc (dapat mengandung semua jenis tipe data) memiliki waktu eksekusi lebih rendah dari doc karena file pdf merupakan fileyang memiliki kompresi khusus sehingga jenis fileini tidak bisa di ubah-ubah seperti jenis filedoc. Selanjutnya jenis filexlsx memiliki waktu eksekusi lebih cepat dari pdf dikarenakan file xlsx hanya mengandung matriks tidak seperti pdf yang dapat mengandung teks, huruf, citra dan grafik vektor dua dimensi. Selanjutnya jenis file txt memiliki waktu eksekusi lebih cepat dari xlsx karena karakteristik file txt yang hanya dapat mengandung tipe data string/ karakter ASCII (array 1 dimensi), sedangkan filexlsx mengandung matrix (array multidimensi).
Jenisfileyang memiliki waktu eksekusi tercepat adalah filecsv, hal ini dikarenakan karakteristik dari file csv yang sederhana tidak memiliki kompresi khusus dan setiap karakter didalamnya hanya dipisahkan oleh koma (,) dan titik koma (;).
B. Hasil percobaan dengan Kapasitas RAM 4GB
Hasil percobaan dengan kapasitas RAM 4GB memiliki grafik yang tidak jauh berbeda dengan grafik sebelumnya, jenis fileCsv masih menjadi jenis file yang waktu eksekusinya paling cepat sedangkan jenis file doc menjadi jenis file yang waktu eksekusinya paling lama, hanya saja pada seluruh jenis file mengalami sedikit peningkatan performansi jika dibandingkan saat melakukan proses percobaan dengan menggunakan kapasitas RAM 2GB, rata-rata peningkatan performansi pada jenis file adalah 2,79second.
Gambar 4.12 Grafik Pembanding Dengan Kapasitas RAM 4GB
C. Hasil Percobaan dengan Kapasitas RAM 8GB
Hasil percobaan dengan kapasitas RAM 8GB memiliki grafik yang tidak jauh berbeda dengan grafik pada percobaan sebelumnya, urutan jenis data berdasarkan kecepatan waktu eksekusi jenis fileCsv menjadi jenis file yang waktu eksekusinya paling cepat sedangkan jenis file doc menjadi jenis file yang waktu eksekusinya paling lama, hanya saja pada seluruh jenis file mengalami sedikit peningkatan performansi, rata-rata peningkatan performansi pada jenis fileadalah 4,86second.
Gambar 4.13 Grafik Pembanding Dengan Kapasitas RAM 8GB
D. Hasil Percobaan dengan Kapasitas RAM 16GB
Hasil percobaan dengan kapasitas RAM 16GB memiliki grafik yang tidak jauh berbeda dengan grafik pada percobaan sebelumnya, urutan jenis data berdasarkan kecepatan waktu eksekusi jenis fileCsv menjadi jenis file yang waktu eksekusinya paling cepat sedangkan jenis file doc menjadi jenis file yang waktu eksekusinya paling lama, hanya saja pada seluruh jenis file mengalami sedikit peningkatan performansi, rata-rata peningkatan performansi pada jenis fileadalah 8,10second.
Gambar 4.14 Grafik Pembanding Dengan Kapasitas RAM 16GB Gambar 4 13 Grafik Pembanding Dengan Kapasitas RAM 8GB
4.5.6 Hasil Percobaan Berdasarkan Jenis File
Hasil percobaan ini didapat dari proses percobaan tahap pertama sampai tahap keempat yang disajikan secara bersama agar dapat dilihat perbedaan dari setiap fileterhadap kapasitas RAM.
A. Hasil PercobaanFileDoc
Berdasarkan proses percobaan yang dilakukan didapatkan selisih waktu eksekusi antara kapasitas RAM 2GB, 4GB, 8GB dan 16GB, dari setiap peningkatan kapasitas RAM terjadi peningkatan waktu eksekusi, namun peningkatan yang terjadi berbeda-beda. Ketika dilakukan proses peningkatan kapasitas RAM dari 2 GB menjadi 4GB diperoleh rata-rata waktu peningkatan sebesar 1,18 second. Sedangkan dari 4GB menjadi 8GB rata-rata peningkatan sebesar 2,99 second dan dari 8GB menjadi 16GB didapatkan rata-rata peningkatan sebesar 7,91 second.
Proses percobaan pada file doc menggambarkan terjadinya kenaikan performansi pada proses ujicoba yang dilakukan ketika kapasitas RAM ditingkatkan, namun peningkatan yang terjadi tidak signifikan. Ketika kapasitas RAM ditingkatkan 100% namun performansi tidak meningkat sebesar 100%. Rata-rata peningkatan performansi ketika kapasitas RAM ditingkatkan 100% pada jenis filedoc adalah sebesar 4,58%.
B. Hasil PercobaanFilePdf
Berdasarkan proses percobaan yang dilakukan didapatkan selisih waktu eksekusi antara kapasitas RAM 2GB, 4GB, 8GB dan 16GB, dari setiap peningkatan kapasitas RAM terjadi peningkatan waktu eksekusi, namun peningkatan yang terjadi berbeda-beda. Ketika dilakukan proses peningkatan kapasitas RAM dari 2 GB menjadi 4GB diperoleh rata-rata waktu peningkatan sebesar 2,25 second. Sedangkan dari 4GB menjadi 8GB rata-rata peningkatan sebesar 5,27 second dan dari 8GB menjadi 16GB didapatkan rata-rata peningkatan sebesar 7,79 second.
Proses percobaan pada file pdf menggambarkan terjadinya kenaikan performansi pada proses ujicoba yang dilakukan ketika kapasitas RAM ditingkatkan, namun peningkatan yang terjadi tidak signifikan. Ketika kapasitas RAM ditingkatkan 100% namun performansi tidak meningkat sebesar 100%. Berbeda dengan file doc, pada file pdf Rata-rata peningkatan performansi lebih besar yaitu sebesar 7,57%, namun peningkatan ini masih relatif kecil jika melihat peningkatan RAM sebesar 100% .
Gambar 4.16 Grafik Pembanding FilePdf Gambar 4 16 Grafik PembandingFil Pdf
C. Hasil PercobaanFileCsv
Berdasarkan proses percobaan yang dilakukan didapatkan selisih waktu eksekusi antara kapasitas RAM 2GB, 4GB, 8GB dan 16GB, dari setiap peningkatan kapasitas RAM terjadi peningkatan waktu eksekusi, namun peningkatan yang terjadi berbeda-beda. Ketika dilakukan proses peningkatan kapasitas RAM dari 2 GB menjadi 4GB diperoleh rata-rata waktu peningkatan sebesar 2,12 second. Sedangkan dari 4GB menjadi 8GB rata-rata peningkatan sebesar 1,35 second dan dari 8GB menjadi 16GB didapatkan rata-rata peningkatan sebesar 3,99second.
Proses percobaan pada file csv menggambarkan terjadinya kenaikan performansi pada proses ujicoba yang dilakukan ketika kapasitas RAM ditingkatkan. Walaupun terjadi peningkatan namun tetap peningkatan performansi belum sebanding dengan peningkatan kapasitas RAM. Rata-rata peningkatan yang terjadi pada proses ujicoba adalah sebesar 8,87%. Kenaikan persentase ini lebih besar jika dibandingkan dengan persentase pada filedoc dan filepdf.
D. Hasil PercobaanFileXlsx
Berdasarkan proses percobaan yang dilakukan didapatkan selisih waktu eksekusi antara kapasitas RAM 2GB, 4GB, 8GB dan 16GB, dari setiap peningkatan kapasitas RAM terjadi peningkatan waktu eksekusi, namun peningkatan yang terjadi berbeda-beda. Ketika dilakukan proses peningkatan kapasitas RAM dari 2 GB menjadi 4GB diperoleh rata-rata waktu peningkatan sebesar 2,08 second. Sedangkan dari 4GB menjadi 8GB rata-rata peningkatan sebesar 4,74 second dan dari 8GB menjadi 16GB didapatkan rata-rata peningkatan sebesar 8,14second.
Proses percobaan pada file Xlsx menggambarkan terjadinya kenaikan performansi pada proses ujicoba yang dilakukan ketika kapasitas RAM ditingkatkan. Dari seluruh proses ujicoba yang dilakukan didapatkan rata-rata persentase kenaikan sebesar 8,35%.
Gambar 4.18 Grafik Pembanding FileXlsx G b 4 18 G fik P b di Fil Xl
E. Hasil percobaanFile Txt
Berdasarkan proses percobaan yang dilakukan didapatkan selisih waktu eksekusi antara kapasitas RAM 2GB, 4GB, 8GB dan 16GB, dari setiap peningkatan kapasitas RAM terjadi peningkatan waktu eksekusi, namun peningkatan yang terjadi berbeda-beda. Ketika dilakukan proses peningkatan kapasitas RAM dari 2 GB menjadi 4GB diperoleh rata-rata waktu peningkatan sebesar 6.32 second. Sedangkan dari 4GB menjadi 8GB rata-rata peningkatan sebesar 9,94 second dan dari 8GB menjadi 16GB didapatkan rata-rata peningkatan sebesar 12,69second.
Proses percobaan pada file Xlsx menggambarkan terjadinya kenaikan performansi pada proses ujicoba yang dilakukan ketika kapasitas RAM ditingkatkan. Jika dibandingkan dengan 4 buah jenis file lainya maka jenis file txt memiliki persentase peningkatan performansi tertinggi, rata-rata peningkatanya adalah sebesar 12,82%. Namun besaran peningkatan performansi yang terjadi masih jauh dari besaran kapasitas RAM yang ditingkatkan 100%.
4.5.7 FileCsv Vs FileXlsx
Diantara 5 buah jenis file yang dilakukan percobaan terdapat 2 buah file yang berasal dari software yang sama namun berbeda jenis ekstensi yaitu, fileCsv dan fileXlsx. Meskipun kedua jenis fileini memiliki isi dan ukuran data yang sama namun memiliki perbedaan waktu yang sangat signifikan pada saat proses percobaan, file csv memiliki waktu eksekusi yang lebih cepat dibandingkan filexlsx, hal ini dikarenakan oleh karakter file csv yang menggunakan koma (,) dan titik koma (;) sebagai pemisah antar elemen sehingga mempermudah saat dilakukan pemrosesan pada data. Tidak seperti jenis yang terdiri dari berbagai macam kompleksitas fungsi.
Karena kesederhanaan karakter ini maka jenis file csv memiliki tingkat kompabilitas yang tinggi, hal ini telah dibuktikan dengan file csv memiliki waktu eksekusi yang lebih cepat dari file xlsx dan menjadikan filecsv sebagai format standar dalam pengolahan data.
5. PENUTUP
5.1 Kesimpulan
Berdasarkan hasil analisis terhadap percobaan yang dilakukan pada sistem, maka dapat diambil beberapa kesimpulan sebagai berikut:
1. Hadoop Cluster telah berhasil diimplementasikan dengan menggunakan cloudera manager sebagai hadoop distribusinya.
2. Peningkatan 2 kalilipat kapasitas RAM pada hadoop cluster tidak membuat performansi meningkat menjadi 2 kalilipat, ketika kapasitas RAM ditingkatkan 100 % hasil percobaan menunjukan performansi dari jenis file doc mengalami peningkatan sebesar 4,58%, file pdf sebesar 7,57%,file csv sebesar 8,87%, file xlsx sebesar 8,35% dan filetxt sebesar 12,82% hal ini dapat disebabkan oleh kompleksitas content yang berbeda-beda disetiap file.
3. Jenis file csv merupakan jenis file terbaik dari segi waktu eksekusi yang dapat diolah oleh hadoop cluster karena memiliki waktu eksekusi paling rendah diantara jenis filelainya.
4. Meskipun berasal dari software yang sama namun jenis file csv memiliki kualitas yang lebih baik dibandingkan dengan jenis file xlsx jika dilihat dari waktu eksekusi pada proses pengolahan data menggunakan hadoop cluster.
5.2 Saran
Pengembangan lebih lanjut yang dapat dilakukan terhadap tugas akhir ini adalah sebagai berikut :
1. Kapasitas RAM dan jumlah slave node dapat ditingkatkan pada pembangunan sistem selanjutnya agar mendapatkan hasil penelitian yang lebih optimal.
2. Pengembangan terkait pengaruh RAM dapat lebih dikembangkan dengan menggunakan tools benchmark yang lainya, seperti TeraSort, TestDFSIO dll.
Proses uji coba pada sistem dapat dikembangkan dengan menggunakan jenis file lainya, seperti gambar, video dan suara.
![Gambar 2.5 Wordcount [12]](https://thumb-ap.123doks.com/thumbv2/123dok/2269714.2182716/19.918.255.751.198.539/gambar-wordcount.webp)